diff --git a/units/en/_toctree.yml b/units/en/_toctree.yml
index 040e10ab..4c289141 100644
--- a/units/en/_toctree.yml
+++ b/units/en/_toctree.yml
@@ -122,6 +122,8 @@
title: Diving deeper into policy-gradient
- local: unit4/pg-theorem
title: (Optional) the Policy Gradient Theorem
+ - local: unit4/glossary
+ title: Glossary
- local: unit4/hands-on
title: Hands-on
- local: unit4/quiz
@@ -146,6 +148,8 @@
title: Hands-on
- local: unit5/bonus
title: Bonus. Learn to create your own environments with Unity and MLAgents
+ - local: unit5/quiz
+ title: Quiz
- local: unit5/conclusion
title: Conclusion
- title: Unit 6. Actor Critic methods with Robotics environments
@@ -157,7 +161,9 @@
- local: unit6/advantage-actor-critic
title: Advantage Actor Critic (A2C)
- local: unit6/hands-on
- title: Advantage Actor Critic (A2C) using Robotics Simulations with PyBullet and Panda-Gym 🤖
+ title: Advantage Actor Critic (A2C) using Robotics Simulations with Panda-Gym 🤖
+ - local: unit6/quiz
+ title: Quiz
- local: unit6/conclusion
title: Conclusion
- local: unit6/additional-readings
@@ -174,6 +180,8 @@
title: Self-Play
- local: unit7/hands-on
title: Let's train our soccer team to beat your classmates' teams (AI vs. AI)
+ - local: unit7/quiz
+ title: Quiz
- local: unit7/conclusion
title: Conclusion
- local: unit7/additional-readings
@@ -210,6 +218,8 @@
title: Model-Based Reinforcement Learning
- local: unitbonus3/offline-online
title: Offline vs. Online Reinforcement Learning
+ - local: unitbonus3/generalisation
+ title: Generalisation Reinforcement Learning
- local: unitbonus3/rlhf
title: Reinforcement Learning from Human Feedback
- local: unitbonus3/decision-transformers
@@ -220,8 +230,12 @@
title: (Automatic) Curriculum Learning for RL
- local: unitbonus3/envs-to-try
title: Interesting environments to try
+ - local: unitbonus3/learning-agents
+ title: An introduction to Unreal Learning Agents
- local: unitbonus3/godotrl
title: An Introduction to Godot RL
+ - local: unitbonus3/student-works
+ title: Students projects
- local: unitbonus3/rl-documentation
title: Brief introduction to RL documentation
- title: Certification and congratulations
diff --git a/units/en/communication/certification.mdx b/units/en/communication/certification.mdx
index 6d7ab34c..d82ef653 100644
--- a/units/en/communication/certification.mdx
+++ b/units/en/communication/certification.mdx
@@ -3,8 +3,10 @@
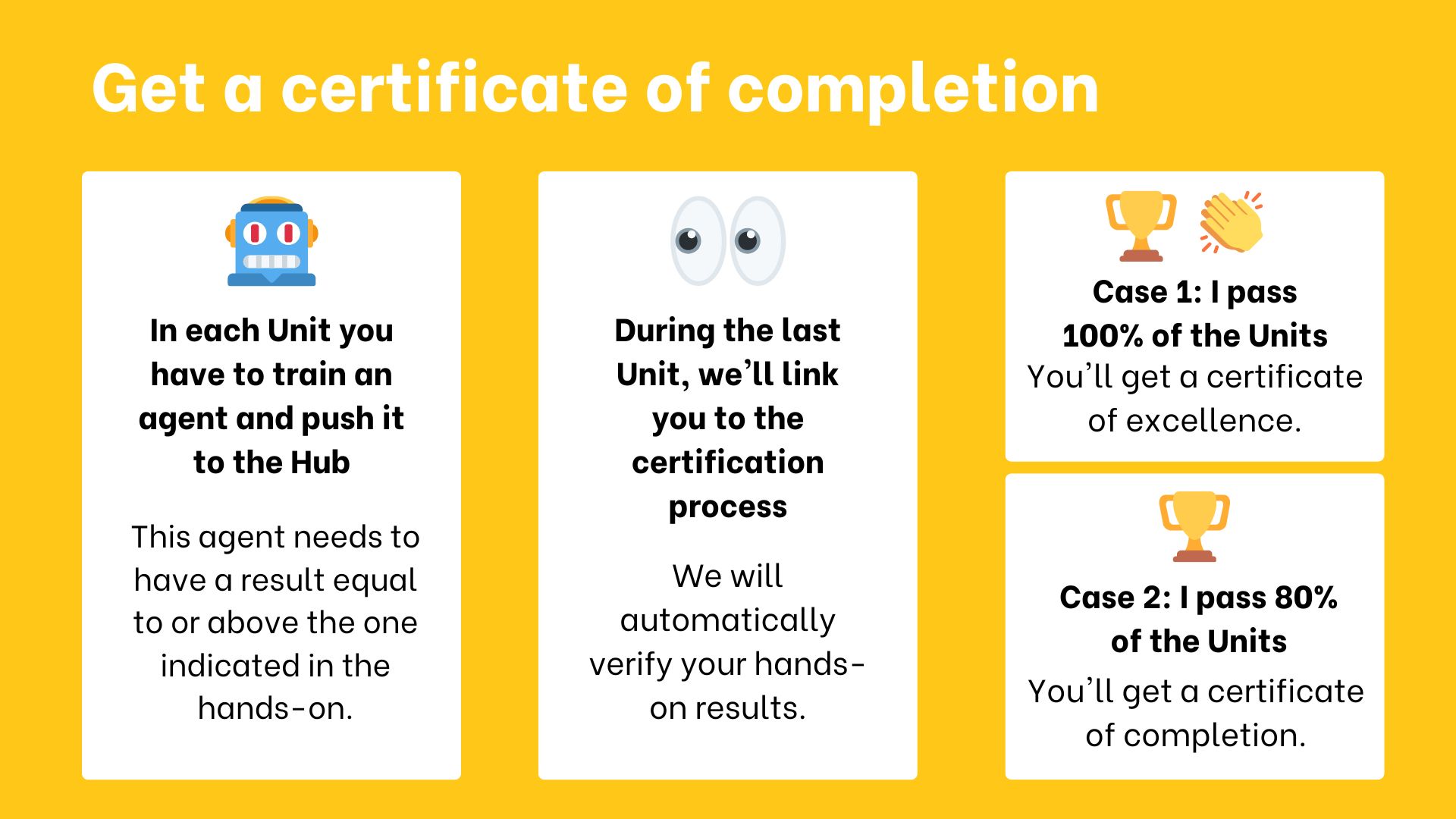
The certification process is **completely free**:
-- To get a *certificate of completion*: you need **to pass 80% of the assignments** before the end of July 2023.
-- To get a *certificate of excellence*: you need **to pass 100% of the assignments** before the end of July 2023.
+- To get a *certificate of completion*: you need **to pass 80% of the assignments**.
+- To get a *certificate of excellence*: you need **to pass 100% of the assignments**.
+
+There's **no deadlines, the course is self-paced**.
 diff --git a/units/en/unit0/discord101.mdx b/units/en/unit0/discord101.mdx
index 0406a976..962c766e 100644
--- a/units/en/unit0/discord101.mdx
+++ b/units/en/unit0/discord101.mdx
@@ -5,20 +5,18 @@ Although I don't know much about fetching sticks (yet), I know one or two things
diff --git a/units/en/unit0/discord101.mdx b/units/en/unit0/discord101.mdx
index 0406a976..962c766e 100644
--- a/units/en/unit0/discord101.mdx
+++ b/units/en/unit0/discord101.mdx
@@ -5,20 +5,18 @@ Although I don't know much about fetching sticks (yet), I know one or two things
 -Discord is a free chat platform. If you've used Slack, **it's quite similar**. There is a Hugging Face Community Discord server with 36000 members you can join with a single click here. So many humans to play with!
+Discord is a free chat platform. If you've used Slack, **it's quite similar**. There is a Hugging Face Community Discord server with 50000 members you can join with a single click here. So many humans to play with!
Starting in Discord can be a bit intimidating, so let me take you through it.
-When you [sign-up to our Discord server](http://hf.co/join/discord), you'll choose your interests. Make sure to **click "Reinforcement Learning"**.
+When you [sign-up to our Discord server](http://hf.co/join/discord), you'll choose your interests. Make sure to **click "Reinforcement Learning,"** and you'll get access to the Reinforcement Learning Category containing all the course-related channels. If you feel like joining even more channels, go for it! 🚀
Then click next, you'll then get to **introduce yourself in the `#introduce-yourself` channel**.
-Discord is a free chat platform. If you've used Slack, **it's quite similar**. There is a Hugging Face Community Discord server with 36000 members you can join with a single click here. So many humans to play with!
+Discord is a free chat platform. If you've used Slack, **it's quite similar**. There is a Hugging Face Community Discord server with 50000 members you can join with a single click here. So many humans to play with!
Starting in Discord can be a bit intimidating, so let me take you through it.
-When you [sign-up to our Discord server](http://hf.co/join/discord), you'll choose your interests. Make sure to **click "Reinforcement Learning"**.
+When you [sign-up to our Discord server](http://hf.co/join/discord), you'll choose your interests. Make sure to **click "Reinforcement Learning,"** and you'll get access to the Reinforcement Learning Category containing all the course-related channels. If you feel like joining even more channels, go for it! 🚀
Then click next, you'll then get to **introduce yourself in the `#introduce-yourself` channel**.
 -## So which channels are interesting to me? [[channels]]
-
-They are in the reinforcement learning lounge. **Don't forget to sign up to these channels** by clicking on 🤖 Reinforcement Learning in `role-assigment`.
+They are in the reinforcement learning category. **Don't forget to sign up to these channels** by clicking on 🤖 Reinforcement Learning in `role-assigment`.
- `rl-announcements`: where we give the **lastest information about the course**.
- `rl-discussions`: where you can **exchange about RL and share information**.
- `rl-study-group`: where you can **ask questions and exchange with your classmates**.
diff --git a/units/en/unit0/introduction.mdx b/units/en/unit0/introduction.mdx
index 07c60faf..fec14228 100644
--- a/units/en/unit0/introduction.mdx
+++ b/units/en/unit0/introduction.mdx
@@ -59,10 +59,11 @@ This is the course's syllabus:
You can choose to follow this course either:
-- *To get a certificate of completion*: you need to complete 80% of the assignments before the end of July 2023.
-- *To get a certificate of honors*: you need to complete 100% of the assignments before the end of July 2023.
-- *As a simple audit*: you can participate in all challenges and do assignments if you want, but you have no deadlines.
+- *To get a certificate of completion*: you need to complete 80% of the assignments.
+- *To get a certificate of honors*: you need to complete 100% of the assignments.
+- *As a simple audit*: you can participate in all challenges and do assignments if you want.
+There's **no deadlines, the course is self-paced**.
Both paths **are completely free**.
Whatever path you choose, we advise you **to follow the recommended pace to enjoy the course and challenges with your fellow classmates.**
@@ -72,8 +73,10 @@ You don't need to tell us which path you choose. **If you get more than 80% of t
The certification process is **completely free**:
-- *To get a certificate of completion*: you need to complete 80% of the assignments before the end of July 2023.
-- *To get a certificate of honors*: you need to complete 100% of the assignments before the end of July 2023.
+- *To get a certificate of completion*: you need to complete 80% of the assignments.
+- *To get a certificate of honors*: you need to complete 100% of the assignments.
+
+Again, there's **no deadline** since the course is self paced. But our advice **is to follow the recommended pace section**.
@@ -100,15 +103,8 @@ You need only 3 things:
## What is the recommended pace? [[recommended-pace]]
-We defined a plan that you can follow to keep up the pace of the course.
-
-
-## So which channels are interesting to me? [[channels]]
-
-They are in the reinforcement learning lounge. **Don't forget to sign up to these channels** by clicking on 🤖 Reinforcement Learning in `role-assigment`.
+They are in the reinforcement learning category. **Don't forget to sign up to these channels** by clicking on 🤖 Reinforcement Learning in `role-assigment`.
- `rl-announcements`: where we give the **lastest information about the course**.
- `rl-discussions`: where you can **exchange about RL and share information**.
- `rl-study-group`: where you can **ask questions and exchange with your classmates**.
diff --git a/units/en/unit0/introduction.mdx b/units/en/unit0/introduction.mdx
index 07c60faf..fec14228 100644
--- a/units/en/unit0/introduction.mdx
+++ b/units/en/unit0/introduction.mdx
@@ -59,10 +59,11 @@ This is the course's syllabus:
You can choose to follow this course either:
-- *To get a certificate of completion*: you need to complete 80% of the assignments before the end of July 2023.
-- *To get a certificate of honors*: you need to complete 100% of the assignments before the end of July 2023.
-- *As a simple audit*: you can participate in all challenges and do assignments if you want, but you have no deadlines.
+- *To get a certificate of completion*: you need to complete 80% of the assignments.
+- *To get a certificate of honors*: you need to complete 100% of the assignments.
+- *As a simple audit*: you can participate in all challenges and do assignments if you want.
+There's **no deadlines, the course is self-paced**.
Both paths **are completely free**.
Whatever path you choose, we advise you **to follow the recommended pace to enjoy the course and challenges with your fellow classmates.**
@@ -72,8 +73,10 @@ You don't need to tell us which path you choose. **If you get more than 80% of t
The certification process is **completely free**:
-- *To get a certificate of completion*: you need to complete 80% of the assignments before the end of July 2023.
-- *To get a certificate of honors*: you need to complete 100% of the assignments before the end of July 2023.
+- *To get a certificate of completion*: you need to complete 80% of the assignments.
+- *To get a certificate of honors*: you need to complete 100% of the assignments.
+
+Again, there's **no deadline** since the course is self paced. But our advice **is to follow the recommended pace section**.
@@ -100,15 +103,8 @@ You need only 3 things:
## What is the recommended pace? [[recommended-pace]]
-We defined a plan that you can follow to keep up the pace of the course.
-
- -
- -
-
Each chapter in this course is designed **to be completed in 1 week, with approximately 3-4 hours of work per week**. However, you can take as much time as necessary to complete the course. If you want to dive into a topic more in-depth, we'll provide additional resources to help you achieve that.
-
## Who are we [[who-are-we]]
About the author:
@@ -120,7 +116,7 @@ About the team:
- Sayak Paul is a Developer Advocate Engineer at Hugging Face. He's interested in the area of representation learning (self-supervision, semi-supervision, model robustness). And he loves watching crime and action thrillers 🔪.
-## When do the challenges start? [[challenges]]
+## What are the challenges in this course? [[challenges]]
In this new version of the course, you have two types of challenges:
- [A leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) to compare your agent's performance to other classmates'.
diff --git a/units/en/unit0/setup.mdx b/units/en/unit0/setup.mdx
index 4f6f442e..73572a22 100644
--- a/units/en/unit0/setup.mdx
+++ b/units/en/unit0/setup.mdx
@@ -15,7 +15,7 @@ You can now sign up for our Discord Server. This is the place where you **can ch
👉🏻 Join our discord server here.
-When you join, remember to introduce yourself in #introduce-yourself and sign-up for reinforcement channels in #role-assignments.
+When you join, remember to introduce yourself in #introduce-yourself and sign-up for reinforcement channels in #channels-and-roles.
We have multiple RL-related channels:
- `rl-announcements`: where we give the latest information about the course.
diff --git a/units/en/unit1/hands-on.mdx b/units/en/unit1/hands-on.mdx
index 7661f8c2..3c87f27d 100644
--- a/units/en/unit1/hands-on.mdx
+++ b/units/en/unit1/hands-on.mdx
@@ -5,7 +5,7 @@
@@ -282,7 +282,7 @@ env.close()
## Create the LunarLander environment 🌛 and understand how it works
-### [The environment 🎮](https://gymnasium.farama.org/environments/box2d/lunar_lander/)
+### The environment 🎮
In this first tutorial, we’re going to train our agent, a [Lunar Lander](https://gymnasium.farama.org/environments/box2d/lunar_lander/), **to land correctly on the moon**. To do that, the agent needs to learn **to adapt its speed and position (horizontal, vertical, and angular) to land correctly.**
@@ -315,8 +315,8 @@ We see with `Observation Space Shape (8,)` that the observation is a vector of s
- Vertical speed (y)
- Angle
- Angular speed
-- If the left leg contact point has touched the land
-- If the right leg contact point has touched the land
+- If the left leg contact point has touched the land (boolean)
+- If the right leg contact point has touched the land (boolean)
```python
@@ -433,7 +433,7 @@ model = PPO(
# TODO: Train it for 1,000,000 timesteps
# TODO: Specify file name for model and save the model to file
-model_name = ""
+model_name = "ppo-LunarLander-v2"
```
#### Solution
diff --git a/units/en/unit1/rl-framework.mdx b/units/en/unit1/rl-framework.mdx
index cf155e7d..97453575 100644
--- a/units/en/unit1/rl-framework.mdx
+++ b/units/en/unit1/rl-framework.mdx
@@ -83,11 +83,11 @@ The actions can come from a *discrete* or *continuous space*:
-
-
Each chapter in this course is designed **to be completed in 1 week, with approximately 3-4 hours of work per week**. However, you can take as much time as necessary to complete the course. If you want to dive into a topic more in-depth, we'll provide additional resources to help you achieve that.
-
## Who are we [[who-are-we]]
About the author:
@@ -120,7 +116,7 @@ About the team:
- Sayak Paul is a Developer Advocate Engineer at Hugging Face. He's interested in the area of representation learning (self-supervision, semi-supervision, model robustness). And he loves watching crime and action thrillers 🔪.
-## When do the challenges start? [[challenges]]
+## What are the challenges in this course? [[challenges]]
In this new version of the course, you have two types of challenges:
- [A leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) to compare your agent's performance to other classmates'.
diff --git a/units/en/unit0/setup.mdx b/units/en/unit0/setup.mdx
index 4f6f442e..73572a22 100644
--- a/units/en/unit0/setup.mdx
+++ b/units/en/unit0/setup.mdx
@@ -15,7 +15,7 @@ You can now sign up for our Discord Server. This is the place where you **can ch
👉🏻 Join our discord server here.
-When you join, remember to introduce yourself in #introduce-yourself and sign-up for reinforcement channels in #role-assignments.
+When you join, remember to introduce yourself in #introduce-yourself and sign-up for reinforcement channels in #channels-and-roles.
We have multiple RL-related channels:
- `rl-announcements`: where we give the latest information about the course.
diff --git a/units/en/unit1/hands-on.mdx b/units/en/unit1/hands-on.mdx
index 7661f8c2..3c87f27d 100644
--- a/units/en/unit1/hands-on.mdx
+++ b/units/en/unit1/hands-on.mdx
@@ -5,7 +5,7 @@
@@ -282,7 +282,7 @@ env.close()
## Create the LunarLander environment 🌛 and understand how it works
-### [The environment 🎮](https://gymnasium.farama.org/environments/box2d/lunar_lander/)
+### The environment 🎮
In this first tutorial, we’re going to train our agent, a [Lunar Lander](https://gymnasium.farama.org/environments/box2d/lunar_lander/), **to land correctly on the moon**. To do that, the agent needs to learn **to adapt its speed and position (horizontal, vertical, and angular) to land correctly.**
@@ -315,8 +315,8 @@ We see with `Observation Space Shape (8,)` that the observation is a vector of s
- Vertical speed (y)
- Angle
- Angular speed
-- If the left leg contact point has touched the land
-- If the right leg contact point has touched the land
+- If the left leg contact point has touched the land (boolean)
+- If the right leg contact point has touched the land (boolean)
```python
@@ -433,7 +433,7 @@ model = PPO(
# TODO: Train it for 1,000,000 timesteps
# TODO: Specify file name for model and save the model to file
-model_name = ""
+model_name = "ppo-LunarLander-v2"
```
#### Solution
diff --git a/units/en/unit1/rl-framework.mdx b/units/en/unit1/rl-framework.mdx
index cf155e7d..97453575 100644
--- a/units/en/unit1/rl-framework.mdx
+++ b/units/en/unit1/rl-framework.mdx
@@ -83,11 +83,11 @@ The actions can come from a *discrete* or *continuous space*:
 -Again, in Super Mario Bros, we have only 5 possible actions: 4 directions and jumping
+In Super Mario Bros, we have only 4 possible actions: left, right, up (jumping) and down (crouching).
-In Super Mario Bros, we have a finite set of actions since we have only 4 directions and jump.
+Again, in Super Mario Bros, we have a finite set of actions since we have only 4 directions.
- *Continuous space*: the number of possible actions is **infinite**.
diff --git a/units/en/unit1/two-methods.mdx b/units/en/unit1/two-methods.mdx
index 44ce264f..fcfc04ad 100644
--- a/units/en/unit1/two-methods.mdx
+++ b/units/en/unit1/two-methods.mdx
@@ -54,7 +54,7 @@ We have two types of policies:
-
+
-Again, in Super Mario Bros, we have only 5 possible actions: 4 directions and jumping
+In Super Mario Bros, we have only 4 possible actions: left, right, up (jumping) and down (crouching).
-In Super Mario Bros, we have a finite set of actions since we have only 4 directions and jump.
+Again, in Super Mario Bros, we have a finite set of actions since we have only 4 directions.
- *Continuous space*: the number of possible actions is **infinite**.
diff --git a/units/en/unit1/two-methods.mdx b/units/en/unit1/two-methods.mdx
index 44ce264f..fcfc04ad 100644
--- a/units/en/unit1/two-methods.mdx
+++ b/units/en/unit1/two-methods.mdx
@@ -54,7 +54,7 @@ We have two types of policies:
-
+ Given an initial state, our stochastic policy will output probability distributions over the possible actions at that state.
diff --git a/units/en/unit2/glossary.mdx b/units/en/unit2/glossary.mdx
index 879931e4..f76ea52e 100644
--- a/units/en/unit2/glossary.mdx
+++ b/units/en/unit2/glossary.mdx
@@ -11,7 +11,7 @@ This is a community-created glossary. Contributions are welcomed!
### Among the value-based methods, we can find two main strategies
- **The state-value function.** For each state, the state-value function is the expected return if the agent starts in that state and follows the policy until the end.
-- **The action-value function.** In contrast to the state-value function, the action-value calculates for each state and action pair the expected return if the agent starts in that state and takes an action. Then it follows the policy forever after.
+- **The action-value function.** In contrast to the state-value function, the action-value calculates for each state and action pair the expected return if the agent starts in that state, takes that action, and then follows the policy forever after.
### Epsilon-greedy strategy:
@@ -32,6 +32,12 @@ This is a community-created glossary. Contributions are welcomed!
- **Off-policy algorithms:** A different policy is used at training time and inference time
- **On-policy algorithms:** The same policy is used during training and inference
+### Monte Carlo and Temporal Difference learning strategies
+
+- **Monte Carlo (MC):** Learning at the end of the episode. With Monte Carlo, we wait until the episode ends and then we update the value function (or policy function) from a complete episode.
+
+- **Temporal Difference (TD):** Learning at each step. With Temporal Difference Learning, we update the value function (or policy function) at each step without requiring a complete episode.
+
If you want to improve the course, you can [open a Pull Request.](https://github.com/huggingface/deep-rl-class/pulls)
This glossary was made possible thanks to:
diff --git a/units/en/unit2/hands-on.mdx b/units/en/unit2/hands-on.mdx
index f8dd666a..f55cc13e 100644
--- a/units/en/unit2/hands-on.mdx
+++ b/units/en/unit2/hands-on.mdx
@@ -2,7 +2,7 @@
@@ -93,16 +93,16 @@ Before diving into the notebook, you need to:
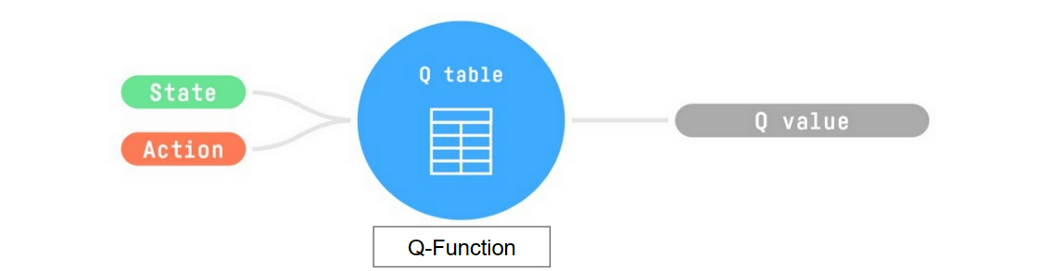
*Q-Learning* **is the RL algorithm that**:
-- Trains *Q-Function*, an **action-value function** that encoded, in internal memory, by a *Q-table* **that contains all the state-action pair values.**
+- Trains *Q-Function*, an **action-value function** that is encoded, in internal memory, by a *Q-table* **that contains all the state-action pair values.**
- Given a state and action, our Q-Function **will search the Q-table for the corresponding value.**
Given an initial state, our stochastic policy will output probability distributions over the possible actions at that state.
diff --git a/units/en/unit2/glossary.mdx b/units/en/unit2/glossary.mdx
index 879931e4..f76ea52e 100644
--- a/units/en/unit2/glossary.mdx
+++ b/units/en/unit2/glossary.mdx
@@ -11,7 +11,7 @@ This is a community-created glossary. Contributions are welcomed!
### Among the value-based methods, we can find two main strategies
- **The state-value function.** For each state, the state-value function is the expected return if the agent starts in that state and follows the policy until the end.
-- **The action-value function.** In contrast to the state-value function, the action-value calculates for each state and action pair the expected return if the agent starts in that state and takes an action. Then it follows the policy forever after.
+- **The action-value function.** In contrast to the state-value function, the action-value calculates for each state and action pair the expected return if the agent starts in that state, takes that action, and then follows the policy forever after.
### Epsilon-greedy strategy:
@@ -32,6 +32,12 @@ This is a community-created glossary. Contributions are welcomed!
- **Off-policy algorithms:** A different policy is used at training time and inference time
- **On-policy algorithms:** The same policy is used during training and inference
+### Monte Carlo and Temporal Difference learning strategies
+
+- **Monte Carlo (MC):** Learning at the end of the episode. With Monte Carlo, we wait until the episode ends and then we update the value function (or policy function) from a complete episode.
+
+- **Temporal Difference (TD):** Learning at each step. With Temporal Difference Learning, we update the value function (or policy function) at each step without requiring a complete episode.
+
If you want to improve the course, you can [open a Pull Request.](https://github.com/huggingface/deep-rl-class/pulls)
This glossary was made possible thanks to:
diff --git a/units/en/unit2/hands-on.mdx b/units/en/unit2/hands-on.mdx
index f8dd666a..f55cc13e 100644
--- a/units/en/unit2/hands-on.mdx
+++ b/units/en/unit2/hands-on.mdx
@@ -2,7 +2,7 @@
@@ -93,16 +93,16 @@ Before diving into the notebook, you need to:
*Q-Learning* **is the RL algorithm that**:
-- Trains *Q-Function*, an **action-value function** that encoded, in internal memory, by a *Q-table* **that contains all the state-action pair values.**
+- Trains *Q-Function*, an **action-value function** that is encoded, in internal memory, by a *Q-table* **that contains all the state-action pair values.**
- Given a state and action, our Q-Function **will search the Q-table for the corresponding value.**
 -- When the training is done,**we have an optimal Q-Function, so an optimal Q-Table.**
+- When the training is done, **we have an optimal Q-Function, so an optimal Q-Table.**
- And if we **have an optimal Q-function**, we
-have an optimal policy, since we **know for, each state, the best action to take.**
+have an optimal policy, since we **know for each state, the best action to take.**
-- When the training is done,**we have an optimal Q-Function, so an optimal Q-Table.**
+- When the training is done, **we have an optimal Q-Function, so an optimal Q-Table.**
- And if we **have an optimal Q-function**, we
-have an optimal policy, since we **know for, each state, the best action to take.**
+have an optimal policy, since we **know for each state, the best action to take.**
 @@ -146,7 +146,8 @@ pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/
```bash
sudo apt-get update
-apt install python-opengl ffmpeg xvfb
+sudo apt-get install -y python3-opengl
+apt install ffmpeg xvfb
pip3 install pyvirtualdisplay
```
@@ -246,7 +247,7 @@ print("Observation Space", env.observation_space)
print("Sample observation", env.observation_space.sample()) # Get a random observation
```
-We see with `Observation Space Shape Discrete(16)` that the observation is an integer representing the **agent’s current position as current_row * nrows + current_col (where both the row and col start at 0)**.
+We see with `Observation Space Shape Discrete(16)` that the observation is an integer representing the **agent’s current position as current_row * ncols + current_col (where both the row and col start at 0)**.
For example, the goal position in the 4x4 map can be calculated as follows: 3 * 4 + 3 = 15. The number of possible observations is dependent on the size of the map. **For example, the 4x4 map has 16 possible observations.**
@@ -352,7 +353,7 @@ def greedy_policy(Qtable, state):
return action
```
-##Define the epsilon-greedy policy 🤖
+## Define the epsilon-greedy policy 🤖
Epsilon-greedy is the training policy that handles the exploration/exploitation trade-off.
@@ -388,9 +389,9 @@ def epsilon_greedy_policy(Qtable, state, epsilon):
```python
def epsilon_greedy_policy(Qtable, state, epsilon):
# Randomly generate a number between 0 and 1
- random_int = random.uniform(0, 1)
- # if random_int > greater than epsilon --> exploitation
- if random_int > epsilon:
+ random_num = random.uniform(0, 1)
+ # if random_num > greater than epsilon --> exploitation
+ if random_num > epsilon:
# Take the action with the highest value given a state
# np.argmax can be useful here
action = greedy_policy(Qtable, state)
@@ -716,13 +717,10 @@ def push_to_hub(repo_id, model, env, video_fps=1, local_repo_path="hub"):
## Usage
- ```python
-
model = load_from_hub(repo_id="{repo_id}", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
- ```
"""
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
diff --git a/units/en/unit2/mc-vs-td.mdx b/units/en/unit2/mc-vs-td.mdx
index 78ef297c..ddc97e8c 100644
--- a/units/en/unit2/mc-vs-td.mdx
+++ b/units/en/unit2/mc-vs-td.mdx
@@ -57,18 +57,26 @@ For instance, if we train a state-value function using Monte Carlo:
@@ -146,7 +146,8 @@ pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/
```bash
sudo apt-get update
-apt install python-opengl ffmpeg xvfb
+sudo apt-get install -y python3-opengl
+apt install ffmpeg xvfb
pip3 install pyvirtualdisplay
```
@@ -246,7 +247,7 @@ print("Observation Space", env.observation_space)
print("Sample observation", env.observation_space.sample()) # Get a random observation
```
-We see with `Observation Space Shape Discrete(16)` that the observation is an integer representing the **agent’s current position as current_row * nrows + current_col (where both the row and col start at 0)**.
+We see with `Observation Space Shape Discrete(16)` that the observation is an integer representing the **agent’s current position as current_row * ncols + current_col (where both the row and col start at 0)**.
For example, the goal position in the 4x4 map can be calculated as follows: 3 * 4 + 3 = 15. The number of possible observations is dependent on the size of the map. **For example, the 4x4 map has 16 possible observations.**
@@ -352,7 +353,7 @@ def greedy_policy(Qtable, state):
return action
```
-##Define the epsilon-greedy policy 🤖
+## Define the epsilon-greedy policy 🤖
Epsilon-greedy is the training policy that handles the exploration/exploitation trade-off.
