diff --git a/chapters/zh-CN/_toctree.yml b/chapters/zh-CN/_toctree.yml
index eab9891..edc35ad 100644
--- a/chapters/zh-CN/_toctree.yml
+++ b/chapters/zh-CN/_toctree.yml
@@ -100,29 +100,22 @@
title: 实战练习
- local: chapter6/supplemental_reading
title: 补充阅读
-#
-#- title: 第7单元:音频到音频合成(ATA)
-# sections:
-# - local: chapter7/introduction
-# title: 单元简介
-# - local: chapter7/tasks
-# title: 音频到音频合成(ATA)任务实例
-# - local: chapter7/choosing_dataset
-# title: 数据集选择
-# - local: chapter7/preprocessing
-# title: 数据加载和预处理
-# - local: chapter7/evaluation
-# title: 音频到音频合成(ATA)的评价指标
-# - local: chapter7/fine-tuning
-# title: 模型微调
-# - local: chapter7/quiz
-# title: 习题
-# quiz: 7
-# - local: chapter7/hands_on
-# title: 实战练习
-# - local: chapter7/supplemental_reading
-# title: 补充阅读
-#
+
+- title: 第7单元:整合实战
+ sections:
+ - local: chapter7/introduction
+ title: 单元简介
+ - local: chapter7/speech-to-speech
+ title: 语音到语音翻译
+ - local: chapter7/voice-assistant
+ title: 构建语音助手
+ - local: chapter7/transcribe-meeting
+ title: 会议转录
+ - local: chapter7/hands_on
+ title: 实战练习
+ - local: chapter7/supplemental_reading
+ title: 补充阅读
+
- title: 第8单元:结束线
sections:
- local: chapter8/introduction
diff --git a/chapters/zh-CN/chapter7/hands_on.mdx b/chapters/zh-CN/chapter7/hands_on.mdx
new file mode 100644
index 0000000..6d4e9a2
--- /dev/null
+++ b/chapters/zh-CN/chapter7/hands_on.mdx
@@ -0,0 +1,20 @@
+# 实战练习
+
+在本单元中,我们整合了前六个单元学到的内容,构建了三个集成音频应用。正如你所体验到的,借助本课程掌握的基础技能,构建复杂一点的音频工具完全是可以实现的。
+
+本次实践任务将基于本单元中的一个应用,并对其进行一些多语言扩展🌍。你的目标是从本单元第一节的[级联式语音翻译Gradio示例](https://huggingface.co/spaces/course-demos/speech-to-speech-translation)出发,修改它以支持**非英语**目标语言的语音翻译。也就是说,示例程序应能将语言X的语音输入,翻译成语言Y的语音输出,且Y不能是英语。你可以通过点击[此处复制](https://huggingface.co/spaces/course-demos/speech-to-speech-translation?duplicate=true)将模板克隆到你在Hugging Face上的命名空间下。无需使用GPU加速器——免费的CPU服务就已足够🤗。不过请确保你的示例项目设置为**公开**,这样我们才能访问并进行评估。
+
+关于如何更新语音翻译函数以实现多语言翻译的技巧可参考[语音到语音翻译](speech-to-speech)一节。按照该说明,你应该可以将示例程序更新为支持从语言X语音到语言Y文本的翻译任务,这已完成一半目标!
