Please log in to use swap functionality
;
+ }
+
+ return (
+
+
+
+ {signAndSendPreparedCallsResult && (
+
+ );
+ }
+ ```
+
+ + {isWaitingForConfirmation + ? "Waiting for confirmation..." + : error + ? `Error: ${error}` + : statusResult?.statusCode === 200 + ? "Swap confirmed!" + : `Status: ${statusResult?.statusCode}`} +
+ )} +Please log in to use swap functionality
;
+ }
+
+ return (
+
+
+
+ {signAndSendPreparedCallsResult && (
+
+ );
+ }
+ ```
+
+ + {isWaitingForConfirmation + ? "Waiting for cross-chain confirmation..." + : error + ? `Error: ${error}` + : statusResult?.statusCode === 200 + ? "Cross-chain swap confirmed!" + : `Status: ${statusResult?.statusCode}`} +
+ )} + +
+In general, public endpoints come in the form of `https://api.goldsky.com/api/public/
+
+In general, public endpoints come in the form of `https://api.goldsky.com/api/public/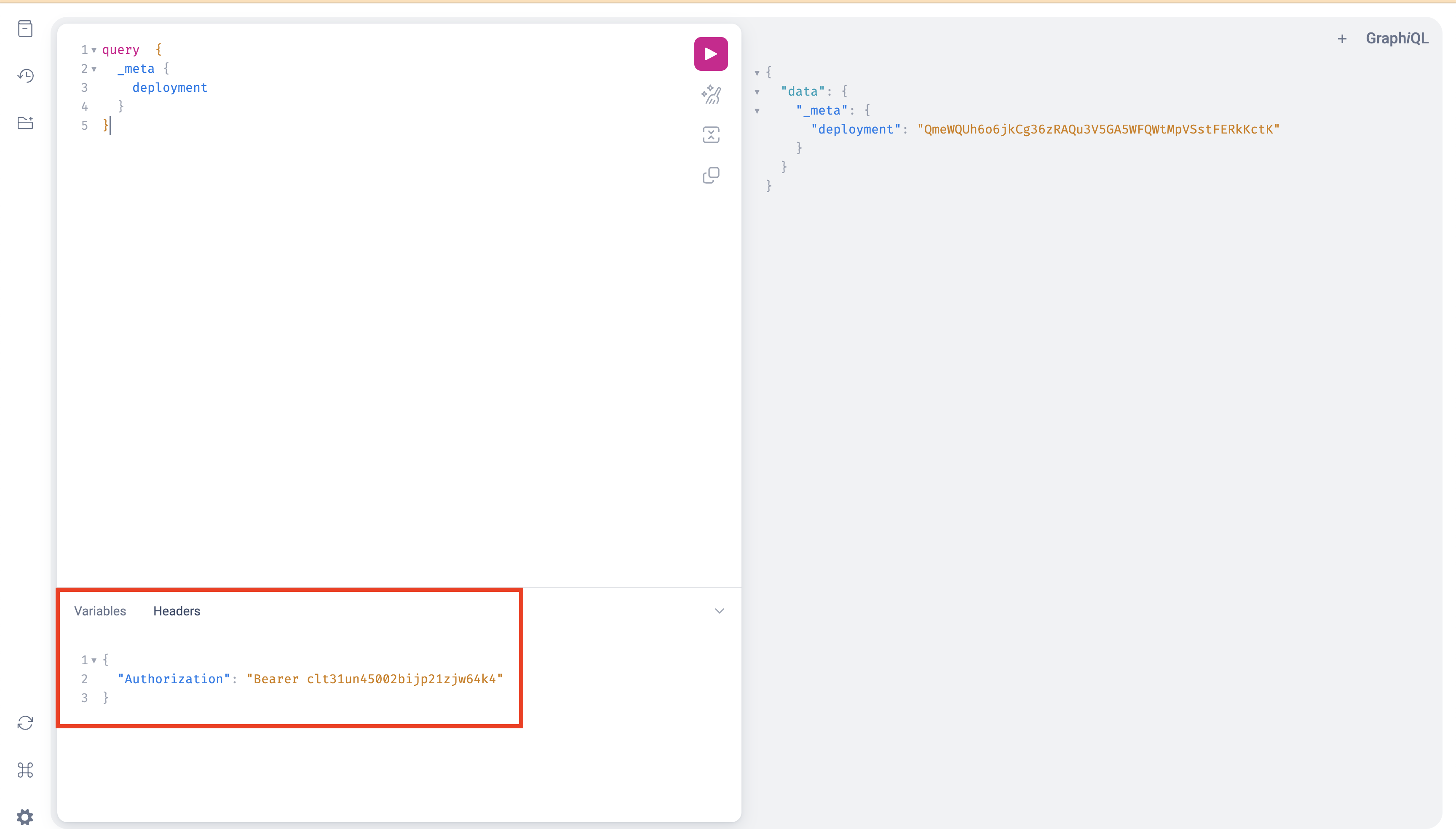 +
+Private subgraphs endpoints follow the same format as public subgraph endpoints except they start with `/api/private`
+instead of `/api/public`. For example, the private endpoint for the `prod` tag of the `uniswap-v3-base/1.0.0` subgraph
+would be `https://api.goldsky.com/api/private/project_cl8ylkiw00krx0hvza0qw17vn/subgraphs/uniswap-v3-base/1.0.0/gn`.
+
+### Revoking access
+
+To revoke access to a private endpoint you can simply delete the API token that was used to access the endpoint. If you
+don't know which key is used to access the endpoint, you'll have to revoke all API tokens for all users that have access
+to the project.
+
+## Enabling and disabling public and private endpoints
+
+By default, all new subgraphs and their tags come with the public endpoint enabled and the private endpoint disabled.
+Both of these settings can be changed using the CLI and the webapp. To change either setting, you must have [`Editor` permissions](../rbac).
+
+### CLI
+
+To toggle one of these settings using the CLI you can use the `goldsky subgraph update` command with the
+`--public-endpoint
+
+Private subgraphs endpoints follow the same format as public subgraph endpoints except they start with `/api/private`
+instead of `/api/public`. For example, the private endpoint for the `prod` tag of the `uniswap-v3-base/1.0.0` subgraph
+would be `https://api.goldsky.com/api/private/project_cl8ylkiw00krx0hvza0qw17vn/subgraphs/uniswap-v3-base/1.0.0/gn`.
+
+### Revoking access
+
+To revoke access to a private endpoint you can simply delete the API token that was used to access the endpoint. If you
+don't know which key is used to access the endpoint, you'll have to revoke all API tokens for all users that have access
+to the project.
+
+## Enabling and disabling public and private endpoints
+
+By default, all new subgraphs and their tags come with the public endpoint enabled and the private endpoint disabled.
+Both of these settings can be changed using the CLI and the webapp. To change either setting, you must have [`Editor` permissions](../rbac).
+
+### CLI
+
+To toggle one of these settings using the CLI you can use the `goldsky subgraph update` command with the
+`--public-endpoint
+ ```mermaid theme={null}
+ stateDiagram-v2
+ state ACTIVE {
+ [*] --> STARTING
+ STARTING --> RUNNING
+ }
+ ```
+
+
+Let's look at a simple example below where we configure a pipeline that consumes Logs from Base chain and streams them into a Postgres database:
+
+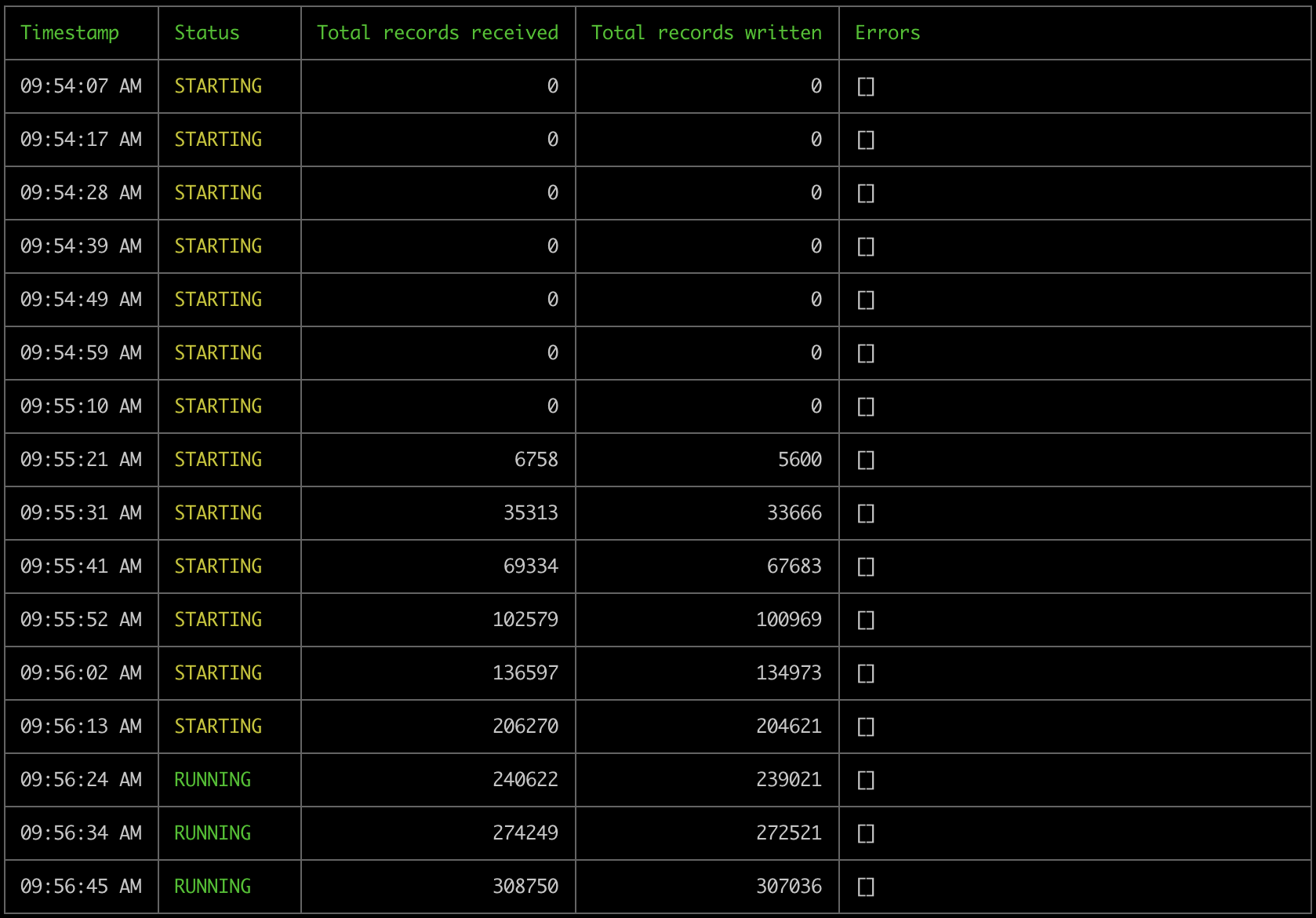 +
+We can see how the pipeline starts in `STARTING` status and becomes `RUNNING` as it starts processing data successfully into our Postgres sink.