@@ -388,9 +389,9 @@ def epsilon_greedy_policy(Qtable, state, epsilon):
```python
def epsilon_greedy_policy(Qtable, state, epsilon):
# Randomly generate a number between 0 and 1
- random_int = random.uniform(0, 1)
- # if random_int > greater than epsilon --> exploitation
- if random_int > epsilon:
+ random_num = random.uniform(0, 1)
+ # if random_num > greater than epsilon --> exploitation
+ if random_num > epsilon:
# Take the action with the highest value given a state
# np.argmax can be useful here
action = greedy_policy(Qtable, state)
@@ -716,13 +717,10 @@ def push_to_hub(repo_id, model, env, video_fps=1, local_repo_path="hub"):
## Usage
- ```python
-
model = load_from_hub(repo_id="{repo_id}", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
- ```
"""
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
diff --git a/units/en/unit2/mc-vs-td.mdx b/units/en/unit2/mc-vs-td.mdx
index 78ef297c..ddc97e8c 100644
--- a/units/en/unit2/mc-vs-td.mdx
+++ b/units/en/unit2/mc-vs-td.mdx
@@ -57,18 +57,26 @@ For instance, if we train a state-value function using Monte Carlo:
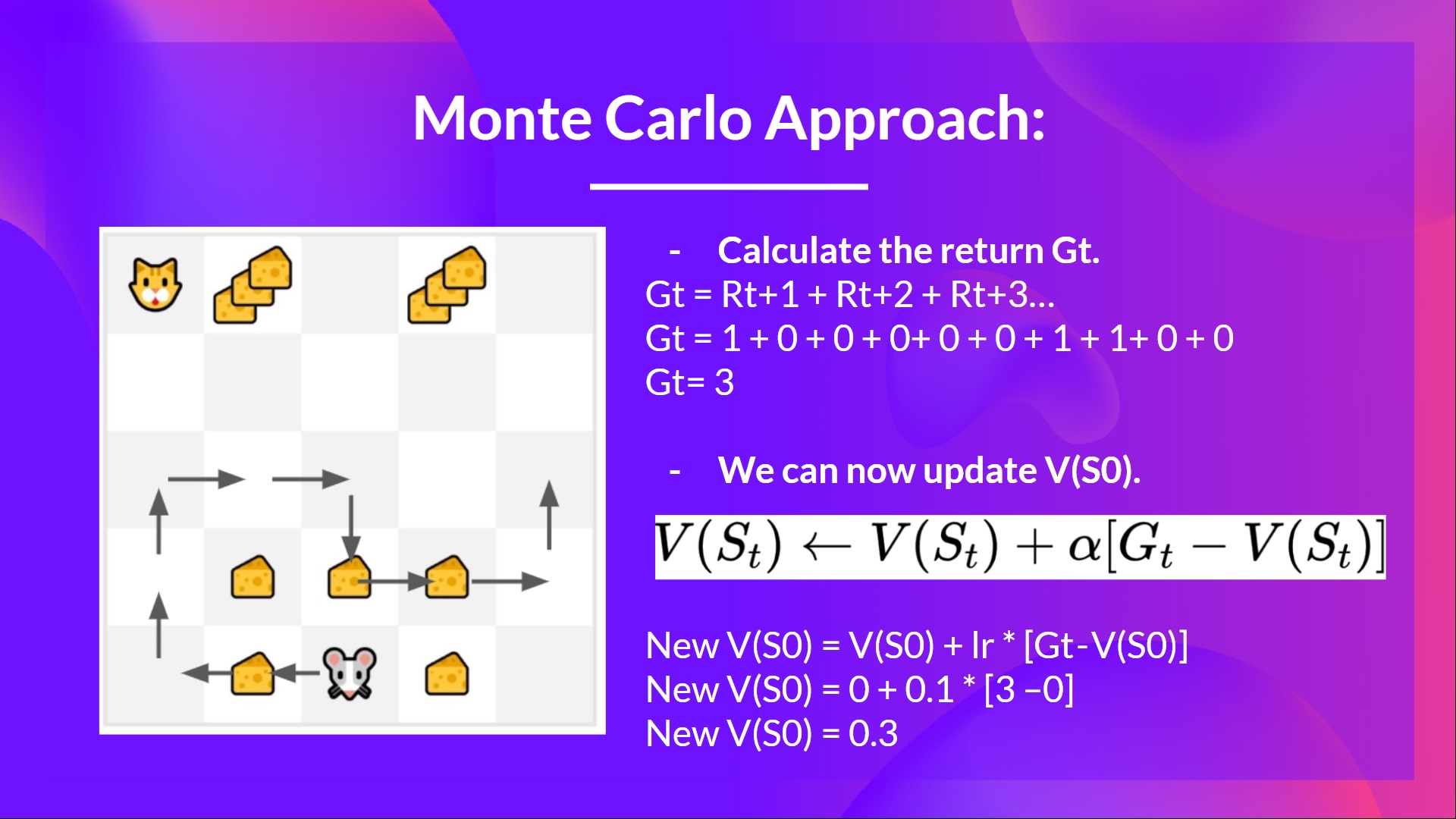
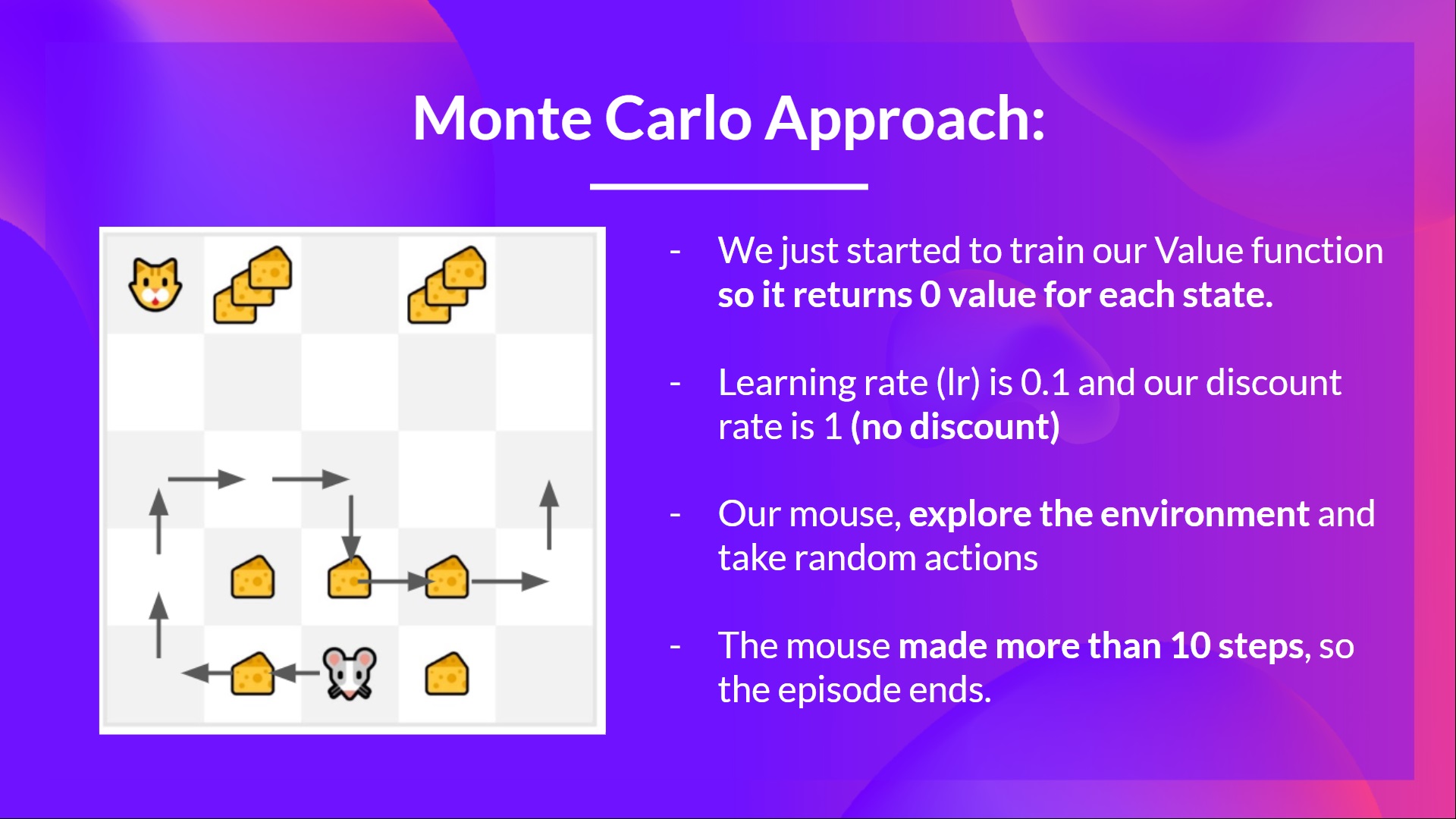 -- We have a list of state, action, rewards, next_state, **we need to calculate the return \\(G{t}\\)**
-- \\(G_t = R_{t+1} + R_{t+2} + R_{t+3} ...\\)
-- \\(G_t = R_{t+1} + R_{t+2} + R_{t+3}…\\) (for simplicity we don’t discount the rewards).
-- \\(G_t = 1 + 0 + 0 + 0+ 0 + 0 + 1 + 1 + 0 + 0\\)
-- \\(G_t= 3\\)
-- We can now update \\(V(S_0)\\):
+
+- We have a list of state, action, rewards, next_state, **we need to calculate the return \\(G{t=0}\\)**
+
+\\(G_t = R_{t+1} + R_{t+2} + R_{t+3} ...\\) (for simplicity, we don't discount the rewards)
+
+\\(G_0 = R_{1} + R_{2} + R_{3}…\\)
+
+\\(G_0 = 1 + 0 + 0 + 0 + 0 + 0 + 1 + 1 + 0 + 0\\)
+
+\\(G_0 = 3\\)
+
+- We can now compute the **new** \\(V(S_0)\\):
-- We have a list of state, action, rewards, next_state, **we need to calculate the return \\(G{t}\\)**
-- \\(G_t = R_{t+1} + R_{t+2} + R_{t+3} ...\\)
-- \\(G_t = R_{t+1} + R_{t+2} + R_{t+3}…\\) (for simplicity we don’t discount the rewards).
-- \\(G_t = 1 + 0 + 0 + 0+ 0 + 0 + 1 + 1 + 0 + 0\\)
-- \\(G_t= 3\\)
-- We can now update \\(V(S_0)\\):
+
+- We have a list of state, action, rewards, next_state, **we need to calculate the return \\(G{t=0}\\)**
+
+\\(G_t = R_{t+1} + R_{t+2} + R_{t+3} ...\\) (for simplicity, we don't discount the rewards)
+
+\\(G_0 = R_{1} + R_{2} + R_{3}…\\)
+
+\\(G_0 = 1 + 0 + 0 + 0 + 0 + 0 + 1 + 1 + 0 + 0\\)
+
+\\(G_0 = 3\\)
+
+- We can now compute the **new** \\(V(S_0)\\):
 -- New \\(V(S_0) = V(S_0) + lr * [G_t — V(S_0)]\\)
-- New \\(V(S_0) = 0 + 0.1 * [3 – 0]\\)
-- New \\(V(S_0) = 0.3\\)
+\\(V(S_0) = V(S_0) + lr * [G_0 — V(S_0)]\\)
+
+\\(V(S_0) = 0 + 0.1 * [3 – 0]\\)
+
+\\(V(S_0) = 0.3\\)
-- New \\(V(S_0) = V(S_0) + lr * [G_t — V(S_0)]\\)
-- New \\(V(S_0) = 0 + 0.1 * [3 – 0]\\)
-- New \\(V(S_0) = 0.3\\)
+\\(V(S_0) = V(S_0) + lr * [G_0 — V(S_0)]\\)
+
+\\(V(S_0) = 0 + 0.1 * [3 – 0]\\)
+
+\\(V(S_0) = 0.3\\)
 diff --git a/units/en/unit2/q-learning.mdx b/units/en/unit2/q-learning.mdx
index ec321720..1ff84565 100644
--- a/units/en/unit2/q-learning.mdx
+++ b/units/en/unit2/q-learning.mdx
@@ -27,7 +27,8 @@ Let's go through an example of a maze.
diff --git a/units/en/unit2/q-learning.mdx b/units/en/unit2/q-learning.mdx
index ec321720..1ff84565 100644
--- a/units/en/unit2/q-learning.mdx
+++ b/units/en/unit2/q-learning.mdx
@@ -27,7 +27,8 @@ Let's go through an example of a maze.
 -The Q-table is initialized. That's why all values are = 0. This table **contains, for each state and action, the corresponding state-action values.**
+The Q-table is initialized. That's why all values are = 0. This table **contains, for each state and action, the corresponding state-action values.**
+For this simple example, the state is only defined by the position of the mouse. Therefore, we have 2*3 rows in our Q-table, one row for each possible position of the mouse. In more complex scenarios, the state could contain more information than the position of the actor.
-The Q-table is initialized. That's why all values are = 0. This table **contains, for each state and action, the corresponding state-action values.**
+The Q-table is initialized. That's why all values are = 0. This table **contains, for each state and action, the corresponding state-action values.**
+For this simple example, the state is only defined by the position of the mouse. Therefore, we have 2*3 rows in our Q-table, one row for each possible position of the mouse. In more complex scenarios, the state could contain more information than the position of the actor.
 @@ -113,7 +114,7 @@ This means that to update our \\(Q(S_t, A_t)\\):
- To update our Q-value at a given state-action pair, we use the TD target.
How do we form the TD target?
-1. We obtain the reward after taking the action \\(R_{t+1}\\).
+1. We obtain the reward \\(R_{t+1}\\) after taking the action \\(A_t\\).
2. To get the **best state-action pair value** for the next state, we use a greedy policy to select the next best action. Note that this is not an epsilon-greedy policy, this will always take the action with the highest state-action value.
Then when the update of this Q-value is done, we start in a new state and select our action **using a epsilon-greedy policy again.**
diff --git a/units/en/unit3/deep-q-algorithm.mdx b/units/en/unit3/deep-q-algorithm.mdx
index adbe44a6..28e7fd50 100644
--- a/units/en/unit3/deep-q-algorithm.mdx
+++ b/units/en/unit3/deep-q-algorithm.mdx
@@ -40,8 +40,8 @@ Experience replay helps by **using the experiences of the training more efficien
⇒ This allows the agent to **learn from the same experiences multiple times**.
-2. **Avoid forgetting previous experiences and reduce the correlation between experiences**.
-- The problem we get if we give sequential samples of experiences to our neural network is that it tends to forget **the previous experiences as it gets new experiences.** For instance, if the agent is in the first level and then in the second, which is different, it can forget how to behave and play in the first level.
+2. **Avoid forgetting previous experiences (aka catastrophic interference, or catastrophic forgetting) and reduce the correlation between experiences**.
+- **[catastrophic forgetting](https://en.wikipedia.org/wiki/Catastrophic_interference)**: The problem we get if we give sequential samples of experiences to our neural network is that it tends to forget **the previous experiences as it gets new experiences.** For instance, if the agent is in the first level and then in the second, which is different, it can forget how to behave and play in the first level.
The solution is to create a Replay Buffer that stores experience tuples while interacting with the environment and then sample a small batch of tuples. This prevents **the network from only learning about what it has done immediately before.**
diff --git a/units/en/unit3/deep-q-network.mdx b/units/en/unit3/deep-q-network.mdx
index dc8cb13a..50cd4f2b 100644
--- a/units/en/unit3/deep-q-network.mdx
+++ b/units/en/unit3/deep-q-network.mdx
@@ -32,7 +32,7 @@ That’s why, to capture temporal information, we stack four frames together.
Then the stacked frames are processed by three convolutional layers. These layers **allow us to capture and exploit spatial relationships in images**. But also, because the frames are stacked together, **we can exploit some temporal properties across those frames**.
-If you don't know what convolutional layers are, don't worry. You can check out [Lesson 4 of this free Deep Reinforcement Learning Course by Udacity](https://www.udacity.com/course/deep-learning-pytorch--ud188)
+If you don't know what convolutional layers are, don't worry. You can check out [Lesson 4 of this free Deep Learning Course by Udacity](https://www.udacity.com/course/deep-learning-pytorch--ud188)
Finally, we have a couple of fully connected layers that output a Q-value for each possible action at that state.
diff --git a/units/en/unit3/introduction.mdx b/units/en/unit3/introduction.mdx
index de755409..b892c751 100644
--- a/units/en/unit3/introduction.mdx
+++ b/units/en/unit3/introduction.mdx
@@ -6,7 +6,7 @@
In the last unit, we learned our first reinforcement learning algorithm: Q-Learning, **implemented it from scratch**, and trained it in two environments, FrozenLake-v1 ☃️ and Taxi-v3 🚕.
-We got excellent results with this simple algorithm, but these environments were relatively simple because the **state space was discrete and small** (14 different states for FrozenLake-v1 and 500 for Taxi-v3). For comparison, the state space in Atari games can **contain \\(10^{9}\\) to \\(10^{11}\\) states**.
+We got excellent results with this simple algorithm, but these environments were relatively simple because the **state space was discrete and small** (16 different states for FrozenLake-v1 and 500 for Taxi-v3). For comparison, the state space in Atari games can **contain \\(10^{9}\\) to \\(10^{11}\\) states**.
But as we'll see, producing and updating a **Q-table can become ineffective in large state space environments.**
diff --git a/units/en/unit4/glossary.mdx b/units/en/unit4/glossary.mdx
new file mode 100644
index 00000000..e2ea67f7
--- /dev/null
+++ b/units/en/unit4/glossary.mdx
@@ -0,0 +1,25 @@
+# Glossary
+
+This is a community-created glossary. Contributions are welcome!
+
+- **Deep Q-Learning:** A value-based deep reinforcement learning algorithm that uses a deep neural network to approximate Q-values for actions in a given state. The goal of Deep Q-learning is to find the optimal policy that maximizes the expected cumulative reward by learning the action-values.
+
+- **Value-based methods:** Reinforcement Learning methods that estimate a value function as an intermediate step towards finding an optimal policy.
+
+- **Policy-based methods:** Reinforcement Learning methods that directly learn to approximate the optimal policy without learning a value function. In practice they output a probability distribution over actions.
+
+ The benefits of using policy-gradient methods over value-based methods include:
+ - simplicity of integration: no need to store action values;
+ - ability to learn a stochastic policy: the agent explores the state space without always taking the same trajectory, and avoids the problem of perceptual aliasing;
+ - effectiveness in high-dimensional and continuous action spaces; and
+ - improved convergence properties.
+
+- **Policy Gradient:** A subset of policy-based methods where the objective is to maximize the performance of a parameterized policy using gradient ascent. The goal of a policy-gradient is to control the probability distribution of actions by tuning the policy such that good actions (that maximize the return) are sampled more frequently in the future.
+
+- **Monte Carlo Reinforce:** A policy-gradient algorithm that uses an estimated return from an entire episode to update the policy parameter.
+
+If you want to improve the course, you can [open a Pull Request.](https://github.com/huggingface/deep-rl-class/pulls)
+
+This glossary was made possible thanks to:
+
+- [Diego Carpintero](https://github.com/dcarpintero)
\ No newline at end of file
diff --git a/units/en/unit5/hands-on.mdx b/units/en/unit5/hands-on.mdx
index adc02c6c..95fe5aa5 100644
--- a/units/en/unit5/hands-on.mdx
+++ b/units/en/unit5/hands-on.mdx
@@ -11,11 +11,11 @@ We learned what ML-Agents is and how it works. We also studied the two environme
@@ -113,7 +114,7 @@ This means that to update our \\(Q(S_t, A_t)\\):
- To update our Q-value at a given state-action pair, we use the TD target.
How do we form the TD target?
-1. We obtain the reward after taking the action \\(R_{t+1}\\).
+1. We obtain the reward \\(R_{t+1}\\) after taking the action \\(A_t\\).
2. To get the **best state-action pair value** for the next state, we use a greedy policy to select the next best action. Note that this is not an epsilon-greedy policy, this will always take the action with the highest state-action value.
Then when the update of this Q-value is done, we start in a new state and select our action **using a epsilon-greedy policy again.**
diff --git a/units/en/unit3/deep-q-algorithm.mdx b/units/en/unit3/deep-q-algorithm.mdx
index adbe44a6..28e7fd50 100644
--- a/units/en/unit3/deep-q-algorithm.mdx
+++ b/units/en/unit3/deep-q-algorithm.mdx
@@ -40,8 +40,8 @@ Experience replay helps by **using the experiences of the training more efficien
⇒ This allows the agent to **learn from the same experiences multiple times**.
-2. **Avoid forgetting previous experiences and reduce the correlation between experiences**.
-- The problem we get if we give sequential samples of experiences to our neural network is that it tends to forget **the previous experiences as it gets new experiences.** For instance, if the agent is in the first level and then in the second, which is different, it can forget how to behave and play in the first level.
+2. **Avoid forgetting previous experiences (aka catastrophic interference, or catastrophic forgetting) and reduce the correlation between experiences**.
+- **[catastrophic forgetting](https://en.wikipedia.org/wiki/Catastrophic_interference)**: The problem we get if we give sequential samples of experiences to our neural network is that it tends to forget **the previous experiences as it gets new experiences.** For instance, if the agent is in the first level and then in the second, which is different, it can forget how to behave and play in the first level.
The solution is to create a Replay Buffer that stores experience tuples while interacting with the environment and then sample a small batch of tuples. This prevents **the network from only learning about what it has done immediately before.**
diff --git a/units/en/unit3/deep-q-network.mdx b/units/en/unit3/deep-q-network.mdx
index dc8cb13a..50cd4f2b 100644
--- a/units/en/unit3/deep-q-network.mdx
+++ b/units/en/unit3/deep-q-network.mdx
@@ -32,7 +32,7 @@ That’s why, to capture temporal information, we stack four frames together.
Then the stacked frames are processed by three convolutional layers. These layers **allow us to capture and exploit spatial relationships in images**. But also, because the frames are stacked together, **we can exploit some temporal properties across those frames**.
-If you don't know what convolutional layers are, don't worry. You can check out [Lesson 4 of this free Deep Reinforcement Learning Course by Udacity](https://www.udacity.com/course/deep-learning-pytorch--ud188)
+If you don't know what convolutional layers are, don't worry. You can check out [Lesson 4 of this free Deep Learning Course by Udacity](https://www.udacity.com/course/deep-learning-pytorch--ud188)
Finally, we have a couple of fully connected layers that output a Q-value for each possible action at that state.
diff --git a/units/en/unit3/introduction.mdx b/units/en/unit3/introduction.mdx
index de755409..b892c751 100644
--- a/units/en/unit3/introduction.mdx
+++ b/units/en/unit3/introduction.mdx
@@ -6,7 +6,7 @@
In the last unit, we learned our first reinforcement learning algorithm: Q-Learning, **implemented it from scratch**, and trained it in two environments, FrozenLake-v1 ☃️ and Taxi-v3 🚕.
-We got excellent results with this simple algorithm, but these environments were relatively simple because the **state space was discrete and small** (14 different states for FrozenLake-v1 and 500 for Taxi-v3). For comparison, the state space in Atari games can **contain \\(10^{9}\\) to \\(10^{11}\\) states**.
+We got excellent results with this simple algorithm, but these environments were relatively simple because the **state space was discrete and small** (16 different states for FrozenLake-v1 and 500 for Taxi-v3). For comparison, the state space in Atari games can **contain \\(10^{9}\\) to \\(10^{11}\\) states**.
But as we'll see, producing and updating a **Q-table can become ineffective in large state space environments.**
diff --git a/units/en/unit4/glossary.mdx b/units/en/unit4/glossary.mdx
new file mode 100644
index 00000000..e2ea67f7
--- /dev/null
+++ b/units/en/unit4/glossary.mdx
@@ -0,0 +1,25 @@
+# Glossary
+
+This is a community-created glossary. Contributions are welcome!
+
+- **Deep Q-Learning:** A value-based deep reinforcement learning algorithm that uses a deep neural network to approximate Q-values for actions in a given state. The goal of Deep Q-learning is to find the optimal policy that maximizes the expected cumulative reward by learning the action-values.
+
+- **Value-based methods:** Reinforcement Learning methods that estimate a value function as an intermediate step towards finding an optimal policy.
+
+- **Policy-based methods:** Reinforcement Learning methods that directly learn to approximate the optimal policy without learning a value function. In practice they output a probability distribution over actions.
+
+ The benefits of using policy-gradient methods over value-based methods include:
+ - simplicity of integration: no need to store action values;
+ - ability to learn a stochastic policy: the agent explores the state space without always taking the same trajectory, and avoids the problem of perceptual aliasing;
+ - effectiveness in high-dimensional and continuous action spaces; and
+ - improved convergence properties.
+
+- **Policy Gradient:** A subset of policy-based methods where the objective is to maximize the performance of a parameterized policy using gradient ascent. The goal of a policy-gradient is to control the probability distribution of actions by tuning the policy such that good actions (that maximize the return) are sampled more frequently in the future.
+
+- **Monte Carlo Reinforce:** A policy-gradient algorithm that uses an estimated return from an entire episode to update the policy parameter.
+
+If you want to improve the course, you can [open a Pull Request.](https://github.com/huggingface/deep-rl-class/pulls)
+
+This glossary was made possible thanks to:
+
+- [Diego Carpintero](https://github.com/dcarpintero)
\ No newline at end of file
diff --git a/units/en/unit5/hands-on.mdx b/units/en/unit5/hands-on.mdx
index adc02c6c..95fe5aa5 100644
--- a/units/en/unit5/hands-on.mdx
+++ b/units/en/unit5/hands-on.mdx
@@ -11,11 +11,11 @@ We learned what ML-Agents is and how it works. We also studied the two environme
 -The ML-Agents integration on the Hub **is still experimental**. Some features will be added in the future. But, for now, to validate this hands-on for the certification process, you just need to push your trained models to the Hub.
-There are no minimum results to attain in order to validate this Hands On. But if you want to get nice results, you can try to reach the following:
+To validate this hands-on for the certification process, you **just need to push your trained models to the Hub.**
+There are **no minimum results to attain** in order to validate this Hands On. But if you want to get nice results, you can try to reach the following:
-- For [Pyramids](https://singularite.itch.io/pyramids): Mean Reward = 1.75
-- For [SnowballTarget](https://singularite.itch.io/snowballtarget): Mean Reward = 15 or 30 targets shoot in an episode.
+- For [Pyramids](https://huggingface.co/spaces/unity/ML-Agents-Pyramids): Mean Reward = 1.75
+- For [SnowballTarget](https://huggingface.co/spaces/ThomasSimonini/ML-Agents-SnowballTarget): Mean Reward = 15 or 30 targets shoot in an episode.
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
@@ -53,9 +53,7 @@ For more information about the certification process, check this section 👉 ht
### 📚 RL-Library:
-- [ML-Agents (HuggingFace Experimental Version)](https://github.com/huggingface/ml-agents)
-
-⚠ We're going to use an experimental version of ML-Agents where you can push to Hub and load from Hub Unity ML-Agents Models **you need to install the same version**
+- [ML-Agents](https://github.com/Unity-Technologies/ml-agents)
We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues).
@@ -86,18 +84,16 @@ Before diving into the notebook, you need to:
## Clone the repository and install the dependencies 🔽
- We need to clone the repository that **contains the experimental version of the library that allows you to push your trained agent to the Hub.**
-```python
-%%capture
+```bash
# Clone the repository
-!git clone --depth 1 --branch hf-integration-save https://github.com/huggingface/ml-agents
+git clone --depth 1 https://github.com/Unity-Technologies/ml-agents
```
-```python
-%%capture
+```bash
# Go inside the repository and install the package
-%cd ml-agents
-!pip3 install -e ./ml-agents-envs
-!pip3 install -e ./ml-agents
+cd ml-agents
+pip install -e ./ml-agents-envs
+pip install -e ./ml-agents
```
## SnowballTarget ⛄
@@ -106,35 +102,35 @@ If you need a refresher on how this environment works check this section 👉
https://huggingface.co/deep-rl-course/unit5/snowball-target
### Download and move the environment zip file in `./training-envs-executables/linux/`
+
- Our environment executable is in a zip file.
- We need to download it and place it to `./training-envs-executables/linux/`
- We use a linux executable because we use colab, and colab machines OS is Ubuntu (linux)
-```python
+```bash
# Here, we create training-envs-executables and linux
-!mkdir ./training-envs-executables
-!mkdir ./training-envs-executables/linux
+mkdir ./training-envs-executables
+mkdir ./training-envs-executables/linux
```
Download the file SnowballTarget.zip from https://drive.google.com/file/d/1YHHLjyj6gaZ3Gemx1hQgqrPgSS2ZhmB5 using `wget`.
Check out the full solution to download large files from GDrive [here](https://bcrf.biochem.wisc.edu/2021/02/05/download-google-drive-files-using-wget/)
-```python
-!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1YHHLjyj6gaZ3Gemx1hQgqrPgSS2ZhmB5' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=1YHHLjyj6gaZ3Gemx1hQgqrPgSS2ZhmB5" -O ./training-envs-executables/linux/SnowballTarget.zip && rm -rf /tmp/cookies.txt
+```bash
+wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1YHHLjyj6gaZ3Gemx1hQgqrPgSS2ZhmB5' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=1YHHLjyj6gaZ3Gemx1hQgqrPgSS2ZhmB5" -O ./training-envs-executables/linux/SnowballTarget.zip && rm -rf /tmp/cookies.txt
```
We unzip the executable.zip file
-```python
-%%capture
-!unzip -d ./training-envs-executables/linux/ ./training-envs-executables/linux/SnowballTarget.zip
+```bash
+unzip -d ./training-envs-executables/linux/ ./training-envs-executables/linux/SnowballTarget.zip
```
Make sure your file is accessible
-```python
-!chmod -R 755 ./training-envs-executables/linux/SnowballTarget
+```bash
+chmod -R 755 ./training-envs-executables/linux/SnowballTarget
```
### Define the SnowballTarget config file
@@ -204,7 +200,7 @@ Train the model and use the `--resume` flag to continue training in case of inte
The training will take 10 to 35min depending on your config. Go take a ☕️ you deserve it 🤗.
```bash
-!mlagents-learn ./config/ppo/SnowballTarget.yaml --env=./training-envs-executables/linux/SnowballTarget/SnowballTarget --run-id="SnowballTarget1" --no-graphics
+mlagents-learn ./config/ppo/SnowballTarget.yaml --env=./training-envs-executables/linux/SnowballTarget/SnowballTarget --run-id="SnowballTarget1" --no-graphics
```
### Push the agent to the Hugging Face Hub
@@ -245,10 +241,10 @@ If the repo does not exist **it will be created automatically**
For instance:
-`!mlagents-push-to-hf --run-id="SnowballTarget1" --local-dir="./results/SnowballTarget1" --repo-id="ThomasSimonini/ppo-SnowballTarget" --commit-message="First Push"`
+`mlagents-push-to-hf --run-id="SnowballTarget1" --local-dir="./results/SnowballTarget1" --repo-id="ThomasSimonini/ppo-SnowballTarget" --commit-message="First Push"`
```python
-!mlagents-push-to-hf --run-id= # Add your run id --local-dir= # Your local dir --repo-id= # Your repo id --commit-message= # Your commit message
+mlagents-push-to-hf --run-id= # Add your run id --local-dir= # Your local dir --repo-id= # Your repo id --commit-message= # Your commit message
```
If everything worked you should see this at the end of the process (but with a different url 😆) :
@@ -269,7 +265,7 @@ This step it's simple:
1. Remember your repo-id
-2. Go here: https://singularite.itch.io/snowballtarget
+2. Go here: https://huggingface.co/spaces/ThomasSimonini/ML-Agents-SnowballTarget
3. Launch the game and put it in full screen by clicking on the bottom right button
@@ -309,11 +305,12 @@ Unzip it
Make sure your file is accessible
-```python
-!chmod -R 755 ./training-envs-executables/linux/Pyramids/Pyramids
+```bash
+chmod -R 755 ./training-envs-executables/linux/Pyramids/Pyramids
```
### Modify the PyramidsRND config file
+
- Contrary to the first environment, which was a custom one, **Pyramids was made by the Unity team**.
- So the PyramidsRND config file already exists and is in ./content/ml-agents/config/ppo/PyramidsRND.yaml
- You might ask why "RND" is in PyramidsRND. RND stands for *random network distillation* it's a way to generate curiosity rewards. If you want to know more about that, we wrote an article explaining this technique: https://medium.com/data-from-the-trenches/curiosity-driven-learning-through-random-network-distillation-488ffd8e5938
@@ -333,37 +330,36 @@ We’re now ready to train our agent 🔥.
The training will take 30 to 45min depending on your machine, go take a ☕️ you deserve it 🤗.
```python
-!mlagents-learn ./config/ppo/PyramidsRND.yaml --env=./training-envs-executables/linux/Pyramids/Pyramids --run-id="Pyramids Training" --no-graphics
+mlagents-learn ./config/ppo/PyramidsRND.yaml --env=./training-envs-executables/linux/Pyramids/Pyramids --run-id="Pyramids Training" --no-graphics
```
### Push the agent to the Hugging Face Hub
- Now that we trained our agent, we’re **ready to push it to the Hub to be able to visualize it playing on your browser🔥.**
-```bash
-!mlagents-push-to-hf --run-id= # Add your run id --local-dir= # Your local dir --repo-id= # Your repo id --commit-message= # Your commit message
+```python
+mlagents-push-to-hf --run-id= # Add your run id --local-dir= # Your local dir --repo-id= # Your repo id --commit-message= # Your commit message
```
### Watch your agent playing 👀
-The temporary link for the Pyramids demo is: https://singularite.itch.io/pyramids
-
+👉 https://huggingface.co/spaces/unity/ML-Agents-Pyramids
+
### 🎁 Bonus: Why not train on another environment?
+
Now that you know how to train an agent using MLAgents, **why not try another environment?**
-MLAgents provides 18 different environments and we’re building some custom ones. The best way to learn is to try things on your own, have fun.
+MLAgents provides 17 different environments and we’re building some custom ones. The best way to learn is to try things on your own, have fun.

You have the full list of the one currently available environments on Hugging Face here 👉 https://github.com/huggingface/ml-agents#the-environments
-For the demos to visualize your agent, the temporary link is: https://singularite.itch.io (temporary because we'll also put the demos on Hugging Face Spaces)
-
-For now we have integrated:
-- [Worm](https://singularite.itch.io/worm) demo where you teach a **worm to crawl**.
-- [Walker](https://singularite.itch.io/walker) demo where you teach an agent **to walk towards a goal**.
+For the demos to visualize your agent 👉 https://huggingface.co/unity
-If you want new demos to be added, please open an issue: https://github.com/huggingface/deep-rl-class 🤗
+For now we have integrated:
+- [Worm](https://huggingface.co/spaces/unity/ML-Agents-Worm) demo where you teach a **worm to crawl**.
+- [Walker](https://huggingface.co/spaces/unity/ML-Agents-Walker) demo where you teach an agent **to walk towards a goal**.
That’s all for today. Congrats on finishing this tutorial!
diff --git a/units/en/unit5/how-mlagents-works.mdx b/units/en/unit5/how-mlagents-works.mdx
index 12acede7..f92054f2 100644
--- a/units/en/unit5/how-mlagents-works.mdx
+++ b/units/en/unit5/how-mlagents-works.mdx
@@ -31,7 +31,7 @@ With Unity ML-Agents, you have six essential components:
## Inside the Learning Component [[inside-learning-component]]
-Inside the Learning Component, we have **three important elements**:
+Inside the Learning Component, we have **two important elements**:
- The first is the *agent component*, the actor of the scene. We’ll **train the agent by optimizing its policy** (which will tell us what action to take in each state). The policy is called the *Brain*.
- Finally, there is the *Academy*. This component **orchestrates agents and their decision-making processes**. Think of this Academy as a teacher who handles Python API requests.
diff --git a/units/en/unit5/quiz.mdx b/units/en/unit5/quiz.mdx
new file mode 100644
index 00000000..7b9ec0c8
--- /dev/null
+++ b/units/en/unit5/quiz.mdx
@@ -0,0 +1,130 @@
+# Quiz
+
+The best way to learn and [to avoid the illusion of competence](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
+
+### Q1: Which of the following tools are specifically designed for video games development?
+
+
+
+### Q2: What of the following statements are true about Unity ML-Agents?
+
+
+
+### Q3: Fill the missing letters
+
+- In Unity ML-Agents, the Policy of an Agent is called a b _ _ _ n
+- The component in charge of orchestrating the agents is called the _ c _ _ _ m _
+
+
-The ML-Agents integration on the Hub **is still experimental**. Some features will be added in the future. But, for now, to validate this hands-on for the certification process, you just need to push your trained models to the Hub.
-There are no minimum results to attain in order to validate this Hands On. But if you want to get nice results, you can try to reach the following:
+To validate this hands-on for the certification process, you **just need to push your trained models to the Hub.**
+There are **no minimum results to attain** in order to validate this Hands On. But if you want to get nice results, you can try to reach the following:
-- For [Pyramids](https://singularite.itch.io/pyramids): Mean Reward = 1.75
-- For [SnowballTarget](https://singularite.itch.io/snowballtarget): Mean Reward = 15 or 30 targets shoot in an episode.
+- For [Pyramids](https://huggingface.co/spaces/unity/ML-Agents-Pyramids): Mean Reward = 1.75
+- For [SnowballTarget](https://huggingface.co/spaces/ThomasSimonini/ML-Agents-SnowballTarget): Mean Reward = 15 or 30 targets shoot in an episode.
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
@@ -53,9 +53,7 @@ For more information about the certification process, check this section 👉 ht
### 📚 RL-Library:
-- [ML-Agents (HuggingFace Experimental Version)](https://github.com/huggingface/ml-agents)
-
-⚠ We're going to use an experimental version of ML-Agents where you can push to Hub and load from Hub Unity ML-Agents Models **you need to install the same version**
+- [ML-Agents](https://github.com/Unity-Technologies/ml-agents)
We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues).
