diff --git a/zh_0_3/GLOSSARY.md b/zh_0_3/GLOSSARY.md
new file mode 100644
index 0000000..d338536
--- /dev/null
+++ b/zh_0_3/GLOSSARY.md
@@ -0,0 +1,2 @@
+
+
diff --git a/zh_0_3/README.md b/zh_0_3/README.md
new file mode 100644
index 0000000..82d3f70
--- /dev/null
+++ b/zh_0_3/README.md
@@ -0,0 +1,29 @@
+
+
+[OpenFalcon](http://open-falcon.com)是一款企业级、高可用、可扩展的开源监控解决方案。
+
+在大家的热心支持和帮助下,OpenFalcon 已经成为国内最流行的监控系统之一。
+
+目前:
+- 在 [github](https://github.com/open-falcon/falcon-plus) 上取得了数千个star,数百次fork,上百个pull-request;
+- 社区用户6000+;
+- 超过200家公司都在不同程度使用open-falcon,包括大陆、新加坡、台湾等地;
+- 社区贡献了包括MySQL、redis、windows、交换机、LVS、Mongodb、Memcache、docker、mesos、URL监控等多种插件支持;
+
+-----
+**Acknowledgements**
+
+- OpenFalcon was initially started by Xiaomi and we would also like to acknowledge contributions by engineers from [these companies](./contributing.html) and [these individual developers](./contributing.html).
+- The OpenFalcon logo and website were contributed by Cepave Design Team.
+- [Wei Lai](https://github.com/laiwei) is the founder of OpenFalcon software and community.
+- The [english doc](http://book.open-falcon.com/en/index.html) is translated by [宋立岭](https://github.com/songliling).
+
+-----
+- QQ五群:42607978 (请加该群)//请大家优先在 github 上提交 [issue](https://github.com/open-falcon/falcon-plus/issues), 方便问题沉淀,github issue 会最高优先级解决。
+- QQ四群:697503992 (已满员)
+- QQ一群:373249123 (已满员)
+- QQ二群:516088946 (已满员)
+- QQ三群:469342415 (已满员)
+
+
+ diff --git a/zh_0_3/SUMMARY.md b/zh_0_3/SUMMARY.md
new file mode 100644
index 0000000..82ddef0
--- /dev/null
+++ b/zh_0_3/SUMMARY.md
@@ -0,0 +1,87 @@
+# SUMMARY
+
+### 第 Ⅰ 部分:社区
+* [社区介绍](README.md)
+* [贡献列表](contributing.md)
+* [项目介绍](intro/README.md)
+
+### 第 Ⅱ 部分:安装
+* [单机安装](quick_install/README.md)
+ * [环境准备](quick_install/prepare.md)
+ * [启动后端](quick_install/backend.md)
+ * [安装前端](quick_install/frontend.md)
+ * [v0.1平滑升级到v0.2](quick_install/upgrade.md)
+* [分布式安装](distributed_install/README.md)
+ * [环境准备](distributed_install/prepare.md)
+ * [Agent](distributed_install/agent.md)
+ * [Transfer](distributed_install/transfer.md)
+ * [Graph](distributed_install/graph.md)
+ * [API](distributed_install/api.md)
+ * [DashBoard](quick_install/frontend.md)
+ * [邮件/短信/微信发送接口](distributed_install/mail-sms.md)
+ * [Heartbeat Server](distributed_install/hbs.md)
+ * [Judge](distributed_install/judge.md)
+ * [Alarm](distributed_install/alarm.md)
+ * [Task](distributed_install/task.md)
+ * [Gateway](distributed_install/gateway.md)
+ * [Nodata](distributed_install/nodata.md)
+ * [Aggregator](distributed_install/aggregator.md)
+ * [Agent-updater](distributed_install/agent-updater.md)
+
+### 第 Ⅲ 部分:手册
+* [使用手册](usage/README.md)
+ * [快速入门](usage/getting-started.md)
+ * [Nodata配置](usage/nodata.md)
+ * [集群监控](usage/aggregator.md)
+ * [报警触发函数](usage/func.md)
+ * [自定义push数据](usage/data-push.md)
+ * [历史数据查询](usage/query.md)
+ * [进程端口监控](usage/proc-port-monitor.md)
+ * [MySQL监控](usage/mymon.md)
+ * [Redis监控](usage/redis.md)
+ * [MongoDB监控](usage/MongoDB.md)
+ * [Memcache监控](usage/memcache.md)
+ * [RabbitMQ监控](usage/rabbitmq.md)
+ * [Solr监控](usage/solr.md)
+ * [交换机监控](usage/switch.md)
+ * [ESXi监控](usage/esxi.md)
+ * [Windows主机监控](usage/win.md)
+ * [HAProxy监控](usage/haproxy.md)
+ * [docker容器监控](usage/docker.md)
+ * [Nginx监控](usage/ngx_metric.md)
+ * [JMX监控](usage/jmx.md)
+ * [硬件监控](usage/hwcheck.md)
+ * [LVS监控](usage/lvs.md)
+ * [Url监控](usage/urlooker.md)
+ * [mesos](usage/mesos.md)
+ * [vSphere监控](usage/vsphere.md)
+ * [Flume监控](usage/flume.md)
+ * [目录和进程资源监控](usage/du-proc.md)
+ * [故障自愈](usage/fault-recovery.md)
+ * [VSphere和ESXI监控](usage/vsphere-esxi.md)
+
+### 第 Ⅳ 部分:理念
+* [设计理念](philosophy/README.md)
+ * [数据模型](philosophy/data-model.md)
+ * [话说数据采集](philosophy/data-collect.md)
+ * [plugin机制](philosophy/plugin.md)
+ * [Tag和HostGroup](philosophy/tags-and-hostgroup.md)
+* [二次开发](dev/README.md)
+ * [社区贡献](dev/community_resource.md)
+ * [修改绘图曲线精度](dev/change_graph_rra.md)
+ * [修改网卡流量单位](dev/change_net_unit.md)
+ * [支持 Grafana 视图展现](dev/support_grafana.md)
+ * [API](api/README.md)
+* [实践经验](practice/README.md)
+ * [部署](practice/deploy.md)
+ * [自监控](practice/monitor.md)
+ * [Graph扩容二三事](practice/graph-scaling.md)
+
+### 第 Ⅴ 部分:FAQ
+* [FAQ](faq/README.md)
+ * [采集相关](faq/collect.md)
+ * [报警相关](faq/alarm.md)
+ * [绘图相关](faq/graph.md)
+ * [Linux常用监控指标](faq/linux-metrics.md)
+ * [QQ群问答整理](faq/qq.md)
+* [Changelog](changelog/README.md)
diff --git a/zh_0_3/api/README.md b/zh_0_3/api/README.md
new file mode 100644
index 0000000..45f742f
--- /dev/null
+++ b/zh_0_3/api/README.md
@@ -0,0 +1,2 @@
+# open-falcon api
+- [api v0.2](http://open-falcon.com/falcon-plus/)
diff --git a/zh_0_3/authors.md b/zh_0_3/authors.md
new file mode 100644
index 0000000..aa9601e
--- /dev/null
+++ b/zh_0_3/authors.md
@@ -0,0 +1 @@
+../zh/authors.md
\ No newline at end of file
diff --git a/zh_0_3/changelog/README.md b/zh_0_3/changelog/README.md
new file mode 100644
index 0000000..258bafe
--- /dev/null
+++ b/zh_0_3/changelog/README.md
@@ -0,0 +1,117 @@
+
+
+## [v0.2.0] 2017-06-17
+
+> https://github.com/open-falcon/falcon-plus/releases/tag/v0.2.0
+
+> http://www.jianshu.com/p/6fb2c2b4d030
+
+> **全新的前端**
+
+- Open-Falcon 所有前端组件进行了统一整合,包括dashboard、screen、portal、alarm-dashboard、UIC、fe、links等统一整合到了 [dashboard](https://github.com/open-falcon/dashboard) 组件;
+- Dashboard 全站增加权限控制;
+- Dashboard 增加删除指定 endpoint、counter 以及对应的 rrd 文件的功能;
+- Dashboard 首页默认展示 endpoint 列表,并支持 endpoint 列表和 counter 列表翻页功能;
+- Dashboard 增加删除一级 screen 的功能;
+- 支持将报警的 callback 参数和内容在 Dashboard 页面上展示;
+- 支持微信报警通道;
+- Dashboard 支持展示过往的历史报警信息;
+
+> **统一的后端**
+
+- alarm支持报警历史信息入库存储和展示;
+- 「报警合并」模块`links`的功能合并到统一前端 Dashboard 中,降低用户配置和维护成本;
+- 「报警发送」模块`sender`的功能合并到 alarm 中,降低用户配置和维护成本;
+- query的功能合并到了falcon-api组件中;
+- 支持非周期性上报数据存储;
+- agent支持通过自定义配置,只采集指定磁盘挂载点的磁盘监控数据;
+- agent支持配置一个默认 tag,这样通过该 agent 上报的所有数据都会自动追加这个tag;
+- judge新增报警判断函数`lookup(#num, limit)`,如果检测到过去num个周期内,有limit次符合条件就报警;
+
+> **过去那些等待已久的bugfix**
+
+- 修复grafana不支持metric含有大写字母的bug;
+- 修复agent写多个transfer高可用不生效的bug;
+- 修复agent发送数据给transfer的超时设置不合理的问题;
+
+> **全新的 [RESTful API](http://open-falcon.com/falcon-plus)**:让 open-falcon 没有难自动化的操作
+
+- 发布了全新设计的组件 falcon-api,falcon-plus 所有的功能都可以通过 RESTful API 来完成;
+- 统一前端 Dashboard 绝大部分功能都是通过 [falcon-plus](https://github.com/open-falcon/falcon-plus) [api](http://open-falcon.com/falcon-plus) 来实现;
+
+
+## [0.1.0] 2016-03-08
+
+> https://github.com/open-falcon/of-release/releases/tag/v0.1.0
+
+> http://www.jianshu.com/p/7751eb324a51
+
+### highlights
+- `文档` API梳理和文档完善 http://docs.openfalcon.apiary.io `OpenFalcon-team @hitripod`
+- `优化` graph集群扩容时,历史数据自动迁移 `OpenFalcon-team @yubo laiwei niean`
+- `优化` 数据上报的最小间隔,可以在配置文件中更改 `OpenFalcon-team @niean`
+- `新功能` 监控数据支持写入opentsdb `美团 OpenFalcon-team @Charlesdong`
+- `新功能` 适配支持grafana `快网 OpenFalcon-team @hitripod`
+- `新功能` 新增集群监控 `OpenFalcon-team @ulricqin`
+- `新功能` 新增nodata监控 `OpenFalcon-team @niean`
+- `新功能` agent内置URL监控 `@onlymellb`
+- `优化` agent支持对多个transfer的负载均衡 `@cmgs`
+- `优化` 往HostGroup中添加机器的时候如果发现机器名不存在,就直接插入host表 `@wkshare`
+- `优化` dashboard绘图线条采用深颜色的配色方案 `美团 OpenFalcon-team @skyeydemon`
+
+### changelog
+- [agent] 优化:agent支持配置多个transfer地址 @CMGS https://github.com/open-falcon/agent/pull/37
+- [agent] 优化:agent支持URL探测 @onlymellb https://github.com/open-falcon/agent/pull/27
+- [alarm] bugfix:修改beego api不兼容引起的编译报错 @ulricqin
+- [common] 新功能:增加tsdb的支持 @Charlesdong https://github.com/open-falcon/common/pull/2
+- [dashboard] 优化:checkbox均支持使用shift快捷多选 @skyeydemon https://github.com/open-falcon/dashboard/pull/14
+- [dashboard] 优化:绘图线条采用深颜色的配色方案 @skydemon https://github.com/open-falcon/dashboard/pull/13
+- [dashboard] 优化:日期选择框高亮当前时间,方便用户选择 @iambocai https://github.com/open-falcon/dashboard/pull/12
+- [dashboard] bugfix: 修复charts页面刷新时偶尔不出图的问题 @niean
+- [fe] bugfix:修改beego api不兼容引起的编译报错 @hitripod
+- [gateway] 优化:gateway支持配置多个transfer列表间负载均衡 @niean
+- [gateway] 优化:gateway引入perfcounter,用来统计gateway自身的稳定性指标 @niean
+- [graph] 数据上报的最小间隔,可以在配置文件中更改 @niean
+- [graph] graph集群扩容时,历史数据自动迁移 @yubo laiwei niean https://github.com/open-falcon/graph/pull/14
+- [hbs] 新功能:配置agent支持URL监控[url.check.health] onlymellb https://github.com/open-falcon/hbs/pull/4
+- [nodata] 新模块:当某些采集项超时未上报数据时,如果配置了nodata策略则会生成一条默认的数据 @niean
+- [portal] API: 增加了获取expression和strategy详情的API @modeyang
+- [portal] 优化:往HostGroup中添加机器的时候如果发现机器名存在,就直接插入host表 @wkshare https://github.com/open-falcon/portal/pull/4
+- [portal] 新功能:支持集群聚合监控 @ulricqin
+- [portal] 新功能:支持nodata @niean
+- [query] 增加API来支持Grafana展示 @hitripod https://github.com/open-falcon/query/pull/5
+- [transfer] 数据支持写入opentsdb @Charlesdong https://github.com/open-falcon/transfer/pull/5
+- [transfer] 数据上报周期的最小限制可配置 @niean https://github.com/open-falcon/transfer/pull/7
+- [transfer] migrating的功能从transfer中去除 @laiwei https://github.com/open-falcon/transfer/pull/8
+- [aggregator] 新模块:集群聚合监控 @ulricqin
+
+----
+## [0.0.5] 2015-08-20
+- [agent] new feature: 增加了udp、du相关采集项
+- [agent] bugfix: 修复了配置了新的插件需要重启agent的bug
+- [agent] bugfix: 修复了reload配置文件,hostname改动可能无法生效的问题 @oiooj
+- [alarm] bugfix: 修复了告警email中的换行问题
+- [alarm] bugfix: 修复了告警分级配置项为空时处理不当的问题
+- [alarm] enhancement: 修改http的默认端口为9912(之前为6060)
+- [transfer] new feature: 新增了数据双写的功能,即transfer可以将同一份数据发送到后端的多个graph或者judge,用于容灾
+- [transfer] enhancement: 发往judge的数据,按照时间戳做对齐和规整(与发往graph保持一致)
+- [transfer] bugfix: 修复transfer返回给客户端的结果中latency单位错误的问题
+- [graph] new feature: 新增了last API接口,可以返回指定counter最新的点
+- [query] new feature: 新增了last API接口,可以返回指定counter最新的点
+- [hbs] bugfix: 配合agent, 修复了配置了新的插件需要重启agent的bug
+- [plugin] new feature: 新增了插件项目,里面有一些常用的插件脚本
+- [gateway] 新增组件,解决网络分区后的监控数据回传问题。代码及功能描述,请移步到[这里](https://github.com/open-falcon/gateway);Gitbook中没有该组件的描述。
+
+
+## [0.0.4] 2015-06-09
+- [alarm] bugfix:修复告警邮件中的换行问题
+- [transfer] bugfix:当某个后端的graph宕机的时候,会引起transfer的发送能力下降
+- [graph] bugfix: 当存储rrd数据文件的目录不存在或者没有读写权限的时候,程序作退出处理
+- [fe] 新增了Golang版本的uic组件
+
+
+## [0.0.3] 2015-06-02
+ - [dashboard] bugfix: search counters by tags in screen
+ - [judge] enhancement: clean stale data in memory
+
+
diff --git a/zh_0_3/contributing.md b/zh_0_3/contributing.md
new file mode 100644
index 0000000..92c19e9
--- /dev/null
+++ b/zh_0_3/contributing.md
@@ -0,0 +1 @@
+../zh/contributing.md
\ No newline at end of file
diff --git a/zh_0_3/dev/README.md b/zh_0_3/dev/README.md
new file mode 100644
index 0000000..7cc5afa
--- /dev/null
+++ b/zh_0_3/dev/README.md
@@ -0,0 +1,23 @@
+
+
+# 环境准备
+
+请参考[环境准备](quick_install/prepare.md)
+# 自定义修改归档策略
+修改open-falcon/graph/rrdtool/rrdtool.go
+
+
+
+
+重新编译graph组件,并替换原有的二进制
+
+清理掉原来的所有rrd文件(默认在/home/work/data/6070/下面)
+
+# 插件机制
+1. 找一个git存放公司的所有插件
+2. 通过调用agent的/plugin/update接口拉取插件repo到本地
+3. 在portal中配置哪些机器可以执行哪些插件
+4. 插件命名方式:$step_xx.yy,需要有可执行权限,分门别类存放到repo的各个目录
+5. 把采集到的数据打印到stdout
+6. 如果觉得git方式不方便,可以改造agent,定期从某个http地址下载打包好的plugin.tar.gz
+
diff --git a/zh_0_3/dev/change_graph_rra.md b/zh_0_3/dev/change_graph_rra.md
new file mode 100644
index 0000000..62ea715
--- /dev/null
+++ b/zh_0_3/dev/change_graph_rra.md
@@ -0,0 +1,87 @@
+
+
+## 修改绘图曲线精度
+
+默认的,Open-Falcon只保存最近12小时的原始监控数据,12小时之后的数据被降低精度、采样存储。
+
+如果默认的精度不能满足你的需求,可以按照如下步骤,修改绘图曲线的存储精度。
+
+#### 第一步,修改graph组件的RRA,并重新编译graph组件
+graph组件的RRA,定义在文件 graph/rrdtool/[rrdtool.go](https://github.com/open-falcon/graph/blob/master/rrdtool/rrdtool.go#L57)中,默认如下:
+
+```golang
+// RRA.Point.Size
+const (
+ RRA1PointCnt = 720 // 1m一个点存12h
+ RRA5PointCnt = 576 // 5m一个点存2d
+ // ...
+)
+
+func create(filename string, item *cmodel.GraphItem) error {
+ now := time.Now()
+ start := now.Add(time.Duration(-24) * time.Hour)
+ step := uint(item.Step)
+
+ c := rrdlite.NewCreator(filename, start, step)
+ c.DS("metric", item.DsType, item.Heartbeat, item.Min, item.Max)
+
+ // 设置各种归档策略
+ // 1分钟一个点存 12小时
+ c.RRA("AVERAGE", 0.5, 1, RRA1PointCnt)
+
+ // 5m一个点存2d
+ c.RRA("AVERAGE", 0.5, 5, RRA5PointCnt)
+ c.RRA("MAX", 0.5, 5, RRA5PointCnt)
+ c.RRA("MIN", 0.5, 5, RRA5PointCnt)
+
+ // ...
+
+ return c.Create(true)
+}
+
+```
+
+比如,你只想保存90天的原始数据,可以将代码修改为:
+
+```golang
+// RRA.Point.Size
+const (
+ RRA1PointCnt = 129600 // 1m一个点存90d,取值 90*24*3600/60
+)
+
+func create(filename string, item *cmodel.GraphItem) error {
+ now := time.Now()
+ start := now.Add(time.Duration(-24) * time.Hour)
+ step := uint(item.Step)
+
+ c := rrdlite.NewCreator(filename, start, step)
+ c.DS("metric", item.DsType, item.Heartbeat, item.Min, item.Max)
+
+ // 设置各种归档策略
+ // 1分钟一个点存 90d
+ c.RRA("AVERAGE", 0.5, 1, RRA1PointCnt)
+
+ return c.Create(true)
+}
+```
+
+#### 第二步,清除graph的历史数据
+清除已上报的所有指标的历史数据,即删除所有的rrdfile。不删除历史数据,已上报指标的精度更改将不能生效。
+
+#### 第三步,重新部署graph服务
+编译修改后的graph源码,关停原有的graph老服务、发布修改后的graph。
+
+只需要修改graph组件、不需要修改Open-Falcon的其他组件,新的精度就能生效。你可以通过Dashboard、Screen来查看新的精度的绘图曲线。
+
+
+
+### 注意事项:
+
+修改监控绘图曲线精度时,需要:
+
++ 修改graph源代码,更新RRA
++ 清除graph的历史数据。不删除历史数据,已上报指标的精度更改将不能生效
++ 除了graph之外,Open-Falcon的其他任何组件 不需要被修改
++ 修改RRA后,可能会出现"绘图曲线点数过多、浏览器被卡死"的问题。请合理规划RRA存储的点数,或者调整绘图曲线查询时的时间段选择。
+
+
diff --git a/zh_0_3/dev/change_net_unit.md b/zh_0_3/dev/change_net_unit.md
new file mode 100644
index 0000000..1fbfaa6
--- /dev/null
+++ b/zh_0_3/dev/change_net_unit.md
@@ -0,0 +1,92 @@
+
+
+## 修改网卡流量单位
+
+目前是以 Bytes 为单位,如果要改为 Bits 的话(如:Mbps),可以修改 agent 代码。
+
+采集原始网卡流量数据的代码 `github.com/toolkits/nux/ifstat.go`,如下:
+
+```golang
+func NetIfs(onlyPrefix []string) ([]*NetIf, error) {
+ ...
+
+ {
+
+ ...
+
+ netIf.InBytes, _ = strconv.ParseInt(fields[0], 10, 64)
+ netIf.InPackages, _ = strconv.ParseInt(fields[1], 10, 64)
+ netIf.InErrors, _ = strconv.ParseInt(fields[2], 10, 64)
+ netIf.InDropped, _ = strconv.ParseInt(fields[3], 10, 64)
+ netIf.InFifoErrs, _ = strconv.ParseInt(fields[4], 10, 64)
+ netIf.InFrameErrs, _ = strconv.ParseInt(fields[5], 10, 64)
+ netIf.InCompressed, _ = strconv.ParseInt(fields[6], 10, 64)
+ netIf.InMulticast, _ = strconv.ParseInt(fields[7], 10, 64)
+
+ netIf.OutBytes, _ = strconv.ParseInt(fields[8], 10, 64)
+ netIf.OutPackages, _ = strconv.ParseInt(fields[9], 10, 64)
+ netIf.OutErrors, _ = strconv.ParseInt(fields[10], 10, 64)
+ netIf.OutDropped, _ = strconv.ParseInt(fields[11], 10, 64)
+ netIf.OutFifoErrs, _ = strconv.ParseInt(fields[12], 10, 64)
+ netIf.OutCollisions, _ = strconv.ParseInt(fields[13], 10, 64)
+ netIf.OutCarrierErrs, _ = strconv.ParseInt(fields[14], 10, 64)
+ netIf.OutCompressed, _ = strconv.ParseInt(fields[15], 10, 64)
+
+ netIf.TotalBytes = netIf.InBytes + netIf.OutBytes
+ netIf.TotalPackages = netIf.InPackages + netIf.OutPackages
+ netIf.TotalErrors = netIf.InErrors + netIf.OutErrors
+ netIf.TotalDropped = netIf.InDropped + netIf.OutDropped
+
+ ret = append(ret, &netIf)
+ }
+
+ return ret, nil
+}
+```
+
+agent 相对应的代码 `github.com/open-falcon/agent/funcs/ifstats.go`,如下:
+
+```golang
+func CoreNetMetrics(ifacePrefix []string) []*model.MetricValue {
+
+ netIfs, err := nux.NetIfs(ifacePrefix)
+ if err != nil {
+ log.Println(err)
+ return []*model.MetricValue{}
+ }
+
+ cnt := len(netIfs)
+ ret := make([]*model.MetricValue, cnt*20)
+
+ for idx, netIf := range netIfs {
+ iface := "iface=" + netIf.Iface
+ ret[idx*20+0] = CounterValue("net.if.in.bytes", netIf.InBytes, iface)
+ ret[idx*20+1] = CounterValue("net.if.in.packets", netIf.InPackages, iface)
+ ret[idx*20+2] = CounterValue("net.if.in.errors", netIf.InErrors, iface)
+ ret[idx*20+3] = CounterValue("net.if.in.dropped", netIf.InDropped, iface)
+ ret[idx*20+4] = CounterValue("net.if.in.fifo.errs", netIf.InFifoErrs, iface)
+ ret[idx*20+5] = CounterValue("net.if.in.frame.errs", netIf.InFrameErrs, iface)
+ ret[idx*20+6] = CounterValue("net.if.in.compressed", netIf.InCompressed, iface)
+ ret[idx*20+7] = CounterValue("net.if.in.multicast", netIf.InMulticast, iface)
+ ret[idx*20+8] = CounterValue("net.if.out.bytes", netIf.OutBytes, iface)
+ ret[idx*20+9] = CounterValue("net.if.out.packets", netIf.OutPackages, iface)
+ ret[idx*20+10] = CounterValue("net.if.out.errors", netIf.OutErrors, iface)
+ ret[idx*20+11] = CounterValue("net.if.out.dropped", netIf.OutDropped, iface)
+ ret[idx*20+12] = CounterValue("net.if.out.fifo.errs", netIf.OutFifoErrs, iface)
+ ret[idx*20+13] = CounterValue("net.if.out.collisions", netIf.OutCollisions, iface)
+ ret[idx*20+14] = CounterValue("net.if.out.carrier.errs", netIf.OutCarrierErrs, iface)
+ ret[idx*20+15] = CounterValue("net.if.out.compressed", netIf.OutCompressed, iface)
+ ret[idx*20+16] = CounterValue("net.if.total.bytes", netIf.TotalBytes, iface)
+ ret[idx*20+17] = CounterValue("net.if.total.packets", netIf.TotalPackages, iface)
+ ret[idx*20+18] = CounterValue("net.if.total.errors", netIf.TotalErrors, iface)
+ ret[idx*20+19] = CounterValue("net.if.total.dropped", netIf.TotalDropped, iface)
+ }
+ return ret
+}
+```
+
+举例來说,我们可以直接在 agent 要上报数据的时候,将 Bit 转换为 Byte,同时修改 Counter 的名称,如下:
+
+```golang
+ret[idx*20+0] = CounterValue("net.if.in.bits", netIf.InBytes*8, iface)
+```
diff --git a/zh_0_3/dev/community_resource.md b/zh_0_3/dev/community_resource.md
new file mode 100644
index 0000000..7ef663b
--- /dev/null
+++ b/zh_0_3/dev/community_resource.md
@@ -0,0 +1,51 @@
+
+
+## 第三方监控插件
+* [Windows Agent](https://github.com/LeonZYang/agent)
+* [MySQL Monitor](https://github.com/open-falcon/mymon)
+* [Redis Monitor](https://github.com/ZhuoRoger/redismon)
+* [RPC Monitor](https://github.com/iambocai/falcon-monit-scripts)
+* [Switch Monitor](https://github.com/gaochao1/swcollector)
+* [Falcon-Agent宕机监控](https://github.com/freedomkk-qfeng/falcon-scripts/tree/master/agent_monitor)
+* [memcached](https://github.com/iambocai/falcon-monit-scripts/tree/master/memcached)
+* [Docker 监控Lib库](https://github.com/HunanTV/eru-metric)
+* [mesos 监控](https://github.com/mesos-utility/mesos-metrics)
+* [Winodws/Linux 自动汇报资产](https://github.com/triaquae/MadKing)
+* [Nginx监控: 企业级监控标准](https://github.com/GuyCheung/falcon-ngx_metric)
+* [JMX监控: 基于open-falcon的jmx监控插件](https://github.com/toomanyopenfiles/jmxmon)
+* [适配Open-Falcon的综合监控SuitAgent](https://github.com/cqyijifu/OpenFalcon-SuitAgent)
+* [Baidu-RPC Monitor](https://github.com/solrex/brpc-open-falcon)
+* [Elasticsearch Monitor](https://github.com/solrex/es-open-falcon)
+* [Redis Monitor (多实例)](https://github.com/solrex/redis-open-falcon)
+* [SSDB Monitor](https://github.com/solrex/ssdb-open-falcon)
+* [ActiveMQ](https://github.com/zhaoxiaole/falcon-plugin/tree/master/ActiveMQ)
+* [统计每个cpu core 详情的插件脚本](https://github.com/open-falcon/plugin/blob/master/common/60_stats_per_cpu_core.py)
+* [统计进程资源消耗的插件脚本](https://github.com/open-falcon/plugin/blob/master/common/60_proc_resource_status.py)
+* [针对falcon开发的监控脚本和服务](https://github.com/sageskr/monitor)
+* [Windows metrics collector](https://github.com/freedomkk-qfeng/falcon-scripts/tree/master/windows_collect)
+* [Dell服务器硬件状态监控脚本](https://github.com/51web/hwcheck)
+
+## SDK
+* [Node.js perfcounter](https://github.com/efeiefei/openfalcon-perfcounter)
+* [Golang perfcounter](https://github.com/niean/goperfcounter)
+
+## 其他
+* [SMS sender](http://book.open-falcon.com/zh/install/mail-sms.html)
+* [Mail sender](https://github.com/niean/mailsender)
+* [Open-Falcon Ansible Playbook](https://github.com/iambocai/falcon-playbook)
+* [Open-Falcon Docker](https://github.com/frostynova/open-falcon-docker)
+
+## 讲稿
+* [OpenFalcon交流:一个适合在公司内部推广OpenFalcon的PPT](http://pan.baidu.com/s/1o7wsrUi)
+* [OpenFalcon @ SACC-2015](http://pan.baidu.com/s/1o6S6t1C)
+* OpenFalcon编写的整个脑洞历程: 开发过程中的权衡与折中
+* [OpenFalcon操作录屏演示 10多分钟](http://pan.baidu.com/s/1dEsW54P)
+* 小米开源监控系统OpenFalcon应对高并发7种手段
+
+
+## 会议
+
+#### 麒麟会技术沙龙-Open-Falcon v0.1.0 发布
+* [来炜——Open-Falcon新版特性解析和规划](http://pan.baidu.com/s/1dFsJa5j)
+* [谢丹博——Open-Falcon在美团的落地与升华](http://pan.baidu.com/s/1o8Cd3MM)
+* [欧曜玮——企业级监控平台的变革与演进](http://pan.baidu.com/s/1hsvuHKg)
diff --git a/zh_0_3/dev/support_grafana.md b/zh_0_3/dev/support_grafana.md
new file mode 100644
index 0000000..64b0ceb
--- /dev/null
+++ b/zh_0_3/dev/support_grafana.md
@@ -0,0 +1,14 @@
+
+
+## 支持 Grafana 视图展现
+
+相较于 Open-Falcon 内建的 Dashboard,Grafana 可以很有弹性的自定义图表,并且可以针对 Dashboard 做权限控管、上标签以及查询,图表的展示选项也更多样化。本篇教学帮助您
+做好 Open-Falcon 的面子工程!
+
+### 安装和使用步骤
+
+请参考 [grafana open-falcon](https://github.com/open-falcon/grafana-openfalcon-datasource)
+
+
+### 致谢
+- 感谢fastweb @kordan @masato25 等朋友的贡献;
diff --git a/zh_0_3/distributed_install/README.md b/zh_0_3/distributed_install/README.md
new file mode 100644
index 0000000..47f81ad
--- /dev/null
+++ b/zh_0_3/distributed_install/README.md
@@ -0,0 +1,26 @@
+
+
+# 概述
+
+Open-Falcon是一个比较大的分布式系统,有十几个组件。按照功能,这十几个组件可以划分为 基础组件、作图链路组件和报警链路组件,其安装部署的架构如下图所示,
+
+
+
+## 在单台机器上快速安装
+
+请直接参考[quick_install](../quick_install/README.md)
+
+## Docker化的Open-Falcon安装
+
+参考:
+- https://github.com/open-falcon/falcon-plus/blob/master/docker/README.md
+- https://github.com/open-falcon/dashboard/blob/master/README.md
+
+## 在多台机器上分布式安装
+
+在多台机器上,分布式安装open-falcon,就是本章的内容,请按照本章节的顺序,安装每个组件。
+
+## 视频教程教你安装
+
+《[Open-Falcon部署与架构解析](http://www.jikexueyuan.com/course/1651.html)》
+
diff --git a/zh_0_3/distributed_install/agent-updater.md b/zh_0_3/distributed_install/agent-updater.md
new file mode 100644
index 0000000..8b09ba9
--- /dev/null
+++ b/zh_0_3/distributed_install/agent-updater.md
@@ -0,0 +1,17 @@
+
+
+# Agent-updater
+
+每台机器都要部署falcon-agent,如果公司机器量比较少,用pssh、ansible、fabric之类的工具手工安装问题也不大。但是公司机器量多了之后,手工安装、升级、回滚falcon-agent将成为噩梦。
+
+个人开发了agent-updater这个工具,用于管理falcon-agent,agent-updater也有一个agent:ops-updater,可以看做是一个超级agent,用于管理其他agent的agent,呵呵,ops-updater推荐在装机的时候一起安装上。ops-updater通常是不会升级的。
+
+具体参看:https://github.com/open-falcon/ops-updater
+
+如果你想学习如何使用Go语言编写一个完整的项目,也可以研究一下agent-updater,我甚至录制了一个视频教程来演示一步一步如何开发出来的。课程链接:
+
+- http://www.jikexueyuan.com/course/1336.html
+- http://www.jikexueyuan.com/course/1357.html
+- http://www.jikexueyuan.com/course/1462.html
+- http://www.jikexueyuan.com/course/1490.html
+
diff --git a/zh_0_3/distributed_install/agent.md b/zh_0_3/distributed_install/agent.md
new file mode 100644
index 0000000..e9f6690
--- /dev/null
+++ b/zh_0_3/distributed_install/agent.md
@@ -0,0 +1,100 @@
+
+
+# Agent
+
+agent用于采集机器负载监控指标,比如cpu.idle、load.1min、disk.io.util等等,每隔60秒push给Transfer。agent与Transfer建立了长连接,数据发送速度比较快,agent提供了一个http接口/v1/push用于接收用户手工push的一些数据,然后通过长连接迅速转发给Transfer。
+
+## 部署说明
+
+agent需要部署到所有要被监控的机器上,比如公司有10万台机器,那就要部署10万个agent。agent本身资源消耗很少,不用担心。
+
+
+## 配置说明
+
+配置文件必须叫cfg.json,可以基于cfg.example.json修改
+
+```
+{
+ "debug": true, # 控制一些debug信息的输出,生产环境通常设置为false
+ "hostname": "", # agent采集了数据发给transfer,endpoint就设置为了hostname,默认通过`hostname`获取,如果配置中配置了hostname,就用配置中的
+ "ip": "", # agent与hbs心跳的时候会把自己的ip地址发给hbs,agent会自动探测本机ip,如果不想让agent自动探测,可以手工修改该配置
+ "plugin": {
+ "enabled": false, # 默认不开启插件机制
+ "dir": "./plugin", # 把放置插件脚本的git repo clone到这个目录
+ "git": "https://github.com/open-falcon/plugin.git", # 放置插件脚本的git repo地址
+ "logs": "./logs" # 插件执行的log,如果插件执行有问题,可以去这个目录看log
+ },
+ "heartbeat": {
+ "enabled": true, # 此处enabled要设置为true
+ "addr": "127.0.0.1:6030", # hbs的地址,端口是hbs的rpc端口
+ "interval": 60, # 心跳周期,单位是秒
+ "timeout": 1000 # 连接hbs的超时时间,单位是毫秒
+ },
+ "transfer": {
+ "enabled": true,
+ "addrs": [
+ "127.0.0.1:18433"
+ ], # transfer的地址,端口是transfer的rpc端口, 可以支持写多个transfer的地址,agent会保证HA
+ "interval": 60, # 采集周期,单位是秒,即agent一分钟采集一次数据发给transfer
+ "timeout": 1000 # 连接transfer的超时时间,单位是毫秒
+ },
+ "http": {
+ "enabled": true, # 是否要监听http端口
+ "listen": ":1988",
+ "backdoor": false
+ },
+ "collector": {
+ "ifacePrefix": ["eth", "em"], # 默认配置只会采集网卡名称前缀是eth、em的网卡流量,配置为空就会采集所有的,lo的也会采集。可以从/proc/net/dev看到各个网卡的流量信息
+ "mountPoint": []
+ },
+ "default_tags": {
+ },
+ "ignore": { # 默认采集了200多个metric,可以通过ignore设置为不采集
+ "cpu.busy": true,
+ "df.bytes.free": true,
+ "df.bytes.total": true,
+ "df.bytes.used": true,
+ "df.bytes.used.percent": true,
+ "df.inodes.total": true,
+ "df.inodes.free": true,
+ "df.inodes.used": true,
+ "df.inodes.used.percent": true,
+ "mem.memtotal": true,
+ "mem.memused": true,
+ "mem.memused.percent": true,
+ "mem.memfree": true,
+ "mem.swaptotal": true,
+ "mem.swapused": true,
+ "mem.swapfree": true
+ }
+}
+```
+
+## 进程管理
+
+```
+./open-falcon start agent 启动进程
+./open-falcon stop agent 停止进程
+./open-falcon monitor agent 查看日志
+
+```
+
+## 验证
+
+看var目录下的log是否正常,或者浏览器访问其1988端口。另外agent提供了一个`--check`参数,可以检查agent是否可以正常跑在当前机器上
+
+```
+./falcon-agent --check
+```
+
+## /v1/push接口
+
+我们设计初衷是不希望用户直接连到Transfer发送数据,而是通过agent的/v1/push接口转发,接口使用范例:
+
+```
+ts=`date +%s`; curl -X POST -d "[{\"metric\": \"metric.demo\", \"endpoint\": \"qd-open-falcon-judge01.hd\", \"timestamp\": $ts,\"step\": 60,\"value\": 9,\"counterType\": \"GAUGE\",\"tags\": \"project=falcon,module=judge\"}]" http://127.0.0.1:1988/v1/push
+```
+
+## 视频教程
+
+为该模块录制了一个视频,做了源码级解读:http://www.jikexueyuan.com/course/2242.html
diff --git a/zh_0_3/distributed_install/aggregator.md b/zh_0_3/distributed_install/aggregator.md
new file mode 100644
index 0000000..126fe24
--- /dev/null
+++ b/zh_0_3/distributed_install/aggregator.md
@@ -0,0 +1,54 @@
+
+
+# Aggregator
+
+集群聚合模块。聚合某集群下的所有机器的某个指标的值,提供一种集群视角的监控体验。
+
+
+## 服务部署
+服务部署,包括配置修改、启动服务、检验服务、停止服务等。这之前,需要将安装包解压到服务的部署目录下。
+
+```
+# 修改配置, 配置项含义见下文
+mv cfg.example.json cfg.json
+vim cfg.json
+
+# 启动服务
+./open-falcon start aggregator
+
+# 检查log
+./open-falcon monitor aggregator
+
+# 停止服务
+./open-falcon stop aggregator
+
+```
+
+
+## 配置说明
+配置文件默认为./cfg.json。默认情况下,安装包会有一个cfg.example.json的配置文件示例。各配置项的含义,如下
+
+```
+{
+ "debug": true,
+ "http": {
+ "enabled": true,
+ "listen": "0.0.0.0:6055"
+ },
+ "database": {
+ "addr": "root:@tcp(127.0.0.1:3306)/falcon_portal?loc=Local&parseTime=true", // 如数据库使用密码, 配置稍有不同: "addr": "root:password@tcp(127.0.0.1:3306)/falcon_portal?loc=Local&parseTime=true&allowNativePasswords=true"
+ "idle": 10,
+ "ids": [1, -1],
+ "interval": 55
+ },
+ "api": {
+ "connect_timeout": 500,
+ "request_timeout": 2000,
+ "plus_api": "http://127.0.0.1:8080", #falcon-plus api模块的运行地址
+ "plus_api_token": "default-token-used-in-server-side", #和falcon-plus api 模块交互的认证token
+ "push_api": "http://127.0.0.1:1988/v1/push" #push数据的http接口,这是agent提供的接口
+ }
+}
+
+
+```
diff --git a/zh_0_3/distributed_install/alarm.md b/zh_0_3/distributed_install/alarm.md
new file mode 100644
index 0000000..c254ff7
--- /dev/null
+++ b/zh_0_3/distributed_install/alarm.md
@@ -0,0 +1,90 @@
+
+
+# Alarm
+
+alarm模块是处理报警event的,judge产生的报警event写入redis,alarm从redis读取处理,并进行不同渠道的发送。
+
+## 设计初衷
+
+报警event的处理逻辑并非仅仅是发邮件、发短信这么简单。为了能够自动化对event做处理,alarm需要支持在产生event的时候回调用户提供的接口;有的时候报警短信、邮件太多,对于优先级比较低的报警,希望做报警合并,这些逻辑都是在alarm中做的。
+
+我们在配置报警策略的时候配置了报警级别,比如P0/P1/P2等等,每个及别的报警都会对应不同的redis队列 alarm去读取这个数据的时候我们希望先读取P0的数据,再读取P1的数据,最后读取P5的数据,因为我们希望先处理优先级高的。于是:用了redis的brpop指令。
+
+已经发送的告警信息,alarm会写入MySQL中保存,这样用户就可以在dashboard中查阅历史报警,同时针对同一个策略发出的多条报警,在MySQL存储的时候,会聚类;历史报警保存的周期,是可配置的,默认为7天。
+
+## 部署说明
+
+alarm是个单点。对于未恢复的告警是放到alarm的内存中的,alarm还需要做报警合并,故而alarm只能部署一个实例。需要对alarm的存活做好监控。
+
+## 配置说明
+
+配置文件必须叫cfg.json,可以基于cfg.example.json修改
+
+```
+{
+ "log_level": "debug",
+ "http": {
+ "enabled": true,
+ "listen": "0.0.0.0:9912"
+ },
+ "redis": {
+ "addr": "127.0.0.1:6379",
+ "maxIdle": 5,
+ "highQueues": [
+ "event:p0",
+ "event:p1",
+ "event:p2"
+ ],
+ "lowQueues": [
+ "event:p3",
+ "event:p4",
+ "event:p5",
+ "event:p6"
+ ],
+ "userIMQueue": "/queue/user/im",
+ "userSmsQueue": "/queue/user/sms",
+ "userMailQueue": "/queue/user/mail"
+ },
+ "api": {
+ "im": "http://127.0.0.1:10086/wechat", //微信发送网关地址
+ "sms": "http://127.0.0.1:10086/sms", //短信发送网关地址
+ "mail": "http://127.0.0.1:10086/mail", //邮件发送网关地址
+ "dashboard": "http://127.0.0.1:8081", //dashboard模块的运行地址
+ "plus_api":"http://127.0.0.1:8080", //falcon-plus api模块的运行地址
+ "plus_api_token": "default-token-used-in-server-side" //用于和falcon-plus api模块服务端之间的通信认证token
+ },
+ "falcon_portal": {
+ "addr": "root:@tcp(127.0.0.1:3306)/alarms?charset=utf8&loc=Asia%2FChongqing",
+ "idle": 10,
+ "max": 100
+ },
+ "worker": {
+ "im": 10,
+ "sms": 10,
+ "mail": 50
+ },
+ "housekeeper": {
+ "event_retention_days": 7, //报警历史信息的保留天数
+ "event_delete_batch": 100
+ }
+}
+
+```
+## 进程管理
+
+```
+# 启动
+./open-falcon start alarm
+
+# 停止
+./open-falcon stop alarm
+
+# 查看日志
+./open-falcon monitor alarm
+```
+
+## 报警合并
+
+如果某个核心服务挂了,可能会造成大面积报警,为了减少报警短信数量,我们做了报警合并功能。把报警信息写入dashboard模块,然后dashboard返回一个url地址给alarm,alarm将这个url链接发给用户,这样用户只要收到一条短信(里边是个url地址),点击url进去就是多条报警内容。
+
+highQueues中配置的几个event队列中的事件是不会做报警合并的,因为那些是高优先级的报警,报警合并只是针对lowQueues中的事件。如果所有的事件都不想做报警合并,就把所有的event队列都配置到highQueues中即可
\ No newline at end of file
diff --git a/zh_0_3/distributed_install/api.md b/zh_0_3/distributed_install/api.md
new file mode 100644
index 0000000..7e652d8
--- /dev/null
+++ b/zh_0_3/distributed_install/api.md
@@ -0,0 +1,67 @@
+
+
+# API
+api组件,提供统一的restAPI操作接口。比如:api组件接收查询请求,根据一致性哈希算法去相应的graph实例查询不同metric的数据,然后汇总拿到的数据,最后统一返回给用户。
+
+## 服务部署
+服务部署,包括配置修改、启动服务、检验服务、停止服务等。这之前,需要将安装包解压到服务的部署目录下。
+
+```
+# 修改配置, 配置项含义见下文, 注意graph集群的配置
+mv cfg.example.json cfg.json
+vim cfg.json
+
+# 启动服务
+./open-falcon start api
+
+# 停止服务
+./open-falcon stop api
+
+# 查看日志
+./open-falcon monitor api
+
+```
+
+## 配置说明
+
+注意: 请确保 `graphs`的内容与transfer的配置**完全一致**
+
+```
+{
+ "log_level": "debug",
+ "db": { //数据库相关的连接配置信息
+ //如数据库使用密码, 配置方式稍有不同, 示例: "dsn": "root:password@tcp(127.0.0.1:3306)/graph?loc=Local&parseTime=true&allowNativePasswords=true"
+ "faclon_portal": "root:@tcp(127.0.0.1:3306)/falcon_portal?charset=utf8&parseTime=True&loc=Local",
+ "graph": "root:@tcp(127.0.0.1:3306)/graph?charset=utf8&parseTime=True&loc=Local",
+ "uic": "root:@tcp(127.0.0.1:3306)/uic?charset=utf8&parseTime=True&loc=Local",
+ "dashboard": "root:@tcp(127.0.0.1:3306)/dashboard?charset=utf8&parseTime=True&loc=Local",
+ "alarms": "root:@tcp(127.0.0.1:3306)/alarms?charset=utf8&parseTime=True&loc=Local",
+ "db_bug": true
+ },
+ "graphs": { // graph模块的部署列表信息
+ "cluster": {
+ "graph-00": "127.0.0.1:6070"
+ },
+ "max_conns": 100,
+ "max_idle": 100,
+ "conn_timeout": 1000,
+ "call_timeout": 5000,
+ "numberOfReplicas": 500
+ },
+ "metric_list_file": "./api/data/metric",
+ "web_port": ":8080", // http监听端口
+ "access_control": true, // 如果设置为false,那么任何用户都可以具备管理员权限
+ "salt": "pleaseinputwhichyouareusingnow", //数据库加密密码的时候的salt
+ "skip_auth": false, //如果设置为true,那么访问api就不需要经过认证
+ "default_token": "default-token-used-in-server-side", //用于服务端各模块间的访问授权
+ "gen_doc": false,
+ "gen_doc_path": "doc/module.html"
+}
+
+
+
+```
+
+## 补充说明
+- 部署完成api组件后,请修改dashboard组件的配置、使其能够正确寻址到api组件。
+- 请确保api组件的graph列表 与 transfer的配置 一致。
diff --git a/zh_0_3/distributed_install/gateway.md b/zh_0_3/distributed_install/gateway.md
new file mode 100644
index 0000000..88432d6
--- /dev/null
+++ b/zh_0_3/distributed_install/gateway.md
@@ -0,0 +1,7 @@
+
+
+# Gateway
+
+**如果您没有遇到机房分区问题,请直接忽略此组件**。
+
+如果您已经遇到机房分区问题、并急需解决机房分区时监控数据回传的问题,请使用该组件。更多的资料在[这里](https://github.com/open-falcon/falcon-plus/blob/master/modules/gateway/README.md)。
diff --git a/zh_0_3/distributed_install/graph.md b/zh_0_3/distributed_install/graph.md
new file mode 100644
index 0000000..ddc6160
--- /dev/null
+++ b/zh_0_3/distributed_install/graph.md
@@ -0,0 +1,64 @@
+
+
+# Graph
+
+graph是存储绘图数据的组件。graph组件 接收transfer组件推送上来的监控数据,同时处理api组件的查询请求、返回绘图数据。
+
+## 服务部署
+服务部署,包括配置修改、启动服务、检验服务、停止服务等。这之前,需要将安装包解压到服务的部署目录下。
+
+```
+# 修改配置, 配置项含义见下文
+mv cfg.example.json cfg.json
+vim cfg.json
+
+# 启动服务
+./open-falcon start graph
+
+# 停止服务
+./open-falcon stop graph
+
+# 查看日志
+./open-falcon monitor graph
+
+```
+
+## 配置说明
+配置文件默认为./cfg.json。默认情况下,安装包会有一个cfg.example.json的配置文件示例。各配置项的含义,如下
+
+```
+{
+ "debug": false, //true or false, 是否开启debug日志
+ "http": {
+ "enabled": true, //true or false, 表示是否开启该http端口,该端口为控制端口,主要用来对graph发送控制命令、统计命令、debug命令
+ "listen": "0.0.0.0:6071" //表示监听的http端口
+ },
+ "rpc": {
+ "enabled": true, //true or false, 表示是否开启该rpc端口,该端口为数据接收端口
+ "listen": "0.0.0.0:6070" //表示监听的rpc端口
+ },
+ "rrd": {
+ "storage": "./data/6070" // 历史数据的文件存储路径(如有必要,请修改为合适的路)
+ },
+ "db": {
+ // 所有的 graph 共用一个数据库
+ "dsn": "root:@tcp(127.0.0.1:3306)/graph?loc=Local&parseTime=true", //MySQL的连接信息,默认用户名是root,密码为空,host为127.0.0.1,database为graph(如有必要,请修改)
+ //如数据库使用密码, 配置稍有不同: "dsn": "root:password@tcp(127.0.0.1:3306)/graph?loc=Local&parseTime=true&allowNativePasswords=true"
+ "maxIdle": 4 //MySQL连接池配置,连接池允许的最大连接数,保持默认即可
+ },
+ "callTimeout": 5000, //RPC调用超时时间,单位ms
+ "ioWorkerNum": 64, //底层io.Worker的数量, 注意: 这个功能是v0.2.1版本之后引入的,v0.2.1版本之前的配置文件不需要该参数
+ "migrate": { //扩容graph时历史数据自动迁移
+ "enabled": false, //true or false, 表示graph是否处于数据迁移状态
+ "concurrency": 2, //数据迁移时的并发连接数,建议保持默认
+ "replicas": 500, //这是一致性hash算法需要的节点副本数量,建议不要变更,保持默认即可(必须和transfer的配置中保持一致)
+ "cluster": { //未扩容前老的graph实例列表
+ "graph-00" : "127.0.0.1:6070"
+ }
+ }
+}
+
+```
+
+## 补充说明
+部署完graph组件后,请修改transfer和api的配置,使这两个组件可以寻址到graph。
diff --git a/zh_0_3/distributed_install/hbs.md b/zh_0_3/distributed_install/hbs.md
new file mode 100644
index 0000000..03e88b2
--- /dev/null
+++ b/zh_0_3/distributed_install/hbs.md
@@ -0,0 +1,61 @@
+
+
+# HBS(Heartbeat Server)
+
+心跳服务器,公司所有agent都会连到HBS,每分钟发一次心跳请求。
+
+## 设计初衷
+
+Portal的数据库中有一个host表,维护了公司所有机器的信息,比如hostname、ip等等。这个表中的数据通常是从公司CMDB中同步过来的。但是有些规模小一些的公司是没有CMDB的,那此时就需要手工往host表中录入数据,这很麻烦。于是我们赋予了HBS第一个功能:agent发送心跳信息给HBS的时候,会把hostname、ip、agent version、plugin version等信息告诉HBS,HBS负责更新host表。
+
+falcon-agent有一个很大的特点,就是自发现,不用配置它应该采集什么数据,就自动去采集了。比如cpu、内存、磁盘、网卡流量等等都会自动采集。我们除了要采集这些基础信息之外,还需要做端口存活监控和进程数监控。那我们是否也要自动采集监听的端口和各个进程数目呢?我们没有这么做,因为这个数据量比较大,汇报上去之后用户大部分都是不关心的,太浪费。于是我们换了一个方式,只采集用户配置的。比如用户配置了对某个机器80端口的监控,我们才会去采集这个机器80端口的存活性。那agent如何知道自己应该采集哪些端口和进程呢?向HBS要,HBS去读取Portal的数据库,返回给agent。
+
+之后我们会介绍一个用于判断报警的组件:Judge,Judge需要获取所有的报警策略,让Judge去读取Portal的DB么?不太好。因为Judge的实例数目比较多,如果公司有几十万机器,Judge实例数目可能会是几百个,几百个Judge实例去访问Portal数据库,也是一个比较大的压力。既然HBS无论如何都要访问Portal的数据库了,那就让HBS去获取所有的报警策略缓存在内存里,然后Judge去向HBS请求。这样一来,对Portal DB的压力就会大大减小。
+
+
+## 部署说明
+
+hbs是可以水平扩展的,至少部署两个实例以保证可用性。一般一个实例可以搞定5000台机器,所以说,如果公司有10万台机器,可以部署20个hbs实例,前面架设lvs,agent中就配置上lvs vip即可。
+
+## 配置说明
+
+配置文件必须叫cfg.json,可以基于cfg.example.json修改
+
+```
+{
+ "debug": true,
+ "database": "root:password@tcp(127.0.0.1:3306)/falcon_portal?loc=Local&parseTime=true", # Portal的数据库地址
+ "hosts": "", # portal数据库中有个host表,如果表中数据是从其他系统同步过来的,此处配置为sync,否则就维持默认,留空即可
+ "maxIdle": 100,
+ "listen": ":6030", # hbs监听的rpc地址
+ "trustable": [""],
+ "http": {
+ "enabled": true,
+ "listen": "0.0.0.0:6031" # hbs监听的http地址
+ }
+}
+```
+
+## 进程管理
+
+```
+# 启动
+./open-falcon start hbs
+
+# 停止
+./open-falcon stop hbs
+
+# 查看日志
+./open-falcon monitor hbs
+
+```
+
+## 补充
+
+如果你先部署了agent,后部署的hbs,那咱们部署完hbs之后需要回去修改agent的配置,把agent配置中的heartbeat部分enabled设置为true,addr设置为hbs的rpc地址。如果hbs的配置文件维持默认,rpc端口就是6030,http端口是6031,agent中应该配置为hbs的rpc端口,小心别弄错了。
+
+
+## 视频教程
+
+为hbs模块录制了一个视频,做了源码级解读:http://www.jikexueyuan.com/course/1873.html
+
diff --git a/zh_0_3/distributed_install/judge.md b/zh_0_3/distributed_install/judge.md
new file mode 100644
index 0000000..fae87e7
--- /dev/null
+++ b/zh_0_3/distributed_install/judge.md
@@ -0,0 +1,74 @@
+
+
+# Judge
+
+Judge用于告警判断,agent将数据push给Transfer,Transfer不但会转发给Graph组件来绘图,还会转发给Judge用于判断是否触发告警。
+
+## 设计初衷
+
+因为监控系统数据量比较大,一台机器显然是搞不定的,所以必须要有个数据分片方案。Transfer通过一致性哈希来分片,每个Judge就只需要处理一小部分数据就可以了。所以判断告警的功能不能放在直接的数据接收端:Transfer,而应该放到Transfer后面的组件里。
+
+
+## 部署说明
+
+Judge监听了一个http端口,提供了一个http接口:/count,访问之,可以得悉当前Judge实例处理了多少数据量。推荐的做法是一个Judge实例处理50万~100万数据,用个5G~10G内存,如果所用物理机内存比较大,比如有128G,可以在一个物理机上部署多个Judge实例。
+
+## 配置说明
+
+配置文件必须叫cfg.json,可以基于cfg.example.json修改
+
+```
+{
+ "debug": true,
+ "debugHost": "nil",
+ "remain": 11,
+ "http": {
+ "enabled": true,
+ "listen": "0.0.0.0:6081"
+ },
+ "rpc": {
+ "enabled": true,
+ "listen": "0.0.0.0:6080"
+ },
+ "hbs": {
+ "servers": ["127.0.0.1:6030"], # hbs最好放到lvs vip后面,所以此处最好配置为vip:port
+ "timeout": 300,
+ "interval": 60
+ },
+ "alarm": {
+ "enabled": true,
+ "minInterval": 300, # 连续两个报警之间至少相隔的秒数,维持默认即可
+ "queuePattern": "event:p%v",
+ "redis": {
+ "dsn": "127.0.0.1:6379", # 与alarm、sender使用一个redis; Open-Falcon v0.3 支持设置redis密码,同时支持无认证格式,支持格式为 127.0.0.1:6379、@127.0.0.1:6379、auth@127.0.0.1:6379
+ "maxIdle": 5,
+ "connTimeout": 5000,
+ "readTimeout": 5000,
+ "writeTimeout": 5000
+ }
+ }
+}
+```
+
+remain这个配置详细解释一下:
+remain指定了judge内存中针对某个数据存多少个点,比如host01这个机器的cpu.idle的值在内存中最多存多少个,配置报警的时候比如all(#3),这个#后面的数字不能超过remain-1,一般维持默认就够用了
+
+## 进程管理
+
+我们提供了一个control脚本来完成常用操作
+
+```
+# 启动
+./open-falcon start judge
+
+# 停止
+./open-falcon stop judge
+
+# 查看日志
+./open-falcon monitor judge
+```
+
+## 视频教程
+
+为judge模块录制了一个视频,做了源码级解读:http://www.jikexueyuan.com/course/1850.html
+
diff --git a/zh_0_3/distributed_install/mail-sms.md b/zh_0_3/distributed_install/mail-sms.md
new file mode 100644
index 0000000..dede31f
--- /dev/null
+++ b/zh_0_3/distributed_install/mail-sms.md
@@ -0,0 +1,104 @@
+
+
+# 邮件、短信、微信、电话发送接口
+
+监控系统产生报警事件之后需要发送报警邮件或者报警短信,各个公司可能有自己的邮件服务器,有自己的邮件发送方法;有自己的短信通道,有自己的短信发送方法。falcon为了适配各个公司,在接入方案上做了一个规范,需要各公司提供http的短信和邮件发送接口。
+
+##### 短信发送http接口:
+
+```
+method: post
+params:
+ - content: 短信内容
+ - tos: 使用逗号分隔的多个手机号
+```
+
+#####邮件发送http接口:
+
+```
+method: post
+params:
+ - content: 邮件内容
+ - subject: 邮件标题
+ - tos: 使用逗号分隔的多个邮件地址
+```
+
+##### im发送http接口:
+
+```
+method: post
+params:
+ - content: im内容
+ - tos: 使用逗号分隔的多个im号码
+```
+
+不过你可以使用社区提供的 `邮件发送网关` 和 `微信网关`,或者使用灵犀提供的 [云告警通道](http://t.cn/RpkS0d2)。
+
+- [邮件网关](https://github.com/open-falcon/mail-provider)
+- [微信网关](https://github.com/Yanjunhui/chat)
+
+----
+# LinkedSee灵犀云通道短信/语音通知接入
+目前open-falcon支持LinkedSee灵犀云通道短信/语音通知API快速接入,只需一个API即可快速对接Open Falcon,快速让您拥有告警通知功能,90%的告警压缩比。云通道短信/语音通知接口接入步骤如下:
+
+#### 1、注册开通LinkedSee灵犀云通道
+LinkedSee灵犀云通道是专为IT运维打造的专属告警通道,多通道接入,最大程度避免堵塞,支持基于通知内容关键字的分析,合并同类事件,可以帮助您快速定位故障问题。访问LinkedSee灵犀标准版官网地址:[注册地址](http://t.cn/RpkS0d2)
+,注册灵犀账号,直接开通云通道服务。若已有账号,则直接登录即可。
+
+
+
+#### 2、创建应用
+注册成功后,登录系统进入控制台后,点击云通道进入工作台页面。击新建应用,创建应用,如下所示,输入应用名称之后点击保存。
+
+
+目前云通道提供短信告警、电话告警、短信通知、语音通知等4种使用场景,创建应用时默认开通短信告警和电话告警两种方式,为保证能正常接收到所有语音和短信告警,应确保短信和电话告警两种方式是打开状态。
+
+#### 3、获取应用token
+创建应用成功之后 ,点击查看应用token,如下所示:
+
+附注:token在后续的api接入步骤中使用。请复制后保存,以备后续使用。
+
+
+#### 4、获取token后拼接URL
+获取token后,需要跟LinkSee灵犀云通道的短信和语音告警url进行拼接:
+
+- 发送短信通知地址为:https://www.linkedsee.com/alarm/falcon_sms/`this_is_your_token`
+- 发送语音通知地址为:https://www.linkedsee.com/alarm/falcon_voice/`this_is_your_token`
+
+如若目前创建的应用的token为:d7a11a42aeac6848c3a389622f8,则:
+
+- 发送短信地址为:https://www.linkedsee.com/alarm/falcon_sms/d7a11a42aeac6848c3a389622f8
+- 发送语音告警的地址为:https://www.linkedsee.com/alarm/falcon_voice/d7a11a42aeac6848c3a389622f8
+
+#### 5、配置open-falcon:
+将上面的url配置在open-falcon alarm模块的配置文件cfg.json中,可以基于cfg.example.json修改,目前直接适配open-falcon v0.2。接口部分如下所示:
+
+```
+"api": {
+ "im": "http://127.0.0.1:10086/wechat", //微信发送网关地址
+ "sms": "http://127.0.0.1:10086/sms", //短信发送网关地址
+ "mail": "http://127.0.0.1:10086/mail", //邮件发送网关地址
+ "dashboard": "http://127.0.0.1:8081", //dashboard模块的运行地址
+ "plus_api":"http://127.0.0.1:8080", //falcon-plus api模块的运行地址
+ "plus_api_token": "default-token-used-in-server-side" //用于和falcon-plus api模块服务端之间的通信认证token
+ }
+```
+将step4的URL写在截图红框处, 如下所示:
+
+
+若发短信,则把短信发送网关地址替换为上一步中拼接的URL;若要发送语音消息,则将sms处的地址替换为语音对应的url。目前falcon暂不支持同时发送语音和短信通知,若要同时使用语音和短信报警,可以开通linkedsee云告警服务,同时还支持微信和邮件报警。
+
+#### 6、触发告警
+Open-Falcon配置完成后,请您触发一条告警,检查是否配置成功。目前Open-Falcon接入LinkedSee灵犀云通道之后,语⾳播报通道是固定内容的语⾳,若想使⽤动态语音播报和更多高级告警功能,欢迎使用云告警产品。>>[接入帮助](https://www.linkedsee.com/standard/support/#/access-falcon)
+
+附注:如果未成功,请确认是否按照上述步骤进行配置。如果确认没有问题,可以联系我们。我们将及时为您提供支持。热线电话:010-84148522
+
+#### 7、认证充值
+目前云通道免费版默认为短信10条,电话10通,完成接入配置之后,为保证信息安全,需要点击申请企业认证,填写企业认证相关信息审核通过之后即可充值购买更多的短信和语音告警数量。充值成功之后 ,可以查看用量统计和通知记录,帮助您更好的监控硬件性能,提升效率。
+
+
+#### 欢迎体验LinkedSee云告警高级服务
+- 一分钟拥有短信、微信、邮件、电话四种告警通知方式;
+- 支持告警升级策略、排班表及关键字合并策略;
+- 可以支持指定时间窗内的告警接收数量;
+- 多个维度的数据分析,更好的支持个性化需求;
diff --git a/zh_0_3/distributed_install/nodata.md b/zh_0_3/distributed_install/nodata.md
new file mode 100644
index 0000000..6cd2281
--- /dev/null
+++ b/zh_0_3/distributed_install/nodata.md
@@ -0,0 +1,61 @@
+
+
+# Nodata
+
+nodata用于检测监控数据的上报异常。nodata和实时报警judge模块协同工作,过程为: 配置了nodata的采集项超时未上报数据,nodata生成一条默认的模拟数据;用户配置相应的报警策略,收到mock数据就产生报警。采集项上报异常检测,作为judge模块的一个必要补充,能够使judge的实时报警功能更加可靠、完善。
+
+## 服务部署
+服务部署,包括配置修改、启动服务、检验服务、停止服务等。这之前,需要将安装包解压到服务的部署目录下。
+
+```
+# 修改配置, 配置项含义见下文
+mv cfg.example.json cfg.json
+vim cfg.json
+
+# 启动服务
+./open-falcon start nodata
+
+# 停止服务
+./open-falcon stop nodata
+
+# 检查日志
+./open-falcon monitor nodata
+
+```
+
+## 配置说明
+配置文件默认为./cfg.json。默认情况下,安装包会有一个cfg.example.json的配置文件示例。各配置项的含义,如下
+
+```
+{
+ "debug": true,
+ "http": {
+ "enabled": true,
+ "listen": "0.0.0.0:6090"
+ },
+ "plus_api":{
+ "connectTimeout": 500,
+ "requestTimeout": 2000,
+ "addr": "http://127.0.0.1:8080", #falcon-plus api模块的运行地址
+ "token": "default-token-used-in-server-side" #用于和falcon-plus api模块的交互认证token
+ },
+ "config": {
+ "enabled": true,
+ "dsn": "root:@tcp(127.0.0.1:3306)/falcon_portal?loc=Local&parseTime=true&wait_timeout=604800",
+ "maxIdle": 4
+ },
+ "collector":{
+ "enabled": true,
+ "batch": 200,
+ "concurrent": 10
+ },
+ "sender":{
+ "enabled": true,
+ "connectTimeout": 500,
+ "requestTimeout": 2000,
+ "transferAddr": "127.0.0.1:6060", #transfer的http监听地址,一般形如"domain.transfer.service:6060"
+ "batch": 500
+ }
+}
+
+```
diff --git a/zh_0_3/distributed_install/prepare.md b/zh_0_3/distributed_install/prepare.md
new file mode 100644
index 0000000..61bcf8d
--- /dev/null
+++ b/zh_0_3/distributed_install/prepare.md
@@ -0,0 +1,4 @@
+
+
+## 环境准备
+请参考[环境准备](./prepare.md)
diff --git a/zh_0_3/distributed_install/task.md b/zh_0_3/distributed_install/task.md
new file mode 100644
index 0000000..56da2ed
--- /dev/null
+++ b/zh_0_3/distributed_install/task.md
@@ -0,0 +1,100 @@
+
+
+# Task
+
+task是监控系统一个必要的辅助模块。定时任务,实现了如下几个功能:
+
++ index更新。包括图表索引的全量更新 和 垃圾索引清理。
++ falcon服务组件的自身状态数据采集。定时任务了采集了transfer、graph、task这三个服务的内部状态数据。
++ falcon自检控任务。
+
+
+## 源码编译
+
+```bash
+# update common lib
+cd $GOPATH/src/github.com/open-falcon/common
+git pull
+
+# compile
+cd $GOPATH/src/github.com/open-falcon/task
+go get ./...
