\n", + "Como es una varialbe cuantitativa discreta le cambio el Dtye a int64, para ello tengo que eliminar el 'min' y 'Season' o 'Seasons'" + ] + }, + { + "cell_type": "code", + "execution_count": 23, + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Tipo de la columna duration de amazon: object\n", + "Tipo de la columna release_year de amazon: int64\n", + "Tipo de la columna duration de disney: object\n", + "Tipo de la columna release_year de disney: int64\n", + "Tipo de la columna duration de netflix: object\n", + "Tipo de la columna release_year de netflix: int64\n", + "Tipo de la columna duration de hulu: object\n", + "Tipo de la columna release_year de hulu: int64\n" + ] + } + ], + "source": [ + "for plataforma, df in dfs.items():\n", + " print(f'Tipo de la columna duration de {plataforma}: {df[\"duration\"].dtype}')\n", + " print(f'Tipo de la columna release_year de {plataforma}: {df[\"release_year\"].dtype}')" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "Cambio el Dtype de la columna 'duration' y 'release_year' a uint16 por ser valores positivos." + ] + }, + { + "attachments": {}, + "cell_type": "markdown", + "metadata": {}, + "source": [ + "# Normalizacion" + ] + }, + { + "cell_type": "code", + "execution_count": 14, + "metadata": {}, + "outputs": [], + "source": [ + "def conseguir_val_unicos(df,col):\n", + " '''\n", + " df: dataframe \n", + " col: str del nimbre de la columna del df \n", + "\n", + " Devulve los valores unicos de la columna en formato Serie de pandas.\n", + " '''\n", + "\n", + " valores=[]\n", + " lista_valores = []\n", + " valores_df = df[col].values\n", + " \n", + " #llena lista_valores con listas del reparto de cada pelicula\n", + " for val in valores_df:\n", + " if type(val) == str:\n", + " \n", + " lista_valores.append(str.split(val,','))\n", + "\n", + " #llena valores con los actores\n", + " for lista in lista_valores:\n", + " for val in lista:\n", + " valores.append(val.lstrip())#utlizo ltrip porque hay valores con un espacio delante\n", + " \n", + " #convierte la lista en una serie de pandas y elimina los repetidos\n", + " valores = pd.Series(valores)\n", + " valores = valores.drop_duplicates()\n", + " return valores\n" + ] + }, + { + "cell_type": "code", + "execution_count": 24, + "metadata": {}, + "outputs": [], + "source": [ + "def valores_col(lista_df,col):\n", + " '''\n", + " lista_df: lista de dataframes\n", + " col: str\n", + "\n", + " Devuelve los valores unicos de todos los dataframes en lista_df de la columna col\n", + " '''\n", + " #serie vacia\n", + " valores_col=pd.Series()\n", + "\n", + " #llena valores_col \n", + " for df in lista_df:\n", + " valores_col=pd.concat([valores_col, conseguir_val_unicos(df,col)])\n", + " \n", + " # elimino los valores repetidos\n", + " valores_col.drop_duplicates(inplace=True)\n", + " #ordeno la lista\n", + " valores_col.sort_values(inplace=True)\n", + " return valores_col" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + " ### Normalizando la columna 'listed_in'" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "Listo las distintas categorias de los dataframes" + ] + }, + { + "cell_type": "code", + "execution_count": 25, + "metadata": {}, + "outputs": [], + "source": [ + "categoria = valores_col([df_a,df_d,df_n,df_h],'listed_in')" + ] + }, + { + "cell_type": "code", + "execution_count": 26, + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "array(['Action', 'Action & Adventure', 'Action-Adventure',\n", + " 'Adult Animation', 'Adventure', 'Animals & Nature', 'Animation',\n", + " 'Anime', 'Anime Features', 'Anime Series', 'Anthology', 'Arthouse',\n", + " 'Arts', 'Biographical', 'Black Stories', 'British TV Shows',\n", + " 'Buddy', 'Cartoons', 'Children & Family Movies',\n", + " 'Classic & Cult TV', 'Classic Movies', 'Classics', 'Comedies',\n", + " 'Comedy', 'Coming of Age', 'Concert Film', 'Cooking & Food',\n", + " 'Crime', 'Crime TV