@@ -86,18 +84,16 @@ Before diving into the notebook, you need to:
## Clone the repository and install the dependencies 🔽
- We need to clone the repository that **contains the experimental version of the library that allows you to push your trained agent to the Hub.**
-```python
-%%capture
+```bash
# Clone the repository
-!git clone --depth 1 --branch hf-integration-save https://github.com/huggingface/ml-agents
+git clone --depth 1 https://github.com/Unity-Technologies/ml-agents
```
-```python
-%%capture
+```bash
# Go inside the repository and install the package
-%cd ml-agents
-!pip3 install -e ./ml-agents-envs
-!pip3 install -e ./ml-agents
+cd ml-agents
+pip install -e ./ml-agents-envs
+pip install -e ./ml-agents
```
## SnowballTarget ⛄
@@ -106,35 +102,35 @@ If you need a refresher on how this environment works check this section 👉
https://huggingface.co/deep-rl-course/unit5/snowball-target
### Download and move the environment zip file in `./training-envs-executables/linux/`
+
- Our environment executable is in a zip file.
- We need to download it and place it to `./training-envs-executables/linux/`
- We use a linux executable because we use colab, and colab machines OS is Ubuntu (linux)
-```python
+```bash
# Here, we create training-envs-executables and linux
-!mkdir ./training-envs-executables
-!mkdir ./training-envs-executables/linux
+mkdir ./training-envs-executables
+mkdir ./training-envs-executables/linux
```
Download the file SnowballTarget.zip from https://drive.google.com/file/d/1YHHLjyj6gaZ3Gemx1hQgqrPgSS2ZhmB5 using `wget`.
Check out the full solution to download large files from GDrive [here](https://bcrf.biochem.wisc.edu/2021/02/05/download-google-drive-files-using-wget/)
-```python
-!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1YHHLjyj6gaZ3Gemx1hQgqrPgSS2ZhmB5' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=1YHHLjyj6gaZ3Gemx1hQgqrPgSS2ZhmB5" -O ./training-envs-executables/linux/SnowballTarget.zip && rm -rf /tmp/cookies.txt
+```bash
+wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1YHHLjyj6gaZ3Gemx1hQgqrPgSS2ZhmB5' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=1YHHLjyj6gaZ3Gemx1hQgqrPgSS2ZhmB5" -O ./training-envs-executables/linux/SnowballTarget.zip && rm -rf /tmp/cookies.txt
```
We unzip the executable.zip file
-```python
-%%capture
-!unzip -d ./training-envs-executables/linux/ ./training-envs-executables/linux/SnowballTarget.zip
+```bash
+unzip -d ./training-envs-executables/linux/ ./training-envs-executables/linux/SnowballTarget.zip
```
Make sure your file is accessible
-```python
-!chmod -R 755 ./training-envs-executables/linux/SnowballTarget
+```bash
+chmod -R 755 ./training-envs-executables/linux/SnowballTarget
```
### Define the SnowballTarget config file
@@ -204,7 +200,7 @@ Train the model and use the `--resume` flag to continue training in case of inte
The training will take 10 to 35min depending on your config. Go take a ☕️ you deserve it 🤗.
```bash
-!mlagents-learn ./config/ppo/SnowballTarget.yaml --env=./training-envs-executables/linux/SnowballTarget/SnowballTarget --run-id="SnowballTarget1" --no-graphics
+mlagents-learn ./config/ppo/SnowballTarget.yaml --env=./training-envs-executables/linux/SnowballTarget/SnowballTarget --run-id="SnowballTarget1" --no-graphics
```
### Push the agent to the Hugging Face Hub
@@ -245,10 +241,10 @@ If the repo does not exist **it will be created automatically**
For instance:
-`!mlagents-push-to-hf --run-id="SnowballTarget1" --local-dir="./results/SnowballTarget1" --repo-id="ThomasSimonini/ppo-SnowballTarget" --commit-message="First Push"`
+`mlagents-push-to-hf --run-id="SnowballTarget1" --local-dir="./results/SnowballTarget1" --repo-id="ThomasSimonini/ppo-SnowballTarget" --commit-message="First Push"`
```python
-!mlagents-push-to-hf --run-id= # Add your run id --local-dir= # Your local dir --repo-id= # Your repo id --commit-message= # Your commit message
+mlagents-push-to-hf --run-id= # Add your run id --local-dir= # Your local dir --repo-id= # Your repo id --commit-message= # Your commit message
```
If everything worked you should see this at the end of the process (but with a different url 😆) :
@@ -269,7 +265,7 @@ This step it's simple:
1. Remember your repo-id
-2. Go here: https://singularite.itch.io/snowballtarget
+2. Go here: https://huggingface.co/spaces/ThomasSimonini/ML-Agents-SnowballTarget
3. Launch the game and put it in full screen by clicking on the bottom right button
@@ -309,11 +305,12 @@ Unzip it
Make sure your file is accessible
-```python
-!chmod -R 755 ./training-envs-executables/linux/Pyramids/Pyramids
+```bash
+chmod -R 755 ./training-envs-executables/linux/Pyramids/Pyramids
```
### Modify the PyramidsRND config file
+
- Contrary to the first environment, which was a custom one, **Pyramids was made by the Unity team**.
- So the PyramidsRND config file already exists and is in ./content/ml-agents/config/ppo/PyramidsRND.yaml
- You might ask why "RND" is in PyramidsRND. RND stands for *random network distillation* it's a way to generate curiosity rewards. If you want to know more about that, we wrote an article explaining this technique: https://medium.com/data-from-the-trenches/curiosity-driven-learning-through-random-network-distillation-488ffd8e5938
@@ -333,37 +330,36 @@ We’re now ready to train our agent 🔥.
The training will take 30 to 45min depending on your machine, go take a ☕️ you deserve it 🤗.
```python
-!mlagents-learn ./config/ppo/PyramidsRND.yaml --env=./training-envs-executables/linux/Pyramids/Pyramids --run-id="Pyramids Training" --no-graphics
+mlagents-learn ./config/ppo/PyramidsRND.yaml --env=./training-envs-executables/linux/Pyramids/Pyramids --run-id="Pyramids Training" --no-graphics
```
### Push the agent to the Hugging Face Hub
- Now that we trained our agent, we’re **ready to push it to the Hub to be able to visualize it playing on your browser🔥.**
-```bash
-!mlagents-push-to-hf --run-id= # Add your run id --local-dir= # Your local dir --repo-id= # Your repo id --commit-message= # Your commit message
+```python
+mlagents-push-to-hf --run-id= # Add your run id --local-dir= # Your local dir --repo-id= # Your repo id --commit-message= # Your commit message
```
### Watch your agent playing 👀
-The temporary link for the Pyramids demo is: https://singularite.itch.io/pyramids
-
+👉 https://huggingface.co/spaces/unity/ML-Agents-Pyramids
+
### 🎁 Bonus: Why not train on another environment?
+
Now that you know how to train an agent using MLAgents, **why not try another environment?**
-MLAgents provides 18 different environments and we’re building some custom ones. The best way to learn is to try things on your own, have fun.
+MLAgents provides 17 different environments and we’re building some custom ones. The best way to learn is to try things on your own, have fun.

You have the full list of the one currently available environments on Hugging Face here 👉 https://github.com/huggingface/ml-agents#the-environments
-For the demos to visualize your agent, the temporary link is: https://singularite.itch.io (temporary because we'll also put the demos on Hugging Face Spaces)
-
-For now we have integrated:
-- [Worm](https://singularite.itch.io/worm) demo where you teach a **worm to crawl**.
-- [Walker](https://singularite.itch.io/walker) demo where you teach an agent **to walk towards a goal**.
+For the demos to visualize your agent 👉 https://huggingface.co/unity
-If you want new demos to be added, please open an issue: https://github.com/huggingface/deep-rl-class 🤗
+For now we have integrated:
+- [Worm](https://huggingface.co/spaces/unity/ML-Agents-Worm) demo where you teach a **worm to crawl**.
+- [Walker](https://huggingface.co/spaces/unity/ML-Agents-Walker) demo where you teach an agent **to walk towards a goal**.
That’s all for today. Congrats on finishing this tutorial!
diff --git a/units/en/unit5/how-mlagents-works.mdx b/units/en/unit5/how-mlagents-works.mdx
index 12acede7..f92054f2 100644
--- a/units/en/unit5/how-mlagents-works.mdx
+++ b/units/en/unit5/how-mlagents-works.mdx
@@ -31,7 +31,7 @@ With Unity ML-Agents, you have six essential components:
## Inside the Learning Component [[inside-learning-component]]
-Inside the Learning Component, we have **three important elements**:
+Inside the Learning Component, we have **two important elements**:
- The first is the *agent component*, the actor of the scene. We’ll **train the agent by optimizing its policy** (which will tell us what action to take in each state). The policy is called the *Brain*.
- Finally, there is the *Academy*. This component **orchestrates agents and their decision-making processes**. Think of this Academy as a teacher who handles Python API requests.
diff --git a/units/en/unit5/quiz.mdx b/units/en/unit5/quiz.mdx
new file mode 100644
index 00000000..7b9ec0c8
--- /dev/null
+++ b/units/en/unit5/quiz.mdx
@@ -0,0 +1,130 @@
+# Quiz
+
+The best way to learn and [to avoid the illusion of competence](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
+
+### Q1: Which of the following tools are specifically designed for video games development?
+
+
+
+### Q2: What of the following statements are true about Unity ML-Agents?
+
+
+
+### Q3: Fill the missing letters
+
+- In Unity ML-Agents, the Policy of an Agent is called a b _ _ _ n
+- The component in charge of orchestrating the agents is called the _ c _ _ _ m _
+
+
+Solution
+- b r a i n
+- a c a d e m y
+
+
+### Q4: Define with your own words what is a `raycast`
+
+
+Solution
+A raycast is (most of the times) a linear projection, as a `laser` which aims to detect collisions through objects.
+
+
+### Q5: Which are the differences between capturing the environment using `frames` or `raycasts`?
+
+
+
+
+### Q6: Name several environment and agent input variables used to train the agent in the Snowball or Pyramid environments
+
+
+Solution
+- Collisions of the raycasts spawned from the agent detecting blocks, (invisible) walls, stones, our target, switches, etc.
+- Traditional inputs describing agent features, as its speed
+- Boolean vars, as the switch (on/off) in Pyramids or the `can I shoot?` in the SnowballTarget.
+
+
+
+Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read the chapter again to reinforce (😏) your knowledge.
diff --git a/units/en/unit6/hands-on.mdx b/units/en/unit6/hands-on.mdx
index 9d34e59f..5bc8e75f 100644
--- a/units/en/unit6/hands-on.mdx
+++ b/units/en/unit6/hands-on.mdx
@@ -1,4 +1,4 @@
-# Advantage Actor Critic (A2C) using Robotics Simulations with PyBullet and Panda-Gym 🤖 [[hands-on]]
+# Advantage Actor Critic (A2C) using Robotics Simulations with Panda-Gym 🤖 [[hands-on]]
-Now that you've studied the theory behind Advantage Actor Critic (A2C), **you're ready to train your A2C agent** using Stable-Baselines3 in robotic environments. And train two robots:
-
-- A spider 🕷️ to learn to move.
+Now that you've studied the theory behind Advantage Actor Critic (A2C), **you're ready to train your A2C agent** using Stable-Baselines3 in a robotic environment. And train a:
- A robotic arm 🦾 to move to the correct position.
-We're going to use two Robotics environments:
-
-- [PyBullet](https://github.com/bulletphysics/bullet3)
+We're going to use
- [panda-gym](https://github.com/qgallouedec/panda-gym)
- -
-
To validate this hands-on for the certification process, you need to push your two trained models to the Hub and get the following results:
-- `AntBulletEnv-v0` get a result of >= 650.
-- `PandaReachDense-v2` get a result of >= -3.5.
+- `PandaReachDense-v3` get a result of >= -3.5.
To find your result, [go to the leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
-**If you don't find your model, go to the bottom of the page and click on the refresh button.**
-
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
**To start the hands-on click on Open In Colab button** 👇 :
@@ -37,11 +27,10 @@ For more information about the certification process, check this section 👉 ht
[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit6/unit6.ipynb)
-# Unit 6: Advantage Actor Critic (A2C) using Robotics Simulations with PyBullet and Panda-Gym 🤖
+# Unit 6: Advantage Actor Critic (A2C) using Robotics Simulations with Panda-Gym 🤖
### 🎮 Environments:
-- [PyBullet](https://github.com/bulletphysics/bullet3)
- [Panda-Gym](https://github.com/qgallouedec/panda-gym)
### 📚 RL-Library:
@@ -54,12 +43,13 @@ We're constantly trying to improve our tutorials, so **if you find some issues i
At the end of the notebook, you will:
-- Be able to use the environment librairies **PyBullet** and **Panda-Gym**.
+- Be able to use **Panda-Gym**, the environment library.
- Be able to **train robots using A2C**.
- Understand why **we need to normalize the input**.
- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.
## Prerequisites 🏗️
+
Before diving into the notebook, you need to:
🔲 📚 Study [Actor-Critic methods by reading Unit 6](https://huggingface.co/deep-rl-course/unit6/introduction) 🤗
@@ -99,27 +89,31 @@ virtual_display.start()
```
### Install dependencies 🔽
-The first step is to install the dependencies, we’ll install multiple ones:
-- `pybullet`: Contains the walking robots environments.
+We’ll install multiple ones:
+
+- `gymnasium`
- `panda-gym`: Contains the robotics arm environments.
-- `stable-baselines3[extra]`: The SB3 deep reinforcement learning library.
+- `stable-baselines3`: The SB3 deep reinforcement learning library.
- `huggingface_sb3`: Additional code for Stable-baselines3 to load and upload models from the Hugging Face 🤗 Hub.
- `huggingface_hub`: Library allowing anyone to work with the Hub repositories.
```bash
-!pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit6/requirements-unit6.txt
+!pip install stable-baselines3[extra]
+!pip install gymnasium
+!pip install huggingface_sb3
+!pip install huggingface_hub
+!pip install panda_gym
```
## Import the packages 📦
```python
-import pybullet_envs
-import panda_gym
-import gym
-
import os
+import gymnasium as gym
+import panda_gym
+
from huggingface_sb3 import load_from_hub, package_to_hub
from stable_baselines3 import A2C
@@ -130,45 +124,61 @@ from stable_baselines3.common.env_util import make_vec_env
from huggingface_hub import notebook_login
```
-## Environment 1: AntBulletEnv-v0 🕸
+## PandaReachDense-v3 🦾
+
+The agent we're going to train is a robotic arm that needs to do controls (moving the arm and using the end-effector).
+
+In robotics, the *end-effector* is the device at the end of a robotic arm designed to interact with the environment.
+
+In `PandaReach`, the robot must place its end-effector at a target position (green ball).
+
+We're going to use the dense version of this environment. It means we'll get a *dense reward function* that **will provide a reward at each timestep** (the closer the agent is to completing the task, the higher the reward). Contrary to a *sparse reward function* where the environment **return a reward if and only if the task is completed**.
+
+Also, we're going to use the *End-effector displacement control*, it means the **action corresponds to the displacement of the end-effector**. We don't control the individual motion of each joint (joint control).
+
+
-
-
To validate this hands-on for the certification process, you need to push your two trained models to the Hub and get the following results:
-- `AntBulletEnv-v0` get a result of >= 650.
-- `PandaReachDense-v2` get a result of >= -3.5.
+- `PandaReachDense-v3` get a result of >= -3.5.
To find your result, [go to the leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
-**If you don't find your model, go to the bottom of the page and click on the refresh button.**
-
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
**To start the hands-on click on Open In Colab button** 👇 :
@@ -37,11 +27,10 @@ For more information about the certification process, check this section 👉 ht
[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit6/unit6.ipynb)
-# Unit 6: Advantage Actor Critic (A2C) using Robotics Simulations with PyBullet and Panda-Gym 🤖
+# Unit 6: Advantage Actor Critic (A2C) using Robotics Simulations with Panda-Gym 🤖
### 🎮 Environments:
-- [PyBullet](https://github.com/bulletphysics/bullet3)
- [Panda-Gym](https://github.com/qgallouedec/panda-gym)
### 📚 RL-Library:
@@ -54,12 +43,13 @@ We're constantly trying to improve our tutorials, so **if you find some issues i
At the end of the notebook, you will:
-- Be able to use the environment librairies **PyBullet** and **Panda-Gym**.
+- Be able to use **Panda-Gym**, the environment library.
- Be able to **train robots using A2C**.
- Understand why **we need to normalize the input**.
- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.
## Prerequisites 🏗️
+
Before diving into the notebook, you need to:
🔲 📚 Study [Actor-Critic methods by reading Unit 6](https://huggingface.co/deep-rl-course/unit6/introduction) 🤗
@@ -99,27 +89,31 @@ virtual_display.start()
```
### Install dependencies 🔽
-The first step is to install the dependencies, we’ll install multiple ones:
-- `pybullet`: Contains the walking robots environments.
+We’ll install multiple ones:
+
+- `gymnasium`
- `panda-gym`: Contains the robotics arm environments.
-- `stable-baselines3[extra]`: The SB3 deep reinforcement learning library.
+- `stable-baselines3`: The SB3 deep reinforcement learning library.
- `huggingface_sb3`: Additional code for Stable-baselines3 to load and upload models from the Hugging Face 🤗 Hub.
- `huggingface_hub`: Library allowing anyone to work with the Hub repositories.
```bash
-!pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit6/requirements-unit6.txt
+!pip install stable-baselines3[extra]
+!pip install gymnasium
+!pip install huggingface_sb3
+!pip install huggingface_hub
+!pip install panda_gym
```
## Import the packages 📦
```python
-import pybullet_envs
-import panda_gym
-import gym
-
import os
+import gymnasium as gym
+import panda_gym
+
from huggingface_sb3 import load_from_hub, package_to_hub
from stable_baselines3 import A2C
@@ -130,45 +124,61 @@ from stable_baselines3.common.env_util import make_vec_env
from huggingface_hub import notebook_login
```
-## Environment 1: AntBulletEnv-v0 🕸
+## PandaReachDense-v3 🦾
+
+The agent we're going to train is a robotic arm that needs to do controls (moving the arm and using the end-effector).
+
+In robotics, the *end-effector* is the device at the end of a robotic arm designed to interact with the environment.
+
+In `PandaReach`, the robot must place its end-effector at a target position (green ball).
+
+We're going to use the dense version of this environment. It means we'll get a *dense reward function* that **will provide a reward at each timestep** (the closer the agent is to completing the task, the higher the reward). Contrary to a *sparse reward function* where the environment **return a reward if and only if the task is completed**.
+
+Also, we're going to use the *End-effector displacement control*, it means the **action corresponds to the displacement of the end-effector**. We don't control the individual motion of each joint (joint control).
+
+ +
+This way **the training will be easier**.
+
+### Create the environment
-### Create the AntBulletEnv-v0
#### The environment 🎮
-In this environment, the agent needs to use its different joints correctly in order to walk.
-You can find a detailled explanation of this environment here: https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet
+In `PandaReachDense-v3` the robotic arm must place its end-effector at a target position (green ball).
```python
-env_id = "AntBulletEnv-v0"
+env_id = "PandaReachDense-v3"
+
# Create the env
env = gym.make(env_id)
# Get the state space and action space
-s_size = env.observation_space.shape[0]
+s_size = env.observation_space.shape
a_size = env.action_space
```
```python
print("_____OBSERVATION SPACE_____ \n")
print("The State Space is: ", s_size)
-print("Sample observation", env.observation_space.sample()) # Get a random observation
+print("Sample observation", env.observation_space.sample()) # Get a random observation
```
-The observation Space (from [Jeffrey Y Mo](https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet)):
-The difference is that our observation space is 28 not 29.
+The observation space **is a dictionary with 3 different elements**:
-
+
+This way **the training will be easier**.
+
+### Create the environment
-### Create the AntBulletEnv-v0
#### The environment 🎮
-In this environment, the agent needs to use its different joints correctly in order to walk.
-You can find a detailled explanation of this environment here: https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet
+In `PandaReachDense-v3` the robotic arm must place its end-effector at a target position (green ball).
```python
-env_id = "AntBulletEnv-v0"
+env_id = "PandaReachDense-v3"
+
# Create the env
env = gym.make(env_id)
# Get the state space and action space
-s_size = env.observation_space.shape[0]
+s_size = env.observation_space.shape
a_size = env.action_space
```
```python
print("_____OBSERVATION SPACE_____ \n")
print("The State Space is: ", s_size)
-print("Sample observation", env.observation_space.sample()) # Get a random observation
+print("Sample observation", env.observation_space.sample()) # Get a random observation
```
-The observation Space (from [Jeffrey Y Mo](https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet)):
-The difference is that our observation space is 28 not 29.
+The observation space **is a dictionary with 3 different elements**:
- +- `achieved_goal`: (x,y,z) position of the goal.
+- `desired_goal`: (x,y,z) distance between the goal position and the current object position.
+- `observation`: position (x,y,z) and velocity of the end-effector (vx, vy, vz).
+Given it's a dictionary as observation, **we will need to use a MultiInputPolicy policy instead of MlpPolicy**.
```python
print("\n _____ACTION SPACE_____ \n")
print("The Action Space is: ", a_size)
-print("Action Space Sample", env.action_space.sample()) # Take a random action
+print("Action Space Sample", env.action_space.sample()) # Take a random action
```
-The action Space (from [Jeffrey Y Mo](https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet)):
-
-
+- `achieved_goal`: (x,y,z) position of the goal.
+- `desired_goal`: (x,y,z) distance between the goal position and the current object position.
+- `observation`: position (x,y,z) and velocity of the end-effector (vx, vy, vz).
+Given it's a dictionary as observation, **we will need to use a MultiInputPolicy policy instead of MlpPolicy**.
```python
print("\n _____ACTION SPACE_____ \n")
print("The Action Space is: ", a_size)
-print("Action Space Sample", env.action_space.sample()) # Take a random action
+print("Action Space Sample", env.action_space.sample()) # Take a random action
```
-The action Space (from [Jeffrey Y Mo](https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet)):
-
- +The action space is a vector with 3 values:
+- Control x, y, z movement
### Normalize observation and rewards
@@ -193,13 +203,11 @@ env = # TODO: Add the wrapper
```python
env = make_vec_env(env_id, n_envs=4)
-env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.0)
+env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.)
```
### Create the A2C Model 🤖
-In this case, because we have a vector of 28 values as input, we'll use an MLP (multi-layer perceptron) as policy.
-
For more information about A2C implementation with StableBaselines3 check: https://stable-baselines3.readthedocs.io/en/master/modules/a2c.html#notes
To find the best parameters I checked the [official trained agents by Stable-Baselines3 team](https://huggingface.co/sb3).
@@ -211,86 +219,71 @@ model = # Create the A2C model and try to find the best parameters
#### Solution
```python
-model = A2C(
- policy="MlpPolicy",
- env=env,
- gae_lambda=0.9,
- gamma=0.99,
- learning_rate=0.00096,
- max_grad_norm=0.5,
- n_steps=8,
- vf_coef=0.4,
- ent_coef=0.0,
- policy_kwargs=dict(log_std_init=-2, ortho_init=False),
- normalize_advantage=False,
- use_rms_prop=True,
- use_sde=True,
- verbose=1,
-)
+model = A2C(policy = "MultiInputPolicy",
+ env = env,
+ verbose=1)
```
### Train the A2C agent 🏃
-- Let's train our agent for 2,000,000 timesteps. Don't forget to use GPU on Colab. It will take approximately ~25-40min
+- Let's train our agent for 1,000,000 timesteps, don't forget to use GPU on Colab. It will take approximately ~25-40min
```python
-model.learn(2_000_000)
+model.learn(1_000_000)
```
```python
# Save the model and VecNormalize statistics when saving the agent
-model.save("a2c-AntBulletEnv-v0")
+model.save("a2c-PandaReachDense-v3")
env.save("vec_normalize.pkl")
```
### Evaluate the agent 📈
-- Now that our agent is trained, we need to **check its performance**.
+
+- Now that's our agent is trained, we need to **check its performance**.
- Stable-Baselines3 provides a method to do that: `evaluate_policy`
-- In my case, I got a mean reward of `2371.90 +/- 16.50`
```python
from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
# Load the saved statistics
-eval_env = DummyVecEnv([lambda: gym.make("AntBulletEnv-v0")])
+eval_env = DummyVecEnv([lambda: gym.make("PandaReachDense-v3")])
eval_env = VecNormalize.load("vec_normalize.pkl", eval_env)
+# We need to override the render_mode
+eval_env.render_mode = "rgb_array"
+
# do not update them at test time
eval_env.training = False
# reward normalization is not needed at test time
eval_env.norm_reward = False
# Load the agent
-model = A2C.load("a2c-AntBulletEnv-v0")
+model = A2C.load("a2c-PandaReachDense-v3")
-mean_reward, std_reward = evaluate_policy(model, env)
+mean_reward, std_reward = evaluate_policy(model, eval_env)
print(f"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}")
```
-
### Publish your trained model on the Hub 🔥
+
Now that we saw we got good results after the training, we can publish our trained model on the Hub with one line of code.
📚 The libraries documentation 👉 https://github.com/huggingface/huggingface_sb3/tree/main#hugging-face--x-stable-baselines3-v20
-Here's an example of a Model Card (with a PyBullet environment):
-
-
+The action space is a vector with 3 values:
+- Control x, y, z movement
### Normalize observation and rewards
@@ -193,13 +203,11 @@ env = # TODO: Add the wrapper
```python
env = make_vec_env(env_id, n_envs=4)
-env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.0)
+env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.)
```
### Create the A2C Model 🤖
-In this case, because we have a vector of 28 values as input, we'll use an MLP (multi-layer perceptron) as policy.
-
For more information about A2C implementation with StableBaselines3 check: https://stable-baselines3.readthedocs.io/en/master/modules/a2c.html#notes
To find the best parameters I checked the [official trained agents by Stable-Baselines3 team](https://huggingface.co/sb3).
@@ -211,86 +219,71 @@ model = # Create the A2C model and try to find the best parameters
#### Solution
```python
-model = A2C(
- policy="MlpPolicy",
- env=env,
- gae_lambda=0.9,
- gamma=0.99,
- learning_rate=0.00096,
- max_grad_norm=0.5,
- n_steps=8,
- vf_coef=0.4,
- ent_coef=0.0,
- policy_kwargs=dict(log_std_init=-2, ortho_init=False),
- normalize_advantage=False,
- use_rms_prop=True,
- use_sde=True,
- verbose=1,
-)
+model = A2C(policy = "MultiInputPolicy",
+ env = env,
+ verbose=1)
```
### Train the A2C agent 🏃
-- Let's train our agent for 2,000,000 timesteps. Don't forget to use GPU on Colab. It will take approximately ~25-40min
+- Let's train our agent for 1,000,000 timesteps, don't forget to use GPU on Colab. It will take approximately ~25-40min
```python
-model.learn(2_000_000)
+model.learn(1_000_000)
```
```python
# Save the model and VecNormalize statistics when saving the agent
-model.save("a2c-AntBulletEnv-v0")
+model.save("a2c-PandaReachDense-v3")
env.save("vec_normalize.pkl")
```
### Evaluate the agent 📈
-- Now that our agent is trained, we need to **check its performance**.
+
+- Now that's our agent is trained, we need to **check its performance**.
- Stable-Baselines3 provides a method to do that: `evaluate_policy`
-- In my case, I got a mean reward of `2371.90 +/- 16.50`
```python
from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
# Load the saved statistics
-eval_env = DummyVecEnv([lambda: gym.make("AntBulletEnv-v0")])
+eval_env = DummyVecEnv([lambda: gym.make("PandaReachDense-v3")])
eval_env = VecNormalize.load("vec_normalize.pkl", eval_env)
+# We need to override the render_mode
+eval_env.render_mode = "rgb_array"
+
# do not update them at test time
eval_env.training = False
# reward normalization is not needed at test time
eval_env.norm_reward = False
# Load the agent
-model = A2C.load("a2c-AntBulletEnv-v0")
+model = A2C.load("a2c-PandaReachDense-v3")
-mean_reward, std_reward = evaluate_policy(model, env)
+mean_reward, std_reward = evaluate_policy(model, eval_env)
print(f"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}")
```
-
### Publish your trained model on the Hub 🔥
+
Now that we saw we got good results after the training, we can publish our trained model on the Hub with one line of code.
📚 The libraries documentation 👉 https://github.com/huggingface/huggingface_sb3/tree/main#hugging-face--x-stable-baselines3-v20
-Here's an example of a Model Card (with a PyBullet environment):
-
- -
By using `package_to_hub`, as we already mentionned in the former units, **you evaluate, record a replay, generate a model card of your agent and push it to the hub**.
This way:
- You can **showcase our work** 🔥
- You can **visualize your agent playing** 👀
-- You can **share an agent with the community that others can use** 💾
+- You can **share with the community an agent that others can use** 💾
- You can **access a leaderboard 🏆 to see how well your agent is performing compared to your classmates** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
-
To be able to share your model with the community there are three more steps to follow:
1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
-2️⃣ Sign in and then you need to get your authentication token from the Hugging Face website.
+2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
- Create a new token (https://huggingface.co/settings/tokens) **with write role**
-
By using `package_to_hub`, as we already mentionned in the former units, **you evaluate, record a replay, generate a model card of your agent and push it to the hub**.
This way:
- You can **showcase our work** 🔥
- You can **visualize your agent playing** 👀
-- You can **share an agent with the community that others can use** 💾
+- You can **share with the community an agent that others can use** 💾
- You can **access a leaderboard 🏆 to see how well your agent is performing compared to your classmates** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
-
To be able to share your model with the community there are three more steps to follow:
1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
-2️⃣ Sign in and then you need to get your authentication token from the Hugging Face website.
+2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
- Create a new token (https://huggingface.co/settings/tokens) **with write role**
 @@ -302,116 +295,68 @@ To be able to share your model with the community there are three more steps to
notebook_login()
!git config --global credential.helper store
```
+If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
-If you don't want to use Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
-
-3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 using `package_to_hub()` function
+3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 using `package_to_hub()` function.
+For this environment, **running this cell can take approximately 10min**
```python
+from huggingface_sb3 import package_to_hub
+
package_to_hub(
model=model,
model_name=f"a2c-{env_id}",
model_architecture="A2C",
env_id=env_id,
eval_env=eval_env,
- repo_id=f"ThomasSimonini/a2c-{env_id}", # Change the username
+ repo_id=f"ThomasSimonini/a2c-{env_id}", # Change the username
commit_message="Initial commit",
)
```
-## Take a coffee break ☕
-- You already trained your first robot that learned to move congratutlations 🥳!
-- It's **time to take a break**. Don't hesitate to **save this notebook** `File > Save a copy to Drive` to work on this second part later.
-
-
-## Environment 2: PandaReachDense-v2 🦾
-
-The agent we're going to train is a robotic arm that needs to do controls (moving the arm and using the end-effector).
-
-In robotics, the *end-effector* is the device at the end of a robotic arm designed to interact with the environment.
-
-In `PandaReach`, the robot must place its end-effector at a target position (green ball).
-
-We're going to use the dense version of this environment. This means we'll get a *dense reward function* that **will provide a reward at each timestep** (the closer the agent is to completing the task, the higher the reward). This is in contrast to a *sparse reward function* where the environment **return a reward if and only if the task is completed**.
-
-Also, we're going to use the *End-effector displacement control*, which means the **action corresponds to the displacement of the end-effector**. We don't control the individual motion of each joint (joint control).
-
-
-
-
-This way **the training will be easier**.
-
-
-
-In `PandaReachDense-v2`, the robotic arm must place its end-effector at a target position (green ball).
-
-
-
-```python
-import gym
-
-env_id = "PandaReachDense-v2"
-
-# Create the env
-env = gym.make(env_id)
-
-# Get the state space and action space
-s_size = env.observation_space.shape
-a_size = env.action_space
-```
-
-```python
-print("_____OBSERVATION SPACE_____ \n")
-print("The State Space is: ", s_size)
-print("Sample observation", env.observation_space.sample()) # Get a random observation
-```
+## Some additional challenges 🏆
-The observation space **is a dictionary with 3 different elements**:
-- `achieved_goal`: (x,y,z) position of the goal.
-- `desired_goal`: (x,y,z) distance between the goal position and the current object position.
-- `observation`: position (x,y,z) and velocity of the end-effector (vx, vy, vz).
+The best way to learn **is to try things by your own**! Why not trying `PandaPickAndPlace-v3`?
-Given it's a dictionary as observation, **we will need to use a MultiInputPolicy policy instead of MlpPolicy**.
+If you want to try more advanced tasks for panda-gym, you need to check what was done using **TQC or SAC** (a more sample-efficient algorithm suited for robotics tasks). In real robotics, you'll use a more sample-efficient algorithm for a simple reason: contrary to a simulation **if you move your robotic arm too much, you have a risk of breaking it**.
-```python
-print("\n _____ACTION SPACE_____ \n")
-print("The Action Space is: ", a_size)
-print("Action Space Sample", env.action_space.sample()) # Take a random action
-```
+PandaPickAndPlace-v1 (this model uses the v1 version of the environment): https://huggingface.co/sb3/tqc-PandaPickAndPlace-v1
-The action space is a vector with 3 values:
-- Control x, y, z movement
+And don't hesitate to check panda-gym documentation here: https://panda-gym.readthedocs.io/en/latest/usage/train_with_sb3.html
-Now it's your turn:
+We provide you the steps to train another agent (optional):
-1. Define the environment called "PandaReachDense-v2".
-2. Make a vectorized environment.
+1. Define the environment called "PandaPickAndPlace-v3"
+2. Make a vectorized environment
3. Add a wrapper to normalize the observations and rewards. [Check the documentation](https://stable-baselines3.readthedocs.io/en/master/guide/vec_envs.html#vecnormalize)
4. Create the A2C Model (don't forget verbose=1 to print the training logs).
-5. Train it for 1M Timesteps.
-6. Save the model and VecNormalize statistics when saving the agent.
-7. Evaluate your agent.
-8. Publish your trained model on the Hub 🔥 with `package_to_hub`.
+5. Train it for 1M Timesteps
+6. Save the model and VecNormalize statistics when saving the agent
+7. Evaluate your agent
+8. Publish your trained model on the Hub 🔥 with `package_to_hub`
+
-### Solution (fill the todo)
+### Solution (optional)
```python
# 1 - 2
-env_id = "PandaReachDense-v2"
+env_id = "PandaPickAndPlace-v3"
env = make_vec_env(env_id, n_envs=4)
# 3
-env = VecNormalize(env, norm_obs=True, norm_reward=False, clip_obs=10.0)
+env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.)