+This pipeline will start processing the historical data of the source dataset, reach its edge and continue streaming data in real time until we either stop it or it encounters error(s) that interrupts it's execution.
+
+### Unsuccessful pipeline lifecycle
+
+Let's now consider the scenario where the pipeline encounters errors during its lifetime and ends up failing.
+
+There can be multitude of reasons for a pipeline to encounter errors such as:
+
+* secrets not being correctly configured
+* sink availability issues
+* policy rules on the sink preventing the pipeline from writing records
+* resource size incompatiblity
+* and many more
+
+These failure scenarios prevents a pipeline from getting-into or staying-in a `RUNNING` runtime status.
+
+
+
+We can see how the pipeline starts in `STARTING` status and becomes `RUNNING` as it starts processing data successfully into our Postgres sink.
+This pipeline will start processing the historical data of the source dataset, reach its edge and continue streaming data in real time until we either stop it or it encounters error(s) that interrupts it's execution.
+
+### Unsuccessful pipeline lifecycle
+
+Let's now consider the scenario where the pipeline encounters errors during its lifetime and ends up failing.
+
+There can be multitude of reasons for a pipeline to encounter errors such as:
+
+* secrets not being correctly configured
+* sink availability issues
+* policy rules on the sink preventing the pipeline from writing records
+* resource size incompatiblity
+* and many more
+
+These failure scenarios prevents a pipeline from getting-into or staying-in a `RUNNING` runtime status.
+
+
+ ```mermaid theme={null}
+ ---
+ title: Healthy pipeline becomes unhealthy
+ ---
+ stateDiagram-v2
+ state status:ACTIVE {
+ [*] --> STARTING
+ STARTING --> RUNNING
+ RUNNING --> FAILING
+ FAILING --> TERMINATED
+ }
+ ```
+
+ ```mermaid theme={null}
+ ---
+ title: Pipeline cannot start
+ ---
+ stateDiagram-v2
+ state status:ACTIVE {
+ [*] --> STARTING
+ STARTING --> FAILING
+ FAILING --> TERMINATED
+ }
+ ```
+
+
+A Pipeline can be in an `ACTIVE` desired status but a `TERMINATED` runtime status in scenarios that lead to terminal failure.
+
+Let's see an example where we'll use the same configuration as above but set a `secret_name` that does not exist.
+
+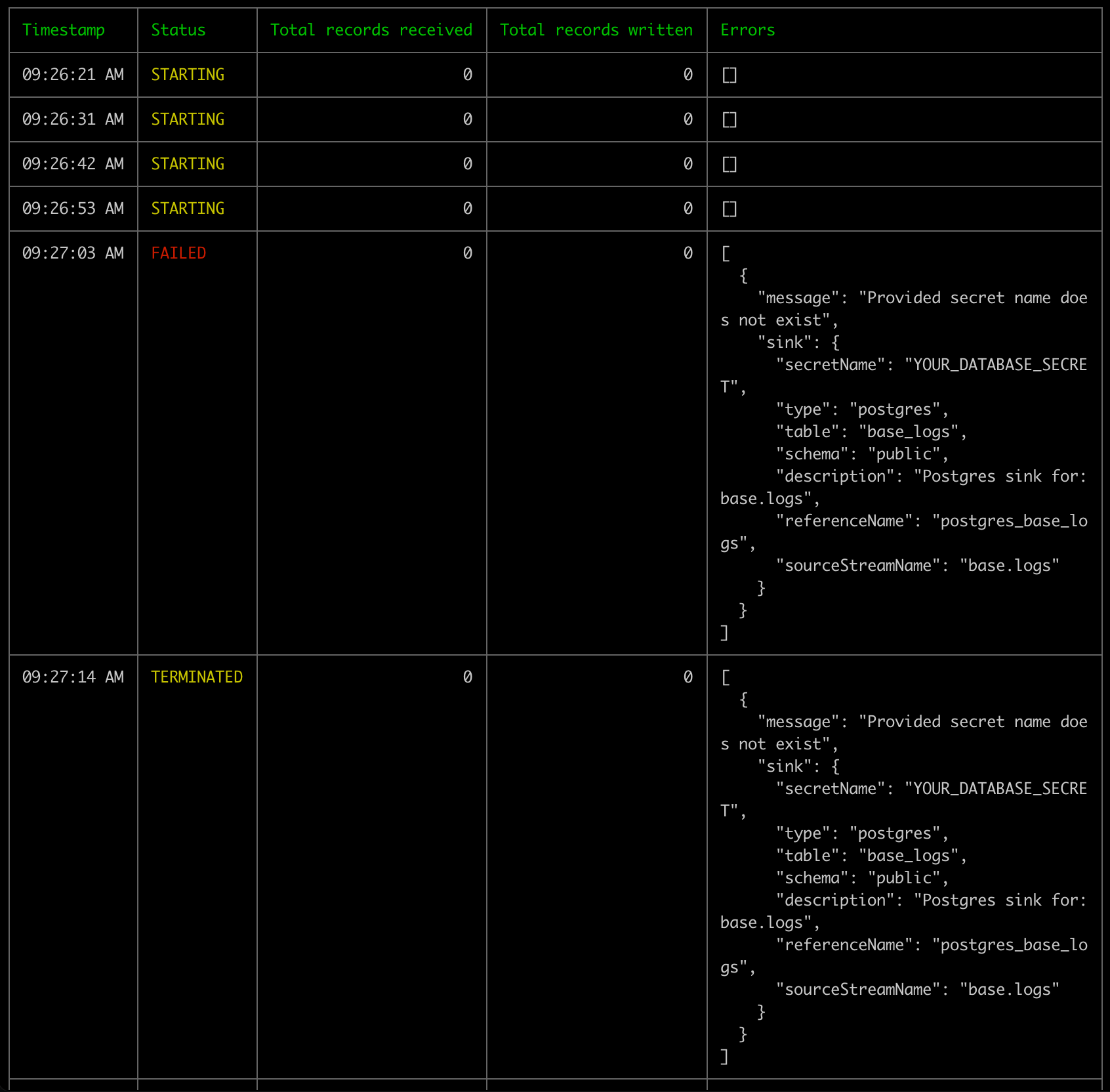 +
+As expected, the pipeline has encountered a terminal error. Please note that the desired status is still `ACTIVE` even though the pipeline runtime status is `TERMINATED`
+
+```
+❯ goldsky pipeline list
+✔ Listing pipelines
+─────────────────────────────────────────
+│ Name │ Version │ Status │ Resource │
+│ │ │ │ Size │
+─────────────────────────────────────────
+│ bad-base-logs-pipeline │ 1 │ ACTIVE │ s │
+─────────────────────────────────────────
+```
+
+## Runtime visibility
+
+Pipeline runtime visibility is an important part of the pipeline development workflow. Mirror pipelines expose:
+
+1. Runtime status and error messages
+2. Logs emitted by the pipeline
+3. Metrics on `Records received`, which counts all the records the pipeline has received from source(s) and, `Records written` which counts all records the pipeline has written to sink(s).
+4. [Email notifications](/mirror/about-pipeline#email-notifications)
+
+Runtime status, error messages and metrics can be seen via two methods:
+
+1. Pipeline dashboard at `https://app.goldsky.com/dashboard/pipelines/stream/
+
+As expected, the pipeline has encountered a terminal error. Please note that the desired status is still `ACTIVE` even though the pipeline runtime status is `TERMINATED`
+
+```
+❯ goldsky pipeline list
+✔ Listing pipelines
+─────────────────────────────────────────
+│ Name │ Version │ Status │ Resource │
+│ │ │ │ Size │
+─────────────────────────────────────────
+│ bad-base-logs-pipeline │ 1 │ ACTIVE │ s │
+─────────────────────────────────────────
+```
+
+## Runtime visibility
+
+Pipeline runtime visibility is an important part of the pipeline development workflow. Mirror pipelines expose:
+
+1. Runtime status and error messages
+2. Logs emitted by the pipeline
+3. Metrics on `Records received`, which counts all the records the pipeline has received from source(s) and, `Records written` which counts all records the pipeline has written to sink(s).
