








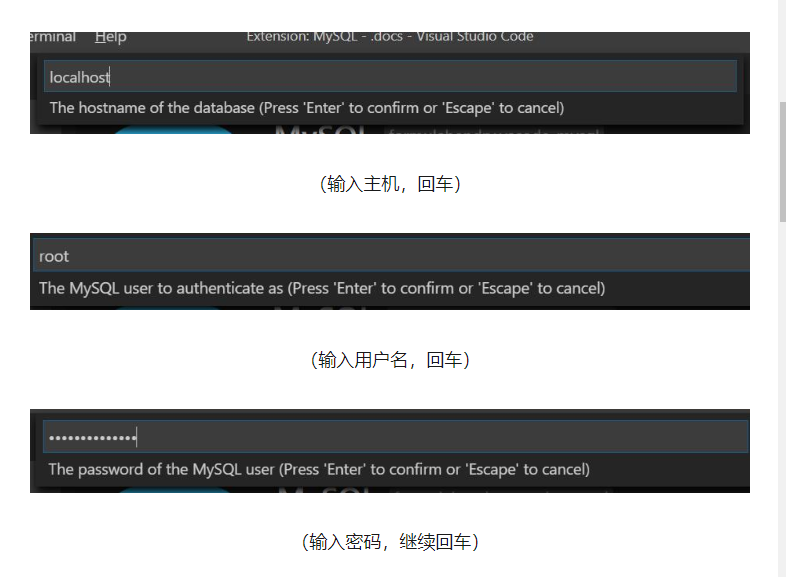
 +
+














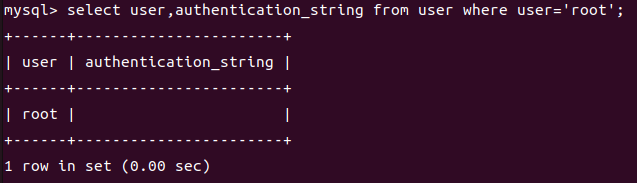
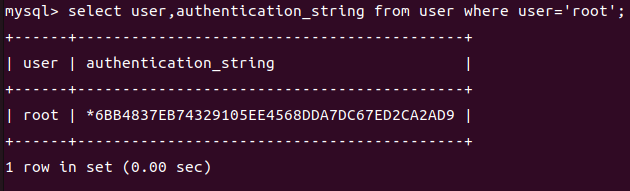
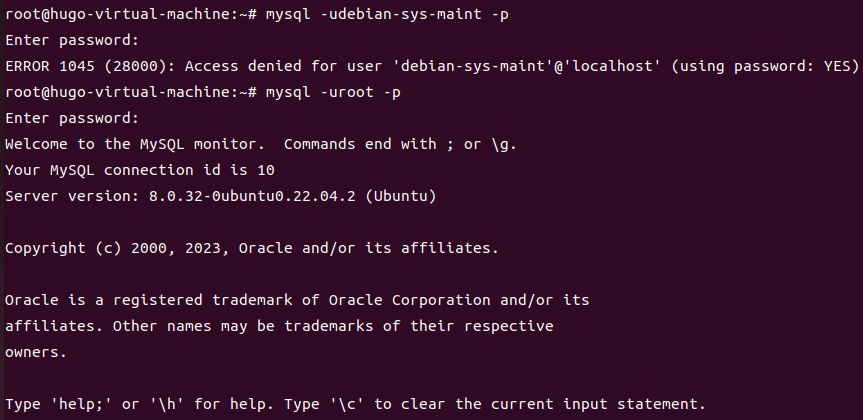


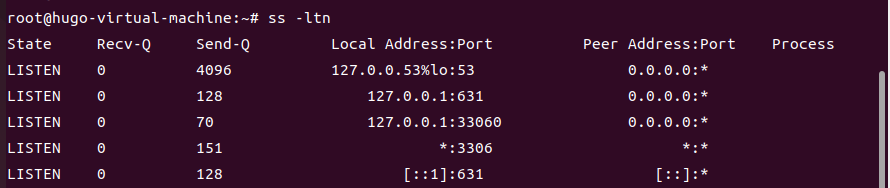

 +Ķ┐׵ğń╗ōµ×£Õ”éõĖŗ’╝Ü
+Ķ┐׵ğń╗ōµ×£Õ”éõĖŗ’╝Ü


 +õĖŖÕøŠõĖŁµłæÕĘ▓ń╗ŵŖŖõĖżķ”¢µŁīµöŠÕł░OneDriveõĖŁõ║åŃĆé
+õĖŖÕøŠõĖŁµłæÕĘ▓ń╗ŵŖŖõĖżķ”¢µŁīµöŠÕł░OneDriveõĖŁõ║åŃĆé

















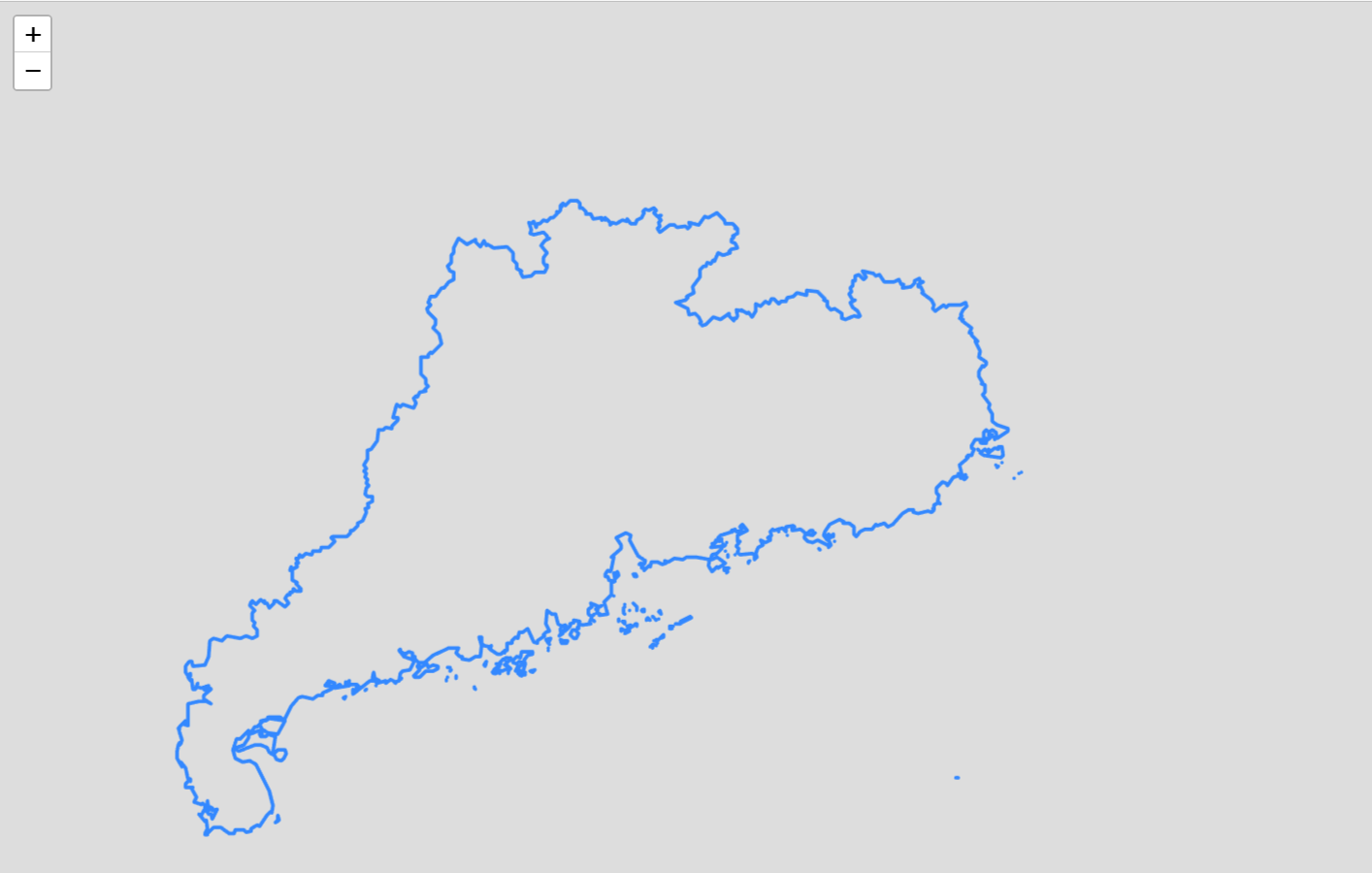





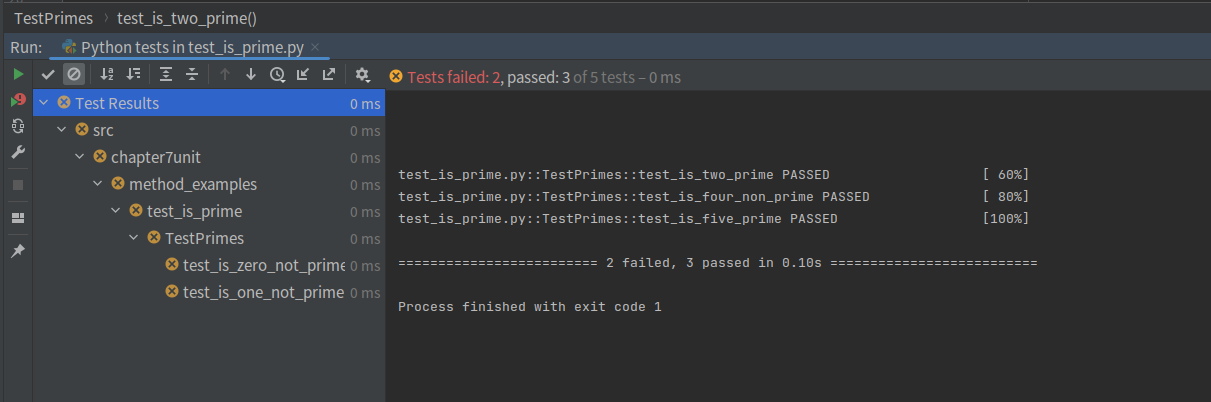


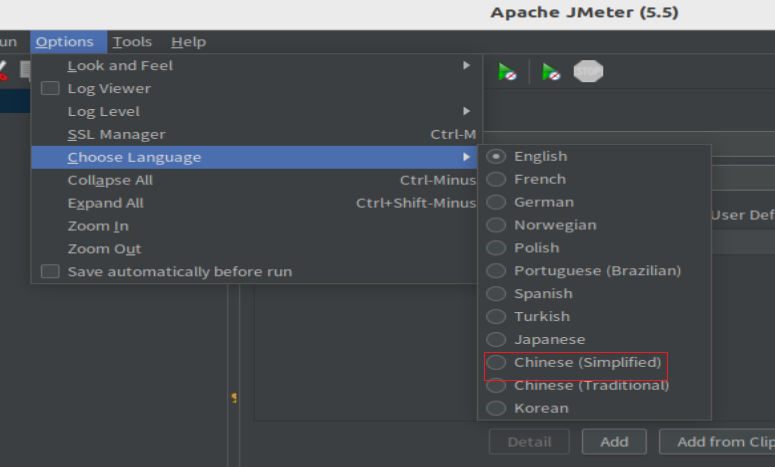
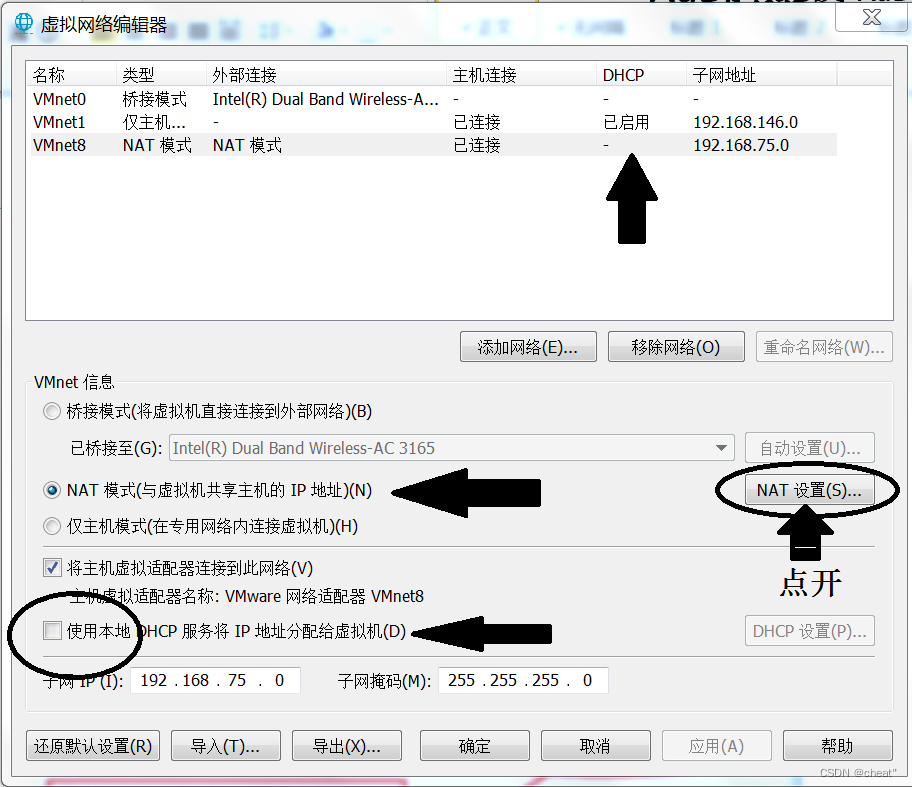
 +µēōÕ╝ĆĶÖܵŗ¤µ£║Ķ«ŠńĮ«’╝īńĮæń╗£ķĆéķģŹÕÖ©’╝īķĆēµŗ®NATµ©ĪÕ╝Å’╝īńäČÕÉÄńé╣Õć╗ķ½śń║¦’╝īķĆēµŗ®ń½»ÕÅŻĶĮ¼ÕÅæ’╝īµĘ╗ÕŖĀń½»ÕÅŻĶĮ¼ÕÅæĶ¦äÕłÖ’╝īÕ”éõĖŗÕøŠµēĆńż║’╝Ü
+
+µēōÕ╝ĆĶÖܵŗ¤µ£║Ķ«ŠńĮ«’╝īńĮæń╗£ķĆéķģŹÕÖ©’╝īķĆēµŗ®NATµ©ĪÕ╝Å’╝īńäČÕÉÄńé╣Õć╗ķ½śń║¦’╝īķĆēµŗ®ń½»ÕÅŻĶĮ¼ÕÅæ’╝īµĘ╗ÕŖĀń½»ÕÅŻĶĮ¼ÕÅæĶ¦äÕłÖ’╝īÕ”éõĖŗÕøŠµēĆńż║’╝Ü
+ +ķćŹÕÉ»ńĮæń╗£
+ķćŹÕÉ»ńĮæń╗£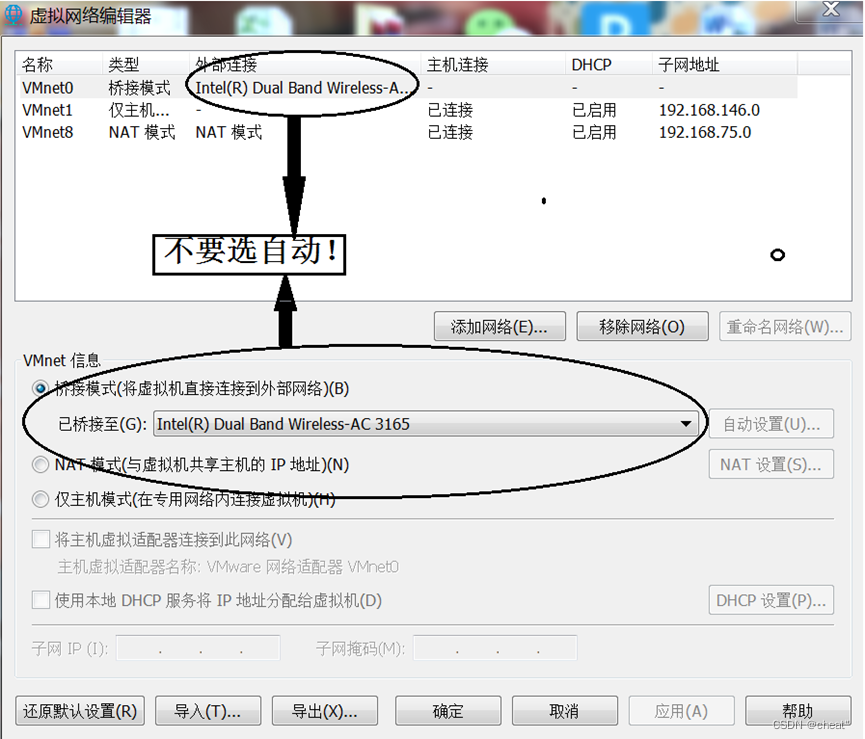 +ĶÖܵŗ¤µ£║ Ķ«ŠńĮ« ńĮæń╗£ķĆéķģŹÕÖ© ķĆēµŗ®µĪźµÄźµ©ĪÕ╝Å’╝īÕ”éõĖŗÕøŠµēĆńż║’╝Ü
+
+ĶÖܵŗ¤µ£║ Ķ«ŠńĮ« ńĮæń╗£ķĆéķģŹÕÖ© ķĆēµŗ®µĪźµÄźµ©ĪÕ╝Å’╝īÕ”éõĖŗÕøŠµēĆńż║’╝Ü
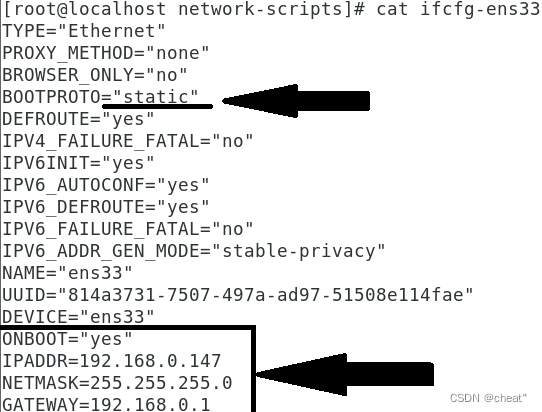
+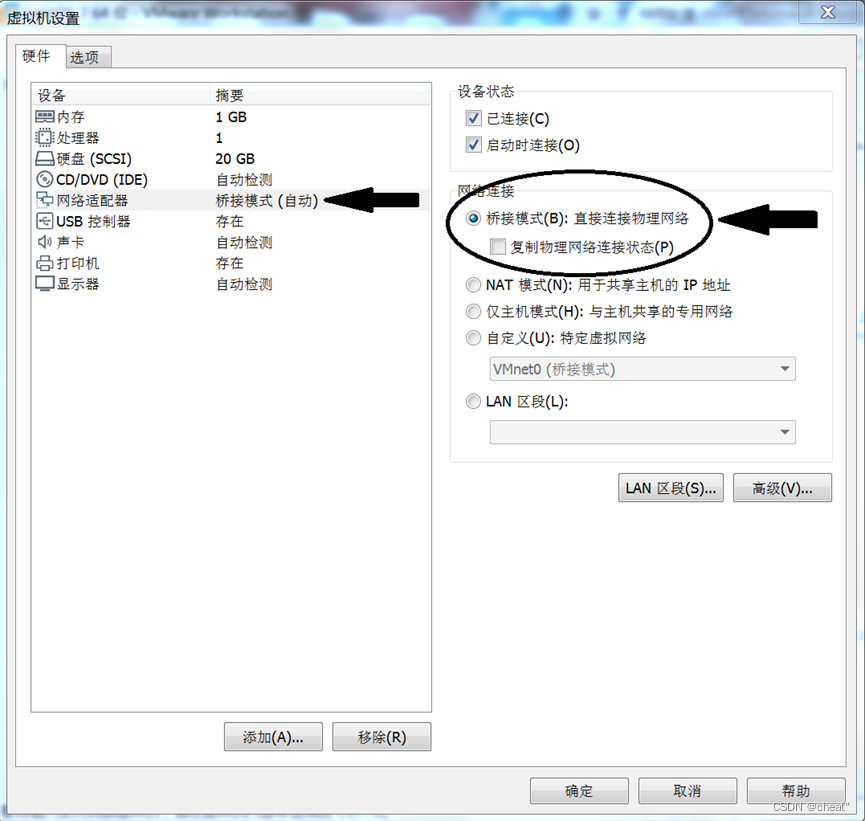 +õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č/etc/sysconfig/network-scripts/ifcfg-ens33
+
+õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č/etc/sysconfig/network-scripts/ifcfg-ens33
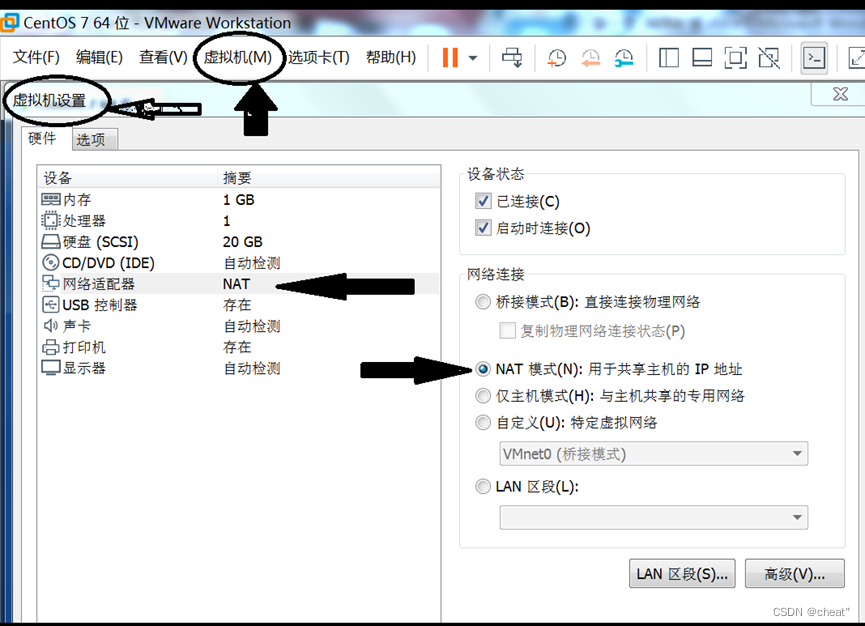
+ +ķćŹÕÉ»ńĮæń╗£µ£ŹÕŖĪ
+ķćŹÕÉ»ńĮæń╗£µ£ŹÕŖĪ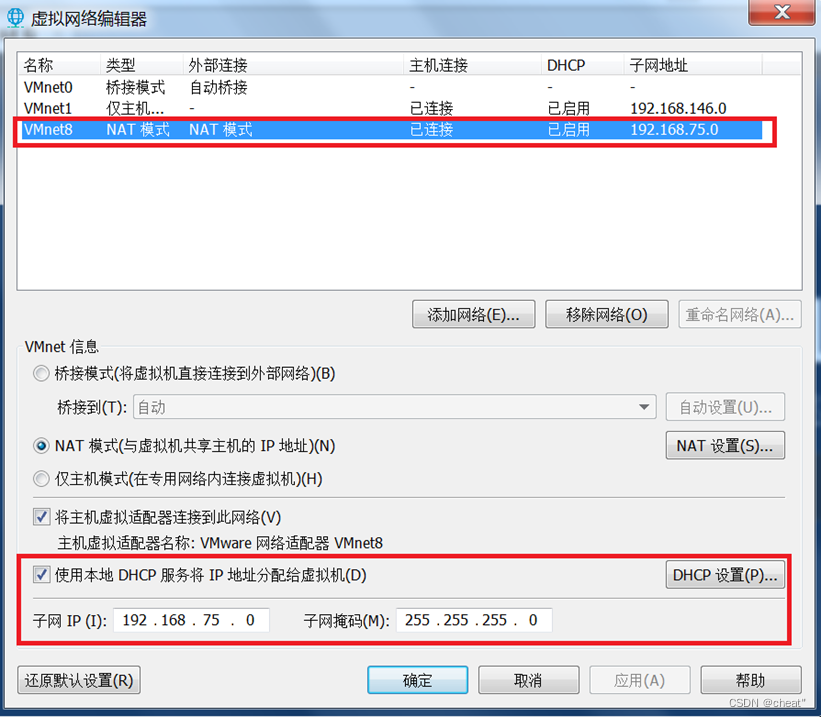 +õĖŹõĮ┐ńö©µ£¼Õ£░DHCPµ£ŹÕŖĪ’╝īĶ┐ÖµĀĘÕ░▒ÕŠŚÕŗŠµČłDHCPķĆēķĪ╣’╝īńäČÕÉĵ¤źń£ŗDHCPńĪ«õ┐ص£¬ÕÉ»ńö©ŃĆé
+
+õĖŹõĮ┐ńö©µ£¼Õ£░DHCPµ£ŹÕŖĪ’╝īĶ┐ÖµĀĘÕ░▒ÕŠŚÕŗŠµČłDHCPķĆēķĪ╣’╝īńäČÕÉĵ¤źń£ŗDHCPńĪ«õ┐ص£¬ÕÉ»ńö©ŃĆé
+
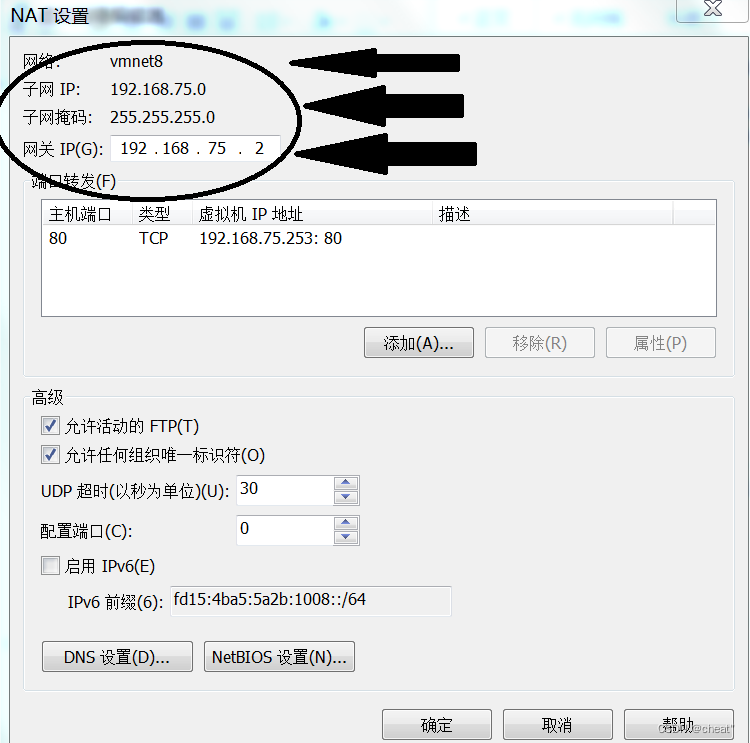
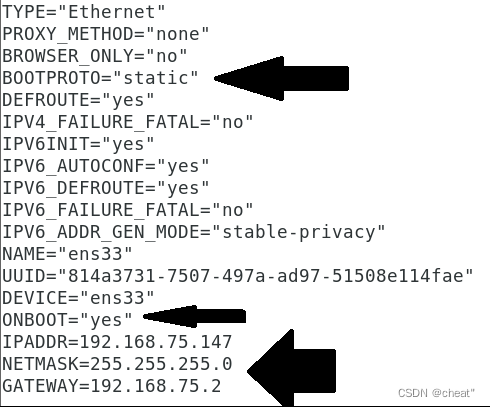
 +ń¼¼ÕģŁµŁź’╝īõ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č/etc/sysconfig/network-scripts/ifcfg-ens33’╝īõ┐«µö╣ńÜ䵌ČÕĆÖÕ┐ģķĪ╗µīēń¼¼ÕøøµŁźńÜäIPńĮ浫ĄÕÆīńĮæÕģ│õ┐«µö╣’╝īÕģĘõĮōµĀ╣µŹ«õĮĀĶć¬ÕĘ▒ńÜäµāģÕåĄÕå│Õ«ÜĶ┐ÖõĖ¬ńĮ浫Ą’╝īµ»öÕ”é’╝īµłæńÜäńĮ浫Ąµś»192.168.75.0’╝īńĮæÕģ│µś»192.168.75.2’╝īÕŁÉńĮæµÄ®ńĀüµś»255.255.255.0ŃĆé
+
+ń¼¼ÕģŁµŁź’╝īõ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č/etc/sysconfig/network-scripts/ifcfg-ens33’╝īõ┐«µö╣ńÜ䵌ČÕĆÖÕ┐ģķĪ╗µīēń¼¼ÕøøµŁźńÜäIPńĮ浫ĄÕÆīńĮæÕģ│õ┐«µö╣’╝īÕģĘõĮōµĀ╣µŹ«õĮĀĶć¬ÕĘ▒ńÜäµāģÕåĄÕå│Õ«ÜĶ┐ÖõĖ¬ńĮ浫Ą’╝īµ»öÕ”é’╝īµłæńÜäńĮ浫Ąµś»192.168.75.0’╝īńĮæÕģ│µś»192.168.75.2’╝īÕŁÉńĮæµÄ®ńĀüµś»255.255.255.0ŃĆé
+ +
+




 -
- -
- -
-#### µä¤Ķ░ó
-
-µ£¼ÕŹÜÕ«óÕ£©[Vno Jekyll](https://github.com/onevcat/vno-jekyll)Õ¤║ńĪĆõĖŖõ┐«µö╣ńÜäŃĆé
\ No newline at end of file
+## ńē®ńÉåµĄĘµ┤ŗÕŁ”Õ£©Ķ»╗
diff --git a/_config.yml b/_config.yml
index 9795797653..c40bd3b830 100755
--- a/_config.yml
+++ b/_config.yml
@@ -1,50 +1,49 @@
# Basic
-title: µĮśµ¤Åõ┐Ī
+title: ķÖłÕÉīÕŁ”
subtitle: õĖ¬õ║║ń½Ö
description: µ¼óĶ┐ÄµØźÕł░µłæńÜäõĖ¬õ║║ń½Ö~
# Õż┤ÕāÅķćīķØóńÜäµĀćķóś
-avatarTitle: leopardpan
+avatarTitle: nothing can stop me
# Õż┤ÕāÅķćīķØóńÜäµÅÅĶ┐░
-avatarDesc: iOS / µ£║ÕÖ©ÕŁ”õ╣Ā
-url: "http://leopardpan.cn"
+avatarDesc: ńē®ńÉåµĄĘµ┤ŗÕŁ”Õ£©Ķ»╗
+url: "https://chanjeunlam.github.io/"
# ÕŹÜÕ«óµś»ÕÉ”Ķć¬ÕŖ©ńö¤µłÉńø«ÕĮĢ’╝īfalseõĖ║õĖŹńö¤µłÉ
enableToc: true
# Comment
-comment:
- # livere: MTAyMC81MDk5NC8yNzQ3Ng # https://www.livere.com
- disqus: leopard
- # uyan: 2143225 # µ£ēĶ©Ćid,ńÖ╗ÕĮĢµ£ēĶ©ĆÕ«śńĮæńö│Ķ»Ę
+# comment:
+# # livere: MTAyMC81MDk5NC8yNzQ3Ng # https://www.livere.com
+# disqus: leopard
+# # uyan: 2143225 # µ£ēĶ©Ćid,ńÖ╗ÕĮĢµ£ēĶ©ĆÕ«śńĮæńö│Ķ»Ę
# Social
social:
- weibo: 5366874726
- github: leopardpan
+ # weibo:
+ # github:
# zhihu: panpanleopard
# juejin: xxx
- jianshu: 2ada30d8d0f7
+ # jianshu: 2ada30d8d0f7
# twitter:
- mail: leopardpan@icloud.com
+ mail: jchenfl@connect.ust.hk
# ńÖŠÕ║”ń╗¤Ķ«Ī
# õĮ┐ńö©ÕŹÜÕ«óµ©ĪµØ┐Ķ»ĘÕÄ╗µÄēµł¢ĶĆģµø┤µŹó id
-baidu:
- id: 8ba1c6be0953b6f9c2ba38e57f615421
+# baidu:
+# id: 8ba1c6be0953b6f9c2ba38e57f615421
# Google Analytics
# õĮ┐ńö©ÕŹÜÕ«óµ©ĪµØ┐Ķ»ĘÕÄ╗µÄēµł¢ĶĆģµø┤µŹó id
-ga:
- id: UA-84134159-3
- host: auto
+# ga:
+# id: UA-84134159-3
+# host: auto
# ŃĆŖ----------------- õĖŖķØóńÜäõ┐Īµü»õ┐«µö╣µłÉõĮĀĶć¬ÕĘ▒ńÜä ---------------------------ŃĆŗ
#
#
# _post/ õĖŗńÜäµ¢ćń½Āµø┤µŹóµłÉõĮĀĶć¬ÕĘ▒ńÜäµ¢ćń½Ā
-# ÕĖ«Õ┐ÖstarõĖĆõĖŗ’╝īµä¤Ķ░ó~¤śå Õ£░ÕØĆ’╝Ü https://github.com/leopardpan/leopardpan.github.io
#
#
# ŃĆŖ--------------- õĖŗķØóńÜäõ┐Īµü»ÕÅ»õ╗źĶć¬ĶĪīķĆēµŗ®µś»ÕÉ”õ┐«µö╣ ------------------------ŃĆŗ
@@ -73,7 +72,16 @@ nav:
# Pagination
gems: [jekyll-paginate,jekyll-sitemap]
+plugins: [jekyll-paginate]
paginate: 20
paginate_path: "page/:num/"
-
+# fomula
+markdown: kramdown
+kramdown:
+ math_engine: mathjax
+ syntax_highlighter: rouge
+ input: GFM
+ hard_wrap: false
+ syntax_highlighter_opts:
+ disable: true
\ No newline at end of file
diff --git a/_includes/open-embed.html b/_includes/open-embed.html
new file mode 100644
index 0000000000..e45e8d553c
--- /dev/null
+++ b/_includes/open-embed.html
@@ -0,0 +1,95 @@
+
+
+
diff --git a/_layouts/default.html b/_layouts/default.html
index e21abb61fd..d4323a978f 100755
--- a/_layouts/default.html
+++ b/_layouts/default.html
@@ -32,8 +32,12 @@
{% include footer.html %}
-
+
+
{% include external.html %}
+ {% include open-embed.html %}
+
+
-
-#### µä¤Ķ░ó
-
-µ£¼ÕŹÜÕ«óÕ£©[Vno Jekyll](https://github.com/onevcat/vno-jekyll)Õ¤║ńĪĆõĖŖõ┐«µö╣ńÜäŃĆé
\ No newline at end of file
+## ńē®ńÉåµĄĘµ┤ŗÕŁ”Õ£©Ķ»╗
diff --git a/_config.yml b/_config.yml
index 9795797653..c40bd3b830 100755
--- a/_config.yml
+++ b/_config.yml
@@ -1,50 +1,49 @@
# Basic
-title: µĮśµ¤Åõ┐Ī
+title: ķÖłÕÉīÕŁ”
subtitle: õĖ¬õ║║ń½Ö
description: µ¼óĶ┐ÄµØźÕł░µłæńÜäõĖ¬õ║║ń½Ö~
# Õż┤ÕāÅķćīķØóńÜäµĀćķóś
-avatarTitle: leopardpan
+avatarTitle: nothing can stop me
# Õż┤ÕāÅķćīķØóńÜäµÅÅĶ┐░
-avatarDesc: iOS / µ£║ÕÖ©ÕŁ”õ╣Ā
-url: "http://leopardpan.cn"
+avatarDesc: ńē®ńÉåµĄĘµ┤ŗÕŁ”Õ£©Ķ»╗
+url: "https://chanjeunlam.github.io/"
# ÕŹÜÕ«óµś»ÕÉ”Ķć¬ÕŖ©ńö¤µłÉńø«ÕĮĢ’╝īfalseõĖ║õĖŹńö¤µłÉ
enableToc: true
# Comment
-comment:
- # livere: MTAyMC81MDk5NC8yNzQ3Ng # https://www.livere.com
- disqus: leopard
- # uyan: 2143225 # µ£ēĶ©Ćid,ńÖ╗ÕĮĢµ£ēĶ©ĆÕ«śńĮæńö│Ķ»Ę
+# comment:
+# # livere: MTAyMC81MDk5NC8yNzQ3Ng # https://www.livere.com
+# disqus: leopard
+# # uyan: 2143225 # µ£ēĶ©Ćid,ńÖ╗ÕĮĢµ£ēĶ©ĆÕ«śńĮæńö│Ķ»Ę
# Social
social:
- weibo: 5366874726
- github: leopardpan
+ # weibo:
+ # github:
# zhihu: panpanleopard
# juejin: xxx
- jianshu: 2ada30d8d0f7
+ # jianshu: 2ada30d8d0f7
# twitter:
- mail: leopardpan@icloud.com
+ mail: jchenfl@connect.ust.hk
# ńÖŠÕ║”ń╗¤Ķ«Ī
# õĮ┐ńö©ÕŹÜÕ«óµ©ĪµØ┐Ķ»ĘÕÄ╗µÄēµł¢ĶĆģµø┤µŹó id
-baidu:
- id: 8ba1c6be0953b6f9c2ba38e57f615421
+# baidu:
+# id: 8ba1c6be0953b6f9c2ba38e57f615421
# Google Analytics
# õĮ┐ńö©ÕŹÜÕ«óµ©ĪµØ┐Ķ»ĘÕÄ╗µÄēµł¢ĶĆģµø┤µŹó id
-ga:
- id: UA-84134159-3
- host: auto
+# ga:
+# id: UA-84134159-3
+# host: auto
# ŃĆŖ----------------- õĖŖķØóńÜäõ┐Īµü»õ┐«µö╣µłÉõĮĀĶć¬ÕĘ▒ńÜä ---------------------------ŃĆŗ
#
#
# _post/ õĖŗńÜäµ¢ćń½Āµø┤µŹóµłÉõĮĀĶć¬ÕĘ▒ńÜäµ¢ćń½Ā
-# ÕĖ«Õ┐ÖstarõĖĆõĖŗ’╝īµä¤Ķ░ó~¤śå Õ£░ÕØĆ’╝Ü https://github.com/leopardpan/leopardpan.github.io
#
#
# ŃĆŖ--------------- õĖŗķØóńÜäõ┐Īµü»ÕÅ»õ╗źĶć¬ĶĪīķĆēµŗ®µś»ÕÉ”õ┐«µö╣ ------------------------ŃĆŗ
@@ -73,7 +72,16 @@ nav:
# Pagination
gems: [jekyll-paginate,jekyll-sitemap]
+plugins: [jekyll-paginate]
paginate: 20
paginate_path: "page/:num/"
-
+# fomula
+markdown: kramdown
+kramdown:
+ math_engine: mathjax
+ syntax_highlighter: rouge
+ input: GFM
+ hard_wrap: false
+ syntax_highlighter_opts:
+ disable: true
\ No newline at end of file
diff --git a/_includes/open-embed.html b/_includes/open-embed.html
new file mode 100644
index 0000000000..e45e8d553c
--- /dev/null
+++ b/_includes/open-embed.html
@@ -0,0 +1,95 @@
+
+
+
diff --git a/_layouts/default.html b/_layouts/default.html
index e21abb61fd..d4323a978f 100755
--- a/_layouts/default.html
+++ b/_layouts/default.html
@@ -32,8 +32,12 @@
{% include footer.html %}
-
+
+
{% include external.html %}
+ {% include open-embed.html %}
+
+
- -> ķŚ«’╝ܵ£¼Õ£░ķā©ńĮ▓µłÉÕŖ¤õ║å’╝īõ╣¤ĶāĮķóäĶ¦łµĢłµ×£’╝īõĮåõĮ┐ńö© username.github.io Ķ«┐ķŚ«’╝ī`Õć║ńÄ░ 404 ` . -> ńŁö’╝Üķ”¢ÕģłńĪ«Ķ«ż hexo d ÕæĮõ╗żµē¦ĶĪīµś»ÕÉ”µŖźķöÖ’╝īÕ”éµ×£µ▓Īµ£ēµŖźķöÖ’╝īÕåŹµ¤źń£ŗõĖĆõĖŗõĮĀńÜä github ńÜä username.github.io õ╗ōÕ║ō’╝īõĮĀńÜäÕŹÜÕ«óµś»ÕÉ”ÕĘ▓ń╗ŵłÉÕŖ¤µÅÉõ║żõ║å’╝īõĮĀńÜä github ķé«ń«▒õ╣¤Ķ”üķĆÜĶ┐ćķ¬īĶ»üµēŹĶĪīŃĆé - -
- -ĶĮ¼ĶĮĮĶ»Ęµ│©µśÄÕĤգ░ÕØĆ’╝īµĮśµ¤Åõ┐ĪńÜäÕŹÜÕ«ó’╝Ü[http://leopardpan.github.io](http://leopardpan.github.io) Ķ░óĶ░ó’╝ü diff --git a/_posts/2016-06-12-HEXO_Advanced.md b/_posts/2016-06-12-HEXO_Advanced.md deleted file mode 100755 index 4cfd755714..0000000000 --- a/_posts/2016-06-12-HEXO_Advanced.md +++ /dev/null @@ -1,81 +0,0 @@ ---- -layout: post -title: HEXOĶ┐øķśČ -tag: hexo ---- - -HEXOµÄźĶ┐æµś»µ£ĆĶ┐æµ£ēõĖĆõ║øµ£ŗÕÅŗµÅÉÕć║ńÜäķŚ«ķóś’╝īńäČÕÉĵłæÕüÜõ║åµĆ╗ń╗ō’╝īÕ”éµ×£õĮĀõ╣¤Õ£©õĮ┐ńö©HEXO’╝īõĖŹÕ”©ń£ŗń£ŗ’╝īÕ║öĶ»źõ╝ܵ£ēõ║øÕĖ«ÕŖ®ŃĆé - -* 1ŃĆüÕŹÜÕ«óķā©ńĮ▓µĀĘÕ╝ÅÕć║ķŚ«ķóśõ║åµĆÄõ╣łÕŖ×’╝¤ -* 2ŃĆüńöĄĶäæķćŹĶŻģµł¢ĶĆģĶ»»ÕłĀõ║åµ£¼Õ£░ÕŹÜÕ«óµĆÄõ╣łÕŖ×’╝¤ -* 3ŃĆüµā│õĮ┐ńö©õĖżÕÅ░ńöĄĶäæÕåÖÕŹÜÕ«óµĆÄõ╣łÕŖ×’╝¤ -* 4ŃĆüõĖ║õĮĢõĮ┐ńö©ńÖŠÕ║”µÉ£õĖŹÕł░µłæńÜäÕŹÜÕ«ó’╝¤ - - -### õĮ┐ńö©JekyllĶ¦ŻÕå│ÕēŹõĖēõĖ¬ķŚ«ķóśŃĆé -õĖŹÕŠŚõĖŹĶ»┤ `Jekyll` ńĪ«Õ«×ÕÅ»õ╗źĶ¦ŻÕå│µłæõĖŖķØóõĖēõĖ¬ķŚ«ķóś, ÕøĀõĖ║ `Jekyll` µś»ńø┤µÄźµŖŖMarkdownµĀ╝Õ╝ÅńÜäµ¢ćń½Āńø┤µÄźµöŠÕ£©githubõ╗ōÕ║ōķćīńÜä, ńøĖÕĮōõ║Äńø┤µÄźńö©gitµØźń«ĪńÉåÕŹÜÕ«óõ║å, `Github` Õ«śµ¢╣õ╣¤ÕŠłµÄ©ĶŹÉ `Jekyll` ŃĆé õĮĀÕÅ»õ╗źÕģłń£ŗõĖŗ `Jekyll` µÉŁÕ╗║ÕŹÜÕ«óńÜä[voyagelab](voyagelab.github.io), [githubÕ£░ÕØĆ](https://github.com/voyagelab/voyagelab.github.io), ÕĮōńäČõ║åĶ┐ÖÕŬµś»ÕŠłµÖ«ķĆÜńÜä, Jekyll õ╣¤µ£ēÕŠłÕżÜõĖ╗ķóśÕÅ»õ╗źķĆēµŗ®ńÜä, µø┤Ķ»”ń╗åńÜäĶ»Ęń£ŗ[JekyllõĖŁµ¢ćµ¢ćµĪŻ](http://jekyll.bootcss.com/)ŃĆü[JekyllĶŗ▒µ¢ćµ¢ćµĪŻ](https://jekyllrb.com/)ŃĆü[JekyllõĖ╗ķóśÕłŚĶĪ©](http://jekyllthemes.org/)ŃĆé -Õ£© `Jekyll` õĖŖķĆøõ║åõĖĆõĖ¬µś¤µ£¤ńÜ䵳æÕÅłÕø×Õł░õ║å `Hexo` , ÕÅæńÄ░ ńø«ÕēŹ `Jekyll` Õ»╣õĖ╗ķóśÕÆīõĖĆõ║øµÅÆõ╗ČńÜäµö»µīüńøĖÕ»╣ `Hexo` µØźĶ»┤, µ▓ĪķéŻõ╣łÕÅŗÕźĮ, ÕÅ»ĶāĮµ£ēõĖĆõ║øÕģČÕ«āńÜäµ¢╣µ│ĢÕŬµś»µłæµ▓ĪµēŠÕł░ĶĆīÕĘ▓,Õģ│õ║Ä `Jekyll` µÉŁÕ╗║ÕŹÜÕ«óÕ░▒õ╗ŗń╗ŹÕł░Ķ┐Ö, Õ”éµ×£µ£ēķŚ«ķóśńÜäĶ»ØÕÅ»õ╗źĶ»äĶ«║, µł¢ĶĆģĶüöń│╗µłæŃĆé - -### õĮ┐ńö©HexoĶ¦ŻÕå│õĖŖķØóÕēŹõĖēõĖ¬ķŚ«ķóś -µś»ńÜä, µłæÕż¦`Hexo`ÕÉīµĀĘÕÅ»õ╗źĶ¦ŻÕå│õĖŖķØóõĖēõĖ¬ķŚ«ķóś, ķéŻÕ░▒µś»õĮ┐ńö©gitŃĆéÕģ│õ║ÄÕ”éõĮĢõĮ┐ńö© `Hexo` µÉŁÕ╗║ÕŹÜÕ«óĶ»Ęń£ŗµłæÕÅ”õĖĆń»ćµ¢ćń½Ā[HEXOµÉŁÕ╗║õĖ¬õ║║ÕŹÜÕ«ó](http://www.leopardpan.cn/2015/08/25/HEXO%E6%90%AD%E5%BB%BA%E4%B8%AA%E4%BA%BA%E5%8D%9A%E5%AE%A2/), Õ”éµ×£µÉŁÕ╗║ńÜäĶ┐ćń©ŗõĖŁÕć║ńÄ░õ║åķŚ«ķóś, µłæõ╗¼ÕÅ»õ╗źõ║żµĄüõ║żµĄüŃĆéńÄ░Õ£©µłæÕüćĶ«ŠõĮĀÕĘ▓ń╗ÅĶāĮÕ¤║µ£¼õĮ┐ńö© `Hexo` õ║å, µÄźõĖŗµØźÕ░▒ń£ŗń£ŗÕ”éõĮĢµØźń«ĪńÉåÕŹÜÕ«óŃĆé - -## õĮ┐ńö©gitń«ĪńÉåÕŹÜÕ«ó -[Blog-Growing](https://github.com/leopardpan/Blog-Growing)µś»µłæń«ĪńÉåÕŹÜÕ«óńÜäõ╗ōÕ║ōÕ£░ÕØĆŃĆéń╗ōµ×äÕż¦Ķć┤µś»: - -> -- Blog-Growing -> ŃĆĆŃĆĆ|-- .git -> ŃĆĆŃĆĆ|-- .gitignore -> ŃĆĆŃĆĆ|-- Hexo -> ŃĆĆŃĆĆŃĆĆŃĆĆ| .. -> ŃĆĆŃĆĆŃĆĆŃĆĆ| .. -> ŃĆĆŃĆĆŃĆĆŃĆĆ| µĢ┤õĖ¬ÕŹÜÕ«óńÜäķģŹńĮ«õ┐Īµü» - -õĮĀÕÅ»õ╗źµŖŖµłæńÜäńÜä[Blog-Growing](https://github.com/leopardpan/Blog-Growing) cloneõĖŗµØź, ń£ŗń£ŗõĖĆõ║øÕ¤║µ£¼ķģŹńĮ«µś»µĆÄõ╣łķģŹńĮ«ńÜäŃĆéķ£ĆĶ”üµÅÉķåÆńÜ䵜», `Ķ”üµŖŖõĖ╗ķóśõĖŗńÜä.gitń╗ÖÕłĀķÖżµÄē` , ÕĮōńäČõ║åõĮĀõ╣¤ÕÅ»õ╗źõĮ┐ńö© `git submodule` µØźń«ĪńÉå, ÕģĘõĮōńÜäń«ĪńÉåµ¢╣µ│ĢµłæĶ┐ÖķćīÕ░▒õĖŹÕüÜÕżÜńÜäõ╗ŗń╗Źõ║å, µā│õ║åĶ¦ŻńÜäĶ»ØÕÅ»õ╗źń¦üõ┐ĪµłæŃĆé -õĖŖķØóńÜäĶ┐ćń©ŗÕ¤║µ£¼ÕüÜÕ«īÕÉÄ, µĆÄõ╣łµØźĶ¦ŻÕå│µłæÕ╝Ćń»ćµÅÉńÜäÕēŹõĖēõĖ¬ķŚ«ķóśõ║åŃĆé - -### ÕģĘõĮōÕ«×ńÄ░: -**õĖĆ’╝ÜÕ«ČķćīńöĄĶäæõĮ┐ńö©ÕŹÜÕ«ó** -ŃĆĆŃĆĆÕ╗║ń½ŗgitĶ┐£ń½»õ╗ōÕ║ōń«ĪńÉåÕŹÜÕ«ó,Õ╣ČõĮ┐ńö©Õ«ČķćīńÜäńöĄĶäæµŖŖµ£¼Õ£░ÕŹÜÕ«óńÜäķģŹńĮ«µÄ©ķĆüÕł░Ķ┐£ń½»õ╗ōÕ║ōŃĆé -**õ║ī’╝ÜÕģ¼ÕÅĖńöĄĶäæõĮ┐ńö©ÕŹÜÕ«ó** -ŃĆĆŃĆĆÕł░õ║åÕģ¼ÕÅĖÕŬķ£ĆĶ”üµē¦ĶĪī`sudo npm install -g hexo`,ńäČÕÉÄcdÕł░õĮĀńÜäÕŹÜÕ«óńø«ÕĮĢõĖŗ,Õ”éµłæcd Õł░Hexońø«ÕĮĢõĖŗ, ńäČÕÉĵē¦ĶĪī `hexo server` Õ░▒ÕÅ»õ╗źÕ£©µ£¼Õ£░ķóäĶ¦łÕŹÜÕ«óõ║åŃĆé -**õĖē’╝ÜõĮ┐ńö©Gitõ┐ØÕŁś** -ŃĆĆŃĆĆõ┐«µö╣ÕźĮÕŹÜÕ«óÕÉÄĶ«░ÕŠŚÕģłõĮ┐ńö©gitµØźµÅÉõ║żõĖŗ, ÕŹ│õĮ┐õĖŗµ¼ĪµŖŖÕŹÜÕ«óńÜäµĀĘÕ╝Åõ┐«µö╣ÕØÅõ║å, õ╣¤ÕÅ»õ╗źõĮ┐ńö© `git reset --hard` µØźÕø×ķĆĆŃĆéÕ”é: µłæcd Õł░ `Blog-Growing` ńø«ÕĮĢõĖŗõĮ┐ńö©gitµÅÉõ║żŃĆé -**Õøø’╝ÜÕŹÜÕ«óµÅÉõ║ż** -ŃĆĆŃĆĆ1ŃĆüõ┐«µö╣ÕźĮńÜäÕŹÜÕ«óõĮ┐ńö© `hexo d` Õ▒Ģńż║Õł░ÕŹÜÕ«óķĪĄõĖŖŃĆé -ŃĆĆŃĆĆ2ŃĆügit push µĢ┤õĖ¬µ£¼Õ£░ÕŹÜÕ«óŃĆé - -**µÅÉńż║:** Õ£©Ķ┐Öķćī `git` õ╗ģõ╗ģÕŬµś»ńö©µłĘÕüÜÕŹÜÕ«óńÜäńēłµ£¼ń«ĪńÉåńÜä, ÕŹÜÕ«óńÜäµĀĘÕ╝Åõ┐«µö╣ŃĆüÕ¤║µ£¼ķā©ńĮ▓Ķ┐śµś»õĮ┐ńö© `hexo` µØźµōŹõĮ£ńÜäŃĆé - -## Ķ«®ńÖŠÕ║”ĶāĮµÉ£ń┤óÕł░õĮĀńÜäÕŹÜÕ«ó - -### õĖ║õ╗Ćõ╣łĶ”üõĮ┐ńö©ńÖŠÕ║”µÉ£ń┤ó’╝¤ - -ŃĆĆŃĆƵ£ēõ║║ÕÅ»ĶāĮõ╝ÜĶ»┤õĮ£õĖ║õĖĆõĖ¬Õ╝ĆÕÅæõ║║Õæś, õĮĀõĖŹõ╝Üńö© `Google` ÕĢŖŃĆé µś»ńÜä, Googleµś»ĶāĮµÉ£Õł░µłæõ╗¼µÉŁÕ╗║Õ£© `Github Page` ńÜäÕŹÜÕ«ó, õ╝Üńö©`Google` õ╣¤µś»õĖĆõĖ¬Õ╝ĆÕÅæõ║║ÕæśÕ┐ģÕżćµŖĆĶāĮõ╣ŗõĖĆŃĆéõĮåµś», µłæõ╗¼ńö¤µ┤╗Õ£©Õż®µ£Ø, µēĆõ╗źńÖŠÕ║”Ķ┐śµś»µĆ╗µ£ēõ╝Üńö©Õł░ńÜ䵌ČÕĆÖ, µł¢ĶĆģµś»õĮĀµā│Ķ«®µø┤ÕżÜńÜäÕż®µ£Øõ║║ĶāĮµÉ£Õł░õĮĀŃĆé - -### õĖ║õ╗Ćõ╣łõĮ┐ńö©ńÖŠÕ║”µÉ£ń┤óõĖŹÕł░ Github Page õĖŖńÜäÕŹÜÕ«ó’╝¤ - -µ£ēõ║║Ķüöń│╗Ķ┐ć Github Support ķā©ķŚ© , ń╗ÖÕć║Õż¦Ķć┤ńÜäµäŵĆØÕ░▒µś»: ńÖŠÕ║”ńł¼ĶÖ½ńł¼ÕŠŚÕż¬ńīøńāł’╝īÕĘ▓ń╗ÅÕ»╣ÕŠłÕżÜ Github ńö©µłĘķĆĀµłÉõ║åķŚ«ķóśŃĆéµēĆõ╗ź Github Õ░åń”üµŁóńÖŠÕ║”ńł¼ĶÖ½ńÜäńł¼ÕÅ¢ŃĆé - -### Õ”éõĮĢĶ«®ńÖŠÕ║”ĶāĮµÉ£ń┤óõĮĀńÜäÕŹÜÕ«ó? - -ŃĆĆŃĆƵĀ╣µŹ«õĖŖķØóĶ»┤ńÜä, ńø«ÕēŹÕÅæńÄ░ÕŬµś»Github Pageń”üµŁóõ║åńÖŠÕ║”µÉ£ń┤ó, µēĆõ╗źĶ«®ńÖŠÕ║”ĶāĮµÉ£ń┤óÕł░õĮĀńÜäÕŹÜÕ«óĶ┐śµś»µ£ēõĖĆõ║øµ¢╣µ│ĢńÜäŃĆéõŠŗÕ”é: -* Ķć¬ÕĘ▒µÉ×õĖ¬VPS,ÕŹÜÕ«óķā©ńĮ▓Õ£©VPSõĖŖŃĆé -* ÕŹÜÕ«óķā©ńĮ▓ `Coding.net` õĖŖ, `GitCafe`ÕĘ▓ń╗ÅÕÉłÕ╣ČÕł░ `Coding` ŃĆé -µłæõĮ┐ńö©ńÜ䵜»ń¼¼õ║īń¦Źµ¢╣µ│Ģ, ÕŹÜÕ«óķā©ńĮ▓Õ£© `Coding.net` õĖŖõ╣¤ńøĖÕ»╣ń«ĆÕŹĢõ║øŃĆé - -#### Õ£©CodingõĖŖķā©ńĮ▓õĮĀńÜäÕŹÜÕ«óŃĆé - -ŃĆĆŃĆĆCodingÕÉīµĀʵö»µīüHexoŃĆüJekyllńŁēÕŹÜÕ«óńÜäķā©ńĮ▓, Coding ĶʤGithubĶ┐śµś»µī║ÕāÅńÜä,ĶĆīõĖöµś»õĖŁµ¢ćŃĆé ÕÉīµĀĘńÜäÕ£©CodingķćīķØóÕ╗║õĖĆõĖ¬ķĪ╣ńø«,ķĪ╣ńø«ÕÉŹÕŁŚĶʤõĮĀńÜäńö©µłĘÕÉŹõĖƵĀĘ,Ķ┐ÖķćīµłæÕ░▒õĖŹÕĢ░ÕŚ”õ║å, Ķ»┤ÕćĀõĖ¬ķ£ĆĶ”üµ│©µäÅńÜäÕ£░µ¢╣: -**µ│©µäÅõĖĆ:** -ŃĆĆŃĆĆÕ£©`Coding Page` õĖŖķā©ńĮ▓ÕŹÜÕ«ó,ķ£ĆĶ”üµŖŖÕŹÜÕ«óµÄ©ķĆüÕł░`coding-pages ` Õłåµö»õĖŖ, Õłåµö»ÕÉŹÕŁŚµś»Õø║Õ«ÜńÜäŃĆé -**µ│©µäÅõ║ī:** -ŃĆĆŃĆĆ`Coding Page` õĖŹµö»µīüĶć¬Õ«Üõ╣ēCNAME, õĮĀķ£ĆĶ”üńé╣Õć╗Õł░Pageµ©ĪÕØŚ,ńäČÕÉĵĘ╗ÕŖĀõĖĆõĖ¬Õ¤¤ÕÉŹµØźń╗æÕ«ÜŃĆé - -µø┤Ķ»”ń╗åńÜäĶ»Ęń£ŗ[Coding Pages Õ«śńĮæõ╗ŗń╗Ź](https://coding.net/help/doc/pages/index.html). - -ÕÅéĶĆāµ¢ćń½Ā: -[Ķ¦ŻÕå│ Github Pages ń”üµŁóńÖŠÕ║”ńł¼ĶÖ½ńÜäµ¢╣µ│ĢõĖÄÕÅ»ĶĪīµĆ¦Õłåµ×É](http://jerryzou.com/posts/feasibility-of-allowing-baiduSpider-for-Github-Pages/) - -
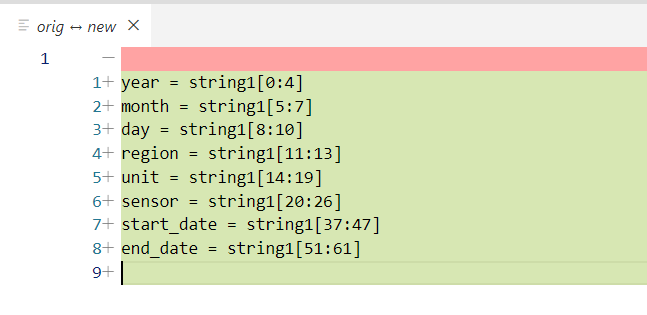
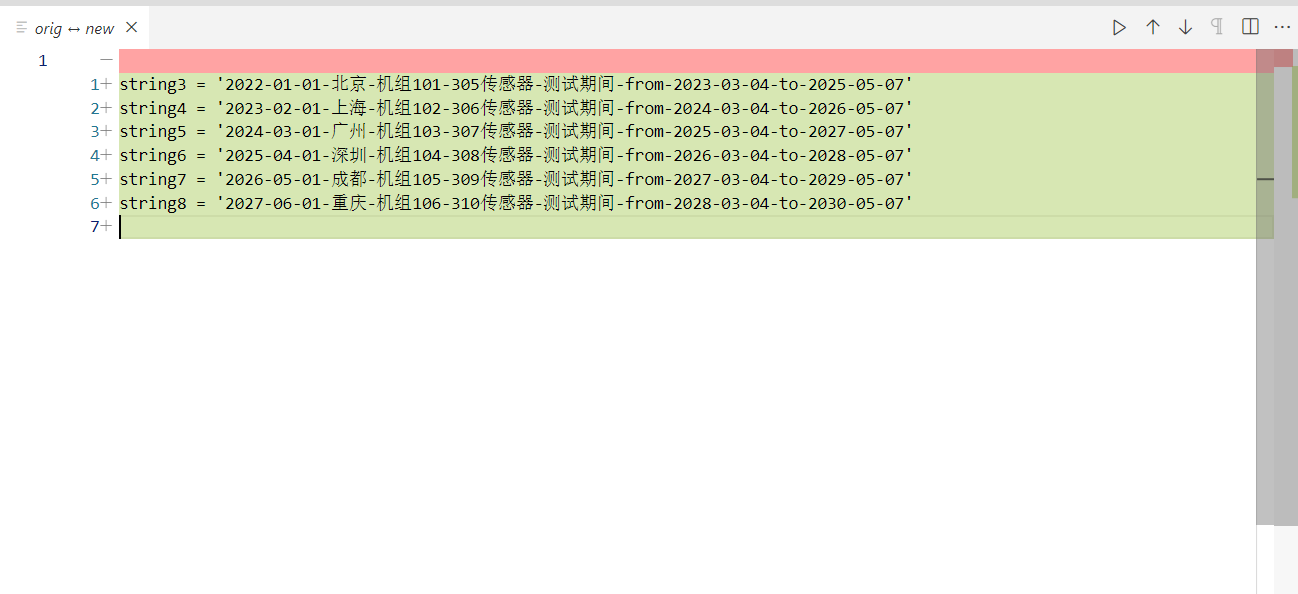
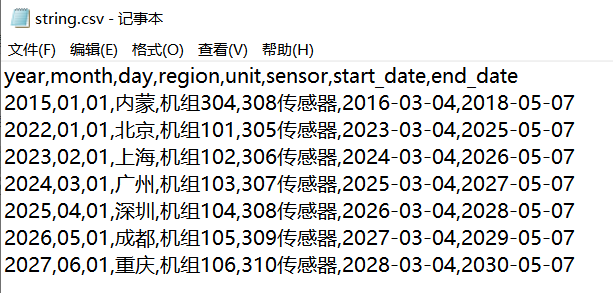
- -ĶĮ¼ĶĮĮĶ»Ęµ│©µśÄ’╝Ü[µĮśµ¤Åõ┐ĪńÜäÕŹÜÕ«ó](http://leopardpan.cn) ┬╗ [ńé╣Õć╗ķśģĶ»╗ÕĤµ¢ć](http://leopardpan.cn/2016/06/HEXO_Advanced/) \ No newline at end of file diff --git a/_posts/2016-10-14-jekyll_tutorials1.md b/_posts/2016-10-14-jekyll_tutorials1.md deleted file mode 100755 index aa913b1545..0000000000 --- a/_posts/2016-10-14-jekyll_tutorials1.md +++ /dev/null @@ -1,291 +0,0 @@ ---- -layout: post -title: JekyllµÉŁÕ╗║õĖ¬õ║║ÕŹÜÕ«ó -date: 2016-10-14 -tags: jekyll ---- - -ŃĆĆõ╣ŗÕēŹÕåÖõ║åõĖĆń»ć[HEXOµÉŁÕ╗║õĖ¬õ║║ÕŹÜÕ«ó](http://leopardpan.cn/2015/08/HEXO%E6%90%AD%E5%BB%BA%E4%B8%AA%E4%BA%BA%E5%8D%9A%E5%AE%A2/)ńÜäµĢÖń©ŗĶÄĘÕŠŚõ║åÕŠłÕźĮĶ»ä’╝īÕ░żÕģȵś»Õ£©[ń«Ćõ╣”](http://www.jianshu.com/p/465830080ea9)õĖŖńø«ÕēŹÕĘ▓ń╗Åń┤»ń¦»õ║å10W+ńÜäķśģĶ»╗ķćÅõ║å’╝īõ╣¤µ£ēÕźĮÕ┐āńÜäĶ»╗ĶĆģõĖ╗ÕŖ©ń╗ÖµłæµēōĶĄÅ’╝īÕ£©µŁżµä¤Ķ░óŃĆé - -ŃĆĆÕ”éµ×£õĮĀń£ŗĶ┐浳æńÜäµ¢ćń½Āõ╝ÜÕÅæńÄ░µłæńÄ░Õ£©ńÜäÕŹÜÕ«óµĀĘÕ╝ÅĶʤõ╣ŗÕēŹµś»µ£ēÕŠłÕż¦ńÜäÕī║Õł½ńÜä’╝īõ╣ŗÕēŹµłæõ╣¤µś»õĮ┐ńö© HEXO µÉŁÕ╗║ńÜäÕŹÜÕ«ó’╝īÕÉÄµØźÕÅæńÄ░õĮ┐ńö© HEXO Õ£©ÕżÜÕÅ░ńöĄĶäæõĖŖÕÅæÕĖāÕŹÜÕ«ó’╝īµōŹõĮ£ĶĄĘµØźÕ╣ČõĖŹµś»ķéŻõ╣łµ¢╣õŠ┐’╝īµ×£µ¢ŁÕ░▒ĶĮ¼Õł░õ║å Jekyll õĖŖ’╝īµÄźõĖŗµØźµłæõ╝ÜĶ«▓Õ”éõĮĢõĮ┐ńö© Jekyll µÉŁÕ╗║ÕŹÜÕ«ó’╝ī[ÕŹÜÕ«óµ©ĪµØ┐µĢłµ×£](http://leopardpan.cn/#blog)ŃĆé - - -### õ╗ŗń╗Ź - - ŃĆĆJekyll µś»õĖĆõĖ¬ń«ĆÕŹĢńÜäÕŹÜÕ«óÕĮóµĆüńÜäķØÖµĆüń½Öńé╣ńö¤õ║¦µ£║ÕÖ©ŃĆéÕ«āµ£ēõĖĆõĖ¬µ©Īńēłńø«ÕĮĢ’╝īÕģČõĖŁÕīģÕɽÕĤզŗµ¢ćµ£¼µĀ╝Õ╝ÅńÜäµ¢ćµĪŻ’╝īķĆÜĶ┐ć Markdown ’╝łµł¢ĶĆģ Textile’╝ē õ╗źÕÅŖ Liquid ĶĮ¼Õī¢µłÉõĖĆõĖ¬Õ«īµĢ┤ńÜäÕÅ»ÕÅæÕĖāńÜäķØÖµĆüńĮæń½Ö’╝īõĮĀÕÅ»õ╗źÕÅæÕĖāÕ£©õ╗╗õĮĢõĮĀÕ¢£ńł▒ńÜäµ£ŹÕŖĪÕÖ©õĖŖŃĆéJekyll õ╣¤ÕÅ»õ╗źĶ┐ÉĶĪīÕ£© GitHub Page õĖŖ’╝īõ╣¤Õ░▒µś»Ķ»┤’╝īõĮĀÕÅ»õ╗źõĮ┐ńö© GitHub ńÜäµ£ŹÕŖĪµØźµÉŁÕ╗║õĮĀńÜäķĪ╣ńø«ķĪĄķØóŃĆüÕŹÜÕ«óµł¢ĶĆģńĮæń½Ö’╝īĶĆīõĖöµś»Õ«īÕģ©ÕģŹĶ┤╣ńÜä - -ŃĆĆõĮ┐ńö© Jekyll µÉŁÕ╗║ÕŹÜÕ«óõ╣ŗÕēŹĶ”üńĪ«Ķ«żõĖŗµ£¼µ£║ńÄ»Õóā’╝īGit ńÄ»Õóā’╝łńö©õ║Äķā©ńĮ▓Õł░Ķ┐£ń½»’╝ēŃĆü[Ruby](http://www.ruby-lang.org/en/downloads/) ńÄ»Õóā’╝łJekyll µś»Õ¤║õ║Ä Ruby Õ╝ĆÕÅæńÜä’╝ēŃĆüÕīģń«ĪńÉåÕÖ© [RubyGems](http://rubygems.org/pages/download) -ŃĆĆŃĆĆÕ”éµ×£õĮĀµś» Mac ńö©µłĘ’╝īõĮĀÕ░▒ķ£ĆĶ”üÕ«ēĶŻģ Xcode ÕÆī Command-Line Toolsõ║åŃĆéõĖŗĶĮĮµ¢╣Õ╝Å Preferences ŌåÆ Downloads ŌåÆ ComponentsŃĆé - -ŃĆĆŃĆĆJekyll µś»õĖĆõĖ¬ÕģŹĶ┤╣ńÜäń«ĆÕŹĢķØÖµĆüńĮæķĪĄńö¤µłÉÕĘźÕģĘ’╝īÕÅ»õ╗źķģŹÕÉłń¼¼õĖēµ¢╣µ£ŹÕŖĪõŠŗÕ”é’╝Ü Disqus’╝łĶ»äĶ«║’╝ēŃĆüÕżÜĶ»┤(Ķ»äĶ«║) õ╗źÕÅŖÕłåõ║½ ńŁēńŁēµē®Õ▒ĢÕŖ¤ĶāĮ’╝īJekyll ÕÅ»õ╗źńø┤µÄźķā©ńĮ▓Õ£© Github’╝łÕøĮÕż¢’╝ē µł¢ Coding’╝łÕøĮÕåģ’╝ē õĖŖ’╝īÕÅ»õ╗źń╗æÕ«ÜĶć¬ÕĘ▒ńÜäÕ¤¤ÕÉŹŃĆé[JekyllõĖŁµ¢ćµ¢ćµĪŻ](http://jekyll.bootcss.com/)ŃĆü[JekyllĶŗ▒µ¢ćµ¢ćµĪŻ](https://jekyllrb.com/)ŃĆü[JekyllõĖ╗ķóśÕłŚĶĪ©](http://jekyllthemes.org/)ŃĆé - - -### Jekyll ńÄ»ÕóāķģŹńĮ« - -Õ«ēĶŻģ jekyll - -``` -$ gem install jekyll -``` - -ÕłøÕ╗║ÕŹÜÕ«ó - -``` -$ jekyll new myBlog -``` - -Ķ┐øÕģźÕŹÜÕ«óńø«ÕĮĢ - -``` -$ cd myBlog -``` - -ÕÉ»ÕŖ©µ£¼Õ£░µ£ŹÕŖĪ - -``` -$ jekyll serve -``` - -Õ£©µĄÅĶ¦łÕÖ©ķćīĶŠōÕģź’╝Ü [http://localhost:4000](http://localhost:4000)’╝īÕ░▒ÕÅ»õ╗źń£ŗÕł░õĮĀńÜäÕŹÜÕ«óµĢłµ×£õ║åŃĆé - - - -so easy ! - -### ńø«ÕĮĢń╗ōµ×ä -ŃĆĆ -ŃĆĆJekyll ńÜäµĀĖÕ┐āÕģČÕ«×µś»õĖĆõĖ¬µ¢ćµ£¼ĶĮ¼µŹóÕ╝ĢµōÄŃĆéÕ«āńÜäµ”éÕ┐ĄÕģČÕ«×Õ░▒µś»’╝Ü õĮĀńö©õĮĀµ£ĆÕ¢£µ¼óńÜäµĀćĶ«░Ķ»ŁĶ©ĆµØźÕåÖµ¢ćń½Ā’╝īÕÅ»õ╗źµś» Markdown’╝īõ╣¤ÕÅ»õ╗źµś» Textile,µł¢ĶĆģÕ░▒µś»ń«ĆÕŹĢńÜä HTML, ńäČÕÉÄ Jekyll Õ░▒õ╝ÜÕĖ«õĮĀÕźŚÕģźõĖĆõĖ¬µł¢õĖĆń│╗ÕłŚńÜäÕĖāÕ▒ĆõĖŁŃĆéÕ£©µĢ┤õĖ¬Ķ┐ćń©ŗõĖŁõĮĀÕÅ»õ╗źĶ«ŠńĮ«URLĶĘ»ÕŠä, õĮĀńÜäµ¢ćµ£¼Õ£©ÕĖāÕ▒ĆõĖŁńÜ䵜Šńż║µĀĘÕ╝ÅńŁēńŁēŃĆéĶ┐Öõ║øķāĮÕÅ»õ╗źķĆÜĶ┐ćń║»µ¢ćµ£¼ń╝¢ĶŠæµØźÕ«×ńÄ░’╝īµ£Ćń╗łńö¤µłÉńÜäķØÖµĆüķĪĄķØóÕ░▒µś»õĮĀńÜ䵳ÉÕōüõ║åŃĆé - - õĖĆõĖ¬Õ¤║µ£¼ńÜä Jekyll ńĮæń½ÖńÜäńø«ÕĮĢń╗ōµ×äõĖĆĶł¼µś»ÕāÅĶ┐ÖµĀĘńÜä’╝Ü - -``` -. -Ōö£ŌöĆŌöĆ _config.yml -Ōö£ŌöĆŌöĆ _includes -| Ōö£ŌöĆŌöĆ footer.html -| ŌööŌöĆŌöĆ header.html -Ōö£ŌöĆŌöĆ _layouts -| Ōö£ŌöĆŌöĆ default.html -| Ōö£ŌöĆŌöĆ post.html -| ŌööŌöĆŌöĆ page.html -Ōö£ŌöĆŌöĆ _posts -| ŌööŌöĆŌöĆ 2016-10-08-welcome-to-jekyll.markdown -Ōö£ŌöĆŌöĆ _sass -| Ōö£ŌöĆŌöĆ _base.scss -| Ōö£ŌöĆŌöĆ _layout.scss -| ŌööŌöĆŌöĆ _syntax-highlighting.scss -Ōö£ŌöĆŌöĆ about.md -Ōö£ŌöĆŌöĆ css -| ŌööŌöĆŌöĆ main.scss -Ōö£ŌöĆŌöĆ feed.xml -ŌööŌöĆŌöĆ index.html - -``` - -Ķ┐Öõ║øńø«ÕĮĢń╗ōµ×äõ╗źÕÅŖÕģĘõĮōńÜäõĮ£ńö©ÕÅ»õ╗źÕÅéĶĆā [Õ«śńĮæµ¢ćµĪŻ](http://jekyll.com.cn/docs/structure/) - -Ķ┐øÕģź _config.yml ķćīķØó’╝īõ┐«µö╣µłÉõĮĀµā│ń£ŗÕł░ńÜäõ┐Īµü»’╝īķ揵¢░ jekyll server ’╝īÕłĘµ¢░µĄÅĶ¦łÕÖ©Õ░▒ÕÅ»õ╗źń£ŗÕł░õĮĀÕłÜÕłÜõ┐«µö╣ńÜäõ┐Īµü»õ║åŃĆé - -Õł░µŁż’╝īÕŹÜÕ«óÕłØµŁźµÉŁÕ╗║ń«Śµś»Õ«īµłÉõ║å’╝ī - -### ÕŹÜÕ«óķā©ńĮ▓Õł░Ķ┐£ń½» - -ŃĆƵłæĶ┐ÖķćīĶ«▓ńÜ䵜»ķā©ńĮ▓Õł░ Github Page ÕłøÕ╗║õĖĆõĖ¬ github Ķ┤”ÕÅĘ’╝īńäČÕÉÄÕłøÕ╗║õĖĆõĖ¬ĶʤõĮĀĶ┤”µłĘÕÉŹõĖƵĀĘńÜäõ╗ōÕ║ō’╝īÕ”éµłæńÜä github Ķ┤”µłĘÕÉŹÕŽ [leopardpan](https://github.com/leopardpan)’╝īµłæńÜä github õ╗ōÕ║ōÕÉŹÕ░▒ÕŽ [leopardpan.github.io](https://github.com/leopardpan/leopardpan.github.io)’╝īÕłøÕ╗║ÕźĮõ║åõ╣ŗÕÉÄ’╝īµŖŖÕłÜµēŹÕ╗║ń½ŗńÜä myBlog ķĪ╣ńø« push Õł░ username.github.ioõ╗ōÕ║ōķćīÕÄ╗’╝łusernameµīćńÜ䵜»õĮĀńÜägithubńö©µłĘÕÉŹ’╝ē’╝īµŻĆµ¤źõĮĀĶ┐£ń½»õ╗ōÕ║ōÕĘ▓ń╗ÅĶʤõĮĀµ£¼Õ£░ myBlog ÕÉīµŁźõ║å’╝īńäČÕÉÄõĮĀÕ£©µĄÅĶ¦łÕÖ©ķćīĶŠōÕģź username.github.io ’╝īÕ░▒ÕÅ»õ╗źĶ«┐ķŚ«õĮĀńÜäÕŹÜÕ«óõ║åŃĆé - - -### ń╝¢ÕåÖµ¢ćń½Ā - -ŃĆĆŃĆƵēƵ£ēńÜäµ¢ćń½ĀķāĮµś» _posts ńø«ÕĮĢõĖŗķØó’╝īµ¢ćń½ĀµĀ╝Õ╝ÅõĖ║ mardown µĀ╝Õ╝Å’╝īµ¢ćń½Āµ¢ćõ╗ČÕÉŹÕÅ»õ╗źµś» .mardown µł¢ĶĆģ .mdŃĆé - -ŃĆĆŃĆĆń╝¢ÕåÖõĖĆń»ćµ¢░µ¢ćń½ĀÕŠłń«ĆÕŹĢ’╝īõĮĀÕÅ»õ╗źńø┤µÄźõ╗Ä _posts/ ńø«ÕĮĢõĖŗÕżŹÕłČõĖĆõ╗ĮÕć║µØź `2016-10-16-welcome-to-jekyllÕē»µ£¼.markdown` ’╝īõ┐«µö╣ÕÉŹÕŁŚõĖ║ 2016-10-16-article1.markdown ’╝īµ│©µäÅ’╝ܵ¢ćń½ĀÕÉŹńÜäµĀ╝Õ╝ÅÕēŹķØóÕ┐ģķĪ╗õĖ║ 2016-10-16- ’╝īµŚźµ£¤ÕÅ»õ╗źõ┐«µö╣’╝īõĮåÕ┐ģķĪ╗õĖ║ Õ╣┤-µ£ł-µŚź- µĀ╝Õ╝Å’╝īÕÉÄķØóńÜä article1 µś»µĢ┤õĖ¬µ¢ćń½ĀńÜäĶ┐׵ğ URL’╝īÕ”éµ×£µ¢ćń½ĀÕÉŹõĖ║õĖŁµ¢ć’╝īķéŻõ╣łµ¢ćń½ĀńÜäĶ┐׵ğURLÕ░▒õ╝ÜÕÅśµłÉĶ┐ÖµĀĘńÜä’╝Ühttp://leopardpan.cn/2015/08/%E6%90%AD%E5/ ’╝ī µēĆõ╗źÕ╗║Ķ««µ¢ćń½ĀÕÉŹµ£ĆÕźĮµś»Ķŗ▒µ¢ćńÜ䵳¢ĶĆģķś┐µŗēõ╝»µĢ░ÕŁŚŃĆé ÕÅīÕć╗ 2016-10-16-article1.markdown µēōÕ╝Ć - -``` - ---- -layout: post -title: "Welcome to Jekyll!" -date: 2016-10-16 11:29:08 +0800 -categories: jekyll update ---- - -µŁŻµ¢ć... - -``` - - -title: µśŠńż║ńÜäµ¢ćń½ĀÕÉŹ’╝ī Õ”é’╝Ütitle: µłæńÜäń¼¼õĖĆń»ćµ¢ćń½Ā -date: µśŠńż║ńÜäµ¢ćń½ĀÕÅæÕĖāµŚźµ£¤’╝īÕ”é’╝Üdate: 2016-10-16 -categories: tagµĀćńŁŠńÜäÕłåń▒╗’╝īÕ”é’╝Ücategories: ķÜÅń¼ö - -µ│©µäÅ’╝ܵ¢ćń½ĀÕż┤ķā©µĀ╝Õ╝ÅÕ┐ģķĪ╗õĖ║õĖŖķØóńÜä’╝ī.... Õ░▒µś»µ¢ćń½ĀńÜ䵣Żµ¢ćÕåģÕ«╣ŃĆé - -µłæÕåÖµ¢ćń½ĀõĮ┐ńö©ńÜ䵜» Sublime Text2 ń╝¢ĶŠæÕÖ©’╝īÕ”éµ×£õĮĀÕ»╣ markdown Ķ»Łµ│ĢõĖŹń夵éēńÜäĶ»Ø’╝īÕÅ»õ╗źń£ŗń£ŗ[õĮ£õĖÜķā©ĶÉĮńÜäµĢÖń©ŗ](https://www.zybuluo.com/) - - -### õĮ┐ńö©µłæńÜäÕŹÜÕ«óµ©ĪµØ┐ - -ĶÖĮńäČÕŹÜÕ«óķā©ńĮ▓Õ«īµłÉõ║å’╝īõĮĀõ╝ÜÕÅæńÄ░ÕŹÜÕ«óÕż¬ń«ĆÕŹĢõĖŹµś»õĮĀµā│Ķ”üńÜä’╝īÕ”éµ×£õĮĀÕ¢£µ¼óµłæńÜ䵩ĪµØ┐ńÜäĶ»Ø’╝īÕÅ»õ╗źõĮ┐ńö©µłæńÜ䵩ĪµØ┐ŃĆé - -ķ”¢ÕģłõĮĀĶ”üĶÄĘÕÅ¢ńÜ䵳æÕŹÜÕ«ó’╝ī[GithubķĪ╣ńø«Õ£░ÕØĆ](https://github.com/leopardpan/leopardpan.github.io.git)’╝īõĮĀÕÅ»õ╗źńø┤µÄź[ńé╣Õć╗õĖŗĶĮĮÕŹÜÕ«ó](https://github.com/leopardpan/leopardpan.github.io/archive/master.zip)’╝īĶ┐øÕÄ╗leopardpan.github.io/ ńø«ÕĮĢõĖŗ’╝ī õĮ┐ńö©ÕæĮõ╗żķā©ńĮ▓µ£¼Õ£░µ£ŹÕŖĪ - -``` -$ jekyll server -``` - -### Õ”éµ×£õĮĀµ£¼µ£║µ▓ĪķģŹńĮ«Ķ┐ćõ╗╗õĮĢjekyllńÜäńÄ»Õóā’╝īÕÅ»ĶāĮõ╝ܵŖźķöÖ - -``` -/Users/xxxxxxxx/.rvm/rubies/ruby-2.2.2/lib/ruby/site_ruby/2.2.0/rubygems/core_ext/kernel_require.rb:54:in `require': cannot load such file -- bundler (LoadError) - from /Users/xxxxxxxx/.rvm/rubies/ruby-2.2.2/lib/ruby/site_ruby/2.2.0/rubygems/core_ext/kernel_require.rb:54:in `require' - from /Users/xxxxxxxx/.rvm/gems/ruby-2.2.2/gems/jekyll-3.3.0/lib/jekyll/plugin_manager.rb:34:in `require_from_bundler' - from /Users/xxxxxxxx/.rvm/gems/ruby-2.2.2/gems/jekyll-3.3.0/exe/jekyll:9:in `
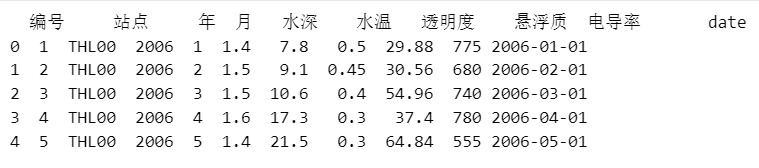
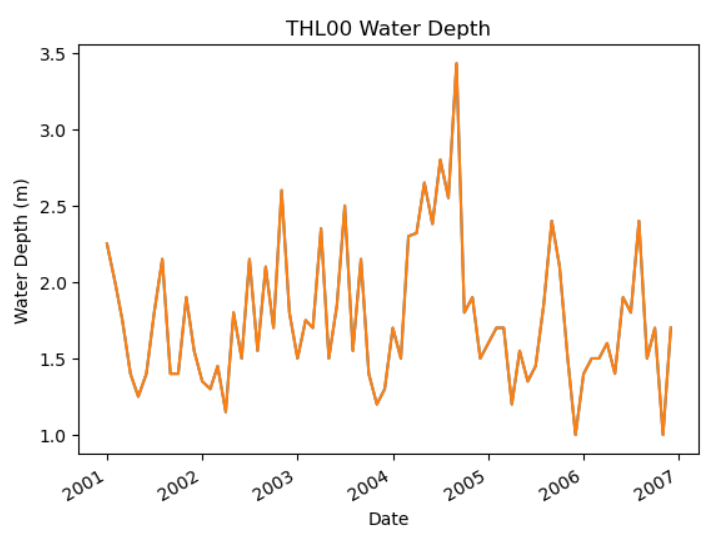
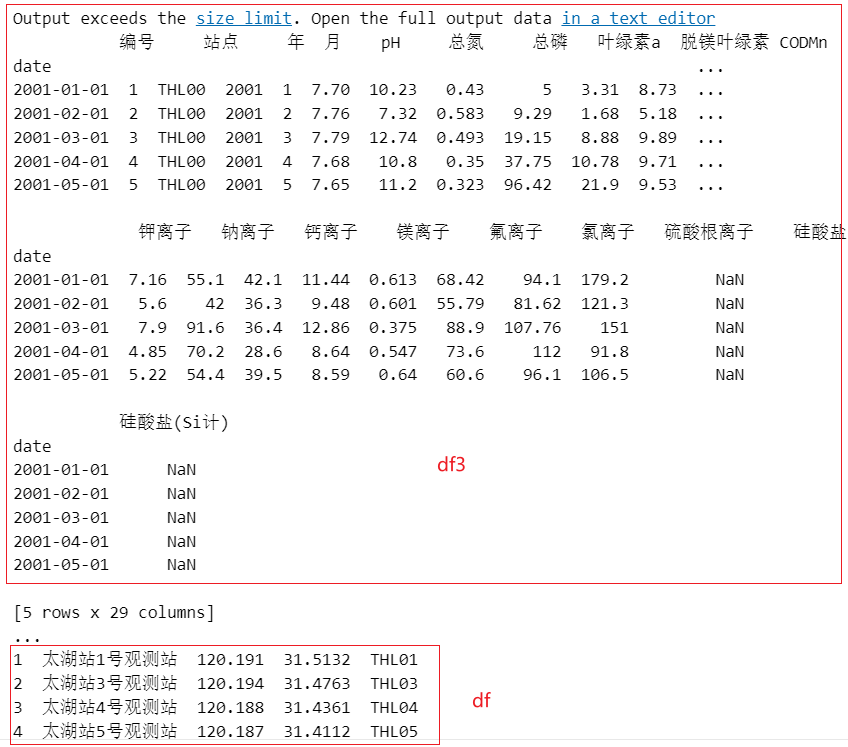
+ Õ£©_layouts/post.htmlõĖŁ’╝īÕ£©headµĀćńŁŠõĖŁÕŖĀÕģźõ╗źõĖŗõ╗ŻńĀü’╝Ü + +``` + + + + + + + +``` + +ńäČÕÉÄÕ£©_config.ymlõĖŁÕŖĀÕģźõ╗źõĖŗõ╗ŻńĀü’╝Ü + +``` +markdown: kramdown +kramdown: + math_engine: mathjax + syntax_highlighter: rouge + input: GFM + hard_wrap: false + syntax_highlighter_opts: + disable: true +``` + + + + +#### ÕåÖÕ«īõ╣ŗÕÉÄÕ”éõĮĢÕÅæÕĖā + +ÕåÖÕ«īµēƵ£ēõ╗ŻńĀüÕ╣ČõĖöÕ£©µ£¼Õ£░µ¤źń£ŗõ║åµĢłµ×£õ╣ŗÕÉÄ’╝īÕ░▒ÕÅ»õ╗źµŖŖµ£¼Õ£░ķĪ╣ńø«µēĆÕüÜńÜäµø┤µö╣pushÕł░githubõĖŖõ║åŃĆéÕ£©µ£¼Õ£░ķĪ╣ńø«ńÜäµĀ╣ńø«ÕĮĢõĖŗ’╝īµēōÕ╝Ćgit bash’╝īĶŠōÕģźõ╗źõĖŗÕæĮõ╗ż’╝Ü + +``` +git add . +git commit -m "µÅÉõ║żõ┐Īµü»" +git push -u origin master + +``` + + +### ÕŠģĶ¦ŻÕå│ÕŖ¤ĶāĮ + +1. Ķ»äĶ«║ÕŖ¤ĶāĮ’╝īµłæõ╣ŗÕēŹµīēńģ¦µĢÖń©ŗÕÄ╗Õ╝ä’╝īõĮåµś»ÕźĮÕāŵś»õĖ¬ķ¤®ÕøĮńÜäńĮæń½Ö’╝īÕ«āń╗ÖµłæÕÅæõ║åµ│©Õåīõ┐Īµü»’╝īõĮåµś»ķāĮĶó½µłæķé«ń«▒Õ×āÕ£ŠµĪČńģ¦ÕŹĢÕģ©µöČõ║åŃĆéõĖżõĖ¬µ£łõ╣ŗÕÉÄ’╝īµłæµēŹÕ£©Õ×āÕ£Šń«▒ķćīķØóµēŠÕł░’╝īõĮåµś»ķéŻõĖ¬µŚČÕĆÖµłæÕĘ▓ń╗ÅõĖŹń¤źķüōµĆÄõ╣łµÉ×õ║å’╝īń£¤ńÜ䵜»ŌĆ£Õć║ÕĖłµ£¬µŹĘĶ║½ÕģłµŁ╗ŃĆéŌĆØ + +### ÕÅéĶĆāĶ┐׵ğ + +1. [JekyllµÉŁÕ╗║õĖ¬õ║║ÕŹÜÕ«ó](http://leopardpan.github.io/2016/10/jekyll_tutorials1/) (õĮåµś»Ķ┐ÖõĖ¬Õż¦õĮ¼ÕźĮÕāÅõ╗źÕÅŖõĖŹµø┤µ¢░õ║å) +2. [ńö© Hugo ķ揵¢░µÉŁÕ╗║ÕŹÜÕ«ó](https://zhajiman.github.io/post/rebuild_blog/) +3. \ No newline at end of file diff --git "a/_posts/2022-12-14-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2501_\347\272\277\346\200\247\344\273\243\346\225\260.md" "b/_posts/2022-12-14-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2501_\347\272\277\346\200\247\344\273\243\346\225\260.md" new file mode 100644 index 0000000000..b5707e22fd --- /dev/null +++ "b/_posts/2022-12-14-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2501_\347\272\277\346\200\247\344\273\243\346\225\260.md" @@ -0,0 +1,491 @@ +--- +layout: post +title: "µ£║ÕÖ©ÕŁ”õ╣ĀÕģźķŚ©1_ń║┐µĆ¦õ╗ŻµĢ░" +date: 2022-12-14 +description: "õ╗ŗń╗Źµ£║ÕÖ©ÕŁ”õ╣ĀÕģźķŚ©ķ£ĆĶ”üńÜäń║┐µĆ¦õ╗ŻµĢ░ń¤źĶ»å’╝īÕ”éń¤®ķśĄĶĮ¼ńĮ«ŃĆüĶīāµĢ░ńŁēńŁē" +tag: µ£║ÕÖ©ÕŁ”õ╣Ā +--- + +# 00 ÕåÖÕ£©ÕēŹķØó +Õ”éõĮĢÕ░åipynbµ¢ćõ╗ČĶĮ¼õĖ║markdownµ¢ćõ╗Č’╝¤ +```shell +jupyter nbconvert --to markdown note.ipynb +``` + +# chapter 01 + + +```python +import numpy as np +# ÕÉæķćÅ +v = np.array([1,2,3]) +# ń¤®ķśĄ +m = np.array([[1,2,3],[4,5,6],[7,8,9]]) +# Õ╝ĀķćÅ +t = np.array([ + [[1,2,3],[4,5,6],[7,8,9]], + [[11,12,13],[14,15,16],[17,18,19]], + [[21,22,23],[24,25,26],[27,28,29]], +]) +print("ÕÉæķćÅ’╝Ü"+str(v)) +print("ń¤®ķśĄ’╝Ü"+str(m)) +print("Õ╝ĀķćÅ’╝Ü"+str(t)) +``` + + ÕÉæķćÅ’╝Ü[1 2 3] + ń¤®ķśĄ’╝Ü[[1 2 3] + [4 5 6] + [7 8 9]] + Õ╝ĀķćÅ’╝Ü[[[ 1 2 3] + [ 4 5 6] + [ 7 8 9]] + + [[11 12 13] + [14 15 16] + [17 18 19]] + + [[21 22 23] + [24 25 26] + [27 28 29]]] + + +## 1.2 ń¤®ķśĄĶĮ¼ńĮ« + + + +```python +a = np.array([[1,2,3],[4,5,6],[7,8,9],[10,11,12]]) +a_t = a.transpose() +print(a) +# print one line to separate the two outputs +print('-'*30) +print(a_t) +``` + + [[ 1 2 3] + [ 4 5 6] + [ 7 8 9] + [10 11 12]] + ------------------------------ + [[ 1 4 7 10] + [ 2 5 8 11] + [ 3 6 9 12]] + + +## 1.3 ń¤®ķśĄÕŖĀµ│Ģ +µ£ēµŚČÕĆÖÕģüĶ«Ėń¤®ķśĄÕÆīÕÉæķćÅńøĖÕŖĀ’╝īÕŠŚÕł░õĖĆõĖ¬ń¤®ķśĄ’╝īµ£¼Ķ┤©õĖŖµś»µ×äķĆĀõ║åõĖĆõĖ¬Õ░åbµīēĶĪīÕżŹÕłČńÜäõĖĆõĖ¬µ¢░ń¤®ķśĄ’╝īĶ┐Öń¦ŹµōŹõĮ£ÕŽÕüÜÕ╣┐µÆŁ’╝łbroadcasting’╝ēŃĆé + + +## 1.4 ń¤®ķśĄõ╣śµ│Ģ +ń¤®ķśĄõ╣śµ│ĢńÜäń╗ōµ×£µś»õĖĆõĖ¬ń¤®ķśĄ’╝īÕģČń¼¼iĶĪīń¼¼jÕłŚńÜäÕģāń┤Āµś»ń¤®ķśĄAńÜäń¼¼iĶĪīõĖÄń¤®ķśĄBńÜäń¼¼jÕłŚńÜäÕåģń¦»ŃĆéAńÜäÕĮóńŖČõĖ║m├Śn’╝īBńÜäÕĮóńŖČõĖ║n├Śp’╝īķéŻõ╣łA├ŚBńÜäÕĮóńŖČõĖ║m├ŚpŃĆéń¤®ķśĄõ╣śµ│ĢńÜäĶ«Īń«ŚÕÅ»õ╗źńö©õĖŗķØóńÜäÕģ¼Õ╝ÅĶĪ©ńż║’╝Ü + $$c[i,j] = a[i,:] * b[:,j]$$ + + +```python +m1 = np.array([[1.0,3.0],[1.0,0.0]]) +m2 = np.array([[1.0,2.0],[3.0,5.0]]) +print(m1) +print(m2) +# ń¤®ķśĄõ╣śµ│Ģ +m3 = np.dot(m1,m2) +print(m3) +# ń¤®ķśĄµīēÕģāń┤ĀńøĖõ╣ś +m4 = np.multiply(m1,m2) +# ń¤®ķśĄµīēÕģāń┤ĀńøĖõ╣ś +m5 = m1*m2 +print(m4) +print(m5) +``` + + [[1. 3.] + [1. 0.]] + [[1. 2.] + [3. 5.]] + [[10. 17.] + [ 1. 2.]] + [[1. 6.] + [3. 0.]] + [[1. 6.] + [3. 0.]] + + +## 1.5 ÕŹĢõĮŹń¤®ķśĄ +ÕŹĢõĮŹń¤®ķśĄµś»õĖĆõĖ¬µ¢╣ķśĄ’╝īÕ»╣Ķ¦Æń║┐õĖŖńÜäÕģāń┤ĀõĖ║1’╝īÕģČõĮÖÕģāń┤ĀõĖ║0ŃĆéÕŹĢõĮŹń¤®ķśĄńÜäõĮ£ńö©µś»õĖŹµö╣ÕÅśń¤®ķśĄńÜäÕĆ╝’╝īÕ«āõ╣śõ╗źõ╗╗õĮĢń¤®ķśĄķāĮńŁēõ║ÄÕĤń¤®ķśĄŃĆé + + +```python +np.identity(3) +``` + array([[1., 0., 0.], + [0., 1., 0.], + [0., 0., 1.]]) + + + +## 1.6 ń¤®ķśĄńÜäķĆå +ń¤®ķśĄAńÜäķĆå’╝łinverse’╝ēµś»õĖĆõĖ¬ń¤®ķśĄB’╝īõĮ┐ÕŠŚA├ŚB=I’╝īÕģČõĖŁIµś»ÕŹĢõĮŹń¤®ķśĄŃĆéń¤®ķśĄAńÜäķĆåĶ«░õĖ║$A^{ŌłÆ1}$ŃĆéÕ”éµ×£Aµś»õĖĆõĖ¬µ¢╣ķśĄ’╝īķéŻõ╣łAńÜäķĆåõ╣¤µś»õĖĆõĖ¬µ¢╣ķśĄŃĆéÕ”éµ×£AńÜäķĆåÕŁśÕ£©’╝īķéŻõ╣łAńÜäķĆåõ╣¤ÕŽÕüÜAńÜäõ╝¬ķĆå’╝łpseudo-inverse’╝ēŃĆé + + +```python +A = [[1,2],[4,5]] +A_inv = np.linalg.inv(A) +print(A_inv) +``` + [[-1.66666667 0.66666667] + [ 1.33333333 -0.33333333]] + + +## 1.7ĶīāµĢ░ norm +ÕÉæķćÅ$L^P$ĶīāµĢ░Õ«Üõ╣ēõĖ║’╝Ü
+$$||x||_p = (\sum_{i=1}^n |x_i|^p)^{1/p},p\geq 1,p\in\mathbb{R}$$ + +L1ĶīāµĢ░’╝ÜÕÉæķćÅõĖŁÕÉäõĖ¬Õģāń┤Āń╗ØÕ»╣ÕĆ╝õ╣ŗÕÆī
+$$||x||_1 = \sum_{i=1}^n |x_i|$$ + +L0ĶīāµĢ░’╝ÜÕÉæķćÅõĖŁķØ×ķøČÕģāń┤ĀńÜäõĖ¬µĢ░
+$$||x||_0 = \sum_{i=1}^n \mathbb{1}(x_i\neq 0)$$ + +L2ĶīāµĢ░’╝ÜÕÉæķćÅõĖŁÕÉäõĖ¬Õģāń┤ĀÕ╣│µ¢╣ÕÆīńÜäÕ╣│µ¢╣µĀ╣,õ╣¤ÕŽµ¼¦Õ╝ÅĶīāµĢ░,µś»ÕÉæķćÅxÕł░ÕĤńé╣ńÜäµ¼¦ÕćĀķćīÕŠŚĶĘØń”╗’╝īµ£ēµŚČÕĆÖõ╣¤ńö©L2ĶīāµĢ░ńÜäµØźĶĪĪķćÅÕÉæķćÅ’╝Ü$x^Tx$.