# 4
-model = A2C(policy="MultiInputPolicy", env=env, verbose=1)
+model = A2C(policy = "MultiInputPolicy",
+ env = env,
+ verbose=1)
# 5
model.learn(1_000_000)
```
```python
# 6
-model_name = "a2c-PandaReachDense-v2"
+model_name = "a2c-PandaPickAndPlace-v3";
model.save(model_name)
env.save("vec_normalize.pkl")
@@ -419,7 +364,7 @@ env.save("vec_normalize.pkl")
from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
# Load the saved statistics
-eval_env = DummyVecEnv([lambda: gym.make("PandaReachDense-v2")])
+eval_env = DummyVecEnv([lambda: gym.make("PandaPickAndPlace-v3")])
eval_env = VecNormalize.load("vec_normalize.pkl", eval_env)
# do not update them at test time
@@ -430,7 +375,7 @@ eval_env.norm_reward = False
# Load the agent
model = A2C.load(model_name)
-mean_reward, std_reward = evaluate_policy(model, env)
+mean_reward, std_reward = evaluate_policy(model, eval_env)
print(f"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}")
@@ -441,26 +386,11 @@ package_to_hub(
model_architecture="A2C",
env_id=env_id,
eval_env=eval_env,
- repo_id=f"ThomasSimonini/a2c-{env_id}", # TODO: Change the username
+ repo_id=f"ThomasSimonini/a2c-{env_id}", # TODO: Change the username
commit_message="Initial commit",
)
```
-## Some additional challenges 🏆
-
-The best way to learn **is to try things on your own**! Why not try `HalfCheetahBulletEnv-v0` for PyBullet and `PandaPickAndPlace-v1` for Panda-Gym?
-
-If you want to try more advanced tasks for panda-gym, you need to check what was done using **TQC or SAC** (a more sample-efficient algorithm suited for robotics tasks). In real robotics, you'll use a more sample-efficient algorithm for a simple reason: contrary to a simulation **if you move your robotic arm too much, you have a risk of breaking it**.
-
-PandaPickAndPlace-v1: https://huggingface.co/sb3/tqc-PandaPickAndPlace-v1
-
-And don't hesitate to check panda-gym documentation here: https://panda-gym.readthedocs.io/en/latest/usage/train_with_sb3.html
-
-Here are some ideas to go further:
-* Train more steps
-* Try different hyperparameters by looking at what your classmates have done 👉 https://huggingface.co/models?other=https://huggingface.co/models?other=AntBulletEnv-v0
-* **Push your new trained model** on the Hub 🔥
-
-
See you on Unit 7! 🔥
+
## Keep learning, stay awesome 🤗
diff --git a/units/en/unit6/introduction.mdx b/units/en/unit6/introduction.mdx
index 4be735f3..9d4c4adf 100644
--- a/units/en/unit6/introduction.mdx
+++ b/units/en/unit6/introduction.mdx
@@ -16,10 +16,7 @@ So today we'll study **Actor-Critic methods**, a hybrid architecture combining v
- *A Critic* that measures **how good the taken action is** (Value-Based method)
-We'll study one of these hybrid methods, Advantage Actor Critic (A2C), **and train our agent using Stable-Baselines3 in robotic environments**. We'll train two robots:
-- A spider 🕷️ to learn to move.
+We'll study one of these hybrid methods, Advantage Actor Critic (A2C), **and train our agent using Stable-Baselines3 in robotic environments**. We'll train:
- A robotic arm 🦾 to move to the correct position.
-
-
Sound exciting? Let's get started!
diff --git a/units/en/unit6/quiz.mdx b/units/en/unit6/quiz.mdx
new file mode 100644
index 00000000..09228d73
--- /dev/null
+++ b/units/en/unit6/quiz.mdx
@@ -0,0 +1,123 @@
+# Quiz
+
+The best way to learn and [to avoid the illusion of competence](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
+
+
+### Q1: Which of the following interpretations of bias-variance tradeoff is the most accurate in the field of Reinforcement Learning?
+
+
+
+### Q2: Which of the following statements are true, when talking about models with bias and/or variance in RL?
+
+
+
+
+### Q3: Which of the following statements are true about Monte Carlo method?
+
+
+
+### Q4: How would you describe, with your own words, the Actor-Critic Method (A2C)?
+
+
@@ -302,116 +295,68 @@ To be able to share your model with the community there are three more steps to
notebook_login()
!git config --global credential.helper store
```
+If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
-If you don't want to use Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
-
-3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 using `package_to_hub()` function
+3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 using `package_to_hub()` function.
+For this environment, **running this cell can take approximately 10min**
```python
+from huggingface_sb3 import package_to_hub
+
package_to_hub(
model=model,
model_name=f"a2c-{env_id}",
model_architecture="A2C",
env_id=env_id,
eval_env=eval_env,
- repo_id=f"ThomasSimonini/a2c-{env_id}", # Change the username
+ repo_id=f"ThomasSimonini/a2c-{env_id}", # Change the username
commit_message="Initial commit",
)
```
-## Take a coffee break ☕
-- You already trained your first robot that learned to move congratutlations 🥳!
-- It's **time to take a break**. Don't hesitate to **save this notebook** `File > Save a copy to Drive` to work on this second part later.
-
-
-## Environment 2: PandaReachDense-v2 🦾
-
-The agent we're going to train is a robotic arm that needs to do controls (moving the arm and using the end-effector).
-
-In robotics, the *end-effector* is the device at the end of a robotic arm designed to interact with the environment.
-
-In `PandaReach`, the robot must place its end-effector at a target position (green ball).
-
-We're going to use the dense version of this environment. This means we'll get a *dense reward function* that **will provide a reward at each timestep** (the closer the agent is to completing the task, the higher the reward). This is in contrast to a *sparse reward function* where the environment **return a reward if and only if the task is completed**.
-
-Also, we're going to use the *End-effector displacement control*, which means the **action corresponds to the displacement of the end-effector**. We don't control the individual motion of each joint (joint control).
-
-
-
-
-This way **the training will be easier**.
-
-
-
-In `PandaReachDense-v2`, the robotic arm must place its end-effector at a target position (green ball).
-
-
-
-```python
-import gym
-
-env_id = "PandaReachDense-v2"
-
-# Create the env
-env = gym.make(env_id)
-
-# Get the state space and action space
-s_size = env.observation_space.shape
-a_size = env.action_space
-```
-
-```python
-print("_____OBSERVATION SPACE_____ \n")
-print("The State Space is: ", s_size)
-print("Sample observation", env.observation_space.sample()) # Get a random observation
-```
+## Some additional challenges 🏆
-The observation space **is a dictionary with 3 different elements**:
-- `achieved_goal`: (x,y,z) position of the goal.
-- `desired_goal`: (x,y,z) distance between the goal position and the current object position.
-- `observation`: position (x,y,z) and velocity of the end-effector (vx, vy, vz).
+The best way to learn **is to try things by your own**! Why not trying `PandaPickAndPlace-v3`?
-Given it's a dictionary as observation, **we will need to use a MultiInputPolicy policy instead of MlpPolicy**.
+If you want to try more advanced tasks for panda-gym, you need to check what was done using **TQC or SAC** (a more sample-efficient algorithm suited for robotics tasks). In real robotics, you'll use a more sample-efficient algorithm for a simple reason: contrary to a simulation **if you move your robotic arm too much, you have a risk of breaking it**.
-```python
-print("\n _____ACTION SPACE_____ \n")
-print("The Action Space is: ", a_size)
-print("Action Space Sample", env.action_space.sample()) # Take a random action
-```
+PandaPickAndPlace-v1 (this model uses the v1 version of the environment): https://huggingface.co/sb3/tqc-PandaPickAndPlace-v1
-The action space is a vector with 3 values:
-- Control x, y, z movement
+And don't hesitate to check panda-gym documentation here: https://panda-gym.readthedocs.io/en/latest/usage/train_with_sb3.html
-Now it's your turn:
+We provide you the steps to train another agent (optional):
-1. Define the environment called "PandaReachDense-v2".
-2. Make a vectorized environment.
+1. Define the environment called "PandaPickAndPlace-v3"
+2. Make a vectorized environment
3. Add a wrapper to normalize the observations and rewards. [Check the documentation](https://stable-baselines3.readthedocs.io/en/master/guide/vec_envs.html#vecnormalize)
4. Create the A2C Model (don't forget verbose=1 to print the training logs).
-5. Train it for 1M Timesteps.
-6. Save the model and VecNormalize statistics when saving the agent.
-7. Evaluate your agent.
-8. Publish your trained model on the Hub 🔥 with `package_to_hub`.
+5. Train it for 1M Timesteps
+6. Save the model and VecNormalize statistics when saving the agent
+7. Evaluate your agent
+8. Publish your trained model on the Hub 🔥 with `package_to_hub`
+
-### Solution (fill the todo)
+### Solution (optional)
```python
# 1 - 2
-env_id = "PandaReachDense-v2"
+env_id = "PandaPickAndPlace-v3"
env = make_vec_env(env_id, n_envs=4)
# 3
-env = VecNormalize(env, norm_obs=True, norm_reward=False, clip_obs=10.0)
+env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.)
# 4
-model = A2C(policy="MultiInputPolicy", env=env, verbose=1)
+model = A2C(policy = "MultiInputPolicy",
+ env = env,
+ verbose=1)
# 5
model.learn(1_000_000)
```
```python
# 6
-model_name = "a2c-PandaReachDense-v2"
+model_name = "a2c-PandaPickAndPlace-v3";
model.save(model_name)
env.save("vec_normalize.pkl")
@@ -419,7 +364,7 @@ env.save("vec_normalize.pkl")
from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
# Load the saved statistics
-eval_env = DummyVecEnv([lambda: gym.make("PandaReachDense-v2")])
+eval_env = DummyVecEnv([lambda: gym.make("PandaPickAndPlace-v3")])
eval_env = VecNormalize.load("vec_normalize.pkl", eval_env)
# do not update them at test time
@@ -430,7 +375,7 @@ eval_env.norm_reward = False
# Load the agent
model = A2C.load(model_name)
-mean_reward, std_reward = evaluate_policy(model, env)
+mean_reward, std_reward = evaluate_policy(model, eval_env)
print(f"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}")
@@ -441,26 +386,11 @@ package_to_hub(
model_architecture="A2C",
env_id=env_id,
eval_env=eval_env,
- repo_id=f"ThomasSimonini/a2c-{env_id}", # TODO: Change the username
+ repo_id=f"ThomasSimonini/a2c-{env_id}", # TODO: Change the username
commit_message="Initial commit",
)
```
-## Some additional challenges 🏆
-
-The best way to learn **is to try things on your own**! Why not try `HalfCheetahBulletEnv-v0` for PyBullet and `PandaPickAndPlace-v1` for Panda-Gym?
-
-If you want to try more advanced tasks for panda-gym, you need to check what was done using **TQC or SAC** (a more sample-efficient algorithm suited for robotics tasks). In real robotics, you'll use a more sample-efficient algorithm for a simple reason: contrary to a simulation **if you move your robotic arm too much, you have a risk of breaking it**.
-
-PandaPickAndPlace-v1: https://huggingface.co/sb3/tqc-PandaPickAndPlace-v1
-
-And don't hesitate to check panda-gym documentation here: https://panda-gym.readthedocs.io/en/latest/usage/train_with_sb3.html
-
-Here are some ideas to go further:
-* Train more steps
-* Try different hyperparameters by looking at what your classmates have done 👉 https://huggingface.co/models?other=https://huggingface.co/models?other=AntBulletEnv-v0
-* **Push your new trained model** on the Hub 🔥
-
-
See you on Unit 7! 🔥
+
## Keep learning, stay awesome 🤗
diff --git a/units/en/unit6/introduction.mdx b/units/en/unit6/introduction.mdx
index 4be735f3..9d4c4adf 100644
--- a/units/en/unit6/introduction.mdx
+++ b/units/en/unit6/introduction.mdx
@@ -16,10 +16,7 @@ So today we'll study **Actor-Critic methods**, a hybrid architecture combining v
- *A Critic* that measures **how good the taken action is** (Value-Based method)
-We'll study one of these hybrid methods, Advantage Actor Critic (A2C), **and train our agent using Stable-Baselines3 in robotic environments**. We'll train two robots:
-- A spider 🕷️ to learn to move.
+We'll study one of these hybrid methods, Advantage Actor Critic (A2C), **and train our agent using Stable-Baselines3 in robotic environments**. We'll train:
- A robotic arm 🦾 to move to the correct position.
-
-
Sound exciting? Let's get started!
diff --git a/units/en/unit6/quiz.mdx b/units/en/unit6/quiz.mdx
new file mode 100644
index 00000000..09228d73
--- /dev/null
+++ b/units/en/unit6/quiz.mdx
@@ -0,0 +1,123 @@
+# Quiz
+
+The best way to learn and [to avoid the illusion of competence](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
+
+
+### Q1: Which of the following interpretations of bias-variance tradeoff is the most accurate in the field of Reinforcement Learning?
+
+
+
+### Q2: Which of the following statements are true, when talking about models with bias and/or variance in RL?
+
+
+
+
+### Q3: Which of the following statements are true about Monte Carlo method?
+
+
+
+### Q4: How would you describe, with your own words, the Actor-Critic Method (A2C)?
+
+
+Solution
+
+The idea behind Actor-Critic is that we learn two function approximations:
+1. A `policy` that controls how our agent acts (π)
+2. A `value` function to assist the policy update by measuring how good the action taken is (q)
+
+ +
+
+
+
+
+### Q5: Which of the following statements are true about the Actor-Critic Method?
+
+
+
+
+
+### Q6: What is `Advantage` in the A2C method?
+
+
+Solution
+
+Instead of using directly the Action-Value function of the Critic as it is, we could use an `Advantage` function. The idea behind an `Advantage` function is that we calculate the relative advantage of an action compared to the others possible at a state, averaging them.
+
+In other words: how taking that action at a state is better compared to the average value of the state
+
+ +
+
+
+
+
+Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read the chapter again to reinforce (😏) your knowledge.
diff --git a/units/en/unit7/hands-on.mdx b/units/en/unit7/hands-on.mdx
index 84856f7b..fc45a6bd 100644
--- a/units/en/unit7/hands-on.mdx
+++ b/units/en/unit7/hands-on.mdx
@@ -26,7 +26,7 @@ More precisely, AI vs. AI is three tools:
In addition to these three tools, your classmate cyllum created a 🤗 SoccerTwos Challenge Analytics where you can check the detailed match results of a model: [https://huggingface.co/spaces/cyllum/soccertwos-analytics](https://huggingface.co/spaces/cyllum/soccertwos-analytics)
-We're going to write a blog post to explain this AI vs. AI tool in detail, but to give you the big picture it works this way:
+We're [wrote a blog post to explain this AI vs. AI tool in detail](https://huggingface.co/blog/aivsai), but to give you the big picture it works this way:
- Every four hours, our algorithm **fetches all the available models for a given environment (in our case ML-Agents-SoccerTwos).**
- It creates a **queue of matches with the matchmaking algorithm.**
@@ -46,8 +46,6 @@ In order for your model to get correctly evaluated against others you need to fo
What will make the difference during this challenge are **the hyperparameters you choose**.
-The AI vs AI algorithm will run until April the 30th, 2023.
-
We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues).
### Chat with your classmates, share advice and ask questions on Discord
@@ -57,23 +55,19 @@ We're constantly trying to improve our tutorials, so **if you find some issues
## Step 0: Install MLAgents and download the correct executable
-⚠ We're going to use an experimental version of ML-Agents which allows you to push and load your models to/from the Hub. **You need to install the same version.**
-
-⚠ ⚠ ⚠ We’re not going to use the same version from Unit 5: Introduction to ML-Agents ⚠ ⚠ ⚠
-
We advise you to use [conda](https://docs.conda.io/en/latest/) as a package manager and create a new environment.
-With conda, we create a new environment called rl with **Python 3.9**:
+With conda, we create a new environment called rl with **Python 3.10.12**:
```bash
-conda create --name rl python=3.9
+conda create --name rl python=3.10.12
conda activate rl
```
-To be able to train our agents correctly and push to the Hub, we need to install an experimental version of ML-Agents (the branch aivsai from Hugging Face ML-Agents fork)
+To be able to train our agents correctly and push to the Hub, we need to install ML-Agents
```bash
-git clone --branch aivsai https://github.com/huggingface/ml-agents
+git clone https://github.com/Unity-Technologies/ml-agents
```
When the cloning is done (it takes 2.63 GB), we go inside the repository and install the package
@@ -84,17 +78,11 @@ pip install -e ./ml-agents-envs
pip install -e ./ml-agents
```
-We also need to install pytorch with:
-
-```bash
-pip install torch
-```
-
Finally, you need to install git-lfs: https://git-lfs.com/
Now that it’s installed, we need to add the environment training executable. Based on your operating system you need to download one of them, unzip it and place it in a new folder inside `ml-agents` that you call `training-envs-executables`
-At the end your executable should be in `mlagents/training-envs-executables/SoccerTwos`
+At the end your executable should be in `ml-agents/training-envs-executables/SoccerTwos`
Windows: Download [this executable](https://drive.google.com/file/d/1sqFxbEdTMubjVktnV4C6ICjp89wLhUcP/view?usp=sharing)
@@ -165,7 +153,6 @@ This allows each agent to **make decisions based only on what it perceives local
-
The solution then is to use Self-Play with an MA-POCA trainer (called poca). The poca trainer will help us to train cooperative behavior and self-play to win against an opponent team.
If you want to dive deeper into this MA-POCA algorithm, you need to read the paper they published [here](https://arxiv.org/pdf/2111.05992.pdf) and the sources we put on the additional readings section.
diff --git a/units/en/unit7/quiz.mdx b/units/en/unit7/quiz.mdx
new file mode 100644
index 00000000..a059ec31
--- /dev/null
+++ b/units/en/unit7/quiz.mdx
@@ -0,0 +1,139 @@
+# Quiz
+
+The best way to learn and [to avoid the illusion of competence](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
+
+
+### Q1: Chose the option which fits better when comparing different types of multi-agent environments
+
+- Your agents aim to maximize common benefits in ____ environments
+- Your agents aim to maximize common benefits while minimizing opponent's in ____ environments
+
+
+
+### Q2: Which of the following statements are true about `decentralized` learning?
+
+
+
+
+### Q3: Which of the following statements are true about `centralized` learning?
+
+
+
+### Q4: Explain in your own words what is the `Self-Play` approach
+
+
+Solution
+
+`Self-play` is an approach to instantiate copies of agents with the same policy as your as opponents, so that your agent learns from agents with same training level.
+
+
+
+### Q5: When configuring `Self-play`, several parameters are important. Could you identify, by their definition, which parameter are we talking about?
+
+- The probability of playing against the current self vs an opponent from a pool
+- Variety (dispersion) of training levels of the opponents you can face
+- The number of training steps before spawning a new opponent
+- Opponent change rate
+
+
+
+### Q6: What are the main motivations to use a ELO rating Score?
+
+
+
+Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read the chapter again to reinforce (😏) your knowledge.
diff --git a/units/en/unit7/self-play.mdx b/units/en/unit7/self-play.mdx
index d716f8c2..f35d0336 100644
--- a/units/en/unit7/self-play.mdx
+++ b/units/en/unit7/self-play.mdx
@@ -24,7 +24,7 @@ This solution is called *self-play*. In self-play, **the agent uses former copie
It’s the same way humans learn in competition:
- We start to train against an opponent of similar level
-- Then we learn from it, and when we acquired some skills, we can move further with stronger opponents.
+- Then we learn from it, and when we acquire some skills, we can move further with stronger opponents.
We do the same with self-play:
diff --git a/units/en/unit8/clipped-surrogate-objective.mdx b/units/en/unit8/clipped-surrogate-objective.mdx
index b2179db6..09d9be1b 100644
--- a/units/en/unit8/clipped-surrogate-objective.mdx
+++ b/units/en/unit8/clipped-surrogate-objective.mdx
@@ -60,7 +60,7 @@ To do that, we have two solutions:
 -This clipped part is a version where rt(theta) is clipped between \\( [1 - \epsilon, 1 + \epsilon] \\).
+This clipped part is a version where \\( r_t(\theta) \\) is clipped between \\( [1 - \epsilon, 1 + \epsilon] \\).
With the Clipped Surrogate Objective function, we have two probability ratios, one non-clipped and one clipped in a range between \\( [1 - \epsilon, 1 + \epsilon] \\), epsilon is a hyperparameter that helps us to define this clip range (in the paper \\( \epsilon = 0.2 \\).).
diff --git a/units/en/unit8/visualize.mdx b/units/en/unit8/visualize.mdx
index af05a571..fd977ca7 100644
--- a/units/en/unit8/visualize.mdx
+++ b/units/en/unit8/visualize.mdx
@@ -65,4 +65,4 @@ The final Clipped Surrogate Objective Loss for PPO Actor-Critic style looks like
-This clipped part is a version where rt(theta) is clipped between \\( [1 - \epsilon, 1 + \epsilon] \\).
+This clipped part is a version where \\( r_t(\theta) \\) is clipped between \\( [1 - \epsilon, 1 + \epsilon] \\).
With the Clipped Surrogate Objective function, we have two probability ratios, one non-clipped and one clipped in a range between \\( [1 - \epsilon, 1 + \epsilon] \\), epsilon is a hyperparameter that helps us to define this clip range (in the paper \\( \epsilon = 0.2 \\).).
diff --git a/units/en/unit8/visualize.mdx b/units/en/unit8/visualize.mdx
index af05a571..fd977ca7 100644
--- a/units/en/unit8/visualize.mdx
+++ b/units/en/unit8/visualize.mdx
@@ -65,4 +65,4 @@ The final Clipped Surrogate Objective Loss for PPO Actor-Critic style looks like
 -That was quite complex. Take time to understand these situations by looking at the table and the graph. **You must understand why this makes sense.** If you want to go deeper, the best resource is the article [Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization" by Daniel Bick, especially part 3.4](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf).
+That was quite complex. Take time to understand these situations by looking at the table and the graph. **You must understand why this makes sense.** If you want to go deeper, the best resource is the article ["Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization" by Daniel Bick, especially part 3.4](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf).
diff --git a/units/en/unitbonus1/train.mdx b/units/en/unitbonus1/train.mdx
index 7d6708fd..814d604d 100644
--- a/units/en/unitbonus1/train.mdx
+++ b/units/en/unitbonus1/train.mdx
@@ -26,12 +26,7 @@ By using Google Colab, **you can focus on learning and experimenting without wor
In this notebook, we'll reinforce what we learned in the first Unit by **teaching Huggy the Dog to fetch the stick and then play with it directly in your browser**
-⬇️ Here is an example of what **you will achieve at the end of the unit.** ⬇️ (launch ▶ to see)
-
-```python
-%%html
-
-```
+
-That was quite complex. Take time to understand these situations by looking at the table and the graph. **You must understand why this makes sense.** If you want to go deeper, the best resource is the article [Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization" by Daniel Bick, especially part 3.4](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf).
+That was quite complex. Take time to understand these situations by looking at the table and the graph. **You must understand why this makes sense.** If you want to go deeper, the best resource is the article ["Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization" by Daniel Bick, especially part 3.4](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf).
diff --git a/units/en/unitbonus1/train.mdx b/units/en/unitbonus1/train.mdx
index 7d6708fd..814d604d 100644
--- a/units/en/unitbonus1/train.mdx
+++ b/units/en/unitbonus1/train.mdx
@@ -26,12 +26,7 @@ By using Google Colab, **you can focus on learning and experimenting without wor
In this notebook, we'll reinforce what we learned in the first Unit by **teaching Huggy the Dog to fetch the stick and then play with it directly in your browser**
-⬇️ Here is an example of what **you will achieve at the end of the unit.** ⬇️ (launch ▶ to see)
-
-```python
-%%html
-
-```
+ ### The environment 🎮
@@ -39,7 +34,7 @@ In this notebook, we'll reinforce what we learned in the first Unit by **teachin
### The library used 📚
-- [MLAgents (Hugging Face version)](https://github.com/huggingface/ml-agents)
+- [MLAgents](https://github.com/Unity-Technologies/ml-agents)
We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the Github Repo](https://github.com/huggingface/deep-rl-class/issues).
@@ -71,11 +66,11 @@ Before diving into the notebook, you need to:
## Clone the repository and install the dependencies 🔽
-- We need to clone the repository, that **contains the experimental version of the library that allows you to push your trained agent to the Hub.**
+- We need to clone the repository, that contains ML-Agents.
```bash
-# Clone this specific repository (can take 3min)
-git clone --depth 1 --branch hf-integration-save https://github.com/huggingface/ml-agents
+# Clone the repository (can take 3min)
+git clone --depth 1 https://github.com/Unity-Technologies/ml-agents
```
```bash
@@ -155,8 +150,46 @@ Our reward function:
- For the scope of this notebook, we're not going to modify the hyperparameters, but if you want to try as an experiment, Unity provides very [good documentation explaining each of them here](https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Training-Configuration-File.md).
-- **In the case you want to modify the hyperparameters**, in Google Colab notebook, you can click here to open the config.yaml: `/content/ml-agents/config/ppo/Huggy.yaml`
+- We need to create a config file for Huggy.
+
+- Go to `/content/ml-agents/config/ppo`
+
+- Create a new file called `Huggy.yaml`
+- Copy and paste the content below 🔽
+
+```
+behaviors:
+ Huggy:
+ trainer_type: ppo
+ hyperparameters:
+ batch_size: 2048
+ buffer_size: 20480
+ learning_rate: 0.0003
+ beta: 0.005
+ epsilon: 0.2
+ lambd: 0.95
+ num_epoch: 3
+ learning_rate_schedule: linear
+ network_settings:
+ normalize: true
+ hidden_units: 512
+ num_layers: 3
+ vis_encode_type: simple
+ reward_signals:
+ extrinsic:
+ gamma: 0.995
+ strength: 1.0
+ checkpoint_interval: 200000
+ keep_checkpoints: 15
+ max_steps: 2e6
+ time_horizon: 1000
+ summary_freq: 50000
+```
+
+- Don't forget to save the file!
+
+- **In the case you want to modify the hyperparameters**, in Google Colab notebook, you can click here to open the config.yaml: `/content/ml-agents/config/ppo/Huggy.yaml`
We’re now ready to train our agent 🔥.
@@ -170,7 +203,7 @@ With ML Agents, we run a training script. We define four parameters:
1. `mlagents-learn `: the path where the hyperparameter config file is.
2. `--env`: where the environment executable is.
-3. `--run_id`: the name you want to give to your training run id.
+3. `--run-id`: the name you want to give to your training run id.
4. `--no-graphics`: to not launch the visualization during the training.
Train the model and use the `--resume` flag to continue training in case of interruption.
diff --git a/units/en/unitbonus3/generalisation.mdx b/units/en/unitbonus3/generalisation.mdx
new file mode 100644
index 00000000..27f38c78
--- /dev/null
+++ b/units/en/unitbonus3/generalisation.mdx
@@ -0,0 +1,12 @@
+# Generalization in Reinforcement Learning
+
+Generalization plays a pivotal role in the realm of Reinforcement Learning. While **RL algorithms demonstrate good performance in controlled environments**, the real world presents a **unique challenge due to its non-stationary and open-ended nature**.
+
+As a result, the development of RL algorithms that stay robust in the face of environmental variations, coupled with the capability to transfer and adapt to uncharted yet analogous tasks and settings, becomes fundamental for real world application of RL.
+
+If you're interested to dive deeper into this research subject, we recommend exploring the following resource:
+
+- [Generalization in Reinforcement Learning by Robert Kirk](https://robertkirk.github.io/2022/01/17/generalisation-in-reinforcement-learning-survey.html): this comprehensive survey provides an insightful **overview of the concept of generalization in RL**, making it an excellent starting point for your exploration.
+
+- [Improving Generalization in Reinforcement Learning using Policy Similarity Embeddings](https://blog.research.google/2021/09/improving-generalization-in.html?m=1)
+
diff --git a/units/en/unitbonus3/godotrl.mdx b/units/en/unitbonus3/godotrl.mdx
index e073c80d..803457e7 100644
--- a/units/en/unitbonus3/godotrl.mdx
+++ b/units/en/unitbonus3/godotrl.mdx
@@ -59,12 +59,12 @@ First click on the AssetLib and search for “rl”
### The environment 🎮
@@ -39,7 +34,7 @@ In this notebook, we'll reinforce what we learned in the first Unit by **teachin
### The library used 📚
-- [MLAgents (Hugging Face version)](https://github.com/huggingface/ml-agents)
+- [MLAgents](https://github.com/Unity-Technologies/ml-agents)
We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the Github Repo](https://github.com/huggingface/deep-rl-class/issues).
@@ -71,11 +66,11 @@ Before diving into the notebook, you need to:
## Clone the repository and install the dependencies 🔽
-- We need to clone the repository, that **contains the experimental version of the library that allows you to push your trained agent to the Hub.**
+- We need to clone the repository, that contains ML-Agents.
```bash
-# Clone this specific repository (can take 3min)
-git clone --depth 1 --branch hf-integration-save https://github.com/huggingface/ml-agents
+# Clone the repository (can take 3min)
+git clone --depth 1 https://github.com/Unity-Technologies/ml-agents
```
```bash
@@ -155,8 +150,46 @@ Our reward function:
- For the scope of this notebook, we're not going to modify the hyperparameters, but if you want to try as an experiment, Unity provides very [good documentation explaining each of them here](https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Training-Configuration-File.md).
-- **In the case you want to modify the hyperparameters**, in Google Colab notebook, you can click here to open the config.yaml: `/content/ml-agents/config/ppo/Huggy.yaml`
+- We need to create a config file for Huggy.
+
+- Go to `/content/ml-agents/config/ppo`
+
+- Create a new file called `Huggy.yaml`
+- Copy and paste the content below 🔽
+
+```
+behaviors:
+ Huggy:
+ trainer_type: ppo
+ hyperparameters:
+ batch_size: 2048
+ buffer_size: 20480
+ learning_rate: 0.0003
+ beta: 0.005
+ epsilon: 0.2
+ lambd: 0.95
+ num_epoch: 3
+ learning_rate_schedule: linear
+ network_settings:
+ normalize: true
+ hidden_units: 512
+ num_layers: 3
+ vis_encode_type: simple
+ reward_signals:
+ extrinsic:
+ gamma: 0.995
+ strength: 1.0
+ checkpoint_interval: 200000
+ keep_checkpoints: 15
+ max_steps: 2e6
+ time_horizon: 1000
+ summary_freq: 50000
+```
+
+- Don't forget to save the file!
+
+- **In the case you want to modify the hyperparameters**, in Google Colab notebook, you can click here to open the config.yaml: `/content/ml-agents/config/ppo/Huggy.yaml`
We’re now ready to train our agent 🔥.
@@ -170,7 +203,7 @@ With ML Agents, we run a training script. We define four parameters:
1. `mlagents-learn `: the path where the hyperparameter config file is.
2. `--env`: where the environment executable is.
-3. `--run_id`: the name you want to give to your training run id.
+3. `--run-id`: the name you want to give to your training run id.
4. `--no-graphics`: to not launch the visualization during the training.
Train the model and use the `--resume` flag to continue training in case of interruption.
diff --git a/units/en/unitbonus3/generalisation.mdx b/units/en/unitbonus3/generalisation.mdx
new file mode 100644
index 00000000..27f38c78
--- /dev/null
+++ b/units/en/unitbonus3/generalisation.mdx
@@ -0,0 +1,12 @@
+# Generalization in Reinforcement Learning
+
+Generalization plays a pivotal role in the realm of Reinforcement Learning. While **RL algorithms demonstrate good performance in controlled environments**, the real world presents a **unique challenge due to its non-stationary and open-ended nature**.
+
+As a result, the development of RL algorithms that stay robust in the face of environmental variations, coupled with the capability to transfer and adapt to uncharted yet analogous tasks and settings, becomes fundamental for real world application of RL.
+
+If you're interested to dive deeper into this research subject, we recommend exploring the following resource:
+
+- [Generalization in Reinforcement Learning by Robert Kirk](https://robertkirk.github.io/2022/01/17/generalisation-in-reinforcement-learning-survey.html): this comprehensive survey provides an insightful **overview of the concept of generalization in RL**, making it an excellent starting point for your exploration.
+
+- [Improving Generalization in Reinforcement Learning using Policy Similarity Embeddings](https://blog.research.google/2021/09/improving-generalization-in.html?m=1)
+
diff --git a/units/en/unitbonus3/godotrl.mdx b/units/en/unitbonus3/godotrl.mdx
index e073c80d..803457e7 100644
--- a/units/en/unitbonus3/godotrl.mdx
+++ b/units/en/unitbonus3/godotrl.mdx
@@ -59,12 +59,12 @@ First click on the AssetLib and search for “rl”
 -Then click on Godot RL Agents, click Download and unselect the LICIENSE and [README.md](http://README.md) files. Then click install.
+Then click on Godot RL Agents, click Download and unselect the LICENSE and README .md files. Then click install.
-Then click on Godot RL Agents, click Download and unselect the LICIENSE and [README.md](http://README.md) files. Then click install.
+Then click on Godot RL Agents, click Download and unselect the LICENSE and README .md files. Then click install.
 -The Godot RL Agents plugin is now downloaded to your machine your machine. Now click on Project → Project settings and enable the addon:
+The Godot RL Agents plugin is now downloaded to your machine. Now click on Project → Project settings and enable the addon:
-The Godot RL Agents plugin is now downloaded to your machine your machine. Now click on Project → Project settings and enable the addon:
+The Godot RL Agents plugin is now downloaded to your machine. Now click on Project → Project settings and enable the addon:
 @@ -156,9 +156,9 @@ func set_action(action) -> void:
move_action = clamp(action["move_action"][0], -1.0, 1.0)
```
-We have now defined the agent’s observation, which is the position and velocity of the ball in its local cooridinate space. We have also defined the action space of the agent, which is a single contuninous value ranging from -1 to +1.
+We have now defined the agent’s observation, which is the position and velocity of the ball in its local coordinate space. We have also defined the action space of the agent, which is a single continuous value ranging from -1 to +1.
-The next step is to update the Player’s script to use the actions from the AIController, edit the Player’s script by clicking on the scroll next to the player node, update the code in `Player.gd` to the following the following:
+The next step is to update the Player’s script to use the actions from the AIController, edit the Player’s script by clicking on the scroll next to the player node, update the code in `Player.gd` to the following:
```python
extends Node3D
@@ -193,9 +193,9 @@ func _on_area_3d_body_entered(body):
We now need to synchronize between the game running in Godot and the neural network being trained in Python. Godot RL agents provides a node that does just that. Open the train.tscn scene, right click on the root node, and click “Add child node”. Then, search for “sync” and add a Godot RL Agents Sync node. This node handles the communication between Python and Godot over TCP.
-You can run training live in the the editor, by first launching the python training with `gdrl`
+You can run training live in the editor, by first launching the python training with `gdrl`.
