HIT Type: 804
New: we publish different HIT types which may look similar but have different instructions and aims. This number is an identifier for you to recognize them. + + Introduction + +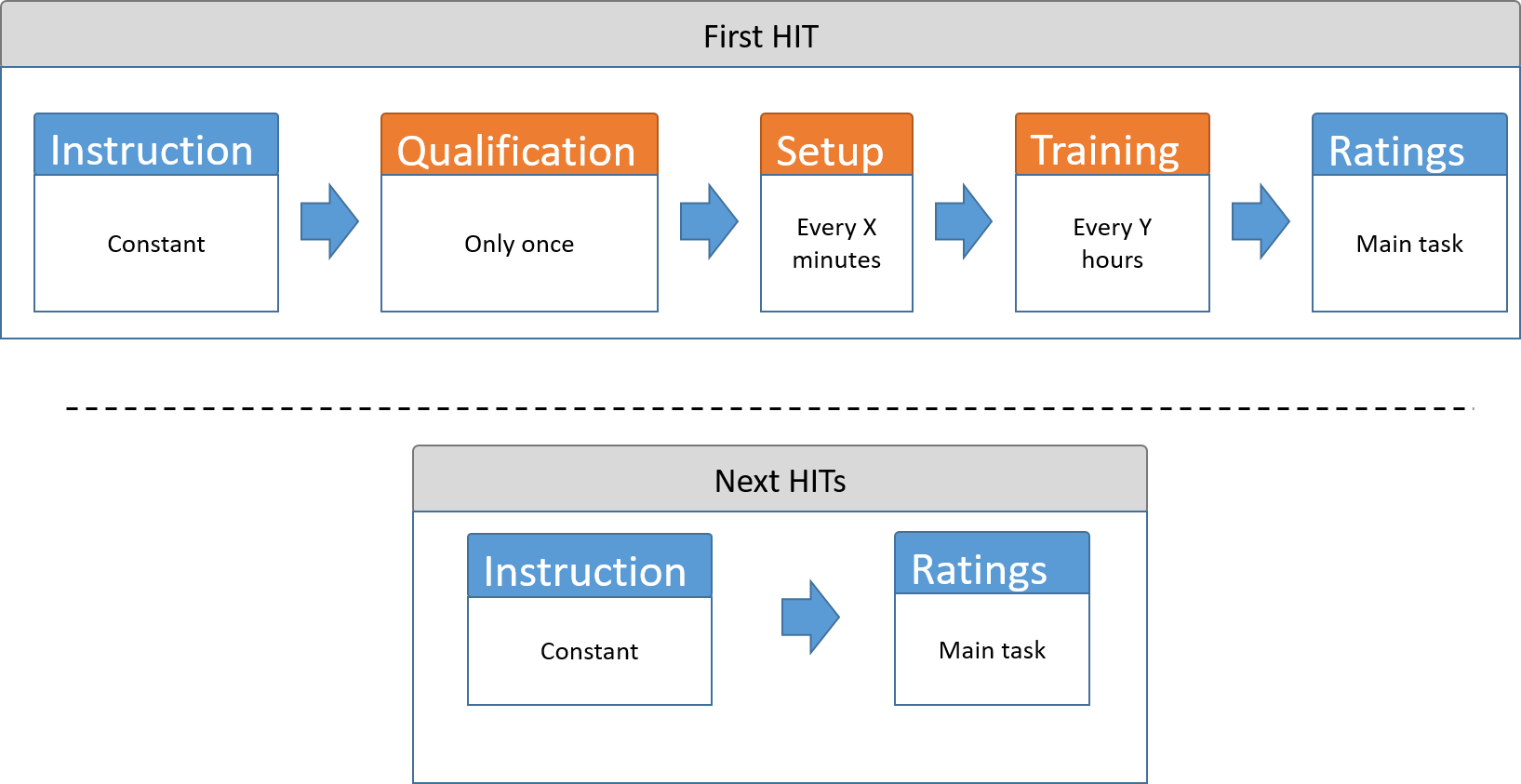 +
+
+
+ Welcome to this Data Labeling task! You are about to participate in our speech quality assessment task! It is a data labeling task in which you are responsible for providing reliable labels that pass our qualifity control system. This HIT has two + + two (just every now and then) sections:
+-
+
- Qualification (just once): Check if you are eligible to perform these HITs +
- Setup (every 0 minutes): Configure your system and validate it + by answering 6 questions +
- Detailed instuction (only once): 12 audio samples, and description of scale. It is crucial to understand what you should do. +
- Training (every 0 hour): 0 questions, same as "Ratings" but appears again after 0 hour from the last HIT you perform in this group. +
- Rating: Listen to 0 audio files and give your opinion + about the quality of the speech you hear. +
You should follow the below mentioned rules, otherwise your answers will be invalid.