Shows', 'Cult Movies', 'Dance', 'Disaster',\n", + " 'Documentaries', 'Documentary', 'Docuseries', 'Drama', 'Dramas',\n", + " 'Entertainment', 'Faith & Spirituality', 'Faith and Spirituality',\n", + " 'Family', 'Fantasy', 'Fitness', 'Game Show / Competition',\n", + " 'Game Shows', 'Health & Wellness', 'Historical', 'History',\n", + " 'Horror', 'Horror Movies', 'Independent Movies', 'International',\n", + " 'International Movies', 'International TV Shows', 'Kids',\n", + " \"Kids' TV\", 'Korean TV Shows', 'LGBTQ', 'LGBTQ Movies', 'LGBTQ+',\n", + " 'Late Night', 'Latino', 'Lifestyle', 'Lifestyle & Culture',\n", + " 'Medical', 'Military and War', 'Movies', 'Music',\n", + " 'Music & Musicals', 'Music Videos and Concerts', 'Musical',\n", + " 'Mystery', 'News', 'Parody', 'Police/Cop', 'Reality', 'Reality TV',\n", + " 'Romance', 'Romantic Comedy', 'Romantic Movies',\n", + " 'Romantic TV Shows', 'Sci-Fi & Fantasy', 'Science & Nature TV',\n", + " 'Science & Technology', 'Science Fiction', 'Series', 'Sitcom',\n", + " 'Sketch Comedy', 'Soap Opera / Melodrama',\n", + " 'Spanish-Language TV Shows', 'Special Interest', 'Sports',\n", + " 'Sports Movies', 'Spy/Espionage', 'Stand Up', 'Stand-Up Comedy',\n", + " 'Stand-Up Comedy & Talk Shows', 'Superhero', 'Survival',\n", + " 'Suspense', 'TV Action & Adventure', 'TV Comedies', 'TV Dramas',\n", + " 'TV Horror', 'TV Mysteries', 'TV Sci-Fi & Fantasy', 'TV Shows',\n", + " 'TV Thrillers', 'Talk Show', 'Talk Show and Variety', 'Teen',\n", + " 'Teen TV Shows', 'Thriller', 'Thrillers', 'Travel', 'Unscripted',\n", + " 'Variety', 'Western', 'Young Adult Audience', 'and Culture'],\n", + " dtype=object)" + ] + }, + "execution_count": 26, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "categoria.values" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "Esta seria la normalizacion para categorias" + ] + }, + { + "cell_type": "code", + "execution_count": 28, + "metadata": {}, + "outputs": [], + "source": [ + "valores_normalizar ={'Action & Adventure':['Action-Adventure','TV Action & Adventure'],\n", + " 'Anime':['Animation','Anime', 'Anime Features', 'Anime Series'],\n", + " 'Classic':['Classic & Cult TV', 'Classic Movies', 'Classics'],\n", + " 'Comedy':['TV Comedies','Comedies'], 'Crime':['Crime TV Shows'], 'Documentary':['Documentaries'],\n", + " 'Drama':['TV Dramas', 'Dramas'],'Faith & Spirituality':['Faith and Spirituality'],'Game Shows':['Game Show / Competition'],\n", + " 'History':['Historical'], 'Horror': ['TV Horror','Horror Movies'],'International':['International Movies', 'International TV Shows'],\n", + " 'Kids':[\"Kids' TV\"],'LGBTQ':['LGBTQ Movies', 'LGBTQ+'],'Lifestyle':['Lifestyle & Culture'],'Mystery':['TV Mysteries'],\n", + " 'Music':['Music & Musicals', 'Music Videos and Concerts', 'Musical'],'Reality':[ 'Reality TV'],\n", + " 'Romance':['Romantic Movies','Romantic TV Shows'], 'Sports':['Sports Movies'],'Sci-Fi & Fantasy':['TV Sci-Fi & Fantasy'],\n", + " 'Stand Up':['Stand-Up Comedy','Stand-Up Comedy & Talk Shows'],'Thriller':['TV Thrillers','Thrillers']\n", + " }" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "# Lleno los datos faltantes con datos de las distintas plataformas" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "Los valores de inteser segun los criterio ya mencionados son:
\n", + "- duration(netflix:3,hulu:479)\n", + "- cast(amazon:1233,disney:190,netflix:825,hulu:3037)\n", + "- realise_year(completo)\n", + "- list_in(completo)" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "Netflix y Hulu tienen valores faltantes en 'duration' y 'cast' uso la funcion completar_df" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "A Dysney+ y Amazon solo falta completar la columna cast " + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "## Ultimas modificaciones" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "Elimino las columnas 'director','country','date_added','rating' y 