+$$||x||_2 = \sqrt{\sum_{i=1}^n x_i^2}$$ + +LŌł×ĶīāµĢ░’╝ÜÕÉæķćÅõĖŁÕÉäõĖ¬Õģāń┤Āń╗ØÕ»╣ÕĆ╝ńÜäµ£ĆÕż¦ÕĆ╝
+$$||x||_\infty = \max_{i=1,\cdots,n}|x_i|$$ + +µ£║ÕÖ©ÕŁ”õ╣ĀõĖŁÕĖĖńö©ńÜäĶīāµĢ░µ£ēL1ĶīāµĢ░ÕÆīL2ĶīāµĢ░’╝īL1ĶīāµĢ░ńö©õ║Äń©Ćń¢ÅµĆ¦ńÜäõ╝śÕī¢’╝īL2ĶīāµĢ░ńö©õ║ÄÕćĖõ╝śÕī¢ŃĆé + +```python +import numpy as np +a = np.array([1.0,3.0,5.0]) +print("ÕÉæķćÅńÜä2ĶīāµĢ░’╝Ü"+str(np.linalg.norm(a,ord=2))) +print("ÕÉæķćÅńÜä1ĶīāµĢ░’╝Ü"+str(np.linalg.norm(a,ord=1))) +print("ÕÉæķćÅńÜ䵌Āń®ĘĶīāµĢ░’╝Ü"+str(np.linalg.norm(a,ord=np.inf))) +# ń¤®ķśĄµēŹµ£ēFrobeniusĶīāµĢ░ +b = np.array([[1.0,3.0,5.0],[2.0,4.0,6.0]]) +print('ÕÉæķćÅńÜäFrobeniusĶīāµĢ░’╝Ü'+str(np.linalg.norm(b,ord='fro'))) +``` + + ÕÉæķćÅńÜä2ĶīāµĢ░’╝Ü5.916079783099616 + ÕÉæķćÅńÜä1ĶīāµĢ░’╝Ü9.0 + ÕÉæķćÅńÜ䵌Āń®ĘĶīāµĢ░’╝Ü5.0 + ÕÉæķćÅńÜäFrobeniusĶīāµĢ░’╝Ü9.539392014169456 + + +## 1.8 ńē╣ÕŠüÕĆ╝ÕłåĶ¦Ż +Õ”éµ×£õĖĆõĖ¬n├ŚnńÜäń¤®ķśĄAµ£ēnń╗äń║┐µĆ¦µŚĀÕģ│ńÜäÕŹĢõĮŹńē╣ÕŠüÕÉæķćÅ{$v^1$, $v^2$, $\cdots$, $v^n$}’╝īÕ╣ČõĖöÕ»╣Õ║öńÜäńē╣ÕŠüÕĆ╝õĖ║{$\lambda_1$, $\lambda_2$, $\cdots$, $\lambda_n$}’╝īķéŻõ╣łń¤®ķśĄAÕÅ»õ╗źĶó½ÕłåĶ¦ŻõĖ║’╝Ü
+ $$A = V diag(\lambda) V^{-1}$$ + +õĖŹµś»µēƵ£ēńÜäń¤®ķśĄķāĮµ£ēńē╣ÕŠüÕĆ╝ÕłåĶ¦Ż’╝īÕ”éµ×£Aµś»õĖĆõĖ¬n├ŚnńÜäń¤®ķśĄ’╝īķéŻõ╣łAńÜäńē╣ÕŠüÕĆ╝ÕłåĶ¦ŻÕŁśÕ£©ÕĮōõĖöõ╗ģÕĮōAµś»ÕÅ»ķĆåńÜäõĖöAńÜäĶĪīÕłŚÕ╝ÅõĖŹõĖ║0ŃĆéÕ”éµ×£AńÜäńē╣ÕŠüÕĆ╝ÕłåĶ¦ŻÕŁśÕ£©’╝īķéŻõ╣łAńÜäńē╣ÕŠüÕĆ╝ÕłåĶ¦Żµś»Õö»õĖĆńÜäŃĆé + + +```python +A = np.array([[1,2,3],[4,5,6],[7,8,9]]) +# Ķ«Īń«Śńē╣ÕŠüÕĆ╝ +eig_value,eig_vector = np.linalg.eig(A) +print("ńē╣ÕŠüÕĆ╝’╝Ü"+str(eig_value)) +print("ńē╣ÕŠüÕÉæķćÅ’╝Ü"+str(eig_vector)) +``` + + ńē╣ÕŠüÕĆ╝’╝Ü[ 1.61168440e+01 -1.11684397e+00 -1.30367773e-15] + ńē╣ÕŠüÕÉæķćÅ’╝Ü[[-0.23197069 -0.78583024 0.40824829] + [-0.52532209 -0.08675134 -0.81649658] + [-0.8186735 0.61232756 0.40824829]] + + +## 1.9 ÕźćÕ╝éÕĆ╝ÕłåĶ¦Ż +ÕźćÕ╝éÕĆ╝ÕłåĶ¦Ż’╝łSingular Value Decomposition’╝īSVD’╝ēµś»õĖĆń¦Źń¤®ķśĄÕłåĶ¦Żµ¢╣µ│Ģ’╝īÕ«āÕ░åõĖĆõĖ¬ń¤®ķśĄÕłåĶ¦ŻõĖ║ÕźćÕ╝éÕÉæķćÅÕÆīÕźćÕ╝éÕĆ╝’╝īÕ«āńÜäÕłåĶ¦ŻÕĮóÕ╝ÅÕ”éõĖŗ’╝Ü
+ $$A = U\Sigma V^T$$ + +ĶŗźAµś»m├ŚnńÜäń¤®ķśĄ’╝īķéŻõ╣łUµś»m├ŚmńÜ䵣Żõ║żń¤®ķśĄ’╝łÕģČÕłŚÕÉæķćÅń¦░õĖ║ÕĘ”ÕźćÕ╝éÕÉæķćÅ’╝ē’╝īVµś»n├ŚnńÜ䵣Żõ║żń¤®ķśĄ’╝łÕģČÕłŚÕÉæķćÅń¦░õĖ║ÕÅ│ÕźćÕ╝éÕÉæķćÅ’╝ē’╝ī$\Sigma$µś»m├ŚnńÜäÕ»╣Ķ¦Æń¤®ķśĄ’╝łÕ»╣Ķ¦Æń║┐õĖŖńÜäÕģāń┤Āń¦░õĖ║ÕźćÕ╝éÕĆ╝’╝ēŃĆéÕźćÕ╝éÕĆ╝ÕłåĶ¦ŻńÜäõĮ£ńö©µś»Õ░åõĖĆõĖ¬ń¤®ķśĄÕłåĶ¦ŻõĖ║õĖēõĖ¬ń¤®ķśĄńÜäõ╣śń¦»’╝īĶ┐ÖõĖēõĖ¬ń¤®ķśĄÕłåÕł½µś»µŁŻõ║żń¤®ķśĄÕÆīÕ»╣Ķ¦Æń¤®ķśĄ’╝īĶ┐ÖµĀĘÕ░▒ÕÅ»õ╗źÕ░åń¤®ķśĄńÜäń¦®ķÖŹõĮÄ’╝īõ╗ÄĶĆīĶŠŠÕł░ķÖŹń╗┤ńÜäńø«ńÜäŃĆé + +õ║ŗÕ«×õĖŖ’╝īÕĘ”ÕźćÕ╝éÕÉæķćÅÕ╝Å$AA^T$ńÜäńē╣ÕŠüÕÉæķćÅ’╝īÕÅ│ÕźćÕ╝éÕÉæķćŵś»$A^TA$ńÜäńē╣ÕŠüÕÉæķćÅ’╝īÕźćÕ╝éÕĆ╝µś»$AA^T$ńē╣ÕŠüÕĆ╝ńÜäÕ╣│µ¢╣µĀ╣ŃĆé + + +```python +A = np.array([[1,2,3],[4,5,6],[7,8,9]]) +U,D,V= np.linalg.svd(A) +print("U’╝Ü"+str(U)) +print("D’╝Ü"+str(D)) +print("V’╝Ü"+str(V)) +``` + + U’╝Ü[[-0.21483724 0.88723069 0.40824829] + [-0.52058739 0.24964395 -0.81649658] + [-0.82633754 -0.38794278 0.40824829]] + D’╝Ü[1.68481034e+01 1.06836951e+00 4.41842475e-16] + V’╝Ü[[-0.47967118 -0.57236779 -0.66506441] + [-0.77669099 -0.07568647 0.62531805] + [-0.40824829 0.81649658 -0.40824829]] + + +## 1.10 PCAÕłåĶ¦Ż +ÕüćĶ«Šµłæõ╗¼µ£ēmõĖ¬µĢ░µŹ«ńé╣$x^1,x^2,\cdot,x^m \in \mathbb{R}^n$,µ»ÅõĖ¬µĢ░µŹ«ńé╣µś»õĖĆõĖ¬nń╗┤ńÜäÕÉæķćÅ’╝īµłæõ╗¼ÕĖīµ£øÕ░åĶ┐Öõ║øµĢ░µŹ«ńé╣µŖĢÕĮ▒Õł░õĖĆõĖ¬lń╗┤ńÜäń®║ķŚ┤õĖŁ(ķÖŹń║¼õ╣ŗÕÉÄńÜ䵏¤Õż▒õ┐Īµü»Õ░ĮÕÅ»ĶāĮÕ£░Õ░æ’╝ē’╝īõĮ┐ÕŠŚµŖĢÕĮ▒ÕÉÄńÜäµĢ░µŹ«ńé╣õ╣ŗķŚ┤ńÜäĶĘØń”╗Õ░ĮÕÅ»ĶāĮńÜäÕż¦’╝īĶĆīµŖĢÕĮ▒ÕÉÄńÜäµĢ░µŹ«ńé╣õĖÄÕĤզŗµĢ░µŹ«ńé╣õ╣ŗķŚ┤ńÜäĶĘØń”╗Õ░ĮÕÅ»ĶāĮńÜäÕ░ÅŃĆéĶ┐ÖÕ░▒µś»PCAÕłåĶ¦ŻŃĆé +PCAÕłåĶ¦Żµś»ń║┐µĆ¦ÕÅśÕī¢’╝īÕüćĶ«Š$x^i$ÕłåĶ¦Żõ╣ŗÕÉÄńÜäÕ»╣Õ║öńé╣õĖ║$c^i$’╝īķéŻõ╣łµ£ē’╝Ü
+ $$f(x) =c $$
+ $$c \approx =g(f(x))$$
+ $$g(c)=Dc,D \in \mathbb{R}^{n\times l}$$
+õĖ║õ║åĶ«Īń«Śµ¢╣õŠ┐’╝īµłæõ╗¼Õ░åĶ┐ÖõĖ¬ń¤®ķśĄńÜäÕłŚÕÉæķćÅń║”µØ¤õĖ║ńøĖõ║ƵŁŻõ║żńÜä’╝øĶĆīõĖö’╝īĶĆāĶÖæÕł░Õ░║Õ║”ń╝®µöŠńÜäķŚ«ķóś’╝īµłæõ╗¼Õ░åĶ┐ÖõĖ¬ń¤®ķśĄńÜäÕłŚÕÉæķćÅń║”µØ¤õĖ║Õģʵ£ēÕŹĢõĮŹĶīāµĢ░µØźĶÄĘÕŠŚÕö»Ō╝ĆĶ¦ŻŃĆé +Õ»╣õ║Äń╗ÖÕ«ÜńÜäx’╝īµłæõ╗¼ķ£ĆĶ”üµēŠÕł░õ┐Īµü»µŹ¤Õż▒µ£ĆÕ░ÅńÜä$\boldsymbol{c}^{\star}$:
+$$\boldsymbol{c}^{\star}=\arg \min _{\boldsymbol{c}}\|\boldsymbol{x}-g(\boldsymbol{c})\|_2=\arg \min _{\boldsymbol{c}}\|\boldsymbol{x}-g(\boldsymbol{c})\|_2^2$$ + +Ķ┐Öķćīµłæõ╗¼ńö©õ║īĶīāµĢ░µØźĶĪĪķćÅõ┐Īµü»ńÜ䵏¤Õż▒ŃĆéÕ▒ĢÕ╝Ćõ╣ŗÕÉĵłæõ╗¼µ£ē:
+$$ +\|\boldsymbol{x}-g(\boldsymbol{c})\|_2^2=(\boldsymbol{x}-g(\boldsymbol{c}))^{\top}(\boldsymbol{x}-g(\boldsymbol{c}))=\boldsymbol{x}^{\top} \boldsymbol{x}-2 \boldsymbol{x}^{\top} g(\boldsymbol{c})+g(\boldsymbol{c})^{\top} g(\boldsymbol{c}) +$$ + +ń╗ōÕÉł $g(\boldsymbol{c})$ ńÜäĶĪ©ĶŠŠÕ╝Å, Õ┐ĮńĢźõĖŹõŠØĶĄ¢ $\boldsymbol{c}$ ńÜä $\boldsymbol{x}^{\top} \boldsymbol{x}$ ķĪ╣, µłæõ╗¼µ£ē:
+$$ +\begin{aligned} +\boldsymbol{c}^{\star} & =\arg \min _{\boldsymbol{c}}-2 \boldsymbol{x}^{\top} \boldsymbol{D} \boldsymbol{c}+\boldsymbol{c}^{\top} \boldsymbol{D}^{\top} \boldsymbol{D} \boldsymbol{c} \\ +& =\arg \min _{\boldsymbol{c}}-2 \boldsymbol{x}^{\top} \boldsymbol{D} \boldsymbol{c}+\boldsymbol{c}^{\top} \boldsymbol{I}_l \boldsymbol{c} \\ +& =\arg \min _{\boldsymbol{c}}-2 \boldsymbol{x}^{\top} \boldsymbol{D} \boldsymbol{c}+\boldsymbol{c}^{\top} \boldsymbol{c} +\end{aligned} +$$ + + +Ķ┐Öķćī $\boldsymbol{D}$ Õģʵ£ēÕŹĢõĮŹµŁŻõ║żµĆ¦ŃĆé +Õ»╣ $\boldsymbol{c}$ µ▒éµó»Õ║”, Õ╣Čõ╗żÕģČõĖ║ķøČ, µłæõ╗¼µ£ē:
+ + +$$ +\begin{aligned} +\nabla_{\boldsymbol{c}}\left(-2 \boldsymbol{x}^{\top} \boldsymbol{D} \boldsymbol{c}+\boldsymbol{c}^{\top} \boldsymbol{c}\right) & =\mathbf{0} \\ +-2 \boldsymbol{D}^{\top} \boldsymbol{x}+2 \boldsymbol{c} & =\mathbf{0} \\ +\boldsymbol{c} & =\boldsymbol{D}^{\top} \boldsymbol{x} +\end{aligned} +$$ + +ÕøĀµŁż, µłæõ╗¼ńÜäń╝¢ńĀüÕćĮµĢ░õĖ║:
+$$ +f(x)=D^{\top} \boldsymbol{x} +$$ + +µŁżµŚČķĆÜĶ┐ćń╝¢ńĀüĶ¦ŻńĀüÕŠŚÕł░ńÜä $ķ揵×ä\boldsymbol{x}$ õĖ║:
+$$r(x)=g(f(x))=DD^{\top}x$$ + +µÄźõĖŗµØźµ▒éĶ¦Żµ£Ćõ╝śńÜäÕÅśµŹó $\boldsymbol{D}$ ŃĆéńö▒õ║ĵłæõ╗¼ķ£ĆĶ”üÕ░å $\boldsymbol{D}$ Õ║öńö©Õł░µēƵ£ēńÜä $\boldsymbol{x}_i$ õĖŖ’╝īµēĆõ╗źµłæõ╗¼ķ£ĆĶ”üµ£Ćõ╝śÕī¢: +$$ +\begin{array}{l} +\boldsymbol{D}^{\star}=\arg \min _{\boldsymbol{D}} \sqrt{\sum_{i, j}\left(\boldsymbol{x}_j^{(i)}-r\left(\boldsymbol{x}^{(i)}\right)_j\right)^2} \\ +\text { s.t. } \boldsymbol{D}^{\top} \boldsymbol{D}=\boldsymbol{I}_l +\end{array} +$$ +
+õĖ║õ║åµ¢╣õŠ┐, µłæõ╗¼ĶĆāĶÖæ $l=1$ ńÜäµāģÕåĄ, µŁżµŚČķŚ«ķóśń«ĆÕī¢õĖ║: +$$ +\begin{array}{l} +\left.\boldsymbol{d}^{\star}=\arg \min _{\boldsymbol{d}} \sum_i\left(\boldsymbol{x}_j^{(i)}-\boldsymbol{d} \boldsymbol{d}^{\top} \boldsymbol{x}^{(i)}\right)\right)^2 \\ +\text { s.t. } \boldsymbol{d}^{\top} \boldsymbol{d}=1 +\end{array} +$$ +
+ĶĆāĶÖæ $\mathrm{F}$ ĶīāµĢ░, Õ╣ČĶ┐øõĖƵŁźńÜäµÄ©Õ»╝:
+$$ +\begin{array}{l} +\boldsymbol{d}^{\star}=\arg \max _{\boldsymbol{d}} \operatorname{Tr}\left(\boldsymbol{d}^{\top} \boldsymbol{X}^{\top} \boldsymbol{X} \boldsymbol{d}\right) \\ +\text { s.t. } \boldsymbol{d}^{\top} \boldsymbol{d}=1 +\end{array} +$$ + +õ╝śÕī¢ķŚ«ķóśÕÅ»õ╗źńö©ńē╣ÕŠüÕĆ╝ÕłåĶ¦ŻµØźµ▒éĶ¦ŻŃĆé + +Õ«×ķÖģĶ«Īń«ŚõĖŁ,PCAÕłåĶ¦ŻńÜäÕ«×ńÄ░µś»Õ¤║õ║ÄSVDÕłåĶ¦ŻńÜä,ÕŹ│ÕüćĶ«Šµ£ēõĖĆõĖ¬ $m \times n$ ńÜäń¤®ķśĄ $\boldsymbol{X}$, µĢ░µŹ«ńÜäÕØćÕĆ╝õĖ║ķøČ, ÕŹ│ $\mathbb{E}[\boldsymbol{x}]=0, \boldsymbol{X}$ Õ»╣Õ║öńÜ䵌ĀÕüŵĀʵ£¼ÕŹÅµ¢╣ÕĘ«ń¤®ķśĄ: $\operatorname{Var}[\boldsymbol{x}]=\frac{1}{m-1} \boldsymbol{X}^{\top} \boldsymbol{X}^{\mathrm{d}}$ + + +PCA µś»ķĆÜĶ┐ćń║┐µĆ¦ÕÅśµŹóµēŠÕł░õĖĆõĖ¬ $\operatorname{Var}[c]$ µś»Õ»╣Ķ¦Æń¤®ķśĄńÜäĶĪ©ńż║ $\boldsymbol{c}=\boldsymbol{V}^{\top} \boldsymbol{x}$, ń¤®ķśĄ $\boldsymbol{X}$ ńÜäõĖ╗µłÉÕłåÕÅ»õ╗źķĆÜĶ┐ćÕźćÕ╝éÕĆ╝ÕłåĶ¦Ż (SVD) ÕŠŚÕł░, õ╣¤Õ░▒µś»Ķ»┤õĖ╗µłÉÕłåµś» $\boldsymbol{X}$ ńÜäÕÅ│ÕźćÕ╝éÕÉæķćÅŃĆéÕüćĶ«Š $\boldsymbol{V}$ µś» $\boldsymbol{X}=\boldsymbol{U} \boldsymbol{\Sigma} \boldsymbol{V}^{\top}$ ÕźćÕ╝éÕĆ╝ÕłåĶ¦ŻńÜäÕÅ│ÕźćÕ╝éÕÉæķćÅ, µłæõ╗¼ÕŠŚÕł░ÕĤµØźńÜäńē╣ÕŠüÕÉæķćŵ¢╣ń©ŗ: +$$ +\boldsymbol{X}^{\top} \boldsymbol{X}=\left(\boldsymbol{U} \boldsymbol{\Sigma} \boldsymbol{V}^{\top}\right)^{\top} \boldsymbol{U} \boldsymbol{\Sigma} \boldsymbol{V}^{\top}=\boldsymbol{V} \boldsymbol{\Sigma}^{\top} \boldsymbol{U}^{\top} \boldsymbol{U} \boldsymbol{\Sigma} \boldsymbol{V}^{\top}=\boldsymbol{V} \boldsymbol{\Sigma}^2 \boldsymbol{V}^{\top} +$$ +ÕøĀõĖ║µĀ╣µŹ«ÕźćÕ╝éÕĆ╝ńÜäÕ«Üõ╣ē $\boldsymbol{U}^{\top} \boldsymbol{U}=\boldsymbol{I}$ ŃĆéÕøĀµŁż $\boldsymbol{X}$ ńÜäµ¢╣ÕĘ«ÕÅ»õ╗źĶĪ©ńż║õĖ║’╝Ü $\operatorname{Var}[\boldsymbol{x}]=\frac{1}{m-1} \boldsymbol{X}^{\top} \boldsymbol{X}=\frac{1}{m-1} \boldsymbol{V} \boldsymbol{\Sigma}^2 \boldsymbol{V}^{\top}$ ŃĆé +µēĆõ╗ź $\boldsymbol{c}$ ńÜäÕŹÅµ¢╣ÕĘ«µ╗ĪĶČ│’╝Ü $\operatorname{Var}[\boldsymbol{c}]=\frac{1}{m-1} \boldsymbol{C}^{\top} \boldsymbol{C}=\frac{1}{m-1} \boldsymbol{V}^{\top} \boldsymbol{X}^{\top} \boldsymbol{X} \boldsymbol{V}=\frac{1}{m-1} \boldsymbol{V}^{\top} \boldsymbol{V} \boldsymbol{\Sigma}^2 \boldsymbol{V}^{\top} \boldsymbol{V}=\frac{1}{m-1} \boldsymbol{\Sigma}^2$, ÕøĀõĖ║µĀ╣µŹ«ÕźćÕ╝éÕĆ╝Õ«Üõ╣ē $\boldsymbol{V}^{\top} \boldsymbol{V}=\boldsymbol{I}$ ŃĆé $\boldsymbol{c}$ ńÜäÕŹÅµ¢╣ÕĘ«µś»Õ»╣ Ķ¦ÆńÜä, $c$ õĖŁńÜäÕģāń┤Āµś»ÕĮ╝µŁżµŚĀÕģ│ńÜäŃĆé + + + + + + +```python +# õ╗ź iris µĢ░µŹ«õĖ║õŠŗ’╝īÕ▒ĢŌĮ░ PCA ńÜäõĮ┐ŌĮżŃĆé +import pandas as pd +import numpy as np +from sklearn.datasets import load_iris +import matplotlib.pyplot as plt +from sklearn.preprocessing import StandardScaler +%matplotlib inline + + # ĶĮĮÕģźµĢ░µŹ« +iris = load_iris() +df = pd.DataFrame(iris.data, columns=iris.feature_names) +df['label'] = iris.target +df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label'] +# µ¤źń£ŗµĢ░µŹ« +df.tail() +``` + + + + +
+
+
+
+
+
+
+
+
+
+```python
+# ÕćåÕżćµĢ░µŹ«
+X = df.iloc[:,0:4]# ÕÅ¢ÕēŹ4ÕłŚõĖ║ńē╣ÕŠü
+y =df.iloc[:,4]# µ£ĆÕÉÄõĖĆÕłŚõĖ║µĀćńŁŠ
+```
+
+
+```python
+class PCA():
+ def __init(self):
+ pass
+ def fit(self,X,n_components):
+ n_samples = np.shape(X)[0]
+ covariance_matrix = 1/(n_samples-1) * (X-X.mean(axis=0)).T.dot(X-X.mean(axis=0))
+ # Õ»╣ÕŹÅµ¢╣ÕĘ«ń¤®ķśĄĶ┐øĶĪīńē╣ÕŠüÕĆ╝ÕłåĶ¦Ż
+ eig_vals, eig_vecs = np.linalg.eig(covariance_matrix)
+ # Õ»╣ńē╣ÕŠüÕĆ╝Ķ┐øĶĪīķÖŹÕ║ŵÄÆÕ║Å
+ idx = eig_vals.argsort()[::-1]
+ eig_vals = eig_vals[idx][:n_components] # ÕÅ¢ÕēŹnõĖ¬ńē╣ÕŠüÕĆ╝
+ # atleast_1dÕćĮµĢ░Õ░åĶŠōÕģźĶĮ¼µŹóõĖ║Ķć│Õ░æõĖ║1ń╗┤ńÜäµĢ░ń╗ä
+ eig_vecs = np.atleast_1d(eig_vecs[:,idx])[:,:n_components]
+
+ # ÕŠŚÕł░ķÖŹń║¼õ╣ŗÕÉÄńÜäµĢ░µŹ«
+ X_transformed = X.dot(eig_vecs)
+ return X_transformed
+
+```
+
+
+```python
+model = PCA()
+Y = model.fit(X,2)# ķÖŹń╗┤Õł░2ń╗┤
+```
+
+
+```python
+# ķÖŹń╗┤ÕÉÄńÜäµĢ░µŹ«,2ÕłŚ’╝īÕłåÕł½µś»pca1ÕÆīpca2,columnsĶĪ©ńż║ÕłŚÕÉŹ
+pcaDf = pd.DataFrame(np.array(Y),columns=['pca1','pca2'])
+Df = pd.concat([pcaDf,y],axis=1)# axis =1ĶĪ©ńż║ÕłŚÕÉłÕ╣Č
+ax= plt.figure(figsize = (5,5))
+ax = plt.subplot(1,1,1)
+ax.set_xlabel('pca1',fontsize = 15)
+ax.set_ylabel('pca2',fontsize = 15)
+
+targets = [0,1,2] # 3õĖ¬ń▒╗Õł½
+colors = ['r','g','b'] # 3ń¦Źķó£Ķē▓’╝īĶĪ©ńż║3õĖ¬ń▒╗Õł½
+# for target,color in zip(targets,colors):
+# ax.scatter(Df[Df['label']==target]['pca1'],Df[Df['label']==target]['pca2'],c=color,s=50)
+for target,color in zip(targets,colors):
+ indicesToKeep = Df['label'] == target
+ ax.scatter(Df.loc[indicesToKeep,'pca1'],Df.loc[indicesToKeep,'pca2'],c=color,s =50)
+ax.legend(targets)
+# title
+ax.set_title('PCA of IRIS dataset')
+ax.grid()
+```
+
+
+
+
+
+
+```python
+# õĮ┐ńö©sklearnÕ«×õ╣ĀPCA
+from sklearn.decomposition import PCA
+sklearn_pca = PCA(n_components=2)
+Y = sklearn_pca.fit_transform(X)
+```
+
+
+```python
+PCADf = pd.DataFrame(np.array(Y),columns=['pca1','pca2'])
+Df = pd.concat([PCADf,y],axis=1)
+ax= plt.figure(figsize = (5,5))
+ax = plt.subplot(1,1,1)
+ax.set_xlabel('pca1',fontsize = 15)
+ax.set_ylabel('pca2',fontsize = 15)
+targets = [0,1,2] # 3õĖ¬ń▒╗Õł½
+colors = ['r','g','b'] # 3ń¦Źķó£Ķē▓’╝īĶĪ©ńż║3õĖ¬ń▒╗Õł½
+for target,color in zip(targets,colors):
+ indicesToKeep = Df['label'] == target
+ ax.scatter(Df.loc[indicesToKeep,'pca1'],Df.loc[indicesToKeep,'pca2'],c=color,s =50)
+ax.legend(targets)
+# title
+ax.set_title('PCA of IRIS dataset')
+ax.grid()
+```
+
+
+
+
+
diff --git "a/_posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272.md" "b/_posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272.md"
new file mode 100644
index 0000000000..e2c0bcc123
--- /dev/null
+++ "b/_posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272.md"
@@ -0,0 +1,825 @@
+---
+layout: post
+title: "µ£║ÕÖ©ÕŁ”õ╣ĀÕģźķŚ©2_µ”éńÄćĶ«║"
+date: 2022-12-16
+description: "õ╗ŗń╗Źµ£║ÕÖ©ÕŁ”õ╣ĀÕģźķŚ©ķ£ĆĶ”üńÜäµ”éńÄćĶ«║ń¤źĶ»åÕÆīõ┐Īµü»Ķ«║ńÜäń¤źĶ»å’╝īÕ”éķ½śµ¢»ÕłåÕĖā’╝īentrophy’╝īÕøŠµ©ĪÕ×ŗńŁēńŁē"
+tag: µ£║ÕÖ©ÕŁ”õ╣Ā
+---
+
+# 02 µ”éńÄćĶ«║õĖÄõ┐Īµü»Ķ«║
+
+### 2.1.1 µ”éĶ«║õĖÄķÜŵ£║ÕÅśķćÅ
+ķóæńÄćÕŁ”µ┤Šµ”éńÄć’╝łfrequency probability):µ”éńÄćÕÆīõ║ŗõ╗ČÕÅæńö¤ńÜäķóæńÄćńøĖÕģ│ŃĆéķóæńÄ浜»µīćõ║ŗõ╗ČÕÅæńö¤ńÜäµ¼ĪµĢ░õĖÄõ║ŗõ╗ȵĆ╗µ¼ĪµĢ░ńÜäµ»öÕĆ╝ŃĆéķóæńÄćÕŁ”µ┤Šµ”éńÄćńÜäń╝║ńé╣µś»’╝īÕ«āÕŬĶāĮńö©õ║Äń”╗µĢŻõ║ŗõ╗Č’╝īĶĆīõĖŹĶāĮńö©õ║ÄĶ┐×ń╗Łõ║ŗõ╗ČŃĆéÕøĀõĖ║Ķ┐×ń╗Łõ║ŗõ╗ČńÜäÕÅæńö¤µ¼ĪµĢ░µś»µŚĀń®ĘńÜä’╝īĶĆīõ║ŗõ╗ȵĆ╗µ¼ĪµĢ░µś»µ£ēķÖÉńÜä’╝īµēĆõ╗źÕ«āõ╗¼ńÜäµ»öÕĆ╝µś»µŚĀń®ĘÕ░ÅńÜä’╝īĶ┐ÖµĀĘÕ░▒µŚĀµ│Ģńö©ķóæńÄćµØźĶĪ©ńż║µ”éńÄćõ║åŃĆéÕøĀµŁż’╝īķóæńÄćÕŁ”µ┤Šµ”éńÄćÕŬĶāĮńö©õ║Äń”╗µĢŻõ║ŗõ╗Č’╝īĶĆīõĖŹĶāĮńö©õ║ÄĶ┐×ń╗Łõ║ŗõ╗ČŃĆé
+Ķ┤ØÕÅȵ¢»ÕŁ”µ┤Šµ”éńÄć’╝łbayesian probability’╝ē:µ”éńÄćÕÆīõ║ŗõ╗ČÕÅæńö¤ńÜäÕģłķ¬īń¤źĶ»åńøĖÕģ│ŃĆéõ╣¤Õ░▒µś»Ķ»┤’╝īµ”éńÄ浜»Õ»╣µ¤Éõ╗Čõ║ŗµāģÕÅæńö¤ńÜäõ┐ĪÕ┐āń©ŗÕ║”ńÜäÕ║”ķćÅŃĆ鵻ŵ¼Īõ║ŗõ╗ČÕÅæńö¤’╝īķāĮõ╝ܵø┤µ¢░Õģłķ¬īń¤źĶ»å’╝īõ╗ÄĶĆīÕŠŚÕł░ÕÉÄķ¬īń¤źĶ»åŃĆéĶ┤ØÕÅȵ¢»ÕŁ”µ┤Šµ”éńÄćńÜäń╝║ńé╣µś»’╝īÕ«āķ£ĆĶ”üÕģłķ¬īń¤źĶ»å’╝īĶĆīÕģłķ¬īń¤źĶ»åÕŠĆÕŠĆµś»õĖŹńĪ«Õ«ÜńÜä’╝īµēĆõ╗źĶ┤ØÕÅȵ¢»ÕŁ”µ┤Šµ”éńÄćõ╣¤µś»õĖŹńĪ«Õ«ÜńÜäŃĆé
+ķÜŵ£║ÕÅśķćÅ’╝łrandom variable)ÕÅśķćÅ’╝ÜõĖĆõĖ¬ÕÅ»ĶāĮķÜŵ£║ÕÅ¢õĖŹÕÉīÕĆ╝ńÜäÕÅśķćÅ’╝īÕ”é’╝īµŖøńĪ¼ÕĖüńÜäń╗ōµ×£’╝īµÄĘķ¬░ÕŁÉńÜäń╗ōµ×£’╝īµŖĮÕÅ¢ńÜäµĀʵ£¼ńÜäńē╣ÕŠüńŁēŃĆéķÜŵ£║ÕÅśķćÅńÜäÕÅ¢ÕĆ╝µś»ķÜŵ£║ńÜä’╝īõĮåµś»ķÜŵ£║ÕÅśķćÅńÜäÕÅ¢ÕĆ╝µś»µ£ēķÖÉńÜä’╝īµēĆõ╗źķÜŵ£║ÕÅśķćŵś»ń”╗µĢŻńÜäŃĆé
+
+### 2.1.2 ķÜŵ£║ÕÅśķćÅńÜäÕłåÕĖā
+
+µ”éĶ«║Ķ┤©ķćÅÕćĮµĢ░(probability Mass Function),Õ»╣õ║Äń”╗µĢŻÕ×ŗÕÅśķćÅ’╝īµłæõ╗¼ÕģłÕ«Üõ╣ēõĖĆõĖ¬ķÜŵ£║ÕÅśķćÅ’╝īńäČÕÉÄńö©µ”éńÄćĶ┤©ķćÅÕćĮµĢ░µØźµÅÅĶ┐░Ķ┐ÖõĖ¬ķÜŵ£║ÕÅśķćÅńÜäÕÅ¢ÕĆ╝ÕłåÕĖāŃĆéµ”éńÄćĶ┤©ķćÅÕćĮµĢ░µś»õĖĆõĖ¬ÕćĮµĢ░’╝īÕ«āńÜäĶŠōÕģźµś»ķÜŵ£║ÕÅśķćÅńÜäÕÅ¢ÕĆ╝’╝īĶŠōÕć║µś»ķÜŵ£║ÕÅśķćÅÕÅ¢Ķ┐ÖõĖ¬ÕĆ╝ńÜäµ”éńÄćŃĆéµ”éńÄćĶ┤©ķćÅÕćĮµĢ░ńÜäÕ«Üõ╣ēµś»’╝īÕ»╣õ║Äń”╗µĢŻÕ×ŗķÜŵ£║ÕÅśķćÅX’╝īÕ«āńÜäµ”éńÄćĶ┤©ķćÅÕćĮµĢ░µś»õĖĆõĖ¬ÕćĮµĢ░P(x)’╝īÕ«āńÜäÕ«Üõ╣ēÕ¤¤µś»ķÜŵ£║ÕÅśķćÅXńÜäÕÅ¢ÕĆ╝ķøåÕÉłŃĆé
+
+Õ”éõĖĆõĖ¬ń”╗µĢŻÕ×ŗxµ£ēkõĖ¬õĖŹÕÉīńÜäÕÅ¢ÕĆ╝’╝īÕüćĶ«Šxµś»ÕØćÕīĆÕłåÕĖāńÜä’╝īķéŻõ╣łµ”éńÄćĶ┤©ķćÅÕćĮµĢ░õĖ║’╝Ü| + | sepal length | +sepal width | +petal length | +petal width | +label | +
|---|---|---|---|---|---|
| 145 | +6.7 | +3.0 | +5.2 | +2.3 | +2 | +
| 146 | +6.3 | +2.5 | +5.0 | +1.9 | +2 | +
| 147 | +6.5 | +3.0 | +5.2 | +2.0 | +2 | +
| 148 | +6.2 | +3.4 | +5.4 | +2.3 | +2 | +
| 149 | +5.9 | +3.0 | +5.1 | +1.8 | +2 | +
+$$P(x=x^i)=\frac{1}{k}$$ + +µ”éĶ«║Õ»åÕ║”ÕćĮµĢ░(probability Density Function),Õ»╣õ║ÄĶ┐×ń╗ŁÕ×ŗÕÅśķćÅ’╝īµłæõ╗¼ÕģłÕ«Üõ╣ēõĖĆõĖ¬ķÜŵ£║ÕÅśķćÅ’╝īńäČÕÉÄńö©µ”éńÄćÕ»åÕ║”ÕćĮµĢ░µØźµÅÅĶ┐░Ķ┐ÖõĖ¬ķÜŵ£║ÕÅśķćÅńÜäÕÅ¢ÕĆ╝ÕłåÕĖāŃĆéµ”éńÄćÕ»åÕ║”ÕćĮµĢ░µś»õĖĆõĖ¬ÕćĮµĢ░’╝īÕ«āńÜäĶŠōÕģźµś»ķÜŵ£║ÕÅśķćÅńÜäÕÅ¢ÕĆ╝’╝īĶŠōÕć║µś»ķÜŵ£║ÕÅśķćÅÕÅ¢Ķ┐ÖõĖ¬ÕĆ╝ńÜäµ”éńÄćŃĆéµ”éńÄćÕ»åÕ║”ÕćĮµĢ░ńÜäÕ«Üõ╣ēµś»’╝īÕ»╣õ║ÄĶ┐×ń╗ŁÕ×ŗķÜŵ£║ÕÅśķćÅX’╝īÕ«āńÜäµ”éńÄćÕ»åÕ║”ÕćĮµĢ░µś»õĖĆõĖ¬ÕćĮµĢ░P(x)’╝īÕ«āńÜäÕ«Üõ╣ēÕ¤¤µś»ķÜŵ£║ÕÅśķćÅXńÜäÕÅ¢ÕĆ╝ķøåÕÉłŃĆéP’╝łx)µś»õĖĆõĖ¬ķØ×Ķ┤¤ńÜäÕćĮµĢ░’╝īÕ«āńÜäń¦»Õłåµś»1’╝īÕŹ│’╝Ü
+$$\int_{-\infty}^{\infty}P(x)dx=1$$ +õĖöµ╗ĪĶČ│ķØ×Ķ┤¤µĆ¦’╝Ü +$$ \forall x \in \mathbb{X}, P(x)\geq 0$$ + +ń┤»Ķ«ĪÕłåÕĖāÕćĮµĢ░(cumulative distribution function)ĶĪ©ńż║Õ»╣Õ░Åõ║ÄxńÜäµ”éńÄćĶ┐øĶĪīń¦»Õłå’╝īÕŹ│’╝Ü
+$$CDF(x)=\int_{-\infty}^{x}P(x)dx$$ + + + +```python +import numpy as np +import matplotlib.pyplot as plt +from scipy.stats import uniform +%matplotlib inline +``` + + +```python +# generate the sample +fig,ax = plt.subplots(1,1) +# õĮ┐ńö©ÕÅéµĢ░locÕÆīscale,ÕÅ»õ╗źÕŠŚÕł░[loc, loc + scale]õĖŖńÜäÕØćÕīĆÕłåÕĖā’╝īsize=1000ĶĪ©ńż║µĀʵ£¼µĢ░’╝īrandom_state=123ĶĪ©ńż║ķÜŵ£║ń¦ŹÕŁÉ +r = uniform.rvs(loc=0,scale=1,size=1000,random_state=123) +# density=TrueĶĪ©ńż║µ”éńÄćÕ»åÕ║”’╝īhisttype='stepfilled'ĶĪ©ńż║ÕĪ½Õģģ’╝īalpha=0.5ĶĪ©ńż║ķĆŵśÄÕ║” +ax.hist(r,density=True,histtype='stepfilled',alpha=0.5) +# ÕØćÕīĆÕłåÕĖāpdf +x = np.linspace(uniform.ppf(0.01),uniform.ppf(0.99),100) +ax.plot(x,uniform.pdf(x),'r-',lw=5,alpha =0.6,label='uniform pdf') + +``` + + + + + [
+$$ \forall x \in \mathbb{X},P(\mathrm{x}=x) = \sum_y P(\mathrm{x}=x,\mathrm{y}=y)$$ + +µØĪõ╗ȵ”éĶ«║’╝łconditional probability’╝ēÕ£©ÕŠłÕżÜµāģÕåĄõĖŗ’╝īµłæõ╗¼õĖŹõ╗ģÕģ│Õ┐āõĖĆõĖ¬õ║ŗõ╗ČńÜäµ”éńÄć’╝īĶ┐śÕģ│Õ┐āÕ£©ÕÅ”õĖĆõĖ¬õ║ŗõ╗ČÕÅæńö¤ńÜäµØĪõ╗ČõĖŗ’╝īĶ┐ÖõĖ¬õ║ŗõ╗ČńÜäµ”éńÄćŃĆéĶ┐Öń¦ŹÕ£©ÕÅ”õĖĆõĖ¬õ║ŗõ╗ČÕÅæńö¤ńÜäµØĪõ╗ČõĖŗ’╝īõ║ŗõ╗ČńÜäµ”éńÄćń¦░õĖ║µØĪõ╗ȵ”éĶ«║ŃĆéµØĪõ╗ȵ”éĶ«║ńÜäÕ«Üõ╣ēµś»’╝Ü
+$$P(\mathrm{x}=x|\mathrm{y}=y)=\frac{P(\mathrm{x}=x,\mathrm{y}=y)}{P(\mathrm{y}=y)}$$ +Ķ┐ÖõĖ¬Õģ¼Õ╝ÅĶĪ©ńż║Õ£©yÕÅæńö¤ńÜäµØĪõ╗ČõĖŗ’╝īxÕÅæńö¤ńÜäµ”éńÄćŃĆé + +µØĪõ╗ȵ”éĶ«║ńÜäķōŠÕ╝ŵ│ĢÕłÖ(chain rule of conditional probability)’╝Üõ╗╗õĮĢÕżÜń╗┤ķÜŵ£║ÕÅśķćÅńÜäĶüöÕÉłµ”éĶ«║ÕłåÕĖā’╝īķāĮÕÅ»õ╗źÕłåĶ¦ŻµłÉÕŬµ£ēÕŬµ£ēõĖĆõĖ¬ÕÅśķćÅńÜäµØĪõ╗ȵ”éĶ«║ńøĖõ╣śńÜäÕĮóÕ╝Å
+$$P(\mathrm{x}=x,\mathrm{y}=y,\mathrm{z}=z)=P(\mathrm{x}=x|\mathrm{y}=y,\mathrm{z}=z)P(\mathrm{y}=y,\mathrm{z}=z)=P(\mathrm{x}=x|\mathrm{y}=y,\mathrm{z}=z)P(\mathrm{y}=y|\mathrm{z}=z)P(\mathrm{z}=z)$$ + +$$P(x_1,x_2,\cdots,x_n)=P(x_1|x_2,\cdots,x_n)P(x_2|x_3,\cdots,x_n)\cdots P(x_{n-1}|x_n)P(x_n)$$ + +ńŗ¼ń½ŗµĆ¦’╝łindependence’╝ēÕ”éµ×£õĖżõĖ¬ķÜŵ£║ÕÅśķćÅXÕÆīYµ╗ĪĶČ│’╝Ü
+$$P(\mathrm{x}=x,\mathrm{y}=y)=P(\mathrm{x}=x)P(\mathrm{y}=y)$$ +õ╣¤ÕŹ│µś»ĶüöÕÉłµ”éĶ«║ÕłåÕĖāÕÅ»õ╗źĶĪ©ńż║µłÉÕŬµ£ēõĖĆõĖ¬ÕÅśķćÅńÜäµØĪõ╗ȵ”éĶ«║ńøĖõ╣śńÜäÕĮóÕ╝ÅŃĆé + +µØĪõ╗Čńŗ¼ń½ŗµĆ¦’╝łconditional independence’╝ēÕ”éµ×£Õģ│õ║ÄxÕÆīyńÜäµØĪõ╗ȵ”éńÄćÕłåÕĖāÕ»╣õ║ÄzńÜäµ»ÅõĖĆõĖ¬ÕĆ╝ķāĮµ╗ĪĶČ│ńŗ¼ń½ŗµĆ¦’╝īķéŻõ╣łµłæõ╗¼Õ░▒Ķ»┤xÕÆīyÕ£©zńÜäµØĪõ╗ČõĖŗµś»µØĪõ╗Čńŗ¼ń½ŗńÜäŃĆé
+$$P(\mathrm{x}=x,\mathrm{y}=y|\mathrm{z}=z)=P(\mathrm{x}=x|\mathrm{z}=z)P(\mathrm{y}=y|\mathrm{z}=z)$$ + +### 2.1.4 ķÜŵ£║ÕÅśķćÅńÜäÕ║”ķćÅ +µ£¤µ£ø’╝łexpectation’╝ēµś»ķÜŵ£║ÕÅśķćÅńÜäÕ╣│ÕØćÕĆ╝’╝īµ£¤µ£øńÜäÕ«Üõ╣ēµś»’╝Ü
+$$E(X)=\sum_x xP(X=x)$$ +Õ»╣õ║ÄĶ┐×ń╗ŁÕ×ŗķÜŵ£║ÕÅśķćÅÕÅ»õ╗źķĆÜĶ┐ćń¦»ÕłåńÜäÕĮóÕ╝ÅĶĪ©ńż║’╝Ü
+$$E(X)=\int_{-\infty}^{\infty}xP(X=x)dx$$ + +ÕÅ”Õż¢’╝īµ£¤µ£øµś»ń║┐µĆ¦ńÜä’╝īÕŹ│’╝Ü
+$$E(aX+bY)=aE(X)+bE(Y)$$ + +µ¢╣ÕĘ«’╝łvariance’╝ēµś»ķÜŵ£║ÕÅśķćÅńÜäń”╗µĢŻń©ŗÕ║”’╝īµ¢╣ÕĘ«ńÜäÕ«Üõ╣ēµś»’╝Ü
+$$Var(X)=E[(X-E(X))^2]$$ + +µĀćÕćåÕĘ«’╝łstandard deviation’╝ēµś»µ¢╣ÕĘ«ńÜäÕ╣│µ¢╣µĀ╣’╝īµĀćÕćåÕĘ«ńÜäÕ«Üõ╣ēµś»’╝Ü
+$$\sigma(X)=\sqrt{Var(X)}$$ + +ÕŹÅµ¢╣ÕĘ«’╝łcovariance’╝ēµś»õĖżõĖ¬ķÜŵ£║ÕÅśķćÅńÜäń║┐µĆ¦ńøĖÕģ│ń©ŗÕ║”’╝īÕŹÅµ¢╣ÕĘ«ńÜäÕ«Üõ╣ēµś»’╝Ü
+$$Cov(X,Y)=E[(X-E(X))(Y-E(Y))]$$ + +**µ│©µäÅ**ÕŹÅµ¢╣ÕĘ«ńÜäń¼”ÕÅĘĶĪ©ńż║õĖżõĖ¬ķÜŵ£║ÕÅśķćÅńÜäń║┐µĆ¦ńøĖÕģ│ń©ŗÕ║”’╝īµŁŻµĢ░ĶĪ©ńż║µŁŻńøĖÕģ│’╝īĶ┤¤µĢ░ĶĪ©ńż║Ķ┤¤ńøĖÕģ│’╝ī0ĶĪ©ńż║õĖŹńøĖÕģ│ŃĆé
+**µ│©µäÅ**ńŗ¼ń½ŗõĖÄķøČÕŹÅµ¢╣ÕĘ«µø┤Õ╝║’╝īÕøĀõĖ║ńŗ¼ń½ŗĶ┐śµÄÆķÖżõ║åķØ×ń║┐µĆ¦ńÜäńøĖÕģ│ŃĆé + + +```python +x= np.array([1,2,3,4,5,6,7,8,9,10]) +y = np.array([10,9,8,7,6,5,4,3,2,1]) +Mean = np.mean(x) +Var = np.var(x) +Var_unbiased = np.var(x,ddof=1)# ddof=1ĶĪ©ńż║µŚĀÕüÅõ╝░Ķ«Ī +Std = np.std(x) +Cov = np.cov(x,y) +Mean,Var,Var_unbiased,Std,Cov +``` + + + + + (5.5, + 8.25, + 9.166666666666666, + 2.8722813232690143, + array([[ 9.16666667, -9.16666667], + [-9.16666667, 9.16666667]])) + + + +### 2.1.5 ÕĖĖńö©µ”éńÄćÕłåÕĖā +õ╝»ÕŖ¬Õł®ÕłåÕĖā’╝łBernoulli distribution’╝ēµś»õĖĆõĖ¬õ║īķĪ╣ÕłåÕĖāńÜäńē╣õŠŗ’╝īÕ«āÕŬµ£ēõĖżõĖ¬ÕÅ»ĶāĮńÜäÕÅ¢ÕĆ╝’╝ī0ÕÆī1’╝īÕ«āńÜäµ”éńÄćĶ┤©ķćÅÕćĮµĢ░µś»’╝łĶĪ©ńż║õĖƵ¼ĪÕ«×ķ¬īµłÉÕŖ¤ńÜäµ”éńÄć’╝ē’╝Ü
+$$P(X=1)=p$$, +$$P(X=0)=1-p$$, +$$P(X=x)=p^x(1-p)^{1-x}$$ + + +```python +def plot_distribution(X,axes=None): + '''ń╗ÖÕ«ÜķÜŵ£║ÕÅśķćÅX’╝īń╗śÕłČÕģČPDF,PMF,CDF''' + if axes is None: + fig,axes = plt.subplots(1,3,figsize=(12,4)) + x_min,x_max = X.interval(0.99)# 99%ńÜäµ”éńÄćÕ»åÕ║”Õ£©Õī║ķŚ┤Õåģ + x = np.linspace(x_min,x_max,1000) + # Ķ┐×ń╗ŁÕ×ŗÕÅśķćÅ’╝īńö╗PDF’╝øń”╗µĢŻÕ×ŗÕÅśķćÅ’╝īńö╗PMF + if hasattr(X.dist,'pdf'): + # axes[0]ĶĪ©ńż║ń¼¼õĖĆĶĪī’╝īń¼¼õĖĆÕłŚ + axes[0].plot(x,X.pdf(x),label='PDF') + axes[0].fill_between(x,X.pdf(x),alpha=0.5) # ÕĪ½Õģģ,ķĆŵśÄÕ║”0.5 + else: + x_int = np.unique(x.astype(int))# ÕÅ¢µĢ┤,uniqueÕÄ╗ķćŹ + axes[0].bar(x_int,X.pmf(x_int),label='PMF') + # CDF + axes[1].plot(x,X.cdf(x),label='CDF') + for ax in axes: + ax.legend() + return axes +``` + + +```python +from scipy.stats import bernoulli +fig,axes = plt.subplots(1,2,figsize=(12,4)) +r = bernoulli(p=0.6) # ńö¤µłÉõ╝»ÕŖ¬Õł®ÕłåÕĖā +plot_distribution(r,axes) +``` + + + + + array([
+$$P(X=k)=p_k$$ + +õŠŗՔ鵻ŵ¼ĪĶ»Ģķ¬īńÜäń╗ōµ×£Õ░▒ÕÅ»õ╗źĶĪ©ńż║µłÉõĖĆõĖ¬kń╗┤ńÜäÕÉæķćÅ’╝īµ»ÅõĖ¬ń╗┤Õ║”ĶĪ©ńż║õĖĆń¦Źń╗ōµ×£’╝īÕŬµ£ēµŁżµ¼ĪĶ»Ģķ¬īńÜäń╗ōµ×£Õ»╣Õ║öńÜäń╗┤Õ║”õĖ║1’╝īÕģČõĮÖń╗┤Õ║”õĖ║0’╝īõŠŗÕ”é’╝Ü
+$$P(X=(1,0,0,0))=p_1$$
+$$P(X=(0,1,0,0))=p_2$$
+$$P(X=(0,0,1,0))=p_3$$
+$$P(X=(0,0,0,1))=p_4$$ + + + +```python +def k_possibilities(k): + '''ńö¤µłÉkõĖ¬ÕÅ»ĶāĮńÜäń╗ōµ×£''' + res = np.random.rand(k)# random.rand(k)ńö¤µłÉkõĖ¬[0,1)õ╣ŗķŚ┤ńÜäķÜŵ£║µĢ░ + _sum = sum(res) # µ▒éÕÆī + for i,x in enumerate(res): + res[i] = x/_sum # ÕĮÆõĖĆÕī¢,enumerateĶ┐öÕø×ń┤óÕ╝ĢÕÆīÕĆ╝,iĶĪ©ńż║ń┤óÕ╝Ģ’╝īxĶĪ©ńż║ÕĆ╝ + return res +fig,axes = plt.subplots(1,2,figsize=(12,4)) +# õĖƵ¼ĪÕ«×ķ¬ī’╝īĶīāńĢ┤ÕłåÕĖā +n_samples = 1 +k=10 +samples = np.random.multinomial(n_samples,k_possibilities(k)) +axes[0].bar(range(len(samples)),samples/n_samples,label ='Multinomial') + +# nµ¼ĪÕ«×ķ¬ī’╝īÕżÜķĪ╣ÕłåÕĖā +n_samples = 1000 +samples = np.random.multinomial(n_samples,k_possibilities(k)) +axes[1].bar(range(len(samples)),samples/n_samples,label ='Multinomial') +for ax in axes: + ax.legend() +``` + + + + + +ķ½śµ¢»ÕłåÕĖā’╝łGaussian distribution’╝īµŁŻµĆüÕłåÕĖā’╝ēµś»õĖĆõĖ¬Ķ┐×ń╗ŁÕ×ŗµ”éńÄćÕłåÕĖā’╝īĶŗźķÜŵ£║ÕÅśķćÅ$X\sim \mathcal{N}(\mu,\sigma^2)$,Õ«āńÜäµ”éńÄćÕ»åÕ║”ÕćĮµĢ░µś»’╝Ü
+$$P(X=x)=\frac{1}{\sqrt{2\pi\sigma^2}}e^{-\frac{(x-\mu)^2}{2\sigma^2}}$$
+µ£ēµŚČõ╣¤õ╝Üńö©$\beta = \frac{1}{\sigma^2}$µØźĶĪ©ńż║ÕłåÕĖāńÜäń▓ŠÕ║”(ń▓ŠÕ║”ĶČŖÕż¦’╝īÕłåÕĖāĶČŖńŗŁń¬ä’╝īprecision)’╝Ü
+$$P(X=x)=\frac{1}{\sqrt{2\pi\beta^{-1}}}e^{-\frac{(x-\mu)^2}{2\beta}}$$ + +õĖŁÕ┐āµ×üķÖÉÕ«ÜńÉå’╝łcentral limit theorem’╝ēµś»õĖĆõĖ¬ķćŹĶ”üńÜäÕ«ÜńÉå’╝īÕ«āĶĪ©ńż║ÕĮōµĀʵ£¼ķćÅĶČ│Õż¤Õż¦µŚČ’╝īµĀʵ£¼ÕØćÕĆ╝ńÜäÕłåÕĖāõ╝ÜĶČŗĶ┐æõ║ĵŁŻµĆüÕłåÕĖā’╝īÕ”éÕÖ¬ÕŻ░ńÜäÕłåÕĖāÕ░▒µś»õĖĆõĖ¬ÕģĖÕ×ŗńÜäõŠŗÕŁÉ’╝īÕÖ¬ÕŻ░ńÜäÕłåÕĖāµś»ÕØćÕīĆÕłåÕĖā’╝īõĮåµś»ÕĮōÕÖ¬ÕŻ░ńÜäµĢ░ķćÅĶČ│Õż¤ÕżÜµŚČ’╝īÕÖ¬ÕŻ░ńÜäÕØćÕĆ╝ńÜäÕłåÕĖāÕ░▒õ╝ÜĶČŗĶ┐æõ║ĵŁŻµĆüÕłåÕĖāŃĆé + +Õ”éµ×£µłæõ╗¼Õ»╣ķÜŵ£║ÕÅśķćÅĶ┐øĶĪīµĀćÕćåÕī¢’╝īÕŹ│Õ░åķÜŵ£║ÕÅśķćÅÕćÅÕÄ╗ÕØćÕĆ╝Õ╣ČķÖżõ╗źµĀćÕćåÕĘ«’╝īķéŻõ╣łµĀćÕćåÕī¢ÕÉÄńÜäķÜŵ£║ÕÅśķćÅńÜäÕØćÕĆ╝õĖ║0’╝īµĀćÕćåÕĘ«õĖ║1’╝īĶ┐ÖµĀĘńÜäķÜŵ£║ÕÅśķćÅń¦░õĖ║µĀćÕćåµŁŻµĆüÕłåÕĖā’╝łstandard normal distribution’╝ē’╝ī
+$$Z=\frac{X-\mu}{\sigma}$$ + + +```python +from scipy.stats import norm +fig,axes = plt.subplots(1,2,figsize= (12,4)) +mu,sigma = 0,1# ÕØćÕĆ╝’╝īµĀćÕćåÕĘ« +r = norm(loc=mu,scale=sigma)# ńö¤µłÉµŁŻµĆüÕłåÕĖā +plot_distribution(r,axes) #ń╗śÕłČrńÜäPDFÕÆīCDF +``` + + + + + array([
+$$P(X=x;\sigma,\Sigma)=\frac{1}{(2\pi)^{n/2}|\Sigma|^{1/2}}e^{-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu)}$$ +
+ÕģĘõĮōµÄ©Õ»╝Ķ┐ćń©ŗÕ”éõĖŗ’╝Ü
+ÕģłÕüćĶ«Š $\mathrm{n}$ õĖ¬ÕÅśķćÅ $x=\left[x_1, x_2, \cdots, x_n\right]^{\mathrm{T}}$ õ║ÆõĖŹńøĖÕģ│’╝īõĖöµ£Źõ╗ĵŁŻµĆüÕłåÕĖā (ń╗┤Õ║”õĖŹńøĖÕģ│ÕżÜÕģāµŁŻµĆüÕłåÕĖā)’╝īÕÉäõĖ¬ń╗┤Õ║”ńÜäÕØćÕĆ╝ $E(x)=\left[\mu_1, \mu_2, \cdots, \mu_n\right]^{\mathrm{T}}$ ’╝īµ¢╣ÕĘ« $\sigma(x)=\left[\sigma_1, \sigma_2, \cdots, \sigma_n\right]^{\mathrm{T}}$ +
+µĀ╣µŹ«ĶüöÕÉłµ”éńÄćÕ»åÕ║”Õģ¼Õ╝Å: +$$ +\begin{aligned} +& f(x)=p\left(x_1, x_2 \ldots x_n\right)=p\left(x_1\right) p\left(x_2\right) \ldots p\left(x_n\right)=\frac{1}{(\sqrt{2 \pi})^n \sigma_1 \sigma_2 \cdots \sigma_n} e^{-\frac{\left(x_1-\mu_1\right)^2}{2 \sigma_1^2}-\frac{\left(x_2-\mu_2\right)^2}{2 \sigma_2^2} \cdots-\frac{\left(x_n-\mu_n\right)^2}{2 \sigma_n}} \\ +& \text { õ╗ż } z^2=\frac{\left(x_1-\mu_1\right)^2}{\sigma_1^2}+\frac{\left(x_2-\mu_2\right)^2}{\sigma_2^2} \cdots+\frac{\left(x_n-\mu_n\right)^2}{\sigma_n^2}, \sigma_z=\sigma_1 \sigma_2 \cdots \sigma_n +\end{aligned} +$$ +Ķ┐ÖµĀĘÕżÜÕģāµŁŻµĆüÕłåÕĖāÕÅłÕÅ»õ╗źÕåÖµłÉõĖĆÕģāķéŻń¦Źµ╝éõ║«ńÜäÕĮóÕ╝Åõ║å(µ│©µäÅõĖĆÕģāõĖÄÕżÜÕģāńÜäÕĘ«Õł½):
+$$ +f(z)=\frac{1}{(\sqrt{2 \pi})^n \sigma_z} e^{-\frac{z^2}{2}} +$$ +
+ÕøĀõĖ║ÕżÜÕģāµŁŻµĆüÕłåÕĖāµ£ēńØĆÕŠłÕ╝║ńÜäÕćĀõĮĢµĆصā│’╝īÕŹĢń║»õ╗Äõ╗ŻµĢ░ńÜäĶ¦ÆÕ║”ń£ŗÕŠģzÕŠłķÜŠń£ŗÕć║ zńÜäµ”éńÄćÕłåÕĖāĶ¦äÕŠŗ’╝īĶ┐Öķćīķ£ĆĶ”üĶĮ¼µŹóµłÉń¤®ķśĄÕĮóÕ╝Å:
+$$ +z^2=z^{\mathrm{T}} z=\left[x_1-\mu_1, x_2-\mu_2, \cdots, x_n-\mu_n\right]\left[\begin{array}{cccc} +\frac{1}{\sigma_1^2} & 0 & \cdots & 0 \\ +0 & \frac{1}{\sigma_2^2} & \cdots & 0 \\ +\vdots & \cdots & \cdots & \vdots \\ +0 & 0 & \cdots & \frac{1}{\sigma_n^2} +\end{array}\right]\left[x_1-\mu_1, x_2-\mu_2, \cdots, x_n-\mu_n\right]^{\mathrm{T}} +$$ +
+ńŁēÕ╝ŵ»öĶŠāķĢ┐’╝īĶ«®µłæõ╗¼Ķ”üÕüÜõĖĆõĖŗÕÅśķćŵø┐µŹó:
+$$ +x-\mu_x=\left[x_1-\mu_1, x_2-\mu_2, \cdots, x_n-\mu_n\right]^{\mathrm{T}} +$$ +
+Õ«Üõ╣ēõĖĆõĖ¬ń¼”ÕÅĘ +$$ +\sum=\left[\begin{array}{cccc} +\sigma_1^2 & 0 & \cdots & 0 \\ +0 & \sigma_2^2 & \cdots & 0 \\ +\vdots & \cdots & \cdots & \vdots \\ +0 & 0 & \cdots & \sigma_n^2 +\end{array}\right] +$$ +
+$\sum$ õ╗ŻĶĪ©ÕÅśķćÅ $\mathrm{X}$ ńÜäÕŹÅµ¢╣ÕĘ«ń¤®ķśĄ’╝ī iĶĪījÕłŚńÜäÕģāń┤ĀÕĆ╝ĶĪ©ńż║ $x_i$ õĖÄ $x_j$ ńÜäÕŹÅµ¢╣ÕĘ« +ÕøĀõĖ║ńÄ░Õ£©ÕÅśķćÅõ╣ŗķŚ┤µś»ńøĖõ║Æńŗ¼ń½ŗńÜä’╝īµēĆõ╗źÕŬµ£ēÕ»╣Ķ¦Æń║┐õĖŖ $(i=j)$ ÕŁśÕ£©Õģāń┤Ā’╝īÕģČõ╗¢Õ£░µ¢╣ķāĮńŁēõ║Ä 0 ’╝īõĖö $x_i$ õĖÄÕ«āµ£¼Ķ║½ńÜäÕŹÅµ¢╣ÕĘ«Õ░▒ńŁēõ║ĵ¢╣ÕĘ«ŃĆé +
+
+$\sum$ µś»õĖĆõĖ¬Õ»╣Ķ¦ÆķśĄ’╝īµĀ╣µŹ«Õ»╣Ķ¦Æń¤®ķśĄńÜäµĆ¦Ķ┤©’╝īÕ«āńÜäķĆåń¤®ķśĄ:
+$$ +\left(\sum\right)^{-1}=\left[\begin{array}{cccc} +\frac{1}{\sigma_1^2} & 0 & \cdots & 0 \\ +0 & \frac{1}{\sigma_2^2} & \cdots & 0 \\ +\vdots & \cdots & \cdots & \vdots \\ +0 & 0 & \cdots & \frac{1}{\sigma_n^2} +\end{array}\right]. +$$ +
+Õ»╣Ķ¦Æń¤®ķśĄńÜäĶĪīÕłŚÕ╝Å $=$ Õ»╣Ķ¦ÆÕģāń┤ĀńÜäõ╣śń¦» +$$ +\sigma_z=\left|\sum\right|^{\frac{1}{2}}=\sigma_1 \sigma_2 \ldots \sigma_n +$$ +
+µø┐µŹóÕÅśķćÅõ╣ŗÕÉÄ’╝īńŁēÕ╝ÅÕÅ»õ╗źń«ĆÕī¢õĖ║: +$$ +z^{\mathrm{T}} z=\left(x-\mu_x\right)^{\mathrm{T}} \sum^{-1}\left(x-\mu_x\right) +$$ +
+õ╗ŻÕģźõ╗źzõĖ║Ķć¬ÕÅśķćÅńÜäµĀćÕćåķ½śµ¢»ÕłåÕĖāÕćĮµĢ░õĖŁ: +$$ +f(z)=\frac{1}{(\sqrt{2 \pi})^n \sigma_z} e^{-\frac{z^2}{2}}=\frac{1}{(\sqrt{2 \pi})^n \sum^{\frac{1}{2}}} e^{-\frac{\left(x-\mu_x\right)^T(\Gamma)^{-1}\left(x-\mu_x\right)}{2}} +$$ +
+µ│©µäÅÕēŹķØóńÜäń│╗µĢ░ÕÅśÕī¢: õ╗ÄķØ×µĀćÕćåµŁŻµĆüÕłåÕĖā $->$ µĀćÕćåµŁŻµĆüÕłåÕĖāķ£ĆĶ”üÕ░åµ”éńÄćÕ»åÕ║”ÕćĮµĢ░ńÜäķ½śÕ║”ÕÄŗń╝® $\left|\sum\right|^{\frac{1}{2}}$ ÕĆŹ’╝īõ╗ÄõĖĆń╗┤ $\rightarrow$ nń╗┤ńÜäĶ┐ć ń©ŗõĖŁ’╝īµ»ÅÕó×ÕŖĀõĖĆń╗┤’╝īķ½śÕ║”Õ░åÕÄŗń╝® $\sqrt{2 \pi}$ ÕĆŹ + +reference: +https://www.cnblogs.com/bingjianing/p/9117330.html + + +```python +from scipy.stats import multivariate_normal +x,y = np.mgrid[-1:1:.01,-1:1:.01]# ńö¤µłÉńĮæµĀ╝ńé╣,µŁźķĢ┐õĖ║0.01 +pos = np.dstack((x,y))# ńö¤µłÉńĮæµĀ╝ńé╣ÕØɵĀć,shape=(200,200,2) +sigma = [[2,0.3],[0.3,0.5]] # ÕŹÅµ¢╣ÕĘ«ń¤®ķśĄ +mu = [0.5,0.2] +X = multivariate_normal(mu,sigma)# ńö¤µłÉÕżÜÕģāµŁŻµĆüÕłåÕĖā +fig,axes = plt.subplots(1,1,figsize=(12,4)) +axes.contourf(x,y,X.pdf(pos))# ń╗śÕłČńŁēķ½śń║┐,posĶĪ©ńż║Õ£©ńĮæµĀ╝ńé╣õĖŖńÜäµ”éńÄćÕ»åÕ║” +``` + + + + +
+ķÖżõ║åńö©õ║ÄÕłåµ×ɵ│ŖµØŠĶ┐ćń©ŗÕż¢’╝īĶ┐śÕÅ»õ╗źÕ£©ÕģČõ╗¢ÕÉäń¦ŹńÄ»ÕóāõĖŁµēŠÕł░’╝īÕģȵ”éńÄćÕ»åÕ║”ÕćĮµĢ░õĖ║’╝Ü +
+$$ +p(x)=\left\{\begin{array}{c} +\frac{1}{\theta} e^{-\frac{x}{\theta}}, x>0 \\ +0, x \leq 0 +\end{array} \quad(\theta>0)\right. +$$ +
+ÕłÖń¦░ķÜŵ£║ÕÅśķćÅ$X$ µ£Źõ╗ÄÕÅéµĢ░õĖ║ $\theta$ ńÜäµīćµĢ░ÕłåÕĖā, Ķ«░õĖ║ $X \sim \operatorname{EXP}(\theta)$. +
+ÕģČõĖŁ $\lambda = \frac{1}{\theta}$ ń¦░õĖ║ńÄćÕÅéµĢ░’╝łrate parameter’╝ēŃĆé +
+ÕŹ│µ»ÅÕŹĢõĮŹµŚČķŚ┤ÕåģÕÅæńö¤µ¤Éõ║ŗõ╗ČńÜäµ¼ĪµĢ░’╝łµ»öµ¢╣Ķ»┤’╝ÜÕ”éµ×£õĮĀÕ╣│ÕØćµ»ÅõĖ¬Õ░ŵŚČµÄźÕł░2µ¼ĪńöĄĶ»Ø’╝īķéŻõ╣łõĮĀķóäµ£¤ńŁēÕŠģµ»ÅõĖƵ¼ĪńöĄĶ»ØńÜ䵌ČķŚ┤µś»ÕŹŖõĖ¬Õ░ŵŚČ’╝ēŃĆéµīćµĢ░ÕłåÕĖāńÜäµ£¤µ£øÕÆīµ¢╣ÕĘ«ÕłåÕł½õĖ║ $\theta$ ÕÆī $\theta^2$. + +µīćµĢ░ÕłåÕĖāńÜäń┤»Ķ«ĪÕłåÕĖāÕćĮµĢ░õĖ║’╝Ü
+$$ P(X \leq x) = 1 - e^{-\frac{x}{\theta}} $$ + + + +```python +from scipy.stats import expon +fig,axes = plt.subplots(1,2,figsize=(12,4)) +r = expon(scale=2)# ńö¤µłÉµīćµĢ░ÕłåÕĖā’╝īscale=2ĶĪ©ńż║╬╗=1/2 +plot_distribution(r,axes) + +``` + + + + + array([
+$$ p(x) = \frac{1}{2 \lambda} e^{ - \frac{|x - \mu|}{\lambda}} $$ + +ÕģČõĖŁ $\mu$ ń¦░õĖ║ÕłåÕĖāńÜäõĮŹńĮ«ÕÅéµĢ░’╝łlocation parameter’╝ē’╝ī$\lambda$ ń¦░õĖ║ÕłåÕĖāńÜäÕ░║Õ║”ÕÅéµĢ░’╝łscale parameter’╝ēŃĆéµŗēµÖ«µŗēµ¢»ÕłåÕĖāńÜäµ£¤µ£øÕÆīµ¢╣ÕĘ«ÕłåÕł½õĖ║ $\mu$ ÕÆī $2 \lambda^2$. + + +```python +from scipy.stats import laplace +fig,axes = plt.subplots(1,2,figsize=(12,4)) +mu,gamma = 0,1 # ÕØćÕĆ╝’╝īµĀćÕćåÕĘ« +r = laplace(loc=0,scale=1)# ńö¤µłÉµŗēµÖ«µŗēµ¢»ÕłåÕĖā +plot_distribution(r,axes) +``` + + + + + array([
+[µ£║ÕÖ©ÕŁ”õ╣ĀńÜäµĢ░ÕŁ”Õ¤║ńĪĆ’╝ł1’╝ē--DirichletÕłåÕĖā](https://blog.csdn.net/jwh_bupt/article/details/8841644) + + +BetaÕłåÕĖāÕ╝Åõ║īķĪ╣ÕłåÕĖāńÜäÕģ▒ĶĮŁÕģłķ¬īÕłåÕĖā. + +DirichletÕłåÕĖāµś»õĖĆõĖ¬ÕżÜń╗┤ńÜäµ”éńÄćÕłåÕĖā’╝īÕ«āµś»õĖĆń╗ä(ÕżÜÕģā’╝ēńŗ¼ń½ŗńÜä $\operatorname{Beta}$ ÕłåÕĖāńÜäÕģ▒ĶĮŁÕģłķ¬īÕłåÕĖāŃĆéÕ£©Ķ┤ØÕÅȵ¢»µÄ©µ¢Ł’╝łBayesian inference’╝ēõĖŁ’╝īńŗäÕł®ÕģŗķøĘÕłåÕĖāõĮ£õĖ║ÕżÜķĪ╣ÕłåÕĖāńÜäÕģ▒ĶĮŁÕģłķ¬īÕŠŚÕł░Õ║öńö©’╝īÕ£©µ£║ÕÖ©ÕŁ”õ╣Ā’╝łmachine learning’╝ēõĖŁĶó½ńö©õ║ĵ×äÕ╗║ńŗäÕł®ÕģŗķøʵĘĘÕÉłµ©ĪÕ×ŗ’╝łDirichlet mixture model’╝ēµś»õĖĆń▒╗Õ£©Õ«×µĢ░Õ¤¤õ╗źµŁŻÕŹĢń║»ÕĮó’╝łstandard simplex’╝ēõĖ║ µö»µÆæķøå’╝łsupport’╝ēńÜäķ½śń╗┤Ķ┐×ń╗Łµ”éńÄćÕłåÕĖā’╝īµś»BetaÕłåÕĖāÕ£©ķ½śń╗┤µāģÕĮóńÜäµÄ©Õ╣┐ŃĆé + +reference:
+[ńÉåĶ¦ŻGammaÕłåÕĖāŃĆüBetaÕłåÕĖāõĖÄDirichletÕłåÕĖā +](https://zhuanlan.zhihu.com/p/37976562) +
+[µ£ĆķĆÜõ┐ŚµśōµćéńÜäńÖĮĶ»ØńŗäÕł®ÕģŗķøĘĶ┐ćń©ŗ(Dirichlet Process’╝ē](https://zhuanlan.zhihu.com/p/76991275) + + + +### 2.1.6 ÕĖĖĶ¦üÕćĮµĢ░ńÜäµ£ēńö©µĆ¦Ķ┤© + +logisitc sigmoidÕćĮµĢ░ķĆÜÕĖĖńö©µØźõ║¦ńö¤õ╝»ÕŖ¬Õł®ÕłåÕĖāńÜäµ”éńÄć’╝īÕøĀõĖ║Õ«āńÜäĶīāÕø┤µś» (0, 1)’╝īÕøĀµŁżÕ«āńÜäÕ»╝µĢ░µś»õ╝»ÕŖ¬Õł®ÕłåÕĖāńÜäµ”éńÄćÕ»åÕ║”ÕćĮµĢ░ŃĆésigmoid ÕćĮµĢ░Õ£©ÕÅśķćÅÕÅ¢ń╗ØÕ»╣ÕĆ╝ŌŠ«ÕĖĖŌ╝żńÜ䵣ŻÕĆ╝µł¢Ķ┤¤ÕĆ╝µŚČõ╝ÜÕć║ńÄ░ķź▒ÕÆī (Saturate)ńÄ░Ķ▒Ī’╝īµäÅÕæ│ńØĆÕćĮµĢ░õ╝ÜÕÅśÕŠŚÕŠłÕ╣│’╝īÕ╣ČõĖöÕ»╣ĶŠōŌ╝ŖńÜäÕŠ«Ō╝®µö╣ÕÅśõ╝ÜÕÅśÕŠŚõĖŹµĢŵä¤ŃĆé
+$$ sigmoid(x) = \frac{1}{1+e^{-x}} $$ + +softplusÕćĮµĢ░
+$$ softplus(x) = \log(1+e^x) $$ + +ÕøĀõĖ║Õ«āńÜäĶīāÕø┤µś» (0, Ōł×)’╝īsoftplusÕćĮµĢ░ÕÅ»õ╗źńö©µØźõ║¦ńö¤µŁŻÕż¬ÕłåÕĖāńÜä$\beta$ÕÆī$\sigma$ÕÅéµĢ░’╝īÕøĀµŁżÕ«āńÜäÕ»╝µĢ░µś»µŁŻÕż¬ÕłåÕĖāńÜäµ”éńÄćÕ»åÕ║”ÕćĮµĢ░ŃĆé +softplusÕćĮµĢ░ÕÉŹń¦░µØźµ║Éõ║ÄÕ«āµś»õĖĆõĖ¬Õ╣│µ╗æńÜäReLUÕćĮµĢ░’╝īReLUÕćĮµĢ░µś»õĖĆõĖ¬ķØ×ń║┐µĆ¦ÕćĮµĢ░’╝īÕ«āńÜäÕ«Üõ╣ēµś» +$$ ReLU(x) = max(0, x) $$ + + + +```python +x = np.linspace(-10,10,1000) +sigmoid = 1/(1+np.exp(-x)) +softplus = np.log(1+np.exp(x)) +fig,axes = plt.subplots(1,2,figsize=(12,4)) +axes[0].plot(x,sigmoid) +axes[0].set_title('Sigmoid') +axes[1].plot(x,softplus) +axes[1].set_title('Softplus') + +``` + + + + + Text(0.5, 1.0, 'Softplus') + + + + + + + +## 2.2 õ┐Īµü»Ķ«║ +õ┐Īµü»Ķ«║ĶāīÕÉÄńÜäµĆصā│’╝ÜõĖĆõ╗ČõĖŹÕż¬ÕÅ»ĶāĮńÜäõ║ŗõ╗ȵ»öõĖĆõ╗ȵ»öĶŠāÕÅ»ĶāĮńÜäõ║ŗõ╗ȵø┤µ£ēõ┐Īµü»ķćÅŃĆé’╝łõ┐Īµü»ķćÅńÜäÕ║”ķćÅÕ░▒ńŁēõ║ÄõĖŹńĪ«Õ«ÜµĆ¦ńÜäÕżÜÕ░æŃĆé’╝ē
+õ┐Īµü» (Information) ķ£ĆĶ”üµ╗ĪŌŠ£ńÜäõĖēõĖ¬µØĪõ╗Č’╝Ü +* ŌĮÉĶŠāÕÅ»ĶāĮÕÅæŌĮŻńÜäõ║ŗõ╗ČńÜäõ┐Īµü»ķćÅĶ”üÕ░æ +* ŌĮÉĶŠāõĖŹÕÅ»ĶāĮÕÅæŌĮŻńÜäõ║ŗõ╗ČńÜäõ┐Īµü»ķćÅĶ”üŌ╝ż +* ńŗ¼ŌĮ┤ÕÅæŌĮŻńÜäõ║ŗõ╗Čõ╣ŗķŚ┤ńÜäõ┐Īµü»ķćÅÕ║öĶ»źµś»ÕÅ»õ╗źÕÅĀÕŖĀńÜäŃĆéõŠŗÕ”é’╝īµŖĢµÄĘńÜäńĪ¼ÕĖüõĖżµ¼ĪµŁŻŌŠ»µ£ØõĖŖõ╝ĀķĆÆńÜäõ┐Īµü»ķćÅ’╝īÕ║öĶ»źµś»µŖĢµÄĘŌ╝Ƶ¼ĪńĪ¼ÕĖüµŁŻŌŠ»µ£ØõĖŖńÜäõ┐Īµü»ķćÅńÜäõĖżÕĆŹ + +Ķć¬õ┐Īµü» (Self-information) µś»õ┐Īµü»Ķ«║õĖŁńÜäÕ¤║µ£¼µ”éÕ┐Ą’╝īÕ«āµś»µīćÕŹĢõĖ¬õ║ŗõ╗ČÕÅæŌĮŻńÜäõ┐Īµü»ķćÅŃĆéĶć¬õ┐Īµü»ńÜäÕ«Üõ╣ēµś»
+$$ I(x) = -\log P(x) $$ + +ķ”ÖÕå£ńåĄ (Shannon Entropy)µś»Õ»╣õ║ĵĢ┤õĖ¬µ”éĶ«║ÕłåÕĖāP’╝īķÜŵ£║ÕÅśķćÅńÜäõĖŹńĪ«Õ«ÜµĆ¦ńÜäĶĪĪķćÅ’╝Ü
+$$ H(P) = -’╝ł p_1 * \log p_1 + p_2 * \log p_2 + \cdots + p_n * \log p_n) =-\sum_{x}P(x)\log P(x) $$ + +ĶüöÕÉłńåĄ (Joint Entropy) µś»Õ»╣õ║ÄõĖżõĖ¬ķÜŵ£║ÕÅśķćÅXÕÆīY’╝īÕ«āõ╗¼ńÜäĶüöÕÉłÕłåÕĖāP(X, Y)’╝īķÜŵ£║ÕÅśķćÅńÜäõĖŹńĪ«Õ«ÜµĆ¦ńÜäĶĪĪķćÅ’╝Ü
+$$ H(X, Y) = -\sum_{x,y}P(x, y)\log P(x, y) $$ + +µØĪõ╗ČńåĄ (Conditional Entropy) µś»Õ»╣õ║ÄõĖżõĖ¬ķÜŵ£║ÕÅśķćÅXÕÆīY’╝īÕ«āõ╗¼ńÜäĶüöÕÉłÕłåÕĖāP(X, Y)’╝īķÜŵ£║ÕÅśķćÅńÜäõĖŹńĪ«Õ«ÜµĆ¦ńÜäĶĪĪķćÅ’╝Ü
+$$ H(Y|X) = -\sum_{x,y}P(x, y)\log P(y|x) $$ + +õ║Æõ┐Īµü» (Mutual Information) ĶĪ©ńż║õĖżõĖ¬õ┐Īµü»ńøĖõ║żńÜäķā©Õłå’╝Ü
+$$ I(X;Y) = H(X)+H(Y) - H(X,Y) $$ + +õ┐Īµü»ÕÅśÕĘ«(Variation of Information) ĶĪ©ńż║õĖżõĖ¬õ║ŗõ╗ČńÜäõ┐Īµü»õĖŹµā│õ║żńÜäķā©Õłå’╝Ü
