From 3292892254587387118fb5d0e5a37b79dead593c Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Thu, 22 Aug 2024 23:24:12 +0300
Subject: [PATCH 01/62] Add docs/source/ar/tasks_explained.md to
Add_docs_source_ar_tasks_explained.md
---
docs/source/ar/tasks_explained.md | 279 ++++++++++++++++++++++++++++++
1 file changed, 279 insertions(+)
create mode 100644 docs/source/ar/tasks_explained.md
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
new file mode 100644
index 000000000000..826be566f0b8
--- /dev/null
+++ b/docs/source/ar/tasks_explained.md
@@ -0,0 +1,279 @@
+# كيف تحل نماذج 🤗 Transformers المهام
+
+في [ما الذي يمكن أن تفعله نماذج 🤗 Transformers](task_summary)، تعلمت عن معالجة اللغات الطبيعية (NLP)، والخطاب والصوت، ورؤية الكمبيوتر، وبعض التطبيقات المهمة لها. ستنظر هذه الصفحة عن كثب في كيفية حل النماذج لهذه المهام وتوضيح ما يحدث تحت الغطاء. هناك العديد من الطرق لحل مهمة معينة، وقد تنفذ بعض النماذج تقنيات معينة أو حتى تتناول المهمة من زاوية جديدة، ولكن بالنسبة لنماذج Transformer، فإن الفكرة العامة هي نفسها. وبفضل تصميمها المرن، فإن معظم النماذج هي متغير لمبنى مشفر أو فك تشفير أو ترميز-فك تشفير. بالإضافة إلى نماذج Transformer، تحتوي مكتبتنا أيضًا على العديد من الشبكات العصبية التلافيفية (CNNs)، والتي لا تزال تستخدم حتى اليوم لمهام رؤية الكمبيوتر. سنشرح أيضًا كيف تعمل شبكة CNN الحديثة.
+
+لشرح كيفية حل المهام، سنشرح ما يحدث داخل النموذج لإخراج تنبؤات مفيدة.
+
+- [Wav2Vec2](model_doc/wav2vec2) لتصنيف الصوت والتعرف التلقائي على الكلام (ASR)
+- [Vision Transformer (ViT)](model_doc/vit) و [ConvNeXT](model_doc/convnext) لتصنيف الصور
+- [DETR](model_doc/detr) للكشف عن الأشياء
+- [Mask2Former](model_doc/mask2former) لتجزئة الصورة
+- [GLPN](model_doc/glpn) لتقدير العمق
+- [BERT](model_doc/bert) لمهام NLP مثل تصنيف النصوص، وتصنيف الرموز، والإجابة على الأسئلة التي تستخدم مشفرًا
+- [GPT2](model_doc/gpt2) لمهام NLP مثل توليد النصوص التي تستخدم فك تشفير
+- [BART](model_doc/bart) لمهام NLP مثل الملخص والترجمة التي تستخدم ترميز-فك تشفير
+
+
+
+قبل المتابعة، من الجيد أن يكون لديك بعض المعرفة الأساسية بهندسة Transformer الأصلية. إن معرفة كيفية عمل المشفرات وفك التشفير والاهتمام سوف تساعدك في فهم كيفية عمل نماذج Transformer المختلفة. إذا كنت مبتدئًا أو بحاجة إلى مراجعة، فراجع [دورتنا](https://huggingface.co/course/chapter1/4؟fw=pt) لمزيد من المعلومات!
+
+
+
+## الكلام والصوت
+
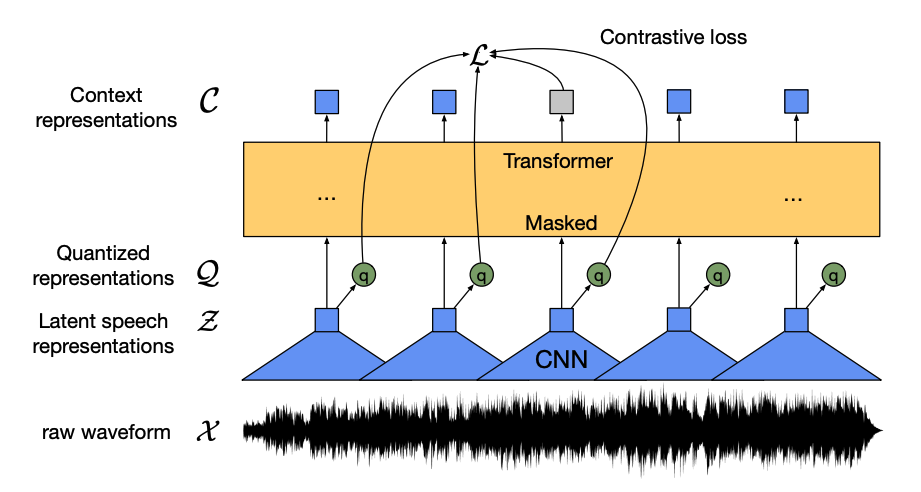
+[Wav2Vec2](model_doc/wav2vec2) هو نموذج ذاتي الإشراف تم تدريبه مسبقًا على بيانات الكلام غير الموسومة وتم ضبط دقته على بيانات موسومة لتصنيف الصوت والتعرف التلقائي على الكلام.
+
+
+
+
+

+
+

+
+

+
+
+
+

+
+

+
+
+
+
+
From 9ed73164a3868eee62bb7c03b23c5b04bdb845d5 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:43:45 +0300
Subject: [PATCH 09/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 125da9c8696e..85adf3d977ba 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -27,9 +27,9 @@
-يحتوي هذا النموذج على أربعة مكونات رئيسية:
+يتكون هذا النموذج على أربعة مكونات رئيسية:
-1. *مشفّر الميزات* يأخذ الموجة الصوتية الخام، ويقوم بتطبيعها إلى متوسط صفري وانحراف معياري بوحدة، وتحويلها إلى تسلسل من متجهات الميزات التي يبلغ طول كل منها 20 مللي ثانية.
+1. *مشفّر الميزات (Feature Encoder)* يأخذ الموجة الصوتية الخام، ويقوم بتطبيعها (Normalization) إلى متوسط صفري وانحراف معياري وحدوي، وتحويلها إلى تسلسل من متجهات الميزات التي يبلغ طول كل منها 20 مللي ثانية.
2. الموجات مستمرة بطبيعتها، لذلك لا يمكن تقسيمها إلى وحدات منفصلة مثل تسلسل النص الذي يمكن تقسيمه إلى كلمات. ولهذا السبب يتم تمرير متجهات الميزات إلى *وحدة التكميم*، والتي تهدف إلى تعلم وحدات الكلام المنفصلة. يتم اختيار وحدة الكلام من مجموعة من كلمات الرمز، والمعروفة باسم *كتاب الرموز* (يمكنك اعتبار هذا بمثابة المفردات). يتم اختيار المتجه أو وحدة الكلام، التي تمثل أفضل تمثيل لإدخال الصوت المستمر، من كتاب الرموز، ثم يتم تمريره عبر النموذج.
3. يتم إخفاء حوالي نصف متجهات الميزات بشكل عشوائي، ويتم تغذية متجه الميزة المخفية في *شبكة السياق*، والتي تعد مشفر Transformer الذي يضيف أيضًا تضمينات موضعية نسبية.
From 241c615d212024d3834cb64c116b116f31d130d8 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:44:16 +0300
Subject: [PATCH 10/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 85adf3d977ba..fe8c9ffcb320 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -31,8 +31,8 @@
1. *مشفّر الميزات (Feature Encoder)* يأخذ الموجة الصوتية الخام، ويقوم بتطبيعها (Normalization) إلى متوسط صفري وانحراف معياري وحدوي، وتحويلها إلى تسلسل من متجهات الميزات التي يبلغ طول كل منها 20 مللي ثانية.
-2. الموجات مستمرة بطبيعتها، لذلك لا يمكن تقسيمها إلى وحدات منفصلة مثل تسلسل النص الذي يمكن تقسيمه إلى كلمات. ولهذا السبب يتم تمرير متجهات الميزات إلى *وحدة التكميم*، والتي تهدف إلى تعلم وحدات الكلام المنفصلة. يتم اختيار وحدة الكلام من مجموعة من كلمات الرمز، والمعروفة باسم *كتاب الرموز* (يمكنك اعتبار هذا بمثابة المفردات). يتم اختيار المتجه أو وحدة الكلام، التي تمثل أفضل تمثيل لإدخال الصوت المستمر، من كتاب الرموز، ثم يتم تمريره عبر النموذج.
-3. يتم إخفاء حوالي نصف متجهات الميزات بشكل عشوائي، ويتم تغذية متجه الميزة المخفية في *شبكة السياق*، والتي تعد مشفر Transformer الذي يضيف أيضًا تضمينات موضعية نسبية.
+2. *وحدة التكميم (Quantization Module):** تتميز أشكال الموجات الصوتية بطبيعتها المُستمرة،، لذلك لا يمكن تقسيمها إلى وحدات منفصلة كما يمكن تقسيم التسلسل النصّي إلى كلمات ولهذا السبب يتم تمرير متجهات الميزات إلى *وحدة التكميم*، والتي تهدف إلى تعلم وحدات الكلام المنفصلة. يتم اختيار وحدة الكلام من مجموعة من الرموز، والمعروفة باسم *كتاب الرموز* (يمكنك اعتبار هذا بمثابة المفردات). ومن كتاب الرموز،يتم اختيار المتجه أو وحدة الكلام التي تُمثّل مدخل الصوت المُستمر على أفضل وجه، ويتم تمريرها عبر النموذج.
+3. **شبكة السياق (Context Network):** يتم إخفاء حوالي نصف متجهات الميزات بشكل عشوائي، ويتم تغذية متجه الميزة المُقنّع إلى *شبكة السياق*، والتي تعد مُشفّر محوّلات (Transformer Encoder) الذي يضيف أيضًا تضمينات موضعية نسبية (Relative Positional Embeddings)..
4. الهدف من التدريب المسبق لشبكة السياق هو *مهمة تناقضية*. يجب على النموذج التنبؤ بالتمثيل الحقيقي للكلام الكمي للتنبؤ المخفي من مجموعة من التمثيلات الكاذبة، مما يشجع النموذج على العثور على متجه السياق الأكثر تشابهًا ووحدة الكلام الكمي (علامة التصنيف).
From ff5dee1d45b37270799fa660b9c3f5b6c6cc4495 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:44:48 +0300
Subject: [PATCH 11/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index fe8c9ffcb320..dde606939895 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -34,9 +34,9 @@
2. *وحدة التكميم (Quantization Module):** تتميز أشكال الموجات الصوتية بطبيعتها المُستمرة،، لذلك لا يمكن تقسيمها إلى وحدات منفصلة كما يمكن تقسيم التسلسل النصّي إلى كلمات ولهذا السبب يتم تمرير متجهات الميزات إلى *وحدة التكميم*، والتي تهدف إلى تعلم وحدات الكلام المنفصلة. يتم اختيار وحدة الكلام من مجموعة من الرموز، والمعروفة باسم *كتاب الرموز* (يمكنك اعتبار هذا بمثابة المفردات). ومن كتاب الرموز،يتم اختيار المتجه أو وحدة الكلام التي تُمثّل مدخل الصوت المُستمر على أفضل وجه، ويتم تمريرها عبر النموذج.
3. **شبكة السياق (Context Network):** يتم إخفاء حوالي نصف متجهات الميزات بشكل عشوائي، ويتم تغذية متجه الميزة المُقنّع إلى *شبكة السياق*، والتي تعد مُشفّر محوّلات (Transformer Encoder) الذي يضيف أيضًا تضمينات موضعية نسبية (Relative Positional Embeddings)..
-4. الهدف من التدريب المسبق لشبكة السياق هو *مهمة تناقضية*. يجب على النموذج التنبؤ بالتمثيل الحقيقي للكلام الكمي للتنبؤ المخفي من مجموعة من التمثيلات الكاذبة، مما يشجع النموذج على العثور على متجه السياق الأكثر تشابهًا ووحدة الكلام الكمي (علامة التصنيف).
+4. **مهمة التناقضية:** يتمثل الهدف من التدريب المسبق لشبكة السياق هو *مهمة تناقضية*. يجب على النموذج التنبؤ بالتمثيل الصحيح للكلام المُكمّم للتنبؤ المقنع من مجموعة من التمثيلات الخاطئة، مما يشجع النموذج على ا إيجاد متجه السياق ووحدة الكلام المُكمّمة الأكثر تشابهًا (التصنيف المستهدف).
-الآن بعد أن تم تدريب Wav2Vec2 مسبقًا، يمكنك ضبط دقته على بياناتك لتصنيف الصوت أو التعرف التلقائي على الكلام!
+بمجرد تدريب Wav2Vec2 مسبقًا، يمكنك ضبط دقته على بياناتك لتصنيف الصوت أو التعرف التلقائي على الكلام!
### تصنيف الصوت
From 069f7d13bf55c0c3a1cbf9cf5f17eeed0cd8d90a Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:45:22 +0300
Subject: [PATCH 12/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index dde606939895..5a474cbea1f3 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -40,9 +40,9 @@
### تصنيف الصوت
-لاستخدام النموذج الذي تم تدريبه مسبقًا لتصنيف الصوت، أضف رأس تصنيف تسلسلي أعلى نموذج Wav2Vec2 الأساسي. رأس التصنيف هو طبقة خطية تقبل الحالات المخفية للمشفر. تمثل الحالات المخفية الميزات التي تم تعلمها من كل إطار صوتي والذي يمكن أن يكون له أطوال مختلفة. لتحويلها إلى متجه ثابت الطول، يتم تجميع الحالات المخفية أولاً ثم تحويلها إلى احتمالات عبر تسميات الفئات. يتم حساب خسارة الانتروبيا الصافية بين الاحتمالات والهدف للعثور على الفئة الأكثر احتمالًا.
+لاستخدام النموذج الذي تم تدريبه مسبقًا لتصنيف الصوت، أضف رأس تصنيف تسلسلي أعلى نموذج Wav2Vec2 الأساسي. رأس التصنيف هو طبقة خطية تستقبل الحالات المخفية للمشفر. تمثل الحالات المخفية الميزات التي تم تعلمها من كل إطار صوتي والذي يمكن أن يكون له أطوال مختلفة. لتحويلها إلى متجه واحد ثابت الطول، يتم تجميع الحالات المخفية أولاً ثم تحويلها إلى احتمالات عبر تصنيفات الفئات. يتم حساب التكلفة (الخسارة المتقاطعة) بين الاحتمالات والتصنيف المستهدف للعثور على الفئة الأكثر احتمالًا.
-هل أنت مستعد لتجربة تصنيف الصوت؟ تحقق من دليلنا الكامل [تصنيف الصوت](tasks/audio_classification) لمعرفة كيفية ضبط دقة Wav2Vec2 واستخدامه للاستدلال!
+هل أنت مستعد لتجربة تصنيف الصوت؟ تحقق من دليلنا الشامل [تصنيف الصوت](tasks/audio_classification) لمعرفة كيفية ضبط دقة نموذج Wav2Vec2 واستخدامه للاستدلال!