+4. [Email notifications](/mirror/about-pipeline#email-notifications)
+
+Runtime status, error messages and metrics can be seen via two methods:
+
+1. Pipeline dashboard at `https://app.goldsky.com/dashboard/pipelines/stream/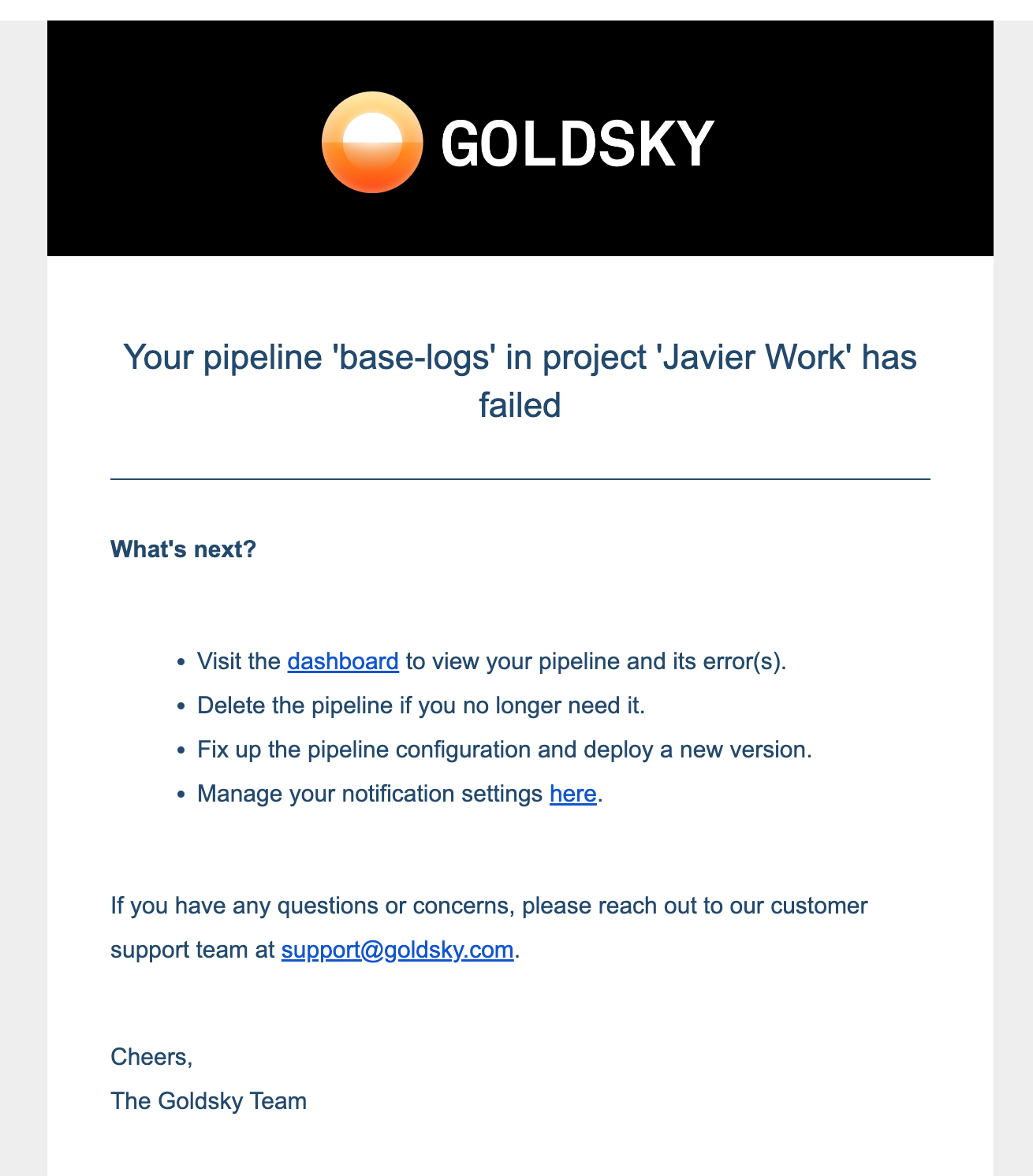 +
+You can configure this nofication in the [Notifications section](https://app.goldsky.com/dashboard/settings#notifications) of your project
+
+## Error handling
+
+There are two broad categories of errors.
+
+**Pipeline configuration schema error**
+
+This means the schema of the pipeline configuration is not valid. These errors are usually caught before pipeline execution. Some possible scenarios:
+
+* a required attribute is missing
+* transform SQL has syntax errors
+* pipeline name is invalid
+
+**Pipeline runtime error**
+
+This means the pipeline encountered error during execution at runtime.
+
+Some possible scenarios:
+
+* credentails stored in the secret are incorrect or do not have needed access privilages
+* sink availability issues
+* poison-pill record that breaks the business logic in the transforms
+* `resource_size` limitation
+
+Transient errors are automatically retried as per retry-policy (for upto 6 hours) whearas non-transient ones immediately terminate the pipeline.
+
+While many errors can be resolved by user intervention, there is a possibility of platform errors as well. Please [reachout to support](/getting-support) for investigation.
+
+## Resource sizing
+
+`resource_size` represents the compute (vCPUs and RAM) available to the pipeline. There are several options for pipeline sizes: `s, m, l, xl, xxl`. This attribute influences [pricing](/pricing/summary#mirror) as well.
+
+Resource sizing depends on a few different factors such as:
+
+* number of sources, transforms, sinks
+* expected amount of data to be processed.
+* transform sql involves joining multiple sources and/or transforms
+
+Here's some general information that you can use as reference:
+
+* A `small` resource size is usually enough in most use case: it can handle full backfill of small chain datasets and write to speeds of up to 300K records per second. For pipelines using
+ subgraphs as source it can reliably handle up to 8 subgraphs.
+* Larger resource sizes are usually needed when backfilling large chains or when doing large JOINS (example: JOIN between accounts and transactions datasets in Solana)
+* It's recommended to always follow a defensive approach: start small and scale up if needed.
+
+## Snapshots
+
+A Pipeline snapshot captures a point-in-time state of a `RUNNING` pipeline allowing users to resume from it in the future.
+
+It can be useful in various scenarios:
+
+* evolving your `RUNNING` pipeline (eg: adding a new source, sink) without losing progress made so far.
+* recover from new bug introductions where the user fix the bug and resume from an earlier snapshot to reprocess data.
+
+Please note that snapshot only contains info about the progress made in reading the source(s) and the sql transform's state. It isn't representative of the state of the source/sink. For eg: if all data in the sink database table is deleted, resuming the pipeline from a snapshot does not recover it.
+
+Currently, a pipeline can only be resumed from the latest available snapshot. If you need to resume from older snapshots, please [reachout to support](/getting-support)
+
+Snapshots are closely tied to pipeline runtime in that all [commands](/reference/config-file/pipeline#pipeline-runtime-commands) that changes pipeline runtime has options to trigger a new snapshot and/or resume from the latest one.
+
+```mermaid theme={null}
+%%{init: { 'gitGraph': {'mainBranchName': 'myPipeline-v1'}, 'theme': 'default' , 'themeVariables': { 'git0': '#ffbf60' }}}%%
+gitGraph
+ commit id: " " type: REVERSE tag:"start"
+ commit id: "snapshot1"
+ commit id: "snapshot2"
+ commit id: "snapshot3"
+ commit id: "snapshot4" tag:"stop" type: HIGHLIGHT
+ branch myPipeline-v2
+ commit id: "snapshot4 " type: REVERSE tag:"start"
+```
+
+### When are snapshots taken?
+
+1. When updating a `RUNNING` pipeline, a snapshot is created before applying the update. This is to ensure that there's an up-to-date snapshot in case the update introduces issues.
+2. When pausing a pipeline.
+3. Automatically on regular intervals. For `RUNNING` pipelines in healthy state, automatic snapshots are taken every 4 hours to ensure minimal data loss in case of errors.
+4. Users can request snapshot creation via the following CLI command:
+
+* `goldsky pipeline snapshot create
+
+You can configure this nofication in the [Notifications section](https://app.goldsky.com/dashboard/settings#notifications) of your project
+
+## Error handling
+
+There are two broad categories of errors.
+
+**Pipeline configuration schema error**
+
+This means the schema of the pipeline configuration is not valid. These errors are usually caught before pipeline execution. Some possible scenarios:
+
+* a required attribute is missing
+* transform SQL has syntax errors
+* pipeline name is invalid
+
+**Pipeline runtime error**
+
+This means the pipeline encountered error during execution at runtime.
+
+Some possible scenarios:
+
+* credentails stored in the secret are incorrect or do not have needed access privilages
+* sink availability issues
+* poison-pill record that breaks the business logic in the transforms
+* `resource_size` limitation
+
+Transient errors are automatically retried as per retry-policy (for upto 6 hours) whearas non-transient ones immediately terminate the pipeline.
+
+While many errors can be resolved by user intervention, there is a possibility of platform errors as well. Please [reachout to support](/getting-support) for investigation.
+
+## Resource sizing
+
+`resource_size` represents the compute (vCPUs and RAM) available to the pipeline. There are several options for pipeline sizes: `s, m, l, xl, xxl`. This attribute influences [pricing](/pricing/summary#mirror) as well.