+./control build
+./control pack
+```
+
+最后一步会pack出一个tar.gz的安装包,拿着这个包去部署服务即可。
+
+## 服务部署
+
+服务部署,包括配置修改、启动服务、检验服务、停止服务等。这之前,需要将安装包解压到服务的部署目录下。
+
+```bash
+# 修改配置, 配置项含义见下文
+mv cfg.example.json cfg.json
+vim cfg.json
+
+# 启动服务
+./control start
+
+# 校验服务,这里假定服务开启了8002的http监听端口。检验结果为ok表明服务正常启动。
+curl -s "127.0.0.1:8002/health"
+
+...
+# 停止服务
+./control stop
+
+```
+
+服务启动后,可以通过日志查看服务的运行状态,日志文件地址为./var/app.log。可以通过调试脚本```./test/debug```查看服务器的内部状态数据,如 运行 ```bash ./test/debug``` 可以得到服务器内部状态的统计信息。
+
+
+## 配置说明
+配置文件默认为./cfg.json。默认情况下,安装包会有一个cfg.example.json的配置文件示例。各配置项的含义,如下
+
+```
+debug: true/false, 如果为true,日志中会打印debug信息
+
+http
+ - enable: true/false, 表示是否开启该http端口,该端口为控制端口,主要用来对task发送控制命令、统计命令、debug命令等
+ - listen: 表示http-server监听的端口
+
+index
+ - enable: true/false, 表示是否开启索引更新任务
+ - dsn: 索引服务的MySQL的连接信息,默认用户名是root,密码为空,host为127.0.0.1,database为graph(如有必要,请修改)
+ - maxIdle: MySQL连接池配置,连接池允许的最大空闲连接数,保持默认即可
+ - cluster: 后端graph索引更新的定时任务描述。一条记录的形如: "graph地址:执行周期描述",通过设置不同的执行周期,来实现负载在时间上的均衡。
+ eg. 后端部署了两个graph实例,cluster可以配置为
+ "cluster":{
+ "test.hostname01:6071" : "0 0 0 ? * 0-5", //周0-5,每天的00:00:00,开始执行索引全量更新;"0 0 0 ? * 0-5"为quartz表达式
+ "test.hostname02:6071" : "0 30 0 ? * 0-5", //周0-5,每天的00:30:00,开始执行索引全量更新
+ }
+ - autoDelete: true|false, 是否自动删除垃圾索引。默认为false
+
+collector
+ - enable: true/false, 表示是否开启falcon的自身状态采集任务
+ - destUrl: 监控数据的push地址,默认为本机的1988接口
+ - srcUrlFmt: 监控数据采集的url格式, %s将由机器名或域名替换
+ - cluster: falcon后端服务列表,用具体的"module,hostname:port"表示,module取值可以为graph、transfer、task等
+
+```
+
+## 补充说明
+
+部署完成task组件后,请修改collector配置、使task能够正确采集transfer & graph的内部状态,请修改monitor配置、使task模块能够自检控Open-Falon的各组件(当前支持transfer、graph、query、judge等)。
+
+### 关于自监控报警
+因为多点监控的需求,自版本v0.0.10开始,我们将自监控报警功能 从Task模块移除。关于Open-Falcon自监控的详情,请参见[这里](http://book.open-falcon.com/zh/practice/monitor.html)。
+
+### 关于过期索引清除
+监控数据停止上报后,该数据对应的索引也会停止更新、变为过期索引。过期索引,影响视听,部分用户希望删除之。
+
+我们原来的方案,是: 通过task模块,有数据上报的索引、每天被更新一次,7天未被更新的索引、清除之。但是,很多用户不能正确配置graph实例的http接口,导致正常上报的监控数据的索引 无法被更新;7天后,合法索引被task模块误删除。
+
+为了解决上述问题,我们在默认配置里面,停掉了task模块自动删除过期索引的功能(autoDelete=false);如果你确定配置的index.cluster正确无误,可以自行打开该功能。
+
+当然,我们提供了更安全的、手动删除过期索引的方法。用户按需触发索引删除操作,具体步骤为:
+
+1.进行一次索引数据的全量更新。方法为: 针对每个graph实例,运行```curl -s "127.0.0.1:6071/index/updateAll"```,异步地触发graph实例的索引全量更新(这里假设graph的http监听端口为6071),等待所有的graph实例完成索引全量更新后 进行第2步操作。单个graph实例,索引全量更新的耗时,因counter数量、mysql数据库性能而不同,一般耗时不大于30min。
+
+2.待索引全量更新完成后,发起过期索引删除 ``` curl -s "$Hostname.Of.Task:$Http.Port/index/delete" ```。运行索引删除前,请务必**确保索引全量更新已完成**。
diff --git a/zh_0_3/distributed_install/transfer.md b/zh_0_3/distributed_install/transfer.md
new file mode 100644
index 0000000..ae48bf9
--- /dev/null
+++ b/zh_0_3/distributed_install/transfer.md
@@ -0,0 +1,91 @@
+
+
+# Transfer
+
+transfer是数据转发服务。它接收agent上报的数据,然后按照哈希规则进行数据分片、并将分片后的数据分别push给graph&judge等组件。
+
+## 服务部署
+服务部署,包括配置修改、启动服务、检验服务、停止服务等。这之前,需要将安装包解压到服务的部署目录下。
+
+```
+# 修改配置, 配置项含义见下文
+mv cfg.example.json cfg.json
+vim cfg.json
+
+# 启动服务
+./open-falcon start transfer
+
+# 校验服务,这里假定服务开启了6060的http监听端口。检验结果为ok表明服务正常启动。
+curl -s "127.0.0.1:6060/health"
+
+# 停止服务
+./open-falcon stop transfer
+
+# 查看日志
+./open-falcon monitor transfer
+```
+
+
+
+## 配置说明
+配置文件默认为./cfg.json。默认情况下,安装包会有一个cfg.example.json的配置文件示例。各配置项的含义,如下
+
+## Configuration
+```
+ debug: true/false, 如果为true,日志中会打印debug信息
+
+ minStep: 30, 允许上报的数据最小间隔,默认为30秒
+
+ http
+ - enabled: true/false, 表示是否开启该http端口,该端口为控制端口,主要用来对transfer发送控制命令、统计命令、debug命令等
+ - listen: 表示监听的http端口
+
+ rpc
+ - enabled: true/false, 表示是否开启该jsonrpc数据接收端口, Agent发送数据使用的就是该端口
+ - listen: 表示监听的http端口
+
+ socket #即将被废弃,请避免使用
+ - enabled: true/false, 表示是否开启该telnet方式的数据接收端口,这是为了方便用户一行行的发送数据给transfer
+ - listen: 表示监听的http端口
+
+ judge
+ - enabled: true/false, 表示是否开启向judge发送数据
+ - batch: 数据转发的批量大小,可以加快发送速度,建议保持默认值
+ - connTimeout: 单位是毫秒,与后端建立连接的超时时间,可以根据网络质量微调,建议保持默认
+ - callTimeout: 单位是毫秒,发送数据给后端的超时时间,可以根据网络质量微调,建议保持默认
+ - pingMethod: 后端提供的ping接口,用来探测连接是否可用,必须保持默认
+ - maxConns: 连接池相关配置,最大连接数,建议保持默认
+ - maxIdle: 连接池相关配置,最大空闲连接数,建议保持默认
+ - replicas: 这是一致性hash算法需要的节点副本数量,建议不要变更,保持默认即可
+ - cluster: key-value形式的字典,表示后端的judge列表,其中key代表后端judge名字,value代表的是具体的ip:port
+
+ graph
+ - enabled: true/false, 表示是否开启向graph发送数据
+ - batch: 数据转发的批量大小,可以加快发送速度,建议保持默认值
+ - connTimeout: 单位是毫秒,与后端建立连接的超时时间,可以根据网络质量微调,建议保持默认
+ - callTimeout: 单位是毫秒,发送数据给后端的超时时间,可以根据网络质量微调,建议保持默认
+ - pingMethod: 后端提供的ping接口,用来探测连接是否可用,必须保持默认
+ - maxConns: 连接池相关配置,最大连接数,建议保持默认
+ - maxIdle: 连接池相关配置,最大空闲连接数,建议保持默认
+ - replicas: 这是一致性hash算法需要的节点副本数量,建议不要变更,保持默认即可
+ - cluster: key-value形式的字典,表示后端的graph列表,其中key代表后端graph名字,value代表的是具体的ip:port(多个地址用逗号隔开, transfer会将同一份数据发送至各个地址,利用这个特性可以实现数据的多重备份)
+
+ tsdb
+ - enabled: true/false, 表示是否开启向open tsdb发送数据
+ - batch: 数据转发的批量大小,可以加快发送速度
+ - connTimeout: 单位是毫秒,与后端建立连接的超时时间,可以根据网络质量微调,建议保持默认
+ - callTimeout: 单位是毫秒,发送数据给后端的超时时间,可以根据网络质量微调,建议保持默认
+ - maxConns: 连接池相关配置,最大连接数,建议保持默认
+ - maxIdle: 连接池相关配置,最大空闲连接数,建议保持默认
+ - retry: 连接后端的重试次数和发送数据的重试次数
+ - address: tsdb地址或者tsdb集群vip地址, 通过tcp连接tsdb.
+
+```
+
+## 补充说明
+部署完成transfer组件后,请修改agent的配置,使其指向正确的transfer地址。在安装完graph和judge后,请修改transfer的相应配置、使其能够正确寻址到这两个组件。
+
+
+## 视频教程
+
+为transfer模块录制了一个视频,做了源码级解读:http://www.jikexueyuan.com/course/2061.html
diff --git a/zh_0_3/donate.md b/zh_0_3/donate.md
new file mode 100644
index 0000000..6d73481
--- /dev/null
+++ b/zh_0_3/donate.md
@@ -0,0 +1 @@
+../zh/donate.md
\ No newline at end of file
diff --git a/zh_0_3/faq/README.md b/zh_0_3/faq/README.md
new file mode 100644
index 0000000..190bfde
--- /dev/null
+++ b/zh_0_3/faq/README.md
@@ -0,0 +1,76 @@
+
+
+1. open-falcon v0.2的api文档是如何生成的?API文档地址 http://open-falcon.com/falcon-plus/
+> 人工生成yaml描述文件,通过Jekyll来生成静态站点,使用github来serve,api站点的源码在 https://github.com/open-falcon/falcon-plus/tree/master/docs 这里。不过可以通过打开api组件的gen_doc选项,然后api会把请求和应答都记录下来,作为撰写api yaml文件的参考。
+
+1. open-falcon v0.2 有管理员帐号吗?
+> 可以通过dashboard自行注册新用户,第一个用户名为root的帐号会被认为是超级管理员,超级管理员可以设置其他用户为管理员。
+
+1. open-falcon v0.2 dashboard 可以禁止用户自己注册吗?
+> 可以的,在api组件的配置文件中,将`signup_disable`配置项修改为true,重启api即可。
+
+1. open-falcon v0.2 dashboard 添加graph或者clone screen的时候,偶尔会出现'record not found'错误。
+> 这是api的bug引起的,已经在 [pull-request #186](https://github.com/open-falcon/falcon-plus/pull/186) 修复,请重新编译最新的api代码。
+
+1. open-falcon 可以监控udp的端口吗?
+> 支持的,参考 [pull-request #66](https://github.com/open-falcon/falcon-plus/pull/66)。
+
+1. open-falcon v0.2 如何单独编译安装api模块?
+> 参考[环境准备](https://book.open-falcon.com/zh_0_2/quick_install/prepare.html), 在falcon-plus的目录下,执行`make api`即可编译最新的api组件。
+
+1. open-falcon 支持Grafana吗?
+> 支持的,请参考[open-falcon grafana datasource](https://github.com/open-falcon/grafana-openfalcon-datasource)。
+
+1. 为什么连续3次报警之后,不再发送报警了?
+> 报警策略配置中,有一个最大报警次数的配置,比如你配置了cpu.idle小于5报警,max设置为3,那么报警达到3次之后即使仍然小于5也不会再报警了,直到接下来某次cpu.idle大于5了,就会报一个ok出来。以后如果又小于5了,那就会再次报警。
+
+1. 手动删除了数据库中 endpoint表、endpoint_counter中的一些记录后,相同的指标不会再次插入到MySQL中了。
+> 可以手工运行一次 graph 的索引刷新命令,即针对每个graph实例执行:`curl -s http://127.0.0.1:6071/index/updateAll` (这里假定graph模块http监听端口为6071)。
+
+1. graph的磁盘占用越来越大,怎么清理掉无用的数据?(rrd文件目录越来越大)
+> 在每台graph机器的rrd文件目录下面,执行如下命令 `find . -name '*.rrd' -mtime +7 | xargs rm -f'` 即可删除过去7天没有更新的rrd文件。
+
+1. 如何清理MySQL表过期的监控指标项?
+> 可以根据 graph.endpoint,graph.endpoint_counter,graph.tag_endpoint 三张表中的t_modify字段,找出很长一段时间都没有更新过的条目,进行删除。建议在操作数据库前,对数据库表做一个备份,免得误操作无法恢复,其次建议在操作前先触发一次索引的全量更新。
+
+1. 报警达到最大次数之后,如何再次报警?
+> 有三种方法:1是调大最大告警次数;2是修改告警阈值让该告警恢复;3是上报一个正常的值让该报警恢复。
+
+1. open-falcon 有英文版本吗?
+> open-falcon v0.2开始,dashboard部分支持i18n,点[这里](https://github.com/open-falcon/dashboard/blob/master/i18n.md)参与。
+
+1. open-falcon 支持发送报警到微信吗?(钉钉呢?)
+> open-falcon v0.2 原生支持发送报警到微信,可以参考 [alarm配置](https://book.open-falcon.com/zh_0_2/distributed_install/mail-sms.html) 和 [微信网关搭建](https://github.com/Yanjunhui/chat) 。发送报警到钉钉,可以参考[issue #134](https://github.com/open-falcon/falcon-plus/issues/134)。
+
+1. open-falcon 扩容增加graph节点,怎么让数据重新迁移?
+> 平滑扩容步骤,请参考 [graph扩容历史数据自动迁移](http://www.jianshu.com/p/16baba04c959)。
+
+1. open-falcon 能监控windows吗?
+> 可以的,请参考社区对 [windows监控的解决方案](https://book.open-falcon.com/zh_0_2/usage/win.html)。
+
+1. open-falcon 能监控交换机吗?
+> 可以的,请参考社区对 [交换机监控的解决方案](https://book.open-falcon.com/zh_0_2/usage/switch.html)。
+
+1. open-falcon v0.2 中没有sender模块了吗?
+> 是的,为了减少维护成本和安装成本,在open-falcon v0.2 中,移除了sender模块,将该功能集成在alarm模块中了。
+
+1. graph中,对于同一个Counter,在收到数据的时候,如果该数据的Timestamp小于Store中第一个数据的Timestamp,则该数据会被丢弃,这是为什么呢? 我想知道,这个地方出于这个考虑,是因为rrdtool的限制么,不能在Store中插入数据,只能追加数据吗? [issue](https://github.com/open-falcon/falcon-plus/issues/292)
+> 是的,在rrdtool的设计模式下,数据只能追加,不能插入。所以falcon在graph中提前对数据做了一个按照时间戳的排序。
+
+1. 宕机后,nodata报警有一定时间的延迟和滞后,是什么原因? [issue](https://github.com/open-falcon/falcon-plus/issues/294)
+> nodata的工作逻辑是:通过api去graph中查询数据,如果没有查询到数据,则对这个counter补发设定后的值。nodata的补发数据 和 用户正常上报数据,都是靠时钟来对齐的,因此在nodata的代码中,强行延迟了一到两个周期,以免造成 nodata 补发的值先到达graph,这样就会造成正常的值失效。
+
+1. counter中的tag字段,里面的所有空格都被去掉这是出于什么考虑呢? [issue](https://github.com/open-falcon/falcon-plus/issues/289)
+> 这算作一个最佳实践的约定吧,并非代码实现层面的考虑。空格建议大家在上报之前自行替换为-号。
+
+1. 报警信息里磁盘信息是以bit计数的,怎么控制单位呢? [issue](https://github.com/open-falcon/falcon-plus/issues/275)
+> open-falcon中没有「单位」的概念,数据都是遵从用户上报时的含义,理解上要保持一致。
+
+1. 上报数据中有中文时,graph 读取数据报错:errno: 0x023a, str:opening error [issue](https://github.com/open-falcon/falcon-plus/issues/274)
+> 这和中文没有关系,这个错误,应该是读取不存在的counter造成的,可以忽略。
+
+1. 按天为单位,上报数据如何正确上报和展现?[issue](https://github.com/open-falcon/falcon-plus/issues/271)
+> step要设置为86400,并且坚持每天push一次数据;push上去后,服务端会对时间戳做归一化,即服务端记录的时间戳 = int(当前时间戳/86400)。
+
+1. open-falcon 的报警历史是存储在什么地方的?
+> 在v0.1版本中,历史报警信息是不存储的,发送后就丢弃了;在v0.2中,做了改进,报警发送后会将历史报警存储在数据库中,请参考 `alarms` 库下面的表。当然,也可以通过 [API](http://open-falcon.com/falcon-plus/#/alarm_eventcases_list) 来访问这些信息。
diff --git a/zh_0_3/faq/alarm.md b/zh_0_3/faq/alarm.md
new file mode 100644
index 0000000..63d9e1b
--- /dev/null
+++ b/zh_0_3/faq/alarm.md
@@ -0,0 +1,39 @@
+
+
+# 报警相关常见问题
+
+#### 配置了策略,一直没有报警,如何排查?
+
+1. 排查sender、alarm、judge、hbs、agent、transfer的log
+2. 浏览器访问alarm的http页面,看是否有未恢复的告警,如果有就是生成报警了,后面没发出去,很可能是邮件、短信发送接口出问题了,检查sender中配置的api
+3. 打开agent的debug,看是否在正常push数据
+4. 看agent配置,是否正确配置了heartbeat(hbs)和transfer的地址,并enabled
+5. 看transfer配置,是否正确配置了judge地址
+6. jduge提供了一个http接口用于debug,可以检查某个数据是否正确push上来了,比如qd-open-falcon-judge01.hd这个机器的cpu.idle数据,可以这么查看
+```bash
+curl http://127.0.0.1:6081/history/qd-open-falcon-judge01.hd/cpu.idle
+```
+7. 检查服务器的时间是否已经同步,可以用 [ntp](https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/System_Administrators_Guide/sect-Understanding_chrony_and-its_configuration.html) 或 chrony 来实现
+
+上面的127.0.0.1:6081指的是judge的http端口
+7. 检查judge配置的hbs地址是否正确
+8. 检查hbs配置的数据库地址是否正确
+9. 检查portal中配置的策略模板是否配置了报警接收人
+10. 检查portal中配置的策略模板是否绑定到某个HostGroup了,并且目标机器恰好在这个HostGroup中
+11. 去UIC检查报警接收组中是否把自己加进去了
+12. 去UIC检查自己的联系信息是否正确
+
+#### 在Portal页面创建了一个HostGroup,往HostGroup中增加机器的时候报错
+
+1. 检查agent是否正确配置了heartbeat地址,并enabled了
+2. 检查hbs log
+3. 检查hbs配置的数据库地址是否正确
+4. 检查hbs的配置hosts是否配置为sync了,只有留空的时候hbs才会去写host表,host表中有数据才能在页面上添加机器
+
+
+#### 在alarm这边配置了短信、邮件、微信通知,在alarm 日志中看到告警写入 redis 队列都有,但实际发送有时候只有1种,有时2种,有时3种都有。
+1. 检查是否有多个alarm进程同时读取一个redis队列,引起相互干扰,如urlooker的alarm。
+2. 修改redis队列名称,如修改urlooker的redis队列名称,使2个alarm读取不同的队列,避免造成干扰。
+
+
+
diff --git a/zh_0_3/faq/collect.md b/zh_0_3/faq/collect.md
new file mode 100644
index 0000000..65f9c82
--- /dev/null
+++ b/zh_0_3/faq/collect.md
@@ -0,0 +1,62 @@
+
+
+# 数据收集相关问题
+Open-Falcon数据收集,分为[绘图数据]收集和[报警数据]收集。下面介绍,如何验证两个链路的数据收集是否正常。
+
+
+### 如何验证[绘图数据]收集是否正常
+数据链路是:`agent->transfer->graph->query->dashboard`。graph有一个http接口可以验证`agent->transfer->graph`这条链路,比如graph的http端口是6071,可以这么访问验证:
+
+```bash
+# $endpoint和$counter是变量
+curl http://127.0.0.1:6071/history/$endpoint/$counter
+
+# 如果上报的数据不带tags,访问方式是这样的:
+curl http://127.0.0.1:6071/history/host01/agent.alive
+
+# 如果上报的数据带有tags,访问方式如下,其中tags为module=graph,project=falcon
+curl http://127.0.0.1:6071/history/host01/qps/module=graph,project=falcon
+```
+如果调用上述接口返回空值,则说明agent没有上报数据、或者transfer服务异常。
+
+
+### 如何验证[报警数据]收集是否正常
+
+数据链路是:`agent->transfer->judge`,judge有一个http接口可以验证`agent->transfer->judge`这条链路,比如judge的http端口是6081,可以这么访问验证:
+
+```bash
+curl http://127.0.0.1:6081/history/$endpoint/$counter
+
+# $endpoint和$counter是变量,举个例子:
+curl http://127.0.0.1:6081/history/host01/cpu.idle
+
+# counter=$metric/sorted($tags)
+# 如果上报的数据带有tag,访问方式是这样的,比如:
+curl http://127.0.0.1:6081/history/host01/qps/module=judge,project=falcon
+```
+如果调用上述接口返回空值,则说明agent没有上报数据、或者transfer服务异常。
+
+**注意**: v0.2.1版本之后judge新增了优化内存使用的功能,如果metric没有对应的strategy或者expression,judge内存中不会存储该metirc的历史数据,所以判断报警数据收集这条链路是否正常时需要先确定metric是否有对应的报警条件
+
+```bash
+# 检查metric是否有对应的strategy
+curl http://127.0.0.1:6081/strategy/$endpoint/$counter
+
+# 检查metric是否有对应的expression
+curl http://127.0.0.1:6081/expression/$counter
+
+
+# $endpoint和$counter是变量
+# expression报警条件必须包含tag,当metric上报数据没有携带tag时只检测是否有对应的strategy即可
+# 举个例子:
+curl http://127.0.0.1:6081/strategy/host01/cpu.idle
+
+# counter=$metric/sorted($tags)
+# 如果上报的数据带有tag,需要检测streategy和expression是否存在
+# 举个例子: 当上报的metric为qps, tag为module=judge,project=falcon时, 访问方式是这样的:
+curl http://127.0.0.1:6081/strategy/host01/qps
+
+curl http://127.0.0.1:6081/expression/qps/module=judge
+
+curl http://127.0.0.1:6081/expression/qps/project=falcon
+```
diff --git a/zh_0_3/faq/graph.md b/zh_0_3/faq/graph.md
new file mode 100644
index 0000000..4267eff
--- /dev/null
+++ b/zh_0_3/faq/graph.md
@@ -0,0 +1,339 @@
+
+
+# 绘图链路常见问题
+
+### 如何清除过期索引
+监控数据停止上报后,该数据对应的索引也会停止更新、变为过期索引。过期索引,影响视听,部分用户希望删除之。
+
+我们原来的方案,是: 通过task模块,有数据上报的索引、每天被更新一次,7天未被更新的索引、清除之。但是,很多用户不能正确配置graph实例的http接口,导致正常上报的监控数据的索引 无法被更新;7天后,合法索引被task模块误删除。
+
+为了解决上述问题,我们停掉了task模块自动删除过期索引的功能、转而提供了过期索引删除的接口。用户按需触发索引删除操作,具体步骤为:
+
+1.运行task模块,并正确配置graph集群及其http端口,即task配置文件中index.cluster的内容。此处配置不正确,不应该进行索引删除操作,否则将导致索引数据的误删除。
+
+2.进行一次索引数据的全量更新。方法为 ``` curl -s "http://$Hostname.Of.Task:$Http.Port/index/updateAll" ```。这里,"$Hostname.Of.Task:$Http.Port"是task的http接口地址。
+PS:索引数据存放在graph实例上,这里,只是通过task,触发了各个graph实例的索引全量更新。更直接的办法,是,到每个graph实例上,运行```curl -s "http://127.0.0.1:6071/index/updateAll"```,直接触发graph实例 进行索引全量更新(这里假设graph的http监听端口为6071)。
+
+3.待索引全量更新完成后,发起过期索引删除 ``` curl -s "http://$Hostname.Of.Task:$Http.Port/index/delete" ```。运行索引删除前,请务必**确保索引全量更新已完成**。典型的做法为,周六运行一次索引全量更新,周日运行一次索引删除;索引更新和删除之间,留出足够的时间。
+
+在此,建议您: **若无必要,请勿删除索引**;若确定要删除索引,请确保删除索引之前,对所有的graph实例进行一次索引全量更新。
+
+
+### Dashboard索引缺失、查询不到endpoint或counter
+手动更改graph的数据库后,可能会出现上述情况。这里的手动更改,包括:更改graph的数据库配置(数据库地址,名称等)、删除重建graph数据库/表、手动更改graph数据表的内容等。出现上述情况后,可以通过 如下两种途径的任一种 来解决问题,
+
+1. 触发graph的索引全量更新、补救手工操作带来的异常。触发方式为,运行```curl -s "http://$hostname:$port/index/updateAll"```,其中```$hostname```为graph所在的服务器地址,```$port```为graph的http监听端口。这种方式,不会删除已上报的监控数据,但是会对数据库造成短时间的读写压力。
+2. 删除graph已存储的数据,并重启graph。默认情况下,graph的数据存储目录为 ```/home/work/data/6070/```。这种方式,会使已上报的数据被删除。
+
+
+
+### Dashboard图表曲线为空
+图表曲线,一般会有3-5个上报周期的延迟。如果5个周期后仍然没有图表曲线,请往下看。
+绘图链路,数据上报的流程为: agent -> transfer -> graph -> query -> dashboard。这个流程中任何一环节出问题,都会导致用户在dashboard中看不到曲线。一个建议的问题排查流程,如下
+
+1. 确保绘图链路的各组件,都已启动。
+2. 排查dashboard的问题。首先查看dashboard的日志,默认地址为```./var/app.log```,常见的日志报错原因有dashboard依赖库安装不完整、本地http代理劫持访问请求等。然后查看dashboard的配置,默认为```./gunicorn.conf```和```./rrd/config.py```。确认gunicorn.conf中指定的访问地址,确认config.py中指定的query地址、dashboard数据库配置 和 graph数据库配置。
+3. 排查query的问题。首先看下query的日志```./var/app.log```是否有报错信息。然后确认query的graph列表配置```./graph_backends.txt```和 服务配置```./cfg.json```。可以通过脚本```./scripts/query```来做一些定量的debug,比如你上报了一个 endpoint="ty-op-mon-cloud.us", metric="agent.alive" 的采集项,可以运行 ```bash ./scripts/query "ty-op-mon-cloud.us" "agent.alive" ``` 来查看该采集项的数据,如果能够查到数据 则说明query及之前的graph、transfer、agent很可能是正常的。
+4. 排查graph的问题。首先看下graph的日志```./var/app.log```是否有报错。然后确认下graph配置文件```./cfg.json```是否配置了正确的数据库db。没有发现问题?启动对graph的debug,方法见***Graph调试***一节。
+5. 排查transfer的问题。首先看transfer的日志```./var/app.log```是否有报错。然后确认配置文件```./cfg.json```是否enable了对graph集群的发送功能、是否正确配置了graph集群列表。确认完毕后,仍没有发现问题,怎么办?启动对transfer的debug,方法见***Transfer调试***一节。
+6. 排查agent的问题。打开agent的debug日志,观察数据上报情况。
+
+
+
+### Dashboard图表曲线有断点
+dashboard出现断点,可能的原因为:
+
+1. 用户监控数据上报异常。可能是用户自动的数据采集 被中断,或者上报周期不规律等。
+2. falcon系统异常,导致监控数据丢失。问题最可能发生在transfer到graph这个链路上,可以通过transfer&graph的debug接口来确认原因。
+
+
+### Graph绘图数据高可用
+默认情况下,绘图数据以分片的形式、存储在单个graph实例上。一旦graph实例所在的机器磁盘坏掉, 绘图数据就会永久丢失。
+
+为了解决这个问题,Open-Falcon提供了绘图数据高可用的解决方案: 数据双打/多打,即 将同一份绘图数据 同时打到2+个graph实例上、使这2+个graph实例的数据完全相同、互为镜像备份,当发生故障时 就可以用 镜像备份实例 来替换 故障的实例。具体的,绘图数据高可用的实现过程,如下:
+
+1. 配置transfer的graph节点列表,使每个节点都有2+个互为镜像的graph实例;transfer会向 互为镜像的几个graph实例 发送相同的数据。eg.你可以配置graph节点 形如``` "g-00" : "host1:6070,host2:6070"```,多个graph实例之间以逗号隔开,这样 ```host1:6070``` 和 ```host2:6070```就会互为镜像。注意,transfer版本应不低于***0.0.14***,否则 不能支持此功能。
+2. 启动/重启transfer,开始数据双打或者多打。transfer的压力,会随着镜像数量的增加而增大,所以 需要合理控制graph镜像的数量。
+3. 配置query的graph列表。当前,query只支持 **一个节点对应一个graph实例**。以第1步的transfer配置为例,你可以配置query的graph节点```g-00```的graph实例为 ```"g-00":"host1:6070"``` 或者 ```"g-00":"host2:6070"```、而不能是 ```"g-00":"host1:6070,host2:6070"```
+4. 当某个graph实例发生故障(eg.磁盘故障)时,修改query的graph列表、踢掉坏死的graph实例、并用其镜像实例顶替之。一方面,更上层的业务只会在query配置修改期间不可用,这个过程可以控制在分钟级别。另一方面,即使坏掉了一个graph实例,其上绘图数据 也可以从镜像实例上找到,从而实现了数据的高可用。
+
+当然,这个高可用方案 需要增加更多的graph实例、会使transfer资源消耗倍增、需要手动进行故障切换,还有很多的改进空间。
+
+
+
+### 如何确定某个counter对应的rrd文件
+每个counter,上报到graph之后,都是以一个独立的rrd文件,存储在磁盘上。那么如何确定counter和rrd的对应关系呢?
+query组件提供了一个调试用的http接口,可以帮助我们查询到该对应关系
+
+`info.py`
+
+```python
+#!/usr/bin/env python
+
+import requests
+import json
+import sys
+
+d = [
+ {
+ "endpoint": sys.argv[1],
+ "counter": sys.argv[2],
+ },
+]
+url = "http://127.0.0.1:9966/graph/info"
+r = requests.post(url, data=json.dumps(d))
+print r.text
+
+```
+
+`使用方法`
+
+ python info.py your.hostname your.metric/tag1=tag1-val,tag2=tag2-val
+
+
+
+### Graph调试
+graph以http的方式提供了多个调试接口。主要有 内部状态统计接口、历史数据查询接口等。脚本```./test/debug```将一些接口封装成了shell的形式,可自行查阅代码、不在此做介绍。
+
+**历史数据查询接口**```HTTP:GET, curl -s "http://hostname:port/history/$endpoint/$metric/$tags"```,返回graph接收到的、最新的3个数据。
+
+```bash
+# history没有tags的数据,$endpoint=test.host, $metric=agent.alive
+curl -s "http://127.0.0.1:6071/history/test.host/agent.alive" | python -m json.tool
+
+# history有tags的数据,$tags='module=graph,pdl=falcon'
+curl -s "http://127.0.0.1:6071/history/test.host/qps/module=graph,pdl=falcon" | python -m json.tool
+```
+
+**内部状态统计接口**```HTTP:GET, curl -s "http://hostname:port/statistics/all"```,输出json格式的内部状态数据,格式如下。这些内部状态数据,被task组件采集后push到falcon系统,用于绘图展示、报警等。
+
+```bash
+curl -s "http://127.0.0.1:6071/statistics/all" | python -m json.tool
+
+# output
+{
+ "data": [
+ { // counter of received items
+ "Cnt": 7, // cnt
+ "Name": "GraphRpcRecvCnt", // name of counter
+ "Other": {}, // other infos
+ "Qps": 0, // growth rate of this counter, per second
+ "Time": "2015-06-18 12:20:06" // time when this counter takes place
+ },
+ { // counter of query requests graph received
+ "Cnt": 0,
+ "Name": "GraphQueryCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-18 12:20:06"
+ },
+ { // counter of all sent items in query
+ "Cnt": 0,
+ "Name": "GraphQueryItemCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-18 12:20:06"
+ },
+ { // counter of info requests graph received
+ "Cnt": 0,
+ "Name": "GraphInfoCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-18 12:20:06"
+ },
+ { // counter of last requests graph received
+ "Cnt": 3,
+ "Name": "GraphLastCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-18 12:20:06"
+ },
+ { // counter of index updates
+ "Cnt": 0,
+ "Name": "IndexUpdateAllCnt",
+ "Other": {},
+ "Time": "2015-06-18 10:58:52"
+ }
+ ],
+ "msg": "success"
+}
+```
+
+
+### Transfer调试
+transfer以http的方式提供了多个调试接口。主要有 内部状态统计接口、转发数据追踪接口等。脚本```./test/debug```将一些http接口封装成了shell的形式,可自行查阅代码、不在此做介绍。
+
+**转发数据追踪接口** ```HTTP:GET, curl -s "http://hostname:port/trace/$endpoint/$metric/$tags"```,输出json格式的trace数据。transfer会过滤出以```/$endpoint/$metric/$tags```标记的数据,第一次调用时设置过滤条件、不会返回数据,之后每次调用返回已接收到的数据、最多3个点。这个接口主要用于debug。
+
+```bash
+# trace没有tags的数据,$endpoint=test.host, $metric=agent.alive
+curl -s "http://127.0.0.1:6060/trace/test.host/agent.alive" | python -m json.tool
+
+# trace有tags的数据,$tags='module=graph,pdl=falcon'
+curl -s "http://127.0.0.1:6060/trace/test.host/qps/module=graph,pdl=falcon" | python -m json.tool
+```
+
+**内部状态统计接口**```HTTP:GET, curl -s "http://hostname:port/statistics/all"```,输出json格式的内部状态数据,格式如下。这些内部状态数据,被task组件采集后push到falcon系统,用于绘图展示、报警等。
+
+```bash
+curl -s "http://127.0.0.1:6060/statistics/all" | python -m json.tool
+
+# output
+{
+ "data": [
+ { // counter of items received
+ "Cnt": 0, // counter, total number of items received since transfer started
+ "Name": "RecvCnt", // name of this this counter
+ "Other": {}, // other infos
+ "Qps": 0, // growth rate of this counter, items per sec
+ "Time": "2015-06-10 07:46:35" // time when this counter takes place
+ },
+ { // counter of items received from RPC
+ "Cnt": 0,
+ "Name": "RpcRecvCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of items received from HTTP-API
+ "Cnt": 0,
+ "Name": "HttpRecvCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of items received from SOCKET
+ "Cnt": 0,
+ "Name": "SocketRecvCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of items sent to judge
+ "Cnt": 0,
+ "Name": "SendToJudgeCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of items sent to graph
+ "Cnt": 0,
+ "Name": "SendToGraphCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of items sent to graph-migrating
+ "Cnt": 0,
+ "Name": "SendToGraphMigratingCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of dropped items sent to judge. transfer would drop items if it could not push them to receivers timely
+ "Cnt": 0,
+ "Name": "SendToJudgeDropCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of dropped items sent to graph
+ "Cnt": 0,
+ "Name": "SendToGraphDropCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of dropped items sent to graph-migrating
+ "Cnt": 0,
+ "Name": "SendToGraphMigratingDropCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of items transfer failed to send to judge
+ "Cnt": 0,
+ "Name": "SendToJudgeFailCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of items transfer failed to send to graph
+ "Cnt": 0,
+ "Name": "SendToGraphFailCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of items transfer failed to send to graph-migrating
+ "Cnt": 0,
+ "Name": "SendToGraphMigratingFailCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of cached items which would be sent to judge instances
+ "Cnt": 0,
+ "Name": "JudgeSendCacheCnt",
+ "Other": {},
+ "Time": "2015-06-10 07:46:33"
+ },
+ { // counter of cached items which would be sent to graph instances
+ "Cnt": 0,
+ "Name": "GraphSendCacheCnt",
+ "Other": {},
+ "Time": "2015-06-10 07:46:33"
+ },
+ { // counter of cached items which would be sent to grap-migrating instances
+ "Cnt": 0,
+ "Name": "GraphMigratingCacheCnt",
+ "Other": {},
+ "Time": "2015-06-10 07:46:33"
+ }
+ ],
+ "msg": "success"
+}
+```
+
+### 设置绘图数据的存储周期
+Graph组件默认保存5年的数据,存储数据的RRA配置为:
+
+```go
+// find this in 'graph/rrdtool/rrdtool.go'
+func create(filename string, item *model.GraphItem) error {
+ now := time.Now()
+ start := now.Add(time.Duration(-24) * time.Hour)
+ step := uint(item.Step)
+
+ c := rrdlite.NewCreator(filename, start, step)
+ c.DS("metric", item.DsType, item.Heartbeat, item.Min, item.Max)
+
+ // 设置各种归档策略
+ // 1分钟一个点存 12小时
+ c.RRA("AVERAGE", 0.5, 1, 720)
+
+ // 5m一个点存2d
+ c.RRA("AVERAGE", 0.5, 5, 576)
+ c.RRA("MAX", 0.5, 5, 576)
+ c.RRA("MIN", 0.5, 5, 576)
+
+ // 20m一个点存7d
+ c.RRA("AVERAGE", 0.5, 20, 504)
+ c.RRA("MAX", 0.5, 20, 504)
+ c.RRA("MIN", 0.5, 20, 504)
+
+ // 3小时一个点存3个月
+ c.RRA("AVERAGE", 0.5, 180, 766)
+ c.RRA("MAX", 0.5, 180, 766)
+ c.RRA("MIN", 0.5, 180, 766)
+
+ // 1天一个点存5year
+ c.RRA("AVERAGE", 0.5, 720, 730)
+ c.RRA("MAX", 0.5, 720, 730)
+ c.RRA("MIN", 0.5, 720, 730)
+
+ return c.Create(true)
+}
+
+```
+你可以通过修改rrdtool的RRA ``` c.RRA($CF, 0.5, $PN, $PCNT) ```,来设置Graph的数据存储周期。关于RRA的概念,请查阅rrdtool的相关资料。
diff --git a/zh_0_3/faq/linux-metrics.md b/zh_0_3/faq/linux-metrics.md
new file mode 100644
index 0000000..7541cf7
--- /dev/null
+++ b/zh_0_3/faq/linux-metrics.md
@@ -0,0 +1,198 @@
+
+
+# Linux运维基础采集项
+
+做运维,不怕出问题,怕的是出了问题,抓不到现场,两眼摸黑。所以,依靠强大的监控系统,收集尽可能多的指标,意义重大。但哪些指标才是有意义的呢,本着从实践中来的思想,各位工程师在长期摸爬滚打中总结出来的经验最有价值。
+
+在各位运维工程师长期的工作实践中,我们总结了在系统运维过程中,经常会参考的一些指标,主要包括以下几个类别:
+
+- CPU
+- Load
+- 内存
+- 磁盘
+- IO
+- 网络相关
+- 内核参数
+- ss 统计输出
+- 端口采集
+- 核心服务的进程存活信息采集
+- 关键业务进程资源消耗
+- NTP offset采集
+- DNS解析采集
+
+每个类别,具体的详细指标如下,这些指标,都是open-falcon的agent组件直接支持的。falcon-agent每隔一定时间间隔(目前是60秒)会采集一次相关的指标,并汇报给server端。
+
+# CPU相关采集项
+
+计算方法:通过采集/proc/stat来得到,大家可以参考sar命令的统计输出来理解。
+
+- cpu.idle:Percentage of time that the CPU or CPUs were idle and the system did not have an outstanding disk I/O request.
+- cpu.busy:与cpu.idle相对,他的值等于100减去cpu.idle。
+- cpu.guest:Percentage of time spent by the CPU or CPUs to run a virtual processor.
+- cpu.iowait:Percentage of time that the CPU or CPUs were idle during which the system had an outstanding disk I/O request.
+- cpu.irq:Percentage of time spent by the CPU or CPUs to service hardware interrupts.
+- cpu.softirq:Percentage of time spent by the CPU or CPUs to service software interrupts.
+- cpu.nice:Percentage of CPU utilization that occurred while executing at the user level with nice priority.
+- cpu.steal:Percentage of time spent in involuntary wait by the virtual CPU or CPUs while the hypervisor was servicing another virtual processor.
+- cpu.system:Percentage of CPU utilization that occurred while executing at the system level (kernel).
+- cpu.user:Percentage of CPU utilization that occurred while executing at the user level (application).
+- cpu.cnt:cpu核数。
+- cpu.switches:cpu上下文切换次数,计数器类型。
+
+
+# 磁盘相关采集项
+
+计算方法:先读取/proc/mounts拿到所有挂载点,然后通过syscall.Statfs_t拿到blocks和inode的使用情况。每个metric都会附加一组tag描述,类似mount=$mount,fstype=$fstype,其中$mount是挂载点,比如/home,$fstype是文件系统,比如ext4。
+
+- df.bytes.free:磁盘可用量,int64
+- df.bytes.free.percent:磁盘可用量占总量的百分比,float64,比如32.1
+- df.bytes.total:磁盘总大小,int64
+- df.bytes.used:磁盘已用大小,int64
+- df.bytes.used.percent:磁盘已用大小占总量的百分比,float64
+- df.inodes.total:inode总数,int64
+- df.inodes.free:可用inode数目,int64
+- df.inodes.free.percent:可用inode占比,float64
+- df.inodes.used:已用的inode数据,int64
+- df.inodes.used.percent:已用inode占比,float64
+
+# megacli工具输出
+使用 megacli 工具读取 RAID 相关信息,每个metric都会附件一组tag描述,用来标明所属PD或者 VD,PD格式为PD=Enclosure_ID:SLOT_ID,比如PD=32:0表明第一块磁盘 ,VD=0 表明第一个逻辑磁盘。
+
+- sys.disk.lsiraid.pd.Media_Error_Count:这个及以下三个指标目前仅作为数据收集,不一定意味磁盘损坏(只是表示损坏概率变大)
+- sys.disk.lsiraid.pd.Other_Error_Count
+- sys.disk.lsiraid.pd.Predictive_Failure_Count
+- sys.disk.lsiraid.pd.Drive_Temperature
+- sys.disk.lsiraid.pd.Firmware_state:如果值不为0,则此物理磁盘出现问题
+- sys.disk.lsiraid.vd.cache_policy:如果值不为0,表示此逻辑磁盘缓存策略和设置不符
+- sys.disk.lsiraid.vd.state: 如果值不为0,表示此逻辑磁盘出现问题
+
+# SMART工具输出
+使用 smartctl 工具读取磁盘 SMART 信息,目前所有指标仅作为数据收集,不一定意味磁盘损坏(只是表示概率变大),每个metric都会有一组tag描述,表明盘符,例如device=/dev/sda。
+
+- sys.disk.smart.Reallocated_Sector_Ct
+- sys.disk.smart.Spin_Retry_Count
+- sys.disk.smart.Reallocated_Event_Count
+- sys.disk.smart.Current_Pending_Sector
+- sys.disk.smart.Offline_Uncorrectable
+- sys.disk.smart.Temperature_Celsius
+
+# 分区读写监控
+测试所有已挂载分区是否可读写,每个metric都会有一组tag描述,表示挂载点,比如mount=/home
+
+- sys.disk.rw: 如果值不为0,表明此分区读写出现问题
+
+# IO相关采集项
+
+计算方法:每秒采集一次/proc/diskstats,计算差值,都是计数器类型的。每个metric都会有一组tag描述,形如device=$device,用来表示具体的设备,比如sda1、sdb。用户可以参考iostat的帮助文档来理解具体的metric含义。
+
+- disk.io.ios_in_progress:Number of actual I/O requests currently in flight.
+- disk.io.msec_read:Total number of ms spent by all reads.
+- disk.io.msec_total:Amount of time during which ios_in_progress >= 1.
+- disk.io.msec_weighted_total:Measure of recent I/O completion time and backlog.
+- disk.io.msec_write:Total number of ms spent by all writes.
+- disk.io.read_merged:Adjacent read requests merged in a single req.
+- disk.io.read_requests:Total number of reads completed successfully.
+- disk.io.read_sectors:Total number of sectors read successfully.
+- disk.io.write_merged:Adjacent write requests merged in a single req.
+- disk.io.write_requests:total number of writes completed successfully.
+- disk.io.write_sectors:total number of sectors written successfully.
+- disk.io.read_bytes:单位是byte的数字
+- disk.io.write_bytes:单位是byte的数字
+- disk.io.avgrq_sz:下面几个值就是iostat -x 1看到的值
+- disk.io.avgqu-sz
+- disk.io.await
+- disk.io.svctm
+- disk.io.util:是个百分数,比如56.43,表示56.43%
+
+
+# 机器负载相关采集项
+
+计算方法:读取/proc/loadavg,都是原始值类型的:
+
+- load.1min
+- load.5min
+- load.15min
+
+# 内存相关采集项
+
+计算方法:读取/proc/meminfo 中的内容,其中的mem.memfree是free+buffers+cached,mem.memused=mem.memtotal-mem.memfree。用户具体可以参考free命令的输出和帮助文档来理解每个metric的含义。
+
+- mem.memtotal:内存总大小
+- mem.memused:使用了多少内存
+- mem.memused.percent:使用的内存占比
+- mem.memfree
+- mem.memfree.percent
+- mem.swaptotal:swap总大小
+- mem.swapused:使用了多少swap
+- mem.swapused.percent:使用的swap的占比
+- mem.swapfree
+- mem.swapfree.percent
+
+
+# 网络相关采集项
+
+计算方法:读取/proc/net/dev的内容,每个metric都附加有一组tag,形如iface=$iface,标明具体那个interface,比如eth0。metric中带有in的表示流入情况,out表示流出情况,total是总量in+out,支持的metric如下:
+
+- net.if.in.bytes
+- net.if.in.compressed
+- net.if.in.dropped
+- net.if.in.errors
+- net.if.in.fifo.errs
+- net.if.in.frame.errs
+- net.if.in.multicast
+- net.if.in.packets
+- net.if.out.bytes
+- net.if.out.carrier.errs
+- net.if.out.collisions
+- net.if.out.compressed
+- net.if.out.dropped
+- net.if.out.errors
+- net.if.out.fifo.errs
+- net.if.out.packets
+- net.if.total.bytes
+- net.if.total.dropped
+- net.if.total.errors
+- net.if.total.packets
+
+# 端口采集项
+
+计算方法,通过ss -ln,来判断指定的端口是否处于listen状态。原始值类型,值要么是1:代表在监听,要么是0,代表没有在监听。每个metric都附件一组tag,形如port=$port,$port就是具体的端口。
+
+- net.port.listen
+
+# 机器内核配置
+
+- kernel.maxfiles: 读取的/proc/sys/fs/file-max
+- kernel.files.allocated:读取的/proc/sys/fs/file-nr第一个Field
+- kernel.files.left:值=kernel.maxfiles-kernel.files.allocated
+- kernel.maxproc:读取的/proc/sys/kernel/pid_max
+
+# ntp采集项
+
+使用 ntpq -pn 获取本机时间相对于 ntp 服务器的 offset。
+
+- sys.ntp.offset: 本机偏移时间,单位为ms,值过大或者为0则表明有异常,需要报警
+
+# 进程监控
+
+- proc.num:判断某个进程的数目,这里需要分两个场景,一种是根据进程的名字来判定,比如name=sshd;另外一种是根据cmdline来判定,比如Java的应用进程名可能都是java,根据第一种情况没法做区分,此时可以配置cmdline,如cmdline=./falcon_agent-c./cfg.ini
+
+
+# 进程资源监控
+
+- process.cpu.all:进程和它的子进程使用的sys+user的cpu,单位是jiffies
+- process.cpu.sys:进程和它的子进程使用的sys cpu,单位是jiffies
+- process.cpu.user:进程和它的子进程使用的user cpu,单位是jiffies
+- process.swap:进程和它的子进程使用的swap,单位是page
+- process.fd:进程使用的文件描述符个数
+- process.mem:进程占用内存,单位byte
+
+# ss命令输出
+
+- ss.orphaned
+- ss.closed
+- ss.timewait
+- ss.slabinfo.timewait
+- ss.synrecv
+- ss.estab
+
diff --git a/zh_0_3/faq/qq.md b/zh_0_3/faq/qq.md
new file mode 100644
index 0000000..772412f
--- /dev/null
+++ b/zh_0_3/faq/qq.md
@@ -0,0 +1,150 @@
+
+
+# 问与答from qq群(373249123)
+## 报警
+
+
+Q: 能不能当网络流量超过某个阀值的时候,发报警邮件把占用流量Top3的程序找出来?each (endpoint=xxx metric=yyy tag1=tttt) expression可以这么写吗? @聂安_小米
+
+>A: 可以。如果endpoint不是机器名,可以用each表达式配置报警策略。如果endpoint是机器名,建议使用 hostgrp + template的方式 配置策略——这种方式 更加便于管理。(当然,endpoint不是机器名,也可以使用hostgrp + template的方式,只不过需要把该endpoint插入到hostgrp中)
+
+Q: 捎带问下,最大报警次数为3,那前三次报警的时间间隔在哪里设置
+
+>A: 比如你的数据是一分钟上来一次,理论上第三分钟,第六分钟,第九分钟分别报警三次就不再报警了。但是这样报警我们觉得太频繁,于是judge中有一个最小报警设置,默认是5分钟,即:两次报警之间至少间隔5分钟:第三分钟、第八分钟、第13分钟。Link不做告警合并,Alarm只合并一分钟内相同类型的报警。
+
+Q: 怎么知道我的策略是否同步成功了?