-In this simple example, a reasonable policy is learned in several minutes. You may wish to speed up training, click on the Sync node in the train scene and you will see there is a “Speed Up” property exposed in the editor:
+In this simple example, a reasonable policy is learned in several minutes. You may wish to speed up training, click on the Sync node in the train scene, and you will see there is a “Speed Up” property exposed in the editor:
@@ -156,9 +156,9 @@ func set_action(action) -> void:
move_action = clamp(action["move_action"][0], -1.0, 1.0)
```
-We have now defined the agent’s observation, which is the position and velocity of the ball in its local cooridinate space. We have also defined the action space of the agent, which is a single contuninous value ranging from -1 to +1.
+We have now defined the agent’s observation, which is the position and velocity of the ball in its local coordinate space. We have also defined the action space of the agent, which is a single continuous value ranging from -1 to +1.
-The next step is to update the Player’s script to use the actions from the AIController, edit the Player’s script by clicking on the scroll next to the player node, update the code in `Player.gd` to the following the following:
+The next step is to update the Player’s script to use the actions from the AIController, edit the Player’s script by clicking on the scroll next to the player node, update the code in `Player.gd` to the following:
```python
extends Node3D
@@ -193,9 +193,9 @@ func _on_area_3d_body_entered(body):
We now need to synchronize between the game running in Godot and the neural network being trained in Python. Godot RL agents provides a node that does just that. Open the train.tscn scene, right click on the root node, and click “Add child node”. Then, search for “sync” and add a Godot RL Agents Sync node. This node handles the communication between Python and Godot over TCP.
-You can run training live in the the editor, by first launching the python training with `gdrl`
+You can run training live in the editor, by first launching the python training with `gdrl`.
-In this simple example, a reasonable policy is learned in several minutes. You may wish to speed up training, click on the Sync node in the train scene and you will see there is a “Speed Up” property exposed in the editor:
+In this simple example, a reasonable policy is learned in several minutes. You may wish to speed up training, click on the Sync node in the train scene, and you will see there is a “Speed Up” property exposed in the editor:
 @@ -205,6 +205,8 @@ Try setting this property up to 8 to speed up training. This can be a great bene
We have only scratched the surface of what can be achieved with Godot RL Agents, the library includes custom sensors and cameras to enrich the information available to the agent. Take a look at the [examples](https://github.com/edbeeching/godot_rl_agents_examples) to find out more!
+For the ability to export the trained model to .onnx so that you can run inference directly from Godot without the Python server, and other useful training options, take a look at the [advanced SB3 tutorial](https://github.com/edbeeching/godot_rl_agents/blob/main/docs/ADV_STABLE_BASELINES_3.md).
+
## Author
This section was written by Edward Beeching
diff --git a/units/en/unitbonus3/learning-agents.mdx b/units/en/unitbonus3/learning-agents.mdx
new file mode 100644
index 00000000..e7754992
--- /dev/null
+++ b/units/en/unitbonus3/learning-agents.mdx
@@ -0,0 +1,37 @@
+# An Introduction to Unreal Learning Agents
+
+[Learning Agents](https://dev.epicgames.com/community/learning/tutorials/8OWY/unreal-engine-learning-agents-introduction) is an Unreal Engine (UE) plugin that allows you **to train AI characters using machine learning (ML) in Unreal**.
+
+It's an exciting new plugin where you can create unique environments using Unreal Engine and train your agents.
+
+Let's see how you can **get started and train a car to drive in an Unreal Engine Environment**.
+
+
+
@@ -205,6 +205,8 @@ Try setting this property up to 8 to speed up training. This can be a great bene
We have only scratched the surface of what can be achieved with Godot RL Agents, the library includes custom sensors and cameras to enrich the information available to the agent. Take a look at the [examples](https://github.com/edbeeching/godot_rl_agents_examples) to find out more!
+For the ability to export the trained model to .onnx so that you can run inference directly from Godot without the Python server, and other useful training options, take a look at the [advanced SB3 tutorial](https://github.com/edbeeching/godot_rl_agents/blob/main/docs/ADV_STABLE_BASELINES_3.md).
+
## Author
This section was written by Edward Beeching
diff --git a/units/en/unitbonus3/learning-agents.mdx b/units/en/unitbonus3/learning-agents.mdx
new file mode 100644
index 00000000..e7754992
--- /dev/null
+++ b/units/en/unitbonus3/learning-agents.mdx
@@ -0,0 +1,37 @@
+# An Introduction to Unreal Learning Agents
+
+[Learning Agents](https://dev.epicgames.com/community/learning/tutorials/8OWY/unreal-engine-learning-agents-introduction) is an Unreal Engine (UE) plugin that allows you **to train AI characters using machine learning (ML) in Unreal**.
+
+It's an exciting new plugin where you can create unique environments using Unreal Engine and train your agents.
+
+Let's see how you can **get started and train a car to drive in an Unreal Engine Environment**.
+
+
+ +Source: [Learning Agents Driving Car Tutorial](https://dev.epicgames.com/community/learning/tutorials/qj2O/unreal-engine-learning-to-drive)
+
+
+## Case 1: I don't know anything about Unreal Engine and Beginners in Unreal Engine
+If you're new to Unreal Engine, don't be scared! We listed two courses you need to follow to be able to use Learning Agents:
+
+1. Master the Basics: Begin by watching this course [your first hour in Unreal Engine 5](https://dev.epicgames.com/community/learning/courses/ZpX/your-first-hour-in-unreal-engine-5/E7L/introduction-to-your-first-hour-in-unreal-engine-5). This comprehensive course will **lay down the foundational knowledge you need to use Unreal**.
+
+2. Dive into Blueprints: Explore the world of Blueprints, the visual scripting component of Unreal Engine. [This video course](https://youtu.be/W0brCeJNMqk?si=zy4t4t1l6FMIzbpz) will familiarize you with this essential tool.
+
+Armed with the basics, **you're now prepared to play with Learning Agents**:
+
+3. Get the Big Picture of Learning Agents by [reading this informative overview](https://dev.epicgames.com/community/learning/tutorials/8OWY/unreal-engine-learning-agents-introduction).
+
+4. [Teach a Car to Drive using Reinforcement Learning in Learning Agents](https://dev.epicgames.com/community/learning/tutorials/qj2O/unreal-engine-learning-to-drive).
+
+5. [Check Imitation Learning with the Unreal Engine 5.3 Learning Agents Plugin](https://www.youtube.com/watch?v=NwYUNlFvajQ)
+
+## Case 2: I'm familiar with Unreal
+
+For those already acquainted with Unreal Engine, you can jump straight into Learning Agents with these two tutorials:
+
+1. Get the Big Picture of Learning Agents by [reading this informative overview](https://dev.epicgames.com/community/learning/tutorials/8OWY/unreal-engine-learning-agents-introduction).
+
+2. [Teach a Car to Drive using Reinforcement Learning in Learning Agents](https://dev.epicgames.com/community/learning/tutorials/qj2O/unreal-engine-learning-to-drive). .
+
+3. [Check Imitation Learning with the Unreal Engine 5.3 Learning Agents Plugin](https://www.youtube.com/watch?v=NwYUNlFvajQ)
\ No newline at end of file
diff --git a/units/en/unitbonus3/student-works.mdx b/units/en/unitbonus3/student-works.mdx
new file mode 100644
index 00000000..15a41531
--- /dev/null
+++ b/units/en/unitbonus3/student-works.mdx
@@ -0,0 +1,57 @@
+# Student Works
+
+Since the launch of the Deep Reinforcement Learning Course, **many students have created amazing projects that you should check out and consider participating in**.
+
+If you've created an interesting project, don't hesitate to [add it to this list by opening a pull request on the GitHub repository](https://github.com/huggingface/deep-rl-class).
+
+The projects are **arranged based on the date of publication in this page**.
+
+
+## Space Scavanger AI
+
+This project is a space game environment with trained neural network for AI.
+
+AI is trained by Reinforcement learning algorithm based on UnityMLAgents and RLlib frameworks.
+
+
+Source: [Learning Agents Driving Car Tutorial](https://dev.epicgames.com/community/learning/tutorials/qj2O/unreal-engine-learning-to-drive)
+
+
+## Case 1: I don't know anything about Unreal Engine and Beginners in Unreal Engine
+If you're new to Unreal Engine, don't be scared! We listed two courses you need to follow to be able to use Learning Agents:
+
+1. Master the Basics: Begin by watching this course [your first hour in Unreal Engine 5](https://dev.epicgames.com/community/learning/courses/ZpX/your-first-hour-in-unreal-engine-5/E7L/introduction-to-your-first-hour-in-unreal-engine-5). This comprehensive course will **lay down the foundational knowledge you need to use Unreal**.
+
+2. Dive into Blueprints: Explore the world of Blueprints, the visual scripting component of Unreal Engine. [This video course](https://youtu.be/W0brCeJNMqk?si=zy4t4t1l6FMIzbpz) will familiarize you with this essential tool.
+
+Armed with the basics, **you're now prepared to play with Learning Agents**:
+
+3. Get the Big Picture of Learning Agents by [reading this informative overview](https://dev.epicgames.com/community/learning/tutorials/8OWY/unreal-engine-learning-agents-introduction).
+
+4. [Teach a Car to Drive using Reinforcement Learning in Learning Agents](https://dev.epicgames.com/community/learning/tutorials/qj2O/unreal-engine-learning-to-drive).
+
+5. [Check Imitation Learning with the Unreal Engine 5.3 Learning Agents Plugin](https://www.youtube.com/watch?v=NwYUNlFvajQ)
+
+## Case 2: I'm familiar with Unreal
+
+For those already acquainted with Unreal Engine, you can jump straight into Learning Agents with these two tutorials:
+
+1. Get the Big Picture of Learning Agents by [reading this informative overview](https://dev.epicgames.com/community/learning/tutorials/8OWY/unreal-engine-learning-agents-introduction).
+
+2. [Teach a Car to Drive using Reinforcement Learning in Learning Agents](https://dev.epicgames.com/community/learning/tutorials/qj2O/unreal-engine-learning-to-drive). .
+
+3. [Check Imitation Learning with the Unreal Engine 5.3 Learning Agents Plugin](https://www.youtube.com/watch?v=NwYUNlFvajQ)
\ No newline at end of file
diff --git a/units/en/unitbonus3/student-works.mdx b/units/en/unitbonus3/student-works.mdx
new file mode 100644
index 00000000..15a41531
--- /dev/null
+++ b/units/en/unitbonus3/student-works.mdx
@@ -0,0 +1,57 @@
+# Student Works
+
+Since the launch of the Deep Reinforcement Learning Course, **many students have created amazing projects that you should check out and consider participating in**.
+
+If you've created an interesting project, don't hesitate to [add it to this list by opening a pull request on the GitHub repository](https://github.com/huggingface/deep-rl-class).
+
+The projects are **arranged based on the date of publication in this page**.
+
+
+## Space Scavanger AI
+
+This project is a space game environment with trained neural network for AI.
+
+AI is trained by Reinforcement learning algorithm based on UnityMLAgents and RLlib frameworks.
+
+ +
+Play the Game here 👉 https://swingshuffle.itch.io/spacescalvagerai
+
+Check the Unity project here 👉 https://github.com/HighExecutor/SpaceScalvagerAI
+
+
+## Neural Nitro 🏎️
+
+
+
+Play the Game here 👉 https://swingshuffle.itch.io/spacescalvagerai
+
+Check the Unity project here 👉 https://github.com/HighExecutor/SpaceScalvagerAI
+
+
+## Neural Nitro 🏎️
+
+ +
+In this project, Sookeyy created a low poly racing game and trained a car to drive.
+
+Check out the demo here 👉 https://sookeyy.itch.io/neuralnitro
+
+
+## Space War 🚀
+
+
+
+In this project, Sookeyy created a low poly racing game and trained a car to drive.
+
+Check out the demo here 👉 https://sookeyy.itch.io/neuralnitro
+
+
+## Space War 🚀
+
+ +
+In this project, Eric Dong recreates Bill Seiler's 1985 version of Space War in Pygame and uses reinforcement learning (RL) to train AI agents.
+
+This project is currently in development!
+
+### Demo
+
+Dev/Edge version:
+* https://e-dong.itch.io/spacewar-dev
+
+Stable version:
+* https://e-dong.itch.io/spacewar
+* https://huggingface.co/spaces/EricofRL/SpaceWarRL
+
+### Community blog posts
+
+TBA
+
+### Other links
+
+Check out the source here 👉 https://github.com/e-dong/space-war-rl
+Check out his blog here 👉 https://dev.to/edong/space-war-rl-0-series-introduction-25dh
+
diff --git a/units/zh-CN/_toctree.yml b/units/zh-CN/_toctree.yml
index 3367aedc..8827deda 100644
--- a/units/zh-CN/_toctree.yml
+++ b/units/zh-CN/_toctree.yml
@@ -122,6 +122,8 @@
title: 深入理解策略梯度
- local: unit4/pg-theorem
title: (可选)策略梯度定理
+ - local: unit4/glossary
+ title: 术语表
- local: unit4/hands-on
title: 动手实践
- local: unit4/quiz
@@ -146,6 +148,8 @@
title: 动手实践
- local: unit5/bonus
title: 奖励部分,学习如何使用 Unity 和 MLAgents 创建自己的环境
+ - local: unit5/quiz
+ title: 测验
- local: unit5/conclusion
title: 结论
- title: 第 6 单元. 带有机器人环境的演员-评论员算法
@@ -158,6 +162,8 @@
title: 优势演员-评论员算法(A2C)
- local: unit6/hands-on
title: 使用 PyBullet 和 Panda-Gym 进行优势演员-评论员算法(A2C)的机器人模拟 🤖
+ - local: unit6/quiz
+ title: 测验
- local: unit6/conclusion
title: 结论
- local: unit6/additional-readings
@@ -174,6 +180,8 @@
title: 自我对弈
- local: unit7/hands-on
title: 让我们训练我们的足球队击败你同学的队伍(AI vs. AI)
+ - local: unit7/quiz
+ title: 测验
- local: unit7/conclusion
title: 结论
- local: unit7/additional-readings
@@ -209,7 +217,9 @@
- local: unitbonus3/model-based
title: 基于模型的强化学习
- local: unitbonus3/offline-online
- title: 离线与在线强化学习
+ title: 离线强化学习与在线强化学习
+ - local: unitbonus3/generalisation
+ title: 泛化强化学习
- local: unitbonus3/rlhf
title: 从人类反馈中进行强化学习
- local: unitbonus3/decision-transformers
@@ -219,9 +229,13 @@
- local: unitbonus3/curriculum-learning
title: (自动)课程学习在强化学习中的应用
- local: unitbonus3/envs-to-try
- title: 值得尝试的有趣环境
+ title: 有趣的环境尝试
+ - local: unitbonus3/learning-agents
+ title: 虚幻学习智能体简介
- local: unitbonus3/godotrl
- title: Godot RL 介绍
+ title: Godot RL 简介
+ - local: unitbonus3/student-works
+ title: 学生项目
- local: unitbonus3/rl-documentation
title: 强化学习文档的简要介绍
- title: 证书和祝贺
diff --git a/units/zh-CN/communication/certification.mdx b/units/zh-CN/communication/certification.mdx
index f89cc853..8c2bea3f 100644
--- a/units/zh-CN/communication/certification.mdx
+++ b/units/zh-CN/communication/certification.mdx
@@ -1,27 +1,31 @@
# 认证流程
-认证过程**完全免费**:
+认证流程**免费进行**:
-- 要获得*结业证书*:你需要在 2023 年 7 月结束前通过 80% 的作业。
-- 要获得*优秀证书*:你需要在 2023 年 7 月结束前通过 100% 的作业。
+- 获得*结业证书*:需通过至少 80% 的作业。
+- 获得*优秀证书*:需全部作业通过。
+本课程**没有截至日期,学习者可以自由安排进度**
-当我们说通过时,**我们的意思是你的模型必须被推送到 Hub 并获得等于或高于最低要求的结果。**
+当我们提到“通过”,**指的是你的模型必须上传到 Hub,并且其表现要达到或超过基本要求。**
-要检查你的进度以及你通过/未通过的单元: https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
+想要查看你的学习进度和已通过/未通过的单元,请访问:https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
-现在你已准备好进行认证过程,你需要:
+准备好进行认证的话,请按以下步骤操作:
-1. 到这里: https://huggingface.co/spaces/huggingface-projects/Deep-RL-Course-Certification/
-2. 输入你的 *hugging face 用户名*, 你的*名*和*姓*
+1. 访问此链接:https://huggingface.co/spaces/huggingface-projects/Deep-RL-Course-Certification/
-3. 点击 "Generate my certificate"。
- - 如果你通过了 80% 的作业,**恭喜**你刚刚获得结业证书。
- - 如果你通过了 100% 的作业,**恭喜**你刚刚获得了优秀证书。
- - 如果你低于 80%,请不要气馁!检查你需要再次完成哪些单元才能获得证书。
+2. 输入你的 **hugging face 用户名**、*名字* 和 *姓氏*
-4. 你可以下载 pdf 格式和 png 格式的证书。
+3. 点击 "Generate my certificate"
+
+ - 如果你完成了至少 80% 的作业,恭喜,你将获得结业证书。
+ - 如果你完成了全部作业,恭喜,你将获得优秀证书。
+ - 如果完成度低于 80%,别灰心!检查并完成需要补充的单元以获取证书。
+
+4. 你可以下载 PDF 或 PNG 格式的证书。
+
+欢迎在 Twitter(@ThomasSimonini 和 @huggingface)和 LinkedIn 上分享你的成就。
-不要犹豫,在 Twitter(@我@ThomasSimonini 和@huggingface)并 Linkedin 上分享你的证书。
diff --git a/units/zh-CN/communication/conclusion.mdx b/units/zh-CN/communication/conclusion.mdx
index 812932c1..959d070b 100644
--- a/units/zh-CN/communication/conclusion.mdx
+++ b/units/zh-CN/communication/conclusion.mdx
@@ -2,17 +2,17 @@
+
+In this project, Eric Dong recreates Bill Seiler's 1985 version of Space War in Pygame and uses reinforcement learning (RL) to train AI agents.
+
+This project is currently in development!
+
+### Demo
+
+Dev/Edge version:
+* https://e-dong.itch.io/spacewar-dev
+
+Stable version:
+* https://e-dong.itch.io/spacewar
+* https://huggingface.co/spaces/EricofRL/SpaceWarRL
+
+### Community blog posts
+
+TBA
+
+### Other links
+
+Check out the source here 👉 https://github.com/e-dong/space-war-rl
+Check out his blog here 👉 https://dev.to/edong/space-war-rl-0-series-introduction-25dh
+
diff --git a/units/zh-CN/_toctree.yml b/units/zh-CN/_toctree.yml
index 3367aedc..8827deda 100644
--- a/units/zh-CN/_toctree.yml
+++ b/units/zh-CN/_toctree.yml
@@ -122,6 +122,8 @@
title: 深入理解策略梯度
- local: unit4/pg-theorem
title: (可选)策略梯度定理
+ - local: unit4/glossary
+ title: 术语表
- local: unit4/hands-on
title: 动手实践
- local: unit4/quiz
@@ -146,6 +148,8 @@
title: 动手实践
- local: unit5/bonus
title: 奖励部分,学习如何使用 Unity 和 MLAgents 创建自己的环境
+ - local: unit5/quiz
+ title: 测验
- local: unit5/conclusion
title: 结论
- title: 第 6 单元. 带有机器人环境的演员-评论员算法
@@ -158,6 +162,8 @@
title: 优势演员-评论员算法(A2C)
- local: unit6/hands-on
title: 使用 PyBullet 和 Panda-Gym 进行优势演员-评论员算法(A2C)的机器人模拟 🤖
+ - local: unit6/quiz
+ title: 测验
- local: unit6/conclusion
title: 结论
- local: unit6/additional-readings
@@ -174,6 +180,8 @@
title: 自我对弈
- local: unit7/hands-on
title: 让我们训练我们的足球队击败你同学的队伍(AI vs. AI)
+ - local: unit7/quiz
+ title: 测验
- local: unit7/conclusion
title: 结论
- local: unit7/additional-readings
@@ -209,7 +217,9 @@
- local: unitbonus3/model-based
title: 基于模型的强化学习
- local: unitbonus3/offline-online
- title: 离线与在线强化学习
+ title: 离线强化学习与在线强化学习
+ - local: unitbonus3/generalisation
+ title: 泛化强化学习
- local: unitbonus3/rlhf
title: 从人类反馈中进行强化学习
- local: unitbonus3/decision-transformers
@@ -219,9 +229,13 @@
- local: unitbonus3/curriculum-learning
title: (自动)课程学习在强化学习中的应用
- local: unitbonus3/envs-to-try
- title: 值得尝试的有趣环境
+ title: 有趣的环境尝试
+ - local: unitbonus3/learning-agents
+ title: 虚幻学习智能体简介
- local: unitbonus3/godotrl
- title: Godot RL 介绍
+ title: Godot RL 简介
+ - local: unitbonus3/student-works
+ title: 学生项目
- local: unitbonus3/rl-documentation
title: 强化学习文档的简要介绍
- title: 证书和祝贺
diff --git a/units/zh-CN/communication/certification.mdx b/units/zh-CN/communication/certification.mdx
index f89cc853..8c2bea3f 100644
--- a/units/zh-CN/communication/certification.mdx
+++ b/units/zh-CN/communication/certification.mdx
@@ -1,27 +1,31 @@
# 认证流程
-认证过程**完全免费**:
+认证流程**免费进行**:
-- 要获得*结业证书*:你需要在 2023 年 7 月结束前通过 80% 的作业。
-- 要获得*优秀证书*:你需要在 2023 年 7 月结束前通过 100% 的作业。
+- 获得*结业证书*:需通过至少 80% 的作业。
+- 获得*优秀证书*:需全部作业通过。
+本课程**没有截至日期,学习者可以自由安排进度**
-当我们说通过时,**我们的意思是你的模型必须被推送到 Hub 并获得等于或高于最低要求的结果。**
+当我们提到“通过”,**指的是你的模型必须上传到 Hub,并且其表现要达到或超过基本要求。**
-要检查你的进度以及你通过/未通过的单元: https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
+想要查看你的学习进度和已通过/未通过的单元,请访问:https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
-现在你已准备好进行认证过程,你需要:
+准备好进行认证的话,请按以下步骤操作:
-1. 到这里: https://huggingface.co/spaces/huggingface-projects/Deep-RL-Course-Certification/
-2. 输入你的 *hugging face 用户名*, 你的*名*和*姓*
+1. 访问此链接:https://huggingface.co/spaces/huggingface-projects/Deep-RL-Course-Certification/
-3. 点击 "Generate my certificate"。
- - 如果你通过了 80% 的作业,**恭喜**你刚刚获得结业证书。
- - 如果你通过了 100% 的作业,**恭喜**你刚刚获得了优秀证书。
- - 如果你低于 80%,请不要气馁!检查你需要再次完成哪些单元才能获得证书。
+2. 输入你的 **hugging face 用户名**、*名字* 和 *姓氏*
-4. 你可以下载 pdf 格式和 png 格式的证书。
+3. 点击 "Generate my certificate"
+
+ - 如果你完成了至少 80% 的作业,恭喜,你将获得结业证书。
+ - 如果你完成了全部作业,恭喜,你将获得优秀证书。
+ - 如果完成度低于 80%,别灰心!检查并完成需要补充的单元以获取证书。
+
+4. 你可以下载 PDF 或 PNG 格式的证书。
+
+欢迎在 Twitter(@ThomasSimonini 和 @huggingface)和 LinkedIn 上分享你的成就。
-不要犹豫,在 Twitter(@我@ThomasSimonini 和@huggingface)并 Linkedin 上分享你的证书。
diff --git a/units/zh-CN/communication/conclusion.mdx b/units/zh-CN/communication/conclusion.mdx
index 812932c1..959d070b 100644
--- a/units/zh-CN/communication/conclusion.mdx
+++ b/units/zh-CN/communication/conclusion.mdx
@@ -2,17 +2,17 @@
 -**恭喜你完成了本课程!**通过坚持不懈、刻苦努力和决心,你已经获得了扎实的深度强化学习背景。
+**恭喜你完成本课程!**通过你的坚持、努力和决心,你已经打下了深度强化学习的扎实基础。
-但完成本课程并不代表你的学习之路已经结束。这只是一个开始:不要犹豫去探索额外的第三单元,在那里我们向你展示了一些你可能有兴趣学习的主题。同时,也请你在 Discord 上分享你正在做的事情,并提出问题。
+但是,完成本课程并不意味着你的学习旅程就此结束。这只是一个新的开始:请勇敢地探索课程的额外第三单元,在那里你会发现更多你感兴趣的主题。同时,欢迎你在 Discord 上分享你的学习经历和提出疑问。
-感谢你参与本课程。**我希望你像我写这门课程一样喜欢它**。
+非常感谢你参加这门课程。我希望你能像我编写这门课程时一样,享受学习的过程。
-别犹豫,请填写[这个问卷](https://forms.gle/BzKXWzLAGZESGNaE9),来**给我们一些我们怎样提升该课程的反馈**
+请不要犹豫,填写[这个问卷](https://forms.gle/BzKXWzLAGZESGNaE9),为**我们提供宝贵的反馈,帮助我们改进这门课程。**
-并且不要忘记在下一部分**查看如何获得(如果通过)结业证书 🎓.**
+另外,请不要忘记在下一部分**查看如何获得结业证书(如果你已通过考核)🎓。**
-最后一件事,请与强化学习团队和我保持联系:
+最后,请继续与我们的强化学习团队和我保持联系:
- [关注我的 Twitter](https://twitter.com/thomassimonini)
- [关注 Hugging Face Twitter 账号](https://twitter.com/huggingface)
diff --git a/units/zh-CN/live1/live1.mdx b/units/zh-CN/live1/live1.mdx
index 3c80b9d9..e1bca87e 100644
--- a/units/zh-CN/live1/live1.mdx
+++ b/units/zh-CN/live1/live1.mdx
@@ -1,9 +1,8 @@
-# 直播 1:课程如何进行、问答以及与 Huggy 一起玩
+# 第一期直播:课程安排、问答环节及与 Huggy 互动游戏
-在第一场直播中,我们解释了课程的运作方式(范围、单元、挑战等)并回答了您的问题。
+在我们的首场直播中,我们详细介绍了课程的运行模式(包括内容范围、各个单元和挑战等),并回答了大家的问题。
-最后,我们看到了一些你训练过的 LunarLander 智能体,并且和 huggy 智能体一起玩🐶
+直播的高潮部分,我们展示了大家训练的 LunarLander 智能体,并与 huggy 智能体共同游戏🐶。
-
-要知道下一次直播的时间**请查看 Discord 社群**。我们还将向**您发送一封电子邮件**。如果您不能参加,请不要担心,我们会录制现场会议。
\ No newline at end of file
+想了解下一次直播的时间,请**关注 Discord 社群**。我们还会通过**电子邮件通知你**。如果你无法参加直播,也无需担心,我们会对会议进行录制。
\ No newline at end of file
diff --git a/units/zh-CN/unit0/discord101.mdx b/units/zh-CN/unit0/discord101.mdx
index c77fd249..e7c9b72d 100644
--- a/units/zh-CN/unit0/discord101.mdx
+++ b/units/zh-CN/unit0/discord101.mdx
@@ -5,18 +5,17 @@
-Discord 是一个免费的聊天平台,如果你之前已经用过 Slack, **它们非常相似**。在 Discord 中有一个超过 36000 人的 Hugging Face 社区的讨论服务器,你可以通过单击这个链接加入我们的讨论服务器。在这里你可以与很多人一起共同学习!
+Discord 是一个免费的聊天平台。如果你用过 Slack,**它们非常相似**。Hugging Face 社区有一个拥有超过 50000 名成员的 Discord 服务器,你可以点击这里一键加入。与很多人一起共同学习!
在一开始接触 Discord 可能会有一些劝退,所以我将带领你一起走进了解他。
-当您[注册我们的 Discord 服务器](http://hf.co/join/discord)时,你将选择你感兴趣的内容。确保**点击“强化学习”**。
+当你[注册我们的 Discord 服务器](http://hf.co/join/discord)时,你将选择你感兴趣的内容。确保**点击“强化学习”**。
然后点击下一步,你将在 `#introduce-yourself` 频道中**介绍自己**。
-## 那么哪些频道比较有趣? [[channels]]
它们在强化学习聊天室中。**不要忘记通过点击 `role-assigment` 中的🤖强化学习来注册这些频道**。
diff --git a/units/zh-CN/unit0/introduction.mdx b/units/zh-CN/unit0/introduction.mdx
index 14342a95..b8dc1ef9 100644
--- a/units/zh-CN/unit0/introduction.mdx
+++ b/units/zh-CN/unit0/introduction.mdx
@@ -58,9 +58,11 @@
你可以选择按照以下方式学习本课程:
-- *获得完成证书*:你需要在 2023 年 7 月底之前完成 80% 的作业。
-- *获得荣誉证书*:你需要在 2023 年 7 月底之前完成 100% 的作业。
-- *作为简单的旁听*:你可以参加所有挑战并按照自己的意愿完成作业,但没有截止日期。
+- *获得完成证书*:需要成 80% 的作业。
+- *获得荣誉证书*:需全部作业通过。
+- *作为简单的旁听*:你可以参加所有挑战并按照自己的意愿完成作业。
+
+本课程**没有截至日期,学习者可以自由安排进度**
两条路线**都是完全免费的**。
无论你选择哪条路线,我们建议你**按照推荐的步伐,与同学一起享受课程和挑战。**
@@ -71,8 +73,10 @@
认证过程是**完全免费的**:
-- *获得完成证书*:你需要在 2023 年 7 月底之前完成 80% 的作业。
-- *获得荣誉证书*:你需要在 2023 年 7 月底之前完成 100% 的作业。
+- *获得完成证书*:需要成 80% 的作业。
+- *获得荣誉证书*:需全部作业通过
+
+ 再次提醒,鉴于本课程**采用自主学习进度**,因此并未设定具体的截止日期。然而,我们建议你按照我们推荐的学习节奏进行学习。
@@ -98,10 +102,6 @@
## 学习计划
-我们制订了一个学习计划,你可以跟随这个学习计划来学习该课程。
-
-
-
该课程的每一个单元都**计划在一个星期内完成**,**每星期大约要学习 3-4 个小时**。不过你可以花尽可能多的时间来完成这个课程。如果你想更深入的研究某个主题,我们将提供额外的资源来帮助你实现这一目标。
@@ -116,7 +116,7 @@
- Omar Sanseviero 是 Hugging Face 的一名机器学习工程师,他在 ML、社区和开源的交叉领域工作。 此前,Omar 在谷歌的 Assistant 和 TensorFlow Graphics 团队担任软件工程师。 他来自秘鲁,喜欢骆驼🦙。
- Sayak Paul 是 Hugging Face 的一名开发工程师。 他对表示学习领域(自监督、半监督、模型鲁棒性)感兴趣。 他喜欢看犯罪和动作惊悚片🔪。
-## 挑战什么时候开始? [[challenges]]
+## 这门课程中有那些挑战 [[challenges]]
在本课程的新版本中,你有两种挑战:
- [排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard),用于比较你的智能体与其他同学的表现。
diff --git a/units/zh-CN/unit0/setup.mdx b/units/zh-CN/unit0/setup.mdx
index 208e61c8..c6b3e630 100644
--- a/units/zh-CN/unit0/setup.mdx
+++ b/units/zh-CN/unit0/setup.mdx
@@ -2,8 +2,8 @@
我们要做两件事:
-1. **创建 Hugging Face 帐户**(如果尚未完成)
-2. **注册 Discord 并自我介绍**(不要害羞🤗)
+1. **创建 Hugging Face 帐户**(如果没有的话)
+2. **注册 Discord 并自我介绍**(大胆一点🤗)
### 创建 Hugging Face 帐户
diff --git a/units/zh-CN/unit1/conclusion.mdx b/units/zh-CN/unit1/conclusion.mdx
index a1b24d8f..0928a7a5 100644
--- a/units/zh-CN/unit1/conclusion.mdx
+++ b/units/zh-CN/unit1/conclusion.mdx
@@ -1,16 +1,14 @@
# 结论 [[conclusion]]
-恭喜完成本单元! **这是重要的一步**。祝贺你完成了本教程。你刚刚训练了你的第一个深度强化学习智能体并在社区分享了它! 🥳
+恭喜你!本单元完成。这是你学习旅程中的**一个重要里程碑**。非常祝贺你完成本教程的这一部分。🥳
-如果你仍然对其中的某些内容感到困惑,这是**正常的**。这对我和所有研究 RL 的人来说都是一样的。
+如果某些内容仍让你感到困惑,请放心,这**完全正常**。我和所有研究强化学习(RL)的同行都经历过类似的困惑。
-**请继续之前花时间真正掌握这些内容**。在进入有趣的部分之前,掌握这些信息并打好基础非常重要。
+在继续之前,请确保你已经深入理解并掌握了这些概念。在我们探索更多有趣内容之前,打下坚实的基础是至关重要的。
-当然,在课程中,我们将再次使用和解释这些术语,但最好在进入下一个单元之前先了解它们。
+在接下来的课程中,我们会重复使用并进一步解释这些术语。但最好是在进入下一个单元之前先了解它们。
-在下一个(奖励)单元中,我们将通过**训练 Huggy 狗叼棍子**来巩固我们刚刚学到的东西。
-
-然后你就可以和他一起玩🤗。
+接下来,在‘奖励’单元中,我们将通过训练 Huggy 进行棍子叼取游戏来巩固我们的学习成果。然后你就可以和他一起玩🤗。
-**恭喜你完成了本课程!**通过坚持不懈、刻苦努力和决心,你已经获得了扎实的深度强化学习背景。
+**恭喜你完成本课程!**通过你的坚持、努力和决心,你已经打下了深度强化学习的扎实基础。
-但完成本课程并不代表你的学习之路已经结束。这只是一个开始:不要犹豫去探索额外的第三单元,在那里我们向你展示了一些你可能有兴趣学习的主题。同时,也请你在 Discord 上分享你正在做的事情,并提出问题。
+但是,完成本课程并不意味着你的学习旅程就此结束。这只是一个新的开始:请勇敢地探索课程的额外第三单元,在那里你会发现更多你感兴趣的主题。同时,欢迎你在 Discord 上分享你的学习经历和提出疑问。
-感谢你参与本课程。**我希望你像我写这门课程一样喜欢它**。
+非常感谢你参加这门课程。我希望你能像我编写这门课程时一样,享受学习的过程。
-别犹豫,请填写[这个问卷](https://forms.gle/BzKXWzLAGZESGNaE9),来**给我们一些我们怎样提升该课程的反馈**
+请不要犹豫,填写[这个问卷](https://forms.gle/BzKXWzLAGZESGNaE9),为**我们提供宝贵的反馈,帮助我们改进这门课程。**
-并且不要忘记在下一部分**查看如何获得(如果通过)结业证书 🎓.**
+另外,请不要忘记在下一部分**查看如何获得结业证书(如果你已通过考核)🎓。**
-最后一件事,请与强化学习团队和我保持联系:
+最后,请继续与我们的强化学习团队和我保持联系:
- [关注我的 Twitter](https://twitter.com/thomassimonini)
- [关注 Hugging Face Twitter 账号](https://twitter.com/huggingface)
diff --git a/units/zh-CN/live1/live1.mdx b/units/zh-CN/live1/live1.mdx
index 3c80b9d9..e1bca87e 100644
--- a/units/zh-CN/live1/live1.mdx
+++ b/units/zh-CN/live1/live1.mdx
@@ -1,9 +1,8 @@
-# 直播 1:课程如何进行、问答以及与 Huggy 一起玩
+# 第一期直播:课程安排、问答环节及与 Huggy 互动游戏
-在第一场直播中,我们解释了课程的运作方式(范围、单元、挑战等)并回答了您的问题。
+在我们的首场直播中,我们详细介绍了课程的运行模式(包括内容范围、各个单元和挑战等),并回答了大家的问题。
-最后,我们看到了一些你训练过的 LunarLander 智能体,并且和 huggy 智能体一起玩🐶
+直播的高潮部分,我们展示了大家训练的 LunarLander 智能体,并与 huggy 智能体共同游戏🐶。
-
-要知道下一次直播的时间**请查看 Discord 社群**。我们还将向**您发送一封电子邮件**。如果您不能参加,请不要担心,我们会录制现场会议。
\ No newline at end of file
+想了解下一次直播的时间,请**关注 Discord 社群**。我们还会通过**电子邮件通知你**。如果你无法参加直播,也无需担心,我们会对会议进行录制。
\ No newline at end of file
diff --git a/units/zh-CN/unit0/discord101.mdx b/units/zh-CN/unit0/discord101.mdx
index c77fd249..e7c9b72d 100644
--- a/units/zh-CN/unit0/discord101.mdx
+++ b/units/zh-CN/unit0/discord101.mdx
@@ -5,18 +5,17 @@
-Discord 是一个免费的聊天平台,如果你之前已经用过 Slack, **它们非常相似**。在 Discord 中有一个超过 36000 人的 Hugging Face 社区的讨论服务器,你可以通过单击这个链接加入我们的讨论服务器。在这里你可以与很多人一起共同学习!