### التعرف التلقائي على الكلام
From 7bf40529369d7f2e4b50235c49ddc68ceafad01b Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:45:51 +0300
Subject: [PATCH 13/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 5a474cbea1f3..54dfdb8e08a5 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -46,9 +46,9 @@
### التعرف التلقائي على الكلام
-لاستخدام النموذج الذي تم تدريبه مسبقًا للتعرف التلقائي على الكلام، أضف رأس نمذجة اللغة أعلى نموذج Wav2Vec2 الأساسي لـ [تصنيف الوقت الاتصالي (CTC)](glossary#connectionist-temporal-classification-ctc). رأس نمذجة اللغة عبارة عن طبقة خطية تقبل الحالات المخفية للمشفر وتحويلها إلى احتمالات. يمثل كل احتمال فئة رمزية (يأتي عدد الرموز من مفردات المهمة). يتم حساب خسارة CTC بين الاحتمالات والأهداف للعثور على تسلسل الرموز الأكثر احتمالًا، والتي يتم فك تشفيرها بعد ذلك إلى نسخة.
+لاستخدام النموذج الذي تم تدريبه مسبقًا للتعرف التلقائي على الكلام، أضف رأس نمذجة لغوية أعلى نموذج Wav2Vec2 الأساسي لـ [[التصنيف الزمني الترابطي (CTC)](glossary#connectionist-temporal-classification-ctc). رأس النمذجة اللغوية عبارة عن طبقة خطية تقبل الحالات المخفية للمُشفّر وتحويلها إلى احتمالات. يمثل كل احتمال فئة رمزية (يأتي عدد الرموز من مفردات المهمة). يتم حساب تكلفة CTC بين الاحتمالات والأهداف للعثور على تسلسل الرموز الأكثر احتمالًا، والتي يتم فك تشفيرها بعد ذلك إلى نص مكتوب.
-هل أنت مستعد لتجربة التعرف التلقائي على الكلام؟ تحقق من دليلنا الكامل [التعرف التلقائي على الكلام](tasks/asr) لمعرفة كيفية ضبط دقة Wav2Vec2 واستخدامه للاستدلال!
+هل أنت مستعد لتجربة التعرف التلقائي على الكلام؟ تحقق من دليلنا الشامل [التعرف التلقائي على الكلام](tasks/asr) لمعرفة كيفية ضبط دقة نموذج Wav2Vec2 واستخدامه للاستدلال!
## رؤية الكمبيوتر
From 6ca7a137f87aa31e86b5f61fb1cf98b1e070bade Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:46:19 +0300
Subject: [PATCH 14/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 8 ++++----
1 file changed, 4 insertions(+), 4 deletions(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 54dfdb8e08a5..2f8d29ea8837 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -50,12 +50,12 @@
هل أنت مستعد لتجربة التعرف التلقائي على الكلام؟ تحقق من دليلنا الشامل [التعرف التلقائي على الكلام](tasks/asr) لمعرفة كيفية ضبط دقة نموذج Wav2Vec2 واستخدامه للاستدلال!
-## رؤية الكمبيوتر
+## رؤية الحاسب
-هناك طريقتان لتناول مهام رؤية الكمبيوتر:
+هناك طريقتان لتناول مهام رؤية الحاسب:
-1. قم بتقسيم الصورة إلى تسلسل من الرقع ومعالجتها بالتوازي مع Transformer.
-2. استخدم شبكة عصبية تلافيفية حديثة، مثل [ConvNeXT](model_doc/convnext)، والتي تعتمد على الطبقات التلافيفية ولكنها تعتمد تصاميم الشبكات الحديثة.
+1. قم بتقسيم الصورة إلى تسلسل من الرقع ومعالجتها بالتوازي باستخدام مُحوّل Transformer.
+2. استخدم شبكة عصبية تلافيفية CNN) حديثة، مثل [ConvNeXT](model_doc/convnext)، والتي تعتمد على الطبقات التلافيفية ولكنها تعتمد تصميمات حديثة للشبكات.
From 7bceeb24cd0d41c1b78fdb39ef0e283d585cf5fd Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:47:07 +0300
Subject: [PATCH 15/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 2f8d29ea8837..f27d78421057 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -59,7 +59,7 @@
-يقوم النهج الثالث بمزج المحولات مع التلافيف (على سبيل المثال، [Convolutional Vision Transformer](model_doc/cvt) أو [LeViT](model_doc/levit)). لن نناقشها لأنها تجمع ببساطة بين النهجين اللذين ندرسهما هنا.
+يقوم النهج الثالث بمزج المحولات مع التلافيف (على سبيل المثال، [Convolutional Vision Transformer](model_doc/cvt) أو [LeViT](model_doc/levit)). لن نناقشها لأنها تجمع ببساطة بين النهجين اللذين نستعرضهما هنا.
From 27ad60741887d179ff15eaddee52ec73387868d2 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:47:32 +0300
Subject: [PATCH 16/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index f27d78421057..ebb72b97bc52 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -63,7 +63,7 @@
-يتم استخدام ViT و ConvNeXT بشكل شائع لتصنيف الصور، ولكن بالنسبة لمهام الرؤية الأخرى مثل اكتشاف الأشياء والتجزئة وتقدير العمق، سنلقي نظرة على DETR و Mask2Former و GLPN، على التوالي؛ هذه النماذج مناسبة بشكل أفضل لتلك المهام.
+يتم استخدام ViT و ConvNeXT بشكل شائع لتصنيف الصور، ولكن بالنسبة لمهام الرؤية الأخرى مثل اكتشاف الكائنات والتجزئة وتقدير العمق، سنلقي نظرة على DETR و Mask2Former و GLPN، على التوالي؛ فهذه النماذج هي الأنسب لتلك المهام.
### تصنيف الصور
From 6672ba944bbd64d2b7ca3f6f3da24481968716e4 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:47:55 +0300
Subject: [PATCH 17/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index ebb72b97bc52..32d5fd94ddbf 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -67,7 +67,7 @@
### تصنيف الصور
-يمكن استخدام كل من ViT و ConvNeXT لتصنيف الصور؛ الفرق الرئيسي هو أن ViT يستخدم آلية اهتمام بينما يستخدم ConvNeXT التلافيف.
+يمكن استخدام كل من ViT و ConvNeXT لتصنيف الصور؛ الاختلاف الرئيسي هو أن ViT يستخدم آلية انتباه بينما يستخدم ConvNeXT الالتفافات.
#### المحول Transformer
From 47f88ea7cbbc90a6d7d36732bcee8bb2046eb1e9 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:48:17 +0300
Subject: [PATCH 18/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 1 -
1 file changed, 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 32d5fd94ddbf..1e7ff1d6a7b9 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -78,7 +78,6 @@
كان التغيير الرئيسي الذي قدمه ViT هو كيفية تغذية الصور إلى Transformer:
-قدم ViT التغيير الرئيسي في كيفية تغذية الصور إلى Transformer:
1. يتم تقسيم الصورة إلى رقع مربعة غير متداخلة، يتم تحويل كل منها إلى متجه أو *تضمين رقعة*. يتم إنشاء تضمينات الرقع من طبقة تلافيفية ثنائية الأبعاد 2D والتي تقوم بإنشاء أبعاد الإدخال الصحيحة (والتي بالنسبة إلى Transformer الأساسي هي 768 قيمة لكل تضمين رقعة). إذا كان لديك صورة 224x224 بكسل، فيمكنك تقسيمها إلى 196 رقعة صورة 16x16. تمامًا مثل كيفية تمييز النص إلى كلمات، يتم "تمييز" الصورة إلى تسلسل من الرقع.
From 956271e7d62c220b76443080053d482c47266d9a Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:48:42 +0300
Subject: [PATCH 19/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 1e7ff1d6a7b9..d0b55c65b8d6 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -79,7 +79,7 @@
كان التغيير الرئيسي الذي قدمه ViT هو كيفية تغذية الصور إلى Transformer:
-1. يتم تقسيم الصورة إلى رقع مربعة غير متداخلة، يتم تحويل كل منها إلى متجه أو *تضمين رقعة*. يتم إنشاء تضمينات الرقع من طبقة تلافيفية ثنائية الأبعاد 2D والتي تقوم بإنشاء أبعاد الإدخال الصحيحة (والتي بالنسبة إلى Transformer الأساسي هي 768 قيمة لكل تضمين رقعة). إذا كان لديك صورة 224x224 بكسل، فيمكنك تقسيمها إلى 196 رقعة صورة 16x16. تمامًا مثل كيفية تمييز النص إلى كلمات، يتم "تمييز" الصورة إلى تسلسل من الرقع.
+1. يتم تقسيم الصورة إلى رقع مربعة غير متداخلة، يتم تحويل كل منها إلى متجه أو يُسمى *تمثيل الرقعة*. يتم إنشاء تضمينات الرقع من طبقة تلافيفية ثنائية الأبعاد 2D والتي تقوم بإنشاء أبعاد الإدخال الصحيحة (والتي بالنسبة إلى Transformer الأساسي هي 768 قيمة لكل تضمين رقعة). إذا كان لديك صورة 224x224 بكسل، فيمكنك تقسيمها إلى 196 رقعة صورة 16x16. تمامًا مثل كيفية تجزئة النص إلى كلمات، يتم "تجزئة" الصورة إلى سلسلة من الرقع.
2. يتم إضافة *تضمين قابل للتعلم* - رمز خاص `[CLS]` - إلى بداية تضمينات الرقع تمامًا مثل BERT. يتم استخدام الحالة المخفية النهائية للرمز `[CLS]` كإدخال لرأس التصنيف المرفق؛ يتم تجاهل الإخراج الآخر. تساعد هذه الرموز النموذج على تعلم كيفية ترميز تمثيل الصورة.
From 89b93ea004eb801afa72ae99ea37e40ab31c5b39 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:49:10 +0300
Subject: [PATCH 20/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index d0b55c65b8d6..29e02cce046b 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -81,7 +81,7 @@
1. يتم تقسيم الصورة إلى رقع مربعة غير متداخلة، يتم تحويل كل منها إلى متجه أو يُسمى *تمثيل الرقعة*. يتم إنشاء تضمينات الرقع من طبقة تلافيفية ثنائية الأبعاد 2D والتي تقوم بإنشاء أبعاد الإدخال الصحيحة (والتي بالنسبة إلى Transformer الأساسي هي 768 قيمة لكل تضمين رقعة). إذا كان لديك صورة 224x224 بكسل، فيمكنك تقسيمها إلى 196 رقعة صورة 16x16. تمامًا مثل كيفية تجزئة النص إلى كلمات، يتم "تجزئة" الصورة إلى سلسلة من الرقع.
-2. يتم إضافة *تضمين قابل للتعلم* - رمز خاص `[CLS]` - إلى بداية تضمينات الرقع تمامًا مثل BERT. يتم استخدام الحالة المخفية النهائية للرمز `[CLS]` كإدخال لرأس التصنيف المرفق؛ يتم تجاهل الإخراج الآخر. تساعد هذه الرموز النموذج على تعلم كيفية ترميز تمثيل الصورة.
+2. يتم إضافة *رمز قابل للتعلم* - تتم إضافة رمز خاص `[CLS]` - إلى بداية تمثيلات الرقع تمامًا مثل BERT. يتم استخدام الحالة المخفية النهائية للرمز `[CLS]` كمدخل لرأس التصنيف المُرفق؛ يتم تجاهل المخرجات الأخرى. تساعد هذه الرموز النموذج على تعلم كيفية ترميز تمثيل الصورة.
3. الشيء الأخير الذي يجب إضافته إلى تضمينات الرقع والتضمينات القابلة للتعلم هو *تضمينات الموضع* لأن النموذج لا يعرف كيفية ترتيب رقع الصورة. تضمينات الموضع قابلة للتعلم أيضًا ولها نفس حجم تضمينات الرقع. أخيرًا، يتم تمرير جميع التضمينات إلى مشفر Transformer.
From c36a2032ac9e520fa2a444c7bae456be6622b2b2 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:49:36 +0300
Subject: [PATCH 21/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 29e02cce046b..e9e548877d84 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -83,7 +83,7 @@
2. يتم إضافة *رمز قابل للتعلم* - تتم إضافة رمز خاص `[CLS]` - إلى بداية تمثيلات الرقع تمامًا مثل BERT. يتم استخدام الحالة المخفية النهائية للرمز `[CLS]` كمدخل لرأس التصنيف المُرفق؛ يتم تجاهل المخرجات الأخرى. تساعد هذه الرموز النموذج على تعلم كيفية ترميز تمثيل الصورة.
-3. الشيء الأخير الذي يجب إضافته إلى تضمينات الرقع والتضمينات القابلة للتعلم هو *تضمينات الموضع* لأن النموذج لا يعرف كيفية ترتيب رقع الصورة. تضمينات الموضع قابلة للتعلم أيضًا ولها نفس حجم تضمينات الرقع. أخيرًا، يتم تمرير جميع التضمينات إلى مشفر Transformer.
+3. الشيء الأخير تتم إضافة "تمثيلات تموضع" إلى تمثيلات الرقع والرمز القابل للتعلم لأن النموذج لا يعرف كيفية ترتيب رقع الصورة. تكون تمثيلات التموضع قابلة للتعلم أيضًا ولها نفس حجم تمثيلات الرقع. وأخيرًا، يتم تمرير جميع التمثيلات إلى مُشفّر Transformer.
4. يتم تمرير الإخراج، وتحديدًا الإخراج مع الرمز `[CLS]`، إلى رأس الإدراك المتعدد الطبقات (MLP). الهدف من التدريب المسبق لـ ViT هو التصنيف البسيط. مثل رؤوس التصنيف الأخرى، يحول رأس MLP الإخراج إلى احتمالات عبر تسميات الفئات ويحسب خسارة الانتروبيا الصافية للعثور على الفئة الأكثر احتمالًا.
From 21e674c46ce1dd8b430234424c5e84c87de1be8f Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:49:58 +0300
Subject: [PATCH 22/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index e9e548877d84..aac4c374f61a 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -85,7 +85,7 @@
3. الشيء الأخير تتم إضافة "تمثيلات تموضع" إلى تمثيلات الرقع والرمز القابل للتعلم لأن النموذج لا يعرف كيفية ترتيب رقع الصورة. تكون تمثيلات التموضع قابلة للتعلم أيضًا ولها نفس حجم تمثيلات الرقع. وأخيرًا، يتم تمرير جميع التمثيلات إلى مُشفّر Transformer.
-4. يتم تمرير الإخراج، وتحديدًا الإخراج مع الرمز `[CLS]`، إلى رأس الإدراك المتعدد الطبقات (MLP). الهدف من التدريب المسبق لـ ViT هو التصنيف البسيط. مثل رؤوس التصنيف الأخرى، يحول رأس MLP الإخراج إلى احتمالات عبر تسميات الفئات ويحسب خسارة الانتروبيا الصافية للعثور على الفئة الأكثر احتمالًا.
+4. يتم تمرير الإخراج، وتحديدًا مخرج الرمز `[CLS]`، إلى رأس الإدراك المتعدد الطبقات (MLP). الهدف من التدريب المسبق لـ ViT هو التصنيف فقط. يقوم رأس MLP، مثل رؤوس التصنيف الأخرى، يحول رأس MLP المخرجات إلى احتمالات عبر تصنيفات الفئات ويحسب دالة التكلفة (الخسارة المتقاطعة) للعثور على الفئة الأكثر احتمالًا.