+
+>A: curl -s "judge-hostname:port/strategy/host.test.01/cpu.idle", 这个是查看 机器host.test.01 & metric为 cpu.idle 对应的策略。
+
+Q: 我想判断磁盘空间少于10%并且剩余空间少于1TB 才报警,有些大容量的存储,10%的剩余空间可能还有好几 TB,这样可以实现吗?
+
+>A: 目前架构不支持组合策略。
+
+Q: 我现在做了一个 ping 检测,会通过2各节点 A,B 去 ping,对应的是2个 tag,ping_server=A,ping_server=b,我现在是想做一个报警项,当 A,B 节点 到目标主机都不通我才报警。还有例子,比如我想设置报警,nginx 的连接数波动超过20% 而且链接数大于1000的才报警,可能有些机器业务的nginx 量很少,从连接数1到连接数2的波动就已经是100%了。
+
+>A: 这个可以划归到集群监控的情况,一个集群两机器都宕机才报警,只有一个宕机不报警。组合策略如果是针对两个不同的采集项,那以现在的架构肯定是实现不了的,因为两个报警项可能落到了两个不同的 judge 实例上了。下个版本不会做,只能想办法在后面的组件比如 alarm 来搞,还挺复杂的
+
+
+Q: 这个max=3 是指同一个监控项 比如cpu.busy 在一定时间内最多发三次报警吗?
+
+>A: max表示最大报警次数,比如你配置了cpu.idle小于5报警,max设置为3那么报警达到3次之后即使仍然小于5也不会再报警了,直到接下来某次cpu.idle大于5了,就会报一个ok出来。以后如果又小于5了,那就会再次报警
+
+
+Q: 为什么未恢复报警那个模块,我把出现的报警标记为已解决后,被监控的主机再次出现同样的问题,没有再次触发报警(新手)
+
+>A: “标记为已解决” 这个动作,和大家理解的不一样。 这个并不是真正的已解决,只是说,有些报警自己没有办法恢复了,就留在alarm-dash里面了,这个solved只是把alarm-dash里面遗留的 清理掉
+
+
+Q: Expression 可以这样写吗?each(metric=net.port.listen port=8100 endpoint=1.2.3.4)
+
+>A: 可以
+
+Q: 报警有自动过滤的机制吗?
+
+>A: 没有自动过滤的机制,hostgrp里配置了策略就会添加到相应的host上。报警判断时,假的host不可能上来数据,因此也就不会触发报警。进一步讲,这种没有数据上报就不报警可能不是用户希望看到。可以透过nodata的报警搞定之。
+
+
+Q: 同比环比报警可能会有一个问题, 就是误报的 case . 假设 A -> B -> C , 其中 B 是异常时间点. 到 B 这个点报警. 然后到 C 这个时间点恢复正常的话, 又会报警一次. 不知道大家有没有什么比较好的思路
+
+>A: 同比环比的告警,用在实际的环境中,误报太多,缺乏实际的操作意义,所以我们不打算支持。只提供了流量突升突降的告警功能。
+
+Q: 报警通知(邮件、短信、等等)在 Open-Falcon 代码里面没有,该如何实现?
+
+>A: alarm将报警邮件内容写入redis队列,sender负责读取并且发送,你可以二次开发sender,让它不通过调用http接口实现邮件发送,或参考 [mail-provider](https://github.com/open-falcon/mail-provider) 以及本书中的'社区贡献'。
+
+
+## 数据
+
+
+Q: 一旦某台机器下线,历史数据就不能查询了?
+
+>A: 是的。一旦数据不更新了,7天后就不能查询了。task索引清除的周期,没有留出配置接口,因为这个周期很少变更。如果需要,可以修改源码中的删除周期。@Fancy_金山 (需要注意的是,这个清理只是清理了索引,历史数据本身,仍然是存储在磁盘上的,当该指标再次被更新的时候,索引会自动再次创建,历史数据仍能被查询到)
+
+
+Q: graph扩容或者摘除机器 ,会对原先数据有损坏吗?
+
+>A: @陈凯军 监控数据,是按照一致性哈希规则,被分片、打在不同的graph实例上的。graph实例数量,会严重影响一致性哈希的数据分片结果。graph集群缩扩容时,监控数据的分布规则将彻底发生变化,新老数据不可能被同时查询到。即使老的数据没有被损坏,也是查询不到了。
+
+
+Q: 为什么是 hostname 唯一,而不是ip唯一?
+
+>A: host表中有个id,这个id通常是CMDB的id,用这个id做唯一标识,如果cmdb中hostname改了,同步的时候发现hostname变了就同步到监控了。ip是agent自动探测的,通常是取内网ip,但是有的机器可能有多个ip,可能没有内网ip,自动探测的ip作为唯一标识不是很好用。
+
+Q: grp表的come_from字段是什么意思
+
+>A: 用来区分 ``机器分组`` 的不同来源: 机器分组可能是用户手动添加的、也可能是从内部其他系统同步过来的、等等。
+
+Q: 我能把历史数据放到falcon中吗?
+
+>A: falcon中的数据,只能按照时间戳进行追加,不能插入。利用这个特性,你可以在今天的某个时间点,按照顺序把昨天的数据追加进来后,再追加今天的数据。
+
+
+Q: 扩容时如何保留历史数据呢?
+
+>A: 扩容的时候,历史数据无法迁移。现在能做的是,在扩容的时候,保持数据双写,比如持续一个月,这样让用户的看图功能,不要中断。然后把历史数据,全部移动到一个大容量磁盘的机器上,搭建一个dashboard,用来专门查询历史数据。
+
+
+## 插件
+
+Q: 自定义的插件同步后,是否要重启一下agent,才会生效?
+
+>A: 不需要。curl -s "hostname:1988/plugin/update",这样就能同步插件。
+
+
+## 负载均衡
+
+Q: Open-Falcon 能做接口代理嗎?负载均衡建议怎么做呢?
+
+>A: 域名解析到ip。用 domain.name:port访问。没有做接口代理。transfer大于1个实例时,ip+port{6060, 8433} 的方式需要配置transfer实例列表、不方便。建议用域名实现负载均衡。
+ task叢集設定:https://github.com/open-falcon/task/blob/master/README.md
+
+
+## 监控
+
+>open-falcon是一个监控框架,理论上任何软件只要可以把数据组装为open-falcon要求的格式,就可以用open-falcon监控。比如刚才大家讨论的mysql的监控,其实就是自己写了一堆采集脚本去采集mysql的一些指标,然后push给open-falcon就可以了。应用本身也可以用类似的做法,写脚本采集应用的监控性能指标,然后push给open-falcon。不过每个人都自己写脚本,可能重复造很多轮子。小米内部的实践是:针对java的应用有一个通用jar包,只要maven引入这个jar包,就可以采集一些基础数据,比如某个接口的调用latency、qps等等。比较好的实践方式是把监控数据的采集直接嵌入业务代码。但是要减少侵入性,通过一些队列、异步之类的方式,不要阻断主要业务逻辑执行流程。收集到数据之后post给本机agent即可
+
+Q: Open-Falcon 支持 Windows 监控吗?
+
+>A: 支持,请见本书中的'Windows 主机监控'。
+
+Q: 请教各位大神,open-falcon怎么监控端口?我没有搜到net.port.listen这个metirc,只有cpu,mem,net
+
+>A: 要先配个模板,才会有port的metric,大概架构是,配置模板,metric是net.port.listen,tag里配置port=xxx,然后模板关联hostgroup,hostgroup里的host就会通过hbs获取到需要监测的port,然后探测上报
+
+Q: docker 中的 agent 一直出现 `index out of range` 的错误
+
+>A: 刚才这个问题很典型,经过追查,问题是这样的:agent运行在docker容器里,docker容器限制了cpu个数,agent拿到了正确的cpu个数,比如宿主机是32个核,限制docker容器为2个核,agent就拿到了cpu核数为2 。于是准备了一个长度为2的数组来放置各个cpu的性能数据。但是,接下来agent要去读取/proc/stat,docker容器内部看到的/proc/stat文件内容和宿主机一般无二,于是看到了32个核,于是index out of range。
+
+Q: 建议用 Agent 做日志分析监控吗?
+
+>A: Agent不采集日志文件,这么做日志监控不是个好的实践方式,我个人推荐的做法是业务程序自己在代码中catch住exception,有问题直接调用报警接口报警得了,RD 收到报警之后自己去查log,小米应该是有个scribe集群来收集日志,具体我也不清楚。
+
+
+## 安全性問題
+
+Q: 任何机器都可以访问 Transfer 会不会有安全性问题?
+
+>A: Transfer部署在内网。不同IDC内网是联通的,因此访问Transfer基本没有ACL的问题
+
+
+## 其他
+
+Q: 组件之间怎么沟通的?
+
+>A: jsonrpc tcp传输,编码为二进制传输的
+
+Q: Open-Falcon 的架构图是用什么画的?
+
+>A: Mindmanager/PPT
+
+Q: QQ 群信息太多、很多重复问题、又容易发散,是否建个论坛?
+
+>A: 论坛现在大家比较少用了。常见问题大家可以 fork github.com/open-falcon/book.git 然后发 PR,其余的可以使用 Github issue 作为论坛使用。
+
+Q: `too many open files` 是什么问题?
+>A: 可以先透过 `ulimit -a` 检查 file descriptor 的限制,如果默认 1024 太小,可以透过 `ulimit -n 65536` 加大。
+
+Q: Open-Falcon 的未来计划?
+
+>A: https://github.com/XiaoMi/open-falcon/issues 一些接下来,要做的事情,我都会更新在这里(大家也可以提,思路更广一些) 有能力、有时间的朋友,可以认领一个或多个issue,或者配合撰写、贡献相关文档,都是热烈欢迎的。 特别是一些重度使用open-falcon的大户哈,希望能把你们自己的一些改进,也都推进到open-falcon的github仓库里哈:)【比如美团、金山云、快网、赶集之类的~~~】 接入并使用了Open-Falcon的公司,可以把相关信息追加到下面这个issue的评论中 https://github.com/XiaoMi/open-falcon/issues/4
+
diff --git a/zh_0_3/image/OpenFalcon_wechat.jpg b/zh_0_3/image/OpenFalcon_wechat.jpg
new file mode 100644
index 0000000..9c80c94
Binary files /dev/null and b/zh_0_3/image/OpenFalcon_wechat.jpg differ
diff --git a/zh_0_3/image/func_aggregator_1.png b/zh_0_3/image/func_aggregator_1.png
new file mode 100644
index 0000000..581c039
Binary files /dev/null and b/zh_0_3/image/func_aggregator_1.png differ
diff --git a/zh_0_3/image/func_aggregator_2.png b/zh_0_3/image/func_aggregator_2.png
new file mode 100644
index 0000000..43cb7f7
Binary files /dev/null and b/zh_0_3/image/func_aggregator_2.png differ
diff --git a/zh_0_3/image/func_aggregator_3.png b/zh_0_3/image/func_aggregator_3.png
new file mode 100644
index 0000000..4dfe658
Binary files /dev/null and b/zh_0_3/image/func_aggregator_3.png differ
diff --git a/zh_0_3/image/func_aggregator_4.png b/zh_0_3/image/func_aggregator_4.png
new file mode 100644
index 0000000..97d4549
Binary files /dev/null and b/zh_0_3/image/func_aggregator_4.png differ
diff --git a/zh_0_3/image/func_aggregator_5.png b/zh_0_3/image/func_aggregator_5.png
new file mode 100644
index 0000000..944159d
Binary files /dev/null and b/zh_0_3/image/func_aggregator_5.png differ
diff --git a/zh_0_3/image/func_getting_started_1.png b/zh_0_3/image/func_getting_started_1.png
new file mode 100644
index 0000000..6b9b1da
Binary files /dev/null and b/zh_0_3/image/func_getting_started_1.png differ
diff --git a/zh_0_3/image/func_getting_started_10.png b/zh_0_3/image/func_getting_started_10.png
new file mode 100644
index 0000000..d532093
Binary files /dev/null and b/zh_0_3/image/func_getting_started_10.png differ
diff --git a/zh_0_3/image/func_getting_started_11.png b/zh_0_3/image/func_getting_started_11.png
new file mode 100644
index 0000000..d2fe099
Binary files /dev/null and b/zh_0_3/image/func_getting_started_11.png differ
diff --git a/zh_0_3/image/func_getting_started_12.png b/zh_0_3/image/func_getting_started_12.png
new file mode 100644
index 0000000..614f9b7
Binary files /dev/null and b/zh_0_3/image/func_getting_started_12.png differ
diff --git a/zh_0_3/image/func_getting_started_2.png b/zh_0_3/image/func_getting_started_2.png
new file mode 100644
index 0000000..2e34713
Binary files /dev/null and b/zh_0_3/image/func_getting_started_2.png differ
diff --git a/zh_0_3/image/func_getting_started_3.png b/zh_0_3/image/func_getting_started_3.png
new file mode 100644
index 0000000..890c359
Binary files /dev/null and b/zh_0_3/image/func_getting_started_3.png differ
diff --git a/zh_0_3/image/func_getting_started_4.png b/zh_0_3/image/func_getting_started_4.png
new file mode 100644
index 0000000..2181a41
Binary files /dev/null and b/zh_0_3/image/func_getting_started_4.png differ
diff --git a/zh_0_3/image/func_getting_started_5.png b/zh_0_3/image/func_getting_started_5.png
new file mode 100644
index 0000000..51e0e2a
Binary files /dev/null and b/zh_0_3/image/func_getting_started_5.png differ
diff --git a/zh_0_3/image/func_getting_started_6.png b/zh_0_3/image/func_getting_started_6.png
new file mode 100644
index 0000000..bd5bb5d
Binary files /dev/null and b/zh_0_3/image/func_getting_started_6.png differ
diff --git a/zh_0_3/image/func_getting_started_7.png b/zh_0_3/image/func_getting_started_7.png
new file mode 100644
index 0000000..5d12367
Binary files /dev/null and b/zh_0_3/image/func_getting_started_7.png differ
diff --git a/zh_0_3/image/func_getting_started_8.png b/zh_0_3/image/func_getting_started_8.png
new file mode 100644
index 0000000..068e604
Binary files /dev/null and b/zh_0_3/image/func_getting_started_8.png differ
diff --git a/zh_0_3/image/func_getting_started_9.png b/zh_0_3/image/func_getting_started_9.png
new file mode 100644
index 0000000..b46c6ae
Binary files /dev/null and b/zh_0_3/image/func_getting_started_9.png differ
diff --git a/zh_0_3/image/func_intro_1.png b/zh_0_3/image/func_intro_1.png
new file mode 100644
index 0000000..fac628b
Binary files /dev/null and b/zh_0_3/image/func_intro_1.png differ
diff --git a/zh_0_3/image/func_intro_2.png b/zh_0_3/image/func_intro_2.png
new file mode 100644
index 0000000..d7a9d1c
Binary files /dev/null and b/zh_0_3/image/func_intro_2.png differ
diff --git a/zh_0_3/image/func_intro_3.png b/zh_0_3/image/func_intro_3.png
new file mode 100644
index 0000000..2c9caee
Binary files /dev/null and b/zh_0_3/image/func_intro_3.png differ
diff --git a/zh_0_3/image/func_intro_4.png b/zh_0_3/image/func_intro_4.png
new file mode 100644
index 0000000..c557f37
Binary files /dev/null and b/zh_0_3/image/func_intro_4.png differ
diff --git a/zh_0_3/image/func_intro_5.png b/zh_0_3/image/func_intro_5.png
new file mode 100644
index 0000000..24eb3f1
Binary files /dev/null and b/zh_0_3/image/func_intro_5.png differ
diff --git a/zh_0_3/image/func_intro_6.png b/zh_0_3/image/func_intro_6.png
new file mode 100644
index 0000000..5d9b9b6
Binary files /dev/null and b/zh_0_3/image/func_intro_6.png differ
diff --git a/zh_0_3/image/func_intro_7.png b/zh_0_3/image/func_intro_7.png
new file mode 100644
index 0000000..8edbe67
Binary files /dev/null and b/zh_0_3/image/func_intro_7.png differ
diff --git a/zh_0_3/image/func_intro_8.png b/zh_0_3/image/func_intro_8.png
new file mode 100644
index 0000000..be29306
Binary files /dev/null and b/zh_0_3/image/func_intro_8.png differ
diff --git a/zh_0_3/image/func_nodata_1.png b/zh_0_3/image/func_nodata_1.png
new file mode 100644
index 0000000..2ac8c0e
Binary files /dev/null and b/zh_0_3/image/func_nodata_1.png differ
diff --git a/zh_0_3/image/func_nodata_2.png b/zh_0_3/image/func_nodata_2.png
new file mode 100644
index 0000000..56e479f
Binary files /dev/null and b/zh_0_3/image/func_nodata_2.png differ
diff --git a/zh_0_3/image/func_nodata_3.png b/zh_0_3/image/func_nodata_3.png
new file mode 100644
index 0000000..35a5036
Binary files /dev/null and b/zh_0_3/image/func_nodata_3.png differ
diff --git a/zh_0_3/image/linkedsee_1.png b/zh_0_3/image/linkedsee_1.png
new file mode 100644
index 0000000..172c110
Binary files /dev/null and b/zh_0_3/image/linkedsee_1.png differ
diff --git a/zh_0_3/image/linkedsee_2.png b/zh_0_3/image/linkedsee_2.png
new file mode 100644
index 0000000..a624f96
Binary files /dev/null and b/zh_0_3/image/linkedsee_2.png differ
diff --git a/zh_0_3/image/linkedsee_3.png b/zh_0_3/image/linkedsee_3.png
new file mode 100644
index 0000000..68b4794
Binary files /dev/null and b/zh_0_3/image/linkedsee_3.png differ
diff --git a/zh_0_3/image/linkedsee_4.png b/zh_0_3/image/linkedsee_4.png
new file mode 100644
index 0000000..287d9f8
Binary files /dev/null and b/zh_0_3/image/linkedsee_4.png differ
diff --git a/zh_0_3/image/linkedsee_5.png b/zh_0_3/image/linkedsee_5.png
new file mode 100644
index 0000000..a5d13a5
Binary files /dev/null and b/zh_0_3/image/linkedsee_5.png differ
diff --git a/zh_0_3/image/practice_graph-scaling_io01.png b/zh_0_3/image/practice_graph-scaling_io01.png
new file mode 100644
index 0000000..69998a8
Binary files /dev/null and b/zh_0_3/image/practice_graph-scaling_io01.png differ
diff --git a/zh_0_3/image/practice_graph-scaling_io02.png b/zh_0_3/image/practice_graph-scaling_io02.png
new file mode 100644
index 0000000..3bc2fcf
Binary files /dev/null and b/zh_0_3/image/practice_graph-scaling_io02.png differ
diff --git a/zh_0_3/image/practice_graph-scaling_io03.png b/zh_0_3/image/practice_graph-scaling_io03.png
new file mode 100644
index 0000000..c8bafed
Binary files /dev/null and b/zh_0_3/image/practice_graph-scaling_io03.png differ
diff --git a/zh_0_3/image/practice_graph-scaling_quantity.png b/zh_0_3/image/practice_graph-scaling_quantity.png
new file mode 100644
index 0000000..689a1a8
Binary files /dev/null and b/zh_0_3/image/practice_graph-scaling_quantity.png differ
diff --git a/zh_0_3/image/practice_graph-scaling_rrd.png b/zh_0_3/image/practice_graph-scaling_rrd.png
new file mode 100644
index 0000000..2502420
Binary files /dev/null and b/zh_0_3/image/practice_graph-scaling_rrd.png differ
diff --git a/zh_0_3/image/practice_graph-scaling_stats.png b/zh_0_3/image/practice_graph-scaling_stats.png
new file mode 100644
index 0000000..3ef17ce
Binary files /dev/null and b/zh_0_3/image/practice_graph-scaling_stats.png differ
diff --git a/zh_0_3/intro/README.md b/zh_0_3/intro/README.md
new file mode 100644
index 0000000..26e8416
--- /dev/null
+++ b/zh_0_3/intro/README.md
@@ -0,0 +1,185 @@
+
+
+# Introduction
+
+监控系统是整个运维环节,乃至整个产品生命周期中最重要的一环,事前及时预警发现故障,事后提供翔实的数据用于追查定位问题。监控系统作为一个成熟的运维产品,业界有很多开源的实现可供选择。当公司刚刚起步,业务规模较小,运维团队也刚刚建立的初期,选择一款开源的监控系统,是一个省时省力,效率最高的方案。之后,随着业务规模的持续快速增长,监控的对象也越来越多,越来越复杂,监控系统的使用对象也从最初少数的几个SRE,扩大为更多的DEVS,SRE。这时候,监控系统的容量和用户的“使用效率”成了最为突出的问题。
+
+监控系统业界有很多杰出的开源监控系统。我们在早期,一直在用zabbix,不过随着业务的快速发展,以及互联网公司特有的一些需求,现有的开源的监控系统在性能、扩展性、和用户的使用效率方面,已经无法支撑了。
+
+因此,我们在过去的一年里,从互联网公司的一些需求出发,从各位SRE、SA、DEVS的使用经验和反馈出发,结合业界的一些大的互联网公司做监控,用监控的一些思考出发,设计开发了小米的监控系统:open-falcon。
+
+**open-falcon的目标是做最开放、最好用的互联网企业级监控产品。**
+
+# Highlights and features
+
+- 强大灵活的数据采集:自动发现,支持falcon-agent、snmp、支持用户主动push、用户自定义插件支持、opentsdb data model like(timestamp、endpoint、metric、key-value tags)
+- 水平扩展能力:支持每个周期上亿次的数据采集、告警判定、历史数据存储和查询
+- 高效率的告警策略管理:高效的portal、支持策略模板、模板继承和覆盖、多种告警方式、支持callback调用
+- 人性化的告警设置:最大告警次数、告警级别、告警恢复通知、告警暂停、不同时段不同阈值、支持维护周期
+- 高效率的graph组件:单机支撑200万metric的上报、归档、存储(周期为1分钟)
+- 高效的历史数据query组件:采用rrdtool的数据归档策略,秒级返回上百个metric一年的历史数据
+- dashboard:多维度的数据展示,用户自定义Screen
+- 高可用:整个系统无核心单点,易运维,易部署,可水平扩展
+- 开发语言: 整个系统的后端,全部golang编写,portal和dashboard使用python编写。
+
+# Architecture
+
+
+
+每台服务器,都有安装falcon-agent,falcon-agent是一个golang开发的daemon程序,用于自发现的采集单机的各种数据和指标,这些指标包括不限于以下几个方面,共计200多项指标。
+
+ - CPU相关
+ - 磁盘相关
+ - IO
+ - Load
+ - 内存相关
+ - 网络相关
+ - 端口存活、进程存活
+ - ntp offset(插件)
+ - 某个进程资源消耗(插件)
+ - netstat、ss 等相关统计项采集
+ - 机器内核配置参数
+
+只要安装了falcon-agent的机器,就会自动开始采集各项指标,主动上报,不需要用户在server做任何配置(这和zabbix有很大的不同),这样做的好处,就是用户维护方便,覆盖率高。当然这样做也会server端造成较大的压力,不过open-falcon的服务端组件单机性能足够高,同时都可以水平扩展,所以自动多采集足够多的数据,反而是一件好事情,对于SRE和DEV来讲,事后追查问题,不再是难题。
+
+另外,falcon-agent提供了一个proxy-gateway,用户可以方便的通过http接口,push数据到本机的gateway,gateway会帮忙高效率的转发到server端。
+
+falcon-agent,可以在我们的github上找到 : https://github.com/open-falcon/falcon-plus
+
+# Data model
+
+Data Model是否强大,是否灵活,对于监控系统用户的“使用效率”至关重要。比如以zabbix为例,上报的数据为hostname(或者ip)、metric,那么用户添加告警策略、管理告警策略的时候,就只能以这两个维度进行。举一个最常见的场景:
+
+hostA的磁盘空间,小于5%,就告警。一般的服务器上,都会有两个主要的分区,根分区和home分区,在zabbix里面,就得加两条规则;如果是hadoop的机器,一般还会有十几块的数据盘,还得再加10多条规则,这样就会痛苦,不幸福,不利于自动化(当然zabbix可以通过配置一些自动发现策略来搞定这个,不过比较麻烦)。
+
+open-falcon,采用和opentsdb相同的数据格式:metric、endpoint加多组key value tags,举两个例子:
+
+```
+{
+ metric: load.1min,
+ endpoint: open-falcon-host,
+ tags: srv=falcon,idc=aws-sgp,group=az1,
+ value: 1.5,
+ timestamp: `date +%s`,
+ counterType: GAUGE,
+ step: 60
+}
+{
+ metric: net.port.listen,
+ endpoint: open-falcon-host,
+ tags: port=3306,
+ value: 1,
+ timestamp: `date +%s`,
+ counterType: GAUGE,
+ step: 60
+}
+```
+通过这样的数据结构,我们就可以从多个维度来配置告警,配置dashboard等等。
+备注:endpoint是一个特殊的tag。
+
+# Data collection
+
+transfer,接收客户端发送的数据,做一些数据规整,检查之后,转发到多个后端系统去处理。在转发到每个后端业务系统的时候,transfer会根据一致性hash算法,进行数据分片,来达到后端业务系统的水平扩展。
+
+transfer 提供jsonRpc接口和telnet接口两种方式,transfer自身是无状态的,挂掉一台或者多台不会有任何影响,同时transfer性能很高,每分钟可以转发超过500万条数据。
+
+transfer目前支持的业务后端,有三种,judge、graph、opentsdb。judge是我们开发的高性能告警判定组件,graph是我们开发的高性能数据存储、归档、查询组件,opentsdb是开源的时间序列数据存储服务。可以通过transfer的配置文件来开启。
+
+transfer的数据来源,一般有三种:
+1. falcon-agent采集的基础监控数据
+2. falcon-agent执行用户自定义的插件返回的数据
+3. client library:线上的业务系统,都嵌入使用了统一的perfcounter.jar,对于业务系统中每个RPC接口的qps、latency都会主动采集并上报
+
+说明:上面这三种数据,都会先发送给本机的proxy-gateway,再由gateway转发给transfer。
+
+>基础监控是指只要是个机器(或容器)就能加的监控,比如cpu mem net io disk等,这些监控采集的方式固定,不需要配置,也不需要用户提供额外参数指定,只要agent跑起来就可以直接采集上报上去;
+非基础监控则相反,比如端口监控,你不给我端口号就不行,不然我上报所有65535个端口的监听状态你也用不了,这类监控需要用户配置后才会开始采集上报的监控(包括类似于端口监控的配置触发类监控,以及类似于mysql的插件脚本类监控),一般就不算基础监控的范畴了。
+
+# Alerting
+
+报警判定,是由judge组件来完成。用户在web portal来配置相关的报警策略,存储在MySQL中。heartbeat server 会定期加载MySQL中的内容。judge也会定期和heartbeat server保持沟通,来获取相关的报警策略。
+
+heartbeat sever不仅仅是单纯的加载MySQL中的内容,根据模板继承、模板项覆盖、报警动作覆盖、模板和hostGroup绑定,计算出最终关联到每个endpoint的告警策略,提供给judge组件来使用。
+
+transfer转发到judge的每条数据,都会触发相关策略的判定,来决定是否满足报警条件,如果满足条件,则会发送给alarm,alarm再以邮件、短信、米聊等形式通知相关用户,也可以执行用户预先配置好的callback地址。
+
+用户可以很灵活的来配置告警判定策略,比如连续n次都满足条件、连续n次的最大值满足条件、不同的时间段不同的阈值、如果处于维护周期内则忽略 等等。
+
+另外也支持突升突降类的判定和告警。
+
+# API
+
+到这里,数据已经成功的存储在了graph里。如何快速的读出来呢,读过去1小时的,过去1天的,过去一月的,过去一年的,都需要在1秒之内返回。
+
+这些都是靠graph和API组件来实现的,transfer会将数据往graph组件转发一份,graph收到数据以后,会以rrdtool的数据归档方式来存储,同时提供查询RPC接口。
+
+API面向终端用户,收到查询请求后,会去多个graph里面,查询不同metric的数据,汇总后统一返回给用户。
+
+# Dashboard
+
+
+dashboard首页,用户可以以多个维度来搜索endpoint列表,即可以根据上报的tags来搜索关联的endpoint。
+
+
+用户可以自定义多个metric,添加到某个screen中,这样每天早上只需要打开screen看一眼,服务的运行情况便尽在掌握了。
+
+
+当然,也可以查看清晰大图,横坐标上zoom in/out,快速筛选反选。总之用户的“使用效率”是第一要务。
+
+
+一个高效的portal,对于提升用户的“使用效率”,加成很大,平时大家都这么忙,能给各位SRE、Devs减轻一些负担,那是再好不过了。
+
+这是host group的管理页面,可以和服务树结合,机器进出服务树节点,相关的模板会自动关联或者解除。这样服务上下线,都不需要手动来变更监控,大大提高效率,降低遗漏和误报警。
+
+
+一个最简单的模板的例子,模板支持继承和策略覆盖,模板和host group绑定后,host group下的机器会自动应用该模板的所有策略。
+
+
+当然,也可以写一个简单的表达式,就能达到监控的目的,这对于那些endpoint不是机器名的场景非常方便。
+
+
+添加一个表达式也是很简单的。
+
+
+# Storage
+
+对于监控系统来讲,历史数据的存储和高效率查询,永远是个很难的问题!
+1. 数据量大:目前我们的监控系统,每个周期,大概有2000万次数据上报(上报周期为1分钟和5分钟两种,各占50%),一天24小时里,从来不会有业务低峰,不管是白天和黑夜,每个周期,总会有那么多的数据要更新。
+2. 写操作多:一般的业务系统,通常都是读多写少,可以方便的使用各种缓存技术,再者各类数据库,对于查询操作的处理效率远远高于写操作。而监控系统恰恰相反,写操作远远高于读。每个周期几千万次的更新操作,对于常用数据库(MySQL、postgresql、mongodb)都是无法完成的。
+3. 高效率的查:我们说监控系统读操作少,是说相对写入来讲。监控系统本身对于读的要求很高,用户经常会有查询上百个meitric,在过去一天、一周、一月、一年的数据。如何在1秒内返回给用户并绘图,这是一个不小的挑战。
+
+open-falcon在这块,投入了较大的精力。我们把数据按照用途分成两类,一类是用来绘图的,一类是用户做数据挖掘的。
+
+对于绘图的数据来讲,查询要快是关键,同时不能丢失信息量。对于用户要查询100个metric,在过去一年里的数据时,数据量本身就在那里了,很难1秒之类能返回,另外就算返回了,前端也无法渲染这么多的数据,还得采样,造成很多无谓的消耗和浪费。我们参考rrdtool的理念,在数据每次存入的时候,会自动进行采样、归档。我们的归档策略如下,历史数据保存5年。同时为了不丢失信息量,数据归档的时候,会按照平均值采样、最大值采样、最小值采样存三份。
+
+```
+// 1分钟一个点存 12小时
+c.RRA("AVERAGE", 0.5, 1, 720)
+
+// 5m一个点存2d
+c.RRA("AVERAGE", 0.5, 5, 576)
+c.RRA("MAX", 0.5, 5, 576)
+c.RRA("MIN", 0.5, 5, 576)
+
+// 20m一个点存7d
+c.RRA("AVERAGE", 0.5, 20, 504)
+c.RRA("MAX", 0.5, 20, 504)
+c.RRA("MIN", 0.5, 20, 504)
+
+// 3小时一个点存3个月
+c.RRA("AVERAGE", 0.5, 180, 766)
+c.RRA("MAX", 0.5, 180, 766)
+c.RRA("MIN", 0.5, 180, 766)
+
+// 1天一个点存1year
+c.RRA("AVERAGE", 0.5, 720, 730)
+c.RRA("MAX", 0.5, 720, 730)
+c.RRA("MIN", 0.5, 720, 730)
+```
+
+对于原始数据,transfer会打一份到hbase,也可以直接使用opentsdb,transfer支持往opentsdb写入数据。
+
+# Contributors
+
+- [authors](../authors.html)
+- [contributing](../contributing.html)
diff --git a/zh_0_3/philosophy/README.md b/zh_0_3/philosophy/README.md
new file mode 100644
index 0000000..f2767e7
--- /dev/null
+++ b/zh_0_3/philosophy/README.md
@@ -0,0 +1,5 @@
+
+
+# 设计理念
+
+阐述open-falcon设计过程中的各种思考
diff --git a/zh_0_3/philosophy/data-collect.md b/zh_0_3/philosophy/data-collect.md
new file mode 100644
index 0000000..1ab922f
--- /dev/null
+++ b/zh_0_3/philosophy/data-collect.md
@@ -0,0 +1,35 @@
+
+
+作为监控系统来讲,首先得有监控数据,然后才能做后面的分析处理、绘图报警等事情,那falcon是如何处理数据采集这个问题的呢?
+
+我们先要考虑有哪些数据要采集,脑洞打开~
+
+- 机器负载信息,这个最常见,cpu.idle/load.1min/mem.memfree.percent/df.bytes.free.percent等等
+- 硬件信息,比如功耗、风扇转速、磁盘是否可写,系统组同学对这些比较关注
+- 服务监控数据,比如某个接口每分钟调用的次数,latency等等
+- 数据库、HBase、Redis、Openstack等开源软件的监控指标
+
+要采集的数据还挺多哩,监控系统的开发人员不是神,没法搞定所有数据,比如MySQL,DBA最懂,他知道应该采集哪些指标,监控只要提供一个数据push的接口即可,大家共建。想知道push给Server的数据长啥样?可以参考[Tag与HostGroup设计理念](tags-and-hostgroup.md)中提到的两条json数据
+
+上面四个方面比较有代表性,咱们挨个阐述。
+
+**机器负载信息**
+
+这部分比较通用,我们提供了一个agent部署在所有机器上去采集。不像zabbix,要采集什么数据需要在服务端配置,falcon无需配置,只要agent部署到机器上,配置好heartbeat和Transfer地址,就自动开始采集了,省去了用户配置的麻烦。目前agent只支持64位Linux,Mac、Windows均不支持。
+
+**硬件信息**
+
+硬件信息的采集脚本由系统组同学提供,作为plugin依托于agent运行,plugin机制介绍请看[这里](plugin.md)。
+
+**服务监控数据**
+
+服务的监控指标采集脚本,通常都是跟着服务的code走的,服务上线或者扩容,这个脚本也跟着上线或者扩容,服务下线,这个采集脚本也要相应下线。公司里Java的项目有不少,研发那边就提供了一个通用jar包,只要引入这个jar包,就可以自动采集接口的调用次数、延迟时间等数据。然后将采集到的数据push给监控,一分钟push一次。目前falcon的agent提供了一个简单的http接口,这个jar包采集到数据之后是post给本机agent。向agent推送数据的一个简单例子,如下:
+
+```bash
+curl -X POST -d '[{"metric": "qps", "endpoint": "open-falcon-graph01.bj", "timestamp": 1431347802, "step": 60,"value": 9,"counterType": "GAUGE","tags": "project=falcon,module=graph"}]' http://127.0.0.1:1988/v1/push
+```
+
+**各种开源软件的监控指标**
+
+这都是大用户,比如DBA自己写一些采集脚本,连到各个MySQL实例上去采集数据,完事直接调用server端的jsonrpc汇报数据,一分钟一次,每次甚至push几十万条数据,比较好的发送方式是500条数据做一个batch,别几十万数据一次性发送。
+
diff --git a/zh_0_3/philosophy/data-model.md b/zh_0_3/philosophy/data-model.md
new file mode 100644
index 0000000..ef157e5
--- /dev/null
+++ b/zh_0_3/philosophy/data-model.md
@@ -0,0 +1,28 @@
+
+
+# Data model
+
+Open-Falcon,采用和OpenTSDB相似的数据格式:metric、endpoint加多组key value tags,举两个例子:
+
+```bash
+{
+ metric: load.1min,
+ endpoint: open-falcon-host,
+ tags: srv=falcon,idc=aws-sgp,group=az1,
+ value: 1.5,
+ timestamp: `date +%s`,
+ counterType: GAUGE,
+ step: 60
+}
+{
+ metric: net.port.listen,
+ endpoint: open-falcon-host,
+ tags: port=3306,
+ value: 1,
+ timestamp: `date +%s`,
+ counterType: GAUGE,
+ step: 60
+}
+```
+
+其中,metric是监控指标名称,endpoint是监控实体,tags是监控数据的属性标签,counterType是Open-Falcon定义的数据类型(取值为GAUGE、COUNTER),step为监控数据的上报周期,value和timestamp是有效的监控数据。
diff --git a/zh_0_3/philosophy/plugin.md b/zh_0_3/philosophy/plugin.md
new file mode 100644
index 0000000..7eb64ea
--- /dev/null
+++ b/zh_0_3/philosophy/plugin.md
@@ -0,0 +1,47 @@
+
+
+对于Plugin机制,叙述之前必须要强调一下:
+
+> Plugin可以看做是对agent功能的扩充。对于业务系统的监控指标采集,最好不要做成plugin,而是把采集脚本放到业务程序发布包中,随着业务代码上线而上线,随着业务代码升级而升级,这样会比较容易管理。
+
+要使用Plugin,步骤如下:
+
+**1. 编写采集脚本**
+
+用什么语言写没关系,只要目标机器上有运行环境就行,脚本本身要有可执行权限。采集到数据之后直接打印到stdout即可,agent会截获并push给server。数据格式是json,举个例子:
+
+```bash
+[root@host01:/path/to/plugins/plugin/sys/ntp]#./600_ntp.py
+[{"endpoint": "host01", "tags": "", "timestamp": 1431349763, "metric": "sys.ntp.offset", "value": 0.73699999999999999, "counterType": "GAUGE", "step": 600}]
+```
+
+注意,这个json数据是个list哦
+
+**2. 上传脚本到git**
+
+插件脚本也是code,所以最好也用git、svn管理,这里我们使用git管理,公司内部如果没有搭建gitlab,可以使用gitcafe、coding.net之类的,将写好的脚本push到git仓库,比如上例中的600_ntp.py,姑且放到git仓库的sys/ntp目录下。注意,这个脚本在push到git仓库之前要加上可执行权限。
+
+**3. 检查agent配置**
+
+大家之前部署agent的时候应该注意到agent配置文件中有配置plugin吧,现在到了用的时候了,把git仓库地址配置上,enabled设置为true。注意,配置的git仓库地址需要是任何机器上都可以拉取的,即`git://`或者`https://`打头的。如果agent之前已经部署到公司所有机器上了,那现在手工改配置可能略麻烦,之前讲过的嘛,用[ops-updater](https://github.com/open-falcon/ops-updater)管理起来~
+
+**4. 拉取plugin脚本**
+
+agent开了一个http端口1988,我们可以挨个curl一下http://ip:1988/plugin/update 这个地址,这会让agent主动git pull这个插件仓库。为啥没做成定期拉取这个仓库呢?主要是怕给git服务器压力太大……大家悠着点用,别给人pull挂了……
+
+**5. 让plugin run起来**
+
+上一步我们拉取了plugin脚本到所有机器上,不过plugin并没有执行。哪些机器执行哪些plugin脚本,是在portal上面配置的。其实我很想做成,只要插件拉取下来了就立马执行,不过实际实践中,有些插件还是不能在所有机器上跑,所以就在portal上通过配置控制了。在portal上找到要执行插件的HostGroup,点击对应的plugins超链接,对于上例sys/ntp目录下的600_ntp.py,直接把sys/ntp绑定上去即可。sys/ntp下的所有插件就都执行了。
+
+**6. 补充**
+
+portal上配置完成之后并不会立马生效,有个同步的过程,最终是agent通过调用hbs的接口获取的,需要一两分钟。上例我们绑定了sys/ntp,这实际是个目录,这个目录下的所有插件都会被执行,那什么样的文件会被看做插件呢?文件名是数字下划线打头的,这个数字代表的是step,即多长时间跑一次,单位是秒,比如60_a.py,就是在通过命名告诉agent,这个插件每60秒跑一次。sys/ntp目录下的子目录、其他命名方式的文件都会被忽略。
+
+**7. 插件如何传递参数**
+
+Open-Falcon 在 [PR #672](https://github.com/open-falcon/falcon-plus/pull/672) 中,对插件传递传递自定义参数进行了支持。在dashboard 中,配置 HostGroup 绑定插件时,可以支持针对单个脚本配置参数。
+
+比如:`sys/ntp/30_xx.sh(a, "33 4", 'test.sh f\,d')`,表示对 hostgroup 绑定一个插件脚本`sys/ntp/30_xx.sh`, 并传递4个参数,多个参数之间用`,`分割,每个参数可以用双引号或者单引号括起来。如果参数中本身就包含逗号,可以使用 `\,` 来转义。
+
+* 参数,只在绑定单个插件脚本时有效。如果绑定的是一个插件目录,传递的参数会忽略掉。
+* 如果某个目录下的某个插件脚本,被单独绑定到某个hostgroup,同时该目录也被绑定到了这个hostgroup,这个插件脚本不会重复被执行,绑定目录时这个插件脚本会被忽略(也就是说,单个脚本的绑定会覆盖目录绑定方式下的同一个脚本)。
diff --git a/zh_0_3/philosophy/tags-and-hostgroup.md b/zh_0_3/philosophy/tags-and-hostgroup.md
new file mode 100644
index 0000000..96f4be6
--- /dev/null
+++ b/zh_0_3/philosophy/tags-and-hostgroup.md
@@ -0,0 +1,80 @@
+
+
+这个话题很难阐述,大家慢慢读:)
+
+咱们从数据push说起,监控系统有个agent部署在所有机器上采集负载信息,比如cpu、内存、磁盘、io、网络等等,但是对于业务监控数据,比如某个接口调用的cps、latency,是没法由agent采集的,需要业务方自行push,其他监控数据,比如MySQL相关监控指标,HBase相关监控指标,Redis相关监控指标,agent也是无能为力,需要业务方自行采集并push给监控。
+
+于是,监控Server端需要制定一个接口规范,大家调用这个接口即可完成数据push,拿agent汇报的cpu.idle数据举个例子:
+
+```
+{
+ "metric": "cpu.idle",
+ "endpoint": `hostname`,
+ "tags": "",
+ "value": 12.34,
+ "timestamp": `date +%s`,
+ "step": 60,
+ "counterType": "GAUGE"
+}
+```
+
+metric即监控指标的名称,比如disk.io.util、load.1min、df.bytes.free.percent;endpoint是这个监控指标所依附的实体,比如cpu.idle,是谁的cpu.idle?显然是所在机器的cpu.idle,所以对于agent采集的机器负载信息而言,endpoint就是机器名;tags待会再说;value就是这个监控指标的值喽;timestamp是时间戳,单位是秒;step是rrdtool中的概念,Falcon后端存储用的rrdtool,我们需要告诉rrdtool这个数据多长时间push上来一次,step就是干这个事的;counterType也是rrdtool中的概念,目前Falcon支持两种类型:GAUGE、COUNTER。
+
+tags没有给大家解释,这是重点,为了便于理解,我再举个例子,某个方法调用的latency:
+
+```
+{
+ "metric": "latency",
+ "endpoint": "11.11.11.11:8080",
+ "tags": "project=falcon,module=judge,method=QueryHistory",
+ "value": 12.34,
+ "timestamp": `date +%s`,
+ "step": 60,
+ "counterType": "GAUGE"
+}
+```
+
+tags可以对push上来的这条数据打一些tag,就像写篇blog,可以打上几个tag便于归类。上例中我们push了一条latency数据,打了三个tag,传达的意思是:这个latency是调用QueryHistory这个方法的延迟,模块是judge,项目是falcon。
+
+对于push上来的这种数据,我们配置监控就很方便了,比如:对于falcon-judge这个模块的所有方法调用的latency只要大于0.5就报警。我们可以配置一个expression(在portal中):
+
+```
+each(metric=latency project=falcon module=judge)
+```
+
+阈值触发条件是:all(#1)>0.5
+
+我们没有写method,所以对于所有method都生效,一条配置搞定!这就是tag的强大之处。
+
+--重头戏分割线--
+
+对于业务方自己push的数据,可以加各种tag来区分,传达更多信息。但是,对于agent采集的数据呢?cpu.idle、load.1min这种数据应该加什么tag呢?这种数据没有任何tag……那我们应该如何配置报警呢?总不至于一台机器一台机器配置吧……
+
+```
+each(metric=latency endpoint=host1)
+```
+
+公司才一万台机器,嗯,这酸爽……
+
+tag,实际是一种分组方式,如果数据push的时候无法声明自己的分类,那我们就要**在上层手工对数据做分组**了。这,也就是HostGroup的设计出发点。
+
+比如我们把falcon这个项目用到的所有机器放到一个HostGroup(名称姑且叫sa.dev.falcon,名称中包含部门、团队信息,这么命名不错吧)中,然后为sa.dev.falcon绑定一个策略模板,下面的所有机器就都生效了,扩容的时候增加的机器塞到sa.dev.falcon,也就自动生效了监控,机器下线直接从该组删掉即可。
+
+总结,HostGroup实际是对endpoint的一种分组。
+
+想象一下一条数据push上来了,我们应该怎么判断这条数据是否应该报警呢?那我们要做的就是找到这条数据关联的Expression和Strategy,Expression比较好说,无非就是看配置的expression中的tag是否是当前push上来的数据的子集;Strategy呢?push上来的数据有endpoint,我们可以看这个endpoint是否属于某几个HostGroup,HostGroup又是跟Template绑定的,Template下就是一堆Strategy,顺藤摸瓜:)
+
+--忧伤的分割线--
+
+但是,HostGroup是一个扁平结构,使用起来可能不是那么方便,举个例子。
+
+- 我们可以把公司所有机器放到一个分组,配置硬件监控,比如磁盘坏,收到报警之后直接发送到系统组
+- A同学和B同学共同管理了3个项目(包括falcon项目),可以把这三个项目的机器放到一个分组,配置机器负载监控,模板名称姑且叫sa.dev.common,配置一下cpu.idle、df.bytes.free.percent之类的,报警发给A、B两个同学
+- falcon这个项目的磁盘io压力比较高,比其他两个项目io压力高,这是正常情况,比如平时我们配置disk.io.util大于40就报警,但是falcon的机器io压力大于80才需要报警,于是,我们需要创建一个新模板继承自sa.dev.common,然后绑定到falcon上,以此覆盖父模板的配置,提供不同的报警阈值
+- falcon中有个judge组件,监听在6080端口,我们需要把judge的所有机器放到一个HostGroup,为其配置端口监控
+
+OK,问题来了,如果judge扩容5台机器,这5台机器就要分别加到上面四个分组里!
