什么是字符编码
ASCII 码
第一次听到ASCII 码已经是上大学的时候了。
ASCII 码是由美国制订的,一共规定了128个字符的编码,对应一个8位字节中的低7位(第8位统一为0),能覆盖常用的英文字符和数字,以及一些常见符号。
比如,97代表a, 65代表A,49代表1,35代表#
但这仅仅只包含了英文字符,对于发明了计算机的老外们是够用了,然而对于比如中文等其他语言的字符,该如何表示呢,毕竟老美也还没有强大到让所有人都只使用English.
于是,就出现了其他编码,其思路是,把第8位给用起来,这样就又可以表示128个字符了。
但是,对于博大精深的中文来说,256还是太小了。
《现代汉语常用字表》由国家语言文字工作委员会、国家教育委员会于1988年发布,共收字3500个。本表为其中的常用字部分,共2500字,覆盖率为97.97%
《康熙字典》.... 共收录汉字四万七千零三十五个(47035个)。
于是,就出现了GB2312,用两个字节表示一个汉字,理论上可以表示 256 * 256 = 65536个汉字。
看下国内编码的发展:
- 1989年发布的GB2312,一共收录了7445个字符,包括6763个汉字和682个其它符号。
- 1995年的汉字扩展规范GBK1.0收录了21886个符号,包括21003个字符,及部分图形符号区。
- 2000年的GB18030,收录了27484个汉字,同时还收录了我国主要的少数民族文字。
但这些标准只是限用于我们国家,适用于国际标准的是另外一个编码:Unicode.
Unicode
Unicode的学名是"Universal Multiple-Octet Coded Character Set",可以简称为UCS。Unicode也是一种字符编码方法,不过它是由国际组织设计,可以容纳全世界所有语言文字的编码方案,这样就不会存在编码差异了。
Unicode的设计哲学是,一个萝卜一个坑,只要你能想的出来的字,我就给你一个码,包括英文字符、数字、汉字、日文,甚至图画和表情,或者远古时期的甲骨文。
比如:
这么多符号,Unicode不是一次性定义的,而是分区定义。每个区可以存放65536个(2^16)字符,称为一个平面(plane)。目前,一共有17个(25)平面,也就是说,整个Unicode字符集的大小现在是2^21。
最前面的65536个字符位,称为基本平面(缩写BMP),它的码点范围是从0一直到2^16-1,写成16进制就是从U+0000到U+FFFF。所有最常见的字符都放在这个平面,这是Unicode最先定义和公布的一个平面。
Unicode只定义了文字的编码,并没有定义如何存储,因此,出现了多种存储形式,比如UTF-8, UTF-16
,其中UTF-8是最为常见及推荐的。
UTF-8与UTF-16的区别
UTF-8与UTF-16是Unicode的两种不同编码方式,UTF-16固定用两个字节来表示,范围0x0000 - 0xffff,不管你是英文还是中文,都用两个字节来表示。UTF-8是一种动态字节长度的编码,根据元素码点的大小,用1-4个字节来进行表示,英文用1个字节,中文用3个字节表示。
UTF-8 的编码规则如下:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
| Unicode 码点范围(16进制) |
UTF-8 字节流(二进制) |
| 0000 - 007F |
0xxxxxxx |
| 0080 - 07FF |
110xxxxx 10xxxxxx |
| 0800 - FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
例如“汉”字的Unicode编码是6C49。
What is BOM
Unicode规范中推荐的标记字节顺序的方法是BOM(Byte Order Mark)。
Unicode 规范定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做"零宽度非换行空格"(zero width no-break space),用FEFF表示。
如果头两个字节是FEFF,表示使用的是Big Endian方式,如果头两个字节是FFFE,表示使用的是Little Endian方式,
UTF-8以字节为编码单元,没有字节序的问题。UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式,字符"ZERO WIDTH NO-BREAK SPACE"的UTF-8编码是EF BB BF,如果收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
如果大家都用UTF-8,那么BOM是可以省略的,目前也是推荐使用UTF-8 without BOM.
UTF-16以两个字节为编码单元,在解释一个UTF-16文本前,首先要弄清楚每个编码单元的字节序。例如收到一个“奎”的Unicode编码是594E,“乙”的Unicode编码是4E59。如果我们收到UTF-16字节流“594E”,那么这是“奎”还是“乙”?