+$$ VI(X;Y) = H(X)+H(Y) - 2I(X;Y) $$ + + +```python +p = np.linspace(1e-6,1-1e-6,1000) # ńö¤µłÉµ”éńÄć +entropy = -p*np.log(p)-(1-p)*np.log(1-p) # ķ”ÖÕå£ńåĄ (Shannon Entropy) +plt.figure(figsize=(4,4)) +plt.plot(p,entropy) +plt.title('Shannon Entropy') + +``` + + + + + Text(0.5, 1.0, 'Shannon Entropy') + + + + + + + +õ┐Īµü»Õó×ńøŖ’╝łKullbackŌĆōLeibler divergence’╝ēÕÅłń¦░information divergence’╝īinformation gain’╝īrelative entropy µł¢ĶĆģKLICŃĆé +Õ£©µ”éńÄćĶ«║ÕÆīõ┐Īµü»Ķ«║õĖŁ’╝īõ┐Īµü»Õó×ńøŖµś»ķØ×Õ»╣ń¦░ńÜä’╝īńö©õ╗źÕ║”ķćÅõĖżń¦Źµ”éńÄćÕłåÕĖāPÕÆīQńÜäÕĘ«Õ╝éŃĆé
+$$ D_{KL}(P||Q) = \sum_{x}P(x)\log \frac{P(x)}{Q(x)} $$ + +õ║żÕÅēńåĄ (Cross Entropy) ÕüćĶ«ŠPµś»ń£¤Õ«×ńÜäÕłåÕĖā’╝īQµś»ķó䵥ŗńÜäÕłåÕĖā’╝īķéŻõ╣łõ║żÕÅēńåĄÕ░▒µś»ń£¤Õ«×ÕłåÕĖāÕÆīķó䵥ŗÕłåÕĖāõ╣ŗķŚ┤ńÜäĶĘØń”╗’╝Ü
+$$ H(P, Q) = H(P) + D_{KL}(P||Q) = -\sum_{x}P(x)\log Q(x) $$ + + +```python +# D_{KL}(P||Q) õĖÄD_{KL}(Q||P)µ»öĶŠā +x = np.linspace(1,8,500) +y1 = norm.pdf(x,loc =3,scale = 0.5) # loc=3,scale=0.5ĶĪ©ńż║ÕØćÕĆ╝õĖ║3’╝īµĀćÕćåÕĘ«õĖ║0.5 +y2 = norm.pdf(x,loc =6,scale = 0.5) +p = y1+y2 #µ×äķĆĀp(x) +KL_pq ,KL_qp = [],[] +q_list = [] +for mu in np.linspace(0,10,50): + for sigma in np.linspace(0.1,1,50): # ńö¤µłÉ50*50õĖ¬q(x),Õ»╗µēŠµ£Ćõ╝śq(x) + q = norm.pdf(x,loc =mu,scale = sigma) # µ×äķĆĀq(x) + q_list.append(q) + KL_pq.append(np.sum(p*np.log(p/q))) # D_{KL}(P||Q) + KL_qp.append(np.sum(q*np.log(q/p))) # D_{KL}(Q||P) +# min +min_KL_pq = np.argmin(KL_pq) # µ£ĆÕ░ÅÕĆ╝ńÜäń┤óÕ╝Ģ +min_KL_qp = np.argmin(KL_qp) + +fig,axes = plt.subplots(1,2,figsize=(12,4)) +axes[0].set_ylim(0,0.8) +axes[0].plot(x,p/2,'b',label='p(x)') +axes[0].plot(x,q_list[min_KL_pq],'r',label='$q^*(x)$') +axes[0].set_title('min D_{KL}(P||Q) ') +axes[0].set_xlabel('x') +axes[0].set_ylabel('p(x)') + +axes[1].set_ylim(0,0.8) +axes[1].plot(x,p/2,'b',label='p(x)') +axes[1].plot(x,q_list[min_KL_qp],'r',label='$q^*(x)$') +axes[1].set_title('min D_{KL}(Q||P)') +axes[1].set_xlabel('x') +axes[1].set_ylabel('p(x)') +``` + +
+$$ IG(X;Y) = H(Y) - H(Y|X) $$ + + +```python +import numpy as np +import pandas as pd +from math import log + +def create_data(): + datasets = [['ķØÆÕ╣┤', 'ÕÉ”', 'ÕÉ”', 'õĖĆĶł¼', 'ÕÉ”'], + ['ķØÆÕ╣┤', 'ÕÉ”', 'ÕÉ”', 'ÕźĮ', 'ÕÉ”'], + ['ķØÆÕ╣┤', 'µś»', 'ÕÉ”', 'ÕźĮ', 'µś»'], + ['ķØÆÕ╣┤', 'µś»', 'µś»', 'õĖĆĶł¼', 'µś»'], + ['ķØÆÕ╣┤', 'ÕÉ”', 'ÕÉ”', 'õĖĆĶł¼', 'ÕÉ”'], + ['õĖŁÕ╣┤', 'ÕÉ”', 'ÕÉ”', 'õĖĆĶł¼', 'ÕÉ”'], + ['õĖŁÕ╣┤', 'ÕÉ”', 'ÕÉ”', 'ÕźĮ', 'ÕÉ”'], + ['õĖŁÕ╣┤', 'µś»', 'µś»', 'ÕźĮ', 'µś»'], + ['õĖŁÕ╣┤', 'ÕÉ”', 'µś»', 'ķØ×ÕĖĖÕźĮ', 'µś»'], + ['õĖŁÕ╣┤', 'ÕÉ”', 'µś»', 'ķØ×ÕĖĖÕźĮ', 'µś»'], + ['ĶĆüÕ╣┤', 'ÕÉ”', 'µś»', 'ķØ×ÕĖĖÕźĮ', 'µś»'], + ['ĶĆüÕ╣┤', 'ÕÉ”', 'µś»', 'ÕźĮ', 'µś»'], + ['ĶĆüÕ╣┤', 'µś»', 'ÕÉ”', 'ÕźĮ', 'µś»'], + ['ĶĆüÕ╣┤', 'µś»', 'ÕÉ”', 'ķØ×ÕĖĖÕźĮ', 'µś»'], + ['ĶĆüÕ╣┤', 'ÕÉ”', 'ÕÉ”', 'õĖĆĶł¼', 'ÕÉ”'], + ] + labels = [u'Õ╣┤ķŠä', u'µ£ēÕĘźõĮ£', u'µ£ēĶć¬ÕĘ▒ńÜ䵳┐ÕŁÉ', u'õ┐ĪĶ┤ʵāģÕåĄ', u'ń▒╗Õł½'] + # Ķ┐öÕø×µĢ░µŹ«ķøåÕÆīµ»ÅõĖ¬ń╗┤Õ║”ńÜäÕÉŹń¦░ + return datasets, labels + + +# ńåĄ +def calc_ent(datasets): + data_length = len(datasets) + label_count = {} + for i in range(data_length): + label = datasets[i][-1] + if label not in label_count: + label_count[label] = 0 + label_count[label] += 1 + ent = -sum([(p / data_length) * log(p / data_length, 2) for p in label_count.values()]) + return ent + + +# ń╗Åķ¬īµØĪõ╗ČńåĄ +def cond_ent(datasets, axis=0): + data_length = len(datasets) + feature_sets = {} + for i in range(data_length): + feature = datasets[i][axis] + if feature not in feature_sets: + feature_sets[feature] = [] + feature_sets[feature].append(datasets[i]) + cond_ent = sum([(len(p) / data_length) * calc_ent(p) for p in feature_sets.values()]) + return cond_ent + + +# õ┐Īµü»Õó×ńøŖ +def info_gain(ent, cond_ent): + return ent - cond_ent + + +def info_gain_train(datasets): + count = len(datasets[0]) - 1 + ent = calc_ent(datasets) + best_feature = [] + for c in range(count): + c_info_gain = info_gain(ent, cond_ent(datasets, axis=c)) + best_feature.append((c, c_info_gain)) + print('ńē╣ÕŠü({}) - info_gain - {:.3f}'.format(labels[c], c_info_gain)) + # µ»öĶŠāÕż¦Õ░Å + best_ = max(best_feature, key=lambda x: x[-1]) + return 'ńē╣ÕŠü({})ńÜäõ┐Īµü»Õó×ńøŖµ£ĆÕż¦’╝īķĆēµŗ®õĖ║µĀ╣ĶŖéńé╣ńē╣ÕŠü'.format(labels[best_[0]]) + +datasets, labels = create_data() +train_data = pd.DataFrame(datasets, columns=labels) +print(train_data) +print('ńē╣ÕŠüõ┐Īµü»Õó×ńøŖõĖ║’╝Ü', info_gain_train(np.array(datasets))) +``` + + Õ╣┤ķŠä µ£ēÕĘźõĮ£ µ£ēĶć¬ÕĘ▒ńÜ䵳┐ÕŁÉ õ┐ĪĶ┤ʵāģÕåĄ ń▒╗Õł½ + 0 ķØÆÕ╣┤ ÕÉ” ÕÉ” õĖĆĶł¼ ÕÉ” + 1 ķØÆÕ╣┤ ÕÉ” ÕÉ” ÕźĮ ÕÉ” + 2 ķØÆÕ╣┤ µś» ÕÉ” ÕźĮ µś» + 3 ķØÆÕ╣┤ µś» µś» õĖĆĶł¼ µś» + 4 ķØÆÕ╣┤ ÕÉ” ÕÉ” õĖĆĶł¼ ÕÉ” + 5 õĖŁÕ╣┤ ÕÉ” ÕÉ” õĖĆĶł¼ ÕÉ” + 6 õĖŁÕ╣┤ ÕÉ” ÕÉ” ÕźĮ ÕÉ” + 7 õĖŁÕ╣┤ µś» µś» ÕźĮ µś» + 8 õĖŁÕ╣┤ ÕÉ” µś» ķØ×ÕĖĖÕźĮ µś» + 9 õĖŁÕ╣┤ ÕÉ” µś» ķØ×ÕĖĖÕźĮ µś» + 10 ĶĆüÕ╣┤ ÕÉ” µś» ķØ×ÕĖĖÕźĮ µś» + 11 ĶĆüÕ╣┤ ÕÉ” µś» ÕźĮ µś» + 12 ĶĆüÕ╣┤ µś» ÕÉ” ÕźĮ µś» + 13 ĶĆüÕ╣┤ µś» ÕÉ” ķØ×ÕĖĖÕźĮ µś» + 14 ĶĆüÕ╣┤ ÕÉ” ÕÉ” õĖĆĶł¼ ÕÉ” + ńē╣ÕŠü(Õ╣┤ķŠä) - info_gain - 0.083 + ńē╣ÕŠü(µ£ēÕĘźõĮ£) - info_gain - 0.324 + ńē╣ÕŠü(µ£ēĶć¬ÕĘ▒ńÜ䵳┐ÕŁÉ) - info_gain - 0.420 + ńē╣ÕŠü(õ┐ĪĶ┤ʵāģÕåĄ) - info_gain - 0.363 + ńē╣ÕŠüõ┐Īµü»Õó×ńøŖõĖ║’╝Ü ńē╣ÕŠü(µ£ēĶć¬ÕĘ▒ńÜ䵳┐ÕŁÉ)ńÜäõ┐Īµü»Õó×ńøŖµ£ĆÕż¦’╝īķĆēµŗ®õĖ║µĀ╣ĶŖéńé╣ńē╣ÕŠü + + +## 2.3 ÕøŠµ©ĪÕ×ŗ +ÕøŠµ©ĪÕ×ŗ’╝łGraphical Model)µś»õĖĆń¦ŹĶĪ©ńż║µ”éńÄćÕłåÕĖāńÜäµ¢╣µ│Ģ’╝īÕ«āÕ░åµ”éńÄćÕłåÕĖāĶĪ©ńż║õĖ║õĖĆõĖ¬ÕøŠ’╝īÕøŠõĖŁńÜäĶŖéńé╣ĶĪ©ńż║ķÜŵ£║ÕÅśķćÅ’╝īĶŖéńé╣õ╣ŗķŚ┤ńÜäĶŠ╣ĶĪ©ńż║ķÜŵ£║ÕÅśķćÅõ╣ŗķŚ┤ńÜäõŠØĶĄ¢Õģ│ń│╗ŃĆé + +### 2.3.1 µ£ēÕÉæÕøŠµ©ĪÕ×ŗ directed graphical model + +µ£ēÕÉæÕøŠµ©ĪÕ×ŗµś»µīćÕøŠõĖŁńÜäĶŠ╣µś»µ£ēÕÉæńÜä’╝īÕŹ│ĶŠ╣ńÜäµ¢╣ÕÉæĶĪ©ńż║õ║åķÜŵ£║ÕÅśķćÅõ╣ŗķŚ┤ńÜäõŠØĶĄ¢Õģ│ń│╗ŃĆéµ£ēÕÉæÕøŠµ©ĪÕ×ŗÕÅ»õ╗źĶĪ©ńż║µØĪõ╗ȵ”éńÄćÕłåÕĖā(CPD)’╝īõ╣¤ÕÅ»õ╗źĶĪ©ńż║ķ®¼Õ░öń¦æÕż½ķÜŵ£║Õ£║ŃĆé + +µ£ēÕÉæÕøŠńÜäõ╗ŻĶĪ©µś»Ķ┤ØÕÅȵ¢»ńĮæŃĆé +Ķ┤ØÕÅȵ¢»ŌĮ╣õĖĵ£┤ń┤ĀĶ┤ØÕÅȵ¢»µ©ĪÕ×ŗÕ╗║ŌĮ┤Õ£©ńøĖÕÉīńÜäńø┤Ķ¦éÕüćĶ«ŠõĖŖ’╝ÜķĆÜĶ┐ćÕł®ńö©ÕłåÕĖāńÜäµØĪõ╗Čńŗ¼ń½ŗµĆ¦µØźĶÄĘÕŠŚń┤¦ÕćæĶĆīĶć¬ńäČńÜäĶĪ©ńż║ŃĆéĶ┤ØÕÅȵ¢»ŌĮ╣µĀĖŌ╝╝µś»Ō╝ĆõĖ¬µ£ēÕÉæŌĮåńÄ»ÕøŠ(DAG)’╝īÕģČĶŖéńé╣õĖ║Ķ«║Õ¤¤õĖŁńÜäķÜŵ£║ÕÅśķćÅ’╝īĶŖéńé╣ķŚ┤ńÜäµ£ēÕÉæń«ŁÕż┤ĶĪ©ŌĮ░Ķ┐ÖõĖżõĖ¬ĶŖéńé╣ńÜäõŠØĶĄ¢Õģ│ń│╗ŃĆé + + + +µ£ēÕÉæŌĮåńÄ»ÕøŠÕÅ»õ╗źńö▒Õ”éõĖŗ 3 ń¦ŹÕģāń╗ōµ×äµ×䵳ɒ╝Ü +* ÕÉīŌĮŚń╗ōµ×ä +* V Õ×ŗń╗ōµ×ä +* ķĪ║Õ║Åń╗ōµ×ä + + +Ķ┤ØÕÅȵ¢»ńĮæńÜäńŗ¼ń½ŗµĆ¦ +* Õ▒Ćķā©ńŗ¼ń½ŗµĆ¦ +* Õģ©Õ▒Ćńŗ¼ń½ŗµĆ¦ + * tail-to-tail + * head-to-tail + * head-to-head + ĶĆāĶÖæÕżŹµØéńÜäµ£ēÕÉæµŚĀńÄ»ÕøŠ’╝īÕ”éµ×£A,B,Cµś»õĖēõĖ¬ķøåÕÉł’╝īÕÅ»õ╗źµś»ÕŹĢńŗ¼ńÜäĶŖéńé╣µł¢ĶĆģĶŖéńé╣ńÜäķøåÕÉłŃĆéõĖ║õ║åÕłżµ¢ŁAÕÆīBµś»ÕÉ”µŚČCµØĪõ╗Čńŗ¼ń½ŗńÜä’╝īµłæõ╗¼ÕÅ»õ╗źĶĆāĶÖæAÕÆīBõ╣ŗķŚ┤ńÜäµēƵ£ēĶĘ»ÕŠäŃĆéÕ»╣õ║ÄÕģČõĖŁńÜäõĖƵØĪĶĘ»ÕŠä’╝īÕ”éµ×£µ╗ĪĶČ│õ╗źõĖŗõĖżńé╣ńÜäõ╗╗µäÅõĖĆńé╣’╝īķéŻõ╣łÕ░▒Ķ»┤Ķ┐ÖµØĪĶĘ»ÕŠäµś»ķś╗ÕĪ×’╝łblocked’╝ēńÜä’╝Ü + 1. ĶĘ»ÕŠäõĖŁÕŁśÕ£©µ¤ÉõĖ¬ĶŖéńé╣ X µś» head-to-tail µł¢ĶĆģ tail-to-tail ĶŖéńé╣’╝īÕ╣ČõĖö X µś»ÕīģÕɽգ© C õĖŁńÜä’╝ø + 2. ĶĘ»ÕŠäõĖŁÕŁśÕ£©µ¤ÉõĖ¬ĶŖéńé╣ X µś» head-to-head ĶŖéńé╣’╝īÕ╣ČõĖö X µł¢ X ńÜäŌ╝ēŌ╝”µś»õĖŹÕīģÕɽգ© C õĖŁńÜäŃĆé + + Õ”éµ×£ A,B ķŚ┤µēƵ£ēńÜäĶĘ»ÕŠäķāĮµś»ķś╗ÕĪ×ńÜä’╝īķéŻõ╣ł A,B Õ░▒µś»Õģ│õ║Ä C µØĪõ╗Čńŗ¼ŌĮ┤ńÜä’╝øÕÉ”ÕłÖ A,B õĖŹµś»Õģ│õ║Ä C µØĪõ╗Čńŗ¼ŌĮ┤ńÜäŃĆé + + + + + + + +```python +import networkx as nx +from pgmpy.models import BayesianModel +from pgmpy.factors.discrete import TabularCPD +import matplotlib.pyplot as plt +%matplotlib inline + +# Õ╗║ń½ŗõĖĆõĖ¬ń«ĆÕŹĢĶ┤ØÕÅȵ¢»µ©ĪÕ×ŗµĪåµ×Č +model = BayesianModel([('a', 'b'), ('a', 'c'), ('b', 'c'), ('b', 'd'), ('c', 'e')]) +# µ£ĆķĪČÕ▒éńÜäńłČĶŖéńé╣ńÜäµ”éńÄćÕłåÕĖāĶĪ© +cpd_a = TabularCPD(variable='a', variable_card=2, values=[[0.6, 0.4]]) # a: (0,1) + +# ÕģČÕ«āÕÉäĶŖéńé╣ńÜäµØĪõ╗ȵ”éńÄćÕłåÕĖāĶĪ©’╝łĶĪīÕ»╣Õ║öÕĮōÕēŹĶŖéńé╣ń┤óÕ╝Ģ’╝īÕłŚÕ»╣Õ║öńłČĶŖéńé╣ń┤óÕ╝Ģ’╝ē +cpd_b = TabularCPD(variable='b', variable_card=2, # b: (0,1) +values=[[0.75, 0.1], +[0.25, 0.9]], +evidence=['a'], +evidence_card=[2]) +cpd_c = TabularCPD(variable='c', variable_card=3, # c: (0,1,2) +values=[[0.3, 0.05, 0.9, 0.5], +[0.4, 0.25, 0.08, 0.3], +[0.3, 0.7, 0.02, 0.2]], +evidence=['a', 'b'], +evidence_card=[2, 2]) +cpd_d = TabularCPD(variable='d', variable_card=2, # d: (0,1) +values=[[0.95, 0.2], +[0.05, 0.8]], +evidence=['b'], +evidence_card=[2]) +cpd_e = TabularCPD(variable='e', variable_card=2, # e: (0,1) +values=[[0.1, 0.4, 0.99], +[0.9, 0.6, 0.01]], +evidence=['c'], +evidence_card=[3]) + +# Õ░åÕÉäĶŖéńé╣ńÜäµ”éńÄćÕłåÕĖāĶĪ©ÕŖĀÕģźńĮæń╗£ +model.add_cpds(cpd_a, cpd_b, cpd_c, cpd_d, cpd_e) +# ķ¬īĶ»üµ©ĪÕ×ŗµĢ░µŹ«ńÜ䵣ŻńĪ«µĆ¦ +print(u"ķ¬īĶ»üµ©ĪÕ×ŗµĢ░µŹ«ńÜ䵣ŻńĪ«µĆ¦:",model.check_model()) +# ń╗śÕłČĶ┤ØÕÅȵ¢»ÕøŠ (ĶŖéńé╣ + õŠØĶĄ¢Õģ│ń│╗) +nx.draw(model, with_labels=True, node_size=1000, font_weight='bold', node_color='y', \ +pos={"e":[4,3],"c":[4,5],"d":[8,5],"a":[2,7],"b":[6,7]}) +plt.text(2,7,model.get_cpds("a"), fontsize=10, color='b') +plt.text(5,6,model.get_cpds("b"), fontsize=10, color='b') +plt.text(1,4,model.get_cpds("c"), fontsize=10, color='b') +plt.text(4.2,2,model.get_cpds("e"), fontsize=10, color='b') +plt.text(7,3.4,model.get_cpds("d"), fontsize=10, color='b') + +plt.show() +``` + + + --------------------------------------------------------------------------- + + ModuleNotFoundError Traceback (most recent call last) + +
+pytest-ordering: µĄŗĶ»ĢķĪ║Õ║ÅµÄ¦ÕłČ +
+pytest-xdist: ÕłåÕĖāÕ╝ŵĄŗĶ»Ģ +
+pytest-cov: ńö¤µłÉµĄŗĶ»ĢĶ”åńø¢ńÄćµŖźÕæŖ +
+pytest-rerunfailures: Õż▒Ķ┤źķćŹĶ»Ģ +
+pytest-timeout: ĶČģµŚČµĄŗĶ»Ģ’╝īÕģüĶ«ĖÕ£©ÕæĮõ╗żĶĪīµīćÕ«ÜĶČģµŚČµŚČķŚ┤’╝īµł¢ĶĆģńø┤µÄźÕ£©µĄŗĶ»Ģõ╗ŻńĀüõĖŁµĀćµ│©ĶČģµŚČµŚČķŚ┤ŃĆé +
+pytest-repeat: ķćŹÕżŹµĄŗĶ»Ģ(ÕÅ»õ╗źõĮ┐ńö©--countÕÅéµĢ░µīćÕ«ÜķćŹÕżŹµ¼ĪµĢ░) +
+pytest-instafail: µĄŗĶ»ĢÕż▒Ķ┤źµŚČń½ŗÕŹ│Õü£µŁó’╝īµ¤źń£ŗķöÖĶ»»ńÜäĶ»”ń╗åõ┐Īµü»ŃĆé +
+pytest-sugar: õ╝śÕī¢µĄŗĶ»ĢµŖźÕæŖ,µśŠńż║Ķē▓ÕĮ®ÕÆīĶ┐øÕ║”µØĪ +
+pytest-html: õĖ║µĄŗĶ»Ģńö¤µłÉHTMLµŖźÕæŖ +```shell +pytest --html=report.html +``` +
+ +**ķØÖµĆüÕłåµ×Éńö©ńÜäµÅÆõ╗Č** + +pytest-pycodestyle: + +
+pytest-pep8: µŻĆµĄŗõ╗ŻńĀüµś»ÕÉ”ń¼”ÕÉł PEP8 Ķ¦äĶīā +
+pytest-flakes: µŻĆµĄŗõ╗ŻńĀüķŻÄµĀ╝ + +
+ +WebÕ╝ĆÕÅæńö©ńÜäµÅÆõ╗Č’╝Ü +WebķĪ╣ńø«µ£ēńē╣Õ«ÜńÜ䵥ŗĶ»ĢķĆ╗ĶŠæ’╝īpytestõ╣¤õĖŹĶāĮĶ«®µĄŗĶ»ĢÕÅśń«ĆÕŹĢ’╝īõĮåµś»µ£ēÕćĀõĖ¬µÅÆõ╗ČÕÅ»õ╗źÕĖ«Õ┐ÖŃĆé +
+pytest-django: ńö©õ║ĵĄŗĶ»Ģ Django ķĪ╣ńø«’╝īDjangoµś»ÕŠłµĄüĶĪīńÜäÕ¤║õ║ÄPythonńÜäwebÕ╝ĆÕÅæµĪåµ×Č’╝īÕ«āµ£¼Ķ║½ÕīģÕɽńö©õ║ĵĄŗĶ»ĢńÜähookÕćĮµĢ░’╝īÕģüĶ«ĖµĄŗĶ»ĢDjangoÕ║öńö©ńÜäÕÉäõĖ¬ń╗äõ╗Č’╝īDjangoµĄŗĶ»ĢõĮ┐ńö©ńÜ䵜»unittest’╝ø +
+pytest-selenium:ÕƤÕŖ®µĄÅĶ¦łÕÖ©Õ«īµłÉĶć¬ÕŖ©Õī¢µĄŗĶ»Ģ’╝īµ»öÕ”éĶ»┤ÕÉ»ÕŖ©õĖĆõĖ¬webµĄÅĶ¦łÕÖ©’╝īµēōÕ╝ĆńĮæÕØĆURL’╝īĶ┐ÉĶĪīwebÕ║öńö©’╝ø +
+pytest-flask’╝ܵĄŗĶ»ĢFlaskÕ║öńö©’╝īFlaskµś»õĖĆõĖ¬ĶĮ╗ķćÅń║¦ńÜäwebµĪåµ×Č,pytest-flaskµÅÆõ╗ȵÅÉõŠøõ║åõĖĆń╗äÕŠłµ£ēńö©ńÜäfixtureµØźÕĖ«ÕŖ®FlaskÕ║öńö©’╝ø + + + + + + + + diff --git "a/_posts/2022-12-28-pytest\346\265\213\350\257\225\345\256\236\346\210\230.md" "b/_posts/2022-12-28-pytest\346\265\213\350\257\225\345\256\236\346\210\230.md" new file mode 100644 index 0000000000..5b7cff572a --- /dev/null +++ "b/_posts/2022-12-28-pytest\346\265\213\350\257\225\345\256\236\346\210\230.md" @@ -0,0 +1,32 @@ +--- +layout: post +title: "pytestµĄŗĶ»ĢÕ«×µłś" +date: 2022-12-28 +description: "õ╗ŗń╗ŹpytestÕ«ēĶŻģTasksķĪ╣ńø«ńö©õ║ÄńÜ«õĖŗµĄŗĶ»Ģ’╝īpytestńÜ䵥ŗĶ»Ģńö©õŠŗ’╝īõ╗źÕÅŖõĮ┐ńö©ÕżÜń¦ŹµÅÆõ╗ČķģŹÕÉłĶ┐øĶĪīµĄŗĶ»ĢńÜ䵥üń©ŗŃĆé" +tag: Ķć¬ÕŖ©Õī¢µĄŗĶ»Ģ +--- + +## ĶĮ»õ╗ȵĄŗĶ»Ģµś»õ╗Ćõ╣ł +ĶĮ»õ╗ȵĄŗĶ»ĢńÜäõĖĆõĖ¬ńø«ńÜ䵜»ķ¬īĶ»üõĮĀńÜäńī£µā│-ńī£µā│ĶĮ»õ╗ČńÜäÕåģķā©ķĆ╗ĶŠæ’╝īÕīģµŗ¼ń¼¼õĖēµ¢╣ńÜ䵩ĪÕØŚŃĆüõ╗ŻńĀüÕīģŃĆéńöÜĶć│PythonńÜäÕåģÕ╗║ńÜäµĢ░µŹ«ń╗ōµ×䵜»Õ”éõĮĢĶ┐ÉĶĪīńÜäŃĆéTasksķĪ╣ńø«õĮ┐ńö©ÕÉŹõĖ║TaskńÜäµĢ░µŹ«ń╗ōµ×ä’╝īÕ«āµś»ńö©namedtupleÕĘźÕÄéÕćĮµĢ░ńö¤µłÉńÜäŃĆéTaskńö©õ║ÄÕ£©UIÕ▒éÕÆīAPIÕ▒éõ╣ŗķŚ┤õ╝ĀķĆÆõ┐Īµü»ŃĆé +```python +from collections import namedtuple +Task = namedtuple('Task', ['summary', 'owner', 'done', 'id']) +# õĮ┐ńö©_new_.defaults_ÕłøÕ╗║õĖĆõĖ¬ķ╗śĶ«żńÜäTaskÕ«×õŠŗ +Task.__new__.__defaults__ = (None, None, False, None) +``` +Ķ┐ÉĶĪīpytestµŚČÕÅ»õ╗źµīćÕ«Üńø«ÕĮĢÕÆīµ¢ćõ╗ČŃĆéÕ”éµ×£õĖŹµīćÕ«Ü’╝īõ╝ܵɣń┤óÕĮōÕēŹńø«ÕĮĢõ╗źÕÅŖÕģČÕŁÉńø«ÕĮĢõĖŁõ╗źtest_Õ╝ĆÕż┤µł¢ĶĆģÕĘ▓_testń╗ōÕ░ŠńÜäµ¢ćõ╗ČŃĆépytestõ╝ÜĶć¬ÕŖ©µÉ£ń┤óĶ┐Öõ║øµ¢ćõ╗ČõĖŁńÜ䵥ŗĶ»Ģńö©õŠŗŃĆé +rootdir: D:\pytest\Tasks\tests, +inifile: pytest.ini & tox.ini & setup.cfg + +µĄŗĶ»Ģń╗ōµ×£ +µ»ÅõĖ¬µ¢ćõ╗ČńÜ䵥ŗĶ»ĢµāģÕåĄÕÅ¬ÕŹĀµŹ«õĖĆĶĪī’╝īõĖżõĖ¬ńé╣ÕÅĘĶĪ©ńż║õĖżõĖ¬µĄŗĶ»Ģńö©õŠŗÕØćÕĘ▓ķĆÜĶ┐ć’╝øĶĆīFailure/erro/skip/xfail/xpassĶĪ©ńż║µĄŗĶ»Ģńö©õŠŗÕż▒Ķ┤ź/ķöÖĶ»»/ĶĘ│Ķ┐ć/ķóäµ£¤Õż▒Ķ┤ź/ķóäµ£¤Õż▒Ķ┤źõĮåķĆÜĶ┐ć’╝īõ╝ÜĶó½µĀćĶ«░õĖ║F/E/s/x/XŃĆé + +## ń╝¢ÕåÖµĄŗĶ»ĢÕćĮµĢ░ +µĄŗĶ»ĢÕćĮµĢ░ńÜäÕæĮÕÉŹĶ¦äÕłÖ’╝Ütest_Õ╝ĆÕż┤µł¢ĶĆģõ╗ź_testń╗ōÕ░ŠŃĆé +µĄŗĶ»ĢTasksķĪ╣ńø«ńÜäµ¢ćõ╗Čńø«ÕĮĢÕ”éõĖŗ’╝Ü + + +µēƵ£ēńÜ䵥ŗĶ»ĢķāĮµöŠÕ£©testsµ¢ćõ╗ČÕż╣õĖŁ’╝īõĖÄÕīģÕɽń©ŗÕ║ŵ║Éõ╗ŻńĀüńÜäsrcµ¢ćõ╗ČÕż╣ÕłåÕ╝ĆŃĆéµ£ēõĖĆõ║øµ¢ćõ╗ȵ»öĶŠāķćŹĶ”ü’╝īÕ”éREADME.rst(rstµś»õĮ┐ńö©reStrucuredTextń╝¢ÕåÖńÜäµ¢ćµĪŻµĀ╝Õ╝Å,readmeµś»ķĪ╣ńø«ķĪ╗ń¤ź’╝īCHANGELOGµś»Ķ«░ÕĮĢķĪ╣ńø«ÕÅśµø┤ńÜ䵌źÕ┐Śµ¢ćõ╗Č)’╝īLICENSE.txt(Ķ«ĖÕÅ»Ķ»üµ¢ćõ╗Č)’╝īsetup.py(Õ«ēĶŻģĶäܵ£¼)’╝īsetup.cfg(ķģŹńĮ«µ¢ćõ╗Č)’╝īpytest.ini(ķģŹńĮ«µ¢ćõ╗Č)’╝ītox.ini(ķģŹńĮ«µ¢ćõ╗Č)’╝īconftest.py’╝łµ£¼Õ£░µÅÆõ╗ČÕ║ō’╝īhookÕćĮµĢ░Õ░åĶć¬Õ«Üõ╣ēķĆ╗ĶŠæÕ╝ĢÕģźpytest,ńö©õ║ĵö╣Õ¢äpytestńÜäµē¦ĶĪīµĄüń©ŗ’╝øfixturesÕłÖµś»õĖĆõ║øńö©õ║ĵĄŗĶ»ĢÕēŹÕÉĵē¦ĶĪīķģŹńĮ«ÕÅŖķöƵ»üķĆ╗ĶŠæńÜäÕż¢ÕŻ│ÕćĮµĢ░’╝ēŃĆü_init_.py(ÕłØÕ¦ŗÕī¢µ¢ćõ╗Č,ĶĪ©ńż║ÕćĮµĢ░õĖ╗ÕģźÕÅŻ)ŃĆé + +## õĮ┐ńö©fixtureµē¦ĶĪīķģŹńĮ«ÕÆīķöƵ»üķĆ╗ĶŠæ +@pytest.fixture()õĖŁńÜäÕÅéµĢ░scopeĶĪ©ńż║fixtureńÜäõĮ£ńö©Õ¤¤’╝īµ£ēfunctionŃĆüclassŃĆümoduleŃĆüsessionÕøøõĖ¬ÕŠģķĆēÕĆ╝ŃĆé diff --git "a/_posts/2023-01-11-Linux\347\275\221\347\273\234\351\205\215\347\275\256.md" "b/_posts/2023-01-11-Linux\347\275\221\347\273\234\351\205\215\347\275\256.md" new file mode 100644 index 0000000000..115b9c599f --- /dev/null +++ "b/_posts/2023-01-11-Linux\347\275\221\347\273\234\351\205\215\347\275\256.md" @@ -0,0 +1,343 @@ +--- +layout: post +title: "LinuxńĮæń╗£ķģŹńĮ«" +date: 2023-01-11 +description: "õ╗ŗń╗ŹÕ”éõĮĢµ¤źń£ŗLinuxń│╗ń╗¤õĖŗńÜäńĮæń╗£ķģŹńĮ«,µ¤źń£ŗõĖ╗µ£║ÕÉŹŃĆüńĮæÕŹĪŃĆüĶĘ»ńö▒ÕÖ©ŃĆüńĮæń╗£Ķ┐׵ğµ¢╣Õ╝Å’╝īµĄŗĶ»ĢńĮæń╗£Ķ┐×ķĆÜńŁēńŁē" +tag: Linux +--- + +# linuxń│╗ń╗¤ńÜäńĮæń╗£Ķ┐׵ğńŖȵĆü + +## LINUXńĮæń╗£Ķ«ŠńĮ« +Ķ┐ÖõĖĆĶŖéõĖ╗Ķ”üĶ«▓Õ”éõĮĢµ¤źń£ŗÕ╣Čõ┐«µö╣Õ”éõĖ╗µ£║ÕÉŹ’╝īĶĘ»ńö▒ÕÖ©’╝īńĮæÕŹĪ’╝īńĮæń╗£Ķ┐׵ğµ¢╣Õ╝ÅńŁēńŁēŃĆé + +### 1.µ¤źń£ŗńĮæń╗£ķģŹńĮ« + +µ¤źń£ŗµēƵ£ēµ┤╗ÕŖ©ńÜäńĮæń╗£µÄźÕÅŻ + + ifconfig -a + +ens33:ń¼¼õĖĆÕØŚõ╗źÕż¬ńĮæÕŹĪńÜäÕÉŹń¦░,"ens33"õĖŁńÜä"en"µś»""EtherNetŌĆØ"ńÜäń╝®ÕåÖ’╝īĶĪ©ńż║ńĮæÕŹĪń▒╗Õ×ŗõĖ║õ╗źÕż¬ńĮæ’╝ī"s"ĶĪ©ńż║ńāŁµÅƵŗöµÅƵ¦ĮõĖŖńÜäĶ«ŠÕżć(hot-plugslot.┬ʵĢ░ÕŁŚŌĆ£33ŌĆØĶĪ©ńż║µÅƵ¦Įń╝¢ÕÅĘŃĆé + + ifconfig ens33 + inet 192.168.245.211 #ipÕ£░ÕØĆ + netmask 255. + broadcast 192.168.245.255 #Õ╣┐µÆŁÕ£░ÕØĆ + inet6 + ether 00:0c:29:5a:5a:5a #macÕ£░ÕØĆ + + + +### 2.µ¤źń£ŗńĮæń╗£ńŖȵĆü + + netstat -tunlp + # -t’╝ܵ¤źń£ŗTCP (Transmission Control Protocol’╝īõ╝ĀĶŠōµÄ¦ÕłČÕŹÅĶ««’╝ēńøĖÕģ│ńÜäõ┐Īµü» + # -u’╝ܵ¤źń£ŗUDP (User Datagram Protocol’╝īńö©µłĘµĢ░µŹ«µŖźÕŹÅĶ««’╝ēńøĖÕģ│ńÜäõ┐Īµü» + # -n’╝ܵśŠńż║µĢ░ÕŁŚµĀ╝Õ╝ÅńÜäIPÕ£░ÕØĆ(õĖ╗µ£║Õ£░ÕØĆŃĆüń½»ÕÅŻõ┐Īµü») + # -l’╝ܵśŠńż║ńøæÕÉ¼ÕźŚµÄźÕŁŚ’╝łListeninńŖȵĆüńÜäńĮæń╗£Ķ┐׵ğÕÅŖń½»ÕÅŻõ┐Īµü»’╝ē + # -p’╝ܵśŠńż║Ķ┐øń©ŗõ┐Īµü»’╝łĶ»źķĆēķĪ╣ķ£ĆĶ”ürootµØāķÖÉ’╝ē + + +### 3. õĖ┤µŚČõ┐«µö╣õĖ╗µ£║ÕÉŹ + + hostnamectl set-hostname +### 4.µ░Ėõ╣ģõ┐«µö╣õĖ╗µ£║ÕÉŹ + + vim /etc/hostname + vim /etc/hosts + +### 5.µĄŗĶ»ĢńĮæń╗£Ķ┐×ķĆܵƦ + + ping www.baidu.com + ping -c 3 www.baidu.com #µĄŗĶ»Ģ3µ¼Ī + ping -c 3 -i 0.2 www.baidu.com #µ»Åµ¼ĪķŚ┤ķÜö0.2ń¦Æ + ping -c 3 -i 0.2 -w 1 www.baidu.com #ĶČģµŚČµŚČķŚ┤õĖ║1ń¦Æ’╝łÕŬpingõ║öń¦Æ’╝ī5ń¦Æõ╣ŗÕÉÄń╗ōµØ¤’╝ē + +õĖĆĶł¼µØźĶ»┤’╝īńĮæń╗£õĖŹķĆÜ’╝īńö©pingµØźÕ«ÜõĮŹķŚ«ķóśĶŖéńé╣ńÜäõĮŹńĮ«’╝īpingńÜäķĪ║Õ║ÅÕ”éõĖŗ’╝Ü + + ping 127.0.0.1 #ping µ£¼Õ£░Õø×ńÄ»’╝īµĄŗĶ»Ģµ£¼Õ£░ńĮæń╗£ÕŹÅĶ««µś»ÕÉ”µŁŻÕĖĖ + ping 192.168.0.31 #ping µ£¼Õ£░IP’╝īµĄŗĶ»Ģµ£¼Õ£░ńĮæń╗£µÄźÕÅŻµś»ÕÉ”µŁŻÕĖĖ + ping 192.168.0.254 # ping ńĮæÕģ│’╝īµĄŗĶ»ĢńĮæÕģ│µś»ÕÉ”ÕĘźõĮ£µŁŻÕĖĖ + ping 202.106.0.20 # ping Õż¢ķā©ńĮæń╗£’╝īµĄŗĶ»Ģµ£ŹÕŖĪÕĢåńĮæń╗£µś»ÕÉ”ÕĘźõĮ£µŁŻÕĖĖ + +### 6.µ¤źń£ŗĶĘ»ńö▒ĶĪ© + + route -n + # -n’╝Üõ╗źµĢ░ÕŁŚµĀ╝Õ╝ŵśŠńż║ĶĘ»ńö▒ĶĪ©õ┐Īµü» + # -v’╝ܵśŠńż║Ķ»”ń╗åńÜäĶĘ»ńö▒ĶĪ©õ┐Īµü» + # -e’╝ܵśŠńż║ĶĘ»ńö▒ĶĪ©õĖŁńÜäķöÖĶ»»õ┐Īµü» + # -A’╝ܵśŠńż║µēƵ£ēńÜäĶĘ»ńö▒ĶĪ©õ┐Īµü» + # -g’╝ܵśŠńż║ńĮæÕģ│õ┐Īµü» + # -C’╝ܵśŠńż║ń╝ōÕŁśõ┐Īµü» + # -F’╝ܵśŠńż║Ķ┐ćµ╗żõ┐Īµü» + # -M’╝ܵśŠńż║ÕżÜµÆŁõ┐Īµü» + # -N’╝ܵśŠńż║ńĮæń╗£õ┐Īµü» + # -S’╝ܵśŠńż║ÕźŚµÄźÕŁŚõ┐Īµü» + # -T’╝ܵśŠńż║TCPõ┐Īµü» + # -U’╝ܵśŠńż║UDPõ┐Īµü» + # -V’╝ܵśŠńż║ńēłµ£¼õ┐Īµü» + # -W’╝ܵśŠńż║ńĮæÕŹĪõ┐Īµü» + # -X’╝ܵśŠńż║X.25õ┐Īµü» + # -Z’╝ܵśŠńż║SCTPõ┐Īµü» + +### 7.µ¤źń£ŗDNSµ£ŹÕŖĪÕÖ© + + cat /etc/resolv.conf + #nameserver + #µĄŗĶ»ĢDNSµ£ŹÕŖĪÕÖ©µś»ÕÉ”ÕÅ»ńö© + nslookup www.baidu.com #ńø«µĀćõĖ╗µ£║Õ£░ÕØĆ + # Ķ¦Żµ×ÉDNSõ┐Īµü»µöČķøå + dig www.baidu.com + # µ£¼Õ£░õĖ╗µ£║µśĀÕ░äµ¢ćõ╗Č + # etc/hosts µ¢ćõ╗ČõĖŁĶ«░ÕĮĢńØĆõĖĆõ╗ĮõĖ╗µ£║ÕÉŹõĖÄ IP Õ£░ÕØĆńÜ䵜ĀÕ░äÕģ│ń│╗ĶĪ©’╝īõĖĆĶł¼ńö©µØźõ┐ØÕŁśń╗ÅÕĖĖķ£ĆĶ”üĶ«┐ķŚ«ńÜäõĖ╗µ£║ńÜäõ┐Īµü»ŃĆé + # ÕĮōĶ«┐ķŚ«õĖĆõĖ¬µ£¬ń¤źńÜäÕ¤¤ÕÉŹµŚČ’╝īÕģłµ¤źµēŠĶ»źµ¢ćõ╗ČõĖŁµś»ÕÉ”µ£ēńøĖÕ║öńÜ䵜ĀÕ░äĶ«░ÕĮĢ’╝īÕ”éµ×£µēŠõĖŹÕł░ÕåŹÕÄ╗ÕÉæDNS µ£ŹÕŖĪÕÖ©µ¤źĶ»ó + cat /etc/hosts + # µ£¼Õ£░õĖ╗µ£║ÕÉŹĶ¦Żµ×ɵ¢ćõ╗Č + # /etc/nsswitch.conf µ¢ćõ╗ČõĖŁĶ«░ÕĮĢńØƵ£¼Õ£░õĖ╗µ£║ÕÉŹĶ¦Żµ×ÉńÜäķĪ║Õ║Å’╝īõĖĆĶł¼µāģÕåĄõĖŗ’╝īµ£¼Õ£░õĖ╗µ£║ÕÉŹĶ¦Żµ×ÉńÜäķĪ║Õ║ÅõĖ║’╝Ü + # hosts > dns > files > nis > nisplus > db > ldap > compat > hesiod > myhostname + +### 8.µ¤źń£ŗńĮæÕŹĪõ┐Īµü» + + ifconfig + # -a’╝ܵśŠńż║µēƵ£ēńĮæÕŹĪõ┐Īµü» + # -s’╝ܵśŠńż║ńĮæÕŹĪńÜäń«ĆĶ”üõ┐Īµü» + # -d’╝ܵśŠńż║ńĮæÕŹĪńÜäĶ»”ń╗åõ┐Īµü» + # -v’╝ܵśŠńż║ńĮæÕŹĪńÜäĶ»”ń╗åõ┐Īµü» + # -r’╝ܵśŠńż║ĶĘ»ńö▒õ┐Īµü» + # -m’╝ܵśŠńż║ÕżÜµÆŁõ┐Īµü» + # -u’╝ܵśŠńż║UDPõ┐Īµü» + # -t’╝ܵśŠńż║TCPõ┐Īµü» + # -x’╝ܵśŠńż║X.25õ┐Īµü» + # -z’╝ܵśŠńż║SCTPõ┐Īµü» + + +### 9.ńĮæń╗£Ķ┐׵ğµ¢╣Õ╝Å + +#### ÕŖ©µĆüńĮæń╗£dhcp + +##### ńĮæµĪźµ¢╣Õ╝Å +link: https://blog.csdn.net/qq_59323083/article/details/125531699 + + # 1.Õ«ēĶŻģńĮæµĪźÕĘźÕģĘ + yum install bridge-utils + # 2.ķģŹńĮ«ńĮæµĪź + vim /etc/sysconfig/network-scripts/ifcfg-eth0 + # µĘ╗ÕŖĀõ╗źõĖŗÕåģÕ«╣ + DEVICE=eth0 + BOOTPROTO=dhcp + ONBOOT=yes + BRIDGE=br0 + # 3.ķģŹńĮ«ńĮæµĪź + vim /etc/sysconfig/network-scripts/ifcfg-br0 + # µĘ╗ÕŖĀõ╗źõĖŗÕåģÕ«╣ + DEVICE=br0 + BOOTPROTO=static + IPADDR= + +##### NATµ¢╣Õ╝Å +µēōÕ╝ĆĶÖܵŗ¤ńĮæń╗£ń╝¢ĶŠæÕÖ©’╝īµēƵ£ēµĢ░µŹ«õĖŹĶ”üÕÄ╗µö╣ÕŖ©’╝īÕ”éõĖŗÕøŠµēĆńż║’╝Ü + +µēōÕ╝ĆĶÖܵŗ¤µ£║Ķ«ŠńĮ«’╝īńĮæń╗£ķĆéķģŹÕÖ©’╝īķĆēµŗ®NATµ©ĪÕ╝Å’╝īńäČÕÉÄńé╣Õć╗ķ½śń║¦’╝īķĆēµŗ®ń½»ÕÅŻĶĮ¼ÕÅæ’╝īµĘ╗ÕŖĀń½»ÕÅŻĶĮ¼ÕÅæĶ¦äÕłÖ’╝īÕ”éõĖŗÕøŠµēĆńż║’╝Ü + +ķćŹÕÉ»ńĮæń╗£ + + systemctl restart network + +µŻĆµ¤źńĮæń╗£Ķ┐×ķĆܵƦ + + ping www.baidu.com + +#### ķØÖµĆüńĮæń╗£ + +##### ńĮæµĪźµ©ĪÕ╝ÅĶüöńĮæ’╝łstatic’╝ē + +ķĆÜĶ┐ćVMwareń╝¢ĶŠæĶÅ£ÕŹĢµĀÅńé╣Õć╗ĶÖܵŗ¤ńĮæń╗£ń╝¢ĶŠæÕÖ©,Ķ«ŠńĮ«VMnet0’╝īķĆēµŗ®µĪźµÄźµ©ĪÕ╝Å’╝īÕż¢ķā©Ķ┐׵ğõĖŹĶ”üķĆēĶć¬ÕŖ©’╝īĶĆīµś»ķĆēµŗ®õĮĀńÜäÕ«┐õĖ╗õĖ╗µ£║ńÜäńĮæÕŹĪ’╝īĶĆāĶÖæÕł░õĖĆĶł¼µ£ēµ£ēń║┐ÕÆīµŚĀń║┐õĖżÕØŚńĮæÕŹĪ’╝īõĮåĶ┐ÖķćīķĆēµŗ®ńÜäĶ┐ÖÕØŚńĮæÕŹĪµś»Ķ┐׵ğInternetńÜä’╝īµ»öÕ”é’╝īĶ┐ÖõĖ¬ÕøŠõĖŁµēĆńż║’╝īµłæõĮ┐ńö©µŚĀń║┐ńĮæÕŹĪĶ┐×µÄźÕł░Internet’╝īµēĆõ╗źķĆēµŗ®Õ«ā’╝īńäČÕÉÄŌĆ£ńĪ«Õ«ÜŌĆØŃĆé(Õ”éÕøŠµēĆńż║) + +ĶÖܵŗ¤µ£║ Ķ«ŠńĮ« ńĮæń╗£ķĆéķģŹÕÖ© ķĆēµŗ®µĪźµÄźµ©ĪÕ╝Å’╝īÕ”éõĖŗÕøŠµēĆńż║’╝Ü + +õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č/etc/sysconfig/network-scripts/ifcfg-ens33 + +ķćŹÕÉ»ńĮæń╗£µ£ŹÕŖĪ + + systemctl restart network + +##### NATµ©ĪÕ╝ÅĶüöńĮæ’╝łstatic’╝ē + +ķĆÜĶ┐ćVMwareń╝¢ĶŠæĶÅ£ÕŹĢµĀÅńé╣Õć╗ĶÖܵŗ¤ńĮæń╗£ń╝¢ĶŠæÕÖ©’╝īķĆēõĖŁVMnet8ńé╣Õć╗NATĶ«ŠńĮ«’╝Ü + +õĖŹõĮ┐ńö©µ£¼Õ£░DHCPµ£ŹÕŖĪ’╝īĶ┐ÖµĀĘÕ░▒ÕŠŚÕŗŠµČłDHCPķĆēķĪ╣’╝īńäČÕÉĵ¤źń£ŗDHCPńĪ«õ┐ص£¬ÕÉ»ńö©ŃĆé + + +ń¼¼ÕøøµŁź’╝īµēōÕ╝ĆNATĶ«ŠńĮ«’╝īĶ«░ÕĮĢõĖŗÕøŠõĖŁĶĪ©ńż║ńÜäµĢ░µŹ«ńö©õ║Äõ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č’╝Ü + + +ń¼¼õ║öµŁź’╝īµēōÕ╝ĆĶÖܵŗ¤µ£║Ķ«ŠńĮ«’╝īķģŹńĮ«ńĮæń╗£ķĆéķģŹÕÖ©’╝īÕ”éõĖŗÕøŠµēĆńż║’╝Ü + +ń¼¼ÕģŁµŁź’╝īõ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č/etc/sysconfig/network-scripts/ifcfg-ens33’╝īõ┐«µö╣ńÜ䵌ČÕĆÖÕ┐ģķĪ╗µīēń¼¼ÕøøµŁźńÜäIPńĮ浫ĄÕÆīńĮæÕģ│õ┐«µö╣’╝īÕģĘõĮōµĀ╣µŹ«õĮĀĶć¬ÕĘ▒ńÜäµāģÕåĄÕå│Õ«ÜĶ┐ÖõĖ¬ńĮ浫Ą’╝īµ»öÕ”é’╝īµłæńÜäńĮ浫Ąµś»192.168.75.0’╝īńĮæÕģ│µś»192.168.75.2’╝īÕŁÉńĮæµÄ®ńĀüµś»255.255.255.0ŃĆé + + + +ń¼¼õĖāµŁź’╝īķćŹÕÉ»µ£ŹÕŖĪ’╝Ü + + systemctl restart network + +## ķģŹńĮ«DNS + +ń¼¼õĖƵŁź’╝Üõ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č /etc/resolv.conf ’╝īÕ”éµ×£õĮĀÕģ¼ÕÅĖµ£ēĶć¬ÕĘ▒ńÜäDNSµ£ŹÕŖĪÕÖ©’╝īķéŻõ╣łńö©µ£¼Õģ¼ÕÅĖńÜä’╝īõ╣¤ÕÅ»õ╗źÕł░ńĮæõĖŖµ¤źµēŠÕģŹĶ┤╣ńÜäDNSµ£ŹÕŖĪÕÖ©’╝īµ»öÕ”é’╝Ü + +õĖŁÕøĮõ║ÆĶüöńĮæń╗£õĖŁÕ┐ā’╝Ü1.2.4.8ŃĆü210.2.4.8ŃĆü101.226.4.6’╝łńöĄõ┐ĪÕÅŖń¦╗ÕŖ©’╝ēŃĆü123.125.81.6’╝łĶüöķĆÜ’╝ē +ķś┐ķćīDNS’╝Ü223.5.5.5ŃĆü223.6.6.6 +googleDNS’╝Ü8.8.8.8ŃĆü8.8.4.4 +openDNS’╝Ü208.67.222.222208.67.220.220208.67.222.220208.67.220.222 +ÕÅ»õ╗źķś╗µīĪÕɽµ£ēµüȵäÅńĮæń½ÖńÜädns +208.67.220.123 + +µŚĀÕŖ½µīü ÕÄ╗Õ╣┐ÕæŖµł¢ń▓Śõ┐ŚńĮæń½Ödns:114.114.114.114 ÕÆī 114.114.115.115 + +µŗ”µł¬ķÆōķ▒╝ńŚģµ»Æµ£©ķ®¼ńĮæń½Ö,ÕÅ»Õó×Õ╝║ńĮæķōČŃĆüĶ»üÕłĖŃĆüĶ┤Łńē®ŃĆüµĖĖµłÅŃĆüķÜÉń¦üõ┐Īµü»Õ«ēÕģ©ńÜäDNS 114.114.114.119 ÕÆī 114.114.115.119 + +ńäČÕÉÄõ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č /etc/resolv.conf’╝īÕ”éõĖŗĶĪ©µēĆńż║’╝Ü + + +**ÕÅ»µ£ĆÕżÜÕåÖ3õĖ¬** + +ÕĮōõĮĀķģŹÕźĮresolv.confµ¢ćõ╗ČÕÉÄ’╝īĶ┐ćõ║åõĖĆõ╝Ü’╝īÕÅæńÄ░ÕłÜµēŹķģŹńĮ«ÕźĮńÜäDNSÕÅłÕż▒µĢłõ║å’╝īÕĤµØźDNSĶó½ń│╗ń╗¤ķ揵¢░Ķ”åńø¢µł¢ĶĆģĶó½µĖģķÖż’╝üµēĆõ╗źõĮĀĶ┐śÕ┐ģķĪ╗Õ«īµłÉõ╗źõĖŗÕĘźõĮ£ŃĆé + +ń¼¼õ║īµŁź’╝Üõ┐«µö╣/etc/NetworkManager/NetworkManager.confµ¢ćõ╗Č + + + +## ńĮæń╗£Õ¤║µ£¼ń«ĪńÉå--õĖÄńĮæń╗£ķģŹńĮ«ńøĖÕģ│ńÜäÕĖĖńö©ÕæĮõ╗ż + +1. µ¤źń£ŗńĮæń╗£ķģŹńĮ«õ┐Īµü» +ifconfig ńÜäÕŖ¤ĶāĮµś»ń«ĪńÉåńĮæń╗£µÄźÕÅŻ’╝īńö©õ║ĵ¤źń£ŗŃĆüķģŹńĮ«ŃĆüÕÉ»ńö©µł¢ń”üńö©ńĮæń╗£µÄźÕÅŻŃĆé + + ifconfig interface [aftype] options | address ŌĆ” + +  + +ifconfigÕæĮõ╗żµś»LinuxõĖŗńö©µØźķģŹńĮ«ÕÆīµśŠńż║ńĮæń╗£µÄźÕÅŻõ┐Īµü»ńÜäÕæĮõ╗ż’╝īÕ«āÕÅ»õ╗źµśŠńż║ńĮæń╗£µÄźÕÅŻńÜäĶ»”ń╗åõ┐Īµü»’╝īÕīģµŗ¼IPÕ£░ÕØĆŃĆüÕŁÉńĮæµÄ®ńĀüŃĆüÕ╣┐µÆŁÕ£░ÕØĆŃĆüMACÕ£░ÕØĆńŁēŃĆé + + ifconfig + #Õ«ēĶŻģifconfigÕæĮõ╗ż + yum -y install net-tools + # õ╗ĵ║ÉÕż┤Õ╝ĆÕ¦ŗÕ«ēĶŻģ + yum -y install net-tools.x86_64 + +ifconfigĶ»Łµ│Ģ + + ifconfig [ķĆēķĪ╣] [µÄźÕÅŻÕÉŹ] + ifconfig [ķĆēķĪ╣] [µÄźÕÅŻÕÉŹ] [Õ£░ÕØĆ] [Õ╣┐µÆŁÕ£░ÕØĆ] [ÕŁÉńĮæµÄ®ńĀü] +ńĮæÕŹĪµÄ¦ÕłČÕæĮõ╗ż + + ifconfig eth0 up # ÕÉ»ÕŖ©ńĮæÕŹĪ + ifconfig eth0 down # Õģ│ķŚŁńĮæÕŹĪ + ifconfig eth0 + ifup eth0 # ÕÉ»ÕŖ©ńĮæÕŹĪ + ifup ens33 + ifup eth0:0 # ÕÉ»ÕŖ©ĶÖܵŗ¤ńĮæÕŹĪ + ifdown ens33 + +nmcliÕæĮõ╗ż +Ķ»źÕæĮõ╗żÕÅ»õ╗źÕ«īµłÉńĮæÕŹĪõĖŖµēƵ£ēńÜäķģŹńĮ«ÕĘźõĮ£’╝īÕ╣ČõĖöÕÅ»õ╗źÕåÖÕģźķģŹńĮ«µ¢ćõ╗Č’╝īķćŹÕÉ»ÕÉÄõŠØńäȵ£ēµĢłŃĆé + + nmcli device show ens33 # µ¤źń£ŗńĮæÕŹĪõ┐Īµü» + nmcli device status # µ¤źń£ŗńĮæÕŹĪńŖȵĆü + nmcli device disconnect ens33 # µ¢ŁÕ╝ĆńĮæÕŹĪ + nmcli device connect ens33 # Ķ┐׵ğńĮæÕŹĪ + nmcli device modify ens33 ipv4.addresses + nmcli device modify ens33 ipv4.addresses + +µŻĆµ¤źńĮæÕŹĪń¤źÕÉ”Ķ┐׵ğńĮæń║┐ńÜäÕæĮõ╗ż + + ethtool ens33 # µ¤źń£ŗńĮæÕŹĪõ┐Īµü» + ethtool ens33 | grep "Link detected" # µ¤źń£ŗńĮæÕŹĪµś»ÕÉ”Ķ┐׵ğńĮæń║┐ + + +2. pingÕæĮõ╗ż + + ping [options] hostname/ip + +  + +3. µŻĆµ¤źńĮæń╗£ńŖȵĆü’╝łnetstat’╝ē + + netstat [-veenNcCF] [
+Õ£©utilsµ¢ćõ╗ČÕż╣õĖŗķØóµ¢░Õ╗║õĖĆõĖ¬YamlUtil.pyµ¢ćõ╗Č’╝īńö©µØźÕ░üĶŻģyamlµ¢ćõ╗ČńÜäĶ»╗ÕÅ¢µōŹõĮ£ŃĆé +```python +import yaml +import os +# set up the class to read the yaml file +class YamlReader: + def __init__(self, yamlf): + # Õłżµ¢Łµ¢ćõ╗ȵś»ÕÉ”ÕŁśÕ£© + if os.path.exists(yamlf): + self.yamlf = yamlf + else: + raise FileNotFoundError("µ¢ćõ╗ČõĖŹÕŁśÕ£©’╝ü") + self._data = None # Õ«Üõ╣ēõĖĆõĖ¬ń¦üµ£ēÕ▒׵Ʀ’╝īńö©µØźÕŁśÕé©Ķ»╗ÕÅ¢ńÜäµĢ░µŹ« + # @propertyĶŻģķź░ÕÖ©ńÜäõĮ£ńö©µś»µŖŖõĖĆõĖ¬µ¢╣µ│ĢÕÅśµłÉÕ▒׵ƦĶ░āńö© + @property + def data(self): + # read data from yaml file + # Õłżµ¢Łµś»ÕÉ”ÕĘ▓ń╗ÅĶ»╗ÕÅ¢Ķ┐ćµĢ░µŹ«’╝īÕ”éµ×£ÕĘ▓ń╗ÅĶ»╗ÕÅ¢Ķ┐ćµĢ░µŹ«’╝īµŁżµŚČself._dataõĖ║ÕŁŚÕģĖ’╝īõĖŹõĖ║None’╝īÕ░▒õĖŹķ£ĆĶ”üÕåŹµ¼ĪĶ»╗ÕÅ¢µĢ░µŹ«ŃĆé + if not self._data: + with open(self.yamlf, 'rb') as f: # rbµś»õ╗źõ║īĶ┐øÕłČĶ»╗ÕÅ¢ + self._data = yaml.safe_load(f) + return self._data # Ķ┐öÕø×Ķ»╗ÕÅ¢ńÜäµĢ░µŹ« +``` +µĄŗĶ»ĢõĖĆõĖŗĶ┐ÖõĖ¬utilµ¢ćõ╗ȵś»ÕÉ”ÕÅ»õ╗źµŁŻÕĖĖĶ»╗ÕÅ¢yamlµ¢ćõ╗Č,Õ£©t_yamlµ¢ćõ╗ČÕż╣õĖŗķØóµ¢░Õ╗║õĖĆõĖ¬yaml_demo.pyµ¢ćõ╗Č’╝īńö©µØźµĄŗĶ»ĢYamlUtil.pyµ¢ćõ╗ȵś»ÕÉ”ÕÅ»õ╗źµŁŻÕĖĖĶ»╗ÕÅ¢yamlµ¢ćõ╗ČŃĆé +```python +from utils.YamlUtil import YamlReader +yaml_path = "./data.yml" +data = YamlReader(yaml_path).data +print(data) +``` +yamlµ¢ćõ╗ČÕåģÕ«╣Õ”éõĖŗ’╝Ü +```yaml +name: "test_yml" +result: "success" +``` +ĶŠōÕć║ń╗ōµ×£Õ”éõĖŗ’╝Ü +```commandline +{'name': 'test_yml', 'result': 'success'} +``` + +õ╗źõĖŖÕ░üĶŻģńÜäYamlUtil.pyµ¢ćõ╗ČÕŬĶāĮĶ»╗ÕÅ¢ÕŹĢõĖ¬yamlµ¢ćõ╗Č’╝īÕ”éµ×£Ķ”üĶ»╗ÕÅ¢ÕżÜõĖ¬yamlµ¢ćõ╗Č’╝īķ£ĆĶ”üÕ£©YamlUtil.pyµ¢ćõ╗ČõĖŁµĘ╗ÕŖĀõĖĆõĖ¬µ¢╣µ│Ģ’╝īńö©µØźĶ»╗ÕÅ¢ÕżÜõĖ¬yamlµ¢ćõ╗ČŃĆé +
+õ╗źõĖŖńÜäYamlUtil.pyµ©ĪÕØŚÕ£©Ķ»╗ÕÅ¢õĖŗÕłŚÕżÜõĖ¬yamlµ¢ćõ╗ȵŚČÕĆÖńÜäµŖźķöÖõ┐Īµü»Õ”éõĖŗ’╝Ü +yamlµ¢ćõ╗ČÕåģÕ«╣’╝Ü +```yaml +--- +"username1": "test123" +"password": "123456" +--- +"username1": "test456" +"password": "123456" +``` +µŖźķöÖõ┐Īµü»Õ”éõĖŗ’╝Ü +```commandline +raise ComposerError("expected a single document in the stream", +yaml.composer.ComposerError: expected a single document in the stream + in "./data.yaml", line *, column 1 +``` + +Õ£©YamlUtil.pyµ¢ćõ╗ČõĖŁµĘ╗ÕŖĀõĖĆõĖ¬µ¢╣µ│Ģ’╝īńö©µØźĶ»╗ÕÅ¢ÕżÜõĖ¬yamlµ¢ćõ╗Č: +```python +import yaml +import os +# set up the class to read the yaml file +class YamlReader: + def __init__(self, yamlf): + # Õłżµ¢Łµ¢ćõ╗ȵś»ÕÉ”ÕŁśÕ£© + if os.path.exists(yamlf): + self.yamlf = yamlf + else: + raise FileNotFoundError("µ¢ćõ╗ČõĖŹÕŁśÕ£©’╝ü") + self._data = None # Õ«Üõ╣ēõĖĆõĖ¬ń¦üµ£ēÕ▒׵Ʀ’╝īńö©µØźÕŁśÕé©Ķ»╗ÕÅ¢ńÜäµĢ░µŹ« + self._data_all = None # Õ«Üõ╣ēõĖĆõĖ¬ń¦üµ£ēÕ▒׵Ʀ’╝īńö©µØźÕŁśÕé©Ķ»╗ÕÅ¢ńÜäµĢ░µŹ« + # @propertyĶŻģķź░ÕÖ©ńÜäõĮ£ńö©µś»µŖŖõĖĆõĖ¬µ¢╣µ│ĢÕÅśµłÉÕ▒׵ƦĶ░āńö© + @property + def data(self): + # read data from yaml file + # Õłżµ¢Łµś»ÕÉ”ÕĘ▓ń╗ÅĶ»╗ÕÅ¢Ķ┐ćµĢ░µŹ«’╝īÕ”éµ×£ÕĘ▓ń╗ÅĶ»╗ÕÅ¢Ķ┐ćµĢ░µŹ«’╝īµŁżµŚČself._dataõĖ║ÕŁŚÕģĖ’╝īõĖŹõĖ║None’╝īÕ░▒õĖŹķ£ĆĶ”üÕåŹµ¼ĪĶ»╗ÕÅ¢µĢ░µŹ«ŃĆé + if not self._data: + with open(self.yamlf, 'rb') as f: # rbµś»õ╗źõ║īĶ┐øÕłČĶ»╗ÕÅ¢ + self._data = yaml.safe_load(f) + return self._data # Ķ┐öÕø×Ķ»╗ÕÅ¢ńÜäµĢ░µŹ« + # Ķ»╗ÕÅ¢ÕżÜõĖ¬yamlµ¢ćõ╗Č + def data_all(self): + # read data from yaml file + # Õłżµ¢Łµś»ÕÉ”ÕĘ▓ń╗ÅĶ»╗ÕÅ¢Ķ┐ćµĢ░µŹ«’╝īÕ”éµ×£ÕĘ▓ń╗ÅĶ»╗ÕÅ¢Ķ┐ćµĢ░µŹ«’╝īµŁżµŚČself._dataõĖ║ÕŁŚÕģĖ’╝īõĖŹõĖ║None’╝īÕ░▒õĖŹķ£ĆĶ”üÕåŹµ¼ĪĶ»╗ÕÅ¢µĢ░µŹ«ŃĆé + if not self._data_all: + with open(self.yamlf, 'rb') as f: # rbµś»õ╗źõ║īĶ┐øÕłČĶ»╗ÕÅ¢ + self._data_all = list(yaml.safe_load_all(f)) # list()ÕćĮµĢ░Õ░åyaml.safe_load_all(f)ĶĮ¼µŹóõĖ║ÕłŚĶĪ© + return self._data_all # Ķ┐öÕø×Ķ»╗ÕÅ¢ńÜäµĢ░µŹ« +``` +yamlµ¢ćõ╗ČÕåģÕ«╣’╝Ü +```yaml +--- +"username1": "test123" +"password": "123456" +--- +"username1": "test456" +"password": "123456" +``` +yaml_demo.pyµ¢ćõ╗ČÕåģÕ«╣’╝Ü +```python +from utils.YamlUtil import YamlReader +yaml_path = "./data.yaml" +data = YamlReader(yaml_path).data_all() +print(data) +``` +ĶŠōÕć║ń╗ōµ×£Õ”éõĖŗ’╝Ü +```commandline +[{'username1': 'test123', 'password': '123456'}, {'username1': 'test456', 'password': '123456'}] +``` +## YamlķģŹńĮ«µ¢ćõ╗ČĶ«ŠńĮ« +Õ£©configµ¢ćõ╗ČõĖŗķØó’╝īµ¢░Õ╗║õĖĆõĖ¬yamlµ¢ćõ╗Č’╝īÕæĮÕÉŹõĖ║config.yaml’╝īµ¢ćõ╗ČÕåģÕ«╣Õ”éõĖŗ’╝Ü +```yaml +# µĄŗĶ»ĢńÄ»Õóā +BASE: + test: + url: "http://211.103.136.242:8064" +``` +Õ£©configµ¢ćõ╗ČõĖŗķØó’╝īµ¢░Õ╗║õĖĆõĖ¬pyµ¢ćõ╗Č’╝īÕæĮÕÉŹõĖ║config.py’╝īńö©µØźĶ»╗ÕÅ¢ķģŹńĮ«µ¢ćõ╗Čconfig.yamlõĖŁńÜäÕåģÕ«╣’╝īµ¢ćõ╗ČÕåģÕ«╣Õ”éõĖŗ’╝Ü +ķ”¢Õģłµś»’╝īĶÄĘÕÅ¢ÕĮōÕēŹńø«ÕĮĢ +```python +# 1. ĶÄĘÕÅ¢ÕĮōÕēŹÕ¤║µ£¼ńø«ÕĮĢ +import os +current = os.path.abspath(__file__)# __file__ĶĪ©ńż║ÕĮōÕēŹµ¢ćõ╗Č,Ķ┐ÖµŁźµōŹõĮ£µś»ĶÄĘÕÅ¢ÕĮōÕēŹµ¢ćõ╗ČńÜäń╗ØÕ»╣ĶĘ»ÕŠä +# /home/hugo/PycharmProjects/InterAutoTest_W/venv/bin/python /home/hugo/PycharmProjects/InterAutoTest_W/config/config.py +tmp_dir = os.path.dirname(current)# ĶÄĘÕÅ¢ÕĮōÕēŹµ¢ćõ╗ČńÜäńłČńø«ÕĮĢ +# /home/hugo/PycharmProjects/InterAutoTest_W/venv/bin/python /home/hugo/PycharmProjects/InterAutoTest_W/config +# ĶÄĘÕÅ¢configńø«ÕĮĢńÜäńłČĶĘ»ÕŠä +base_dir = os.path.dirname(tmp_dir) +# /home/hugo/PycharmProjects/InterAutoTest_W/venv/bin/python /home/hugo/PycharmProjects/InterAutoTest_W +# Õ«Üõ╣ēconfigńø«ÕĮĢńÜäĶĘ»ÕŠä +_config_dir = os.path.join(base_dir, "config") # _Õ╝ĆÕż┤ńÜäÕÅśķćÅĶĪ©ńż║ń¦üµ£ēÕÅśķćÅ +# /home/hugo/PycharmProjects/InterAutoTest_W/venv/bin/python /home/hugo/PycharmProjects/InterAutoTest_W/config +# µł¢ĶĆģõ╣¤ÕÅ»õ╗źĶ┐ÖµĀĘÕåÖ’╝Ü +# _config_dir = base_dir + os.sep + "config" +# Õ«Üõ╣ēconfig.yamlµ¢ćõ╗ČńÜäĶĘ»ÕŠä +_config_yaml = os.path.join(_config_dir, "config.yaml") + +def get_config_path(): + return _config_dir +def get_config_file(): + return _config_yaml +``` + +ńäČÕÉĵś»’╝īĶ»╗ÕÅ¢ķģŹńĮ«µ¢ćõ╗Čconfig.yamlõĖŁńÜäÕåģÕ«╣ +```python +from utils.YamlUtil import YamlReader +# 1. ĶÄĘÕÅ¢ÕĮōÕēŹÕ¤║µ£¼ńø«ÕĮĢ +import os +current = os.path.abspath(__file__)# __file__ĶĪ©ńż║ÕĮōÕēŹµ¢ćõ╗Č,Ķ┐ÖµŁźµōŹõĮ£µś»ĶÄĘÕÅ¢ÕĮōÕēŹµ¢ćõ╗ČńÜäń╗ØÕ»╣ĶĘ»ÕŠä +# /home/hugo/PycharmProjects/InterAutoTest_W/venv/bin/python /home/hugo/PycharmProjects/InterAutoTest_W/config/config.py +tmp_dir = os.path.dirname(current)# ĶÄĘÕÅ¢ÕĮōÕēŹµ¢ćõ╗ČńÜäńłČńø«ÕĮĢ +# /home/hugo/PycharmProjects/InterAutoTest_W/venv/bin/python /home/hugo/PycharmProjects/InterAutoTest_W/config +# ĶÄĘÕÅ¢configńø«ÕĮĢńÜäńłČĶĘ»ÕŠä +base_dir = os.path.dirname(tmp_dir) +# /home/hugo/PycharmProjects/InterAutoTest_W/venv/bin/python /home/hugo/PycharmProjects/InterAutoTest_W +# Õ«Üõ╣ēconfigńø«ÕĮĢńÜäĶĘ»ÕŠä +_config_dir = os.path.join(base_dir, "config") # _Õ╝ĆÕż┤ńÜäÕÅśķćÅĶĪ©ńż║ń¦üµ£ēÕÅśķćÅ +# /home/hugo/PycharmProjects/InterAutoTest_W/venv/bin/python /home/hugo/PycharmProjects/InterAutoTest_W/config +# µł¢ĶĆģõ╣¤ÕÅ»õ╗źĶ┐ÖµĀĘÕåÖ’╝Ü +# _config_dir = base_dir + os.sep + "config" +# Õ«Üõ╣ēconfig.yamlµ¢ćõ╗ČńÜäĶĘ»ÕŠä +_config_yaml = os.path.join(_config_dir, "config.yaml") + +def get_config_path(): + return _config_dir +def get_config_file(): + return _config_yaml # _õĖŗÕłÆń║┐Õ╝ĆÕż┤ńÜäÕÅśķćÅĶĪ©ńż║ń¦üµ£ēÕÅśķćÅ + +# 2. Ķ»╗ÕÅ¢ķģŹńĮ«µ¢ćõ╗Č +class ConfigYaml: + # ÕłØÕ¦ŗÕī¢yamlĶ»╗ÕÅ¢ķģŹńĮ«µ¢ćõ╗Č + def __init__(self): + self.config = YamlReader(get_config_file()).data # self.ĶĪ©ńż║ÕĮōÕēŹń▒╗ńÜäÕ«×õŠŗ + # ĶÄĘÕÅ¢url + def get_conf_url(self): + return self.config['BASE']['test']['url'] +if __name__ == '__main__': + conf_read = ConfigYaml() + print(conf_read.get_conf_url()) +``` +Ķ┐ÖõĖƵŁźÕüÜÕ«īõ╣ŗÕÉÄ’╝īÕø×Õł░µĄŗĶ»Ģńö©õŠŗµ¢ćõ╗Čtest_mall.py’╝īÕ£©Ķ┐ÖõĖ¬µĄŗĶ»Ģńö©õŠŗ’╝īĶ░āńö©config.pyµ¢ćõ╗ČõĖŁńÜäÕåģÕ«╣’╝īÕÅ»õ╗źÕ«×ńÄ░µĄŗĶ»ĢµĢ░µŹ«ÕÆīµĄŗĶ»Ģńö©õŠŗńÜäÕłåń”╗ŃĆé +