+
+略麻烦哈~所以我们内部使用falcon实际是配合机器管理系统的,机器管理对机器的管理组织方式是一棵树,机器加到叶子节点,上层节点也就同样拥有了这个机器。
+
+所以,大家在用falcon的时候,规模如果比较小,就用扁平化的HostGroup即可。如果规模比较大,可能就需要做个二次开发,与内部机器管理系统结合了。如果你们内部没有机器管理,我们过段时间可能会提供一个树状机器管理系统,敬请期待。
diff --git a/zh_0_3/practice/README.md b/zh_0_3/practice/README.md
new file mode 100644
index 0000000..5b1ab3b
--- /dev/null
+++ b/zh_0_3/practice/README.md
@@ -0,0 +1,3 @@
+
+
+Open-Falcon实践经验整理
diff --git a/zh_0_3/practice/deploy.md b/zh_0_3/practice/deploy.md
new file mode 100644
index 0000000..701dffa
--- /dev/null
+++ b/zh_0_3/practice/deploy.md
@@ -0,0 +1,305 @@
+
+
+# 部署实践
+本文介绍了小米公司部署Open-Falcon的一些实践经验,同时试图以量化的方式分析Open-Falcon各组件的特性。
+
+## 概述
+Open-Falcon组件,包括基础组件、作图链路、报警链路。小米公司部署Open-Falcon的架构,如下:
+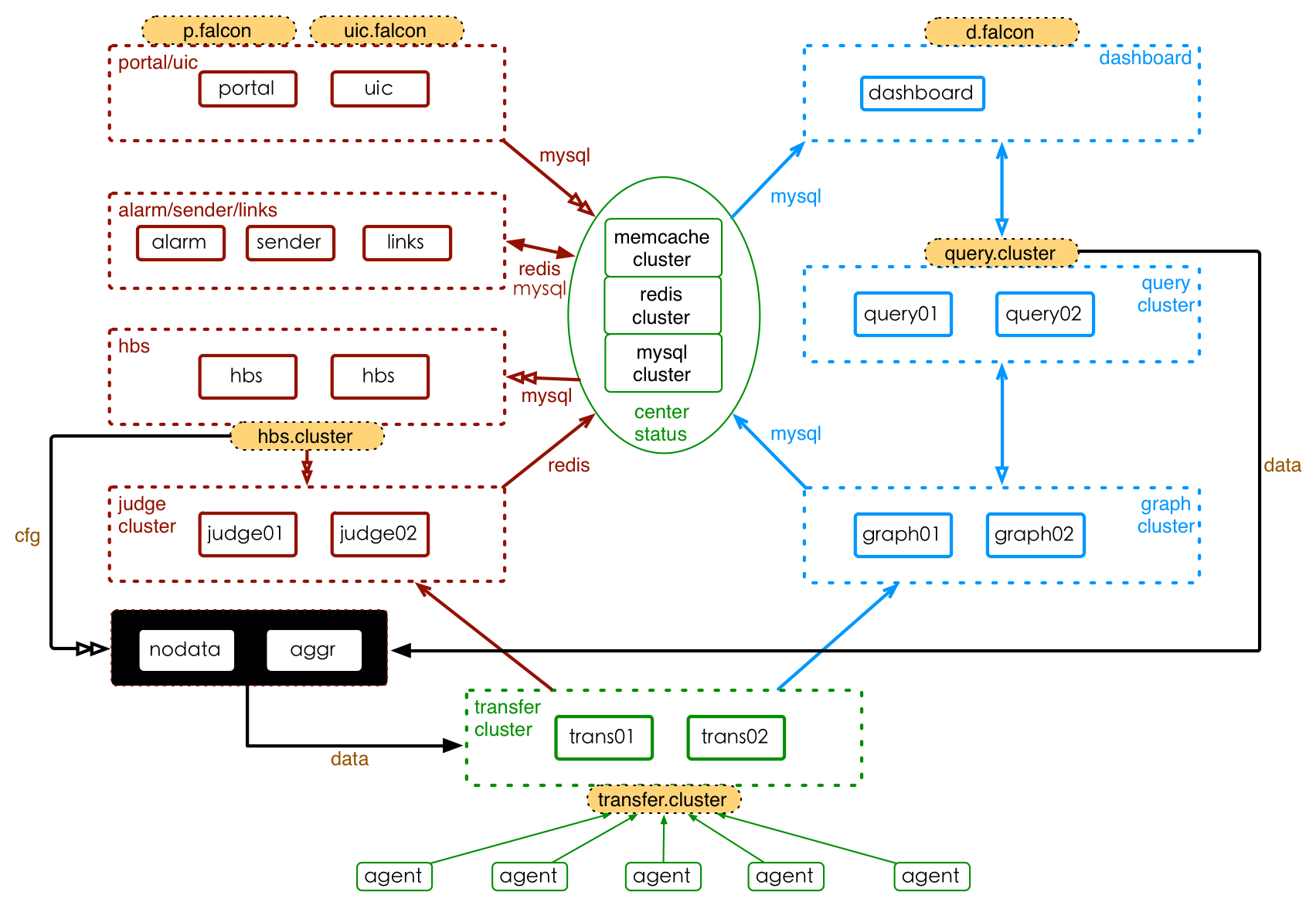
+
+其中,基础组件以绿色标注圈住、作图链路以蓝色圈住、报警链路以红色圈住,橙色填充的组件为域名。每个模块(子服务)都有自己的特性,根据其特性来制定部署策略。接下来,我们首先以白话的方式、**定性**描述Open-Falcon的部署演进,然后试图量化地分析每个组件的特点并给出一些部署建议。
+
+## 部署演进
+Open-Falon的部署情况,会随着机器量(监控对象)的增加而逐渐演进,描述如下,
+
+**初始阶段,机器量很小(<100量级)**。几乎无高可用的考虑,所有子服务可以混合部署在**1台**服务器上。此时,1台中高配的服务器就能满足性能要求。
+
+**机器量增加,到500量级**。graph可能是第一个扛不住的,拿出来单独部署;接着judge也扛不住了,拿出来单独部署;transfer居然扛不住了,拿出来吧。这是系统的三个大件,把它们拆出来后devops可以安心一段时间了。
+
+**机器数量再增加,到1K量级**。graph、judge、transfer单实例扛不住了,于是开始考虑增加到2+个实例、并考虑混合部署。开始有明确的高可用要求?除了alarm,都能搞成2+个实例的高可用结构。再往后,机器继续不停的增加,性能问题频现。好吧,见招拆招,Open-Falcon支持水平扩展、表示毫无压力。
+
+**机器量达到了10K量级**,这正是我们现在的情况。系统已经有3000+万个采集项。transfer部署了20个实例,graph部署了20个实例,judge扩到了60个实例(三大件混合部署在20台高配服务器上,judge单机多实例)。query有5个实例、平时很闲;hbs也有5个实例、很闲的样子;dashborad、portal、uic都有2个实例;alarm、sender、links仍然是bug般的单实例部署(这几个子服务部署在10左右台低配服务器上,资源消耗很小)。graph的db已经和portal、uic的db实例分开了,因为graph的索引已经达到了5000万量级、混用会危及到其他子系统。redis仍然是共享、单实例。这是我们的使用方式,有不合理的地方、正在持续改进。
+
+**机器上100K量级了**。不好意思、木有经历过。目测graph索引、hbs将成为系统较为头疼的地方,Open-Falcon的系统运维可能需要1个劳动力来完成。
+
+
+## 基础组件
+### agent
+agent应该随装机过程部署到每个机器实例上。agent从hbs拉取配置信息,进行数据采集、收集,将数据上报给transfer。agent资源消耗很少、运行稳定可靠。小米公司部署了10K+个agent实例,已稳定运行了1Y+。
+
+### transfer
+transfer是一个无状态的集群。transfer接收agent上报的数据,然后使用一致性哈希进行数据分片、并把分片后的数据转发给graph、judge集群(transfer还会打一份数据到opentsdb)。
+
+transfer集群会有缩扩容的情况,也会有服务器迁移的情况,导致集群实例不固定。如某个transfer实例故障后,要将其从transfer集群中踢出。为了屏蔽这种变化对agent的影响,建议在transfer集群前挂一个域名,agent通过域名方式访问transfer集群、实现自动切换。多IDC时,为了减少跨机房流量,建议每个IDC都部署一定数量的transfer实例、agent将数据push到本IDC的transfer(可以配置dns规则,优先将transfer域名解析为本地IDC内的transfer实例)。
+
+transfer消耗的资源 主要是网络和CPU。使用机型/操作系统选择为Dell-R620/Centos6.3,对transfer进行性能测试。Dell-R620配置为24核心、1000Gb双工网卡。测试的结果为:
+
+
diff --git a/zh_0_3/SUMMARY.md b/zh_0_3/SUMMARY.md
new file mode 100644
index 0000000..82ddef0
--- /dev/null
+++ b/zh_0_3/SUMMARY.md
@@ -0,0 +1,87 @@
+# SUMMARY
+
+### 第 Ⅰ 部分:社区
+* [社区介绍](README.md)
+* [贡献列表](contributing.md)
+* [项目介绍](intro/README.md)
+
+### 第 Ⅱ 部分:安装
+* [单机安装](quick_install/README.md)
+ * [环境准备](quick_install/prepare.md)
+ * [启动后端](quick_install/backend.md)
+ * [安装前端](quick_install/frontend.md)
+ * [v0.1平滑升级到v0.2](quick_install/upgrade.md)
+* [分布式安装](distributed_install/README.md)
+ * [环境准备](distributed_install/prepare.md)
+ * [Agent](distributed_install/agent.md)
+ * [Transfer](distributed_install/transfer.md)
+ * [Graph](distributed_install/graph.md)
+ * [API](distributed_install/api.md)
+ * [DashBoard](quick_install/frontend.md)
+ * [邮件/短信/微信发送接口](distributed_install/mail-sms.md)
+ * [Heartbeat Server](distributed_install/hbs.md)
+ * [Judge](distributed_install/judge.md)
+ * [Alarm](distributed_install/alarm.md)
+ * [Task](distributed_install/task.md)
+ * [Gateway](distributed_install/gateway.md)
+ * [Nodata](distributed_install/nodata.md)
+ * [Aggregator](distributed_install/aggregator.md)
+ * [Agent-updater](distributed_install/agent-updater.md)
+
+### 第 Ⅲ 部分:手册
+* [使用手册](usage/README.md)
+ * [快速入门](usage/getting-started.md)
+ * [Nodata配置](usage/nodata.md)
+ * [集群监控](usage/aggregator.md)
+ * [报警触发函数](usage/func.md)
+ * [自定义push数据](usage/data-push.md)
+ * [历史数据查询](usage/query.md)
+ * [进程端口监控](usage/proc-port-monitor.md)
+ * [MySQL监控](usage/mymon.md)
+ * [Redis监控](usage/redis.md)
+ * [MongoDB监控](usage/MongoDB.md)
+ * [Memcache监控](usage/memcache.md)
+ * [RabbitMQ监控](usage/rabbitmq.md)
+ * [Solr监控](usage/solr.md)
+ * [交换机监控](usage/switch.md)
+ * [ESXi监控](usage/esxi.md)
+ * [Windows主机监控](usage/win.md)
+ * [HAProxy监控](usage/haproxy.md)
+ * [docker容器监控](usage/docker.md)
+ * [Nginx监控](usage/ngx_metric.md)
+ * [JMX监控](usage/jmx.md)
+ * [硬件监控](usage/hwcheck.md)
+ * [LVS监控](usage/lvs.md)
+ * [Url监控](usage/urlooker.md)
+ * [mesos](usage/mesos.md)
+ * [vSphere监控](usage/vsphere.md)
+ * [Flume监控](usage/flume.md)
+ * [目录和进程资源监控](usage/du-proc.md)
+ * [故障自愈](usage/fault-recovery.md)
+ * [VSphere和ESXI监控](usage/vsphere-esxi.md)
+
+### 第 Ⅳ 部分:理念
+* [设计理念](philosophy/README.md)
+ * [数据模型](philosophy/data-model.md)
+ * [话说数据采集](philosophy/data-collect.md)
+ * [plugin机制](philosophy/plugin.md)
+ * [Tag和HostGroup](philosophy/tags-and-hostgroup.md)
+* [二次开发](dev/README.md)
+ * [社区贡献](dev/community_resource.md)
+ * [修改绘图曲线精度](dev/change_graph_rra.md)
+ * [修改网卡流量单位](dev/change_net_unit.md)
+ * [支持 Grafana 视图展现](dev/support_grafana.md)
+ * [API](api/README.md)
+* [实践经验](practice/README.md)
+ * [部署](practice/deploy.md)
+ * [自监控](practice/monitor.md)
+ * [Graph扩容二三事](practice/graph-scaling.md)
+
+### 第 Ⅴ 部分:FAQ
+* [FAQ](faq/README.md)
+ * [采集相关](faq/collect.md)
+ * [报警相关](faq/alarm.md)
+ * [绘图相关](faq/graph.md)
+ * [Linux常用监控指标](faq/linux-metrics.md)
+ * [QQ群问答整理](faq/qq.md)
+* [Changelog](changelog/README.md)
diff --git a/zh_0_3/api/README.md b/zh_0_3/api/README.md
new file mode 100644
index 0000000..45f742f
--- /dev/null
+++ b/zh_0_3/api/README.md
@@ -0,0 +1,2 @@
+# open-falcon api
+- [api v0.2](http://open-falcon.com/falcon-plus/)
diff --git a/zh_0_3/authors.md b/zh_0_3/authors.md
new file mode 100644
index 0000000..aa9601e
--- /dev/null
+++ b/zh_0_3/authors.md
@@ -0,0 +1 @@
+../zh/authors.md
\ No newline at end of file
diff --git a/zh_0_3/changelog/README.md b/zh_0_3/changelog/README.md
new file mode 100644
index 0000000..258bafe
--- /dev/null
+++ b/zh_0_3/changelog/README.md
@@ -0,0 +1,117 @@
+
+
+## [v0.2.0] 2017-06-17
+
+> https://github.com/open-falcon/falcon-plus/releases/tag/v0.2.0
+
+> http://www.jianshu.com/p/6fb2c2b4d030
+
+> **全新的前端**
+
+- Open-Falcon 所有前端组件进行了统一整合,包括dashboard、screen、portal、alarm-dashboard、UIC、fe、links等统一整合到了 [dashboard](https://github.com/open-falcon/dashboard) 组件;
+- Dashboard 全站增加权限控制;
+- Dashboard 增加删除指定 endpoint、counter 以及对应的 rrd 文件的功能;
+- Dashboard 首页默认展示 endpoint 列表,并支持 endpoint 列表和 counter 列表翻页功能;
+- Dashboard 增加删除一级 screen 的功能;
+- 支持将报警的 callback 参数和内容在 Dashboard 页面上展示;
+- 支持微信报警通道;
+- Dashboard 支持展示过往的历史报警信息;
+
+> **统一的后端**
+
+- alarm支持报警历史信息入库存储和展示;
+- 「报警合并」模块`links`的功能合并到统一前端 Dashboard 中,降低用户配置和维护成本;
+- 「报警发送」模块`sender`的功能合并到 alarm 中,降低用户配置和维护成本;
+- query的功能合并到了falcon-api组件中;
+- 支持非周期性上报数据存储;
+- agent支持通过自定义配置,只采集指定磁盘挂载点的磁盘监控数据;
+- agent支持配置一个默认 tag,这样通过该 agent 上报的所有数据都会自动追加这个tag;
+- judge新增报警判断函数`lookup(#num, limit)`,如果检测到过去num个周期内,有limit次符合条件就报警;
+
+> **过去那些等待已久的bugfix**
+
+- 修复grafana不支持metric含有大写字母的bug;
+- 修复agent写多个transfer高可用不生效的bug;
+- 修复agent发送数据给transfer的超时设置不合理的问题;
+
+> **全新的 [RESTful API](http://open-falcon.com/falcon-plus)**:让 open-falcon 没有难自动化的操作
+
+- 发布了全新设计的组件 falcon-api,falcon-plus 所有的功能都可以通过 RESTful API 来完成;
+- 统一前端 Dashboard 绝大部分功能都是通过 [falcon-plus](https://github.com/open-falcon/falcon-plus) [api](http://open-falcon.com/falcon-plus) 来实现;
+
+
+## [0.1.0] 2016-03-08
+
+> https://github.com/open-falcon/of-release/releases/tag/v0.1.0
+
+> http://www.jianshu.com/p/7751eb324a51
+
+### highlights
+- `文档` API梳理和文档完善 http://docs.openfalcon.apiary.io `OpenFalcon-team @hitripod`
+- `优化` graph集群扩容时,历史数据自动迁移 `OpenFalcon-team @yubo laiwei niean`
+- `优化` 数据上报的最小间隔,可以在配置文件中更改 `OpenFalcon-team @niean`
+- `新功能` 监控数据支持写入opentsdb `美团 OpenFalcon-team @Charlesdong`
+- `新功能` 适配支持grafana `快网 OpenFalcon-team @hitripod`
+- `新功能` 新增集群监控 `OpenFalcon-team @ulricqin`
+- `新功能` 新增nodata监控 `OpenFalcon-team @niean`
+- `新功能` agent内置URL监控 `@onlymellb`
+- `优化` agent支持对多个transfer的负载均衡 `@cmgs`
+- `优化` 往HostGroup中添加机器的时候如果发现机器名不存在,就直接插入host表 `@wkshare`
+- `优化` dashboard绘图线条采用深颜色的配色方案 `美团 OpenFalcon-team @skyeydemon`
+
+### changelog
+- [agent] 优化:agent支持配置多个transfer地址 @CMGS https://github.com/open-falcon/agent/pull/37
+- [agent] 优化:agent支持URL探测 @onlymellb https://github.com/open-falcon/agent/pull/27
+- [alarm] bugfix:修改beego api不兼容引起的编译报错 @ulricqin
+- [common] 新功能:增加tsdb的支持 @Charlesdong https://github.com/open-falcon/common/pull/2
+- [dashboard] 优化:checkbox均支持使用shift快捷多选 @skyeydemon https://github.com/open-falcon/dashboard/pull/14
+- [dashboard] 优化:绘图线条采用深颜色的配色方案 @skydemon https://github.com/open-falcon/dashboard/pull/13
+- [dashboard] 优化:日期选择框高亮当前时间,方便用户选择 @iambocai https://github.com/open-falcon/dashboard/pull/12
+- [dashboard] bugfix: 修复charts页面刷新时偶尔不出图的问题 @niean
+- [fe] bugfix:修改beego api不兼容引起的编译报错 @hitripod
+- [gateway] 优化:gateway支持配置多个transfer列表间负载均衡 @niean
+- [gateway] 优化:gateway引入perfcounter,用来统计gateway自身的稳定性指标 @niean
+- [graph] 数据上报的最小间隔,可以在配置文件中更改 @niean
+- [graph] graph集群扩容时,历史数据自动迁移 @yubo laiwei niean https://github.com/open-falcon/graph/pull/14
+- [hbs] 新功能:配置agent支持URL监控[url.check.health] onlymellb https://github.com/open-falcon/hbs/pull/4
+- [nodata] 新模块:当某些采集项超时未上报数据时,如果配置了nodata策略则会生成一条默认的数据 @niean
+- [portal] API: 增加了获取expression和strategy详情的API @modeyang
+- [portal] 优化:往HostGroup中添加机器的时候如果发现机器名存在,就直接插入host表 @wkshare https://github.com/open-falcon/portal/pull/4
+- [portal] 新功能:支持集群聚合监控 @ulricqin
+- [portal] 新功能:支持nodata @niean
+- [query] 增加API来支持Grafana展示 @hitripod https://github.com/open-falcon/query/pull/5
+- [transfer] 数据支持写入opentsdb @Charlesdong https://github.com/open-falcon/transfer/pull/5
+- [transfer] 数据上报周期的最小限制可配置 @niean https://github.com/open-falcon/transfer/pull/7
+- [transfer] migrating的功能从transfer中去除 @laiwei https://github.com/open-falcon/transfer/pull/8
+- [aggregator] 新模块:集群聚合监控 @ulricqin
+
+----
+## [0.0.5] 2015-08-20
+- [agent] new feature: 增加了udp、du相关采集项
+- [agent] bugfix: 修复了配置了新的插件需要重启agent的bug
+- [agent] bugfix: 修复了reload配置文件,hostname改动可能无法生效的问题 @oiooj
+- [alarm] bugfix: 修复了告警email中的换行问题
+- [alarm] bugfix: 修复了告警分级配置项为空时处理不当的问题
+- [alarm] enhancement: 修改http的默认端口为9912(之前为6060)
+- [transfer] new feature: 新增了数据双写的功能,即transfer可以将同一份数据发送到后端的多个graph或者judge,用于容灾
+- [transfer] enhancement: 发往judge的数据,按照时间戳做对齐和规整(与发往graph保持一致)
+- [transfer] bugfix: 修复transfer返回给客户端的结果中latency单位错误的问题
+- [graph] new feature: 新增了last API接口,可以返回指定counter最新的点
+- [query] new feature: 新增了last API接口,可以返回指定counter最新的点
+- [hbs] bugfix: 配合agent, 修复了配置了新的插件需要重启agent的bug
+- [plugin] new feature: 新增了插件项目,里面有一些常用的插件脚本
+- [gateway] 新增组件,解决网络分区后的监控数据回传问题。代码及功能描述,请移步到[这里](https://github.com/open-falcon/gateway);Gitbook中没有该组件的描述。
+
+
+## [0.0.4] 2015-06-09
+- [alarm] bugfix:修复告警邮件中的换行问题
+- [transfer] bugfix:当某个后端的graph宕机的时候,会引起transfer的发送能力下降
+- [graph] bugfix: 当存储rrd数据文件的目录不存在或者没有读写权限的时候,程序作退出处理
+- [fe] 新增了Golang版本的uic组件
+
+
+## [0.0.3] 2015-06-02
+ - [dashboard] bugfix: search counters by tags in screen
+ - [judge] enhancement: clean stale data in memory
+
+
diff --git a/zh_0_3/contributing.md b/zh_0_3/contributing.md
new file mode 100644
index 0000000..92c19e9
--- /dev/null
+++ b/zh_0_3/contributing.md
@@ -0,0 +1 @@
+../zh/contributing.md
\ No newline at end of file
diff --git a/zh_0_3/dev/README.md b/zh_0_3/dev/README.md
new file mode 100644
index 0000000..7cc5afa
--- /dev/null
+++ b/zh_0_3/dev/README.md
@@ -0,0 +1,23 @@
+
+
+# 环境准备
+
+请参考[环境准备](quick_install/prepare.md)
+# 自定义修改归档策略
+修改open-falcon/graph/rrdtool/rrdtool.go
+
+
+
+
+重新编译graph组件,并替换原有的二进制
+
+清理掉原来的所有rrd文件(默认在/home/work/data/6070/下面)
+
+# 插件机制
+1. 找一个git存放公司的所有插件
+2. 通过调用agent的/plugin/update接口拉取插件repo到本地
+3. 在portal中配置哪些机器可以执行哪些插件
+4. 插件命名方式:$step_xx.yy,需要有可执行权限,分门别类存放到repo的各个目录
+5. 把采集到的数据打印到stdout
+6. 如果觉得git方式不方便,可以改造agent,定期从某个http地址下载打包好的plugin.tar.gz
+
diff --git a/zh_0_3/dev/change_graph_rra.md b/zh_0_3/dev/change_graph_rra.md
new file mode 100644
index 0000000..62ea715
--- /dev/null
+++ b/zh_0_3/dev/change_graph_rra.md
@@ -0,0 +1,87 @@
+
+
+## 修改绘图曲线精度
+
+默认的,Open-Falcon只保存最近12小时的原始监控数据,12小时之后的数据被降低精度、采样存储。
+
+如果默认的精度不能满足你的需求,可以按照如下步骤,修改绘图曲线的存储精度。
+
+#### 第一步,修改graph组件的RRA,并重新编译graph组件
+graph组件的RRA,定义在文件 graph/rrdtool/[rrdtool.go](https://github.com/open-falcon/graph/blob/master/rrdtool/rrdtool.go#L57)中,默认如下:
+
+```golang
+// RRA.Point.Size
+const (
+ RRA1PointCnt = 720 // 1m一个点存12h
+ RRA5PointCnt = 576 // 5m一个点存2d
+ // ...
+)
+
+func create(filename string, item *cmodel.GraphItem) error {
+ now := time.Now()
+ start := now.Add(time.Duration(-24) * time.Hour)
+ step := uint(item.Step)
+
+ c := rrdlite.NewCreator(filename, start, step)
+ c.DS("metric", item.DsType, item.Heartbeat, item.Min, item.Max)
+
+ // 设置各种归档策略
+ // 1分钟一个点存 12小时
+ c.RRA("AVERAGE", 0.5, 1, RRA1PointCnt)
+
+ // 5m一个点存2d
+ c.RRA("AVERAGE", 0.5, 5, RRA5PointCnt)
+ c.RRA("MAX", 0.5, 5, RRA5PointCnt)
+ c.RRA("MIN", 0.5, 5, RRA5PointCnt)
+
+ // ...
+
+ return c.Create(true)
+}
+
+```
+
+比如,你只想保存90天的原始数据,可以将代码修改为:
+
+```golang
+// RRA.Point.Size
+const (
+ RRA1PointCnt = 129600 // 1m一个点存90d,取值 90*24*3600/60
+)
+
+func create(filename string, item *cmodel.GraphItem) error {
+ now := time.Now()
+ start := now.Add(time.Duration(-24) * time.Hour)
+ step := uint(item.Step)
+
+ c := rrdlite.NewCreator(filename, start, step)
+ c.DS("metric", item.DsType, item.Heartbeat, item.Min, item.Max)
+
+ // 设置各种归档策略
+ // 1分钟一个点存 90d
+ c.RRA("AVERAGE", 0.5, 1, RRA1PointCnt)
+
+ return c.Create(true)
+}
+```
+
+#### 第二步,清除graph的历史数据
+清除已上报的所有指标的历史数据,即删除所有的rrdfile。不删除历史数据,已上报指标的精度更改将不能生效。
+
+#### 第三步,重新部署graph服务
+编译修改后的graph源码,关停原有的graph老服务、发布修改后的graph。
+
+只需要修改graph组件、不需要修改Open-Falcon的其他组件,新的精度就能生效。你可以通过Dashboard、Screen来查看新的精度的绘图曲线。
+
+
+
+### 注意事项:
+
+修改监控绘图曲线精度时,需要:
+
++ 修改graph源代码,更新RRA
++ 清除graph的历史数据。不删除历史数据,已上报指标的精度更改将不能生效
++ 除了graph之外,Open-Falcon的其他任何组件 不需要被修改
++ 修改RRA后,可能会出现"绘图曲线点数过多、浏览器被卡死"的问题。请合理规划RRA存储的点数,或者调整绘图曲线查询时的时间段选择。
+
+
diff --git a/zh_0_3/dev/change_net_unit.md b/zh_0_3/dev/change_net_unit.md
new file mode 100644
index 0000000..1fbfaa6
--- /dev/null
+++ b/zh_0_3/dev/change_net_unit.md
@@ -0,0 +1,92 @@
+
+
+## 修改网卡流量单位
+
+目前是以 Bytes 为单位,如果要改为 Bits 的话(如:Mbps),可以修改 agent 代码。
+
+采集原始网卡流量数据的代码 `github.com/toolkits/nux/ifstat.go`,如下:
+
+```golang
+func NetIfs(onlyPrefix []string) ([]*NetIf, error) {
+ ...
+
+ {
+
+ ...
+
+ netIf.InBytes, _ = strconv.ParseInt(fields[0], 10, 64)
+ netIf.InPackages, _ = strconv.ParseInt(fields[1], 10, 64)
+ netIf.InErrors, _ = strconv.ParseInt(fields[2], 10, 64)
+ netIf.InDropped, _ = strconv.ParseInt(fields[3], 10, 64)
+ netIf.InFifoErrs, _ = strconv.ParseInt(fields[4], 10, 64)
+ netIf.InFrameErrs, _ = strconv.ParseInt(fields[5], 10, 64)
+ netIf.InCompressed, _ = strconv.ParseInt(fields[6], 10, 64)
+ netIf.InMulticast, _ = strconv.ParseInt(fields[7], 10, 64)
+
+ netIf.OutBytes, _ = strconv.ParseInt(fields[8], 10, 64)
+ netIf.OutPackages, _ = strconv.ParseInt(fields[9], 10, 64)
+ netIf.OutErrors, _ = strconv.ParseInt(fields[10], 10, 64)
+ netIf.OutDropped, _ = strconv.ParseInt(fields[11], 10, 64)
+ netIf.OutFifoErrs, _ = strconv.ParseInt(fields[12], 10, 64)
+ netIf.OutCollisions, _ = strconv.ParseInt(fields[13], 10, 64)
+ netIf.OutCarrierErrs, _ = strconv.ParseInt(fields[14], 10, 64)
+ netIf.OutCompressed, _ = strconv.ParseInt(fields[15], 10, 64)
+
+ netIf.TotalBytes = netIf.InBytes + netIf.OutBytes
+ netIf.TotalPackages = netIf.InPackages + netIf.OutPackages
+ netIf.TotalErrors = netIf.InErrors + netIf.OutErrors
+ netIf.TotalDropped = netIf.InDropped + netIf.OutDropped
+
+ ret = append(ret, &netIf)
+ }
+
+ return ret, nil
+}
+```
+
+agent 相对应的代码 `github.com/open-falcon/agent/funcs/ifstats.go`,如下:
+
+```golang
+func CoreNetMetrics(ifacePrefix []string) []*model.MetricValue {
+
+ netIfs, err := nux.NetIfs(ifacePrefix)
+ if err != nil {
+ log.Println(err)
+ return []*model.MetricValue{}
+ }
+
+ cnt := len(netIfs)
+ ret := make([]*model.MetricValue, cnt*20)
+
+ for idx, netIf := range netIfs {
+ iface := "iface=" + netIf.Iface
+ ret[idx*20+0] = CounterValue("net.if.in.bytes", netIf.InBytes, iface)
+ ret[idx*20+1] = CounterValue("net.if.in.packets", netIf.InPackages, iface)
+ ret[idx*20+2] = CounterValue("net.if.in.errors", netIf.InErrors, iface)
+ ret[idx*20+3] = CounterValue("net.if.in.dropped", netIf.InDropped, iface)
+ ret[idx*20+4] = CounterValue("net.if.in.fifo.errs", netIf.InFifoErrs, iface)
+ ret[idx*20+5] = CounterValue("net.if.in.frame.errs", netIf.InFrameErrs, iface)
+ ret[idx*20+6] = CounterValue("net.if.in.compressed", netIf.InCompressed, iface)
+ ret[idx*20+7] = CounterValue("net.if.in.multicast", netIf.InMulticast, iface)
+ ret[idx*20+8] = CounterValue("net.if.out.bytes", netIf.OutBytes, iface)
+ ret[idx*20+9] = CounterValue("net.if.out.packets", netIf.OutPackages, iface)
+ ret[idx*20+10] = CounterValue("net.if.out.errors", netIf.OutErrors, iface)
+ ret[idx*20+11] = CounterValue("net.if.out.dropped", netIf.OutDropped, iface)
+ ret[idx*20+12] = CounterValue("net.if.out.fifo.errs", netIf.OutFifoErrs, iface)
+ ret[idx*20+13] = CounterValue("net.if.out.collisions", netIf.OutCollisions, iface)
+ ret[idx*20+14] = CounterValue("net.if.out.carrier.errs", netIf.OutCarrierErrs, iface)
+ ret[idx*20+15] = CounterValue("net.if.out.compressed", netIf.OutCompressed, iface)
+ ret[idx*20+16] = CounterValue("net.if.total.bytes", netIf.TotalBytes, iface)
+ ret[idx*20+17] = CounterValue("net.if.total.packets", netIf.TotalPackages, iface)
+ ret[idx*20+18] = CounterValue("net.if.total.errors", netIf.TotalErrors, iface)
+ ret[idx*20+19] = CounterValue("net.if.total.dropped", netIf.TotalDropped, iface)
+ }
+ return ret
+}
+```
+
+举例來说,我们可以直接在 agent 要上报数据的时候,将 Bit 转换为 Byte,同时修改 Counter 的名称,如下:
+
+```golang
+ret[idx*20+0] = CounterValue("net.if.in.bits", netIf.InBytes*8, iface)
+```
diff --git a/zh_0_3/dev/community_resource.md b/zh_0_3/dev/community_resource.md
new file mode 100644
index 0000000..7ef663b
--- /dev/null
+++ b/zh_0_3/dev/community_resource.md
@@ -0,0 +1,51 @@
+
+
+## 第三方监控插件
+* [Windows Agent](https://github.com/LeonZYang/agent)
+* [MySQL Monitor](https://github.com/open-falcon/mymon)
+* [Redis Monitor](https://github.com/ZhuoRoger/redismon)
+* [RPC Monitor](https://github.com/iambocai/falcon-monit-scripts)
+* [Switch Monitor](https://github.com/gaochao1/swcollector)
+* [Falcon-Agent宕机监控](https://github.com/freedomkk-qfeng/falcon-scripts/tree/master/agent_monitor)
+* [memcached](https://github.com/iambocai/falcon-monit-scripts/tree/master/memcached)
+* [Docker 监控Lib库](https://github.com/HunanTV/eru-metric)
+* [mesos 监控](https://github.com/mesos-utility/mesos-metrics)
+* [Winodws/Linux 自动汇报资产](https://github.com/triaquae/MadKing)
+* [Nginx监控: 企业级监控标准](https://github.com/GuyCheung/falcon-ngx_metric)
+* [JMX监控: 基于open-falcon的jmx监控插件](https://github.com/toomanyopenfiles/jmxmon)
+* [适配Open-Falcon的综合监控SuitAgent](https://github.com/cqyijifu/OpenFalcon-SuitAgent)
+* [Baidu-RPC Monitor](https://github.com/solrex/brpc-open-falcon)
+* [Elasticsearch Monitor](https://github.com/solrex/es-open-falcon)
+* [Redis Monitor (多实例)](https://github.com/solrex/redis-open-falcon)
+* [SSDB Monitor](https://github.com/solrex/ssdb-open-falcon)
+* [ActiveMQ](https://github.com/zhaoxiaole/falcon-plugin/tree/master/ActiveMQ)
+* [统计每个cpu core 详情的插件脚本](https://github.com/open-falcon/plugin/blob/master/common/60_stats_per_cpu_core.py)
+* [统计进程资源消耗的插件脚本](https://github.com/open-falcon/plugin/blob/master/common/60_proc_resource_status.py)
+* [针对falcon开发的监控脚本和服务](https://github.com/sageskr/monitor)
+* [Windows metrics collector](https://github.com/freedomkk-qfeng/falcon-scripts/tree/master/windows_collect)
+* [Dell服务器硬件状态监控脚本](https://github.com/51web/hwcheck)
+
+## SDK
+* [Node.js perfcounter](https://github.com/efeiefei/openfalcon-perfcounter)
+* [Golang perfcounter](https://github.com/niean/goperfcounter)
+
+## 其他
+* [SMS sender](http://book.open-falcon.com/zh/install/mail-sms.html)
+* [Mail sender](https://github.com/niean/mailsender)
+* [Open-Falcon Ansible Playbook](https://github.com/iambocai/falcon-playbook)
+* [Open-Falcon Docker](https://github.com/frostynova/open-falcon-docker)
+
+## 讲稿
+* [OpenFalcon交流:一个适合在公司内部推广OpenFalcon的PPT](http://pan.baidu.com/s/1o7wsrUi)
+* [OpenFalcon @ SACC-2015](http://pan.baidu.com/s/1o6S6t1C)
+* OpenFalcon编写的整个脑洞历程: 开发过程中的权衡与折中
+* [OpenFalcon操作录屏演示 10多分钟](http://pan.baidu.com/s/1dEsW54P)
+* 小米开源监控系统OpenFalcon应对高并发7种手段
+
+
+## 会议
+
+#### 麒麟会技术沙龙-Open-Falcon v0.1.0 发布
+* [来炜——Open-Falcon新版特性解析和规划](http://pan.baidu.com/s/1dFsJa5j)
+* [谢丹博——Open-Falcon在美团的落地与升华](http://pan.baidu.com/s/1o8Cd3MM)
+* [欧曜玮——企业级监控平台的变革与演进](http://pan.baidu.com/s/1hsvuHKg)
diff --git a/zh_0_3/dev/support_grafana.md b/zh_0_3/dev/support_grafana.md
new file mode 100644
index 0000000..64b0ceb
--- /dev/null
+++ b/zh_0_3/dev/support_grafana.md
@@ -0,0 +1,14 @@
+
+
+## 支持 Grafana 视图展现
+
+相较于 Open-Falcon 内建的 Dashboard,Grafana 可以很有弹性的自定义图表,并且可以针对 Dashboard 做权限控管、上标签以及查询,图表的展示选项也更多样化。本篇教学帮助您
+做好 Open-Falcon 的面子工程!
+
+### 安装和使用步骤
+
+请参考 [grafana open-falcon](https://github.com/open-falcon/grafana-openfalcon-datasource)
+
+
+### 致谢
+- 感谢fastweb @kordan @masato25 等朋友的贡献;
diff --git a/zh_0_3/distributed_install/README.md b/zh_0_3/distributed_install/README.md
new file mode 100644
index 0000000..47f81ad
--- /dev/null
+++ b/zh_0_3/distributed_install/README.md
@@ -0,0 +1,26 @@
+
+
+# 概述
+
+Open-Falcon是一个比较大的分布式系统,有十几个组件。按照功能,这十几个组件可以划分为 基础组件、作图链路组件和报警链路组件,其安装部署的架构如下图所示,
+
+
+
+## 在单台机器上快速安装
+
+请直接参考[quick_install](../quick_install/README.md)
+
+## Docker化的Open-Falcon安装
+
+参考:
+- https://github.com/open-falcon/falcon-plus/blob/master/docker/README.md
+- https://github.com/open-falcon/dashboard/blob/master/README.md
+
+## 在多台机器上分布式安装
+
+在多台机器上,分布式安装open-falcon,就是本章的内容,请按照本章节的顺序,安装每个组件。
+
+## 视频教程教你安装
+
+《[Open-Falcon部署与架构解析](http://www.jikexueyuan.com/course/1651.html)》
+
diff --git a/zh_0_3/distributed_install/agent-updater.md b/zh_0_3/distributed_install/agent-updater.md
new file mode 100644
index 0000000..8b09ba9
--- /dev/null
+++ b/zh_0_3/distributed_install/agent-updater.md
@@ -0,0 +1,17 @@
+
+
+# Agent-updater
+
+每台机器都要部署falcon-agent,如果公司机器量比较少,用pssh、ansible、fabric之类的工具手工安装问题也不大。但是公司机器量多了之后,手工安装、升级、回滚falcon-agent将成为噩梦。
+
+个人开发了agent-updater这个工具,用于管理falcon-agent,agent-updater也有一个agent:ops-updater,可以看做是一个超级agent,用于管理其他agent的agent,呵呵,ops-updater推荐在装机的时候一起安装上。ops-updater通常是不会升级的。
+
+具体参看:https://github.com/open-falcon/ops-updater
+
+如果你想学习如何使用Go语言编写一个完整的项目,也可以研究一下agent-updater,我甚至录制了一个视频教程来演示一步一步如何开发出来的。课程链接:
+
+- http://www.jikexueyuan.com/course/1336.html
+- http://www.jikexueyuan.com/course/1357.html
+- http://www.jikexueyuan.com/course/1462.html
+- http://www.jikexueyuan.com/course/1490.html
+
diff --git a/zh_0_3/distributed_install/agent.md b/zh_0_3/distributed_install/agent.md
new file mode 100644
index 0000000..e9f6690
--- /dev/null
+++ b/zh_0_3/distributed_install/agent.md
@@ -0,0 +1,100 @@
+
+
+# Agent
+
+agent用于采集机器负载监控指标,比如cpu.idle、load.1min、disk.io.util等等,每隔60秒push给Transfer。agent与Transfer建立了长连接,数据发送速度比较快,agent提供了一个http接口/v1/push用于接收用户手工push的一些数据,然后通过长连接迅速转发给Transfer。
+
+## 部署说明
+
+agent需要部署到所有要被监控的机器上,比如公司有10万台机器,那就要部署10万个agent。agent本身资源消耗很少,不用担心。
+
+
+## 配置说明
+
+配置文件必须叫cfg.json,可以基于cfg.example.json修改
+
+```
+{
+ "debug": true, # 控制一些debug信息的输出,生产环境通常设置为false
+ "hostname": "", # agent采集了数据发给transfer,endpoint就设置为了hostname,默认通过`hostname`获取,如果配置中配置了hostname,就用配置中的
+ "ip": "", # agent与hbs心跳的时候会把自己的ip地址发给hbs,agent会自动探测本机ip,如果不想让agent自动探测,可以手工修改该配置
+ "plugin": {
+ "enabled": false, # 默认不开启插件机制
+ "dir": "./plugin", # 把放置插件脚本的git repo clone到这个目录
+ "git": "https://github.com/open-falcon/plugin.git", # 放置插件脚本的git repo地址
+ "logs": "./logs" # 插件执行的log,如果插件执行有问题,可以去这个目录看log
+ },
+ "heartbeat": {
+ "enabled": true, # 此处enabled要设置为true
+ "addr": "127.0.0.1:6030", # hbs的地址,端口是hbs的rpc端口
+ "interval": 60, # 心跳周期,单位是秒
+ "timeout": 1000 # 连接hbs的超时时间,单位是毫秒
+ },
+ "transfer": {
+ "enabled": true,
+ "addrs": [
+ "127.0.0.1:18433"
+ ], # transfer的地址,端口是transfer的rpc端口, 可以支持写多个transfer的地址,agent会保证HA
+ "interval": 60, # 采集周期,单位是秒,即agent一分钟采集一次数据发给transfer
+ "timeout": 1000 # 连接transfer的超时时间,单位是毫秒
+ },
+ "http": {
+ "enabled": true, # 是否要监听http端口
+ "listen": ":1988",
+ "backdoor": false
+ },
+ "collector": {
+ "ifacePrefix": ["eth", "em"], # 默认配置只会采集网卡名称前缀是eth、em的网卡流量,配置为空就会采集所有的,lo的也会采集。可以从/proc/net/dev看到各个网卡的流量信息
+ "mountPoint": []
+ },
+ "default_tags": {
+ },
+ "ignore": { # 默认采集了200多个metric,可以通过ignore设置为不采集
+ "cpu.busy": true,
+ "df.bytes.free": true,
+ "df.bytes.total": true,
+ "df.bytes.used": true,
+ "df.bytes.used.percent": true,
+ "df.inodes.total": true,
+ "df.inodes.free": true,
+ "df.inodes.used": true,
+ "df.inodes.used.percent": true,
+ "mem.memtotal": true,
+ "mem.memused": true,
+ "mem.memused.percent": true,
+ "mem.memfree": true,
+ "mem.swaptotal": true,
+ "mem.swapused": true,
+ "mem.swapfree": true
+ }
+}
+```
+
+## 进程管理
+
+```
+./open-falcon start agent 启动进程
+./open-falcon stop agent 停止进程
+./open-falcon monitor agent 查看日志
+
+```
+
+## 验证
+
+看var目录下的log是否正常,或者浏览器访问其1988端口。另外agent提供了一个`--check`参数,可以检查agent是否可以正常跑在当前机器上
+
+```
+./falcon-agent --check
+```
+
+## /v1/push接口
+
+我们设计初衷是不希望用户直接连到Transfer发送数据,而是通过agent的/v1/push接口转发,接口使用范例:
+
+```
+ts=`date +%s`; curl -X POST -d "[{\"metric\": \"metric.demo\", \"endpoint\": \"qd-open-falcon-judge01.hd\", \"timestamp\": $ts,\"step\": 60,\"value\": 9,\"counterType\": \"GAUGE\",\"tags\": \"project=falcon,module=judge\"}]" http://127.0.0.1:1988/v1/push
+```
+
+## 视频教程
+
+为该模块录制了一个视频,做了源码级解读:http://www.jikexueyuan.com/course/2242.html
diff --git a/zh_0_3/distributed_install/aggregator.md b/zh_0_3/distributed_install/aggregator.md
new file mode 100644
index 0000000..126fe24
--- /dev/null
+++ b/zh_0_3/distributed_install/aggregator.md
@@ -0,0 +1,54 @@
+
+
+# Aggregator
+
+集群聚合模块。聚合某集群下的所有机器的某个指标的值,提供一种集群视角的监控体验。
+
+
+## 服务部署
+服务部署,包括配置修改、启动服务、检验服务、停止服务等。这之前,需要将安装包解压到服务的部署目录下。
+
+```
+# 修改配置, 配置项含义见下文
+mv cfg.example.json cfg.json
+vim cfg.json
+
+# 启动服务
+./open-falcon start aggregator
+
+# 检查log
+./open-falcon monitor aggregator
+
+# 停止服务
+./open-falcon stop aggregator
+
+```
+
+
+## 配置说明
+配置文件默认为./cfg.json。默认情况下,安装包会有一个cfg.example.json的配置文件示例。各配置项的含义,如下
+
+```
+{
+ "debug": true,
+ "http": {
+ "enabled": true,
+ "listen": "0.0.0.0:6055"
+ },
+ "database": {
+ "addr": "root:@tcp(127.0.0.1:3306)/falcon_portal?loc=Local&parseTime=true", // 如数据库使用密码, 配置稍有不同: "addr": "root:password@tcp(127.0.0.1:3306)/falcon_portal?loc=Local&parseTime=true&allowNativePasswords=true"
+ "idle": 10,
+ "ids": [1, -1],
+ "interval": 55
+ },
+ "api": {
+ "connect_timeout": 500,
+ "request_timeout": 2000,
+ "plus_api": "http://127.0.0.1:8080", #falcon-plus api模块的运行地址
+ "plus_api_token": "default-token-used-in-server-side", #和falcon-plus api 模块交互的认证token
+ "push_api": "http://127.0.0.1:1988/v1/push" #push数据的http接口,这是agent提供的接口
+ }
+}
+
+
+```
diff --git a/zh_0_3/distributed_install/alarm.md b/zh_0_3/distributed_install/alarm.md
new file mode 100644
index 0000000..c254ff7
--- /dev/null
+++ b/zh_0_3/distributed_install/alarm.md
@@ -0,0 +1,90 @@
+
+
+# Alarm
+
+alarm模块是处理报警event的,judge产生的报警event写入redis,alarm从redis读取处理,并进行不同渠道的发送。
+
+## 设计初衷
+
+报警event的处理逻辑并非仅仅是发邮件、发短信这么简单。为了能够自动化对event做处理,alarm需要支持在产生event的时候回调用户提供的接口;有的时候报警短信、邮件太多,对于优先级比较低的报警,希望做报警合并,这些逻辑都是在alarm中做的。
+
+我们在配置报警策略的时候配置了报警级别,比如P0/P1/P2等等,每个及别的报警都会对应不同的redis队列 alarm去读取这个数据的时候我们希望先读取P0的数据,再读取P1的数据,最后读取P5的数据,因为我们希望先处理优先级高的。于是:用了redis的brpop指令。
+
+已经发送的告警信息,alarm会写入MySQL中保存,这样用户就可以在dashboard中查阅历史报警,同时针对同一个策略发出的多条报警,在MySQL存储的时候,会聚类;历史报警保存的周期,是可配置的,默认为7天。
+
+## 部署说明
+
+alarm是个单点。对于未恢复的告警是放到alarm的内存中的,alarm还需要做报警合并,故而alarm只能部署一个实例。需要对alarm的存活做好监控。
+
+## 配置说明
+
+配置文件必须叫cfg.json,可以基于cfg.example.json修改
+
+```
+{
+ "log_level": "debug",
+ "http": {
+ "enabled": true,
+ "listen": "0.0.0.0:9912"
+ },
+ "redis": {
+ "addr": "127.0.0.1:6379",
+ "maxIdle": 5,
+ "highQueues": [
+ "event:p0",
+ "event:p1",
+ "event:p2"
+ ],
+ "lowQueues": [
+ "event:p3",
+ "event:p4",
+ "event:p5",
+ "event:p6"
+ ],
+ "userIMQueue": "/queue/user/im",
+ "userSmsQueue": "/queue/user/sms",
+ "userMailQueue": "/queue/user/mail"
+ },
+ "api": {
+ "im": "http://127.0.0.1:10086/wechat", //微信发送网关地址
+ "sms": "http://127.0.0.1:10086/sms", //短信发送网关地址
+ "mail": "http://127.0.0.1:10086/mail", //邮件发送网关地址
+ "dashboard": "http://127.0.0.1:8081", //dashboard模块的运行地址
+ "plus_api":"http://127.0.0.1:8080", //falcon-plus api模块的运行地址
+ "plus_api_token": "default-token-used-in-server-side" //用于和falcon-plus api模块服务端之间的通信认证token
+ },
+ "falcon_portal": {
+ "addr": "root:@tcp(127.0.0.1:3306)/alarms?charset=utf8&loc=Asia%2FChongqing",
+ "idle": 10,
+ "max": 100
+ },
+ "worker": {
+ "im": 10,
+ "sms": 10,
+ "mail": 50
+ },
+ "housekeeper": {
+ "event_retention_days": 7, //报警历史信息的保留天数
+ "event_delete_batch": 100
+ }
+}
+
+```
+## 进程管理
+
+```
+# 启动
+./open-falcon start alarm
+
+# 停止
+./open-falcon stop alarm
+
+# 查看日志
+./open-falcon monitor alarm
+```
+
+## 报警合并
+
+如果某个核心服务挂了,可能会造成大面积报警,为了减少报警短信数量,我们做了报警合并功能。把报警信息写入dashboard模块,然后dashboard返回一个url地址给alarm,alarm将这个url链接发给用户,这样用户只要收到一条短信(里边是个url地址),点击url进去就是多条报警内容。
+
+highQueues中配置的几个event队列中的事件是不会做报警合并的,因为那些是高优先级的报警,报警合并只是针对lowQueues中的事件。如果所有的事件都不想做报警合并,就把所有的event队列都配置到highQueues中即可
\ No newline at end of file
diff --git a/zh_0_3/distributed_install/api.md b/zh_0_3/distributed_install/api.md
new file mode 100644
index 0000000..7e652d8
--- /dev/null
+++ b/zh_0_3/distributed_install/api.md
@@ -0,0 +1,67 @@
+
+
+# API
+api组件,提供统一的restAPI操作接口。比如:api组件接收查询请求,根据一致性哈希算法去相应的graph实例查询不同metric的数据,然后汇总拿到的数据,最后统一返回给用户。
+
+## 服务部署
+服务部署,包括配置修改、启动服务、检验服务、停止服务等。这之前,需要将安装包解压到服务的部署目录下。
+
+```
+# 修改配置, 配置项含义见下文, 注意graph集群的配置
+mv cfg.example.json cfg.json
+vim cfg.json
+
+# 启动服务
+./open-falcon start api
+
+# 停止服务
+./open-falcon stop api
+
+# 查看日志
+./open-falcon monitor api
+
+```
+
+## 配置说明
+
+注意: 请确保 `graphs`的内容与transfer的配置**完全一致**
+
+```
+{
+ "log_level": "debug",
+ "db": { //数据库相关的连接配置信息
+ //如数据库使用密码, 配置方式稍有不同, 示例: "dsn": "root:password@tcp(127.0.0.1:3306)/graph?loc=Local&parseTime=true&allowNativePasswords=true"
+ "faclon_portal": "root:@tcp(127.0.0.1:3306)/falcon_portal?charset=utf8&parseTime=True&loc=Local",
+ "graph": "root:@tcp(127.0.0.1:3306)/graph?charset=utf8&parseTime=True&loc=Local",
+ "uic": "root:@tcp(127.0.0.1:3306)/uic?charset=utf8&parseTime=True&loc=Local",
+ "dashboard": "root:@tcp(127.0.0.1:3306)/dashboard?charset=utf8&parseTime=True&loc=Local",
+ "alarms": "root:@tcp(127.0.0.1:3306)/alarms?charset=utf8&parseTime=True&loc=Local",
+ "db_bug": true
+ },
+ "graphs": { // graph模块的部署列表信息
+ "cluster": {
+ "graph-00": "127.0.0.1:6070"
+ },
+ "max_conns": 100,
+ "max_idle": 100,
+ "conn_timeout": 1000,
+ "call_timeout": 5000,
+ "numberOfReplicas": 500
+ },
+ "metric_list_file": "./api/data/metric",
+ "web_port": ":8080", // http监听端口
+ "access_control": true, // 如果设置为false,那么任何用户都可以具备管理员权限
+ "salt": "pleaseinputwhichyouareusingnow", //数据库加密密码的时候的salt
+ "skip_auth": false, //如果设置为true,那么访问api就不需要经过认证
+ "default_token": "default-token-used-in-server-side", //用于服务端各模块间的访问授权
+ "gen_doc": false,
+ "gen_doc_path": "doc/module.html"
+}
+
+
+
+```
+
+## 补充说明
+- 部署完成api组件后,请修改dashboard组件的配置、使其能够正确寻址到api组件。
+- 请确保api组件的graph列表 与 transfer的配置 一致。
diff --git a/zh_0_3/distributed_install/gateway.md b/zh_0_3/distributed_install/gateway.md
new file mode 100644
index 0000000..88432d6
--- /dev/null
+++ b/zh_0_3/distributed_install/gateway.md
@@ -0,0 +1,7 @@
+
+
+# Gateway
+
+**如果您没有遇到机房分区问题,请直接忽略此组件**。
+
+如果您已经遇到机房分区问题、并急需解决机房分区时监控数据回传的问题,请使用该组件。更多的资料在[这里](https://github.com/open-falcon/falcon-plus/blob/master/modules/gateway/README.md)。
diff --git a/zh_0_3/distributed_install/graph.md b/zh_0_3/distributed_install/graph.md
new file mode 100644
index 0000000..ddc6160
--- /dev/null
+++ b/zh_0_3/distributed_install/graph.md
@@ -0,0 +1,64 @@
+
+
+# Graph
+
+graph是存储绘图数据的组件。graph组件 接收transfer组件推送上来的监控数据,同时处理api组件的查询请求、返回绘图数据。
+
+## 服务部署
+服务部署,包括配置修改、启动服务、检验服务、停止服务等。这之前,需要将安装包解压到服务的部署目录下。
+
+```
+# 修改配置, 配置项含义见下文
+mv cfg.example.json cfg.json
+vim cfg.json
+
+# 启动服务
+./open-falcon start graph
+
+# 停止服务
+./open-falcon stop graph
+
+# 查看日志
+./open-falcon monitor graph
+
+```
+
+## 配置说明
+配置文件默认为./cfg.json。默认情况下,安装包会有一个cfg.example.json的配置文件示例。各配置项的含义,如下
+
+```
+{
+ "debug": false, //true or false, 是否开启debug日志
+ "http": {
+ "enabled": true, //true or false, 表示是否开启该http端口,该端口为控制端口,主要用来对graph发送控制命令、统计命令、debug命令
+ "listen": "0.0.0.0:6071" //表示监听的http端口
+ },
+ "rpc": {
+ "enabled": true, //true or false, 表示是否开启该rpc端口,该端口为数据接收端口
+ "listen": "0.0.0.0:6070" //表示监听的rpc端口
+ },
+ "rrd": {
+ "storage": "./data/6070" // 历史数据的文件存储路径(如有必要,请修改为合适的路)
+ },
+ "db": {
+ // 所有的 graph 共用一个数据库
+ "dsn": "root:@tcp(127.0.0.1:3306)/graph?loc=Local&parseTime=true", //MySQL的连接信息,默认用户名是root,密码为空,host为127.0.0.1,database为graph(如有必要,请修改)
+ //如数据库使用密码, 配置稍有不同: "dsn": "root:password@tcp(127.0.0.1:3306)/graph?loc=Local&parseTime=true&allowNativePasswords=true"
+ "maxIdle": 4 //MySQL连接池配置,连接池允许的最大连接数,保持默认即可
+ },
+ "callTimeout": 5000, //RPC调用超时时间,单位ms
+ "ioWorkerNum": 64, //底层io.Worker的数量, 注意: 这个功能是v0.2.1版本之后引入的,v0.2.1版本之前的配置文件不需要该参数
+ "migrate": { //扩容graph时历史数据自动迁移
+ "enabled": false, //true or false, 表示graph是否处于数据迁移状态
+ "concurrency": 2, //数据迁移时的并发连接数,建议保持默认
+ "replicas": 500, //这是一致性hash算法需要的节点副本数量,建议不要变更,保持默认即可(必须和transfer的配置中保持一致)
+ "cluster": { //未扩容前老的graph实例列表
+ "graph-00" : "127.0.0.1:6070"
+ }
+ }
+}
+
+```
+
+## 补充说明
+部署完graph组件后,请修改transfer和api的配置,使这两个组件可以寻址到graph。
diff --git a/zh_0_3/distributed_install/hbs.md b/zh_0_3/distributed_install/hbs.md
new file mode 100644
index 0000000..03e88b2
--- /dev/null
+++ b/zh_0_3/distributed_install/hbs.md
@@ -0,0 +1,61 @@
+
+
+# HBS(Heartbeat Server)
+
+心跳服务器,公司所有agent都会连到HBS,每分钟发一次心跳请求。
+
+## 设计初衷
+
+Portal的数据库中有一个host表,维护了公司所有机器的信息,比如hostname、ip等等。这个表中的数据通常是从公司CMDB中同步过来的。但是有些规模小一些的公司是没有CMDB的,那此时就需要手工往host表中录入数据,这很麻烦。于是我们赋予了HBS第一个功能:agent发送心跳信息给HBS的时候,会把hostname、ip、agent version、plugin version等信息告诉HBS,HBS负责更新host表。
+
+falcon-agent有一个很大的特点,就是自发现,不用配置它应该采集什么数据,就自动去采集了。比如cpu、内存、磁盘、网卡流量等等都会自动采集。我们除了要采集这些基础信息之外,还需要做端口存活监控和进程数监控。那我们是否也要自动采集监听的端口和各个进程数目呢?我们没有这么做,因为这个数据量比较大,汇报上去之后用户大部分都是不关心的,太浪费。于是我们换了一个方式,只采集用户配置的。比如用户配置了对某个机器80端口的监控,我们才会去采集这个机器80端口的存活性。那agent如何知道自己应该采集哪些端口和进程呢?向HBS要,HBS去读取Portal的数据库,返回给agent。
+
+之后我们会介绍一个用于判断报警的组件:Judge,Judge需要获取所有的报警策略,让Judge去读取Portal的DB么?不太好。因为Judge的实例数目比较多,如果公司有几十万机器,Judge实例数目可能会是几百个,几百个Judge实例去访问Portal数据库,也是一个比较大的压力。既然HBS无论如何都要访问Portal的数据库了,那就让HBS去获取所有的报警策略缓存在内存里,然后Judge去向HBS请求。这样一来,对Portal DB的压力就会大大减小。
+
+
+## 部署说明
+
+hbs是可以水平扩展的,至少部署两个实例以保证可用性。一般一个实例可以搞定5000台机器,所以说,如果公司有10万台机器,可以部署20个hbs实例,前面架设lvs,agent中就配置上lvs vip即可。
+
+## 配置说明
+
+配置文件必须叫cfg.json,可以基于cfg.example.json修改
+
+```
+{
+ "debug": true,
+ "database": "root:password@tcp(127.0.0.1:3306)/falcon_portal?loc=Local&parseTime=true", # Portal的数据库地址
+ "hosts": "", # portal数据库中有个host表,如果表中数据是从其他系统同步过来的,此处配置为sync,否则就维持默认,留空即可
+ "maxIdle": 100,
+ "listen": ":6030", # hbs监听的rpc地址
+ "trustable": [""],
+ "http": {
+ "enabled": true,
+ "listen": "0.0.0.0:6031" # hbs监听的http地址
+ }
+}
+```
+
+## 进程管理
+
+```
+# 启动
+./open-falcon start hbs
+
+# 停止
+./open-falcon stop hbs
+
+# 查看日志
+./open-falcon monitor hbs
+
+```
+
+## 补充
+
+如果你先部署了agent,后部署的hbs,那咱们部署完hbs之后需要回去修改agent的配置,把agent配置中的heartbeat部分enabled设置为true,addr设置为hbs的rpc地址。如果hbs的配置文件维持默认,rpc端口就是6030,http端口是6031,agent中应该配置为hbs的rpc端口,小心别弄错了。
+
+
+## 视频教程
+
+为hbs模块录制了一个视频,做了源码级解读:http://www.jikexueyuan.com/course/1873.html
+
diff --git a/zh_0_3/distributed_install/judge.md b/zh_0_3/distributed_install/judge.md
new file mode 100644
index 0000000..fae87e7
--- /dev/null
+++ b/zh_0_3/distributed_install/judge.md
@@ -0,0 +1,74 @@
+
+
+# Judge
+
+Judge用于告警判断,agent将数据push给Transfer,Transfer不但会转发给Graph组件来绘图,还会转发给Judge用于判断是否触发告警。
+
+## 设计初衷
+
+因为监控系统数据量比较大,一台机器显然是搞不定的,所以必须要有个数据分片方案。Transfer通过一致性哈希来分片,每个Judge就只需要处理一小部分数据就可以了。所以判断告警的功能不能放在直接的数据接收端:Transfer,而应该放到Transfer后面的组件里。
+
+
+## 部署说明
+
+Judge监听了一个http端口,提供了一个http接口:/count,访问之,可以得悉当前Judge实例处理了多少数据量。推荐的做法是一个Judge实例处理50万~100万数据,用个5G~10G内存,如果所用物理机内存比较大,比如有128G,可以在一个物理机上部署多个Judge实例。
+
+## 配置说明
+
+配置文件必须叫cfg.json,可以基于cfg.example.json修改
+
+```
+{
+ "debug": true,
+ "debugHost": "nil",
+ "remain": 11,
+ "http": {
+ "enabled": true,
+ "listen": "0.0.0.0:6081"
+ },
+ "rpc": {
+ "enabled": true,
+ "listen": "0.0.0.0:6080"
+ },
+ "hbs": {
+ "servers": ["127.0.0.1:6030"], # hbs最好放到lvs vip后面,所以此处最好配置为vip:port
+ "timeout": 300,
+ "interval": 60
+ },
+ "alarm": {
+ "enabled": true,
+ "minInterval": 300, # 连续两个报警之间至少相隔的秒数,维持默认即可
+ "queuePattern": "event:p%v",
+ "redis": {
+ "dsn": "127.0.0.1:6379", # 与alarm、sender使用一个redis; Open-Falcon v0.3 支持设置redis密码,同时支持无认证格式,支持格式为 127.0.0.1:6379、@127.0.0.1:6379、auth@127.0.0.1:6379
+ "maxIdle": 5,
+ "connTimeout": 5000,
+ "readTimeout": 5000,
+ "writeTimeout": 5000
+ }
+ }
+}
+```
+
+remain这个配置详细解释一下:
+remain指定了judge内存中针对某个数据存多少个点,比如host01这个机器的cpu.idle的值在内存中最多存多少个,配置报警的时候比如all(#3),这个#后面的数字不能超过remain-1,一般维持默认就够用了
+
+## 进程管理
+
+我们提供了一个control脚本来完成常用操作
+
+```
+# 启动
+./open-falcon start judge
+
+# 停止
+./open-falcon stop judge
+
+# 查看日志
+./open-falcon monitor judge
+```
+
+## 视频教程
+
+为judge模块录制了一个视频,做了源码级解读:http://www.jikexueyuan.com/course/1850.html
+
diff --git a/zh_0_3/distributed_install/mail-sms.md b/zh_0_3/distributed_install/mail-sms.md
new file mode 100644
index 0000000..dede31f
--- /dev/null
+++ b/zh_0_3/distributed_install/mail-sms.md
@@ -0,0 +1,104 @@
+
+
+# 邮件、短信、微信、电话发送接口
+
+监控系统产生报警事件之后需要发送报警邮件或者报警短信,各个公司可能有自己的邮件服务器,有自己的邮件发送方法;有自己的短信通道,有自己的短信发送方法。falcon为了适配各个公司,在接入方案上做了一个规范,需要各公司提供http的短信和邮件发送接口。
+
+##### 短信发送http接口:
+
+```
+method: post
+params:
+ - content: 短信内容
+ - tos: 使用逗号分隔的多个手机号
+```
+
+#####邮件发送http接口:
+
+```
+method: post
+params:
+ - content: 邮件内容
+ - subject: 邮件标题
+ - tos: 使用逗号分隔的多个邮件地址
+```
+
+##### im发送http接口:
+
+```
+method: post
+params:
+ - content: im内容
+ - tos: 使用逗号分隔的多个im号码
+```
+
+不过你可以使用社区提供的 `邮件发送网关` 和 `微信网关`,或者使用灵犀提供的 [云告警通道](http://t.cn/RpkS0d2)。
+
+- [邮件网关](https://github.com/open-falcon/mail-provider)
+- [微信网关](https://github.com/Yanjunhui/chat)
+
+----
+# LinkedSee灵犀云通道短信/语音通知接入
+目前open-falcon支持LinkedSee灵犀云通道短信/语音通知API快速接入,只需一个API即可快速对接Open Falcon,快速让您拥有告警通知功能,90%的告警压缩比。云通道短信/语音通知接口接入步骤如下:
+
+#### 1、注册开通LinkedSee灵犀云通道
+LinkedSee灵犀云通道是专为IT运维打造的专属告警通道,多通道接入,最大程度避免堵塞,支持基于通知内容关键字的分析,合并同类事件,可以帮助您快速定位故障问题。访问LinkedSee灵犀标准版官网地址:[注册地址](http://t.cn/RpkS0d2)
+,注册灵犀账号,直接开通云通道服务。若已有账号,则直接登录即可。
+
+
+
+#### 2、创建应用
+注册成功后,登录系统进入控制台后,点击云通道进入工作台页面。击新建应用,创建应用,如下所示,输入应用名称之后点击保存。
+
+
+目前云通道提供短信告警、电话告警、短信通知、语音通知等4种使用场景,创建应用时默认开通短信告警和电话告警两种方式,为保证能正常接收到所有语音和短信告警,应确保短信和电话告警两种方式是打开状态。
+
+#### 3、获取应用token
+创建应用成功之后 ,点击查看应用token,如下所示:
+
+附注:token在后续的api接入步骤中使用。请复制后保存,以备后续使用。
+
+
+#### 4、获取token后拼接URL
+获取token后,需要跟LinkSee灵犀云通道的短信和语音告警url进行拼接:
+
+- 发送短信通知地址为:https://www.linkedsee.com/alarm/falcon_sms/`this_is_your_token`
+- 发送语音通知地址为:https://www.linkedsee.com/alarm/falcon_voice/`this_is_your_token`
+
+如若目前创建的应用的token为:d7a11a42aeac6848c3a389622f8,则:
+
+- 发送短信地址为:https://www.linkedsee.com/alarm/falcon_sms/d7a11a42aeac6848c3a389622f8
+- 发送语音告警的地址为:https://www.linkedsee.com/alarm/falcon_voice/d7a11a42aeac6848c3a389622f8
+
+#### 5、配置open-falcon:
+将上面的url配置在open-falcon alarm模块的配置文件cfg.json中,可以基于cfg.example.json修改,目前直接适配open-falcon v0.2。接口部分如下所示:
+
+```
+"api": {
+ "im": "http://127.0.0.1:10086/wechat", //微信发送网关地址
+ "sms": "http://127.0.0.1:10086/sms", //短信发送网关地址
+ "mail": "http://127.0.0.1:10086/mail", //邮件发送网关地址
+ "dashboard": "http://127.0.0.1:8081", //dashboard模块的运行地址
+ "plus_api":"http://127.0.0.1:8080", //falcon-plus api模块的运行地址
+ "plus_api_token": "default-token-used-in-server-side" //用于和falcon-plus api模块服务端之间的通信认证token
+ }
+```
+将step4的URL写在截图红框处, 如下所示:
+
+
+若发短信,则把短信发送网关地址替换为上一步中拼接的URL;若要发送语音消息,则将sms处的地址替换为语音对应的url。目前falcon暂不支持同时发送语音和短信通知,若要同时使用语音和短信报警,可以开通linkedsee云告警服务,同时还支持微信和邮件报警。
+
+#### 6、触发告警
+Open-Falcon配置完成后,请您触发一条告警,检查是否配置成功。目前Open-Falcon接入LinkedSee灵犀云通道之后,语⾳播报通道是固定内容的语⾳,若想使⽤动态语音播报和更多高级告警功能,欢迎使用云告警产品。>>[接入帮助](https://www.linkedsee.com/standard/support/#/access-falcon)
+
+附注:如果未成功,请确认是否按照上述步骤进行配置。如果确认没有问题,可以联系我们。我们将及时为您提供支持。热线电话:010-84148522
+
+#### 7、认证充值
+目前云通道免费版默认为短信10条,电话10通,完成接入配置之后,为保证信息安全,需要点击申请企业认证,填写企业认证相关信息审核通过之后即可充值购买更多的短信和语音告警数量。充值成功之后 ,可以查看用量统计和通知记录,帮助您更好的监控硬件性能,提升效率。
+
+
+#### 欢迎体验LinkedSee云告警高级服务
+- 一分钟拥有短信、微信、邮件、电话四种告警通知方式;
+- 支持告警升级策略、排班表及关键字合并策略;
+- 可以支持指定时间窗内的告警接收数量;
+- 多个维度的数据分析,更好的支持个性化需求;
diff --git a/zh_0_3/distributed_install/nodata.md b/zh_0_3/distributed_install/nodata.md
new file mode 100644
index 0000000..6cd2281
--- /dev/null
+++ b/zh_0_3/distributed_install/nodata.md
@@ -0,0 +1,61 @@
+
+
+# Nodata
+
+nodata用于检测监控数据的上报异常。nodata和实时报警judge模块协同工作,过程为: 配置了nodata的采集项超时未上报数据,nodata生成一条默认的模拟数据;用户配置相应的报警策略,收到mock数据就产生报警。采集项上报异常检测,作为judge模块的一个必要补充,能够使judge的实时报警功能更加可靠、完善。
+
+## 服务部署
+服务部署,包括配置修改、启动服务、检验服务、停止服务等。这之前,需要将安装包解压到服务的部署目录下。
+
+```
+# 修改配置, 配置项含义见下文
+mv cfg.example.json cfg.json
+vim cfg.json
+
+# 启动服务
+./open-falcon start nodata
+
+# 停止服务
+./open-falcon stop nodata
+
+# 检查日志
+./open-falcon monitor nodata
+
+```
+
+## 配置说明
+配置文件默认为./cfg.json。默认情况下,安装包会有一个cfg.example.json的配置文件示例。各配置项的含义,如下
+
+```
+{
+ "debug": true,
+ "http": {
+ "enabled": true,
+ "listen": "0.0.0.0:6090"
+ },
+ "plus_api":{
+ "connectTimeout": 500,
+ "requestTimeout": 2000,
+ "addr": "http://127.0.0.1:8080", #falcon-plus api模块的运行地址
+ "token": "default-token-used-in-server-side" #用于和falcon-plus api模块的交互认证token
+ },
+ "config": {
+ "enabled": true,
+ "dsn": "root:@tcp(127.0.0.1:3306)/falcon_portal?loc=Local&parseTime=true&wait_timeout=604800",
+ "maxIdle": 4
+ },
+ "collector":{
+ "enabled": true,
+ "batch": 200,
+ "concurrent": 10
+ },
+ "sender":{
+ "enabled": true,
+ "connectTimeout": 500,
+ "requestTimeout": 2000,
+ "transferAddr": "127.0.0.1:6060", #transfer的http监听地址,一般形如"domain.transfer.service:6060"
+ "batch": 500
+ }
+}
+
+```
diff --git a/zh_0_3/distributed_install/prepare.md b/zh_0_3/distributed_install/prepare.md
new file mode 100644
index 0000000..61bcf8d
--- /dev/null
+++ b/zh_0_3/distributed_install/prepare.md
@@ -0,0 +1,4 @@
+
+
+## 环境准备
+请参考[环境准备](./prepare.md)
diff --git a/zh_0_3/distributed_install/task.md b/zh_0_3/distributed_install/task.md
new file mode 100644
index 0000000..56da2ed
--- /dev/null
+++ b/zh_0_3/distributed_install/task.md
@@ -0,0 +1,100 @@
+
+
+# Task
+
+task是监控系统一个必要的辅助模块。定时任务,实现了如下几个功能:
+
++ index更新。包括图表索引的全量更新 和 垃圾索引清理。
++ falcon服务组件的自身状态数据采集。定时任务了采集了transfer、graph、task这三个服务的内部状态数据。
++ falcon自检控任务。
+
+
+## 源码编译
+
+```bash
+# update common lib
+cd $GOPATH/src/github.com/open-falcon/common
+git pull
+
+# compile
+cd $GOPATH/src/github.com/open-falcon/task
+go get ./...
