 @@ -60,7 +63,8 @@ Check out this simple [*Vectorless RAG Notebook*](https://github.com/VectifyAI/P
---
# 📦 PageIndex Tree Structure
-PageIndex can transform lengthy PDF documents into a semantic **tree structure**, similar to a _"table of contents"_ but optimized for use with Large Language Models (LLMs). It's ideal for: financial reports, regulatory filings, academic textbooks, legal or technical manuals, and any document that exceeds LLM context limits.
+
+PageIndex can transform lengthy PDF documents into a semantic **tree structure**, similar to a *"table of contents"* but optimized for use with Large Language Models (LLMs). It's ideal for: financial reports, regulatory filings, academic textbooks, legal or technical manuals, and any document that exceeds LLM context limits.
Here is an example output. See more [example documents](https://github.com/VectifyAI/PageIndex/tree/main/tests/pdfs) and [generated trees](https://github.com/VectifyAI/PageIndex/tree/main/tests/results).
@@ -92,7 +96,7 @@ Here is an example output. See more [example documents](https://github.com/Vecti
...
```
- You can either generate the PageIndex tree structure with this open-source repo or try our ☁️ **[Cloud Service](https://dash.pageindex.ai/)** — instantly accessible via our 🖥️ [Dashboard](https://dash.pageindex.ai/) or 🔌 [API](https://docs.pageindex.ai/quickstart), with no setup required.
+You can either generate the PageIndex tree structure with this open-source repo or try our ☁️ **[Cloud Service](https://dash.pageindex.ai/)** — instantly accessible via our 🖥️ [Dashboard](https://dash.pageindex.ai/) or 🔌 [API](https://docs.pageindex.ai/quickstart), with no setup required.
---
@@ -114,6 +118,14 @@ Create a `.env` file in the root directory and add your API key:
CHATGPT_API_KEY=your_openai_key_here
```
+Optional: if you're using an OpenAI-compatible endpoint (self-hosted proxy, gateway, or vendor), set a custom API base URL:
+
+```bash
+CHATGPT_API_BASE_URL=https://your-openai-compatible-endpoint/v1
+```
+
+When set, PageIndex will automatically use this base URL for all Chat Completions requests.
+
### 3. Run PageIndex on your PDF
```bash
@@ -135,6 +147,7 @@ You can customize the processing with additional optional arguments:
--if-add-node-summary Add node summary (yes/no, default: no)
--if-add-doc-description Add doc description (yes/no, default: yes)
```
+
---
@@ -180,7 +193,7 @@ Refer to the [API Documentation](https://docs.pageindex.ai/quickstart) for integ
# ⭐ Support Us
-Leave a star if you like our project — thank you!
+Leave a star if you like our project — thank you!
@@ -60,7 +63,8 @@ Check out this simple [*Vectorless RAG Notebook*](https://github.com/VectifyAI/P
---
# 📦 PageIndex Tree Structure
-PageIndex can transform lengthy PDF documents into a semantic **tree structure**, similar to a _"table of contents"_ but optimized for use with Large Language Models (LLMs). It's ideal for: financial reports, regulatory filings, academic textbooks, legal or technical manuals, and any document that exceeds LLM context limits.
+
+PageIndex can transform lengthy PDF documents into a semantic **tree structure**, similar to a *"table of contents"* but optimized for use with Large Language Models (LLMs). It's ideal for: financial reports, regulatory filings, academic textbooks, legal or technical manuals, and any document that exceeds LLM context limits.
Here is an example output. See more [example documents](https://github.com/VectifyAI/PageIndex/tree/main/tests/pdfs) and [generated trees](https://github.com/VectifyAI/PageIndex/tree/main/tests/results).
@@ -92,7 +96,7 @@ Here is an example output. See more [example documents](https://github.com/Vecti
...
```
- You can either generate the PageIndex tree structure with this open-source repo or try our ☁️ **[Cloud Service](https://dash.pageindex.ai/)** — instantly accessible via our 🖥️ [Dashboard](https://dash.pageindex.ai/) or 🔌 [API](https://docs.pageindex.ai/quickstart), with no setup required.