+õŠŗÕ”é’╝īÕĤµØźńÜäńÖ╗ÕĮĢµĄŗĶ»Ģõ╗ŻńĀüÕ”éõĖŗ’╝Ü +```python +from utils.RequestsUtils import requests_get, requests_post + +def login(): +# define the testing data + + url = "http://211.103.136.242:8064/autuorizations/" + data ={"username":"python","password":"12345678"} + # # sent the POST request + # response = requests.post(url=url,json=data) + # # print the response + # print(response.json()) + + # õĮ┐ńö©utilsÕ░üĶŻģńÜäµ¢╣µ│Ģ + response = requests_post(url=url,json=data,headers=None) + # print the response + print(response) +``` + +ÕÉÄµØźńÜäõ╗ŻńĀüÕ”éõĖŗ’╝Ü +```python +from utils.RequestsUtils import requests_get, requests_post +from config.config import ConfigYaml + +# Õ«Üõ╣ēµĄŗĶ»ĢńÜäurl +conf_y = ConfigYaml() +url_path = conf_y.get_conf_url() +## define login in function + +def login(): + # define the testing data + + url = url_path +"/autuorizations/" + # url = "http://211.103.136.242:8064/autuorizations/" + data = {"username": "python", "password": "12345678"} + + # õĮ┐ńö©utilsÕ░üĶŻģńÜäµ¢╣µ│Ģ + response = requests_post(url=url, json=data, headers=None) + # print the response + print(response) +``` diff --git "a/_posts/2023-01-16-\346\216\245\345\217\243\350\207\252\345\212\250\345\214\226\346\265\213\350\257\225\344\271\213requests.md" "b/_posts/2023-01-16-\346\216\245\345\217\243\350\207\252\345\212\250\345\214\226\346\265\213\350\257\225\344\271\213requests.md" new file mode 100644 index 0000000000..c39a5990ce --- /dev/null +++ "b/_posts/2023-01-16-\346\216\245\345\217\243\350\207\252\345\212\250\345\214\226\346\265\213\350\257\225\344\271\213requests.md" @@ -0,0 +1,217 @@ +--- +layout: post +title: "µÄźÕÅŻĶć¬ÕŖ©Õī¢µĄŗĶ»Ģõ╣ŗrequests" +date: 2023-01-16 +description: "õĖ╗Ķ”üÕīģµŗ¼requestsÕ║ōńÜäÕ«ēĶŻģ’╝īµÄźÕÅŻńö©õŠŗń╝¢ÕåÖ’╝īrequestsÕ║ōńÜäõĮ┐ńö©’╝īrequestsÕ║ōńÜäĶ┐öÕø×ÕĆ╝õ╗ŗń╗Ź’╝īrequestsÕ║ōńÜäńö©õŠŗń╝¢ÕåÖõ╗źÕÅŖRequestsńÜäÕ░üĶŻģńŁēńŁē" +tag: Ķć¬ÕŖ©Õī¢µĄŗĶ»Ģ +--- + +õĖ╗Ķ”üÕīģµŗ¼requestsÕ║ōńÜäÕ«ēĶŻģ’╝īµÄźÕÅŻńö©õŠŗń╝¢ÕåÖ’╝īrequestsÕ║ōńÜäõĮ┐ńö©’╝īrequestsÕ║ōńÜäĶ┐öÕø×ÕĆ╝õ╗ŗń╗Ź’╝īrequestsÕ║ōńÜäńö©õŠŗń╝¢ÕåÖõ╗źÕÅŖRequestsńÜäÕ░üĶŻģńŁēńŁēŃĆé + + +# µÄźÕÅŻńö©õŠŗń╝¢ÕåÖ +Õ«×ķÖģµāģÕåĄõĖŗ’╝īµ»ÅõĖ¬µ©ĪÕØŚńÜ䵥ŗĶ»Ģńö©õŠŗÕåÖńÜäĶČŖĶ»”ń╗åĶČŖÕźĮ’╝īĶ”üµĀ╣µŹ«µÄźÕÅŻµ¢ćµĪŻĶ┐øĶĪīń╝¢ÕåÖŃĆé + + + + +# Õ«ēĶŻģķĪ╣ńø«õŠØĶĄ¢ +õĖŗĶĮĮrequirements.txtõĖŁµēĆķ£ĆńÜäpackage: +```commandline +pip install -r requirements.txt +``` +ÕłŚÕć║ÕĘ▓ń╗ÅÕ«ēĶŻģńÜäÕīģĶŻ╣ +```commandline +pip list +``` + +pip installõĖ┤µŚČµĘ╗ÕŖĀķĢ£Õāŵ║É’╝Ü +```commandline +pip install pytest -i https://pypi.tuna.tsinghua.edu.cn/simple +``` +ÕøĮÕåģķĢ£Õāŵ║ÉÕīģµŗ¼’╝Ü + +| ķĢ£Õāŵ║É | Õ£░ÕØĆ | +| :----- | :----- | +| µĖģÕŹÄ | https://pypi.tuna.tsinghua.edu.cn/simple | +| ķś┐ķćī | http://mirrors.aliyun.com/pypi/simple/ | +| Ķ▒åńōŻ | http://pypi.douban.com/simple/ | +| ńÖŠÕ║” | https://mirror.baidu.com/pypi/simple | + +# Requests +Requestsµś»õĖĆõĖ¬Python HTTPÕ║ō’╝īńö©õ║ÄÕÅæķĆüHTTPĶ»Ęµ▒éŃĆéÕ«āµ»öurllibµø┤ÕŖĀµ¢╣õŠ┐’╝īõĮåµś»Õ«āõĖŹµö»µīüķ¬īĶ»üŃĆücookiesµł¢ĶĆģÕģČÕ«āÕżŹµØéńÜäHTTPÕ«óµłĘń½»ÕŖ¤ĶāĮŃĆéRequestsµś»õĖĆõĖ¬Apache2 LicensedÕ╝Ƶ║ÉķĪ╣ńø«’╝īńö▒Kenneth ReitzÕłøÕ╗║ÕÆīń╗┤µŖżŃĆé +## Õ«ēĶŻģ +```commandline +pip install requests +``` +## õĮ┐ńö© +```python +import requests +r = requests.get('https://api.github.com/events') +print(r.text) +``` +## Ķ»Ęµ▒éĶ┐öÕø×õ╗ŗń╗Ź +``` +r.status_code #ÕōŹÕ║öńŖȵĆü +r.content #ÕŁŚĶŖéµ¢╣Õ╝ÅńÜäÕōŹÕ║öõĮō’╝īõ╝ÜĶć¬ÕŖ©õĖ║õĮĀĶ¦ŻńĀü gzip ÕÆī deflate ÕÄŗń╝® +r.headers #õ╗źÕŁŚÕģĖÕ»╣Ķ▒ĪÕŁśÕ驵£ŹÕŖĪÕÖ©ÕōŹÕ║öÕż┤’╝īĶŗźķö«õĖŹÕŁśÕ£©ÕłÖĶ┐öÕø×None +r.json() #RequestsõĖŁÕåģńĮ«ńÜäJSON +r.url # ĶÄĘÕÅ¢url +r.encoding # ń╝¢ńĀüµĀ╝Õ╝Å +r.cookies # ĶÄĘÕÅ¢cookie +r.raw #Ķ┐öÕø×ÕĤզŗÕōŹÕ║öõĮō +r.text #ÕŁŚń¼”õĖ▓µ¢╣Õ╝ÅńÜäÕōŹÕ║öõĮō’╝īõ╝ÜĶć¬ÕŖ©µĀ╣µŹ«ÕōŹÕ║öÕż┤ķā©ńÜäÕŁŚń¼”ń╝¢ńĀüĶ┐øĶĪī +r.raise_for_status() #Õż▒Ķ┤źĶ»Ęµ▒é(ķØ×200ÕōŹÕ║ö)µŖøÕć║Õ╝éÕĖĖ +``` +## Requestsńö©õŠŗń╝¢ÕåÖ + +### ń╝¢ÕåÖńÖ╗ÕĮĢĶäܵ£¼ +```python +import requests +def login(): + url = "http://172.17.0.139:5004/authorizations/" + data = {"username":"python", + "password":"12345678"} + r= requests.post(url,json=data) + print(r.text) +``` +### ń╝¢ÕåÖõĖ¬õ║║õ┐Īµü»ĶÄĘÕÅ¢Ķäܵ£¼ + +```python +import requests +def info(): + url = "http://172.17.0.139:5004/user/" + token = "***" + headers = { + "Authorization": "JWT"+token + } + r = requests.get(url,headers=headers) + print(r.text) +``` + +### ń╝¢ÕåÖÕĢåÕōüÕłŚĶĪ©Ķäܵ£¼ +```python +import requests +def goods_list(): + url = "http://172.17.0.139:5004/categories/115/skus" + data = { + # "categroy_id":"115", + "page":"1", + "page_size": "10", + "ordering": "create_time",#'create_time', 'price', 'sales' + } + r = requests.get(url, json=data) + print(r.text) + print(r.json) +``` +### µĘ╗ÕŖĀÕł░Ķ┤Łńē®ĶĮ” +```python +import requests +def cart(): + url = "http://172.17.0.139:5004/cart/" + data = { + "sku_id": "3", + "count": "1", + "selected": "true", + } + token = "***" + headers = { + "Authorization": "JWT"+token + } + r = requests.post(url, json=data,headers=headers) + print(r.text) +``` +### õ┐ØÕŁśĶ«óÕŹĢ +```python +import requests +def order(): + url = "http://172.17.0.139:5004/cart/" + token = "***" + headers = { + "Authorization": "JWT"+token + } + r = requests.get(url,headers=headers) + print(r.text) +``` + +## RequestsńÜäÕ░üĶŻģ +### Õ░üĶŻģrequests_getµ¢╣µ│Ģ +```python +#1ŃĆüÕłøÕ╗║Õ░üĶŻģgetµ¢╣µ│Ģ +def requests_get(url,headers): + #2ŃĆüÕÅæķĆürequests getĶ»Ęµ▒é + r = requests.get(url,headers = headers) + #3ŃĆüĶÄĘÕÅ¢ń╗ōµ×£ńøĖÕ║öÕåģÕ«╣ + code = r.status_code + try: + body = r.json() + except Exception as e: + body = r.text + #4ŃĆüÕåģÕ«╣ÕŁśÕł░ÕŁŚÕģĖ + res = dict() + res["code"] = code + res["body"] = body + #5ŃĆüÕŁŚÕģĖĶ┐öÕø× + return res +``` +### requests_postµ¢╣µ│ĢÕ░üĶŻģ +```python +#1ŃĆüÕłøÕ╗║postµ¢╣µ│Ģ +def requests_post(url,json=None,headers=None): + #2ŃĆüÕÅæķĆüpostĶ»Ęµ▒é + r= requests.post(url,json=json,headers=headers) + #3ŃĆüĶÄĘÕÅ¢ń╗ōµ×£ÕåģÕ«╣ + code = r.status_code + try: + body = r.json() + except Exception as e: + body = r.text + #4ŃĆüÕåģÕ«╣ÕŁśÕł░ÕŁŚÕģĖ + res = dict() + res["code"] = code + res["body"] = body + #5ŃĆüÕŁŚÕģĖĶ┐öÕø× + return res +``` + +ÕÅ»õ╗źÕÅæńÄ░,requests_getÕÆīrequests_postµ¢╣µ│ĢńÜäÕī║Õł½Õ░▒µś»Ķ»Ęµ▒éµ¢╣Õ╝ÅõĖŹÕÉī,ÕģČõ╗¢ķāĮµś»õĖƵĀĘńÜä,µēĆõ╗źµłæõ╗¼ÕÅ»õ╗źµŖŖĶ┐ÖõĖżõĖ¬µ¢╣µ│ĢÕÉłÕ╣ȵłÉõĖĆõĖ¬µ¢╣µ│Ģ,Ķ┐ÖµĀĘÕ░▒ÕÅ»õ╗źÕćÅÕ░æõ╗ŻńĀüķćÅ,µÅÉķ½śõ╗ŻńĀüńÜäÕżŹńö©µĆ¦. +```python +# ķ揵×ä +# 1ŃĆüÕłøÕ╗║ń▒╗ +class Requests: +# 2ŃĆüÕ«Üõ╣ēÕģ¼Õģ▒µ¢╣µ│Ģ +# 2.1 Õó×ÕŖĀµ¢╣µ│ĢńÜäÕÅéµĢ░’╝īµĀ╣µŹ«ÕÅéµĢ░µØźķ¬īĶ»üĶ»Ęµ▒éµ¢╣Õ╝ŵś»getĶ┐śµś»post +# 2.2 ķćŹÕżŹńÜäÕåģÕ«╣’╝īÕżŹÕłČĶ┐øµØźÕŹ│ÕÅ» +# ÕÉÄń╗ŁÕÅéµĢ░Ķ┐śÕÅ»õ╗źÕŖĀÕģźdataŃĆücookiesńŁē + def requests_api(self,url,json=None,headers=None,method="get"): + # 3ŃĆüÕłżµ¢ŁĶ»Ęµ▒éµ¢╣Õ╝Å + if method == "get": + r = requests.get(url,headers=headers) + elif method == "post": + r = requests.post(url,json=json,headers=headers) + # 4ŃĆüĶÄĘÕÅ¢ń╗ōµ×£ÕåģÕ«╣ + code = r.status_code + try: + body = r.json() + except Exception as e: + body = r.text + # 5ŃĆüÕåģÕ«╣ÕŁśÕł░ÕŁŚÕģĖ + res = dict() + res["code"] = code + res["body"] = body + # 6ŃĆüÕŁŚÕģĖĶ┐öÕø× + return res +### ķ揵×äget/postµ¢╣µ│Ģ + def get(self,**kwargs): + # Ķ░āńö©Õģ¼Õģ▒µ¢╣µ│Ģ + return self.requests_api(url,method="get",**kwargs) + def post(self,**kwargs): + # Ķ░āńö©Õģ¼Õģ▒µ¢╣µ│Ģ + return self.requests_api(url,method="post",**kwargs) +``` + + + + + + diff --git "a/_posts/2023-01-17-Python\344\270\255\345\206\205\345\255\230\345\222\214\345\217\230\351\207\217\347\256\241\347\220\206.md" "b/_posts/2023-01-17-Python\344\270\255\345\206\205\345\255\230\345\222\214\345\217\230\351\207\217\347\256\241\347\220\206.md" new file mode 100644 index 0000000000..c026f775df --- /dev/null +++ "b/_posts/2023-01-17-Python\344\270\255\345\206\205\345\255\230\345\222\214\345\217\230\351\207\217\347\256\241\347\220\206.md" @@ -0,0 +1,211 @@ +--- +layout: post +title: "PythonõĖŁÕåģÕŁśÕÆīÕÅśķćÅń«ĪńÉå" +date: 2023-01-17 +description: "õ╗ŗń╗ŹpythonõĖŁÕ╝Ģńö©õĖÄÕ»╣Ķ▒Ī’╝īÕÅ»ÕÅśµĢ░µŹ«ń▒╗Õ×ŗõĖÄõĖŹÕÅ»ÕÅśµĢ░µŹ«ń▒╗Õ×ŗ’╝īÕĆ╝õ╝ĀķĆÆ’╝īÕÅśķćÅÕÆīÕåģÕŁśń«ĪńÉåńŁēµ¢╣ķØóńÜäÕåģÕ«╣" +tag: Python +--- + +õ╗ŗń╗ŹpythonõĖŁÕ╝Ģńö©õĖÄÕ»╣Ķ▒Ī’╝īÕÅ»ÕÅśµĢ░µŹ«ń▒╗Õ×ŗõĖÄõĖŹÕÅ»ÕÅśµĢ░µŹ«ń▒╗Õ×ŗ’╝īÕĆ╝õ╝ĀķĆÆ’╝īÕÅśķćÅÕÆīÕåģÕŁśń«ĪńÉåńŁēµ¢╣ķØóńÜäÕåģÕ«╣ + +## Õ╝Ģńö©õĖÄÕ»╣Ķ▒Ī + +Python õĖŁ’╝īõĖĆÕłćńÜåÕ»╣Ķ▒ĪŃĆé µ»ÅõĖ¬Õ»╣Ķ▒Īńö▒’╝ܵĀćĶ»å’╝łidentity’╝ēŃĆüń▒╗Õ×ŗ’╝łtype’╝ēŃĆüvalue’╝łÕĆ╝’╝ē +ń╗䵳ÉŃĆé +1. µĀćĶ»åńö©õ║ÄÕö»õĖƵĀćĶ»åÕ»╣Ķ▒Ī’╝īķĆÜÕĖĖÕ»╣Õ║öõ║ÄÕ»╣Ķ▒ĪÕ£©Ķ«Īń«Śµ£║ÕåģÕŁśõĖŁńÜäÕ£░ÕØĆŃĆéõĮ┐ńö©ÕåģńĮ«ÕćĮµĢ░ id(obj)ÕÅ»Ķ┐öÕø×Õ»╣Ķ▒Ī obj ńÜäµĀćĶ»åŃĆé +2. ń▒╗Õ×ŗńö©õ║ÄĶĪ©ńż║Õ»╣Ķ▒ĪÕŁśÕé©ńÜäŌĆ£µĢ░µŹ«ŌĆØńÜäń▒╗Õ×ŗŃĆéń▒╗Õ×ŗÕÅ»õ╗źķÖÉÕłČÕ»╣Ķ▒ĪńÜäÕÅ¢ÕĆ╝ĶīāÕø┤õ╗źÕÅŖÕÅ»µē¦ĶĪīńÜä +µōŹõĮ£ŃĆéÕÅ»õ╗źõĮ┐ńö© type(obj)ĶÄĘÕŠŚÕ»╣Ķ▒ĪńÜäµēĆÕ▒×ń▒╗Õ×ŗŃĆé +3. ÕĆ╝ĶĪ©ńż║Õ»╣Ķ▒ĪµēĆÕŁśÕé©ńÜäµĢ░µŹ«ńÜäõ┐Īµü»ŃĆéõĮ┐ńö© print(obj)ÕÅ»õ╗źńø┤µÄźµēōÕŹ░Õć║ÕĆ╝ŃĆé + +**Õ»╣Ķ▒ĪńÜäµ£¼Ķ┤©Õ░▒µś»’╝ÜõĖĆõĖ¬ÕåģÕŁśÕØŚ’╝īµŗźµ£ēńē╣Õ«ÜńÜäÕĆ╝’╝īµö»µīüńē╣Õ«Üń▒╗Õ×ŗńÜäńøĖÕģ│µōŹõĮ£.** + +ÕÅśķćÅõ╣¤µłÉõĖ║’╝ÜÕ»╣Ķ▒ĪńÜäÕ╝Ģńö©ŃĆéÕøĀõĖ║’╝īÕÅśķćÅÕŁśÕé©ńÜäÕ░▒µś»Õ»╣Ķ▒ĪńÜäÕ£░ÕØĆŃĆé +ÕÅśķćÅķĆÜĶ┐ćÕ£░ÕØĆÕ╝Ģńö©õ║åŌĆ£Õ»╣Ķ▒ĪŌĆØŃĆé + +ń«ĆÕŹĢµØźĶ»┤’╝īÕ£© PythonõĖŁ,ķććńö©ńÜ䵜»Õ¤║õ║ÄÕĆ╝ńÜäÕåģÕŁśń«ĪńÉåµ¢╣Õ╝Å,µ»ÅõĖ¬ÕĆ╝Õ£©ÕåģÕŁśõĖŁÕŬµ£ēõĖĆõ╗ĮÕŁśÕé©ŃĆéÕ”éµ×£ń╗ÖÕżÜõĖ¬ÕÅśķćÅĶĄŗńøĖÕÉīńÜäÕĆ╝(Õ”éµĢ░ÕĆ╝ń▒╗Õ×ŗŃĆüÕŁŚń¼”õĖ▓ń▒╗Õ×ŗŃĆüÕģāń╗ä),ķéŻõ╣łÕżÜõĖ¬ÕÅśķćÅÕŁśÕé©ńÜäķāĮµś»µīćÕÉæĶ┐ÖõĖ¬ÕĆ╝ńÜäÕåģÕŁśÕ£░ÕØĆ,ÕŹ│idŃĆéõ╣¤Õ░▒µś»Ķ»┤’╝īPythonõĖŁńÜäÕÅśķćÅÕ╣ȵ▓Īµ£ēÕŁśÕé©ÕÅśķćÅńÜäÕĆ╝,ĶĆīµś»ÕŁśÕ驵īćÕÉæĶ┐ÖõĖ¬ÕĆ╝ńÜäÕ£░ÕØƵł¢Õ╝Ģńö©ŃĆé + + + + +### Python ńÜäĶĄŗÕĆ╝µ£║ÕłČ + +```python +x = 666 +y = x +print(id(x)) +print(id(y)) + +x = x + 1 +print(id(x)) +print(id(y)) +``` +ń╗ōµ×£Õ”éõĖŗ’╝Ü +```console +2015992431536 +2015992431536 +2015992431024 +2015992431536 +``` +µē¦ĶĪīõ╗źõĖŖõĖēÕÅź’╝īÕ£© python õĖŁµäÅÕæ│ńØĆõ╗Ćõ╣ł, Õ«×ķÖģÕÅæńö¤õ║åõ╗Ćõ╣ł’╝¤ + +x = 666õ╝ÜÕ£©ÕåģÕŁśõĖŁÕłøÕ╗║õĖĆõĖ¬µĢ┤Õ×ŗÕ»╣Ķ▒Ī’╝īńäČÕÉÄÕÅśķćÅxńøĖÕĮōõ║ÄõĖĆõĖ¬µĀćńŁŠ,Ķ┤┤Õ£©µŁżÕ»╣Ķ▒ĪõĖŖŃĆé +y = x Õ░åyõ╣¤õĮ£õĖ║Ķ┐ÖõĖ¬µĢ┤Õ×ŗÕ»╣Ķ▒ĪńÜäµĀćńŁŠ’╝īĶĆīõĖŹµś»ķ揵¢░Õ£©ÕåģÕŁśõĖŁÕłøÕ╗║õĖĆõĖ¬Õ»╣Ķ▒ĪŃĆé +x = x+1 Õ░å x ńÜäÕĆ╝ÕŖĀ 1’╝īńäČÕÉÄÕ£©ÕåģÕŁśõĖŁÕłøÕ╗║ÕÅ”õĖĆõĖ¬µĢ┤Õ×ŗÕ»╣Ķ▒Ī667’╝īÕ░åxĶ┤┤Õ£©Ķ┐ÖõĖ¬Õ»╣Ķ▒ĪõĖŖ’╝īĶĆīõĖŹµś»ÕĤµØźńÜä666 õĖŖŃĆé + +```python +a=3 +b=3 +c=1 +print("a is bń╗ōµ×£’╝Ü"+str(a is b)) #True +print("a is cń╗ōµ×£’╝Ü"+str(a is c)) #False +print("id(a)=%d,id(b)=%d,id(c)=%d"%(id(a),id(b),id(c))) +``` +Ķ┐ÉĶĪīń╗ōµ×£Õ”éõĖŗ’╝Ü +```console +a is bń╗ōµ×£’╝ÜTrue +a is cń╗ōµ×£’╝ÜFalse +id(a)=140730432239456,id(b)=140730432239456,id(c)=140730432239392 +``` +Õ»╣Ķ▒Īõ┐ØÕŁśÕ£©ÕåģÕŁśń®║ķŚ┤,Ķ┐ÖķćīńÜä'a'ÕÆī'b'µś»ÕÅśķćÅ,ÕÅśķćŵś»Õ»╣Ķ▒ĪńÜäÕ╝Ģńö©,Õż¢ķā©µā│Ķ”üõĮ┐ńö©Õ»╣Ķ▒ĪńÜäÕĆ╝’╝īķ£ĆĶ”üķĆÜĶ┐ćÕÅśķćÅµØźÕ╝Ģńö©Õ»╣Ķ▒ĪŃĆéÕÉīµĀĘńÜäÕĆ╝Õ£©ÕåģÕŁśõĖŁÕŬµ£ēõĖĆõ╗ĮÕŁśÕé©,µēĆõ╗ź'a'ÕÆī'b'Õ╝Ģńö©ńÜäÕ»╣Ķ▒Īµś»ńøĖÕÉīńÜä’╝īid(a)=140730432239456=id(b)’╝īĶ┐ÖõĖ¬Õ»╣Ķ▒ĪńÜäÕ╝Ģńö©µĢ░ķćÅõĖ║2ŃĆéÕĮōµ¤ÉõĖ¬Õ»╣Ķ▒ĪńÜäÕ╝Ģńö©µĢ░ķćÅõĖ║0µŚČ’╝īÕ»╣Ķ▒Īõ╝ÜĶó½Õø×µöČŃĆé + +### ÕÅśķćÅÕø×µöȵ£║ÕłČ +ÕĮōµłæõ╗¼õĮ┐ńö© del ÕłĀķÖżÕÅśķćŵŚČ’╝īµłæõ╗¼Õł░Õ║ĢÕüÜõ║åõ╗Ćõ╣ł’╝¤ +õĖĆÕÅźĶ»Ø : ÕłĀķÖżĶ┤┤Õ£©Õ»╣Ķ▒ĪõĖŖńÜäµĀćńŁŠ’╝īĶĆīõĖŹµś»ń£¤ńÜäÕłĀķÖżÕåģÕŁśõĖŁńÜäÕ»╣Ķ▒ĪŃĆé +ķéŻõ╣łµłæõ╗¼Õ░▒µŚĀµ│ĢÕłĀķÖżÕåģÕŁśõĖŁńÜäÕ»╣Ķ▒Ī’╝īńäČÕÉÄĶŖéń£üÕåģÕŁśÕÉŚ’╝¤ +ÕÅ»õ╗ź’╝īõĮåµś»ķ£ĆĶ”üķĆÜĶ┐ć python ńÜäÕ×āÕ£ŠÕø×µöȵ£║ÕłČŃĆéń«ĆÕŹĢµØźĶ»┤,Õ░▒µś»Ķ┤┤Õ£©Õ»╣Ķ▒ĪõĖŖńÜäµĀćńŁŠµĢ░ķćÅõĖ║ 0 µŚČ’╝īõ╝ÜĶó½ python Ķć¬ÕŖ©Õø×µöČŃĆé + +## ÕÅ»ÕÅśµĢ░µŹ«ń▒╗Õ×ŗõĖÄõĖŹÕÅ»ÕÅśµĢ░µŹ«ń▒╗Õ×ŗ + +* ÕÅ»ÕÅśµĢ░µŹ«ń▒╗Õ×ŗ’╝ÜÕłŚĶĪ©listÕÆīÕŁŚÕģĖdict +* õĖŹÕÅ»ÕÅśµĢ░µŹ«ń▒╗Õ×ŗ’╝ܵĢ┤Õ×ŗintŃĆüµĄ«ńé╣Õ×ŗfloatŃĆüÕŁŚń¼”õĖ▓Õ×ŗstringÕÆīÕģāń╗ätuple + +Ķ┐ÖķćīńÜäÕÅ»ÕÅśõĖŹÕÅ»ÕÅś’╝īµś»µīćÕåģÕŁśõĖŁńÜäķéŻÕØŚÕåģÕ«╣’╝łvalue’╝ēµś»ÕÉ”ÕÅ»õ╗źĶó½µö╣ÕÅśŃĆéÕ”éµ×£µś»õĖŹÕÅ»ÕÅśń▒╗Õ×ŗ’╝īÕ£©Õ»╣Õ»╣Ķ▒Īµ£¼Ķ║½µōŹõĮ£ńÜ䵌ČÕĆÖ’╝īÕ┐ģķĪ╗Õ£©ÕåģÕŁśõĖŁµ¢░ńö│Ķ»ĘõĖĆÕØŚÕī║Õ¤¤(ÕøĀõĖ║ĶĆüÕī║Õ¤¤õĖŹÕÅ»ÕÅś)ŃĆéÕ”éµ×£µś»ÕÅ»ÕÅśń▒╗Õ×ŗ’╝īÕ»╣Õ»╣Ķ▒ĪµōŹõĮ£ńÜ䵌ČÕĆÖ’╝īõĖŹķ£ĆĶ”üÕåŹÕ£©ÕģČõ╗¢Õ£░µ¢╣ńö│Ķ»ĘÕåģÕŁś’╝īÕŬķ£ĆĶ”üÕ£©µŁżÕ»╣Ķ▒ĪÕÉÄķØóĶ┐×ń╗Łńö│Ķ»Ę(+/-)ÕŹ│ÕÅ»’╝īõ╣¤Õ░▒µś»Õ«āńÜäaddressõ╝Üõ┐صīüõĖŹÕÅś’╝īõĮåÕī║Õ¤¤õ╝ÜÕÅśķĢ┐µł¢ĶĆģÕÅśń¤ŁŃĆé + +õ╣¤Õ░▒µś»Ķ»┤’╝Ü +* pythonõĖŁńÜäõĖŹÕÅ»ÕÅśµĢ░µŹ«ń▒╗Õ×ŗ’╝īõĖŹÕģüĶ«ĖÕÅśķćÅńÜäÕĆ╝ÕÅæńö¤ÕÅśÕī¢’╝īÕ”éµ×£µö╣ÕÅśõ║åÕÅśķćÅńÜäÕĆ╝’╝īńøĖÕĮōõ║ĵś»µ¢░Õ╗║õ║åõĖĆõĖ¬Õ»╣Ķ▒Ī’╝īĶĆīÕ»╣õ║ÄńøĖÕÉīńÜäÕĆ╝ńÜäÕ»╣Ķ▒Ī’╝īÕ£©ÕåģÕŁśõĖŁÕłÖÕŬµ£ēõĖĆõĖ¬Õ»╣Ķ▒Ī’╝īÕåģķā©õ╝ܵ£ēõĖĆõĖ¬Õ╝Ģńö©Ķ«ĪµĢ░µØźĶ«░ÕĮĢµ£ēÕżÜÕ░æõĖ¬ÕÅśķćÅÕ╝Ģńö©Ķ┐ÖõĖ¬Õ»╣Ķ▒Ī’╝ø +* ÕÅ»ÕÅśµĢ░µŹ«ń▒╗Õ×ŗ’╝īÕģüĶ«ĖÕÅśķćÅńÜäÕĆ╝ÕÅæńö¤ÕÅśÕī¢’╝īÕŹ│Õ”éµ×£Õ»╣ÕÅśķćÅĶ┐øĶĪīappendŃĆü+=ńŁēĶ┐Öń¦ŹµōŹõĮ£ÕÉÄ’╝īÕŬµś»µö╣ÕÅśõ║åÕÅśķćÅńÜäÕĆ╝’╝īĶĆīõĖŹõ╝ܵ¢░Õ╗║õĖĆõĖ¬Õ»╣Ķ▒Ī’╝īÕÅśķćÅÕ╝Ģńö©ńÜäÕ»╣Ķ▒ĪńÜäÕ£░ÕØĆõ╣¤õĖŹõ╝ÜÕÅśÕī¢’╝øÕ»╣õ║ÄńøĖÕÉīńÜäÕĆ╝ńÜäõĖŹÕÉīÕ»╣Ķ▒Ī’╝īÕ£©ÕåģÕŁśõĖŁÕłÖõ╝ÜÕŁśÕ£©õĖŹÕÉīńÜäÕ»╣Ķ▒Ī’╝īÕŹ│µ»ÅõĖ¬Õ»╣Ķ▒ĪķāĮµ£ēĶć¬ÕĘ▒ńÜäÕ£░ÕØĆ’╝īńøĖÕĮōõ║ÄÕåģÕŁśõĖŁÕ»╣õ║ÄÕÉīÕĆ╝ńÜäÕ»╣Ķ▒Īõ┐ØÕŁśõ║åÕżÜõ╗Į’╝īĶ┐ÖķćīõĖŹÕŁśÕ£©Õ╝Ģńö©Ķ«ĪµĢ░’╝īµś»Õ«×Õ«×Õ£©Õ£©ńÜäÕ»╣Ķ▒ĪŃĆé + + + + + +## Õ╝Ģńö©õ╝ĀķĆÆõĖÄÕĆ╝õ╝ĀķĆÆ + +ÕÅ»ÕÅśÕ»╣Ķ▒ĪõĖ║Õ╝Ģńö©õ╝ĀķĆÆ’╝łõ╝ĀÕØĆ’╝ē’╝īõĖŹÕÅ»ÕÅśÕ»╣Ķ▒ĪõĖ║ÕĆ╝õ╝ĀķĆÆ’╝łõ╝ĀÕĆ╝’╝ēŃĆé + +õ╝ĀÕĆ╝ÕÆīõ╝ĀÕØĆńÜäÕī║Õł½ +õ╝ĀÕĆ╝Õ░▒µś»õ╝ĀÕģźõĖĆõĖ¬ÕÅéµĢ░ńÜäÕĆ╝’╝īõ╝ĀÕØĆÕ░▒µś»õ╝ĀÕģźõĖĆõĖ¬ÕÅéµĢ░ńÜäÕ£░ÕØĆ’╝īõ╣¤Õ░▒µś»ÕåģÕŁśńÜäÕ£░ÕØĆ’╝łńøĖÕĮōõ║ĵīćķÆł’╝ēŃĆéõ╗¢õ╗¼ńÜä**Õī║Õł½µś»Õ”éµ×£ÕćĮµĢ░ķćīķØóÕ»╣õ╝ĀÕģźńÜäÕÅéµĢ░ķ揵¢░ĶĄŗÕĆ╝’╝īÕćĮµĢ░Õż¢ńÜäÕģ©Õ▒ĆÕÅśķćŵś»ÕÉ”ńøĖÕ║öµö╣ÕÅś**’╝īńö©**õ╝ĀÕĆ╝õ╝ĀÕģźńÜäÕÅéµĢ░µś»õĖŹõ╝ܵö╣ÕÅśńÜä’╝īńö©õ╝ĀÕØĆõ╝ĀÕģźÕ░▒õ╝ܵö╣ÕÅś**ŃĆé + +PythonÕćĮµĢ░ÕÅéµĢ░õ╝ĀķĆƵ¢╣Õ╝Å’╝Üõ╝ĀķĆÆÕ»╣Ķ▒ĪÕ╝Ģńö©’╝łõ╝ĀÕĆ╝ÕÆīõ╝ĀÕØĆńÜäµĘĘÕÉłµ¢╣Õ╝Å’╝ē’╝īÕ”éµ×£µś»µĢ░ÕŁŚ’╝īÕŁŚń¼”õĖ▓’╝īÕģāń╗ä’╝łõĖŹÕÅ»ÕÅśÕ»╣Ķ▒Ī’╝ēÕłÖõ╝ĀÕĆ╝’╝øÕ”éµ×£µś»ÕłŚĶĪ©’╝īÕŁŚÕģĖ’╝łÕÅ»ÕÅśÕ»╣Ķ▒Ī’╝ēÕłÖõ╝ĀÕØĆ’╝ø + +õĖŠõĖ¬õŠŗÕŁÉ’╝Ü +```python +a=1 +def f(a): + a+=1 +f(a) +print(a) +``` + +ń╗ōµ×£Õ”éõĖŗ’╝Ü + +```console +1 +``` + +Ķ┐Öµ«Ąõ╗ŻńĀüķćīķØó’╝īÕøĀõĖ║aµś»µĢ░ÕŁŚń▒╗Õ×ŗ’╝īµēĆõ╗źµś»õ╝ĀÕĆ╝ńÜäµ¢╣Õ╝Å’╝īańÜäÕĆ╝Õ╣ČõĖŹõ╝ÜÕÅś’╝īĶŠōÕć║õĖ║1 + +```python +a=[1] +def f(a): + a[0]+=1 +f(a) +print(a) +``` + +ń╗ōµ×£Õ”éõĖŗ’╝Ü + +```console +[2] +``` + +Ķ┐Öµ«Ąõ╗ŻńĀüķćīķØó’╝īÕøĀõĖ║ańÜäń▒╗Õ×ŗµś»ÕłŚĶĪ©’╝īµēĆõ╗źµś»õ╝ĀÕØĆńÜäÕĮóÕ╝Å’╝ī$a[0]$ńÜäÕĆ╝õ╝ܵö╣ÕÅś’╝īĶŠōÕć║õĖ║$[2]$. + + + +## µĄģµŗĘĶ┤ØÕÆīµĘ▒µŗĘĶ┤Ø + +õĖŹµŁóµś»ÕćĮµĢ░ķćīķØó’╝īÕćĮµĢ░Õż¢ķØóńÜäÕ╝Ģńö©õ╣¤ÕÉīµĀĘķüĄÕŠ¬Ķ┐ÖõĖ¬Ķ¦äÕłÖ’╝Ü + +```python +a=1 +b=a +a=2 +print(a,b) +a=[1] +b=a +a[0]=2 +print(a,b) +``` +ĶŠōÕć║ń╗ōµ×£Õ”éõĖŗ’╝Ü +```console +2 1 +[2] [2] +``` +µēĆõ╗źÕ£©pythonõĖŁ’╝īÕĮōĶ┐ÉĶĪīõĖŖķØóńÜäõ╗ŻńĀüµŚČ’╝īÕ”éµ×£aµś»ÕŁŚÕģĖµł¢ĶĆģÕłŚĶĪ©ńÜäĶ»Ø’╝īń©ŗÕ║ŵē¦ĶĪīńÜäµōŹõĮ£Õ╣ČõĖŹµś»µ¢░Õ╗║õĖĆõĖ¬bÕÅśķćÅ’╝īńäČÕÉÄańÜäÕĆ╝ÕżŹÕłČń╗Öb’╝īĶĆīµś»µ¢░Õ╗║õĖĆõĖ¬bÕÅśķćÅ’╝īµŖŖbńÜäÕĆ╝µīćÕÉæa,õ╣¤Õ░▒µś»ńøĖÕĮōõ║ÄÕ£©cĶ»ŁĶ©ĆķćīķØóńÜäµ¢░Õ╗║õĖĆõĖ¬µīćÕÉæańÜäµīćķÆłŃĆé +µēĆõ╗źÕĮōańÜäÕĆ╝ÕÅæńö¤µö╣ÕÅśµŚČ’╝ībńÜäÕĆ╝õ╝ÜńøĖÕ║öµö╣ÕÅśŃĆé + +Õ”éµ×£µā│Ķ”üańÜäÕĆ╝µö╣ÕÅśµŚČ’╝ībńÜäÕĆ╝õĖŹµö╣ÕÅś’╝īÕ░▒ķ£ĆĶ”üńö©Õł░µĄģµŗĘĶ┤ØÕÆīµĘ▒µŗĘĶ┤ØŃĆé + +```python +import copy + +a=[1,2,3] +b=a +a.append(4) +print(a,b) + +a=[1,2,3] +b=copy.copy(a) +a.append(4) +print(a,b) +``` +ĶŠōÕć║ń╗ōµ×£Õ”éõĖŗ’╝Ü +```console +[1, 2, 3, 4] [1, 2, 3, 4] +[1, 2, 3, 4] [1, 2, 3] +``` +Ķ┐Öķćīńö©õ║åcopyµØźĶ«®bõĖÄańøĖńŁē’╝īÕÉÄķØóÕ”éµ×£õ┐«µö╣õ║åańÜäÕĆ╝’╝ībńÜäÕĆ╝Õ╣ČõĖŹõ╝ܵö╣ÕÅśŃĆéń£ŗµØźcopyÕĘ▓ń╗ÅÕÅ»õ╗źÕ«×ńÄ░µłæõ╗¼õĖŖķØóńÜäµÅÉÕł░ńÜäķ£Ćµ▒éõ║å’╝īķéŻõ╣łdeepcopyÕÅłµ£ēõ╗Ćõ╣łńö©’╝¤ + +Õ”éµ×£µłæõ╗¼ķüćÕł░Ķ┐Öń¦ŹµāģÕåĄ’╝īcopyÕ░▒Ķ¦ŻÕå│õĖŹõ║åõ║å’╝Ü +```python +import copy +a = [1,[1,2],3] +b = copy.copy(a) +a[1].append(3) +print(a,b) +``` +ĶŠōÕć║ń╗ōµ×£Õ”éõĖŗ’╝Ü +```console +[1, [1, 2, 3], 3] [1, [1, 2, 3], 3] +``` +Ķ┐ÖķćīaÕÆībńÜäÕĆ╝ķāĮµö╣ÕÅśõ║å’╝īĶ┐Öµś»ÕøĀõĖ║copyÕŬµś»ÕżŹÕłČõ║åõĖĆÕ▒é’╝īÕ”éµ×£aķćīķØóĶ┐śµ£ēÕłŚĶĪ©’╝īķéŻõ╣łbķćīķØóńÜäÕłŚĶĪ©õ╣¤µś»µīćÕÉæaķćīķØóńÜäÕłŚĶĪ©ńÜä’╝īµēĆõ╗źaķćīķØóńÜäÕłŚĶĪ©µö╣ÕÅśõ║å’╝ībķćīķØóńÜäÕłŚĶĪ©õ╣¤õ╝ܵö╣ÕÅśŃĆé +Ķ┐ÖµŚČÕĆÖÕ░▒ķ£ĆĶ”üńö©Õł░deepcopyõ║å’╝Ü +```python +import copy +a = [1,[1,2],3] +b = copy.deepcopy(a) +a[1].append(3) +print(a,b) +``` +ĶŠōÕć║ń╗ōµ×£Õ”éõĖŗ’╝Ü +```console +[1, [1, 2, 3], 3] [1, [1, 2], 3] +``` +Ķ┐ÖķćīańÜäÕĆ╝µö╣ÕÅśõ║å,bńÜäÕĆ╝µ▓Īµ£ēµö╣ÕÅś’╝īĶ┐Öµś»ÕøĀõĖ║deepcopyµś»ķĆÆÕĮÆńÜäÕżŹÕłČõ║åµēƵ£ēńÜäÕĆ╝’╝īµēĆõ╗źaķćīķØóńÜäÕłŚĶĪ©µö╣ÕÅśõ║å’╝ībķćīķØóńÜäÕłŚĶĪ©õĖŹõ╝ܵö╣ÕÅśŃĆé + +µĆ╗ń╗ōÕ”éõĖŗ’╝Ü +µĄģµŗĘĶ┤Ø’╝ܵĄģµŗĘĶ┤ØõĖŁńÜäÕģāń┤Ā,µś»Õ»╣ÕĤջ╣Ķ▒ĪõĖŁÕŁÉÕ»╣Ķ▒ĪńÜäÕ╝Ģńö©ŃĆ鵣żµŚČÕ”éµ×£ÕĤջ╣Ķ▒ĪõĖŁµ¤ÉõĖĆÕŁÉÕ»╣Ķ▒Īµś»ÕÅ»ÕÅśńÜä’╝īµö╣ÕÅśÕÉÄõ╝ÜÕĮ▒ÕōŹµŗĘĶ┤ØÕÉÄńÜäÕ»╣Ķ▒Ī’╝īÕŁśÕ£©Õē»õĮ£ńö©ŃĆéõĖĆõĖŹÕ░ÅÕ┐āÕ░▒õ╝ÜĶ¦”ÕÅæÕŠłÕż¦ńÜäķŚ«ķóśŃĆé + +µĘ▒µŗĘĶ┤Ø’╝ܵĘ▒µŗĘĶ┤ØÕłÖõ╝ÜķĆÆÕĮÆńÜäµŗĘĶ┤ØÕĤջ╣Ķ▒ĪõĖŁńÜäµ»ÅõĖĆõĖ¬ÕŁÉÕ»╣Ķ▒Ī’╝īµŗĘĶ┤Øõ╣ŗÕÉÄńÜäÕ»╣Ķ▒ĪõĖÄÕĤջ╣Ķ▒Īµ▓Īµ£ēÕģ│ń│╗ŃĆé + diff --git "a/_posts/2023-01-17-bash\350\204\232\346\234\254\346\265\213\350\257\225Ubuntu\346\234\215\345\212\241\345\231\250\347\232\204\346\200\247\350\203\275\345\271\266\350\276\223\345\207\272\346\212\245\345\221\212.md" "b/_posts/2023-01-17-bash\350\204\232\346\234\254\346\265\213\350\257\225Ubuntu\346\234\215\345\212\241\345\231\250\347\232\204\346\200\247\350\203\275\345\271\266\350\276\223\345\207\272\346\212\245\345\221\212.md" new file mode 100644 index 0000000000..c50393bbbb --- /dev/null +++ "b/_posts/2023-01-17-bash\350\204\232\346\234\254\346\265\213\350\257\225Ubuntu\346\234\215\345\212\241\345\231\250\347\232\204\346\200\247\350\203\275\345\271\266\350\276\223\345\207\272\346\212\245\345\221\212.md" @@ -0,0 +1,81 @@ +--- +layout: post +title: "bashĶäܵ£¼µĄŗĶ»ĢUbuntuµ£ŹÕŖĪÕÖ©ńÜäµĆ¦ĶāĮÕ╣ČĶŠōÕć║µŖźÕæŖ" +date: 2023-01-17 +description: "bashĶäܵ£¼µĄŗĶ»ĢUbuntuµ£ŹÕŖĪÕÖ©ńÜäµĆ¦ĶāĮÕ╣ČĶŠōÕć║µŖźÕæŖ" +tag: Linux +--- + +bashĶäܵ£¼µĄŗĶ»ĢUbuntuµ£ŹÕŖĪÕÖ©ńÜäµĆ¦ĶāĮÕ╣ČĶŠōÕć║µŖźÕæŖ + +```bash + +#!/bin/bash + +# This script is used to test server performance and output report + +# Get the system information +hostname=`hostname` +kernel=`uname -r` + +# Get the CPU information +cpu_model=`cat /proc/cpuinfo | grep "model name" | head -1 | cut -d: -f2` +cpu_cores=`cat /proc/cpuinfo | grep "cpu cores" | head -1 | cut -d: -f2` +cpu_freq=`cat /proc/cpuinfo | grep "cpu MHz" | head -1 | cut -d: -f2` + +# Get the memory information +mem_total=`cat /proc/meminfo | grep "MemTotal" | cut -d: -f2` +swap_total=`cat /proc/meminfo | grep "SwapTotal" | cut -d: -f2` + +# Get the disk information +disk_total=`df -h | grep "/$" | awk '{print $2}'` +disk_used=`df -h | grep "/$" | awk '{print $3}'` + +# Print the report +echo "System Information" +echo "-----------------" +echo "Hostname: $hostname" +echo "Kernel: $kernel" +echo "" +echo "CPU Information" +echo "---------------" +echo "Model: $cpu_model" +echo "Cores: $cpu_cores" +echo "Frequency: $cpu_freq MHz" +echo "" +echo "Memory Information" +echo "-----------------" +echo "Total: $mem_total" +echo "Swap: $swap_total" +echo "" +echo "Disk Information" +echo "----------------" +echo "Total: $disk_total" +echo "Used: $disk_used" +echo "" +``` + +ń╗ōµ×£Õ”éõĖŗ’╝Ü +```console +root@hugo-virtual-machine:/opt# sh service.sh +System Information +----------------- +Hostname: hugo-virtual-machine +Kernel: 5.15.0-58-generic + +CPU Information +--------------- +Model: AMD Ryzen 7 4800H with Radeon Graphics +Cores: 2 +Frequency: 2894.461 MHz + +Memory Information +----------------- +Total: 8105812 kB +Swap: 1999868 kB + +Disk Information +---------------- +Total: 23G +Used: 12G +``` \ No newline at end of file diff --git "a/_posts/2023-01-17-python\350\277\233\351\230\266(\344\270\200)_args \345\222\214 kwargs, pdb, Map, Reduce, Filter.md" "b/_posts/2023-01-17-python\350\277\233\351\230\266(\344\270\200)_args \345\222\214 kwargs, pdb, Map, Reduce, Filter.md" new file mode 100644 index 0000000000..6fdf98f960 --- /dev/null +++ "b/_posts/2023-01-17-python\350\277\233\351\230\266(\344\270\200)_args \345\222\214 kwargs, pdb, Map, Reduce, Filter.md" @@ -0,0 +1,247 @@ +--- +layout: post +title: "pythonĶ┐øķśČ’╝łõĖĆ’╝ē: *args ÕÆī **kwargs, pdb, Map, Reduce, Filter" +date: 2023-01-17 +description: "õĖ╗Ķ”üÕīģµŗ¼pythonõĖĆõ║øõĖŹÕż¬ÕĖĖĶ¦üńÜäń¤źĶ»åńé╣õ╗źÕÅŖpythonķ½śķśČń╝¢ń©ŗķ£ĆĶ”üńö©Õł░ńÜäń¤źĶ»åńé╣ńŁēńŁē" +tag: Python +--- + +õĖ╗Ķ”üÕīģµŗ¼pythonõĖĆõ║øõĖŹÕż¬ÕĖĖĶ¦üńÜäń¤źĶ»åńé╣õ╗źÕÅŖpythonķ½śķśČń╝¢ń©ŗķ£ĆĶ”üńö©Õł░ńÜäń¤źĶ»åńé╣ńŁēńŁēŃĆé +µ»öÕ”éĶ»┤*args ÕÆī **kwargsÕ£©ÕćĮµĢ░õ╝ĀÕÅéõ╗źÕÅŖÕćĮµĢ░Ķ░āńö©õĖŁńÜäńö©µ│Ģ’╝īõ╗źÕÅŖpythonõĖŁńÜäĶŻģķź░ÕÖ©ńŁēńŁēŃĆé +Ķ┐śµ»öÕ”éĶ»┤pdbÕ£©ń©ŗÕ║ÅĶ┐ÉĶĪīµŚČµ¤źń£ŗÕÅśķćÅńÜäÕĆ╝’╝īµ¤źń£ŗń©ŗÕ║ÅńÜäµē¦ĶĪīµĄüń©ŗ’╝īõ╗źÕÅŖµ¤źń£ŗÕćĮµĢ░ńÜäĶ░āńö©µĀłŃĆé +Ķ┐śõŠŗÕ”é’╝īpythonõĖŁńÜäMapŃĆüReduceŃĆüFilterŃĆüLambdańŁēÕ£©ÕćĮµĢ░Õ╝Åń╝¢ń©ŗõĖŁńÜäńö©µ│ĢŃĆé + +## *args ÕÆī **kwargs + +ÕģČÕ«×Õ╣ČõĖŹµś»Õ┐ģķĪ╗ÕåÖµłÉ\*args ÕÆī\**kwargsŃĆé ÕŬµ£ēÕÅśķćÅÕēŹķØóńÜä \*(µś¤ÕÅĘ)µēŹµś»Õ┐ģķĪ╗ńÜä. õĮĀõ╣¤ÕÅ»õ╗źÕåÖµłÉ\*var ÕÆī\**vars. ĶĆīÕåÖµłÉ\*args ÕÆī\**kwargsÕŬµś»õĖĆõĖ¬ķĆÜõ┐ŚńÜäÕæĮÕÉŹń║”Õ«ÜŃĆé + +\*args ÕÆī \**kwargs õĖ╗Ķ”üńö©õ║ÄÕćĮµĢ░Õ«Üõ╣ēŃĆé õĮĀÕÅ»õ╗źÕ░åõĖŹÕ«ÜµĢ░ķćÅńÜäÕÅéµĢ░õ╝ĀķĆÆń╗ÖõĖĆõĖ¬ÕćĮµĢ░ŃĆé + +ķóäÕģłÕ╣ČõĖŹń¤źķüō, ÕćĮµĢ░õĮ┐ńö©ĶĆģõ╝Üõ╝ĀķĆÆÕżÜÕ░æõĖ¬ÕÅéµĢ░ń╗ÖõĮĀ, µēĆõ╗źÕ£©Ķ┐ÖõĖ¬Õ£║µÖ»õĖŗõĮ┐ńö©Ķ┐ÖõĖżõĖ¬Õģ│ķö«ÕŁŚŃĆé + +**\*args** µś»ńö©µØźÕÅæķĆüõĖĆõĖ¬ķØ×ķö«ÕĆ╝Õ»╣ńÜäÕÅ»ÕÅśµĢ░ķćÅńÜäÕÅéµĢ░ÕłŚĶĪ©ń╗ÖõĖĆõĖ¬ÕćĮµĢ░. + +```python +def test_var_args(f_arg, *argv): + print("first normal arg:", f_arg) + for arg in argv: + print("another arg through *argv:", arg) + +test_var_args('yasoob', 'python', 'eggs', 'test') +``` +Ķ┐Öõ╝Üõ║¦ńö¤Õ”éõĖŗĶŠōÕć║: +```console +first normal arg: yasoob +another arg through *argv: python +another arg through *argv: eggs +another arg through *argv: test +``` + +**\*\*kwargs** ÕģüĶ«ĖõĮĀÕ░åõĖŹÕ«ÜķĢ┐Õ║”ńÜäķö«ÕĆ╝Õ»╣, õĮ£õĖ║ÕÅéµĢ░õ╝ĀķĆÆń╗ÖõĖĆõĖ¬ÕćĮµĢ░. Õ”éµ×£õĮĀµā│Ķ”üÕ£©õĖĆõĖ¬ÕćĮµĢ░ķćīÕżäńÉåÕĖ”ÕÉŹÕŁŚńÜäÕÅéµĢ░, õĮĀÕ║öĶ»źõĮ┐ńö©**\*\*kwargs**. + +õĖŠõĖ¬õŠŗÕŁÉ’╝Ü + +```python +def greet_me(**kwargs): + for key, value in kwargs.items(): + print("{0} == {1}".format(key, value)) # .format()µś»python3ńÜäµ¢░ńē╣µĆ¦, ńö©õ║ĵĀ╝Õ╝ÅÕī¢ÕŁŚń¼”õĖ▓,{0}ĶĪ©ńż║ń¼¼õĖĆõĖ¬ÕÅéµĢ░,{1}ĶĪ©ńż║ń¼¼õ║īõĖ¬ÕÅéµĢ░ + # õ╣¤ÕÅ»õ╗źńö©%µØźµĀ╝Õ╝ÅÕī¢ÕŁŚń¼”õĖ▓ + print("%s == %s" % (key, value)) %sĶĪ©ńż║ÕŁŚń¼”õĖ▓,%dĶĪ©ńż║µĢ┤µĢ░,%fĶĪ©ńż║µĄ«ńé╣µĢ░ +gree_me(name="yasoob") +``` +Ķ┐Öõ╝Üõ║¦ńö¤Õ”éõĖŗĶŠōÕć║: +```console +name == yasoob +name == yasoob +``` + +### õĮ┐ńö© *args ÕÆī **kwargs µØźĶ░āńö©ÕćĮµĢ░ + +ķéŻńÄ░Õ£©µłæõ╗¼Õ░åń£ŗÕł░µĆĵĀĘõĮ┐ńö©*argsÕÆī**kwargs µØźĶ░āńö©õĖĆõĖ¬ÕćĮµĢ░ŃĆé ÕüćĶ«Š’╝īõĮĀµ£ēĶ┐ÖµĀĘõĖĆõĖ¬Õ░ÅÕćĮµĢ░’╝Ü +```python +def test_args_kwargs(arg1, arg2, arg3): + print("arg1:", arg1) + print("arg2:", arg2) + print("arg3:", arg3) +``` +µłæõ╗¼ÕÅ»õ╗źõĮ┐ńö©õĖŗķØóńÜäµ¢╣Õ╝ÅµØźĶ░āńö©Ķ┐ÖõĖ¬ÕćĮµĢ░’╝Ü +```python +# first with *args +args = ("two", 3, 5) +test_args_kwargs(*args) +# now with **kwargs: +kwargs = {"arg3": 3, "arg2": "two", "arg1": 5} +test_args_kwargs(**kwargs) +``` +Ķ┐Öõ╝Üõ║¦ńö¤Õ”éõĖŗĶŠōÕć║: +```console +arg1: two +arg2: 3 +arg3: 5 +arg1: 5 +arg2: two +arg3: 3 +``` +### õĮ┐ńö©ķĪ║Õ║Å + +ķéŻõ╣łÕ”éµ×£õĮĀµā│Õ£©ÕćĮµĢ░ķćīÕÉīµŚČõĮ┐ńö©µēƵ£ēĶ┐ÖõĖēń¦ŹÕÅéµĢ░’╝ī ķĪ║Õ║ŵś»Ķ┐ÖµĀĘńÜä’╝Ü +```python +some_func(fargs, *args, **kwargs) +``` + +```python +def test_args_kwargs(arg1, arg2, arg3, *args, **kwargs): + print("arg1:", arg1) + print("arg2:", arg2) + print("arg3:", arg3) + for arg in args: + print("another arg:", arg) + for kwarg in kwargs: + print("another keyword arg: {0} = {1}".format(kwarg, kwargs[kwarg])) +``` + +### õ╗Ćõ╣łµŚČÕĆÖõĮ┐ńö©Õ«āõ╗¼’╝¤ +Ķ”üń£ŗõĮĀńÜäķ£Ćµ▒éĶĆīÕ«Ü’╝īµ£ĆÕĖĖĶ¦üńÜäńö©õŠŗµś»Õ£©ÕåÖÕćĮµĢ░ĶŻģķź░ÕÖ©ńÜ䵌ČÕĆÖ’╝īµŁżÕż¢Õ«āõ╣¤ÕÅ»õ╗źńö©µØźÕüÜńī┤ÕŁÉĶĪźõĖü(monkey patching)ŃĆéńī┤ÕŁÉĶĪźõĖüńÜäµäŵĆصś»Õ£©ń©ŗÕ║ÅĶ┐ÉĶĪīµŚČ(runtime)õ┐«µö╣µ¤Éõ║øõ╗ŻńĀüŃĆé + +µēōõĖ¬µ»öµ¢╣’╝īõĮĀµ£ēõĖĆõĖ¬ń▒╗’╝īķćīķØóµ£ēõĖ¬ÕŽget_infońÜäÕćĮµĢ░õ╝ÜĶ░āńö©õĖĆõĖ¬APIÕ╣ČĶ┐öÕø×ńøĖÕ║öńÜäµĢ░µŹ«ŃĆéÕ”éµ×£µłæõ╗¼µā│µĄŗĶ»ĢÕ«ā’╝īÕÅ»õ╗źµŖŖAPIĶ░āńö©µø┐µŹóµłÉõĖĆõ║øµĄŗĶ»ĢµĢ░µŹ«ŃĆéõŠŗÕ”é’╝Ü + +```python +import someclass # someclassµś»õĮĀÕ«Üõ╣ēńÜäń▒╗ + +def get_info(self, *args): # Ķ┐ÖķćīńÜäselfµś»ń▒╗ńÜäÕ«×õŠŗ’╝ī*argsµś»ÕÅ»ÕÅśÕÅéµĢ░’╝īÕÅ»õ╗źõ╝ĀÕģźõ╗╗µäÅÕżÜõĖ¬µĄŗĶ»ĢµĢ░µŹ« + return "Test data" + +someclass.get_info = get_info +``` + +## Ķ░āĶ»Ģ’╝łDebugging’╝ē + +Õł®ńö©ÕźĮĶ░āĶ»Ģ’╝īĶāĮÕż¦Õż¦µÅÉķ½śõĮĀµŹĢµŹēõ╗ŻńĀüBugńÜäŃĆé +Python debugger(pdb)ÕÅ»õ╗źÕĖ«ÕŖ®µłæõ╗¼Õ£©ń©ŗÕ║ÅĶ┐ÉĶĪīµŚČµ¤źń£ŗÕÅśķćÅńÜäÕĆ╝’╝īµ¤źń£ŗń©ŗÕ║ÅńÜäµē¦ĶĪīµĄüń©ŗ’╝īõ╗źÕÅŖµ¤źń£ŗÕćĮµĢ░ńÜäĶ░āńö©µĀłŃĆé + +pdb µ©ĪÕØŚÕ«Üõ╣ēõ║åõĖĆõĖ¬õ║żõ║ÆÕ╝ŵ║Éõ╗ŻńĀüĶ░āĶ»ĢÕÖ©’╝īńö©õ║Ä Python ń©ŗÕ║ÅŃĆéÕ«āµö»µīüÕ£©µ║ÉńĀüĶĪīķŚ┤Ķ«ŠńĮ«’╝łµ£ēµØĪõ╗ČńÜä’╝ēµ¢Łńé╣ÕÆīÕŹĢµŁźµē¦ĶĪī’╝īµŻĆĶ¦åÕĀåµĀłÕĖ¦’╝īÕłŚÕć║µ║ÉńĀüÕłŚĶĪ©’╝īõ╗źÕÅŖÕ£©õ╗╗õĮĢÕĀåµĀłÕĖ¦ńÜäõĖŖõĖŗµ¢ćõĖŁĶ┐ÉĶĪīõ╗╗µäÅ Python õ╗ŻńĀüŃĆéÕ«āĶ┐śµö»µīüõ║ŗÕÉÄĶ░āĶ»Ģ’╝īÕÅ»õ╗źÕ£©ń©ŗÕ║ÅµÄ¦ÕłČõĖŗĶ░āńö©ŃĆé + +Ķ░āĶ»ĢÕÖ©µś»ÕÅ»µē®Õ▒ĢńÜäŌĆöŌĆöĶ░āĶ»ĢÕÖ©Õ«×ķÖģĶó½Õ«Üõ╣ēõĖ║ Pdb ń▒╗ŃĆéĶ»źń▒╗ńø«ÕēŹµ▓Īµ£ēµ¢ćµĪŻ’╝īõĮåķĆÜĶ┐ćķśģĶ»╗µ║ÉńĀüÕŠłÕ«╣µśōńÉåĶ¦ŻÕ«āŃĆéµē®Õ▒ĢµÄźÕÅŻõĮ┐ńö©õ║å bdb ÕÆī cmd µ©ĪÕØŚŃĆé + +### pdb +#### õ╗ÄÕæĮõ╗żĶĪīĶ┐ÉĶĪī +Õ░å pdb.py õĮ£õĖ║Ķäܵ£¼Ķ░āńö©’╝īµØźĶ░āĶ»ĢÕģČõ╗¢Ķäܵ£¼ŃĆéõĮĀÕÅ»õ╗źÕ£©ÕæĮõ╗żĶĪīõĮ┐ńö©Python debuggerĶ┐ÉĶĪīõĖĆõĖ¬Ķäܵ£¼’╝ī õĖŠõĖ¬õŠŗÕŁÉ’╝Ü +```commandline +python -m pdb myscript.py +``` +Ķ┐Öõ╝ÜĶ¦”ÕÅædebuggerÕ£©Ķäܵ£¼ń¼¼õĖĆĶĪīµīćõ╗żÕżäÕü£µŁóµē¦ĶĪīŃĆéĶ┐ÖÕ£©Ķäܵ£¼ÕŠłń¤ŁµŚČõ╝ÜÕŠłµ£ēÕĖ«ÕŖ®ŃĆéõĮĀÕÅ»õ╗źķĆÜĶ┐ć(Pdb)µ©ĪÕ╝ÅµÄźńØƵ¤źń£ŗÕÅśķćÅõ┐Īµü»’╝īÕ╣ČõĖöķĆÉĶĪīĶ░āĶ»ĢŃĆé + +#### õ╗ÄĶäܵ£¼Õåģķā©Ķ┐ÉĶĪī + + +ÕÉīµŚČ’╝īõĮĀõ╣¤ÕÅ»õ╗źÕ£©Ķäܵ£¼Õåģķā©Ķ«ŠńĮ«µ¢Łńé╣’╝īĶ┐ÖµĀĘÕ░▒ÕÅ»õ╗źÕ£©µ¤Éõ║øńē╣Õ«Üńé╣µ¤źń£ŗÕÅśķćÅõ┐Īµü»ÕÆīÕÉäń¦Źµē¦ĶĪīµŚČõ┐Īµü»õ║åŃĆéĶ┐ÖķćīÕ░åõĮ┐ńö©**pdb.set_trace()**µ¢╣µ│ĢµØźÕ«×ńÄ░ŃĆéõĖŠõĖ¬õŠŗÕŁÉ’╝Ü +```python +import pdb +def make_bread(): + pdb.set_trace() # Ķ┐ÖķćīĶ«ŠńĮ«µ¢Łńé╣,ń©ŗÕ║Åõ╝ÜÕ£©Ķ┐ÖķćīÕü£µŁó,õĮĀÕÅ»õ╗źµ¤źń£ŗĶ┐ÉĶĪīÕł░Ķ┐ÖķćīµŚČńÜäÕÅśķćÅõ┐Īµü»’╝īńäČÕÉĵīēõ╗╗µäÅķö«ń╗¦ń╗Łµē¦ĶĪī’╝īµł¢ĶĆģµīēcń╗¦ń╗Łµē¦ĶĪīÕł░õĖŗõĖĆõĖ¬µ¢Łńé╣ + return "I don't have time" +``` +Ķ»ĢõĖŗõ┐ØÕŁśõĖŖķØóńÜäĶäܵ£¼ÕÉÄĶ┐ÉĶĪīõ╣ŗŃĆéõĮĀõ╝ÜÕ£©Ķ┐ÉĶĪīµŚČķ®¼õĖŖĶ┐øÕģźdebuggerµ©ĪÕ╝ÅŃĆéńÄ░Õ£©µś»µŚČÕĆÖõ║åĶ¦ŻõĖŗdebuggerµ©ĪÕ╝ÅõĖŗńÜäõĖĆõ║øÕæĮõ╗żõ║åŃĆé + +| ÕæĮõ╗ż | ń«ĆÕåÖ | Ķ»┤µśÄ | +| --- | --- | --- | +| help | h | µśŠńż║ÕĖ«ÕŖ®õ┐Īµü» | +| list | l | µ¤źń£ŗÕĮōÕēŹĶĪīńÜäõ╗ŻńĀüµ«Ą| +| continue | c | ń╗¦ń╗Łµē¦ĶĪīÕł░õĖŗõĖĆõĖ¬µ¢Łńé╣ | +| quit | q | ķĆĆÕć║debugger | +| print | p | µēōÕŹ░ÕÅśķćÅńÜäÕĆ╝ | +| args | a | µēōÕŹ░ÕćĮµĢ░ńÜäÕÅéµĢ░ | +| break | b | Ķ«ŠńĮ«µ¢Łńé╣ | +| bt | | µēōÕŹ░ÕćĮµĢ░ńÜäĶ░āńö©µĀł | +| return | r | µēōÕŹ░ÕćĮµĢ░ńÜäĶ┐öÕø×ÕĆ╝ | +| next | n | µē¦ĶĪīõĖŗõĖĆĶĪīõ╗ŻńĀü | +| step | s | Ķ┐øÕģźÕćĮµĢ░Õåģķā© | + +ÕŹĢµŁźĶĘ│Ķ┐ć’╝łnext’╝ēÕÆīÕŹĢµŁźĶ┐øÕģź’╝łstep’╝ēńÜäÕī║Õł½Õ£©õ║Ä’╝ī ÕŹĢµŁźĶ┐øÕģźõ╝ÜĶ┐øÕģźÕĮōÕēŹĶĪīĶ░āńö©ńÜäÕćĮµĢ░Õåģķā©Õ╣ČÕü£Õ£©ķćīķØó’╝ī ĶĆīÕŹĢµŁźĶĘ│Ķ┐ćõ╝Ü’╝łÕćĀõ╣Ä’╝ēÕģ©ķƤµē¦ĶĪīÕ«īÕĮōÕēŹĶĪīĶ░āńö©ńÜäÕćĮµĢ░’╝īÕ╣ČÕü£Õ£©ÕĮōÕēŹÕćĮµĢ░ńÜäõĖŗõĖĆĶĪīŃĆé + +## Map’╝īFilter ÕÆī Reduce + +Map’╝īFilter ÕÆī Reduce õĖēõĖ¬ÕćĮµĢ░ĶāĮõĖ║ÕćĮµĢ░Õ╝Åń╝¢ń©ŗµÅÉõŠøõŠ┐Õł®ŃĆ鵳æõ╗¼õ╝ÜķĆÜĶ┐ćÕ«×õŠŗõĖĆõĖ¬õĖĆõĖ¬Ķ«©Ķ«║Õ╣ČńÉåĶ¦ŻÕ«āõ╗¼ŃĆé + +### Map +Mapõ╝ÜÕ░åõĖĆõĖ¬ÕćĮµĢ░µśĀÕ░äÕł░õĖĆõĖ¬ĶŠōÕģźÕłŚĶĪ©ńÜäµēƵ£ēÕģāń┤ĀõĖŖŃĆéĶ┐Öµś»Õ«āńÜäĶ¦äĶīā’╝Ü + +```python +map(function_to_apply, list_of_inputs) +``` + +Õż¦ÕżÜµĢ░µŚČÕĆÖ’╝īµłæõ╗¼Ķ”üµŖŖÕłŚĶĪ©õĖŁµēƵ£ēÕģāń┤ĀõĖĆõĖ¬õĖ¬Õ£░õ╝ĀķĆÆń╗ÖõĖĆõĖ¬ÕćĮµĢ░’╝īÕ╣ȵöČķøåĶŠōÕć║ŃĆéµ»öµ¢╣Ķ»┤’╝Ü + +```python +items = [1, 2, 3, 4, 5] +squared = [] +for i in items: + squared.append(i**2) +``` + +Ķ┐Öķćīµłæõ╗¼õĮ┐ńö©õ║åõĖĆõĖ¬ÕŠ¬ńÄ»µØźĶ«Īń«ŚÕłŚĶĪ©õĖŁµ»ÅõĖ¬Õģāń┤ĀńÜäÕ╣│µ¢╣MapÕÅ»õ╗źĶ«®µłæõ╗¼ńö©õĖĆń¦Źń«ĆÕŹĢĶĆīµ╝éõ║«ÕŠŚÕżÜńÜäµ¢╣Õ╝ÅµØźÕ«×ńÄ░ŃĆé + +```python +items = [1, 2, 3, 4, 5] +squared = list(map(lambda x: x**2, items)) # map()Ķ┐öÕø×õĖĆõĖ¬Ķ┐Łõ╗ŻÕÖ©’╝īµēĆõ╗źµłæõ╗¼ķ£ĆĶ”üÕ░åÕ«āĶĮ¼µŹóõĖ║õĖĆõĖ¬ÕłŚĶĪ© +``` + + +õĖŹõ╗ģńö©õ║ÄõĖĆÕłŚĶĪ©ńÜäĶŠōÕģź’╝ī µłæõ╗¼ńöÜĶć│ÕÅ»õ╗źńö©õ║ÄõĖĆÕłŚĶĪ©ńÜäÕćĮµĢ░’╝üõ╣¤ÕŹ│µś»Ķ»┤’╝īlist_of_inputsõĖŹõ╗ģÕÅ»õ╗źµś»õĖĆõĖ¬ÕłŚĶĪ©’╝īĶ┐śÕÅ»õ╗źµś»õĖĆõĖ¬ÕćĮµĢ░ÕłŚĶĪ©ŃĆéµ»öµ¢╣Ķ»┤’╝Ü + +```python +def multiply(x): + return (x*x) +def add(x): + return (x+x) +def exponent(x): + return (x**x) # xńÜäxµ¼Īµ¢╣ + +funcs = [multiply, add,exponent] # Ķ┐Öķćīµłæõ╗¼µ£ēõĖĆõĖ¬ÕćĮµĢ░ÕłŚĶĪ©,µłæõ╗¼ÕÅ»õ╗źÕ░åÕ«āõ╝ĀķĆÆń╗Ömap, +for i in range(5): + value = list(map(lambda x: x(i), funcs)) # x(i)Õ░åõ╝ÜĶ░āńö©funcsõĖŁńÜäÕćĮµĢ░,Õ╣Čõ╝ĀķĆÆiõĮ£õĖ║ÕÅéµĢ░ + print(list(value)) +``` + +ĶŠōÕć║ń╗ōµ×£õĖ║’╝Ü +```console +[0, 0, 1] +[1, 2, 1] +[4, 4, 4] +[9, 6, 27] +[16, 8, 256] +``` + +### Filter + +ķĪŠÕÉŹµĆØõ╣ē’╝īfilterĶ┐ćµ╗żÕłŚĶĪ©õĖŁńÜäÕģāń┤Ā’╝īÕ╣ČõĖöĶ┐öÕø×õĖĆõĖ¬ńö▒µēƵ£ēń¼”ÕÉłĶ”üµ▒éńÜäÕģāń┤ĀµēƵ×䵳ÉńÜäÕłŚĶĪ©’╝īń¼”ÕÉłĶ”üµ▒éÕŹ│ÕćĮµĢ░µśĀÕ░äÕł░Ķ»źÕģāń┤ĀµŚČĶ┐öÕø×ÕĆ╝õĖ║True. Ķ┐Öķćīµś»õĖĆõĖ¬ń«Ćń¤ŁńÜäõŠŗÕŁÉ’╝Ü + +```python +number_list = range(-5, 5) +less_than_zero = filter(lambda x: x < 0, number_list) # lambda x: x < 0µś»õĖĆõĖ¬ÕćĮµĢ░’╝īÕ«āÕ░åõ╝ܵśĀÕ░äÕł░number_listõĖŁńÜäµ»ÅõĖ¬Õģāń┤ĀõĖŖ,ń¼”ÕÉłĶ”üµ▒éńÜäÕģāń┤ĀÕ░åõ╝ÜĶó½õ┐ØńĢÖ +print(list(less_than_zero)) +``` +ĶŠōÕć║ń╗ōµ×£õĖ║’╝Ü +```console +[-5, -4, -3, -2, -1] +``` +Ķ┐ÖõĖ¬filterń▒╗õ╝╝õ║ÄõĖĆõĖ¬forÕŠ¬ńÄ»’╝īõĮåÕ«āµś»õĖĆõĖ¬ÕåģńĮ«ÕćĮµĢ░’╝īÕ╣ČõĖöµø┤Õ┐½ŃĆé +µ│©µäÅ’╝ÜÕ”éµ×£mapÕÆīfilterÕ»╣õĮĀµØźĶ»┤ń£ŗĶĄĘµØźÕ╣ČõĖŹõ╝śķøģńÜäĶ»Ø’╝īķéŻõ╣łõĮĀÕÅ»õ╗źń£ŗń£ŗÕłŚĶĪ©/ÕŁŚÕģĖ/Õģāń╗äµÄ©Õ»╝Õ╝ÅŃĆé + +### Reduce + +ÕĮōķ£ĆĶ”üÕ»╣õĖĆõĖ¬ÕłŚĶĪ©Ķ┐øĶĪīõĖĆõ║øĶ«Īń«ŚÕ╣ČĶ┐öÕø×ń╗ōµ×£µŚČ’╝īReduce µś»õĖ¬ķØ×ÕĖĖµ£ēńö©ńÜäÕćĮµĢ░ŃĆéõĖŠõĖ¬õŠŗÕŁÉ’╝īÕĮōõĮĀķ£ĆĶ”üĶ«Īń«ŚõĖĆõĖ¬µĢ┤µĢ░ÕłŚĶĪ©ńÜäõ╣śń¦»µŚČŃĆé + +ķĆÜÕĖĖÕ£© python õĖŁõĮĀÕÅ»ĶāĮõ╝ÜõĮ┐ńö©Õ¤║µ£¼ńÜä for ÕŠ¬ńÄ»µØźÕ«īµłÉĶ┐ÖõĖ¬õ╗╗ÕŖĪŃĆé + +ńÄ░Õ£©µłæõ╗¼µØźĶ»ĢĶ»Ģ reduce’╝Ü + +```python +from functools import reduce # python3õĖŁreduceĶó½ń¦╗Õł░õ║åfunctoolsµ©ĪÕØŚõĖŁ +product = reduce((lambda x, y: x * y), [1, 2, 3, 4]) # reduce()ÕćĮµĢ░Õ░åõ╝ÜÕ»╣ÕłŚĶĪ©õĖŁńÜäÕģāń┤ĀĶ┐øĶĪīĶ┐Łõ╗ŻĶ«Īń«Ś’╝īxµś»õĖŖõĖƵ¼ĪĶ«Īń«ŚńÜäń╗ōµ×£’╝īyµś»õĖŗõĖĆõĖ¬Õģāń┤Ā’╝īĶ┐Öķćīµłæõ╗¼Ķ«Īń«ŚńÜ䵜»1*2*3*4’╝īń¼¼õĖƵ¼ĪĶ┐Łõ╗ŻµŚČx=1,y=2,ń¼¼õ║īµ¼ĪĶ┐Łõ╗ŻµŚČx=2,y=3,ń¼¼õĖēµ¼ĪĶ┐Łõ╗ŻµŚČx=6,y=4’╝īµ£ĆÕÉÄõ┐ØńĢÖńÜäń╗ōµ×£õĖ║24’╝īµś»xńÜäµ£Ćń╗łÕĆ╝ŃĆé +print(product) +``` +ĶŠōÕć║ń╗ōµ×£õĖ║’╝Ü +```console +24 +``` diff --git "a/_posts/2023-01-18-Python\344\270\255\345\207\275\346\225\260\347\232\204\344\275\234\347\224\250\345\237\237.md" "b/_posts/2023-01-18-Python\344\270\255\345\207\275\346\225\260\347\232\204\344\275\234\347\224\250\345\237\237.md" new file mode 100644 index 0000000000..a18671a89a --- /dev/null +++ "b/_posts/2023-01-18-Python\344\270\255\345\207\275\346\225\260\347\232\204\344\275\234\347\224\250\345\237\237.md" @@ -0,0 +1,195 @@ +--- +layout: post +title: "PythonõĖŁÕćĮµĢ░ńÜäõĮ£ńö©Õ¤¤" +date: 2023-01-18 +description: "õ╗ŗń╗ŹPythonõĖŁÕćĮµĢ░ńÜäõĮ£ńö©Õ¤¤’╝īÕ▒Ćķā©ÕÅśķćÅÕÆīÕģ©Õ▒ĆÕÅśķćÅńŁēńŁēµ”éÕ┐Ą" +tag: Python +--- + + + +Õø×ķĪŠõĖĆõĖŗµś©Õż®µ£ēÕģ│Õ╝Ģńö©õ╝ĀķĆÆõĖÄÕĆ╝õ╝ĀķĆƵ£ēÕģ│ńÜäÕåģÕ«╣ŃĆé + +## Õ╝Ģńö©õ╝ĀķĆÆõĖÄÕĆ╝õ╝ĀķĆÆ + +ÕÅ»ÕÅśÕ»╣Ķ▒ĪõĖ║Õ╝Ģńö©õ╝ĀķĆÆ’╝łõ╝ĀÕØĆ’╝ē’╝īõĖŹÕÅ»ÕÅśÕ»╣Ķ▒ĪõĖ║ÕĆ╝õ╝ĀķĆÆ’╝łõ╝ĀÕĆ╝’╝ēŃĆé + +õ╝ĀÕĆ╝ÕÆīõ╝ĀÕØĆńÜäÕī║Õł½ +õ╝ĀÕĆ╝Õ░▒µś»õ╝ĀÕģźõĖĆõĖ¬ÕÅéµĢ░ńÜäÕĆ╝’╝īõ╝ĀÕØĆÕ░▒µś»õ╝ĀÕģźõĖĆõĖ¬ÕÅéµĢ░ńÜäÕ£░ÕØĆ’╝īõ╣¤Õ░▒µś»ÕåģÕŁśńÜäÕ£░ÕØĆ’╝łńøĖÕĮōõ║ĵīćķÆł’╝ēŃĆéõ╗¢õ╗¼ńÜä**Õī║Õł½µś»Õ”éµ×£ÕćĮµĢ░ķćīķØóÕ»╣õ╝ĀÕģźńÜäÕÅéµĢ░ķ揵¢░ĶĄŗÕĆ╝’╝īÕćĮµĢ░Õż¢ńÜäÕģ©Õ▒ĆÕÅśķćŵś»ÕÉ”ńøĖÕ║öµö╣ÕÅś**’╝īńö©**õ╝ĀÕĆ╝õ╝ĀÕģźńÜäÕÅéµĢ░µś»õĖŹõ╝ܵö╣ÕÅśńÜä’╝īńö©õ╝ĀÕØĆõ╝ĀÕģźÕ░▒õ╝ܵö╣ÕÅś**ŃĆé + +PythonÕćĮµĢ░ÕÅéµĢ░õ╝ĀķĆƵ¢╣Õ╝Å’╝Üõ╝ĀķĆÆÕ»╣Ķ▒ĪÕ╝Ģńö©’╝łõ╝ĀÕĆ╝ÕÆīõ╝ĀÕØĆńÜäµĘĘÕÉłµ¢╣Õ╝Å’╝ē’╝īÕ”éµ×£µś»µĢ░ÕŁŚ’╝īÕŁŚń¼”õĖ▓’╝īÕģāń╗ä’╝łõĖŹÕÅ»ÕÅśÕ»╣Ķ▒Ī’╝ēÕłÖõ╝ĀÕĆ╝’╝øÕ”éµ×£µś»ÕłŚĶĪ©’╝īÕŁŚÕģĖ’╝łÕÅ»ÕÅśÕ»╣Ķ▒Ī’╝ēÕłÖõ╝ĀÕØĆ’╝ø + +õĖŠõĖ¬õŠŗÕŁÉ’╝Ü +```python +a=1 +def f(a): + a+=1 +f(a) +print(a) +``` + +ń╗ōµ×£Õ”éõĖŗ’╝Ü + +```console +1 +``` + +Ķ┐Öµ«Ąõ╗ŻńĀüķćīķØó’╝īÕøĀõĖ║aµś»µĢ░ÕŁŚń▒╗Õ×ŗ’╝īµēĆõ╗źµś»õ╝ĀÕĆ╝ńÜäµ¢╣Õ╝Å’╝īańÜäÕĆ╝Õ╣ČõĖŹõ╝ÜÕÅś’╝īĶŠōÕć║õĖ║1 + +```python +a=[1] +def f(a): + a[0]+=1 +f(a) +print(a) +``` + +ń╗ōµ×£Õ”éõĖŗ’╝Ü + +```console +[2] +``` + +Ķ┐Öµ«Ąõ╗ŻńĀüķćīķØó’╝īÕøĀõĖ║ańÜäń▒╗Õ×ŗµś»ÕłŚĶĪ©’╝īµēĆõ╗źµś»õ╝ĀÕØĆńÜäÕĮóÕ╝Å’╝ī$a[0]$ńÜäÕĆ╝õ╝ܵö╣ÕÅś’╝īĶŠōÕć║õĖ║$[2]$. + +µłæõ╗¼ÕåŹµēōÕŹ░õĖĆõĖŗańÜäÕ£░ÕØĆ’╝Ü +```python +def changelist(a): + a.append(0) + print(id(a)) + print(a) +a = [4,5,6] + +changelist(a) +print("-"*60) +print(id(a)) +print(a) +``` +Ķ┐öÕø×ń╗ōµ×£õĖ║’╝Ü +```console +2375999356032 +[4, 5, 6, 0] +------------------------------------------------------------ +2375999356032 +[4, 5, 6, 0] +``` +ÕÅæńÄ░Õ£©ÕćĮµĢ░Õåģķā©ÕÆīÕćĮµĢ░Õż¢ķā©’╝īańÜäÕ£░ÕØƵś»õĖƵĀĘńÜä’╝īĶ»┤µśÄaµś»õ╝ĀÕØĆńÜä’╝īĶĆīõĖöÕ£©ÕćĮµĢ░Õåģķā©µö╣ÕÅśõ║åańÜäÕĆ╝’╝īÕćĮµĢ░Õż¢ķā©ńÜäańÜäÕĆ╝õ╣¤µö╣ÕÅśõ║åŃĆé + + +## ÕćĮµĢ░õĮ£ńö©Õ¤¤ + +µēĆĶ░ōõĮ£ńö©Õ¤¤’╝łScope’╝ē’╝īÕ░▒µś»ÕÅśķćÅńÜäµ£ēµĢłĶīāÕø┤’╝īÕ░▒µś»ÕÅśķćÅÕÅ»õ╗źÕ£©Õō¬õĖ¬ĶīāÕø┤õ╗źÕåģõĮ┐ńö©ŃĆéµ£ēõ║øÕÅśķćÅÕÅ»õ╗źÕ£©µĢ┤µ«Ąõ╗ŻńĀüńÜäõ╗╗µäÅõĮŹńĮ«õĮ┐ńö©’╝īµ£ēõ║øÕÅśķćÅÕŬĶāĮÕ£©ÕćĮµĢ░Õåģķā©õĮ┐ńö©’╝īµ£ēõ║øÕÅśķćÅÕŬĶāĮÕ£© for ÕŠ¬ńÄ»Õåģķā©õĮ┐ńö©ŃĆé + +### PythonÕ▒Ćķā©ÕÅśķćÅ + +Õ£©ÕćĮµĢ░Õåģķā©Õ«Üõ╣ēńÜäÕÅśķćÅ’╝īÕ«āńÜäõĮ£ńö©Õ¤¤õ╣¤õ╗ģķÖÉõ║ÄÕćĮµĢ░Õåģķā©’╝īÕć║õ║åÕćĮµĢ░Õ░▒õĖŹĶāĮõĮ┐ńö©õ║å’╝īµłæõ╗¼Õ░åĶ┐ÖµĀĘńÜäÕÅśķćÅń¦░õĖ║Õ▒Ćķā©ÕÅśķćÅ’╝łLocal Variable’╝ēŃĆé + +Ķ”üń¤źķüō’╝īÕĮōÕćĮµĢ░Ķó½µē¦ĶĪīµŚČ’╝īPython õ╝ÜõĖ║ÕģČÕłåķģŹõĖĆÕØŚõĖ┤µŚČńÜäÕŁśÕé©ń®║ķŚ┤’╝īµēƵ£ēÕ£©ÕćĮµĢ░Õåģķā©Õ«Üõ╣ēńÜäÕÅśķćÅ’╝īķāĮõ╝ÜÕŁśÕé©Õ£©Ķ┐ÖÕØŚń®║ķŚ┤õĖŁŃĆéĶĆīÕ£©ÕćĮµĢ░µē¦ĶĪīÕ«īµ»ĢÕÉÄ’╝īĶ┐ÖÕØŚõĖ┤µŚČÕŁśÕé©ń®║ķŚ┤ķÜÅÕŹ│õ╝ÜĶó½ķćŖµöŠÕ╣ČÕø×µöČ’╝īĶ»źń®║ķŚ┤õĖŁÕŁśÕé©ńÜäÕÅśķćÅĶć¬ńäČõ╣¤Õ░▒µŚĀµ│ĢÕåŹĶó½õĮ┐ńö©ŃĆé + +õĖŠõŠŗÕŁÉ’╝Ü +```python +def demo(): + add = "http://c.biancheng.net/python/" + print("ÕćĮµĢ░Õåģķā© add =",add) +demo() +print("ÕćĮµĢ░Õż¢ķā© add =",add) +``` + +Ķ┐ÉĶĪīń╗ōµ×£Õ”éõĖŗ’╝Ü +```console +ÕćĮµĢ░Õåģķā© add = http://c.biancheng.net/python/ +Traceback (most recent call last): + + File "
" \ + "Ķ»Ęµ▒éń▒╗Õ×ŗ: {}
" \ + "µ£¤µ£øń╗ōµ×£: {}