'description' que no aporta a las query requeridas." + ] + }, + { + "attachments": {}, + "cell_type": "markdown", + "metadata": {}, + "source": [ + "Lleno los valores faltantes con 'sin datos'" + ] + }, + { + "attachments": {}, + "cell_type": "markdown", + "metadata": {}, + "source": [ + "Pongo en minuscula los valores" + ] + }, + { + "attachments": {}, + "cell_type": "markdown", + "metadata": {}, + "source": [ + "Elimino los espacios al principio y final de los valores" + ] + } + ], + "metadata": { + "kernelspec": { + "display_name": "api_series", + "language": "python", + "name": "python3" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 3 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython3", + "version": "3.10.0" + }, + "orig_nbformat": 4 + }, + "nbformat": 4, + "nbformat_minor": 2 +} diff --git a/ETL/cargar.py b/ETL/cargar.py new file mode 100644 index 00000000..e63260f1 --- /dev/null +++ b/ETL/cargar.py @@ -0,0 +1,7 @@ +import pandas as pd + +def Guardar(df): + """ + Guarda el DataFrame procesado en un archivo CSV. + """ + df.to_csv('../Datos/procesados/df_procesado.csv', index=False) \ No newline at end of file diff --git a/ETL/etl.py b/ETL/etl.py new file mode 100644 index 00000000..436b57cb --- /dev/null +++ b/ETL/etl.py @@ -0,0 +1,19 @@ +from extraer import Extracion +from transformar import Transformacion +from cargar import Guardar + + +def realizar_etl(): + """ + Ejecuta el pipeline completo de ETL. + """ + ruta = "../Datos/archivos/" + dfs = Extracion(ruta) + df_final = Transformacion(dfs) + Guardar(df_final) + return + + +if __name__ == "__main__": + realizar_etl() + diff --git a/ETL/extraer.py b/ETL/extraer.py new file mode 100644 index 00000000..1239c307 --- /dev/null +++ b/ETL/extraer.py @@ -0,0 +1,24 @@ +import pandas as pd +import numpy as np + +def Extracion(ruta:str)-> dict[str, pd.DataFrame]: + '''Carga los datos de las distintas plataformas de streaming y los devuelve en una lista de dataframes. + df_a: df de amazon + df_d: df de disney + df_n: df de netflix + df_h: df de hulu + ''' + df_a: pd.DataFrame= pd.read_csv(ruta +'amazon_prime_titles.csv') + df_d: pd.DataFrame= pd.read_csv(ruta + 'disney_plus_titles.csv') + df_n: pd.DataFrame= pd.read_json(ruta + 'netflix_titles.json') + df_h: pd.DataFrame= pd.read_csv(ruta + 'hulu_titles.csv') + + #lista con los df para iterar en los distintos procesos + dfs:dict[str, pd.DataFrame] = { + "amazon": df_a, + "disney": df_d, + "netflix": df_n, + "hulu": df_h + } + + return dfs diff --git a/ETL/transformar.py b/ETL/transformar.py new file mode 100644 index 00000000..7a504346 --- /dev/null +++ b/ETL/transformar.py @@ -0,0 +1,142 @@ +import pandas as pd +import numpy as np + + +def limpiar_datos_num(df:pd.DataFrame) -> pd.DataFrame: + """ + Limpia la columna duration eliminando texto y dejando solo valores numéricos. + """ + + def limp_segun_duracion(duracion): + if duracion == None or duracion == 'nan': + return '0' + elif type(duracion) == float: + return limp_segun_duracion(str(duracion)) + elif 'min' in duracion: + return duracion[:-3] + else: + return duracion[:-7] + + df['duration'] = df['duration'].map(lambda x: limp_segun_duracion(x)) + # return df + +def dar_formato(df): + """ + Convierte columnas numéricas al tipo uint16. + """ + columns_int = ['release_year', 'duration'] + for col in columns_int: + df[col] = df[col].astype('uint16') + + # return df + + +def normalizar_col(df, dict_valores, col): + """ + Normaliza los valores de una columna según un diccionario de equivalencias. + """ + for key, valores in dict_valores.items(): + for str_valores in df[col]: + for val in valores: + if val in str_valores: + df[col][df[col] == str_valores] = ( + df[col][df[col] == str_valores] + .replace({str_valores: str_valores.replace(val, key)}) + ) + + +def completar_col(df, columna, df_comprobar): + """ + Completa valores nulos de una columna usando