TL;DR
I reproducibly trained three variants of a 117.8 M-parameter OpenMythos (MLA + MoE, dim=768, n_experts=16, 2 prelude + 2 coda layers, GPT-2 tokenizer) on ~491 M tokens of HuggingFaceFW/fineweb-edu on a single H100 SXM, then swept n_loops at inference. The result contradicts the depth-extrapolation claim on this codebase: neither training style produces a monotonically decreasing PPL curve, which is the defining empirical signature of depth extrapolation.
All three runs share the exact same backbone, data, tokenizer, optimizer, and step count. The only difference is how n_loops is chosen during training:
| Run |
Training n_loops |
Final train loss |
Best eval PPL |
PPL(n_loops=16) |
baseline_1 |
fixed at 1 |
4.19 |
70.0 @ 1 |
— |
looped_8 |
fixed at 8 |
3.99 |
57.9 @ 8 |
170.7 (!) |
looped_random |
uniform random ∈ {4, 6, 8, 12, 16} |
4.07 |
65.2 @ any of {4,6,8,12,16} |
65.2 |
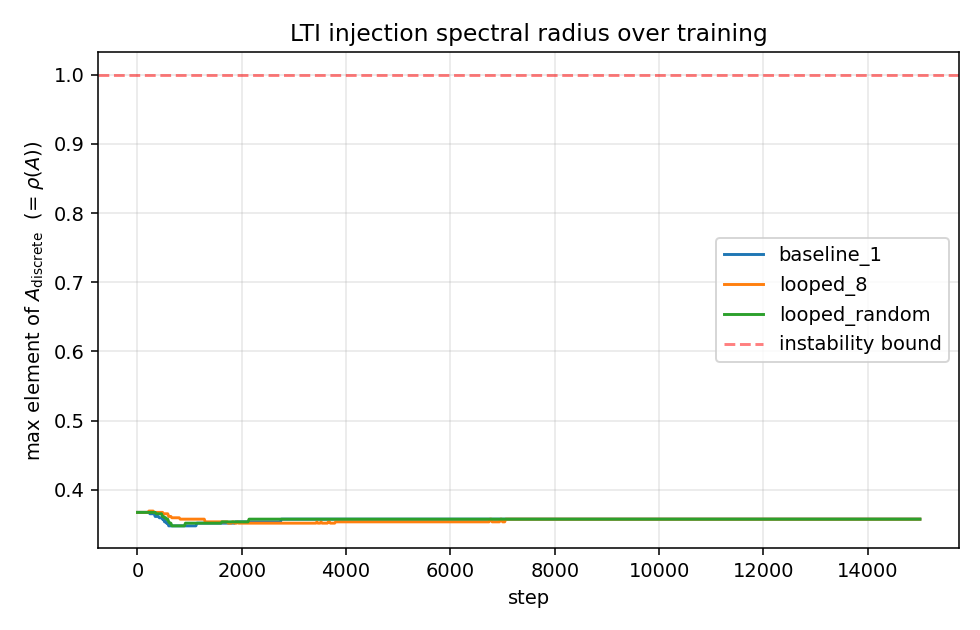
ρ(A) stays at ~0.357 across all three runs (Parcae LTI stability behaves as advertised, see rho_A.png).
The figure
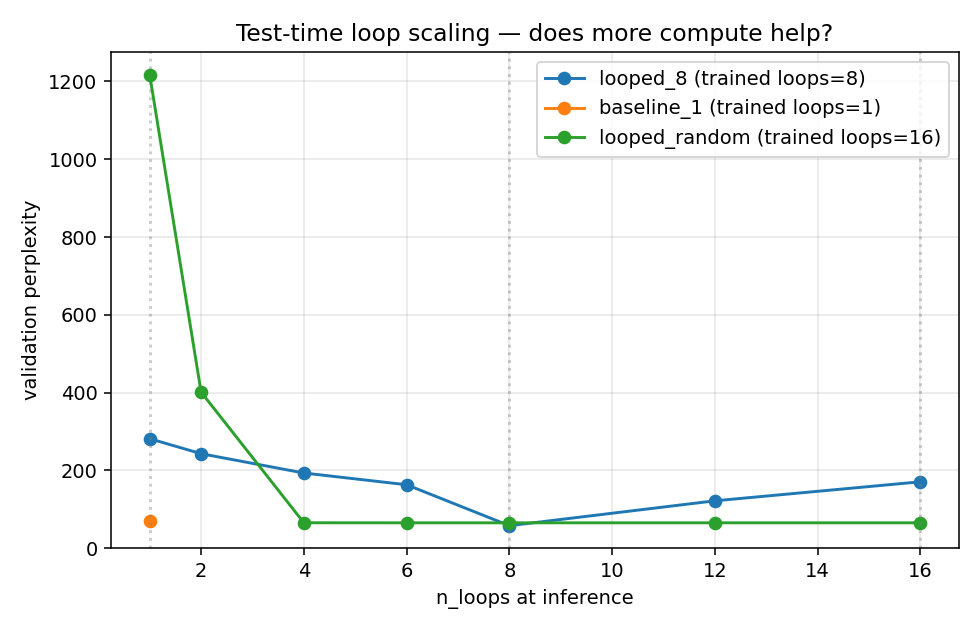
Three qualitatively different shapes:
-
looped_8 (blue): a sharp V minimum exactly at the training loop count. Moving inference depth by one step in either direction (7 or 9 would interpolate between the points, 6 and 12 already tripled PPL) degrades drastically. PPL(1)=281, PPL(8)=58, PPL(16)=171.