Demo UTF-8 vs UTF-16 and BOM vs without BOM
汉的 Unicode码 是6C49,UTF-8 编码是E6 B1 89
新建demo.txt
用xxd命令查看文件二进制
在Sublime Text中使用不同的编码方式进行保存
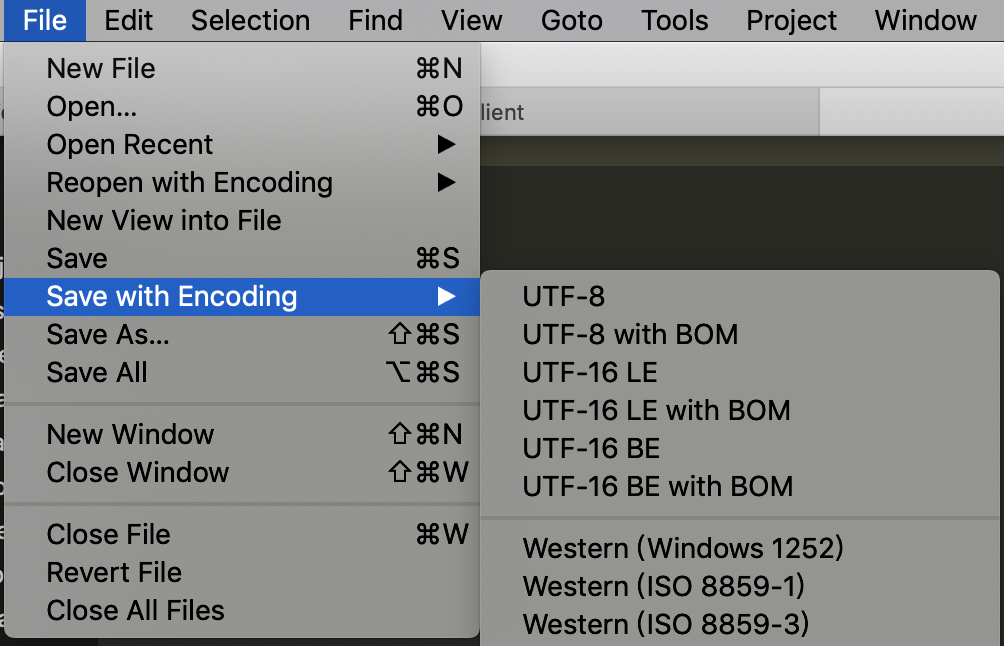
看下不同方式存储的结果。
UTF-8
E6 B1 89
UTF-8 with BOM (EF BB BF)
EF BB BF E6 B1 89
UTF-16 LE (Little Endian)
49 6C
UTF-16 LE with BOM
FF FE 49 6C
UTF-16 BE ((Big Endian))
6C 49
UTF-16 BE with BOM
FE FF 6C 49
Buffer Read using BE/LE in Nodejs
let arr = [0, 5];
let num = Buffer.from(arr).readInt16LE(0);
console.log(num); // 1280 (0x0500)
let num1 = Buffer.from(arr).readInt16BE(0);
console.log(num1); // 5 (0x0005)
JavaScript使用哪一种编码
看下时间线:
- 1990年,UCS-2编码(UTF-16前身)发布,使用2个字节
- 1995年5月,Brendan Eich用了10天设计了JavaScript语言
- 1996年7月,UTF-16编码公布
因此,JavaScript使用的是UCS-2编码,可以把它理解为UTF-16的子集。
| UCS-2编码(16进制) |
UTF-8 字节流(二进制) |
| 0000 - 007F |
0xxxxxxx |
| 0080 - 07FF |
110xxxxx 10xxxxxx |
| 0800 - FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
由于JavaScript只能处理UCS-2编码,造成所有字符在这门语言中都是2个字节,如果是4个字节的字符,会当作两个双字节的字符处理。
在ES6中,增强了Unicode支持,提供了codePointAt方法,可以用来识别多字节字符。
Demo
// 汉字“𠮷”(注意,这个字不是“吉祥”的“吉”)的码点是0x20BB7, (十进制134071) , 用4个字节存储
// UTF-16 编码为0xD842 0xDFB7(十进制为55362 57271)
let s = '𠮷a'; // 55362 57271 97
console.log(s.length); // 3
console.log(s.codePointAt(0)) // 134071 == 55362 57271 (正确读取了两个字节)
console.log(s.codePointAt(1)) // 57271 单独读取第2个字节
console.log(s.codePointAt(2)) // 97
console.log(s.charCodeAt(0)) // 55362
console.log(s.charCodeAt(1)) // 57271
console.log(s.charCodeAt(2)) // 97
// 汉字‘李’, 码点是 26446, 0x674e
let s1 = '李a';
console.log(s1.length); // 2
console.log(s1.codePointAt(0)) // 26446
console.log(s1.codePointAt(1)) // 97
console.log(s1.charCodeAt(0)) // 26446
console.log(s1.charCodeAt(1)) // 97
// charCodeAt(n) 读取第n个字符, 返回UNICODE码点, 不能正确处理超过0xffff等占用3个字节长度以上的字符
// codePointAt(n) 读取第n个字符, 返回UNICODE码点, 可以正确处理超过0xffff等占用3个字节长度以上的字符
参考
什么是字符编码
ASCII 码
第一次听到ASCII 码已经是上大学的时候了。
ASCII 码是由美国制订的,一共规定了128个字符的编码,对应一个8位字节中的低7位(第8位统一为0),能覆盖常用的英文字符和数字,以及一些常见符号。
比如,97代表a, 65代表A,49代表1,35代表#
但这仅仅只包含了英文字符,对于发明了计算机的老外们是够用了,然而对于比如中文等其他语言的字符,该如何表示呢,毕竟老美也还没有强大到让所有人都只使用English.