هل أنت مستعد لتجربة تصنيف الصور؟ تحقق من دليلنا الكامل [تصنيف الصور](tasks/image_classification) لمعرفة كيفية ضبط دقة ViT واستخدامه للاستدلال!
From 1241c6192b7994283f82d86e90f4a67b3bb7b9d9 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:50:24 +0300
Subject: [PATCH 23/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index aac4c374f61a..12c5a7dda226 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -87,7 +87,7 @@
4. يتم تمرير الإخراج، وتحديدًا مخرج الرمز `[CLS]`، إلى رأس الإدراك المتعدد الطبقات (MLP). الهدف من التدريب المسبق لـ ViT هو التصنيف فقط. يقوم رأس MLP، مثل رؤوس التصنيف الأخرى، يحول رأس MLP المخرجات إلى احتمالات عبر تصنيفات الفئات ويحسب دالة التكلفة (الخسارة المتقاطعة) للعثور على الفئة الأكثر احتمالًا.
-هل أنت مستعد لتجربة تصنيف الصور؟ تحقق من دليلنا الكامل [تصنيف الصور](tasks/image_classification) لمعرفة كيفية ضبط دقة ViT واستخدامه للاستدلال!
+هل أنت مستعد لتجربة تصنيف الصور؟ تحقق من دليلنا الشامل [تصنيف الصور](tasks/image_classification) لمعرفة كيفية ضبط دقة نموذج ViT واستخدامه للاستدلال!
#### CNN
From e943558ba9c0df7635a42e248636fcc1d74f9408 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:50:44 +0300
Subject: [PATCH 24/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 12c5a7dda226..bc6b2aa1713f 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -89,7 +89,7 @@
هل أنت مستعد لتجربة تصنيف الصور؟ تحقق من دليلنا الشامل [تصنيف الصور](tasks/image_classification) لمعرفة كيفية ضبط دقة نموذج ViT واستخدامه للاستدلال!
-#### CNN
+#### الشبكات العصبية التلافيفية (CNN)
From 7028f25704e68298119ccb950206b7eedce88009 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:51:11 +0300
Subject: [PATCH 25/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index bc6b2aa1713f..d5fe5eb4443f 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -93,7 +93,7 @@
-يوضح هذا القسم بشكل موجز عمليات التجميع، ولكن سيكون من المفيد أن يكون لديك فهم مسبق لكيفية تغيير شكل الصورة وحجمها. إذا كنت غير معتاد على التجميعات، تحقق من [شبكات التجميع العصبية الفصل](https://github.com/fastai/fastbook/blob/master/13_convolutions.ipynb) من كتاب fastai!
+يشرح هذا القسم بإيجاز الالتفافات، ولكن سيكون من المفيد أن يكون لديك فهم مسبق لكيفية تغيير شكل الصورة وحجمها. إذا كنت غير معتاد على الالتفافات، تحقق من [فصل الشبكات العصبية التلافيفية](https://github.com/fastai/fastbook/blob/master/13_convolutions.ipynb) من كتاب fastai!
From e0c4d6ba651c1d5c1cf29306d0b15ee6fe2c5cda Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:51:31 +0300
Subject: [PATCH 26/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index d5fe5eb4443f..e4615acd28d8 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -97,7 +97,7 @@
-[ConvNeXT](model_doc/convnext) هو بنية CNN تعتمد تصاميم الشبكات الجديدة والحديثة لتحسين الأداء. ومع ذلك، لا تزال التجميعات في قلب النموذج. من منظور عالي المستوى، [التجميع](glossary#convolution) هو عملية حيث يتم ضرب مصفوفة أصغر (*kernel*) بمقطع صغير من بكسلات الصورة. يحسب بعض الميزات منه، مثل نسيج معين أو انحناء خط. ثم ينزلق إلى النافذة التالية من البكسلات؛ المسافة التي تقطعها التجميع تسمى *الخطوة*.
+[ConvNeXT](model_doc/convnext) هو بنية CNN تعتمد تصاميم الشبكات الجديدة والحديثة لتحسين الأداء. ومع ذلك، لا تزال الالتفافات هي جوهر النموذج. من منظور عام، [الالتفاف](glossary#convolution) هو عملية حيث يتم ضرب مصفوفة أصغر (*نواة*) بمقطع صغير من وحدات بكسل الصورة. يحسب بعض الميزات منه، مثل نسيج معين أو انحناء خط. ثم ينزلق إلى النافذة التالية من البكسلات؛ المسافة التي تقطعها الالتفاف تسمى *الخطوة*.
From c03bcdb05430b8156db6254ada3976ffc39ce458 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:51:51 +0300
Subject: [PATCH 27/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index e4615acd28d8..207c657e2fb0 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -103,7 +103,7 @@
-تجميع أساسي بدون حشو أو خطوة، مأخوذ من دليل الحساب التجميعي للتعلم العميق.
+عملية التفاف أساسية بدون حشو أو خطو خطوة واسعة، مأخوذة من دليل لحساب الالتفاف للتعلم العميق.
يمكنك إدخال هذا الإخراج إلى طبقة تجميع أخرى، ومع كل طبقة متتالية، تتعلم الشبكة أشياء أكثر تعقيدًا وتجريدية مثل الهوت دوج أو الصواريخ. بين طبقات التجميع، من الشائع إضافة طبقة تجميع لتقليل الأبعاد وجعل النموذج أكثر قوة ضد تباين موضع ميزة.
From 7090e618f6a60ae3d764ad8144c17d62428cdd26 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:52:15 +0300
Subject: [PATCH 28/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 207c657e2fb0..a8d8c403e5c7 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -105,7 +105,7 @@
عملية التفاف أساسية بدون حشو أو خطو خطوة واسعة، مأخوذة من دليل لحساب الالتفاف للتعلم العميق.
-يمكنك إدخال هذا الإخراج إلى طبقة تجميع أخرى، ومع كل طبقة متتالية، تتعلم الشبكة أشياء أكثر تعقيدًا وتجريدية مثل الهوت دوج أو الصواريخ. بين طبقات التجميع، من الشائع إضافة طبقة تجميع لتقليل الأبعاد وجعل النموذج أكثر قوة ضد تباين موضع ميزة.
+يمكنك تغذية هذا الناتج إلى طبقة التفاف أخرى، ومع كل طبقة متتالية، تتعلم الشبكة أشياء أكثر تعقيدًا وتجريدية مثل النقانق أو الصواريخ. بين طبقات الالتفاف، من الشائع إضافة طبقة تجميع لتقليل الأبعاد وجعل النموذج أكثر قوة للتغيرات في موضع الميزة.
From 9ca241d05530c2eb5caa17ff2eda50713f9a0c99 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:52:44 +0300
Subject: [PATCH 29/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index a8d8c403e5c7..5f3ae1a4dc03 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -113,9 +113,9 @@
يقوم ConvNeXT بتحديث شبكة CNN بطرق خمس:
-1. تغيير عدد الكتل في كل مرحلة و"patchify" صورة باستخدام خطوة أكبر وحجم نواة مطابق. تجعل استراتيجية التجزئة غير المتداخلة هذه مشابهة للطريقة التي يقسم بها ViT صورة إلى رقع.
+1. تغيير عدد الكتل في كل مرحلة و"ترقيع" الصورة باستخدام خطوة أكبر وحجم نواة المقابل. تجعل استراتيجية التجزئة غير المتداخلة استراتيجية الترقيع مشابهة للطريقة التي يقسم بها ViT للصورة إلى رقع.
-2. تقلص طبقة *العنق الزجاجي* عدد القنوات ثم تستعيدها لأنها أسرع في إجراء تجميع 1x1، ويمكنك زيادة العمق. يقوم عنق الزجاجة المعكوس بالعكس عن طريق توسيع عدد القنوات وتقلصها، وهو أكثر كفاءة في الذاكرة.
+2. تقلص طبقة *العنق الزجاجي* عدد القنوات ثم تعيدها لأنها أسرع في إجراء التفاف 1x1، ويمكنك زيادة العمق. يقوم عنق الزجاجة المقلوب بالعكس عن طريق توسيع عدد القنوات وتقلصها، وهو أكثر كفاءة من حيث الذاكرة.
3. استبدل طبقة التجميع 3x3 النموذجية في طبقة عنق الزجاجة بـ *التجميع بالعمق*، والذي يطبق تجميعًا على كل قناة إدخال بشكل منفصل ثم يقوم بتراصها مرة أخرى في النهاية. هذا يوسع عرض الشبكة لتحسين الأداء.
From d3ddd46c2753ea2d4f95d58db7c3dadee30f523c Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:53:17 +0300
Subject: [PATCH 30/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 5f3ae1a4dc03..cc0049241c0f 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -117,9 +117,9 @@
2. تقلص طبقة *العنق الزجاجي* عدد القنوات ثم تعيدها لأنها أسرع في إجراء التفاف 1x1، ويمكنك زيادة العمق. يقوم عنق الزجاجة المقلوب بالعكس عن طريق توسيع عدد القنوات وتقلصها، وهو أكثر كفاءة من حيث الذاكرة.
-3. استبدل طبقة التجميع 3x3 النموذجية في طبقة عنق الزجاجة بـ *التجميع بالعمق*، والذي يطبق تجميعًا على كل قناة إدخال بشكل منفصل ثم يقوم بتراصها مرة أخرى في النهاية. هذا يوسع عرض الشبكة لتحسين الأداء.
+3. استبدل طبقة الالتفاف النموذجية 3x3 في طبقة عنق الزجاجة بـ *الالتفاف بالعمق*، والذي يطبق الالتفاف على كل قناة إدخال بشكل منفصل ثم يقوم بتكديسها معًا مرة أخرى في النهاية. هذا يوسع عرض الشبكة لتحسين الأداء.
-4. لدى ViT مجال استقبال عالمي مما يعني أنه يمكنه رؤية المزيد من الصورة في وقت واحد بفضل آلية الاهتمام الخاصة به. تحاول ConvNeXT محاكاة هذا التأثير عن طريق زيادة حجم النواة إلى 7x7.
+4. لدى ViT مجال استقبال عالمي مما يعني أنه يمكنه رؤية المزيد من الصورة في وقت واحد بفضل آلية الانتباه الخاصة به. تحاول ConvNeXT محاكاة هذا التأثير عن طريق زيادة حجم النواة إلى 7x7.
5. يقوم ConvNeXT أيضًا بإجراء العديد من تغييرات تصميم الطبقة التي تحاكي نماذج المحول. هناك عدد أقل من طبقات التنشيط والطبقات العادية، يتم تبديل دالة التنشيط إلى GELU بدلاً من ReLU، ويستخدم LayerNorm بدلاً من BatchNorm.
From 6766559da6252f30d43c0d602231f6889c1d2df2 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:53:57 +0300
Subject: [PATCH 31/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index cc0049241c0f..2e568640f595 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -121,9 +121,9 @@
4. لدى ViT مجال استقبال عالمي مما يعني أنه يمكنه رؤية المزيد من الصورة في وقت واحد بفضل آلية الانتباه الخاصة به. تحاول ConvNeXT محاكاة هذا التأثير عن طريق زيادة حجم النواة إلى 7x7.
-5. يقوم ConvNeXT أيضًا بإجراء العديد من تغييرات تصميم الطبقة التي تحاكي نماذج المحول. هناك عدد أقل من طبقات التنشيط والطبقات العادية، يتم تبديل دالة التنشيط إلى GELU بدلاً من ReLU، ويستخدم LayerNorm بدلاً من BatchNorm.
+5. يقوم ConvNeXT أيضًا بإجراء العديد من تغييرات تصميم الطبقة التي تُحاكي نماذج المحولات. هناك عدد أقل من طبقات التنشيط والطبقات التطبيع، يتم تبديل دالة التنشيط إلى GELU بدلاً من ReLU، ويستخدم LayerNorm بدلاً من BatchNorm.
-يتم تمرير الإخراج من كتل التجميع إلى رأس تصنيف يحول الإخراج إلى احتمالات ويحسب الخسارة المتقاطعة للعثور على التصنيف الأكثر احتمالاً.
+يتم تمرير الإخراج من كتل الالتفاف إلى رأس تصنيف يحول المخرجات إلى احتمالات ويحسب دالة التكلفة (الخسارة المتقاطعة) للعثور على التصنيف الأكثر احتمالاً.
### اكتشاف الكائنات
From 924e740586273ac5ca123ab454c74d8681387700 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:54:43 +0300
Subject: [PATCH 32/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 2e568640f595..1037c89541fa 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
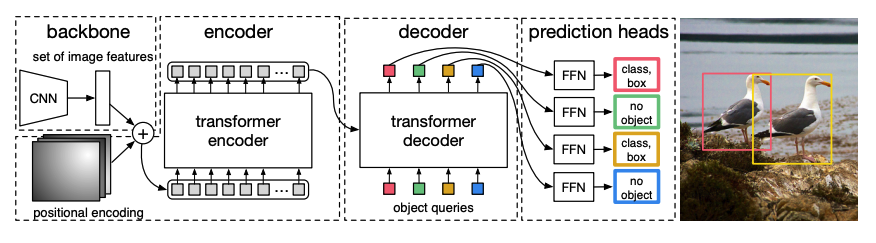
@@ -133,7 +133,7 @@
-1. يأخذ العمود الفقري CNN *المدرب مسبقًا* صورة، ممثلة بقيم بكسلاتها، وينشئ خريطة ميزات منخفضة الدقة لها. يتم تطبيق تجميع 1x1 على خريطة الميزات لتقليل الأبعاد، ويتم إنشاء خريطة ميزات جديدة بتمثيل صورة عالي المستوى. نظرًا لأن المحول هو نموذج تسلسلي، يتم تسطيح خريطة الميزات إلى تسلسل من متجهات الميزات التي يتم دمجها مع تضمينات الموضع.
+1. يأخذ العمود الفقري CNN *المدرب مسبقًا* صورة، ممثلة بقيم بكسلاتها، وينشئ خريطة ميزات منخفضة الدقة لها. يتم تطبيق التفاف 1x1 على خريطة الميزات لتقليل الأبعاد، و إنشاء خريطة ميزات جديدة بتمثيل صورة عالي المستوى. نظرًا لأن المحول (Transformer) هو نموذج تسلسلي، يتم تسوية خريطة الميزات إلى تسلسل من متجهات الميزات التي يتم دمجها مع تمثيلات التموضع.
2. يتم تمرير متجهات الميزات إلى المشفر، والذي يتعلم تمثيلات الصورة باستخدام طبقات الاهتمام الخاصة به. بعد ذلك، يتم دمج حالات المشفر المخفية مع *استعلامات الكائن* في فك التشفير. استعلامات الكائن هي تضمينات مكتسبة تركز على مناطق مختلفة من الصورة، ويتم تحديثها أثناء مرورها عبر كل طبقة اهتمام. يتم تمرير حالات فك التشفير المخفية إلى شبكة تغذية إلى الأمام التي تتنبأ بإحداثيات مربع الحدود وتصنيف العلامة لكل استعلام كائن، أو `no object` إذا لم يكن هناك أي منها.