+You can either generate the PageIndex tree structure with this open-source repo or try our ☁️ **[Cloud Service](https://dash.pageindex.ai/)** — instantly accessible via our 🖥️ [Dashboard](https://dash.pageindex.ai/) or 🔌 [API](https://docs.pageindex.ai/quickstart), with no setup required.
---
@@ -114,6 +118,14 @@ Create a `.env` file in the root directory and add your API key:
CHATGPT_API_KEY=your_openai_key_here
```
+Optional: if you're using an OpenAI-compatible endpoint (self-hosted proxy, gateway, or vendor), set a custom API base URL:
+
+```bash
+CHATGPT_API_BASE_URL=https://your-openai-compatible-endpoint/v1
+```
+
+When set, PageIndex will automatically use this base URL for all Chat Completions requests.
+
### 3. Run PageIndex on your PDF
```bash
@@ -135,6 +147,7 @@ You can customize the processing with additional optional arguments:
--if-add-node-summary Add node summary (yes/no, default: no)
--if-add-doc-description Add doc description (yes/no, default: yes)
```
+
---
@@ -180,7 +193,7 @@ Refer to the [API Documentation](https://docs.pageindex.ai/quickstart) for integ
# ⭐ Support Us
-Leave a star if you like our project — thank you!
+Leave a star if you like our project — thank you!
 diff --git a/pageindex/utils.py b/pageindex/utils.py
index dc7acd8..860ba87 100644
--- a/pageindex/utils.py
+++ b/pageindex/utils.py
@@ -18,6 +18,14 @@
from types import SimpleNamespace as config
CHATGPT_API_KEY = os.getenv("CHATGPT_API_KEY")
+CHATGPT_API_BASE_URL = os.getenv("CHATGPT_API_BASE_URL")
+
+def _openai_kwargs(api_key):
+ """Build kwargs for OpenAI clients with optional base_url from env."""
+ kwargs = {"api_key": api_key}
+ if CHATGPT_API_BASE_URL:
+ kwargs["base_url"] = CHATGPT_API_BASE_URL
+ return kwargs
def count_tokens(text, model=None):
if not text:
@@ -28,7 +36,7 @@ def count_tokens(text, model=None):
def ChatGPT_API_with_finish_reason(model, prompt, api_key=CHATGPT_API_KEY, chat_history=None):
max_retries = 10
- client = openai.OpenAI(api_key=api_key)
+ client = openai.OpenAI(**_openai_kwargs(api_key))
for i in range(max_retries):
try:
if chat_history:
@@ -60,7 +68,7 @@ def ChatGPT_API_with_finish_reason(model, prompt, api_key=CHATGPT_API_KEY, chat_
def ChatGPT_API(model, prompt, api_key=CHATGPT_API_KEY, chat_history=None):
max_retries = 10
- client = openai.OpenAI(api_key=api_key)
+ client = openai.OpenAI(**_openai_kwargs(api_key))
for i in range(max_retries):
try:
if chat_history:
@@ -91,7 +99,7 @@ async def ChatGPT_API_async(model, prompt, api_key=CHATGPT_API_KEY):
messages = [{"role": "user", "content": prompt}]
for i in range(max_retries):
try:
- async with openai.AsyncOpenAI(api_key=api_key) as client:
+ async with openai.AsyncOpenAI(**_openai_kwargs(api_key)) as client:
response = await client.chat.completions.create(
model=model,
messages=messages,
diff --git a/pageindex/utils.py b/pageindex/utils.py
index dc7acd8..860ba87 100644
--- a/pageindex/utils.py
+++ b/pageindex/utils.py
@@ -18,6 +18,14 @@
from types import SimpleNamespace as config
CHATGPT_API_KEY = os.getenv("CHATGPT_API_KEY")
+CHATGPT_API_BASE_URL = os.getenv("CHATGPT_API_BASE_URL")
+
+def _openai_kwargs(api_key):
+ """Build kwargs for OpenAI clients with optional base_url from env."""