+
+Resource sizing depends on a few different factors such as:
+
+* number of sources, transforms, sinks
+* expected amount of data to be processed.
+* transform sql involves joining multiple sources and/or transforms
+
+Here's some general information that you can use as reference:
+
+* A `small` resource size is usually enough in most use case: it can handle full backfill of small chain datasets and write to speeds of up to 300K records per second. For pipelines using
+ subgraphs as source it can reliably handle up to 8 subgraphs.
+* Larger resource sizes are usually needed when backfilling large chains or when doing large JOINS (example: JOIN between accounts and transactions datasets in Solana)
+* It's recommended to always follow a defensive approach: start small and scale up if needed.
+
+## Snapshots
+
+A Pipeline snapshot captures a point-in-time state of a `RUNNING` pipeline allowing users to resume from it in the future.
+
+It can be useful in various scenarios:
+
+* evolving your `RUNNING` pipeline (eg: adding a new source, sink) without losing progress made so far.
+* recover from new bug introductions where the user fix the bug and resume from an earlier snapshot to reprocess data.
+
+Please note that snapshot only contains info about the progress made in reading the source(s) and the sql transform's state. It isn't representative of the state of the source/sink. For eg: if all data in the sink database table is deleted, resuming the pipeline from a snapshot does not recover it.
+
+Currently, a pipeline can only be resumed from the latest available snapshot. If you need to resume from older snapshots, please [reachout to support](/getting-support)
+
+Snapshots are closely tied to pipeline runtime in that all [commands](/reference/config-file/pipeline#pipeline-runtime-commands) that changes pipeline runtime has options to trigger a new snapshot and/or resume from the latest one.
+
+```mermaid theme={null}
+%%{init: { 'gitGraph': {'mainBranchName': 'myPipeline-v1'}, 'theme': 'default' , 'themeVariables': { 'git0': '#ffbf60' }}}%%
+gitGraph
+ commit id: " " type: REVERSE tag:"start"
+ commit id: "snapshot1"
+ commit id: "snapshot2"
+ commit id: "snapshot3"
+ commit id: "snapshot4" tag:"stop" type: HIGHLIGHT
+ branch myPipeline-v2
+ commit id: "snapshot4 " type: REVERSE tag:"start"
+```
+
+### When are snapshots taken?
+
+1. When updating a `RUNNING` pipeline, a snapshot is created before applying the update. This is to ensure that there's an up-to-date snapshot in case the update introduces issues.
+2. When pausing a pipeline.
+3. Automatically on regular intervals. For `RUNNING` pipelines in healthy state, automatic snapshots are taken every 4 hours to ensure minimal data loss in case of errors.
+4. Users can request snapshot creation via the following CLI command:
+
+* `goldsky pipeline snapshot create 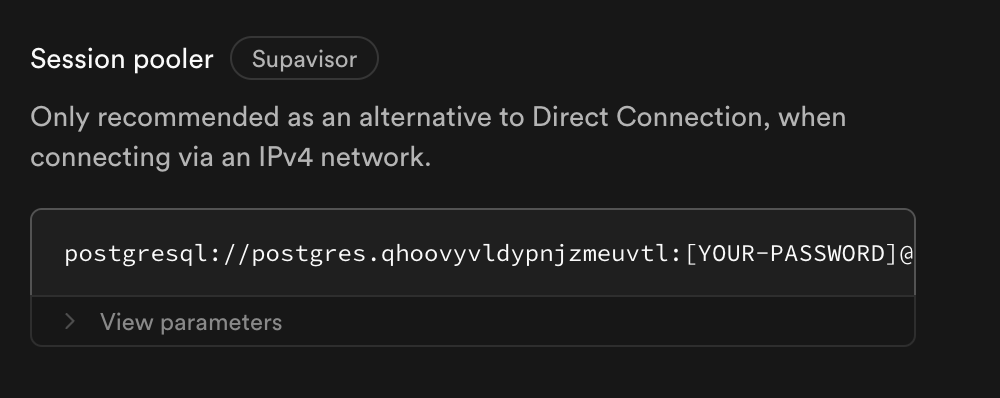 +2. Alternatively, buy the IPv4 add-on, if session pooling doesn't fit your needs. It can lead to more persistent direct connections,
+
+
+---
+
+> To find navigation and other pages in this documentation, fetch the llms.txt file at: https://docs.goldsky.com/llms.txt
+
+# PostgreSQL
+
+[PostgreSQL](https://www.postgresql.org/) is a powerful, open source object-relational database system used for OLTP workloads.
+
+Mirror supports PostgreSQL as a sink, allowing you to write data directly into PostgreSQL. This provides a robust and flexible solution for both mid-sized analytical workloads and high performance REST and GraphQL APIs.
+
+When you create a new pipeline, a table will be automatically created with columns from the source dataset. If a table is already created, the pipeline will write to it. As an example, you can set up partitions before you setup the pipeline, allowing you to scale PostgreSQL even further.
+
+The PostgreSQL also supports Timescale hypertables, if the hypertable is already setup. We have a separate Timescale sink in technical preview that will automatically setup hypertables for you - contact [support@goldsky.com](mailto:support@goldsky.com) for access.
+
+Full configuration details for PostgreSQL sink is available in the [reference](/reference/config-file/pipeline#postgresql) page.
+
+## Role Creation
+
+Here is an example snippet to give the permissions needed for pipelines.
+
+```sql theme={null}
+
+CREATE ROLE goldsky_writer WITH LOGIN PASSWORD 'supersecurepassword';
+
+-- Allow the pipeline to create schemas.
+-- This is needed even if the schemas already exist
+GRANT CREATE ON DATABASE postgres TO goldsky_writer;
+
+-- For existing schemas that you want the pipeline to write to:
+GRANT USAGE, CREATE ON SCHEMA
+2. Alternatively, buy the IPv4 add-on, if session pooling doesn't fit your needs. It can lead to more persistent direct connections,
+
+
+---
+
+> To find navigation and other pages in this documentation, fetch the llms.txt file at: https://docs.goldsky.com/llms.txt
+
+# ClickHouse
+
+[ClickHouse](https://clickhouse.com/) is a highly performant and cost-effective OLAP database that can support real-time inserts. Mirror pipelines can write subgraph or blockchain data directly into ClickHouse with full data guarantees and reorganization handling.
+
+Mirror can work with any ClickHouse setup, but we have several strong defaults. From our experimentation, the `ReplacingMergeTree` table engine with `append_only_mode` offers the best real-time data performance for large datasets.
+
+[ReplacingMergeTree](https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/replacingmergetree) engine is used for all sink tables by default. If you don't want to use a ReplacingMergeTree, you can pre-create the table with any data engine you'd like. If you don't want to use a ReplacingMergeTree, you can disable `append_only_mode`.
+
+Full configuration details for Clickhouse sink is available in the [reference](/reference/config-file/pipeline#clickhouse) page.
+
+## Secrets
+
+
+2. Alternatively, buy the IPv4 add-on, if session pooling doesn't fit your needs. It can lead to more persistent direct connections,
+
+
+---
+
+> To find navigation and other pages in this documentation, fetch the llms.txt file at: https://docs.goldsky.com/llms.txt
+
+# PostgreSQL
+
+[PostgreSQL](https://www.postgresql.org/) is a powerful, open source object-relational database system used for OLTP workloads.
+
+Mirror supports PostgreSQL as a sink, allowing you to write data directly into PostgreSQL. This provides a robust and flexible solution for both mid-sized analytical workloads and high performance REST and GraphQL APIs.
+
+When you create a new pipeline, a table will be automatically created with columns from the source dataset. If a table is already created, the pipeline will write to it. As an example, you can set up partitions before you setup the pipeline, allowing you to scale PostgreSQL even further.
+
+The PostgreSQL also supports Timescale hypertables, if the hypertable is already setup. We have a separate Timescale sink in technical preview that will automatically setup hypertables for you - contact [support@goldsky.com](mailto:support@goldsky.com) for access.
+
+Full configuration details for PostgreSQL sink is available in the [reference](/reference/config-file/pipeline#postgresql) page.
+
+## Role Creation
+
+Here is an example snippet to give the permissions needed for pipelines.
+
+```sql theme={null}
+
+CREATE ROLE goldsky_writer WITH LOGIN PASSWORD 'supersecurepassword';
+
+-- Allow the pipeline to create schemas.
+-- This is needed even if the schemas already exist
+GRANT CREATE ON DATABASE postgres TO goldsky_writer;
+
+-- For existing schemas that you want the pipeline to write to:
+GRANT USAGE, CREATE ON SCHEMA
+2. Alternatively, buy the IPv4 add-on, if session pooling doesn't fit your needs. It can lead to more persistent direct connections,
+
+
+---
+
+> To find navigation and other pages in this documentation, fetch the llms.txt file at: https://docs.goldsky.com/llms.txt
+
+# ClickHouse
+
+[ClickHouse](https://clickhouse.com/) is a highly performant and cost-effective OLAP database that can support real-time inserts. Mirror pipelines can write subgraph or blockchain data directly into ClickHouse with full data guarantees and reorganization handling.
+
+Mirror can work with any ClickHouse setup, but we have several strong defaults. From our experimentation, the `ReplacingMergeTree` table engine with `append_only_mode` offers the best real-time data performance for large datasets.
+
+[ReplacingMergeTree](https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/replacingmergetree) engine is used for all sink tables by default. If you don't want to use a ReplacingMergeTree, you can pre-create the table with any data engine you'd like. If you don't want to use a ReplacingMergeTree, you can disable `append_only_mode`.