otro DataFrame como referencia. + """ + mask_nan = df[columna].isna() + films_nan = df['title'][mask_nan] + + mask_comp = films_nan.isin(df_comprobar['title']) + film_comp = films_nan[mask_comp] + + for title in film_comp: + valor_col_df = df[columna][df['title'] == title] + if valor_col_df.isnull().values: + valor_col = df_comprobar[columna][df_comprobar['title'] == title] + if not valor_col.isnull().values: + index = df[df['title'] == title].index + index_col = list(df[0:0]).index(columna) + df.iloc[index, index_col] = valor_col + + +def completar_datos_faltantes(df, lista_col, lista_df_comprobar): + """ + Completa múltiples columnas utilizando una lista de DataFrames de referencia. + """ + for col in lista_col: + for df_com in lista_df_comprobar: + completar_col(df, col, df_com) + + + +# dfs = [df_a,df_d,df_n,df_h] + +def Transformacion(dfs:dict[str, pd.DataFrame]) -> pd.DataFrame: + """ + Aplica todas las transformaciones necesarias a los datasets y devuelve + un único DataFrame consolidado. + """ + + dfs['hulu']['cast'] = dfs['hulu']['cast'].astype('object') + + valores_normalizar: dict[str, list[str]] = { + 'Action & Adventure': ['Action-Adventure', 'TV Action & Adventure'], + 'Anime': ['Animation', 'Anime', 'Anime Features', 'Anime Series'], + 'Classic': ['Classic & Cult TV', 'Classic Movies', 'Classics'], + 'Comedy': ['TV Comedies', 'Comedies'], + 'Crime': ['Crime TV Shows'], + 'Documentary': ['Documentaries'], + 'Drama': ['TV Dramas', 'Dramas'], + 'Faith & Spirituality': ['Faith and Spirituality'], + 'Game Shows': ['Game Show / Competition'], + 'History': ['Historical'], + 'Horror': ['TV Horror', 'Horror Movies'], + 'International': ['International Movies', 'International TV Shows'], + 'Kids': ["Kids' TV"], + 'LGBTQ': ['LGBTQ Movies', 'LGBTQ+'], + 'Lifestyle': ['Lifestyle & Culture'], + 'Mystery': ['TV Mysteries'], + 'Music': ['Music & Musicals', 'Music Videos and Concerts', 'Musical'], + 'Reality': ['Reality TV'], + 'Romance': ['Romantic Movies', 'Romantic TV Shows'], + 'Sports': ['Sports Movies'], + 'Sci-Fi & Fantasy': ['TV Sci-Fi & Fantasy'], + 'Stand Up': ['Stand-Up Comedy', 'Stand-Up Comedy & Talk Shows'], + 'Thriller': ['TV Thrillers', 'Thrillers'] + } + + + for plataforma, df in dfs.items(): + df['show_id'] = df['show_id'].map(lambda x: plataforma[0] + x[1:]) + limpiar_datos_num(df) + dar_formato(df) + normalizar_col(df, valores_normalizar, 'listed_in') + df['platform'] = plataforma + + completar_datos_faltantes(dfs['hulu'], ['duration', 'cast'], [dfs['amazon'], dfs['disney'], dfs['netflix']]) + completar_datos_faltantes(dfs['netflix'], ['duration', 'cast'], [dfs['amazon'], dfs['disney'], dfs['hulu']]) + completar_datos_faltantes(dfs['amazon'], ['cast'], [dfs['netflix'], dfs['disney'], dfs['hulu']]) + completar_datos_faltantes(dfs['disney'], ['cast'], [dfs['netflix'], dfs['amazon'], dfs['hulu']]) + + df_queries = pd.concat(list(dfs.values()), ignore_index=True) + + df_queries.drop( + ['director', 'country', 'date_added', 'rating', 'description'], + axis=1, + inplace=True + ) + + df_queries.fillna('sin datos', inplace=True) + + columnas = ['type', 'title', 'cast', 'listed_in'] + for col in columnas: + df_queries[col] = df_queries[col].apply(lambda x: x.lower()) + df_queries[col] = df_queries[col].apply(lambda x: x.rstrip().lstrip()) + + return df_queries diff --git a/README.md b/README.md index bfc910dd..b286d37f 100644 --- a/README.md +++ b/README.md @@ -1,147 +1,152 @@ -
![]()
+# Proyecto: Pipeline de Datos y API REST para Películas y Series -#
**PROYECTO INDIVIDUAL Nº1**
+## 📌 Descripción +Este proyecto implementa un **pipeline completo de datos**, desde el análisis exploratorio (EDA), pasando por un proceso de **ETL**, hasta la **exposición de los datos mediante una API REST** desarrollada con FastAPI. -#**`Data Engineering`**