+ kwargs = {"api_key": api_key}
+ if CHATGPT_API_BASE_URL:
+ kwargs["base_url"] = CHATGPT_API_BASE_URL
+ return kwargs
def count_tokens(text, model=None):
if not text:
@@ -28,7 +36,7 @@ def count_tokens(text, model=None):
def ChatGPT_API_with_finish_reason(model, prompt, api_key=CHATGPT_API_KEY, chat_history=None):
max_retries = 10
- client = openai.OpenAI(api_key=api_key)
+ client = openai.OpenAI(**_openai_kwargs(api_key))
for i in range(max_retries):
try:
if chat_history:
@@ -60,7 +68,7 @@ def ChatGPT_API_with_finish_reason(model, prompt, api_key=CHATGPT_API_KEY, chat_
def ChatGPT_API(model, prompt, api_key=CHATGPT_API_KEY, chat_history=None):
max_retries = 10
- client = openai.OpenAI(api_key=api_key)
+ client = openai.OpenAI(**_openai_kwargs(api_key))
for i in range(max_retries):
try:
if chat_history:
@@ -91,7 +99,7 @@ async def ChatGPT_API_async(model, prompt, api_key=CHATGPT_API_KEY):
messages = [{"role": "user", "content": prompt}]
for i in range(max_retries):
try:
- async with openai.AsyncOpenAI(api_key=api_key) as client:
+ async with openai.AsyncOpenAI(**_openai_kwargs(api_key)) as client:
response = await client.chat.completions.create(
model=model,
messages=messages,
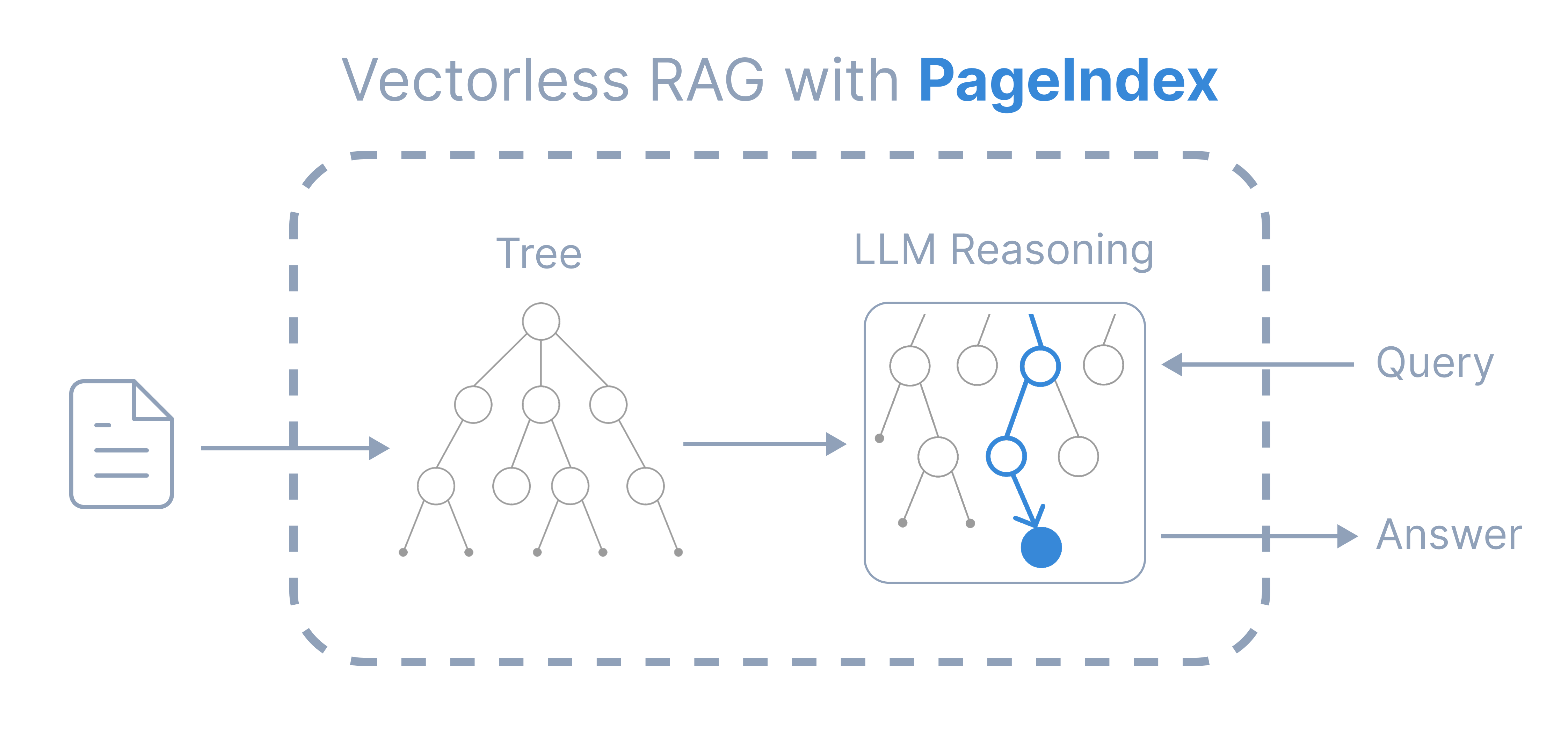 -### 💡 Features
+### 💡 Features
Compared to traditional vector-based RAG, PageIndex features:
+
- **No Vectors Needed**: Uses document structure and LLM reasoning for retrieval.