" \ + "Õ«×ķÖģń╗ōµ×£: {}".format(url,method,expect_result,res) + allure.dynamic.description(desc) + + #µ¢ŁĶ©Ćķ¬īĶ»ü + #ńŖȵĆüńĀü’╝īĶ┐öÕø×ń╗ōµ×£ÕåģÕ«╣’╝īµĢ░µŹ«Õ║ōńøĖÕģ│ńÜäń╗ōµ×£ńÜäķ¬īĶ»ü + #ńŖȵĆüńĀü + assert_util = AssertUtil() + assert_util.assert_code(int(res["code"]),int(code)) + #Ķ┐öÕø×ń╗ōµ×£ÕåģÕ«╣ + assert_util.assert_in_body(str(res["body"]),str(expect_result)) + #µĢ░µŹ«Õ║ōń╗ōµ×£µ¢ŁĶ©Ć + Base.assert_db("db_1",res["body"],db_verify) + + + #1ŃĆüÕłØÕ¦ŗÕī¢µĢ░µŹ«Õ║ō + # from common.Base import init_db + # sql = init_db("db_1") + # #2ŃĆüµ¤źĶ»ósql’╝īexcelÕ«Üõ╣ēÕźĮńÜä + # db_res = sql.fetchone(db_verify) + # log.debug("µĢ░µŹ«Õ║ōµ¤źĶ»óń╗ōµ×£’╝Ü{}".format(str(db_res))) + # #3ŃĆüµĢ░µŹ«Õ║ōńÜäń╗ōµ×£õĖĵğÕÅŻĶ┐öÕø×ńÜäń╗ōµ×£ķ¬īĶ»ü + # #ĶÄĘÕÅ¢µĢ░µŹ«Õ║ōń╗ōµ×£ńÜäkey + # verify_list = list(dict(db_res).keys()) + # #µĀ╣µŹ«keyĶÄĘÕÅ¢µĢ░µŹ«Õ║ōń╗ōµ×£’╝īµÄźÕÅŻń╗ōµ×£ + # for line in verify_list: + # res_line = res["body"][line] + # res_db_line = dict(db_res)[line] + # #ķ¬īĶ»ü + # assert_util.assert_body(res_line,res_db_line) + # 1.Õłżµ¢Łheadersµś»ÕÉ”ÕŁśÕ£©’╝ījsonĶĮ¼õ╣ē’╝īµŚĀķ£Ć + # if headers: + # header = json.loads(headers) + # else: + # header = headers + # # 3.Õó×ÕŖĀcookies + # if cookies: + # cookie = json.loads(cookies) + # else: + # cookie = cookies + + # #2’╝ē.µÄźÕÅŻĶ»Ęµ▒é + # request = Request() + # #params ĶĮ¼õ╣ējson + # #ķ¬īĶ»üparamsµ£ēµ▓Īµ£ēÕåģÕ«╣ + # if len(str(params).strip()) is not 0: + # params = json.loads(params) + # #method post/get + # if str(method).lower()=="get": + # # 2.Õó×ÕŖĀHeaders + # res = request.get(url,json=params,headers = header,cookies=cookie) + # elif str(method).lower()=="post": + # res = request.post(url, json=params,headers = header,cookies=cookie) + # else: + # log.error("ķöÖĶ»»Ķ»Ęµ▒émethod: %s"%method) + # print(res) +#TestExcel().test_run() + + def get_correlation(self,headers,cookies,pre_res): + """ + Õģ│Ķüö + :param headers: + :param cookies: + :param pre_res: + :return: + """ + #ķ¬īĶ»üµś»ÕÉ”µ£ēÕģ│Ķüö + headers_para,cookies_para = Base.params_find(headers,cookies) + #µ£ēÕģ│Ķüö’╝īµē¦ĶĪīÕēŹńĮ«ńö©õŠŗ’╝īĶÄĘÕÅ¢ń╗ōµ×£ + if len(headers_para): + headers_data = pre_res["body"][headers_para[0]] + #ń╗ōµ×£µø┐µŹó + headers = Base.res_sub(headers,headers_data) + if len(cookies_para): + cookies_data = pre_res["body"][cookies_para[0]] + # ń╗ōµ×£µø┐µŹó + cookies = Base.res_sub(headers, cookies_data) + return headers,cookies +if __name__ == '__main__': + #pass + report_path = Conf.get_report_path()+os.sep+"result" + report_html_path = Conf.get_report_path()+os.sep+"html" + pytest.main(["-s","test_excel_case.py","--alluredir",report_path]) + + + #Base.allure_report("./report/result","./report/html") + #Base.send_mail(title="µÄźÕÅŻµĄŗĶ»ĢµŖźÕæŖń╗ōµ×£",content=report_html_path) + #Õø║Õ«ÜheadersĶ»Ęµ▒é + #1.Õłżµ¢Łheadersµś»ÕÉ”ÕŁśÕ£©’╝ījsonĶĮ¼õ╣ē’╝īµŚĀķ£Ć + #2.Õó×ÕŖĀHeaders + #3.Õó×ÕŖĀcookies + #4.ÕÅæķĆüĶ»Ęµ▒é + + #ÕŖ©µĆüÕģ│Ķüö + #1ŃĆüķ¬īĶ»üÕēŹńĮ«µØĪõ╗Č + #if pre_exec: + #pass + #2ŃĆüµēŠÕł░µē¦ĶĪīńö©õŠŗ + #3ŃĆüÕÅæķĆüĶ»Ęµ▒é’╝īĶÄĘÕÅ¢ÕēŹńĮ«ńö©õŠŗń╗ōµ×£ + #ÕÅæķĆüĶÄĘÕÅ¢ÕēŹńĮ«µĄŗĶ»Ģńö©õŠŗ’╝īńö©õŠŗń╗ōµ×£ + #µĢ░µŹ«ÕłØÕ¦ŗÕī¢’╝īget/post’╝īķ揵×ä + #4ŃĆüµø┐µŹóHeadersÕÅśķćÅ + #1ŃĆüķ¬īĶ»üĶ»Ęµ▒éõĖŁµś»ÕÉ”${}$’╝īĶ┐öÕø×${}$ÕåģÕ«╣ + # str1 = '{"Authorization": "JWT ${token}$"}' + # if "${" in str1: + # print(str1) + # import re + # pattern = re.compile('\${(.*)}\$') + # re_res = pattern.findall(str1) + # print(re_res[0]) + # #2ŃĆüµĀ╣µŹ«ÕåģÕ«╣token’╝īµ¤źĶ»ó ÕēŹńĮ«µØĪõ╗ȵĄŗĶ»Ģńö©õŠŗĶ┐öÕø×ń╗ōµ×£token = ÕĆ╝ + # token = "123" + # #3ŃĆüµĀ╣µŹ«ÕÅśķćÅń╗ōµ×£ÕåģÕ«╣’╝īµø┐µŹó + # res = re.sub(pattern,token,str1) + # print(res) + #5ŃĆüĶ»Ęµ▒éÕÅæķĆü + + #1ŃĆüµ¤źĶ»ó’╝īÕģ¼Õģ▒µ¢╣µ│Ģ + #2ŃĆüµø┐µŹó’╝īÕģ¼Õģ▒µ¢╣µ│Ģ + #3ŃĆüķ¬īĶ»üĶ»Ęµ▒éõĖŁµś»ÕÉ”${}$’╝īĶ┐öÕø×${}$ÕåģÕ«╣’╝īÕģ¼Õģ▒µ¢╣µ│Ģ + #4ŃĆüÕģ│Ķüöµ¢╣µ│Ģ +``` + diff --git "a/_posts/2023-01-30-Allure\346\212\245\345\221\212.md" "b/_posts/2023-01-30-Allure\346\212\245\345\221\212.md" new file mode 100644 index 0000000000..cb618b4116 --- /dev/null +++ "b/_posts/2023-01-30-Allure\346\212\245\345\221\212.md" @@ -0,0 +1,266 @@ +--- +layout: post +title: "AllureµŖźÕæŖ" +date: 2023-01-30 +description: "õ╗ŗń╗Źõ║åAllureńÜäÕ«ēĶŻģ’╝īńÄ»ÕóāķģŹńĮ«’╝øAllureÕæĮõ╗ż’╝īķģŹńĮ«pytest.iniµ¢ćõ╗Č’╝īÕł®ńö©allureÕĘźÕģĘńö¤µłÉhtmlµŖźÕæŖ’╝øµ£ĆÕÉÄ’╝īĶ«▓õ║åAllureńÜäÕ║öńö©Õ«×õŠŗŃĆé" +tag: Ķć¬ÕŖ©Õī¢µĄŗĶ»Ģ +--- + +õ╗ŗń╗Źõ║åAllureńÜäÕ«ēĶŻģ’╝īńÄ»ÕóāķģŹńĮ«’╝øAllureÕæĮõ╗ż’╝īķģŹńĮ«pytest.iniµ¢ćõ╗Č’╝īÕł®ńö©allureÕĘźÕģĘńö¤µłÉhtmlµŖźÕæŖ’╝øµ£ĆÕÉÄ’╝īĶ«▓õ║åAllureńÜäÕ║öńö©Õ«×õŠŗŃĆé + +# Allure + +## Õ┐½ķƤÕģźķŚ© + +### Õ«ēĶŻģ + +1. Õ«ēĶŻģallureńÜäpythonµÅÆõ╗Č + +```bash +pip install allure-pytest -i https://mirrors.aliyun.com/pypi/simple/ +``` +µł¢ĶĆģÕåÖÕģźrequirements.txt + +```bash +allure-pytest==2.8.18 +``` + +```bash +pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ +``` + +2. allureÕĘźÕģĘńÜäÕ«ēĶŻģ +allureńÜäpythonµÅÆõ╗Č’╝łĶĆīõĖöńö¤µłÉńÜäõĖŹµś»htmlµĀ╝Õ╝ÅńÜäµ¢ćõ╗Č’╝ēõŠØĶĄ¢allureÕĘźÕģĘ’╝īµēĆõ╗źķ£ĆĶ”üÕģłÕ«ēĶŻģallureÕĘźÕģĘ’╝Ü + +allureķ£ĆĶ”üµ£ējdkńÄ»Õóā’╝īµēĆõ╗źķ£ĆĶ”üÕģłÕ«ēĶŻģjdkŃĆé + +```bash +sudo apt-get update +sudo apt-get install openjdk-8-jdk +sudo update-alternatives --set java /usr/lib/jvm/java-1.8.0-openjdk-amd64/bin/java # Ķ«ŠńĮ«ńÄ»ÕóāÕÅśķćÅ +java -version # µśŠńż║ńēłµ£¼õ┐Īµü»ĶĪ©ńż║Õ«ēĶŻģµłÉÕŖ¤ +``` + +Õ«ēĶŻģAllure + +µ¢╣µ│ĢõĖĆ’╝Ü + +```bash +sudo apt-get install allure +# µ¤źń£ŗÕ«ēĶŻģĶĘ»ÕŠä +whereis allure +# allure: /usr/share/allure +# ķģŹńĮ«ĶĮ»Ķ┐׵ğµł¢ĶĆģńÄ»ÕóāÕÅśķćÅ +sudo ln -s /usr/share/allure /usr/bin/allure +``` + + + +õĖŖĶ┐░Õ«ēĶŻģµ¢╣Õ╝ÅõĮ┐ńö©allure -- versionµŚČÕĆÖµŖź’╝Üallure: command can not found ’╝īķ£ĆĶ”üĶ«ŠńĮ«allureńÜäbinµöŠÕł░PATHķćīĶŠ╣ŃĆé Ķŗźwhereis allureµēŠõĖŹÕł░allure’╝īµŹóõĖŗĶŠ╣µ¢╣Õ╝ÅÕ«ēĶŻģŃĆé + +µ¢╣µ│Ģõ║ī’╝Ü + +```bash +curl -O https://repo.maven.apache.org/maven2/io/qameta/allure/allure-commandline/2.13.8/allure-commandline-2.13.8.tgz # õĖŗĶĮĮallure’╝īµ¢ćõ╗Čõ╝ÜõĖŗĶĮĮÕł░ÕĮōÕēŹńø«ÕĮĢ;curlÕæĮõ╗żµś»linuxõĖŗńÜäõĖŗĶĮĮÕĘźÕģĘ’╝īwindowsõĖŗÕÅ»õ╗źńö©wget +sudo tar -zxvf allure-commandline-2.13.8.tgz -C /opt/ # -CµīćÕ«ÜĶ¦ŻÕÄŗńø«ÕĮĢ,Ķ┐ÖķćīĶ¦ŻÕÄŗÕł░/opt/allure-2.13.8;õĖĆĶł¼µØźĶ»┤’╝ī/optńø«ÕĮĢõĖŗńÜäµ¢ćõ╗ČķāĮµś»Õ«ēĶŻģĶĮ»õ╗ČńÜä. +sudo ln -s /opt/allure-2.13.8/bin/allure /usr/bin/allure +allure --version # µ¤źń£ŗńēłµ£¼õ┐Īµü»õ╗źÕÅŖµś»ÕɔիēĶŻģµłÉÕŖ¤ +``` + +ķģŹńĮ«ńÄ»Õóā’╝łĶĮ»Ķ┐×µÄźÕźĮÕāÅõĖŹĶĄĘõĮ£ńö©’╝ē’╝Ü + +```bash +vi /etc/profile +# Õ£©PATHÕÉÄĶ┐ĮÕŖĀõ╗źõĖŗÕåģÕ«╣’╝īõ┐ØÕŁś +export PATH=$PATH:/home/allure-2.13.8/bin +# õĮ┐ńÄ»ÕóāÕÅśķćÅńö¤µĢł +source /etc/profile +``` +µ£ĆÕÉÄ’╝īķģŹńĮ«ÕźĮńÄ»ÕóāÕÅśķćÅÕÉÄĶ«░ÕŠŚķćŹÕÉ»õĖŗide’╝łÕŠłķćŹĶ”ü’╝ē’╝ü’╝ü’╝ü +ÕģČõ╗¢õĖŗĶĮĮÕ£░ÕØĆ’╝Ü +https://repo.maven.apache.org/maven2/io/qameta/allure/allure-commandline/ + +https://github.com/allure-framework/allure2/releases + + + +### õĮ┐ńö© + +ķ”¢ÕģłĶ”üķģŹńĮ«pytest.iniµ¢ćõ╗Č’╝īÕæŖĶ»ēpytestõĮ┐ńö©allureµÅÆõ╗Č;µĘ╗ÕŖĀallureõ╗ŻńĀü’╝øĶ┐ÉĶĪī’╝øµ£ĆÕÉÄ’╝īÕł®ńö©allureÕĘźÕģĘńö¤µłÉhtmlµŖźÕæŖŃĆé + +```ini +addopts = -s --alluredir ./report/result + +``` + +µĘ╗ÕŖĀallureõ╗ŻńĀü’╝īÕ£©testcaseµ¢ćõ╗ČÕż╣õĖŗķØóÕłøÕ╗║t_allureµ¢ćõ╗ČÕż╣’╝īµ¢░Õ╗║test_allure.pyµ¢ćõ╗Č’╝īµĘ╗ÕŖĀÕ”éõĖŗõ╗ŻńĀü’╝Ü + +```python +import pytest +def test_1(): + print("test 1") + +def test_2(): + print("test 2") + +def test_3(): + print("test 3") + +if __name__ == '__main__': + pytest.main(["allure_demo.py"]) +``` + +Ķ┐ÉĶĪīõ╗ŻńĀü’╝īÕÅ»õ╗źń£ŗÕł░Õ£©ÕÉīń║¦reportµ¢ćõ╗ČÕż╣õĖŗńö¤µłÉõ║åresultµ¢ćõ╗ČÕż╣’╝īķćīĶŠ╣µ£ēallureńøĖÕģ│ńÜäµ¢ćõ╗ČŃĆé + +µ£ĆÕÉÄ’╝īńé╣Õć╗terminal’╝īÕ£©ń╗łń½»õĖŁĶŠōÕģźallure generate ./report/result -o ./report/html --clean’╝īńö¤µłÉhtmlµŖźÕæŖŃĆé + +```bash +# Ķ┐øÕģźµ¢ćõ╗ČÕż╣ +cd testcase/t_allure/ +ls +# ńö¤µłÉhtmlµŖźÕæŖ +allure generate ./report/result -o ./report/html --clean +# --cleanĶĪ©ńż║µĖģķÖżõ╣ŗÕēŹńÜäµŖźÕæŖ -oĶĪ©ńż║ĶŠōÕć║ńÜäµ¢ćõ╗ČÕż╣ +# µēōÕ╝ĆhtmlµŖźÕæŖ,ÕÅ»õ╗źµēŠÕł░index.htmlµ¢ćõ╗Č’╝īõ╣¤ÕÅ»õ╗źõĮ┐ńö©allure openÕæĮõ╗żµēōÕ╝Ć +allure open ./report/html +``` + + +## Allure ÕæĮõ╗ż + +### Title + +ÕÅ»õ╗źĶć¬Õ«Üõ╣ēńö©õŠŗµĀćķóś’╝īµĀćķóśķ╗śĶ«żõĖ║ÕćĮµĢ░ÕÉŹŃĆé@allure.title("ńö©õŠŗµĀćķóś") + +### Description + +ÕÅ»õ╗źµĘ╗ÕŖĀµĄŗĶ»ĢńÜäĶ»”ń╗åĶ»┤µśÄ’╝īµö»µīüMarkdownĶ»Łµ│ĢŃĆé@allure.description("ńö©õŠŗĶ»”ń╗åµÅÅĶ┐░") + +### Feature + +ÕŖ¤ĶāĮ’╝īÕÅ»õ╗źńÉåĶ¦ŻõĖ║µ©ĪÕØŚŃĆé@allure.feature("ÕŖ¤ĶāĮµ©ĪÕØŚ") + +### Story + +Story’╝īÕÅ»õ╗źńÉåĶ¦ŻõĖ║ÕŁÉµ©ĪÕØŚŃĆé@allure.story("ÕŁÉµ©ĪÕØŚ") + +### Severity + +Õ«Üõ╣ēńö©õŠŗńÜäõĖźķćŹń©ŗÕ║”’╝īÕłåõĖ║blockerŃĆücriticalŃĆünormalŃĆüminorŃĆütrivialŃĆé@allure.severity(allure.severity_level.CRITICAL) + +ķ╗śĶ«żõĖ║normalŃĆé + +ÕŬĶ┐ÉĶĪīµīćÕ«Üń║¦Õł½ńÜäńö©õŠŗ’╝Ü + +```bash +pytest -s -q --alluredir=./report/result --allure-severities=critical # -sĶĪ©ńż║µēōÕŹ░µŚźÕ┐Ś -qĶĪ©ńż║ń«ĆÕī¢ĶŠōÕć║;--allure-severities=criticalĶĪ©ńż║ÕŬĶ┐ÉĶĪīõĖźķćŹń║¦Õł½õĖ║criticalńÜäńö©õŠŗ; +``` + + +### Allure.dynamic + +ÕÅ»õ╗źÕŖ©µĆüµĘ╗ÕŖĀµĄŗĶ»ĢµŁźķ¬ż’╝īµö»µīüMarkdownĶ»Łµ│Ģ,ÕÅ»õ╗źõĮ┐ńö©ÕćĮµĢ░õĮōÕåģńÜäµĢ░µŹ«ÕŖ©µĆüńö¤µłÉ. + +@allure.dynamic.description("µĄŗĶ»ĢµŁźķ¬ż") + +```python +@pytest.mark.parametrize("case",["case1","case2"]) +def test_4(self,case): + print(case) + allure.dynamic.title(case) +``` + +## AllureÕ║öńö© + +### AllureµĄŗĶ»Ģńö©õŠŗ + +µēōÕ╝Ćdataµ¢ćõ╗ČķøåõĖŗķØóńÜätestcase.xlsxµ¢ćõ╗Č’╝īµ¤źń£ŗµĄŗĶ»ĢµĢ░µŹ«ńÜäÕģĘõĮōõ┐Īµü»’╝īµĀ╣µŹ«Ķ┐ÖõĖ¬õ┐Īµü»’╝īÕ»╣allureµŖźÕæŖńÜäÕåģÕ«╣Ķ┐øĶĪīÕ”éõĖŗĶ«ŠńĮ«’╝Ü +```console +sheetÕÉŹń¦░ feature õĖĆń║¦µĀćńŁŠ +µ©ĪÕØŚ story õ║īń║¦µĀćńŁŠ +ńö©õŠŗID+µÄźÕÅŻÕÉŹń¦░ title +Ķ»Ęµ▒éURL Ķ»Ęµ▒éń▒╗Õ×ŗ µ£¤µ£øń╗ōµ×£ Õ«×ķÖģń╗ōµ×£µÅÅĶ┐░ +``` + +```python +import allure +#allure +#sheetÕÉŹń¦░ feature õĖĆń║¦µĀćńŁŠ +allure.dynamic.feature(sheet_name) +#µ©ĪÕØŚ story õ║īń║¦µĀćńŁŠ +allure.dynamic.story(case_model) +#ńö©õŠŗID+µÄźÕÅŻÕÉŹń¦░ title +allure.dynamic.title(case_id+case_name) +#Ķ»Ęµ▒éURL Ķ»Ęµ▒éń▒╗Õ×ŗ µ£¤µ£øń╗ōµ×£ Õ«×ķÖģń╗ōµ×£µÅÅĶ┐░ +desc = "Ķ»Ęµ▒éURL: {}
" \ + "Ķ»Ęµ▒éń▒╗Õ×ŗ: {}
" \ + "µ£¤µ£øń╗ōµ×£: {}
" \ + "Õ«×ķÖģń╗ōµ×£: {}".format(url,method,expect_result,res) +allure.dynamic.description(desc) +``` + +Ķ«ŠńĮ«Õ«īµłÉõ╣ŗÕÉÄ’╝īµ»Åµ¼ĪķāĮķ£ĆĶ”üallure generate ./report/result -o ./report/html --cleanµØźµēŗÕŖ©ńö¤µłÉhtmlµŖźÕæŖ’╝īÕÅ»õ╗źõĮ┐ńö©SubprocessµØźÕ«×ńÄ░Ķć¬ÕŖ©Õī¢ńö¤µłÉµŖźÕæŖŃĆé + +Subprocessµś»PythonõĖŁńÜäõĖĆõĖ¬µ©ĪÕØŚ’╝īńö©õ║ÄÕłøÕ╗║µ¢░Ķ┐øń©ŗ’╝īĶ┐×µÄźÕł░Õ«āõ╗¼ńÜäĶŠōÕģź/ĶŠōÕć║/ķöÖĶ»»ń«Īķüō’╝īÕ╣ČĶÄĘÕÅ¢Õ«āõ╗¼ńÜäĶ┐öÕø×õ╗ŻńĀüŃĆé + +µ¢╣µ│Ģ’╝Ü +* Subprocess.call()’╝ÜńłČĶ┐øń©ŗńŁēÕŠģÕŁÉĶ┐øń©ŗ’╝īĶ┐öÕø×ķĆĆÕć║õ┐Īµü»’╝łreturncode’╝īńøĖÕĮōõ║Älinux exit code’╝ē’╝ø0ĶĪ©ńż║µŁŻÕĖĖķĆĆÕć║’╝īķØ×0ĶĪ©ńż║Õ╝éÕĖĖķĆĆÕć║ŃĆé +* shell=True’╝ÜĶĪ©ńż║õĮ┐ńö©shellµē¦ĶĪīÕæĮõ╗ż’╝īÕÉ”ÕłÖķ╗śĶ«żõĮ┐ńö©cmdµē¦ĶĪīÕæĮõ╗ż;µö»µīüÕæĮõ╗żõ╗źÕŁŚń¼”õĖ▓ńÜäÕĮóÕ╝Åõ╝ĀÕģź’╝īõĖŹķ£ĆĶ”üÕåŹõĮ┐ńö©ÕłŚĶĪ©ńÜäÕĮóÕ╝Åõ╝ĀÕģźŃĆé + +```python +import subprocess + + +res = subprocess.call(["ls","-l"]) +print(res) # 0õ╗ŻĶĪ©µŁŻÕĖĖķĆĆÕć║’╝īķØ×0õ╗ŻĶĪ©Õ╝éÕĖĖķĆĆÕć║ + +subprocess.call("ls -l",shell=True) # shell=True’╝īµö»µīüÕæĮõ╗żõ╗źÕŁŚń¼”õĖ▓ńÜäÕĮóÕ╝Åõ╝ĀÕģź +``` + +ĶŠōÕć║ń╗ōµ×£’╝Ü + +```console +µĆ╗ńö©ķćÅ 4 +-rw-rw-r-- 1 hugo hugo 0 1µ£ł 30 10:00 __init__.py +-rw-rw-r-- 1 hugo hugo 138 1µ£ł 30 10:06 subprocess_demo.py +0 +µĆ╗ńö©ķćÅ 4 +-rw-rw-r-- 1 hugo hugo 0 1µ£ł 30 10:00 __init__.py +-rw-rw-r-- 1 hugo hugo 138 1µ£ł 30 10:06 subprocess_demo.py + +µĆ╗ńö©ķćÅ 4 +-rw-rw-r-- 1 hugo hugo 0 1µ£ł 30 10:00 __init__.py +-rw-rw-r-- 1 hugo hugo 138 1µ£ł 30 10:06 subprocess_demo.py +0 +µĆ╗ńö©ķćÅ 4 +-rw-rw-r-- 1 hugo hugo 0 1µ£ł 30 10:00 __init__.py +-rw-rw-r-- 1 hugo hugo 138 1µ£ł 30 10:06 subprocess_demo.py + +Ķ┐øń©ŗÕĘ▓ń╗ōµØ¤,ķĆĆÕć║õ╗ŻńĀü0 +``` + + +### AllureķĪ╣ńø«Ķ┐ÉĶĪī + +Õ£©commonµ¢ćõ╗ČÕż╣õĖŗķØóńÜäBase.pyµ¢ćõ╗ČõĖŁ’╝īµĘ╗ÕŖĀÕ”éõĖŗõ╗ŻńĀü’╝Ü(Ķ┐Éńö©µłæõ╗¼õĖŖõĖĆĶŖéÕŁ”õ╣ĀńÜäsubprocessµ©ĪÕØŚ) + + + +```python +def allure_report(report_path,report_html): + """ + ńö¤µłÉallure µŖźÕæŖ + :param report_path: + :param report_html: + :return: + """ + #µē¦ĶĪīÕæĮõ╗ż allure generate + allure_cmd ="allure generate %s -o %s --clean"%(report_path,report_html) + #subprocess.call + log.info("µŖźÕæŖÕ£░ÕØĆ") + try: + subprocess.call(allure_cmd,shell=True) + except: + log.error("µē¦ĶĪīńö©õŠŗÕż▒Ķ┤ź’╝īĶ»ĘµŻĆµ¤źõĖĆõĖŗµĄŗĶ»ĢńÄ»ÕóāńøĖÕģ│ķģŹńĮ«") + raise +``` \ No newline at end of file diff --git "a/_posts/2023-01-30-\346\216\245\345\217\243\350\207\252\345\212\250\345\214\226\346\265\213\350\257\225\344\273\245\345\217\212\346\265\213\350\257\225\347\224\250\344\276\213\350\256\276\350\256\241\346\200\273\347\273\223.md" "b/_posts/2023-01-30-\346\216\245\345\217\243\350\207\252\345\212\250\345\214\226\346\265\213\350\257\225\344\273\245\345\217\212\346\265\213\350\257\225\347\224\250\344\276\213\350\256\276\350\256\241\346\200\273\347\273\223.md" new file mode 100644 index 0000000000..4b5ef5b71a --- /dev/null +++ "b/_posts/2023-01-30-\346\216\245\345\217\243\350\207\252\345\212\250\345\214\226\346\265\213\350\257\225\344\273\245\345\217\212\346\265\213\350\257\225\347\224\250\344\276\213\350\256\276\350\256\241\346\200\273\347\273\223.md" @@ -0,0 +1,117 @@ +--- +layout: post +title: "µÄźÕÅŻĶć¬ÕŖ©Õī¢µĄŗĶ»Ģõ╗źÕÅŖµĄŗĶ»Ģńö©õŠŗĶ«ŠĶ«ĪµĆ╗ń╗ō" +date: 2023-01-30 +description: "õ╗ŗń╗Źõ║åµÄźÕÅŻĶć¬ÕŖ©Õī¢µĄŗĶ»ĢµĪåµ×ȵĪåµ×ȵɣÕ╗║’╝īń¼¼õĖēµ¢╣µÅÆõ╗Č’╝īķģŹńĮ«µ¢ćõ╗ČĶ«ŠńĮ«ÕÆīĶ»╗ÕÅ¢’╝īµĄŗĶ»ĢµĄüń©ŗńŁēÕåģÕ«╣ŃĆ鵥ŗĶ»Ģńö©õŠŗĶ«ŠĶ«Īķā©Õłå’╝īÕłÖÕīģµŗ¼ExcelµĄŗĶ»Ģńö©õŠŗ’╝īµÄ¦ÕłČµĄüÕÆīµĢ░µŹ«µĄü’╝īµ¢╣µ│ĢńÜäÕ║öńö©Õ£║µÖ»’╝īµĄŗĶ»Ģńö©õŠŗõ╣”ÕåÖµĀćÕćåõ╗źÕÅŖµĄŗĶ»ĢķøåńÜäÕłøÕ╗║ŃĆé" +tag: Ķć¬ÕŖ©Õī¢µĄŗĶ»Ģ +--- + +õ╗ŗń╗Źõ║åµÄźÕÅŻĶć¬ÕŖ©Õī¢µĄŗĶ»ĢµĪåµ×ȵĪåµ×ȵɣÕ╗║’╝īń¼¼õĖēµ¢╣µÅÆõ╗Č’╝īķģŹńĮ«µ¢ćõ╗ČĶ«ŠńĮ«ÕÆīĶ»╗ÕÅ¢’╝īµĄŗĶ»ĢµĄüń©ŗńŁēÕåģÕ«╣ŃĆ鵥ŗĶ»Ģńö©õŠŗĶ«ŠĶ«Īķā©Õłå’╝īÕłÖÕīģµŗ¼ExcelµĄŗĶ»Ģńö©õŠŗ’╝īµÄ¦ÕłČµĄüÕÆīµĢ░µŹ«µĄü’╝īµ¢╣µ│ĢńÜäÕ║öńö©Õ£║µÖ»’╝īµĄŗĶ»Ģńö©õŠŗõ╣”ÕåÖµĀćÕćåõ╗źÕÅŖµĄŗĶ»ĢķøåńÜäÕłøÕ╗║ŃĆé + +# µÄźÕÅŻĶć¬ÕŖ©Õī¢µĄŗĶ»ĢµĆ╗ń╗ō + +## µĪåµ×ȵɣÕ╗║ + +* ÕĘźÕģĘ +* ńø«ÕĮĢ +* ķģŹńĮ« +* pytestµĪåµ×Č + * pytest.ini + * conftest.py + * Õ¤║µ£¼ÕæĮõ╗ż + * õĖēµ¢╣µÅÆõ╗Č + +* YamlķģŹńĮ«µ¢ćõ╗Č + * ķģŹńĮ«µ¢ćõ╗Č + * µĢ░µŹ«ķ®▒ÕŖ© +* Excel + * µĄŗĶ»ĢµĢ░µŹ«ķģŹńĮ« + * µĢ░µŹ«ķ®▒ÕŖ© +* µŚźÕ┐Ś + * µŚźÕ┐ŚķģŹńĮ« + * µŚźÕ┐ŚĶŠōÕć║ +* AllureµŖźÕæŖ + * Õ«ēĶŻģ + * õĮ┐ńö© + * µĄŗĶ»Ģńö©õŠŗ +* ķé«õ╗ČķģŹńĮ« + * ķé«õ╗ČķģŹńĮ« + * ķé«õ╗ČÕÅæķĆü +* µÄźÕÅŻµĄŗĶ»ĢµĪåµ×ȵĄüń©ŗ + +õĖ╗ń©ŗÕ║Å -> ExcelµĄŗĶ»Ģńö©õŠŗ -> RequestĶ»Ęµ▒é -> µ¢ŁĶ©Ć -> µŚźÕ┐Ś -> AllureµŖźÕæŖ -> ķé«õ╗ČÕÅæķĆü + +## µĄŗĶ»ĢĶ«ŠĶ«Ī + +### µĄŗĶ»ĢµĪåµ×ČńÜäĶ«ŠĶ«Ī + +#### µĄŗĶ»Ģńö©õŠŗńÜäĶ«ŠĶ«Ī + +µĄŗĶ»Ģńö©õŠŗµś»õĖ║õ║嵤ÉõĖ¬ńē╣Õ«ÜńÜ䵥ŗĶ»Ģńø«µĀćĶĆīĶ«ŠĶ«ĪńÜä’╝īÕ«āµś»µĄŗĶ»ĢµōŹõĮ£Ķ┐ćń©ŗÕ║ÅÕłŚŃĆüµØĪõ╗ČŃĆüµ£¤µ£øń╗ōµ×£ÕÆīńøĖÕģ│µĢ░µŹ«ńÜäõĖĆõĖ¬ńē╣Õ«ÜńÜäķøåÕÉłŃĆé + +õ╗Äķ£Ćµ▒éÕć║ÕÅæ’╝īĶ«ŠĶ«ĪµĄŗĶ»Ģńö©õŠŗ’╝īõĖŹÕÉīńÜ䵥ŗĶ»ĢµĢ░µŹ«µł¢µĄŗĶ»ĢµØĪõ╗ČÕÆīńö©µłĘµĢģõ║ŗ’╝łuser story’╝ēŃĆüÕ║öńö©Õ£║µÖ»ÕÅĀÕŖĀ’╝īÕĮóµłÉµĄŗĶ»Ģńö©õŠŗŃĆé + +Ķ┐śÕÅ»õ╗źÕ¤║õ║ÄĶó½µĄŗń│╗ń╗¤(system under test)ńÜäÕŖ¤ĶāĮńé╣ŃĆüõĖÜÕŖĪµĄüń©ŗŃĆüõĖÜÕŖĪĶ¦äÕłÖŃĆüõĖÜÕŖĪµĢ░µŹ«ńŁē’╝īĶ«ŠĶ«ĪµĄŗĶ»Ģńö©õŠŗŃĆé + +µĄŗĶ»Ģńö©õŠŗÕÆīÕŖ¤ĶāĮń╗ōµ×äµ£ēÕ»╣Õ║öÕģ│ń│╗’╝īÕæłńÄ░Õć║Õ▒éµ¼Īń╗ōµ×äŃĆé + +õŠŗÕ”é’╝īÕ£©ŌĆ£ńÖ╗ÕĮĢŌĆØÕŖ¤ĶāĮµ©ĪÕØŚõĖŁ’╝īÕ▒éµ¼Īń╗ōµ×äÕ”éõĖŗ’╝Ü + +* ńö©µłĘĶ║½õ╗ĮÕÉłµ│ĢµĆ¦ķ¬īĶ»ü’╝łńłČńö©õŠŗ’╝ē + * ńö©µłĘÕÉŹķ¬īĶ»ü’╝łÕŁÉńö©õŠŗ’╝ē + * µŁŻÕĖĖńö©µłĘÕÉŹńÜäĶŠōÕģź’╝łÕŁÖńö©õŠŗ’╝ē + * Õɽµ£ēńē╣µ«ŖÕŁŚń¼”ńÜäńö©µłĘÕÉŹĶŠōÕģź + * ÕŁŚµ»ŹÕż¦Õ░ÅÕåÖµŚĀÕģ│µĆ¦µĄŗĶ»Ģ + * ķØ×µ│Ģńö©µłĘÕÉŹĶŠōÕģź + * Õ»åńĀüķ¬īĶ»ü’╝łÕŁÉńö©õŠŗ’╝ē + * µŁŻÕĖĖÕ»åńĀü + * Õɽµ£ēńē╣µ«ŖÕŁŚń¼”ńÜäÕ»åńĀü + * ÕŁŚµ»ŹÕī║ÕłåÕż¦Õ░ÅÕåÖńÜ䵥ŗĶ»Ģ + * Õ»åńĀüµ£ēµĢłµ£¤ķ¬īĶ»ü + * Õ»åńĀüõ┐ØÕŁś + * Õ┐śĶ«░Õ»åńĀüõ╣ŗÕÉĵēŠÕø×Õ»åńĀüÕŖ¤ĶāĮ + +#### ExcelµĄŗĶ»Ģńö©õŠŗ + +õĖĆõĖ¬Õ«īµĢ┤ńÜäExcelµĄŗĶ»Ģńö©õŠŗĶĪ©Õ║öĶ»źÕīģµŗ¼õ╗źõĖŗÕćĀõĖ¬ķā©Õłå’╝Ü + +ńö©õŠŗń╝¢ÕÅĘ’╝īńö©õŠŗÕÉŹń¦░’╝īńö©õŠŗń▒╗Õ×ŗ’╝īńö©õŠŗõ╝śÕģłń║¦’╝īńö©õŠŗńŖȵĆü’╝īńö©õŠŗńēłµ£¼’╝īńö©õŠŗÕłøÕ╗║õ║║’╝īńö©õŠŗÕłøÕ╗║µŚČķŚ┤’╝īńö©õŠŗõ┐«µö╣õ║║’╝īńö©õŠŗõ┐«µö╣µŚČķŚ┤’╝īńö©õŠŗµÅÅĶ┐░’╝īńö©õŠŗÕēŹńĮ«µØĪõ╗Č’╝īńö©õŠŗÕÉÄńĮ«µØĪõ╗Č’╝īńö©õŠŗµŁźķ¬ż’╝īńö©õŠŗķóäµ£¤ń╗ōµ×£’╝īńö©õŠŗķÖäõ╗Č’╝īńö©õŠŗÕżćµ│©ŃĆé + +#### µÄ¦ÕłČµĄüÕÆīµĢ░µŹ«µĄü + +ÕÅ»õ╗źõ╗Äõ╗ŻńĀüŃĆüÕŖ¤ĶāĮńé╣ÕÆīÕ£║µÖ»ńŁēń╗┤Õ║”ÕÄ╗ĶĪĪķćŵĄŗĶ»ĢĶ”åńø¢ńÄć’╝īõĮåµś»Õ£║µÖ»ŃĆüÕŖ¤ĶāĮńé╣Õģʵ£ēõĖŹńĪ«Õ«ÜµĆ¦’╝īµ»öĶŠāńĪ«Õ«ÜńÜ䵥ŗĶ»ĢĶ”åńø¢ńÄ浜»Õ¤║õ║ĵĢ░µŹ«Õłåµ×ÉńÜäµĢ░µŹ«µĄüÕÆīÕ¤║õ║ÄķĆ╗ĶŠæń╗ōµ×äńÜäµÄ¦ÕłČµĄüŃĆ鵥ŗĶ»ĢĶ«ŠĶ«Īµ¢╣µ│ĢÕ░▒µś»ķĆÜĶ┐浥ŗĶ»Ģńö©õŠŗńÜäõĖŹµ¢ŁĶ«ŠĶ«ĪŃĆüõ╝śÕī¢’╝īµ£Ćń╗łĶŠŠÕł░µÄ¦ÕłČµĄüÕÆīµĢ░µŹ«µĄüńÜäĶ”åńø¢ŃĆé + +Õ£©õĖÜÕŖĪÕ▒é’╝īµÄ¦ÕłČµĄüõĖ╗Ķ”üõĮōńÄ░Õ£©õĖÜÕŖĪµĄüń©ŗÕøŠ’╝īµĢ░µŹ«µĄüõĮōńÄ░Õ£©µĢ░µŹ«µĄüń©ŗÕøŠŃĆé + +Õ”éŌĆ£ńö©µłĘńÖ╗ÕĮĢŌĆØÕŖ¤ĶāĮµ©ĪÕØŚńÜäõĖÜÕŖĪµĄüń©ŗÕøŠ’╝Ü + + + +µĀ╣µŹ«õĖŖĶ┐░µĄüń©ŗÕøŠµØźĶ«ŠĶ«ĪµĄŗĶ»Ģńö©õŠŗ’╝īķ£ĆĶ”üĶ”åńø¢µ»ÅõĖ¬Õłåµö»ÕÆīµØĪõ╗Č’╝īõ╗źõ┐ØĶ»üµĄŗĶ»ĢńÜäĶ”åńø¢ńÄćŃĆé + +ķ”¢Õģł’╝īĶ”üĶĆāĶÖæÕłåµłÉŌĆ£õĖŹĶāĮĶć¬ÕŖ©ńÖ╗ÕĮĢŌĆØÕÆīŌĆ£Ķć¬ÕŖ©ńÖ╗ÕĮĢŌĆØõĖżń▒╗’╝øÕ»╣õ║ÄŌĆ£õĖŹĶāĮĶć¬ÕŖ©ńÖ╗ÕĮĢŌĆØ’╝īĶ”üĶĆāĶÖæŌĆ£Ķ«░õĮÅÕ»åńĀüŌĆØÕÆīŌĆ£õĖŹĶ«░õĮÅÕ»åńĀüŌĆØõĖżń¦ŹµāģÕåĄ’╝øÕ»╣õ║ÄŌĆ£Ķć¬ÕŖ©ńÖ╗ÕĮĢŌĆØ’╝īĶ”üĶĆāĶÖæŌĆ£Ķ«░õĮÅÕ»åńĀüŌĆØÕÆīŌĆ£õĖŹĶ«░õĮÅÕ»åńĀüŌĆØõĖżń¦ŹµāģÕåĄŃĆéÕ»╣õ║ÄõĖŹÕÉīĶŠōÕģźķĪ╣ńÜäķöÖĶ»»’╝īÕÅ»õ╗źÕłåµłÉŌĆ£ńö©µłĘÕÉŹķöÖĶ»»ŌĆØŃĆüŌĆ£Õ»åńĀüķöÖĶ»»ŌĆØŃĆüŌĆ£ķ¬īĶ»üńĀüķöÖĶ»»ŌĆØŃĆüŌĆ£ńö©µłĘÕÉŹÕÆīÕ»åńĀüķöÖĶ»»ŌĆØŃĆüŌĆ£ńö©µłĘÕÉŹÕÆīķ¬īĶ»üńĀüķöÖĶ»»ŌĆØŃĆüŌĆ£Õ»åńĀüÕÆīķ¬īĶ»üńĀüķöÖĶ»»ŌĆØŃĆüŌĆ£ńö©µłĘÕÉŹŃĆüÕ»åńĀüÕÆīķ¬īĶ»üńĀüķöÖĶ»»ŌĆØńŁēµāģÕåĄŃĆéĶ┐ÖµĀĘ’╝īÕ░▒ÕÅ»õ╗źĶ«ŠĶ«ĪÕć║Õ»╣ÕæĆńÜ䵥ŗĶ»Ģńö©õŠŗŃĆé + +#### µĖģµźÜµ¢╣µ│ĢńÜäÕ║öńö©Õ£║µÖ» + +* ĶĪ©ÕŹĢõĖŁÕŹĢõĖ¬ĶŠōÕģźµĪåńÜ䵥ŗĶ»ĢÕ▒×õ║ÄÕŹĢÕøĀń┤ĀµĄŗĶ»Ģ’╝īÕÅ»õ╗źõĮ┐ńö©ńŁēõ╗Ęń▒╗ÕłÆÕłåµ│ĢŃĆüĶŠ╣ńĢīÕĆ╝Õłåµ×ɵ│ĢńŁēµ¢╣µ│ĢŃĆéńŁēõ╗Ęń▒╗ÕłÆÕłåĶ«®µłæõ╗¼õ╝śÕī¢µĄŗĶ»ĢµĢ░µŹ«’╝īÕ╣ČÕģ│µ│©µŚĀµĢłńŁēõ╗Ęń▒╗’╝øĶŠ╣ńĢīÕĆ╝Õłåµ×ɵ¢╣µ│ĢÕłÖĶ«®µłæõ╗¼Õģ│µ│©ĶŠ╣ńĢīÕĆ╝ŃĆé +* Õ”éµ×£ĶĆāĶÖæÕżÜõĖ¬µØĪõ╗Č’╝łµØĪõ╗ČÕŬÕīģµŗ¼µłÉń½ŗÕÆīõĖŹµłÉń½ŗ’╝ēń╗äÕÉłõĮ£ńö©µŚČ’╝īĶ┐ÖµŚČķĆēńö©Õå│ńŁ¢ĶĪ©µ¢╣µ│ĢŃĆéÕ”éµ×£ÕŠłķÜŠµ×äķĆĀÕć║Õå│ńŁ¢ĶĪ©’╝īÕÅ»õ╗źÕģłńö©ÕøĀµ×£ÕøŠÕłåµ×É’╝īÕåŹńö▒ÕøĀµ×£ÕøŠõ║¦ńö¤Õå│ńŁ¢ĶĪ©ŃĆé +* Õ”éµ×£õĖŹµś»µØĪõ╗Č’╝īĶĆīµś»ÕżÜõĖ¬ÕøĀń┤Ā/ÕÅśķćÅ’╝īµ»ÅõĖ¬ÕøĀń┤Ā/ÕÅśķćŵ£ēÕżÜõĖ¬ķĆēķĪ╣’╝łÕÅ¢ÕĆ╝’╝ē’╝īĶ┐ÖµŚČĶ”üń£ŗĶāĮÕɔիīÕģ©ń╗äÕÉłŃĆéÕ”éµ×£Õ«īÕģ©ń╗äÕÉłµĢ░ÕŠłÕż¦’╝īÕ░▒ĶĆāĶÖæńö©õĖżõĖżń╗äÕÉł’╝łpairwise’╝ēµ¢╣µ│Ģµł¢ĶĆģµŁŻõ║żÕ«×ķ¬īµ¢╣µ│ĢŃĆé + +### µĄŗĶ»Ģńö©õŠŗõ╣”ÕåÖµĀćÕćå + +µĄŗĶ»Ģńö©õŠŗµĀćÕć嵩ĪµØ┐ńÜäõĖ╗Ķ”üÕģāń┤ĀÕ”éõĖŗ’╝Ü + +* µĀćĶ»åń¼” +* µĄŗĶ»ĢķĪ╣ +* µĄŗĶ»ĢńÄ»ÕóāĶ”üµ▒é +* ĶŠōÕģźµĀćÕćå +* ĶŠōÕć║µĀćÕćå +* µĄŗĶ»Ģńö©õŠŗõ╣ŗķŚ┤ńÜäÕģ│Ķüö + +### µĄŗĶ»ĢķøåńÜäÕłøÕ╗║ + +µĄŗĶ»Ģķøåµś»µĄŗĶ»Ģńö©õŠŗńÜäķøåÕÉł’╝īÕÅ»õ╗źÕ»╣µĄŗĶ»Ģńö©õŠŗĶ┐øĶĪīÕłåń▒╗ń«ĪńÉåŃĆ鵥ŗĶ»ĢķøåńÜäÕłøÕ╗║ÕÅ»õ╗źµīēńģ¦µ©ĪÕØŚŃĆüÕŖ¤ĶāĮŃĆüÕŖ¤ĶāĮµ©ĪÕØŚŃĆüÕŖ¤ĶāĮńé╣ńŁēµ¢╣Õ╝ÅĶ┐øĶĪīÕłåń▒╗ŃĆé + + + + diff --git "a/_posts/2023-01-30-\351\202\256\344\273\266\351\205\215\347\275\256.md" "b/_posts/2023-01-30-\351\202\256\344\273\266\351\205\215\347\275\256.md" new file mode 100644 index 0000000000..f4499d0df8 --- /dev/null +++ "b/_posts/2023-01-30-\351\202\256\344\273\266\351\205\215\347\275\256.md" @@ -0,0 +1,133 @@ +--- +layout: post +title: "ķé«õ╗ČķģŹńĮ«" +date: 2023-01-30 +description: "õ╗ŗń╗Źõ║åķé«õ╗ČķģŹńĮ«ńÜäńø«ńÜä’╝īķé«õ╗ČķģŹńĮ«ńÜäµ¢╣µ│Ģ’╝īķé«õ╗ČÕ░üĶŻģõ╗źÕÅŖķé«õ╗ČĶ┐ÉĶĪī" +tag: Ķć¬ÕŖ©Õī¢µĄŗĶ»Ģ +--- + +õ╗ŗń╗Źõ║åķé«õ╗ČķģŹńĮ«ńÜäńø«ńÜä’╝īķé«õ╗ČķģŹńĮ«ńÜäµ¢╣µ│Ģ’╝īķé«õ╗ČÕ░üĶŻģõ╗źÕÅŖķé«õ╗ČĶ┐ÉĶĪīŃĆé + +# ķé«õ╗ČķģŹńĮ« + +## ńø«ńÜä + +õĮ┐ńö©ķé«õ╗Č’╝īµ¢╣õŠ┐ĶÄĘÕÅ¢Ķć¬ÕŖ©Õī¢µĄŗĶ»ĢńÜäń╗ōµ×£ + +## ķģŹńĮ«µ¢ćõ╗ČĶ«ŠńĮ«õ╗źÕÅŖķé«õ╗ČÕ░üĶŻģ + +### ķé«õ╗ČķģŹńĮ« + +õĖŠõĖ¬õŠŗÕŁÉ’╝Ü + +µēōÕ╝Ć163ķé«ń«▒µł¢ĶĆģqqķé«ń«▒ńÜäĶ«ŠńĮ«ķĪĄķØó’╝īÕ£©Ķ«ŠńĮ«ķĪĄķØóõĖŁµēŠÕł░POP3/SMTP/IMAPµ£ŹÕŖĪ’╝īÕ╝ĆÕÉ»µ£ŹÕŖĪ’╝łµ¤źń£ŗµ£ŹÕŖĪÕÖ©Õ£░ÕØĆ’╝ē’╝īĶÄĘÕÅ¢µÄłµØāńĀü’╝īÕĪ½ÕåÖÕł░ķģŹńĮ«µ¢ćõ╗Čconfig.ymlõĖŁ + +```yaml +email: + smtpserver: "smtp.itcast.com" + username: "wangxu@itcast.com" + password: "FDSArewq1" + receiver: "wangxu@itcast.com" +``` + +õ┐«µö╣õ║åķģŹńĮ«µ¢ćõ╗ČÕÉÄ’╝īķ£ĆĶ”üÕ£©Conf.pyõĖŁµĘ╗ÕŖĀÕ”éõĖŗõ╗ŻńĀü,µØźĶ»╗ÕÅ¢emailķģŹńĮ«µ£ēÕģ│õ┐Īµü»’╝Ü + +```python +def get_email_info(self): + """ + ĶÄĘÕÅ¢ķé«õ╗ČķģŹńĮ«ńøĖÕģ│õ┐Īµü» + :return: + """ + return self.config["email"] +``` + +### ķé«õ╗ČÕ░üĶŻģ + +Õ£©utilsµ¢ćõ╗ČÕż╣õĖŗµ¢░Õ╗║õĖĆõĖ¬EmailUtil.pyµ¢ćõ╗Č’╝īńö©µØźÕ░üĶŻģķé«õ╗ČÕÅæķĆüńÜäµ¢╣µ│Ģ + +```python +from email.mime.multipart import MIMEMultipart # MIMEMultipartń▒╗ĶĪ©ńż║ķé«õ╗ČńÜäõĖ╗õĮō,ÕÅ»õ╗źÕīģÕÉ½ÕżÜõĖ¬ķé«õ╗ČõĮō,ÕÅ»õ╗źÕīģÕɽµ¢ćµ£¼,ķÖäõ╗ČńŁē +from email.mime.text import MIMEText # MIMETextń▒╗ĶĪ©ńż║ķé«õ╗ČńÜäµ¢ćµ£¼ÕåģÕ«╣ +import smtplib +#ÕłØÕ¦ŗÕī¢ +#smtpÕ£░ÕØĆ’╝īńö©µłĘÕÉŹ’╝īÕ»åńĀü’╝īµÄźµöČķé«õ╗ČĶĆģ’╝īķé«õ╗ȵĀćķóś’╝īķé«õ╗ČÕåģÕ«╣’╝īķé«õ╗ČķÖäõ╗Č +class SendEmail: + # __init__µ¢╣µ│ĢĶĪ©ńż║ÕłØÕ¦ŗÕī¢µ¢╣µ│Ģ’╝īÕĮōń▒╗Ķó½Õ«×õŠŗÕī¢µŚČ’╝īõ╝ÜĶć¬ÕŖ©Ķ░āńö©Ķ»źµ¢╣µ│Ģ + def __init__(self,smtp_addr,username,password,recv, + title,content=None,file=None): + self.smtp_addr = smtp_addr # ķé«õ╗ȵ£ŹÕŖĪÕÖ©Õ£░ÕØĆ + self.username = username + self.password = password + self.recv = recv + self.title = title + self.content = content + self.file = file + #ÕÅæķĆüķé«õ╗ȵ¢╣µ│Ģ + def send_mail(self): + #MIME + msg = MIMEMultipart() + #ÕłØÕ¦ŗÕī¢ķé«õ╗Čõ┐Īµü» + msg.attach(MIMEText(self.content,_charset="utf-8")) + msg["Subject"] = self.title + msg["From"] = self.username + msg["To"] = self.recv + #ķé«õ╗ČķÖäõ╗Č + #Õłżµ¢Łµś»ÕÉ”ķÖäõ╗Č + if self.file: + #MIMETextĶ»╗ÕÅ¢µ¢ćõ╗Č + att = MIMEText(open(self.file).read()) + #Ķ«ŠńĮ«ÕåģÕ«╣ń▒╗Õ×ŗ + att["Content-Type"] = 'application/octet-stream' + #Ķ«ŠńĮ«ķÖäõ╗ČÕż┤ + att["Content-Disposition"] = 'attachment;filename="%s"'%self.file + #Õ░åÕåģÕ«╣ķÖäÕŖĀÕł░ķé«õ╗ČõĖ╗õĮōõĖŁ + msg.attach(att) + #ńÖ╗ÕĮĢķé«õ╗ȵ£ŹÕŖĪÕÖ© + self.smtp = smtplib.SMTP(self.smtp_addr,port=25) + self.smtp.login(self.username,self.password) + #ÕÅæķĆüķé«õ╗Č + self.smtp.sendmail(self.username,self.recv,msg.as_string()) + +if __name__ == "__main__": + #ÕłØÕ¦ŗÕī¢ń▒╗(self,smtp_addr,username,password,recv, + # title,content=None,file=None): + from config.Conf import ConfigYaml + email_info = ConfigYaml().get_email_info() + smtp_addr = email_info["smtpserver"] + username = email_info["username"] + password = email_info["password"] + recv = email_info["receiver"] + email = SendEmail(smtp_addr,username,password,recv,"µĄŗĶ»Ģ") + email.send_mail() +``` + +## ķé«õ╗ČĶ┐ÉĶĪī + +Ķ┐ÖõĖƵŁźõĖ╗Ķ”üÕīģµŗ¼’╝Ü’╝ł1’╝ēÕ░üĶŻģÕģ¼Õģ▒µ¢╣µ│Ģ’╝ø(2) Õ║öńö©µĄŗĶ»ĢÕÅæķĆü + +Õ£©commonµ¢ćõ╗ČÕż╣õĖŗķØóńÜäBase.pyµ¢ćõ╗ČõĖŁ’╝īµĘ╗ÕŖĀÕ”éõĖŗõ╗ŻńĀü’╝Ü + +```python +def send_mail(report_html_path="",content="",title="µĄŗĶ»Ģ"): + """ + ÕÅæķĆüķé«õ╗Č + :param report_html_path: + :param content: + :param title: + :return: + """ + email_info = ConfigYaml().get_email_info() + smtp_addr = email_info["smtpserver"] + username = email_info["username"] + password = email_info["password"] + recv = email_info["receiver"] + email = SendEmail( + smtp_addr=smtp_addr, + username=username, + password=password, + recv=recv, + title=title, + content=content, + file=report_html_path) + email.send_mail() +``` \ No newline at end of file diff --git "a/_posts/2023-01-31-vscode+PicGO+Github\346\220\255\345\273\272\344\270\252\344\272\272\345\215\232\345\256\242\345\233\276\345\272\212.md" "b/_posts/2023-01-31-vscode+PicGO+Github\346\220\255\345\273\272\344\270\252\344\272\272\345\215\232\345\256\242\345\233\276\345\272\212.md" new file mode 100644 index 0000000000..529f5ed05d --- /dev/null +++ "b/_posts/2023-01-31-vscode+PicGO+Github\346\220\255\345\273\272\344\270\252\344\272\272\345\215\232\345\256\242\345\233\276\345\272\212.md" @@ -0,0 +1,70 @@ +--- +layout: post +title: "MarkdowmµÅÆõ╗ČOffice Viewerõ╗ŗń╗Źõ╗źÕÅŖvscode+PicGO+GithubµÉŁÕ╗║õĖ¬õ║║ÕŹÜÕ«óÕøŠÕ║Ŗ" +date: 2023-01-31 +description: "MarkdowmµÅÆõ╗ČOffice Viewerõ╗ŗń╗Źõ╗źÕÅŖvscode+PicGO+GithubµÉŁÕ╗║õĖ¬õ║║ÕŹÜÕ«óÕøŠÕ║Ŗ" +tag: õĖ¬õ║║ńĮæń½Ö +--- +MarkdowmµÅÆõ╗ČOffice Viewerõ╗ŗń╗Źõ╗źÕÅŖvscode+PicGO+GithubµÉŁÕ╗║õĖ¬õ║║ÕŹÜÕ«óÕøŠÕ║Ŗ + +## MarkdowmµÅÆõ╗Č + +* Markdown All in One +* Office Viewer + + Ķ┐ÖõĖ¬µÅÆõ╗Čń£¤ńÜäÕż¬µŻÆõ║å’╝īÕ»╣õ║Ämdµ¢ćõ╗ČÕ░▒ÕāÅÕ╝Ćõ║åµīéõĖƵĀĘńÜäÕźĮńö©ŃĆéÕ«ēĶŻģÕ«īõ╣ŗÕÉÄ’╝īõ╝ÜĶ«ŠńĮ«ÕźĮVditor’╝īÕ«āµś»õĖƵ¼ŠµĄÅĶ¦łÕÖ©ń½»ńÜä Markdown ń╝¢ĶŠæÕÖ©’╝īµö»µīüµēĆĶ¦üÕŹ│µēĆÕŠŚŃĆüÕŹ│µŚČµĖ▓µ¤ō’╝łń▒╗õ╝╝ Typora’╝ēÕÆīÕłåÕ▒ÅķóäĶ¦łµ©ĪÕ╝ÅŃĆé Õ«āõĮ┐ńö© TypeScript Õ«×ńÄ░’╝īµö»µīüÕĤńö¤ JavaScript õ╗źÕÅŖ VueŃĆüReactŃĆüAngular ÕÆī Svelte ńŁēµĪåµ×ČŃĆé + ń©ŹÕŠ«õĮōķ¬īõ║åõĖĆõĖŗ’╝īµ£ēÕ”éõĖŗõ╝śńé╣’╝Ü + +ÕøŠńēćŃĆüĶĪ©µĀ╝ŃĆüõ╗ŻńĀüÕØŚ’╝īÕłŚĶĪ©’╝łµ£ēÕ║ÅŃĆüµŚĀÕ║ÅŃĆüõ╗╗ÕŖĪ’╝ēŃĆüÕ╝Ģńö©ŃĆüÕłåķÜöŃĆüµ¢£õĮōńŁēÕé╗ńō£Õ╝ŵōŹõĮ£’╝øµ¢╣õŠ┐Õ┐½ķƤÕåÖµĀćķóśõ╗źÕÅŖÕż¦ń║▓Ķ¦åÕøŠ’╝øÕ»╝Õć║PDFµ×üÕģȵ¢╣õŠ┐’╝øµ£ĆõĖŖµ¢╣ķóäĶ¦łÕ░ŵīēķÆ«ńé╣Õć╗õ╣ŗÕÉÄĶ┐øÕģźķóäĶ¦łńĢīķØó’╝īÕÅ»õ╗źķĆēµŗ®µĪīķØóµł¢ĶĆģµēŗµ£║ń½»µĄÅĶ¦ł’╝īÕÅ»õ╗źµŖŖÕåÖÕźĮńÜäÕåģÕ«╣ńø┤µÄźÕÅæÕĖāÕł░ÕŠ«õ┐ĪÕģ¼õ╝ŚÕÅʵł¢ĶĆģń¤źõ╣Ä’╝øCSDNÕŹÜÕ«óńÜäÕåģÕ«╣Õ”éµ×£µś»ńö©markdownÕåÖńÜä’╝īńø┤µÄźÕżŹÕłČĶ┐øµØź’╝īµĀ╝Õ╝ÅķāĮõĖŹńö©Ķ░āµĢ┤ŃĆé + + + +## PicGOõ╗ŗń╗Ź + +vscodeõĖŖµ£ēõĖĆõĖ¬picgoµÅÆõ╗Č’╝īÕÅ»õ╗źĶ«®µłæõ╗¼ńö©Õ┐½µŹĘķö«ÕŹ│ÕÅ»õĖŖõ╝ĀÕøŠńēćÕł░ķ╗śĶ«żńÜäÕģŹĶ┤╣µ£ŹÕŖĪÕÖ©’╝īÕģĘõĮōńÜäõĮ┐ńö©µ¢╣µ│Ģµś»’╝īÕ«ēĶŻģÕ«īµłÉÕÉÄ’╝Ü + +1. Ctrl+Alt+U õ╗ÄÕē¬ÕłćµØ┐ń▓śĶ┤┤ÕøŠńēć’╝īõĖŖõ╝ĀÕł░µ£ŹÕŖĪÕÖ©’╝ø +2. Ctrl+Alt+E µēōÕ╝ĆĶĄäµ║Éń«ĪńÉåÕÖ©’╝īķĆēµŗ®ÕøŠńēćŃĆé + +picgoķ╗śĶ«żõĖŖõ╝ĀńÜäµ£ŹÕŖĪÕÖ©µś» `SM.MS`µ£ŹÕŖĪÕÖ©’╝īńö▒õ║ÄõĮĀµćéÕŠŚÕĤÕøĀ’╝īÕøĮÕåģńÜäĶ«┐ķŚ«ķƤÕ║”Ķ«®õ║║µŖōńŗé’╝īõĮåµś»picgoµö»µīügithubõ╗źÕÅŖķś┐ķćīõ║æõĮ£õĖ║ÕøŠÕ║ŖŃĆé + +ÕģČõĖŁ’╝īgithubÕøŠÕ║Ŗµ£ĆõĖ║ń©│Õ«Ü’╝īõĖöõĖĆõĖ¬õ╗ōÕ║ōõĖŖķÖɵś»100G’╝īÕŬÕüÜÕøŠÕ║Ŗń╗░ń╗░µ£ēõĮÖŃĆéµ£Ćń│¤ń│ĢńÜäõĖĆńé╣µś»ķƤÕ║”’╝īõĮåµś»õĮ┐ńö©cdnÕŖĀķƤõ╣ŗÕÉÄķƤÕ║”Ķ┐śµś»ÕÅ»õ╗źńÜäŃĆé + +## GithubÕøŠÕ║ŖĶ«ŠńĮ« + +1. µēōÕ╝Ćgithub’╝īÕłøÕ╗║µ¢░ńÜäpublicõ╗ōÕ║ō’╝īõ╗ōÕ║ōÕÉŹń¦░ÕÅ»õ╗źĶ«ŠńĮ«õĖ║[PicgoBed](https://github.com/ChanJeunlam/PicgoBed)ŃĆé +2. Ķ┐øÕģźõĖ¬õ║║Ķ«ŠńĮ«ķĪĄķØó’╝īķĆēµŗ®Õ╝ĆÕÅæĶĆģĶ«ŠńĮ« + +  +3. ķĆēµŗ®Personal access tokens’╝īķĆēµŗ®ńö¤µłÉµ¢░token’╝īµŁżtokenµś»ÕøŠÕ║ŖõĖŖõ╝ĀµŚČķ¬īĶ»üĶ║½õ╗Įńö©ńÜä’╝øµĘ╗ÕŖĀµÅÅĶ┐░’╝īÕ░årepoķĆēõĖŖ’╝īExpirationķĆēµŗ®no expiration + +  +4. Õ░åńö¤µłÉńÜäÕŁŚń¼”õĖ▓õ┐ØÕŁś’╝ī**Õģ│ķŚŁķĪĄķØóÕÉÄÕ░åÕåŹõ╣¤µŚĀµ│Ģń£ŗÕł░Ķ┐ÖõĖ¬ÕŁŚń¼”õĖ▓õ║å** + +## PicGOĶ«ŠńĮ« + +GitHubĶ«ŠńĮ«Õ«īõ╣ŗÕÉÄ’╝īµłæõ╗¼ķ£ĆĶ”üõ┐«µö╣picgoµÅÆõ╗ČńÜäĶ«ŠńĮ«’╝īµŖŖµ£ŹÕŖĪÕÖ©ń╝¢ń©ŗµłæõ╗¼ńÜäÕøŠÕ║Ŗ’╝īÕģĘõĮōĶ«ŠńĮ«Õ”éõĖŗ’╝Ü + +1. vscodeÕÅ│õĖŗĶ¦ÆķĆēµŗ®Ķ«ŠńĮ«,µÉ£ń┤óĶ«ŠńĮ«ķćīķØóĶŠōÕģźPicGO,µēōÕ╝Ƶē®Õ▒ĢķćīķØóńÜäPicGO +2. Ķ«ŠńĮ«Õ”éõĖŗ,github tokenÕåÖµłæõ╗¼ÕłÜµēŹÕżŹÕłČõĖŗµØźńÜä + +  + +* `current`Ķ«ŠńĮ«õĖ║GitHub +* `Branch`µś»µłæõ╗¼õ╗ōÕ║ōńÜäÕłåµö»’╝īķ╗śĶ«żõĖ║ `master` µł¢ĶĆģ `main` +* `custom url` õĮ┐µłæõ╗¼ÕøŠńēćõĖŖõ╝ĀńÜäĶ┐׵ğ’╝īµ£ēõĖżń¦Źµ¢╣Õ╝ÅÕÅ»õ╗źõĮ┐ńö© + * ÕĤńö¤µ¢╣Õ╝Å + * õĮ┐ńö©GitHubÕĤńö¤Ķ┐׵ğ’╝īµĀ╝Õ╝ÅõĖ║ `https://raw.githubusercontent.com/ńö©µłĘÕÉŹ/õ╗ōÕ║ōÕÉŹ/Õłåµö»ÕÉŹ` + * µłæńÜäõŠŗÕŁÉ `https://raw.githubusercontent.com/ChanJeunlam/PicgoBed` + * ÕĤńö¤µ¢╣Õ╝ŵ£ēõĖĆõĖ¬Õ╝Ŗń½»Õ░▒µś»’╝īÕøĮÕåģķƤÕ║”µ»öĶŠāµģó + * cdnÕŖĀķƤµ¢╣Õ╝Å + * µĀ╝Õ╝ÅõĖ║ `https://cdn.jsdelivr.net/gh/ńö©µłĘÕÉŹ/õ╗ōÕ║ōÕÉŹ@Õłåµö»ÕÉŹ` + * µłæńÜäõŠŗÕŁÉ `https://cdn.jsdelivr.net/gh/ChanJeunlam/PicgoBed` + * cdnÕŖĀķƤńÜäõ╝śńé╣µś»ÕøĮÕåģĶ«┐ķŚ«ķƤÕ║”µ»öĶŠāÕ┐½ +* `path`µś»µłæõ╗¼ńÜäÕøŠńēćÕŁśÕé©Õ£©õ╗ōÕ║ōõĖŁńÜäĶĘ»ÕŠä’╝īµ»öÕ”éµłæńÜ䵜» `blogs/pictures/` +* `Repo`µś»µłæõ╗¼ńÜäõ╗ōÕ║ōÕ£░ÕØĆ’╝ī`Username/Repo`,µ»öÕ”éĶ»┤µłæńÜ䵜» ``ChanJeunlam/PicgoBed``. + +ÕģČõ╗¢ÕÅ»ĶāĮÕć║ńÄ░ńÜäķŚ«ķóśńÜäÕżäńÉå: + +* `Branch`ķćīķØóńÜämainÕåÖķöÖµłÉmaster +* `ChanJeunlam/PicgoBed` ÕŖĀõ║åń®║µĀ╝’╝īÕåÖķöÖµłÉ `ChanJeunlam / PicgoBed`’╝īÕ»╝Ķć┤õĖŖõ╝ĀÕł░µ£ŹÕŖĪÕÖ©Õż▒Ķ┤źŃĆé diff --git "a/_posts/2023-01-31-\347\276\216\345\244\232\345\225\206\345\237\216\346\216\245\345\217\243\350\207\252\345\212\250\345\214\226\346\265\213\350\257\225\351\241\271\347\233\256\344\273\243\347\240\201\346\241\206\346\236\266.md" "b/_posts/2023-01-31-\347\276\216\345\244\232\345\225\206\345\237\216\346\216\245\345\217\243\350\207\252\345\212\250\345\214\226\346\265\213\350\257\225\351\241\271\347\233\256\344\273\243\347\240\201\346\241\206\346\236\266.md" new file mode 100644 index 0000000000..d26f88d576 --- /dev/null +++ "b/_posts/2023-01-31-\347\276\216\345\244\232\345\225\206\345\237\216\346\216\245\345\217\243\350\207\252\345\212\250\345\214\226\346\265\213\350\257\225\351\241\271\347\233\256\344\273\243\347\240\201\346\241\206\346\236\266.md" @@ -0,0 +1,361 @@ +--- +layout: post +title: "ńŠÄÕżÜÕĢåÕ¤ÄµÄźÕÅŻĶć¬ÕŖ©Õī¢µĄŗĶ»ĢķĪ╣ńø«õ╗ŻńĀüµĪåµ×Č" +date: 2023-01-31 +description: "ńŠÄÕżÜÕĢåÕ¤ÄµÄźÕÅŻĶć¬ÕŖ©Õī¢µĄŗĶ»ĢķĪ╣ńø«õ╗ŻńĀüµĪåµ×Č" +tag: Ķć¬ÕŖ©Õī¢µĄŗĶ»Ģ +--- + + + +## utils + +### AssertUtil.py + +- AssertUtilń▒╗’╝łµ¢ŁĶ©ĆÕ░üĶŻģ’╝ē + + - assert_codeµ¢╣µ│Ģ + +ķ¬īĶ»üĶ┐öÕø×ńŖȵĆüńĀü + +assert int(code) == int(expected_code) + + - assert_bodyµ¢╣µ│Ģ + +ķ¬īĶ»üĶ┐öÕø×ń╗ōµ×£ÕåģÕ«╣ńøĖńŁē + +assert body == expected_body + + - assert_in_bodyµ¢╣µ│Ģ + +ķ¬īĶ»üĶ┐öÕø×ń╗ōµ×£µś»ÕÉ”ÕīģÕɽµ£¤µ£øńÜäń╗ōµ×£ + +assert expected_body in body + +### EmailUtil.py + +- SendEmailń▒╗ + + - __init__µ¢╣µ│Ģ’╝ÜÕłØÕ¦ŗÕī¢’╝īÕĮōń▒╗Ķó½Õ«×õŠŗÕī¢õ╣ŗÕÉÄ’╝īõ╝ÜĶÄĘÕŠŚsmtpÕ£░ÕØĆ’╝īńö©µłĘÕÉŹ’╝īÕ»åńĀü’╝īµÄźµöČķé«õ╗ČĶĆģ’╝īķé«õ╗ȵĀćķóś’╝īķé«õ╗ČÕåģÕ«╣’╝īķé«õ╗ČķÖäõ╗ČńŁēõ┐Īµü» + - send_mailµ¢╣µ│Ģ + + - ÕłØÕ¦ŗÕī¢ķé«õ╗Čõ┐Īµü» + - Õłżµ¢Łµś»ÕÉ”µ£ēķÖäõ╗Č + - MIMETextĶ»╗ÕÅ¢µ¢ćõ╗ČŃĆüĶ«ŠńĮ«ÕåģÕ«╣ń▒╗Õ×ŗŃĆüĶ«ŠńĮ«ķÖäõ╗ČÕż┤ + - Õ░åÕåģÕ«╣ķÖäÕŖĀÕł░ķé«õ╗ČõĖ╗õĮōõĖŁ + - ńÖ╗ÕĮĢķé«õ╗ȵ£ŹÕŖĪÕÖ© + - ÕÅæķĆüķé«õ╗Č + +### ExcelUtil.py + +- ExcelReaderń▒╗ + + - dataµ¢╣µ│Ģ:Ķ»╗ÕÅ¢sheetµ¢╣Õ╝Å’╝īÕÉŹń¦░’╝īń┤óÕ╝Ģ + +### LogUtil.py + +- Loggerń▒╗ + + - ĶŠōÕć║µÄ¦ÕłČÕÅ░ + - ĶŠōÕć║µ¢ćõ╗Č +- my_log’╝ÜÕ»╣Õż¢µ¢╣µ│Ģ’╝īÕłØÕ¦ŗlogÕĘźÕģĘń▒╗’╝īµÅÉõŠøÕģČÕ«āń▒╗õĮ┐ńö© + +### MysqlUtil.py + +Õż¦ÕżÜµĢ░µāģÕåĄõĖŗ’╝īµłæõ╗¼µÄźÕÅŻĶć¬ÕŖ©Õī¢µĄŗĶ»Ģķ£ĆĶ”üÕ»╣µĢ░µŹ«Õ║ōĶ┐øĶĪīķ¬īĶ»ü’╝īµ»öÕ”éĶ»┤’╝īµłæõ╗¼Õ£©µ│©ÕåīµÄźÕÅŻõĖŁ’╝īķ£ĆĶ”üķ¬īĶ»üµĢ░µŹ«Õ║ōõĖŁµś»ÕÉ”µ£ēµ¢░Õó×ńÜäµĢ░µŹ«’╝īĶ┐ÖµŚČÕĆÖµłæõ╗¼Õ░▒ķ£ĆĶ”üÕ»╣µĢ░µŹ«Õ║ōĶ┐øĶĪīµ¤źĶ»ó’╝īńäČÕÉÄÕ»╣µ¤źĶ»óń╗ōµ×£Ķ┐øĶĪīµ¢ŁĶ©ĆŃĆéµ»öÕ”éĶ»┤’╝īµłæõ╗¼ķ£ĆĶ”üÕ»╣Ķ«óÕŹĢµÄźÕÅŻĶ┐øĶĪīµĄŗĶ»Ģ’╝īķ£ĆĶ”üķ¬īĶ»üµĢ░µŹ«Õ║ōõĖŁńÜäĶ«óÕŹĢµĢ░µŹ«µś»ÕÉ”µŁŻńĪ«’╝īĶ┐ÖµŚČÕĆÖµłæõ╗¼Õ░▒ķ£ĆĶ”üÕ»╣µĢ░µŹ«Õ║ōĶ┐øĶĪīµ¤źĶ»ó’╝īńäČÕÉÄÕ»╣µ¤źĶ»óń╗ōµ×£Ķ┐øĶĪīµ¢ŁĶ©ĆŃĆé + +- MysqlÕ░üĶŻģń▒╗ + + - __init__µ¢╣µ│Ģ’╝ÜķōŠµÄźµĢ░µŹ«Õ║ō’╝īÕģēµĀćÕ»╣Ķ▒Ī + - fetchoneµ¢╣µ│Ģ’╝ÜÕŹĢõĖ¬µ¤źĶ»ó + - fetchallµ¢╣µ│Ģ’╝ÜÕżÜõĖ¬µ¤źĶ»ó + - execµ¢╣µ│Ģ’╝ܵē¦ĶĪīµĢ░µŹ«Õ║ō’╝īµ»öÕ”éĶ»┤Õó×ÕłĀµ¤źµö╣ + +### RequestsUtil.py + +- Requestń▒╗ + + - getµ¢╣µ│Ģ + - postµ¢╣µ│Ģ + +### YamlUtil.py + +- YamlReaderń▒╗ + + - dataµ¢╣µ│Ģ’╝ÜÕŹĢõĖ¬µ¢ćõ╗ČĶ»╗ÕÅ¢ + - data_allµ¢╣µ│Ģ’╝ÜÕżÜõĖ¬µ¢ćµĪŻĶ»╗ÕÅ¢ + +## config + +### Conf.py + +- ĶÄĘÕÅ¢µ¢ćõ╗Č/ńø«ÕĮĢĶĘ»ÕŠäµ¢╣µ│Ģ + + - reportĶĘ»ÕŠä + - µĄŗĶ»ĢµĢ░µŹ«dataĶĘ»ÕŠä + - db_conf.ymlĶĘ»ÕŠä + - configńø«ÕĮĢńÜäĶĘ»ÕŠä + + - conf.ymlµ¢ćõ╗ČńÜäĶĘ»ÕŠä + - Logµ¢ćõ╗ČĶĘ»ÕŠä +- ConfigYamlń▒╗ + + - get_excel_file’╝ÜĶÄĘÕÅ¢µĄŗĶ»Ģńö©õŠŗexcelÕÉŹń¦░µ¢╣µ│Ģ + - get_excel_sheet’╝ÜĶÄĘÕÅ¢µĄŗĶ»Ģńö©õŠŗsheetÕÉŹń¦░µ¢╣µ│Ģ + - get_conf_url’╝ÜĶÄĘÕÅ¢µÄźÕÅŻÕ£░ÕØƵ¢╣µ│Ģ + - get_conf_log’╝ÜĶÄĘÕÅ¢µŚźÕ┐Śń║¦Õł½µ¢╣µ│Ģ + - get_conf_log_extension’╝ÜĶÄĘÕÅ¢µ¢ćõ╗ȵē®Õ▒ĢÕÉŹµ¢╣µ│Ģ + - get_db_conf_info’╝ܵĀ╣µŹ«db_aliasĶÄĘÕÅ¢Ķ»źÕÉŹń¦░õĖŗńÜäµĢ░µŹ«Õ║ōõ┐Īµü»µ¢╣µ│Ģ + - get_email_info’╝ÜĶÄĘÕÅ¢ķé«õ╗ČķģŹńĮ«ńøĖÕģ│õ┐Īµü» + +### conf.yml + +- BASE + + - log_level + + - debug’╝Üķ╗śĶ«ż + - info + - warning + - error + - log_extension + - test + + - url + - cae_file + - case_sheet +- email + + - smtpserver + - username + - password + - receiver + +### db_conf.yml + +- dh_1 + + - dh_host + - dh_user + - dh_password + - dh_name + - dh_charset + - dh_port +- dh_2 + + - ... +- dh_3 + + - ... + +## common + +### Base.py + +- init_dbµ¢╣µ│Ģ’╝ÜÕłØÕ¦ŗµĢ░µŹ«Õī¢õ┐Īµü»’╝īÕłØÕ¦ŗÕī¢mysqlÕ»╣Ķ▒Ī +- assert_dbµ¢╣µ│Ģ’╝ܵĢ░µŹ«Õ║ōńÜäń╗ōµ×£õĖĵğÕÅŻĶ┐öÕø×ńÜäń╗ōµ×£ķ¬īĶ»ü +- json_parseµ¢╣µ│Ģ’╝ܵĀ╝Õ╝ÅÕī¢ÕŁŚń¼”’╝īĶĮ¼µŹójson +- res_findµ¢╣µ│Ģ’╝ܵ¤źĶ»óń¼”ÕÉł'\${(.*)}\$'ńÜäµēƵ£ēÕŁŚń¼”õĖ▓ +- res_subµ¢╣µ│Ģ’╝ܵø┐µŹóÕŁŚń¼”õĖ▓ +- params_findµ¢╣µ│Ģ’╝Üķ¬īĶ»üĶ»Ęµ▒éõĖŁµś»ÕÉ”µ£ē${}$ķ£ĆĶ”üń╗ōµ×£Õģ│Ķüö +- allure_reportµ¢╣µ│Ģ’╝Üńö¤µłÉallure µŖźÕæŖ + + - #µē¦ĶĪīÕæĮõ╗ż allure generate + allure_cmd ="allure generate %s -o %s --clean"%(report_path,report_html) + - #subprocess.call + subprocess.call(allure_cmd,shell=True) +- send_mailµ¢╣µ│Ģ + + - õĮ┐ńö©ConfigYaml().get_email_info()ĶÄĘÕŠŚemailõ┐Īµü» + - õĮ┐ńö©SendEmailń▒╗ńÜäsend_mailµ¢╣µ│ĢÕÅæķĆüķé«õ╗Č + +### ExcelConfig.py + +- DataConfigń▒╗ + + - Õīģµŗ¼ńö©õŠŗID’╝īµ©ĪÕØŚ’╝īµÄźÕÅŻÕÉŹń¦░’╝īĶ»Ęµ▒éURL’╝īÕēŹńĮ«µØĪõ╗Č’╝īĶ»Ęµ▒éń▒╗Õ×ŗ’╝īĶ»Ęµ▒éÕÅéµĢ░ń▒╗Õ×ŗ’╝īĶ»Ęµ▒éÕÅéµĢ░ ķóäµ£¤ń╗ōµ×£’╝īÕ«×ķÖģń╗ōµ×£’╝īÕżćµ│©’╝īµś»ÕÉ”Ķ┐ÉĶĪī’╝īheaders’╝īcookies’╝īstatus_code’╝īµĢ░µŹ«Õ║ōķ¬īĶ»üńŁēńŁē + +### ExcelData.py + +- Datań▒╗ + + - get_run_dataµ¢╣µ│Ģ’╝Ü + ĶÄĘÕÅ¢Õģ©ķā©µĄŗĶ»Ģńö©õŠŗ + - get_run_dataµ¢╣µ│Ģ’╝Ü + µĀ╣µŹ«µś»ÕÉ”Ķ┐ÉĶĪīÕłŚ==y’╝īĶÄĘÕÅ¢µē¦ĶĪīµĄŗĶ»Ģńö©õŠŗ + - get_case_preµ¢╣µ│Ģ’╝Ü + µĀ╣µŹ«ÕēŹńĮ«µØĪõ╗Č’╝Üõ╗ÄÕģ©ķā©µĄŗĶ»Ģńö©õŠŗÕÅ¢Õł░µĄŗĶ»Ģńö©õŠŗ + +## data + +### testdata.xlsx + +- ńÖ╗ÕĮĢ + + - Ķ»Ęµ▒éµ¢╣Õ╝Å’╝ÜPOST/authorizations + - Ķ»Ęµ▒éÕÅéµĢ░’╝Ü1. username 2. password + Ķ┐öÕø×µĢ░µŹ«’╝Ü1. username 2. user_id 3. token(Ķ║½õ╗ĮĶ«żĶ»üÕ棵Ź«’╝ē + + - ń®║ńÖĮ + + - µŚĀµĢłµĢ░µŹ«ŃĆéµ£¤ÕŠģõĖ║ÕŁŚÕģĖń▒╗Õ×ŗ + - {"username":"","password":"12345678"} + + - username': ['Ķ»źÕŁŚµ«ĄõĖŹĶāĮõĖ║ń®║ŃĆé'] + - {"username":"","password":""} + + - password': ['Ķ»źÕŁŚµ«ĄõĖŹĶāĮõĖ║ń®║ŃĆé'] + - {"username":"python","password":"12345678"} + + - user_id': 1, 'username': 'python' + - {"username":"python","password":"test123"} + + - µŚĀµ│ĢõĮ┐ńö©µÅÉõŠøńÜäĶ«żĶ»üõ┐Īµü»ńÖ╗ÕĮĢ +- ńö©µłĘõĖŁÕ┐āõĖ¬õ║║õ┐Īµü» + + - Ķ»Ęµ▒éµ¢╣Õ╝Å’╝Ü GET /user/ + - Ķ┐öÕø×µĢ░µŹ«’╝Üid username mobile email email_active + + - Ķ║½õ╗ĮĶ«żĶ»üõ┐Īµü»µ£¬µÅÉõŠø + - id': 1, 'username': 'python', 'mobile': '17701397029', 'email': '952673638@qq.com' +- ĶÄĘÕÅ¢ÕĢåÕōüÕłŚĶĪ©µĢ░µŹ« + + - Ķ»Ęµ▒éµ¢╣Õ╝Å’╝Ü GET `/categories/(?P
https://link.jscdn.cn/sharepoint/aHR0cHM6Ly9oa3VzdGNvbm5lY3QtbXkuc2hhcmVwb2ludC5jb20vOnU6L2cvcGVyc29uYWwvamNoZW5mbF9jb25uZWN0X3VzdF9oay9FVE1tNEYwRU1CSkt0UGJKNDlmbkFVWUJWdUZXYUJ0RzVZTlVoRlFGV0FtY2NBP2U9RlZ4bkxB.mp3