+
+要将语言Y的文本合成成语言Y的语音(即多语言语音合成),你需要使用一个多语言TTS模型检查点。为此,你可以使用上一个实践练习中自己微调的SpeechT5模型,或者使用一个预训练的多语言TTS检查点。有两个推荐选项:一个是[sanchit-gandhi/speecht5\_tts\_vox\_nl](https://huggingface.co/sanchit-gandhi/speecht5_tts_vox_nl),它是在[VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli)数据集的荷兰语子集上微调的SpeechT5模型;另一个是MMS TTS检查点(详见[语音合成的预训练模型](../chapter6/pre-trained_models)一节)。
+
+
+
+在我们的测试中,对于荷兰语(Dutch),MMS TTS检查点效果优于微调后的SpeechT5模型。但你可能会发现自己微调的模型在某些语言上表现更佳。如果你决定使用MMS TTS检查点,需要修改demo的requirements.txt文件,以安装该分支的transformers:
+git+https://github.com/hollance/transformers.git@6900e8ba6532162a8613d2270ec2286c3f58f57b
+
+
+
+你的程序应接收一个音频文件作为输入,并输出一个音频文件作为结果,其函数接口需匹配模板demo中的[`speech_to_speech_translation`](https://huggingface.co/spaces/course-demos/speech-to-speech-translation/blob/3946ba6705a6632a63de8672ac52a482ab74b3fc/app.py#L35)。因此,我们建议你保留主函数`speech_to_speech_translation`不变,仅根据需要更新[`translate`](https://huggingface.co/spaces/course-demos/speech-to-speech-translation/blob/a03175878f522df7445290d5508bfb5c5178f787/app.py#L24)和[`synthesise`](https://huggingface.co/spaces/course-demos/speech-to-speech-translation/blob/a03175878f522df7445290d5508bfb5c5178f787/app.py#L29)两个函数。
+
+构建好Gradio demo后,你可以提交它以供评估。访问Space [audio-course-u7-assessment](https://huggingface.co/spaces/huggingface-course/audio-course-u7-assessment),并在提示时提供你项目的repository id。该Space会自动发送一个音频样本到你的demo,并检测返回的音频是否为非英语语种。如果通过测试,你的名字旁边会在[总进度页面](https://huggingface.co/spaces/MariaK/Check-my-progress-Audio-Course)上显示一个绿色对勾✅。
diff --git a/chapters/zh-CN/chapter7/introduction.mdx b/chapters/zh-CN/chapter7/introduction.mdx
new file mode 100644
index 0000000..9f87680
--- /dev/null