-
looped_random (green): catastrophic below the minimum training depth (PPL(1)=1217, PPL(2)=401); a knee at n_loops=4 (the minimum training value); then a completely flat plateau for any loop count in [4, 16]. PPLs at 4/6/8/12/16 agree to ≤ 0.1%:
n_loops PPL(looped_random)
4 65.347
6 65.237
8 65.237
12 65.240
16 65.236
-
baseline_1 (orange): a single point at n_loops=1, PPL 70.0.
Why the sharp V in looped_8
Two mechanisms currently make each loop step functionally distinct:
loop_index_embedding injects sin(t · ω) / cos(t · ω) into the first dim/8 channels of h at each step t (main.py loop_index_embedding)LoRAAdapter uses self.scale = nn.Embedding(max_loops, rank), i.e. a per-loop-depth learnable scale vector that multiplies the LoRA intermediate representation (main.py LoRAAdapter.forward)
Both were introduced intentionally — the README argues for them on the grounds that "each loop is not a repetition — it is a distinct computational phase". But under fixed-n_loops training, they also tightly bind each loop step to a specific role: the scale for step t is only ever gradient-updated on inputs that passed through steps 0..t-1 with their corresponding sin/cos signatures. At inference, running fewer loops cuts the reasoning chain short; running more replays the final LoRA row (thanks to the clamp in #10 / the existing t_idx = loop_t if loop_t <= max_t else max_t) but against sin/cos phases the scale has never seen, so behaviour becomes OOD.
Why the plateau in looped_random
Replacing model(x, n_loops=cfg.max_loop_iters) with model(x, n_loops=random.choice([4,6,8,12,16])) makes every in-range depth a valid training signal. The V disappears — good — but rather than collapsing onto a monotonically-decreasing curve, it collapses onto a flat one: PPL is identical to four decimal places across the entire training range.
That is also consistent with the mechanism: the model has learned a function that converges within 4 loops and produces the same output thereafter, regardless of how many additional loops you give it. Extra compute at inference buys nothing. This is the opposite of the claim that "more loops at inference = deeper reasoning chains = harder problems solved" — more loops simply idle.
What this means for the central claim
Both training strategies tested leave OpenMythos without the inference-time depth extrapolation behaviour the README advertises:
- Fixed loops → single-point optimum, no scaling in either direction.
- Random loops → robust plateau, but also no scaling.
Saunshi et al. 2025 / Parcae-style depth extrapolation appears to require architectural choices that OpenMythos has chosen not to make (purely anonymous loops without per-step embeddings/adapters, or a substantially different curriculum). The current loop_index_embedding + per-loop LoRAAdapter.scale design seems to be the proximate cause of the failure — they improve peak quality at the training loop count at the direct cost of depth extrapolation.
What works as claimed (positives)
- LTI stability is real. Across all three runs ρ(A) stays pinned at ≈ 0.357 for every one of 15,000 steps. No divergence, no drift, no residual explosion. Parcae's LTI injection behaves exactly as the README and paper promise. (
rho_A.png attached below.)
- Same-params advantage of looped vs non-looped is real.
looped_8@8 beats baseline_1@1 by ≈ 18 % PPL (57.9 vs 70.0) at the same parameter count (the trade being ~8× inference FLOPs per forward pass).
Reproduction
The full pipeline used to generate these numbers is in PR #27 (experiments/ directory). All commands, seeds, and default hyperparameters are in experiments/README.md; a run_all.sh orchestrator reproduces looped_8 + baseline_1 end-to-end. The looped_random run uses:
python train.py --run_name looped_random \
--max_loop_iters 16 \
--loop_sample_mode random_set --loop_choices 4 6 8 12 16 \
--batch_size 16 --grad_accum_steps 2 --max_steps 15000Wall-clock on H100 SXM: ~4 h for looped_8, ~1.5 h for baseline_1, ~3.2 h for looped_random. Requires PR #26 (bf16 dtype fix) to run in bfloat16.
Appendix: training loss and ρ(A)
Questions for maintainers / community
- Is the sharp-V behaviour under fixed-loop training already known? The README section "The Loop Index Embedding Hypothesis" discusses the design motivation but doesn't discuss this trade-off with depth extrapolation explicitly.
- Is there a training recipe that the author believes would produce monotonic inference-time scaling with the current architecture? (Curriculum? Larger
max_loop_iters? Annealing the loop-index embedding strength?) Happy to run additional ablations if there's a specific hypothesis worth testing.
- Would the project be open to adding an optional flag that disables
loop_index_embedding / per-step LoRA scale, so users can choose the "depth extrapolation" regime vs. the "peak quality at fixed depth" regime?