- **No Chunking Needed**: Documents are organized into natural sections, not artificial chunks.
- **Human-like Retrieval**: Simulates how human experts navigate and extract knowledge from complex documents.
@@ -45,12 +46,14 @@ Compared to traditional vector-based RAG, PageIndex features:
PageIndex powers a reasoning-based RAG system that achieved [98.7% accuracy](https://github.com/VectifyAI/Mafin2.5-FinanceBench) on FinanceBench, showing state-of-the-art performance in professional document analysis (see our [blog post](https://vectify.ai/blog/Mafin2.5) for details).
### 🚀 Deployment Options
+
- 🛠️ Self-host — run locally with this open-source repo
- ☁️ **[Cloud Service](https://dash.pageindex.ai/)** — try instantly with our 🖥️ [Dashboard](https://dash.pageindex.ai/) or 🔌 [API](https://docs.pageindex.ai/quickstart), no setup required
### ⚡ Quick Hands-on
-Check out this simple [*Vectorless RAG Notebook*](https://github.com/VectifyAI/PageIndex/blob/main/cookbook/pageindex_RAG_simple.ipynb) — a minimal, hands-on, reasoning-based RAG pipeline using **PageIndex**.
+Check out this simple [_Vectorless RAG Notebook_](https://github.com/VectifyAI/PageIndex/blob/main/cookbook/pageindex_RAG_simple.ipynb) — a minimal, hands-on, reasoning-based RAG pipeline using **PageIndex**.
+
-### 💡 Features
+### 💡 Features
Compared to traditional vector-based RAG, PageIndex features:
+
- **No Vectors Needed**: Uses document structure and LLM reasoning for retrieval.
- **No Chunking Needed**: Documents are organized into natural sections, not artificial chunks.
- **Human-like Retrieval**: Simulates how human experts navigate and extract knowledge from complex documents.
@@ -45,12 +46,14 @@ Compared to traditional vector-based RAG, PageIndex features:
PageIndex powers a reasoning-based RAG system that achieved [98.7% accuracy](https://github.com/VectifyAI/Mafin2.5-FinanceBench) on FinanceBench, showing state-of-the-art performance in professional document analysis (see our [blog post](https://vectify.ai/blog/Mafin2.5) for details).
### 🚀 Deployment Options
+
- 🛠️ Self-host — run locally with this open-source repo
- ☁️ **[Cloud Service](https://dash.pageindex.ai/)** — try instantly with our 🖥️ [Dashboard](https://dash.pageindex.ai/) or 🔌 [API](https://docs.pageindex.ai/quickstart), no setup required
### ⚡ Quick Hands-on
-Check out this simple [*Vectorless RAG Notebook*](https://github.com/VectifyAI/PageIndex/blob/main/cookbook/pageindex_RAG_simple.ipynb) — a minimal, hands-on, reasoning-based RAG pipeline using **PageIndex**.
+Check out this simple [_Vectorless RAG Notebook_](https://github.com/VectifyAI/PageIndex/blob/main/cookbook/pageindex_RAG_simple.ipynb) — a minimal, hands-on, reasoning-based RAG pipeline using **PageIndex**.
+