From e4448a562bf7803aeab37ce83278a1449e47b89d Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 18:55:14 +0300
Subject: [PATCH 33/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 1037c89541fa..f3a8319ba25d 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -135,7 +135,7 @@
1. يأخذ العمود الفقري CNN *المدرب مسبقًا* صورة، ممثلة بقيم بكسلاتها، وينشئ خريطة ميزات منخفضة الدقة لها. يتم تطبيق التفاف 1x1 على خريطة الميزات لتقليل الأبعاد، و إنشاء خريطة ميزات جديدة بتمثيل صورة عالي المستوى. نظرًا لأن المحول (Transformer) هو نموذج تسلسلي، يتم تسوية خريطة الميزات إلى تسلسل من متجهات الميزات التي يتم دمجها مع تمثيلات التموضع.
-2. يتم تمرير متجهات الميزات إلى المشفر، والذي يتعلم تمثيلات الصورة باستخدام طبقات الاهتمام الخاصة به. بعد ذلك، يتم دمج حالات المشفر المخفية مع *استعلامات الكائن* في فك التشفير. استعلامات الكائن هي تضمينات مكتسبة تركز على مناطق مختلفة من الصورة، ويتم تحديثها أثناء مرورها عبر كل طبقة اهتمام. يتم تمرير حالات فك التشفير المخفية إلى شبكة تغذية إلى الأمام التي تتنبأ بإحداثيات مربع الحدود وتصنيف العلامة لكل استعلام كائن، أو `no object` إذا لم يكن هناك أي منها.
+2. يتم تمرير متجهات الميزات إلى المشفر، والذي يتعلم تمثيلات الصورة باستخدام طبقات الانتباه الخاصة به. بعد ذلك، يتم دمج الحالات المخفية للمُشفّر مع *استعلامات الكائنات* في فك التشفير. استعلامات الكائنات هي تمثيلات مكتسبة تركز على مناطق مختلفة من الصورة، ويتم تحديثها أثناء مرورها عبر كل طبقة انتباه. يتم تمرير الحالات المخفية لفك التشفير إلى شبكة تغذية أمامية التي تتنبأ بإحداثيات مربعات الإحاطة وتصنيف العلامة لكل استعلام كائن، أو `بدون كائن` إذا لم يكن هناك أي كائن.
يفك تشفير كل استعلام كائن بالتوازي لإخراج *N* تنبؤات نهائية، حيث *N* هو عدد الاستعلامات. على عكس نموذج التلقائي النموذجي الذي يتنبأ بعنصر واحد في كل مرة، فإن اكتشاف الكائنات هو مهمة تنبؤ مجموعة (`bounding box`، `class label`) التي تقوم بـ *N* تنبؤات في مرور واحد.
From 728daa6fc4f565fc36318909ede3cc37fc0edcc7 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:00:20 +0300
Subject: [PATCH 34/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index f3a8319ba25d..f758a97b6629 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -137,7 +137,7 @@
2. يتم تمرير متجهات الميزات إلى المشفر، والذي يتعلم تمثيلات الصورة باستخدام طبقات الانتباه الخاصة به. بعد ذلك، يتم دمج الحالات المخفية للمُشفّر مع *استعلامات الكائنات* في فك التشفير. استعلامات الكائنات هي تمثيلات مكتسبة تركز على مناطق مختلفة من الصورة، ويتم تحديثها أثناء مرورها عبر كل طبقة انتباه. يتم تمرير الحالات المخفية لفك التشفير إلى شبكة تغذية أمامية التي تتنبأ بإحداثيات مربعات الإحاطة وتصنيف العلامة لكل استعلام كائن، أو `بدون كائن` إذا لم يكن هناك أي كائن.
- يفك تشفير كل استعلام كائن بالتوازي لإخراج *N* تنبؤات نهائية، حيث *N* هو عدد الاستعلامات. على عكس نموذج التلقائي النموذجي الذي يتنبأ بعنصر واحد في كل مرة، فإن اكتشاف الكائنات هو مهمة تنبؤ مجموعة (`bounding box`، `class label`) التي تقوم بـ *N* تنبؤات في مرور واحد.
+ يقوم DETR بفك تشفير كل استعلام كائن بالتوازي لإخراج *N* من التنبؤات النهائية، حيث *N* هو عدد الاستعلامات. على عكس النموذج التلقائي الذي يتنبأ بعنصر واحد في كل مرة، فإن "اكتشاف الكائنات" هو مهمة تنبؤ بمجموعة من التنبؤات (مثل `مربع إحاطة`، `تصنيف`) تقوم بإجراء *N* من التنبؤات في مرور واحدة.
3. يستخدم DETR *خسارة المطابقة ثنائية* أثناء التدريب لمقارنة عدد ثابت من التنبؤات بمجموعة ثابتة من علامات التصنيف الحقيقية. إذا كان هناك عدد أقل من علامات التصنيف الحقيقية في مجموعة من العلامات *N*، فيتم حشوها باستخدام فئة `no object`. تشجع وظيفة الخسارة هذه DETR على العثور على تعيين واحد لواحد بين التنبؤات وعلامات التصنيف الحقيقية. إذا لم تكن مربعات الحدود أو علامات التصنيف صحيحة، يتم تكبد خسارة. وبالمثل، إذا تنبأ DETR بكائن غير موجود، فإنه يتم معاقبته. وهذا يشجع DETR على العثور على كائنات أخرى في الصورة بدلاً من التركيز على كائن بارز حقًا.
From 6cb47c2bf0d34036fc70d0ea569d9e2ee0801dd0 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:01:29 +0300
Subject: [PATCH 35/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 6 +++---
1 file changed, 3 insertions(+), 3 deletions(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index f758a97b6629..d90183c645af 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -139,11 +139,11 @@
يقوم DETR بفك تشفير كل استعلام كائن بالتوازي لإخراج *N* من التنبؤات النهائية، حيث *N* هو عدد الاستعلامات. على عكس النموذج التلقائي الذي يتنبأ بعنصر واحد في كل مرة، فإن "اكتشاف الكائنات" هو مهمة تنبؤ بمجموعة من التنبؤات (مثل `مربع إحاطة`، `تصنيف`) تقوم بإجراء *N* من التنبؤات في مرور واحدة.
-3. يستخدم DETR *خسارة المطابقة ثنائية* أثناء التدريب لمقارنة عدد ثابت من التنبؤات بمجموعة ثابتة من علامات التصنيف الحقيقية. إذا كان هناك عدد أقل من علامات التصنيف الحقيقية في مجموعة من العلامات *N*، فيتم حشوها باستخدام فئة `no object`. تشجع وظيفة الخسارة هذه DETR على العثور على تعيين واحد لواحد بين التنبؤات وعلامات التصنيف الحقيقية. إذا لم تكن مربعات الحدود أو علامات التصنيف صحيحة، يتم تكبد خسارة. وبالمثل، إذا تنبأ DETR بكائن غير موجود، فإنه يتم معاقبته. وهذا يشجع DETR على العثور على كائنات أخرى في الصورة بدلاً من التركيز على كائن بارز حقًا.
+3. يستخدم DETR دالة *خسارة المطابقة ثنائية الفئات* أثناء التدريب لمقارنة عدد ثابت من التنبؤات بمجموعة ثابتة من تصنيفات البيانات الحقيقية. إذا كان هناك عدد أقل من تصنيفات البيانات الحقيقية في مجموعة *N* من التصنيفات، فيتم حشوها بفئة "بدون كائن". تشجع دالة الخسارة هذه DETR على العثور على تعيين واحد لواحد بين التنبؤات وتصنيفات البيانات الحقيقية. إذا لم تكن مربعات الإحاطة أو تصنيفات الفئات صحيحة، يتم تكبد خسارة. وبالمثل، إذا تنبأ DETR بكائن غير موجود، فإنه يتم معاقبته. وهذا يشجع DETR على العثور على كائنات أخرى في الصورة بدلاً من التركيز على كائن بارز حقًا.
-يتم إضافة رأس اكتشاف كائن أعلى DETR للعثور على تصنيف العلامة وإحداثيات مربع الحدود. هناك مكونان لرأس اكتشاف الكائنات: طبقة خطية لتحويل حالات فك التشفير المخفية إلى احتمالات عبر علامات التصنيف، وMLP للتنبؤ بمربع الحدود.
+يتم إضافة رأس اكتشاف كائن أعلى DETR للعثور على تصنيف الكائن وإحداثيات مربع الإحاطة. هناك مكونان لرأس اكتشاف الكائنات: طبقة خطية لتحويل حالات فك التشفير المخفية إلى احتمالات عبر تصنيفات الفئات، وشبكةMLP للتنبؤ بمربع الإحاطة.
-هل أنت مستعد لتجربة يدك في اكتشاف الكائنات؟ تحقق من دليلنا الكامل [دليل اكتشاف الكائنات](tasks/object_detection) لمعرفة كيفية ضبط DETR واستخدامه للاستدلال!
+هل أنت مستعد لتجربة اكتشاف الكائنات؟ تحقق من دليلنا الشامل [دليل اكتشاف الكائنات](tasks/object_detection) لمعرفة كيفية ضبط نموذج DETR واستخدامه للاستدلال!
### تجزئة الصورة
From 60ca4eaf19ca5b2ceaa33af32ed50c9933433025 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:02:09 +0300
Subject: [PATCH 36/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index d90183c645af..b560a283a00a 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -147,7 +147,7 @@
### تجزئة الصورة
-[Mask2Former](model_doc/mask2former) هو بنية عالمية لحل جميع أنواع مهام تجزئة الصورة. عادةً ما تكون نماذج التجزئة التقليدية مصممة خصيصًا لمهمة فرعية معينة من مهام تجزئة الصورة، مثل مثيل أو تجزئة دلالية أو تجزئة بانوبتيك. يُنشئ Mask2Former كلًا من تلك المهام كمشكلة *تصنيف الأقنعة*. يصنف تصنيف الأقنعة البكسلات إلى *N* مقاطع، ويتنبأ بـ *N* أقنعة وتصنيفها المقابل لعلامة التسمية لمقابل صورة معينة. سنشرح كيفية عمل Mask2Former في هذا القسم، وبعد ذلك يمكنك تجربة ضبط SegFormer في النهاية.
+يُعد [Mask2Former](model_doc/mask2former) بنيةً شاملةً لحل جميع أنواع مهام تجزئة الصور. عادةً ما تُصمم نماذج التجزئة التقليدية لمهمة فرعية محددة من مهام تجزئة الصور، مثل تجزئة المثيل أو التجزئة الدلالية أو التجزئة الشاملة. يصوغ Mask2Former كل مهمة من تلك المهام على أنها مشكلة *تصنيف الأقنعة*. يقوم تصنيف القناع بتجميع وحدات البكسل في *N* قطعة، ويتنبأ بـ *N* أقنعة وتصنيف الفئة المقابل لها لصورة معينة. سنشرح في هذا القسم كيفية عمل Mask2Former، ويمكنك بعد ذلك تجربة ضبط SegFormer في النهاية.
From 716f56d681f6511ac1c2aa07023809ed7739c5b6 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:02:53 +0300
Subject: [PATCH 37/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index b560a283a00a..c059a579e09c 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -155,9 +155,9 @@
هناك ثلاثة مكونات رئيسية لـ Mask2Former:
-1. العمود الفقري [Swin](model_doc/swin) يقبل صورة وينشئ خريطة ميزات ذات دقة منخفضة من 3 عمليات تجميع متتالية 3x3.
+1. العمود الفقري [Swin](model_doc/swin) يقبل صورة وينشئ خريطة ميزات منخفضة الدقة من 3 عمليات التفافات متتالية 3x3.
-2. يتم تمرير خريطة الميزات إلى *فك تشفير البكسل* الذي يقوم تدريجياً بزيادة حجم ميزات الدقة المنخفضة إلى تضمينات لكل بكسل. في الواقع، يقوم فك تشفير البكسل بإنشاء ميزات متعددة النطاقات (تحتوي على كل من الميزات منخفضة وعالية الدقة) بدقة 1/32 و1/16 و1/8 من الصورة الأصلية.
+2. يتم تمرير خريطة الميزات إلى *فك تشفير البكسل* الذي يقوم تدريجياً بزيادة الميزات منخفضة الدقة إلى تمثيلات عالية الدقة لكل بكسل. في الواقع، يقوم فك تشفير البكسل بإنشاء ميزات متعددة المقاييس (تحتوي على كل من الميزات منخفضة وعالية الدقة) بدقة 1/32 و1/16 و1/8 من الصورة الأصلية.
3. يتم تغذية كل من خرائط الميزات ذات المقاييس المختلفة هذه بشكل متتالي إلى طبقة واحدة من طبقات فك التشفير في كل مرة لالتقاط الأجسام الصغيرة من ميزات الدقة العالية. المفتاح إلى Mask2Former هو آلية *الاهتمام المقنع* في فك التشفير. على عكس الاهتمام المتقاطع الذي يمكن أن يركز على الصورة بأكملها، يركز الاهتمام المقنع فقط على منطقة معينة من الصورة. هذا أسرع ويؤدي إلى أداء أفضل لأن الميزات المحلية لصورة كافية للنموذج للتعلم منها.
From e806a62a34485d07c7dd17e5217b6b8a898da1f1 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:03:37 +0300
Subject: [PATCH 38/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index c059a579e09c..a4fc7ab7301f 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -159,7 +159,7 @@
2. يتم تمرير خريطة الميزات إلى *فك تشفير البكسل* الذي يقوم تدريجياً بزيادة الميزات منخفضة الدقة إلى تمثيلات عالية الدقة لكل بكسل. في الواقع، يقوم فك تشفير البكسل بإنشاء ميزات متعددة المقاييس (تحتوي على كل من الميزات منخفضة وعالية الدقة) بدقة 1/32 و1/16 و1/8 من الصورة الأصلية.
-3. يتم تغذية كل من خرائط الميزات ذات المقاييس المختلفة هذه بشكل متتالي إلى طبقة واحدة من طبقات فك التشفير في كل مرة لالتقاط الأجسام الصغيرة من ميزات الدقة العالية. المفتاح إلى Mask2Former هو آلية *الاهتمام المقنع* في فك التشفير. على عكس الاهتمام المتقاطع الذي يمكن أن يركز على الصورة بأكملها، يركز الاهتمام المقنع فقط على منطقة معينة من الصورة. هذا أسرع ويؤدي إلى أداء أفضل لأن الميزات المحلية لصورة كافية للنموذج للتعلم منها.
+3. يتم تغذية كل من خرائط الميزات ذات المقاييس المختلفة على التوالي إلى طبقة واحدة من طبقات فك التشفير في كل مرة لالتقاط الأجسام الصغيرة من ميزات الدقة العالية. يتمثل مفتاح Mask2Former آلية *الاهتمام المقنع* في فك التشفير. على عكس الانتباه المتقاطع الذي يمكن أن يركز على الصورة بأكملها، يركز الانتباه المقنع فقط على منطقة معينة من الصورة. هذا أسرع ويؤدي إلى أداء أفضل لأن الميزات المحلية لصورة كافية للنموذج للتعلم منها.