+
+Full configuration details for Clickhouse sink is available in the [reference](/reference/config-file/pipeline#clickhouse) page.
+
+## Secrets
+
+ +
+
+# Account profile
+Source: https://paragraph.com/docs/account/profile
+
+How to update your account profile on Paragraph.
+
+Your profile details appear on your author profile, on your posts, and whenever someone hovers over your profile pic across the Paragraph product.
+
+**Where to find these settings:** Avatar in top-right corner → [****Settings → Author****](https://paragraph.com/settings/account/author).
+
+**Fields:**
+
+* **Name** – shown on your posts.
+* **Bio** – up to **500 characters**; a short description that appears on your profile.
+* **Profile photo** – upload a square image (recommended **400 × 400 px**).
+
+
+
+
+# Account profile
+Source: https://paragraph.com/docs/account/profile
+
+How to update your account profile on Paragraph.
+
+Your profile details appear on your author profile, on your posts, and whenever someone hovers over your profile pic across the Paragraph product.
+
+**Where to find these settings:** Avatar in top-right corner → [****Settings → Author****](https://paragraph.com/settings/account/author).
+
+**Fields:**
+
+* **Name** – shown on your posts.
+* **Bio** – up to **500 characters**; a short description that appears on your profile.
+* **Profile photo** – upload a square image (recommended **400 × 400 px**).
+
+ +
+Here's an example of the profile being shown when hovering over someone's profile picture:
+
+
+
+Here's an example of the profile being shown when hovering over someone's profile picture:
+
+ +
+
+# Social
+Source: https://paragraph.com/docs/account/social
+
+Add social links and find people you follow on Farcaster.
+
+You can add your social accounts to your profile so readers can follow you across platforms. Connecting our Farcaster account also allows you to easily find and subscribe to Paragraph writers you follow.
+
+**Where to find these settings:** Avatar in top-right corner → [****Settings → Social****](https://paragraph.com/settings/account/social).
+
+### **Social media links**
+
+* Add handles for **X**, **GitHub**, **Instagram**, and **Facebook**.
+* These links are shown to readers so they can follow you beyond your publication.
+
+### **Farcaster**
+
+* In the **Farcaster** section, discover people you already follow on Farcaster and **subscribe** to their publications on Paragraph with one click.
+* Entries show follower counts and a **Subscribe/Subscribed** button.
+
+
+
+
+# Social
+Source: https://paragraph.com/docs/account/social
+
+Add social links and find people you follow on Farcaster.
+
+You can add your social accounts to your profile so readers can follow you across platforms. Connecting our Farcaster account also allows you to easily find and subscribe to Paragraph writers you follow.
+
+**Where to find these settings:** Avatar in top-right corner → [****Settings → Social****](https://paragraph.com/settings/account/social).
+
+### **Social media links**
+
+* Add handles for **X**, **GitHub**, **Instagram**, and **Facebook**.
+* These links are shown to readers so they can follow you beyond your publication.
+
+### **Farcaster**
+
+* In the **Farcaster** section, discover people you already follow on Farcaster and **subscribe** to their publications on Paragraph with one click.
+* Entries show follower counts and a **Subscribe/Subscribed** button.
+
+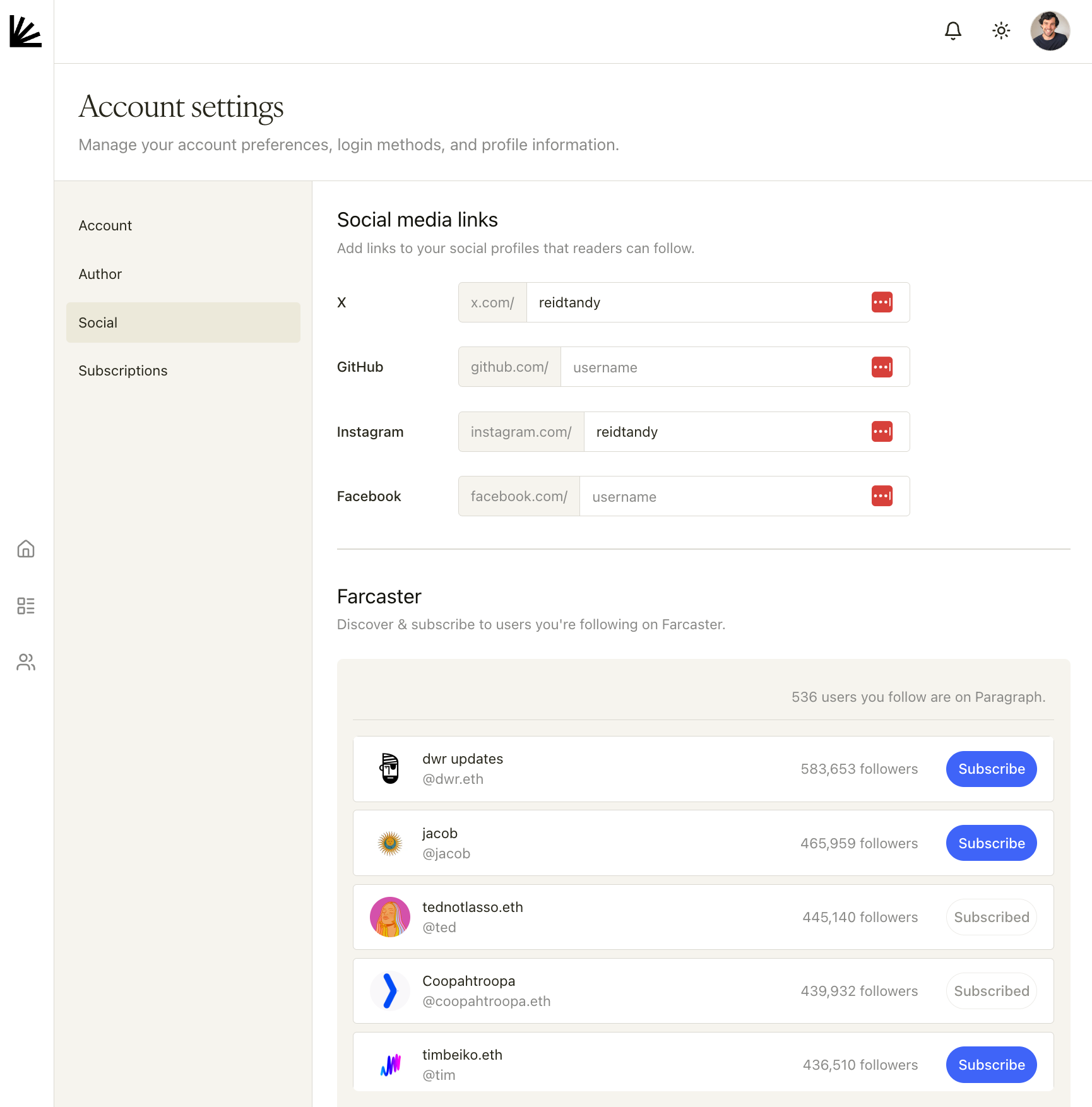 +
+
+# Subscriptions
+Source: https://paragraph.com/docs/account/subscriptions
+
+See and manage everything you’re subscribed to on Paragraph.
+
+**Where to find these settings:** Avatar in top-right corner → [****Settings → Subscriptions****](https://paragraph.com/settings/account/subscriptions).
+
+**On this page you can:**
+
+* **Review your subscriptions** (publication name and date subscribed).
+* **Adjust email preferences** per publication (e.g., “All emails”). Click the gear icon to change delivery settings.
+* **Unsubscribe** from a publication.
+
+
+
+
+# Subscriptions
+Source: https://paragraph.com/docs/account/subscriptions
+
+See and manage everything you’re subscribed to on Paragraph.
+
+**Where to find these settings:** Avatar in top-right corner → [****Settings → Subscriptions****](https://paragraph.com/settings/account/subscriptions).
+
+**On this page you can:**
+
+* **Review your subscriptions** (publication name and date subscribed).
+* **Adjust email preferences** per publication (e.g., “All emails”). Click the gear icon to change delivery settings.
+* **Unsubscribe** from a publication.