+ +## Ķ”üµ▒é + +* jekyll +* õĖāńēø +* Onedrive + +## Õ╝ĆÕ¦ŗõĮ┐ńö© + +step1 + +ķ”¢ÕģłõĖŗĶĮĮĶ┐ÖõĖ¬µ¢ćõ╗Č[open-embed.html](https://raw.githubusercontent.com/jhvanderschee/jekyllcodex/gh-pages/_includes/open-embed.html),ÕÅ│ķö«,ÕÅ”ÕŁśõĖ║ `Html`;õĖŗķØ󵜻µ║ÉńĀü,õ╣¤ÕÅ»õ╗źÕżŹÕłČõ┐ØÕŁśõĖŗķØóńÜäµ║ÉńĀü; + +```javascript + + + +``` + +step2 + +Õ░åõĖŖõĖƵŁźÕŁśÕé©ÕźĮńÜäµ¢ćõ╗Č,õ┐ØÕŁśÕł░**`_includes`**ńø«ÕĮĢõĖŗ,Õ░▒ÕāÅõĖŗķØóĶ┐ÖõĖ¬µĀĘÕŁÉ + + + +step3 + +Õ£©**`_layouts`**ńø«ÕĮĢõĖŗ,**`default.html`**Ķ┐ÖõĖ¬µ¢ćõ╗Č,µēōÕ╝Ć,Õ£©µ£ĆõĖŗķØó,µēŠÕł░Õ»╣Õ║öńÜäµĀćńŁŠ **``** ,ÕŖĀÕģźÕ”éõĖŗõ╗ŻńĀü,µ│©µäÅ:µĀćńŁŠõĖŹĶ”üķćŹÕżŹõ║å + + + +### õĮ┐ńö©Ķ»Łµ│Ģ + +ÕƤÕŖ®õĖāńēøõ║æõ╣ŗń▒╗ńÜäÕøŠÕ║Ŗµł¢õ║æń½»ÕŁśÕé©’╝īÕ░åķ£ĆĶ”üńÜäķ¤│õ╣ɵ¢ćõ╗ČõĖŖõ╝ĀĶć│ÕøŠÕ║Ŗ’╝īÕ╣ČĶÄĘÕŠŚÕż¢ķōŠŃĆé + +ńäČÕÉÄ’╝īÕ£©MarkdownõĖŁńø┤µÄźõĮ┐ńö©’╝Ü + +```cobol +ķ¤│õ╣ÉÕż¢ķōŠurl
+``` + +µ│©µäÅ’╝Üķ¤│õ╣ÉķōŠµÄźurlÕó×ÕŖĀõ║åµö»µīüMP3ŃĆüwmaŃĆüm4aµĀ╝Õ╝Å + +### Onedriveķ¤│õ╣ɵ¢ćõ╗ČĶÄĘÕÅ¢Õż¢ķōŠ + +ÕÅéĶĆāÕ”éõĖŗķōŠµÄź’╝Ü + +#### ńö¤µłÉÕż¢ķōŠ + +Õģłµā│ÕŖ×µ│ĢµŖŖõĮĀĶ”üńö¤µłÉÕż¢ķōŠńÜäķ¤│õ╣ɵł¢ĶĆģÕøŠńēćõĖŖõ╝ĀÕł░OneDriveõĖŁŃĆé +ńĮæķĪĄńēłńÜäÕ║öĶ»źµś»Ķó½ÕóÖõ║å’╝īõĖŹń¦æÕŁ”õĖŖńĮæńö©õĖŹõ║åŃĆé +ńÄ░Õ£©ńÜäńöĄĶäæõĖŖõĖĆĶł¼ķāĮµ£ēOneDriveńÜä’╝īĶć¬ÕĘ▒µÉ£õĖĆõĖŗŃĆé + + +õĖŖÕøŠõĖŁµłæÕĘ▓ń╗ŵŖŖõĖżķ”¢µŁīµöŠÕł░OneDriveõĖŁõ║åŃĆé + +ńäČÕÉĵŖŖµ¢ćõ╗ČÕģ▒õ║½’╝ÜÕ£©µ¢ćõ╗ČõĖŖÕÅ│Õć╗’╝īńé╣ `Õģ▒õ║½` + + + +Õģ▒õ║½õ╣ŗÕÉÄõĮĀÕ░▒ĶāĮń£ŗÕł░Ķ┐ÖõĖ¬’╝īńé╣ÕĘ”õĖŗĶ¦ÆńÜäµīēķÆ«ÕżŹÕłČķōŠµÄźŃĆé + + + +µłæÕżŹÕłČÕł░ńÜäķōŠµÄźÕ”éõĖŗ’╝Ü + +> https://1drv.ms/u/s!AjennNdWMahGijT1WWHNP-Wjj_CF?e=LNajCn + +ńÄ░Õ£©Ķ┐ÖµĀĘÕŁÉĶé»Õ«ÜõĖŹĶāĮńø┤µÄźńö©õ║å’╝īķ£ĆĶ”üÕƤÕŖ®ĶĮ¼µŹóÕĘźÕģĘŃĆé + +ÕÅ»õ╗źńø┤µÄźńö©Ķ┐ÖõĖ¬ńö¤µłÉķōŠµÄź’╝Ü + +[https://onedrive.gimhoy.com/](https://onedrive.gimhoy.com/) + +õĮĀĶŠōÕģźõ╣ŗÕÉÄÕ░▒õ╝ÜÕÅ»õ╗źńö¤µłÉõ║åŃĆé + + + + **Ķ┐śµ£ēõĖĆõĖ¬Õ░ÅÕĘźÕģĘÕÅ»õ╗źµē╣ķćÅńö¤µłÉ** ’╝Ü + +[https://github.com/Mapaler/GetOneDriveDirectLink](https://github.com/Mapaler/GetOneDriveDirectLink) + +[https://mapaler.github.io/GetOneDriveDirectLink/](https://mapaler.github.io/GetOneDriveDirectLink/) diff --git "a/_posts/2023-03-22-\351\253\230\345\271\266\345\217\221Locust\351\253\230\345\271\266\345\217\221\346\216\245\345\217\243\346\265\213\350\257\225\346\241\206\346\236\266\344\273\213\347\273\215.md" "b/_posts/2023-03-22-\351\253\230\345\271\266\345\217\221Locust\351\253\230\345\271\266\345\217\221\346\216\245\345\217\243\346\265\213\350\257\225\346\241\206\346\236\266\344\273\213\347\273\215.md" new file mode 100644 index 0000000000..47bc6298b5 --- /dev/null +++ "b/_posts/2023-03-22-\351\253\230\345\271\266\345\217\221Locust\351\253\230\345\271\266\345\217\221\346\216\245\345\217\243\346\265\213\350\257\225\346\241\206\346\236\266\344\273\213\347\273\215.md" @@ -0,0 +1,110 @@ +--- +layout: post + +title: "ķ½śÕ╣ČÕÅæLocustķ½śÕ╣ČÕÅæµÄźÕÅŻµĄŗĶ»ĢµĪåµ×Čõ╗ŗń╗Ź" + +date: 2023-03-18 + +description: "õ╗ŗń╗Źõ║åķ½śÕ╣ČÕÅæLocustķ½śÕ╣ČÕÅæµÄźÕÅŻµĄŗĶ»ĢµĪåµ×Č’╝īĶ┐øĶĪīµĆ¦ĶāĮµĄŗĶ»Ģ’╝īµ¤źń£ŗ" + +tag: Ķć¬ÕŖ©Õī¢µĄŗĶ»Ģ +--- +## Ķ░󵜟ĶŖ▒ńÜ䵣ī + +https://link.jscdn.cn/sharepoint/aHR0cHM6Ly9oa3VzdGNvbm5lY3QtbXkuc2hhcmVwb2ludC5jb20vOnU6L2cvcGVyc29uYWwvamNoZW5mbF9jb25uZWN0X3VzdF9oay9FVThfNm53Y1ZSQkVtc1FCdzY1WDJnNEJmcnhjaXBrSDdKZHZvWWg2R1Z0ekR3P2U9QUh6cWhP.mp3
+ +## õ╗Ćõ╣łµś»[locust](https://so.csdn.net/so/search?q=locust&spm=1001.2101.3001.7020)’╝¤ + +locustµś»õĖĆõĖ¬ń«ĆÕŹĢµśōńö©ńÜäÕłåÕĖāÕ╝Å[Ķ┤¤ĶĮĮµĄŗĶ»Ģ](https://so.csdn.net/so/search?q=%E8%B4%9F%E8%BD%BD%E6%B5%8B%E8%AF%95&spm=1001.2101.3001.7020)ÕĘźÕģĘ’╝īõĖ╗Ķ”üńö©µØźÕ»╣ńĮæń½ÖĶ┐øĶĪīĶ┤¤ĶĮĮÕÄŗÕŖøµĄŗĶ»ĢŃĆélocustõĮ┐ńö©pythonĶ»ŁĶ©ĆÕ╝ĆÕÅæ’╝īµĄŗĶ»ĢĶĄäµ║ɵȳĶĆŚĶ┐£Ķ┐£Õ░Åõ║ÄjavaĶ»ŁĶ©ĆÕ╝ĆÕÅæńÜäjmeterŃĆéõĖöÕģȵö»µīüÕłåÕĖāÕ╝Åķā©ńĮ▓µĄŗĶ»Ģ’╝īĶāĮÕż¤ĶĮ╗µØŠµ©Īµŗ¤ńÖŠõĖćń║¦ńö©µłĘÕ╣ČÕÅæµĄŗĶ»ĢŃĆé + + +## õ╗Ćõ╣łµś»µĆ¦ĶāĮµĄŗĶ»Ģ + + +[µĆ¦ĶāĮµĄŗĶ»Ģ](https://so.csdn.net/so/search?q=%E6%80%A7%E8%83%BD%E6%B5%8B%E8%AF%95&spm=1001.2101.3001.7020)ńø«ńÜäõĖ╗Ķ”üµś»Ķ¦ŻÕå│õĖēõĖ¬ķŚ«ķóś’╝Ü + +* ń│╗ń╗¤ÕÅŖµ£ŹÕŖĪĶāĮµē┐ÕÅŚńÜäµ£ĆÕż¦Ķ┤¤ĶĮĮµś»ÕżÜÕ░æ ’╝¤ +* µ£ēµ▓Īµ£ēµĆ¦ĶāĮÕ╣│ńōČķół ’╝¤ +* Õ”éµ×£µ£ēµĆ¦ĶāĮńōČķół’╝īńōČķółÕ£©Õō¬ķćī’╝¤ + +Ķ┐ÖõĖēõĖ¬ķŚ«ķóśķ£ĆĶ”üõ╗ĵĄŗĶ»ĢńÜäń╗ōµ×£õĖŁÕłåµ×ÉÕŠŚÕć║’╝īÕģČõĖŁµ£ĆķćŹĶ”üńÜäµĆ¦ĶāĮµīćµĀćµ£ēõĖēńé╣’╝Ü + +’╝ł1’╝ēÕōŹÕ║öµŚČķŚ┤ + +’╝ł2’╝ēÕÉ×ÕÉÉķćÅ + +’╝ł3’╝ēµłÉÕŖ¤ńÄć + + +õ╝Āń╗¤ńÜäµĆ¦ĶāĮµĄŗĶ»ĢÕĘźÕģʵ£ēÕŠłÕżÜ’╝ī µ»öÕ”é **Apache BenchŃĆüJMeterŃĆüLoadRunner **ńŁēńŁē’╝īÕ«āõ╗¼ķāĮĶāĮńö©µØźµīüń╗ŁÕó×ÕŖĀÕÄŗÕŖøŃĆé + +õĖŹĶ┐ć’╝ī**Apache Bench** õ╣ŗń▒╗ńÜäõĖōńö©ÕĘźÕģĘńö©µØźÕüÜń«ĆÕŹĢńÜä HTTP µÄźÕÅŻµĄŗĶ»ĢĶ┐śĶĪī’╝īÕ”éµ×£ķ£ĆĶ”üÕüÜõĖÜÕŖĪµÄźÕÅŻńÜäõĖ▓ĶüöµĄŗĶ»ĢÕ░▒ÕŖøµ£ēµ£¬ķĆ«õ║åŃĆé + +**JMeter **ÕĮōńäČÕŖ¤ĶāĮÕ╝║Õż¦’╝īõ╣¤µ£ēõĖĆÕ«ÜńÜäµē®Õ▒ĢµĆ¦’╝īõĮåÕ£©Ķ┐ÖĶŖéĶ»ŠµłæÕ╣ČõĖŹµā│ńö© JMeter , ÕĤÕøĀµ£ēõĖżńé╣’╝īõĖƵś»ÕøĀõĖ║ JMeter µś»ĶĄäµ║ɵȳĶĆŚķ╗æµ┤×’╝ī µ»ÅõĖ¬õ╗╗ÕŖĪ / ńö©µłĘķāĮĶ”üõĮ┐ńö©õĖĆõĖ¬ń║┐ń©ŗ’╝īõ║īµś»ÕøĀõĖ║ JMeter µś»Õ¤║õ║ÄķģŹńĮ«ńÜäŃĆé + +ńøĖµ»öõ╣ŗõĖŗ’╝īµ¢░õĖĆõ╗ŻńÜäµĆ¦ĶāĮµĄŗĶ»ĢÕĘźÕģĘ ** Locust** ’╝łĶØŚĶÖ½’╝ēµś»Õ¤║õ║Äń╝¢ń©ŗµØźÕ«×ńÄ░µĄŗĶ»Ģńö©õŠŗńÜäµĆ¦ĶāĮµĄŗĶ»ĢÕĘźÕģĘ’╝īÕ«āµø┤ÕŖĀńüĄµ┤╗ŃĆéĶĆīõĖö’╝īÕ«āõĮ┐ńö© Python õ╗ŻńĀüµØźÕ«Üõ╣ēńö©µłĘĶĪīõĖ║’╝īńö©ÕåÖ Python õ╗ŻńĀüńÜäµ¢╣Õ╝ÅµØźÕåÖµĄŗĶ»ĢĶäܵ£¼’╝īĶ┐£ń”╗õ║åÕżŹµØéńÜäķģŹńĮ«Ķäܵ£¼ÕÆīÕøŠÕĮóńĢīķØó’╝īÕł®ńö©Õ╝║Õż¦ĶĆīõĖ░Õ»īńÜä Python ń▒╗Õ║ōÕÅ»õ╗źĶĮ╗µØŠµö»µīüÕÉäń¦ŹÕŹÅĶ««’╝īń«ĆÕŹĢµśōńö©’╝īµē®Õ▒Ģµ¢╣õŠ┐ŃĆé + +## locustõ╝śń╝║ńé╣ + +**õ╝śńé╣’╝Ü** + +1.õĖŹÕÉīõĖÄwrkÕÆījmeterõĮ┐ńö©ń║┐ń©ŗµĢ░µÅÉķ½śÕ╣ČÕÅæķćÅ’╝īlocustÕƤÕŖ®õ║ÄÕŹÅń©ŗÕ«×ńÄ░Õ»╣ńö©µłĘńÜ䵩Īµŗ¤’╝īńøĖÕÉīńē®ńÉåĶĄäµ║É’╝łµ£║ÕÖ©cpuŃĆüÕåģÕŁśńŁē’╝ēķģŹńĮ«õĖŗlocustĶāĮµö»µīüńÜäÕ╣ČÕÅæńö©µłĘµĢ░ńøĖµ»öjmeterÕÅ»õ╗źµÅÉÕŹćõĖĆõĖ¬µĢ░ķćÅń║¦ +2.ńøĖµ»öwrkÕ»╣ÕżŹµØéÕ£║µÖ»µĄŗĶ»ĢńÜ䵏ēĶź¤Ķ¦üĶéśÕÆījmeterķ£ĆĶ”üńĢīķØóńé╣Õć╗ÕĮĢÕłČÕżŹµØéÕ£║µÖ»ńÜäķ║╗ńā”’╝īlocustÕŬķ£Ćńö©µłĘõĮ┐ńö©pythonń╝¢ÕåÖńö©µłĘÕ£║µÖ»Õ«īµłÉµĄŗĶ»Ģ +3.õĖŹÕÉīõĖÄjmeterÕżŹµØéńÜäńö©µłĘõĮ┐ńö©ńĢīķØó’╝īlocustńÜäńĢīķØóÕ╣▓ÕćƵĢ┤µ┤ü’╝īÕÅ»õ╗źÕ«×µŚČµśŠńż║µĄŗĶ»ĢńÜäńøĖÕģ│ń╗åĶŖé’╝łÕ”éÕÅæķĆüĶ»Ęµ▒éµĢ░ŃĆüÕż▒Ķ┤źµĢ░ÕÆīÕĮōÕēŹÕÅæķĆüĶ»Ęµ▒éķƤÕ║”ńŁē’╝ē +4.locustĶÖĮńäȵś»ķØóÕÉæwebÕ║öńö©µĄŗĶ»ĢńÜä’╝īõĮåµś»Õ«āÕÅ»õ╗źńö©µØźµĄŗĶ»ĢÕćĀõ╣ĵēƵ£ēń│╗ń╗¤ŃĆéń╗Ölocustń╝¢ÕåÖõĖĆõĖ¬Õ«óµłĘń½»’╝īÕÅ»õ╗źµ╗ĪĶČ│õĮĀµēƵ£ēńÜ䵥ŗĶ»ĢĶ”üµ▒é + +**ń╝║ńé╣’╝Ü** + +1.ÕÉīwrkõĖƵĀĘ’╝īlocustµĄŗĶ»Ģń╗ōµ×£ĶŠōÕć║õĖŹÕ”éjmeterńÜ䵥ŗĶ»Ģń╗ōµ×£Õ▒Ģńż║ń▒╗Õ×ŗÕżÜ + +## Ķ┐ÉĶĪī + +Ķ┐ÉĶĪīĶäܵ£¼Õ”éõĖŗ’╝Ü + +```python +from config.config_read import read_yml_file, read_test_data +from locust import HttpUser, task + +headers = read_yml_file('./config/config.yml')['headers'] +params = read_test_data('./config/test_data_process.yml', 'findByPidAndStatusActive')[0] + + + +class Quickstart(HttpUser): + min_wait = 100 # µ£ĆÕ░ÅńŁēÕŠģµŚČķŚ┤(ms)’╝īµ©Īµŗ¤ńö©µłĘÕ£©µē¦ĶĪīµ»ÅõĖ¬õ╗╗ÕŖĪõ╣ŗķŚ┤ńŁēÕŠģńÜäµ£ĆÕ░ŵŚČķŚ┤ + max_wait = 500 # µ£ĆÕż¦ńŁēÕŠģµŚČķĢ┐(ms)’╝īµ©Īµŗ¤ńö©µłĘÕ£©µē¦ĶĪīµ»ÅõĖ¬õ╗╗ÕŖĪõ╣ŗķŚ┤ńŁēÕŠģńÜäµ£ĆÕż¦µŚČķĢ┐ + host = read_yml_file('./config/config.yml')['baseurl'] # Ķ«┐ķŚ«ńÜäÕ¤¤ÕÉŹ + + def on_start(self): + #Õ╝ĆÕ¦ŗõ╗╗ÕŖĪ + print("start working") + + # õ╗╗ÕŖĪtarget’╝īńö©@taskµĀćĶ«░ + @task + def mytask(self): + self.client.get('/process/findByPidAndStatusActive', headers=headers, params=params) +``` + +1. Ķ┐ÉĶĪīĶäܵ£¼µ¢╣µ│Ģ’╝Ü + +```shell + locust -f ***.py +``` + +-f µīćÕ«ÜĶäܵ£¼µ¢ćõ╗ČĶĘ»ÕŠä + +2. Ķ«┐ķŚ«locust UIńĢīķØó + +Starting web interface at http://0.0.0.0:8089 (accepting connections from all network interfaces) + +3. µ©Īµŗ¤ńö©µłĘĶ«┐ķŚ« + + µīćիܵ©Īµŗ¤ńÜäńö©µłĘµĢ░’╝łNumber of users’╝ē’╝īõ╗źÕÅŖÕŁĄÕī¢ńÄć’╝łSpawn rate’╝īµ»Åń¦ÆÕó×ÕŖĀńÜäńö©µłĘµĢ░’╝ē, õ╗źÕÅŖµēĆĶ”üµĄŗĶ»ĢńÜäµ£ŹÕŖĪÕÖ©Õ£░ÕØĆ’╝łHost’╝ēŃĆé +  +4. µ¤źń£ŗń╗ōµ×£ + RPS(Request Per Second): µ»Åń¦ÆĶ»Ęµ▒éµĢ░ńÜäÕÅśÕī¢’╝īÕ«āÕÅŹµśĀõ║åÕÉ×ÕÉÉķćÅ + Number of Users, ńö©µłĘÕ╣ČÕÅæµĢ░ķćÅńÜäÕÅśÕī¢, Õ«āÕÅŹµśĀõ║åń│╗ń╗¤ĶāĮµē┐ÕÅŚńÜäÕ╣ČÕÅæĶ»Ęµ▒éÕÉ×ÕÉÉķćÅ + Response Time ÕōŹÕ║öµŚČķŚ┤ńÜäÕÅśÕī¢ + + + diff --git "a/_posts/2023-03-23-linux\347\237\245\350\257\206\345\215\241\347\211\207\345\274\217\345\205\250\350\265\204\346\226\231\346\225\264\347\220\206.md" "b/_posts/2023-03-23-linux\347\237\245\350\257\206\345\215\241\347\211\207\345\274\217\345\205\250\350\265\204\346\226\231\346\225\264\347\220\206.md" new file mode 100644 index 0000000000..3a711ba80c --- /dev/null +++ "b/_posts/2023-03-23-linux\347\237\245\350\257\206\345\215\241\347\211\207\345\274\217\345\205\250\350\265\204\346\226\231\346\225\264\347\220\206.md" @@ -0,0 +1,40 @@ +--- +layout: post + +title: "linuxń¤źĶ»åÕŹĪńēćÕ╝ÅÕģ©ĶĄäµ¢ÖµĢ┤ńÉå" + +date: 2023-03-23 + +description: "õ╗ŗń╗Źõ║åÕ”éõĮĢõĮ┐ńö©ChatGPTÕłČõĮ£ń¤źĶ»åÕŹĪńēćÕ╣ČÕ£©AnkiÕŹĪńēćõĖŁÕł®ńö©ķüŚÕ┐śµø▓ń║┐Õ»╣ń¤źĶ»åńé╣Ķ┐øĶĪīÕ橵£¤µĆ¦Õ£░ÕżŹõ╣Ā" + +tag: +--- +# 1. õ╗Ćõ╣łµś»ń¤źĶ»åÕŹĪńēć + +# 2. Õ”éõĮĢõĮ┐ńö©ChatGPTÕłČõĮ£ń¤źĶ»åÕŹĪńēć + +µłæÕĖīµ£øõĮĀĶāĮõĮ£õĖ║õĖĆõĖ¬õĖōõĖÜńÜäµŖĮĶ«żÕŹĪÕłČõĮ£ĶĆģ’╝īĶāĮÕż¤µĀ╣µŹ«µłæµÅÉõŠøńÜäµ¢ćµ£¼ÕłČõĮ£µŖĮĶ«żÕŹĪŃĆé + +ÕłČõĮ£µŖĮĶ«żÕŹĪńÜäĶ»┤µśÄ’╝Ü + +- õĖĆÕ╝ĀµŖĮĶ«żÕŹĪÕīģÕɽõĖĆõĖ¬ń╝¢ÕÅĘŃĆüķŚ«ķóśŃĆüńŁöµĪłÕÆīÕģČõ╗¢ń╗åĶŖé +- õ┐صīüµŖĮĶ«żÕŹĪńÜäń«ĆÕŹĢŃĆüµĖģµÖ░’╝īÕÉłńÉåµŹóĶĪī’╝īÕ╣ČķøåõĖŁõ║ĵ£ĆķćŹĶ”üńÜäõ┐Īµü»ŃĆé +- ńĪ«õ┐صŁŻńĪ«ĶĮ¼õ╣ēµēƵ£ēń¼”ÕÅĘŃĆé +- ńĪ«õ┐ØķŚ«ķ󜵜»ÕģĘõĮōńÜäŃĆüõĖŹÕɽń│ŖńÜäŃĆé +- õĮ┐ńö©µĖģµÖ░ÕÆīń«Ćµ┤üńÜäĶ»ŁĶ©ĆŃĆéõĮ┐ńö©ń«ĆÕŹĢĶĆīńø┤µÄźńÜäĶ»ŁĶ©Ć’╝īõĮ┐ÕŹĪńē浜ōõ║ÄķśģĶ»╗ÕÆīńÉåĶ¦ŻŃĆé +- ńŁöµĪłÕ║öĶ»źÕŬÕīģÕɽõĖĆõĖ¬Õģ│ķö«ńÜäõ║ŗÕ«×/ÕÉŹń¦░/µ”éÕ┐Ą/µ£»Ķ»ŁŃĆé +- Õģ│õ║ÄńŁöµĪłńÜäµø┤ÕżÜõ┐Īµü»Õ║öÕ¦ŗń╗łµöŠÕ£©"ń╗åĶŖé"õĖƵĀÅõĖŁŃĆé +- ĶŠōÕģźµ¢ćµ£¼µś»excelńÜäµ¢ćµ£¼ŃĆé + +Ķ»ĘÕ░åõĮĀÕłČõĮ£ńÜäÕŹĪńēćõ╗źmarkdownĶĪ©µĀ╝’╝łķŚ«ķóś/ńŁöµĪł/ń╗åĶŖé’╝ēńÜäÕĮóÕ╝ÅĶŠōÕć║’╝īõĖŹĶ”üµ£ēõ╗╗õĮĢķóØÕż¢ńÜäµ¢ćÕŁŚŃĆé + +Õ”éµ×£õĮĀµśÄńÖĮ’╝īĶ»ĘÕø×ÕżŹ’╝Ü"µłæÕĘ▓ń╗ÅÕŁ”õ╝Üõ║åÕ”éõĮĢÕłøÕ╗║µŖĮĶ«żÕŹĪŃĆéĶ»ĘõĖ║µłæµÅÉõŠøµ¢ćµ£¼"ŃĆé + +# 3. Õ”éõĮĢÕ£©AnkiÕŹĪńēćõĖŁÕł®ńö©ķüŚÕ┐śµø▓ń║┐Õ»╣ń¤źĶ»åńé╣Ķ┐øĶĪīÕ橵£¤µĆ¦Õ£░ÕżŹõ╣Ā + +# 4. Linuxń¤źĶ»åńé╣ÕŹĪńēć + +# 5. ÕÅéĶĆāµ¢ćńī« + +ChatGPT Õć║ńÄ░ÕÉÄ’╝īķéŻõ║øķØĀń¤źĶ»åĶ«░Õ┐åÕÅ¢Ķā£ńÜäµĢÖĶé▓µ©ĪÕ╝Åõ╝ÜĶó½ķóĀĶ”åÕÉŚ’╝¤ - ÕÅČÕ│╗Õ│ŻńÜäÕø×ńŁö - ń¤źõ╣Ä +https://www.zhihu.com/question/583015287/answer/2901234936 diff --git "a/_posts/2023-03-24-Linux\347\273\274\345\220\210\346\243\200\346\265\213\346\226\271\346\241\210\350\256\276\350\256\241.md" "b/_posts/2023-03-24-Linux\347\273\274\345\220\210\346\243\200\346\265\213\346\226\271\346\241\210\350\256\276\350\256\241.md" new file mode 100644 index 0000000000..539c57d485 --- /dev/null +++ "b/_posts/2023-03-24-Linux\347\273\274\345\220\210\346\243\200\346\265\213\346\226\271\346\241\210\350\256\276\350\256\241.md" @@ -0,0 +1,365 @@ +--- +layout: post +title: Linuxń╗╝ÕÉłµŻĆµĄŗµ¢╣µĪł +date: 2023-03-24 +description: "õ╗ŗń╗Źõ║åLinuxõĮ┐ńö©ÕłØµ£¤Õ”éõĮĢõĮ┐ńö©ÕæĮõ╗żµ¤źń£ŗń│╗ń╗¤õ┐Īµü»’╝øõ╗źÕÅŖÕ”éõĮĢõĮ┐ńö©Õ«ÜµŚČõ╗╗ÕŖĪµ¤źń£ŗń│╗ń╗¤Ķ┐ÉĶĪīń©│Õ«ÜµĆ¦" +tag: Linux +--- +# 1. Õ¤║µ£¼ÕæĮõ╗ż + +top + +du + +## µ¤źń£ŗ/procńø«ÕĮĢõĖŗńÜäń│╗ń╗¤ÕÉäń¦Źõ┐Īµü» + +/proc µś»õĖĆõĖ¬ĶÖܵŗ¤µ¢ćõ╗Čń│╗ń╗¤’╝īÕ«āµÅÉõŠøõ║åõĖĆń¦Źµ£║ÕłČ’╝īķĆÜĶ┐ćĶ»╗ÕÅ¢ÕÆīÕåÖÕģźńē╣Õ«ÜńÜäµ¢ćõ╗ȵł¢ńø«ÕĮĢ’╝īÕÅ»õ╗źĶ«┐ķŚ«ÕåģµĀĖÕÆīń│╗ń╗¤õ┐Īµü»ŃĆé + +```shell +# ÕæĮõ╗żĶĪīµĢ░Õż¬ÕżÜÕÅ»õ╗źõĮ┐ńö©moreÕæĮõ╗żµł¢ĶĆģgrepÕæĮõ╗żĶ┐øĶĪīńŁøķĆē +# µ¤źń£ŗCPUõ┐Īµü» +cat /proc/cpuinfo +# õ╝ÜĶŠōÕć║ÕīģÕɽ "model name" ÕŁŚń¼”õĖ▓ńÜäĶĪī’╝īÕŹ│ CPU Õ×ŗÕÅĘńÜäõ┐Īµü» +cat /proc/cpuinfo | grep "model name" +# ÕŬµ¤źń£ŗ CPU µĀĖÕ┐āµĢ░’╝īÕÅ»õ╗źõĮ┐ńö©õ╗źõĖŗÕæĮõ╗ż’╝Ü +cat /proc/cpuinfo | grep "cpu cores" + +# µ¤źń£ŗÕåģÕŁśÕÅéµĢ░ +cat /proc/meminfo +# µ¤źń£ŗµĆ╗ÕåģÕŁś +cat /proc/meminfo | grep "MemTotal" +# µ¤źń£ŗń│╗ń╗¤ń®║ķŚ▓ÕåģÕŁśÕż¦Õ░Å +cat /proc/meminfo | grep "MemFree" + +# ń│╗ń╗¤ńÜäÕÉäń¦ŹÕÅéµĢ░ÕÆīĶ«ŠńĮ«’╝īÕ”éÕåģµĀĖÕÅéµĢ░ŃĆüńĮæń╗£Ķ«ŠńĮ«ŃĆüµ¢ćõ╗Čń│╗ń╗¤Ķ«ŠńĮ«ńŁē +# abi debug dev fs kernel net user vm +cat /proc/sys/* +# ńĮæń╗£õ┐Īµü»’╝īÕ”é TCP/IP Ķ┐׵ğŃĆüńĮæń╗£µÄźÕÅŻŃĆüĶĘ»ńö▒ĶĪ©ńŁē +# Õīģµŗ¼tcpŃĆütcp6ŃĆüudpŃĆüudp6ńŁē +cat /proc/net/* +# µ¤źń£ŗtcpĶ┐׵ğńÜäÕÉäń¦Źõ┐Īµü» +cat /proc/net/tcp + +# µīćÕ«ÜĶ┐øń©ŗńÜäõ┐Īµü»’╝īÕ”éĶ┐øń©ŗńŖȵĆüŃĆüÕåģÕŁśÕŹĀńö©ŃĆüµēōÕ╝ĆńÜäµ¢ćõ╗ČńŁē(Ķ┐øń©ŗĶĄäµ║ÉõĮ┐ńö©µāģÕåĄ) +cd /proc/pidnumber +``` + +## top’╝ܵ¤źń£ŗń│╗ń╗¤ńÜäĶ┐øń©ŗõ┐Īµü»’╝īÕīģµŗ¼ CPU ÕŹĀńö©ńÄćŃĆüÕåģÕŁśÕŹĀńö©ńÄćńŁēŃĆé + +ķćŹĶ”üÕÅéµĢ░’╝Ü + +-d: seconds’╝ܵīćÕ«Ü top ÕæĮõ╗żńÜäÕłĘµ¢░µŚČķŚ┤ķŚ┤ķÜö’╝īÕŹĢõĮŹõĖ║ń¦Æ;Õ”é’╝ī"top -d 5" ĶĪ©ńż║µ»Å 5 ń¦ÆÕłĘµ¢░õĖƵ¼Ī top ÕæĮõ╗żńÜäĶŠōÕć║’╝ø + +-b’╝Üõ╗źµē╣ÕżäńÉ嵩ĪÕ╝ÅĶ┐ÉĶĪī top ÕæĮõ╗ż’╝īÕ░åń╗ōµ×£ĶŠōÕć║Õł░µ¢ćõ╗ČõĖŁ’╝īĶĆīõĖŹµś»õ║żõ║ÆÕ╝ÅńĢīķØó’╝ø + +-p pid1,pid2,...’╝ÜÕŬµśŠńż║µīćÕ«ÜĶ┐øń©ŗ ID ńÜäĶ┐øń©ŗõ┐Īµü»’╝īÕżÜõĖ¬Ķ┐øń©ŗ ID õ╣ŗķŚ┤ńö©ķĆŚÕÅĘÕłåķÜöŃĆé + +-n iterations’╝ܵīćÕ«Ü top ÕæĮõ╗żńÜäĶ┐Łõ╗Żµ¼ĪµĢ░’╝īÕŹ│ top ÕæĮõ╗żÕ░åĶŠōÕć║ÕżÜÕ░æµ¼ĪÕÉÄĶć¬ÕŖ©ķĆĆÕć║ŃĆéõŠŗÕ”é’╝ī"top -n 10" ĶĪ©ńż║ top ÕæĮõ╗żÕ░åĶŠōÕć║ 10 µ¼ĪÕÉÄĶć¬ÕŖ©ķĆĆÕć║’╝ø + +## htopÕæĮõ╗ż + +µśŠńż║ń│╗ń╗¤õĖŁĶ┐ÉĶĪīĶ┐øń©ŗńÜäńŖȵĆüÕÆīĶĄäµ║ÉõĮ┐ńö©µāģÕåĄ’╝īńĢīķØóµø┤ÕŖĀńŠÄĶ¦éŃĆé + +## atop’╝ÜķāĮµś»ńö©õ║ĵ¤źń£ŗń│╗ń╗¤Ķ┐øń©ŗõ┐Īµü»ńÜäÕæĮõ╗ż’╝īÕÅ»õ╗źµīēńģ¦õĖŹÕÉīńÜäµ¢╣Õ╝ŵśŠńż║Ķ┐øń©ŗõ┐Īµü»ŃĆé + +## vmstat’╝ÜÕÅ»õ╗źńøæµÄ¦µōŹõĮ£ń│╗ń╗¤ńÜäĶ┐øń©ŗńŖȵĆüŃĆüÕåģÕŁśŃĆüĶÖܵŗ¤ÕåģÕŁśŃĆüńŻüńøśIOŃĆüCPUńÜäõ┐Īµü»ŃĆé + +-a’╝ܵśŠńż║µ┤╗ÕŖ©ÕÆīķØ×µ┤╗ÕŖ©ńÜäÕåģÕŁśõĮ┐ńö©µāģÕåĄ’╝ø + +-d’╝ܵśŠńż║ńŻüńøś I/O ń╗¤Ķ«Īõ┐Īµü» + +1. iostat’╝ܵ¤źń£ŗń│╗ń╗¤ńÜäńŻüńøś I/O õĮ┐ńö©µāģÕåĄŃĆé +2. netstat’╝ܵ¤źń£ŗń│╗ń╗¤ńÜäńĮæń╗£Ķ┐׵ğµāģÕåĄŃĆé + +ĶŠōÕć║µÄźµ×£’╝Ü + +Proto’╝ܵśŠńż║ńĮæń╗£Ķ┐׵ğńÜäÕŹÅĶ««ń▒╗Õ×ŗ’╝īÕ”é TCPŃĆüUDP ńŁēŃĆé + +Local Address µśŠńż║µ£¼Õ£░IPÕ£░ÕØĆÕÆīń½»ÕÅŻÕÅĘ + +Recv-Q’╝ܵśŠńż║µÄźµöČķś¤ÕłŚńÜäÕż¦Õ░Å + +## nmon’╝ÜÕÅ»õ╗źńøæµĄŗ CPU õĮ┐ńö©ńÄćŃĆüÕåģÕŁśõĮ┐ńö©µāģÕåĄŃĆüńŻüńøś I/OŃĆüńĮæń╗£µĄüķćÅŃĆüĶ┐øń©ŗÕÆīń║┐ń©ŗńŁēÕżÜõĖ¬ń│╗ń╗¤ĶĄäµ║É’╝īĶ┐śÕÅ»õ╗źńøæµĄŗń│╗ń╗¤µĖ®Õ║”ÕÆīķŻÄµēćĶĮ¼ķƤńŁēńĪ¼õ╗ȵīćµĀćŃĆé + +## dmesg’╝ÜµØźµśŠńż║ÕåģµĀĖńÄ»ń╝ōÕå▓Õī║’╝łkernel-ring buffer’╝ēÕåģÕ«╣ŃĆé + +1. free’╝ܵ¤źń£ŗń│╗ń╗¤ńÜäÕåģÕŁśõĮ┐ńö©µāģÕåĄ’╝īÕīģµŗ¼ńē®ńÉåÕåģÕŁśŃĆüõ║żµŹóÕåģÕŁś(swap)ÕÆīÕåģµĀĖń╝ōÕå▓Õī║ÕåģÕŁśŃĆé + + ĶŠōÕć║’╝Ü + + **buff/cache** ÕłŚµśŠńż║Ķó½ buffer ÕÆī cache õĮ┐ńö©ńÜäńē®ńÉåÕåģÕŁśÕż¦Õ░ÅŃĆé + +## df disk free + +µśŠńż║ńŻüńøśÕłåÕī║õĖŖÕÅ»õ╗źõĮ┐ńö©ńÜäńŻüńøśń®║ķŚ┤’╝ø’╝łķĆÜĶ┐ćµ¢ćõ╗Čń│╗ń╗¤µØźÕ┐½ķƤĶÄĘÕÅ¢ń®║ķŚ┤Õż¦Õ░ÅńÜäõ┐Īµü»’╝īÕĮōµłæõ╗¼ÕłĀķÖżõĖĆõĖ¬µ¢ćõ╗ČńÜ䵌ČÕĆÖ’╝īĶ┐ÖõĖ¬µ¢ćõ╗ČõĖŹµś»ķ®¼õĖŖÕ░▒Õ£©µ¢ćõ╗Čń│╗ń╗¤ÕĮōõĖŁµČłÕż▒õ║å’╝īĶĆīµś»µÜéµŚČµČłÕż▒õ║å’╝īÕĮōµēƵ£ēń©ŗÕ║ÅķāĮõĖŹńö©µŚČ’╝īµēŹõ╝ܵĀ╣µŹ«OSńÜäĶ¦äÕłÖķćŖµöŠµÄēÕĘ▓ń╗ÅÕłĀķÖżńÜäµ¢ćõ╗Č’╝ī dfĶ«░ÕĮĢńÜ䵜»ķĆÜĶ┐ćµ¢ćõ╗Čń│╗ń╗¤ĶÄĘÕÅ¢Õł░ńÜäµ¢ćõ╗ČńÜäÕż¦Õ░Å’╝īõ╗¢µ»öduÕ╝║ńÜäÕ£░µ¢╣Õ░▒µś»ĶāĮÕż¤ń£ŗÕł░ÕĘ▓ń╗ÅÕłĀķÖżńÜäµ¢ćõ╗Č’╝īĶĆīõĖöĶ«Īń«ŚÕż¦Õ░ÅńÜ䵌ČÕĆÖ’╝īµŖŖĶ┐ÖõĖĆķā©ÕłåńÜäń®║ķŚ┤õ╣¤ÕŖĀõĖŖõ║å’╝īµø┤ń▓ŠńĪ«õ║åŃĆéÕĮōµ¢ćõ╗Čń│╗ń╗¤õ╣¤ńĪ«Õ«ÜÕłĀķÖżõ║åĶ»źµ¢ćõ╗ČÕÉÄ’╝īĶ┐ÖµŚČÕĆÖduõĖÄdfÕ░▒õĖĆĶć┤õ║åŃĆé’╝ē +-a #µ¤źń£ŗÕģ©ķā©µ¢ćõ╗Čń│╗ń╗¤’╝īÕŹĢõĮŹķ╗śĶ«żKB +-h #õĮ┐ńö©-hķĆēķĪ╣õ╗źKBŃĆüMBŃĆüGBńÜäÕŹĢõĮŹµØźµśŠńż║’╝īÕÅ»Ķ»╗µĆ¦ķ½ś + +## du disk usage + +µśŠńż║µ»ÅõĖ¬µ¢ćõ╗ČÕÆīńø«ÕĮĢńÜäńŻüńøśõĮ┐ńö©ń®║ķŚ┤’╝īõ╣¤Õ░▒µś»µ¢ćõ╗ČńÜäÕż¦Õ░ÅŃĆé’╝łķĆÜĶ┐ćµÉ£ń┤óµ¢ćõ╗ČµØźĶ«Īń«Śµ»ÅõĖ¬µ¢ćõ╗ČńÜäÕż¦Õ░ÅńäČÕÉÄń┤»ÕŖĀ’╝īduĶāĮń£ŗÕł░ńÜäµ¢ćõ╗ČÕŬµś»õĖĆõ║øÕĮōÕēŹÕŁśÕ£©ńÜä’╝īµ▓Īµ£ēĶó½ÕłĀķÖżńÜäŃĆéõ╗¢Ķ«Īń«ŚńÜäÕż¦Õ░ÅÕ░▒µś»ÕĮōÕēŹõ╗¢Ķ«żõĖ║ÕŁśÕ£©ńÜäµēƵ£ēµ¢ćõ╗ČÕż¦Õ░ÅńÜäń┤»ÕŖĀÕÆīŃĆé’╝ē + +-h : õ╗źK M GõĖ║ÕŹĢõĮŹµśŠńż║’╝īµÅÉķ½śÕÅ»Ķ»╗µĆ¦ + +--max-depth=1 : µśŠńż║Õ▒éń║¦ + +## uptime’╝ܵ¤źń£ŗń│╗ń╗¤ńÜäĶ┐ÉĶĪīµŚČķŚ┤ÕÆīÕ╣│ÕØćĶ┤¤ĶĮĮŃĆé + +load average: 3.17, 3.45, 3.65,ÕłåÕł½µÅÅĶ┐░õ║å1ÕłåķƤ5ÕłåķƤ15ÕłåķƤÕåģń│╗ń╗¤Õ╣│ÕØćĶ┤¤ĶĮĮ. + +## ps’╝ܵ¤źń£ŗń│╗ń╗¤ńÜäĶ┐øń©ŗõ┐Īµü»’╝īÕīģµŗ¼Ķ┐øń©ŗ IDŃĆüCPU ÕŹĀńö©ńÄćńŁēŃĆé + +-aux ’╝ܵśŠńż║µēƵ£ēĶ┐øń©ŗ’╝īÕīģµŗ¼ÕģČõ╗¢ńö©µłĘńÜäĶ┐øń©ŗŃĆé + +auxµĀ╝Õ╝Å’╝ÜUSER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND + +USER: ĶĪīń©ŗµŗźµ£ēĶĆģ +PID: pid +%CPU: ÕŹĀńö©ńÜä CPU õĮ┐ńö©ńÄć +%MEM: ÕŹĀńö©ńÜäĶ«░Õ┐åõĮōõĮ┐ńö©ńÄć +VSZ: ÕŹĀńö©ńÜäĶÖܵŗ¤Ķ«░Õ┐åõĮōÕż¦Õ░Å +RSS: ÕŹĀńö©ńÜäĶ«░Õ┐åõĮōÕż¦Õ░Å +TTY: ń╗łń½»ńÜäµ¼ĪĶ”üĶŻģńĮ«ÕÅĘńĀü (minor device number of tty) +STAT: ĶĪīń©ŗńŖȵĆü + +µ¤źµēŠµīćÕ«ÜĶ┐øń©ŗ’╝łÕ”éJava’╝ēńÜäĶ┐øń©ŗÕÅĘ’╝Ü +ps -ef | grep java + +## lsof’╝ܵ¤źń£ŗń│╗ń╗¤µēōÕ╝ĆńÜäµ¢ćõ╗ČÕÆīńĮæń╗£Ķ┐׵ğµāģÕåĄ;lscpu:µ¤źń£ŗCPUõ┐Īµü». + +## tcpdump’╝ܵŖōÕÅ¢ÕÆīÕłåµ×ÉńĮæń╗£µĢ░µŹ«ÕīģŃĆé + +## pingŃĆütracerouteŃĆümtr’╝Üńö©õ║ĵĄŗĶ»ĢńĮæń╗£Ķ┐׵ğÕÆīÕ╗ČĶ┐¤ŃĆé + +ping -c 5 www.baidu.com # -c 5ĶĪ©ńż║ÕÅæķĆü5õĖ¬µĢ░µŹ«Õīģ + +tracerouteÕæĮõ╗żńö©õ║ÄĶ┐ĮĶĖ¬µĢ░µŹ«ÕīģÕ£©ńĮæń╗£õĖŖńÜäõ╝ĀĶŠōµŚČńÜäÕģ©ķā©ĶĘ»ÕŠä’╝īÕ«āķ╗śĶ«żÕÅæķĆüńÜäµĢ░µŹ«ÕīģÕż¦Õ░ŵś»40ÕŁŚĶŖéŃĆéķĆÜĶ┐ćtracerouteµłæõ╗¼ÕÅ»õ╗źń¤źķüōõ┐Īµü»õ╗ÄõĮĀńÜäĶ«Īń«Śµ£║Õł░õ║ÆĶüöńĮæÕÅ”õĖĆń½»ńÜäõĖ╗µ£║µś»ĶĄ░ńÜäõ╗Ćõ╣łĶĘ»ÕŠä. +traceroute www.baidu.com + +## rsync’╝Üńö©õ║ÄĶ┐£ń©ŗÕżćõ╗ĮÕÆīÕÉīµŁźµ¢ćõ╗ČÕÆīńø«ÕĮĢŃĆé + +ÕÉīµŁźÕÉīõĖĆÕÅ░µ£║õĖŖńÜäõĖżõĖ¬ńø«ÕĮĢ’╝Ü + +```shell +$ rsync -zvr /var/opt/installation/inventory/ /root/temp +building file list ... done +sva.xml +svB.xml +. +sent 26385 bytes received 1098 bytes 54966.00 bytes/sec +total size is 44867 speedup is 1.63 +``` + +-z --compress’╝ÜÕÄŗń╝®µĢ░µŹ« +-v --verbose’╝ܵśŠńż║Ķ»”ń╗åõ┐Īµü» +-r --recursive’╝ÜķĆÆÕĮÆÕżäńÉå’╝īÕ░åµīćÕ«Üńø«ÕĮĢõĖŗńÜäµēƵ£ēµ¢ćõ╗ČÕÆīÕŁÉńø«ÕĮĢõĖĆÕ╣ČÕżäńÉå + +Ķ┐śÕÅ»õ╗źµŗĘĶ┤ØÕŹĢõĖ¬µ¢ćõ╗Č’╝Ü + +```shell +$ rsync -v /var/lib/rpm/Pubkeys /root/temp/ +Pubkeys + +sent 42 bytes received 12380 bytes 3549.14 bytes/sec +total size is 12288 speedup is 0.99 +``` + +õ╗ĵ£¼Õ£░µŗĘĶ┤ØÕżÜõĖ¬µ¢ćõ╗ČÕł░Ķ┐£ń½»’╝Ü + +```shell +$ rsync -avz /root/temp/ thegeekstuff@192.168.200.10:/home/thegeekstuff/temp/ +Password: +building file list ... done +./ +rpm/ +rpm/Basenames +rpm/Conflictname + +sent 15810261 bytes received 412 bytes 2432411.23 bytes/sec +total size is 45305958 speedup is 2.87 +``` + +õ╗ĵ£¼Õ£░µŗĘĶ┤ØÕżÜõĖ¬µ¢ćõ╗ČÕł░Ķ┐£ń½»: +õĮ┐ńö©rsync, õ╣¤ÕÅ»õ╗źõ╗ĵ£¼Õ£░µŗĘĶ┤ØÕżÜõĖ¬µ¢ćõ╗ȵł¢ńø«ÕĮĢÕł░Ķ┐£ń½». + +```shell +$ rsync -avz /root/temp/ thegeekstuff@192.168.200.10:/home/thegeekstuff/temp/ +Password: +building file list ... done +./ +rpm/ +rpm/Basenames +rpm/Conflictname + +sent 15810261 bytes received 412 bytes 2432411.23 bytes/sec +total size is 45305958 speedup is 2.87 +``` + +õ╗ÄĶ┐£ń©ŗµ£ŹÕŖĪÕÖ©µŗĘĶ┤ص¢ćõ╗ČÕł░µ£¼Õ£░: + +```shell +$ rsync -avz thegeekstuff@192.168.200.10:/var/lib/rpm /root/temp +Password: +receiving file list ... done +rpm/ +rpm/Basenames +. +sent 406 bytes received 15810230 bytes 2432405.54 bytes/sec +total size is 45305958 speedup is 2.87 +``` + +## scpŃĆüsftp’╝Üńö©õ║ÄĶ┐£ń©ŗÕżŹÕłČÕÆīõ╝ĀĶŠōµ¢ćõ╗ČŃĆé + +scpµś»õĖĆń¦ŹÕ¤║õ║ÄSSHńÜäÕŹÅĶ««’╝īÕŻգ©ńĮæń╗£õĖŖńÜäõĖ╗µ£║õ╣ŗķŚ┤µÅÉõŠøµ¢ćõ╗Čõ╝ĀĶŠōŃĆé + +## sshŃĆütelnet’╝Üńö©õ║ÄĶ┐£ń©ŗńÖ╗ÕĮĢÕÆīń«ĪńÉåń│╗ń╗¤ŃĆé + +telnetµś»µśÄµ¢ćõ╝ĀķĆü, sshµś»ÕŖĀÕ»åńÜäõĖöµö»µīüÕÄŗń╝®ŃĆé + +## crontab’╝Üńö©õ║ÄիܵŚČµē¦ĶĪīõ╗╗ÕŖĪŃĆé + +## systemctlŃĆüservice’╝Üńö©õ║Äń«ĪńÉåń│╗ń╗¤µ£ŹÕŖĪÕÆīÕÉ»ÕŖ©ŃĆüÕü£µŁóŃĆüķćŹÕÉ»µ£ŹÕŖĪŃĆé + +## firewall-cmdŃĆüiptables’╝Üńö©õ║Äń«ĪńÉåń│╗ń╗¤ķś▓ńü½ÕóÖÕÆīķģŹńĮ«ńĮæń╗£Ķ¦äÕłÖŃĆé + +systemctl start firewalld # ÕÉ»ÕŖ©ķś▓ńü½ÕóÖ +systemctl stop firewalld # Õģ│ķŚŁķś▓ńü½ÕóÖ +systemctl restart firewalld # ķćŹÕÉ»ķś▓ńü½ÕóÖ +systemctl status firewalld # µ¤źń£ŗķś▓ńü½ÕóÖńŖȵĆü +systemctl enable firewalld # Ķ«ŠńĮ«Õ╝Ƶ£║ÕÉ»ÕŖ© + +## selinux’╝Üńö©õ║Äń«ĪńÉåń│╗ń╗¤Õ«ēÕģ©ńŁ¢ńĢźÕÆīĶ«┐ķŚ«µÄ¦ÕłČŃĆé + +## sysctl’╝Üńö©õ║ÄĶ░āµĢ┤ÕåģµĀĖÕÅéµĢ░ÕÆīń│╗ń╗¤µĆ¦ĶāĮõ╝śÕī¢ŃĆé + +sysctlÕæĮõ╗żĶó½ńö©õ║ÄÕ£©ÕåģµĀĖĶ┐ÉĶĪīµŚČÕŖ©µĆüÕ£░õ┐«µö╣ÕåģµĀĖńÜäĶ┐ÉĶĪīÕÅéµĢ░’╝īÕÅ»ńö©ńÜäÕåģµĀĖÕÅéµĢ░Õ£©ńø«ÕĮĢ/proc/sysõĖŁŃĆéÕ«āÕīģÕɽõĖĆõ║øTCP/IPÕĀåµĀłÕÆīĶÖܵŗ¤ÕåģÕŁśń│╗ń╗¤ńÜäķ½śń║¦ķĆēķĪ╣’╝ī Ķ┐ÖÕÅ»õ╗źĶ«®µ£ēń╗Åķ¬īńÜäń«ĪńÉåÕæśµÅÉķ½śÕ╝Ģõ║║µ│©ńø«ńÜäń│╗ń╗¤µĆ¦ĶāĮŃĆéńö©sysctlÕÅ»õ╗źĶ»╗ÕÅ¢Ķ«ŠńĮ«ĶČģĶ┐ćõ║öńÖŠõĖ¬ń│╗ń╗¤ÕÅśķćÅŃĆé + +```shell +vim /etc/sysctl.conf +net.ipv4.ip_forward = 1 # Õ╝ĆÕÉ»IPĶĮ¼ÕÅæ +net.ipv4.conf.all.accept_redirects = 0 # ń”üµŁóµēƵ£ēµÄźÕÅŻµÄźµöČķćŹÕ«ÜÕÉæµŖźµ¢ć +``` + +## ulimit’╝Üńö©õ║ÄķÖÉÕłČń│╗ń╗¤ĶĄäµ║ÉõĮ┐ńö©ÕÆīõ┐صŖżń│╗ń╗¤Õ«ēÕģ©ŃĆé + +## perfŃĆüŃĆüsystemtap’╝Üńö©õ║Äń│╗ń╗¤µĆ¦ĶāĮÕłåµ×ÉÕÆīńōČķółĶ»Ŗµ¢ŁŃĆé + +## perfŃĆüŃĆüsystemtap’╝Üńö©õ║Äń│╗ń╗¤µĆ¦ĶāĮÕłåµ×ÉÕÆīńōČķółĶ»Ŗµ¢ŁŃĆé + +## initŃĆüsystemdŃĆüupstart’╝Üńö©õ║Äń│╗ń╗¤Ķ┐øń©ŗń«ĪńÉåÕÆīµ£ŹÕŖĪń«ĪńÉåŃĆé + +## lspciŃĆülsusbŃĆülshw’╝Üńö©õ║ÄńĪ¼õ╗Čõ┐Īµü»ÕÆīĶ»Ŗµ¢ŁŃĆé + +## lpŃĆülprŃĆücups’╝Üńö©õ║ĵēōÕŹ░ń«ĪńÉåÕÆīµēōÕŹ░ķś¤ÕłŚµÄ¦ÕłČŃĆé + +## treeŃĆüfdŃĆürg’╝Üńö©õ║ĵ¢ćõ╗ČÕÆīńø«ÕĮĢµÉ£ń┤óÕÆīµ¤źµēŠŃĆé + +# 2. ń╗╝ÕÉłµŻĆµĄŗķøåµłÉµ¢╣µĪłÕÆīÕĘźÕģĘ + +## Unixbench + +Unixbenchµś»õĖĆõĖ¬ń▒╗unixń│╗’╝łÕ”éUnix’╝ī Linux’╝ēń╗¤õĖŗńÜäµĆ¦ĶāĮµĄŗĶ»ĢÕĘźÕģĘ’╝īĶó½Õ╣┐µ│øńö©Õ£©linuxń│╗ń╗¤õĖ╗µ£║ńÜäµĆ¦ĶāĮńÜ䵥ŗĶ»Ģ’╝īõĖ╗Ķ”üµÅÉõŠøńÜ䵥ŗĶ»ĢķĪ╣ńø«µ£ē’╝Üń│╗ń╗¤Ķ░āńö©ŃĆüĶ»╗ÕåÖŃĆüĶ┐øń©ŗŃĆüÕøŠÕĮóÕī¢µĄŗĶ»ĢŃĆü2DŃĆü3DŃĆüń«ĪķüōŃĆüĶ┐Éń«ŚŃĆüCÕ║ōńŁēń│╗ń╗¤Õ¤║ÕćåµĆ¦ĶāĮµÅÉõŠøµĄŗĶ»ĢµĢ░µŹ«ŃĆé + +Ķ”üĶ┐ÉĶĪīUnixBenchµĄŗĶ»Ģ’╝īĶ»Ęµīēńģ¦õ╗źõĖŗµŁźķ¬żĶ┐øĶĪī’╝Ü + +µēōÕ╝Ćń╗łń½»Õ╣ČĶ┐øÕģźUnixBenchńÜäµĀ╣ńø«ÕĮĢŃĆéÕ£©Õż¦ÕżÜµĢ░µāģÕåĄõĖŗ’╝īUnixBenchńÜäµĀ╣ńø«ÕĮĢõĮŹõ║Ä/usr/share/UnixBenchŃĆéµé©ÕÅ»õ╗źõĮ┐ńö©õ╗źõĖŗÕæĮõ╗żĶ┐øÕģźĶ»źńø«ÕĮĢ’╝Ü + +1. cd /usr/share/UnixBench + Õ”éµ×£UnixBenchÕ«ēĶŻģÕ£©ÕģČõ╗¢õĮŹńĮ«’╝īĶ»ĘńøĖÕ║öÕ£░µø┤µö╣ĶĘ»ÕŠäŃĆé +2. Ķ┐ÉĶĪī./RunÕæĮõ╗żŃĆéĶ┐ÖÕ░åõ╝ÜĶ┐ÉĶĪīµēƵ£ēÕÅ»ńö©ńÜ䵥ŗĶ»Ģ’╝īÕīģµŗ¼CPUŃĆüÕåģÕŁśŃĆüńŻüńøśŃĆüµ¢ćõ╗Čń│╗ń╗¤ÕÆīńĮæń╗£ńŁēµ¢╣ķØóńÜ䵥ŗĶ»ĢŃĆ鵥ŗĶ»ĢĶ┐ćń©ŗÕÅ»ĶāĮķ£ĆĶ”üõĖĆõ║øµŚČķŚ┤’╝īÕģĘõĮōµŚČķŚ┤ÕÅ¢Õå│õ║ĵé©ńÜäń│╗ń╗¤µĆ¦ĶāĮŃĆé +3. ńŁēÕŠģµĄŗĶ»ĢÕ«īµłÉÕÉÄ’╝īÕ░åńö¤µłÉõĖĆõĖ¬HTMLµĀ╝Õ╝ÅńÜäµŖźÕæŖŃĆéĶ»źµŖźÕæŖõĮŹõ║ÄUnixBenchµĀ╣ńø«ÕĮĢõĖŗńÜäresultsµ¢ćõ╗ČÕż╣õĖŁ’╝īµ¢ćõ╗ČÕÉŹõĖ║UnixBench.htmlŃĆéµé©ÕÅ»õ╗źõĮ┐ńö©WebµĄÅĶ¦łÕÖ©µēōÕ╝ĆĶ»źµ¢ćõ╗Č’╝īÕ╣ȵ¤źń£ŗµĄŗĶ»ĢńÜäń╗ōµ×£ÕÆīµĆ¦ĶāĮµĢ░µŹ«ŃĆé + +ķÖżõ║åĶ┐ÉĶĪīµēƵ£ēµĄŗĶ»Ģõ╣ŗÕż¢’╝īµé©Ķ┐śÕÅ»õ╗źĶ┐ÉĶĪīÕŹĢõĖ¬µĄŗĶ»Ģµł¢õĖĆń╗䵥ŗĶ»ĢŃĆéõ╗źõĖŗµś»õĖĆõ║øńż║õŠŗÕæĮõ╗ż’╝Ü + +Ķ┐ÉĶĪīCPUµĄŗĶ»Ģ’╝Ü./Run cpu +Ķ┐ÉĶĪīÕåģÕŁśµĄŗĶ»Ģ’╝Ü./Run memory +Ķ┐ÉĶĪīńŻüńøśµĄŗĶ»Ģ’╝Ü./Run disk +Ķ┐ÉĶĪīµ¢ćõ╗Čń│╗ń╗¤µĄŗĶ»Ģ’╝Ü./Run fs +Ķ┐ÉĶĪīńĮæń╗£µĄŗĶ»Ģ’╝Ü./Run network + +## SysbenchÕĘźÕģĘ + +ÕåģÕ╗║µĄŗĶ»ĢķĪ╣ + +fileio’╝ܵ¢ćõ╗ČI/OµĄŗĶ»ĢŃĆé +cpu’╝ÜCPUµĆ¦ĶāĮµĄŗĶ»ĢŃĆé +memory’╝ÜÕåģÕŁśķƤÕ║”µĄŗĶ»ĢŃĆé +threads’╝Üń║┐ń©ŗÕŁÉń│╗ń╗¤µĆ¦ĶāĮµĄŗĶ»ĢŃĆé +mutex’╝Üõ║Ƶ¢źµĆ¦ĶāĮµĄŗĶ»ĢŃĆé +oltp’╝ÜOLTP’╝łÕ£©ń║┐õ║ŗÕŖĪÕżäńÉå’╝ēµĄŗĶ»ĢŃĆé + +## ÕģČõ╗¢ÕĘźÕģĘ + +Nagios’╝ÜõĖƵ¼ŠÕ╝Ƶ║ÉńÜäõ╝üõĖÜń║¦ IT Õ¤║ńĪĆĶ«Šµ¢ĮńøæµÄ¦ĶĮ»õ╗Č’╝īÕÅ»ńøæµĄŗµ£ŹÕŖĪÕÖ©ŃĆüńĮæń╗£Ķ«ŠÕżćŃĆüÕ║öńö©ń©ŗÕ║ÅńŁēÕżÜń¦ŹĶ«ŠÕżćÕÆīµ£ŹÕŖĪńŖȵĆüŃĆé + +Zabbix’╝ÜõĖƵ¼ŠÕŖ¤ĶāĮÕ╝║Õż¦ńÜäÕ╝Ƶ║ÉńĮæń╗£ńøæµÄ¦ĶĮ»õ╗Č’╝īµö»µīüÕżÜń¦ŹńøæµĄŗµ¢╣Õ╝Å’╝īÕ”é SNMPŃĆüJMXŃĆüIPMIŃĆüHTTP ńŁē’╝īÕ╣ČÕģʵ£ēĶć¬Õ«Üõ╣ēÕæŖĶŁ”ŃĆüµĢ░µŹ«ÕÅ»Ķ¦åÕī¢ńŁēÕŖ¤ĶāĮŃĆé + +Munin’╝ÜõĖƵ¼ŠÕ¤║õ║Ä Web ńÜäńøæµĄŗĶĮ»õ╗Č’╝īÕÅ»õ╗źńøæµĄŗ CPUŃĆüÕåģÕŁśŃĆüńŻüńøśŃĆüńĮæń╗£ńŁēÕżÜń¦Źń│╗ń╗¤µīćµĀć’╝īĶ┐śµö»µīüµÅÆõ╗ȵē®Õ▒ĢÕÆīµĢ░µŹ«ÕÅ»Ķ¦åÕī¢ŃĆé + +Cacti’╝ÜõĖƵ¼ŠÕ¤║õ║Ä RRDtool ńÜäńĮæń╗£ÕøŠÕĮóÕī¢ńøæµĄŗÕĘźÕģĘ’╝īÕÅ»õ╗źńøæµĄŗńĮæń╗£ÕĖ”Õ«ĮŃĆüĶĘ»ńö▒ÕÖ©ŃĆüõ║żµŹóµ£║ńŁēĶ«ŠÕżćńÜäńŖȵĆü’╝īÕ╣Čńö¤µłÉÕøŠĶĪ©ÕÆīµŖźÕæŖŃĆé + +Prometheus’╝ÜõĖƵ¼ŠÕ╝Ƶ║ÉńÜäµ£ŹÕŖĪńøæµĄŗń│╗ń╗¤’╝īÕÅ»ńøæµĄŗÕżÜń¦ŹÕ║öńö©ń©ŗÕ║ÅŃĆüµĢ░µŹ«Õ║ōŃĆüõĖŁķŚ┤õ╗ČńŁēµ£ŹÕŖĪńŖȵĆü’╝īÕ╣ȵÅÉõŠøµĢ░µŹ«ÕÅ»Ķ¦åÕī¢ÕÆīÕæŖĶŁ”ÕŖ¤ĶāĮŃĆé + +Sysdig’╝ÜõĖƵ¼ŠÕ¤║õ║Äń│╗ń╗¤Ķ░āńö©ĶʤĶĖ¬ńÜäÕ«╣ÕÖ©ńøæµĄŗÕĘźÕģĘ’╝īÕÅ»õ╗źńøæµĄŗÕ«╣ÕÖ©ńÜäĶ┐ÉĶĪīńŖȵĆüŃĆüĶĄäµ║ÉõĮ┐ńö©µāģÕåĄŃĆüńĮæń╗£µĄüķćÅńŁē’╝īÕ╣ȵÅÉõŠøµĢ░µŹ«ÕÅ»Ķ¦åÕī¢ÕÆīÕ«ēÕģ©Õłåµ×ÉÕŖ¤ĶāĮŃĆé + +Netdata’╝ÜõĖƵ¼ŠĶĮ╗ķćÅń║¦ńÜäÕ«×µŚČń│╗ń╗¤ńøæµĄŗÕĘźÕģĘ’╝īµö»µīüÕżÜń¦Źń│╗ń╗¤µīćµĀćÕÆīńĮæń╗£µĄüķćÅńøæµĄŗ’╝īÕ╣ČÕģʵ£ēµĢ░µŹ«ÕÅ»Ķ¦åÕī¢ÕÆīÕæŖĶŁ”ÕŖ¤ĶāĮŃĆé + +## ńĮæń╗£ńøæĶ¦åÕÖ©’╝īÕ”é tcpdumpŃĆüWireshark + +# 3. µŻĆµĄŗµŁźķ¬ż + +µŻĆµ¤źń│╗ń╗¤ĶĄäµ║ÉõĮ┐ńö©µāģÕåĄ’╝ÜÕÅ»õ╗źõĮ┐ńö© top ÕæĮõ╗żµ¤źń£ŗń│╗ń╗¤õĖŁµŁŻÕ£©Ķ┐ÉĶĪīńÜäĶ┐øń©ŗ’╝īõ╗źÕÅŖÕ«āõ╗¼ÕŹĀńö©ńÜä CPU ÕÆīÕåģÕŁśĶĄäµ║ÉŃĆéÕÅ»õ╗źõĮ┐ńö© free ÕæĮõ╗żµ¤źń£ŗń│╗ń╗¤õĖŁÕÅ»ńö©ńÜäÕåģÕŁśÕÆīõ║żµŹóń®║ķŚ┤ńÜäõĮ┐ńö©µāģÕåĄŃĆé + +µŻĆµ¤źńŻüńøśõĮ┐ńö©µāģÕåĄ’╝ÜÕÅ»õ╗źõĮ┐ńö© df ÕæĮõ╗żµ¤źń£ŗń│╗ń╗¤õĖŁńŻüńøśÕłåÕī║ńÜäõĮ┐ńö©µāģÕåĄ’╝īõ╗źÕÅŖÕē®õĮÖńÜäÕÅ»ńö©ń®║ķŚ┤ŃĆéÕÅ»õ╗źõĮ┐ńö© du ÕæĮõ╗żµ¤źń£ŗńē╣Õ«Üńø«ÕĮĢµł¢µ¢ćõ╗ČńÜäńŻüńøśõĮ┐ńö©µāģÕåĄŃĆé + +µŻĆµ¤źńĮæń╗£ÕĖ”Õ«ĮÕÆīĶ┐׵ğµāģÕåĄ’╝ÜÕÅ»õ╗źõĮ┐ńö© iftop ÕæĮõ╗żµ¤źń£ŗń│╗ń╗¤õĖŁµŁŻÕ£©õĮ┐ńö©ńÜäńĮæń╗£Ķ┐׵ğÕÆīÕĖ”Õ«ĮõĮ┐ńö©µāģÕåĄŃĆéÕÅ»õ╗źõĮ┐ńö© netstat ÕæĮõ╗żµ¤źń£ŗńē╣Õ«Üń½»ÕÅŻµł¢ÕŹÅĶ««ńÜäńĮæń╗£Ķ┐׵ğµāģÕåĄŃĆé + +µŻĆµ¤źń│╗ń╗¤Ķ┤¤ĶĮĮÕÆīµĆ¦ĶāĮµīćµĀć’╝ÜÕÅ»õ╗źõĮ┐ńö© uptime ÕæĮõ╗żµ¤źń£ŗń│╗ń╗¤ńÜäĶ┤¤ĶĮĮµāģÕåĄŃĆéÕÅ»õ╗źõĮ┐ńö© vmstat ÕæĮõ╗żµ¤źń£ŗń│╗ń╗¤ńÜäĶÖܵŗ¤ÕåģÕŁśõĮ┐ńö©µāģÕåĄÕÆī CPU õĮ┐ńö©µāģÕåĄŃĆéÕÅ»õ╗źõĮ┐ńö© iostat ÕæĮõ╗żµ¤źń£ŗń│╗ń╗¤ńÜäńŻüńøś I/O õĮ┐ńö©µāģÕåĄŃĆé + +Ķ┐øĶĪīÕ¤║ÕćåµĄŗĶ»Ģ’╝ÜÕÅ»õ╗źõĮ┐ńö©õĖĆõ║øÕ¤║ÕćåµĄŗĶ»ĢÕĘźÕģĘ’╝īÕ”é UnixBenchŃĆüGeekbenchŃĆüSysbench ńŁē’╝īÕ»╣ń│╗ń╗¤Ķ┐øĶĪīµĆ¦ĶāĮµĄŗĶ»Ģ’╝īõ╗źõŠ┐µ»öĶŠāõĖŹÕÉīń│╗ń╗¤µł¢õĖŹÕÉīķģŹńĮ«ńÜäµĆ¦ĶāĮÕĘ«Õ╝éŃĆé + +# 4. õĮ┐ńö©crontabիܵŚČĶ░āÕ║”õ╗╗ÕŖĪĶ┐øĶĪīĶć¬ÕŖ©Õī¢Ķ┐Éń╗┤’╝łÕ»╣ń│╗ń╗¤µŚźÕ┐ŚĶ┐øĶĪīÕżćõ╗ĮńŁē’╝ē + +µ£ēµŚČÕĆÖ’╝īõĖ║õ║åń│╗ń╗¤ń©│Õ«ÜµĆ¦,ķÖżõ║åÕ£©/var/logķĆÜĶ┐ćÕø×µ╗ܵ£║ÕłČńö¤µłÉÕÉäń¦ŹµŚźÕ┐Śµ¢ćõ╗Čõ╗źµÄƵ¤źń│╗ń╗¤µĢģķÜ£õ╣ŗÕż¢’╝īµłæõ╗¼õ╣¤µā│µŖŖĶ┐Öõ║øÕģ│ķö«ńÜ䵌źÕ┐Śµ¢ćõ╗Čõ┐ØÕŁśÕł░µīćիܵ¢ćõ╗ČÕż╣’╝īķś▓µŁóń¬üńäȵ¢ŁńöĄµł¢ĶĆģńŻüńøśÕłåÕī║Ķó½ńĀ┤ÕØÅõ╣ŗÕÉÄõĖóÕż▒Õģ│ķö«ńÜ䵌źÕ┐Śõ┐Īµü»ŃĆé + +õ╗ŻńĀüÕ”éõĖŗ’╝Ü’╝łµ¢ćõ╗ČÕÉŹõĖ║backup_sysconfig.sh’╝ē + +```shell +#! /bin/bash +# this script is used to backup the syslog file in /var/log dir everyday +echo `date` +cp /var/log/syslog /home/hugo/test_BASH/log/ +# adding the user with x permission +chmod u+x /home/hugo/test_BASH/log/syslog +# chnage the firname +today=$(date +%y%m%d) +echo $today +mv /home/hugo/test_BASH/log/syslog /home/hugo/test_BASH/log/syslog_$today +``` + +## իܵŚČĶ░āÕ║”õ╗╗ÕŖĪ + +crontab ńÜäĶ»ŁÕÅźµś»ŌĆ£Õłå µŚČ µŚź µ£ł Õæ© ÕæĮõ╗żŌĆØ. + +Õ╝ĆÕɻիܵŚČĶ░āÕ║”õ╗╗ÕŖĪ’╝īµ»ÅÕż®ÕćīµÖ©1ńé╣µē¦ĶĪīõĖƵ¼Ī + +```shell +crontab -e +# 0 1 * * * /home/hugo/test_BASH/backup_sysconfig.sh +``` + +µśŠńż║ `crontab: installing new crontab`’╝īĶĪ©ńż║իܵŚČõ╗╗ÕŖĪÕĘ▓ń╗ÅÕ╝ĆÕÉ»ŃĆé + +µ¤źń£ŗիܵŚČõ╗╗ÕŖĪ + +```shell +crontab -l +``` + +Õ╝ĆÕÉ»µł¢ĶĆģÕģ│ķŚŁÕ«ÜµŚČõ╗╗ÕŖĪ + +```shell +service crondstart +service crondstop + +``` diff --git "a/_posts/2023-03-26-\344\275\277\347\224\250cursor\350\207\252\345\212\250\345\214\226\347\224\237\346\210\220\344\273\243\347\240\201\347\273\230\345\210\266\345\271\277\344\270\234\347\234\201\345\234\260\345\233\276.md" "b/_posts/2023-03-26-\344\275\277\347\224\250cursor\350\207\252\345\212\250\345\214\226\347\224\237\346\210\220\344\273\243\347\240\201\347\273\230\345\210\266\345\271\277\344\270\234\347\234\201\345\234\260\345\233\276.md" new file mode 100644 index 0000000000..9e03157de9 --- /dev/null +++ "b/_posts/2023-03-26-\344\275\277\347\224\250cursor\350\207\252\345\212\250\345\214\226\347\224\237\346\210\220\344\273\243\347\240\201\347\273\230\345\210\266\345\271\277\344\270\234\347\234\201\345\234\260\345\233\276.md" @@ -0,0 +1,149 @@ +--- +layout: post +title: õĮ┐ńö©cursorĶć¬ÕŖ©Õī¢ńö¤µłÉõ╗ŻńĀüń╗śÕłČÕ╣┐õĖ£ń£üÕ£░ÕøŠ +date: 2023-03-26 +description: "õ╗ŗń╗Źõ║åÕ”éõĮĢõĮ┐ńö©cursorĶć¬ÕŖ©Õī¢ńö¤µłÉõ╗ŻńĀüń╗śÕłČÕ╣┐õĖ£ń£üÕ£░ÕøŠ" +tag: ńē®ńÉåµĄĘµ┤ŗÕŁ” +--- +## ÕćåÕżćÕĘźõĮ£ + +shpµ¢ćõ╗ȵś»õĖĆõĖ¬ń¤óķćŵ¢ćõ╗Č’╝īÕÅ»õ╗źńö©µØźń╗śÕłČÕ£░ÕøŠ’╝īÕīģµŗ¼guangdong.dbf’╝łÕ▒׵ƦĶĪ©’╝ēŃĆüguangdong.shp’╝łÕ£░ÕøŠõ┐Īµü»’╝ēŃĆüguangdong.shx’╝łń┤óÕ╝Ģõ┐Īµü»’╝ēŃĆé + +## cursorµś»õ╗Ćõ╣ł’╝¤ + +Cursor.so µś»õĖĆõĖ¬ķøåµłÉõ║å GPT-4 ńÜäÕøĮÕåģńø┤µÄźÕÅ»õ╗źĶ«┐ķŚ«ńÜä’╝īõ╝śń¦ĆĶĆīÕ╝║Õż¦ńÜäÕģŹĶ┤╣õ╗ŻńĀüńö¤µłÉÕÖ©’╝īÕÅ»õ╗źÕĖ«ÕŖ®õĮĀÕ┐½ķƤń╝¢ÕåÖŃĆüń╝¢ĶŠæÕÆīĶ«©Ķ«║õ╗ŻńĀüŃĆé + Õ«āµö»µīüÕżÜń¦Źń╝¢ń©ŗĶ»ŁĶ©Ć’╝īÕ”é Python, Java, C#, JavaScript ńŁē’╝īÕ╣ČõĖöÕÅ»õ╗źµĀ╣µŹ«õĮĀńÜäĶŠōÕģźÕÆīķ£Ćµ▒éĶć¬ÕŖ©ńö¤µłÉõ╗ŻńĀüńē浫ĄŃĆé + Cursor.so Ķ┐śÕÅ»õ╗źÕĖ«ÕŖ®õĮĀķ揵×äŃĆüńÉåĶ¦ŻÕÆīõ╝śÕī¢õ╗ŻńĀü’╝īµÅÉķ½śÕ╝ĆÕÅæµĢłńÄćŃĆé + +Õ«śńĮæÕ£░ÕØĆ’╝Ü[https://www.cursor.so/](https://www.cursor.so/) + +## õ╗ŻńĀüńö¤µłÉ + +### õĮ┐ńö©geopandas + +```python +import geopandas as gpd +import matplotlib.pyplot as plt + +# Read the shapefile +gdf = gpd.read_file('guangdong.shp', encoding='utf-8') + +# Plot the map +gdf.plot() + +# Show the plot +plt.show() +``` + +ń╗ōµ×£Õ”éõĖŗ’╝Ü + + + +### foliumÕÆīgeopandas + +folium Õ╗║ń½ŗÕ£© Python ńö¤µĆüń│╗ń╗¤ńÜäµĢ░µŹ«Õ║öńö©ĶāĮÕŖøÕÆī Leaflet.js Õ║ōńÜ䵜ĀÕ░äĶāĮÕŖøõ╣ŗõĖŖ’╝īÕ£©PythonõĖŁµōŹõĮ£µĢ░µŹ«’╝īńäČÕÉÄķĆÜĶ┐ć folium Õ£© Leaflet Õ£░ÕøŠõĖŁÕÅ»Ķ¦åÕī¢ŃĆé + +```python +import geopandas as gpd +import folium + +# Read the shapefile +gdf = gpd.read_file('guangdong.shp', encoding='utf-8') + +# Set the CRS of the GeoDataFrame +gdf = gdf.set_crs('EPSG:4326') + +# Create a new map +m = folium.Map(location=[23.5, 116.5], zoom_start=7) + +# Add the shapefile to the map +folium.GeoJson(gdf).add_to(m) + +# Save the map as an HTML file +m.save('map.html') +``` + +ń╗ōµ×£Õ”éõĖŗ’╝Ü + + + +### õĮ┐ńö©shapefile + +```python +import shapefile +import matplotlib.pyplot as plt + +# Read the shapefile +sf = shapefile.Reader("guangdong.shp") + +# Plot the map +for shape in sf.shapeRecords(): + x = [i[0] for i in shape.shape.points[:]] + y = [i[1] for i in shape.shape.points[:]] + plt.plot(x, y) + +# Show the plot +plt.show() + +# %% +import shapefile +import matplotlib.pyplot as plt + +# Read the shapefile +sf = shapefile.Reader("guangdong.shp") +``` + +### shapefile2 + +``` +import shapefile +import matplotlib.pyplot as plt + +# Read the shapefile +sf = shapefile.Reader("guangdong.shp") + +# Plot the map +for shape in sf.shapeRecords(): + x, y = zip(*shape.shape.points) + plt.plot(x, y) + +# Show the plot +plt.show() +``` + +ń╗ōµ×£Õ”éõĖŗ’╝Ü + + + +### õĮ┐ńö©basemap + + +```python +from mpl_toolkits.basemap import Basemap +import shapefile +import matplotlib.pyplot as plt + +# Read the shapefile +sf = shapefile.Reader("guangdong.shp") + +# Create a new map +m = Basemap(llcrnrlon=109, llcrnrlat=20, urcrnrlon=118, urcrnrlat=26, projection='lcc', lat_1=33, lat_2=45, lon_0=100) + +# Plot the map +for shape in sf.shapeRecords(): + x, y = zip(*shape.shape.points) + x, y = m(x, y) + m.plot(x, y, 'k-', linewidth=0.5) + +# Show the plot +plt.show() +``` + +ń╗ōµ×£Õ”éõĖŗ’╝Ü + + + + +## ķĪ╣ńø«Õ£░ÕØĆ + +[guangdong_map](https://github.com/ChanJeunlam/guangdong_map) \ No newline at end of file diff --git "a/_posts/2023-03-28-Linux\347\273\274\345\220\210\346\243\200\346\265\213\346\226\271\346\241\210\350\276\223\345\207\272\350\207\252\345\212\250\345\214\226\346\212\245\345\221\212.md" "b/_posts/2023-03-28-Linux\347\273\274\345\220\210\346\243\200\346\265\213\346\226\271\346\241\210\350\276\223\345\207\272\350\207\252\345\212\250\345\214\226\346\212\245\345\221\212.md" new file mode 100644 index 0000000000..905bc66a53 --- /dev/null +++ "b/_posts/2023-03-28-Linux\347\273\274\345\220\210\346\243\200\346\265\213\346\226\271\346\241\210\350\276\223\345\207\272\350\207\252\345\212\250\345\214\226\346\212\245\345\221\212.md" @@ -0,0 +1,106 @@ +--- +layout: post +title: Linuxń╗╝ÕÉłµŻĆµĄŗµ¢╣µĪłĶŠōÕć║Ķć¬ÕŖ©Õī¢µŖźÕæŖ +date: 2023-03-28 +description: "õĮ┐ńö©SHELLĶäܵ£¼ń╝¢ń©ŗ’╝īÕ»╣LinuxĶ┐øĶĪīń╗╝ÕÉłµŻĆµĄŗÕ╣ČÕ░åµŻĆµĄŗµ¢╣µĪłĶŠōÕć║Ķć¬ÕŖ©Õī¢µŖźÕæŖ" +tag: Linux +--- + + + +## õ╗ŻńĀü + +```shell +# µĘ╗ÕŖĀÕĮōÕēŹµŚČķŚ┤õ┐Īµü» +echo "ÕĮōÕēŹµŚČķŚ┤õĖ║$(date)" >> output.txt + +# õ╝ÜĶŠōÕć║ÕīģÕɽ "model name" ÕŁŚń¼”õĖ▓ńÜäĶĪī’╝īÕŹ│ CPU Õ×ŗÕÅĘńÜäõ┐Īµü» +model_name=$(cat /proc/cpuinfo | grep "model name" | head -n 1 | cut -d ":" -f 2 | xargs) +echo "CPUÕ×ŗÕÅĘõ┐Īµü»õĖ║$model_name" >> output.txt +# µ¤źń£ŗÕåģµĀĖµĀĖÕ┐āµĢ░ķćÅ +cpucores=$(cat /proc/cpuinfo | grep "cpu cores" | head -n 1 | cut -d ":" -f 2 | xargs) +echo "ÕåģµĀĖµĀĖÕ┐āµĢ░ķćÅõĖ║$cpucores" >> output.txt +# µ¤źń£ŗń│╗ń╗¤ CPU õĮ┐ńö©µāģÕåĄ +echo "ń│╗ń╗¤ CPU õĮ┐ńö©µāģÕåĄÕ”éõĖŗ’╝Ü" >> output.txt +iostat -c | awk '{if(NR==4){print "CPUń╣üÕ┐ÖÕ║”: "$1"%"} }' >> output.txt +iowait=$(iostat -c | awk '{if(NR==4){print $4} }') +if [ $(echo "$iowait >=60" | bc -l) -eq 1 ]; +then + echo "CPUńŁēÕŠģĶŠōÕģźĶŠōÕć║Õ«īµłÉµŚČķŚ┤ńÜäńÖŠÕłåµ»öõĖ║$iowait%,Ķ┐ćķ½ś’╝īĶĪ©ńż║ńĪ¼ńøśÕŁśÕ£©I/OńōČķółŃĆé" >> output.txt +else + echo "CPUńŁēÕŠģĶŠōÕģźĶŠōÕć║Õ«īµłÉµŚČķŚ┤ńÜäńÖŠÕłåµ»öõĖ║$iowait%,µŁŻÕĖĖŃĆé" >> output.txt +fi +# Õ”éµ×£%idleÕĆ╝ķ½ś’╝īĶĪ©ńż║CPUĶŠāń®║ķŚ▓ +# Õ”éµ×£%idleÕĆ╝µīüń╗ŁõĮÄõ║Ä10’╝īĶĪ©µśÄCPUÕżäńÉåĶāĮÕŖøńøĖÕ»╣ĶŠāõĮÄ’╝īń│╗ń╗¤õĖŁµ£Ćķ£ĆĶ”üĶ¦ŻÕå│ńÜäĶĄäµ║ɵś»CPUŃĆé +idle=$(iostat -c | awk '{if(NR==4){print $6} }') +if [ $(echo "$idle >= 90" | bc -l) -eq 1 ]; +then + echo "CPUĶŠāń®║ķŚ▓’╝ī%idleÕĆ╝õĖ║$idle" >> output.txt +elif [ $(echo "$idle < 10" | bc -l) -eq 1 ]; +then + echo "CPUÕżäńÉåĶāĮÕŖøńøĖÕ»╣ĶŠāõĮÄ’╝īidleÕĆ╝õĖ║$idle%" >> output.txt +fi + + +# ĶŠōÕć║ń│╗ń╗¤µĆ╗ÕåģÕŁś +MemTotal=$(cat /proc/meminfo | grep "MemTotal" | cut -d ":" -f 2 | xargs) +echo "ń│╗ń╗¤µĆ╗ÕåģÕŁśõĖ║$MemTotal" >> output.txt +# µ¤źń£ŗń│╗ń╗¤ń®║ķŚ▓ÕåģÕŁśÕż¦Õ░Å +MemFree=$(cat /proc/meminfo | grep "MemFree" | cut -d ":" -f 2 | xargs) +echo "ń│╗ń╗¤ń®║ķŚ▓ÕåģÕŁśõĖ║$MemFree" >> output.txt +# Cached’╝ÜÕłåķģŹń╗Öµ¢ćõ╗Čń╝ōÕå▓Õī║ńÜäÕåģÕŁś’╝łµ»öՔ鵣¬õ┐ØÕŁśńÜäµ¢ćõ╗ČÕ░▒µś»ÕåÖÕł░Ķ»źń╝ōÕå▓Õī║’╝ē +Cached=$(cat /proc/meminfo | grep "Cached" | head -n 1 | cut -d ":" -f 2 | xargs) +echo "ÕłåķģŹń╗Öµ¢ćõ╗Čń╝ōÕå▓Õī║ńÜäÕåģÕŁś’╝łµ»öՔ鵣¬õ┐ØÕŁśńÜäµ¢ćõ╗ČÕ░▒µś»ÕåÖÕł░Ķ»źń╝ōÕå▓Õī║’╝ēõĖ║$CachedŃĆé" >> output.txt + +# µ¤źń£ŗńŻüńøśõ┐Īµü» +echo "ńŻüńøśÕ«╣ķćÅõ┐Īµü»Õ”éõĖŗ’╝Ü" >> output.txt +df -h | sort -k 4 -hr | grep "µ¢ćõ╗Čń│╗ń╗¤" >> output.txt +df -h | sort -k 4 -hr | grep -v "µ¢ćõ╗Čń│╗ń╗¤" | grep -v "tmpfs" >> output.txt + +# µ¤źń£ŗńĮæń╗£ +PingInfo=$(ping -c 5 www.baidu.com | grep "bytes from" | head -n 1 ) +echo "ķĆÜĶ┐ćpingĶ«┐ķŚ«ńÖŠÕ║”ÕŠŚÕł░ńÜäõ┐Īµü»Õ”éõĖŗ’╝Ü\n $PingInfo">> output.txt +PingStatics=$(ping -c 5 www.baidu.com | grep "1 packets transmitted" | head -n 1 ) +echo "$PingStatics">> output.txt + +rtt=$(ping -c 5 www.baidu.com | grep "rtt" | cut -d "=" -f 2 | head -n 1 ) +rttmin=$(echo $rtt | cut -d "/" -f 1) +rttavg=$(echo $rtt | cut -d "/" -f 2) +rttmax=$(echo $rtt | cut -d "/" -f 3) +rttmdev=$(echo $rtt | cut -d "/" -f 4) +echo "ńĮæń╗£µ£ĆÕ░ŵŚČÕ╗ČõĖ║$rttmin ms" >> output.txt +echo "ńĮæń╗£Õ╣│ÕØ浌ČÕ╗ČõĖ║$rttavg ms" >> output.txt +echo "ńĮæń╗£µ£ĆÕż¦µŚČÕ╗ČõĖ║$rttmax ms" >> output.txt +echo "ńĮæń╗£µŚČÕ╗ČÕ╣│ÕØćÕüÅÕĘ«õĖ║$rttmdev" >> output.txt + +# perfµĆ¦ĶāĮńōČķółÕłåµ×É’╝īµ¤źń£ŗÕō¬õ║øĶ┐øń©ŗÕŹĀńö©CPUĶŠāķ½ś +# Õ«ēĶŻģÕæĮõ╗ż +# apt-get install linux-tools-$(uname -r) linux-tools-generic -y +# https://blog.51cto.com/liuzhengwei521/2360430 +#echo "CPUµĆ¦ĶāĮńōČķółÕłåµ×ÉÕ”éõĖŗ’╝Ü" >> output.txt +#perf top -b -p $(pidof nginx) >> output.txt + + +# µ¤źń£ŗń│╗ń╗¤Ķ┤¤ĶĮĮ +# https://blog.51cto.com/ghostwritten/5344990 +# Õ»╣CPUĶ┐øĶĪīÕÄŗÕŖøµĄŗĶ»Ģ +#cpu_number=$(grep -c 'processor' /proc/cpuinfo) +#ÕłøÕ╗║8õĖ¬stressĶ┐øń©ŗÕÆī100õĖ¬ioĶ┐øń©ŗ’╝īµīüń╗ŁµŚČķŚ┤600ń¦Æ’╝īµ©Īµŗ¤CPUÕ£©ńö©µłĘµĆüÕÆīÕåģµĀĖµĆüµĆ╗õĮ┐ńö©ńÄćĶŠŠÕł░100%ńÜäÕ£║µÖ»ŃĆé +#stress -c $cpu_number -i 100 --verbose --timeout 600 + +# Õ»╣ÕåģÕŁśĶ┐øĶĪīÕÄŗÕŖøµĄŗĶ»Ģ +# õĖŗķØóõŠŗÕŁÉ’╝īÕ░▒µś»ÕłøÕ╗║5õĖ¬Ķ┐øń©ŗ’╝īÕÉīµŚČÕÄ╗mallocÕłåķģŹÕåģÕŁś’╝īÕ╣ČõĖöõ┐صīü100sÕÉÄÕåŹķćŖµöŠÕåģÕŁś’╝Ü +# stress --vm 5 --vm-bytes 1G --vm-hang 100 --timeout 100s +# stress µĄŗĶ»ĢÕåģÕŁśńÜ䵌ČÕĆÖ’╝ī--vm-bytes 1G --vm-hang 100 Ķ┐Öķćī2õĖ¬ÕÅéµĢ░µś»Õģ│ķö«’╝ü’╝ü’╝ü’╝ü +# --vm-bytes ĶĪ©ńż║mallocÕłåķģŹÕżÜÕ░æÕåģÕŁś +# --vm-hang ĶĪ©ńż║mallocÕłåķģŹńÜäÕåģÕŁśÕżÜÕ░æµŚČķŚ┤ÕÉÄÕ£©free()ķćŖµöŠµÄē +# --vm µīćÕ«ÜĶ┐øń©ŗµĢ░ķćÅ’╝īÕłåķģŹńÜäÕåģÕŁśµĆ╗µĢ░õĖ║vm*vm-bytes +# --timeout µīüń╗ŁµŚČķŚ┤ + +# Õ»╣ńŻüńøśĶ┐øĶĪīÕÄŗÕŖøµĄŗĶ»Ģ’╝īÕ╣ČĶŠōÕć║ń╗ōµ×£Õł░µ¢ćõ╗Č +# stress --hdd 2 --hdd-bytes 3G --timeout 200 +# -hdd forks õ║¦ńö¤ÕżÜõĖ¬µē¦ĶĪīwrite()ÕćĮµĢ░ńÜäĶ┐øń©ŗ +# --hdd-bytes bytes µīćÕ«ÜÕåÖńÜäBytesµĢ░’╝īķ╗śĶ«żµś»1GB +``` + +## ń╗ōµ×£ diff --git "a/_posts/2023-03-29-Docker\345\205\245\351\227\250\345\237\272\347\241\200\347\237\245\350\257\206.md" "b/_posts/2023-03-29-Docker\345\205\245\351\227\250\345\237\272\347\241\200\347\237\245\350\257\206.md" new file mode 100644 index 0000000000..edaf919ceb --- /dev/null +++ "b/_posts/2023-03-29-Docker\345\205\245\351\227\250\345\237\272\347\241\200\347\237\245\350\257\206.md" @@ -0,0 +1,496 @@ +--- +layout: post +title: DockerÕģźķŚ©Õ¤║ńĪĆń¤źĶ»å +date: 2023-03-29 +description: "õ╗ŗń╗Źõ║åDockerÕģźķŚ©Õ¤║ńĪĆń¤źĶ»å" +tag: Docker +--- +### DockerńøĖÕģ│ńÜäµ”éÕ┐Ą + +#### 1.1 ĶÖܵŗ¤µ£║ÕÆīÕ«╣ÕÖ© + +ÕƤÕŖ®õ║ÄVMWareńŁēĶĮ»õ╗Č’╝īÕÅ»õ╗źÕ£©õĖĆÕÅ░Ķ«Īń«Śµ£║õĖŖÕłøÕ╗║ÕżÜõĖ¬ĶÖܵŗ¤µ£║’╝īµ»ÅõĖ¬ĶÖܵŗ¤µ£║ķāĮµŗźµ£ēńŗ¼ń½ŗńÜäµōŹõĮ£ń│╗ń╗¤’╝īÕÅ»õ╗źÕÉäĶć¬ńŗ¼ń½ŗńÜäĶ┐ÉĶĪīń©ŗÕ║ÅŃĆéĶ┐Öń¦ŹÕłåĶ║½µ£»ĶÖĮńäČķÜöń”╗Õ║”ķ½ś’╝łµōŹõĮ£ń│╗ń╗¤ń║¦’╝ē’╝īõĮ┐ńö©µ¢╣õŠ┐’╝łń▒╗õ╝╝ńē®ńÉåµ£║’╝ē’╝īõĮåÕŹĀńö©ÕŁśÕé©ĶĄäµ║ÉÕżÜ’╝łGBń║¦’╝ēŃĆüÕÉ»ÕŖ©ķƤÕ║”µģó’╝łÕłåķƤń║¦’╝ēńÜäń╝║ńé╣õ╣¤µś»µśŠĶĆīµśōĶ¦üńÜäŃĆé + +ńøĖĶŠāõ║ÄĶÖܵŗ¤µ£║’╝īÕ«╣ÕÖ©’╝łContainer’╝ēµś»õĖĆń¦ŹĶĮ╗ķćÅÕ×ŗńÜäĶÖܵŗ¤Õī¢µŖƵ£»’╝īÕ«āĶÖܵŗ¤ńÜ䵜»µ£Ćń«ĆĶ┐ÉĶĪīńÄ»Õóā’╝łń▒╗õ╝╝õ║ĵ▓ÖńøÆ’╝ēĶĆīķØ×µōŹõĮ£ń│╗ń╗¤’╝īÕÉ»ÕŖ©ķƤÕ║”Õ┐½’╝łń¦Æń║¦’╝ēŃĆüÕŹĀńö©ÕŁśÕé©ĶĄäµ║ÉÕ░æ’╝łKBń║¦µł¢MBń║¦’╝ē’╝īÕ«╣ÕÖ©ķŚ┤ķÜöń”╗Õ║”õĖ║Ķ┐øń©ŗń║¦ŃĆéÕ£©õĖĆÕÅ░Ķ«Īń«Śµ£║õĖŖÕÅ»õ╗źĶ┐ÉĶĪīõĖŖÕŹāõĖ¬Õ«╣ÕÖ©’╝īĶ┐Öµś»Õ«╣ÕÖ©µŖƵ£»Õ»╣ĶÖܵŗ¤µ£║ńÜäńóŠÕÄŗÕ╝Åõ╝śÕŖ┐ŃĆé + +#### 1.2 Õ«╣ÕÖ©ŃĆüķĢ£ÕāÅÕÆīDocker + +Dockerµś»õĖĆõĖ¬Õ╝Ƶ║ÉńÜäÕ║öńö©Õ«╣ÕÖ©Õ╝ĢµōÄ’╝īÕÅ»õ╗źÕłøÕ╗║Õ«╣ÕÖ©õ╗źÕÅŖÕ¤║õ║ÄÕ«╣ÕÖ©Ķ┐ÉĶĪīńÜäń©ŗÕ║ÅŃĆéDockerÕÅ»õ╗źĶ«®Õ╝ĆÕÅæĶĆģµēōÕīģõ╗¢õ╗¼ńÜäÕ║öńö©ÕÆīõŠØĶĄ¢ÕīģÕł░õĖĆõĖ¬ĶĮ╗ķćÅń║¦ŃĆüÕÅ»ń¦╗µżŹńÜäÕ«╣ÕÖ©õĖŁ’╝īńäČÕÉÄÕÅæÕĖāÕł░õ╗╗õĮĢµĄüĶĪīńÜäLinuxµ£║ÕÖ©õĖŖ’╝īõ╣¤ÕÅ»õ╗źÕ«×ńÄ░ĶÖܵŗ¤Õī¢ŃĆéÕ£©DockerÕÆīÕ«╣ÕÖ©õ╣ŗķŚ┤’╝īĶ┐śķÜÉĶŚÅńØĆõĖĆõĖ¬ķĢ£ÕāÅńÜäµ”éÕ┐ĄŃĆéµ£¼Ķ┤©õĖŖ’╝īDockerķĢ£Õāŵś»õĖĆõĖ¬ńē╣µ«ŖńÜäµ¢ćõ╗Čń│╗ń╗¤’╝īÕ«āµÅÉõŠøÕ«╣ÕÖ©Ķ┐ÉĶĪīµŚČµēĆķ£ĆńÜäń©ŗÕ║ÅŃĆüÕ║ōŃĆüĶĄäµ║ÉŃĆüķģŹńĮ«ńŁēµ¢ćõ╗ČŃĆéDockerķĢ£ÕāÅń▒╗õ╝╝õ║ÄõĖĆõĖ¬pyµ¢ćõ╗Č’╝īÕ«āķ£ĆĶ”üDockerńÜäĶ┐ÉĶĪīµŚČ’╝łń▒╗õ╝╝õ║ÄPythonĶ¦ŻķćŖÕÖ©’╝ēĶ┐ÉĶĪīŃĆéķĢ£ÕāÅĶó½Ķ┐ÉĶĪīµŚČ’╝īÕŹ│ÕłøÕ╗║õ║åõĖĆõĖ¬ķĢ£ÕāÅńÜäÕ«×õŠŗ’╝īõĖĆõĖ¬Õ«×õŠŗÕ░▒µś»õĖĆõĖ¬Õ«╣ÕÖ©ŃĆé + +ķĢ£ÕāÅ +µś»õĖĆõĖ¬µ×äÕ╗║Õ«╣ÕÖ©ńÜäÕŬĶ»╗µ©ĪµØ┐’╝īµś»õĖĆõĖ¬ÕīģÕɽõ║åÕ║öńö©ń©ŗÕ║ÅÕÆīÕģČĶ┐ÉĶĪīµŚČõŠØĶĄ¢ńÄ»ÕóāńÜäÕŬĶ»╗µ¢ćõ╗ČŃĆéÕ«āÕīģÕɽõ║åÕ«╣ÕÖ©ÕÉ»ÕŖ©µēĆķ£ĆńÜäµēƵ£ēõ┐Īµü»’╝īÕīģµŗ¼Ķ┐ÉĶĪīń©ŗÕ║ÅÕÆīķģŹńĮ«µĢ░µŹ«ŃĆéµ»ÅõĖĆõĖ¬ķĢ£ÕāÅńö▒õĖĆń│╗ÕłŚńÜäÕ▒é (layers) ń╗䵳ÉŃĆéDocker õĮ┐ńö© UnionFS µØźÕ░åĶ┐Öõ║øÕ▒éĶüöÕÉłÕł░ÕŹĢńŗ¼ńÜäķĢ£ÕāÅõĖŁŃĆéUnionFS ÕģüĶ«Ėńŗ¼ń½ŗµ¢ćõ╗Čń│╗ń╗¤õĖŁńÜäµ¢ćõ╗ČÕÆīµ¢ćõ╗ČÕż╣(ń¦░õ╣ŗõĖ║Õłåµö»)Ķó½ķĆŵśÄĶ”åńø¢’╝īÕĮóµłÉõĖĆõĖ¬ÕŹĢńŗ¼Ķ┐×Ķ┤»ńÜäµ¢ćõ╗Čń│╗ń╗¤ŃĆ鵣ŻÕøĀõĖ║µ£ēõ║åĶ┐Öõ║øÕ▒éńÜäÕŁśÕ£©’╝īDocker µś»Õ”鵣żńÜäĶĮ╗ķćÅŃĆéÕĮōõĮĀµö╣ÕÅśõ║åõĖĆõĖ¬ Docker ķĢ£ÕāÅ’╝īµ»öÕ”éÕŹćń║¦Õł░µ¤ÉõĖ¬ń©ŗÕ║ÅÕł░µ¢░ńÜäńēłµ£¼’╝īõĖĆõĖ¬µ¢░ńÜäÕ▒éõ╝ÜĶó½ÕłøÕ╗║ŃĆéÕøĀµŁż’╝īõĖŹńö©µø┐µŹóµĢ┤õĖ¬ÕĤÕģłńÜäķĢ£Õāŵł¢ĶĆģķ揵¢░Õ╗║ń½ŗ(Õ£©õĮ┐ńö©ĶÖܵŗ¤µ£║ńÜ䵌ČÕĆÖõĮĀÕÅ»ĶāĮõ╝ÜĶ┐Öõ╣łÕüÜ)’╝īÕŬµś»õĖĆõĖ¬µ¢░ńÜäÕ▒éĶó½µĘ╗ÕŖĀµł¢ÕŹćń║¦õ║åŃĆéńÄ░Õ£©õĮĀõĖŹńö©ķ揵¢░ÕÅæÕĖāµĢ┤õĖ¬ķĢ£ÕāÅ’╝īÕŬķ£ĆĶ”üÕŹćń║¦’╝īÕ▒éõĮ┐ÕŠŚÕłåÕÅæ Docker ķĢ£ÕāÅÕÅśÕŠŚń«ĆÕŹĢÕÆīÕ┐½ķƤŃĆé + +Õ«╣ÕÖ© +Õ«╣ÕÖ©µś»õ╗ÄķĢ£ÕāÅÕłøÕ╗║ńÜäĶ┐ÉĶĪīÕ«×õŠŗŃĆéÕ«āÕÅ»õ╗źĶó½ÕÉ»ÕŖ©ŃĆüÕ╝ĆÕ¦ŗŃĆüÕü£µŁóŃĆüÕłĀķÖżŃĆéµ»ÅõĖ¬Õ«╣ÕÖ©ķāĮµś»ńøĖõ║ÆķÜöń”╗ńÜäŃĆüõ┐ØĶ»üÕ«ēÕģ©ńÜäÕ╣│ÕÅ░ŃĆéDocker Õł®ńö©Õ«╣ÕÖ©µØźĶ┐ÉĶĪīÕ║öńö©ŃĆéõĖĆõĖ¬ Docker Õ«╣ÕÖ©ķāĮµś»ńŗ¼ń½ŗÕÆīÕ«ēÕģ©ńÜäÕ║öńö©Õ╣│ÕÅ░’╝īDocker Õ«╣ÕÖ©µś» Docker ńÜäĶ┐ÉĶĪīķā©ÕłåŃĆéÕÅ»õ╗źµŖŖÕ«╣ÕÖ©ń£ŗÕüܵś»õĖĆõĖ¬ń«ĆµśōńēłńÜä Linux ńÄ»Õóā’╝łÕīģµŗ¼rootńö©µłĘµØāķÖÉŃĆüĶ┐øń©ŗń®║ķŚ┤ŃĆüńö©µłĘń®║ķŚ┤ÕÆīńĮæń╗£ń®║ķŚ┤ńŁē’╝ēÕÆīĶ┐ÉĶĪīÕ£©ÕģČõĖŁńÜäÕ║öńö©ń©ŗÕ║ÅŃĆé + +µ│©’╝Ü ķĢ£Õāŵś»ÕŬĶ»╗ńÜä’╝īÕ«╣ÕÖ©Õ£©ÕÉ»ÕŖ©ńÜ䵌ČÕĆÖÕłøÕ╗║õĖĆÕ▒éÕÅ»ÕåÖÕ▒éõĮ£õĖ║µ£ĆõĖŖÕ▒éŃĆé + + + +Ķ┐ÉĶĪīÕ«╣ÕÖ©Õ«×õŠŗµ£ēõĖżń¦Źµ¢╣Õ╝Å’╝Ü + +õ║żõ║ÆÕ×ŗÕ«╣ÕÖ©’╝Ü ÕēŹÕÅ░Ķ┐ÉĶĪī’╝īÕÅ»õ╗źķĆÜĶ┐ćµÄ¦ÕłČÕÅ░õĖÄÕ«╣ÕÖ©õ║żõ║ÆŃĆéÕ”éµ×£ÕłøÕ╗║Ķ»źÕ«╣ÕÖ©ńÜäń╗łń½»Ķó½Õģ│ķŚŁ’╝īÕłÖÕ«╣ÕÖ©Õ░▒ÕÅśõĖ║Õü£µŁóńŖȵĆüŃĆ鵣żÕż¢’╝īÕ£©Õ«╣ÕÖ©µÄ¦ÕłČÕÅ░õĖŁĶŠōÕģźexitµł¢ĶĆģķĆÜĶ┐ćdocker stopµł¢docker killõ╣¤ĶāĮń╗łµŁóÕ«╣ÕÖ©ŃĆé +ÕÉÄÕÅ░Õ×ŗÕ«╣ÕÖ©’╝Ü ÕÉÄÕÅ░Ķ┐ÉĶĪī’╝īÕłøÕ╗║ÕÉ»ÕŖ©õ╣ŗÕÉÄÕ░▒õĖÄń╗łń½»µŚĀÕģ│õ║å’╝īķ£ĆĶ”üńö© docker stop µł¢ docker kill µØźń╗łµŁó’╝īµł¢ĶĆģ docker logs µ¤źń£ŗĶ┐ÉĶĪīõĖŁńÜäĶŠōÕć║ŃĆé +õ╗ōÕ║ō +Docker õ╗ōÕ║ōńö©µØźõ┐ØÕŁśķĢ£ÕāÅ’╝īÕÅ»õ╗źńÉåĶ¦ŻõĖ║õ╗ŻńĀüµÄ¦ÕłČõĖŁńÜäõ╗ŻńĀüõ╗ōÕ║ōŃĆéÕÉīµĀĘńÜä’╝īDocker õ╗ōÕ║ōõ╣¤µ£ēÕģ¼µ£ēÕÆīń¦üµ£ēńÜäµ”éÕ┐ĄŃĆéÕģ¼µ£ēńÜä Docker õ╗ōÕ║ōÕÉŹÕŁŚµś» Docker HubŃĆéDocker Hub µÅÉõŠøõ║åÕ║×Õż¦ńÜäķĢ£ÕāÅķøåÕÉłõŠøõĮ┐ńö©ŃĆéĶ┐Öõ║øķĢ£ÕāÅÕÅ»õ╗źµś»Ķć¬ÕĘ▒ÕłøÕ╗║’╝īµł¢ĶĆģÕ£©Õł½õ║║ńÜäķĢ£ÕāÅÕ¤║ńĪĆõĖŖÕłøÕ╗║ŃĆéDocker õ╗ōÕ║ōµś» Docker ńÜäÕłåÕÅæķā©ÕłåŃĆé + +Docker õ╗ōÕ║ōńÜäµ”éÕ┐ĄõĖÄ Git ńēłµ£¼µÄ¦ÕłČÕĘźÕģʵ£ēõ║øń▒╗õ╝╝’╝īµ│©Õåīµ£ŹÕŖĪÕÖ©ÕÅ»õ╗źńÉåĶ¦ŻõĖ║ GitHub Ķ┐ÖµĀĘńÜäµēśń«Īµ£ŹÕŖĪŃĆé + +### DockerńÜäÕ«ēĶŻģ + +#### 2.1 Õ£©ubuntuõĖŁÕ«ēĶŻģ + +Õ£©linuxń│╗ń╗¤õĖŁÕ«ēĶŻģDockerķØ×ÕĖĖń«ĆÕŹĢ’╝īÕ«śµ¢╣õĖ║µłæõ╗¼µÅÉõŠøõ║åõĖĆķö«Õ«ēĶŻģĶäܵ£¼ŃĆéĶ┐ÖõĖ¬µ¢╣µ│Ģõ╣¤ķĆéńö©õ║ÄDebianµł¢CentOSńŁēÕÅæĶĪīńēłŃĆé + +``` +curl┬Ā-sSL┬Āhttps://get.daocloud.io/docker┬Ā|┬Āsh +``` + +Õ«ēĶŻģĶ┐ćń©ŗÕ”éµ×£Õć║ńÄ░ĶČģµŚČ’╝īõĖŹĶ”üńü░Õ┐ā’╝īÕżÜĶ»ĢÕćĀµ¼Ī’╝īµĆ╗õ╝ܵłÉÕŖ¤ńÜäŃĆéÕ«ēĶŻģÕ«īµłÉÕÉÄ’╝īDockerÕŬĶāĮĶó½rootńö©µłĘõĮ┐ńö©’╝īÕÅ»õ╗źõĮ┐ńö©õĖŗķØóńÜäÕæĮõ╗żÕÅ¢µČłµØāķÖÉķÖÉÕłČ’╝Ü + +``` +sudo┬Āgpasswd┬Ā-a┬Ā<õĮĀńÜäńö©µłĘÕÉŹ>┬Ādocker +``` + +ńäČÕÉÄ’╝īķćŹÕÉ»dockerµ£ŹÕŖĪ’╝Ü + +``` +sudo┬Āservice┬Ādocker┬Ārestart +``` + +µ£ĆÕÉÄ’╝īÕģ│ķŚŁÕĮōÕēŹńÜäÕæĮõ╗żĶĪī’╝īķ揵¢░µēōÕ╝Ƶ¢░ńÜäÕæĮõ╗żĶĪīÕ░▒ÕÅ»õ╗źõ║åŃĆé + +### DockerķĢ£ÕāÅńÜäõĮ┐ńö© + +dockerÕ«śµ¢╣ńÜäķĢ£ÕāÅÕ║ōµ»öĶŠāµģó’╝īÕ£©Ķ┐øĶĪīķĢ£ÕāŵōŹõĮ£õ╣ŗÕēŹ’╝īķ£ĆĶ”üÕ░åķĢ£Õāŵ║ÉĶ«ŠńĮ«õĖ║ÕøĮÕåģńÜäń½Öńé╣ŃĆé + +µ¢░Õ╗║µ¢ćõ╗Č/etc/docker/daemon.json’╝īĶŠōÕģźÕ”éõĖŗÕåģÕ«╣’╝Ü + +``` +{ +┬Ā┬Ā┬Ā┬Ā"registry-mirrors"┬Ā:┬Ā[ +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā"https://registry.docker-cn.com", +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā"https://docker.mirrors.ustc.edu.cn", +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā"http://hub-mirror.c.163.com", +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā"https://cr.console.aliyun.com/" +┬Ā┬Ā┬Ā┬Ā] +} +``` + +ńäČÕÉÄķćŹÕÉ»dockerńÜäµ£ŹÕŖĪ’╝Ü + +``` +systemctl┬Ārestart┬Ādocker +``` + +#### 3.1 ÕłŚÕć║µ£¼Õ£░µēƵ£ēķĢ£ÕāÅ + +µē¦ĶĪīÕæĮõ╗ż docker images ÕÅ»õ╗źµ¤źń£ŗ + +``` +$┬Ādocker┬Āimages +REPOSITORY┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀTAG┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀIMAGE┬ĀID┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀCREATED┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀSIZE +ubuntu┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā20.04┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āf643c72bc252┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā5┬Āweeks┬Āago┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā72.9MB +hello-world┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ālatest┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ābf756fb1ae65┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā12┬Āmonths┬Āago┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā13.3kB +``` + +ÕĮōÕēŹµłæµ£¼Õ£░ÕŬµ£ēÕłÜµēŹÕ«ēĶŻģńÜäõĖżõĖ¬ķĢ£ÕāÅŃĆé + +#### 3.2 õ╗ÄķĢ£ÕāÅÕ║ōõĖŁµ¤źµēŠķĢ£ÕāÅ + +µē¦ĶĪīÕæĮõ╗ż docker search ķĢ£ÕāÅÕÉŹń¦░ÕÅ»õ╗źõ╗ÄdockerķĢ£ÕāÅÕ║ōõĖŁµ¤źµēŠķĢ£ÕāÅŃĆé + +``` +$┬Ādocker┬Āsearch┬Āpython +NAME┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀDESCRIPTION┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀSTARS┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀOFFICIAL┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀAUTOMATED +python┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀPython┬Āis┬Āan┬Āinterpreted,┬Āinteractive,┬ĀobjecŌĆ”┬Ā┬Ā┬Ā5757┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā[OK]┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā +django┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀDjango┬Āis┬Āa┬Āfree┬Āweb┬Āapplication┬Āframework,┬ĀŌĆ”┬Ā┬Ā┬Ā1039┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā[OK]┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā +pypy┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀPyPy┬Āis┬Āa┬Āfast,┬Ācompliant┬Āalternative┬ĀimplemŌĆ”┬Ā┬Ā┬Ā260┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā[OK]┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā +joyzoursky/python-chromedriver┬Ā┬Ā┬ĀPython┬Āwith┬ĀChromedriver,┬Āfor┬Ārunning┬ĀautomaŌĆ”┬Ā┬Ā┬Ā57┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā[OK] +nikolaik/python-nodejs┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀPython┬Āwith┬ĀNode.js┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā57┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā[OK] +arm32v7/python┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀPython┬Āis┬Āan┬Āinterpreted,┬Āinteractive,┬ĀobjecŌĆ”┬Ā┬Ā┬Ā53┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā +circleci/python┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀPython┬Āis┬Āan┬Āinterpreted,┬Āinteractive,┬ĀobjecŌĆ”┬Ā┬Ā┬Ā42┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā +centos/python-35-centos7┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀPlatform┬Āfor┬Ābuilding┬Āand┬Ārunning┬ĀPython┬Ā3.5ŌĆ”┬Ā┬Ā┬Ā38┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā +centos/python-36-centos7┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀPlatform┬Āfor┬Ābuilding┬Āand┬Ārunning┬ĀPython┬Ā3.6ŌĆ”┬Ā┬Ā┬Ā30┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā +hylang┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀHy┬Āis┬Āa┬ĀLisp┬Ādialect┬Āthat┬Ātranslates┬ĀexpressŌĆ”┬Ā┬Ā┬Ā29┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā[OK]┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā +arm64v8/python┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀPython┬Āis┬Āan┬Āinterpreted,┬Āinteractive,┬ĀobjecŌĆ”┬Ā┬Ā┬Ā24┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā +revolutionsystems/python┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀOptimized┬ĀPython┬ĀImages┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā18┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā +centos/python-27-centos7┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀPlatform┬Āfor┬Ābuilding┬Āand┬Ārunning┬ĀPython┬Ā2.7ŌĆ”┬Ā┬Ā┬Ā17┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā +bitnami/python┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀBitnami┬ĀPython┬ĀDocker┬ĀImage┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā10┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā[OK] +publicisworldwide/python-conda┬Ā┬Ā┬ĀBasic┬ĀPython┬Āenvironments┬Āwith┬ĀConda.┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā6┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā[OK] +d3fk/python_in_bottle┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀSimple┬Āpython:alpine┬Ācompleted┬Āby┬ĀBottle+ReqŌĆ”┬Ā┬Ā┬Ā5┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā[OK] +dockershelf/python┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀRepository┬Āfor┬Ādocker┬Āimages┬Āof┬ĀPython.┬ĀTestŌĆ”┬Ā┬Ā┬Ā5┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā[OK] +clearlinux/python┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀPython┬Āprogramming┬Āinterpreted┬Ālanguage┬ĀwithŌĆ”┬Ā┬Ā┬Ā4┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā +i386/python┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀPython┬Āis┬Āan┬Āinterpreted,┬Āinteractive,┬ĀobjecŌĆ”┬Ā┬Ā┬Ā3┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā +ppc64le/python┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀPython┬Āis┬Āan┬Āinterpreted,┬Āinteractive,┬ĀobjecŌĆ”┬Ā┬Ā┬Ā2┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā +centos/python-34-centos7┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀPlatform┬Āfor┬Ābuilding┬Āand┬Ārunning┬ĀPython┬Ā3.4ŌĆ”┬Ā┬Ā┬Ā2┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā +amd64/python┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀPython┬Āis┬Āan┬Āinterpreted,┬Āinteractive,┬ĀobjecŌĆ”┬Ā┬Ā┬Ā1┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā +ccitest/python┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀCircleCI┬Ātest┬Āimages┬Āfor┬ĀPython┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā0┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā[OK] +s390x/python┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀPython┬Āis┬Āan┬Āinterpreted,┬Āinteractive,┬ĀobjecŌĆ”┬Ā┬Ā┬Ā0┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā +saagie/python┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀRepo┬Āfor┬Āpython┬Ājobs┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā0 +``` + +µ£ĆÕźĮķĆēµŗ®Õ«śµ¢╣’╝łOFFICIAL’╝ēńÜäķĢ£ÕāÅ’╝īĶ┐ÖµĀĘńÜäķĢ£Õāŵ£Ćń©│Õ«ÜõĖĆõ║øŃĆé + +#### 3.3 õĖŗĶĮĮµ¢░ńÜäķĢ£ÕāÅ + +µē¦ĶĪīÕæĮõ╗żdocker pull ķĢ£ÕāÅÕÉŹń¦░:ńēłµ£¼ÕÅĘÕŹ│ÕÅ»õĖŗĶĮĮµ¢░ńÜäķĢ£ÕāÅŃĆé + +``` +$┬Ādocker┬Āpull┬Āpython:3.8 +3.8:┬ĀPulling┬Āfrom┬Ālibrary/python +6c33745f49b4:┬ĀPull┬Ācomplete┬Ā +ef072fc32a84:┬ĀPull┬Ācomplete┬Ā +c0afb8e68e0b:┬ĀPull┬Ācomplete┬Ā +d599c07d28e6:┬ĀPull┬Ācomplete┬Ā +f2ecc74db11a:┬ĀPull┬Ācomplete┬Ā +26856d31ce86:┬ĀPull┬Ācomplete┬Ā +2cd68d824f12:┬ĀPull┬Ācomplete┬Ā +7ea1535f18c3:┬ĀPull┬Ācomplete┬Ā +2bef93d9a76e:┬ĀPull┬Ācomplete┬Ā +Digest:┬Āsha256:9079aa8582543494225d2b3a28fce526d9a6b06eb06ce2bac3eeee592fcfc49e +Status:┬ĀDownloaded┬Ānewer┬Āimage┬Āfor┬Āpython:3.8 +docker.io/library/python:3.8 +``` + +ķĢ£ÕāÅõĖŗĶĮĮÕÉÄ’╝īÕ░▒ÕÅ»õ╗źõĮ┐ńö©ķĢ£ÕāÅµØźÕłøÕ╗║Õ«╣ÕÖ©õ║åŃĆé + +### DockerÕ«╣ÕÖ©ńÜäõĮ┐ńö© + +#### 4.1 ÕÉ»ÕŖ©Õ«╣ÕÖ© + +µē¦ĶĪīÕæĮõ╗żdocker runÕŹ│ÕÅ»ÕÉ»ÕŖ©Õ«╣ÕÖ©’╝īõ╣¤Õ░▒µś»ÕłøÕ╗║µ¤ÉõĖ¬ķĢ£ÕāÅńÜäÕ«×õŠŗŃĆédocker runÕæĮõ╗żķØ×ÕĖĖÕżŹµØé’╝īÕÅ»õ╗źÕģłµē¦ĶĪīõĖĆõĖ¬docker run --helpµØźµ¤źń£ŗÕĖ«ÕŖ®’╝Ü + +``` +$┬Ādocker┬Ārun┬Ā--help + +Usage:┬Ā┬Ādocker┬Ārun┬Ā[OPTIONS]┬ĀIMAGE┬Ā[COMMAND]┬Ā[ARG...] + +Run┬Āa┬Ācommand┬Āin┬Āa┬Ānew┬Ācontainer + +Options: +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--add-host┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀAdd┬Āa┬Ācustom┬Āhost-to-IP┬Āmapping┬Ā(host:ip) +┬Ā┬Ā-a,┬Ā--attach┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀAttach┬Āto┬ĀSTDIN,┬ĀSTDOUT┬Āor┬ĀSTDERR +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--blkio-weight┬Āuint16┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀBlock┬ĀIO┬Ā(relative┬Āweight),┬Ābetween┬Ā10┬Āand┬Ā1000,┬Āor┬Ā0┬Āto┬Ādisable┬Ā(default┬Ā0) +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--blkio-weight-device┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀBlock┬ĀIO┬Āweight┬Ā(relative┬Ādevice┬Āweight)┬Ā(default┬Ā[]) +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--cap-add┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀAdd┬ĀLinux┬Ācapabilities +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--cap-drop┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀDrop┬ĀLinux┬Ācapabilities +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--cgroup-parent┬Āstring┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀOptional┬Āparent┬Ācgroup┬Āfor┬Āthe┬Ācontainer +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--cidfile┬Āstring┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀWrite┬Āthe┬Ācontainer┬ĀID┬Āto┬Āthe┬Āfile +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--cpu-period┬Āint┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀLimit┬ĀCPU┬ĀCFS┬Ā(Completely┬ĀFair┬ĀScheduler)┬Āperiod +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--cpu-quota┬Āint┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀLimit┬ĀCPU┬ĀCFS┬Ā(Completely┬ĀFair┬ĀScheduler)┬Āquota +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--cpu-rt-period┬Āint┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀLimit┬ĀCPU┬Āreal-time┬Āperiod┬Āin┬Āmicroseconds +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--cpu-rt-runtime┬Āint┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀLimit┬ĀCPU┬Āreal-time┬Āruntime┬Āin┬Āmicroseconds +┬Ā┬Ā-c,┬Ā--cpu-shares┬Āint┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀCPU┬Āshares┬Ā(relative┬Āweight) +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--cpus┬Ādecimal┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀNumber┬Āof┬ĀCPUs +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--cpuset-cpus┬Āstring┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀCPUs┬Āin┬Āwhich┬Āto┬Āallow┬Āexecution┬Ā(0-3,┬Ā0,1) +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--cpuset-mems┬Āstring┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀMEMs┬Āin┬Āwhich┬Āto┬Āallow┬Āexecution┬Ā(0-3,┬Ā0,1) +┬Ā┬Ā-d,┬Ā--detach┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀRun┬Ācontainer┬Āin┬Ābackground┬Āand┬Āprint┬Ācontainer┬ĀID +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--detach-keys┬Āstring┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀOverride┬Āthe┬Ākey┬Āsequence┬Āfor┬Ādetaching┬Āa┬Ācontainer +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--device┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀAdd┬Āa┬Āhost┬Ādevice┬Āto┬Āthe┬Ācontainer +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--device-cgroup-rule┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀAdd┬Āa┬Ārule┬Āto┬Āthe┬Ācgroup┬Āallowed┬Ādevices┬Ālist +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--device-read-bps┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀLimit┬Āread┬Ārate┬Ā(bytes┬Āper┬Āsecond)┬Āfrom┬Āa┬Ādevice┬Ā(default┬Ā[]) +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--device-read-iops┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀLimit┬Āread┬Ārate┬Ā(IO┬Āper┬Āsecond)┬Āfrom┬Āa┬Ādevice┬Ā(default┬Ā[]) +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--device-write-bps┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀLimit┬Āwrite┬Ārate┬Ā(bytes┬Āper┬Āsecond)┬Āto┬Āa┬Ādevice┬Ā(default┬Ā[]) +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--device-write-iops┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀLimit┬Āwrite┬Ārate┬Ā(IO┬Āper┬Āsecond)┬Āto┬Āa┬Ādevice┬Ā(default┬Ā[]) +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--disable-content-trust┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀSkip┬Āimage┬Āverification┬Ā(default┬Ātrue) +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--dns┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀSet┬Ācustom┬ĀDNS┬Āservers +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--dns-option┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀSet┬ĀDNS┬Āoptions +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--dns-search┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀSet┬Ācustom┬ĀDNS┬Āsearch┬Ādomains +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--domainname┬Āstring┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀContainer┬ĀNIS┬Ādomain┬Āname +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--entrypoint┬Āstring┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀOverwrite┬Āthe┬Ādefault┬ĀENTRYPOINT┬Āof┬Āthe┬Āimage +┬Ā┬Ā-e,┬Ā--env┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀSet┬Āenvironment┬Āvariables +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--env-file┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀRead┬Āin┬Āa┬Āfile┬Āof┬Āenvironment┬Āvariables +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--expose┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀExpose┬Āa┬Āport┬Āor┬Āa┬Ārange┬Āof┬Āports +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--gpus┬Āgpu-request┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀGPU┬Ādevices┬Āto┬Āadd┬Āto┬Āthe┬Ācontainer┬Ā('all'┬Āto┬Āpass┬Āall┬ĀGPUs) +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--group-add┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀAdd┬Āadditional┬Āgroups┬Āto┬Ājoin +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--health-cmd┬Āstring┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀCommand┬Āto┬Ārun┬Āto┬Ācheck┬Āhealth +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--health-interval┬Āduration┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀTime┬Ābetween┬Ārunning┬Āthe┬Ācheck┬Ā(ms|s|m|h)┬Ā(default┬Ā0s) +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--health-retries┬Āint┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀConsecutive┬Āfailures┬Āneeded┬Āto┬Āreport┬Āunhealthy +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--health-start-period┬Āduration┬Ā┬Ā┬ĀStart┬Āperiod┬Āfor┬Āthe┬Ācontainer┬Āto┬Āinitialize┬Ābefore┬Āstarting┬Āhealth-retries┬Ācountdown┬Ā(ms|s|m|h)┬Ā(default┬Ā0s) +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--health-timeout┬Āduration┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀMaximum┬Ātime┬Āto┬Āallow┬Āone┬Ācheck┬Āto┬Ārun┬Ā(ms|s|m|h)┬Ā(default┬Ā0s) +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--help┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀPrint┬Āusage +┬Ā┬Ā-h,┬Ā--hostname┬Āstring┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀContainer┬Āhost┬Āname +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--init┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀRun┬Āan┬Āinit┬Āinside┬Āthe┬Ācontainer┬Āthat┬Āforwards┬Āsignals┬Āand┬Āreaps┬Āprocesses +┬Ā┬Ā-i,┬Ā--interactive┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀKeep┬ĀSTDIN┬Āopen┬Āeven┬Āif┬Ānot┬Āattached +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--ip┬Āstring┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀIPv4┬Āaddress┬Ā(e.g.,┬Ā172.30.100.104) +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--ip6┬Āstring┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀIPv6┬Āaddress┬Ā(e.g.,┬Ā2001:db8::33) +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--ipc┬Āstring┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀIPC┬Āmode┬Āto┬Āuse +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--isolation┬Āstring┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀContainer┬Āisolation┬Ātechnology +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--kernel-memory┬Ābytes┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀKernel┬Āmemory┬Ālimit +┬Ā┬Ā-l,┬Ā--label┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀSet┬Āmeta┬Ādata┬Āon┬Āa┬Ācontainer +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--label-file┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀRead┬Āin┬Āa┬Āline┬Ādelimited┬Āfile┬Āof┬Ālabels +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--link┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀAdd┬Ālink┬Āto┬Āanother┬Ācontainer +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--link-local-ip┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀContainer┬ĀIPv4/IPv6┬Ālink-local┬Āaddresses +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--log-driver┬Āstring┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀLogging┬Ādriver┬Āfor┬Āthe┬Ācontainer +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--log-opt┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀLog┬Ādriver┬Āoptions +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--mac-address┬Āstring┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀContainer┬ĀMAC┬Āaddress┬Ā(e.g.,┬Ā92:d0:c6:0a:29:33) +┬Ā┬Ā-m,┬Ā--memory┬Ābytes┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀMemory┬Ālimit +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--memory-reservation┬Ābytes┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀMemory┬Āsoft┬Ālimit +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--memory-swap┬Ābytes┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀSwap┬Ālimit┬Āequal┬Āto┬Āmemory┬Āplus┬Āswap:┬Ā'-1'┬Āto┬Āenable┬Āunlimited┬Āswap +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--memory-swappiness┬Āint┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀTune┬Ācontainer┬Āmemory┬Āswappiness┬Ā(0┬Āto┬Ā100)┬Ā(default┬Ā-1) +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--mount┬Āmount┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀAttach┬Āa┬Āfilesystem┬Āmount┬Āto┬Āthe┬Ācontainer +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--name┬Āstring┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀAssign┬Āa┬Āname┬Āto┬Āthe┬Ācontainer +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--network┬Ānetwork┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀConnect┬Āa┬Ācontainer┬Āto┬Āa┬Ānetwork +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--network-alias┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀAdd┬Ānetwork-scoped┬Āalias┬Āfor┬Āthe┬Ācontainer +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--no-healthcheck┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀDisable┬Āany┬Ācontainer-specified┬ĀHEALTHCHECK +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--oom-kill-disable┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀDisable┬ĀOOM┬ĀKiller +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--oom-score-adj┬Āint┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀTune┬Āhost's┬ĀOOM┬Āpreferences┬Ā(-1000┬Āto┬Ā1000) +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--pid┬Āstring┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀPID┬Ānamespace┬Āto┬Āuse +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--pids-limit┬Āint┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀTune┬Ācontainer┬Āpids┬Ālimit┬Ā(set┬Ā-1┬Āfor┬Āunlimited) +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--platform┬Āstring┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀSet┬Āplatform┬Āif┬Āserver┬Āis┬Āmulti-platform┬Ācapable +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--privileged┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀGive┬Āextended┬Āprivileges┬Āto┬Āthis┬Ācontainer +┬Ā┬Ā-p,┬Ā--publish┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀPublish┬Āa┬Ācontainer's┬Āport(s)┬Āto┬Āthe┬Āhost +┬Ā┬Ā-P,┬Ā--publish-all┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀPublish┬Āall┬Āexposed┬Āports┬Āto┬Ārandom┬Āports +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--read-only┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀMount┬Āthe┬Ācontainer's┬Āroot┬Āfilesystem┬Āas┬Āread┬Āonly +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--restart┬Āstring┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀRestart┬Āpolicy┬Āto┬Āapply┬Āwhen┬Āa┬Ācontainer┬Āexits┬Ā(default┬Ā"no") +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--rm┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀAutomatically┬Āremove┬Āthe┬Ācontainer┬Āwhen┬Āit┬Āexits +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--runtime┬Āstring┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀRuntime┬Āto┬Āuse┬Āfor┬Āthis┬Ācontainer +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--security-opt┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀSecurity┬ĀOptions +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--shm-size┬Ābytes┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀSize┬Āof┬Ā/dev/shm +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--sig-proxy┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀProxy┬Āreceived┬Āsignals┬Āto┬Āthe┬Āprocess┬Ā(default┬Ātrue) +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--stop-signal┬Āstring┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀSignal┬Āto┬Āstop┬Āa┬Ācontainer┬Ā(default┬Ā"SIGTERM") +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--stop-timeout┬Āint┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀTimeout┬Ā(in┬Āseconds)┬Āto┬Āstop┬Āa┬Ācontainer +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--storage-opt┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀStorage┬Ādriver┬Āoptions┬Āfor┬Āthe┬Ācontainer +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--sysctl┬Āmap┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀSysctl┬Āoptions┬Ā(default┬Āmap[]) +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--tmpfs┬Ālist┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀMount┬Āa┬Ātmpfs┬Ādirectory +┬Ā┬Ā-t,┬Ā--tty┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀAllocate┬Āa┬Āpseudo-TTY +┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā--ulimit┬Āulimit┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀUlimit┬Āoptions┬Ā(default┬Ā[]) +┬Ā┬Ā-u,┬Ā--user┬Āstring┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀUsername┬Āor┬ĀUID┬Ā(format:┬ĀHello World!
' +``` + +õ┐«ķź░ÕÖ©ÕÅ»õ╗źõĮ┐ńö©õĖŹÕÉīńÜäµ¢╣µ│Ģõ┐«ķź░ÕćĮµĢ░ńÜäĶĪīõĖ║’╝īµā»ÕĖĖµ¢╣µ│Ģµś»õĮ┐ńö©õ┐«ķź░ÕÖ©µŖŖÕćĮµĢ░µ│©ÕåīõĖ║õ║ŗõ╗ČńÜäÕżäńÉåń©ŗÕ║ÅŃĆé + +ÕāÅindex()Ķ┐ÖµĀĘńÜäÕćĮµĢ░Ķó½ń¦░õĖ║Ķ¦åÕøŠÕćĮµĢ░(view function)’╝īĶ¦åÕøŠÕćĮµĢ░ńÜäĶ┐öÕø×ÕĆ╝ÕÅ»õ╗źµś»ÕīģÕɽHTM;ńÜäń«ĆÕŹĢÕŁŚń¼”õĖ▓’╝īõ╣¤ÕÅ»õ╗źµś»ÕżŹµØéńÜäĶĪ©ÕŹĢŃĆé + +ńø┤µÄźÕÅ│ķö«Ķ┐ÉĶĪīń©ŗÕ║Å’╝īflaskõĖŹÕÉ»ÕŖ©’╝īÕĤÕøĀµś»µ▓Īµ£ēķģŹńĮ«ńÄ»ÕóāÕÅśķćÅ’╝īķ£ĆĶ”üÕ£©ÕæĮõ╗żĶĪīõĖŁĶ┐ÉĶĪīń©ŗÕ║Å’╝Ü + +```bash +export FLASK_APP=hello.py +export FLASK_ENV=development +flask run +# flask run -h ipaddress -p port +``` + +Õ£©windowsń│╗ń╗¤õĖŁ’╝īµ▓Īµ£ēexportÕæĮõ╗ż’╝īÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗÕæĮõ╗ż’╝Ü + +```bash +set FLASK_APP=hello.py +set FLASK_ENV=development +flask run +``` + +Ķ┐śµś»õĖŹĶĪī’╝īĶ»ĢõĖĆĶ»ĢĶ┐ÖõĖ¬’╝Ü + +```bash +$env:FLASK_APP="hello.py" +$env:FLASK_ENV="development" +flask run +``` + +Õ£©pycharmõĖŁÕÅ»õ╗źńø┤µÄźķģŹńĮ«configurationµØźĶ┐ÉĶĪīŃĆé + +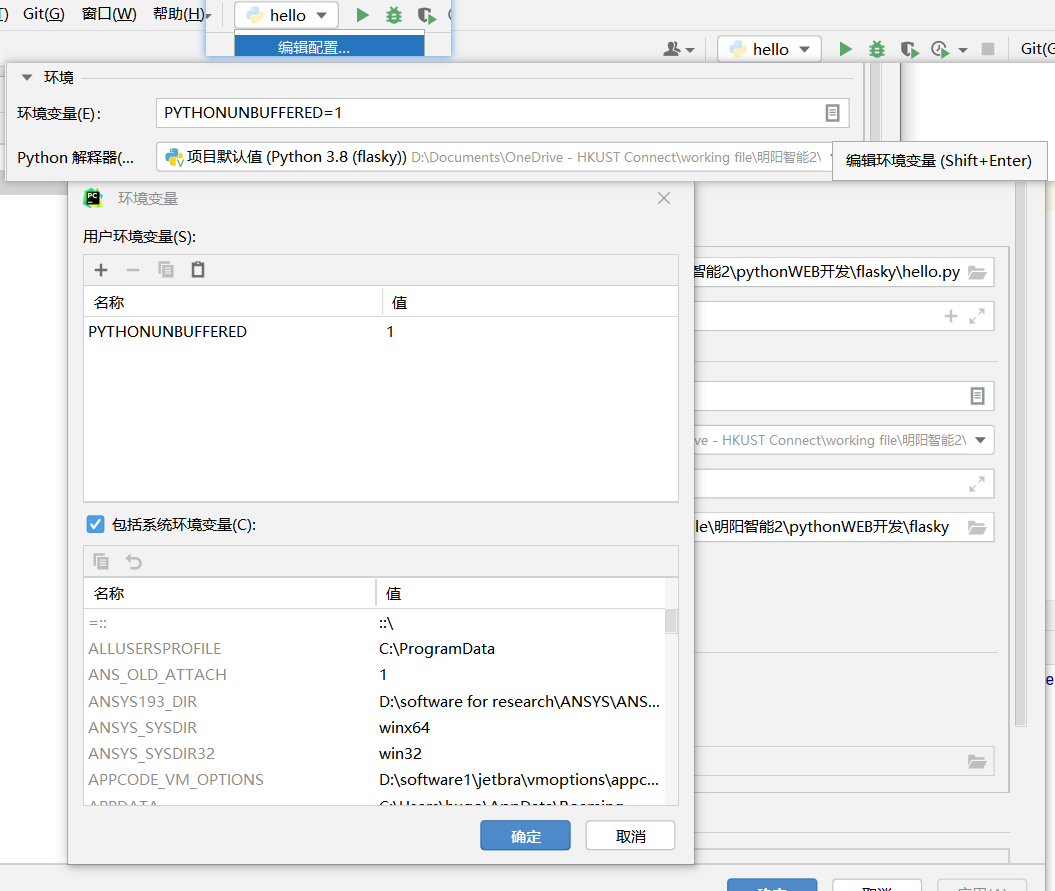 + +hello.pyµ¢ćõ╗ČõĖŁńÜäõ╗ŻńĀüÕ”éõĖŗ’╝Ü + +```python +from flask import Flask +app = Flask(__name__) + + +@app.route('/') +def index(): + return 'Hello World!
' + + +@app.route('/user/Hello, {}!