+./control build
+./control pack
+```
+
+最后一步会pack出一个tar.gz的安装包,拿着这个包去部署服务即可。
+
+## 服务部署
+
+服务部署,包括配置修改、启动服务、检验服务、停止服务等。这之前,需要将安装包解压到服务的部署目录下。
+
+```bash
+# 修改配置, 配置项含义见下文
+mv cfg.example.json cfg.json
+vim cfg.json
+
+# 启动服务
+./control start
+
+# 校验服务,这里假定服务开启了8002的http监听端口。检验结果为ok表明服务正常启动。
+curl -s "127.0.0.1:8002/health"
+
+...
+# 停止服务
+./control stop
+
+```
+
+服务启动后,可以通过日志查看服务的运行状态,日志文件地址为./var/app.log。可以通过调试脚本```./test/debug```查看服务器的内部状态数据,如 运行 ```bash ./test/debug``` 可以得到服务器内部状态的统计信息。
+
+
+## 配置说明
+配置文件默认为./cfg.json。默认情况下,安装包会有一个cfg.example.json的配置文件示例。各配置项的含义,如下
+
+```
+debug: true/false, 如果为true,日志中会打印debug信息
+
+http
+ - enable: true/false, 表示是否开启该http端口,该端口为控制端口,主要用来对task发送控制命令、统计命令、debug命令等
+ - listen: 表示http-server监听的端口
+
+index
+ - enable: true/false, 表示是否开启索引更新任务
+ - dsn: 索引服务的MySQL的连接信息,默认用户名是root,密码为空,host为127.0.0.1,database为graph(如有必要,请修改)
+ - maxIdle: MySQL连接池配置,连接池允许的最大空闲连接数,保持默认即可
+ - cluster: 后端graph索引更新的定时任务描述。一条记录的形如: "graph地址:执行周期描述",通过设置不同的执行周期,来实现负载在时间上的均衡。
+ eg. 后端部署了两个graph实例,cluster可以配置为
+ "cluster":{
+ "test.hostname01:6071" : "0 0 0 ? * 0-5", //周0-5,每天的00:00:00,开始执行索引全量更新;"0 0 0 ? * 0-5"为quartz表达式
+ "test.hostname02:6071" : "0 30 0 ? * 0-5", //周0-5,每天的00:30:00,开始执行索引全量更新
+ }
+ - autoDelete: true|false, 是否自动删除垃圾索引。默认为false
+
+collector
+ - enable: true/false, 表示是否开启falcon的自身状态采集任务
+ - destUrl: 监控数据的push地址,默认为本机的1988接口
+ - srcUrlFmt: 监控数据采集的url格式, %s将由机器名或域名替换
+ - cluster: falcon后端服务列表,用具体的"module,hostname:port"表示,module取值可以为graph、transfer、task等
+
+```
+
+## 补充说明
+
+部署完成task组件后,请修改collector配置、使task能够正确采集transfer & graph的内部状态,请修改monitor配置、使task模块能够自检控Open-Falon的各组件(当前支持transfer、graph、query、judge等)。
+
+### 关于自监控报警
+因为多点监控的需求,自版本v0.0.10开始,我们将自监控报警功能 从Task模块移除。关于Open-Falcon自监控的详情,请参见[这里](http://book.open-falcon.com/zh/practice/monitor.html)。
+
+### 关于过期索引清除
+监控数据停止上报后,该数据对应的索引也会停止更新、变为过期索引。过期索引,影响视听,部分用户希望删除之。
+
+我们原来的方案,是: 通过task模块,有数据上报的索引、每天被更新一次,7天未被更新的索引、清除之。但是,很多用户不能正确配置graph实例的http接口,导致正常上报的监控数据的索引 无法被更新;7天后,合法索引被task模块误删除。
+
+为了解决上述问题,我们在默认配置里面,停掉了task模块自动删除过期索引的功能(autoDelete=false);如果你确定配置的index.cluster正确无误,可以自行打开该功能。
+
+当然,我们提供了更安全的、手动删除过期索引的方法。用户按需触发索引删除操作,具体步骤为:
+
+1.进行一次索引数据的全量更新。方法为: 针对每个graph实例,运行```curl -s "127.0.0.1:6071/index/updateAll"```,异步地触发graph实例的索引全量更新(这里假设graph的http监听端口为6071),等待所有的graph实例完成索引全量更新后 进行第2步操作。单个graph实例,索引全量更新的耗时,因counter数量、mysql数据库性能而不同,一般耗时不大于30min。
+
+2.待索引全量更新完成后,发起过期索引删除 ``` curl -s "$Hostname.Of.Task:$Http.Port/index/delete" ```。运行索引删除前,请务必**确保索引全量更新已完成**。
diff --git a/zh_0_3/distributed_install/transfer.md b/zh_0_3/distributed_install/transfer.md
new file mode 100644
index 0000000..ae48bf9
--- /dev/null
+++ b/zh_0_3/distributed_install/transfer.md
@@ -0,0 +1,91 @@
+
+
+# Transfer
+
+transfer是数据转发服务。它接收agent上报的数据,然后按照哈希规则进行数据分片、并将分片后的数据分别push给graph&judge等组件。
+
+## 服务部署
+服务部署,包括配置修改、启动服务、检验服务、停止服务等。这之前,需要将安装包解压到服务的部署目录下。
+
+```
+# 修改配置, 配置项含义见下文
+mv cfg.example.json cfg.json
+vim cfg.json
+
+# 启动服务
+./open-falcon start transfer
+
+# 校验服务,这里假定服务开启了6060的http监听端口。检验结果为ok表明服务正常启动。
+curl -s "127.0.0.1:6060/health"
+
+# 停止服务
+./open-falcon stop transfer
+
+# 查看日志
+./open-falcon monitor transfer
+```
+
+
+
+## 配置说明
+配置文件默认为./cfg.json。默认情况下,安装包会有一个cfg.example.json的配置文件示例。各配置项的含义,如下
+
+## Configuration
+```
+ debug: true/false, 如果为true,日志中会打印debug信息
+
+ minStep: 30, 允许上报的数据最小间隔,默认为30秒
+
+ http
+ - enabled: true/false, 表示是否开启该http端口,该端口为控制端口,主要用来对transfer发送控制命令、统计命令、debug命令等
+ - listen: 表示监听的http端口
+
+ rpc
+ - enabled: true/false, 表示是否开启该jsonrpc数据接收端口, Agent发送数据使用的就是该端口
+ - listen: 表示监听的http端口
+
+ socket #即将被废弃,请避免使用
+ - enabled: true/false, 表示是否开启该telnet方式的数据接收端口,这是为了方便用户一行行的发送数据给transfer
+ - listen: 表示监听的http端口
+
+ judge
+ - enabled: true/false, 表示是否开启向judge发送数据
+ - batch: 数据转发的批量大小,可以加快发送速度,建议保持默认值
+ - connTimeout: 单位是毫秒,与后端建立连接的超时时间,可以根据网络质量微调,建议保持默认
+ - callTimeout: 单位是毫秒,发送数据给后端的超时时间,可以根据网络质量微调,建议保持默认
+ - pingMethod: 后端提供的ping接口,用来探测连接是否可用,必须保持默认
+ - maxConns: 连接池相关配置,最大连接数,建议保持默认
+ - maxIdle: 连接池相关配置,最大空闲连接数,建议保持默认
+ - replicas: 这是一致性hash算法需要的节点副本数量,建议不要变更,保持默认即可
+ - cluster: key-value形式的字典,表示后端的judge列表,其中key代表后端judge名字,value代表的是具体的ip:port
+
+ graph
+ - enabled: true/false, 表示是否开启向graph发送数据
+ - batch: 数据转发的批量大小,可以加快发送速度,建议保持默认值
+ - connTimeout: 单位是毫秒,与后端建立连接的超时时间,可以根据网络质量微调,建议保持默认
+ - callTimeout: 单位是毫秒,发送数据给后端的超时时间,可以根据网络质量微调,建议保持默认
+ - pingMethod: 后端提供的ping接口,用来探测连接是否可用,必须保持默认
+ - maxConns: 连接池相关配置,最大连接数,建议保持默认
+ - maxIdle: 连接池相关配置,最大空闲连接数,建议保持默认
+ - replicas: 这是一致性hash算法需要的节点副本数量,建议不要变更,保持默认即可
+ - cluster: key-value形式的字典,表示后端的graph列表,其中key代表后端graph名字,value代表的是具体的ip:port(多个地址用逗号隔开, transfer会将同一份数据发送至各个地址,利用这个特性可以实现数据的多重备份)
+
+ tsdb
+ - enabled: true/false, 表示是否开启向open tsdb发送数据
+ - batch: 数据转发的批量大小,可以加快发送速度
+ - connTimeout: 单位是毫秒,与后端建立连接的超时时间,可以根据网络质量微调,建议保持默认
+ - callTimeout: 单位是毫秒,发送数据给后端的超时时间,可以根据网络质量微调,建议保持默认
+ - maxConns: 连接池相关配置,最大连接数,建议保持默认
+ - maxIdle: 连接池相关配置,最大空闲连接数,建议保持默认
+ - retry: 连接后端的重试次数和发送数据的重试次数
+ - address: tsdb地址或者tsdb集群vip地址, 通过tcp连接tsdb.
+
+```
+
+## 补充说明
+部署完成transfer组件后,请修改agent的配置,使其指向正确的transfer地址。在安装完graph和judge后,请修改transfer的相应配置、使其能够正确寻址到这两个组件。
+
+
+## 视频教程
+
+为transfer模块录制了一个视频,做了源码级解读:http://www.jikexueyuan.com/course/2061.html
diff --git a/zh_0_3/donate.md b/zh_0_3/donate.md
new file mode 100644
index 0000000..6d73481
--- /dev/null
+++ b/zh_0_3/donate.md
@@ -0,0 +1 @@
+../zh/donate.md
\ No newline at end of file
diff --git a/zh_0_3/faq/README.md b/zh_0_3/faq/README.md
new file mode 100644
index 0000000..190bfde
--- /dev/null
+++ b/zh_0_3/faq/README.md
@@ -0,0 +1,76 @@
+
+
+1. open-falcon v0.2的api文档是如何生成的?API文档地址 http://open-falcon.com/falcon-plus/
+> 人工生成yaml描述文件,通过Jekyll来生成静态站点,使用github来serve,api站点的源码在 https://github.com/open-falcon/falcon-plus/tree/master/docs 这里。不过可以通过打开api组件的gen_doc选项,然后api会把请求和应答都记录下来,作为撰写api yaml文件的参考。
+
+1. open-falcon v0.2 有管理员帐号吗?
+> 可以通过dashboard自行注册新用户,第一个用户名为root的帐号会被认为是超级管理员,超级管理员可以设置其他用户为管理员。
+
+1. open-falcon v0.2 dashboard 可以禁止用户自己注册吗?
+> 可以的,在api组件的配置文件中,将`signup_disable`配置项修改为true,重启api即可。
+
+1. open-falcon v0.2 dashboard 添加graph或者clone screen的时候,偶尔会出现'record not found'错误。
+> 这是api的bug引起的,已经在 [pull-request #186](https://github.com/open-falcon/falcon-plus/pull/186) 修复,请重新编译最新的api代码。
+
+1. open-falcon 可以监控udp的端口吗?
+> 支持的,参考 [pull-request #66](https://github.com/open-falcon/falcon-plus/pull/66)。
+
+1. open-falcon v0.2 如何单独编译安装api模块?
+> 参考[环境准备](https://book.open-falcon.com/zh_0_2/quick_install/prepare.html), 在falcon-plus的目录下,执行`make api`即可编译最新的api组件。
+
+1. open-falcon 支持Grafana吗?
+> 支持的,请参考[open-falcon grafana datasource](https://github.com/open-falcon/grafana-openfalcon-datasource)。
+
+1. 为什么连续3次报警之后,不再发送报警了?
+> 报警策略配置中,有一个最大报警次数的配置,比如你配置了cpu.idle小于5报警,max设置为3,那么报警达到3次之后即使仍然小于5也不会再报警了,直到接下来某次cpu.idle大于5了,就会报一个ok出来。以后如果又小于5了,那就会再次报警。
+
+1. 手动删除了数据库中 endpoint表、endpoint_counter中的一些记录后,相同的指标不会再次插入到MySQL中了。
+> 可以手工运行一次 graph 的索引刷新命令,即针对每个graph实例执行:`curl -s http://127.0.0.1:6071/index/updateAll` (这里假定graph模块http监听端口为6071)。
+
+1. graph的磁盘占用越来越大,怎么清理掉无用的数据?(rrd文件目录越来越大)
+> 在每台graph机器的rrd文件目录下面,执行如下命令 `find . -name '*.rrd' -mtime +7 | xargs rm -f'` 即可删除过去7天没有更新的rrd文件。
+
+1. 如何清理MySQL表过期的监控指标项?
+> 可以根据 graph.endpoint,graph.endpoint_counter,graph.tag_endpoint 三张表中的t_modify字段,找出很长一段时间都没有更新过的条目,进行删除。建议在操作数据库前,对数据库表做一个备份,免得误操作无法恢复,其次建议在操作前先触发一次索引的全量更新。
+
+1. 报警达到最大次数之后,如何再次报警?
+> 有三种方法:1是调大最大告警次数;2是修改告警阈值让该告警恢复;3是上报一个正常的值让该报警恢复。
+
+1. open-falcon 有英文版本吗?
+> open-falcon v0.2开始,dashboard部分支持i18n,点[这里](https://github.com/open-falcon/dashboard/blob/master/i18n.md)参与。
+
+1. open-falcon 支持发送报警到微信吗?(钉钉呢?)
+> open-falcon v0.2 原生支持发送报警到微信,可以参考 [alarm配置](https://book.open-falcon.com/zh_0_2/distributed_install/mail-sms.html) 和 [微信网关搭建](https://github.com/Yanjunhui/chat) 。发送报警到钉钉,可以参考[issue #134](https://github.com/open-falcon/falcon-plus/issues/134)。
+
+1. open-falcon 扩容增加graph节点,怎么让数据重新迁移?
+> 平滑扩容步骤,请参考 [graph扩容历史数据自动迁移](http://www.jianshu.com/p/16baba04c959)。
+
+1. open-falcon 能监控windows吗?
+> 可以的,请参考社区对 [windows监控的解决方案](https://book.open-falcon.com/zh_0_2/usage/win.html)。
+
+1. open-falcon 能监控交换机吗?
+> 可以的,请参考社区对 [交换机监控的解决方案](https://book.open-falcon.com/zh_0_2/usage/switch.html)。
+
+1. open-falcon v0.2 中没有sender模块了吗?
+> 是的,为了减少维护成本和安装成本,在open-falcon v0.2 中,移除了sender模块,将该功能集成在alarm模块中了。
+
+1. graph中,对于同一个Counter,在收到数据的时候,如果该数据的Timestamp小于Store中第一个数据的Timestamp,则该数据会被丢弃,这是为什么呢? 我想知道,这个地方出于这个考虑,是因为rrdtool的限制么,不能在Store中插入数据,只能追加数据吗? [issue](https://github.com/open-falcon/falcon-plus/issues/292)
+> 是的,在rrdtool的设计模式下,数据只能追加,不能插入。所以falcon在graph中提前对数据做了一个按照时间戳的排序。
+
+1. 宕机后,nodata报警有一定时间的延迟和滞后,是什么原因? [issue](https://github.com/open-falcon/falcon-plus/issues/294)
+> nodata的工作逻辑是:通过api去graph中查询数据,如果没有查询到数据,则对这个counter补发设定后的值。nodata的补发数据 和 用户正常上报数据,都是靠时钟来对齐的,因此在nodata的代码中,强行延迟了一到两个周期,以免造成 nodata 补发的值先到达graph,这样就会造成正常的值失效。
+
+1. counter中的tag字段,里面的所有空格都被去掉这是出于什么考虑呢? [issue](https://github.com/open-falcon/falcon-plus/issues/289)
+> 这算作一个最佳实践的约定吧,并非代码实现层面的考虑。空格建议大家在上报之前自行替换为-号。
+
+1. 报警信息里磁盘信息是以bit计数的,怎么控制单位呢? [issue](https://github.com/open-falcon/falcon-plus/issues/275)
+> open-falcon中没有「单位」的概念,数据都是遵从用户上报时的含义,理解上要保持一致。
+
+1. 上报数据中有中文时,graph 读取数据报错:errno: 0x023a, str:opening error [issue](https://github.com/open-falcon/falcon-plus/issues/274)
+> 这和中文没有关系,这个错误,应该是读取不存在的counter造成的,可以忽略。
+
+1. 按天为单位,上报数据如何正确上报和展现?[issue](https://github.com/open-falcon/falcon-plus/issues/271)
+> step要设置为86400,并且坚持每天push一次数据;push上去后,服务端会对时间戳做归一化,即服务端记录的时间戳 = int(当前时间戳/86400)。
+
+1. open-falcon 的报警历史是存储在什么地方的?
+> 在v0.1版本中,历史报警信息是不存储的,发送后就丢弃了;在v0.2中,做了改进,报警发送后会将历史报警存储在数据库中,请参考 `alarms` 库下面的表。当然,也可以通过 [API](http://open-falcon.com/falcon-plus/#/alarm_eventcases_list) 来访问这些信息。
diff --git a/zh_0_3/faq/alarm.md b/zh_0_3/faq/alarm.md
new file mode 100644
index 0000000..63d9e1b
--- /dev/null
+++ b/zh_0_3/faq/alarm.md
@@ -0,0 +1,39 @@
+
+
+# 报警相关常见问题
+
+#### 配置了策略,一直没有报警,如何排查?
+
+1. 排查sender、alarm、judge、hbs、agent、transfer的log
+2. 浏览器访问alarm的http页面,看是否有未恢复的告警,如果有就是生成报警了,后面没发出去,很可能是邮件、短信发送接口出问题了,检查sender中配置的api
+3. 打开agent的debug,看是否在正常push数据
+4. 看agent配置,是否正确配置了heartbeat(hbs)和transfer的地址,并enabled
+5. 看transfer配置,是否正确配置了judge地址
+6. jduge提供了一个http接口用于debug,可以检查某个数据是否正确push上来了,比如qd-open-falcon-judge01.hd这个机器的cpu.idle数据,可以这么查看
+```bash
+curl http://127.0.0.1:6081/history/qd-open-falcon-judge01.hd/cpu.idle
+```
+7. 检查服务器的时间是否已经同步,可以用 [ntp](https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/System_Administrators_Guide/sect-Understanding_chrony_and-its_configuration.html) 或 chrony 来实现
+
+上面的127.0.0.1:6081指的是judge的http端口
+7. 检查judge配置的hbs地址是否正确
+8. 检查hbs配置的数据库地址是否正确
+9. 检查portal中配置的策略模板是否配置了报警接收人
+10. 检查portal中配置的策略模板是否绑定到某个HostGroup了,并且目标机器恰好在这个HostGroup中
+11. 去UIC检查报警接收组中是否把自己加进去了
+12. 去UIC检查自己的联系信息是否正确
+
+#### 在Portal页面创建了一个HostGroup,往HostGroup中增加机器的时候报错
+
+1. 检查agent是否正确配置了heartbeat地址,并enabled了
+2. 检查hbs log
+3. 检查hbs配置的数据库地址是否正确
+4. 检查hbs的配置hosts是否配置为sync了,只有留空的时候hbs才会去写host表,host表中有数据才能在页面上添加机器
+
+
+#### 在alarm这边配置了短信、邮件、微信通知,在alarm 日志中看到告警写入 redis 队列都有,但实际发送有时候只有1种,有时2种,有时3种都有。
+1. 检查是否有多个alarm进程同时读取一个redis队列,引起相互干扰,如urlooker的alarm。
+2. 修改redis队列名称,如修改urlooker的redis队列名称,使2个alarm读取不同的队列,避免造成干扰。
+
+
+
diff --git a/zh_0_3/faq/collect.md b/zh_0_3/faq/collect.md
new file mode 100644
index 0000000..65f9c82
--- /dev/null
+++ b/zh_0_3/faq/collect.md
@@ -0,0 +1,62 @@
+
+
+# 数据收集相关问题
+Open-Falcon数据收集,分为[绘图数据]收集和[报警数据]收集。下面介绍,如何验证两个链路的数据收集是否正常。
+
+
+### 如何验证[绘图数据]收集是否正常
+数据链路是:`agent->transfer->graph->query->dashboard`。graph有一个http接口可以验证`agent->transfer->graph`这条链路,比如graph的http端口是6071,可以这么访问验证:
+
+```bash
+# $endpoint和$counter是变量
+curl http://127.0.0.1:6071/history/$endpoint/$counter
+
+# 如果上报的数据不带tags,访问方式是这样的:
+curl http://127.0.0.1:6071/history/host01/agent.alive
+
+# 如果上报的数据带有tags,访问方式如下,其中tags为module=graph,project=falcon
+curl http://127.0.0.1:6071/history/host01/qps/module=graph,project=falcon
+```
+如果调用上述接口返回空值,则说明agent没有上报数据、或者transfer服务异常。
+
+
+### 如何验证[报警数据]收集是否正常
+
+数据链路是:`agent->transfer->judge`,judge有一个http接口可以验证`agent->transfer->judge`这条链路,比如judge的http端口是6081,可以这么访问验证:
+
+```bash
+curl http://127.0.0.1:6081/history/$endpoint/$counter
+
+# $endpoint和$counter是变量,举个例子:
+curl http://127.0.0.1:6081/history/host01/cpu.idle
+
+# counter=$metric/sorted($tags)
+# 如果上报的数据带有tag,访问方式是这样的,比如:
+curl http://127.0.0.1:6081/history/host01/qps/module=judge,project=falcon
+```
+如果调用上述接口返回空值,则说明agent没有上报数据、或者transfer服务异常。
+
+**注意**: v0.2.1版本之后judge新增了优化内存使用的功能,如果metric没有对应的strategy或者expression,judge内存中不会存储该metirc的历史数据,所以判断报警数据收集这条链路是否正常时需要先确定metric是否有对应的报警条件
+
+```bash
+# 检查metric是否有对应的strategy
+curl http://127.0.0.1:6081/strategy/$endpoint/$counter
+
+# 检查metric是否有对应的expression
+curl http://127.0.0.1:6081/expression/$counter
+
+
+# $endpoint和$counter是变量
+# expression报警条件必须包含tag,当metric上报数据没有携带tag时只检测是否有对应的strategy即可
+# 举个例子:
+curl http://127.0.0.1:6081/strategy/host01/cpu.idle
+
+# counter=$metric/sorted($tags)
+# 如果上报的数据带有tag,需要检测streategy和expression是否存在
+# 举个例子: 当上报的metric为qps, tag为module=judge,project=falcon时, 访问方式是这样的:
+curl http://127.0.0.1:6081/strategy/host01/qps
+
+curl http://127.0.0.1:6081/expression/qps/module=judge
+
+curl http://127.0.0.1:6081/expression/qps/project=falcon
+```
diff --git a/zh_0_3/faq/graph.md b/zh_0_3/faq/graph.md
new file mode 100644
index 0000000..4267eff
--- /dev/null
+++ b/zh_0_3/faq/graph.md
@@ -0,0 +1,339 @@
+
+
+# 绘图链路常见问题
+
+### 如何清除过期索引
+监控数据停止上报后,该数据对应的索引也会停止更新、变为过期索引。过期索引,影响视听,部分用户希望删除之。
+
+我们原来的方案,是: 通过task模块,有数据上报的索引、每天被更新一次,7天未被更新的索引、清除之。但是,很多用户不能正确配置graph实例的http接口,导致正常上报的监控数据的索引 无法被更新;7天后,合法索引被task模块误删除。
+
+为了解决上述问题,我们停掉了task模块自动删除过期索引的功能、转而提供了过期索引删除的接口。用户按需触发索引删除操作,具体步骤为:
+
+1.运行task模块,并正确配置graph集群及其http端口,即task配置文件中index.cluster的内容。此处配置不正确,不应该进行索引删除操作,否则将导致索引数据的误删除。
+
+2.进行一次索引数据的全量更新。方法为 ``` curl -s "http://$Hostname.Of.Task:$Http.Port/index/updateAll" ```。这里,"$Hostname.Of.Task:$Http.Port"是task的http接口地址。
+PS:索引数据存放在graph实例上,这里,只是通过task,触发了各个graph实例的索引全量更新。更直接的办法,是,到每个graph实例上,运行```curl -s "http://127.0.0.1:6071/index/updateAll"```,直接触发graph实例 进行索引全量更新(这里假设graph的http监听端口为6071)。
+
+3.待索引全量更新完成后,发起过期索引删除 ``` curl -s "http://$Hostname.Of.Task:$Http.Port/index/delete" ```。运行索引删除前,请务必**确保索引全量更新已完成**。典型的做法为,周六运行一次索引全量更新,周日运行一次索引删除;索引更新和删除之间,留出足够的时间。
+
+在此,建议您: **若无必要,请勿删除索引**;若确定要删除索引,请确保删除索引之前,对所有的graph实例进行一次索引全量更新。
+
+
+### Dashboard索引缺失、查询不到endpoint或counter
+手动更改graph的数据库后,可能会出现上述情况。这里的手动更改,包括:更改graph的数据库配置(数据库地址,名称等)、删除重建graph数据库/表、手动更改graph数据表的内容等。出现上述情况后,可以通过 如下两种途径的任一种 来解决问题,
+
+1. 触发graph的索引全量更新、补救手工操作带来的异常。触发方式为,运行```curl -s "http://$hostname:$port/index/updateAll"```,其中```$hostname```为graph所在的服务器地址,```$port```为graph的http监听端口。这种方式,不会删除已上报的监控数据,但是会对数据库造成短时间的读写压力。
+2. 删除graph已存储的数据,并重启graph。默认情况下,graph的数据存储目录为 ```/home/work/data/6070/```。这种方式,会使已上报的数据被删除。
+
+
+
+### Dashboard图表曲线为空
+图表曲线,一般会有3-5个上报周期的延迟。如果5个周期后仍然没有图表曲线,请往下看。
+绘图链路,数据上报的流程为: agent -> transfer -> graph -> query -> dashboard。这个流程中任何一环节出问题,都会导致用户在dashboard中看不到曲线。一个建议的问题排查流程,如下
+
+1. 确保绘图链路的各组件,都已启动。
+2. 排查dashboard的问题。首先查看dashboard的日志,默认地址为```./var/app.log```,常见的日志报错原因有dashboard依赖库安装不完整、本地http代理劫持访问请求等。然后查看dashboard的配置,默认为```./gunicorn.conf```和```./rrd/config.py```。确认gunicorn.conf中指定的访问地址,确认config.py中指定的query地址、dashboard数据库配置 和 graph数据库配置。
+3. 排查query的问题。首先看下query的日志```./var/app.log```是否有报错信息。然后确认query的graph列表配置```./graph_backends.txt```和 服务配置```./cfg.json```。可以通过脚本```./scripts/query```来做一些定量的debug,比如你上报了一个 endpoint="ty-op-mon-cloud.us", metric="agent.alive" 的采集项,可以运行 ```bash ./scripts/query "ty-op-mon-cloud.us" "agent.alive" ``` 来查看该采集项的数据,如果能够查到数据 则说明query及之前的graph、transfer、agent很可能是正常的。
+4. 排查graph的问题。首先看下graph的日志```./var/app.log```是否有报错。然后确认下graph配置文件```./cfg.json```是否配置了正确的数据库db。没有发现问题?启动对graph的debug,方法见***Graph调试***一节。
+5. 排查transfer的问题。首先看transfer的日志```./var/app.log```是否有报错。然后确认配置文件```./cfg.json```是否enable了对graph集群的发送功能、是否正确配置了graph集群列表。确认完毕后,仍没有发现问题,怎么办?启动对transfer的debug,方法见***Transfer调试***一节。
+6. 排查agent的问题。打开agent的debug日志,观察数据上报情况。
+
+
+
+### Dashboard图表曲线有断点
+dashboard出现断点,可能的原因为:
+
+1. 用户监控数据上报异常。可能是用户自动的数据采集 被中断,或者上报周期不规律等。
+2. falcon系统异常,导致监控数据丢失。问题最可能发生在transfer到graph这个链路上,可以通过transfer&graph的debug接口来确认原因。
+
+
+### Graph绘图数据高可用
+默认情况下,绘图数据以分片的形式、存储在单个graph实例上。一旦graph实例所在的机器磁盘坏掉, 绘图数据就会永久丢失。
+
+为了解决这个问题,Open-Falcon提供了绘图数据高可用的解决方案: 数据双打/多打,即 将同一份绘图数据 同时打到2+个graph实例上、使这2+个graph实例的数据完全相同、互为镜像备份,当发生故障时 就可以用 镜像备份实例 来替换 故障的实例。具体的,绘图数据高可用的实现过程,如下:
+
+1. 配置transfer的graph节点列表,使每个节点都有2+个互为镜像的graph实例;transfer会向 互为镜像的几个graph实例 发送相同的数据。eg.你可以配置graph节点 形如``` "g-00" : "host1:6070,host2:6070"```,多个graph实例之间以逗号隔开,这样 ```host1:6070``` 和 ```host2:6070```就会互为镜像。注意,transfer版本应不低于***0.0.14***,否则 不能支持此功能。
+2. 启动/重启transfer,开始数据双打或者多打。transfer的压力,会随着镜像数量的增加而增大,所以 需要合理控制graph镜像的数量。
+3. 配置query的graph列表。当前,query只支持 **一个节点对应一个graph实例**。以第1步的transfer配置为例,你可以配置query的graph节点```g-00```的graph实例为 ```"g-00":"host1:6070"``` 或者 ```"g-00":"host2:6070"```、而不能是 ```"g-00":"host1:6070,host2:6070"```
+4. 当某个graph实例发生故障(eg.磁盘故障)时,修改query的graph列表、踢掉坏死的graph实例、并用其镜像实例顶替之。一方面,更上层的业务只会在query配置修改期间不可用,这个过程可以控制在分钟级别。另一方面,即使坏掉了一个graph实例,其上绘图数据 也可以从镜像实例上找到,从而实现了数据的高可用。
+
+当然,这个高可用方案 需要增加更多的graph实例、会使transfer资源消耗倍增、需要手动进行故障切换,还有很多的改进空间。
+
+
+
+### 如何确定某个counter对应的rrd文件
+每个counter,上报到graph之后,都是以一个独立的rrd文件,存储在磁盘上。那么如何确定counter和rrd的对应关系呢?
+query组件提供了一个调试用的http接口,可以帮助我们查询到该对应关系
+
+`info.py`
+
+```python
+#!/usr/bin/env python
+
+import requests
+import json
+import sys
+
+d = [
+ {
+ "endpoint": sys.argv[1],
+ "counter": sys.argv[2],
+ },
+]
+url = "http://127.0.0.1:9966/graph/info"
+r = requests.post(url, data=json.dumps(d))
+print r.text
+
+```
+
+`使用方法`
+
+ python info.py your.hostname your.metric/tag1=tag1-val,tag2=tag2-val
+
+
+
+### Graph调试
+graph以http的方式提供了多个调试接口。主要有 内部状态统计接口、历史数据查询接口等。脚本```./test/debug```将一些接口封装成了shell的形式,可自行查阅代码、不在此做介绍。
+
+**历史数据查询接口**```HTTP:GET, curl -s "http://hostname:port/history/$endpoint/$metric/$tags"```,返回graph接收到的、最新的3个数据。
+
+```bash
+# history没有tags的数据,$endpoint=test.host, $metric=agent.alive
+curl -s "http://127.0.0.1:6071/history/test.host/agent.alive" | python -m json.tool
+
+# history有tags的数据,$tags='module=graph,pdl=falcon'
+curl -s "http://127.0.0.1:6071/history/test.host/qps/module=graph,pdl=falcon" | python -m json.tool
+```
+
+**内部状态统计接口**```HTTP:GET, curl -s "http://hostname:port/statistics/all"```,输出json格式的内部状态数据,格式如下。这些内部状态数据,被task组件采集后push到falcon系统,用于绘图展示、报警等。
+
+```bash
+curl -s "http://127.0.0.1:6071/statistics/all" | python -m json.tool
+
+# output
+{
+ "data": [
+ { // counter of received items
+ "Cnt": 7, // cnt
+ "Name": "GraphRpcRecvCnt", // name of counter
+ "Other": {}, // other infos
+ "Qps": 0, // growth rate of this counter, per second
+ "Time": "2015-06-18 12:20:06" // time when this counter takes place
+ },
+ { // counter of query requests graph received
+ "Cnt": 0,
+ "Name": "GraphQueryCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-18 12:20:06"
+ },
+ { // counter of all sent items in query
+ "Cnt": 0,
+ "Name": "GraphQueryItemCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-18 12:20:06"
+ },
+ { // counter of info requests graph received
+ "Cnt": 0,
+ "Name": "GraphInfoCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-18 12:20:06"
+ },
+ { // counter of last requests graph received
+ "Cnt": 3,
+ "Name": "GraphLastCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-18 12:20:06"
+ },
+ { // counter of index updates
+ "Cnt": 0,
+ "Name": "IndexUpdateAllCnt",
+ "Other": {},
+ "Time": "2015-06-18 10:58:52"
+ }
+ ],
+ "msg": "success"
+}
+```
+
+
+### Transfer调试
+transfer以http的方式提供了多个调试接口。主要有 内部状态统计接口、转发数据追踪接口等。脚本```./test/debug```将一些http接口封装成了shell的形式,可自行查阅代码、不在此做介绍。
+
+**转发数据追踪接口** ```HTTP:GET, curl -s "http://hostname:port/trace/$endpoint/$metric/$tags"```,输出json格式的trace数据。transfer会过滤出以```/$endpoint/$metric/$tags```标记的数据,第一次调用时设置过滤条件、不会返回数据,之后每次调用返回已接收到的数据、最多3个点。这个接口主要用于debug。
+
+```bash
+# trace没有tags的数据,$endpoint=test.host, $metric=agent.alive
+curl -s "http://127.0.0.1:6060/trace/test.host/agent.alive" | python -m json.tool
+
+# trace有tags的数据,$tags='module=graph,pdl=falcon'
+curl -s "http://127.0.0.1:6060/trace/test.host/qps/module=graph,pdl=falcon" | python -m json.tool
+```
+
+**内部状态统计接口**```HTTP:GET, curl -s "http://hostname:port/statistics/all"```,输出json格式的内部状态数据,格式如下。这些内部状态数据,被task组件采集后push到falcon系统,用于绘图展示、报警等。
+
+```bash
+curl -s "http://127.0.0.1:6060/statistics/all" | python -m json.tool
+
+# output
+{
+ "data": [
+ { // counter of items received
+ "Cnt": 0, // counter, total number of items received since transfer started
+ "Name": "RecvCnt", // name of this this counter
+ "Other": {}, // other infos
+ "Qps": 0, // growth rate of this counter, items per sec
+ "Time": "2015-06-10 07:46:35" // time when this counter takes place
+ },
+ { // counter of items received from RPC
+ "Cnt": 0,
+ "Name": "RpcRecvCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of items received from HTTP-API
+ "Cnt": 0,
+ "Name": "HttpRecvCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of items received from SOCKET
+ "Cnt": 0,
+ "Name": "SocketRecvCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of items sent to judge
+ "Cnt": 0,
+ "Name": "SendToJudgeCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of items sent to graph
+ "Cnt": 0,
+ "Name": "SendToGraphCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of items sent to graph-migrating
+ "Cnt": 0,
+ "Name": "SendToGraphMigratingCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of dropped items sent to judge. transfer would drop items if it could not push them to receivers timely
+ "Cnt": 0,
+ "Name": "SendToJudgeDropCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of dropped items sent to graph
+ "Cnt": 0,
+ "Name": "SendToGraphDropCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of dropped items sent to graph-migrating
+ "Cnt": 0,
+ "Name": "SendToGraphMigratingDropCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of items transfer failed to send to judge
+ "Cnt": 0,
+ "Name": "SendToJudgeFailCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of items transfer failed to send to graph
+ "Cnt": 0,
+ "Name": "SendToGraphFailCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of items transfer failed to send to graph-migrating
+ "Cnt": 0,
+ "Name": "SendToGraphMigratingFailCnt",
+ "Other": {},
+ "Qps": 0,
+ "Time": "2015-06-10 07:46:35"
+ },
+ { // counter of cached items which would be sent to judge instances
+ "Cnt": 0,
+ "Name": "JudgeSendCacheCnt",
+ "Other": {},
+ "Time": "2015-06-10 07:46:33"
+ },
+ { // counter of cached items which would be sent to graph instances
+ "Cnt": 0,
+ "Name": "GraphSendCacheCnt",
+ "Other": {},
+ "Time": "2015-06-10 07:46:33"
+ },
+ { // counter of cached items which would be sent to grap-migrating instances
+ "Cnt": 0,
+ "Name": "GraphMigratingCacheCnt",
+ "Other": {},
+ "Time": "2015-06-10 07:46:33"
+ }
+ ],
+ "msg": "success"
+}
+```
+
+### 设置绘图数据的存储周期
+Graph组件默认保存5年的数据,存储数据的RRA配置为:
+
+```go
+// find this in 'graph/rrdtool/rrdtool.go'
+func create(filename string, item *model.GraphItem) error {
+ now := time.Now()
+ start := now.Add(time.Duration(-24) * time.Hour)
+ step := uint(item.Step)
+
+ c := rrdlite.NewCreator(filename, start, step)
+ c.DS("metric", item.DsType, item.Heartbeat, item.Min, item.Max)
+
+ // 设置各种归档策略
+ // 1分钟一个点存 12小时
+ c.RRA("AVERAGE", 0.5, 1, 720)
+
+ // 5m一个点存2d
+ c.RRA("AVERAGE", 0.5, 5, 576)
+ c.RRA("MAX", 0.5, 5, 576)
+ c.RRA("MIN", 0.5, 5, 576)
+
+ // 20m一个点存7d
+ c.RRA("AVERAGE", 0.5, 20, 504)
+ c.RRA("MAX", 0.5, 20, 504)
+ c.RRA("MIN", 0.5, 20, 504)
+
+ // 3小时一个点存3个月
+ c.RRA("AVERAGE", 0.5, 180, 766)
+ c.RRA("MAX", 0.5, 180, 766)
+ c.RRA("MIN", 0.5, 180, 766)
+
+ // 1天一个点存5year
+ c.RRA("AVERAGE", 0.5, 720, 730)
+ c.RRA("MAX", 0.5, 720, 730)
+ c.RRA("MIN", 0.5, 720, 730)
+
+ return c.Create(true)
+}
+
+```
+你可以通过修改rrdtool的RRA ``` c.RRA($CF, 0.5, $PN, $PCNT) ```,来设置Graph的数据存储周期。关于RRA的概念,请查阅rrdtool的相关资料。
diff --git a/zh_0_3/faq/linux-metrics.md b/zh_0_3/faq/linux-metrics.md
new file mode 100644
index 0000000..7541cf7
--- /dev/null
+++ b/zh_0_3/faq/linux-metrics.md
@@ -0,0 +1,198 @@
+
+
+# Linux运维基础采集项
+
+做运维,不怕出问题,怕的是出了问题,抓不到现场,两眼摸黑。所以,依靠强大的监控系统,收集尽可能多的指标,意义重大。但哪些指标才是有意义的呢,本着从实践中来的思想,各位工程师在长期摸爬滚打中总结出来的经验最有价值。
+
+在各位运维工程师长期的工作实践中,我们总结了在系统运维过程中,经常会参考的一些指标,主要包括以下几个类别:
+
+- CPU
+- Load
+- 内存
+- 磁盘
+- IO
+- 网络相关
+- 内核参数
+- ss 统计输出
+- 端口采集
+- 核心服务的进程存活信息采集
+- 关键业务进程资源消耗
+- NTP offset采集
+- DNS解析采集
+
+每个类别,具体的详细指标如下,这些指标,都是open-falcon的agent组件直接支持的。falcon-agent每隔一定时间间隔(目前是60秒)会采集一次相关的指标,并汇报给server端。
+
+# CPU相关采集项
+
+计算方法:通过采集/proc/stat来得到,大家可以参考sar命令的统计输出来理解。
+
+- cpu.idle:Percentage of time that the CPU or CPUs were idle and the system did not have an outstanding disk I/O request.
+- cpu.busy:与cpu.idle相对,他的值等于100减去cpu.idle。
+- cpu.guest:Percentage of time spent by the CPU or CPUs to run a virtual processor.
+- cpu.iowait:Percentage of time that the CPU or CPUs were idle during which the system had an outstanding disk I/O request.
+- cpu.irq:Percentage of time spent by the CPU or CPUs to service hardware interrupts.
+- cpu.softirq:Percentage of time spent by the CPU or CPUs to service software interrupts.
+- cpu.nice:Percentage of CPU utilization that occurred while executing at the user level with nice priority.
+- cpu.steal:Percentage of time spent in involuntary wait by the virtual CPU or CPUs while the hypervisor was servicing another virtual processor.
+- cpu.system:Percentage of CPU utilization that occurred while executing at the system level (kernel).
+- cpu.user:Percentage of CPU utilization that occurred while executing at the user level (application).
+- cpu.cnt:cpu核数。
+- cpu.switches:cpu上下文切换次数,计数器类型。
+
+
+# 磁盘相关采集项
+
+计算方法:先读取/proc/mounts拿到所有挂载点,然后通过syscall.Statfs_t拿到blocks和inode的使用情况。每个metric都会附加一组tag描述,类似mount=$mount,fstype=$fstype,其中$mount是挂载点,比如/home,$fstype是文件系统,比如ext4。
+
+- df.bytes.free:磁盘可用量,int64
+- df.bytes.free.percent:磁盘可用量占总量的百分比,float64,比如32.1
+- df.bytes.total:磁盘总大小,int64
+- df.bytes.used:磁盘已用大小,int64
+- df.bytes.used.percent:磁盘已用大小占总量的百分比,float64
+- df.inodes.total:inode总数,int64
+- df.inodes.free:可用inode数目,int64
+- df.inodes.free.percent:可用inode占比,float64
+- df.inodes.used:已用的inode数据,int64
+- df.inodes.used.percent:已用inode占比,float64
+
+# megacli工具输出
+使用 megacli 工具读取 RAID 相关信息,每个metric都会附件一组tag描述,用来标明所属PD或者 VD,PD格式为PD=Enclosure_ID:SLOT_ID,比如PD=32:0表明第一块磁盘 ,VD=0 表明第一个逻辑磁盘。
+
+- sys.disk.lsiraid.pd.Media_Error_Count:这个及以下三个指标目前仅作为数据收集,不一定意味磁盘损坏(只是表示损坏概率变大)
+- sys.disk.lsiraid.pd.Other_Error_Count
+- sys.disk.lsiraid.pd.Predictive_Failure_Count
+- sys.disk.lsiraid.pd.Drive_Temperature
+- sys.disk.lsiraid.pd.Firmware_state:如果值不为0,则此物理磁盘出现问题
+- sys.disk.lsiraid.vd.cache_policy:如果值不为0,表示此逻辑磁盘缓存策略和设置不符
+- sys.disk.lsiraid.vd.state: 如果值不为0,表示此逻辑磁盘出现问题
+
+# SMART工具输出
+使用 smartctl 工具读取磁盘 SMART 信息,目前所有指标仅作为数据收集,不一定意味磁盘损坏(只是表示概率变大),每个metric都会有一组tag描述,表明盘符,例如device=/dev/sda。
+
+- sys.disk.smart.Reallocated_Sector_Ct
+- sys.disk.smart.Spin_Retry_Count
+- sys.disk.smart.Reallocated_Event_Count
+- sys.disk.smart.Current_Pending_Sector
+- sys.disk.smart.Offline_Uncorrectable
+- sys.disk.smart.Temperature_Celsius
+
+# 分区读写监控
+测试所有已挂载分区是否可读写,每个metric都会有一组tag描述,表示挂载点,比如mount=/home
+
+- sys.disk.rw: 如果值不为0,表明此分区读写出现问题
+
+# IO相关采集项
+
+计算方法:每秒采集一次/proc/diskstats,计算差值,都是计数器类型的。每个metric都会有一组tag描述,形如device=$device,用来表示具体的设备,比如sda1、sdb。用户可以参考iostat的帮助文档来理解具体的metric含义。
+
+- disk.io.ios_in_progress:Number of actual I/O requests currently in flight.
+- disk.io.msec_read:Total number of ms spent by all reads.
+- disk.io.msec_total:Amount of time during which ios_in_progress >= 1.
+- disk.io.msec_weighted_total:Measure of recent I/O completion time and backlog.
+- disk.io.msec_write:Total number of ms spent by all writes.
+- disk.io.read_merged:Adjacent read requests merged in a single req.
+- disk.io.read_requests:Total number of reads completed successfully.
+- disk.io.read_sectors:Total number of sectors read successfully.
+- disk.io.write_merged:Adjacent write requests merged in a single req.
+- disk.io.write_requests:total number of writes completed successfully.
+- disk.io.write_sectors:total number of sectors written successfully.
+- disk.io.read_bytes:单位是byte的数字
+- disk.io.write_bytes:单位是byte的数字
+- disk.io.avgrq_sz:下面几个值就是iostat -x 1看到的值
+- disk.io.avgqu-sz
+- disk.io.await
+- disk.io.svctm
+- disk.io.util:是个百分数,比如56.43,表示56.43%
+
+
+# 机器负载相关采集项
+
+计算方法:读取/proc/loadavg,都是原始值类型的:
+
+- load.1min
+- load.5min
+- load.15min
+
+# 内存相关采集项
+
+计算方法:读取/proc/meminfo 中的内容,其中的mem.memfree是free+buffers+cached,mem.memused=mem.memtotal-mem.memfree。用户具体可以参考free命令的输出和帮助文档来理解每个metric的含义。
+
+- mem.memtotal:内存总大小
+- mem.memused:使用了多少内存
+- mem.memused.percent:使用的内存占比
+- mem.memfree
+- mem.memfree.percent
+- mem.swaptotal:swap总大小
+- mem.swapused:使用了多少swap
+- mem.swapused.percent:使用的swap的占比
+- mem.swapfree
+- mem.swapfree.percent
+
+
+# 网络相关采集项
+
+计算方法:读取/proc/net/dev的内容,每个metric都附加有一组tag,形如iface=$iface,标明具体那个interface,比如eth0。metric中带有in的表示流入情况,out表示流出情况,total是总量in+out,支持的metric如下:
+
+- net.if.in.bytes
+- net.if.in.compressed
+- net.if.in.dropped
+- net.if.in.errors
+- net.if.in.fifo.errs
+- net.if.in.frame.errs
+- net.if.in.multicast
+- net.if.in.packets
+- net.if.out.bytes
+- net.if.out.carrier.errs
+- net.if.out.collisions
+- net.if.out.compressed
+- net.if.out.dropped
+- net.if.out.errors
+- net.if.out.fifo.errs
+- net.if.out.packets
+- net.if.total.bytes
+- net.if.total.dropped
+- net.if.total.errors
+- net.if.total.packets
+
+# 端口采集项
+
+计算方法,通过ss -ln,来判断指定的端口是否处于listen状态。原始值类型,值要么是1:代表在监听,要么是0,代表没有在监听。每个metric都附件一组tag,形如port=$port,$port就是具体的端口。
+
+- net.port.listen
+
+# 机器内核配置
+
+- kernel.maxfiles: 读取的/proc/sys/fs/file-max
+- kernel.files.allocated:读取的/proc/sys/fs/file-nr第一个Field
+- kernel.files.left:值=kernel.maxfiles-kernel.files.allocated
+- kernel.maxproc:读取的/proc/sys/kernel/pid_max
+
+# ntp采集项
+
+使用 ntpq -pn 获取本机时间相对于 ntp 服务器的 offset。
+
+- sys.ntp.offset: 本机偏移时间,单位为ms,值过大或者为0则表明有异常,需要报警
+
+# 进程监控
+
+- proc.num:判断某个进程的数目,这里需要分两个场景,一种是根据进程的名字来判定,比如name=sshd;另外一种是根据cmdline来判定,比如Java的应用进程名可能都是java,根据第一种情况没法做区分,此时可以配置cmdline,如cmdline=./falcon_agent-c./cfg.ini
+
+
+# 进程资源监控
+
+- process.cpu.all:进程和它的子进程使用的sys+user的cpu,单位是jiffies
+- process.cpu.sys:进程和它的子进程使用的sys cpu,单位是jiffies
+- process.cpu.user:进程和它的子进程使用的user cpu,单位是jiffies
+- process.swap:进程和它的子进程使用的swap,单位是page
+- process.fd:进程使用的文件描述符个数
+- process.mem:进程占用内存,单位byte
+
+# ss命令输出
+
+- ss.orphaned
+- ss.closed
+- ss.timewait
+- ss.slabinfo.timewait
+- ss.synrecv
+- ss.estab
+
diff --git a/zh_0_3/faq/qq.md b/zh_0_3/faq/qq.md
new file mode 100644
index 0000000..772412f
--- /dev/null
+++ b/zh_0_3/faq/qq.md
@@ -0,0 +1,150 @@
+
+
+# 问与答from qq群(373249123)
+## 报警
+
+
+Q: 能不能当网络流量超过某个阀值的时候,发报警邮件把占用流量Top3的程序找出来?each (endpoint=xxx metric=yyy tag1=tttt) expression可以这么写吗? @聂安_小米
+
+>A: 可以。如果endpoint不是机器名,可以用each表达式配置报警策略。如果endpoint是机器名,建议使用 hostgrp + template的方式 配置策略——这种方式 更加便于管理。(当然,endpoint不是机器名,也可以使用hostgrp + template的方式,只不过需要把该endpoint插入到hostgrp中)
+
+Q: 捎带问下,最大报警次数为3,那前三次报警的时间间隔在哪里设置
+
+>A: 比如你的数据是一分钟上来一次,理论上第三分钟,第六分钟,第九分钟分别报警三次就不再报警了。但是这样报警我们觉得太频繁,于是judge中有一个最小报警设置,默认是5分钟,即:两次报警之间至少间隔5分钟:第三分钟、第八分钟、第13分钟。Link不做告警合并,Alarm只合并一分钟内相同类型的报警。
+
+Q: 怎么知道我的策略是否同步成功了?
+
+>A: curl -s "judge-hostname:port/strategy/host.test.01/cpu.idle", 这个是查看 机器host.test.01 & metric为 cpu.idle 对应的策略。
+
+Q: 我想判断磁盘空间少于10%并且剩余空间少于1TB 才报警,有些大容量的存储,10%的剩余空间可能还有好几 TB,这样可以实现吗?
+
+>A: 目前架构不支持组合策略。
+
+Q: 我现在做了一个 ping 检测,会通过2各节点 A,B 去 ping,对应的是2个 tag,ping_server=A,ping_server=b,我现在是想做一个报警项,当 A,B 节点 到目标主机都不通我才报警。还有例子,比如我想设置报警,nginx 的连接数波动超过20% 而且链接数大于1000的才报警,可能有些机器业务的nginx 量很少,从连接数1到连接数2的波动就已经是100%了。
+
+>A: 这个可以划归到集群监控的情况,一个集群两机器都宕机才报警,只有一个宕机不报警。组合策略如果是针对两个不同的采集项,那以现在的架构肯定是实现不了的,因为两个报警项可能落到了两个不同的 judge 实例上了。下个版本不会做,只能想办法在后面的组件比如 alarm 来搞,还挺复杂的
+
+
+Q: 这个max=3 是指同一个监控项 比如cpu.busy 在一定时间内最多发三次报警吗?
+
+>A: max表示最大报警次数,比如你配置了cpu.idle小于5报警,max设置为3那么报警达到3次之后即使仍然小于5也不会再报警了,直到接下来某次cpu.idle大于5了,就会报一个ok出来。以后如果又小于5了,那就会再次报警
+
+
+Q: 为什么未恢复报警那个模块,我把出现的报警标记为已解决后,被监控的主机再次出现同样的问题,没有再次触发报警(新手)
+
+>A: “标记为已解决” 这个动作,和大家理解的不一样。 这个并不是真正的已解决,只是说,有些报警自己没有办法恢复了,就留在alarm-dash里面了,这个solved只是把alarm-dash里面遗留的 清理掉
+
+
+Q: Expression 可以这样写吗?each(metric=net.port.listen port=8100 endpoint=1.2.3.4)
+
+>A: 可以
+
+Q: 报警有自动过滤的机制吗?