+Discord 是一个免费的聊天平台。如果你用过 Slack,**它们非常相似**。Hugging Face 社区有一个拥有超过 50000 名成员的 Discord 服务器,你可以点击这里一键加入。与很多人一起共同学习!
在一开始接触 Discord 可能会有一些劝退,所以我将带领你一起走进了解他。
-当您[注册我们的 Discord 服务器](http://hf.co/join/discord)时,你将选择你感兴趣的内容。确保**点击“强化学习”**。
+当你[注册我们的 Discord 服务器](http://hf.co/join/discord)时,你将选择你感兴趣的内容。确保**点击“强化学习”**。
然后点击下一步,你将在 `#introduce-yourself` 频道中**介绍自己**。
-## 那么哪些频道比较有趣? [[channels]]
它们在强化学习聊天室中。**不要忘记通过点击 `role-assigment` 中的🤖强化学习来注册这些频道**。
diff --git a/units/zh-CN/unit0/introduction.mdx b/units/zh-CN/unit0/introduction.mdx
index 14342a95..b8dc1ef9 100644
--- a/units/zh-CN/unit0/introduction.mdx
+++ b/units/zh-CN/unit0/introduction.mdx
@@ -58,9 +58,11 @@
你可以选择按照以下方式学习本课程:
-- *获得完成证书*:你需要在 2023 年 7 月底之前完成 80% 的作业。
-- *获得荣誉证书*:你需要在 2023 年 7 月底之前完成 100% 的作业。
-- *作为简单的旁听*:你可以参加所有挑战并按照自己的意愿完成作业,但没有截止日期。
+- *获得完成证书*:需要成 80% 的作业。
+- *获得荣誉证书*:需全部作业通过。
+- *作为简单的旁听*:你可以参加所有挑战并按照自己的意愿完成作业。
+
+本课程**没有截至日期,学习者可以自由安排进度**
两条路线**都是完全免费的**。
无论你选择哪条路线,我们建议你**按照推荐的步伐,与同学一起享受课程和挑战。**
@@ -71,8 +73,10 @@
认证过程是**完全免费的**:
-- *获得完成证书*:你需要在 2023 年 7 月底之前完成 80% 的作业。
-- *获得荣誉证书*:你需要在 2023 年 7 月底之前完成 100% 的作业。
+- *获得完成证书*:需要成 80% 的作业。
+- *获得荣誉证书*:需全部作业通过
+
+ 再次提醒,鉴于本课程**采用自主学习进度**,因此并未设定具体的截止日期。然而,我们建议你按照我们推荐的学习节奏进行学习。
@@ -98,10 +102,6 @@
## 学习计划
-我们制订了一个学习计划,你可以跟随这个学习计划来学习该课程。
-
-
-
该课程的每一个单元都**计划在一个星期内完成**,**每星期大约要学习 3-4 个小时**。不过你可以花尽可能多的时间来完成这个课程。如果你想更深入的研究某个主题,我们将提供额外的资源来帮助你实现这一目标。
@@ -116,7 +116,7 @@
- Omar Sanseviero 是 Hugging Face 的一名机器学习工程师,他在 ML、社区和开源的交叉领域工作。 此前,Omar 在谷歌的 Assistant 和 TensorFlow Graphics 团队担任软件工程师。 他来自秘鲁,喜欢骆驼🦙。
- Sayak Paul 是 Hugging Face 的一名开发工程师。 他对表示学习领域(自监督、半监督、模型鲁棒性)感兴趣。 他喜欢看犯罪和动作惊悚片🔪。
-## 挑战什么时候开始? [[challenges]]
+## 这门课程中有那些挑战 [[challenges]]
在本课程的新版本中,你有两种挑战:
- [排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard),用于比较你的智能体与其他同学的表现。
diff --git a/units/zh-CN/unit0/setup.mdx b/units/zh-CN/unit0/setup.mdx
index 208e61c8..c6b3e630 100644
--- a/units/zh-CN/unit0/setup.mdx
+++ b/units/zh-CN/unit0/setup.mdx
@@ -2,8 +2,8 @@
我们要做两件事:
-1. **创建 Hugging Face 帐户**(如果尚未完成)
-2. **注册 Discord 并自我介绍**(不要害羞🤗)
+1. **创建 Hugging Face 帐户**(如果没有的话)
+2. **注册 Discord 并自我介绍**(大胆一点🤗)
### 创建 Hugging Face 帐户
diff --git a/units/zh-CN/unit1/conclusion.mdx b/units/zh-CN/unit1/conclusion.mdx
index a1b24d8f..0928a7a5 100644
--- a/units/zh-CN/unit1/conclusion.mdx
+++ b/units/zh-CN/unit1/conclusion.mdx
@@ -1,16 +1,14 @@
# 结论 [[conclusion]]
-恭喜完成本单元! **这是重要的一步**。祝贺你完成了本教程。你刚刚训练了你的第一个深度强化学习智能体并在社区分享了它! 🥳
+恭喜你!本单元完成。这是你学习旅程中的**一个重要里程碑**。非常祝贺你完成本教程的这一部分。🥳
-如果你仍然对其中的某些内容感到困惑,这是**正常的**。这对我和所有研究 RL 的人来说都是一样的。
+如果某些内容仍让你感到困惑,请放心,这**完全正常**。我和所有研究强化学习(RL)的同行都经历过类似的困惑。
-**请继续之前花时间真正掌握这些内容**。在进入有趣的部分之前,掌握这些信息并打好基础非常重要。
+在继续之前,请确保你已经深入理解并掌握了这些概念。在我们探索更多有趣内容之前,打下坚实的基础是至关重要的。
-当然,在课程中,我们将再次使用和解释这些术语,但最好在进入下一个单元之前先了解它们。
+在接下来的课程中,我们会重复使用并进一步解释这些术语。但最好是在进入下一个单元之前先了解它们。
-在下一个(奖励)单元中,我们将通过**训练 Huggy 狗叼棍子**来巩固我们刚刚学到的东西。
-
-然后你就可以和他一起玩🤗。
+接下来,在‘奖励’单元中,我们将通过训练 Huggy 进行棍子叼取游戏来巩固我们的学习成果。然后你就可以和他一起玩🤗。
 diff --git a/units/zh-CN/unit1/deep-rl.mdx b/units/zh-CN/unit1/deep-rl.mdx
index fcc08493..39fc1afe 100644
--- a/units/zh-CN/unit1/deep-rl.mdx
+++ b/units/zh-CN/unit1/deep-rl.mdx
@@ -1,21 +1,21 @@
# 强化学习中的“深度”[[deep-rl]]
-到目前为止,我们讨论的是强化学习。但是“深度”在哪里发挥作用呢?
+迄今为止的讨论主要集中在强化学习本身。但是,何为‘深度’强化学习?
深度强化学习引入了**深度神经网络来解决强化学习问题**——因此得名“深度”。
-例如,在下一个单元中,我们将学习两种基于价值的算法:Q 学习(经典强化学习)和深度 Q 学习。
+例如,在下一个单元中,我们将学习两种基于价值的算法:Q-learning(经典强化学习)和深度 Q-learning。
-您会发现不同之处在于,在第一种方法中,**我们使用传统算法**创建一个 Q 表格,帮助我们找到每个状态可采取的动作。
+你会发现不同之处在于,在第一种方法中,**我们使用传统算法**创建一个 Q 表格,帮助我们找到每个状态可采取的动作。
在第二种方法中,**我们将使用神经网络**(近似 Q 值)。
diff --git a/units/zh-CN/unit1/deep-rl.mdx b/units/zh-CN/unit1/deep-rl.mdx
index fcc08493..39fc1afe 100644
--- a/units/zh-CN/unit1/deep-rl.mdx
+++ b/units/zh-CN/unit1/deep-rl.mdx
@@ -1,21 +1,21 @@
# 强化学习中的“深度”[[deep-rl]]
-到目前为止,我们讨论的是强化学习。但是“深度”在哪里发挥作用呢?
+迄今为止的讨论主要集中在强化学习本身。但是,何为‘深度’强化学习?
深度强化学习引入了**深度神经网络来解决强化学习问题**——因此得名“深度”。
-例如,在下一个单元中,我们将学习两种基于价值的算法:Q 学习(经典强化学习)和深度 Q 学习。
+例如,在下一个单元中,我们将学习两种基于价值的算法:Q-learning(经典强化学习)和深度 Q-learning。
-您会发现不同之处在于,在第一种方法中,**我们使用传统算法**创建一个 Q 表格,帮助我们找到每个状态可采取的动作。
+你会发现不同之处在于,在第一种方法中,**我们使用传统算法**创建一个 Q 表格,帮助我们找到每个状态可采取的动作。
在第二种方法中,**我们将使用神经网络**(近似 Q 值)。
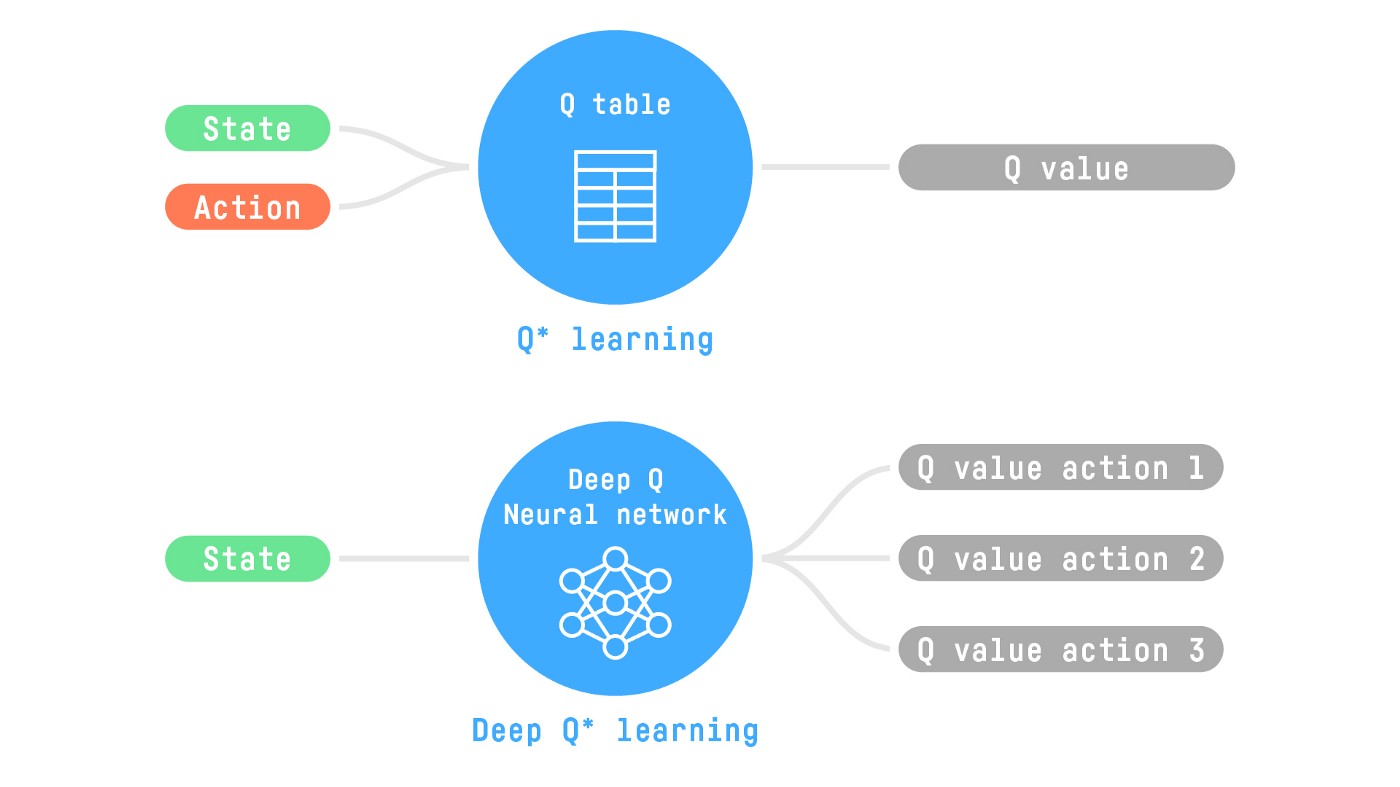 -示意图灵感来自 Udacity 的 Q 学习 notebook
+示意图灵感来自 Udacity 的 Q-learning notebook
-如果您不熟悉深度学习,非常推荐观看 [面向程序员的 FastAI 实用深度学习](https://course.fast.ai)(免费)。
\ No newline at end of file
+如果你不熟悉深度学习,非常推荐观看 [面向程序员的 FastAI 实用深度学习这门课程](https://course.fast.ai)(免费)。
\ No newline at end of file
diff --git a/units/zh-CN/unit1/exp-exp-tradeoff.mdx b/units/zh-CN/unit1/exp-exp-tradeoff.mdx
index 4d33d081..6234129a 100644
--- a/units/zh-CN/unit1/exp-exp-tradeoff.mdx
+++ b/units/zh-CN/unit1/exp-exp-tradeoff.mdx
@@ -5,7 +5,7 @@
- *探索* 正在通过尝试随机动作来探索环境,以**找到有关环境的更多信息。**
- *利用* 是**利用已知信息来最大化奖励。**
-请记住,我们的 RL 智能体的目标是最大化预期的累积奖励。然而,**我们可能会陷入一个常见的陷阱**。
+请记住,我们的 RL 智能体的目标是最大化期望累积奖励。然而,**我们可能会陷入一个常见的陷阱**。
让我们举个例子:
diff --git a/units/zh-CN/unit1/hands-on.mdx b/units/zh-CN/unit1/hands-on.mdx
index a4dc1afb..09b2a482 100644
--- a/units/zh-CN/unit1/hands-on.mdx
+++ b/units/zh-CN/unit1/hands-on.mdx
@@ -98,19 +98,19 @@
- 强化学习是一种**从动作学习**的计算方法。我们建立了一个智能体,通过**通过试错**与环境进行互动,并获得奖励(负或正面)作为反馈。
-- 任何 RL 智能体的目标是**最大化其期望的累积奖励**(也称为期望回报),因为 RL 基于 _奖励假设_,即所有目标都可以描述为最大化期望累积奖励。
+- 任何 RL 智能体的目标是**最大化其期望累积奖励**(也称为期望回报),因为 RL 基于 _奖励假设_,即所有目标都可以描述为最大化期望累积奖励。
- RL 过程是一个**循环,该循环输出一个 **状态、动作、奖励 和 下一个状态的序列。**
-- 为了计算预期的累积奖励(期望回报),我们对奖励进行折扣:较早出现的奖励(在游戏开始时)**更有可能发生,因为它们比长期的未来奖励更可预测。* *
+- 为了计算期望累积奖励(期望回报),我们对奖励进行折扣:较早出现的奖励(在游戏开始时)**更有可能发生,因为它们比长期的未来奖励更可预测。* *
- 要解决 RL 问题,你需要**找到最优策略**。该策略是你智能体的“大脑”,它将告诉我们**在给定状态下采取什么动作。**最优策略**为你提供了最大化期望回报的动作。**
有两种方法可以找到你的最佳策略:
- 通过直接训练你的策略:**基于策略的方法。**
-- 通过训练一个价值函数来告诉我们智能体在每个状态下将获得的预期回报,并使用这个函数来定义我们的策略:**基于价值的方法。**
+- 通过训练一个价值函数来告诉我们智能体在每个状态下将获得的期望回报,并使用这个函数来定义我们的策略:**基于价值的方法。**
- 最后,我们谈到深度强化学习,因为我们引入了**深度神经网络来估计要采取的动作(基于策略)或估计状态的价值(基于价值),因此得名“深度”。**
@@ -285,7 +285,7 @@ env.close()
## 创建月球发射器环境🌛并了解其工作原理
-### [环境 🎮](https://www.gymlibrary.dev/environments/box2d/lunar_lander/)
+### [环境 🎮]
在本教程中, 我们要训练一个智能体, 一个**正确着陆在月球**的 [月球发射器](https://gymnasium.farama.org/environments/box2d/lunar_lander/) . 为此,智能体需要学习**以适应其速度和位置(水平,垂直和角度)才能正确降落。**
---
@@ -317,8 +317,8 @@ print("Sample observation", env.observation_space.sample()) # Get a random obser
- 垂直速度( y )
- 角度
- 角速度
-- 如果左腿有接触点触及土地
-- 如果右腿有接触点触及土地
+- 如果左腿有接触点触及土地(布尔值)
+- 如果右腿有接触点触及土地(布尔值)
@@ -439,7 +439,7 @@ model = PPO(
# 目标: 训练 1,000,000 时间步长
# 目标: 改名字并将模型存入文件
-model_name = ""
+model_name = "ppo-LunarLander-v2"
```
diff --git a/units/zh-CN/unit1/quiz.mdx b/units/zh-CN/unit1/quiz.mdx
index 2d3c239d..5e294fd3 100644
--- a/units/zh-CN/unit1/quiz.mdx
+++ b/units/zh-CN/unit1/quiz.mdx
@@ -1,6 +1,6 @@
# 测验 [[quiz]]
-学习和[避免自以为是](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf)**的最好方法是对自己进行测试。**这将帮助您找到需要**加强知识的地方**。
+学习和[避免自以为是](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf)**的最好方法是对自己进行测试。**这将帮助你找到需要**加强知识的地方**。
### Q1:什么是强化学习?
diff --git a/units/zh-CN/unit1/rl-framework.mdx b/units/zh-CN/unit1/rl-framework.mdx
index 08459391..d4902613 100644
--- a/units/zh-CN/unit1/rl-framework.mdx
+++ b/units/zh-CN/unit1/rl-framework.mdx
@@ -29,7 +29,7 @@
因为 RL 是基于**奖励假设**,即所有目标都可以描述为**期望回报**(期望累积奖励)的最大化。
-这就是为什么在强化学习中,**为了获得最佳行为**,我们的目标是学习采取动作以**最大化预期的累积奖励。**
+这就是为什么在强化学习中,**为了获得最佳行为**,我们的目标是学习采取动作以**最大化期望累积奖励。**
## 马尔可夫性质 [[马尔可夫性质]]
@@ -83,11 +83,11 @@
-同样,在《超级马里奥》中,我们只有 5 种可能的动作:4 个方向和跳跃
+同样,在《超级马里奥》中,我们只有 4 种可能的动作:左,右,上(跳跃),下(蹲着)/figcaption>
-在《超级马里奥》中,我们只有一组有限的动作,因为我们只有 4 个方向和跳跃。
+在《超级马里奥》中,我们只有一组有限的动作,因为我们只有 4 个方向。
- *连续空间*:可能的动作数量是**无限**。
@@ -134,11 +134,11 @@
为了折扣奖励,我们这样做:
-1. 我们定义一个称为 gamma 的折扣率,**其必须介于 0 和 1 之间。** 大多数情况下介于 **0.95 和 0.99** 之间。
-- gamma 越大,折扣越小。这意味着我们的智能体**更关心长期奖励。**
-- 另一方面, gamma 越小,折扣越大。这意味着我们的 **智能体 更关心短期奖励(最近的奶酪)。**
+1. 我们定义一个称为 γ 的折扣率,**其必须介于 0 和 1 之间。** 大多数情况下介于 **0.95 和 0.99** 之间。
+- γ 越大,折扣越小。这意味着我们的智能体**更关心长期奖励。**
+- 另一方面, γ 越小,折扣越大。这意味着我们的 **智能体 更关心短期奖励(最近的奶酪)。**
-2. 然后,每个奖励将通过 gamma 时间步数的指数来打折扣。随着时间步数的增加,猫离我们越来越近,**因此未来奖励发生的可能性越来越小。**
+2. 然后,每个奖励将通过 γ 时间步数的指数来打折扣。随着时间步数的增加,猫离我们越来越近,**因此未来奖励发生的可能性越来越小。**
-我们的折扣预期累积奖励是:
+我们的折扣期望累积奖励是:
-示意图灵感来自 Udacity 的 Q 学习 notebook
+示意图灵感来自 Udacity 的 Q-learning notebook
-如果您不熟悉深度学习,非常推荐观看 [面向程序员的 FastAI 实用深度学习](https://course.fast.ai)(免费)。
\ No newline at end of file
+如果你不熟悉深度学习,非常推荐观看 [面向程序员的 FastAI 实用深度学习这门课程](https://course.fast.ai)(免费)。
\ No newline at end of file
diff --git a/units/zh-CN/unit1/exp-exp-tradeoff.mdx b/units/zh-CN/unit1/exp-exp-tradeoff.mdx
index 4d33d081..6234129a 100644
--- a/units/zh-CN/unit1/exp-exp-tradeoff.mdx
+++ b/units/zh-CN/unit1/exp-exp-tradeoff.mdx
@@ -5,7 +5,7 @@
- *探索* 正在通过尝试随机动作来探索环境,以**找到有关环境的更多信息。**
- *利用* 是**利用已知信息来最大化奖励。**
-请记住,我们的 RL 智能体的目标是最大化预期的累积奖励。然而,**我们可能会陷入一个常见的陷阱**。
+请记住,我们的 RL 智能体的目标是最大化期望累积奖励。然而,**我们可能会陷入一个常见的陷阱**。
让我们举个例子:
diff --git a/units/zh-CN/unit1/hands-on.mdx b/units/zh-CN/unit1/hands-on.mdx
index a4dc1afb..09b2a482 100644
--- a/units/zh-CN/unit1/hands-on.mdx
+++ b/units/zh-CN/unit1/hands-on.mdx
@@ -98,19 +98,19 @@
- 强化学习是一种**从动作学习**的计算方法。我们建立了一个智能体,通过**通过试错**与环境进行互动,并获得奖励(负或正面)作为反馈。
-- 任何 RL 智能体的目标是**最大化其期望的累积奖励**(也称为期望回报),因为 RL 基于 _奖励假设_,即所有目标都可以描述为最大化期望累积奖励。
+- 任何 RL 智能体的目标是**最大化其期望累积奖励**(也称为期望回报),因为 RL 基于 _奖励假设_,即所有目标都可以描述为最大化期望累积奖励。
- RL 过程是一个**循环,该循环输出一个 **状态、动作、奖励 和 下一个状态的序列。**
-- 为了计算预期的累积奖励(期望回报),我们对奖励进行折扣:较早出现的奖励(在游戏开始时)**更有可能发生,因为它们比长期的未来奖励更可预测。* *
+- 为了计算期望累积奖励(期望回报),我们对奖励进行折扣:较早出现的奖励(在游戏开始时)**更有可能发生,因为它们比长期的未来奖励更可预测。* *
- 要解决 RL 问题,你需要**找到最优策略**。该策略是你智能体的“大脑”,它将告诉我们**在给定状态下采取什么动作。**最优策略**为你提供了最大化期望回报的动作。**
有两种方法可以找到你的最佳策略:
- 通过直接训练你的策略:**基于策略的方法。**
-- 通过训练一个价值函数来告诉我们智能体在每个状态下将获得的预期回报,并使用这个函数来定义我们的策略:**基于价值的方法。**
+- 通过训练一个价值函数来告诉我们智能体在每个状态下将获得的期望回报,并使用这个函数来定义我们的策略:**基于价值的方法。**
- 最后,我们谈到深度强化学习,因为我们引入了**深度神经网络来估计要采取的动作(基于策略)或估计状态的价值(基于价值),因此得名“深度”。**
@@ -285,7 +285,7 @@ env.close()
## 创建月球发射器环境🌛并了解其工作原理
-### [环境 🎮](https://www.gymlibrary.dev/environments/box2d/lunar_lander/)
+### [环境 🎮]
在本教程中, 我们要训练一个智能体, 一个**正确着陆在月球**的 [月球发射器](https://gymnasium.farama.org/environments/box2d/lunar_lander/) . 为此,智能体需要学习**以适应其速度和位置(水平,垂直和角度)才能正确降落。**
---
@@ -317,8 +317,8 @@ print("Sample observation", env.observation_space.sample()) # Get a random obser
- 垂直速度( y )
- 角度
- 角速度
-- 如果左腿有接触点触及土地
-- 如果右腿有接触点触及土地
+- 如果左腿有接触点触及土地(布尔值)
+- 如果右腿有接触点触及土地(布尔值)
@@ -439,7 +439,7 @@ model = PPO(
# 目标: 训练 1,000,000 时间步长
# 目标: 改名字并将模型存入文件
-model_name = ""
+model_name = "ppo-LunarLander-v2"
```
diff --git a/units/zh-CN/unit1/quiz.mdx b/units/zh-CN/unit1/quiz.mdx
index 2d3c239d..5e294fd3 100644
--- a/units/zh-CN/unit1/quiz.mdx
+++ b/units/zh-CN/unit1/quiz.mdx
@@ -1,6 +1,6 @@
# 测验 [[quiz]]
-学习和[避免自以为是](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf)**的最好方法是对自己进行测试。**这将帮助您找到需要**加强知识的地方**。
+学习和[避免自以为是](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf)**的最好方法是对自己进行测试。**这将帮助你找到需要**加强知识的地方**。
### Q1:什么是强化学习?
diff --git a/units/zh-CN/unit1/rl-framework.mdx b/units/zh-CN/unit1/rl-framework.mdx
index 08459391..d4902613 100644
--- a/units/zh-CN/unit1/rl-framework.mdx
+++ b/units/zh-CN/unit1/rl-framework.mdx
@@ -29,7 +29,7 @@
因为 RL 是基于**奖励假设**,即所有目标都可以描述为**期望回报**(期望累积奖励)的最大化。
-这就是为什么在强化学习中,**为了获得最佳行为**,我们的目标是学习采取动作以**最大化预期的累积奖励。**
+这就是为什么在强化学习中,**为了获得最佳行为**,我们的目标是学习采取动作以**最大化期望累积奖励。**
## 马尔可夫性质 [[马尔可夫性质]]
@@ -83,11 +83,11 @@
-同样,在《超级马里奥》中,我们只有 5 种可能的动作:4 个方向和跳跃
+同样,在《超级马里奥》中,我们只有 4 种可能的动作:左,右,上(跳跃),下(蹲着)/figcaption>
-在《超级马里奥》中,我们只有一组有限的动作,因为我们只有 4 个方向和跳跃。
+在《超级马里奥》中,我们只有一组有限的动作,因为我们只有 4 个方向。
- *连续空间*:可能的动作数量是**无限**。
@@ -134,11 +134,11 @@
为了折扣奖励,我们这样做:
-1. 我们定义一个称为 gamma 的折扣率,**其必须介于 0 和 1 之间。** 大多数情况下介于 **0.95 和 0.99** 之间。
-- gamma 越大,折扣越小。这意味着我们的智能体**更关心长期奖励。**
-- 另一方面, gamma 越小,折扣越大。这意味着我们的 **智能体 更关心短期奖励(最近的奶酪)。**
+1. 我们定义一个称为 γ 的折扣率,**其必须介于 0 和 1 之间。** 大多数情况下介于 **0.95 和 0.99** 之间。
+- γ 越大,折扣越小。这意味着我们的智能体**更关心长期奖励。**
+- 另一方面, γ 越小,折扣越大。这意味着我们的 **智能体 更关心短期奖励(最近的奶酪)。**
-2. 然后,每个奖励将通过 gamma 时间步数的指数来打折扣。随着时间步数的增加,猫离我们越来越近,**因此未来奖励发生的可能性越来越小。**
+2. 然后,每个奖励将通过 γ 时间步数的指数来打折扣。随着时间步数的增加,猫离我们越来越近,**因此未来奖励发生的可能性越来越小。**
-我们的折扣预期累积奖励是:
+我们的折扣期望累积奖励是:
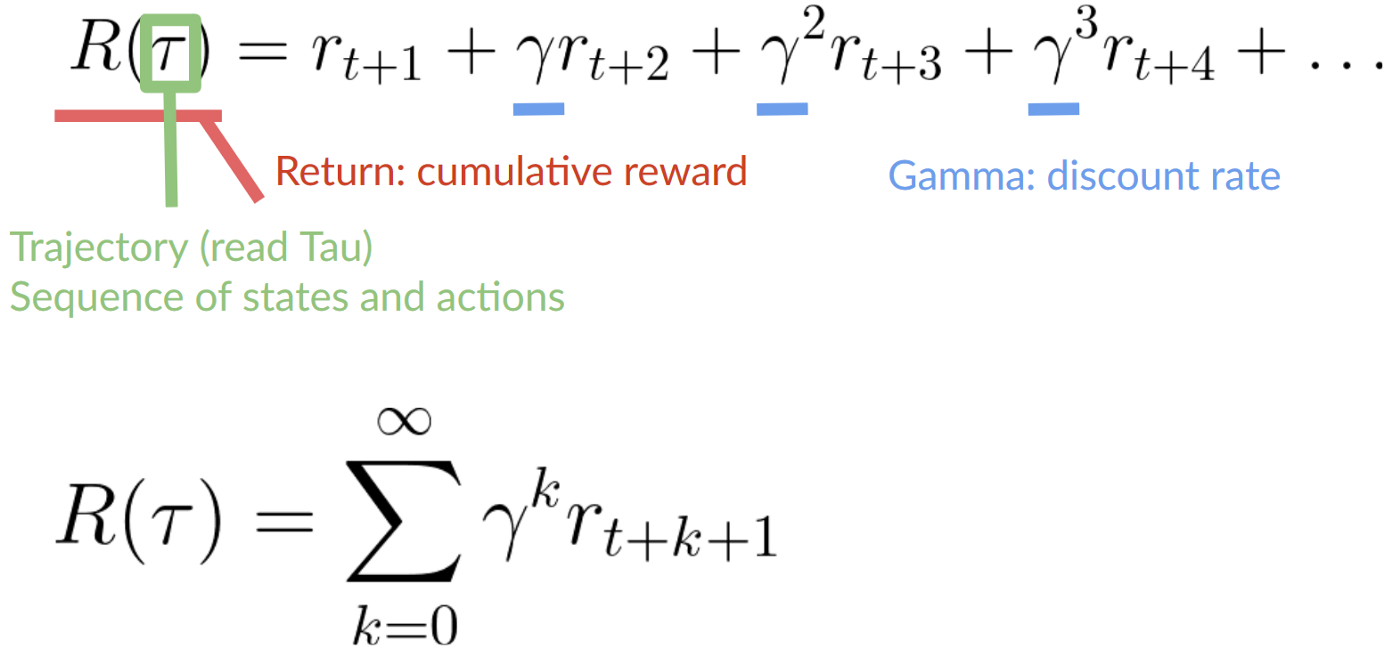 \ No newline at end of file
diff --git a/units/zh-CN/unit1/summary.mdx b/units/zh-CN/unit1/summary.mdx
index 5796e2ef..91a536a8 100644
--- a/units/zh-CN/unit1/summary.mdx
+++ b/units/zh-CN/unit1/summary.mdx
@@ -1,19 +1,19 @@
# 摘要 [[summary]]
-这里有很多信息!让我们总结一下:
+前面涉及了很多信息!现在让我们简单概括一下:
- 强化学习是一种从动作中学习的计算方法。我们构建了一个从环境中学习的智能体**通过试错与它交互**并接收奖励(负面或正面)作为反馈。
-- 任何RL智能体的目标都是最大化其预期累积奖励(也称为预期回报),因为 RL 基于**奖励假设**,即**所有目标都可以描述为最大化预期累积奖励。**
+- 任何RL智能体的目标都是最大化其期望累积奖励(也称为期望回报),因为 RL 基于**奖励假设**,即**所有目标都可以描述为最大化期望累积奖励。**
- RL 过程是一个循环,该循环输出一个 **状态、动作、奖励 和 下一个状态的序列。**
-- 为了计算预期的累积奖励(期望回报),我们对奖励进行折扣:较早出现的奖励(在游戏开始时)**更有可能发生,因为它们比长期的未来奖励更可预测。* *
+- 为了计算期望的累积奖励(期望回报),我们对奖励进行折扣:较早出现的奖励(在游戏开始时)**更有可能发生,因为它们比长期的未来奖励更可预测。* *
- 要解决 RL 问题,你需要**找到最优策略**。该策略是你智能体的“大脑”,它将告诉我们**在给定状态下采取什么动作。**最优策略**为你提供了最大化期望回报的动作。**
- 有两种方法可以找到你的最佳策略:
1. 通过直接训练你的策略:**基于策略的方法。**
- 2. 通过训练一个价值函数来告诉我们智能体在每个状态下将获得的预期回报,并使用这个函数来定义我们的策略:**基于价值的方法。**
+ 2. 通过训练一个价值函数来告诉我们智能体在每个状态下将获得的期望回报,并使用这个函数来定义我们的策略:**基于价值的方法。**
- 最后,我们谈到深度强化学习,因为我们引入了**深度神经网络来估计要采取的动作(基于策略)或估计状态的价值(基于价值)**因此得名“深度”。
\ No newline at end of file
diff --git a/units/zh-CN/unit1/tasks.mdx b/units/zh-CN/unit1/tasks.mdx
index ad135d02..70385a71 100644
--- a/units/zh-CN/unit1/tasks.mdx
+++ b/units/zh-CN/unit1/tasks.mdx
@@ -15,7 +15,7 @@
-## 持续任务 [[continuing-tasks]]
+## 持续性任务 [[continuing-tasks]]
这些是永远持续的任务(没有终止状态)。在这种情况下,智能体必须**学习如何选择最佳动作并同时与环境交互。**
diff --git a/units/zh-CN/unit1/two-methods.mdx b/units/zh-CN/unit1/two-methods.mdx
index 80de4435..314a280c 100644
--- a/units/zh-CN/unit1/two-methods.mdx
+++ b/units/zh-CN/unit1/two-methods.mdx
@@ -54,7 +54,7 @@
-
+
给定一个初始状态,我们的随机策略将输出该状态下可能动作的概率分布。
diff --git a/units/zh-CN/unit2/golssary.mdx b/units/zh-CN/unit2/golssary.mdx
index 725f301e..155e3cc6 100644
--- a/units/zh-CN/unit2/golssary.mdx
+++ b/units/zh-CN/unit2/golssary.mdx
@@ -10,8 +10,7 @@
### 在基于价值的方法中,我们可以找到两种主要的策略
- **状态价值函数。** 对于每个状态,状态价值函数是如果智能体从当前状态开始,遵循该策略直到结束时的期望回报。
-- **动作价值函数。** 与状态价值函数相比,动作价值函数不仅考虑了状态,还考虑了在该状态下采取的动作,它计算了智能体在某个状态下执行某个动作后,根据策略所能获得的期望回报。之后智能体会一直遵循这个策略,以最大化回报。
-
+- **动作价值函数。** 与状态价值函数相比,动作价值函数计算的是在智能体从某一状态出发,执行某一动作,然后永远遵循该策略后的期望回报。
### Epsilon-greedy 策略:
- 常用的强化学习探索策略,涉及平衡探索和利用。
@@ -26,6 +25,10 @@
- 不包括任何探索。
- 在有不确定性或未知最优动作的环境中可能是不利的。
+### 蒙特卡洛和时序差分学习策略
+
+- **蒙特卡洛(MC):** 在回合结束时进行学习。使用蒙特卡洛方法,我们等待整个回合结束后,再根据完整的回合来更新价值函数(或策略函数)。
+- **时序差分(TD):** 在每一步进行学习。使用时序差分学习,我们在每一步都更新价值函数(或策略函数),而无需等待整个回合结束。
如果你想改进这门课程,你可以[提交一个 Pull Request.](https://github.com/huggingface/deep-rl-class/pulls)
diff --git a/units/zh-CN/unit2/hands-on.mdx b/units/zh-CN/unit2/hands-on.mdx
index c624a91c..2f694835 100644
--- a/units/zh-CN/unit2/hands-on.mdx
+++ b/units/zh-CN/unit2/hands-on.mdx
@@ -141,7 +141,8 @@ pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/
```bash
sudo apt-get update
-apt install python-opengl ffmpeg xvfb
+sudo apt-get install -y python3-opengl
+apt install ffmpeg xvfb
pip3 install pyvirtualdisplay
```
@@ -243,7 +244,7 @@ print("Observation Space", env.observation_space)
print("Sample observation", env.observation_space.sample()) # 获得一个随机观测值
```
-我们通过`Observation Space Shape Discrete(16)`可以看到,观测值是一个整数,表示**智能体当前位置为current_row \* nrows + current_col(其中行和列都从0开始)**。
+我们通过`Observation Space Shape Discrete(16)`可以看到,观测值是一个整数,表示**智能体当前位置为current_row \* ncols + current_col(其中行和列都从0开始)**。
例如,4x4地图中的目标位置可以按以下方式计算:3 * 4 + 3 = 15。可能的观测值数量取决于地图的大小。**例如,4x4地图有16个可能的观测值。**
@@ -384,9 +385,9 @@ def epsilon_greedy_policy(Qtable, state, epsilon):
```python
def epsilon_greedy_policy(Qtable, state, epsilon):
# 在 0 和 1 之间随机生成一个数字
- random_int = random.uniform(0, 1)
- # 如果 random_int > epsilon --> 利用
- if random_int > epsilon:
+ random_num = random.uniform(0, 1)
+ # 如果 random_num > epsilon --> 利用
+ if random_num > epsilon:
# 采取给定状态下最高值的动作
# 这里可以用 np.argmax
action = greedy_policy(Qtable, state)
@@ -710,13 +711,11 @@ def push_to_hub(repo_id, model, env, video_fps=1, local_repo_path="hub"):
## 用法
- ```python
model = load_from_hub(repo_id="{repo_id}", filename="q-learning.pkl")
# 不要忘记检查是否需要添加额外的属性 (is_slippery=False等)
env = gym.make(model["env_id"])
-```
"""
diff --git a/units/zh-CN/unit2/mc-vs-td.mdx b/units/zh-CN/unit2/mc-vs-td.mdx
index 7ab0ee9f..41861bec 100644
--- a/units/zh-CN/unit2/mc-vs-td.mdx
+++ b/units/zh-CN/unit2/mc-vs-td.mdx
@@ -71,15 +71,15 @@
- \\(G_t= 3\\)
-- 现在更新状态(V(S_0)
+- 现在可以计算**新的** \\(V(S_0)\\):
-- 新 (V(S_0) = V(S_0) + lr * [G_t — V(S_0)])
+- (V(S_0) = V(S_0) + lr * [G_t — V(S_0)])
-- 新 (V(S_0) = 0 + 0.1 * [3 – 0])
+- (V(S_0) = 0 + 0.1 * [3 – 0])
-- 新 (V(S_0) = 0.3)
+- (V(S_0) = 0.3)
diff --git a/units/zh-CN/unit2/q-learning.mdx b/units/zh-CN/unit2/q-learning.mdx
index 4befdb75..e4b49e03 100644
--- a/units/zh-CN/unit2/q-learning.mdx
+++ b/units/zh-CN/unit2/q-learning.mdx
@@ -28,6 +28,8 @@ Q-Learning是一种**异策略的基于价值**的方法,它**使用时序差
我们对Q表格进行初始化,所以其中的值都为0. 这个表格**包含了每个状态的四个状态-动作值。**
+对于这个简单的例子,状态仅由鼠标的位置定义。因此,在我们的Q表中我们有2*3行,每行对应鼠标可能的每一种位置。在更复杂的情况下,状态可能包含比行动者位置更多的信息。
+
@@ -109,7 +111,7 @@ epsilon-贪心策略是一种处理探索与利用权衡的策略。
如何形成时序差分目标?