4. مثل [DETR](tasks_explained#object-detection)، يستخدم Mask2Former أيضًا استعلامات كائن مكتسبة ويجمعها مع ميزات الصورة من فك تشفير البكسل لإجراء تنبؤ مجموعة (`class label`، `mask prediction`). يتم تمرير حالات فك التشفير المخفية إلى طبقة خطية وتحويلها إلى احتمالات عبر علامات التصنيف. يتم حساب الخسارة المتقاطعة بين الاحتمالات وعلامة التسمية لتحديد الأكثر احتمالاً.
From 6ef4135d239c1c4c011fe29ffb395495baedb911 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:04:11 +0300
Subject: [PATCH 39/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 6 +++---
1 file changed, 3 insertions(+), 3 deletions(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index a4fc7ab7301f..104f283abc77 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -161,11 +161,11 @@
3. يتم تغذية كل من خرائط الميزات ذات المقاييس المختلفة على التوالي إلى طبقة واحدة من طبقات فك التشفير في كل مرة لالتقاط الأجسام الصغيرة من ميزات الدقة العالية. يتمثل مفتاح Mask2Former آلية *الاهتمام المقنع* في فك التشفير. على عكس الانتباه المتقاطع الذي يمكن أن يركز على الصورة بأكملها، يركز الانتباه المقنع فقط على منطقة معينة من الصورة. هذا أسرع ويؤدي إلى أداء أفضل لأن الميزات المحلية لصورة كافية للنموذج للتعلم منها.
-4. مثل [DETR](tasks_explained#object-detection)، يستخدم Mask2Former أيضًا استعلامات كائن مكتسبة ويجمعها مع ميزات الصورة من فك تشفير البكسل لإجراء تنبؤ مجموعة (`class label`، `mask prediction`). يتم تمرير حالات فك التشفير المخفية إلى طبقة خطية وتحويلها إلى احتمالات عبر علامات التصنيف. يتم حساب الخسارة المتقاطعة بين الاحتمالات وعلامة التسمية لتحديد الأكثر احتمالاً.
+4. مثل [DETR](tasks_explained#object-detection)، يستخدم Mask2Former أيضًا استعلامات كائن مكتسبة ويجمعها مع ميزات الصورة من فك تشفير البكسل لإجراء تنبؤ مجموعة (`تصنيف الفئة`، `التنبؤ بالقناع`). يتم تمرير حالات فك التشفير المخفية إلى طبقة خطية وتحويلها إلى احتمالات عبر علامات التصنيف. يتم حساب دالة التكلفة (الخسارة المتقاطعة) بين الاحتمالات وتصنيف الفئة لتحديد الأكثر احتمالاً.
- يتم إنشاء تنبؤات الأقنعة عن طريق الجمع بين تضمينات البكسل وحالات فك التشفير المخفية النهائية. يتم حساب الخسارة المتقاطعة سيجمويد وخسارة النرد بين الاحتمالات والقناع الحقيقي لتحديد القناع الأكثر احتمالاً.
+ يتم إنشاء تنبؤات الأقنعة عن طريق الجمع بين تمثيلات البكسل وحالات فك التشفير المخفية النهائية. يتم حساب دالة الخسارة المتقاطعة سيجمويد وخسارة النرد بين الاحتمالات والقناع البيانات الحقيقية للعثور على القناع الأكثر احتمالاً.
-هل أنت مستعد لتجربة يدك في اكتشاف الكائنات؟ تحقق من دليلنا الكامل [دليل تجزئة الصورة](tasks/semantic_segmentation) لمعرفة كيفية ضبط SegFormer واستخدامه للاستدلال!
+هل أنت مستعد لتجربة يدك في اكتشاف الكائنات؟ تحقق من دليلنا الشامل [دليل تجزئة الصورة](tasks/semantic_segmentation) لمعرفة كيفية ضبط SegFormer واستخدامه للاستدلال!
### تقدير العمق
From ff1138948d99adc24ecbf577d74e1b71dc4bff3a Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:04:41 +0300
Subject: [PATCH 40/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 104f283abc77..8b087d33c7e1 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -175,7 +175,7 @@
-1. مثل ViT، يتم تقسيم الصورة إلى تسلسل من الرقع، باستثناء أن هذه رقع الصورة أصغر. هذا أفضل لمهام التنبؤ الكثيفة مثل التجزئة أو تقدير العمق. يتم تحويل رقع الصورة إلى تضمينات رقعة (راجع قسم [تصنيف الصور](#image-classification) لمزيد من التفاصيل حول كيفية إنشاء تضمينات الرقع)، والتي يتم تغذيتها إلى المشفر.
+1. مثل ViT، يتم تقسيم الصورة إلى تسلسل من الرقع، باستثناء أن هذه رقع الصورة أصغر. هذا أفضل لمهام التنبؤ الكثيفة مثل التجزئة أو تقدير العمق. يتم تحويل رقع الصورة إلى تمثيلات للرقع (راجع قسم [تصنيف الصور](#image-classification) لمزيد من التفاصيل حول كيفية إنشاء تمثيلات الرقع)، والتي يتم تغذيتها إلى المشفر.
2. يقبل المشفر تضمينات الرقع، ويمررها عبر عدة كتل مشفرة. يتكون كل كتلة من طبقات الاهتمام وMix-FFN. الغرض من هذا الأخير هو توفير معلومات الموضع. في نهاية كل كتلة مشفرة توجد طبقة *دمج الرقع* لإنشاء تمثيلات هرمية. يتم دمج ميزات كل مجموعة من الرقع المجاورة، ويتم تطبيق طبقة خطية على الميزات المجمعة لتقليل عدد الرقع إلى دقة 1/4. يصبح هذا الإدخال للكتلة المشفرة التالية، حيث تتم تكرار هذه العملية بأكملها حتى تحصل على ميزات الصورة بدقة 1/8 و1/16 و1/32.
From 122ae0f6f334850bacc7ec6fce3039c49616fb4b Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:05:19 +0300
Subject: [PATCH 41/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 8b087d33c7e1..f07cea8f1b27 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -177,7 +177,7 @@
1. مثل ViT، يتم تقسيم الصورة إلى تسلسل من الرقع، باستثناء أن هذه رقع الصورة أصغر. هذا أفضل لمهام التنبؤ الكثيفة مثل التجزئة أو تقدير العمق. يتم تحويل رقع الصورة إلى تمثيلات للرقع (راجع قسم [تصنيف الصور](#image-classification) لمزيد من التفاصيل حول كيفية إنشاء تمثيلات الرقع)، والتي يتم تغذيتها إلى المشفر.
-2. يقبل المشفر تضمينات الرقع، ويمررها عبر عدة كتل مشفرة. يتكون كل كتلة من طبقات الاهتمام وMix-FFN. الغرض من هذا الأخير هو توفير معلومات الموضع. في نهاية كل كتلة مشفرة توجد طبقة *دمج الرقع* لإنشاء تمثيلات هرمية. يتم دمج ميزات كل مجموعة من الرقع المجاورة، ويتم تطبيق طبقة خطية على الميزات المجمعة لتقليل عدد الرقع إلى دقة 1/4. يصبح هذا الإدخال للكتلة المشفرة التالية، حيث تتم تكرار هذه العملية بأكملها حتى تحصل على ميزات الصورة بدقة 1/8 و1/16 و1/32.
+2. يقبل المشفر تمثيلات الرقع، ويمررها عبر عدة كتل مشفرة. يتكون كل كتلة من طبقات انتباه وMix-FFN. الغرض من هذا الأخير هو توفير معلومات موضعية. في نهاية كل كتلة مشفرة توجد طبقة *دمج الرقع* لإنشاء تمثيلات هرمية. يتم دمج ميزات كل مجموعة من الرقع المجاورة، ويتم تطبيق طبقة خطية على الميزات المدمجة لتقليل عدد الرقع إلى دقة 1/4. يصبح هذا المُدخل للكتلة المشفرة التالية، حيث تتكرر هذه العملية بأكملها حتى تحصل على ميزات الصورة بدقة 1/8 و1/16 و1/32.
3. يقوم فك تشفير خفيف الوزن بأخذ خريطة الميزات الأخيرة (مقياس 1/32) من المشفر وزيادة حجمها إلى مقياس 1/16. من هنا، يتم تمرير الميزة إلى وحدة *دمج الميزات الانتقائية (SFF)*، والتي تقوم باختيار ودمج الميزات المحلية والعالمية من خريطة اهتمام لكل ميزة ثم زيادة حجمها إلى 1/8. تتم إعادة هذه العملية حتى تصبح الميزات فك التشفير بنفس حجم الصورة الأصلية. يتم تمرير الإخراج عبر طبقتين من طبقات التجميع ثم يتم تطبيق تنشيط سيجمويد للتنبؤ بعمق كل بكسل.
From 6125cf98244182adb692e9f74d269f0847378773 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:05:45 +0300
Subject: [PATCH 42/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index f07cea8f1b27..92e33baf5c17 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -179,7 +179,7 @@
2. يقبل المشفر تمثيلات الرقع، ويمررها عبر عدة كتل مشفرة. يتكون كل كتلة من طبقات انتباه وMix-FFN. الغرض من هذا الأخير هو توفير معلومات موضعية. في نهاية كل كتلة مشفرة توجد طبقة *دمج الرقع* لإنشاء تمثيلات هرمية. يتم دمج ميزات كل مجموعة من الرقع المجاورة، ويتم تطبيق طبقة خطية على الميزات المدمجة لتقليل عدد الرقع إلى دقة 1/4. يصبح هذا المُدخل للكتلة المشفرة التالية، حيث تتكرر هذه العملية بأكملها حتى تحصل على ميزات الصورة بدقة 1/8 و1/16 و1/32.
-3. يقوم فك تشفير خفيف الوزن بأخذ خريطة الميزات الأخيرة (مقياس 1/32) من المشفر وزيادة حجمها إلى مقياس 1/16. من هنا، يتم تمرير الميزة إلى وحدة *دمج الميزات الانتقائية (SFF)*، والتي تقوم باختيار ودمج الميزات المحلية والعالمية من خريطة اهتمام لكل ميزة ثم زيادة حجمها إلى 1/8. تتم إعادة هذه العملية حتى تصبح الميزات فك التشفير بنفس حجم الصورة الأصلية. يتم تمرير الإخراج عبر طبقتين من طبقات التجميع ثم يتم تطبيق تنشيط سيجمويد للتنبؤ بعمق كل بكسل.
+3. يقوم فك تشفير خفيف الوزن بأخذ خريطة الميزات الأخيرة (مقياس 1/32) من المشفر وزيادة حجمها إلى مقياس 1/16. من هنا، يتم تمرير الميزة إلى وحدة *دمج الميزات الانتقائية (SFF)*، والتي تقوم باختيار ودمج الميزات المحلية والعالمية من خريطة انتباه لكل ميزة ثم زيادة حجمها إلى 1/8. تتم إعادة هذه العملية حتى تصبح الميزات فك التشفير بنفس حجم الصورة الأصلية. يتم تمرير الإخراج عبر طبقتين تلافيفتين ثم يتم تطبيق تنشيط سيجمويد للتنبؤ بعمق كل بكسل.
## معالجة اللغات الطبيعية
From b1c58f1fb8f6538446301f26103fc9f7194cad78 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:06:17 +0300
Subject: [PATCH 43/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 92e33baf5c17..3b0498129311 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -263,7 +263,7 @@
### الترجمة
-الترجمة هي مثال آخر على مهمة التسلسل إلى التسلسل، مما يعني أنه يمكنك استخدام نموذج المشفر-فك التشفير مثل [BART](model_doc/bart) أو [T5](model_doc/t5) للقيام بذلك. سنشرح كيف يعمل BART في هذا القسم، ثم يمكنك تجربة ضبط T5 في النهاية.
+تُعد الترجمة مثالًا آخر على مهام التسلسل إلى التسلسل، مما يعني أنه يمكنك استخدام نموذج المشفر-فك التشفير مثل [BART](model_doc/bart) أو [T5](model_doc/t5) للقيام بذلك. سنشرح كيف يعمل BART في هذا القسم، ثم يمكنك تجربة ضبط T5 في النهاية.
يتكيف BART مع الترجمة عن طريق إضافة مشفر منفصل يتم تهيئته بشكل عشوائي لتعيين لغة المصدر إلى إدخال يمكن فك تشفيره إلى لغة الهدف. يتم تمرير تضمينات هذا المشفر الجديد إلى المشفر المسبق التدريب بدلاً من تضمينات الكلمات الأصلية. يتم تدريب مشفر المصدر عن طريق تحديث مشفر المصدر والتضمينات الموضعية وتضمينات الإدخال باستخدام الخسارة المتقاطعة من إخراج النموذج. يتم تجميد معلمات النموذج في هذه الخطوة الأولى، ويتم تدريب جميع معلمات النموذج معًا في الخطوة الثانية.
From 52a9f932ac1bf28b98797ec00c33d5ceeddd55f7 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:06:52 +0300
Subject: [PATCH 44/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 3b0498129311..7792230364d1 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -265,7 +265,7 @@
تُعد الترجمة مثالًا آخر على مهام التسلسل إلى التسلسل، مما يعني أنه يمكنك استخدام نموذج المشفر-فك التشفير مثل [BART](model_doc/bart) أو [T5](model_doc/t5) للقيام بذلك. سنشرح كيف يعمل BART في هذا القسم، ثم يمكنك تجربة ضبط T5 في النهاية.
-يتكيف BART مع الترجمة عن طريق إضافة مشفر منفصل يتم تهيئته بشكل عشوائي لتعيين لغة المصدر إلى إدخال يمكن فك تشفيره إلى لغة الهدف. يتم تمرير تضمينات هذا المشفر الجديد إلى المشفر المسبق التدريب بدلاً من تضمينات الكلمات الأصلية. يتم تدريب مشفر المصدر عن طريق تحديث مشفر المصدر والتضمينات الموضعية وتضمينات الإدخال باستخدام الخسارة المتقاطعة من إخراج النموذج. يتم تجميد معلمات النموذج في هذه الخطوة الأولى، ويتم تدريب جميع معلمات النموذج معًا في الخطوة الثانية.
+يتكيف BART مع الترجمة عن طريق إضافة مشفر منفصل يتم تهيئته بشكل عشوائي لتعيين لغة المصدر بمدخلات يمكن فك تشفيرها إلى لغة الهدف. يتم تمرير تمثيلات هذا المشفر الجديد إلى المشفر المسبق التدريب بدلاً من تمثيلات الكلمات الأصلية. يتم تدريب مشفر المصدر عن طريق تحديث مشفر المصدر وتمثيلات التموضع وتمثيلات الإدخال باستخدام دالة التكلفة (الخسارة المتقاطعة) من ناتج النموذج. يتم تجميد معلمات النموذج في هذه الخطوة الأولى، ويتم تدريب جميع معلمات النموذج معًا في الخطوة الثانية.
تمت متابعة BART منذ ذلك الحين بواسطة إصدار متعدد اللغات، mBART، مصمم للترجمة ومدرب مسبقًا على العديد من اللغات المختلفة.