+Se procesan datasets de distintas plataformas de streaming (CSV y JSON), se aplican procesos de limpieza, normalización y consolidación, y el dataset resultante es expuesto mediante endpoints de solo lectura (GET). -
- -
-
+1. **EDA (Exploratory Data Analysis)** + Análisis exploratorio de los datasets originales para detectar inconsistencias, valores faltantes y definir reglas de normalización. -## **Introducción** +2. **ETL (Extract, Transform, Load)** + - **Extract:** lectura de datos desde archivos CSV/JSON + - **Transform:** limpieza, normalización de categorías y unificación de formatos + - **Load:** generación de un dataset consolidado en CSV -La idea de este proyecto es que el alumno logre internalizar los conocimientos requeridos para la elaboración y ejecución de una API. +3. **API REST** + La API carga el dataset procesado una única vez en memoria y expone endpoints para consultas analíticas. -`Application Programming Interface` es una interfaz que permite que dos aplicaciones se comuniquen entre sí, independientemente de la infraestructura subyacente. Son herramientas muy versátiles y fundamentales para la creación de, por ejemplo, pipelines, ya que permiten mover y brindar acceso simple a los datos que se quieran disponibilizar a través de los diferentes endpoints, o puntos de salida de la API. +--- -Hoy en día contamos con **FastAPI**, un web framework moderno y de alto rendimiento para construir APIs con Python. -
-
+## 🛠 Tecnologías Utilizadas +- **Lenguaje:** Python +- **Procesamiento de datos:** pandas, numpy +- **API:** FastAPI +- **Contenerización:** Docker +- **Almacenamiento:** Archivos CSV y JSON -## **Propuesta de trabajo** +--- -El proyecto consiste en realizar una ingesta de datos desde diversas fuentes, posteriormente aplicar las transformaciones que consideren pertinentes, y luego disponibilizar los datos limpios para su consulta a través de una API. Esta API deberán construirla en un entorno virtual dockerizado. +## 📁 Estructura del Proyecto -Los datos serán provistos en archivos de diferentes extensiones, como *csv* o *json*. Se espera que realicen un EDA para cada dataset y corrijan los tipos de datos, valores nulos y duplicados, entre otras tareas. Posteriormente, tendrán que relacionar los datasets así pueden acceder a su información por medio de consultas a la API. +```text +app/ +├── main.py # API FastAPI (endpoints GET) -Las consultas a realizar son: +Datos/ +├── archivos/ # Datasets originales (raw) +└── procesados/ + └── df_procesado.csv # Dataset final generado por el ETL -+ Duración según tipo de ítem (película/serie), por plataforma y por año +ETL/ +├── extraer.py # Extracción de datos +├── transformar.py # Transformaciones y normalización +├── cargar.py # Carga del dataset final +├── etl.py # Orquestador del proceso ETL +└── EDA.ipynb # Análisis exploratorio de datos -+ Cantidad de películas y series por plataforma +Dockerfile +requirements.txt +README.md +```` -+ Género más visto por plataforma +--- -+ Película y serie con mejor rating (los null deberán pasarlos a 0) +## ⚙️ Ejecución del ETL -## **Pasos del proyecto** +Desde la raíz del proyecto: -1. Ingesta y normalización de datos +```bash +python ETL/etl.py +``` -2. Relacionar el conjunto de datos y crear la tabla necesaria para realizar consultas. Aquí se recomienda corroborar qué datos necesitarán en base a las consultas a realizar y concatenar las 4 tablas +Este proceso genera el archivo: -3. Leer documentación en links provistos e indagar sobre Uvicorn, FastAPI y Docker +```text +Datos/procesados/df_procesado.csv +``` -4. Crear la API en un entorno Docker → leer documentación en links provistos +--- -5. Realizar consultas solicitadas +## 🚀 Ejecución de la API por Consola -6. Realizar un video demostrativo +```bash +uvicorn app.main:app --reload +``` +*Para detener el programa* `ctrl + C`. -7. **PLUS**: realizar un deployment en Mogenius +## 🚀 Ejecución de la API con Docker -
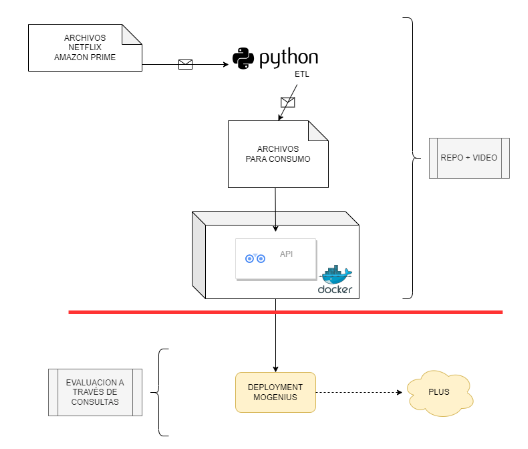
-
-