-1. 在采取动作后获得奖励 \(R_{t+1}\)。
+1. 在采取动作 \\(A_t\\) 后获得奖励 \\(R_{t+1}\\)。
2. 为了获得**最佳的下一个状态-动作对值**,使用贪心策略来选择下一个最佳动作。需要注意的是,这不是一个 ε-贪心策略,其将始终采取具有最高状态-动作值的动作。
然后,在此Q值更新完成后,将开始一个新的状态,并**再次使用 ε-贪心策略选择动作。**
diff --git a/units/zh-CN/unit3/deep-q-network.mdx b/units/zh-CN/unit3/deep-q-network.mdx
index 7d439a98..2177d33c 100644
--- a/units/zh-CN/unit3/deep-q-network.mdx
+++ b/units/zh-CN/unit3/deep-q-network.mdx
@@ -30,7 +30,7 @@
后面,堆叠的帧经过三层卷积层处理,这些层允许我们**捕获和利用图片中的空间关系**。同样因为帧是堆叠在一起的,你也**可以从中利用一些时序属性**。
-如果你不知道啥是卷积层,别担心。你可以查看[Udacity 的深度强化学习课程第四课](https://www.udacity.com/course/deep-learning-pytorch--ud188)
+如果你不知道啥是卷积层,别担心。你可以查看[Udacity 的深度学习课程第四课](https://www.udacity.com/course/deep-learning-pytorch--ud188)
最后,我们有几个全连接层,其在该状态下为每个可能的动作输出一个 Q 值。
diff --git a/units/zh-CN/unit3/introduction.mdx b/units/zh-CN/unit3/introduction.mdx
index 3fb5929f..69e8e3e2 100644
--- a/units/zh-CN/unit3/introduction.mdx
+++ b/units/zh-CN/unit3/introduction.mdx
@@ -4,7 +4,7 @@
在上一单元,我们学习了我们的第一个强化学习算法:Q-learning,**从头开始实现**,并将其在两个环境(FrozenLake-v1 ☃️ and Taxi-v3 🚕.)中训练。
-我们通过简单的算法就取得了极佳的结果,但是由于**状态空间离散并且较小**(FrozenLake-v1 ☃️ 有14种不同状态,Taxi-v3 🚕 有500种)所以导致这些环境相对简单。相比之下, 雅达利(Atari)的状态空间包含 **$\\(10^{9}\\) 到 \\(10^{11}\\)$ 个状态**。
+我们通过简单的算法就取得了极佳的结果,但是由于**状态空间离散并且较小**(FrozenLake-v1 ☃️ 有16种不同状态,Taxi-v3 🚕 有500种)所以导致这些环境相对简单。相比之下, 雅达利(Atari)的状态空间包含 **$\\(10^{9}\\) 到 \\(10^{11}\\)$ 个状态**。
但是据目前所知,当环境的状态空间较大时,**产生和更新 Q 表格会失效**。
diff --git a/units/zh-CN/unit4/glossary.mdx b/units/zh-CN/unit4/glossary.mdx
new file mode 100644
index 00000000..4c1cbcad
--- /dev/null
+++ b/units/zh-CN/unit4/glossary.mdx
@@ -0,0 +1,25 @@
+# 术语表
+
+这是一个由社区创建的术语表。欢迎大家贡献!
+
+- **深度 Q-learning(Deep Q-Learning):** 一种基于价值的深度强化学习算法,使用深度神经网络来近似给定状态下动作的Q值。深度Q学习的目标是通过学习动作值来找到最大化预期累积奖励的最优策略。
+
+- **基于价值的方法(Value-based methods):** 强化学习方法,估计价值函数作为找到最优策略的中间步骤。
+
+- **基于策略的方法(Policy-based methods):** 强化学习方法,直接学习近似最优策略,而不学习价值函数。在实践中,它们输出动作的概率分布。
+
+ 使用基于策略梯度方法相比基于价值的方法的好处包括:
+ - 集成的简单性:无需存储动作值;
+ - 学习随机策略的能力:代理探索状态空间时不总是采取相同的轨迹,避免了感知别名问题;
+ - 在高维和连续动作空间中的有效性;以及
+ - 改进的收敛性能。
+
+- **策略梯度(Policy Gradient):** 基于策略方法的一个子集,其目标是使用梯度上升来最大化参数化策略的性能。策略梯度的目标是通过调整策略来控制动作的概率分布,使得好的动作(最大化回报的动作)在未来更频繁地被采样。
+
+- **蒙特卡罗强化(Monte Carlo Reinforce):** 一种策略梯度算法,使用整个剧集的估计回报来更新策略参数。
+
+如果你想改进课程,可以[打开一个拉取请求(Pull Request)](https://github.com/huggingface/deep-rl-class/pulls)。
+
+感谢以下人员,本词汇表得以制作:
+
+- [Diego Carpintero](https://github.com/dcarpintero)
\ No newline at end of file
diff --git a/units/zh-CN/unit5/hands-on.mdx b/units/zh-CN/unit5/hands-on.mdx
index dc9f6b9b..d48a6a18 100644
--- a/units/zh-CN/unit5/hands-on.mdx
+++ b/units/zh-CN/unit5/hands-on.mdx
@@ -11,10 +11,10 @@ notebooks={[
-Hub 上的 ML-Agents 部分**仍处于试验阶段**。将来会添加一些功能。但就目前而言,要验证认证过程的实际操作,你只需将经过训练的模型推送到 Hub 上。验证此动手尝试没有最低限度结果。但如果你想获得不错的结果,你可以尝试在下面结果之上:
+为了在认证过程中验证这个实践操作,**您只需将训练好的模型上传到Hub中**。验证这个实践操作不需要达到**最低结果要求**。但如果您希望获得更好的结果,可以尝试达到以下目标:
-- 针对 [Pyramids 环境](https://singularite.itch.io/pyramids): 平均奖励 = 1.75
-- 针对 [SnowballTarget 环境](https://singularite.itch.io/snowballtarget): 平均奖励 = 一回合 15 或 30 个目标射击。
+- 针对 [Pyramids 环境](https://huggingface.co/spaces/unity/ML-Agents-Pyramids): 平均奖励 = 1.75
+- 针对 [SnowballTarget 环境](https://huggingface.co/spaces/ThomasSimonini/ML-Agents-SnowballTarget): 平均奖励 = 一回合 15 或 30 个目标射击。
有关认证过程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
@@ -53,9 +53,9 @@ Hub 上的 ML-Agents 部分**仍处于试验阶段**。将来会添加一些功
### 📚 RL-库:
-- [ML-Agents (HuggingFace 实验版本)](https://github.com/huggingface/ml-agents)
+- [ML-Agents](https://github.com/Unity-Technologies/ml-agents)
+
-⚠ 我们将使用一个实验版本的 ML-Agents ,你可以将其推送到 Hub 并从 Hub 中加载 Unity ML-Agents 模型。请注意,**你需要安装相同的版本**。
我们会持续提升我们的教程质量,**如果你在本 notebook 中发现了什么问题**请 [在 Github Repo 上提出 issue](https://github.com/huggingface/deep-rl-class/issues)。
diff --git a/units/zh-CN/unit5/how-mlagents-works.mdx b/units/zh-CN/unit5/how-mlagents-works.mdx
index 427f454b..de8b7164 100644
--- a/units/zh-CN/unit5/how-mlagents-works.mdx
+++ b/units/zh-CN/unit5/how-mlagents-works.mdx
@@ -31,7 +31,7 @@ ML-Agents 是 [Unity Technologies](https://unity.com/), Unity 的开发者们
## 学习组件内部 [[inside-learning-component]]
-在学习组件中,我们有**三个重要元素**:
+在学习组件中,我们有**两个重要元素**:
- 首先是**智能体组件**,是场景的演员。我们**将通过优化其策略**(这将告诉我们在每个状态下采取什么动作)来训练训练智能体。该策略称为 *Brain*。
- 最后,还有 *学院*。该组件**协调智能体及其决策过程**。将这个学院想象成处理 Python API 请求的老师。
diff --git a/units/zh-CN/unit5/quiz.mdx b/units/zh-CN/unit5/quiz.mdx
new file mode 100644
index 00000000..79a3d7c0
--- /dev/null
+++ b/units/zh-CN/unit5/quiz.mdx
@@ -0,0 +1,113 @@
+### 测验
+学习和避免能力错觉的最佳方式就是测试自己。这将帮助你发现你需要加强知识的领域。
+### Q1: 以下哪些工具是专门为视频游戏开发设计的?
+
+### Q2: 关于Unity ML-Agents的以下哪些陈述是正确的?
+
+### Q3: 填写缺失的字母
+- 在Unity ML-Agents中,代理的策略被称为b _ _ _ n
+- 负责编排代理的组件被称为 _ c _ _ _ m _
+
\ No newline at end of file
diff --git a/units/zh-CN/unit1/summary.mdx b/units/zh-CN/unit1/summary.mdx
index 5796e2ef..91a536a8 100644
--- a/units/zh-CN/unit1/summary.mdx
+++ b/units/zh-CN/unit1/summary.mdx
@@ -1,19 +1,19 @@
# 摘要 [[summary]]
-这里有很多信息!让我们总结一下:
+前面涉及了很多信息!现在让我们简单概括一下:
- 强化学习是一种从动作中学习的计算方法。我们构建了一个从环境中学习的智能体**通过试错与它交互**并接收奖励(负面或正面)作为反馈。
-- 任何RL智能体的目标都是最大化其预期累积奖励(也称为预期回报),因为 RL 基于**奖励假设**,即**所有目标都可以描述为最大化预期累积奖励。**
+- 任何RL智能体的目标都是最大化其期望累积奖励(也称为期望回报),因为 RL 基于**奖励假设**,即**所有目标都可以描述为最大化期望累积奖励。**
- RL 过程是一个循环,该循环输出一个 **状态、动作、奖励 和 下一个状态的序列。**
-- 为了计算预期的累积奖励(期望回报),我们对奖励进行折扣:较早出现的奖励(在游戏开始时)**更有可能发生,因为它们比长期的未来奖励更可预测。* *
+- 为了计算期望的累积奖励(期望回报),我们对奖励进行折扣:较早出现的奖励(在游戏开始时)**更有可能发生,因为它们比长期的未来奖励更可预测。* *
- 要解决 RL 问题,你需要**找到最优策略**。该策略是你智能体的“大脑”,它将告诉我们**在给定状态下采取什么动作。**最优策略**为你提供了最大化期望回报的动作。**
- 有两种方法可以找到你的最佳策略:
1. 通过直接训练你的策略:**基于策略的方法。**
- 2. 通过训练一个价值函数来告诉我们智能体在每个状态下将获得的预期回报,并使用这个函数来定义我们的策略:**基于价值的方法。**
+ 2. 通过训练一个价值函数来告诉我们智能体在每个状态下将获得的期望回报,并使用这个函数来定义我们的策略:**基于价值的方法。**
- 最后,我们谈到深度强化学习,因为我们引入了**深度神经网络来估计要采取的动作(基于策略)或估计状态的价值(基于价值)**因此得名“深度”。
\ No newline at end of file
diff --git a/units/zh-CN/unit1/tasks.mdx b/units/zh-CN/unit1/tasks.mdx
index ad135d02..70385a71 100644
--- a/units/zh-CN/unit1/tasks.mdx
+++ b/units/zh-CN/unit1/tasks.mdx
@@ -15,7 +15,7 @@
-## 持续任务 [[continuing-tasks]]
+## 持续性任务 [[continuing-tasks]]
这些是永远持续的任务(没有终止状态)。在这种情况下,智能体必须**学习如何选择最佳动作并同时与环境交互。**
diff --git a/units/zh-CN/unit1/two-methods.mdx b/units/zh-CN/unit1/two-methods.mdx
index 80de4435..314a280c 100644
--- a/units/zh-CN/unit1/two-methods.mdx
+++ b/units/zh-CN/unit1/two-methods.mdx
@@ -54,7 +54,7 @@
-
+
给定一个初始状态,我们的随机策略将输出该状态下可能动作的概率分布。
diff --git a/units/zh-CN/unit2/golssary.mdx b/units/zh-CN/unit2/golssary.mdx
index 725f301e..155e3cc6 100644
--- a/units/zh-CN/unit2/golssary.mdx
+++ b/units/zh-CN/unit2/golssary.mdx
@@ -10,8 +10,7 @@
### 在基于价值的方法中,我们可以找到两种主要的策略
- **状态价值函数。** 对于每个状态,状态价值函数是如果智能体从当前状态开始,遵循该策略直到结束时的期望回报。
-- **动作价值函数。** 与状态价值函数相比,动作价值函数不仅考虑了状态,还考虑了在该状态下采取的动作,它计算了智能体在某个状态下执行某个动作后,根据策略所能获得的期望回报。之后智能体会一直遵循这个策略,以最大化回报。
-
+- **动作价值函数。** 与状态价值函数相比,动作价值函数计算的是在智能体从某一状态出发,执行某一动作,然后永远遵循该策略后的期望回报。
### Epsilon-greedy 策略:
- 常用的强化学习探索策略,涉及平衡探索和利用。
@@ -26,6 +25,10 @@
- 不包括任何探索。
- 在有不确定性或未知最优动作的环境中可能是不利的。
+### 蒙特卡洛和时序差分学习策略
+
+- **蒙特卡洛(MC):** 在回合结束时进行学习。使用蒙特卡洛方法,我们等待整个回合结束后,再根据完整的回合来更新价值函数(或策略函数)。
+- **时序差分(TD):** 在每一步进行学习。使用时序差分学习,我们在每一步都更新价值函数(或策略函数),而无需等待整个回合结束。
如果你想改进这门课程,你可以[提交一个 Pull Request.](https://github.com/huggingface/deep-rl-class/pulls)
diff --git a/units/zh-CN/unit2/hands-on.mdx b/units/zh-CN/unit2/hands-on.mdx
index c624a91c..2f694835 100644
--- a/units/zh-CN/unit2/hands-on.mdx
+++ b/units/zh-CN/unit2/hands-on.mdx
@@ -141,7 +141,8 @@ pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/
```bash
sudo apt-get update
-apt install python-opengl ffmpeg xvfb
+sudo apt-get install -y python3-opengl
+apt install ffmpeg xvfb
pip3 install pyvirtualdisplay
```
@@ -243,7 +244,7 @@ print("Observation Space", env.observation_space)
print("Sample observation", env.observation_space.sample()) # 获得一个随机观测值
```
-我们通过`Observation Space Shape Discrete(16)`可以看到,观测值是一个整数,表示**智能体当前位置为current_row \* nrows + current_col(其中行和列都从0开始)**。
+我们通过`Observation Space Shape Discrete(16)`可以看到,观测值是一个整数,表示**智能体当前位置为current_row \* ncols + current_col(其中行和列都从0开始)**。
例如,4x4地图中的目标位置可以按以下方式计算:3 * 4 + 3 = 15。可能的观测值数量取决于地图的大小。**例如,4x4地图有16个可能的观测值。**
@@ -384,9 +385,9 @@ def epsilon_greedy_policy(Qtable, state, epsilon):
```python
def epsilon_greedy_policy(Qtable, state, epsilon):
# 在 0 和 1 之间随机生成一个数字
- random_int = random.uniform(0, 1)
- # 如果 random_int > epsilon --> 利用
- if random_int > epsilon:
+ random_num = random.uniform(0, 1)
+ # 如果 random_num > epsilon --> 利用
+ if random_num > epsilon:
# 采取给定状态下最高值的动作
# 这里可以用 np.argmax
action = greedy_policy(Qtable, state)
@@ -710,13 +711,11 @@ def push_to_hub(repo_id, model, env, video_fps=1, local_repo_path="hub"):
## 用法
- ```python
model = load_from_hub(repo_id="{repo_id}", filename="q-learning.pkl")
# 不要忘记检查是否需要添加额外的属性 (is_slippery=False等)
env = gym.make(model["env_id"])
-```
"""
diff --git a/units/zh-CN/unit2/mc-vs-td.mdx b/units/zh-CN/unit2/mc-vs-td.mdx
index 7ab0ee9f..41861bec 100644
--- a/units/zh-CN/unit2/mc-vs-td.mdx
+++ b/units/zh-CN/unit2/mc-vs-td.mdx
@@ -71,15 +71,15 @@
- \\(G_t= 3\\)
-- 现在更新状态(V(S_0)
+- 现在可以计算**新的** \\(V(S_0)\\):
-- 新 (V(S_0) = V(S_0) + lr * [G_t — V(S_0)])
+- (V(S_0) = V(S_0) + lr * [G_t — V(S_0)])
-- 新 (V(S_0) = 0 + 0.1 * [3 – 0])
+- (V(S_0) = 0 + 0.1 * [3 – 0])
-- 新 (V(S_0) = 0.3)
+- (V(S_0) = 0.3)
diff --git a/units/zh-CN/unit2/q-learning.mdx b/units/zh-CN/unit2/q-learning.mdx
index 4befdb75..e4b49e03 100644
--- a/units/zh-CN/unit2/q-learning.mdx
+++ b/units/zh-CN/unit2/q-learning.mdx
@@ -28,6 +28,8 @@ Q-Learning是一种**异策略的基于价值**的方法,它**使用时序差
我们对Q表格进行初始化,所以其中的值都为0. 这个表格**包含了每个状态的四个状态-动作值。**
+对于这个简单的例子,状态仅由鼠标的位置定义。因此,在我们的Q表中我们有2*3行,每行对应鼠标可能的每一种位置。在更复杂的情况下,状态可能包含比行动者位置更多的信息。
+
@@ -109,7 +111,7 @@ epsilon-贪心策略是一种处理探索与利用权衡的策略。
如何形成时序差分目标?
-1. 在采取动作后获得奖励 \(R_{t+1}\)。
+1. 在采取动作 \\(A_t\\) 后获得奖励 \\(R_{t+1}\\)。
2. 为了获得**最佳的下一个状态-动作对值**,使用贪心策略来选择下一个最佳动作。需要注意的是,这不是一个 ε-贪心策略,其将始终采取具有最高状态-动作值的动作。
然后,在此Q值更新完成后,将开始一个新的状态,并**再次使用 ε-贪心策略选择动作。**
diff --git a/units/zh-CN/unit3/deep-q-network.mdx b/units/zh-CN/unit3/deep-q-network.mdx
index 7d439a98..2177d33c 100644
--- a/units/zh-CN/unit3/deep-q-network.mdx
+++ b/units/zh-CN/unit3/deep-q-network.mdx
@@ -30,7 +30,7 @@
后面,堆叠的帧经过三层卷积层处理,这些层允许我们**捕获和利用图片中的空间关系**。同样因为帧是堆叠在一起的,你也**可以从中利用一些时序属性**。
-如果你不知道啥是卷积层,别担心。你可以查看[Udacity 的深度强化学习课程第四课](https://www.udacity.com/course/deep-learning-pytorch--ud188)
+如果你不知道啥是卷积层,别担心。你可以查看[Udacity 的深度学习课程第四课](https://www.udacity.com/course/deep-learning-pytorch--ud188)
最后,我们有几个全连接层,其在该状态下为每个可能的动作输出一个 Q 值。
diff --git a/units/zh-CN/unit3/introduction.mdx b/units/zh-CN/unit3/introduction.mdx
index 3fb5929f..69e8e3e2 100644
--- a/units/zh-CN/unit3/introduction.mdx
+++ b/units/zh-CN/unit3/introduction.mdx
@@ -4,7 +4,7 @@
在上一单元,我们学习了我们的第一个强化学习算法:Q-learning,**从头开始实现**,并将其在两个环境(FrozenLake-v1 ☃️ and Taxi-v3 🚕.)中训练。
-我们通过简单的算法就取得了极佳的结果,但是由于**状态空间离散并且较小**(FrozenLake-v1 ☃️ 有14种不同状态,Taxi-v3 🚕 有500种)所以导致这些环境相对简单。相比之下, 雅达利(Atari)的状态空间包含 **$\\(10^{9}\\) 到 \\(10^{11}\\)$ 个状态**。
+我们通过简单的算法就取得了极佳的结果,但是由于**状态空间离散并且较小**(FrozenLake-v1 ☃️ 有16种不同状态,Taxi-v3 🚕 有500种)所以导致这些环境相对简单。相比之下, 雅达利(Atari)的状态空间包含 **$\\(10^{9}\\) 到 \\(10^{11}\\)$ 个状态**。
但是据目前所知,当环境的状态空间较大时,**产生和更新 Q 表格会失效**。
diff --git a/units/zh-CN/unit4/glossary.mdx b/units/zh-CN/unit4/glossary.mdx
new file mode 100644
index 00000000..4c1cbcad
--- /dev/null
+++ b/units/zh-CN/unit4/glossary.mdx
@@ -0,0 +1,25 @@
+# 术语表
+
+这是一个由社区创建的术语表。欢迎大家贡献!
+
+- **深度 Q-learning(Deep Q-Learning):** 一种基于价值的深度强化学习算法,使用深度神经网络来近似给定状态下动作的Q值。深度Q学习的目标是通过学习动作值来找到最大化预期累积奖励的最优策略。
+
+- **基于价值的方法(Value-based methods):** 强化学习方法,估计价值函数作为找到最优策略的中间步骤。
+
+- **基于策略的方法(Policy-based methods):** 强化学习方法,直接学习近似最优策略,而不学习价值函数。在实践中,它们输出动作的概率分布。
+
+ 使用基于策略梯度方法相比基于价值的方法的好处包括:
+ - 集成的简单性:无需存储动作值;
+ - 学习随机策略的能力:代理探索状态空间时不总是采取相同的轨迹,避免了感知别名问题;
+ - 在高维和连续动作空间中的有效性;以及
+ - 改进的收敛性能。
+
+- **策略梯度(Policy Gradient):** 基于策略方法的一个子集,其目标是使用梯度上升来最大化参数化策略的性能。策略梯度的目标是通过调整策略来控制动作的概率分布,使得好的动作(最大化回报的动作)在未来更频繁地被采样。
+
+- **蒙特卡罗强化(Monte Carlo Reinforce):** 一种策略梯度算法,使用整个剧集的估计回报来更新策略参数。
+
+如果你想改进课程,可以[打开一个拉取请求(Pull Request)](https://github.com/huggingface/deep-rl-class/pulls)。
+
+感谢以下人员,本词汇表得以制作:
+
+- [Diego Carpintero](https://github.com/dcarpintero)
\ No newline at end of file
diff --git a/units/zh-CN/unit5/hands-on.mdx b/units/zh-CN/unit5/hands-on.mdx
index dc9f6b9b..d48a6a18 100644
--- a/units/zh-CN/unit5/hands-on.mdx
+++ b/units/zh-CN/unit5/hands-on.mdx
@@ -11,10 +11,10 @@ notebooks={[
-Hub 上的 ML-Agents 部分**仍处于试验阶段**。将来会添加一些功能。但就目前而言,要验证认证过程的实际操作,你只需将经过训练的模型推送到 Hub 上。验证此动手尝试没有最低限度结果。但如果你想获得不错的结果,你可以尝试在下面结果之上:
+为了在认证过程中验证这个实践操作,**您只需将训练好的模型上传到Hub中**。验证这个实践操作不需要达到**最低结果要求**。但如果您希望获得更好的结果,可以尝试达到以下目标:
-- 针对 [Pyramids 环境](https://singularite.itch.io/pyramids): 平均奖励 = 1.75
-- 针对 [SnowballTarget 环境](https://singularite.itch.io/snowballtarget): 平均奖励 = 一回合 15 或 30 个目标射击。
+- 针对 [Pyramids 环境](https://huggingface.co/spaces/unity/ML-Agents-Pyramids): 平均奖励 = 1.75
+- 针对 [SnowballTarget 环境](https://huggingface.co/spaces/ThomasSimonini/ML-Agents-SnowballTarget): 平均奖励 = 一回合 15 或 30 个目标射击。
有关认证过程的更多信息,请查看此部分 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
@@ -53,9 +53,9 @@ Hub 上的 ML-Agents 部分**仍处于试验阶段**。将来会添加一些功
### 📚 RL-库:
-- [ML-Agents (HuggingFace 实验版本)](https://github.com/huggingface/ml-agents)
+- [ML-Agents](https://github.com/Unity-Technologies/ml-agents)
+
-⚠ 我们将使用一个实验版本的 ML-Agents ,你可以将其推送到 Hub 并从 Hub 中加载 Unity ML-Agents 模型。请注意,**你需要安装相同的版本**。
我们会持续提升我们的教程质量,**如果你在本 notebook 中发现了什么问题**请 [在 Github Repo 上提出 issue](https://github.com/huggingface/deep-rl-class/issues)。
diff --git a/units/zh-CN/unit5/how-mlagents-works.mdx b/units/zh-CN/unit5/how-mlagents-works.mdx
index 427f454b..de8b7164 100644
--- a/units/zh-CN/unit5/how-mlagents-works.mdx
+++ b/units/zh-CN/unit5/how-mlagents-works.mdx
@@ -31,7 +31,7 @@ ML-Agents 是 [Unity Technologies](https://unity.com/), Unity 的开发者们
## 学习组件内部 [[inside-learning-component]]
-在学习组件中,我们有**三个重要元素**:
+在学习组件中,我们有**两个重要元素**:
- 首先是**智能体组件**,是场景的演员。我们**将通过优化其策略**(这将告诉我们在每个状态下采取什么动作)来训练训练智能体。该策略称为 *Brain*。
- 最后,还有 *学院*。该组件**协调智能体及其决策过程**。将这个学院想象成处理 Python API 请求的老师。
diff --git a/units/zh-CN/unit5/quiz.mdx b/units/zh-CN/unit5/quiz.mdx
new file mode 100644
index 00000000..79a3d7c0
--- /dev/null
+++ b/units/zh-CN/unit5/quiz.mdx
@@ -0,0 +1,113 @@
+### 测验
+学习和避免能力错觉的最佳方式就是测试自己。这将帮助你发现你需要加强知识的领域。
+### Q1: 以下哪些工具是专门为视频游戏开发设计的?
+
+### Q2: 关于Unity ML-Agents的以下哪些陈述是正确的?
+
+### Q3: 填写缺失的字母
+- 在Unity ML-Agents中,代理的策略被称为b _ _ _ n
+- 负责编排代理的组件被称为 _ c _ _ _ m _
+
+解决方案
+- b r a i n
+- a c a d e m y
+
+### Q4: 用你自己的话定义什么是`raycast`
+
+解决方案
+`Raycast`通常是一个线性投影,就像`激光`一样,旨在通过物体检测碰撞。
+
+### Q5: 使用`frames`或`raycasts`捕获环境有什么区别?
+
+### Q6: 列出在Snowball或Pyramid环境中训练代理时使用的环境和代理输入变量
+
+解决方案
+- 从代理发出的射线检测到的块、(不可见的)墙、石头、我们的目标、开关等的碰撞。
+- 描述代理特征的常规输入,比如它的速度。
+- 布尔变量,比如Pyramid中的开关(开/关)或SnowballTarget中的“我能射击吗?”。
+
+### 恭喜你完成了这个测验🥳,如果你错过了某些元素,花时间再次阅读章节以加强(😏)你的知识。
diff --git a/units/zh-CN/unit6/hands-on.mdx b/units/zh-CN/unit6/hands-on.mdx
index dd94c896..bdf9ab94 100644
--- a/units/zh-CN/unit6/hands-on.mdx
+++ b/units/zh-CN/unit6/hands-on.mdx
@@ -1,4 +1,4 @@
-# 利用 PyBullet 和 Panda-Gym 进行机器人模拟的优势演员--评论员方法 (A2C) 🤖[[hands-on]]
+# 利用 Panda-Gym 进行机器人模拟的优势演员--评论员方法 (A2C) 🤖[[hands-on]]
```
```
-现在你已经研究了优势阶演员--评论员方法 (A2C) 背后的理论,**你已准备好在机器人环境中使用 Stable-Baselines3 训练你的 A2C 智能体**。 并训练两个机器人:
+现在你已经研究了优势阶演员--评论员方法 (A2C) 背后的理论,**你已准备好在机器人环境中使用 Stable-Baselines3 训练你的 A2C 智能体**。 并训练机器人:
-- 一个正在学习移动的蜘蛛。🕷️
-- 一个正在学习移动到正确位置的机械臂。 🦾
-我们将使用两个机器人开发环境:
+- 一个机器人手臂🦾,使其移动到正确的位置。
+
+我们将使用的机器人开发环境:
-- [PyBullet](https://github.com/bulletphysics/bullet3)
- [panda-gym](https://github.com/qgallouedec/panda-gym)
-
-要验证认证过程的实际操作,你需要将两个经过训练的模型推送到 Hub 并获得以下结果:
+要验证认证过程的实际操作,你需要将经过训练的模型推送到 Hub 并获得以下结果:
-- `AntBulletEnv-v0` 得到的结果需 >= 650.