+
+>A: 没有自动过滤的机制,hostgrp里配置了策略就会添加到相应的host上。报警判断时,假的host不可能上来数据,因此也就不会触发报警。进一步讲,这种没有数据上报就不报警可能不是用户希望看到。可以透过nodata的报警搞定之。
+
+
+Q: 同比环比报警可能会有一个问题, 就是误报的 case . 假设 A -> B -> C , 其中 B 是异常时间点. 到 B 这个点报警. 然后到 C 这个时间点恢复正常的话, 又会报警一次. 不知道大家有没有什么比较好的思路
+
+>A: 同比环比的告警,用在实际的环境中,误报太多,缺乏实际的操作意义,所以我们不打算支持。只提供了流量突升突降的告警功能。
+
+Q: 报警通知(邮件、短信、等等)在 Open-Falcon 代码里面没有,该如何实现?
+
+>A: alarm将报警邮件内容写入redis队列,sender负责读取并且发送,你可以二次开发sender,让它不通过调用http接口实现邮件发送,或参考 [mail-provider](https://github.com/open-falcon/mail-provider) 以及本书中的'社区贡献'。
+
+
+## 数据
+
+
+Q: 一旦某台机器下线,历史数据就不能查询了?
+
+>A: 是的。一旦数据不更新了,7天后就不能查询了。task索引清除的周期,没有留出配置接口,因为这个周期很少变更。如果需要,可以修改源码中的删除周期。@Fancy_金山 (需要注意的是,这个清理只是清理了索引,历史数据本身,仍然是存储在磁盘上的,当该指标再次被更新的时候,索引会自动再次创建,历史数据仍能被查询到)
+
+
+Q: graph扩容或者摘除机器 ,会对原先数据有损坏吗?
+
+>A: @陈凯军 监控数据,是按照一致性哈希规则,被分片、打在不同的graph实例上的。graph实例数量,会严重影响一致性哈希的数据分片结果。graph集群缩扩容时,监控数据的分布规则将彻底发生变化,新老数据不可能被同时查询到。即使老的数据没有被损坏,也是查询不到了。
+
+
+Q: 为什么是 hostname 唯一,而不是ip唯一?
+
+>A: host表中有个id,这个id通常是CMDB的id,用这个id做唯一标识,如果cmdb中hostname改了,同步的时候发现hostname变了就同步到监控了。ip是agent自动探测的,通常是取内网ip,但是有的机器可能有多个ip,可能没有内网ip,自动探测的ip作为唯一标识不是很好用。
+
+Q: grp表的come_from字段是什么意思
+
+>A: 用来区分 ``机器分组`` 的不同来源: 机器分组可能是用户手动添加的、也可能是从内部其他系统同步过来的、等等。
+
+Q: 我能把历史数据放到falcon中吗?
+
+>A: falcon中的数据,只能按照时间戳进行追加,不能插入。利用这个特性,你可以在今天的某个时间点,按照顺序把昨天的数据追加进来后,再追加今天的数据。
+
+
+Q: 扩容时如何保留历史数据呢?
+
+>A: 扩容的时候,历史数据无法迁移。现在能做的是,在扩容的时候,保持数据双写,比如持续一个月,这样让用户的看图功能,不要中断。然后把历史数据,全部移动到一个大容量磁盘的机器上,搭建一个dashboard,用来专门查询历史数据。
+
+
+## 插件
+
+Q: 自定义的插件同步后,是否要重启一下agent,才会生效?
+
+>A: 不需要。curl -s "hostname:1988/plugin/update",这样就能同步插件。
+
+
+## 负载均衡
+
+Q: Open-Falcon 能做接口代理嗎?负载均衡建议怎么做呢?
+
+>A: 域名解析到ip。用 domain.name:port访问。没有做接口代理。transfer大于1个实例时,ip+port{6060, 8433} 的方式需要配置transfer实例列表、不方便。建议用域名实现负载均衡。
+ task叢集設定:https://github.com/open-falcon/task/blob/master/README.md
+
+
+## 监控
+
+>open-falcon是一个监控框架,理论上任何软件只要可以把数据组装为open-falcon要求的格式,就可以用open-falcon监控。比如刚才大家讨论的mysql的监控,其实就是自己写了一堆采集脚本去采集mysql的一些指标,然后push给open-falcon就可以了。应用本身也可以用类似的做法,写脚本采集应用的监控性能指标,然后push给open-falcon。不过每个人都自己写脚本,可能重复造很多轮子。小米内部的实践是:针对java的应用有一个通用jar包,只要maven引入这个jar包,就可以采集一些基础数据,比如某个接口的调用latency、qps等等。比较好的实践方式是把监控数据的采集直接嵌入业务代码。但是要减少侵入性,通过一些队列、异步之类的方式,不要阻断主要业务逻辑执行流程。收集到数据之后post给本机agent即可
+
+Q: Open-Falcon 支持 Windows 监控吗?
+
+>A: 支持,请见本书中的'Windows 主机监控'。
+
+Q: 请教各位大神,open-falcon怎么监控端口?我没有搜到net.port.listen这个metirc,只有cpu,mem,net
+
+>A: 要先配个模板,才会有port的metric,大概架构是,配置模板,metric是net.port.listen,tag里配置port=xxx,然后模板关联hostgroup,hostgroup里的host就会通过hbs获取到需要监测的port,然后探测上报
+
+Q: docker 中的 agent 一直出现 `index out of range` 的错误
+
+>A: 刚才这个问题很典型,经过追查,问题是这样的:agent运行在docker容器里,docker容器限制了cpu个数,agent拿到了正确的cpu个数,比如宿主机是32个核,限制docker容器为2个核,agent就拿到了cpu核数为2 。于是准备了一个长度为2的数组来放置各个cpu的性能数据。但是,接下来agent要去读取/proc/stat,docker容器内部看到的/proc/stat文件内容和宿主机一般无二,于是看到了32个核,于是index out of range。
+
+Q: 建议用 Agent 做日志分析监控吗?
+
+>A: Agent不采集日志文件,这么做日志监控不是个好的实践方式,我个人推荐的做法是业务程序自己在代码中catch住exception,有问题直接调用报警接口报警得了,RD 收到报警之后自己去查log,小米应该是有个scribe集群来收集日志,具体我也不清楚。
+
+
+## 安全性問題
+
+Q: 任何机器都可以访问 Transfer 会不会有安全性问题?
+
+>A: Transfer部署在内网。不同IDC内网是联通的,因此访问Transfer基本没有ACL的问题
+
+
+## 其他
+
+Q: 组件之间怎么沟通的?
+
+>A: jsonrpc tcp传输,编码为二进制传输的
+
+Q: Open-Falcon 的架构图是用什么画的?
+
+>A: Mindmanager/PPT
+
+Q: QQ 群信息太多、很多重复问题、又容易发散,是否建个论坛?
+
+>A: 论坛现在大家比较少用了。常见问题大家可以 fork github.com/open-falcon/book.git 然后发 PR,其余的可以使用 Github issue 作为论坛使用。
+
+Q: `too many open files` 是什么问题?
+>A: 可以先透过 `ulimit -a` 检查 file descriptor 的限制,如果默认 1024 太小,可以透过 `ulimit -n 65536` 加大。
+
+Q: Open-Falcon 的未来计划?
+
+>A: https://github.com/XiaoMi/open-falcon/issues 一些接下来,要做的事情,我都会更新在这里(大家也可以提,思路更广一些) 有能力、有时间的朋友,可以认领一个或多个issue,或者配合撰写、贡献相关文档,都是热烈欢迎的。 特别是一些重度使用open-falcon的大户哈,希望能把你们自己的一些改进,也都推进到open-falcon的github仓库里哈:)【比如美团、金山云、快网、赶集之类的~~~】 接入并使用了Open-Falcon的公司,可以把相关信息追加到下面这个issue的评论中 https://github.com/XiaoMi/open-falcon/issues/4
+
diff --git a/zh_0_3/image/OpenFalcon_wechat.jpg b/zh_0_3/image/OpenFalcon_wechat.jpg
new file mode 100644
index 0000000..9c80c94
Binary files /dev/null and b/zh_0_3/image/OpenFalcon_wechat.jpg differ
diff --git a/zh_0_3/image/func_aggregator_1.png b/zh_0_3/image/func_aggregator_1.png
new file mode 100644
index 0000000..581c039
Binary files /dev/null and b/zh_0_3/image/func_aggregator_1.png differ
diff --git a/zh_0_3/image/func_aggregator_2.png b/zh_0_3/image/func_aggregator_2.png
new file mode 100644
index 0000000..43cb7f7
Binary files /dev/null and b/zh_0_3/image/func_aggregator_2.png differ
diff --git a/zh_0_3/image/func_aggregator_3.png b/zh_0_3/image/func_aggregator_3.png
new file mode 100644
index 0000000..4dfe658
Binary files /dev/null and b/zh_0_3/image/func_aggregator_3.png differ
diff --git a/zh_0_3/image/func_aggregator_4.png b/zh_0_3/image/func_aggregator_4.png
new file mode 100644
index 0000000..97d4549
Binary files /dev/null and b/zh_0_3/image/func_aggregator_4.png differ
diff --git a/zh_0_3/image/func_aggregator_5.png b/zh_0_3/image/func_aggregator_5.png
new file mode 100644
index 0000000..944159d
Binary files /dev/null and b/zh_0_3/image/func_aggregator_5.png differ
diff --git a/zh_0_3/image/func_getting_started_1.png b/zh_0_3/image/func_getting_started_1.png
new file mode 100644
index 0000000..6b9b1da
Binary files /dev/null and b/zh_0_3/image/func_getting_started_1.png differ
diff --git a/zh_0_3/image/func_getting_started_10.png b/zh_0_3/image/func_getting_started_10.png
new file mode 100644
index 0000000..d532093
Binary files /dev/null and b/zh_0_3/image/func_getting_started_10.png differ
diff --git a/zh_0_3/image/func_getting_started_11.png b/zh_0_3/image/func_getting_started_11.png
new file mode 100644
index 0000000..d2fe099
Binary files /dev/null and b/zh_0_3/image/func_getting_started_11.png differ
diff --git a/zh_0_3/image/func_getting_started_12.png b/zh_0_3/image/func_getting_started_12.png
new file mode 100644
index 0000000..614f9b7
Binary files /dev/null and b/zh_0_3/image/func_getting_started_12.png differ
diff --git a/zh_0_3/image/func_getting_started_2.png b/zh_0_3/image/func_getting_started_2.png
new file mode 100644
index 0000000..2e34713
Binary files /dev/null and b/zh_0_3/image/func_getting_started_2.png differ
diff --git a/zh_0_3/image/func_getting_started_3.png b/zh_0_3/image/func_getting_started_3.png
new file mode 100644
index 0000000..890c359
Binary files /dev/null and b/zh_0_3/image/func_getting_started_3.png differ
diff --git a/zh_0_3/image/func_getting_started_4.png b/zh_0_3/image/func_getting_started_4.png
new file mode 100644
index 0000000..2181a41
Binary files /dev/null and b/zh_0_3/image/func_getting_started_4.png differ
diff --git a/zh_0_3/image/func_getting_started_5.png b/zh_0_3/image/func_getting_started_5.png
new file mode 100644
index 0000000..51e0e2a
Binary files /dev/null and b/zh_0_3/image/func_getting_started_5.png differ
diff --git a/zh_0_3/image/func_getting_started_6.png b/zh_0_3/image/func_getting_started_6.png
new file mode 100644
index 0000000..bd5bb5d
Binary files /dev/null and b/zh_0_3/image/func_getting_started_6.png differ
diff --git a/zh_0_3/image/func_getting_started_7.png b/zh_0_3/image/func_getting_started_7.png
new file mode 100644
index 0000000..5d12367
Binary files /dev/null and b/zh_0_3/image/func_getting_started_7.png differ
diff --git a/zh_0_3/image/func_getting_started_8.png b/zh_0_3/image/func_getting_started_8.png
new file mode 100644
index 0000000..068e604
Binary files /dev/null and b/zh_0_3/image/func_getting_started_8.png differ
diff --git a/zh_0_3/image/func_getting_started_9.png b/zh_0_3/image/func_getting_started_9.png
new file mode 100644
index 0000000..b46c6ae
Binary files /dev/null and b/zh_0_3/image/func_getting_started_9.png differ
diff --git a/zh_0_3/image/func_intro_1.png b/zh_0_3/image/func_intro_1.png
new file mode 100644
index 0000000..fac628b
Binary files /dev/null and b/zh_0_3/image/func_intro_1.png differ
diff --git a/zh_0_3/image/func_intro_2.png b/zh_0_3/image/func_intro_2.png
new file mode 100644
index 0000000..d7a9d1c
Binary files /dev/null and b/zh_0_3/image/func_intro_2.png differ
diff --git a/zh_0_3/image/func_intro_3.png b/zh_0_3/image/func_intro_3.png
new file mode 100644
index 0000000..2c9caee
Binary files /dev/null and b/zh_0_3/image/func_intro_3.png differ
diff --git a/zh_0_3/image/func_intro_4.png b/zh_0_3/image/func_intro_4.png
new file mode 100644
index 0000000..c557f37
Binary files /dev/null and b/zh_0_3/image/func_intro_4.png differ
diff --git a/zh_0_3/image/func_intro_5.png b/zh_0_3/image/func_intro_5.png
new file mode 100644
index 0000000..24eb3f1
Binary files /dev/null and b/zh_0_3/image/func_intro_5.png differ
diff --git a/zh_0_3/image/func_intro_6.png b/zh_0_3/image/func_intro_6.png
new file mode 100644
index 0000000..5d9b9b6
Binary files /dev/null and b/zh_0_3/image/func_intro_6.png differ
diff --git a/zh_0_3/image/func_intro_7.png b/zh_0_3/image/func_intro_7.png
new file mode 100644
index 0000000..8edbe67
Binary files /dev/null and b/zh_0_3/image/func_intro_7.png differ
diff --git a/zh_0_3/image/func_intro_8.png b/zh_0_3/image/func_intro_8.png
new file mode 100644
index 0000000..be29306
Binary files /dev/null and b/zh_0_3/image/func_intro_8.png differ
diff --git a/zh_0_3/image/func_nodata_1.png b/zh_0_3/image/func_nodata_1.png
new file mode 100644
index 0000000..2ac8c0e
Binary files /dev/null and b/zh_0_3/image/func_nodata_1.png differ
diff --git a/zh_0_3/image/func_nodata_2.png b/zh_0_3/image/func_nodata_2.png
new file mode 100644
index 0000000..56e479f
Binary files /dev/null and b/zh_0_3/image/func_nodata_2.png differ
diff --git a/zh_0_3/image/func_nodata_3.png b/zh_0_3/image/func_nodata_3.png
new file mode 100644
index 0000000..35a5036
Binary files /dev/null and b/zh_0_3/image/func_nodata_3.png differ
diff --git a/zh_0_3/image/linkedsee_1.png b/zh_0_3/image/linkedsee_1.png
new file mode 100644
index 0000000..172c110
Binary files /dev/null and b/zh_0_3/image/linkedsee_1.png differ
diff --git a/zh_0_3/image/linkedsee_2.png b/zh_0_3/image/linkedsee_2.png
new file mode 100644
index 0000000..a624f96
Binary files /dev/null and b/zh_0_3/image/linkedsee_2.png differ
diff --git a/zh_0_3/image/linkedsee_3.png b/zh_0_3/image/linkedsee_3.png
new file mode 100644
index 0000000..68b4794
Binary files /dev/null and b/zh_0_3/image/linkedsee_3.png differ
diff --git a/zh_0_3/image/linkedsee_4.png b/zh_0_3/image/linkedsee_4.png
new file mode 100644
index 0000000..287d9f8
Binary files /dev/null and b/zh_0_3/image/linkedsee_4.png differ
diff --git a/zh_0_3/image/linkedsee_5.png b/zh_0_3/image/linkedsee_5.png
new file mode 100644
index 0000000..a5d13a5
Binary files /dev/null and b/zh_0_3/image/linkedsee_5.png differ
diff --git a/zh_0_3/image/practice_graph-scaling_io01.png b/zh_0_3/image/practice_graph-scaling_io01.png
new file mode 100644
index 0000000..69998a8
Binary files /dev/null and b/zh_0_3/image/practice_graph-scaling_io01.png differ
diff --git a/zh_0_3/image/practice_graph-scaling_io02.png b/zh_0_3/image/practice_graph-scaling_io02.png
new file mode 100644
index 0000000..3bc2fcf
Binary files /dev/null and b/zh_0_3/image/practice_graph-scaling_io02.png differ
diff --git a/zh_0_3/image/practice_graph-scaling_io03.png b/zh_0_3/image/practice_graph-scaling_io03.png
new file mode 100644
index 0000000..c8bafed
Binary files /dev/null and b/zh_0_3/image/practice_graph-scaling_io03.png differ
diff --git a/zh_0_3/image/practice_graph-scaling_quantity.png b/zh_0_3/image/practice_graph-scaling_quantity.png
new file mode 100644
index 0000000..689a1a8
Binary files /dev/null and b/zh_0_3/image/practice_graph-scaling_quantity.png differ
diff --git a/zh_0_3/image/practice_graph-scaling_rrd.png b/zh_0_3/image/practice_graph-scaling_rrd.png
new file mode 100644
index 0000000..2502420
Binary files /dev/null and b/zh_0_3/image/practice_graph-scaling_rrd.png differ
diff --git a/zh_0_3/image/practice_graph-scaling_stats.png b/zh_0_3/image/practice_graph-scaling_stats.png
new file mode 100644
index 0000000..3ef17ce
Binary files /dev/null and b/zh_0_3/image/practice_graph-scaling_stats.png differ
diff --git a/zh_0_3/intro/README.md b/zh_0_3/intro/README.md
new file mode 100644
index 0000000..26e8416
--- /dev/null
+++ b/zh_0_3/intro/README.md
@@ -0,0 +1,185 @@
+
+
+# Introduction
+
+监控系统是整个运维环节,乃至整个产品生命周期中最重要的一环,事前及时预警发现故障,事后提供翔实的数据用于追查定位问题。监控系统作为一个成熟的运维产品,业界有很多开源的实现可供选择。当公司刚刚起步,业务规模较小,运维团队也刚刚建立的初期,选择一款开源的监控系统,是一个省时省力,效率最高的方案。之后,随着业务规模的持续快速增长,监控的对象也越来越多,越来越复杂,监控系统的使用对象也从最初少数的几个SRE,扩大为更多的DEVS,SRE。这时候,监控系统的容量和用户的“使用效率”成了最为突出的问题。
+
+监控系统业界有很多杰出的开源监控系统。我们在早期,一直在用zabbix,不过随着业务的快速发展,以及互联网公司特有的一些需求,现有的开源的监控系统在性能、扩展性、和用户的使用效率方面,已经无法支撑了。
+
+因此,我们在过去的一年里,从互联网公司的一些需求出发,从各位SRE、SA、DEVS的使用经验和反馈出发,结合业界的一些大的互联网公司做监控,用监控的一些思考出发,设计开发了小米的监控系统:open-falcon。
+
+**open-falcon的目标是做最开放、最好用的互联网企业级监控产品。**
+
+# Highlights and features
+
+- 强大灵活的数据采集:自动发现,支持falcon-agent、snmp、支持用户主动push、用户自定义插件支持、opentsdb data model like(timestamp、endpoint、metric、key-value tags)
+- 水平扩展能力:支持每个周期上亿次的数据采集、告警判定、历史数据存储和查询
+- 高效率的告警策略管理:高效的portal、支持策略模板、模板继承和覆盖、多种告警方式、支持callback调用
+- 人性化的告警设置:最大告警次数、告警级别、告警恢复通知、告警暂停、不同时段不同阈值、支持维护周期
+- 高效率的graph组件:单机支撑200万metric的上报、归档、存储(周期为1分钟)
+- 高效的历史数据query组件:采用rrdtool的数据归档策略,秒级返回上百个metric一年的历史数据
+- dashboard:多维度的数据展示,用户自定义Screen
+- 高可用:整个系统无核心单点,易运维,易部署,可水平扩展
+- 开发语言: 整个系统的后端,全部golang编写,portal和dashboard使用python编写。
+
+# Architecture
+
+
+
+每台服务器,都有安装falcon-agent,falcon-agent是一个golang开发的daemon程序,用于自发现的采集单机的各种数据和指标,这些指标包括不限于以下几个方面,共计200多项指标。
+
+ - CPU相关
+ - 磁盘相关
+ - IO
+ - Load
+ - 内存相关
+ - 网络相关
+ - 端口存活、进程存活
+ - ntp offset(插件)
+ - 某个进程资源消耗(插件)
+ - netstat、ss 等相关统计项采集
+ - 机器内核配置参数
+
+只要安装了falcon-agent的机器,就会自动开始采集各项指标,主动上报,不需要用户在server做任何配置(这和zabbix有很大的不同),这样做的好处,就是用户维护方便,覆盖率高。当然这样做也会server端造成较大的压力,不过open-falcon的服务端组件单机性能足够高,同时都可以水平扩展,所以自动多采集足够多的数据,反而是一件好事情,对于SRE和DEV来讲,事后追查问题,不再是难题。
+
+另外,falcon-agent提供了一个proxy-gateway,用户可以方便的通过http接口,push数据到本机的gateway,gateway会帮忙高效率的转发到server端。
+
+falcon-agent,可以在我们的github上找到 : https://github.com/open-falcon/falcon-plus
+
+# Data model
+
+Data Model是否强大,是否灵活,对于监控系统用户的“使用效率”至关重要。比如以zabbix为例,上报的数据为hostname(或者ip)、metric,那么用户添加告警策略、管理告警策略的时候,就只能以这两个维度进行。举一个最常见的场景:
+
+hostA的磁盘空间,小于5%,就告警。一般的服务器上,都会有两个主要的分区,根分区和home分区,在zabbix里面,就得加两条规则;如果是hadoop的机器,一般还会有十几块的数据盘,还得再加10多条规则,这样就会痛苦,不幸福,不利于自动化(当然zabbix可以通过配置一些自动发现策略来搞定这个,不过比较麻烦)。
+
+open-falcon,采用和opentsdb相同的数据格式:metric、endpoint加多组key value tags,举两个例子:
+
+```
+{
+ metric: load.1min,
+ endpoint: open-falcon-host,
+ tags: srv=falcon,idc=aws-sgp,group=az1,
+ value: 1.5,
+ timestamp: `date +%s`,
+ counterType: GAUGE,
+ step: 60
+}
+{
+ metric: net.port.listen,
+ endpoint: open-falcon-host,
+ tags: port=3306,
+ value: 1,
+ timestamp: `date +%s`,
+ counterType: GAUGE,
+ step: 60
+}
+```
+通过这样的数据结构,我们就可以从多个维度来配置告警,配置dashboard等等。
+备注:endpoint是一个特殊的tag。
+
+# Data collection
+
+transfer,接收客户端发送的数据,做一些数据规整,检查之后,转发到多个后端系统去处理。在转发到每个后端业务系统的时候,transfer会根据一致性hash算法,进行数据分片,来达到后端业务系统的水平扩展。
+
+transfer 提供jsonRpc接口和telnet接口两种方式,transfer自身是无状态的,挂掉一台或者多台不会有任何影响,同时transfer性能很高,每分钟可以转发超过500万条数据。
+
+transfer目前支持的业务后端,有三种,judge、graph、opentsdb。judge是我们开发的高性能告警判定组件,graph是我们开发的高性能数据存储、归档、查询组件,opentsdb是开源的时间序列数据存储服务。可以通过transfer的配置文件来开启。
+
+transfer的数据来源,一般有三种:
+1. falcon-agent采集的基础监控数据
+2. falcon-agent执行用户自定义的插件返回的数据
+3. client library:线上的业务系统,都嵌入使用了统一的perfcounter.jar,对于业务系统中每个RPC接口的qps、latency都会主动采集并上报
+
+说明:上面这三种数据,都会先发送给本机的proxy-gateway,再由gateway转发给transfer。
+
+>基础监控是指只要是个机器(或容器)就能加的监控,比如cpu mem net io disk等,这些监控采集的方式固定,不需要配置,也不需要用户提供额外参数指定,只要agent跑起来就可以直接采集上报上去;
+非基础监控则相反,比如端口监控,你不给我端口号就不行,不然我上报所有65535个端口的监听状态你也用不了,这类监控需要用户配置后才会开始采集上报的监控(包括类似于端口监控的配置触发类监控,以及类似于mysql的插件脚本类监控),一般就不算基础监控的范畴了。
+
+# Alerting
+
+报警判定,是由judge组件来完成。用户在web portal来配置相关的报警策略,存储在MySQL中。heartbeat server 会定期加载MySQL中的内容。judge也会定期和heartbeat server保持沟通,来获取相关的报警策略。
+
+heartbeat sever不仅仅是单纯的加载MySQL中的内容,根据模板继承、模板项覆盖、报警动作覆盖、模板和hostGroup绑定,计算出最终关联到每个endpoint的告警策略,提供给judge组件来使用。
+
+transfer转发到judge的每条数据,都会触发相关策略的判定,来决定是否满足报警条件,如果满足条件,则会发送给alarm,alarm再以邮件、短信、米聊等形式通知相关用户,也可以执行用户预先配置好的callback地址。
+
+用户可以很灵活的来配置告警判定策略,比如连续n次都满足条件、连续n次的最大值满足条件、不同的时间段不同的阈值、如果处于维护周期内则忽略 等等。
+
+另外也支持突升突降类的判定和告警。
+
+# API
+
+到这里,数据已经成功的存储在了graph里。如何快速的读出来呢,读过去1小时的,过去1天的,过去一月的,过去一年的,都需要在1秒之内返回。
+
+这些都是靠graph和API组件来实现的,transfer会将数据往graph组件转发一份,graph收到数据以后,会以rrdtool的数据归档方式来存储,同时提供查询RPC接口。
+
+API面向终端用户,收到查询请求后,会去多个graph里面,查询不同metric的数据,汇总后统一返回给用户。
+
+# Dashboard
+
+
+dashboard首页,用户可以以多个维度来搜索endpoint列表,即可以根据上报的tags来搜索关联的endpoint。
+
+
+用户可以自定义多个metric,添加到某个screen中,这样每天早上只需要打开screen看一眼,服务的运行情况便尽在掌握了。
+
+
+当然,也可以查看清晰大图,横坐标上zoom in/out,快速筛选反选。总之用户的“使用效率”是第一要务。
+
+
+一个高效的portal,对于提升用户的“使用效率”,加成很大,平时大家都这么忙,能给各位SRE、Devs减轻一些负担,那是再好不过了。
+
+这是host group的管理页面,可以和服务树结合,机器进出服务树节点,相关的模板会自动关联或者解除。这样服务上下线,都不需要手动来变更监控,大大提高效率,降低遗漏和误报警。
+
+
+一个最简单的模板的例子,模板支持继承和策略覆盖,模板和host group绑定后,host group下的机器会自动应用该模板的所有策略。
+
+
+当然,也可以写一个简单的表达式,就能达到监控的目的,这对于那些endpoint不是机器名的场景非常方便。
+
+
+添加一个表达式也是很简单的。
+
+
+# Storage
+
+对于监控系统来讲,历史数据的存储和高效率查询,永远是个很难的问题!
+1. 数据量大:目前我们的监控系统,每个周期,大概有2000万次数据上报(上报周期为1分钟和5分钟两种,各占50%),一天24小时里,从来不会有业务低峰,不管是白天和黑夜,每个周期,总会有那么多的数据要更新。
+2. 写操作多:一般的业务系统,通常都是读多写少,可以方便的使用各种缓存技术,再者各类数据库,对于查询操作的处理效率远远高于写操作。而监控系统恰恰相反,写操作远远高于读。每个周期几千万次的更新操作,对于常用数据库(MySQL、postgresql、mongodb)都是无法完成的。
+3. 高效率的查:我们说监控系统读操作少,是说相对写入来讲。监控系统本身对于读的要求很高,用户经常会有查询上百个meitric,在过去一天、一周、一月、一年的数据。如何在1秒内返回给用户并绘图,这是一个不小的挑战。
+
+open-falcon在这块,投入了较大的精力。我们把数据按照用途分成两类,一类是用来绘图的,一类是用户做数据挖掘的。
+
+对于绘图的数据来讲,查询要快是关键,同时不能丢失信息量。对于用户要查询100个metric,在过去一年里的数据时,数据量本身就在那里了,很难1秒之类能返回,另外就算返回了,前端也无法渲染这么多的数据,还得采样,造成很多无谓的消耗和浪费。我们参考rrdtool的理念,在数据每次存入的时候,会自动进行采样、归档。我们的归档策略如下,历史数据保存5年。同时为了不丢失信息量,数据归档的时候,会按照平均值采样、最大值采样、最小值采样存三份。
+
+```
+// 1分钟一个点存 12小时
+c.RRA("AVERAGE", 0.5, 1, 720)
+
+// 5m一个点存2d
+c.RRA("AVERAGE", 0.5, 5, 576)
+c.RRA("MAX", 0.5, 5, 576)
+c.RRA("MIN", 0.5, 5, 576)
+
+// 20m一个点存7d
+c.RRA("AVERAGE", 0.5, 20, 504)
+c.RRA("MAX", 0.5, 20, 504)
+c.RRA("MIN", 0.5, 20, 504)
+
+// 3小时一个点存3个月
+c.RRA("AVERAGE", 0.5, 180, 766)
+c.RRA("MAX", 0.5, 180, 766)
+c.RRA("MIN", 0.5, 180, 766)
+
+// 1天一个点存1year
+c.RRA("AVERAGE", 0.5, 720, 730)
+c.RRA("MAX", 0.5, 720, 730)
+c.RRA("MIN", 0.5, 720, 730)
+```
+
+对于原始数据,transfer会打一份到hbase,也可以直接使用opentsdb,transfer支持往opentsdb写入数据。
+
+# Contributors
+
+- [authors](../authors.html)
+- [contributing](../contributing.html)
diff --git a/zh_0_3/philosophy/README.md b/zh_0_3/philosophy/README.md
new file mode 100644
index 0000000..f2767e7
--- /dev/null
+++ b/zh_0_3/philosophy/README.md
@@ -0,0 +1,5 @@
+
+
+# 设计理念
+
+阐述open-falcon设计过程中的各种思考
diff --git a/zh_0_3/philosophy/data-collect.md b/zh_0_3/philosophy/data-collect.md
new file mode 100644
index 0000000..1ab922f
--- /dev/null
+++ b/zh_0_3/philosophy/data-collect.md
@@ -0,0 +1,35 @@
+
+
+作为监控系统来讲,首先得有监控数据,然后才能做后面的分析处理、绘图报警等事情,那falcon是如何处理数据采集这个问题的呢?
+
+我们先要考虑有哪些数据要采集,脑洞打开~
+
+- 机器负载信息,这个最常见,cpu.idle/load.1min/mem.memfree.percent/df.bytes.free.percent等等
+- 硬件信息,比如功耗、风扇转速、磁盘是否可写,系统组同学对这些比较关注
+- 服务监控数据,比如某个接口每分钟调用的次数,latency等等
+- 数据库、HBase、Redis、Openstack等开源软件的监控指标
+
+要采集的数据还挺多哩,监控系统的开发人员不是神,没法搞定所有数据,比如MySQL,DBA最懂,他知道应该采集哪些指标,监控只要提供一个数据push的接口即可,大家共建。想知道push给Server的数据长啥样?可以参考[Tag与HostGroup设计理念](tags-and-hostgroup.md)中提到的两条json数据
+
+上面四个方面比较有代表性,咱们挨个阐述。
+
+**机器负载信息**
+
+这部分比较通用,我们提供了一个agent部署在所有机器上去采集。不像zabbix,要采集什么数据需要在服务端配置,falcon无需配置,只要agent部署到机器上,配置好heartbeat和Transfer地址,就自动开始采集了,省去了用户配置的麻烦。目前agent只支持64位Linux,Mac、Windows均不支持。
+
+**硬件信息**
+
+硬件信息的采集脚本由系统组同学提供,作为plugin依托于agent运行,plugin机制介绍请看[这里](plugin.md)。
+
+**服务监控数据**
+
+服务的监控指标采集脚本,通常都是跟着服务的code走的,服务上线或者扩容,这个脚本也跟着上线或者扩容,服务下线,这个采集脚本也要相应下线。公司里Java的项目有不少,研发那边就提供了一个通用jar包,只要引入这个jar包,就可以自动采集接口的调用次数、延迟时间等数据。然后将采集到的数据push给监控,一分钟push一次。目前falcon的agent提供了一个简单的http接口,这个jar包采集到数据之后是post给本机agent。向agent推送数据的一个简单例子,如下:
+
+```bash
+curl -X POST -d '[{"metric": "qps", "endpoint": "open-falcon-graph01.bj", "timestamp": 1431347802, "step": 60,"value": 9,"counterType": "GAUGE","tags": "project=falcon,module=graph"}]' http://127.0.0.1:1988/v1/push
+```
+
+**各种开源软件的监控指标**
+
+这都是大用户,比如DBA自己写一些采集脚本,连到各个MySQL实例上去采集数据,完事直接调用server端的jsonrpc汇报数据,一分钟一次,每次甚至push几十万条数据,比较好的发送方式是500条数据做一个batch,别几十万数据一次性发送。
+
diff --git a/zh_0_3/philosophy/data-model.md b/zh_0_3/philosophy/data-model.md
new file mode 100644
index 0000000..ef157e5
--- /dev/null
+++ b/zh_0_3/philosophy/data-model.md
@@ -0,0 +1,28 @@
+
+
+# Data model
+
+Open-Falcon,采用和OpenTSDB相似的数据格式:metric、endpoint加多组key value tags,举两个例子:
+
+```bash
+{
+ metric: load.1min,
+ endpoint: open-falcon-host,
+ tags: srv=falcon,idc=aws-sgp,group=az1,
+ value: 1.5,
+ timestamp: `date +%s`,
+ counterType: GAUGE,
+ step: 60
+}
+{
+ metric: net.port.listen,
+ endpoint: open-falcon-host,
+ tags: port=3306,
+ value: 1,
+ timestamp: `date +%s`,
+ counterType: GAUGE,
+ step: 60
+}
+```
+
+其中,metric是监控指标名称,endpoint是监控实体,tags是监控数据的属性标签,counterType是Open-Falcon定义的数据类型(取值为GAUGE、COUNTER),step为监控数据的上报周期,value和timestamp是有效的监控数据。
diff --git a/zh_0_3/philosophy/plugin.md b/zh_0_3/philosophy/plugin.md
new file mode 100644
index 0000000..7eb64ea
--- /dev/null
+++ b/zh_0_3/philosophy/plugin.md
@@ -0,0 +1,47 @@
+
+
+对于Plugin机制,叙述之前必须要强调一下:
+
+> Plugin可以看做是对agent功能的扩充。对于业务系统的监控指标采集,最好不要做成plugin,而是把采集脚本放到业务程序发布包中,随着业务代码上线而上线,随着业务代码升级而升级,这样会比较容易管理。
+
+要使用Plugin,步骤如下:
+
+**1. 编写采集脚本**
+
+用什么语言写没关系,只要目标机器上有运行环境就行,脚本本身要有可执行权限。采集到数据之后直接打印到stdout即可,agent会截获并push给server。数据格式是json,举个例子:
+
+```bash
+[root@host01:/path/to/plugins/plugin/sys/ntp]#./600_ntp.py
+[{"endpoint": "host01", "tags": "", "timestamp": 1431349763, "metric": "sys.ntp.offset", "value": 0.73699999999999999, "counterType": "GAUGE", "step": 600}]
+```
+
+注意,这个json数据是个list哦
+
+**2. 上传脚本到git**
+
+插件脚本也是code,所以最好也用git、svn管理,这里我们使用git管理,公司内部如果没有搭建gitlab,可以使用gitcafe、coding.net之类的,将写好的脚本push到git仓库,比如上例中的600_ntp.py,姑且放到git仓库的sys/ntp目录下。注意,这个脚本在push到git仓库之前要加上可执行权限。
+
+**3. 检查agent配置**
+
+大家之前部署agent的时候应该注意到agent配置文件中有配置plugin吧,现在到了用的时候了,把git仓库地址配置上,enabled设置为true。注意,配置的git仓库地址需要是任何机器上都可以拉取的,即`git://`或者`https://`打头的。如果agent之前已经部署到公司所有机器上了,那现在手工改配置可能略麻烦,之前讲过的嘛,用[ops-updater](https://github.com/open-falcon/ops-updater)管理起来~
+
+**4. 拉取plugin脚本**
+
+agent开了一个http端口1988,我们可以挨个curl一下http://ip:1988/plugin/update 这个地址,这会让agent主动git pull这个插件仓库。为啥没做成定期拉取这个仓库呢?主要是怕给git服务器压力太大……大家悠着点用,别给人pull挂了……
+
+**5. 让plugin run起来**
+
+上一步我们拉取了plugin脚本到所有机器上,不过plugin并没有执行。哪些机器执行哪些plugin脚本,是在portal上面配置的。其实我很想做成,只要插件拉取下来了就立马执行,不过实际实践中,有些插件还是不能在所有机器上跑,所以就在portal上通过配置控制了。在portal上找到要执行插件的HostGroup,点击对应的plugins超链接,对于上例sys/ntp目录下的600_ntp.py,直接把sys/ntp绑定上去即可。sys/ntp下的所有插件就都执行了。
+
+**6. 补充**
+
+portal上配置完成之后并不会立马生效,有个同步的过程,最终是agent通过调用hbs的接口获取的,需要一两分钟。上例我们绑定了sys/ntp,这实际是个目录,这个目录下的所有插件都会被执行,那什么样的文件会被看做插件呢?文件名是数字下划线打头的,这个数字代表的是step,即多长时间跑一次,单位是秒,比如60_a.py,就是在通过命名告诉agent,这个插件每60秒跑一次。sys/ntp目录下的子目录、其他命名方式的文件都会被忽略。
+
+**7. 插件如何传递参数**
+
+Open-Falcon 在 [PR #672](https://github.com/open-falcon/falcon-plus/pull/672) 中,对插件传递传递自定义参数进行了支持。在dashboard 中,配置 HostGroup 绑定插件时,可以支持针对单个脚本配置参数。
+
+比如:`sys/ntp/30_xx.sh(a, "33 4", 'test.sh f\,d')`,表示对 hostgroup 绑定一个插件脚本`sys/ntp/30_xx.sh`, 并传递4个参数,多个参数之间用`,`分割,每个参数可以用双引号或者单引号括起来。如果参数中本身就包含逗号,可以使用 `\,` 来转义。
+
+* 参数,只在绑定单个插件脚本时有效。如果绑定的是一个插件目录,传递的参数会忽略掉。
+* 如果某个目录下的某个插件脚本,被单独绑定到某个hostgroup,同时该目录也被绑定到了这个hostgroup,这个插件脚本不会重复被执行,绑定目录时这个插件脚本会被忽略(也就是说,单个脚本的绑定会覆盖目录绑定方式下的同一个脚本)。
diff --git a/zh_0_3/philosophy/tags-and-hostgroup.md b/zh_0_3/philosophy/tags-and-hostgroup.md
new file mode 100644
index 0000000..96f4be6
--- /dev/null
+++ b/zh_0_3/philosophy/tags-and-hostgroup.md
@@ -0,0 +1,80 @@
+
+
+这个话题很难阐述,大家慢慢读:)
+
+咱们从数据push说起,监控系统有个agent部署在所有机器上采集负载信息,比如cpu、内存、磁盘、io、网络等等,但是对于业务监控数据,比如某个接口调用的cps、latency,是没法由agent采集的,需要业务方自行push,其他监控数据,比如MySQL相关监控指标,HBase相关监控指标,Redis相关监控指标,agent也是无能为力,需要业务方自行采集并push给监控。
+
+于是,监控Server端需要制定一个接口规范,大家调用这个接口即可完成数据push,拿agent汇报的cpu.idle数据举个例子:
+
+```
+{
+ "metric": "cpu.idle",
+ "endpoint": `hostname`,
+ "tags": "",
+ "value": 12.34,
+ "timestamp": `date +%s`,
+ "step": 60,
+ "counterType": "GAUGE"
+}
+```
+
+metric即监控指标的名称,比如disk.io.util、load.1min、df.bytes.free.percent;endpoint是这个监控指标所依附的实体,比如cpu.idle,是谁的cpu.idle?显然是所在机器的cpu.idle,所以对于agent采集的机器负载信息而言,endpoint就是机器名;tags待会再说;value就是这个监控指标的值喽;timestamp是时间戳,单位是秒;step是rrdtool中的概念,Falcon后端存储用的rrdtool,我们需要告诉rrdtool这个数据多长时间push上来一次,step就是干这个事的;counterType也是rrdtool中的概念,目前Falcon支持两种类型:GAUGE、COUNTER。
+
+tags没有给大家解释,这是重点,为了便于理解,我再举个例子,某个方法调用的latency:
+
+```
+{
+ "metric": "latency",
+ "endpoint": "11.11.11.11:8080",
+ "tags": "project=falcon,module=judge,method=QueryHistory",
+ "value": 12.34,
+ "timestamp": `date +%s`,
+ "step": 60,
+ "counterType": "GAUGE"
+}
+```
+
+tags可以对push上来的这条数据打一些tag,就像写篇blog,可以打上几个tag便于归类。上例中我们push了一条latency数据,打了三个tag,传达的意思是:这个latency是调用QueryHistory这个方法的延迟,模块是judge,项目是falcon。
+
+对于push上来的这种数据,我们配置监控就很方便了,比如:对于falcon-judge这个模块的所有方法调用的latency只要大于0.5就报警。我们可以配置一个expression(在portal中):
+
+```
+each(metric=latency project=falcon module=judge)
+```
+
+阈值触发条件是:all(#1)>0.5
+
+我们没有写method,所以对于所有method都生效,一条配置搞定!这就是tag的强大之处。
+
+--重头戏分割线--
+
+对于业务方自己push的数据,可以加各种tag来区分,传达更多信息。但是,对于agent采集的数据呢?cpu.idle、load.1min这种数据应该加什么tag呢?这种数据没有任何tag……那我们应该如何配置报警呢?总不至于一台机器一台机器配置吧……
+
+```
+each(metric=latency endpoint=host1)
+```
+
+公司才一万台机器,嗯,这酸爽……
+
+tag,实际是一种分组方式,如果数据push的时候无法声明自己的分类,那我们就要**在上层手工对数据做分组**了。这,也就是HostGroup的设计出发点。
+
+比如我们把falcon这个项目用到的所有机器放到一个HostGroup(名称姑且叫sa.dev.falcon,名称中包含部门、团队信息,这么命名不错吧)中,然后为sa.dev.falcon绑定一个策略模板,下面的所有机器就都生效了,扩容的时候增加的机器塞到sa.dev.falcon,也就自动生效了监控,机器下线直接从该组删掉即可。
+
+总结,HostGroup实际是对endpoint的一种分组。
+
+想象一下一条数据push上来了,我们应该怎么判断这条数据是否应该报警呢?那我们要做的就是找到这条数据关联的Expression和Strategy,Expression比较好说,无非就是看配置的expression中的tag是否是当前push上来的数据的子集;Strategy呢?push上来的数据有endpoint,我们可以看这个endpoint是否属于某几个HostGroup,HostGroup又是跟Template绑定的,Template下就是一堆Strategy,顺藤摸瓜:)
+
+--忧伤的分割线--
+
+但是,HostGroup是一个扁平结构,使用起来可能不是那么方便,举个例子。
+
+- 我们可以把公司所有机器放到一个分组,配置硬件监控,比如磁盘坏,收到报警之后直接发送到系统组
+- A同学和B同学共同管理了3个项目(包括falcon项目),可以把这三个项目的机器放到一个分组,配置机器负载监控,模板名称姑且叫sa.dev.common,配置一下cpu.idle、df.bytes.free.percent之类的,报警发给A、B两个同学
+- falcon这个项目的磁盘io压力比较高,比其他两个项目io压力高,这是正常情况,比如平时我们配置disk.io.util大于40就报警,但是falcon的机器io压力大于80才需要报警,于是,我们需要创建一个新模板继承自sa.dev.common,然后绑定到falcon上,以此覆盖父模板的配置,提供不同的报警阈值
+- falcon中有个judge组件,监听在6080端口,我们需要把judge的所有机器放到一个HostGroup,为其配置端口监控
+
+OK,问题来了,如果judge扩容5台机器,这5台机器就要分别加到上面四个分组里!
+
+略麻烦哈~所以我们内部使用falcon实际是配合机器管理系统的,机器管理对机器的管理组织方式是一棵树,机器加到叶子节点,上层节点也就同样拥有了这个机器。
+
+所以,大家在用falcon的时候,规模如果比较小,就用扁平化的HostGroup即可。如果规模比较大,可能就需要做个二次开发,与内部机器管理系统结合了。如果你们内部没有机器管理,我们过段时间可能会提供一个树状机器管理系统,敬请期待。
diff --git a/zh_0_3/practice/README.md b/zh_0_3/practice/README.md
new file mode 100644
index 0000000..5b1ab3b
--- /dev/null
+++ b/zh_0_3/practice/README.md
@@ -0,0 +1,3 @@
+
+
+Open-Falcon实践经验整理
diff --git a/zh_0_3/practice/deploy.md b/zh_0_3/practice/deploy.md
new file mode 100644
index 0000000..701dffa
--- /dev/null
+++ b/zh_0_3/practice/deploy.md
@@ -0,0 +1,305 @@
+
+
+# 部署实践
+本文介绍了小米公司部署Open-Falcon的一些实践经验,同时试图以量化的方式分析Open-Falcon各组件的特性。
+
+## 概述
+Open-Falcon组件,包括基础组件、作图链路、报警链路。小米公司部署Open-Falcon的架构,如下:
+
+
+其中,基础组件以绿色标注圈住、作图链路以蓝色圈住、报警链路以红色圈住,橙色填充的组件为域名。每个模块(子服务)都有自己的特性,根据其特性来制定部署策略。接下来,我们首先以白话的方式、**定性**描述Open-Falcon的部署演进,然后试图量化地分析每个组件的特点并给出一些部署建议。
+
+## 部署演进
+Open-Falon的部署情况,会随着机器量(监控对象)的增加而逐渐演进,描述如下,
+
+**初始阶段,机器量很小(<100量级)**。几乎无高可用的考虑,所有子服务可以混合部署在**1台**服务器上。此时,1台中高配的服务器就能满足性能要求。
+
+**机器量增加,到500量级**。graph可能是第一个扛不住的,拿出来单独部署;接着judge也扛不住了,拿出来单独部署;transfer居然扛不住了,拿出来吧。这是系统的三个大件,把它们拆出来后devops可以安心一段时间了。
+
+**机器数量再增加,到1K量级**。graph、judge、transfer单实例扛不住了,于是开始考虑增加到2+个实例、并考虑混合部署。开始有明确的高可用要求?除了alarm,都能搞成2+个实例的高可用结构。再往后,机器继续不停的增加,性能问题频现。好吧,见招拆招,Open-Falcon支持水平扩展、表示毫无压力。
+
+**机器量达到了10K量级**,这正是我们现在的情况。系统已经有3000+万个采集项。transfer部署了20个实例,graph部署了20个实例,judge扩到了60个实例(三大件混合部署在20台高配服务器上,judge单机多实例)。query有5个实例、平时很闲;hbs也有5个实例、很闲的样子;dashborad、portal、uic都有2个实例;alarm、sender、links仍然是bug般的单实例部署(这几个子服务部署在10左右台低配服务器上,资源消耗很小)。graph的db已经和portal、uic的db实例分开了,因为graph的索引已经达到了5000万量级、混用会危及到其他子系统。redis仍然是共享、单实例。这是我们的使用方式,有不合理的地方、正在持续改进。
+
+**机器上100K量级了**。不好意思、木有经历过。目测graph索引、hbs将成为系统较为头疼的地方,Open-Falcon的系统运维可能需要1个劳动力来完成。
+
+
+## 基础组件
+### agent
+agent应该随装机过程部署到每个机器实例上。agent从hbs拉取配置信息,进行数据采集、收集,将数据上报给transfer。agent资源消耗很少、运行稳定可靠。小米公司部署了10K+个agent实例,已稳定运行了1Y+。
+
+### transfer
+transfer是一个无状态的集群。transfer接收agent上报的数据,然后使用一致性哈希进行数据分片、并把分片后的数据转发给graph、judge集群(transfer还会打一份数据到opentsdb)。
+
+transfer集群会有缩扩容的情况,也会有服务器迁移的情况,导致集群实例不固定。如某个transfer实例故障后,要将其从transfer集群中踢出。为了屏蔽这种变化对agent的影响,建议在transfer集群前挂一个域名,agent通过域名方式访问transfer集群、实现自动切换。多IDC时,为了减少跨机房流量,建议每个IDC都部署一定数量的transfer实例、agent将数据push到本IDC的transfer(可以配置dns规则,优先将transfer域名解析为本地IDC内的transfer实例)。
+
+transfer消耗的资源 主要是网络和CPU。使用机型/操作系统选择为Dell-R620/Centos6.3,对transfer进行性能测试。Dell-R620配置为24核心、1000Gb双工网卡。测试的结果为:
+
+
+
+ | 进入数据吞吐率 |
+ 流出数据吞吐率 |
+ 进入流量 |
+ 流出流量 |
+ CPU消耗(均值) |
+
+
+ | 50K条/s |
+ 100K条/s |
+ 180Mb/s |
+ 370Mb/s |
+ 300% |
+
+
+ | 100K条/s |
+ 200K条/s |
+ 360Mb/s |
+ 740Mb/s |
+ 620% |
+
+
+
+性能测试是在理想条件下进行的,且远远未达到服务器的资源极限。当出现流量峰值、数据接收端处理缓慢时,transfer的内存会积压一些待发送的数据、使MEM消耗出现增加(可以调整发送缓存上限,来限制最大内存消耗)。考虑到流量不均、流量峰值、集群高可用等问题,评估transfer集群容量时要做至少1倍的冗余。这里给一个建议,10K/s的进入数据吞吐率、20K/s的流出数据吞吐率,网卡配置不小于100Mb、CPU不小于100%。
+
+
+### opentsdb
+该功能已经完成。欢迎进群一起交流tsdb相关的使用经验。
+
+### center-status
+center-status是中心存储的统称。Open-Falcon用到的中心存储,包括Mysql、Redis(Memcached要被弃用)。Mysql主要用于存储配置信息(如HostGroup、报警策略、UIC信息、Screen信息等)、索引数据等,Redis主要被用作报警缓存队列。索引生成、查询比较频繁和耗资源,当监控数据上报量超过100K条/min时 建议为其单独部署Mysql实例、并配置SSD硬盘。一个有意义的数据是: graph索引库,开启bin日志,保存4000万个counter且连续运行60天,消耗了20GB的磁盘空间。
+
+当前,我们的Mysql和Redis都是单实例部署的、存在高可用的问题。Mysql还没有做读写分离、分库分表等。
+
+
+## 作图链路
+### graph
+graph组件用于存储、归档作图数据,可以集群部署。每个graph实例会处理一个分片的数据: 接收transfer发送来的分片数据,归档、存储、生成索引;接受query对该数据分片的查询请求。
+
+graph会持久存储监控数据,频繁写入磁盘,状态数据会缓存在内存,因此graph消耗的主要资源是磁盘存储、磁盘IO和内存资源。用"机型/系统/磁盘"为"Dell-R620/Centos6.3/SSD 2TB"的环境 对graph进行性能测试,结果为:
+
+
+
+ | 采集项数目 |
+ 存储时长 |
+ DISK |
+ 进入数据
吞吐率 |
+ DISK.WIRTE
REQUEST |
+ DISK.IO
UTIL |
+ MEM |
+
+
+ | 900K |
+ 5Y |
+ 91GB |
+ 4.42K/s |
+ 1.6K/s |
+ 3.0% |
+ 5.2GB |
+
+
+ | 1800K |
+ 5Y |
+ 183GB |
+ 8.78K/s |
+ 3.2K/s |
+ 7.9% |
+ 10.0GB |
+
+
+
+上述测试远远没有达到服务器的资源极限。根据测试结果,建议部署graph的服务器,配置大容量SSD硬盘、大容量内存。一个参考值是: 存储10K个采集项、数据吞吐率100条/s时,配置SSD磁盘不小于1GB、MEM 不小于100M;一个采集项存5年,消耗100KB的磁盘空间。
+
+### query
+数据分片存储在graph上,用户查询起来比较麻烦。query负责提供一个统一的查询入口、屏蔽数据分片的细节。query的使用场景主要有:(1)dashboard图表展示 (2)使用监控数据做二次开发。
+
+为了方便用户访问,建议将query集群挂载到一个域名下。考虑到高可用,query至少部署两个实例(当前,两个实例部署的IDC、机架等需要负责高可用的规范)。具体的性能统计,**待续**。小米公司的部署实践为: 公司开发和运维人员均使用Open-Falcon的情况下,部署5个query实例(这个其实非常冗余,2个实例足够)。
+
+
+### dashboard
+dashboard用户监控数据的图表展示,是一个web应用。对于监控系统来说,读数据 或者 看图的需求相对较少,需要的query较少、需要的dashboard更少。建议以web应用的方式 部署2+个实例。小米公司的部署实践为: 公司开发和运维人员均使用dashboard的情况下,部署2个dashboard实例。
+
+
+## 报警链路
+### judge
+judge用于实现报警策略的触发逻辑。judge可以集群部署,每个实例上处理固定分片的采集项数据(transfer给哪些,就处理哪些)。judge实现触发计算时,会在本地缓存 触发逻辑的中间状态和定量的监控历史数据,因此会消耗较多的内存资源和计算资源。下面给出一组统计数据,
+
+
+
+ | 采集项数目 |
+ 报警策略数 |
+ MEM消耗 |
+ CPU消耗(均值) |
+
+
+ | 550K |
+ xxx |
+ 10GB |
+ 100% |
+
+
+ | 1100K |
+ xxx |
+ 20GB |
+ 200% |
+
+
+
+上述统计值来自线上judge的运行数据。根据上述统计,MEM消耗、CPU消耗(均值) 随着 处理的采集项数目 基本呈线性增长。关于MEM消耗的一个参考值是,**10K个采集项占用200MB的内存资源、50%个CPU资源**。建议部署judge时,单实例处理的采集项数目不大于1000K。
+
+### hbs
+hbs是Open-Falcon的配置中心,负责 适配系统的配置信息、管理agent信息等。hbs单实例部署,每个实例都有完整的配置信息。可以考虑,部署2+个实例、挂在hbs域名下,实现高可用的同时又方便用户使用。
+
+hbs消耗的资源较少,这里给出小米公司部署hbs的参考值: 10K个agent实例、3000万个采集项、150K/s的监控数据吞吐率时,部署5个hbs实例,每个hbs实例的资源消耗为{MEM:1.0GB, CPU:<100%, NET、DISK消耗忽略不计}; 这5个hbs需要处理的配置数据,量级如下
+
+
+
+ | host数量 |
+ hostGroup数量 |
+ hostGroup策略数量 |
+ express策略数量 |
+
+
+ | 10K |
+ 1.2K |
+ 1.1K |
+ 300 |
+
+
+
+
+### portal
+portal提供监控策略管理相关的UI,使用频率较低、系统负载很小。建议以web应用的方式 部署2+个实例。小米公司的部署实践为: 公司开发和运维人员均使用portal的情况下,部署2个portal实例。
+
+
+### uic
+uic是用户信息管理中心,提供用户管理的UI,使用频率较低、系统负载较小。建议以web应用的方式 部署2+个实例。小米公司的部署实践为: 360个用户、120个用户分组,部署2个uic实例。
+
+
+### alarm(sender)
+alarm负责整理报警信息,使变成适合发送的形式。alarm做了一些报警合并相关的工作,当前只能单实例部署(待优化);报警信息的数量很少,alarm服务的压力非常小、单实例完全满足资源要求;考虑到高可用,当前只能做一个冷备。sender负责将报警内容发送给最终用户。sender本身无状态,可以部署多个实例。考虑到报警信息很少,2个sender实例 能满足性能及高可用的要求。
+
+
+### links
+links负责报警合并后的详情展示工作。links支持多实例部署、分片处理报警合并相关的工作。该服务压力很小,资源消耗很少;可以部署2个实例。
+
+## 混合部署
+混合部署可以提高资源使用率。这里先总结下Open-Falcon各子服务的资源消耗特点,
+
+
+
+ | 子服务 |
+ MEM消耗 |
+ CPU消耗 |
+ DISK消耗 |
+ NET消耗 |
+ 关键资源 |
+
+
+ | agent |
+ 低 |
+ 低 |
+ 低 |
+ 低 |
+ |
+
+
+ | transfer |
+ 低 |
+ 低 |
+ 可忽略 |
+ 高 |
+ NET |
+
+
+ | graph |
+ 中 |
+ 中 |
+ 高 |
+ 中 |
+ DISK |
+
+
+ | query |
+ 低 |
+ 低 |
+ 可忽略 |
+ 中 |
+ |
+
+
+ | dashboard |
+ 低 |
+ 低 |
+ 可忽略 |
+ 低 |
+ |
+
+
+ | judge |
+ 高 |
+ 中 |
+ 可忽略 |
+ 低 |
+ MEM |
+
+
+ | hbs |
+ 中 |
+ 中 |
+ 可忽略 |
+ 低 |
+ |
+
+
+ | portal |
+ 低 |
+ 低 |
+ 可忽略 |
+ 低 |
+ |
+
+
+ | uic |
+ 低 |
+ 低 |
+ 可忽略 |
+ 低 |
+ |
+
+
+ | alarm |
+ 低 |
+ 低 |
+ 可忽略 |
+ 低 |
+ |
+
+
+ | sender |
+ 低 |
+ 低 |
+ 可忽略 |
+ 低 |
+ |
+
+
+ | links |
+ 低 |
+ 低 |
+ 可忽略 |
+ 低 |
+ |
+
+
+
+根据资源消耗特点、高可用要求等,可以尝试做一些混合部署。比如,
+
++ transfer&graph&judge是Open-Falcon的三大件,承受的压力最大、资源消耗最大、但彼此间又不冲突,可以考虑在高配服务器上混合部署这三个子服务
++ alarm&sender&links资源消耗较少、但稳定性要求高,可以选择低配稳定机型、单独部署
++ hbs资源消耗稳定、不易受外部影响,可以选择低配主机、单独部署
++ dashboard、portal、uic等是web应用,资源消耗都比较小、但易受用户行为影响,可以选择低配主机、混合部署、并留足余量
++ query受用户行为影响较大、资源消耗波动较大,建议选择低配主机、单独部署、留足余量
+
+
+## 踩过的坑
++ 为了提高服务器的资源利用率,单机部署了同一子服务的多个实例。这种情况会加大系统运维的难度、可能占用较多的人力资源。可以考虑使用低配服务器,来解决单机资源使用率低的问题。
+
diff --git a/zh_0_3/practice/graph-scaling.md b/zh_0_3/practice/graph-scaling.md
new file mode 100644
index 0000000..3c2c0a6
--- /dev/null
+++ b/zh_0_3/practice/graph-scaling.md
@@ -0,0 +1,149 @@
+
+
+### 前言
+
+监控系统是整个运维环节,乃至整个产品生命周期中最重要的一环。而Open-Falcon是目前业界做的最开放、最好用的互联网企业级监控产品。
+
+Open-Falcon的底层存储,使用RRDTool时间序列数据库。在Transfer & Query模块,使用一致性哈希来对数据做均匀的分片。完美的满足了海量数据的存储以及高效、快速的查询。
+
+然而当存储、IO、或者某一方面资源到达瓶颈的时候,我们的存储组件就需要通过扩容来继续满足使用的压力及需求。
+本篇文章就将我们扩容的经验及过程分享给大家。
+
+
+### 本文面向对象
+
+ 1、Open-Falcon老鸟,但是没有经历过存储扩容,准备扩容的人。
+ 2、眼一闭、一睁,啥也没管,就扩容完成了,心里仍然有一点懵逼的人。
+
+### 方案原理
+
+本篇文章不讨论代码细节,这里对应扩容步骤简单给大家讲下原理。
+从修改Transfer开始,流量会按**新的哈希规则**进入到原始集群和扩容集群;此时扩容集群发现,**migrate开关**是打开状态;于是,扩容集群接收到流量之后,并没有很着急的去落盘,而是先按照**旧的哈希规则**从原始集群拉取历史数据(本质上就是一个rrd文件),拉取成功则将整个rrd文件写入本地,若拉取超时(默认1s),则将此次接收到的数据发送给旧的集群,下一个周期会再次重复此过程。
+
+同样的,Query的查询,也是按照**新的哈希规则**。当查询的流量到达扩容集群,如果Graph发现,本地已有RRD文件,则直接查询返回;如果本地无RRD文件,则Graph会通过**旧的哈希规则**,去原始集群中拉取到旧数据;然后跟自己cache中的数据做一个聚合,再返回给查询者。
+
+整个过程从技术上来说,可以说是:无损的、可以热迁移。
+
+### 方案缺陷
+
+整个方案,经过我们测试,比较稳定。但仍有如下缺点:
+
+ 1、无回滚方案。开弓没有回头箭。一旦扩容失败,会导致扩容期间部分数据丢失。
+ 2、自监控不够完善。官方提供给我们的统计数据,只有迁移的成功、失败的数量等较少几个指标,在扩容过程中,很可能会导致操作者不能完全掌控扩容的详细情况。
+
+### 扩容前,我们做了哪些准备
+
+在扩容之前,由于此方案容错率较低,可以提前做一些准备,保证第一时间可以发现问题的所在:
+
+#### 补全自监控
+
+ 【写】Transfer接收点数(实际扩容并不会影响这个数值,主要用于比较)
+ 【写】Transfer转发点数
+ 【写】Graph接收点数
+ 【写】扩容集群Trans数据到老集群点数
+ 【读】Query到Graph查询总次数
+ 【读】Graph转发查询的次数、耗时、错误率
+ 【迁移】迁移的成功个数/成功率,失败个数/失败率,迁移延迟
+
+#### 功能测试
+
+很多公司都对开源版本的Graph进行了一些修改和定制。很可能会对这个过程有影响。
+之前笔者公司,对内存进行过优化,存储在内存中的数据格式有所变化。但是migrate时,哈希规则的计算正好依赖此数据。Graph扩容时计算出来的的哈希值,与Transfer不一致,最终导致丢掉了一部分数据。
+
+因此,在真正的扩容前,针对自己的公司Graph版本,进行一个准确性测试,是很有必要的。
+
+#### 压力测试
+
+不同的公司,监控系统会有不同的量级和瓶颈。
+一般来讲,监控系统都是写入量大,查询量少。但是笔者所在的公司,由于重构了Judge,改原有的Transfer推送方式为Judge自行拉取。导致查询的量非常大,基本可以达到读写比 1:1的量级。
+因此,在真正的扩容之前,进行一个与自己线上环境相符的压力测试,也是很有必要的。
+
+跟大家分享下我们的压测结果:
+
+ 测试环境:CentOS 7.2
+ 内存:8 * 16G
+ 硬盘:3.2TB Nvme SSD
+ 扩容台数:2台 => 4台
+ 压测过程中:单机持续写入130万点/秒,持续查询100W点/秒
+
+
+
+压测结论,各项指标正常,各项资源使用并没有明显增加。
+concurrency的提高,并没有对扩容效率带来明显的提升。也从侧面说明,此方案,在读写比1:1的情况下,可以完美热扩容。
+
+
+### 扩容过程
+
+#### 分批扩容
+
+ 30台 => 31台 (灰度1台)
+ 31台 => 33台 (再小流量2台)
+ 33台 => 38台 (再中流量5台)
+ 38台 => 50台 (全量)
+
+#### 扩容过程观察的指标
+
+ 【基础指标】老集群和扩容集群的内存和IO情况
+ 【写入链路】Transfer接收点数、Transfer转发点数、Graph接收点数
+ 【查询链路】Query到Graph查询的次数、错误率、延迟。Graph转发查询的次数。
+ 【迁移效果】RRD文件的迁移量、成功率、迁移时间。
+
+**扩容过程中指标变化**
+
+每次扩容,都严格遵守扩容步骤,观察所有性能指标及数据的稳定性,并没有出现严重的断层及数据异常。下面将我们多次扩容的性能及指标数据分享给大家:(所有concurrency配置为:5)
+
+
+
+* 说明1:此处主要说明性能上限,IO及内存的值,均为**峰值**
+* 说明2:由于笔者公司的监控系统持续有新指标的写入,因此**迁移指标稳定时间**这个值,对开源版Graph无太大参考意义
+
+#### 如何确保扩容完成
+
+ 1、Graph接受指标总量稳定,且与Transfer转发指标数持平
+ 2、所有查询量没有跌,且所有查询错误率稳定
+ 3、迁移RRD文件数及迁移效率,逐渐稳定。趋于0或一个固定的值。(若无新指标,会趋于0)
+ 4、找N个确定会落在扩容集群上的指标,确定这N条线的数据,连续且并没有断开。
+
+#### 需注意的点
+
++ 重启有害
+
+ 扩容过程中,没有完成RRD文件迁移之前,扩容集群重启就意味着扩容失败:
+ 重启时,内存中的数据会被强制落盘,导致未迁移完成的RRD文件无法再次迁移。
+
+
++ 建议分批扩容
+
+ 由于此方案无法回滚,对于数据敏感的场景,建议考虑分批次扩容。
+ 此次扩容过程中,我们就采用了分批次扩容的方案。先灰度一台,再小流量2台、5台,直至最终完全上线。
+ 实际证明,分批次扩容是完全可行、安全、可以降低风险的。
+
+### 总结
+
+总而言之,这个方案是可行、稳定、可操作的。
+只要做好事前准备,对扩容过程了解到位,可以很容易扩容成功。
+
+### 附:扩容中的指标变化情况
+
+
+RRD文件迁移量变化:
+
+
+老集群IO.util:
+
+
+老集群IO.read.MB:
+
+
+新集群IO.write.MB:
+
+
+
+> 作者:[高家升](http://blog.gaojiasheng.com/) [聂安](https://github.com/niean) [钱威](https://github.com/n4mine)
+
+ 链接:http://www.jianshu.com/p/a87ab10e09c7
+ 來源:简书
+
+> 参考资料:
+- [graph扩容历史数据自动迁移 - laiwei](http://www.jianshu.com/p/16baba04c959)
+- [扩容graph问题和补充](https://github.com/open-falcon/falcon-plus/issues/726)
\ No newline at end of file
diff --git a/zh_0_3/practice/monitor.md b/zh_0_3/practice/monitor.md
new file mode 100644
index 0000000..10b3d0b
--- /dev/null
+++ b/zh_0_3/practice/monitor.md
@@ -0,0 +1,205 @@
+
+
+# 自监控实践
+本文介绍了,小米公司在 Open-Falcon集群自监控方面 的一些实践。
+
+## 概述
+我们把对监控系统的监控,称为监控系统的自监控。自监控的需求,没有超出监控的业务范畴。同其他系统一样,自监控要做好两方面的工作: 故障报警和状态展示。故障报警,要求尽量实时的发现故障、及时的通知负责人,要求高可用性。状态展示,多用于事前预测、事后追查,实时性、可用性要求 较故障报警 低一个量级。下面我们从这两个方面,分别进行介绍。
+
+## 故障报警
+故障报警相对简单。我们使用第三方监控组件[AntEye](https://github.com/niean/anteye),来监控Open-Falcon实例的健康状况。
+
+Open-Falcon各个组件,都会提供一个描述自身服务可用性的自监控接口,描述如下。AntEye服务会定时巡检、主动调用Open-Falcon各实例的自监控接口,如果发现某个实例的接口没有如约返回"ok",就认为这个组件故障了(约定),就通过短信、邮件等方式 通知相应负责人员。为了减少报警通知的频率,AntEye采用了简单的报警退避策略,并会酌情合并一些报警通知的内容。
+
+```bash
+ # API for my availability
+ 接口URL
+ /health 检测本服务是否正常
+
+ 请求方法
+ GET http://$host:$port/health
+ $host 服务所在机器的名称或IP
+ $port 服务的http.server监听端口
+
+ 请求参数
+ 无参数
+
+ 返回结果(string)
+ "ok"(没有返回"ok", 则服务不正常)
+
+```
+
+AntyEye组件主动拉取状态数据,通过本地配置加载监控实例、报警接收人信息、报警通道信息等,这样做,是为了简化报警链路、使故障的发现过程尽量实时&可靠。AntEye组件足够轻量,代码少、功能简单,这样能够保障单个AntEye实例的可用性;同时,AntEye是无状态的,能够部署多套,这进一步保证了自监控服务的高可用。
+
+在同一个重要的网络分区内,通常要部署3+个AntEye,如下图所示。我们一般不会让AntEye做跨网络分区的监控,因为这样会带来很多网络层面的误报。多套部署,会造成报警通知的重复发送,这是高可用的代价;从我们的实践经验来看,这个重复可以接受。
+
+
+
+值得注意的是,原来故障发现功能是Open-Falcon的Task组件的一个代码片段。后来,为了满足多套部署的需求,我们把故障发现的逻辑从Task中剔除,转而使用独立的第三方监控组件AntEye。
+
+
+## 状态展示
+状态展示,是将Open-Falcon各组件实例的状态数据,以图形化的形式展示出来,方便人的查看。鉴于实时性、可用性要求不高,我们选择Open-Falcon来做自身状态数据的存储、展示(用Open-Falcon监控Open-Falcon,自举了),剩下的工作就是状态数据的采集了。
+
+Open-Falcon的多数组件,都会提供一个查询服务状态数据的接口,描述如下。
+
+```bash
+ # API for querying my statistics
+ 接口URL
+ /counter/all 返回所有的状态数据
+
+ 请求方法
+ GET http://$host:$port/counter/all
+ $host 服务所在机器的名称或IP
+ $port 服务的http.server监听端口
+
+ 请求参数
+ 无参数
+
+ 返回结果
+ // json格式
+ {
+ "msg": "success", // "success"表示请求被成功处理,其他均是失败
+ "data":[ // 自身状态数据的list
+ // 每个状态数据, 都包含字段 Name(名称)、Cnt(计数)、Time(时间),可能包含字段Qps
+ {
+ "Name": "RecvCnt",
+ "Cnt": 6458396967,
+ "Qps": 81848,
+ "Time": "2015-08-19 15:52:08"
+ },
+ ...