+Rules:
+-
+
- You must use a headset, not the loudspeaker: otherwise your response will be rejected + +
- You must perform the task in a quiet environment +
- Do not change the volume after modifying it in the Setup section. +
Payment:
+The result of this experiment is very important for us and other scientist working in this + area. We have methods that analyse the consistency of your answers. We will use these methods to + rank the submitted assignments according to quality.
+For this experiment, we will pay a base reward of ${{cfg.hit_base_payment}}/HIT for every + accepted HIT. We have made available a set of 0 different HITs. You + will receive a bonus of:
+ +-
+
- ${{cfg.quantity_bonus}}/HIT (for a total of ${{cfg.sum_quantity}}/HIT) if you submit + more than {{cfg.quantity_hits_more_than}} HITs or +
- ${{cfg.quality_bonus}}/HIT (for a total of ${{cfg.sum_quality }}/HIT) if you submit + more than {{cfg.quantity_hits_more_than}} HITs and be in the top + {{cfg.quality_top_percentage}}% quality group. +
Bonuses will be assigned with in 7 days.
+ Please perform up to 0 HITs from this group. If you do more than + that, the rest will be rejected. + +Attention:
+This hit includes one or more Control clips (gold clips). Control clips are ones that we know that answer for and should be very easy to rate (they are clearly very good or very poor). They may target one or more scales. We include control clips in the HIT to ensure raters are paying attention and their environment hasn't changed. + Wrong answer to control clip(s) will result in rejection of the HIT.
+ + + Please wear your headphones now.
Please wear your headphones now.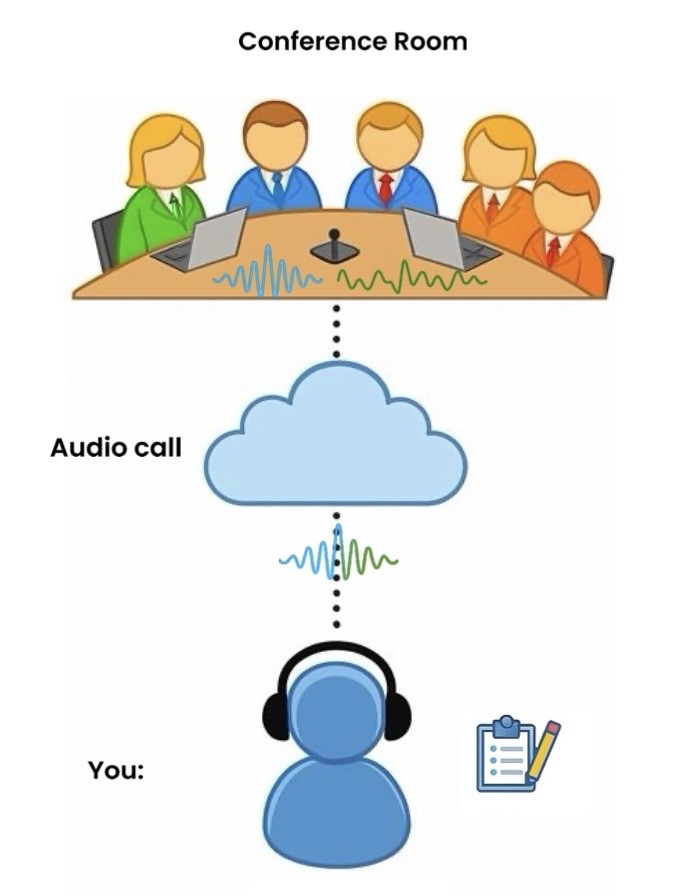 +
+ 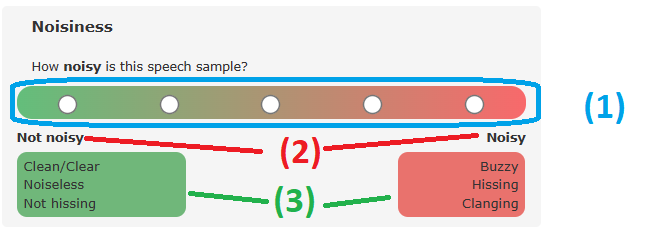 +
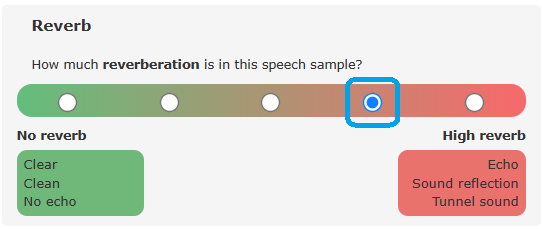
+ Beside the main question about the characteristic, the scale has the following features:
+
+
+ Beside the main question about the characteristic, the scale has the following features:
+  +
+  +
+  +
+  +
+
+
+
+
+  +
+