+
+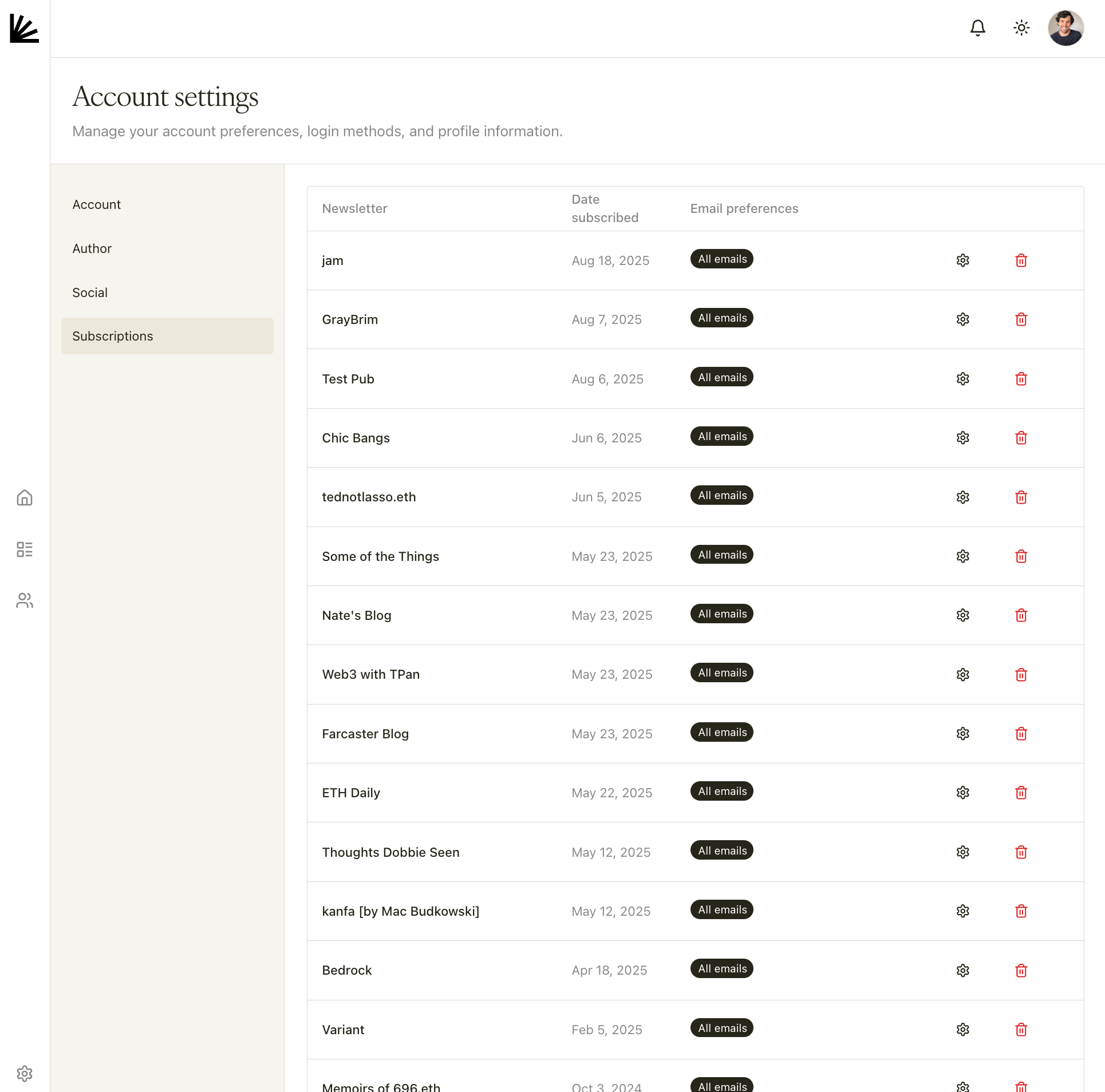 \ No newline at end of file
diff --git a/.agent/rules/paragraph-api-sdk.md b/.agent/rules/paragraph-api-sdk.md
new file mode 100644
index 000000000..7de77efd2
--- /dev/null
+++ b/.agent/rules/paragraph-api-sdk.md
@@ -0,0 +1,32 @@
+---
+trigger: model_decision
+description: Developers can interact with Paragraph data using a REST API or a TypeScript SDK, both of which are currently in alpha and provide access to publications, posts, coins, and user profiles
+---
+
+Using the TypeScript SDK
+The SDK is a wrapper around the REST API designed for ease of use and type safety.
+• Installation and Setup: Developers can install the SDK via npm using npm i @paragraph-com/sdk. It requires Node.js version 19 or higher.
+• Initialization: To start, instantiate the ParagraphAPI class. Public endpoints do not require an API key, but protected endpoints (like creating posts) require an API key passed in the configuration.
+• Common Patterns:
+ ◦ Fetching Data: Use methods like api.publications.get({ slug }) to find publication IDs.
+ ◦ Pagination: The SDK supports cursor-based pagination for listing posts, allowing developers to fetch subsequent pages by passing the cursor from the previous response.
+ ◦ Specialized Queries: Developers can retrieve a specific object using the .single() method or fetch related data simultaneously, such as a coin and its holders, using Promise.all.
+Interacting via the REST API
+The REST API allows for direct HTTP requests to manage the lifecycle of Paragraph content.
+• Authentication: Protected endpoints identify the publication using an API key provided in the Authorization header.
+• Core Capabilities:
+ ◦ Posts: Developers can programmatically create new posts by providing a title and markdown content. They can also retrieve detailed post info by ID or slug.
+ ◦ Subscribers: The API supports adding individual subscribers (via email or wallet), listing active subscribers, and bulk-importing them from CSV files.
+ ◦ Coins: There are dedicated endpoints to retrieve information about tokenized posts, fetch price quotes in ETH, and get the specific arguments needed to buy or sell coins using a wallet.
+ ◦ Users: Detailed user profiles can be looked up using either a unique user ID or an Ethereum wallet address.
+Alternative and On-Chain Methods
+For more decentralized or real-time integrations, developers have additional options:
+• Arweave Access: Because Paragraph offers permanent storage on Arweave, developers can permissionlessly fetch posts without using Paragraph's own API. This involves querying Arweave via GraphQL for transaction IDs and then using the Arweave JS SDK to retrieve the TipTap JSON or HTML content.
+• On-Chain Events: Integrators can listen to Airlock (factory) events on the Base network to discover new Paragraph coins as they are launched. This is done by verifying if a coin's integrator address matches the Paragraph integrator address.
+• AI-Assisted Development: Developers can provide the full documentation URL (https://paragraph.com/docs/llms-full.txt) to LLMs to give them complete knowledge of the API. There is also a Paragraph MCP server available to integrate documentation and API access directly into AI clients like Claude Code.
+Important Constraints
+• Rate Limiting: The API is rate-limited; developers must implement appropriate retry logic and can request limit increases via support.
+• Breaking Changes: Because the API is in alpha, breaking changes may occur until the design is finalized.
+
+--------------------------------------------------------------------------------
+Analogy: Think of Paragraph’s infrastructure as a modular library. You can use the front desk (REST API) for direct requests, hire a dedicated assistant (TypeScript SDK) who speaks your language fluently to handle the paperwork, or if the building is closed, you can always check the public archives (Arweave) for a permanent record.
\ No newline at end of file
diff --git a/.agent/rules/paragraph-coins-posts.md b/.agent/rules/paragraph-coins-posts.md
new file mode 100644
index 000000000..c800f7cb0
--- /dev/null
+++ b/.agent/rules/paragraph-coins-posts.md
@@ -0,0 +1,168 @@
+---
+trigger: model_decision
+description: Paragraphs coins and publications
+---
+
+# Get coin by contract address
+Source: https://paragraph.com/docs/api-reference/coins/get-coin-by-contract-address
+
+paragraph-api/openapi.json get /v1/coins/contract/{contractAddress}
+Retrieve information about a tokenized post using its contract address
+
+
+
+# Get coin by ID
+Source: https://paragraph.com/docs/api-reference/coins/get-coin-by-id
+
+paragraph-api/openapi.json get /v1/coins/{id}
+Retrieve information about a tokenized post using its unique ID
+
+
+
+# Get coin quote by contract address
+Source: https://paragraph.com/docs/api-reference/coins/get-coin-quote-by-contract-address
+
+paragraph-api/openapi.json get /v1/coins/quote/contract/{contractAddress}
+Retrieve a quote for the amount of the coin in exchange of ETH
+
+
+
+# Get coin quote by ID
+Source: https://paragraph.com/docs/api-reference/coins/get-coin-quote-by-id
+
+paragraph-api/openapi.json get /v1/coins/quote/{id}
+Retrieve a quote for the amount of coin in exchange of ETH
+
+
+
+# Get coin's buy args by contract address
+Source: https://paragraph.com/docs/api-reference/coins/get-coins-buy-args-by-contract-address
+
+paragraph-api/openapi.json get /v1/coins/buy/contract/{contractAddress}
+Retrieve the args needed to buy a coin using a wallet
+
+
+
+# Get coin's buy args by ID
+Source: https://paragraph.com/docs/api-reference/coins/get-coins-buy-args-by-id
+
+paragraph-api/openapi.json get /v1/coins/buy/{id}
+Retrieve the args needed to buy a coin using a wallet
+
+
+
+# Get coin's sell args by contract address
+Source: https://paragraph.com/docs/api-reference/coins/get-coins-sell-args-by-contract-address
+
+paragraph-api/openapi.json get /v1/coins/sell/contract/{contractAddress}
+Retrieve the args needed to sell a coin using a wallet that has it
+
+
+
+# Get coin's sell args by ID
+Source: https://paragraph.com/docs/api-reference/coins/get-coins-sell-args-by-id
+
+paragraph-api/openapi.json get /v1/coins/sell/{id}
+Retrieve the args needed to sell a coin using a wallet that has it
+
+
+
+# Get popular coins
+Source: https://paragraph.com/docs/api-reference/coins/get-popular-coins
+
+paragraph-api/openapi.json get /v1/coins/list/popular
+Retrieve popular coins
+
+
+
+# List coin holders by contract address
+Source: https://paragraph.com/docs/api-reference/coins/list-coin-holders-by-contract-address
+
+paragraph-api/openapi.json get /v1/coins/contract/{contractAddress}/holders
+Retrieve a paginated list of holders for a tokenized post
+
+
+
+# List coin holders by ID
+Source: https://paragraph.com/docs/api-reference/coins/list-coin-holders-by-id
+
+paragraph-api/openapi.json get /v1/coins/{id}/holders
+Retrieve a paginated list of holders for a coined post
+
+
+
+# Create a new post
+Source: https://paragraph.com/docs/api-reference/posts/create-a-new-post
+
+paragraph-api/openapi.json post /v1/posts
+Create a new post in your publication. The publication is identified by the API key provided in the Authorization header.