+++ b/chapters/zh-CN/chapter7/introduction.mdx
@@ -0,0 +1,11 @@
+# 第7单元:整合实战 🪢
+
+恭喜你来到第7单元🥳!现在你距离完成整个课程只差最后几步了,也即将掌握构建完整音频机器学习应用所需的核心技能。从理解角度来看,你已经掌握了音频领域的关键知识点:我们已经系统学习了音频数据处理、音频分类、语音识别以及语音合成等核心主题及其背后的理论知识。本单元的目标是帮助你**将这些内容整合起来**:既然你已经分别了解了每一类任务的原理和实践方法,现在我们将探索如何将它们组合在一起,构建一些真实世界的应用。
+
+## 你将学到什么,构建什么
+
+在本单元中,我们将学习以下三个主题:
+
+* [语音到语音翻译](speech-to-speech):将一种语言的语音翻译为另一种语言的语音
+* [构建语音助手](voice-assistant):开发一个类似 Alexa 或 Siri 的语音助手
+* [会议转写](transcribe-meeting):将会议内容转写成文本,并标注每位说话者的发言时间和内容
diff --git a/chapters/zh-CN/chapter7/speech-to-speech.mdx b/chapters/zh-CN/chapter7/speech-to-speech.mdx
new file mode 100644
index 0000000..b1d54cb
--- /dev/null
+++ b/chapters/zh-CN/chapter7/speech-to-speech.mdx
@@ -0,0 +1,211 @@
+# 语音到语音翻译
+
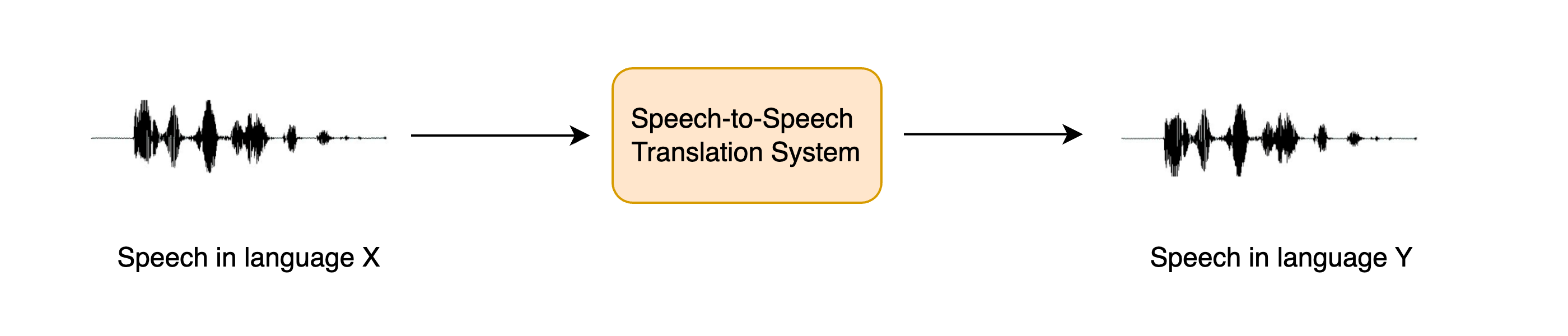
+语音到语音翻译(Speech-to-speech translation,简称STST或S2ST)是一项相对较新的语音语言处理任务,其目标是将一种语言的语音翻译成**另一种**语言的语音:
+
+
+
+
+

+
+
+
ASRDiarizationPipeline:
+pipeline = ASRDiarizationPipeline.from_pretrained("openai/whisper-base")
+
+
+
+将音频输入该组合流水线,看看输出结果如何:
+
+```python
+pipeline(sample["audio"].copy())
+```
+
+```text
+[{'speaker': 'SPEAKER_01',
+ 'text': ' The second and importance is as follows. Sovereignty may be defined to be the right of making laws. In France, the king really exercises a portion of the sovereign power, since the laws have no weight.',
+ 'timestamp': (0.0, 15.48)},
+ {'speaker': 'SPEAKER_00',
+ 'text': " He was in a favored state of mind, owing to the blight his wife's action threatened to cast upon his entire future.",
+ 'timestamp': (15.48, 21.28)}]
+```
+
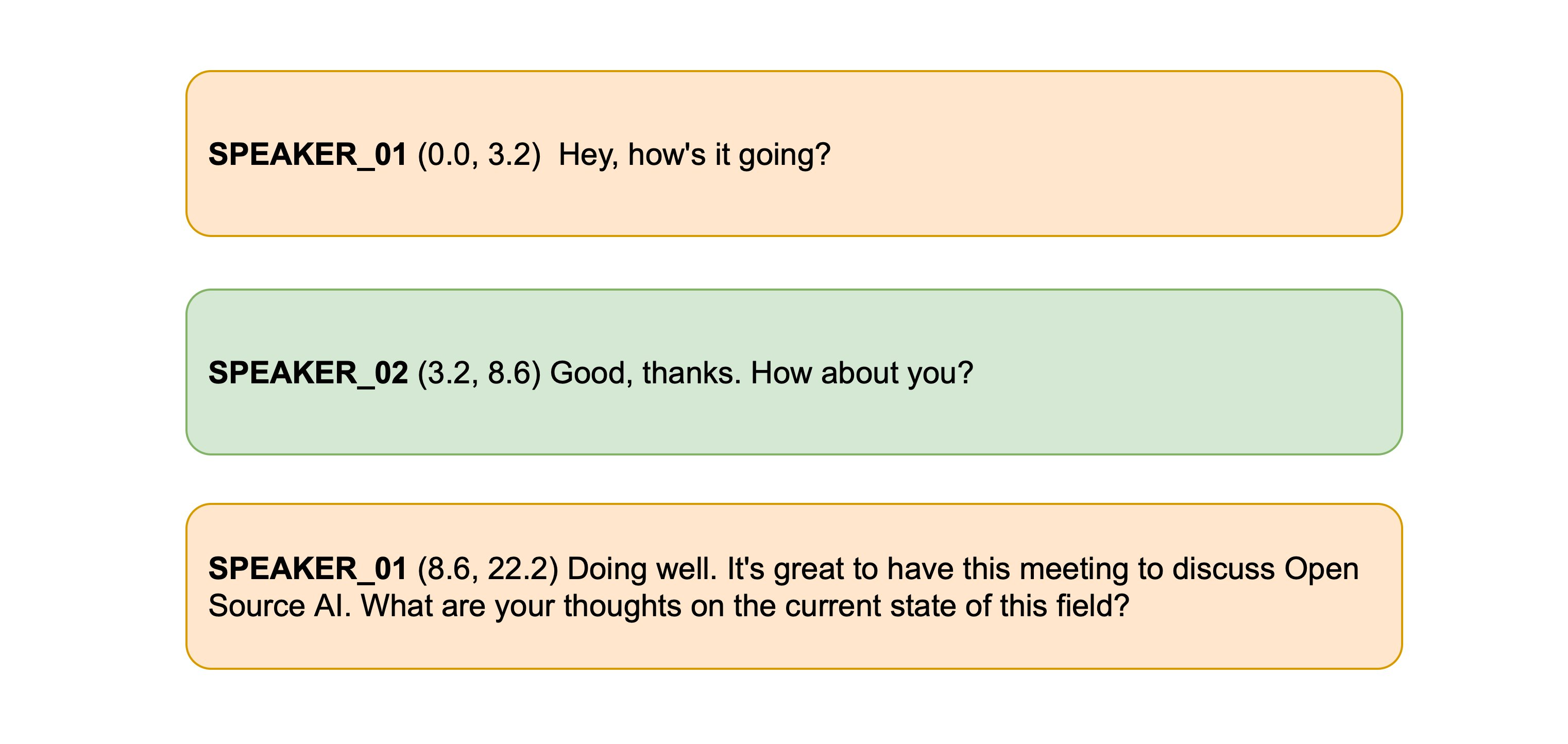
+太棒了!第一位说话者的发言时间为0到15.48秒,第二位说话者为15.48到21.28秒,并分别对应各自的转录文本。
+