From d08751b4ef39f01c2bf3713b94700078d34bb0aa Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:07:21 +0300
Subject: [PATCH 45/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 8 ++++----
1 file changed, 4 insertions(+), 4 deletions(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 7792230364d1..f82f1363ed5e 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -267,12 +267,12 @@
يتكيف BART مع الترجمة عن طريق إضافة مشفر منفصل يتم تهيئته بشكل عشوائي لتعيين لغة المصدر بمدخلات يمكن فك تشفيرها إلى لغة الهدف. يتم تمرير تمثيلات هذا المشفر الجديد إلى المشفر المسبق التدريب بدلاً من تمثيلات الكلمات الأصلية. يتم تدريب مشفر المصدر عن طريق تحديث مشفر المصدر وتمثيلات التموضع وتمثيلات الإدخال باستخدام دالة التكلفة (الخسارة المتقاطعة) من ناتج النموذج. يتم تجميد معلمات النموذج في هذه الخطوة الأولى، ويتم تدريب جميع معلمات النموذج معًا في الخطوة الثانية.
-تمت متابعة BART منذ ذلك الحين بواسطة إصدار متعدد اللغات، mBART، مصمم للترجمة ومدرب مسبقًا على العديد من اللغات المختلفة.
+تم إصدار نسخة متعددة اللغات من BART، تسمى mBART، مُخصصة للترجمة ومُدرّبة مسبقًا على العديد من اللغات المختلفة.
-هل أنت مستعد لتجربة يدك في الترجمة؟ تحقق من دليل الترجمة الكامل الخاص بنا لمعرفة كيفية ضبط نموذج T5 واستخدامه للاستنتاج!
+هل أنت مستعد لتجربة الترجمة؟ تحقق من دليل الترجمة الشامل الخاص بنا لمعرفة كيفية ضبط نموذج T5 واستخدامه للاستنتاج!
-للحصول على مزيد من المعلومات حول توليد النص، راجع دليل استراتيجيات توليد النص!
-
+ **للحصول على مزيد من المعلومات حول توليد النصوص، راجع دليل [استراتيجيات توليد النصوص](generation_strategies)!**
+
\ No newline at end of file
From bde1ee67123f60419ba7ded8397b4cb4a2910922 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:08:00 +0300
Subject: [PATCH 46/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index f82f1363ed5e..163d5412a806 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -249,7 +249,7 @@
-1. تتشابه بنية المشفر BART كثيرًا مع BERT وتقبل رمزًا وتضمينًا موضعيًا للنص. يتم تدريب BART المسبق عن طريق إتلاف الإدخال ثم إعادة بنائه باستخدام فك التشفير. على عكس المشفرات الأخرى ذات استراتيجيات الإتلاف المحددة، يمكن لـ BART تطبيق أي نوع من الإتلاف. ومع ذلك، فإن استراتيجية إتلاف "ملء النص" تعمل بشكل أفضل. في ملء النص، يتم استبدال عدد من نطاقات النص برمز **واحد** [`mask`]. هذا أمر مهم لأن النموذج يجب أن يتنبأ بالرموز المقنعة، ويعلّم النموذج التنبؤ بعدد الرموز المفقودة. يتم تمرير تضمينات الإدخال والنطاقات المقنعة عبر المشفر لإخراج بعض الحالات المخفية النهائية، ولكن على عكس BERT، لا يضيف BART شبكة تغذية أمامية نهائية في النهاية للتنبؤ بكلمة.
+1. تتشابه بنية المشفر BART كثيرًا مع BERT وتقبل رمزًا وتمثيلًا موضعيًا للنص. يتم تدريب BART مسبقًا عن طريق إتلاف المُدخلات ثم إعادة بنائه باستخدام فك التشفير. على عكس المشفرات الأخرى ذات استراتيجيات الإتلاف المحددة، يمكن لـ BART تطبيق أي نوع من الإتلاف. ومع ذلك، فإن استراتيجية إتلاف "ملء النص" تعمل بشكل أفضل. في ملء النص، يتم استبدال عدد من امتدادات النص برمز **واحد** [`mask`]. هذا أمر مهم لأن النموذج يجب أن يتنبأ بالرموز المقنعة، ويعلّم النموذج التنبؤ بعدد الرموز المفقودة. يتم تمرير تمثيلات الإدخال والامتدادات المقنعة عبر المشفر لإخراج بعض الحالات المخفية النهائية، ولكن على عكس BERT، لا يضيف BART شبكة تغذية أمامية نهائية في النهاية للتنبؤ بكلمة.
2. يتم تمرير إخراج المشفر إلى فك التشفير، والذي يجب أن يتنبأ بالرموز المقنعة وأي رموز غير تالفة من إخراج المشفر. يمنح هذا فك التشفير سياقًا إضافيًا للمساعدة في استعادة النص الأصلي. يتم تمرير الإخراج من فك التشفير إلى رأس نمذجة اللغة، والذي يقوم بتحويل خطي لتحويل الحالات المخفية إلى logits. يتم حساب الخسارة المتقاطعة بين logits والتصنيف، وهو مجرد الرمز المنقول إلى اليمين.
From fd60b446950612864fa72f57061e6d953b27abca Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:08:40 +0300
Subject: [PATCH 47/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 163d5412a806..b354a414192a 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -251,7 +251,7 @@
1. تتشابه بنية المشفر BART كثيرًا مع BERT وتقبل رمزًا وتمثيلًا موضعيًا للنص. يتم تدريب BART مسبقًا عن طريق إتلاف المُدخلات ثم إعادة بنائه باستخدام فك التشفير. على عكس المشفرات الأخرى ذات استراتيجيات الإتلاف المحددة، يمكن لـ BART تطبيق أي نوع من الإتلاف. ومع ذلك، فإن استراتيجية إتلاف "ملء النص" تعمل بشكل أفضل. في ملء النص، يتم استبدال عدد من امتدادات النص برمز **واحد** [`mask`]. هذا أمر مهم لأن النموذج يجب أن يتنبأ بالرموز المقنعة، ويعلّم النموذج التنبؤ بعدد الرموز المفقودة. يتم تمرير تمثيلات الإدخال والامتدادات المقنعة عبر المشفر لإخراج بعض الحالات المخفية النهائية، ولكن على عكس BERT، لا يضيف BART شبكة تغذية أمامية نهائية في النهاية للتنبؤ بكلمة.
-2. يتم تمرير إخراج المشفر إلى فك التشفير، والذي يجب أن يتنبأ بالرموز المقنعة وأي رموز غير تالفة من إخراج المشفر. يمنح هذا فك التشفير سياقًا إضافيًا للمساعدة في استعادة النص الأصلي. يتم تمرير الإخراج من فك التشفير إلى رأس نمذجة اللغة، والذي يقوم بتحويل خطي لتحويل الحالات المخفية إلى logits. يتم حساب الخسارة المتقاطعة بين logits والتصنيف، وهو مجرد الرمز المنقول إلى اليمين.
+2. يتم تمرير إخراج المشفر إلى فك التشفير، والذي يجب أن يتنبأ بالرموز المقنعة وأي رموز غير تالفة من ناتج المشفر. يمنح هذا فك التشفير سياقًا إضافيًا للمساعدة في استعادة النص الأصلي. يتم تمرير ناتج فك التشفير إلى رأس نمذجة اللغوية، والذي يجري تحويلًا خطيًا لتحويل الحالات المخفية إلى احتمالات(logits). يتم حساب دالة التكلفة (الخسارة المتقاطعة) بين الاحتمالات logits والتصنيف، وهو مجرد الرمز الذي تم تغيير موضعه إلى اليمين.
هل أنت مستعد لتجربة يدك في التلخيص؟ تحقق من دليل التلخيص الكامل الخاص بنا لمعرفة كيفية ضبط نموذج T5 واستخدامه للاستنتاج!
From d038dfc7879c8b6b9d39523f4c50ad0b48d45fa0 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:09:09 +0300
Subject: [PATCH 48/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index b354a414192a..a820bde80375 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -253,7 +253,7 @@
2. يتم تمرير إخراج المشفر إلى فك التشفير، والذي يجب أن يتنبأ بالرموز المقنعة وأي رموز غير تالفة من ناتج المشفر. يمنح هذا فك التشفير سياقًا إضافيًا للمساعدة في استعادة النص الأصلي. يتم تمرير ناتج فك التشفير إلى رأس نمذجة اللغوية، والذي يجري تحويلًا خطيًا لتحويل الحالات المخفية إلى احتمالات(logits). يتم حساب دالة التكلفة (الخسارة المتقاطعة) بين الاحتمالات logits والتصنيف، وهو مجرد الرمز الذي تم تغيير موضعه إلى اليمين.
-هل أنت مستعد لتجربة يدك في التلخيص؟ تحقق من دليل التلخيص الكامل الخاص بنا لمعرفة كيفية ضبط نموذج T5 واستخدامه للاستنتاج!
+هل أنت مستعد لتجربة التلخيص؟ تحقق من دليل التلخيص الشامل الخاص بنا لمعرفة كيفية ضبط نموذج T5 واستخدامه للاستنتاج!
From 9ef4306c346dce8393d83759a0c15de986f0bbdd Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:09:43 +0300
Subject: [PATCH 49/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index a820bde80375..d6867534a893 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -221,7 +221,7 @@
### توليد النصوص
-[GPT-2](model_doc/gpt2) هو نموذج قائم على فك التشفير فقط تم تدريبه المسبق على كمية كبيرة من النصوص. يمكنه توليد نص مقنع (على الرغم من أنه ليس دائمًا صحيحًا!) بالنظر إلى موجه واستكمال مهام NLP الأخرى مثل الإجابة على الأسئلة على الرغم من أنه لم يتم تدريبه بشكل صريح على ذلك.
+يُعد [GPT-2](model_doc/gpt2) نموذجًا قائم على فك التشفير فقط تم تدريبه المسبق على كمية كبيرة من النصوص. يمكنه توليد نص مقنع (على الرغم من أنه ليس دائمًا صحيحًا!) بناءً على مُحفّز معين واستكمال مهام NLP الأخرى مثل الإجابة على الأسئلة على الرغم من أنه لم يتم تدريبه بشكل صريح على ذلك.
From c6792f34407eb20ec0e27dd35e9c67db7a484179 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:10:18 +0300
Subject: [PATCH 50/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index d6867534a893..947c62ef256a 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -227,7 +227,7 @@
-1. يستخدم GPT-2 [ترميز الأزواج البايتية (BPE)](tokenizer_summary#byte-pair-encoding-bpe) لتمييز الكلمات وتوليد تضمين الرمز. يتم إضافة الترميزات الموضعية إلى تضمينات الرموز للإشارة إلى موضع كل رمز في التسلسل. يتم تمرير تضمينات الإدخال عبر عدة كتل فك تشفير لإخراج بعض الحالات المخفية النهائية. داخل كل كتلة فك تشفير، يستخدم GPT-2 طبقة *اهتمام ذاتي مقنع* مما يعني أن GPT-2 لا يمكنه الاهتمام بالرموز المستقبلية. يُسمح له فقط بالاهتمام بالرموز الموجودة على اليسار. يختلف هذا عن رمز [`mask`] الخاص بـ BERT لأنه، في الاهتمام الذاتي المقنع، يتم استخدام قناع اهتمام لتحديد الدرجة إلى `0` للرموز المستقبلية.
+1. يستخدم GPT-2 [ترميز الأزواج البايتية (BPE)](tokenizer_summary#byte-pair-encoding-bpe) لتجزئة الكلمات وإنشاء تمثيل رمزى. يتم إضافة تمثيلات موضعية إلى تمثيلات الرموز للإشارة إلى موضع كل رمز في التسلسل. يتم تمرير تمثيلات الإدخال عبر عدة كتل فك تشفير لإخراج بعض الحالات المخفية النهائية. داخل كل كتلة فك تشفير، يستخدم GPT-2 طبقة *انتباه ذاتي مقنع* مما يعني أن GPT-2 لا يمكنه الانتباه بالرموز المستقبلية. يُسمح له فقط بالاهتمام بالرموز الموجودة على اليسار. يختلف هذا عن رمز [`mask`] الخاص بـ BERT لأنه، في الانتباه الذاتي المقنع، يتم استخدام قناع انتباه لتعيين النتيجة إلى `0` للرموز المستقبلية.
2. يتم تمرير الإخراج من فك التشفير إلى رأس نمذجة اللغة، والذي يقوم بتحويل خطي لتحويل الحالات المخفية إلى logits. التصنيف هو الرمز التالي في التسلسل، والذي يتم إنشاؤه عن طريق تحويل logits إلى اليمين بمقدار واحد. يتم حساب الخسارة المتقاطعة بين logits المنقولة والتصنيفات لإخراج الرمز التالي الأكثر احتمالًا.
From 9ce74d7f1549d30aac23e49b0999b0e3b011bb45 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:10:53 +0300
Subject: [PATCH 51/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 8 ++++----
1 file changed, 4 insertions(+), 4 deletions(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 947c62ef256a..891b99afcc6e 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -229,15 +229,15 @@
1. يستخدم GPT-2 [ترميز الأزواج البايتية (BPE)](tokenizer_summary#byte-pair-encoding-bpe) لتجزئة الكلمات وإنشاء تمثيل رمزى. يتم إضافة تمثيلات موضعية إلى تمثيلات الرموز للإشارة إلى موضع كل رمز في التسلسل. يتم تمرير تمثيلات الإدخال عبر عدة كتل فك تشفير لإخراج بعض الحالات المخفية النهائية. داخل كل كتلة فك تشفير، يستخدم GPT-2 طبقة *انتباه ذاتي مقنع* مما يعني أن GPT-2 لا يمكنه الانتباه بالرموز المستقبلية. يُسمح له فقط بالاهتمام بالرموز الموجودة على اليسار. يختلف هذا عن رمز [`mask`] الخاص بـ BERT لأنه، في الانتباه الذاتي المقنع، يتم استخدام قناع انتباه لتعيين النتيجة إلى `0` للرموز المستقبلية.
-2. يتم تمرير الإخراج من فك التشفير إلى رأس نمذجة اللغة، والذي يقوم بتحويل خطي لتحويل الحالات المخفية إلى logits. التصنيف هو الرمز التالي في التسلسل، والذي يتم إنشاؤه عن طريق تحويل logits إلى اليمين بمقدار واحد. يتم حساب الخسارة المتقاطعة بين logits المنقولة والتصنيفات لإخراج الرمز التالي الأكثر احتمالًا.
+2. يتم تمرير الإخراج من فك التشفير إلى رأس نمذجة اللغة، والتي تُجري تحويلًا خطيًا لتحويل الحالات المخفية إلى احتمالات logits. التصنيف هو الرمز التالي في التسلسل، والذي يتم إنشاؤه عن طريق تغيير موضع logits إلى اليمين بمقدار واحد. يتم حساب دالة التكلفة (الخسارة المتقاطعة) بين logits التي تم تغيير موضعها والتصنيفات لإخراج الرمز التالي الأكثر احتمالًا.
-يستند هدف التدريب المسبق لـ GPT-2 بالكامل إلى نمذجة اللغة السببية، والتنبؤ بالكلمة التالية في تسلسل. يجعل هذا GPT-2 جيدًا بشكل خاص في المهام التي تتضمن توليد النص.