+
+**Requirements:**
+- `markdown` field is required and will be converted to TipTap JSON format
+- `title` field is required
+
+**Behavior:**
+- The post will be created as published by default
+- If `sendNewsletter` is true, an email will be sent to all subscribers
+
+
+
+# Get post by ID
+Source: https://paragraph.com/docs/api-reference/posts/get-post-by-id
+
+paragraph-api/openapi.json get /v1/posts/{postId}
+Retrieve detailed information about a specific post
+
+
+
+# Get post by publication ID and post slug
+Source: https://paragraph.com/docs/api-reference/posts/get-post-by-publication-id-and-post-slug
+
+paragraph-api/openapi.json get /v1/publications/{publicationId}/posts/slug/{postSlug}
+Retrieve a post using its publication ID and its URL-friendly slug
+
+
+
+# Get post by publication slug and post slug
+Source: https://paragraph.com/docs/api-reference/posts/get-post-by-publication-slug-and-post-slug
+
+paragraph-api/openapi.json get /v1/publications/slug/{publicationSlug}/posts/slug/{postSlug}
+Retrieve a post using its publication's slug and the post's slug. This is useful for building user-facing URLs.
+
+
+
+# Get posts feed
+Source: https://paragraph.com/docs/api-reference/posts/get-posts-feed
+
+paragraph-api/openapi.json get /v1/posts/feed
+Retrieve a curated, paginated list of posts.
+
+
+
+# List posts in a publication
+Source: https://paragraph.com/docs/api-reference/posts/list-posts-in-a-publication
+
+paragraph-api/openapi.json get /v1/publications/{publicationId}/posts
+Retrieve a paginated list of posts from a publication
+
+
+
+# Get publication by custom domain
+Source: https://paragraph.com/docs/api-reference/publications/get-publication-by-custom-domain
+
+paragraph-api/openapi.json get /v1/publications/domain/{domain}
+Retrieve publication details using its custom domain
+
+# Get publication by ID
+Source: https://paragraph.com/docs/api-reference/publications/get-publication-by-id
+
+paragraph-api/openapi.json get /v1/publications/{publicationId}
+Retrieve detailed information about a specific publication
+
+
+
+# Get publication by slug
+Source: https://paragraph.com/docs/api-reference/publications/get-publication-by-slug
+
+paragraph-api/openapi.json get /v1/publications/slug/{slug}
+Retrieve publication details using its URL-friendly slug. Optionally include an @ before the slug.
diff --git a/.agent/rules/react-joyride-accessibility.md b/.agent/rules/react-joyride-accessibility.md
new file mode 100644
index 000000000..7440ef5b5
--- /dev/null
+++ b/.agent/rules/react-joyride-accessibility.md
@@ -0,0 +1,14 @@
+---
+trigger: model_decision
+description: react-joyride aims to be fully accessible, using the WAI-ARIA guidelines to support users of assistive technologies.
+---
+
+# Accessibility
+
+react-joyride aims to be fully accessible, using the [WAI-ARIA](https://www.w3.org/WAI/intro/aria) guidelines to support users of assistive technologies.
+
+## Keyboard navigation
+
+When the dialog is open, the TAB key will keep the focus on the dialog elements (input|select|textarea|button|object) within its contents. Elements outside the tooltip will not receive focus.
+
+When the tooltip is closed the focus returns to the default.
diff --git a/.agent/rules/react-joyride-callback.md b/.agent/rules/react-joyride-callback.md
new file mode 100644
index 000000000..9fa1526d9
--- /dev/null
+++ b/.agent/rules/react-joyride-callback.md
@@ -0,0 +1,106 @@
+---
+trigger: model_decision
+description: You can get Joyride's state changes using the callback prop.
+---
+
+# Callback
+
+You can get Joyride's state changes using the `callback` prop.\
+It will receive an object with the current state.
+
+## Example data
+
+```typescript
+{
+ action: 'start',
+ controlled: true,
+ index: 0,
+ lifecycle: 'init',
+ origin: null,
+ size: 4,
+ status: 'running',
+ step: { /* the current step */ },
+ type: 'tour:start'
+}
+```
+
+```typescript
+{
+ action: 'update',
+ controlled: true,
+ index: 0,
+ lifecycle: 'beacon',
+ origin: null,
+ size: 4,
+ status: 'running',
+ step: { /* the current step */ },
+ type: 'beacon'
+}
+```
+
+```typescript
+{
+ action: 'next',
+ controlled: true,
+ index: 0,
+ lifecycle: 'complete',
+ origin: null,
+ size: 4,
+ status: 'running',
+ step: { /* the current step */ },
+ type: 'step:after'
+}
+```
+
+## Usage
+
+```tsx
+import React, { useState } from 'react';
+import Joyride, { ACTIONS, EVENTS, ORIGIN, STATUS, CallBackProps } from 'react-joyride';
+
+const steps = [
+ {
+ target: '.my-first-step',
+ content: 'This is my awesome feature!',
+ },
+];
+
+export default function App() {
+ const [run, setRun] = useState(false);
+ const [stepIndex, setStepIndex] = useState(0);
+
+ const handleJoyrideCallback = (data: CallBackProps) => {
+ const { action, index, origin, status, type } = data;
+
+ if (action === ACTIONS.CLOSE && origin === ORIGIN.KEYBOARD) {
+ // do something
+ }
+
+ if ([EVENTS.STEP_AFTER, EVENTS.TARGET_NOT_FOUND].includes(type)) {
+ // Update state to advance the tour
+ setStepIndex(index + (action === ACTIONS.PREV ? -1 : 1));
+ } else if ([STATUS.FINISHED, STATUS.SKIPPED].includes(status)) {
+ // You need to set our running state to false, so we can restart if we click start again.
+ setRun(false);
+ }
+
+ console.groupCollapsed(type);
+ console.log(data); //eslint-disable-line no-console
+ console.groupEnd();
+ };
+
+ const handleClickStart = () => {
+ setRun(true);
+ };
+
+ return (
+
\ No newline at end of file
diff --git a/.agent/rules/paragraph-api-sdk.md b/.agent/rules/paragraph-api-sdk.md
new file mode 100644
index 000000000..7de77efd2
--- /dev/null
+++ b/.agent/rules/paragraph-api-sdk.md
@@ -0,0 +1,32 @@
+---
+trigger: model_decision
+description: Developers can interact with Paragraph data using a REST API or a TypeScript SDK, both of which are currently in alpha and provide access to publications, posts, coins, and user profiles
+---
+
+Using the TypeScript SDK
+The SDK is a wrapper around the REST API designed for ease of use and type safety.
+• Installation and Setup: Developers can install the SDK via npm using npm i @paragraph-com/sdk. It requires Node.js version 19 or higher.
+• Initialization: To start, instantiate the ParagraphAPI class. Public endpoints do not require an API key, but protected endpoints (like creating posts) require an API key passed in the configuration.
+• Common Patterns:
+ ◦ Fetching Data: Use methods like api.publications.get({ slug }) to find publication IDs.
+ ◦ Pagination: The SDK supports cursor-based pagination for listing posts, allowing developers to fetch subsequent pages by passing the cursor from the previous response.
+ ◦ Specialized Queries: Developers can retrieve a specific object using the .single() method or fetch related data simultaneously, such as a coin and its holders, using Promise.all.
+Interacting via the REST API
+The REST API allows for direct HTTP requests to manage the lifecycle of Paragraph content.
+• Authentication: Protected endpoints identify the publication using an API key provided in the Authorization header.
+• Core Capabilities:
+ ◦ Posts: Developers can programmatically create new posts by providing a title and markdown content. They can also retrieve detailed post info by ID or slug.
+ ◦ Subscribers: The API supports adding individual subscribers (via email or wallet), listing active subscribers, and bulk-importing them from CSV files.
+ ◦ Coins: There are dedicated endpoints to retrieve information about tokenized posts, fetch price quotes in ETH, and get the specific arguments needed to buy or sell coins using a wallet.
+ ◦ Users: Detailed user profiles can be looked up using either a unique user ID or an Ethereum wallet address.
+Alternative and On-Chain Methods
+For more decentralized or real-time integrations, developers have additional options:
+• Arweave Access: Because Paragraph offers permanent storage on Arweave, developers can permissionlessly fetch posts without using Paragraph's own API. This involves querying Arweave via GraphQL for transaction IDs and then using the Arweave JS SDK to retrieve the TipTap JSON or HTML content.
+• On-Chain Events: Integrators can listen to Airlock (factory) events on the Base network to discover new Paragraph coins as they are launched. This is done by verifying if a coin's integrator address matches the Paragraph integrator address.
+• AI-Assisted Development: Developers can provide the full documentation URL (https://paragraph.com/docs/llms-full.txt) to LLMs to give them complete knowledge of the API. There is also a Paragraph MCP server available to integrate documentation and API access directly into AI clients like Claude Code.
+Important Constraints
+• Rate Limiting: The API is rate-limited; developers must implement appropriate retry logic and can request limit increases via support.
+• Breaking Changes: Because the API is in alpha, breaking changes may occur until the design is finalized.
+
+--------------------------------------------------------------------------------
+Analogy: Think of Paragraph’s infrastructure as a modular library. You can use the front desk (REST API) for direct requests, hire a dedicated assistant (TypeScript SDK) who speaks your language fluently to handle the paperwork, or if the building is closed, you can always check the public archives (Arweave) for a permanent record.
