기존 로직은 아래와 같다.
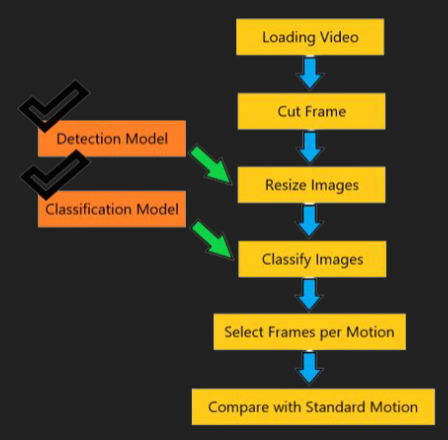
모델은 2개가 필요하고, 과정은 다음과 같다.
- 영상을 프레임 별로 잘라서 폴더에 이미지로 저장
- 저장된 이미지를 훈련된 다중 분류 모델이 동작을 구별
- 구별한 결과대로 6개의 폴더에 나눠서 저장
- 그 중 모범 동작과 가장 유사한 이미지를 한장씩 추출
- 비교
이 과정에서 이미지를 모두 저장하는 과정을 2번이나 실행하기에 매우 느리고 데이터 처리에 낭비가 심하다.
보완 로직

- mediapipe를 통해 skeleton을 입힌다.
- landmark의 좌표값을 통해 해당 좌표에 들어가면 동작별로 이미지 한장씩 추출
- 비교
보완 로직대로라면 이미지를 모두 처리할 필요도 없고 처리 속도도 굉장히 빠를 것이다.
그리고 OpenCV를 이용하기에 결과 비교에도 연계하여 더 용이하게 비교할 수 있을 것이다.
번외
Yolo
Yolo도 사용할 수 있겠지만, 훈련시킬 데이터에 bounding box로 전처리된 데이터가 필요하다. 그럼 보완 로직의 과정과 같이 한장씩을 추출하는 것이 가능해진다. 하지만 bounding box로 전처리된 데이터가 없기에 이 방안은 기각되었다.
기존 로직은 아래와 같다.
모델은 2개가 필요하고, 과정은 다음과 같다.
이 과정에서 이미지를 모두 저장하는 과정을 2번이나 실행하기에 매우 느리고 데이터 처리에 낭비가 심하다.
보완 로직
보완 로직대로라면 이미지를 모두 처리할 필요도 없고 처리 속도도 굉장히 빠를 것이다.
그리고 OpenCV를 이용하기에 결과 비교에도 연계하여 더 용이하게 비교할 수 있을 것이다.
번외
Yolo
Yolo도 사용할 수 있겠지만, 훈련시킬 데이터에 bounding box로 전처리된 데이터가 필요하다. 그럼 보완 로직의 과정과 같이 한장씩을 추출하는 것이 가능해진다. 하지만 bounding box로 전처리된 데이터가 없기에 이 방안은 기각되었다.