+يستند هدف التدريب المسبق لـ GPT-2 بالكامل إلى [نمذجة اللغة السببية](glossary#causal-language-modeling)، والتنبؤ بالكلمة التالية في تسلسل. يجعل هذا GPT-2 جيدًا بشكل خاص في المهام التي تتضمن توليد النص.
-هل أنت مستعد لتجربة يدك في توليد النص؟ تحقق من دليل نمذجة اللغة السببية الكامل الخاص بنا لمعرفة كيفية ضبط نموذج DistilGPT-2 واستخدامه للاستنتاج!
+هل أنت مستعد لتجربة توليد النصوص؟ تحقق من دليل [دليل نمذجة اللغة السببية](tasks/language_modeling#causal- الشامل الخاص بنا لمعرفة كيفية ضبط نموذج DistilGPT-2 واستخدامه للاستنتاج!
-للحصول على مزيد من المعلومات حول توليد النص، راجع دليل استراتيجيات توليد النص!
+للحصول على مزيد من المعلومات حول توليد النص، راجع دليل [استراتيجيات توليد النصوص](generation_strategies)!
From 5fa124895e901b27d2637a8858a49697dd739ce9 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:11:28 +0300
Subject: [PATCH 52/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 891b99afcc6e..ac74a5067343 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -183,7 +183,7 @@
## معالجة اللغات الطبيعية
-تم تصميم محول Transformer في الأصل للترجمة الآلية، ومنذ ذلك الحين أصبح في الواقع البنية الافتراضية لحل جميع مهام NLP. تناسب بعض المهام بنية المشفر في المحول، في حين أن البعض الآخر أكثر ملاءمة لفك التشفير. لا تزال مهام أخرى تستخدم بنية المشفر-فك التشفير في المحول.
+تم تصميم نموذج المحول Transformer في الأصل للترجمة الآلية، ومنذ ذلك الحين أصبح في الواقع البنية الافتراضية لحل جميع مهام NLP. تناسب بعض المهام بنية المشفر في نموذج المحول، في حين أن البعض الآخر أكثر ملاءمة لفك التشفير. لا تزال مهام أخرى تستخدم بنية المشفر-فك التشفير في نموذج المحول.
### تصنيف النصوص
From e0493dc24f9c2246d9a1d662586c5ca31a26e2db Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:11:58 +0300
Subject: [PATCH 53/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index ac74a5067343..e795bd14f416 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -187,7 +187,7 @@
### تصنيف النصوص
-[BERT](model_doc/bert) هو نموذج قائم على المشفر فقط وهو أول نموذج ينفذ بشكل فعال ثنائية الاتجاه العميقة لتعلم تمثيلات أغنى للنص من خلال الاهتمام بالكلمات على كلا الجانبين.
+يعد [BERT](model_doc/bert) نموذج يعتمد على المُشفّر فقط، وهو أول نموذج يُطبق بشكل فعال ثنائية الاتجاه العميقة لتعلم تمثيلات أكثر ثراءً للنص من خلال الانتباه إلى الكلمات على كلا الجانبين.
1. يستخدم BERT التمييز إلى [WordPiece](tokenizer_summary#wordpiece) لإنشاء تضمين رمز للنص. للتمييز بين جملة واحدة وزوج من الجمل، تتم إضافة رمز خاص `[SEP]` للتفريق بينهما. تتم إضافة رمز خاص `[CLS]` إلى بداية كل تسلسل نصي. ويتم استخدام الإخراج النهائي مع الرمز `[CLS]` كإدخال لرأس التصنيف لمهام التصنيف. كما يضيف BERT تضمينًا للجزء للإشارة إلى ما إذا كان الرمز ينتمي إلى الجملة الأولى أو الثانية في زوج من الجمل.
From dfb5e4d4eec0ad817bae2a890e38d76ac842c21b Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:12:38 +0300
Subject: [PATCH 54/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index e795bd14f416..1c14b09589b2 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -189,7 +189,7 @@
يعد [BERT](model_doc/bert) نموذج يعتمد على المُشفّر فقط، وهو أول نموذج يُطبق بشكل فعال ثنائية الاتجاه العميقة لتعلم تمثيلات أكثر ثراءً للنص من خلال الانتباه إلى الكلمات على كلا الجانبين.
-1. يستخدم BERT التمييز إلى [WordPiece](tokenizer_summary#wordpiece) لإنشاء تضمين رمز للنص. للتمييز بين جملة واحدة وزوج من الجمل، تتم إضافة رمز خاص `[SEP]` للتفريق بينهما. تتم إضافة رمز خاص `[CLS]` إلى بداية كل تسلسل نصي. ويتم استخدام الإخراج النهائي مع الرمز `[CLS]` كإدخال لرأس التصنيف لمهام التصنيف. كما يضيف BERT تضمينًا للجزء للإشارة إلى ما إذا كان الرمز ينتمي إلى الجملة الأولى أو الثانية في زوج من الجمل.
+1. يستخدم BERT تجزئة [WordPiece](tokenizer_summary#wordpiece) لإنشاء تمثيل رمزي للنص. للتمييز بين جملة واحدة وزوج من الجمل، تتم إضافة رمز خاص `[SEP]` للتفريق بينهما. تتم إضافة رمز خاص `[CLS]` إلى بداية كل تسلسل نصي. ويتم استخدام الإخراج النهائي مع الرمز `[CLS]` كمدخل لرأس التصنيف لمهام التصنيف. كما يضيف BERT تضمينًا للمقطع للإشارة إلى ما إذا كان الرمز ينتمي إلى الجملة الأولى أو الثانية في زوج من الجمل.
2. يتم تدريب BERT المسبق باستخدام هدفين: نمذجة اللغة المقنعة وتوقع الجملة التالية. في نمذجة اللغة المقنعة، يتم إخفاء نسبة مئوية معينة من رموز الإدخال بشكل عشوائي، ويجب على النموذج التنبؤ بها. يحل هذا مشكلة ثنائية الاتجاه، حيث يمكن للنموذج أن يغش ويرى جميع الكلمات و"يتنبأ" بالكلمة التالية. تتم تمرير الحالات المخفية النهائية للرموز المقنعة المتوقعة إلى شبكة تغذية أمامية مع softmax عبر المفردات للتنبؤ بالكلمة المقنعة.
From 730e7731e653e666c20ae99bef0b2081dbc8d6a6 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:13:24 +0300
Subject: [PATCH 55/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 1c14b09589b2..05c61a9608dd 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -191,9 +191,9 @@
1. يستخدم BERT تجزئة [WordPiece](tokenizer_summary#wordpiece) لإنشاء تمثيل رمزي للنص. للتمييز بين جملة واحدة وزوج من الجمل، تتم إضافة رمز خاص `[SEP]` للتفريق بينهما. تتم إضافة رمز خاص `[CLS]` إلى بداية كل تسلسل نصي. ويتم استخدام الإخراج النهائي مع الرمز `[CLS]` كمدخل لرأس التصنيف لمهام التصنيف. كما يضيف BERT تضمينًا للمقطع للإشارة إلى ما إذا كان الرمز ينتمي إلى الجملة الأولى أو الثانية في زوج من الجمل.
-2. يتم تدريب BERT المسبق باستخدام هدفين: نمذجة اللغة المقنعة وتوقع الجملة التالية. في نمذجة اللغة المقنعة، يتم إخفاء نسبة مئوية معينة من رموز الإدخال بشكل عشوائي، ويجب على النموذج التنبؤ بها. يحل هذا مشكلة ثنائية الاتجاه، حيث يمكن للنموذج أن يغش ويرى جميع الكلمات و"يتنبأ" بالكلمة التالية. تتم تمرير الحالات المخفية النهائية للرموز المقنعة المتوقعة إلى شبكة تغذية أمامية مع softmax عبر المفردات للتنبؤ بالكلمة المقنعة.
+2. يتم تدريب BERT المسبق باستخدام هدفين: نمذجة اللغة المقنعة وتنبؤ الجملة التالية. في نمذجة اللغة المقنعة، يتم إخفاء نسبة مئوية مُعيّنة من رموز الإدخال بشكل عشوائي، ويجب على النموذج التنبؤ بها. يحل هذا مشكلة ثنائية الاتجاه، حيث يمكن للنموذج أن يغش ويرى جميع الكلمات و"يتنبأ" بالكلمة التالية. تتم تمرير الحالات المخفية النهائية للرموز المقنعة المتوقعة إلى شبكة تغذية أمامية مع دالة Softmax عبر مفردات اللغة للتنبؤ بالكلمة المقنعة.
- الهدف الثاني من التدريب المسبق هو توقع الجملة التالية. يجب على النموذج التنبؤ بما إذا كانت الجملة B تتبع الجملة A. نصف الوقت تكون الجملة B هي الجملة التالية، والنصف الآخر من الوقت، تكون الجملة B عبارة عشوائية. يتم تمرير التنبؤ، سواء كانت الجملة التالية أم لا، إلى شبكة تغذية أمامية مع softmax عبر الفئتين (`IsNext` و`NotNext`).
+ الهدف الثاني من التدريب المسبق هو توقع الجملة التالية. يجب على النموذج التنبؤ بما إذا كانت الجملة "ب" تتبع الجملة"أ". نصف الوقت تكون الجملة "ب" هي الجملة التالية، والنصف الآخر من الوقت، تكون الجملة "ب" عبارة عشوائية. يتم تمرير التنبؤ، سواء كانت الجملة التالية أم لا، إلى شبكة تغذية أمامية مع دالة Softmax عبر الفئتين (`IsNext` و`NotNext`).
3. يتم تمرير تضمينات الإدخال عبر عدة طبقات مشفرة لإخراج بعض الحالات المخفية النهائية.
From 07044687e38fc7dcfa4825010d16c72ba710c1dd Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:14:00 +0300
Subject: [PATCH 56/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 6 +++---
1 file changed, 3 insertions(+), 3 deletions(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 05c61a9608dd..ed9ccdf4b7c5 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -195,11 +195,11 @@
الهدف الثاني من التدريب المسبق هو توقع الجملة التالية. يجب على النموذج التنبؤ بما إذا كانت الجملة "ب" تتبع الجملة"أ". نصف الوقت تكون الجملة "ب" هي الجملة التالية، والنصف الآخر من الوقت، تكون الجملة "ب" عبارة عشوائية. يتم تمرير التنبؤ، سواء كانت الجملة التالية أم لا، إلى شبكة تغذية أمامية مع دالة Softmax عبر الفئتين (`IsNext` و`NotNext`).
-3. يتم تمرير تضمينات الإدخال عبر عدة طبقات مشفرة لإخراج بعض الحالات المخفية النهائية.
+3. يتم تمرير تمثيلات الإدخال عبر عدة طبقات مشفرة لإخراج بعض الحالات المخفية النهائية.
-لاستخدام النموذج المسبق التدريب لتصنيف النصوص، أضف رأس تصنيف تسلسل أعلى نموذج BERT الأساسي. رأس تصنيف التسلسل هو طبقة خطية تقبل الحالات المخفية النهائية وتقوم بتحويل خطي لتحويلها إلى logits. يتم حساب الخسارة المتقاطعة بين logits والهدف للعثور على التصنيف الأكثر احتمالًا.
+لاستخدام النموذج المسبق التدريب لتصنيف النصوص، أضف رأس تصنيف تسلسلي أعلى نموذج BERT الأساسي. رأس تصنيف التسلسلي هو طبقة خطية تقبل الحالات المخفية النهائية وتجري تحويلًا خطيًا لتحويلها إلى احتمالات logits. يتم حساب دالة التكلفة (الخسارة المتقاطعة) بين logits والهدف للعثور على التصنيف الأكثر احتمالًا.
-هل أنت مستعد لتجربة يدك في تصنيف النصوص؟ تحقق من دليل تصنيف النص الكامل الخاص بنا لمعرفة كيفية ضبط نموذج DistilBERT واستخدامه للاستنتاج!
+هل أنت مستعد لتجربة تصنيف النصوص؟ تحقق من [دليل تصنيف النصوص](tasks/sequence_classification) الشامل الخاص بنا لمعرفة كيفية ضبط نموذج DistilBERT واستخدامه للاستنتاج!
### تصنيف الرموز
From 0186f9bf16bd1a8cccf49b4503a4e9c914577662 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:14:24 +0300
Subject: [PATCH 57/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index ed9ccdf4b7c5..2c182409c060 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -203,7 +203,7 @@
### تصنيف الرموز
-لاستخدام BERT لمهام تصنيف الرموز مثل التعرف على الكيانات المسماة (NER)، أضف رأس تصنيف الرموز أعلى نموذج BERT الأساسي. رأس تصنيف الرمز هو طبقة خطية تقبل الحالات المخفية النهائية وتقوم بتحويل خطي لتحويلها إلى logits. يتم حساب الخسارة المتقاطعة بين logits وكل رمز للعثور على التصنيف الأكثر احتمالًا.
+لاستخدام BERT لمهام تصنيف الرموز مثل التعرف على الكيانات المسماة (NER)، أضف رأس تصنيف الرموز أعلى نموذج BERT الأساسي. رأس تصنيف الرموز هو طبقة خطية تقبل الحالات المخفية النهائية وتجري تحويلًا خطيًا لتحويلها إلى logits. يتم حساب دالة التكلفة (الخسارة المتقاطعة) بين logits وكل رمز للعثور على التصنيف الأكثر احتمالًا.
هل أنت مستعد لتجربة يدك في تصنيف الرموز؟ تحقق من دليل تصنيف الرموز الكامل الخاص بنا لمعرفة كيفية ضبط نموذج DistilBERT واستخدامه للاستنتاج!
From 5f36cf33631e0aeb85a7053099a8f4a5172f372e Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:14:35 +0300
Subject: [PATCH 58/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 2c182409c060..b3f1fa792d1d 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -205,7 +205,7 @@
لاستخدام BERT لمهام تصنيف الرموز مثل التعرف على الكيانات المسماة (NER)، أضف رأس تصنيف الرموز أعلى نموذج BERT الأساسي. رأس تصنيف الرموز هو طبقة خطية تقبل الحالات المخفية النهائية وتجري تحويلًا خطيًا لتحويلها إلى logits. يتم حساب دالة التكلفة (الخسارة المتقاطعة) بين logits وكل رمز للعثور على التصنيف الأكثر احتمالًا.
-هل أنت مستعد لتجربة يدك في تصنيف الرموز؟ تحقق من دليل تصنيف الرموز الكامل الخاص بنا لمعرفة كيفية ضبط نموذج DistilBERT واستخدامه للاستنتاج!
+هل أنت مستعد لتجربة تصنيف الرموز؟ تحقق من [دليل تصنيف الرموز](tasks/token_classification) الشامل الخاص بنا لمعرفة كيفية ضبط نموذج DistilBERT واستخدامه للاستنتاج!
### الإجابة على الأسئلة
From d083c278f8312e362dd70b701a4bb278d1ae766a Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:14:49 +0300
Subject: [PATCH 59/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index b3f1fa792d1d..5662c68e7671 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -209,7 +209,7 @@
### الإجابة على الأسئلة
-لاستخدام BERT للإجابة على الأسئلة، أضف رأس تصنيف المدى أعلى نموذج BERT الأساسي. تقبل هذه الطبقة الخطية الحالات المخفية النهائية وتقوم بتحويل خطي لحساب logits `span` البداية والنهاية المقابلة للإجابة. يتم حساب الخسارة المتقاطعة بين logits وموضع التصنيف للعثور على أكثر نطاقات النص احتمالًا المقابلة للإجابة.