\ No newline at end of file
diff --git a/.agent/rules/paragraph-coins-posts.md b/.agent/rules/paragraph-coins-posts.md
new file mode 100644
index 000000000..c800f7cb0
--- /dev/null
+++ b/.agent/rules/paragraph-coins-posts.md
@@ -0,0 +1,168 @@
+---
+trigger: model_decision
+description: Paragraphs coins and publications
+---
+
+# Get coin by contract address
+Source: https://paragraph.com/docs/api-reference/coins/get-coin-by-contract-address
+
+paragraph-api/openapi.json get /v1/coins/contract/{contractAddress}
+Retrieve information about a tokenized post using its contract address
+
+
+
+# Get coin by ID
+Source: https://paragraph.com/docs/api-reference/coins/get-coin-by-id
+
+paragraph-api/openapi.json get /v1/coins/{id}
+Retrieve information about a tokenized post using its unique ID
+
+
+
+# Get coin quote by contract address
+Source: https://paragraph.com/docs/api-reference/coins/get-coin-quote-by-contract-address
+
+paragraph-api/openapi.json get /v1/coins/quote/contract/{contractAddress}
+Retrieve a quote for the amount of the coin in exchange of ETH
+
+
+
+# Get coin quote by ID
+Source: https://paragraph.com/docs/api-reference/coins/get-coin-quote-by-id
+
+paragraph-api/openapi.json get /v1/coins/quote/{id}
+Retrieve a quote for the amount of coin in exchange of ETH
+
+
+
+# Get coin's buy args by contract address
+Source: https://paragraph.com/docs/api-reference/coins/get-coins-buy-args-by-contract-address
+
+paragraph-api/openapi.json get /v1/coins/buy/contract/{contractAddress}
+Retrieve the args needed to buy a coin using a wallet
+
+
+
+# Get coin's buy args by ID
+Source: https://paragraph.com/docs/api-reference/coins/get-coins-buy-args-by-id
+
+paragraph-api/openapi.json get /v1/coins/buy/{id}
+Retrieve the args needed to buy a coin using a wallet
+
+
+
+# Get coin's sell args by contract address
+Source: https://paragraph.com/docs/api-reference/coins/get-coins-sell-args-by-contract-address
+
+paragraph-api/openapi.json get /v1/coins/sell/contract/{contractAddress}
+Retrieve the args needed to sell a coin using a wallet that has it
+
+
+
+# Get coin's sell args by ID
+Source: https://paragraph.com/docs/api-reference/coins/get-coins-sell-args-by-id
+
+paragraph-api/openapi.json get /v1/coins/sell/{id}
+Retrieve the args needed to sell a coin using a wallet that has it
+
+
+
+# Get popular coins
+Source: https://paragraph.com/docs/api-reference/coins/get-popular-coins
+
+paragraph-api/openapi.json get /v1/coins/list/popular
+Retrieve popular coins
+
+
+
+# List coin holders by contract address
+Source: https://paragraph.com/docs/api-reference/coins/list-coin-holders-by-contract-address
+
+paragraph-api/openapi.json get /v1/coins/contract/{contractAddress}/holders
+Retrieve a paginated list of holders for a tokenized post
+
+
+
+# List coin holders by ID
+Source: https://paragraph.com/docs/api-reference/coins/list-coin-holders-by-id
+
+paragraph-api/openapi.json get /v1/coins/{id}/holders
+Retrieve a paginated list of holders for a coined post
+
+
+
+# Create a new post
+Source: https://paragraph.com/docs/api-reference/posts/create-a-new-post
+
+paragraph-api/openapi.json post /v1/posts
+Create a new post in your publication. The publication is identified by the API key provided in the Authorization header.
+
+**Requirements:**
+- `markdown` field is required and will be converted to TipTap JSON format
+- `title` field is required
+
+**Behavior:**
+- The post will be created as published by default
+- If `sendNewsletter` is true, an email will be sent to all subscribers
+
+
+
+# Get post by ID
+Source: https://paragraph.com/docs/api-reference/posts/get-post-by-id
+
+paragraph-api/openapi.json get /v1/posts/{postId}
+Retrieve detailed information about a specific post
+
+
+
+# Get post by publication ID and post slug
+Source: https://paragraph.com/docs/api-reference/posts/get-post-by-publication-id-and-post-slug
+
+paragraph-api/openapi.json get /v1/publications/{publicationId}/posts/slug/{postSlug}
+Retrieve a post using its publication ID and its URL-friendly slug
+
+
+
+# Get post by publication slug and post slug
+Source: https://paragraph.com/docs/api-reference/posts/get-post-by-publication-slug-and-post-slug
+
+paragraph-api/openapi.json get /v1/publications/slug/{publicationSlug}/posts/slug/{postSlug}
+Retrieve a post using its publication's slug and the post's slug. This is useful for building user-facing URLs.
+
+
+
+# Get posts feed
+Source: https://paragraph.com/docs/api-reference/posts/get-posts-feed
+
+paragraph-api/openapi.json get /v1/posts/feed
+Retrieve a curated, paginated list of posts.
+
+
+
+# List posts in a publication
+Source: https://paragraph.com/docs/api-reference/posts/list-posts-in-a-publication
+
+paragraph-api/openapi.json get /v1/publications/{publicationId}/posts
+Retrieve a paginated list of posts from a publication
+
+
+
+# Get publication by custom domain
+Source: https://paragraph.com/docs/api-reference/publications/get-publication-by-custom-domain
+
+paragraph-api/openapi.json get /v1/publications/domain/{domain}
+Retrieve publication details using its custom domain
+
+# Get publication by ID
+Source: https://paragraph.com/docs/api-reference/publications/get-publication-by-id
+
+paragraph-api/openapi.json get /v1/publications/{publicationId}
+Retrieve detailed information about a specific publication
+
+
+
+# Get publication by slug
+Source: https://paragraph.com/docs/api-reference/publications/get-publication-by-slug
+
+paragraph-api/openapi.json get /v1/publications/slug/{slug}
+Retrieve publication details using its URL-friendly slug. Optionally include an @ before the slug.
diff --git a/.agent/rules/react-joyride-accessibility.md b/.agent/rules/react-joyride-accessibility.md
new file mode 100644
index 000000000..7440ef5b5
--- /dev/null
+++ b/.agent/rules/react-joyride-accessibility.md
@@ -0,0 +1,14 @@
+---
+trigger: model_decision
+description: react-joyride aims to be fully accessible, using the WAI-ARIA guidelines to support users of assistive technologies.
+---
+
+# Accessibility
+
+react-joyride aims to be fully accessible, using the [WAI-ARIA](https://www.w3.org/WAI/intro/aria) guidelines to support users of assistive technologies.
+
+## Keyboard navigation
+
+When the dialog is open, the TAB key will keep the focus on the dialog elements (input|select|textarea|button|object) within its contents. Elements outside the tooltip will not receive focus.
+
+When the tooltip is closed the focus returns to the default.
diff --git a/.agent/rules/react-joyride-callback.md b/.agent/rules/react-joyride-callback.md
new file mode 100644
index 000000000..9fa1526d9
--- /dev/null
+++ b/.agent/rules/react-joyride-callback.md
@@ -0,0 +1,106 @@
+---
+trigger: model_decision
+description: You can get Joyride's state changes using the callback prop.
+---
+
+# Callback
+
+You can get Joyride's state changes using the `callback` prop.\
+It will receive an object with the current state.
+
+## Example data
+
+```typescript
+{
+ action: 'start',
+ controlled: true,
+ index: 0,
+ lifecycle: 'init',
+ origin: null,
+ size: 4,
+ status: 'running',
+ step: { /* the current step */ },
+ type: 'tour:start'
+}
+```
+
+```typescript
+{
+ action: 'update',
+ controlled: true,
+ index: 0,
+ lifecycle: 'beacon',
+ origin: null,
+ size: 4,
+ status: 'running',
+ step: { /* the current step */ },
+ type: 'beacon'
+}
+```
+
+```typescript
+{
+ action: 'next',
+ controlled: true,
+ index: 0,
+ lifecycle: 'complete',
+ origin: null,
+ size: 4,
+ status: 'running',
+ step: { /* the current step */ },
+ type: 'step:after'
+}
+```
+
+## Usage
+
+```tsx
+import React, { useState } from 'react';
+import Joyride, { ACTIONS, EVENTS, ORIGIN, STATUS, CallBackProps } from 'react-joyride';
+
+const steps = [
+ {
+ target: '.my-first-step',
+ content: 'This is my awesome feature!',
+ },
+];
+
+export default function App() {
+ const [run, setRun] = useState(false);
+ const [stepIndex, setStepIndex] = useState(0);
+
+ const handleJoyrideCallback = (data: CallBackProps) => {
+ const { action, index, origin, status, type } = data;
+
+ if (action === ACTIONS.CLOSE && origin === ORIGIN.KEYBOARD) {
+ // do something
+ }
+
+ if ([EVENTS.STEP_AFTER, EVENTS.TARGET_NOT_FOUND].includes(type)) {
+ // Update state to advance the tour
+ setStepIndex(index + (action === ACTIONS.PREV ? -1 : 1));
+ } else if ([STATUS.FINISHED, STATUS.SKIPPED].includes(status)) {
+ // You need to set our running state to false, so we can restart if we click start again.
+ setRun(false);
+ }
+
+ console.groupCollapsed(type);
+ console.log(data); //eslint-disable-line no-console
+ console.groupEnd();
+ };
+
+ const handleClickStart = () => {
+ setRun(true);
+ };
+
+ return (
+