+ ]
+ }
+
+```
+
+Open-Falcon的[Task组件](https://github.com/open-falcon/task),通过上述接口,周期性的主动拉取Open-Falcon各实例的状态数据;然后,处理这些状态数据,适配成Open-Falcon要求的数据格式;再将适配后的数据,push给本地的Agent;本地的Agent会将这些数据转发到监控系统Open-Falcon。
+
+Task组件,通过[配置文件](https://github.com/open-falcon/task/blob/master/cfg.example.json)中的`collector`项,定义状态数据采集的相关特性,如下
+
+```base
+ "collector":{
+ "enable": true,
+ "destUrl" : "http://127.0.0.1:1988/v1/push", // 适配后的状态数据发送到本地的1988端口(Agent接收器)
+ "srcUrlFmt" : "http://%s/counter/all", // 状态数据查询接口的Format, %s将被替换为 cluster配置项中的 $hostname:$port
+ "cluster" : [
+ // "$module,$hostname:$port",表示: 地址$hostname:$port对应了一个$module服务
+ // 结合"srcUrlFmt"的配置,可以得到状态数据查询接口 "http://test.host01:6060/counter/all" 等
+ "transfer,test.host01:6060",
+ "graph,test.host01:6071",
+ "task,test.host01:8001"
+ ]
+ }
+```
+
+Task做数据适配时,将endpoint设置为数据来源的机器名`$hostname`($hostname为Task采集配置collector.cluster某条记录中的机器名),将metric设置为原始状态数据的`$Name`和`$Name.Qps`,将tags设置为`module=$module,port=$port,type=statistics,pdl=falcon`($module,$port为Task采集配置collector.cluster某条记录中的模块名和端口,其他两项为固定填充), 将数据类型设置为`GAUGE`,将周期设置为Task的数据采集周期。比如,采用了上述采集配置的Task,将会做如下适配:
+
+```
+ # 一条原始的状态数据,来自"transfer,test.host01:6060"
+ {
+ "Name": "RecvCnt",
+ "Cnt": 6458396967,
+ "Qps": 81848,
+ "Time": "2015-08-19 15:52:08"
+ }
+
+ # Task适配之后,得到两条监控数据
+ {
+ "endpoint": "test.host01", // Task配置collector.cluster中的配置项"transfer,test.host01:6060"中的机器名
+ "metric": "RecvCnt", // 原始状态数据中的$Name
+ "value": 6458396967, // 原始状态数据中的$Cnt
+ "type": "GAUGE", // 固定为GAUGE
+ "step": 60, // Task的数据采集周期, 默认为60s
+ "tags": "module=transfer,port=6060,pdl=falcon,type=statistics", // 前两个对应于Task的collector.cluster配置项"transfer,test.host01:6060"中的模块名和端口,后两个是固定填充
+ ...
+ },
+ {
+ "endpoint": "test.host01",
+ "metric": "RecvCnt.Qps", // 原始状态数据中的$Name + ".Qps"
+ "value": 81848, // 原始状态数据中的$Qps
+ "type": "GAUGE",
+ "step": 60,
+ "tags": "module=transfer,port=6060,pdl=falcon,type=statistics",
+ ...
+ }
+```
+
+我们只能向监控系统Open-Falcon,push一份状态数据(push多份会有重叠、不利于观察),因此,在每个网络分区中只能部署一个Task实例(同样地,不建议跨网络分区采集状态数据)。单点部署,可用性太差了吧?确实。不过好在,AntEye服务会监控Task的状态,能够及时发现Task的故障,在一定程度上可以缓解 状态数据采集服务 的单点风险。
+
+状态数据入Open-Falcon之后,我们就可以定制Screen页面。如下图,是小米Open-Falcon的状态数据统计页面。定制页面时,需要先找到您关注的counter,这个可以通过dashboard进行搜索,如下图。不同组件的自监控counter,具体见[附录](#appendix.falcon.counter)。
+
+筛选自监控相关的状态指标
+
+
+定制你的自监控状态数据Screen
+
+
+
+有了Open-Falcon自身状态数据的Screen,运维就会变得很方便: 每天早上开始正式工作之前,花10分钟时间看看这些历史曲线,小则发现已经发生的问题,大则预测故障、评估容量等。
+
+
+## 总结
+对于自监控,简单整理下。
+
++ 神医难自医。大型监控系统的故障监控,往往需要借助第三方监控系统([AntEye](https://github.com/niean/anteye))。第三方监控系统,越简单、越独立,越好。
+
++ 吃自己的狗粮。一个系统,充分暴露自身的状态数据,才更有利于维护。我们尽量,把[状态数据的存储容器](https://github.com/niean/gotools/blob/master/proc/counter.go)做成通用的、把获取状态数据的接口做成一致的、把状态数据的采集服务做成集中式的,方便继承、方便运维。当前,程序获取自己状态数据的过程还不太优雅、入侵严重;如果您能指点一二,我们将不胜感激。
+
+
+## 附录
+### 1. Open-Falcon状态指标
+以下是Open-Falcon较重要的状态指标(非全部)及其含义。
+
+```bash
+ ## transfer
+ RecvCnt.Qps 接收数据的Qps
+
+ GraphSendCacheCnt 转发数据至Graph的缓存长度
+ SendToGraphCnt.Qps 转发数据至Graph的Qps
+ SendToGraphDropCnt.Qps 转发数据至Graph时, 由于缓存溢出而Drop数据的Qps
+ SendToGraphFailCnt.Qps 转发数据至Graph时, 发送数据失败的Qps
+
+ JudgeSendCacheCnt 转发数据至Judge的缓存长度
+ SendToJudgeCnt.Qps 转发数据至Judge的Qps
+ SendToJudgeDropCnt.Qps 转发数据至Judge时, 由于缓存溢出而Drop数据的Qps
+ SendToJudgeFailCnt.Qps 转发数据至Judge时, 发送数据失败的Qps
+
+ ## graph
+ GraphRpcRecvCnt.Qps 接收数据的Qps
+ GraphQueryCnt.Qps 处理Query请求的Qps
+ GraphLastCnt.Qps 处理Last请求的Qps
+ IndexedItemCacheCnt 已缓存的索引数量,即监控指标数量
+ IndexUpdateAll 全量更新索引的次数
+
+ ## query
+ HistoryRequestCnt.Qps 历史数据查询请求的Qps
+ HistoryResponseItemCnt.Qps 历史数据查询请求返回点数的Qps
+ LastRequestCnt.Qps Last查询请求的Qps
+
+ ## task
+ CollectorCronCnt 自监控状态数据采集的次数
+ IndexDeleteCnt 索引垃圾清除的次数
+ IndexUpdateCnt 索引全量更新的次数
+
+ ## gateway
+ RecvCnt.Qps 接收数据的Qps
+ SendCnt.Qps 发送数据至transfer的Qps
+ SendDropCnt.Qps 发送数据至transfer时,由于缓存溢出而Drop数据的Qps
+ SendFailCnt.Qps 发送数据至transfer时,发送失败的Qps
+ SendQueuesCnt 发送数据至transfer时,发送缓存的长度
+
+ ## anteye
+ MonitorCronCnt 自监控进行状态判断的总次数
+ MonitorAlarmMailCnt 自监控报警发送邮件的次数
+ MonitorAlarmSmsCnt 自监控报警发送短信的次数
+ MonitorAlarmCallbackCnt 自监控报警调用callback的次数
+
+ ## nodata
+ FloodRate nodata发生的百分比
+ CollectorCronCnt 数据采集的次数
+ JudgeCronCnt nodata判断的次数
+ NdConfigCronCnt 拉取nodata配置的次数
+ SenderCnt.Qps 发送模拟数据的Qps
+
+```
diff --git a/zh_0_3/quick_install/README.md b/zh_0_3/quick_install/README.md
new file mode 100644
index 0000000..c69e0dc
--- /dev/null
+++ b/zh_0_3/quick_install/README.md
@@ -0,0 +1,6 @@
+
+
+Open-Falcon,为前后端分离的架构,包含backend 和 frontend两部分:
+
+- [安装后端](./backend.md)
+- [安装前端](./frontend.md)
diff --git a/zh_0_3/quick_install/backend.md b/zh_0_3/quick_install/backend.md
new file mode 100644
index 0000000..4ff631b
--- /dev/null
+++ b/zh_0_3/quick_install/backend.md
@@ -0,0 +1,53 @@
+
+
+## 环境准备
+
+请参考[环境准备](./prepare.md)
+
+### 创建工作目录
+```bash
+export FALCON_HOME=/home/work
+export WORKSPACE=$FALCON_HOME/open-falcon
+mkdir -p $WORKSPACE
+```
+
+### 解压二进制包
+```bash
+tar -xzvf open-falcon-v0.2.1.tar.gz -C $WORKSPACE
+```
+
+### 在一台机器上启动所有的后端组件
+# 首先确认配置文件中数据库账号密码与实际相同,否则需要修改配置文件。
+```
+cd $WORKSPACE
+grep -Ilr 3306 ./ | xargs -n1 -- sed -i 's/root:/real_user:real_password/g'
+```
+# 启动
+```bash
+cd $WORKSPACE
+./open-falcon start
+
+# 检查所有模块的启动状况
+./open-falcon check
+
+```
+
+### 更多的命令行工具用法
+```bash
+# ./open-falcon [start|stop|restart|check|monitor|reload] module
+./open-falcon start agent
+
+./open-falcon check
+ falcon-graph UP 53007
+ falcon-hbs UP 53014
+ falcon-judge UP 53020
+ falcon-transfer UP 53026
+ falcon-nodata UP 53032
+ falcon-aggregator UP 53038
+ falcon-agent UP 53044
+ falcon-gateway UP 53050
+ falcon-api UP 53056
+ falcon-alarm UP 53063
+
+For debugging , You can check $WorkDir/$moduleName/log/logs/xxx.log
+```
diff --git a/zh_0_3/quick_install/frontend.md b/zh_0_3/quick_install/frontend.md
new file mode 100644
index 0000000..610f678
--- /dev/null
+++ b/zh_0_3/quick_install/frontend.md
@@ -0,0 +1,83 @@
+
+----
+
+## 环境准备
+
+请参考[环境准备](./prepare.md)
+
+### 创建工作目录
+```
+export HOME=/home/work
+export WORKSPACE=$HOME/open-falcon
+mkdir -p $WORKSPACE
+cd $WORKSPACE
+```
+
+### 克隆前端组件代码
+```
+cd $WORKSPACE
+git clone https://github.com/open-falcon/dashboard.git
+```
+
+### 安装依赖包
+```
+yum install -y python-virtualenv
+yum install -y python-devel
+yum install -y openldap-devel
+yum install -y mysql-devel
+yum groupinstall "Development tools"
+
+
+cd $WORKSPACE/dashboard/
+virtualenv ./env
+
+./env/bin/pip install -r pip_requirements.txt -i https://pypi.douban.com/simple
+```
+
+### 初始化数据库
+请参考[环境准备](./prepare.md)
+
+
+### 修改配置
+```
+dashboard的配置文件为: 'rrd/config.py',请根据实际情况修改
+
+## API_ADDR 表示后端api组件的地址
+API_ADDR = "http://127.0.0.1:8080/api/v1"
+
+## 根据实际情况,修改PORTAL_DB_*, 默认用户名为root,默认密码为""
+## 根据实际情况,修改ALARM_DB_*, 默认用户名为root,默认密码为""
+```
+
+### 以开发者模式启动
+```
+./env/bin/python wsgi.py
+
+open http://127.0.0.1:8081 in your browser.
+```
+
+### 在生产环境启动
+```
+bash control start
+
+open http://127.0.0.1:8081 in your browser.
+```
+
+### 停止dashboard运行
+```
+bash control stop
+```
+
+### 查看日志
+```
+bash control tail
+```
+
+### dashbord用户管理
+```
+dashbord没有默认创建任何账号包括管理账号,需要你通过页面进行注册账号。
+想拥有管理全局的超级管理员账号,需要手动注册用户名为root的账号(第一个帐号名称为root的用户会被自动设置为超级管理员)。
+超级管理员可以给普通用户分配权限管理。
+
+小提示:注册账号能够被任何打开dashboard页面的人注册,所以当给相关的人注册完账号后,需要去关闭注册账号功能。只需要去修改api组件的配置文件cfg.json,将signup_disable配置项修改为true,重启api即可。当需要给人开账号的时候,再将配置选项改回去,用完再关掉即可。
+```
diff --git a/zh_0_3/quick_install/prepare.md b/zh_0_3/quick_install/prepare.md
new file mode 100644
index 0000000..a9028a4
--- /dev/null
+++ b/zh_0_3/quick_install/prepare.md
@@ -0,0 +1,54 @@
+
+
+# 环境准备
+
+### 安装redis
+ yum install -y redis
+
+### 安装mysql
+ yum install -y mysql-server
+
+**注意,请确保redis和MySQL已启动。**
+
+### 初始化MySQL表结构
+
+```
+cd /tmp/ && git clone https://github.com/open-falcon/falcon-plus.git
+cd /tmp/falcon-plus/scripts/mysql/db_schema/
+mysql -h 127.0.0.1 -u root -p < 1_uic-db-schema.sql
+mysql -h 127.0.0.1 -u root -p < 2_portal-db-schema.sql
+mysql -h 127.0.0.1 -u root -p < 3_dashboard-db-schema.sql
+mysql -h 127.0.0.1 -u root -p < 4_graph-db-schema.sql
+mysql -h 127.0.0.1 -u root -p < 5_alarms-db-schema.sql
+rm -rf /tmp/falcon-plus/
+```
+
+**如果你是从v0.1.0升级到当前版本v0.2.0,那么只需要执行如下命令:**
+
+```
+mysql -h 127.0.0.1 -u root -p < 5_alarms-db-schema.sql
+```
+
+# 从源码编译
+
+首先,请确保你已经安装好了golang环境,如果没有安装,请参考 https://golang.org/doc/install
+
+```
+cd $GOPATH/src/github.com/open-falcon/falcon-plus/
+
+# make all modules
+make all
+
+# pack all modules
+make pack
+
+```
+
+这时候,你会在当前目录下面,得到open-falcon-v0.2.0.tar.gz的压缩包,就表示已经编译和打包成功了。
+
+# 下载编译好的二进制版本
+
+如果你不想自己编译的话,那么可以下载官方编译好的[二进制版本(x86 64位平台)](https://github.com/open-falcon/falcon-plus/releases)。
+
+
+到这一步,准备工作就完成了。 open-falcon-v0.2.0.tar.gz 这个二进制包,请大家解压到合适的位置,暂时保存,后续步骤需要使用。
diff --git a/zh_0_3/quick_install/upgrade.md b/zh_0_3/quick_install/upgrade.md
new file mode 100644
index 0000000..139d100
--- /dev/null
+++ b/zh_0_3/quick_install/upgrade.md
@@ -0,0 +1,297 @@
+
+
+> **如何从OpenFalcon v0.1 平滑升级到 FalconPlus v0.2?**
+
+###新增数据库表
+```
+cd $GOPATH/src/github.com/open-falcon/falcon-plus/scripts/mysql/db_schema/
+mysql -h 127.0.0.1 -u root -p < 5_alarms-db-schema.sql
+```
+
+**NOTE:**
+1. falcon-plus 如何编译,请参考 [falcon-plus readme](https://github.com/open-falcon/falcon-plus) ;
+2. 或者直接下载官方编译好的[二进制包](https://github.com/open-falcon/falcon-plus/releases);
+
+---
+现在正式开始升级之旅:)
+
+###1. 升级agent
+
+用falcon-plus agent 二进制文件替换掉v0.1版本 agent 的二进制,同时注意修改agent的配置文件:
+
+```
+diff --git v0.1/agent/cfg.example.json v0.2/agent/cfg.example.json
+--- v0.1
++++ v0.2
+
+ "backdoor": false
+ },
+ "collector": {
+- "ifacePrefix": ["eth", "em"]
++ "ifacePrefix": ["eth", "em"],
++ "mountPoint": []
++ },
++ "default_tags": {
+ },
+ "ignore": {
+ "cpu.busy": true,
+```
+
+###2. 升级transfer
+用falcon-plus transfer 二进制文件替换掉v0.1版本 transfer 的二进制即可,配置文件无需变化。
+
+###3. 升级graph
+用falcon-plus graph 二进制文件替换掉v0.1版本 graph 的二进制即可,配置文件无需变化。
+
+###4. 用api模块来代替query模块
+ 1. 停止query的运行;
+ 2. 从 `make pack`得到的 tar.gz 包中解压得到 api 及其配置文件,检查配置文件如下,然后启动api组件即可。
+
+```
+{
+ "log_level": "debug",
+ "db": {
+ "faclon_portal": "root:@tcp(127.0.0.1:3306)/falcon_portal?charset=utf8&parseTime=True&loc=Local",
+ "graph": "root:@tcp(127.0.0.1:3306)/graph?charset=utf8&parseTime=True&loc=Local",
+ "uic": "root:@tcp(127.0.0.1:3306)/uic?charset=utf8&parseTime=True&loc=Local",
+ "dashboard": "root:@tcp(127.0.0.1:3306)/dashboard?charset=utf8&parseTime=True&loc=Local",
+ "alarms": "root:@tcp(127.0.0.1:3306)/alarms?charset=utf8&parseTime=True&loc=Local",
+ "db_bug": true
+ },
+ "graphs": {
+ "cluster": {
+ "graph-00": "127.0.0.1:6070"
+ },
+ "max_conns": 100,
+ "max_idle": 100,
+ "conn_timeout": 1000,
+ "call_timeout": 5000,
+ "numberOfReplicas": 500
+ },
+ "metric_list_file": "./api/data/metric",
+ "web_port": ":8080",
+ "access_control": true,
+ "salt": "",
+ "skip_auth": false,
+ "signup_disable": false,
+ "default_token": "default-token-used-in-server-side",
+ "gen_doc": false,
+ "gen_doc_path": "doc/module.html"
+}
+
+```
+ 其中`db`部分为数据库连接信息相关,按需修改即可;`graphs`部分为后端的graph列表信息,可以和v0.1版本的query cfg.json部分内容保持一致即可。
+
+###5. 升级hbs
+用falcon-plus hbs 二进制文件替换掉v0.1版本 hbs 的二进制即可,配置文件无需变化。
+
+###6. 升级judge
+用falcon-plus judge 二进制文件替换掉v0.1版本 judge 的二进制即可,配置文件无需变化。
+
+###7. 升级alarm
+用falcon-plus alarm 二进制文件替换掉v0.1版本 alarm 的二进制,同时注意修改alarm 的配置文件:
+
+```
+diff --git v0.1/alarm/cfg.example.json v0.2/alarm/cfg.example.json
+--- v0.1/alarm/cfg.example.json
++++ v0.2/alarm/cfg.example.json
+
+@@ -1,36 +1,47 @@
+ {
+- "debug": true,
+- "uicToken": "",
++ "log_level": "debug",
+ "http": {
+ "enabled": true,
+ "listen": "0.0.0.0:9912"
+ },
+- "queue": {
+- "sms": "/sms",
+- "mail": "/mail"
+- },
+ "redis": {
+ "addr": "127.0.0.1:6379",
+ "maxIdle": 5,
+@@@@@@@@@@
++ "userIMQueue": "/queue/user/im",
+ "userSmsQueue": "/queue/user/sms",
+ "userMailQueue": "/queue/user/mail"
+ },
+- "database": "root:@tcp(127.0.0.1:3306)/alarm?loc=Local&parseTime=true",
+- "maxIdle": 100,
+ "api": {
+- "portal": "http://falcon.example.com",
+- "uic": "http://uic.example.com",
+- "links": "http://link.example.com"
++ "im": "http://127.0.0.1:10086/wechat",
++ "sms": "http://127.0.0.1:10086/sms",
++ "mail": "http://127.0.0.1:10086/mail",
++ "dashboard": "http://127.0.0.1:8081",
++ "plus_api":"http://127.0.0.1:8080",
++ "plus_api_token": "default-token-used-in-server-side"
++ },
++ "falcon_portal": {
++ "addr": "root:@tcp(127.0.0.1:3306)/alarms?charset=utf8&loc=Asia%2FChongqing",
++ "idle": 10,
++ "max": 100
++ },
++ "worker": {
++ "im": 10,
++ "sms": 10,
++ "mail": 50
++ },
++ "housekeeper": {
++ "event_retention_days": 7,
++ "event_delete_batch": 100
+ }
+ }
+```
+*NOTE: v0.2版本中,去除了sender模块,将sender模块的功能,合并到了alarm组件中,降低了用户的配置和维护成本; 同时增加了对微信的发送支持。*
+
+###8. 升级aggregator
+用falcon-plus aggregator 二进制文件替换掉v0.1版本 aggregator 的二进制,同时注意修改aggregator 的配置文件:
+
+```
+diff --git v0.1/aggregator/cfg.example.json v0.2/aggregator/cfg.example.json
+--- v0.1/aggregator/cfg.example.json
++++ v0.2/aggregator/cfg.example.json
+@@@@@@@@@@@
+ "interval": 55
+ },
+ "api": {
+- "hostnames": "http://127.0.0.1:5050/api/group/%s/hosts.json",
+- "push": "http://127.0.0.1:6060/api/push",
+- "graphLast": "http://127.0.0.1:9966/graph/last"
++ "connect_timeout": 500,
++ "request_timeout": 2000,
++ "plus_api": "http://127.0.0.1:8080",
++ "plus_api_token": "default-token-used-in-server-side",
++ "push_api": "http://127.0.0.1:1988/v1/push"
+ }
+ }
+```
+*NOTE: aggregator 直接和falcon-plus 的api组件进行交互,即plus_api所配置的地址。*
+
+###9. 升级nodata
+用falcon-plus nodata 二进制文件替换掉v0.1版本 nodata 的二进制,同时注意修改nodata 的配置文件:
+
+```
+diff --git v0.1/nodata/cfg.example.json v0.2/nodata/cfg.example.json
+--- a/../nodata/cfg.example.json
++++ b/modules/nodata/cfg.example.json
+@@ -4,10 +4,11 @@
+ "enabled": true,
+ "listen": "0.0.0.0:6090"
+ },
+- "query":{
+- "connectTimeout": 5000,
+- "requestTimeout": 30000,
+- "queryAddr": "127.0.0.1:9966"
++ "plus_api":{
++ "connectTimeout": 500,
++ "requestTimeout": 2000,
++ "addr": "http://127.0.0.1:8080",
++ "token": "default-token-used-in-server-side"
+ },
+ "config": {
+ "enabled": true,
+@@ -21,13 +22,9 @@
+ },
+ "sender":{
+ "enabled": true,
+- "connectTimeout": 5000,
+- "requestTimeout": 30000,
++ "connectTimeout": 500,
++ "requestTimeout": 2000,
+ "transferAddr": "127.0.0.1:6060",
+- "batch": 500,
+- "block": {
+- "enabled": false,
+- "threshold": 32
+- }
++ "batch": 500
+ }
+ }
+```
+*NOTE: nodata不再访问query组件了, 而是直接和falcon-plus 的api组件进行交互,即plus_api所配置的信息。*
+
+###10. 升级gateway
+用falcon-plus gateway 二进制文件替换掉v0.1版本 gateway 的二进制即可,配置文件无需变化。
+
+###11. 开启全新的统一[前端模块](https://github.com/open-falcon/dashboard)
+- 安装步骤请直接参考:[dashboard readme](https://github.com/open-falcon/dashboard)
+- 注意修改配置:
+
+```
+diff --git a/rrd/config.py b/rrd/config.py
+index e9e500d..d57b1c7 100755
+--- a/rrd/config.py
++++ b/rrd/config.py
+@@ -1,34 +1,50 @@
+ #-*-coding:utf8-*-
+ import os
++LOG_LEVEL = os.environ.get("LOG_LEVEL",'DEBUG')
++SECRET_KEY = os.environ.get("SECRET_KEY","secret-key")
++PERMANENT_SESSION_LIFETIME = os.environ.get("PERMANENT_SESSION_LIFETIME",3600 * 24 * 30)
++SITE_COOKIE = os.environ.get("SITE_COOKIE","open-falcon-ck")
+
+-#-- dashboard db config --
+-DASHBOARD_DB_HOST = "127.0.0.1"
+-DASHBOARD_DB_PORT = 3306
+-DASHBOARD_DB_USER = "root"
+-DASHBOARD_DB_PASSWD = ""
+-DASHBOARD_DB_NAME = "dashboard"
++# Falcon+ API
++API_ADDR = os.environ.get("API_ADDR","http://127.0.0.1:8080/api/v1")
+
+-#-- graph db config --
+-GRAPH_DB_HOST = "127.0.0.1"
+-GRAPH_DB_PORT = 3306
+-GRAPH_DB_USER = "root"
+-GRAPH_DB_PASSWD = ""
+-GRAPH_DB_NAME = "graph"
++# portal database
++# TODO: read from api instead of db
++PORTAL_DB_HOST = os.environ.get("PORTAL_DB_HOST","127.0.0.1")
++PORTAL_DB_PORT = int(os.environ.get("PORTAL_DB_PORT",3306))
++PORTAL_DB_USER = os.environ.get("PORTAL_DB_USER","root")
++PORTAL_DB_PASS = os.environ.get("PORTAL_DB_PASS","")
++PORTAL_DB_NAME = os.environ.get("PORTAL_DB_NAME","falcon_portal")
+
+-#-- app config --
+-DEBUG = True
+-SECRET_KEY = "secret-key"
+-SESSION_COOKIE_NAME = "open-falcon"
+-PERMANENT_SESSION_LIFETIME = 3600 * 24 * 30
+-SITE_COOKIE = "open-falcon-ck"
++# alarm database
++# TODO: read from api instead of db
++ALARM_DB_HOST = os.environ.get("ALARM_DB_HOST","127.0.0.1")
++ALARM_DB_PORT = int(os.environ.get("ALARM_DB_PORT",3306))
++ALARM_DB_USER = os.environ.get("ALARM_DB_USER","root")
++ALARM_DB_PASS = os.environ.get("ALARM_DB_PASS","")
++ALARM_DB_NAME = os.environ.get("ALARM_DB_NAME","alarms")
+
+-#-- query config --
+-QUERY_ADDR = "http://127.0.0.1:9966"
++# ldap config
++LDAP_ENABLED = os.environ.get("LDAP_ENABLED",False)
++LDAP_SERVER = os.environ.get("LDAP_SERVER","ldap.forumsys.com:389")
++LDAP_BASE_DN = os.environ.get("LDAP_BASE_DN","dc=example,dc=com")
++LDAP_BINDDN_FMT = os.environ.get("LDAP_BINDDN_FMT","uid=%s,dc=example,dc=com")
++LDAP_SEARCH_FMT = os.environ.get("LDAP_SEARCH_FMT","uid=%s")
++LDAP_ATTRS = ["cn","mail","telephoneNumber"]
++LDAP_TLS_START_TLS = False
++LDAP_TLS_CACERTDIR = ""
++LDAP_TLS_CACERTFILE = "/etc/openldap/certs/ca.crt"
++LDAP_TLS_CERTFILE = ""
++LDAP_TLS_KEYFILE = ""
++LDAP_TLS_REQUIRE_CERT = True
++LDAP_TLS_CIPHER_SUITE = ""
+
+-BASE_DIR = "/home/work/open-falcon/dashboard/"
+-LOG_PATH = os.path.join(BASE_DIR,"log/")
++# portal site config
++MAINTAINERS = ['root']
++CONTACT = 'root@open-falcon.com'
+```
diff --git a/zh_0_3/styles/website.css b/zh_0_3/styles/website.css
new file mode 100644
index 0000000..66910c0
--- /dev/null
+++ b/zh_0_3/styles/website.css
@@ -0,0 +1,72 @@
+/* CSS for website */
+h1 , h2{
+ border-bottom: 1px solid #EFEAEA;
+ padding-bottom: 3px;
+}
+.markdown-section>:first-child {
+ margin-top: 0!important;
+}
+.markdown-section blockquote:last-child {
+ margin-bottom: 0.85em!important;
+}
+.page-wrapper {
+ margin-top: -1.275em;
+}
+.book .book-body .page-wrapper .page-inner section.normal {
+ min-height:350px;
+ margin-bottom: 30px;
+}
+
+.book .book-body .page-wrapper .page-inner section.normal hr {
+ height: 0px;
+ padding: 0;
+ margin: 1.7em 0;
+ overflow: hidden;
+ background-color: #e7e7e7;
+ border-bottom: 1px dotted #e7e7e7;
+}
+
+.video-js {
+ width:100%;
+ height: 100%;
+}
+
+pre[class*="language-"] {
+ border: none;
+ background-color: #f7f7f7;
+ font-size: 1em;
+ line-height: 1.2em;
+}
+
+.book .book-body .page-wrapper .page-inner section.normal {
+ font-size: 14px;
+ font-family: "ubuntu", "Tahoma", "Microsoft YaHei", arial, sans-serif;
+}
+
+.aceCode {
+ font-size: 14px !important;
+}
+
+input[type=checkbox]{
+ margin-left: -2em;
+}
+
+.page-footer span{
+ font-size: 12px;
+}
+
+.page-footer .copyright {
+ float: left;
+}
+
+.body, html {
+ overflow-y: hidden;
+}
+
+.versions-select select {
+ height: 2em;
+ line-height: 2em;
+ border-radius: 4px;
+ background: #efefef;
+}
+
diff --git a/zh_0_3/usage/MongoDB.md b/zh_0_3/usage/MongoDB.md
new file mode 100644
index 0000000..6039f1d
--- /dev/null
+++ b/zh_0_3/usage/MongoDB.md
@@ -0,0 +1,244 @@
+
+
+[MongoDB performance monitor plugin for Open-Falcon](https://github.com/ZhuoRoger/mongomon)
+--------------------------------
+
+功能支持
+------------------
+
+已测试版本: 支持MongoDB版本2.4,2.6 3.0,3.2, 以及Percona MongoDB3.0
+
+支持存储引擎:MMAPv1, wiredTiger, RocksDB, PerconaFT 存储引擎(部分存储引擎的指标未采集完,可直接代码中添加)
+
+支持结构: standlone, 副本集,分片集群
+
+支持节点:mongod数据节点,配置节点,Primary/Secondary, mongos; 不支持Arbiter节点
+
+监控数据采集原理
+---------------
+1 存活监控: 包括auth
+
+2 serverStatus
+
+3 replSetGetStatus
+
+4 oplog.rs
+
+5 mongos
+
+通过cron每分钟采集上报,采集对MongoDB理论无性能影响
+
+环境要求
+---------------
+操作系统: Linux
+
+Python 2.6
+
+PyYAML > 3.10
+
+python-requests > 0.11
+
+mongomon部署
+-------------------
+1 目录解压到/path/to/mongomon
+
+2 配置当前服务器的MongoDB多实例(mongod,配置节点,mongos)信息,/path/to/mongomon/conf/mongomon.conf 每行记录一个实例: 端口,用户名,密码
+
+- {port: 27017, user: "",password: ""}
+
+3 配置crontab, 修改mongomon/conf/mongomon_cron文件中mongomon安装path; cp mongomon_cron /etc/cron.d/
+
+4 几分钟后,可从open-falcon的dashboard中查看MongoDB metric
+
+5 endpoint默认是hostname
+
+MongoDB falcon screen
+----------
+
+
+
+采集的MongoDB指标
+----------------------------------------
+
+--------------------------------
+| Counters | Type | Notes|
+|-----|------|------|
+|mongo_local_alive| GAUGE |mongodb存活本地监控,如果开启Auth,要求连接认证成功
+|asserts_msg| COUNTER |消息断言数/秒
+|asserts_regular| COUNTER |常规断言数/秒
+|asserts_rollovers| COUNTER |计数器roll over的次数/秒,计数器每2^30个断言就会清零
+|asserts_user| COUNTER |用户断言数/秒
+|asserts_warning| COUNTER |警告断言数/秒
+|page_faults| COUNTER |页缺失次数/秒
+|connections_available| GAUGE |未使用的可用连接数
+|connections_current| GAUGE |当前所有客户端的已连接的连接数
+|connections_used_percent| GAUGE |已使用连接数百分比
+|connections_totalCreated| COUNTER |创建的新连接数/秒
+|globalLock_currentQueue_total| GAUGE |当前队列中等待锁的操作数
+|globalLock_currentQueue_readers| GAUGE |当前队列中等待读锁的操作数
+|globalLock_currentQueue_writers| GAUGE |当前队列中等待写锁的操作数
+|locks_Global_acquireCount_ISlock| COUNTER |实例级意向共享锁获取次数
+|locks_Global_acquireCount_IXlock| COUNTER |实例级意向排他锁获取次数
+|locks_Global_acquireCount_Slock| COUNTER |实例级共享锁获取次数
+|locks_Global_acquireCount_Xlock| COUNTER |实例级排他锁获取次数
+|locks_Global_acquireWaitCount_ISlock| COUNTER |实例级意向共享锁等待次数
+|locks_Global_acquireWaitCount_IXlock| COUNTER |实例级意向排他锁等待次数
+|locks_Global_timeAcquiringMicros_ISlock| COUNTER |实例级共享锁获取耗时 单位:微秒
+|locks_Global_timeAcquiringMicros_IXlock| COUNTER |实例级共排他获取耗时 单位:微秒
+|locks_Database_acquireCount_ISlock| COUNTER |数据库级意向共享锁获取次数
+|locks_Database_acquireCount_IXlock| COUNTER |数据库级意向排他锁获取次数
+|locks_Database_acquireCount_Slock| COUNTER |数据库级共享锁获取次数
+|locks_Database_acquireCount_Xlock| COUNTER |数据库级排他锁获取次数
+|locks_Collection_acquireCount_ISlock| COUNTER |集合级意向共享锁获取次数
+|locks_Collection_acquireCount_IXlock| COUNTER |集合级意向排他锁获取次数
+|locks_Collection_acquireCount_Xlock| COUNTER |集合级排他锁获取次数
+|opcounters_command| COUNTER |数据库执行的所有命令/秒
+|opcounters_insert| COUNTER |数据库执行的插入操作次数/秒
+|opcounters_delete| COUNTER |数据库执行的删除操作次数/秒
+|opcounters_update| COUNTER |数据库执行的更新操作次数/秒
+|opcounters_query| COUNTER |数据库执行的查询操作次数/秒
+|opcounters_getmore| COUNTER |数据库执行的getmore操作次数/秒
+|opcountersRepl_command| COUNTER |数据库复制执行的所有命令次数/秒
+|opcountersRepl_insert| COUNTER |数据库复制执行的插入命令次数/秒
+|opcountersRepl_delete| COUNTER |数据库复制执行的删除命令次数/秒
+|opcountersRepl_update| COUNTER |数据库复制执行的更新命令次数/秒
+|opcountersRepl_query| COUNTER |数据库复制执行的查询命令次数/秒
+|opcountersRepl_getmore| COUNTER |数据库复制执行的gtemore命令次数/秒
+|network_bytesIn| COUNTER |数据库接受的网络传输字节数/秒
+|network_bytesOut| COUNTER |数据库发送的网络传输字节数/秒
+|network_numRequests| COUNTER |数据库接收到的请求的总次数/秒
+|mem_virtual| GAUGE |数据库进程使用的虚拟内存
+|mem_resident| GAUGE |数据库进程使用的物理内存
+|mem_mapped| GAUGE |mapped的内存,只用于MMAPv1 存储引擎
+|mem_bits| GAUGE |64 or 32bit
+|mem_mappedWithJournal| GAUGE |journal日志消耗的映射内存,只用于MMAPv1 存储引擎
+|backgroundFlushing_flushes| COUNTER |数据库刷新写操作到磁盘的次数/秒
+|backgroundFlushing_average_ms| GAUGE |数据库刷新写操作到磁盘的平均耗时,单位ms
+|backgroundFlushing_last_ms| COUNTER |当前最近一次数据库刷新写操作到磁盘的耗时,单位ms
+|backgroundFlushing_total_ms| GAUGE |数据库刷新写操作到磁盘的总耗时/秒,单位ms
+|cursor_open_total| GAUGE |当前数据库为客户端维护的游标总数
+|cursor_timedOut| COUNTER |数据库timout的游标个数/秒
+|cursor_open_noTimeout| GAUGE |设置DBQuery.Option.noTimeout的游标数
+|cursor_open_pinned| GAUGE |打开的pinned的游标数
+|repl_health| GAUGE |复制的健康状态
+|repl_myState| GAUGE |当前节点的副本集状态
+|repl_oplog_window| GAUGE |oplog的窗口大小
+|repl_optime| GAUGE |上次执行的时间戳
+|replication_lag_percent| GAUGE |延时占比(lag/oplog_window)
+|repl_lag| GAUGE |Secondary复制延时,单位秒
+|shards_size| GAUGE |数据库集群的分片个数; config.shards.count
+|shards_mongosSize| GAUGE |数据库集群中mongos节点个数;config.mongos.count
+|shards_chunkSize| GAUGE |数据库集群的chunksize大小设置,以config.settings集合中获取
+|shards_activeWindow| GAUGE |数据库集群的数据均衡器是否设置了时间窗口,1/0
+|shards_activeWindow_start| GAUGE |数据库集群的数据均衡器时间窗口开始时间,格式23.30表示 23:30分
+|shards_activeWindow_stop| GAUGE |数据库集群的数据均衡器时间窗口结束时间,格式23.30表示 23:30分
+|shards_BalancerState| GAUGE |数据库集群的数据均衡器的状态,是否为打开
+|shards_isBalancerRunning| GAUGE |数据库集群的数据均衡器是否正在运行块迁移
+|wt_cache_used_total_bytes| GAUGE |wiredTiger cache的字节数
+|wt_cache_dirty_bytes| GAUGE |wiredTiger cache中"dirty"数据的字节数
+|wt_cache_readinto_bytes| COUNTER |数据库写入wiredTiger cache的字节数/秒
+|wt_cache_writtenfrom_bytes| COUNTER |数据库从wiredTiger cache写入到磁盘的字节数/秒
+|wt_concurrentTransactions_write| GAUGE |write tickets available to the WiredTiger storage engine
+|wt_concurrentTransactions_read| GAUGE |read tickets available to the WiredTiger storage engine
+|wt_bm_bytes_read| COUNTER |block-manager read字节数/秒
+|wt_bm_bytes_written| COUNTER |block-manager write字节数/秒
+|wt_bm_blocks_read| COUNTER |block-manager read块数/秒
+|wt_bm_blocks_written| COUNTER |block-manager write块数/秒
+|rocksdb_num_immutable_mem_table|
+|rocksdb_mem_table_flush_pending|
+|rocksdb_compaction_pending|
+|rocksdb_background_errors|
+|rocksdb_num_entries_active_mem_table|
+|rocksdb_num_entries_imm_mem_tables|
+|rocksdb_num_snapshots|
+|rocksdb_oldest_snapshot_time|
+|rocksdb_num_live_versions|
+|rocksdb_total_live_recovery_units|
+|PerconaFT_cachetable_size_current|
+|PerconaFT_cachetable_size_limit|
+|PerconaFT_cachetable_size_writing|
+|PerconaFT_checkpoint_count|
+|PerconaFT_checkpoint_time|
+|PerconaFT_checkpoint_write_leaf_bytes_compressed|
+|PerconaFT_checkpoint_write_leaf_bytes_uncompressed|
+|PerconaFT_checkpoint_write_leaf_count|
+|PerconaFT_checkpoint_write_leaf_time|
+|PerconaFT_checkpoint_write_nonleaf_bytes_compressed|
+|PerconaFT_checkpoint_write_nonleaf_bytes_uncompressed|
+|PerconaFT_checkpoint_write_nonleaf_count|
+|PerconaFT_checkpoint_write_nonleaf_time|
+|PerconaFT_compressionRatio_leaf|
+|PerconaFT_compressionRatio_nonleaf|
+|PerconaFT_compressionRatio_overall|
+|PerconaFT_fsync_count|
+|PerconaFT_fsync_time|
+|PerconaFT_log_bytes|
+|PerconaFT_log_count|
+|PerconaFT_log_time|
+|PerconaFT_serializeTime_leaf_compress|
+|PerconaFT_serializeTime_leaf_decompress|
+|PerconaFT_serializeTime_leaf_deserialize|
+|PerconaFT_serializeTime_leaf_serialize|
+|PerconaFT_serializeTime_nonleaf_compress|
+|PerconaFT_serializeTime_nonleaf_decompress|
+|PerconaFT_serializeTime_nonleaf_deserialize|
+|PerconaFT_serializeTime_nonleaf_serialize|
+
+
+建议设置监控告警项
+-----------------------------
+说明:系统级监控项由falcon agent提供;监控触发条件根据场景自行调整
+--------------------------------
+
+|告警项|
+|-----|
+|load.1min>10|
+|cpu.idle<10|
+|df.bytes.free.percent<30|
+|df.bytes.free.percent<10|
+|mem.memfree.percent<20|
+|mem.memfree.percent<10|
+|mem.memfree.percent<5|
+|mem.swapfree.percent<50|
+|mem.memused.percent>=50|
+|mem.memused.percent>=10|
+|net.if.out.bytes>94371840|
+|net.if.in.bytes>94371840|
+|disk.io.util>90|
+|mongo_local_alive=0|
+|page_faults>100|
+|connections_current>5000|
+|connections_used_percent>60|
+|connections_used_percent>80|
+|connections_totalCreated>1000|
+|globalLock_currentQueue_total>10|
+|globalLock_currentQueue_readers>10|
+|globalLock_currentQueue_writers>10|
+|opcounters_command|
+|opcounters_insert|
+|opcounters_delete|
+|opcounters_update|
+|opcounters_query|
+|opcounters_getmore|
+|opcountersRepl_command|
+|opcountersRepl_insert|
+|opcountersRepl_delete|
+|opcountersRepl_update|
+|opcountersRepl_query|
+|opcountersRepl_getmore|
+|network_bytesIn|
+|network_bytesOut|
+|network_numRequests|
+|repl_health=0|
+|repl_myState not 1/2/7|
+|repl_oplog_window<168|
+|repl_oplog_window<48|
+|replication_lag_percent>50|
+|repl_lag>60|
+|repl_lag>300|
+|shards_mongosSize
+
+
+Contributors
+------------------------------------------
+- 卓汝林: mail:zhuorulintec@163.com; weibo: http://weibo.com/u/2540962412
diff --git a/zh_0_3/usage/README.md b/zh_0_3/usage/README.md
new file mode 100644
index 0000000..be5f28e
--- /dev/null
+++ b/zh_0_3/usage/README.md
@@ -0,0 +1,4 @@
+
+
+open-falcon使用手册
+
diff --git a/zh_0_3/usage/aggregator.md b/zh_0_3/usage/aggregator.md
new file mode 100644
index 0000000..6a9bc1f
--- /dev/null
+++ b/zh_0_3/usage/aggregator.md
@@ -0,0 +1,92 @@
+
+
+# 集群聚合
+
+集群监控的本质是一个聚合功能。
+
+单台机器的监控指标难以反应整个集群的情况,我们需要把整个集群的机器(体现为某个HostGroup下的机器)综合起来看。比如所有机器的qps加和才是整个集群的qps,所有机器的request_fail数量 ÷ 所有机器的request_total数量=整个集群的请求失败率。
+
+我们计算出集群的某个整体指标之后,也会有“查看该指标的历史趋势图” “为该指标配置报警” 这种需求,故而,我们会把这个指标重新push回监控server端,于是,你就可以把它当成一个普通监控数据来对待了。
+
+背景交代清楚了……现在来介绍我们的实现……
+
+首先,用户要在某个HostGroup下添加集群聚合规则,我们就知道这个规则涵盖的机器是当前这个HostGroup下的所有机器。
+其次,整个集群的指标计算是一个除法,除法的话就有分子,有分母。
+
+* 场景一:“所有机器的qps加和才是整个集群的qps” 这个场景中每个机器应该有个qps的counter,每个counter在书写的时候要求用`$()`包裹起来,故而,分子可以这么描述:`$(qps/module=judge,project=falcon)`,分母就填写 1 就行了。
+* 场景二:“所有机器的request_fail数量 ÷ 所有机器的request_total数量=整个集群的请求失败率” 分子就是:`$(request_fail/module=graph,project=falcon)` 分母就是:`$(request_total/module=graph,project=falcon)`
+* 场景三:“集群中cpu使用使用率大于40%的机器比例” 这个场景我们称为**集群百分比**,这是比较运算,分子是`$(cpu.busy)>40`,分母就是$#,当然同时支持" > < = >= <= "五种比较运算
+场景一和场景三的区别:以分子为例,前者是累加指定counter返回的数值,如集群中三个机器分别返回2,4,5,则分子为 2+4+5=11;后者是如果counter符合条件则分子加1,如三个机器分别返回29,41,45,则分子为 0+1+1=2
+
+另外,对于分子和分母,我们是支持加减计算的,不过不支持除法、乘法、括号,举个没意义的分母:`$(cpu.idle) + $(cpu.busy) `,可以两个counter相加
+
+分子和分母不但支持配置counter,也支持配置成纯数字,支持配置 `$#`,`$#`在shell编程中是参数个数的意思,我们这里也类似。
+
+如果是比较运算中使用加减法,需要使用()括起来,就像常规运算中优先级一样,比如:`($(cpu.idle) + $(cpu.busy)) > 40`,两个counter相加之后再作比较运算
+
+对于分子而言,我们就会拿着HostGroup下的所有机器去查询相对counter的最新值,然后把所有值相加(不同机器计算出来的分子要相加),但是有的机器可能查不到数据,`$#`表示的是正常查到数据的机器数量。整个表达式假设涉及到3个counter,对某个机器而言,必须3个counter都查到数据才被使用,只要有一个counter没有查到数据,那就忽略这个机器。
+
+下面列举些配置实例:
+```
+# 合法 计算集群qps平均值
+分子:$(qps/module=judge,project=falcon)
+分母:$#
+
+# 合法 计算集群qps总值
+分子:$(qps/module=judge,project=falcon)
+分母:1
+
+# 合法 计算集群disk.io.util大于等于40%的机器个数
+分子:$(disk.io.util)>=40
+分母:1
+
+# 合法 计算整个集群diso.io.util大于40%的比率
+分子:$(disk.io.util)>40
+分母:$#
+
+# 合法 计算集群中cpu.idle + cpu.busy为100的机器个数
+分子:($(cpu.idle) + $(cpu.busy)) = 100
+分母:1
+
+# 合法 分母与分子配置无差别,都可使用Counter,仅举个例子
+分子:$(cpu.busy)
+分母:$(cpu.busy)
+
+# 非法 对于使用了加减去处的比较运算,需要使用( )
+分子:$(cpu.idle) + $(cpu.busy) > 40
+分母:1
+
+# 非法 分子和分母至少配置一个counter
+分子:$#
+分母:1
+
+# 非法 加减运算中变量和数字不能混合使用
+分子:($(cpu.idle) + $(cpu.busy) - 60) > 100
+分母:1
+```
+
+注意:分子、分母中至少配置一个counter,不能都配置成纯数字或$#,因为这种配置是没啥意义的。除了配置分子、分母之外,还有很多其他配置,比如endpoint、metric、tags、step等等,这些是为了把数据重新push回监控server的时候用的。监控的数据有好几个字段,缺一不可,我们可以计算出集群监控指标的value和时间戳,但是无法自动填充endpoint、metric、tags、step等字段,所以,仍然要用户手工填写。
+
+
+## 用户手册
+使用集群聚合监控,需要进行两个配置: 集群聚合 和 报警策略。下面,我们以一个例子,讲述如何使用集群聚合监控提供的服务。
+
+### 用户需求
+获取节点cop.xiaomi_owt.inf_pdl.falcon下cpu.busy>80的机器在集群中所占比例,达到阈值后通知给用户。
+
+### 集群聚合配置
+访问HostGroup,搜索节点cop.xiaomi_owt.inf_pdl.falcon,点击后面的aggregator链接,进入当前节点对应的aggregator列表,如下图所示:
+
+
+点击右上角的“新建”按钮,可进入aggregator编辑页面,如下图所示:
+
+
+注:Endpoint最好是跟HostGroup有绑定关系,这样方便使用模板来配置报警;否则需要Expression来配置报警
+
+### 模板策略配置
+下面以报警模板为例,配置了aggregator后,如果想收到关于聚合的值的报警,需要在 **Endpoint所在的节点** 绑定的模板里面配下监控策略:
+
+
+### 策略表达式配置
+如果已经配置模板策略,就不用再配置 [策略表达式](../philosophy/tags-and-hostgroup.md)
+
\ No newline at end of file
diff --git a/zh_0_3/usage/data-push.md b/zh_0_3/usage/data-push.md
new file mode 100644
index 0000000..c023a86
--- /dev/null
+++ b/zh_0_3/usage/data-push.md
@@ -0,0 +1,75 @@
+
+
+# 自定义push数据到open-falcon
+
+不仅仅是falcon-agent采集的数据可以push到监控系统,一些场景下,我们自定义的一些数据指标,也可以push到open-falcon中,比如:
+
+1. 线上某服务的qps
+2. 某业务的在线人数
+3. 某个接⼝的响应时间
+4. 某个⻚面的状态码(500、200)
+5. 某个接⼝的请求出错次数
+6. 某个业务的每分钟的收⼊统计
+7. ......