于是,就出现了其他编码,其思路是,把第8位给用起来,这样就又可以表示128个字符了。
但是,对于博大精深的中文来说,256还是太小了。
于是,就出现了GB2312,用两个字节表示一个汉字,理论上可以表示 256 * 256 = 65536个汉字。
看下国内编码的发展:
但这些标准只是限用于我们国家,适用于国际标准的是另外一个编码:Unicode.
Unicode
Unicode的学名是"Universal Multiple-Octet Coded Character Set",可以简称为UCS。Unicode也是一种字符编码方法,不过它是由国际组织设计,可以容纳全世界所有语言文字的编码方案,这样就不会存在编码差异了。
Unicode的设计哲学是,一个萝卜一个坑,只要你能想的出来的字,我就给你一个码,包括英文字符、数字、汉字、日文,甚至图画和表情,或者远古时期的甲骨文。
比如:

这么多符号,Unicode不是一次性定义的,而是分区定义。每个区可以存放65536个(2^16)字符,称为一个平面(plane)。目前,一共有17个(25)平面,也就是说,整个Unicode字符集的大小现在是2^21。
最前面的65536个字符位,称为基本平面(缩写BMP),它的码点范围是从0一直到2^16-1,写成16进制就是从U+0000到U+FFFF。所有最常见的字符都放在这个平面,这是Unicode最先定义和公布的一个平面。
Unicode只定义了文字的编码,并没有定义如何存储,因此,出现了多种存储形式,比如UTF-8, UTF-16
,其中UTF-8是最为常见及推荐的。
UTF-8与UTF-16的区别
UTF-8与UTF-16是Unicode的两种不同编码方式,UTF-16固定用两个字节来表示,范围0x0000 - 0xffff,不管你是英文还是中文,都用两个字节来表示。UTF-8是一种动态字节长度的编码,根据元素码点的大小,用1-4个字节来进行表示,英文用1个字节,中文用3个字节表示。
UTF-8 的编码规则如下:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
例如“汉”字的Unicode编码是
6C49。用UTF-8表示
6C49在0800-FFFF之间,所以肯定要用3字节模板了:1110xxxx 10xxxxxx 10xxxxxx。将6C49写成二进制是:0110 110001 001001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。用UTF-16表示
使用两个字节,和Unicode的码点数相同,
6C 49What is BOM
Unicode规范中推荐的标记字节顺序的方法是BOM(Byte Order Mark)。
Unicode 规范定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做"零宽度非换行空格"(zero width no-break space),用
FEFF表示。如果头两个字节是
FEFF,表示使用的是Big Endian方式,如果头两个字节是FFFE,表示使用的是Little Endian方式,UTF-8以字节为编码单元,没有字节序的问题。UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式,字符"ZERO WIDTH NO-BREAK SPACE"的UTF-8编码是
EF BB BF,如果收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。如果大家都用UTF-8,那么BOM是可以省略的,目前也是推荐使用UTF-8 without BOM.
UTF-16以两个字节为编码单元,在解释一个UTF-16文本前,首先要弄清楚每个编码单元的字节序。例如收到一个“奎”的Unicode编码是594E,“乙”的Unicode编码是4E59。如果我们收到UTF-16字节流“594E”,那么这是“奎”还是“乙”?
Demo UTF-8 vs UTF-16 and BOM vs without BOM
汉的 Unicode码 是6C49,UTF-8 编码是E6 B1 89新建demo.txt
用xxd命令查看文件二进制
在Sublime Text中使用不同的编码方式进行保存

看下不同方式存储的结果。
UTF-8
UTF-8 with BOM (
EF BB BF)UTF-16 LE (Little Endian)
UTF-16 LE with BOM
UTF-16 BE ((Big Endian))
UTF-16 BE with BOM
Buffer Read using BE/LE in Nodejs
JavaScript使用哪一种编码
看下时间线:
因此,JavaScript使用的是UCS-2编码,可以把它理解为UTF-16的子集。
由于JavaScript只能处理UCS-2编码,造成所有字符在这门语言中都是2个字节,如果是4个字节的字符,会当作两个双字节的字符处理。
在ES6中,增强了Unicode支持,提供了
codePointAt方法,可以用来识别多字节字符。Demo
参考