pd.DataFrame.to_dict('records') increase precision unexpectedly #12
Description
When a Pandas DataFrame is converted into a Python dictionary:
Line 141 in 3127f6f
precision of some numbers increase unexpectedly (0.999-->0.999000000001):
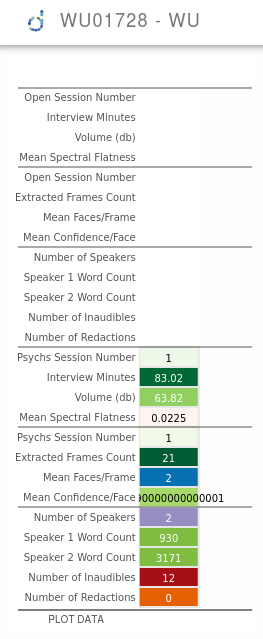
There is also a post on stackoverflow about it.
Tashrif's solution:
chunk.round(5).to_dict('records')