+لاستخدام BERT للإجابة على الأسئلة، أضف رأس تصنيف المدى أعلى نموذج BERT الأساسي. تقبل هذه الطبقة الخطية الحالات المخفية النهائية وتُجري تحويلًا خطيًا لحساب داية ونهاية `الامتداد` logits `span` البداية والنهاية المقابلة للإجابة. يتم حسابدالة التكلفة (الخسارة المتقاطعة) بين logits وموقع التصنيف للعثور على الامتداد الأكثر احتمالًا من النص المقابل للإجابة.
هل أنت مستعد لتجربة يدك في الإجابة على الأسئلة؟ تحقق من دليل الإجابة على الأسئلة الكامل الخاص بنا لمعرفة كيفية ضبط نموذج DistilBERT واستخدامه للاستنتاج!
From 14d104188c0c15964ffaaa9ff61b7f6060b9e622 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:15:03 +0300
Subject: [PATCH 60/62] Update docs/source/ar/tasks_explained.md
Co-authored-by: Abdullah Mohammed <554032+abodacs@users.noreply.github.com>
---
docs/source/ar/tasks_explained.md | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 5662c68e7671..388d58fc62b2 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -211,7 +211,8 @@
لاستخدام BERT للإجابة على الأسئلة، أضف رأس تصنيف المدى أعلى نموذج BERT الأساسي. تقبل هذه الطبقة الخطية الحالات المخفية النهائية وتُجري تحويلًا خطيًا لحساب داية ونهاية `الامتداد` logits `span` البداية والنهاية المقابلة للإجابة. يتم حسابدالة التكلفة (الخسارة المتقاطعة) بين logits وموقع التصنيف للعثور على الامتداد الأكثر احتمالًا من النص المقابل للإجابة.
-هل أنت مستعد لتجربة يدك في الإجابة على الأسئلة؟ تحقق من دليل الإجابة على الأسئلة الكامل الخاص بنا لمعرفة كيفية ضبط نموذج DistilBERT واستخدامه للاستنتاج!
+هل أنت مستعد لتجربة الإجابة على الأسئلة؟ راجع [دليل الإجابة على الأسئلة](tasks/question_answering) الشامل الخاص بنا لمعرفة كيفية ضبط نموذج DistilBERT واستخدامه في الاستدلال!
+
From 41d72eff853fcd20864a81f20cb598c5e956f8d3 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:17:19 +0300
Subject: [PATCH 61/62] Update _toctree.yml - tasks_explained
---
docs/source/ar/_toctree.yml | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/docs/source/ar/_toctree.yml b/docs/source/ar/_toctree.yml
index c1e6493aaece..3fcb9800ab18 100644
--- a/docs/source/ar/_toctree.yml
+++ b/docs/source/ar/_toctree.yml
@@ -223,8 +223,8 @@
title: (قاموس المصطلحات (قائمة الكلمات
- local: task_summary
title: ما الذي يمكن أن تفعله 🤗 المحولات
- # - local: tasks_explained
- # title: كيف تحل المحولات المهام
+ - local: tasks_explained
+ title: كيف تحل المحولات المهام
# - local: model_summary
# title: عائلة نماذج المحول
# - local: tokenizer_summary
From fd588be79420ff9a6089ae12e31b382630811985 Mon Sep 17 00:00:00 2001
From: Ahmed Almaghz <53489256+AhmedAlmaghz@users.noreply.github.com>
Date: Sun, 22 Sep 2024 19:29:50 +0300
Subject: [PATCH 62/62] Update tasks_explained.md
---
docs/source/ar/tasks_explained.md | 32 +++++++++++++++----------------
1 file changed, 16 insertions(+), 16 deletions(-)
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
index 388d58fc62b2..b91297be7d27 100644
--- a/docs/source/ar/tasks_explained.md
+++ b/docs/source/ar/tasks_explained.md
@@ -19,7 +19,7 @@
-## الكلام والصوت
+## الكلام والصوت (Speech and audio)
يُعدّ [Wav2Vec2](model_doc/wav2vec2) نموذجًا مُدرَّبًا ذاتيًا (Self-Supervised) على بيانات الكلام غير المُصنّفة، ويُمكن ضبطه بدقة (Fine-tuning) على بيانات موسومة لأداء مهام تصنيف الصوت والتعرف التلقائي على الكلام.
@@ -38,19 +38,19 @@
بمجرد تدريب Wav2Vec2 مسبقًا، يمكنك ضبط دقته على بياناتك لتصنيف الصوت أو التعرف التلقائي على الكلام!
-### تصنيف الصوت
+### تصنيف الصوت (Audio classification)
لاستخدام النموذج الذي تم تدريبه مسبقًا لتصنيف الصوت، أضف رأس تصنيف تسلسلي أعلى نموذج Wav2Vec2 الأساسي. رأس التصنيف هو طبقة خطية تستقبل الحالات المخفية للمشفر. تمثل الحالات المخفية الميزات التي تم تعلمها من كل إطار صوتي والذي يمكن أن يكون له أطوال مختلفة. لتحويلها إلى متجه واحد ثابت الطول، يتم تجميع الحالات المخفية أولاً ثم تحويلها إلى احتمالات عبر تصنيفات الفئات. يتم حساب التكلفة (الخسارة المتقاطعة) بين الاحتمالات والتصنيف المستهدف للعثور على الفئة الأكثر احتمالًا.
هل أنت مستعد لتجربة تصنيف الصوت؟ تحقق من دليلنا الشامل [تصنيف الصوت](tasks/audio_classification) لمعرفة كيفية ضبط دقة نموذج Wav2Vec2 واستخدامه للاستدلال!
-### التعرف التلقائي على الكلام
+### التعرف التلقائي على الكلام (Automatic speech recognition - ASR)
لاستخدام النموذج الذي تم تدريبه مسبقًا للتعرف التلقائي على الكلام، أضف رأس نمذجة لغوية أعلى نموذج Wav2Vec2 الأساسي لـ [[التصنيف الزمني الترابطي (CTC)](glossary#connectionist-temporal-classification-ctc). رأس النمذجة اللغوية عبارة عن طبقة خطية تقبل الحالات المخفية للمُشفّر وتحويلها إلى احتمالات. يمثل كل احتمال فئة رمزية (يأتي عدد الرموز من مفردات المهمة). يتم حساب تكلفة CTC بين الاحتمالات والأهداف للعثور على تسلسل الرموز الأكثر احتمالًا، والتي يتم فك تشفيرها بعد ذلك إلى نص مكتوب.
هل أنت مستعد لتجربة التعرف التلقائي على الكلام؟ تحقق من دليلنا الشامل [التعرف التلقائي على الكلام](tasks/asr) لمعرفة كيفية ضبط دقة نموذج Wav2Vec2 واستخدامه للاستدلال!
-## رؤية الحاسب
+## رؤية الحاسب (Computer vision)
هناك طريقتان لتناول مهام رؤية الحاسب:
@@ -65,7 +65,7 @@
يتم استخدام ViT و ConvNeXT بشكل شائع لتصنيف الصور، ولكن بالنسبة لمهام الرؤية الأخرى مثل اكتشاف الكائنات والتجزئة وتقدير العمق، سنلقي نظرة على DETR و Mask2Former و GLPN، على التوالي؛ فهذه النماذج هي الأنسب لتلك المهام.
-### تصنيف الصور
+### تصنيف الصور (Image classification)
يمكن استخدام كل من ViT و ConvNeXT لتصنيف الصور؛ الاختلاف الرئيسي هو أن ViT يستخدم آلية انتباه بينما يستخدم ConvNeXT الالتفافات.
@@ -125,7 +125,7 @@
يتم تمرير الإخراج من كتل الالتفاف إلى رأس تصنيف يحول المخرجات إلى احتمالات ويحسب دالة التكلفة (الخسارة المتقاطعة) للعثور على التصنيف الأكثر احتمالاً.
-### اكتشاف الكائنات
+### اكتشاف الكائنات (Object detection)
[DETR](model_doc/detr)، *DEtection TRansformer*، هو نموذج اكتشاف كائنات من البداية إلى النهاية يجمع بين CNN مع محول المشفر-فك التشفير.
@@ -145,7 +145,7 @@
هل أنت مستعد لتجربة اكتشاف الكائنات؟ تحقق من دليلنا الشامل [دليل اكتشاف الكائنات](tasks/object_detection) لمعرفة كيفية ضبط نموذج DETR واستخدامه للاستدلال!
-### تجزئة الصورة
+### تجزئة الصورة (Image segmentation)
يُعد [Mask2Former](model_doc/mask2former) بنيةً شاملةً لحل جميع أنواع مهام تجزئة الصور. عادةً ما تُصمم نماذج التجزئة التقليدية لمهمة فرعية محددة من مهام تجزئة الصور، مثل تجزئة المثيل أو التجزئة الدلالية أو التجزئة الشاملة. يصوغ Mask2Former كل مهمة من تلك المهام على أنها مشكلة *تصنيف الأقنعة*. يقوم تصنيف القناع بتجميع وحدات البكسل في *N* قطعة، ويتنبأ بـ *N* أقنعة وتصنيف الفئة المقابل لها لصورة معينة. سنشرح في هذا القسم كيفية عمل Mask2Former، ويمكنك بعد ذلك تجربة ضبط SegFormer في النهاية.
@@ -167,7 +167,7 @@
هل أنت مستعد لتجربة يدك في اكتشاف الكائنات؟ تحقق من دليلنا الشامل [دليل تجزئة الصورة](tasks/semantic_segmentation) لمعرفة كيفية ضبط SegFormer واستخدامه للاستدلال!
-### تقدير العمق
+### تقدير العمق (Depth estimation)
[GLPN](model_doc/glpn)، شبكة المسار العالمية المحلية، هي محول ل تقدير العمق الذي يجمع بين مشفر [SegFormer](model_doc/segformer) مع فك تشفير خفيف الوزن.
@@ -181,11 +181,11 @@
3. يقوم فك تشفير خفيف الوزن بأخذ خريطة الميزات الأخيرة (مقياس 1/32) من المشفر وزيادة حجمها إلى مقياس 1/16. من هنا، يتم تمرير الميزة إلى وحدة *دمج الميزات الانتقائية (SFF)*، والتي تقوم باختيار ودمج الميزات المحلية والعالمية من خريطة انتباه لكل ميزة ثم زيادة حجمها إلى 1/8. تتم إعادة هذه العملية حتى تصبح الميزات فك التشفير بنفس حجم الصورة الأصلية. يتم تمرير الإخراج عبر طبقتين تلافيفتين ثم يتم تطبيق تنشيط سيجمويد للتنبؤ بعمق كل بكسل.
-## معالجة اللغات الطبيعية
+## معالجة اللغات الطبيعية (Natural language processing -NLP)
تم تصميم نموذج المحول Transformer في الأصل للترجمة الآلية، ومنذ ذلك الحين أصبح في الواقع البنية الافتراضية لحل جميع مهام NLP. تناسب بعض المهام بنية المشفر في نموذج المحول، في حين أن البعض الآخر أكثر ملاءمة لفك التشفير. لا تزال مهام أخرى تستخدم بنية المشفر-فك التشفير في نموذج المحول.
-### تصنيف النصوص
+### تصنيف النصوص (Text classification)
يعد [BERT](model_doc/bert) نموذج يعتمد على المُشفّر فقط، وهو أول نموذج يُطبق بشكل فعال ثنائية الاتجاه العميقة لتعلم تمثيلات أكثر ثراءً للنص من خلال الانتباه إلى الكلمات على كلا الجانبين.
@@ -201,13 +201,13 @@
هل أنت مستعد لتجربة تصنيف النصوص؟ تحقق من [دليل تصنيف النصوص](tasks/sequence_classification) الشامل الخاص بنا لمعرفة كيفية ضبط نموذج DistilBERT واستخدامه للاستنتاج!
-### تصنيف الرموز
+### تصنيف الرموز (Token classification)
لاستخدام BERT لمهام تصنيف الرموز مثل التعرف على الكيانات المسماة (NER)، أضف رأس تصنيف الرموز أعلى نموذج BERT الأساسي. رأس تصنيف الرموز هو طبقة خطية تقبل الحالات المخفية النهائية وتجري تحويلًا خطيًا لتحويلها إلى logits. يتم حساب دالة التكلفة (الخسارة المتقاطعة) بين logits وكل رمز للعثور على التصنيف الأكثر احتمالًا.
هل أنت مستعد لتجربة تصنيف الرموز؟ تحقق من [دليل تصنيف الرموز](tasks/token_classification) الشامل الخاص بنا لمعرفة كيفية ضبط نموذج DistilBERT واستخدامه للاستنتاج!
-### الإجابة على الأسئلة
+### الإجابة على الأسئلة (Question answering)
لاستخدام BERT للإجابة على الأسئلة، أضف رأس تصنيف المدى أعلى نموذج BERT الأساسي. تقبل هذه الطبقة الخطية الحالات المخفية النهائية وتُجري تحويلًا خطيًا لحساب داية ونهاية `الامتداد` logits `span` البداية والنهاية المقابلة للإجابة. يتم حسابدالة التكلفة (الخسارة المتقاطعة) بين logits وموقع التصنيف للعثور على الامتداد الأكثر احتمالًا من النص المقابل للإجابة.
@@ -220,7 +220,7 @@
-### توليد النصوص
+### توليد النصوص (Text generation)
يُعد [GPT-2](model_doc/gpt2) نموذجًا قائم على فك التشفير فقط تم تدريبه المسبق على كمية كبيرة من النصوص. يمكنه توليد نص مقنع (على الرغم من أنه ليس دائمًا صحيحًا!) بناءً على مُحفّز معين واستكمال مهام NLP الأخرى مثل الإجابة على الأسئلة على الرغم من أنه لم يتم تدريبه بشكل صريح على ذلك.
@@ -242,7 +242,7 @@
-### تلخيص
+### التلخيص (Summarization)
تم تصميم نماذج المشفر-فك التشفير مثل [BART](model_doc/bart) و [T5](model_doc/t5) لنمط تسلسل إلى تسلسل لمهمة التلخيص. سنشرح كيف يعمل BART في هذا القسم، ثم يمكنك تجربة ضبط T5 في النهاية.
@@ -262,7 +262,7 @@
-### الترجمة
+### الترجمة (Translation)
تُعد الترجمة مثالًا آخر على مهام التسلسل إلى التسلسل، مما يعني أنه يمكنك استخدام نموذج المشفر-فك التشفير مثل [BART](model_doc/bart) أو [T5](model_doc/t5) للقيام بذلك. سنشرح كيف يعمل BART في هذا القسم، ثم يمكنك تجربة ضبط T5 في النهاية.
@@ -276,4 +276,4 @@
**للحصول على مزيد من المعلومات حول توليد النصوص، راجع دليل [استراتيجيات توليد النصوص](generation_strategies)!**
-
\ No newline at end of file
+