- `PandaReachDense-v2` 得到的结果需 >= -3.5.
要找到你的结果,[转到排行榜](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) 并找到你的模型,**结果 = 平均奖励 - 奖励标准* *
@@ -33,11 +30,10 @@
[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit6/unit6.ipynb)
-# 第 6 单元:利用 PyBullet 和 Panda-Gym 进行机器人模拟的 高阶演员--评论家方法 (A2C) 🤖
+# 第 6 单元:利用 Panda-Gym 进行机器人模拟的高阶演员--评论家方法 (A2C) 🤖
### 🎮 开发环境:
-- [PyBullet](https://github.com/bulletphysics/bullet3)
- [Panda-Gym](https://github.com/qgallouedec/panda-gym)
### 📚 强化学习库:
@@ -50,7 +46,7 @@
在本notebook的最后,你将:
-- 有能力能够使用环境库 **PyBullet** 和 **Panda-Gym**。
+- 有能力能够使用环境库 **Panda-Gym**。
- 能够**使用 A2C** 训练机器人。
- 理解为什么**我们需要规范化输入**。
- 能够**将你训练有素的智能体和代码推送到 Hub**,并附带有漂亮的视频回放和评估分数 🔥。
@@ -99,22 +95,25 @@ virtual_display.start()
第一步是安装依赖项,我们将安装多个依赖:
-- `pybullet`: 包含步行机器人环境。
+- `gymnasium`
- `panda-gym`: 包含机械臂环境。
-- `stable-baselines3[extra]`: SB3 深度强化学习库。
+- `stable-baselines3`: SB3 深度强化学习库。
- `huggingface_sb3`: Stable-baselines3 的附加代码,用于从 Hugging Face 🤗 Hub 加载和上传模型。
- `huggingface_hub`: Library允许任何人使用 Hub 的仓库。
```bash
-!pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit6/requirements-unit6.txt
+!pip install stable-baselines3[extra]
+!pip install gymnasium
+!pip install huggingface_sb3
+!pip install huggingface_hub
+!pip install panda_gym
```
## 导入相关包 📦
```python
-import pybullet_envs
+import gymnasium as gym
import panda_gym
-import gym
import os
@@ -128,22 +127,31 @@ from stable_baselines3.common.env_util import make_vec_env
from huggingface_hub import notebook_login
```
-## 环境 1: AntBulletEnv-v0 🕸
+## PandaReachDense-v3 🦾
+
+我们将训练的智能体是一个需要进行控制的机器人手臂(移动手臂并使用末端执行器)。
+在机器人学中,*末端执行器*是安装在机器人手臂末端的设备,用于与环境互动。
+在 `PandaReach` 中,机器人必须将其末端执行器放置在目标位置(绿色球)。
+我们将使用这个环境的密集型版本。这意味着我们将获得一个*密集奖励函数*,它**在每个时间步都会提供奖励**(代理完成任务越接近,奖励越高)。这与*稀疏奖励函数*不同,后者只有在任务完成时才**返回奖励**。
+同时,我们将使用*末端执行器位移控制*,这意味着**动作对应于末端执行器的位移**。我们不控制每个关节的单独运动(关节控制)。
+
+
+
+通过这种方式,**训练将会更加容易**。
-### 创建 AntBulletEnv-v0环境
+### 创建环境
#### 环境依赖 🎮
-在这种环境中,智能体需要正确使用其不同的关节才能正确行走。
-你可以在此处找到此环境的详细说明: https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet
+在 PandaReachDense-v3 中,机器人手臂必须将其末端执行器放置在目标位置(绿色球)
```python
-env_id = "AntBulletEnv-v0"
+env_id = "PandaReachDense-v3"
# Create the env
env = gym.make(env_id)
# Get the state space and action space
-s_size = env.observation_space.shape[0]
+s_size = env.observation_space.shape
a_size = env.action_space
```
@@ -153,10 +161,15 @@ print("The State Space is: ", s_size)
print("Sample observation", env.observation_space.sample()) # Get a random observation
```
-observation space (来自 [Jeffrey Y Mo](https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet)):
-区别在于我们的 observation space 是 28 而不是 29.
+观察空间**是一个具有3个不同元素的字典**:
+
+- `Achased_goal`: (X,Y,Z)目标的位置。
+
+- `desired_goal`: (x,y,z)目标位置与当前对象位置之间的距离。
-
+- `observation`: 位置(x,y,z)和最终效果的速度(VX,VY,VZ)。
+
+鉴于它是一个字典,**我们需要使用 MultiInputpolicy 策略而不是 Mlppolicy 策略**。
```python
print("\n _____ACTION SPACE_____ \n")
@@ -164,9 +177,9 @@ print("The Action Space is: ", a_size)
print("Action Space Sample", env.action_space.sample()) # Take a random action
```
-The action Space (来自 [Jeffrey Y Mo](https://hackmd.io/@jeffreymo/SJJrSJh5_#PyBullet)):
+动作空间是一个具有3个值的向量:
-
+- 控制 X,Y,Z 运动
### 归一化观测和奖励
@@ -190,16 +203,16 @@ env = # TODO: Add the wrapper
```python
env = make_vec_env(env_id, n_envs=4)
-env = VecNormalize(env, norm_obs=True, norm_reward=False, clip_obs=10.0)
+env = VecNormalize(env, norm_obs=True, norm_reward=False, clip_obs=10.)
```
### 创建 A2C 模型 🤖
-在这种情况下,因为我们有一个包含 28 个值的向量作为输入,所以我们将使用多层感知机(MLP)作为策略。
+
有关使用 StableBaselines3 实现 A2C 的更多信息,请查看: https://stable-baselines3.readthedocs.io/en/master/modules/a2c.html#notes
-为了找到最佳参数,我检查了 [official trained agents by Stable-Baselines3 team](https://huggingface.co/sb3).
+为了找到最佳参数,检查了 [official trained agents by Stable-Baselines3 team](https://huggingface.co/sb3).
```python
model = # Create the A2C model and try to find the best parameters
@@ -208,35 +221,22 @@ model = # Create the A2C model and try to find the best parameters
#### 参考答案
```python
-model = A2C(
- policy="MlpPolicy",
- env=env,
- gae_lambda=0.9,
- gamma=0.99,
- learning_rate=0.00096,
- max_grad_norm=0.5,
- n_steps=8,
- vf_coef=0.4,
- ent_coef=0.0,
- policy_kwargs=dict(log_std_init=-2, ortho_init=False),
- normalize_advantage=False,
- use_rms_prop=True,
- use_sde=True,
- verbose=1,
-)
+model = A2C(policy = "MultiInputPolicy",
+ env = env,
+ verbose=1)
```
### 训练 A2C 智能体 🏃
-- 让我们用 2,000,000 个时间步训练我们的智能体,不要忘记在 Colab 上使用 GPU。 大约需要 25-40 分钟
+- 让我们用 1,000,000 个时间步训练我们的智能体,不要忘记在 Colab 上使用 GPU。 大约需要 25-40 分钟
```python
-model.learn(2_000_000)
+model.learn(1_000_000)
```
```python
# Save the model and VecNormalize statistics when saving the agent
-model.save("a2c-AntBulletEnv-v0")
+model.save("a2c-PandaReachDense-v3")
env.save("vec_normalize.pkl")
```
@@ -244,13 +244,13 @@ env.save("vec_normalize.pkl")
- 现在我们的智能体已经过了训练,我们需要**检查其性能**。
- Stable-Baselines3 提供了一种方法来做到这一点: `evaluate_policy`
-- 就我而言,我得到的平均奖励是 `2371.90 +/- 16.50`
+
```python
from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
# Load the saved statistics
-eval_env = DummyVecEnv([lambda: gym.make("AntBulletEnv-v0")])
+eval_env = DummyVecEnv([lambda: gym.make("PandaReachDense-v3")])
eval_env = VecNormalize.load("vec_normalize.pkl", eval_env)
# do not update them at test time
@@ -259,9 +259,9 @@ eval_env.training = False
eval_env.norm_reward = False
# Load the agent
-model = A2C.load("a2c-AntBulletEnv-v0")
+model = A2C.load("a2c-PandaReachDense-v3")
-mean_reward, std_reward = evaluate_policy(model, env)
+mean_reward, std_reward = evaluate_policy(model, eval_env)
print(f"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}")
```
@@ -272,9 +272,6 @@ print(f"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}")
📚 libraries 文档👉 https://github.com/huggingface/huggingface_sb3/tree/main#hugging-face--x-stable-baselines3-v20
-这是模型卡的示例(使用 PyBullet 环境):
-
-
通过使用 `package_to_hub`, 正如我们在之前的单元中提到的,**评估、录制回放、生成智能体的模型卡并将其推送到Hub**。
@@ -319,71 +316,21 @@ package_to_hub(
)
```
-## 喝杯咖啡休息一下吧! ☕
-
-- 恭喜你已经训练了第一个学会移动的机器人 🥳!
-- **该休息了**。 不要犹豫,**保存此笔记本**“文件 > 将副本保存到云端硬盘”,以便稍后处理第二部分。
-
-## 开发环境 2:PandaReachDense-v2 🦾
-
-我们要训练的智能体是一个需要进行控制(移动手臂和使用末端执行器)的机械臂。
-
-在机器人技术中,*末端执行器*是位于机械臂末端的装置,旨在与环境进行交互。
-
-在 `PandaReach`中, 机器人必须将其末端执行器放置在目标位置(绿色球)。
-
-我们将使用此环境的密集版本。 这意味着我们将获得一个*密集的奖励函数*,**将在每个时间步提供奖励**(智能体越接近完成任务,奖励越高)。 与*稀疏奖励函数*相反,其中环境**当且仅当任务完成时才返回奖励**。
-
-此外,我们将使用*末端执行器位移控制*,这意味着**动作对应于末端执行器的位移**。 我们不控制每个关节的单独运动(关节控制)。
-
-
-
-这种方法会使得**训练会更容易**。
-
-
-
-在 `PandaReachDense-v2`中, 机械臂必须将其末端执行器放置在目标位置(绿色球)。
-
-```python
-import gym
-
-env_id = "PandaPushDense-v2"
-
-# Create the env
-env = gym.make(env_id)
-
-# Get the state space and action space
-s_size = env.observation_space.shape
-a_size = env.action_space
-```
-
-```python
-print("_____OBSERVATION SPACE_____ \n")
-print("The State Space is: ", s_size)
-print("Sample observation", env.observation_space.sample()) # Get a random observation
-```
+## 一些额外的挑战 🏆
-The observation space **是一个包含 3 个不同元素的字典**:
+学习**的最佳方法是自己尝试**! 为什么不尝试“ pandapickandplace-v3”?
-- `achieved_goal`: (x,y,z) 目标的位置。
-- `desired_goal`: (x,y,z) 目标位置和当前对象位置之间的距离。
-- `observation`: 末端执行器的位置 (x,y,z) 和速度 (vx, vy, vz)。
-鉴于它是一个作为观测的字典,**我们将需要使用 MultiInputPolicy 而不是 MlpPolicy**。
+如果你想尝试 panda-gym 的更高级任务,你需要查看使用 **TQC 或 SAC**(一种更适合机器人任务的样本高效算法)所做的工作。在实际的机器人学中,出于一个简单的原因,你会使用更高效的样本算法:与模拟不同,**如果你过度移动你的机器人手臂,就有可能导致它损坏**。
-```python
-print("\n _____ACTION SPACE_____ \n")
-print("The Action Space is: ", a_size)
-print("Action Space Sample", env.action_space.sample()) # Take a random action
-```
+PandaPickAndPlace-v1 (这个模型使用v1版本环境): https://huggingface.co/sb3/tqc-PandaPickAndPlace-v1
-动作空间是一个具有 3 个值的向量:
+对了,别忘了查看 panda-gym 文档:https://panda-gym.readthedocs.io/en/latest/usage/train_with_sb3.html
-- 控制 x, y, z 移动
+我们提供了训练另一个智能体的步骤(可选):
-现在轮到你了:
-1. 定义名为“PandaReachDense-v2”的环境
+1. 定义名为“PandaPickAndPlace-v3”的环境
2. 制作矢量化环境
3. 添加 wrapper 以规范化观察和奖励。 [Check the documentation](https://stable-baselines3.readthedocs.io/en/master/guide/vec_envs.html#vecnormalize)
4. 创建 A2C 模型(不要忘记使 verbose=1 来打印训练日志)。
@@ -392,25 +339,27 @@ print("Action Space Sample", env.action_space.sample()) # Take a random action
7. 评估你的智能体
8. 在 Hub 上发布你的训练模型 🔥通过使用 `package_to_hub`函数
-### 参考答案(完成待办事项)
+### 参考答案(可选)
```python
# 1 - 2
-env_id = "PandaReachDense-v2"
+env_id = "PandaPickAndPlace-v3"
env = make_vec_env(env_id, n_envs=4)
# 3
-env = VecNormalize(env, norm_obs=True, norm_reward=False, clip_obs=10.0)
+env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.0)
# 4
-model = A2C(policy="MultiInputPolicy", env=env, verbose=1)
+model = A2C(policy="MultiInputPolicy",
+ env=env,
+ verbose=1)
# 5
model.learn(1_000_000)
```
```python
# 6
-model_name = "a2c-PandaReachDense-v2"
+model_name = "a2c-PandaPickAndPlace-v3"
model.save(model_name)
env.save("vec_normalize.pkl")
@@ -418,7 +367,7 @@ env.save("vec_normalize.pkl")
from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
# Load the saved statistics
-eval_env = DummyVecEnv([lambda: gym.make("PandaReachDense-v2")])
+eval_env = DummyVecEnv([lambda: gym.make("PandaPickAndPlace-v3")])
eval_env = VecNormalize.load("vec_normalize.pkl", eval_env)
# do not update them at test time
@@ -429,7 +378,7 @@ eval_env.norm_reward = False
# Load the agent
model = A2C.load(model_name)
-mean_reward, std_reward = evaluate_policy(model, env)
+mean_reward, std_reward = evaluate_policy(model, eval_env)
print(f"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}")
@@ -445,22 +394,6 @@ package_to_hub(
)
```
-## 一些额外的挑战 🏆
-
-学习**的最佳方法是自己尝试**! 为什么不为 PyBullet 尝试“HalfCheetah Bullet Env-v0”,为 Panda-Gym 尝试“PandaPick Place-v1”?
-
-如果你想为 panda-gym 尝试更高级的任务,你需要检查使用 **TQC 或 SAC**(一种更适合机器人任务的样本效率更高的算法)完成了什么。 在真实的机器人技术中,出于一个简单的原因,你将使用样本效率更高的算法:与模拟过程相反**如果你将机械臂移动太多,则有损坏它的风险**。
-
-PandaPickAndPlace-v1: https://huggingface.co/sb3/tqc-PandaPickAndPlace-v1
-
-不要犹豫,在这里查看 panda-gym 文档: https://panda-gym.readthedocs.io/en/latest/usage/train_with_sb3.html
-
-以下是实现此目标的一些想法:
-
-- 训练更多步数
-- 通过查看其他同学所做的工作,尝试不同的超参数 👉 https://huggingface.co/models?other=https://huggingface.co/models?other=AntBulletEnv-v0
-- **在 Hub 上推送你新训练的模型** 🔥
-
第7单元见! 🔥
## 保持热爱,奔赴山海 🤗
\ No newline at end of file
diff --git a/units/zh-CN/unit6/introduction.mdx b/units/zh-CN/unit6/introduction.mdx
index 652bbada..88970ff9 100644
--- a/units/zh-CN/unit6/introduction.mdx
+++ b/units/zh-CN/unit6/introduction.mdx
@@ -15,11 +15,9 @@
- *一个演员* 控制 **我们的 智能体 的行为方式**(基于策略的方法)
- *评论家* 衡量 **采取的行动的好坏** (基于价值的方法)
-我们将研究其中一种混合方法 高级演员--评论员方法 (A2C),**并在机器人环境中使用 Stable-Baselines3 训练我们的智能体**。 我们将训练两个机器人:
+我们将研究其中一种混合方法 高级演员--评论员方法 (A2C),**并在机器人环境中使用 Stable-Baselines3 训练我们的智能体**。 我们将训练下面的机器人:
-- 一个蜘蛛🕷️正在学习如何移动。
- 一个机械臂 🦾 正在移动向正确的位置。
-
听起来很令人兴奋? 让我们开始吧!
\ No newline at end of file
diff --git a/units/zh-CN/unit6/quiz.mdx b/units/zh-CN/unit6/quiz.mdx
new file mode 100644
index 00000000..fb959b13
--- /dev/null
+++ b/units/zh-CN/unit6/quiz.mdx
@@ -0,0 +1,98 @@
+### 测验
+学习和避免[胜任力错觉](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf)的最好方法就是测试自己。这将帮助你找到需要加强知识的地方。
+#### Q1: 在强化学习领域,关于偏差-方差折衷的以下哪种解释是最准确的?
+
+#### Q2: 在讨论具有偏差和/或方差的RL模型时,以下哪些陈述是正确的?
+
+#### Q3: 关于蒙特卡洛方法的以下哪些陈述是正确的?
+
+#### Q4: 请用你自己的话描述演员-评论家方法(A2C)。
+
+答案
+演员-评论家方法背后的思想是,我们学习两个函数近似:
+1. 控制我们的代理如何行动的策略(π)
+2. 通过衡量所采取行动的好坏来帮助策略更新的价值函数(q)
+
+
+#### Q5: 关于演员-评论家方法的以下哪些陈述是正确的?
+
+#### Q6: 在A2C方法中,什么是“优势”?
+
+答案
+我们不是直接使用评论家的动作-价值函数,而是可以使用一个“优势”函数。优势函数背后的思想是,我们计算与状态中可能的其他动作相比,采取该动作的相对优势,并对它们取平均值。
+换句话说:在某个状态下采取该动作比平均状态价值更好
+
+
+恭喜你完成这个测验🥳,如果你错过了某些元素,花时间再次阅读章节,以加强
diff --git a/units/zh-CN/unit7/hands-on.mdx b/units/zh-CN/unit7/hands-on.mdx
index fbe2442d..6bfa2539 100644
--- a/units/zh-CN/unit7/hands-on.mdx
+++ b/units/zh-CN/unit7/hands-on.mdx
@@ -26,7 +26,7 @@ AI vs. AI 是我们在 Hugging Face 开发的一个开源工具,用于在 Hub
除了这三个工具,你的同学 cyllum 还创建了一个 🤗 SoccerTwos Challenge Analytics,你可以在其中查看模型的详细比赛结果:[https://huggingface.co/spaces/cyllum/soccertwos-analytics](https://huggingface.co/spaces/cyllum/soccertwos-analytics)
-我们将撰写一篇博文详细介绍这个 AI vs. AI 工具,但为了给你一个大致的概念,它的工作原理如下:
+我们撰写了[一篇博文](https://huggingface.co/blog/aivsai)详细介绍这个 AI vs. AI 工具,但为了给你一个大致的概念,它的工作原理如下:
- 每隔四个小时,我们的算法**获取给定环境(在我们的情况下是 ML-Agents-SoccerTwos)的所有可用模型**。
- 它使用匹配算法创建一个**匹配队列**。
@@ -45,7 +45,6 @@ AI vs. AI 是我们在 Hugging Face 开发的一个开源工具,用于在 Hub
在这次竞赛中,决定胜负的将是你选择的超参数。
-AI 对战 AI 算法将持续运行直到 2023 年 4 月 30 日。
我们一直在努力改进我们的教程,如果你在这个 Notebook 中发现了一些问题,请在[GitHub 仓库上提出问题](https://github.com/huggingface/deep-rl-class/issues)。
@@ -56,23 +55,20 @@ AI 对战 AI 算法将持续运行直到 2023 年 4 月 30 日。
## 步骤 0:安装 MLAgents 并下载正确的可执行文件
-⚠ 我们将使用一个实验版本的 ML-Agents,它允许你将模型从 Hub 中上传和下载到 / 。** 你需要安装相同的版本。**
-
-⚠ ⚠ ⚠ 我们将不使用与第5单元相同的版本:ML-Agents 入门 ⚠ ⚠ ⚠
我们建议使用 [conda](https://docs.conda.io/en/latest/) 作为包管理器,并创建一个新的环境。
-使用 conda,我们创建一个名为 rl 的新环境,使用 **Python 3.9**:
+使用 conda,我们创建一个名为 rl 的新环境,使用 **Python 3.10.12**:
```bash
-conda create --name rl python=3.9
+conda create --name rl python=3.10.12
conda activate rl
```
-为了能够正确训练我们的智能体并推送到 Hub,我们需要安装一个实验版本的 ML-Agents(Hugging Face ML-Agents 分支中的 aivsai)
+为了能够正确训练我们的智能体并推送到 Hub,我们需要安装 ML-Agents
```bash
-git clone --branch aivsai https://github.com/huggingface/ml-agents
+git clone https://github.com/Unity-Technologies/ml-agents
```
当克隆完成(需要 2.63 GB)后,我们进入仓库并安装该软件包。
@@ -83,17 +79,12 @@ pip install -e ./ml-agents-envs
pip install -e ./ml-agents
```
-我们同样需要用以下命令安装 PyTorch:
-
-```bash
-pip install torch
-```
最后,你需要安装 git-lfs:https://git-lfs.com/
安装完成后,我们需要添加环境训练可执行文件。根据你的操作系统,你需要下载其中一个可执行文件,并解压缩并放置在 `ml-agents` 目录下的一个名为 `training-envs-executables` 的新文件夹中。
-最终,你的可执行文件应位于 `mlagents/training-envs-executables/SoccerTwos` 中。
+最终,你的可执行文件应位于 `ml-agents/training-envs-executables/SoccerTwos` 中。
Windows:下载[此可执行文件](https://drive.google.com/file/d/1sqFxbEdTMubjVktnV4C6ICjp89wLhUcP/view?usp=sharing)
diff --git a/units/zh-CN/unit7/quiz.mdx b/units/zh-CN/unit7/quiz.mdx
new file mode 100644
index 00000000..d550a09f
--- /dev/null
+++ b/units/zh-CN/unit7/quiz.mdx
@@ -0,0 +1,119 @@
+# 测验
+学习和避免能力错觉的最佳方式就是测试自己。这将帮助你发现你需要加强知识的领域。
+### Q1: 选择与比较不同类型的多人环境时更适合的选项
+- 在____环境中,你的智能体旨在最大化共同利益
+- 在____环境中,你的智能体旨在最大化共同利益,同时最小化对手的利益
+
+### Q2: 关于`分布式`学习的以下哪些陈述是正确的?
+
+### Q3: 关于`集中式`学习的以下哪些陈述是正确的?
+
+### Q4: 请用你自己的话解释`自我对弈`方法
+
+解决方案
+`自我对弈`是一种方法,通过实例化与你的对手具有相同策略的智能体的副本,让你的智能体从具有相同训练水平的智能体中学习。
+
+### Q5: 在配置`自我对弈`时,有几个参数非常重要。你能通过它们的定义识别出我们在谈论哪个参数吗?
+- 与当前自我对弈与从池中对抗对手的概率
+- 你可能面临的对手的训练水平(多样性)的差异
+- 在生成新对手之前训练步骤的数量
+- 对手变更率
+
+### Q6: 使用ELO评分的主要动机是什么?
+
+恭喜你完成这个测验🥳,如果你错过了某些元素,花时间再次阅读章节以加强(😏)你的知识。
diff --git a/units/zh-CN/unit8/clipped-surrogate-objective.mdx b/units/zh-CN/unit8/clipped-surrogate-objective.mdx
index 852ac417..025e9ab7 100644
--- a/units/zh-CN/unit8/clipped-surrogate-objective.mdx
+++ b/units/zh-CN/unit8/clipped-surrogate-objective.mdx
@@ -64,7 +64,7 @@
-这个裁剪部分是 rt(theta) 在 \\( [1 - \epsilon, 1 + \epsilon] \\) 范围内被裁剪的版本。
+这个裁剪部分是 \\( r_t(\theta) \\) 在 \\( [1 - \epsilon, 1 + \epsilon] \\) 范围内被裁剪的版本。
使用裁剪替代目标函数,我们有两个概率比率,一个非裁剪的,一个在范围内裁剪的(在 \\( [1 - \epsilon, 1 + \epsilon] \\)之间,epsilon 是一个超参数,帮助我们定义这个裁剪范围(在论文中 \\( \epsilon = 0.2 \\))。
diff --git a/units/zh-CN/unitbonus1/train.mdx b/units/zh-CN/unitbonus1/train.mdx
index 1775aea0..87fdbbed 100644
--- a/units/zh-CN/unitbonus1/train.mdx
+++ b/units/zh-CN/unitbonus1/train.mdx
@@ -21,12 +21,8 @@
在本 notebook 中,我们将通过**教 Huggy 狗拿起棍子然后直接在浏览器中玩它**来巩固我们在第一个单元中学到的知识
-⬇️ 这是**你将在本单元结束时实现的示例。** ⬇️(启动 ▶ 以查看)
-```python
-%%html
-
-```
+
### 环境🎮
@@ -34,7 +30,7 @@
### 使用的库📚
-- [MLAgents(Hugging Face 版本)](https://github.com/huggingface/ml-agents)
+- [MLAgents](https://github.com/Unity-Technologies/ml-agents)
我们一直在努力改进我们的教程,所以**如果你在此 Notebook 中发现一些问题**,请[在 Github Repo 上打开一个 issue](https://github.com/huggingface/deep-rl-class/issues)。
@@ -66,11 +62,11 @@
## 克隆仓库并安装依赖项🔽
-- 我们需要克隆仓库,它**包含允许你将训练有素的代理推送到 Hub 的实验版本。**
+- 我们需要克隆包含 ML-Agents 的存储库。
```bash
-# 克隆这个特定的仓库(可能需要 3 分钟)
-git clone https://github.com/huggingface/ml-agents/
+# 克隆这个仓库(可能需要 3 分钟)
+git clone --depth 1 https://github.com/Unity-Technologies/ml-agents
```
```bash
@@ -150,6 +146,45 @@ chmod -R 755 ./trained-envs-executables/linux/Huggy
- 对于本笔记本的范围,我们不打算修改超参数,但如果你想尝试作为实验,你还应该尝试修改其他一些超参数,Unity 提供了非常好的文档,在这里解释了它们中的每一个] (https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Training-Configuration-File.md)。
+- 我们需要为 Huggy 创建一个 config 文件
+
+- 转到目录 `/content/ml-agents/config/ppo`
+
+- 创建一个新文件叫 `Huggy.yaml`
+
+- 复制粘贴以下内容 🔽
+
+```
+behaviors:
+ Huggy:
+ trainer_type: ppo
+ hyperparameters:
+ batch_size: 2048
+ buffer_size: 20480
+ learning_rate: 0.0003
+ beta: 0.005
+ epsilon: 0.2
+ lambd: 0.95
+ num_epoch: 3
+ learning_rate_schedule: linear
+ network_settings:
+ normalize: true
+ hidden_units: 512
+ num_layers: 3
+ vis_encode_type: simple
+ reward_signals:
+ extrinsic:
+ gamma: 0.995
+ strength: 1.0
+ checkpoint_interval: 200000
+ keep_checkpoints: 15
+ max_steps: 2e6
+ time_horizon: 1000
+ summary_freq: 50000
+```
+
+- 别忘了保存文件
+
- **如果你想修改超参数**,在Google Colab notebook中,你可以点击这里打开config.yaml: `/content/ml-agents/config/ppo/Huggy.yaml`
@@ -165,7 +200,7 @@ chmod -R 755 ./trained-envs-executables/linux/Huggy
1. `mlagents-learn `:超参数配置文件所在路径。
2. `--env`:环境可执行文件所在的位置。
-3. `--run_id`:你要为训练运行 ID 指定的名称。
+3. `--run-id`:你要为训练运行 ID 指定的名称。
4. `--no-graphics`:在训练期间不启动可视化。
训练模型并使用 `--resume` 标志在中断的情况下继续训练。
diff --git a/units/zh-CN/unitbonus3/generalisation.mdx b/units/zh-CN/unitbonus3/generalisation.mdx
new file mode 100644
index 00000000..b123818e
--- /dev/null
+++ b/units/zh-CN/unitbonus3/generalisation.mdx
@@ -0,0 +1,11 @@
+# 在强化学习中的泛化
+
+泛化在强化学习领域中扮演了关键角色。虽然**RL算法在受控环境中表现良好**,但真实世界由于其非静态和开放性质,呈现出**独特的挑战**。
+
+因此,开发能够在环境变化中保持稳健的RL算法,并具备转移和适应到未知但类似任务和设置的能力,成为RL在真实世界应用的基础。
+
+如果你有兴趣更深入地研究这个研究课题,我们推荐探索以下资源:
+
+- [强化学习中的泛化,作者 Robert Kirk](https://robertkirk.github.io/2022/01/17/generalisation-in-reinforcement-learning-survey.html):这篇全面的调查提供了对RL中泛化概念的深刻**概述**,是你探索的绝佳起点。
+
+- [使用策略相似性嵌入改进强化学习中的泛化](https://blog.research.google/2021/09/improving-generalization-in.html?m=1)
\ No newline at end of file
diff --git a/units/zh-CN/unitbonus3/learning-agents.mdx b/units/zh-CN/unitbonus3/learning-agents.mdx
new file mode 100644
index 00000000..0ac42f95
--- /dev/null
+++ b/units/zh-CN/unitbonus3/learning-agents.mdx
@@ -0,0 +1,37 @@
+# 了解虚幻引擎中的学习智能体简介
+
+[学习智能体](https://dev.epicgames.com/community/learning/tutorials/8OWY/unreal-engine-learning-agents-introduction)是一个虚幻引擎 (UE) 插件,允许你**在虚幻中使用机器学习(ML)训练 AI 角色**。
+
+这是一个令人兴奋的新插件,你可以使用虚幻引擎创建独特的环境并训练你的智能体。
+
+让我们看看你如何**开始训练一辆汽车在虚幻引擎环境中行驶**。
+
+
+
+来源:[学习智能体驾驶汽车教程](https://dev.epicgames.com/community/learning/tutorials/qj2O/unreal-engine-learning-to-drive)
+
+
+## 情况 1:我对虚幻引擎一无所知,是虚幻引擎的初学者
+如果你是虚幻引擎的新手,不要害怕!我们列出了两个你需要遵循的课程,以便能够使用学习智能体:
+
+1. 掌握基础知识:首先观看这个课程[虚幻引擎 5 中的第一个小时](https://dev.epicgames.com/community/learning/courses/ZpX/your-first-hour-in-unreal-engine-5/E7L/introduction-to-your-first-hour-in-unreal-engine-5)。这个全面的课程将**为你使用虚幻引擎奠定基础知识**。
+
+2. 深入蓝图:探索蓝图的世界,虚幻引擎的视觉脚本组件。[这个视频课程](https://youtu.be/W0brCeJNMqk?si=zy4t4t1l6FMIzbpz)将使你熟悉这个必不可少的工具。
+
+掌握了基础知识,**你现在已准备好使用学习智能体了**:
+
+3. 通过[阅读这个信息丰富的概览](https://dev.epicgames.com/community/learning/tutorials/8OWY/unreal-engine-learning-agents-introduction)了解学习智能体的大局。
+
+4. [使用学习智能体中的强化学习教车驾驶](https://dev.epicgames.com/community/learning/tutorials/qj2O/unreal-engine-learning-to-drive)。
+
+5. [检查虚幻引擎 5.3 学习智能体插件的模仿学习](https://www.youtube.com/watch?v=NwYUNlFvajQ)
+
+## 情况 2:我熟悉虚幻引擎
+
+对于已经熟悉虚幻引擎的人,你可以直接通过这两个教程进入学习智能体:
+
+1. 通过[阅读这个信息丰富的概览](https://dev.epicgames.com/community/learning/tutorials/8OWY/unreal-engine-learning-agents-introduction)了解学习智能体的大局。
+
+2. [使用学习智能体中的强化学习教车驾驶](https://dev.epicgames.com/community/learning/tutorials/qj2O/unreal-engine-learning-to-drive)。
+
+3. [检查虚幻引擎 5.3 学习智能体插件的模仿学习](https://www.youtube.com/watch?v=NwYUNlFvajQ)。
\ No newline at end of file
diff --git a/units/zh-CN/unitbonus3/student-works.mdx b/units/zh-CN/unitbonus3/student-works.mdx
new file mode 100644
index 00000000..c885b081
--- /dev/null
+++ b/units/zh-CN/unitbonus3/student-works.mdx
@@ -0,0 +1,38 @@
+# 学生作品
+
+自深度强化学习课程推出以来,**许多学生创作了令人惊叹的项目,你应该去查看,并考虑参与其中**。
+
+如果你创作了一个有趣的项目,不要犹豫,[通过在 GitHub 仓库上开启一个拉取请求将其添加到此列表中](https://github.com/huggingface/deep-rl-class)。
+
+这些项目是**根据在此页面上的发布日期排列的**。
+
+## 太空清道夫 AI
+
+这个项目是一个带有训练神经网络的太空游戏环境。
+
+AI 通过基于 UnityMLAgents 和 RLlib 框架的强化学习算法进行训练。
+
+
+
+在这里玩游戏 👉 https://swingshuffle.itch.io/spacescalvagerai
+
+在这里查看 Unity 项目 👉 https://github.com/HighExecutor/SpaceScalvagerAI
+
+
+
+## 神经涡轮 🏎️
+
+
+
+在这个项目中,Sookeyy 创建了一个低多边形赛车游戏,并训练了一辆汽车进行驾驶。
+
+在这里查看演示 👉 https://sookeyy.itch.io/neuralnitro
+
+## 太空战 🚀
+
+
+
+在这个项目中,Eric Dong 在 Pygame 中重现了 Bill Seiler 1985 年的太空战版本,并使用强化学习 (RL) 训练 AI 智能体。
+
+在这里查看项目 👉 https://github.com/e-dong/space-war-rl
+在这里查看他的博客 👉 https://dev.to/edong/space-war-rl-0-series-introduction-25dh