+我们可以通过定义两个辅助函数来让时间戳的格式更美观一些。第一个函数将时间戳元组格式化为字符串,并保留指定的小数位数。第二个函数将说话人ID、时间戳和文本组合成一行,并将不同说话人分行展示,方便阅读:
+
+```python
+def tuple_to_string(start_end_tuple, ndigits=1):
+ return str((round(start_end_tuple[0], ndigits), round(start_end_tuple[1], ndigits)))
+
+
+def format_as_transcription(raw_segments):
+ return "\n\n".join(
+ [
+ chunk["speaker"] + " " + tuple_to_string(chunk["timestamp"]) + chunk["text"]
+ for chunk in raw_segments
+ ]
+ )
+```
+
+我们再次运行流水线,并使用刚刚定义的格式化函数美化输出:
+
+```python
+outputs = pipeline(sample["audio"].copy())
+
+format_as_transcription(outputs)
+```
+
+```text
+SPEAKER_01 (0.0, 15.5) The second and importance is as follows. Sovereignty may be defined to be the right of making laws.
+In France, the king really exercises a portion of the sovereign power, since the laws have no weight.
+
+SPEAKER_00 (15.5, 21.3) He was in a favored state of mind, owing to the blight his wife's action threatened to cast upon
+his entire future.
+```
+
+就这样!我们已经成功完成了音频的说话人分离与文本转录,并返回了按说话人分段的完整转录内容。尽管我们使用的是最小距离算法来对齐时间戳,这一方法在实际中效果非常好。如果你想进一步探索更复杂的对齐策略,不妨查看`ASRDiarizationPipeline`的源码:[speechbox/diarize.py](https://github.com/huggingface/speechbox/blob/96d2d1a180252d92263f862a1cd25a48860f1aed/src/speechbox/diarize.py#L12)。
diff --git a/chapters/zh-CN/chapter7/voice-assistant.mdx b/chapters/zh-CN/chapter7/voice-assistant.mdx
new file mode 100644
index 0000000..4bd340b
--- /dev/null
+++ b/chapters/zh-CN/chapter7/voice-assistant.mdx
@@ -0,0 +1,374 @@
+# 构建语音助手
+
+在本节中,我们将组合三个之前已经实践过的模型,构建一个端到端的语音助手,名为**Marvin** 🤖。就像Amazon的Alexa或Apple的Siri一样,Marvin是一个虚拟语音助手,会响应特定的“唤醒词”,然后监听用户的语音提问,并以语音作答。
+
+我们可以将语音助手的流程拆解为四个阶段,每个阶段都对应一个独立的模型:
+
+
+

+
+
+
+
+
+
+
+

+
+

+
+

+