This repository was archived by the owner on Jan 29, 2024. It is now read-only.
This repository was archived by the owner on Jan 29, 2024. It is now read-only.
Explore Re-Ranking models to improve results of Semantic Search #625
Description
Context
- As explained in
sentence-transformersdocs (here), the typical structure of an Information Retrieval pipeline consists of two stages. The top K best results of the first stage are fed into the second stage for a more refined sorting/ranking.- Retrieval Bi-Encoder — Typically a symmetric model, feeds the same neural net first with the query and then with the candidate sentence, then computes the similarity between the two as the cosine/Euclidean/dot-product distance between the two embeddings.
- Re-Ranker Cross-Encoder — Typically an asymmetric model (especially in the case of asymmetric tasks where the query is much shorter than the documents, e.g. given a question retrieve candidate contexts), feeds a neural network with the query and a candidate sentence concatenated and directly outputs a similarity score.
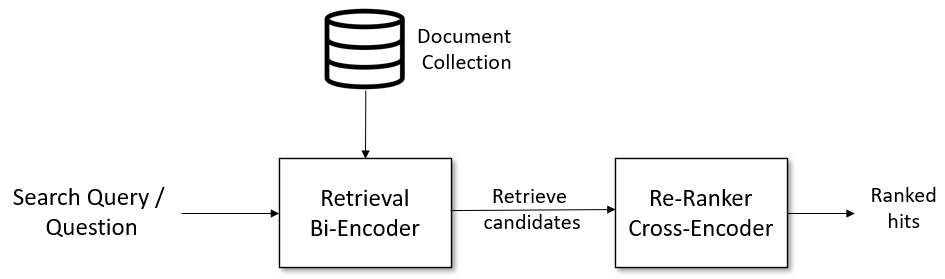
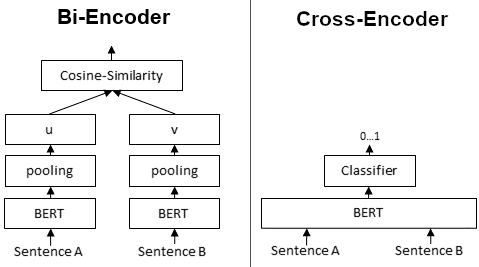
- Why not just stopping after the first retrieval stage? Because hopefully "the advantage of Cross-Encoders is the higher performance, as they perform attention across the query and the document" (here).
- We already tested models for sentence embedding corresponding to the Retrieval Bi-Encoder (see Deploy embedding model on Kubernetes using Seldom #623). We now want to try out the Re-Ranking.
Actions
- Set up a dataset/experiment to evaluate the performance of simple retrieval vs. retrieval+re-ranked.
- Evaluate results using various re-ranking models (here). Models trained on the QNLI dataset (here) could be particularly relevant: these models are trained to predict, for the SQuAD dataset, if a context contains an answer to a given question.