Happy to rerun with any suggested variations; each ablation is ~$10 and ~4 hours on an H100.
TL;DR
I reproducibly trained three variants of a 117.8 M-parameter OpenMythos (MLA + MoE,
dim=768,n_experts=16, 2 prelude + 2 coda layers, GPT-2 tokenizer) on ~491 M tokens ofHuggingFaceFW/fineweb-eduon a single H100 SXM, then sweptn_loopsat inference. The result contradicts the depth-extrapolation claim on this codebase: neither training style produces a monotonically decreasing PPL curve, which is the defining empirical signature of depth extrapolation.All three runs share the exact same backbone, data, tokenizer, optimizer, and step count. The only difference is how
n_loopsis chosen during training:n_loopsbaseline_1looped_8looped_randomρ(A) stays at ~0.357 across all three runs (Parcae LTI stability behaves as advertised, see
rho_A.png).The figure
Three qualitatively different shapes:
looped_8(blue): a sharp V minimum exactly at the training loop count. Moving inference depth by one step in either direction (7 or 9 would interpolate between the points, 6 and 12 already tripled PPL) degrades drastically. PPL(1)=281, PPL(8)=58, PPL(16)=171.looped_random(green): catastrophic below the minimum training depth (PPL(1)=1217, PPL(2)=401); a knee atn_loops=4(the minimum training value); then a completely flat plateau for any loop count in [4, 16]. PPLs at 4/6/8/12/16 agree to ≤ 0.1%:baseline_1(orange): a single point atn_loops=1, PPL 70.0.Why the sharp V in
looped_8Two mechanisms currently make each loop step functionally distinct:
loop_index_embeddinginjectssin(t · ω)/cos(t · ω)into the firstdim/8channels ofhat each stept(main.pyloop_index_embedding)LoRAAdapterusesself.scale = nn.Embedding(max_loops, rank), i.e. a per-loop-depth learnable scale vector that multiplies the LoRA intermediate representation (main.pyLoRAAdapter.forward)Both were introduced intentionally — the README argues for them on the grounds that "each loop is not a repetition — it is a distinct computational phase". But under fixed-
n_loopstraining, they also tightly bind each loop step to a specific role: the scale for steptis only ever gradient-updated on inputs that passed through steps0..t-1with their corresponding sin/cos signatures. At inference, running fewer loops cuts the reasoning chain short; running more replays the final LoRA row (thanks to the clamp in #10 / the existingt_idx = loop_t if loop_t <= max_t else max_t) but against sin/cos phases the scale has never seen, so behaviour becomes OOD.Why the plateau in
looped_randomReplacing
model(x, n_loops=cfg.max_loop_iters)withmodel(x, n_loops=random.choice([4,6,8,12,16]))makes every in-range depth a valid training signal. The V disappears — good — but rather than collapsing onto a monotonically-decreasing curve, it collapses onto a flat one: PPL is identical to four decimal places across the entire training range.That is also consistent with the mechanism: the model has learned a function that converges within 4 loops and produces the same output thereafter, regardless of how many additional loops you give it. Extra compute at inference buys nothing. This is the opposite of the claim that "more loops at inference = deeper reasoning chains = harder problems solved" — more loops simply idle.
What this means for the central claim
Both training strategies tested leave OpenMythos without the inference-time depth extrapolation behaviour the README advertises:
Saunshi et al. 2025 / Parcae-style depth extrapolation appears to require architectural choices that OpenMythos has chosen not to make (purely anonymous loops without per-step embeddings/adapters, or a substantially different curriculum). The current
loop_index_embedding+ per-loopLoRAAdapter.scaledesign seems to be the proximate cause of the failure — they improve peak quality at the training loop count at the direct cost of depth extrapolation.What works as claimed (positives)
rho_A.pngattached below.)looped_8@8 beatsbaseline_1@1 by ≈ 18 % PPL (57.9 vs 70.0) at the same parameter count (the trade being ~8× inference FLOPs per forward pass).Reproduction
The full pipeline used to generate these numbers is in PR #27 (
experiments/directory). All commands, seeds, and default hyperparameters are inexperiments/README.md; arun_all.shorchestrator reproduceslooped_8+baseline_1end-to-end. Thelooped_randomrun uses:python train.py --run_name looped_random \ --max_loop_iters 16 \ --loop_sample_mode random_set --loop_choices 4 6 8 12 16 \ --batch_size 16 --grad_accum_steps 2 --max_steps 15000Wall-clock on H100 SXM: ~4 h for
looped_8, ~1.5 h forbaseline_1, ~3.2 h forlooped_random. Requires PR #26 (bf16 dtype fix) to run in bfloat16.Appendix: training loss and ρ(A)
Questions for maintainers / community
max_loop_iters? Annealing the loop-index embedding strength?) Happy to run additional ablations if there's a specific hypothesis worth testing.loop_index_embedding/ per-step LoRA scale, so users can choose the "depth extrapolation" regime vs. the "peak quality at fixed depth" regime?Happy to rerun with any suggested variations; each ablation is ~$10 and ~4 hours on an H100.