'.format(name) +``` + +Õ£░ÕØĆĶŠōÕģźhttp://127.0.0.1:5000/user/hugo’╝īÕÅ»õ╗źń£ŗÕł░ķĪĄķØ󵜊ńż║Hello, hugo! + +Õ£░ÕØĆĶŠōÕģźhttp://127.0.0.1:5000’╝īÕÅ»õ╗źń£ŗÕł░ķĪĄķØ󵜊ńż║Hello World! diff --git "a/_posts/2023-04-20-Hugging face\344\275\277\347\224\250\345\210\235\344\275\223\351\252\214.md" "b/_posts/2023-04-20-Hugging face\344\275\277\347\224\250\345\210\235\344\275\223\351\252\214.md" new file mode 100644 index 0000000000..d0c5d91182 --- /dev/null +++ "b/_posts/2023-04-20-Hugging face\344\275\277\347\224\250\345\210\235\344\275\223\351\252\214.md" @@ -0,0 +1,224 @@ +--- +layout: post +title: "Hugging faceõĮ┐ńö©ÕłØõĮōķ¬ī" +date: 2023-04-20 +description: "Hugging faceõĮ┐ńö©ÕłØõĮōķ¬ī" +tag: ÕĘźÕģĘń«▒ +--- +## 1. õ╗Ćõ╣łµś»Hugging face + +Hugging Face HubÕÆī Github ń▒╗õ╝╝’╝īķāĮµś»Hub(ńżŠÕī║)ŃĆéHugging FaceÕÅ»õ╗źĶ»┤ńÜäõĖŖµś»µ£║ÕÖ©ÕŁ”õ╣ĀńĢīńÜäGithubŃĆéHugging FaceõĖ║ńö©µłĘµÅÉõŠøõ║åõ╗źõĖŗõĖ╗Ķ”üÕŖ¤ĶāĮ’╝Ü + +* [µ©ĪÕ×ŗõ╗ōÕ║ō’╝łModel Repository’╝ē](https://huggingface.co/docs/hub/repositories-getting-started)’╝ÜGitõ╗ōÕ║ōÕÅ»õ╗źĶ«®õĮĀń«ĪńÉåõ╗ŻńĀüńēłµ£¼ŃĆüÕ╝Ƶ║Éõ╗ŻńĀüŃĆéĶĆīµ©ĪÕ×ŗõ╗ōÕ║ōÕÅ»õ╗źĶ«®õĮĀń«ĪńÉ嵩ĪÕ×ŗńēłµ£¼ŃĆüÕ╝Ƶ║ɵ©ĪÕ×ŗńŁēŃĆéõĮ┐ńö©µ¢╣Õ╝ÅõĖÄGithubń▒╗õ╝╝ŃĆé +* [µ©ĪÕ×ŗ’╝łModels’╝ē](https://huggingface.co/docs/hub/models)’╝ÜHugging FaceõĖ║õĖŹÕÉīńÜäµ£║ÕÖ©ÕŁ”õ╣Āõ╗╗ÕŖĪµÅÉõŠøõ║åĶ«ĖÕżÜ[ķóäĶ«Łń╗āÕźĮńÜäµ£║ÕÖ©ÕŁ”õ╣Āµ©ĪÕ×ŗ](https://huggingface.co/models)õŠøÕż¦Õ«ČõĮ┐ńö©’╝īĶ┐Öõ║øµ©ĪÕ×ŗÕ░▒ÕŁśÕé©Õ£©µ©ĪÕ×ŗõ╗ōÕ║ōõĖŁŃĆé +* [µĢ░µŹ«ķøå’╝łDataset’╝ē](https://huggingface.co/docs/hub/datasets)’╝ÜHugging FaceõĖŖµ£ēĶ«ĖÕżÜÕģ¼Õ╝ƵĢ░µŹ«ķøåŃĆé + +## 2. Hugging faceńÜäõĮ┐ńö© + +hugging faceÕ£©NLPķóåÕ¤¤µ£ĆÕć║ÕÉŹ’╝īÕģȵÅÉõŠøńÜ䵩ĪÕ×ŗÕż¦ÕżÜķāĮµś»Õ¤║õ║ÄTransformerńÜäŃĆé + +õĮĀÕÅ»õ╗źńö©Õ«āÕüÜõ╗źõĖŗõ║ŗµāģ’╝Ü + +* ńø┤µÄźõĮ┐ńö©ķóäĶ«Łń╗āµ©ĪÕ×ŗĶ┐øĶĪīµÄ©ńÉå +* µÅÉõŠøõ║åÕż¦ķćÅķóäĶ«Łń╗āµ©ĪÕ×ŗÕÅ»õŠøõĮ┐ńö© +* õĮ┐ńö©ķóäĶ«Łń╗āµ©ĪÕ×ŗĶ┐øĶĪīĶ┐üń¦╗ÕŁ”õ╣Ā + +### TransformersÕ«ēĶŻģ + +Õ«ēĶŻģTransformersķØ×ÕĖĖń«ĆÕŹĢ’╝īńø┤µÄźÕ«ēĶŻģÕŹ│ÕÅ»ŃĆé + +```shell +pip install transformers +1 +``` + +### õĮ┐ńö©TransformersĶ┐øĶĪīµÄ©ńÉå + +Õ”éµ×£õĮĀńÜäõ╗╗ÕŖĪµś»õĖĆõĖ¬µ»öĶŠāÕĖĖĶ¦üńÜä’╝īÕż¦µ”éńÄćÕÅ»õ╗źńø┤µÄźõĮ┐ńö©TransformerµÅÉõŠøńÜäPipelineĶ¦ŻÕå│ŃĆé + +µ»öÕ”éĶ»┤Ķ┐Ö’╝ī[PipelineŌĆöŌĆötransformers/v4.21.0/en/main_classes/pipelines](https://huggingface.co/docs/transformers/v4.21.0/en/main_classes/pipelines)APIĶ¦ŻÕå│’╝īÕģČõĮ┐ńö©µ¢╣Õ╝ÅķØ×ÕĖĖń«ĆÕŹĢ’╝īÕÅ»õ╗źĶ»┤µś»ńø┤µÄźńö©ÕŹ│ÕÅ»ŃĆé + +```python +from transformers import pipeline + +translator = pipeline("translation_en_to_fr") +print(translator("How old are you?")) +``` + +### Õ”éõĮĢµÉ£ń┤óµ©ĪÕ×ŗ + +ķ”¢Õģł’╝īµłæõ╗¼ķ£ĆĶ”üÕł░µØźÕł░Õ«śńĮæńÜä[µ©ĪÕ×ŗµ©ĪÕØŚ](https://huggingface.co/models)ŃĆé + +ÕģČõĖ╗Ķ”üÕīģÕɽõĖēķā©Õłå’╝Ü + +1. **Filter** : ńö©õ║ÄńŁøķĆēõĮĀµā│Ķ”üńÜ䵩ĪÕ×ŗ +2. **µ©ĪÕ×ŗÕłŚĶĪ©** : Õ▒Ģńż║õ║åÕÅ»õĮ┐ńö©ńÜ䵩ĪÕ×ŗŃĆéõĖŹÕĖ”ÕēŹń╝ĆńÜ䵜»Õ«śµ¢╣µÅÉõŠøńÜ䵩ĪÕ×ŗ’╝īõŠŗÕ”égpt2’╝īĶĆīÕĖ”ÕēŹń╝ĆńÜ䵜»ń¼¼õĖēµ¢╣µÅÉõŠøńÜ䵩ĪÕ×ŗŃĆé +3. **µÉ£ń┤óµĪå** ’╝ÜõĮĀÕÅ»õ╗źķĆÜĶ┐ćµÉ£ń┤óµĪåµīēÕÉŹÕŁŚµÉ£ń┤óµ©ĪÕ×ŗŃĆé + +ńé╣Ķ┐øÕÄ╗µ¤ÉõĖĆõĖ¬µ©ĪÕ×ŗ’╝īõĖ╗Ķ”üÕīģµŗ¼õ╗źõĖŗÕåģÕ«╣’╝Ü + +1. **µ©ĪÕ×ŗõ╗ŗń╗Ź’╝łModel Card’╝ē** : µłæõ╗¼ÕÅ»õ╗źķĆÜĶ┐ćĶ»źµ¢ćµĪŻµ¤źń£ŗĶ»źµ©ĪÕ×ŗķāĮµÅÉõŠøõ║åÕō¬õ║øÕŖ¤ĶāĮ’╝īµ©ĪÕ×ŗńÜäĶĪ©ńÄ░ńŁēŃĆé +2. **µ©ĪÕ×ŗµ¢ćõ╗Č’╝łFiles and versions)** : õ╗ÄĶ»źµ©ĪÕØŚÕÅ»õ╗źõĖŗĶĮĮµ©ĪÕ×ŗµ¢ćõ╗Č’╝īõĖĆĶł¼ÕīģÕÉ½ÕżÜń¦ŹµĪåµ×ČńÜä’╝łTFŃĆüPytorchńŁē’╝ēµ©ĪÕ×ŗµ¢ćõ╗ČÕÆīķģŹńĮ«µ¢ćõ╗ČńŁē’╝īÕÅ»õ╗źńö©õ║Äń”╗ń║┐ÕŖĀĶĮĮŃĆé +3. **µĄŗĶ»Ģµ©ĪÕ×ŗ(Hosted inference API)** : ÕÅ»õ╗źńø┤µÄźķĆÜĶ┐ćĶ»źµ©ĪÕØŚµĄŗĶ»ĢĶć¬ÕĘ▒ńÜ䵩ĪÕ×ŗŃĆéÕÉīµŚČHugging Faceõ╣¤µÅÉõŠøõ║åHttp APIÕÅ»õ╗źĶ░āńö©’╝īĶ┐ÖµĀĘÕ░▒õĖŹķ£ĆĶ”üµ£¼Õ£░ķā©ńĮ▓õ║åŃĆéĶ»”µāģĶ»ĘÕÅéĶĆā’╝Ühttps://huggingface.co/docs/api-inference/index +4. **õĮ┐ńö©Ķ»źµ©ĪÕ×ŗńÜäÕ║öńö©’╝łSpaces using ŌĆ”’╝ē** ’╝ÜĶ┐ÖķćīÕ▒Ģńż║õ║åõĮ┐ńö©Ķ»źµ©ĪÕ×ŗńÜäÕ║öńö©’╝īÕÅ»õ╗źńé╣Ķ┐øÕÄ╗ńÄ®õĖĆńÄ®ŃĆé +5. **õ╗ŻńĀüµĀĘõŠŗ’╝łUse in Transformers’╝ē** ’╝ÜõĮĀÕÅ»õ╗źķĆÜĶ┐ćĶ»źµ©ĪÕØŚńø┤µÄźµ¤źń£ŗĶ»źµ©ĪÕ×ŗńÜäõĮ┐ńö©µ¢╣Õ╝Å’╝īńø┤µÄźµŗĘĶ┤Øõ╗ŻńĀüÕł░ķĪ╣ńø«ķćīÕ░▒ÕÅ»õ╗źńö©õ║åŃĆé + +## ķā©ńĮ▓ + +### õĮ┐ńö©API + +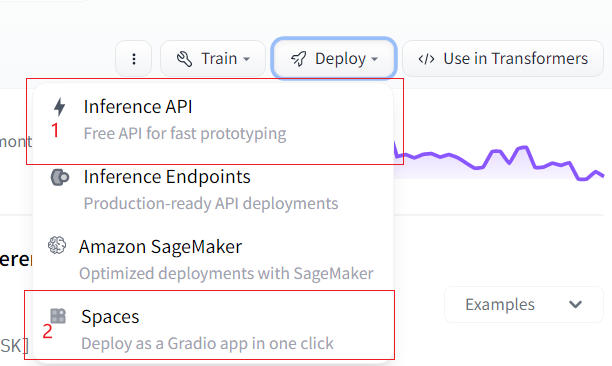 + +[bert-base-chinese](https://huggingface.co/bert-base-chinese) + + +```python +import requests + +API_URL = "https://api-inference.huggingface.co/models/bert-base-chinese" +headers = {"Authorization": "Bearer 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"} + +def query(payload): + response = requests.post(API_URL, headers=headers, json=payload) + return response.json() + +output = query({ + "inputs": "The answer to the universe is [MASK].", +}) +``` + +### õĮ┐ńö©space + +Ķ┐Öķćīµ£ēõĖ¬µ¢ćÕŁŚĶĮ¼µłÉĶ»Łķ¤│ńÜ䵩ĪÕ×ŗ’╝īÕÅ»õ╗źńø┤µÄźduplicate this space’╝īõ╗¢õ╝ÜÕ£©Ķć¬ÕĘ▒ńÜäń®║ķŚ┤ńö¤µłÉõĖĆõĖ¬GradiońÜäAPP,ńäČÕÉÄÕ░▒ÕÅ»õ╗źńø┤µÄźõĮ┐ńö©õ║åŃĆé + +[LINGUISTIC_ACCENTS](https://huggingface.co/spaces/Chandrabhan01/LINGUISTIC_ACCENTS) + +õ╣¤ÕÅ»õ╗źń£ŗõĖĆõĖŗĶ┐ÖõĖ¬repository’╝īķćīķØóńÜäfile’╝īÕÅæńÄ░ķØ×ÕĖĖń«ĆÕŹĢŃĆé + + + +ÕģČõĖŁńÜäapp.pyÕ”éõĖŗ’╝Ü’╝łĶ┐Öµ«Ąõ╗ŻńĀüµś»õĖĆõĖ¬µ¢ćµ£¼ĶĮ¼Ķ»Łķ¤│ńÜäÕ║öńö©ń©ŗÕ║Å’╝īµö»µīü50ÕżÜń¦ŹĶ»ŁĶ©ĆŃĆéÕ«āõĮ┐ńö©õ║åPythonõĖŁńÜägTTSÕ║ōÕÆīGradioÕ║ōŃĆéńö©µłĘÕÅ»õ╗źÕ£©µ¢ćµ£¼µĪåõĖŁĶŠōÕģźĶ”üĶĮ¼µŹóõĖ║Ķ»Łķ¤│ńÜäµ¢ćµ£¼’╝īķĆēµŗ®ńø«µĀćĶ»ŁĶ©ĆÕÆīÕÅŻķ¤│’╝īńäČÕÉĵīēõĖŗµÅÉõ║żµīēķÆ«ÕŹ│ÕÅ»ŃĆéÕ║öńö©ń©ŗÕ║ÅĶ┐śµÅÉõŠøõ║åõĖĆõĖ¬ķĆēķĪ╣ÕŹĪÕ╝ÅńĢīķØó’╝īńö©µłĘÕÅ»õ╗źÕ£©ÕģČõĖŁÕ░åĶŗ▒Ķ»ŁÕÅźÕŁÉń┐╗Ķ»æµłÉÕģČõ╗¢Ķ»ŁĶ©ĆÕ╣ČĶ┐øĶĪīĶ»Łķ¤│ÕÉłµłÉŃĆé’╝ē + +```python +import os +from gtts import gTTS +import gradio as gr +from translate import Translator + + +# os.environ['TF_CPP_MIN_LOG_LEVEL']='3' + +# auth_token = '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' # For accessing HuggingFace Facebook Model. + +class Languages: + """ Languages currently supported by the application. """ + # Language code + # lang (string, optional) ŌĆō The language (IETF language tag) to read the text in. Default is en. + lang = {'Afrikaans': 'af', 'Arabic': 'ar', 'Bulgarian': 'bg', 'Bengali': 'bn', 'Bosnian': 'bs', + 'Catalan': 'ca', 'Czech': 'cs', 'Danish': 'da', 'German': 'de', 'Greek': 'el', 'English': 'en', + 'Spanish': 'es', 'Estonian': 'et', 'Finnish': 'fi', 'French': 'fr', 'Gujarati': 'gu', 'Hindi': 'hi', + 'Croatian': 'hr', 'Hungarian': 'hu', 'Indonesian': 'id', 'Icelandic': 'is', 'Italian': 'it', + 'Hebrew': 'iw', 'Japanese': 'ja', 'Javanese': 'jw', 'Khmer': 'km', 'Kannada': 'kn', 'Korean': 'ko', + 'Latin': 'la', 'Latvian': 'lv', 'Malayalam': 'ml', 'Marathi': 'mr', 'Malay': 'ms', + 'Myanmar (Burmese)': 'my', 'Nepali': 'ne', 'Dutch': 'nl', 'Norwegian': 'no', + 'Polish': 'pl', 'Portuguese': 'pt', 'Romanian': 'ro', 'Russian': 'ru', 'Sinhala': 'si', + 'Slovak': 'sk', 'Albanian': 'sq', 'Serbian': 'sr', 'Sundanese': 'su', 'Swedish': 'sv', + 'Swahili': 'sw', 'Tamil': 'ta', 'Telugu': 'te', 'Thai': 'th', 'Filipino': 'tl', 'Turkish': 'tr', + 'Ukrainian': 'uk', 'Urdu': 'ur', 'Vietnamese': 'vi', 'Chinese (Simplified)': 'zh-CN', + 'Chinese (Mandarin/Taiwan)': 'zh-TW', + 'Chinese (Mandarin)': 'zh'} + + +class TLD: + """ Depending on the top-level domain, gTTS can speak in different accents. """ + + tld = {'English(Australia)': 'com.au', 'English (United Kingdom)': 'co.uk', + 'English (United States)': 'us', 'English (Canada)': 'ca', 'English (India)': 'co.in', + 'English (Ireland)': 'ie', 'English (South Africa)': 'co.za', 'French (Canada)': 'ca', + 'French (France)': 'fr', 'Portuguese (Brazil)': 'com.br', 'Portuguese (Portugal)': 'pt', + 'Spanish (Mexico)': 'com.mx', 'Spanish (Spain)': 'es', 'Spanish (United States)': 'us'} + + +class TTSLayer(): + """ Layer on top of gTTS - providing text to speech for """ + + def __init__(self, text, tld, lang) -> None: + """ [Constructor takes in text, the top-level domain and the language in which the text is : ] """ + self.text = text + self.tld = tld + self.lang = lang + + def tts(self): + """ [Converts the text to speech.] """ + tts = gTTS(text=self.text, tld=TLD.tld[self.tld], lang=Languages.lang[self.lang]) + tts.save('tts.mp3') + with open('tts.mp3') as fp: + return fp.name + + +langs = Languages() +top_level_domain = TLD() + +""" [Utiility Functions] """ + + +def T2TConversion(text, dest): + """ [(Utility Function) : Converts sentence from english to another language ] """ + translator = Translator(to_lang=langs.lang[dest]) + return translator.translate(text) + + +def convert_text(Text, Language, Accent): + """ [(Utility Function) : Performs Text-To-Speech provided language and accent.] """ + tts = TTSLayer(Text, Accent, Language) + return tts.tts() + + +class GRadioInterface: + """ [Class for managing UI for the application.] """ + + def __init__(self, function) -> None: + """ [Interface for packaging GRadio Application] """ + + # Necessary for interface + self._function = function + self._inputs = [ + gr.TextArea(label='The Text to be Converted to Audio'), + gr.Dropdown([key for key, _ in langs.lang.items()], label='Languages Available', ), + gr.Dropdown([key for key, _ in top_level_domain.tld.items()])] + + self.outputs = gr.Audio() + + # Necessary for descriptive content + self.title = 'A Text-To-Speech Converter for Low Resource Languages' + self.description = 'Support over 50 languages !' + self.article = 'How does it work ? Just write a sentence (in target language) in the space provided and select the target language and accent and press submit. That is it. Wait and Enjoy.' + + def start(self): + """ [Launching the interface in a tabbed manner.] """ + + it_1 = gr.Interface(fn=self._function, inputs=self._inputs, outputs=self.outputs, + title=self.title, + description=self.description, + article=self.article) + + it_2 = gr.Interface(fn=T2TConversion, + inputs=[ + gr.Text(label='Write a sentence in English'), + gr.Dropdown([key for key, _ in langs.lang.items()])], + outputs=gr.Text(label='The Converted Text'), + title='Translation from English', + description='Write a sentence in english and convert to other languages for speech synthesis', + article='What if you do not have a sentence in a particular language? Just write the sentence in english and let us do the magic.') + + demo = gr.TabbedInterface([it_1, it_2], ['Speech Synthesis', 'Sentence Translation']) + demo.launch() + + +demo_app = GRadioInterface(function=convert_text) +demo_app.start() +``` + +ńø┤µÄźµēƵŗēÕł░µ£¼Õ£░’╝īńäČÕÉÄĶ┐ÉĶĪī’╝īÕ░▒ÕÅ»õ╗źń£ŗÕł░ÕÆīspaceķćīķØóõĖƵĀĘńÜäµĢłµ×£õ║åŃĆé + +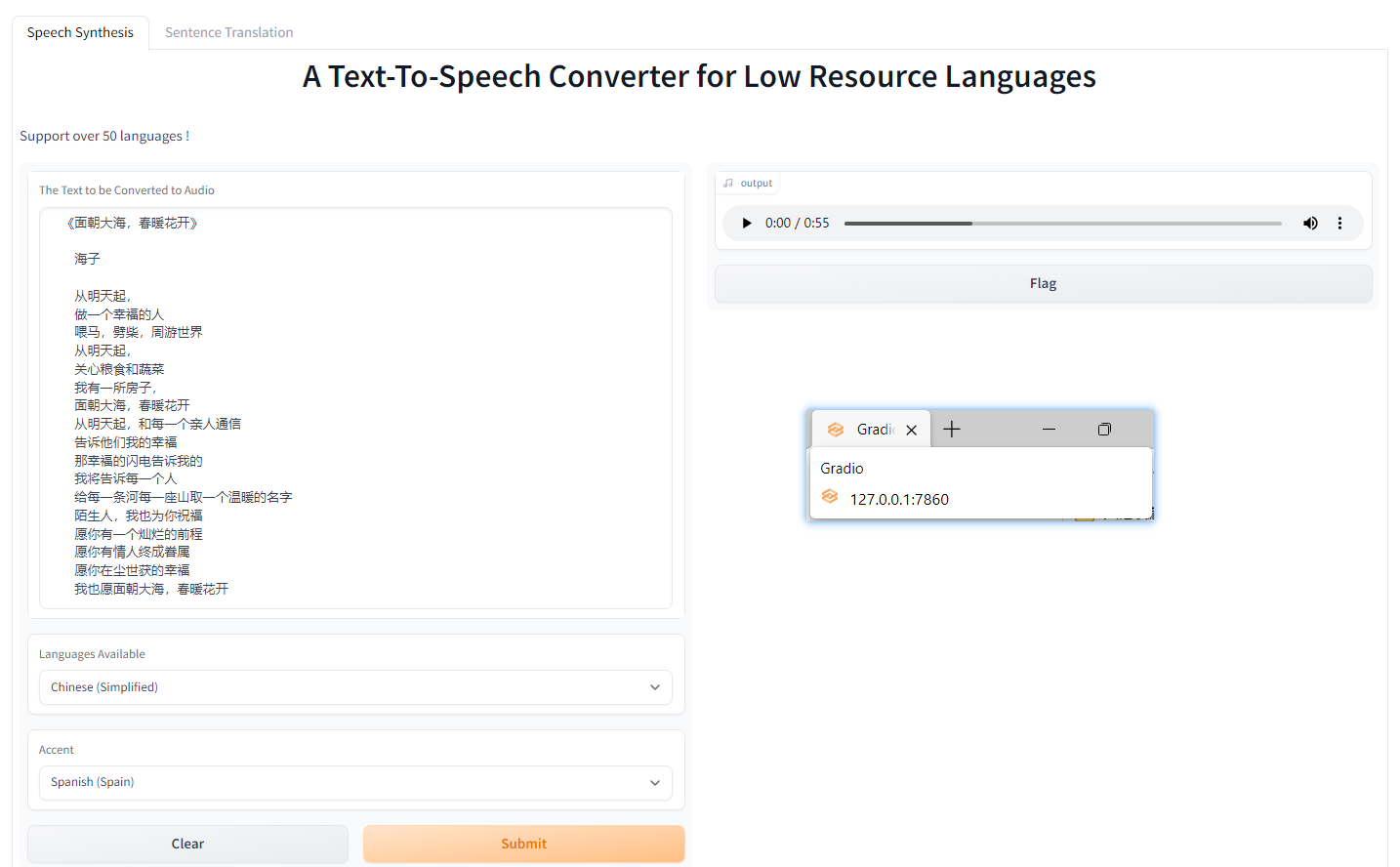 \ No newline at end of file diff --git "a/_posts/2023-04-20-\346\211\223\351\200\240\344\270\252\344\272\272github\351\246\226\351\241\265.md" "b/_posts/2023-04-20-\346\211\223\351\200\240\344\270\252\344\272\272github\351\246\226\351\241\265.md" new file mode 100644 index 0000000000..e6f4ae1b76 --- /dev/null +++ "b/_posts/2023-04-20-\346\211\223\351\200\240\344\270\252\344\272\272github\351\246\226\351\241\265.md" @@ -0,0 +1,227 @@ +--- +layout: post + +title: "µēōķĆĀõĖ¬õ║║githubķ”¢ķĪĄ" + +date: 2023-04-20 + +description: "õ╗ŖÕż®µĢÖÕż¦Õ«ČµēōķĆĀõĖĆõĖ¬ńé½ķģĘńÜä GitHub ķ”¢ķĪĄ" + +tag: õĖ¬õ║║ńĮæń½Ö +--- + +õ╗ŖÕż®µĢÖÕż¦Õ«ČµēōķĆĀõĖĆõĖ¬ńé½ķģĘńÜä GitHub ķ”¢ķĪĄŃĆé + +# Õ”éõĮĢÕ«×ńÄ░ + +ÕģČÕ«×Ķć¬Õ«Üõ╣ē Github ńÜäķ”¢ķĪĄÕŠłń«ĆÕŹĢ’╝īµłæõ╗¼ÕŬķ£ĆĶ”üµ¢░Õ╗║õĖĆõĖ¬õ╗ōÕ║ōÕÉŹÕÆīĶć¬ÕĘ▒ Github ńö©µłĘ ID ńøĖÕÉīńÜäõ╗ōÕ║ōÕ╣ČõĖöµĘ╗ÕŖĀõĖĆõĖ¬ README.md Ķć¬Ķ┐░µ¢ćõ╗ČÕŹ│ÕÅ»ŃĆé + +ńÉåĶ«║ÕŁśÕ£©’╝īÕ«×ĶĘĄÕ╝ĆÕ¦ŗ +µ¢░Õ╗║õĖĆõĖ¬ÕÉīÕÉŹõ╗ōÕ║ō’╝īµĘ╗ÕŖĀõĖĆõĖ¬Ķć¬Ķ┐░µ¢ćõ╗ČÕÉÄńé╣Õć╗ńĪ«Ķ«żŃĆé + +## 1ŃĆüTyping svg + +ńö©õ║Äńö¤µłÉÕŖ©µĆüńö¤µłÉńÜäŃĆüÕŻիÜÕłČńÜä SVGŃĆé + +Õ╝Ƶ║ÉķĪ╣ńø«Õ£░ÕØĆ’╝Ü [https://github.com/DenverCoder1/readme-typing-svg](https://github.com/DenverCoder1/readme-typing-svg) + +Õ£©ń║┐demoÕ£░ÕØĆ’╝Ü + +[Readme Typing SVG - Demo Site (demolab.com)](https://readme-typing-svg.demolab.com/demo/) + +µłæĶć¬ÕĘ▒ńö¤µłÉńÜäÕŖ©µĆüÕøŠÕ”éõĖŗ’╝Ü + +```markdown +[](https://git.io/typing-svg) +``` + +[](https://git.io/typing-svg) + +## 2ŃĆüShields.io + +Õ╝Ƶ║ÉķĪ╣ńø«Õ£░ÕØĆ’╝Ü [https://github.com/badges/shields](https://github.com/badges/shields) + +ÕÅéĶĆāķĪ╣ńø«Ķ»┤µśÄ’╝īÕżŹÕłČÕ”éõĖŗõ╗ŻńĀü’╝īõŠ┐ÕÅ»õ╗źÕ£© GitHub ķ”¢ķĪĄõĖŁÕ▒Ģńż║µé©µēĆķ£ĆĶ”üńÜäÕŠĮń½ĀÕøŠµĀćŃĆé + +Õ£©ń║┐demoÕ£░ÕØĆ’╝Ü + +[Shields.io: Quality metadata badges for open source projects](https://shields.io/#your-badge) + +µłæĶć¬ÕĘ▒ńö¤µłÉńÜäÕŠĮń½ĀÕøŠµĀćÕ”éõĖŗ’╝Üń¼¼õ║īõĖ¬ÕŠĮµĀćÕøŠµĀćÕż¢ķØóÕĄīÕźŚõ║åõĖĆõĖ¬ķōŠµÄź’╝īńé╣Õć╗ÕÉÄõ╝ÜĶĘ│ĶĮ¼Õł░µłæńÜäõĖ¬õ║║ńĮæń½ÖŃĆé + +```markdown + + +[](https://chanjeunlam.github.io/) +``` + + [](https://chanjeunlam.github.io/) + +## 3ŃĆüVisitor Badge + +Õ╝Ƶ║ÉķĪ╣ńø«Õ£░ÕØĆ’╝Ü https://github.com/jwenjian/visitor-badge + +Ķ┐ÖõĖ¬ÕøŠµĀćÕÆīõĖŖķØóńÜäÕŠĮń½Āń▒╗õ╝╝’╝īõĮåõĮ£ńö©õĖŹÕÉī’╝īĶ┐ÖõĖ¬ÕŠĮµĀćõ╝ÜÕ«×µŚČµö╣ÕÅś’╝īĶ«░ÕĮĢµŁżķĪĄķØóĶó½Ķ«┐ķŚ«ńÜäµ¼ĪµĢ░ŃĆé’╝łµ│©µäÅõ┐«µö╣ ID’╝ē + +```html +
+  +
+
+```
+
+µł¢ĶĆģńö©markdownĶ»Łµ│Ģ’╝Ü
+
+```markdown
+
+```
+
+## 4ŃĆüSpotify
+
+Õ╝Ƶ║ÉķĪ╣ńø«Õ£░ÕØĆ’╝Ü https://github.com/kittinan/spotify-github-profile
+
+ÕÅéĶĆāķĪ╣ńø«Ķ»┤µśÄ’╝īÕżŹÕłČÕ”éõĖŗõ╗ŻńĀü’╝łõ╗ģõŠøÕÅéĶĆā’╝ē’╝īõŠ┐ÕÅ»õ╗źÕ£© GitHub ķ”¢ķĪĄõĖŁÕ▒Ģńż║µé©µ£ĆĶ┐æÕ£© spotify õĖŁµēĆÕɼĶ┐ćńÜäķ¤│õ╣ÉŃĆé
+
+```html
+
+  +
+
+```
+
+µł¢ĶĆģńö©markdownĶ»Łµ│Ģ’╝Ü
+
+```markdown
+[](https://git.io/streak-stats)
+```
+
+## 7ŃĆüMetrics
+
+ÕĘźÕģĘńĮæń½Ö’╝Ü https://metrics.lecoq.io/
+
+Õ£©µĄÅĶ¦łÕÖ©õĖŁµēōÕ╝ĆõĖŖµ¢╣ķōŠµÄź’╝īÕ£©ÕĘ”õŠ¦ķĆēµŗ®µé©Ķ”üÕ▒Ģńż║ńÜäÕåģÕ«╣’╝īÕżŹÕłČÕÅ│ĶŠ╣ńÜä Maekdown õ╗ŻńĀüÕŹ│ÕÅ»ŃĆé
+
+
+
+```html
+
+  +
+
+```
+
+µł¢ĶĆģńö©markdownĶ»Łµ│Ģ’╝Ü
+
+```markdown
+
+
+```
+
+## 8ŃĆüQuotes
+
+Õ╝Ƶ║ÉķĪ╣ńø«Õ£░ÕØĆ’╝Ü https://github.com/shravan20/github-readme-quotes
+
+ÕÅéĶĆāķĪ╣ńø«Ķ»┤µśÄ’╝īÕżŹÕłČÕ”éõĖŗõ╗ŻńĀü’╝īõŠ┐ÕÅ»õ╗źÕ£© GitHub ķ”¢ķĪĄõĖŁķÜŵ£║Õ▒Ģńż║õĖƵ«ĄÕÉŹõ║║ÕÉŹĶ©ĆŃĆé
+
+```html
+
+  +
+
+```
+
+µł¢ĶĆģńö©markdownĶ»Łµ│Ģ’╝Ü
+
+```markdown
+[](https://github.com/ryo-ma/github-profile-trophy)
+```
+
+## 10ŃĆüGitHub ń╗¤Ķ«ĪÕŹĪńēć
+
+Õ╝Ƶ║ÉķĪ╣ńø«Õ£░ÕØĆ’╝Ü https://github.com/anuraghazra/github-readme-statsŌĆā
+
+ÕÅéĶĆāķĪ╣ńø«Ķ»┤µśÄ’╝īÕżŹÕłČÕ”éõĖŗõ╗ŻńĀü’╝īõŠ┐ÕÅ»õ╗źÕ£© GitHub ķ”¢ķĪĄõĖŁÕ▒Ģńż║µé©ńÜäń╝¢ńĀüµĢ░µŹ«ń╗¤Ķ«ĪÕøŠ’╝łµ│©µäÅõ┐«µö╣ ID’╝ē
+
+
+
+[](https://github.com/anuraghazra/github-readme-stats)
+
+
+```html
+
+  +
+
+
+  +
+
+```
+
+µł¢ĶĆģńö©markdownĶ»Łµ│Ģ’╝Ü
+
+```markdown
+
+
+[](https://github.com/anuraghazra/github-readme-stats)
+```
+
+## 11ŃĆüGitHub Readme Activity Graph
+
+Õ╝Ƶ║ÉķĪ╣ńø«Õ£░ÕØĆ’╝Ü https://github.com/Ashutosh00710/github-readme-activity-graph
+
+ÕÅéĶĆāķĪ╣ńø«Ķ»┤µśÄ’╝īÕżŹÕłČÕ”éõĖŗõ╗ŻńĀü’╝īõŠ┐ÕÅ»õ╗źÕ£© GitHub ķ”¢ķĪĄõĖŁÕ▒Ģńż║ GitHub µ┤╗ÕŖ©ń╗¤Ķ«ĪÕøŠ’╝łµ│©µäÅõ┐«µö╣ ID’╝ē
+
+```html
+
+  +
+
+```
+
+µł¢ĶĆģńö©markdownĶ»Łµ│Ģ’╝Ü
+
+```markdown
+[](https://github.com/sun0225SUN)
+```
+
+## µĪłõŠŗõ╗ōÕ║ō
+
+ÕźĮńÜäÕłøµäŵĆ╗µś»ĶāĮÕŹÜÕŠŚõ║║ńÜäÕģ│µ│©’╝īÕÉĖÕ╝Ģõ║║ńÜäń£╝ńÉāŃĆé
+
+ÕĮōµłæõ╗¼Õ£©ķĆø GitHub µŚČ’╝īÕ”éµ×£ķüćÕł░õ║åÕźĮń£ŗńÜäõĖ╗ķĪĄ’╝īµłæõ╗¼õŠ┐ÕÅ»õ╗źńø┤µÄźµŖŖõ╗¢µēÆõĖŗµØź’╝īõĖ║µłæµēĆńö©ŃĆé
+
+õĖŗķØóÕćĀõĖ¬õ╗ōÕ║ōµöČķøåõ║åõĖĆõ║øÕźĮń£ŗńÜä GitHub õĖ╗ķĪĄ’╝īõ╗ģõŠøÕż¦Õ«Čµ¼ŻĶĄÅÕÆīÕÅéĶĆāŃĆé
+
+Õ╝Ƶ║ÉÕ£░ÕØĆ’╝Ü https://github.com/EddieHubCommunity/awesome-github-profiles
+
+Õ╝Ƶ║ÉÕ£░ÕØĆ’╝Ü https://github.com/abhisheknaiidu/awesome-github-profile-readme
+
+Õ╝Ƶ║ÉÕ£░ÕØĆ’╝Ü https://github.com/eryajf/awesome-github-profile-readme-chinese
+
+# ÕÅéĶĆāķōŠµÄź
+
+[Õ░ÅÕŁÖÕÉīÕŁ”](https://blog.sunguoqi.com/archives/github_profile_0)
diff --git "a/_posts/2023-04-21-FlaskWeb\345\274\200\345\217\221\345\237\272\344\272\216Python\347\232\204Web\345\272\224\347\224\250\345\274\200\345\217\221\345\256\236\346\210\2302.md" "b/_posts/2023-04-21-FlaskWeb\345\274\200\345\217\221\345\237\272\344\272\216Python\347\232\204Web\345\272\224\347\224\250\345\274\200\345\217\221\345\256\236\346\210\2302.md"
new file mode 100644
index 0000000000..70d490c311
--- /dev/null
+++ "b/_posts/2023-04-21-FlaskWeb\345\274\200\345\217\221\345\237\272\344\272\216Python\347\232\204Web\345\272\224\347\224\250\345\274\200\345\217\221\345\256\236\346\210\2302.md"
@@ -0,0 +1,149 @@
+---
+layout: post
+title: "FlaskWebÕ╝ĆÕÅæÕ¤║õ║ÄPythonńÜäWebÕ║öńö©Õ╝ĆÕÅæÕ«×µłś2"
+date: 2023-04-21
+description: "FlaskWebÕ╝ĆÕÅæÕ¤║õ║ÄPythonńÜäWebÕ║öńö©Õ╝ĆÕÅæÕ«×µłś2"
+tag: Python
+---
+
+## 2.5 Ķ»Ęµ▒é-ÕōŹÕ║öÕŠ¬ńÄ»
+
+### 2.5.1 ń©ŗÕ║ÅÕÆīĶ»Ęµ▒éõĖŖõĖŗµ¢ć
+
+Flaskõ╗ÄÕ«óµłĘń½»µöČÕł░Ķ»Ęµ▒鵌Ȓ╝īĶ”üĶ«®Ķ¦åÕøŠÕćĮµĢ░ĶāĮĶ«┐ķŚ«õĖĆõ║øÕ»╣Ķ▒Ī’╝īĶ┐ÖµĀʵēŹĶāĮÕżäńÉåĶ»Ęµ▒éŃĆéFlaskµŖŖĶ┐Öõ║øÕ»╣Ķ▒ĪÕ░üĶŻģÕ£©õĖĆõĖ¬ÕŽÕüÜĶ»Ęµ▒éõĖŖõĖŗµ¢ć’╝łrequest context’╝ēńÜäÕ»╣Ķ▒ĪõĖŁ’╝īĶ┐ÖõĖ¬Õ»╣Ķ▒ĪÕ£©Ķ»Ęµ▒éĶó½ÕżäńÉåÕēŹĶó½µ┐Ƶ┤╗’╝īÕżäńÉåÕ«īµłÉÕÉÄĶó½Ķć¬ÕŖ©ķöƵ»üŃĆéFlaskõĮ┐ńö©õĖŖõĖŗµ¢ćÕģ©Õ▒ĆÕÅśķćÅ’╝łcontext global variable’╝ē**g**µØźÕŁśÕé©ÕżäńÉåĶ»Ęµ▒éµ£¤ķŚ┤ÕÅ»ĶāĮńö©Õł░ńÜäõĖ┤µŚČÕÅśķćÅŃĆéĶ┐Öõ║øÕÅśķćÅÕ£©Ķ»Ęµ▒éń╗ōµØ¤ÕÉÄĶć¬ÕŖ©µĖģńÉåŃĆé
+
+õĖŠõŠŗÕŁÉ’╝Ü
+
+```python
+from flask import request
+@app.route('/')
+def index():
+ user_agent = request.headers.get('User-Agent')
+ return 'Your browser is %s
' % user_agent +``` + +Õ£©Ķ┐ÖõĖ¬Ķ¦åÕøŠÕćĮµĢ░õĖŁ’╝īµłæõ╗¼µŖŖrequestÕĮōÕüÜÕģ©Õ▒ĆÕÅśķćÅõĮ┐ńö©ŃĆéõ║ŗÕ«×õĖŖ’╝īrequestõĖŹÕÅ»ĶāĮµś»Õģ©Õ▒ĆÕÅśķćÅŃĆéÕżÜõĖ¬ń║┐ń©ŗÕ£©ÕżäńÉåõĖŹÕÉīÕ«óµłĘń½»ÕÅæķĆüńÜäõĖŹķĆܵ░öĶ»Ęµ▒鵌Ȓ╝īµ»ÅõĖ¬ń║┐ń©ŗń£ŗÕł░ńÜärequestÕ»╣Ķ▒ĪÕ┐ģńäČõĖŹÕÉīŃĆéFlaskõĮ┐ńö©õĖŖõĖŗµ¢ćĶ«®ńē╣Õ«ÜńÜäÕÅśķćÅÕ£©õĖĆõĖ¬ń║┐ń©ŗõĖŁÕģ©Õ▒ĆÕÅ»Ķ«┐ķŚ«’╝īõĖĵŁżÕÉīµŚČń╝║õĖŹõ╝ÜÕ╣▓µē░ÕģČõ╗¢ń║┐ń©ŗŃĆé + + +’╝łÕżÜń║┐ń©ŗWebµ£ŹÕŖĪÕÖ©õ╝ÜÕłøÕ╗║õĖĆõĖ¬ń║┐ń©ŗµ▒Ā’╝īÕåŹõ╗Äń║┐ń©ŗµ▒ĀõĖŁÕÅ¢Õć║õĖĆõĖ¬ń║┐ń©ŗµØźÕżäńÉåĶ»Ęµ▒éŃĆé’╝ē + +ń©ŗÕ║ÅÕ£©õĖŖõĖŗµ¢ćĶó½µÄ©ķĆüÕÉÄ’╝īÕÅ»õ╗źÕ£©ń║┐ń©ŗõĖŁõĮ┐ńö©current_appÕÆīgÕÅśķćÅŃĆécurrent_appµś»ń©ŗÕ║ÅÕ«×õŠŗµ£¼Ķ║½’╝īgµś»õĖĆõĖ¬ń®║Õ»╣Ķ▒Ī’╝īńö©õ║ÄÕŁśÕé©Ķ»Ęµ▒éµ£¤ķŚ┤ńÜäõĖ┤µŚČÕÅśķćÅŃĆéĶ»Ęµ▒éõĖŖõĖŗµ¢ćĶó½µÄ©ķĆüõ╣ŗÕÉÄ’╝īÕ░▒ÕÅ»õ╗źõĮ┐ńö©requestÕÆīsessionÕÅśķćÅõ║åŃĆé + +õ╗źõĖŗµ╝öńż║õ║åń©ŗÕ║ÅõĖŖõĖŗµ¢ćńÜäõĮ┐ńö©µ¢╣µ│Ģ’╝Ü + + + + + +µ▓Īµ£ēµ┐Ƶ┤╗ń©ŗÕ║ÅõĖŖõĖŗµ¢ćõ╣ŗÕēŹÕ░▒Ķ░āńö©current_app.nameõ╝ܵŖźķöÖ’╝īõĮåµÄ©ķĆüÕ«īõĖŖõĖŗµ¢ćÕÉÄÕ░▒ÕÅ»õ╗źĶ░āńö©õ║åŃĆé’╝łÕ£©ń©ŗÕ║ÅÕ«×õŠŗõĖŖĶ░āńö©app.app_context()µ¢╣µ│Ģ’╝īĶ┐öÕø×õĖĆõĖ¬ń©ŗÕ║ÅõĖŖõĖŗµ¢ćÕ»╣Ķ▒ĪŃĆé’╝ē + + +### 2.5.2 Ķ»Ęµ▒éĶ░āÕ║” + +ń©ŗÕ║ŵöČÕł░Õ«óµłĘń½»ÕÅæµØźńÜäĶ»Ęµ▒鵌Ȓ╝īĶ”üµēŠÕł░ÕżäńÉåĶ»źĶ»Ęµ▒éńÜäĶ¦åÕøŠÕćĮµĢ░ŃĆéFlaskõĮ┐ńö©URLµśĀÕ░ä’╝łURL map’╝ēµØźÕ«×ńÄ░Ķ┐ÖõĖĆÕŖ¤ĶāĮŃĆéURLµśĀÕ░䵜»õĖĆõĖ¬µŖŖURLÕÆīĶ¦åÕøŠÕćĮµĢ░Õģ│ĶüöĶĄĘµØźńÜäÕŁŚÕģĖŃĆéFlaskÕ£©Ķ»Ęµ▒éĶó½ÕżäńÉåÕēŹ’╝īõ╝ܵŖŖURLµśĀÕ░äĶĪ©õ┐ØÕŁśÕ£©ń©ŗÕ║ÅõĖŖõĖŗµ¢ćõĖŁŃĆéĶ┐ÖµĀĘ’╝īÕĮōĶ»Ęµ▒éÕł░µØźµŚČ’╝īÕ░▒ÕÅ»õ╗źķĆÜĶ┐ćURLµśĀÕ░äĶĪ©µēŠÕł░Õ»╣Õ║öńÜäĶ¦åÕøŠÕćĮµĢ░ŃĆé + +FlaskõĮ┐ńö©app.routeõ┐«ķź░ÕÖ©µł¢ĶĆģķØ×õ┐«ķź░ÕÖ©ÕĮóÕ╝ÅńÜäapp.add_url_rule()ÕćĮµĢ░µØźńö¤µłÉURLµśĀÕ░äŃĆé + +µŻĆµ¤źõĖ║hello.pyń©ŗÕ║Åńö¤µłÉńÜäURLµśĀÕ░äĶĪ©’╝Ü + +```shell +(venv) $ python +>>> from hello import app +>>> app.url_map +Map([
+
+
+
+
+```
+
+Õ£©frontendµ¢ćõ╗ČÕż╣õĖŁµēōÕ╝Ćvue.config.jsµ¢ćõ╗Č’╝īÕ╣ČÕ░åõ╗źõĖŗõ╗ŻńĀüÕżŹÕłČÕł░Ķ»źµ¢ćõ╗ČõĖŁ’╝Ü
+
+```js
+module.exports = {
+ outputDir: '../backend/static'
+};
+```
+
+µŁżõ╗ŻńĀüÕ░åńö¤µłÉńÜäķØÖµĆüµ¢ćõ╗ČĶŠōÕć║Õł░backend/staticµ¢ćõ╗ČÕż╣õĖŁ!
+
+### Õ«ēĶŻģõŠØĶĄ¢
+
+Ķ┐öÕø×myappµ¢ćõ╗ČÕż╣’╝īÕ╣ČĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żµØźÕ«ēĶŻģÕ┐ģĶ”üńÜäPythonÕÆīJavaScriptõŠØĶĄ¢ķĪ╣’╝ü
+
+```bash
+cd .. # Ķ┐öÕø×myappµ¢ćõ╗ČÕż╣
+pip install -r backend/requirements.txt # Õ«ēĶŻģflask
+cd frontend
+npm install axios # Õ«ēĶŻģaxios,Ķ┐ÖõĖ¬µś»ńö©µØźÕÅæķĆühttpĶ»Ęµ▒éńÜä
+```
+
+## ÕÉ»ÕŖ©ķĪ╣ńø«
+
+### ÕÉ»ÕŖ©ÕÉÄń½»
+
+```bash
+cd .. # Ķ┐öÕø×myappµ¢ćõ╗ČÕż╣
+python backend/app.py
+```
+
+### ÕÉ»ÕŖ©ÕēŹń½»
+
+```bash
+cd frontend
+npm run serve
+```
+
+### Ķ«┐ķŚ«ķĪ╣ńø«
+
+µŁżµŚČ,ÕēŹÕÉÄń½»ķĪ╣ńø«ÕĘ▓ń╗ÅÕÉ»ÕŖ©!ÕÅ»õ╗źÕ£©WebµĄÅĶ¦łÕÖ©õĖŁĶ«┐ķŚ«http://localhost:5000µØźµ¤źń£ŗÕ║öńö©ń©ŗÕ║ÅŃĆé
+
+### ńø«ÕĮĢµĀæń╗ōµ×ä
+
+```
+myapp/
+Ōö£ŌöĆŌöĆ backend/
+Ōöé Ōö£ŌöĆŌöĆ app.py
+Ōöé ŌööŌöĆŌöĆ static/
+Ōöé Ōö£ŌöĆŌöĆ css/
+Ōöé Ōö£ŌöĆŌöĆ img/
+Ōöé ŌööŌöĆŌöĆ js/
+ŌööŌöĆŌöĆ frontend/
+ Ōö£ŌöĆŌöĆ public/
+ Ōö£ŌöĆŌöĆ src/
+ Ōö£ŌöĆŌöĆ vue.config.js
+ Ōö£ŌöĆŌöĆ package.json
+ ŌööŌöĆŌöĆ ...
+```
+
+ÕģČõ╗¢’╝Ü
+
+```
+project
+Ōö£ŌöĆŌöĆ backend
+| Ōö£ŌöĆŌöĆ app.py (FlaskÕÉÄń½»õĖ╗µ¢ćõ╗Č)
+| ŌööŌöĆŌöĆ requirements.txt (ÕÉÄń½»õŠØĶĄ¢)
+Ōö£ŌöĆŌöĆ frontend
+| Ōö£ŌöĆŌöĆ public
+| | ŌööŌöĆŌöĆ index.html
+| Ōö£ŌöĆŌöĆ src
+| | Ōö£ŌöĆŌöĆ main.js (ÕģźÕÅŻµ¢ćõ╗Č)
+| | Ōö£ŌöĆŌöĆ App.vue (õĖ╗ń╗äõ╗Č)
+| | ŌööŌöĆŌöĆ components (ÕģČõ╗¢ń╗äõ╗Č)
+| Ōö£ŌöĆŌöĆ package.json (ÕēŹń½»õŠØĶĄ¢)
+| ŌööŌöĆŌöĆ webpack.config.js (webpackķģŹńĮ«)
+ŌööŌöĆŌöĆ nginx
+ ŌööŌöĆŌöĆ default.conf (nginxķģŹńĮ«µ¢ćõ╗Č)
+```
+
+Õ£©µŁżńø«ÕĮĢµĀæń╗ōµ×äõĖŁ’╝ībackendµ¢ćõ╗ČÕż╣ÕīģÕɽÕÉÄń½»õ╗ŻńĀüÕÆīķØÖµĆüµ¢ćõ╗Č’╝īfrontendµ¢ćõ╗ČÕż╣ÕīģÕɽÕēŹń½»õ╗ŻńĀüÕÆīõŠØĶĄ¢ķĪ╣ŃĆéĶ»Ęµ│©µäÅ’╝īfrontend/publicµ¢ćõ╗ČÕż╣õĖŁńÜäµ¢ćõ╗ČÕ░åńø┤µÄźÕżŹÕłČÕł░ńö¤µłÉńÜäķØÖµĆüµ¢ćõ╗ČõĖŁ’╝īĶĆīfrontend/srcµ¢ćõ╗ČÕż╣õĖŁńÜäµ¢ćõ╗ČÕ░åĶó½ń╝¢Ķ»æÕÆīµēōÕīģõĖ║JavaScriptµ¢ćõ╗ČŃĆé
+
+## ķĪ╣ńø«ķā©ńĮ▓
+
+ķā©ńĮ▓ÕÅ»õ╗źµīēõ╗źõĖŗµĄüń©ŗĶ┐øĶĪī’╝Ü
+1.Õ£©µ£ŹÕŖĪÕÖ©õĖŖÕćåÕżćPythonŃĆüNodejsńŁēĶ┐ÉĶĪīńÄ»Õóā
+2. ķģŹńĮ«nginx,õ╗źÕÅŹÕÉæõ╗ŻńÉåµ¢╣Õ╝ÅÕżäńÉåÕēŹÕÉÄń½»Ķ»Ęµ▒é
+3. ÕÉÄń½»:
+ - õĖŖõ╝ĀFlaskÕ║öńö©õ╗ŻńĀü
+ - Õ«ēĶŻģõŠØĶĄ¢ pip install -r requirements.txt
+ - ÕÉ»ÕŖ©FlaskÕ║öńö©
+4. ÕēŹń½»:
+ - µ×äÕ╗║ńö¤µłÉķØÖµĆüµ¢ćõ╗Č npm run build
+ - õĖŖõ╝Ādistńø«ÕĮĢõĖŁńÜäķØÖµĆüµ¢ćõ╗ČÕł░µ£ŹÕŖĪÕÖ©
+5. nginxķģŹńĮ«:
+ - ķģŹńĮ«ĶĘ»ńö▒Ķ¦äÕłÖ,õŠŗÕ”é:/apiĶĮ¼ÕÅæÕł░flaskń½»ÕÅŻ/ĶĮ¼ÕÅæÕł░ķØÖµĆüµ¢ćõ╗Čńø«ÕĮĢ
+6. ÕÉ»ÕŖ©nginx
+7.µĄŗĶ»Ģķā©ńĮ▓µś»ÕÉ”µłÉÕŖ¤
+
+## µ│©µäÅõ║ŗķĪ╣
+
+- ÕēŹń½»’╝Ü
+
+1’╝ēĶ┐ÉĶĪīÕÉÄńÜäķĪ╣ńø«’╝īÕģČõ╗¢ń╗łń½»ĶāĮķĆÜĶ┐ć http://localhost:8080 Ķ«┐ķŚ«µ¤źń£ŗķĪĄķØóÕÉŚ’╝¤
+A’╝Ünpm run dev ÕæĮõ╗żÕŬńö©Õüܵ£¼Õ£░Ķ░āĶ»Ģ’╝īÕģ▒Õ╝ĆÕÅæĶĆģķóäĶ¦łķĪĄķØó’╝īÕÉīķā©ńĮ▓Õł░µ£ŹÕŖĪÕÖ©õŠøÕģČõ╗¢ń╗łń½»Ķ«┐ķŚ«µś»õĖŹÕÉīńÜä’╝īÕ”éµ×£Ķ”üµÅÉõŠøń╗ÖÕģČõ╗¢µĄÅĶ¦łÕÖ©µł¢ń╗łń½»õĮ┐ńö©’╝īÕłÖķ£ĆĶ”üķā©ńĮ▓Õł░ÕģĘõĮōńÜäµ£ŹÕŖĪÕÖ©µēŹĶĪīŃĆé
+2’╝ēÕ”éõĮĢÕ░å Vue ķĪ╣ńø«ķā©ńĮ▓Õł░µ£ŹÕŖĪÕÖ©õĖŖÕæó’╝¤
+µē¦ĶĪīÕæĮõ╗ż npm run build ńö¤µłÉ dist µ¢ćõ╗ČÕż╣’╝īńäČÕÉÄÕ░åĶ»źńø«ÕĮĢõĖŗńÜäµ¢ćõ╗Čķā©ńĮ▓Õł░µ£ŹÕŖĪÕÖ©’╝łµ£ŹÕŖĪÕÖ©Õ”épython’╝ītomcat’╝īnginx’╝ēŃĆé
+cd Õł░ dist ńø«ÕĮĢõĖŗ’╝īĶ┐ÖķćīõĮ┐ńö©µ£Ćń«ĆÕŹĢńÜä python µÉŁÕ╗║µ£ŹÕŖĪÕÖ©’╝īĶ┐ÉĶĪīÕæĮõ╗ż’╝Üpython -m http.server’╝īÕ░å dist õĖŗńÜäµ¢ćõ╗Čķā©ńĮ▓Õł░ Python Ķć¬ÕĖ”ńÜäµ£ŹÕŖĪÕÖ©õĖŁ’╝ø
+Ķ«┐ķŚ« http://YourIpAddress:8000/ ÕÅ»õ╗źńø┤µÄźÕ£©ÕģČõ╗¢ń╗łń½»µēōÕ╝ĆÕ»╣Õ║öńÜäķĪĄķØó’╝łpythonµÉŁÕ╗║ńÜäµ£ŹÕŖĪÕÖ©ÕåŹ8000ń½»ÕÅŻńøæÕɼ’╝ēŃĆé
+3’╝ēÕ”éõĮĢķĆÜĶ┐ć Vue Ķ»Ęµ▒éµ£ŹÕŖĪÕÖ©µÄźÕÅŻÕ╣ČĶÄĘÕÅ¢µĢ░µŹ«Õæó’╝¤
+
+- ÕÉÄń½»’╝Ü
+
+1’╝ēÕ”éõĮĢõĖ║Õż¢ķā©µÅÉõŠøµÄźÕÅŻ’╝¤’╝łbase_url = http://ip:5000’╝ē
+µ£ĆõĖ╗Ķ”üńÜäõĖĆõĖ¬Õ║ōµś» flask_cors’╝īķ£ĆĶ”üń╗¦ń╗ŁÕ«ēĶŻģ’╝īÕæĮõ╗ż’╝Üpip3 install -U flask-cors’╝ø
+µÄźÕÅŻÕÅ»õ╗źµś»’╝Übase_url, base_url + 'flask-route-method' , Õ»╣Õ║öµ¢╣µ│ĢõĖŁ’╝īreturn õŠ┐µś»Ķ┐öÕø×ń╗ÖÕ«óµłĘń½»ńÜäÕōŹÕ║öµĢ░µŹ«ŃĆé
+Tips’╝ÜĶ┐Öķćīµ£ēõĖĆõĖ¬ķŚ«ķóśÕ░▒µś»Õ”éµ×£Ķ┐ÉĶĪīµŚČńø┤µÄźµś» app.run() Õ░▒µś»Ķ┐ÉĶĪīÕ£©µ£¼Õ£░’╝īĶŗźµś»ķģŹńĮ«õ║å host ÕłÖÕÅ»õ╗źĶ┐ÉĶĪīÕ£©µīćիܵöČõ┐Īõ╗╗ńÜäÕģ¼ńĮæ’╝īÕģĘõĮōÕÅ»µ¤źń£ŗõĖŗķØóŃĆÉflask µ£ŹÕŖĪÕÖ©Õ«×ńÄ░õ╗ŻńĀüŃĆæń½ĀĶŖéŃĆé
+
+## ÕÅéĶĆāķōŠµÄź
+
+[flask+Python+VueÕ«×ńÄ░ÕēŹÕÉÄń½»Õłåń”╗ńÜäwebķĪ╣ńø«Õ╣Čķā©ńĮ▓Ķć│õ║æµ£ŹÕŖĪÕÖ©_flaskķĪ╣ńø«µēōÕīģÕ╣Čķā©ńĮ▓_chongÕó®Õä┐ńÜäÕŹÜÕ«ó-CSDNÕŹÜÕ«ó](https://blog.csdn.net/qq_42244418/article/details/129363764)
+
+[Vue ÕÆī Flask ÕēŹÕÉÄń½»Õłåń”╗µĢÖń©ŗ’╝łõĖĆ’╝ē - ń¤źõ╣Ä (zhihu.com)](https://zhuanlan.zhihu.com/p/622418838)
diff --git "a/_posts/2023-08-14-Ubuntu\345\210\233\345\273\272pycharm\347\232\204\345\277\253\346\215\267\346\226\271\345\274\217\344\270\244\347\247\215\346\226\271\346\263\225.md" "b/_posts/2023-08-14-Ubuntu\345\210\233\345\273\272pycharm\347\232\204\345\277\253\346\215\267\346\226\271\345\274\217\344\270\244\347\247\215\346\226\271\346\263\225.md"
new file mode 100644
index 0000000000..6206b57a86
--- /dev/null
+++ "b/_posts/2023-08-14-Ubuntu\345\210\233\345\273\272pycharm\347\232\204\345\277\253\346\215\267\346\226\271\345\274\217\344\270\244\347\247\215\346\226\271\346\263\225.md"
@@ -0,0 +1,30 @@
+---
+layout: post
+title: UbuntuÕłøÕ╗║pycharmńÜäÕ┐½µŹĘµ¢╣Õ╝ÅõĖżń¦Źµ¢╣µ│Ģ
+date: 2023-08-14
+description: "UbuntuÕłøÕ╗║pycharmńÜäÕ┐½µŹĘµ¢╣Õ╝ÅõĖżń¦Źµ¢╣µ│Ģ"
+tag: Linux
+---
+## µ¢╣µ│ĢõĖĆ
+
+1. µēōÕ╝Ćń╗łń½»’╝īĶŠōÕģźÕæĮõ╗ż’╝Ü`sudo gedit /usr/share/applications/pycharm.desktop`’╝īÕłøÕ╗║pycharm.desktopµ¢ćõ╗Č
+2. Õ£©pycharm.desktopµ¢ćõ╗ČõĖŁĶŠōÕģźõ╗źõĖŗÕåģÕ«╣’╝Ü
+
+```txt
+[Desktop Entry]
+Type=Application
+Name=Pycharm
+GenericName=Pycharm3
+Comment=Pycharm3:The Python IDE
+Exec=sh /home/hugo/Downloads/pycharm-community-2023.1.3/bin/pycharm.sh
+Icon=/home/hugo/Downloads/pycharm-community-2023.1.3/bin/pycharm.png
+Terminal=pycharm
+Categories=Pycharm;
+```
+
+## µ¢╣µ│Ģõ║ī
+
+1. µēōÕ╝ĆpycharmµēĆÕ£©ńø«ÕĮĢ’╝īĶ┐ÉĶĪīÕæĮõ╗ż’╝Ü`./bin/pycharm.sh`’╝īµēōÕ╝Ćpycharm;
+2. ńé╣Õć╗tools;
+3. ńé╣Õć╗Create Desktop Entry;
+4. add to favorites;
diff --git "a/_posts/2023-08-14-flask\344\270\255\345\246\202\344\275\225\346\223\215\344\275\234\346\225\260\346\215\256\345\272\223.md" "b/_posts/2023-08-14-flask\344\270\255\345\246\202\344\275\225\346\223\215\344\275\234\346\225\260\346\215\256\345\272\223.md"
new file mode 100644
index 0000000000..3dc426cd41
--- /dev/null
+++ "b/_posts/2023-08-14-flask\344\270\255\345\246\202\344\275\225\346\223\215\344\275\234\346\225\260\346\215\256\345\272\223.md"
@@ -0,0 +1,78 @@
+---
+layout: post
+title: flaskõĖŁÕ”éõĮĢµōŹõĮ£µĢ░µŹ«Õ║ō
+date: 2023-08-14
+description: "flaskõĖŁÕ”éõĮĢµōŹõĮ£µĢ░µŹ«Õ║ō"
+tag: ÕÉÄń½»
+---
+
+
+## pythonõĖŁµōŹõĮ£µĢ░µŹ«Õ║ō
+
+### ÕłøÕ╗║µĢ░µŹ«Õ║ō
+
+```python
+# pip install flask-sqlalchemy
+from flask_sqlalchemy import SQLAlchemy
+from flask import Flask
+# Ķ┐׵ğmysqlµĢ░µŹ«Õ║ōķ£ĆĶ”üÕ»╝Õģźpymysql
+import pymysql
+
+# ÕłøÕ╗║flaskÕ»╣Ķ▒Ī
+app = Flask(__name__)
+# Ķ┐׵ğmysql
+# app.config['SQLALCHEMY_DATABASE_URL']= 'mysql+pymysql://root:123456@localhost:3306/flask'
+# Ķ┐׵ğĶć¬ÕĖ”ńÜäsqliteµĢ░µŹ«Õ║ō
+app.config['SQLALCHEMY_DATABASE_URL']='sqlite:///'+"/home/hugo/test.db"
+
+app.config['SQLALCHEMY_TRACK_MODIFICATIONS']=False
+
+# Õ»åķÆź
+app.config['SECRET_KEY']='*'
+
+# Õ«×õŠŗÕī¢µĢ░µŹ«Õ║ōÕ»╣Ķ▒Ī
+db = SQLAlchemy(app)
+
+if __name__ == '__main__':
+ # ÕłĀķÖżĶĪ©
+ db.drop_all()
+ # ÕłøÕ╗║ĶĪ©
+ db.create_all()
+ # Ķ┐ÉĶĪīflask
+ app.run(debug=True)
+```
+
+
+## ķĆÜĶ┐浩ĪµØ┐Ķ┐øĶĪīõ║żõ║Æ
+
+### Jinja2µ©ĪµØ┐Ķ»ŁĶ©Ć
+
+```python
+
+
+Õ£©ķĪ╣ńø«µ¢ćõ╗ČÕż╣õĖŗÕłøÕ╗║templatesµ¢ćõ╗ČÕż╣’╝īńö©õ║ÄÕŁśµöŠhtmlµ¢ćõ╗Č’╝īµ»öÕ”éĶ»┤ÕŁśµöŠhello.htmlµ¢ćõ╗Č,Ķ┐ÖõĖ¬µ©ĪµØ┐µ¢ćõ╗Čńż║µäÅÕ”éõĖŗ’╝Ü
+
+```html
+
+Hello, {{ name }}!
+ +{{ code }}
+ Hello, {{ name }}!
+{% else %} +Hello, World!
+{% endif %} +{% block content %}{% endblock %} +``` + +Õ£©ķĪ╣ńø«ńÜäõĖ╗µ¢ćõ╗ČõĖŗ’╝īµ»öÕ”éĶ»┤app.pyµ¢ćõ╗Č’╝īńż║µäÅÕ”éõĖŗ’╝Ü + +```python +from flask import Flask, render_template + +app = Flask(__name__) + +@app.route('/hello/') +@app.route('/hello/õĖ║ÕĢźµā│ÕåÖÕŹÜÕ«ó
-µłæõ╗¼ńÜäÕŹÜÕ«ó
- -Ķ┐ÖõĖ¬ÕŹÜÕ«óµś»µłæõ╗¼Õż¦Õ«ČńÜä’╝īńø«ÕēŹÕĘ▓ń╗ŵ£ēÕŠłÕż¦õĖĆķā©Õłåõ║║Õ£©õĮ┐ńö©µłæńÜäÕŹÜÕ«óµ©ĪµØ┐õ║å’╝īµłæõ╣¤ÕŠłķ½śÕģ┤Õż¦Õ«ČõĮ┐ńö©µłæńÜ䵩ĪµØ┐ŃĆé - -Õ”éµ×£õĮĀµā│µÉŁÕ╗║õĖĆõĖ¬ĶʤµłæõĖƵĀĘńÜäÕŹÜÕ«ó’╝īÕÅ»õ╗źń£ŗµłæńÜä - Jekyll µÉŁÕ╗║õĖ¬õ║║ÕŹÜÕ«ó -µĢÖń©ŗ - - -µ£ēÕģ│õ║ÄÕŹÜÕ«óõĖ╗ķóśńÜäÕ╗║Ķ««ÕÆīµäÅĶ¦üķāĮÕÅ»õ╗źµÅÉń╗Öµłæ’╝īĶ«®µłæõ╗¼õĖĆĶĄĘµØźµēōķĆĀõĖĆõĖ¬ń▓ŠńŠÄńÜäõĖ╗ķóśÕɦ~ - -ÕŹÜÕ«óµ║ÉńĀüÕ£© Github õĖŖ’╝īõĮĀńÜä Star µś»µłæµø┤µ¢░ńÜäÕŖ©ÕŖø’╝īĶ░óĶ░ó~ - - -µÉŁÕ╗║ÕŹÜÕ«óķüćÕł░õ║åķŚ«ķóśĶ¦Żµ│Ģµ¢╣µ│Ģ
- -µ¤źń£ŗ [µŖƵ£»µö»µīü](http://leopardpan.cn/support/) ķ£Ćµ▒éÕĖ«ÕŖ® - -ÕŹÜÕ«óµ©ĪµØ┐õ╝ÜõĖĆńø┤µīüń╗Łµø┤µ¢░’╝īĶ»Ęµīüń╗ŁÕģ│µ│©µłæ’╝īĶ░óĶ░ó~ - -{% include comments.html %} diff --git "a/code/.ipynb_checkpoints/2022-07-11-D-Tale\345\272\223\344\273\213\347\273\215-checkpoint.ipynb" "b/code/.ipynb_checkpoints/2022-07-11-D-Tale\345\272\223\344\273\213\347\273\215-checkpoint.ipynb" new file mode 100644 index 0000000000..83e777a4d5 --- /dev/null +++ "b/code/.ipynb_checkpoints/2022-07-11-D-Tale\345\272\223\344\273\213\347\273\215-checkpoint.ipynb" @@ -0,0 +1,56 @@ +{ + "cells": [ + { + "cell_type": "code", + "execution_count": null, + "metadata": {}, + "outputs": [], + "source": [] + } + ], + "metadata": { + "kernelspec": { + "display_name": "Python 3", + "language": "python", + "name": "python3" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 3 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython3", + "version": "3.8.3" + }, + "toc": { + "base_numbering": 1, + "nav_menu": {}, + "number_sections": true, + "sideBar": true, + "skip_h1_title": false, + "title_cell": "Table of Contents", + "title_sidebar": "Contents", + "toc_cell": false, + "toc_position": {}, + "toc_section_display": true, + "toc_window_display": false + }, + "vp": { + "vp_config_version": "1.0.0", + "vp_menu_width": 273, + "vp_note_display": false, + "vp_note_width": 0, + "vp_position": { + "width": 278 + }, + "vp_section_display": false, + "vp_signature": "VisualPython" + } + }, + "nbformat": 4, + "nbformat_minor": 4 +} diff --git "a/code/2022-07-11-D-Tale\345\272\223\344\273\213\347\273\215.ipynb" "b/code/2022-07-11-D-Tale\345\272\223\344\273\213\347\273\215.ipynb" new file mode 100644 index 0000000000..83e777a4d5 --- /dev/null +++ "b/code/2022-07-11-D-Tale\345\272\223\344\273\213\347\273\215.ipynb" @@ -0,0 +1,56 @@ +{ + "cells": [ + { + "cell_type": "code", + "execution_count": null, + "metadata": {}, + "outputs": [], + "source": [] + } + ], + "metadata": { + "kernelspec": { + "display_name": "Python 3", + "language": "python", + "name": "python3" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 3 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython3", + "version": "3.8.3" + }, + "toc": { + "base_numbering": 1, + "nav_menu": {}, + "number_sections": true, + "sideBar": true, + "skip_h1_title": false, + "title_cell": "Table of Contents", + "title_sidebar": "Contents", + "toc_cell": false, + "toc_position": {}, + "toc_section_display": true, + "toc_window_display": false + }, + "vp": { + "vp_config_version": "1.0.0", + "vp_menu_width": 273, + "vp_note_display": false, + "vp_note_width": 0, + "vp_position": { + "width": 278 + }, + "vp_section_display": false, + "vp_signature": "VisualPython" + } + }, + "nbformat": 4, + "nbformat_minor": 4 +} diff --git a/images/avatar.jpg b/images/avatar.jpg index 524ad69fb2..2513539a37 100644 Binary files a/images/avatar.jpg and b/images/avatar.jpg differ diff --git a/images/payimg/alipayimg.jpg b/images/payimg/alipayimg.jpg index c966c0e145..3f3358833d 100644 Binary files a/images/payimg/alipayimg.jpg and b/images/payimg/alipayimg.jpg differ diff --git a/images/payimg/weipayimg.jpg b/images/payimg/weipayimg.jpg index a6ce0fe9aa..f4537f3e9b 100644 Binary files a/images/payimg/weipayimg.jpg and b/images/payimg/weipayimg.jpg differ diff --git "a/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/Copernicus Marine Service.jpg" "b/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/Copernicus Marine Service.jpg" new file mode 100644 index 0000000000..9e89bc491b Binary files /dev/null and "b/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/Copernicus Marine Service.jpg" differ diff --git "a/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/code.jpg" "b/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/code.jpg" new file mode 100644 index 0000000000..7ee50283b8 Binary files /dev/null and "b/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/code.jpg" differ diff --git "a/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/\344\270\213\350\275\275\346\214\211\351\222\256.jpg" "b/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/\344\270\213\350\275\275\346\214\211\351\222\256.jpg" new file mode 100644 index 0000000000..cde2d231ef Binary files /dev/null and "b/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/\344\270\213\350\275\275\346\214\211\351\222\256.jpg" differ diff --git "a/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/\345\205\250\347\220\203\344\270\234\350\245\277\345\220\221\346\265\201\351\200\237.jpg" "b/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/\345\205\250\347\220\203\344\270\234\350\245\277\345\220\221\346\265\201\351\200\237.jpg" new file mode 100644 index 0000000000..4bd77e30db Binary files /dev/null and "b/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/\345\205\250\347\220\203\344\270\234\350\245\277\345\220\221\346\265\201\351\200\237.jpg" differ diff --git "a/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/\346\225\260\346\215\256\344\273\213\347\273\215.jpg" "b/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/\346\225\260\346\215\256\344\273\213\347\273\215.jpg" new file mode 100644 index 0000000000..c07ebcae89 Binary files /dev/null and "b/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/\346\225\260\346\215\256\344\273\213\347\273\215.jpg" differ diff --git "a/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/\346\225\260\346\215\256\345\234\250\347\272\277\346\237\245\347\234\213.jpg" "b/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/\346\225\260\346\215\256\345\234\250\347\272\277\346\237\245\347\234\213.jpg" new file mode 100644 index 0000000000..e93f25f8ca Binary files /dev/null and "b/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/\346\225\260\346\215\256\345\234\250\347\272\277\346\237\245\347\234\213.jpg" differ diff --git "a/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/\346\225\260\346\215\256\346\243\200\347\264\242.jpg" "b/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/\346\225\260\346\215\256\346\243\200\347\264\242.jpg" new file mode 100644 index 0000000000..97cbdfe33f Binary files /dev/null and "b/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/\346\225\260\346\215\256\346\243\200\347\264\242.jpg" differ diff --git "a/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/\346\225\260\346\215\256\350\214\203\345\233\264.jpg" "b/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/\346\225\260\346\215\256\350\214\203\345\233\264.jpg" new file mode 100644 index 0000000000..1f98fa0bda Binary files /dev/null and "b/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/\346\225\260\346\215\256\350\214\203\345\233\264.jpg" differ diff --git "a/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/\346\246\202\345\277\265\345\233\276.png" "b/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/\346\246\202\345\277\265\345\233\276.png" new file mode 100644 index 0000000000..7b5bdbbdfa Binary files /dev/null and "b/images/posts/2022-08-09-\346\265\267\350\241\250\351\235\242\351\253\230\345\272\246\346\225\260\346\215\256\344\270\213\350\275\275/\346\246\202\345\277\265\345\233\276.png" differ diff --git "a/images/posts/2022-10-26-\345\211\215\347\253\257\345\205\245\351\227\250/class.jpg" "b/images/posts/2022-10-26-\345\211\215\347\253\257\345\205\245\351\227\250/class.jpg" new file mode 100644 index 0000000000..4d2b55f8c5 Binary files /dev/null and "b/images/posts/2022-10-26-\345\211\215\347\253\257\345\205\245\351\227\250/class.jpg" differ diff --git "a/images/posts/2022-10-26-\345\211\215\347\253\257\345\205\245\351\227\250/live Server.jpg" "b/images/posts/2022-10-26-\345\211\215\347\253\257\345\205\245\351\227\250/live Server.jpg" new file mode 100644 index 0000000000..93bf8ac3c5 Binary files /dev/null and "b/images/posts/2022-10-26-\345\211\215\347\253\257\345\205\245\351\227\250/live Server.jpg" differ diff --git "a/images/posts/2022-10-26-\345\211\215\347\253\257\345\205\245\351\227\250/\345\274\200\345\244\264\346\250\241\346\235\277.jpg" "b/images/posts/2022-10-26-\345\211\215\347\253\257\345\205\245\351\227\250/\345\274\200\345\244\264\346\250\241\346\235\277.jpg" new file mode 100644 index 0000000000..889a014820 Binary files /dev/null and "b/images/posts/2022-10-26-\345\211\215\347\253\257\345\205\245\351\227\250/\345\274\200\345\244\264\346\250\241\346\235\277.jpg" differ diff --git "a/images/posts/2022-12-14-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2501_\347\272\277\346\200\247\344\273\243\346\225\260/note_23_0.png" "b/images/posts/2022-12-14-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2501_\347\272\277\346\200\247\344\273\243\346\225\260/note_23_0.png" new file mode 100644 index 0000000000..8be3464207 Binary files /dev/null and "b/images/posts/2022-12-14-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2501_\347\272\277\346\200\247\344\273\243\346\225\260/note_23_0.png" differ diff --git "a/images/posts/2022-12-14-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2501_\347\272\277\346\200\247\344\273\243\346\225\260/note_25_0.png" "b/images/posts/2022-12-14-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2501_\347\272\277\346\200\247\344\273\243\346\225\260/note_25_0.png" new file mode 100644 index 0000000000..3ae1ded5be Binary files /dev/null and "b/images/posts/2022-12-14-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2501_\347\272\277\346\200\247\344\273\243\346\225\260/note_25_0.png" differ diff --git "a/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_10_1.png" "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_10_1.png" new file mode 100644 index 0000000000..959705daa2 Binary files /dev/null and "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_10_1.png" differ diff --git "a/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_11_0.png" "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_11_0.png" new file mode 100644 index 0000000000..70eb44ba32 Binary files /dev/null and "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_11_0.png" differ diff --git "a/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_13_0.png" "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_13_0.png" new file mode 100644 index 0000000000..fdee2dfb13 Binary files /dev/null and "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_13_0.png" differ diff --git "a/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_15_1.png" "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_15_1.png" new file mode 100644 index 0000000000..2f2a96ad4c Binary files /dev/null and "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_15_1.png" differ diff --git "a/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_17_1.png" "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_17_1.png" new file mode 100644 index 0000000000..4f65668056 Binary files /dev/null and "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_17_1.png" differ diff --git "a/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_19_1.png" "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_19_1.png" new file mode 100644 index 0000000000..2408dcbad7 Binary files /dev/null and "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_19_1.png" differ diff --git "a/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_21_1.png" "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_21_1.png" new file mode 100644 index 0000000000..2e0869d3d9 Binary files /dev/null and "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_21_1.png" differ diff --git "a/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_26_1.png" "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_26_1.png" new file mode 100644 index 0000000000..139c15a671 Binary files /dev/null and "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_26_1.png" differ diff --git "a/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_28_1.png" "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_28_1.png" new file mode 100644 index 0000000000..4f8cc8b057 Binary files /dev/null and "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_28_1.png" differ diff --git "a/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_30_2.png" "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_30_2.png" new file mode 100644 index 0000000000..93fc002c62 Binary files /dev/null and "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_30_2.png" differ diff --git "a/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_4_1.png" "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_4_1.png" new file mode 100644 index 0000000000..dbdb2c6465 Binary files /dev/null and "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/output_4_1.png" differ diff --git "a/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/\346\234\211\345\220\221\345\233\276\347\244\272\344\276\213.jpg" "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/\346\234\211\345\220\221\345\233\276\347\244\272\344\276\213.jpg" new file mode 100644 index 0000000000..90a4e169d7 Binary files /dev/null and "b/images/posts/2022-12-16-\346\234\272\345\231\250\345\255\246\344\271\240\345\205\245\351\227\2502_\346\246\202\347\216\207\350\256\272/\346\234\211\345\220\221\345\233\276\347\244\272\344\276\213.jpg" differ diff --git "a/images/posts/2022-12-28-pytest\346\265\213\350\257\225\345\256\236\346\210\230/Task\351\241\271\347\233\256\346\226\207\344\273\266\345\244\271\347\233\256\345\275\225.jpg" "b/images/posts/2022-12-28-pytest\346\265\213\350\257\225\345\256\236\346\210\230/Task\351\241\271\347\233\256\346\226\207\344\273\266\345\244\271\347\233\256\345\275\225.jpg" new file mode 100644 index 0000000000..7e54e96b8f Binary files /dev/null and "b/images/posts/2022-12-28-pytest\346\265\213\350\257\225\345\256\236\346\210\230/Task\351\241\271\347\233\256\346\226\207\344\273\266\345\244\271\347\233\256\345\275\225.jpg" differ diff --git "a/images/posts/2023-01-11-Linux\347\275\221\347\273\234\351\205\215\347\275\256/ifcfg\345\270\270\350\247\201\351\205\215\347\275\256.jpg" "b/images/posts/2023-01-11-Linux\347\275\221\347\273\234\351\205\215\347\275\256/ifcfg\345\270\270\350\247\201\351\205\215\347\275\256.jpg" new file mode 100644 index 0000000000..2862763040 Binary files /dev/null and "b/images/posts/2023-01-11-Linux\347\275\221\347\273\234\351\205\215\347\275\256/ifcfg\345\270\270\350\247\201\351\205\215\347\275\256.jpg" differ diff --git "a/images/posts/2023-01-11-Linux\347\275\221\347\273\234\351\205\215\347\275\256/ifconfig\345\221\275\344\273\244\347\232\204\344\270\273\350\246\201\345\217\202\346\225\260.jpg" "b/images/posts/2023-01-11-Linux\347\275\221\347\273\234\351\205\215\347\275\256/ifconfig\345\221\275\344\273\244\347\232\204\344\270\273\350\246\201\345\217\202\346\225\260.jpg" new file mode 100644 index 0000000000..93951bedfa Binary files /dev/null and "b/images/posts/2023-01-11-Linux\347\275\221\347\273\234\351\205\215\347\275\256/ifconfig\345\221\275\344\273\244\347\232\204\344\270\273\350\246\201\345\217\202\346\225\260.jpg" differ diff --git "a/images/posts/2023-01-11-Linux\347\275\221\347\273\234\351\205\215\347\275\256/ping\345\221\275\344\273\244\345\270\270\347\224\250\345\217\202\346\225\260.jpg" "b/images/posts/2023-01-11-Linux\347\275\221\347\273\234\351\205\215\347\275\256/ping\345\221\275\344\273\244\345\270\270\347\224\250\345\217\202\346\225\260.jpg" new file mode 100644 index 0000000000..3c3c31d3d7 Binary files /dev/null and "b/images/posts/2023-01-11-Linux\347\275\221\347\273\234\351\205\215\347\275\256/ping\345\221\275\344\273\244\345\270\270\347\224\250\345\217\202\346\225\260.jpg" differ diff --git "a/images/posts/2023-01-16-\346\216\245\345\217\243\350\207\252\345\212\250\345\214\226\346\265\213\350\257\225\344\271\213requests/\346\216\245\345\217\243\347\224\250\344\276\213\347\274\226\345\206\231\344\276\213\345\255\220.jpg" "b/images/posts/2023-01-16-\346\216\245\345\217\243\350\207\252\345\212\250\345\214\226\346\265\213\350\257\225\344\271\213requests/\346\216\245\345\217\243\347\224\250\344\276\213\347\274\226\345\206\231\344\276\213\345\255\220.jpg" new file mode 100644 index 0000000000..05f8d4c6e2 Binary files /dev/null and "b/images/posts/2023-01-16-\346\216\245\345\217\243\350\207\252\345\212\250\345\214\226\346\265\213\350\257\225\344\271\213requests/\346\216\245\345\217\243\347\224\250\344\276\213\347\274\226\345\206\231\344\276\213\345\255\220.jpg" differ diff --git "a/images/posts/2023-01-17-Python\344\270\255\345\206\205\345\255\230\345\222\214\345\217\230\351\207\217\347\256\241\347\220\206/\344\270\215\345\217\257\345\217\230\345\257\271\350\261\241.png" "b/images/posts/2023-01-17-Python\344\270\255\345\206\205\345\255\230\345\222\214\345\217\230\351\207\217\347\256\241\347\220\206/\344\270\215\345\217\257\345\217\230\345\257\271\350\261\241.png" new file mode 100644 index 0000000000..e4c763476f Binary files /dev/null and "b/images/posts/2023-01-17-Python\344\270\255\345\206\205\345\255\230\345\222\214\345\217\230\351\207\217\347\256\241\347\220\206/\344\270\215\345\217\257\345\217\230\345\257\271\350\261\241.png" differ diff --git "a/images/posts/2023-01-17-Python\344\270\255\345\206\205\345\255\230\345\222\214\345\217\230\351\207\217\347\256\241\347\220\206/\345\217\257\345\217\230\345\257\271\350\261\241.png" "b/images/posts/2023-01-17-Python\344\270\255\345\206\205\345\255\230\345\222\214\345\217\230\351\207\217\347\256\241\347\220\206/\345\217\257\345\217\230\345\257\271\350\261\241.png" new file mode 100644 index 0000000000..9ac69fecbb Binary files /dev/null and "b/images/posts/2023-01-17-Python\344\270\255\345\206\205\345\255\230\345\222\214\345\217\230\351\207\217\347\256\241\347\220\206/\345\217\257\345\217\230\345\257\271\350\261\241.png" differ diff --git "a/images/posts/2023-01-17-Python\344\270\255\345\206\205\345\255\230\345\222\214\345\217\230\351\207\217\347\256\241\347\220\206/\345\274\225\347\224\250\344\270\216\345\257\271\350\261\241.jpg" "b/images/posts/2023-01-17-Python\344\270\255\345\206\205\345\255\230\345\222\214\345\217\230\351\207\217\347\256\241\347\220\206/\345\274\225\347\224\250\344\270\216\345\257\271\350\261\241.jpg" new file mode 100644 index 0000000000..bc3928e4cb Binary files /dev/null and "b/images/posts/2023-01-17-Python\344\270\255\345\206\205\345\255\230\345\222\214\345\217\230\351\207\217\347\256\241\347\220\206/\345\274\225\347\224\250\344\270\216\345\257\271\350\261\241.jpg" differ diff --git "a/images/posts/2023-01-19-\350\275\257\344\273\266\346\265\213\350\257\225\347\232\204\345\210\206\347\261\273/\350\275\257\344\273\266\346\265\213\350\257\225\347\232\204\345\210\206\347\261\273.png" "b/images/posts/2023-01-19-\350\275\257\344\273\266\346\265\213\350\257\225\347\232\204\345\210\206\347\261\273/\350\275\257\344\273\266\346\265\213\350\257\225\347\232\204\345\210\206\347\261\273.png" new file mode 100644 index 0000000000..e2fa4ea16f Binary files /dev/null and "b/images/posts/2023-01-19-\350\275\257\344\273\266\346\265\213\350\257\225\347\232\204\345\210\206\347\261\273/\350\275\257\344\273\266\346\265\213\350\257\225\347\232\204\345\210\206\347\261\273.png" differ diff --git "a/images/posts/2023-01-29-\346\225\260\346\215\256\351\251\261\345\212\250\347\232\204\350\207\252\345\212\250\345\214\226\346\265\213\350\257\2251/Excel\347\224\250\344\276\213\350\256\276\350\256\241.png" "b/images/posts/2023-01-29-\346\225\260\346\215\256\351\251\261\345\212\250\347\232\204\350\207\252\345\212\250\345\214\226\346\265\213\350\257\2251/Excel\347\224\250\344\276\213\350\256\276\350\256\241.png" new file mode 100644 index 0000000000..426ef270e6 Binary files /dev/null and "b/images/posts/2023-01-29-\346\225\260\346\215\256\351\251\261\345\212\250\347\232\204\350\207\252\345\212\250\345\214\226\346\265\213\350\257\2251/Excel\347\224\250\344\276\213\350\256\276\350\256\241.png" differ diff --git "a/images/posts/2023-01-30-\346\216\245\345\217\243\350\207\252\345\212\250\345\214\226\346\265\213\350\257\225\344\273\245\345\217\212\346\265\213\350\257\225\347\224\250\344\276\213\350\256\276\350\256\241\346\200\273\347\273\223/\347\224\250\346\210\267\347\231\273\345\275\225\346\265\201\347\250\213\345\233\2762.png" "b/images/posts/2023-01-30-\346\216\245\345\217\243\350\207\252\345\212\250\345\214\226\346\265\213\350\257\225\344\273\245\345\217\212\346\265\213\350\257\225\347\224\250\344\276\213\350\256\276\350\256\241\346\200\273\347\273\223/\347\224\250\346\210\267\347\231\273\345\275\225\346\265\201\347\250\213\345\233\2762.png" new file mode 100644 index 0000000000..c9d3407f68 Binary files /dev/null and "b/images/posts/2023-01-30-\346\216\245\345\217\243\350\207\252\345\212\250\345\214\226\346\265\213\350\257\225\344\273\245\345\217\212\346\265\213\350\257\225\347\224\250\344\276\213\350\256\276\350\256\241\346\200\273\347\273\223/\347\224\250\346\210\267\347\231\273\345\275\225\346\265\201\347\250\213\345\233\2762.png" differ diff --git a/images/posts/Wifilist/PastedGraphic.png b/images/posts/Wifilist/PastedGraphic.png deleted file mode 100644 index b5ec853fd8..0000000000 Binary files a/images/posts/Wifilist/PastedGraphic.png and /dev/null differ diff --git a/images/posts/Wifilist/WLAN.png b/images/posts/Wifilist/WLAN.png deleted file mode 100644 index 282e9399ef..0000000000 Binary files a/images/posts/Wifilist/WLAN.png and /dev/null differ diff --git a/images/posts/Wifilist/entitlement.png b/images/posts/Wifilist/entitlement.png deleted file mode 100644 index 52c8204111..0000000000 Binary files a/images/posts/Wifilist/entitlement.png and /dev/null differ diff --git a/images/posts/Wifilist/infoplist.png b/images/posts/Wifilist/infoplist.png deleted file mode 100644 index 2cbc879893..0000000000 Binary files a/images/posts/Wifilist/infoplist.png and /dev/null differ diff --git a/images/posts/Wifilist/systemVersion.png b/images/posts/Wifilist/systemVersion.png deleted file mode 100644 index 46361a8d36..0000000000 Binary files a/images/posts/Wifilist/systemVersion.png and /dev/null differ diff --git a/images/posts/Xcode8/image1.png b/images/posts/Xcode8/image1.png deleted file mode 100644 index 4617c0b1d1..0000000000 Binary files a/images/posts/Xcode8/image1.png and /dev/null differ diff --git a/images/posts/Xcode8/image10.png b/images/posts/Xcode8/image10.png deleted file mode 100644 index 921c368b95..0000000000 Binary files a/images/posts/Xcode8/image10.png and /dev/null differ diff --git a/images/posts/Xcode8/image11.png b/images/posts/Xcode8/image11.png deleted file mode 100644 index a570a7d6fe..0000000000 Binary files a/images/posts/Xcode8/image11.png and /dev/null differ diff --git a/images/posts/Xcode8/image12.png b/images/posts/Xcode8/image12.png deleted file mode 100644 index e9a02f272d..0000000000 Binary files a/images/posts/Xcode8/image12.png and /dev/null differ diff --git a/images/posts/Xcode8/image13.png b/images/posts/Xcode8/image13.png deleted file mode 100644 index be5bcd798d..0000000000 Binary files a/images/posts/Xcode8/image13.png and /dev/null differ diff --git a/images/posts/Xcode8/image2.png b/images/posts/Xcode8/image2.png deleted file mode 100644 index a557cdaf4e..0000000000 Binary files a/images/posts/Xcode8/image2.png and /dev/null differ diff --git a/images/posts/Xcode8/image3.png b/images/posts/Xcode8/image3.png deleted file mode 100644 index 416ea41d98..0000000000 Binary files a/images/posts/Xcode8/image3.png and /dev/null differ diff --git a/images/posts/Xcode8/image4.png b/images/posts/Xcode8/image4.png deleted file mode 100644 index 219ee6204b..0000000000 Binary files a/images/posts/Xcode8/image4.png and /dev/null differ diff --git a/images/posts/Xcode8/image5.png b/images/posts/Xcode8/image5.png deleted file mode 100644 index 6c53085795..0000000000 Binary files a/images/posts/Xcode8/image5.png and /dev/null differ diff --git a/images/posts/Xcode8/image6.png b/images/posts/Xcode8/image6.png deleted file mode 100644 index 56b6662805..0000000000 Binary files a/images/posts/Xcode8/image6.png and /dev/null differ diff --git a/images/posts/Xcode8/image7.png b/images/posts/Xcode8/image7.png deleted file mode 100644 index 46741143f4..0000000000 Binary files a/images/posts/Xcode8/image7.png and /dev/null differ diff --git a/images/posts/Xcode8/image8.png b/images/posts/Xcode8/image8.png deleted file mode 100644 index ee6900a05a..0000000000 Binary files a/images/posts/Xcode8/image8.png and /dev/null differ diff --git a/images/posts/Xcode8/image9.png b/images/posts/Xcode8/image9.png deleted file mode 100644 index 45949c1788..0000000000 Binary files a/images/posts/Xcode8/image9.png and /dev/null differ diff --git a/images/posts/codeless/code.png b/images/posts/codeless/code.png deleted file mode 100644 index 61da6c1972..0000000000 Binary files a/images/posts/codeless/code.png and /dev/null differ diff --git a/images/posts/codeless/codeless1.png b/images/posts/codeless/codeless1.png deleted file mode 100644 index 36f08816a8..0000000000 Binary files a/images/posts/codeless/codeless1.png and /dev/null differ diff --git a/images/posts/codeless/codeless2.png b/images/posts/codeless/codeless2.png deleted file mode 100644 index 5797b9b669..0000000000 Binary files a/images/posts/codeless/codeless2.png and /dev/null differ diff --git a/images/posts/codeless/image01.png b/images/posts/codeless/image01.png deleted file mode 100644 index 5d3a60b31b..0000000000 Binary files a/images/posts/codeless/image01.png and /dev/null differ diff --git a/images/posts/codeless/image02.png b/images/posts/codeless/image02.png deleted file mode 100644 index 7bcf64fa57..0000000000 Binary files a/images/posts/codeless/image02.png and /dev/null differ diff --git a/images/posts/codeless/image03.png b/images/posts/codeless/image03.png deleted file mode 100644 index 2dce89fd87..0000000000 Binary files a/images/posts/codeless/image03.png and /dev/null differ diff --git a/images/posts/codeless/image04.png b/images/posts/codeless/image04.png deleted file mode 100644 index d3985d8a2e..0000000000 Binary files a/images/posts/codeless/image04.png and /dev/null differ diff --git a/images/posts/codeless/image05.png b/images/posts/codeless/image05.png deleted file mode 100644 index 028c616220..0000000000 Binary files a/images/posts/codeless/image05.png and /dev/null differ diff --git a/images/posts/codeless/img1.png b/images/posts/codeless/img1.png deleted file mode 100644 index 6400699c20..0000000000 Binary files a/images/posts/codeless/img1.png and /dev/null differ diff --git a/images/posts/codeless/img2.png b/images/posts/codeless/img2.png deleted file mode 100644 index b3933ae01c..0000000000 Binary files a/images/posts/codeless/img2.png and /dev/null differ diff --git a/images/posts/iBeacon/iBeacon.png b/images/posts/iBeacon/iBeacon.png deleted file mode 100755 index bb4362e223..0000000000 Binary files a/images/posts/iBeacon/iBeacon.png and /dev/null differ diff --git a/images/posts/icon/image01.png b/images/posts/icon/image01.png deleted file mode 100644 index 19c66e2f06..0000000000 Binary files a/images/posts/icon/image01.png and /dev/null differ diff --git a/images/posts/jekyll/image1.png b/images/posts/jekyll/image1.png deleted file mode 100644 index c7cffb9ddb..0000000000 Binary files a/images/posts/jekyll/image1.png and /dev/null differ diff --git a/images/posts/markdown/image1.png b/images/posts/markdown/image1.png deleted file mode 100644 index 654615f0f9..0000000000 Binary files a/images/posts/markdown/image1.png and /dev/null differ diff --git a/images/posts/markdown/image2.png b/images/posts/markdown/image2.png deleted file mode 100644 index 5479feecb7..0000000000 Binary files a/images/posts/markdown/image2.png and /dev/null differ diff --git a/images/posts/markdown/image3.png b/images/posts/markdown/image3.png deleted file mode 100644 index 060069ff35..0000000000 Binary files a/images/posts/markdown/image3.png and /dev/null differ diff --git a/images/posts/tfimg/ck.jpg b/images/posts/tfimg/ck.jpg deleted file mode 100644 index 355cfcdf92..0000000000 Binary files a/images/posts/tfimg/ck.jpg and /dev/null differ diff --git a/images/posts/tfimg/image01.png b/images/posts/tfimg/image01.png deleted file mode 100644 index 906da7ea29..0000000000 Binary files a/images/posts/tfimg/image01.png and /dev/null differ diff --git a/images/posts/tfimg/image02.png b/images/posts/tfimg/image02.png deleted file mode 100644 index bdb6385cae..0000000000 Binary files a/images/posts/tfimg/image02.png and /dev/null differ diff --git a/images/posts/tfimg/ipod1.jpg b/images/posts/tfimg/ipod1.jpg deleted file mode 100644 index e0865e8272..0000000000 Binary files a/images/posts/tfimg/ipod1.jpg and /dev/null differ diff --git a/images/posts/tfimg/ipod2.jpg b/images/posts/tfimg/ipod2.jpg deleted file mode 100644 index 7af0682836..0000000000 Binary files a/images/posts/tfimg/ipod2.jpg and /dev/null differ diff --git a/images/posts/tfimg/logo.jpg b/images/posts/tfimg/logo.jpg deleted file mode 100644 index d5005c10ad..0000000000 Binary files a/images/posts/tfimg/logo.jpg and /dev/null differ diff --git a/images/posts/tfimg/mouse1.jpg b/images/posts/tfimg/mouse1.jpg deleted file mode 100644 index 7c0ad42346..0000000000 Binary files a/images/posts/tfimg/mouse1.jpg and /dev/null differ diff --git a/images/posts/tfimg/mouse2.jpg b/images/posts/tfimg/mouse2.jpg deleted file mode 100644 index 6cf07069da..0000000000 Binary files a/images/posts/tfimg/mouse2.jpg and /dev/null differ diff --git a/images/posts/tfimg/notebook.jpg b/images/posts/tfimg/notebook.jpg deleted file mode 100644 index 0ef56d6e58..0000000000 Binary files a/images/posts/tfimg/notebook.jpg and /dev/null differ diff --git a/images/posts/tfimg/wb.jpg b/images/posts/tfimg/wb.jpg deleted file mode 100644 index a3b97a1dc1..0000000000 Binary files a/images/posts/tfimg/wb.jpg and /dev/null differ diff --git a/images/posts/tfimg/wq.jpg b/images/posts/tfimg/wq.jpg deleted file mode 100644 index 58c311ed9b..0000000000 Binary files a/images/posts/tfimg/wq.jpg and /dev/null differ diff --git a/images/readme/icon.gif b/images/readme/icon.gif deleted file mode 100644 index d916237dc4..0000000000 Binary files a/images/readme/icon.gif and /dev/null differ diff --git a/images/readme/img1.png b/images/readme/img1.png deleted file mode 100644 index ee6d289ac1..0000000000 Binary files a/images/readme/img1.png and /dev/null differ diff --git a/images/readme/img2.png b/images/readme/img2.png deleted file mode 100644 index b8a9047495..0000000000 Binary files a/images/readme/img2.png and /dev/null differ diff --git a/images/readme/img3.png b/images/readme/img3.png deleted file mode 100644 index c4d5670ceb..0000000000 Binary files a/images/readme/img3.png and /dev/null differ diff --git a/images/readme/img4.png b/images/readme/img4.png deleted file mode 100644 index 3ad19d6c35..0000000000 Binary files a/images/readme/img4.png and /dev/null differ diff --git a/images/readme/img5.png b/images/readme/img5.png deleted file mode 100644 index 8704ad959a..0000000000 Binary files a/images/readme/img5.png and /dev/null differ diff --git a/support.md b/support.md index fd4d025058..072b0c0409 100755 --- a/support.md +++ b/support.md @@ -3,54 +3,6 @@ layout: page title: µŖƵ£»µö»µīü --- -ÕŹÜÕ«óµ║ÉńĀüÕ£© Github õĖŖ’╝īõĮĀńÜä Star µś»µłæµø┤µ¢░ńÜäÕŖ©ÕŖø’╝īĶ░óĶ░ó~ +## Ķüöń│╗µ¢╣Õ╝Å -ķüćÕł░ķŚ«ķóśĶ»ĘÕģłĶć¬ĶĪīµÄƵ¤ź’╝īÕÅ»õ╗źńø┤µÄźÕ£©[Issues](https://github.com/leopardpan/leopardpan.github.io/issues)ķćīķØóµÅÉķŚ«’╝īõĖŹĶ┐ćÕø×ÕżŹńÜäÕÅ»ĶāĮõĖŹÕÅŖµŚČŃĆé - -ńø«ÕēŹµłæÕĘ▓ń╗Åń╗ÖÕŠłÕżÜÕ░Åõ╝Öõ╝┤ÕüÜĶ┐ćÕŹĢńŗ¼ńÜäµŖƵ£»µö»µīüõ║å’╝īńÄ░Õ£©Ķ«ŠńĮ« `õ╗śĶ┤╣µö»µīüÕŖ¤ĶāĮ` - -õ╗śĶ┤╣µēōĶĄÅµŖƵ£»µö»µīü
- -Õ”éµ×£õĮĀõ╗śĶ┤╣õ║å’╝īĶ»Ęķé«õ╗ČĶüöń│╗µłæ’╝īµŖŖõ╗śĶ┤╣ńÜ䵳¬ÕøŠÕÆīõĮĀńÜäQQÕÅĘõĖĆĶĄĘÕÅæń╗Öµłæ, µä¤Ķ░óõĮĀńÜäĶĄ×ÕŖ®ŃĆé - -õĮĀÕÉæµłæµÅÉķŚ«ķ󜵳æõ╣¤Ķ”üĶŖ▒µŚČķŚ┤ÕĖ«õĮĀĶ¦ŻńŁö’╝īõ╗śĶ┤╣ÕżÜÕ░æń£ŗõĮĀĶć¬ÕĘ▒ńÜäÕ┐āµäÅ’╝ī`10ŃĆü20ÕØŚõĖŹÕ½īÕ░æ`’╝ī`100ŃĆü200ÕØŚõĖŹÕ½īÕżÜ`ŃĆé - -**µ│©’╝Ü** õ╗śµ¼ŠÕÉĵ”éõĖŹķĆƵ¼Š’╝īµŗÆń╗صē»ńÜ«’╝īµłæńÜäÕŹÜÕ«óµ©ĪµØ┐õĖĆńø┤ķāĮµś»ÕģŹĶ┤╣ń╗ÖÕż¦Õ«ČõĮ┐ńö©ŃĆé - - -µłæĶāĮń╗ÖõĮĀĶ¦ŻńŁöńÜäķŚ«ķóśµ£ē
- -* Hexo ŃĆüJekyll µÉŁÕ╗║õĖ¬õ║║ÕŹÜÕ«óķüćÕł░ńÜäķŚ«ķóśµŖƵ£»µö»µīü -* Õ¤¤ÕÉŹńö│Ķ»Ę’╝īDNSķģŹńĮ«ķüćÕł░ńÜäķŚ«ķóśµŖƵ£»µö»µīü -* Ķć¬Õ╗║µ£ŹÕŖĪÕÖ©ķā©ńĮ▓õĖ¬õ║║ÕŹÜÕ«ó’╝īµ£ŹÕŖĪÕÖ©ķģŹńĮ« -* Nginx ÕÅŹÕÉæõ╗ŻńÉåŃĆüsupervisor Õ«łµŖżĶ┐øń©ŗ -* Õ¤¤ÕÉŹÕżćµĪłŃĆüSSLĶ»üõ╣”ķģŹńĮ« - -µłæÕÅ»ĶāĮõĖŹµś»µēƵ£ēńÜäķŚ«ķóśķāĮĶāĮĶ¦ŻńŁö’╝īõĮåµś»µłæõ╝ÜÕĖ”ńØĆõĮĀÕÄ╗ÕŁ”õ╣Ā’╝īõĖĆĶĄĘµłÉķĢ┐’╝ü - -µłæµś»õĖĆõĖ¬iOSÕ╝ĆÕÅæĶĆģ
- -ÕģČÕ«×µłæµś»õĖĆõĖ¬µŁŻµŁŻń╗Åń╗ÅńÜäiOSÕ╝ĆÕÅæĶĆģ, Õ╣ČõĖöõĖĆńø┤Õ£©ÕüÜ iOS Õ╝ĆÕÅæ6Õ╣┤õ║åŃĆé - -ńøĖÕ»╣õ║ĵɣÕ╗║ÕŹÜÕ«óńÜäķŚ«ķóś’╝īµłæiOS µŖƵ£»õ╝ܵø┤õĖōõĖÜŃĆé - -Õ”éµ×£µ£ēÕģ│õ║ÄiOSńÜäķŚ«ķ󜵳æõ╗¼õ╣¤ÕÅ»õ╗źõĖĆĶĄĘĶ«©Ķ«║ - - -µä¤Ķ░óµé©ńÜäµēōĶĄÅ
- - - - - -Õ”éõĮĢĶüöń│╗Õł░µłæ
- --email’╝Üleoparpan@icloud.com -
-qq: 1499065178 -
- -{% include comments.html %} -