+
+## 一个shell脚本编写的,自定义push数据到open-falcon的例子
+
+```
+# 注意,http request body是个json,这个json是个列表
+
+ts=`date +%s`;
+
+curl -X POST -d "[{\"metric\": \"test-metric\", \"endpoint\": \"test-endpoint\", \"timestamp\": $ts,\"step\": 60,\"value\": 1,\"counterType\": \"GAUGE\",\"tags\": \"idc=lg,project=xx\"}]" http://127.0.0.1:1988/v1/push
+
+```
+
+## 一个python的、自定义push数据到open-falcon的例子
+
+```
+#!-*- coding:utf8 -*-
+
+import requests
+import time
+import json
+
+ts = int(time.time())
+payload = [
+ {
+ "endpoint": "test-endpoint",
+ "metric": "test-metric",
+ "timestamp": ts,
+ "step": 60,
+ "value": 1,
+ "counterType": "GAUGE",
+ "tags": "idc=lg,loc=beijing",
+ },
+
+ {
+ "endpoint": "test-endpoint",
+ "metric": "test-metric2",
+ "timestamp": ts,
+ "step": 60,
+ "value": 2,
+ "counterType": "GAUGE",
+ "tags": "idc=lg,loc=beijing",
+ },
+]
+
+r = requests.post("http://127.0.0.1:1988/v1/push", data=json.dumps(payload))
+
+print r.text
+```
+
+## API详解
+
+- metric: 最核心的字段,代表这个采集项具体度量的是什么, 比如是cpu_idle呢,还是memory_free, 还是qps
+- endpoint: 标明Metric的主体(属主),比如metric是cpu_idle,那么Endpoint就表示这是哪台机器的cpu_idle
+- timestamp: 表示汇报该数据时的unix时间戳,注意是整数,代表的是秒
+- value: 代表该metric在当前时间点的值,float64
+- step: 表示该数据采集项的汇报周期,这对于后续的配置监控策略很重要,必须明确指定。
+- counterType: 只能是COUNTER或者GAUGE二选一,前者表示该数据采集项为计时器类型,后者表示其为原值 (注意大小写)
+ - GAUGE:即用户上传什么样的值,就原封不动的存储
+ - COUNTER:指标在存储和展现的时候,会被计算为speed,即(当前值 - 上次值)/ 时间间隔
+- tags: 一组逗号分割的键值对, 对metric进一步描述和细化, 可以是空字符串. 比如idc=lg,比如service=xbox等,多个tag之间用逗号分割
+
+说明:这7个字段都是必须指定
diff --git a/zh_0_3/usage/docker.md b/zh_0_3/usage/docker.md
new file mode 100644
index 0000000..580c19c
--- /dev/null
+++ b/zh_0_3/usage/docker.md
@@ -0,0 +1,42 @@
+
+
+
+# Docker容器监控实践
+
+在[数据采集](../philosophy/data-collect.md)一节中我们介绍了常见的监控数据源。open-falcon作为一个监控框架,可以去采集任何系统的监控指标数据,只要将监控数据组织为open-falcon规范的格式就OK了。
+
+docker container的数据采集可以通过[micadvisor_open](https://github.com/open-falcon/micadvisor_open)来做。
+
+## 工作原理
+
+micadvisor-open是基于open-falcon的docker容器资源监控插件,监控容器的cpu、内存、diskio以及网络io等,数据采集后上报到open-falcon
+
+## 采集的指标
+
+| Counters | Notes|
+|-----|------|
+|cpu.busy|cpu使用情况百分比|
+|cpu.user|用户态使用的CPU百分比|
+|cpu.system|内核态使用的CPU百分比|
+|cpu.core.busy|每个cpu的使用情况|
+|mem.memused.percent|内存使用百分比|
+|mem.memused|内存使用原值|
+|mem.memtotal|内存总量|
+|mem.memused.hot|内存热使用情况|
+|disk.io.read_bytes|磁盘io读字节数|
+|disk.io.write_bytes|磁盘io写字节数|
+|net.if.in.bytes|网络io流入字节数|
+|net.if.in.packets|网络io流入包数|
+|net.if.in.errors|网络io流入出错数|
+|net.if.in.dropped|网络io流入丢弃数|
+|net.if.out.bytes|网络io流出字节数|
+|net.if.out.packets|网络io流出包数|
+|net.if.out.errors|网络io流出出错数|
+|net.if.out.dropped|网络io流出丢弃数|
+
+## Contributors
+- mengzhuo: QQ:296142139; MAIL:mengzhuo@xiaomi.com
+
+## 补充
+- 另外一个docker metric采集的lib库:https://github.com/projecteru/eru-metric
+
diff --git a/zh_0_3/usage/du-proc.md b/zh_0_3/usage/du-proc.md
new file mode 100644
index 0000000..8db67b3
--- /dev/null
+++ b/zh_0_3/usage/du-proc.md
@@ -0,0 +1,22 @@
+
+
+
+# 目录监控和进程详情监控实践
+
+目录大小和进程详情的数据采集可用脚本[falcon-scripts](https://github.com/ZoneTong/falcon-scripts)来做。
+
+收集的指标如下:
+
+| 指标名 | 注释 |
+|--------|------|
+|du.bytes.used|目录大小,单位byte|
+|proc.cpu|进程所占cpu,百分比|
+|proc.mem|进程所占内存,单位byte|
+|proc.io.in|进程io输入,单位byte|
+|proc.io.out|进程io输出,单位byte|
+
+## 工作原理
+
+du.sh脚本借助du命令采集数据
+
+proc.sh脚本分析/proc/$PID/status /proc/$PID/io等数据
diff --git a/zh_0_3/usage/esxi.md b/zh_0_3/usage/esxi.md
new file mode 100644
index 0000000..84d96c7
--- /dev/null
+++ b/zh_0_3/usage/esxi.md
@@ -0,0 +1,84 @@
+
+
+# ESXi监控
+
+VMware的主体机器(host machine)是运行ESXi作业系统。没有办法安装Open-Falcon agent来监控,所以不能用普通的方式来做监控。
+
+ESXi作业系统设备的运行指标的采集,可以透过写脚本,通过SNMP协议来采集交换机的各项运行指标,包括内存占用、CPU使用、流量、磁盘用量等。[esxicollector](https://github.com/humorless/esxicollector)就是這樣子的腳本。
+
+## 工作原理
+
+esxicollector是一系列整理过的脚本。由[humorless](https://github.com/humorless/)设计开发。
+
+esxicollector需要透过cronjob来配置。在一台可以跑cronjob的机器上,配置好cronjob。并且在esxi_collector.sh这个脚本中,写清楚要监控的设备、用来接受监控结果的Open-Falcon agent的位址。esxicollector就会照cronjob的时间间隔,预设是每分钟一次,定期地去采集ESXi作业系统设备的监控项,并透过上报到Open-Falcon的agent。
+
+采集的metric列表:
+
+* CPU利用率
+
+ `esxi.cpu.core`
+
+* 内存總量/利用率
+
+ `esxi.cpu.memory.kliobytes.size`
+ `esxi.cpu.memory.kliobytes.used`
+ `esxi.cpu.memory.kliobytes.avail`
+
+* 运行的进程数
+
+ `esxi.current.process`
+
+* 登入的使用者数
+
+ `esxi.current.user`
+
+* 虚拟机器数
+
+ `esxi.current.vhost`
+
+* 磁盤總量/利用率
+
+ `esxi.df.size.kilobytes`
+ `esxi.df.used.percentage`
+
+* 磁盤錯誤
+
+ `esxi.disk.allocationfailure`
+
+* 網卡的輸出入流量/封包數
+
+ `esxi.net.in.octets`
+ `esxi.net.in.ucast.pkts`
+ `esxi.net.in.multicast.pkts`
+ `esxi.net.in.broadcast.pkts`
+ `esxi.net.out.octets`
+ `esxi.net.out.ucast.pkts`
+ `esxi.net.out.multicast.pkts`
+ `esxi.net.out.broadcast.pkts`
+
+
+## 安装
+
+从[这里](https://github.com/humorless/esxicollector)下载。
+
+ 1. 安装SNMP指令
+
+ `yum -y install net-snmp net-snmp-utils`
+
+ 2. 下载VMware ESXi MIB档案,并且复制它们到资料夹`/usr/share/snmp/mibs`
+
+ 3. 设置SNMP的环境
+
+ `mkdir ~/.snmp`
+ `echo "mibs +ALL" > ~/.snmp/snmp.conf`
+
+ 4. 在`esxi_collector.sh`填入合适的参数
+
+ 5. 设置cronjobs
+
+ ` * * * * * esxi_collector.sh `
+
+
+## 延伸开发新的监控项
+
+脚本 ```snmp_queries.sh``` 会呼叫基本的snmp指令,并且输出snmp执行完的结果。可以透过比较执行 ```60_esxi_*.sh```的结果,来设计新的脚本。
diff --git a/zh_0_3/usage/fault-recovery.md b/zh_0_3/usage/fault-recovery.md
new file mode 100644
index 0000000..5d1ca4b
--- /dev/null
+++ b/zh_0_3/usage/fault-recovery.md
@@ -0,0 +1,9 @@
+
+
+# 对接蓝鲸-故障自愈平台
+
+蓝鲸故障自愈,是腾讯蓝鲸推出的一款SaaS服务,目前可以支持和open-falcon无缝对接了,通过接入蓝鲸故障自愈系统,可以帮助使用open-falcon的用户,做到告警无人值守。
+
+- 具体的配置非常简单: [open-falcon接入蓝鲸](https://docs.bk.tencent.com/product_white_paper/fta/Getting_Started/Integrated_Openfalcon.html)
+- 腾讯蓝鲸故障自愈的使用案例参考:[蓝鲸故障自愈案例](https://docs.bk.tencent.com/product_white_paper/fta/Community_users_cases/Community_users_share_cases.html)
+- [那些年我们想做的无人值守](https://mp.weixin.qq.com/s/MX74-vDEOkFA0Om6WDrwYQ)
diff --git a/zh_0_3/usage/flume.md b/zh_0_3/usage/flume.md
new file mode 100644
index 0000000..9b98a64
--- /dev/null
+++ b/zh_0_3/usage/flume.md
@@ -0,0 +1,14 @@
+
+
+# Flume监控
+
+在[数据采集](../philosophy/data-collect.md)一节中我们介绍了常见的监控数据源。open-falcon作为一个监控框架,可以去采集任何系统的监控指标数据,只要将监控数据组织为open-falcon规范的格式就OK了。
+
+Flume的数据采集可以通过脚本[flume-monitor](https://github.com/mdh67899/openfalcon-monitor-scripts/tree/master/flume)来做。
+
+## 工作原理
+```flume-monitor.py```是一个采集脚本,只需要放到falcon-agent的plugin目录,在portal中将对应的plugin绑定到主机组,falcon-agent会主动执行```flume-monitor.py```脚本,```flume-monitor.py```脚本执行结束后会输出json格式数据,由falcon-agent读取和解析数据
+
+Flume运行时需要在配置文件中加入java环境变量,启动成功之后flume进程会监听一个端口,可以通过http请求的方式来抓取flume提供的metrics,```flume-monitor.py```脚本中配置了需要抓取的Flume组件metric,通过http的方式从flume端口中抓取需要的组件信息,输出json格式数据
+
+比如我们在单台机器上部署了3个flume实例,可以在将脚本复制三份,改一下脚本中的```http url```地址,与flume监听的http端口一一对应,在portal中绑定好插件即可
diff --git a/zh_0_3/usage/func.md b/zh_0_3/usage/func.md
new file mode 100644
index 0000000..c7ceece
--- /dev/null
+++ b/zh_0_3/usage/func.md
@@ -0,0 +1,33 @@
+
+
+# 报警函数说明
+
+配置报警策略的时候open-falcon支持多种报警触发函数,比如`all(#3)` `diff(#10)`等等。
+这些#后面的数字表示的是最新的历史点,比如`#3`代表的是最新的三个点。该数字默认不能大于`10`,大于`10`将当作`10`处理,即只计算最新`10`个点的值。
+
+说明:`#`后面的数字的最大值,即在 judge 内存中保留最近几个点,是支持自定义的,具体参考 book 中[描述](http://book.open-falcon.com/zh_0_2/distributed_install/judge.html) ; 源码位置 => [cfg.example.json](https://github.com/open-falcon/falcon-plus/blob/master/modules/judge/cfg.example.json#L4:6)
+
+```bash
+all(#3): 最新的3个点都满足阈值条件则报警
+max(#3): 对于最新的3个点,其最大值满足阈值条件则报警
+min(#3): 对于最新的3个点,其最小值满足阈值条件则报警
+sum(#3): 对于最新的3个点,其和满足阈值条件则报警
+avg(#3): 对于最新的3个点,其平均值满足阈值条件则报警
+diff(#3): 拿最新push上来的点(被减数),与历史最新的3个点(3个减数)相减,得到3个差,只要有一个差满足阈值条件则报警
+pdiff(#3): 拿最新push上来的点,与历史最新的3个点相减,得到3个差,再将3个差值分别除以减数,得到3个商值,只要有一个商值满足阈值则报警
+lookup(#2,3): 最新的3个点中有2个满足条件则报警;
+stddev(#7) = 3:离群点检测函数,取最新 **7** 个点的数据分别计算得到他们的标准差和均值,分别计为 σ 和 μ,其中当前值计为 X,那么当 X 落在区间 [μ-3σ, μ+3σ] 之外时,则认为当前值波动过大,触发报警;更多请参考3-sigma算法:https://en.wikipedia.org/wiki/68%E2%80%9395%E2%80%9399.7_rule。
+
+```
+
+最常用的就是`all`函数了,比如cpu.idle `all(#3) < 5`,表示cpu.idle的值连续3次小于5%则报警。
+
+`lookup`为非连续性报警函数,适用于在一定范围内容忍监控指标抖动的场景,比如某个主机的cpu.busy忽高忽低,使用`all(#1)>80`明显过于严格,会产生大量报警干扰视线,使用`all(#3)>80`则连续三次偏高的概率很小,可能永远不会触发报警,不能帮助我们发现系统的不稳定,那么如果使用`lookup(#3,5)`,我们就可以知道cpu.busy最近抖动频繁,超过了我们容忍的界线。
+
+新增 `stddev` 函数,基于高斯分布的离群点检测方式,比如cpu.idle `stddev(#5) = 3` ,表示获取cpu.idle的历史5个点数据,计算得到他们的标准差和均值,分别计为 σ 和 μ,看其是否分布在`(μ-3σ,μ+3σ)`范围之内,如果不在范围之内则报警。具体参考wiki中[描述](https://zh.wikipedia.org/wiki/%E6%AD%A3%E6%80%81%E5%88%86%E5%B8%83)
+
+diff和pdiff理解起来没那么容易,设计diff和pdiff是为了解决流量突增突降报警。实在看不懂,那只能去读代码了:https://github.com/open-falcon/judge/blob/master/store/func.go
+
+
+
+
diff --git a/zh_0_3/usage/getting-started.md b/zh_0_3/usage/getting-started.md
new file mode 100644
index 0000000..e9c4d72
--- /dev/null
+++ b/zh_0_3/usage/getting-started.md
@@ -0,0 +1,87 @@
+
+
+系统搭建好了,应该如何用起来,这节给大家逐步介绍一下
+
+# 查看监控数据
+
+我们说agent只要部署到机器上,并且配置好了heartbeat和transfer就自动采集数据了,我们就可以去dashboard上面搜索监控数据查看了。dashboard是个web项目,浏览器访问之。左侧输入endpoint搜索,endpoint是什么?应该用什么搜索?对于agent采集的数据,endpoint都是机器名,去目标机器上执行`hostname`,看到的输出就是endpoint,拿着hostname去搜索。
+
+搜索到了吧?嗯,选中前面的复选框,点击“查看counter列表”,可以列出隶属于这个endpoint的counter,counter是什么?`counter=${metric}/sorted(${tags})`
+
+假如我们要查看cpu.busy,在counter搜索框中输入cpu并回车。看到cpu.busy了吧,点击,会看到一个新页面,图表中就是这个机器的cpu.busy的近一小时数据了,想看更长时间的?右上角有个小三角,展开菜单,可以选择更长的时间跨度
+
+
+- - - - -
+
+
+
+# 如何配置报警策略
+
+上节我们已经了解到如何查看监控数据了,如果数据达到阈值,比如cpu.busy太大的时候,我们应该如何配置告警呢?
+
+## 配置报警接收人
+
+falcon的报警接收人不是一个具体的手机号,也不是一个具体的邮箱,因为手机号、邮箱都是容易发生变化的,如果变化了去修改所有相关配置那就太麻烦了。我们把用户的联系信息维护在一个叫 `帐户/Profile` 里,以后如果要修改手机号、邮箱,只要修改自己的帐户信息即可。报警接收人也不是单个的人,而是一个组(Teams),比如falcon这个系统的任何组件出问题了,都应该发报警给falcon的运维和开发人员,发给falcon这个团队,这样一来,新员工入职只要加入falcon这个Team即可;员工离职,只要从falcon这个Team删掉即可。
+
+浏览器访问UIC,如果启用了LDAP,那就用LDAP账号登陆,如果没有启用,那就注册一个或者找管理员帮忙开通。创建一个Team,名称姑且叫falcon,把自己加进去,待会用来做测试。
+
+首先修改帐户信息,保证邮箱和手机号正确
+
+
+然后添加报警组,添加成员
+
+- - - -
+
+
+## 创建HostGroup
+
+比如我们要对falcon-judge这个组件做端口监控,那首先创建一个HostGroup,把所有部署了falcon-judge这个模块的机器都塞进去,以后要扩容或下线机器的时候直接从这个HostGroup增删机器即可,报警策略会自动生效、失效。咱们为这个HostGroup取名为:sa.dev.falcon.judge,这个名称有讲究,sa是我们部门,dev是我们组,falcon是项目名,judge是组件名,传达出了很多信息,这样命名比较容易管理,推荐大家这么做。
+
+
+
+在往组里加机器的时候如果报错,需要检查portal的数据库中host表,看里边是否有相关机器。那host表中的机器从哪里来呢?agent有个heartbeat(hbs)的配置,agent每分钟会发心跳给hbs,把自己的ip、hostname、agent version等信息告诉hbs,hbs负责写入host表。如果host表中没数据,需要检查这条链路是否通畅。
+
+## 创建策略模板
+
+portal最上面有个Templates链接,这就是策略模板管理的入口。我们进去之后创建一个模板,名称姑且也叫:sa.dev.falcon.judge.tpl,与HostGroup名称相同,在里边配置一个端口监控,通常进程监控有两种手段,一个是进程本身是否存活,一个是端口是否在监听,此处我们使用端口监控。
+
+
+- - - - -
+
+
+右上角那个加号按钮是用于增加策略的,一个模板中可以有多个策略,此处我们只添加了一个。下面可以配置报警接收人,此处填写的是falcon,这是之前在UIC中创建的Team。
+
+## 将HostGroup与模板绑定
+
+一个模板是可以绑定到多个HostGroup的,现在我们重新回到HostGroups页面,找到sa.dev.falcon.judge这个HostGroup,右侧有几个超链接,点击【templates】进入一个新页面,输入模板名称,绑定一下就行了。
+
+
+- - - - -
+
+
+## 补充
+
+上面步骤做完了,也就配置完了。如果judge组件宕机,端口不再监听了,就会报警。不过大家不要为了测试报警效果,直接把judge组件给干掉了,因为judge本身就是负责判断报警的,把它干掉了,那就没法判断了……所以说falcon现在并不完善,没法用来监控本身的组件。为了测试,大家可以修改一下端口监控的策略配置,改成一个没有在监听的端口,这样就触发报警了。
+
+上面的策略只是对falcon-judge做了端口监控,那如果我们要对falcon这个项目的所有机器加一些负载监控,应该如何做呢?
+
+1. 创建一个HostGroup:sa.dev.falcon,把所有falcon的机器都塞进去
+2. 创建一个模板:sa.dev.falcon.common,添加一些像ping, df.bytes.free.percent, load.5min等策略
+3. 将sa.dev.falcon.common绑定到sa.dev.falcon这个HostGroup
+
+附:sa.dev.falcon.common的配置样例
+
+
+
+大家可能不知道各个指标分别叫什么,自己push的数据肯定知道自己的metric了,agent push的数据可以参考:https://github.com/open-falcon/agent/tree/master/funcs
+
+# 如何配置策略表达式
+
+策略表达式,即expression,具体可以参考 [HostGroup与Tags设计理念](../philosophy/tags-and-hostgroup.md),这里只是举个例子:
+
+
+
+
+上例中的配置传达出的意思是:endpoint=aggregator 并且 metric=cpu.busy 的所有的监控指标,只要连续3次 >= 0.5 则报警给`falcon-test1`这个报警组。
+
+expression无需绑定到HostGroup,enjoy it
\ No newline at end of file
diff --git a/zh_0_3/usage/haproxy.md b/zh_0_3/usage/haproxy.md
new file mode 100644
index 0000000..fb41142
--- /dev/null
+++ b/zh_0_3/usage/haproxy.md
@@ -0,0 +1,11 @@
+
+
+#HAProxy 监控
+
+在[数据采集](../philosophy/data-collect.md)一节中我们介绍了常见的监控数据源。open-falcon作为一个监控框架,可以去采集任何系统的监控指标数据,只要将监控数据组织为open-falcon规范的格式就OK了。
+
+HAProxy的数据采集可以通过[haproxymon](https://github.com/iask/haproxymon)来做。
+
+## 工作原理
+
+haproxymon是一个cron,每分钟跑一次采集脚本```haproxymon.py```,haproxymon通过Haproxy的stats socket接口来采集Haproxy基础状态信息,比如qcur、scur、rate等,然后组装为open-falcon规定的格式的数据,post给本机的falcon-agent。falcon-agent提供了一个http接口,使用方法可以参考[数据采集](../philosophy/data-collect.md)中的例子。
\ No newline at end of file
diff --git a/zh_0_3/usage/hwcheck.md b/zh_0_3/usage/hwcheck.md
new file mode 100644
index 0000000..d48d37c
--- /dev/null
+++ b/zh_0_3/usage/hwcheck.md
@@ -0,0 +1,94 @@
+
+
+# 硬件监控
+
+在[数据采集](../philosophy/data-collect.md)一节中我们介绍了常见的监控数据源。open-falcon作为一个监控框架,可以去采集任何系统的监控指标数据,只要将监控数据组织为open-falcon规范的格式就OK了。
+
+硬件的数据采集可以通过 [HWCheck](https://github.com/51web/hwcheck) 来做。
+
+# HWCheck
+
+rvadmin工具等组件实现硬件监控,需要安装falcon-agent
+
+仅支持dell物理机,可以监控的指标有:
+
+cpu 内存 阵列卡 物理磁盘 虚拟磁盘 阵列卡电池 BIOS 主板电池 风扇 电压 主板温度 cpu温度
+
+# 如何安装
+
+1. 配置dell官方repo,安装srvadmin等依赖包
+
+```
+#参考: http://linux.dell.com/repo/hardware/latest/
+wget -q -O - http://linux.dell.com/repo/hardware/latest/bootstrap.cgi | bash
+
+yum install srvadmin-omacore srvadmin-omcommon srvadmin-storage-cli smbios-utils-bin lm_sensors dmidecode cronie
+# 启动srvadmin服务
+/opt/dell/srvadmin/sbin/srvadmin-services.sh enable
+/opt/dell/srvadmin/sbin/srvadmin-services.sh restart
+# 配置lm-sensors
+echo yes | /usr/sbin/sensors-detect
+```
+
+## 你也可以打包rpm来简化部署
+
+```
+git clone https://github.com/51web/hwcheck hwcheck-0.2
+tar czf hwcheck-0.2.tar.gz hwcheck-0.2
+rpmbuild -tb hwcheck-0.2.tar.gz
+```
+
+
+# 如何使用
+
+## 参数说明
+
+直接执行hwcheck不带参数默认会打印出详细的监控数据
+
+```
+hwcheck -d # 打印metrics信息,即是push到falcon-agent的数据
+ -p # push数据到falcon-agent
+ -s # 设置push数据中的STEP数值,表示监控频率,默认值是600秒
+ -m # 指定单个metric
+```
+
+## 配置crontab
+
+配置cron来定期检测,如:
+
+```
+cat /etc/cron.d/hwcheck
+PATH=/sbin:/bin:/usr/sbin:/usr/bin:/opt/dell/srvadmin/sbin:/opt/dell/srvadmin/bin
+SHELL=/bin/bash
+
+18 * * * * root /usr/bin/hwcheck -s 3600 -p >/dev/null 2>&1 &
+```
+
+表示每个小时执行一次检测,相应的STEP值被设置为3600
+
+
+## falcon-portal中配置报警策略
+
+hwcheck push到falcon-agent的metric均以 hw 打头,如hw.cpu_temp,除温度是实际的数值外,
+
+其他metric的value中 0表示故障,1表示警告,2表示OK,例如在portal中配置如下策略:
+
+| metric/tags/note | condition | max | P |
+------------------------------ | --------- | ----- | --- |
+| hw.bios [BIOS中C1E/Cstate未禁用] | all(#2)<2 | 1 | 4 |
+| hw.board_temp [主板温度过高] | all(#3)>=35 | 1 | 4 |
+| hw.cmos_bat [主板电池有问题] | all(#3)<2 |1 | 4 |
+| hw.cpu [CPU可能故障] | all(#2)==1 | 1 | 4 |
+| hw.cpu [严重: CPU严重故障] | all(#2)==0 | 2 | 0 |
+| hw.fan [风扇出现故障] | all(#3)<2 | 1 | 4 |
+| hw.memory [内存可能故障] | all(#1)==1 | 1 | 4 |
+| hw.memory [严重: 内存严重故障] | all(#1)==0 | 2 | 0 |
+| hw.pdisk [严重: 物理盘严重故障] | all(#1)==0 | 2 | 0 |
+| hw.raidcard [阵列卡出现警告] | all(#2)==1 | 1 | 4 |
+| hw.raidcard [严重: 阵列卡严重故障] | all(#1)==0 | 2 | 0 |
+| hw.raidcard_bat [阵列卡电池出现警告] | all(#2)==1 | 1 | 4 |
+| hw.raidcard_bat [严重: 阵列卡电池严重故障] | all(#2)==0 | 2 | 0 |
+| hw.vdisk [磁盘阵列出现警告] | all(#2)==1 | 1 | 4 |
+| hw.vdisk [严重: 磁盘阵列严重故障] | all(#2)==0 | 2 | 0 |
+
+
diff --git a/zh_0_3/usage/jmx.md b/zh_0_3/usage/jmx.md
new file mode 100644
index 0000000..fecd016
--- /dev/null
+++ b/zh_0_3/usage/jmx.md
@@ -0,0 +1,41 @@
+
+
+# jmxmon 简介
+jmxmon是一个基于open-falcon的jmx监控插件,通过这个插件,结合open-falcon agent,可以采集任何开启了JMX服务端口的java进程的服务状态,并将采集信息自动上报给open-falcon服务端
+
+## 主要功能
+
+通过jmx采集java进程的jvm信息,包括gc耗时、gc次数、gc吞吐、老年代使用率、新生代晋升大小、活跃线程数等信息。
+
+对应用程序代码无侵入,几乎不占用系统资源。
+
+
+## 采集指标
+| Counters | Type | Notes|
+|-----|------|------|
+| parnew.gc.avg.time | GAUGE | 一分钟内,每次YoungGC(parnew)的平均耗时 |
+| concurrentmarksweep.gc.avg.time | GAUGE | 一分钟内,每次CMSGC的平均耗时 |
+| parnew.gc.count | GAUGE | 一分钟内,YoungGC(parnew)的总次数 |
+| concurrentmarksweep.gc.count | GAUGE | 一分钟内,CMSGC的总次数 |
+| gc.throughput | GAUGE | GC的总吞吐率(应用运行时间/进程总运行时间) |
+| new.gen.promotion | GAUGE | 一分钟内,新生代的内存晋升总大小 |
+| new.gen.avg.promotion | GAUGE | 一分钟内,平均每次YoungGC的新生代内存晋升大小 |
+| old.gen.mem.used | GAUGE | 老年代的内存使用量 |
+| old.gen.mem.ratio | GAUGE | 老年代的内存使用率 |
+| thread.active.count | GAUGE | 当前活跃线程数 |
+| thread.peak.count | GAUGE | 峰值线程数 |
+
+## 建议设置监控告警项
+
+不同应用根据其特点,可以灵活调整触发条件及触发阈值
+
+| 告警项 | 触发条件 | 备注|
+|-----|------|------|
+| gc.throughput | all(#3)<98 | gc吞吐率低于98%,影响性能 |
+| old.gen.mem.ratio | all(#3)>90 | 老年代内存使用率高于90%,需要调优 |
+| thread.active.count | all(#3)>500 | 线程数过多,影响性能 |
+
+
+# 使用帮助
+详细的使用方法常见:[jmxmon](https://github.com/toomanyopenfiles/jmxmon)
+
diff --git a/zh_0_3/usage/lvs.md b/zh_0_3/usage/lvs.md
new file mode 100644
index 0000000..b032d57
--- /dev/null
+++ b/zh_0_3/usage/lvs.md
@@ -0,0 +1,34 @@
+
+
+# lvs-metrics 简介
+lvs-metrics是一个基于open-falcon的LVS监控插件,通过这个插件,结合open-falcon agent/transfer,可以采集LVS服务状态,并将采集信息自动上报给open-falcon服务端
+
+## 主要功能
+
+通过google开源的ipvs/netlink库及proc下文件采集lvs的监控信息,包括所有VIP的连接数(活跃/非活跃)/LVS主机的连接数(活跃/非活跃).进出数据包数/字节数.
+
+对应用程序代码无侵入,几乎不占用系统资源。
+
+
+## 采集指标
+
+| Counters | Type | Notes |
+|-----|-----|-----|
+| lvs.in.bytes | GUAGE | network in bytes per host |
+| lvs.out.bytes | GUAGE | network out bytes per host |
+| lvs.in.packets | GUAGE | network in packets per host |
+| lvs.out.packets | GUAGE | network out packets per host |
+| lvs.total.conns | GUAGE | lvs total connections per vip now |
+| lvs.active.conn | GUAGE | lvs active connections per vip now |
+| lvs.inact.conn | GUAGE | lvs inactive connections per vip now |
+| lvs.realserver.num | GUAGE | lvs live realserver num per vip now |
+| lvs.vip.conns | COUNTER | lvs conns counter from service start per vip |
+| lvs.vip.inbytes | COUNTER | lvs inbytes counter from service start per vip |
+| lvs.vip.outbytes | COUNTER | lvs outpkts counter from service start per vip |
+| lvs.vip.inpkts | COUNTER | lvs inpkts counter from service start per vip |
+| lvs.vip.outpkts | COUNTER | lvs outpkts counter from service start per vip |
+
+
+# 使用帮助
+详细的使用方法常见:[lvs-metrics](https://github.com/mesos-utility/lvs-metrics)
+
diff --git a/zh_0_3/usage/memcache.md b/zh_0_3/usage/memcache.md
new file mode 100644
index 0000000..29d0b9d
--- /dev/null
+++ b/zh_0_3/usage/memcache.md
@@ -0,0 +1,15 @@
+
+
+# Memcache监控
+
+在[数据采集](../philosophy/data-collect.md)一节中我们介绍了常见的监控数据源。open-falcon作为一个监控框架,可以去采集任何系统的监控指标数据,只要将监控数据组织为open-falcon规范的格式就OK了。
+
+Memcache的数据采集可以通过采集脚本[memcached-monitor](https://github.com/iambocai/falcon-monit-scripts/tree/master/memcached)来做。
+
+## 工作原理
+
+memcached-monitor是一个cron,每分钟跑一次采集脚本```memcached-monitor.py```,脚本可以自动检测Memcached的端口,并连到Memcached实例,采集一些监控指标,比如get_hit_ratio、usage等等,然后组装为open-falcon规定的格式的数据,post给本机的falcon-agent。falcon-agent提供了一个http接口,使用方法可以参考[数据采集](../philosophy/data-collect.md)中的例子。
+
+比如,我们有1000台机器都部署了Memcached实例,可以在这1000台机器上分别部署1000个cron,即:与Memcached实例一一对应。
+
+需要说明的是,脚本```memcached-monitor.py```通过```ps -ef |grep memcached|grep -v grep |sed -n 's/.* *-p *\([0-9]\{1,5\}\).*/\1/p```来自动发现Memcached端口的。如果Memcached启动时 没有通过 ```-p```参数来指定端口,端口的自动发现将失败,这时需要手动修改脚本、指定端口。
\ No newline at end of file
diff --git a/zh_0_3/usage/mesos.md b/zh_0_3/usage/mesos.md
new file mode 100644
index 0000000..2e226e1
--- /dev/null
+++ b/zh_0_3/usage/mesos.md
@@ -0,0 +1,7 @@
+
+
+# mesos监控
+
+mesos.py是leancloud开发的open-falcon插件脚本,通过这个插件,结合open-falcon agent/transfer,可以采集mesos相关数据,并将采集信息自动上报给open-falcon服务端
+
+[https://github.com/leancloud/satori/tree/master/satori-rules/plugin/mesos](https://github.com/leancloud/satori/tree/master/satori-rules/plugin/mesos)
diff --git a/zh_0_3/usage/mymon.md b/zh_0_3/usage/mymon.md
new file mode 100644
index 0000000..854c219
--- /dev/null
+++ b/zh_0_3/usage/mymon.md
@@ -0,0 +1,17 @@
+
+
+# MySQL监控实践
+
+在[数据采集](../philosophy/data-collect.md)一节中我们介绍了常见的监控数据源。open-falcon作为一个监控框架,可以去采集任何系统的监控指标数据,只要将监控数据组织为open-falcon规范的格式就OK了。
+
+MySQL的数据采集可以通过[mymon](https://github.com/open-falcon/mymon)来做。
+
+## 工作原理
+
+mymon是一个cron,每分钟跑一次,配置文件中配置了数据库连接地址,mymon连到该数据库,采集一些监控指标,比如global status, global variables, slave status等等,然后组装为open-falcon规定的格式的数据,post给本机的falcon-agent。falcon-agent提供了一个http接口,使用方法可以参考[数据采集](../philosophy/data-collect.md)中的例子。
+
+比如我们有1000台机器都部署了MySQL实例,可以在这1000台机器上分别部署1000个cron,即:与数据库实例一一对应。
+
+## 补充
+***远程监控mysql实例***
+如果希望通过hostA上的mymon、采集hostB上的mysql实例指标,你可以这样做:将hostA上mymon的配置文件中的"endpoint设置为hostB的机器名、同时将[mysql]配置项设置为hostB的mysql实例"。查看mysql指标、对mysql指标加策略时,需要找hostB机器名对应的指标。
diff --git a/zh_0_3/usage/ngx_metric.md b/zh_0_3/usage/ngx_metric.md
new file mode 100644
index 0000000..bdcf52a
--- /dev/null
+++ b/zh_0_3/usage/ngx_metric.md
@@ -0,0 +1,15 @@
+
+
+# Nginx 监控
+
+在[数据采集](../philosophy/data-collect.md)一节中我们介绍了常见的监控数据源。open-falcon作为一个监控框架,可以去采集任何系统的监控指标数据,只要将监控数据组织为open-falcon规范的格式就OK了。
+
+Nginx的数据采集可以通过[ngx_metric](https://github.com/GuyCheung/falcon-ngx_metric)来做。
+
+# 工作原理
+
+ngx_metric是借助lua-nginx-module的`log_by_lua`功能实现nginx请求的实时分析,然后借助`ngx.shared.DICT`存储中间结果。最后通过外部python脚本取出中间结果加以计算、格式化并输出。按falcon格式输出的结果可直接push到falcon agent。
+
+# 使用帮助
+
+详细的使用方法常见:[ngx_metric](https://github.com/GuyCheung/falcon-ngx_metric)
diff --git a/zh_0_3/usage/nodata.md b/zh_0_3/usage/nodata.md
new file mode 100644
index 0000000..dc96ff7
--- /dev/null
+++ b/zh_0_3/usage/nodata.md
@@ -0,0 +1,30 @@
+
+
+# Nodata配置
+使用Nodata,需要进行两个配置: Nodata配置 和 策略配置。下面,我们以一个例子,讲述如何使用Nodata提供的服务。
+
+### 用户需求
+当机器分组`cop.xiaomi_owt.inf_pdl.falcon`下的所有机器,其采集指标 `agent.alive` 上报中断时,通知用户。
+
+### Nodata配置
+进入Nodata配置主页,可以看到Nodata配置列表
+
+
+点击右上角的添加按钮,添加nodata配置。
+
+
+进行完上述配置后,分组`cop.xiaomi_owt.inf_pdl.falcon`下的所有机器,其采集项 `agent.alive`上报中断后,nodata服务就会补发一个取值为 `-1.0`、agent.alive的监控数据给监控系统。
+
+### 策略配置
+配置了Nodata后,如果有数据上报中断的情况,Nodata配置中的默认值就会被上报。我们可以针对这个默认值,设置报警;只要收到了默认值,就认为发生了数据上报的中断(如果你设置的默认值,可能与正常上报的数据相等,那么请修改你的Nodata配置、使默认值有别于正常值)。将此策略,绑定到分组`cop.xiaomi_owt.inf_pdl.falcon`即可。
+
+
+
+### 注意事项
+1. 配置名称name,要全局唯一。这是为了方便Nodata配置的管理。
+2. 监控实例endpoint, 可以是机器分组、机器名或者其他 这三种类型,只能选择其中的一种。同一类型,支持多个记录,但建议不超过5个,多条记录换行分割、每行一条记录。选择机器分组时,系统会帮忙展开成具体机器名,支持动态生效。监控实体不是机器名时,只能选择“其他”类型。
+3. 监控指标metric。
+4. 数据标签tags,多个tag要用逗号隔开。必须填写完整的tags串,因为nodata会按照此tags串,去完全匹配、筛选监控数指标项。
+5. 数据类型type,只支持原始值类型GAUGE。因为,nodata只应该监控 "特征指标"(如agent.alive),"特征指标"都是GAUGE类型的。
+6. 采集周期step,单位是秒。必须填写 完整&真实step。该字段不完整 或者 不真实,将会导致nodata监控的误报、漏报。
+7. 补发值default,必须有别于上报的真实数据。比如,`cpu.idle`的取值范围是[0,100],那么它的nodata默认取值 只能取小于0或者大于100的值。否则,会发生误报、漏报。
diff --git a/zh_0_3/usage/proc-port-monitor.md b/zh_0_3/usage/proc-port-monitor.md
new file mode 100644
index 0000000..30142e3
--- /dev/null
+++ b/zh_0_3/usage/proc-port-monitor.md
@@ -0,0 +1,64 @@
+
+
+# 引言
+
+我们说falcon-agent是无需配置即可自动化采集200多项监控指标数据,比如cpu相关的、内存相关的、磁盘io相关的、网卡相关的等等,都可以自动发现,自动采集。
+
+# 端口监控
+
+falcon-agent编写初期是把本机监听的所有端口上报给server端,比如机器监听了80、443、22三个端口,就会自动上报三条数据:
+
+```
+net.port.listen/port=22
+net.port.listen/port=80
+net.port.listen/port=443
+```
+
+上报的端口数据,value是1,如果后来某些端口不再监听了,那就会停止上报数据。这样是否OK呢?存在两个问题:
+
+- 机器监听的端口可能很多很多,但是真正想做监控的端口可能不多,这会造成资源浪费
+- 目前Open-Falcon已经支持nodata监控,通过nodata机制去发现端口存活情况
+
+改进之。
+
+agent到底要采集哪些端口是通过用户配置的策略自动计算得出的。因为无论如何,监控配置策略是少不了的。比如用户配置了2个端口:
+
+```
+net.port.listen/port=8080 if all(#3) == 0 then alarm()
+net.port.listen/port=8081 if all(#3) == 0 then alarm()
+```
+
+将策略绑定到某个HostGroup,那么这个HostGroup下的机器就要去采集8080和8081这俩端口的情况了。这个信息是通过agent和hbs的心跳机制下发的。
+
+agent通过`ss -tln`拿到当前有哪些端口在监听,如果8080在监听,就设置value=1,汇报给transfer,如果发现8081没在监听,就设置value=0,汇报给transfer。
+
+# 进程监控
+
+进程监控和端口监控类似,也是通过用户配置的策略自动计算出来要采集哪个进程的信息然后上报。举个例子:
+
+```
+proc.num/name=ntpd if all(#2) == 0 then alarm()
+proc.num/name=crond if all(#2) == 0 then alarm()
+proc.num/cmdline=uic.properties if all(#2) == 0 then alarm()
+```
+
+proc.num表示进程数,比如进程名叫做crond的进程,其实可以有多个。支持两种tag配置,一个是进程name,一个是配置进程cmdline,但是不能同时出现。
+
+那现在DEV写了一个程序,我怎么知道进程名呢?
+首先要拿到进程ID,然后`cat /proc/$pid/status`,看到里面的name字段了么?falcon-agent就是根据这个name字段来采集的。此处有个坑,就是这个name字段最多15个字节,所以,如果你的进程名特别长可能被截断,截断之前的原始进程名我们不管,agent以这个status文件中的name为准。所以,你配置name这个tag的时候,一定要看一眼这个status文件,从这里获取name,而不是想当然的去写一个你自认为对的进程名。
+
+再说说cmdline,name是从`/proc/$pid/status`文件采集的,cmdline是从`/proc/$pid/cmdline`采集的。这个文件存放的是你启动进程的时候用到的命令,比如你用`java -c uic.properties`启动了一个Java进程,进程名是java,其实所有的java进程,进程名都是java,那我们是没法通过name字段做区分的。怎么办呢?此时就要求助于这个`/proc/$pid/cmdline`文件的内容了。
+
+cmdline中的内容是你的启动命令,这么说不准确,你会发现空格都没了。其实是把空格自动替换成`\0`了。不用关心,直接鼠标选中,拷贝之即可。不要自以为是的手工加空格配置到策略中哈,监控策略的tag是不允许有空格的。
+
+上面的例子,`java -c uic.properties`在cmdline中的内容会变成:`java-cuic.properties`,无需把整个cmdline都拷贝并配置到策略中。虽然name这个tag是全匹配的,即用的`==`比较name,但是cmdline不是,我们只需要拷贝cmdline的一部分字符串,能够与其他进程区分开即可。比如上面的配置:
+
+```
+proc.num/cmdline=uic.properties if all(#2) == 0 then alarm()
+```
+
+就已经OK了。falcon-agent拿到cmdline文件的内容之后会使用`strings.Contains()`方法来做判断
+
+听起来是不是挺复杂的?呵呵,如果你的进程有端口在监听,就配置一个端口监控就可以了,无需既配置端口监控、又配置进程监控,毕竟如果进程挂了,端口肯定就不会监听了。
+
+
diff --git a/zh_0_3/usage/query.md b/zh_0_3/usage/query.md
new file mode 100644
index 0000000..a30f8c2
--- /dev/null
+++ b/zh_0_3/usage/query.md
@@ -0,0 +1,7 @@
+
+
+# 历史数据查询
+
+任何push到open-falcon中的数据,事后都可以通过api组件提供的restAPI,来查询得到。
+
+具体请参考[API文档](http://open-falcon.com/falcon-plus/#/graph_histroy)
diff --git a/zh_0_3/usage/rabbitmq.md b/zh_0_3/usage/rabbitmq.md
new file mode 100644
index 0000000..a91049e
--- /dev/null
+++ b/zh_0_3/usage/rabbitmq.md
@@ -0,0 +1,18 @@
+
+
+# RMQ监控
+
+在[数据采集](../philosophy/data-collect.md)一节中我们介绍了常见的监控数据源。open-falcon作为一个监控框架,可以去采集任何系统的监控指标数据,只要将监控数据组织为open-falcon规范的格式就OK了。
+
+RMQ的数据采集可以通过脚本[rabbitmq-monitor](https://github.com/iambocai/falcon-monit-scripts/tree/master/rabbitmq)来做。
+
+## 工作原理
+
+rabbitmq-monitor是一个cron,每分钟跑一次脚本```rabbitmq-monitor.py```,其中配置了RMQ的用户名&密码等,脚本连到该RMQ实例,采集一些监控指标,比如messages_ready、messages_total、deliver_rate、publish_rate等等,然后组装为open-falcon规定的格式的数据,post给本机的falcon-agent。falcon-agent提供了一个http接口,使用方法可以参考[数据采集](../philosophy/data-collect.md)中的例子。
+
+比如我们部署了5个RMQ实例,可以在 每个RMQ实例机器上运行一个cron,即:与RMQ实例一一对应。
+
+
+# 可选方案
+
+这是另外一个rabbitmq的监控插件,请参考 [rmqmonitor](https://github.com/barryz/rmqmonitor), [issue](https://github.com/open-falcon/falcon-plus/issues/443)
diff --git a/zh_0_3/usage/redis.md b/zh_0_3/usage/redis.md
new file mode 100644
index 0000000..3fc04c1
--- /dev/null
+++ b/zh_0_3/usage/redis.md
@@ -0,0 +1,13 @@
+
+
+# Redis监控
+
+在[数据采集](../philosophy/data-collect.md)一节中我们介绍了常见的监控数据源。open-falcon作为一个监控框架,可以去采集任何系统的监控指标数据,只要将监控数据组织为open-falcon规范的格式就OK了。
+
+Redis的数据采集可以通过采集脚本[redis-monitor](https://github.com/iambocai/falcon-monit-scripts/tree/master/redis) 或者 [redismon](https://github.com/ZhuoRoger/redismon)来做。
+
+## 工作原理
+
+redis-monitor是一个cron,每分钟跑一次采集脚本```redis-monitor.py```,其中配置了redis服务的地址,redis-monitor连到redis实例,采集一些监控指标,比如connected_clients、used_memory等等,然后组装为open-falcon规定的格式的数据,post给本机的falcon-agent。falcon-agent提供了一个http接口,使用方法可以参考[数据采集](../philosophy/data-collect.md)中的例子。
+
+比如,我们有1000台机器都部署了Redis实例,可以在这1000台机器上分别部署1000个cron,即:与Redis实例一一对应。
diff --git a/zh_0_3/usage/solr.md b/zh_0_3/usage/solr.md
new file mode 100644
index 0000000..9bbd1d9
--- /dev/null
+++ b/zh_0_3/usage/solr.md
@@ -0,0 +1,15 @@
+
+
+# Solr监控
+
+在[数据采集](../philosophy/data-collect.md)一节中我们介绍了常见的监控数据源。open-falcon作为一个监控框架,可以去采集任何系统的监控指标数据,只要将监控数据组织为open-falcon规范的格式就OK了。
+
+Solr的数据采集可以通过脚本[solr_monitor](https://github.com/shanshouchen/falcon-scripts/tree/master/solr-monitor)来做。
+
+## 工作原理
+
+solr_monitor是一个cron,每分钟跑一次脚本```solr_monitor.py```,主要采集一些solr实例内存信息和缓存命中信息等等,然后组装为open-falcon规定的格式的数据,post给本机的falcon-agent。
+
+脚本可以部署到Solr的各个实例,每个实例上运行一个cron,定时执行数据收集,即:与Solr实例一一对应
+
+如果一台服务器存在多个Solr实例,可以通过修改```solr_monitor.py```中的```servers```属性,增加Solr实例的地址完成本地一对多的数据收集
diff --git a/zh_0_3/usage/switch.md b/zh_0_3/usage/switch.md
new file mode 100644
index 0000000..e934981
--- /dev/null
+++ b/zh_0_3/usage/switch.md
@@ -0,0 +1,268 @@
+
+
+# 交换机监控
+
+在[数据采集](../philosophy/data-collect.md)一节中我们介绍了常见的监控数据源。open-falcon作为一个监控框架,可以去采集任何系统的监控指标数据,只要将监控数据组织为open-falcon规范的格式就OK了。
+
+交换机设备的运行指标的采集,可以写脚本,通过SNMP协议来采集交换机的各项运行指标,包括内存占用、CPU使用、流量、ping延时等。
+
+可以直接使用 [swcollector](https://github.com/gaochao1/swcollector) 来实现对交换机设备的监控指标采集。
+
+## 工作原理
+
+swcollector是一个Golang开发的后台程序,由[gaochao](https://github.com/gaochao1)设计开发,目前由[freedomkk-qfeng](https://github.com/freedomkk-qfeng)进行后续开发和维护。
+
+swcollector根据配置文件中,配置好的交换机IP列表或者IP网段,每隔一个固定的周期,通过SNMP协议,来采集交换机的运行指标,并上报给Open-Falcon。
+
+采集的metric列表:
+
+* CPU利用率
+* 内存利用率
+* Ping延时(正常返回延时,超时返回 -1,可以用于存活告警)
+* IfHCInOctets
+* IfHCOutOctets
+* IfHCInUcastPkts
+* IfHCOutUcastPkts
+* IfHCInBroadcastPkts
+* IfHCOutBroadcastPkts
+* IfHCInMulticastPkts
+* IfHCOutMulticastPkts
+* IfInDiscards
+* IfOutDiscards
+* IfInErrors
+* IfOutErros
+* IfInUnknownProtos
+* IfOutQLen
+* IfSpeed
+* IfSpeedPercent
+* IfOperStatus(接口状态,1 up, 2 down, 3 testing, 4 unknown, 5 dormant, 6 notPresent, 7 lowerLayerDown)
+
+
+CPU和内存的OID私有,根据设备厂家和OS版本可能不同。目前测试过的设备:
+
+* Cisco IOS(Version 12)
+* Cisco NX-OS(Version 6)
+* Cisco IOS XR(Version 5)
+* Cisco IOS XE(Version 15)
+* Cisco ASA (Version 9)
+* Ruijie 10G Routing Switch
+* Huawei VRP(Version 8)
+* Huawei VRP(Version 5.20)
+* Huawei VRP(Version 5.120)
+* Huawei VRP(Version 5.130)
+* Huawei VRP(Version 5.70)
+* Juniper JUNOS(Version 10)
+* H3C(Version 5)
+* H3C(Version 5.20)
+* H3C(Version 7)
+* DELL
+
+#### 二进制安装
+从[这里](https://github.com/gaochao1/swcollector/releases) 下载编译好的最新二进制版本即可。注意:这些二进制只能跑在64位Linux上
+
+#### 源码安装
+```
+ 依赖$GOPATH/src/github.com/gaochao1/sw
+ cd $GOPATH/src/github.com/gaochao1/swcollector
+ go get ./...
+ chmod +x control
+ ./control build
+ ./control pack
+ 最后一步会pack出一个tar.gz的安装包,拿着这个包去部署服务即可。
+
+ 升级时,确保先更新sw
+ cd $GOPATH/src/github.com/gaochao1/sw
+ git pull
+```
+
+#### 部署说明
+
+swcollector需要部署到有交换机SNMP访问权限的服务器上。
+
+使用Go原生的ICMP协议进行Ping探测,swcollector需要root权限运行。
+
+支持使用 Gosnmp 或 snmpwalk 进行数据采集,如果使用 snmpwalk 模式,需要在监控探针服务器上安装个snmpwalk命令
+
+#### 配置说明
+
+配置文件请参照cfg.example.json,修改该文件名为cfg.json,将该文件里的IP换成实际使用的IP。
+
+配置说明:
+```
+{
+ "debug": true,
+ "debugmetric":{ # 在日志中 debug 具体的指标
+ "endpoints":["192.168.56.101","192.168.56.102"], # 必填
+ "metrics":["switch.if.In","switch.if.Out"], # 必填
+ "tags":"ifName=Fa0/1" # 有则匹配 tag,如为 "" 则打印该 metric 的全部信息
+ },
+ "switch":{
+ "enabled": true,
+ "ipRange":[ #交换机IP地址段,对该网段有效IP,先发Ping包探测,对存活IP发SNMP请求
+ "192.168.56.101/32",
+ "192.168.56.102-192.168.56.120",#现在支持这样的配置方式,对区域内的ip进行ping探测,对存活ip发起snmp请求。
+ "172.16.114.233"
+ ],
+ "gosnmp":true, #是否使用 gosnmp 采集, false 则使用 snmpwalk
+ "pingTimeout":300, #Ping超时时间,单位毫秒
+ "pingRetry":4, #Ping探测重试次数
+ "community":"public", #SNMP认证字符串
+ "snmpTimeout":1000, #SNMP超时时间,单位毫秒
+ "snmpRetry":5, #SNMP重试次数
+ "ignoreIface": ["Nu","NU","Vlan","Vl"], #忽略的接口,如Nu匹配ifName为*Nu*的接口
+ "ignoreOperStatus": true, #不采集IfOperStatus
+ "speedlimit":0, #流量的上限,如果采集计算出的流量超过这个数值,则抛弃不上报。如果填0,则以接口的速率(ifSpeed)作为上限计算。注意 interface vlan 这样的虚接口是没有 ifSpeed 的,因此不进行最大值的比较。
+ "ignorePkt": true, #不采集IfHCInUcastPkts和IfHCOutUcastPkts
+ "pktlimit": 0, #pkt的上限,如果采集计算出的包速率超过这个数值,则抛弃不上报。如果填0,则不进行最大值比较。
+ "ignoreBroadcastPkt": true, #不采集IfHCInBroadcastPkts和IfHCOutBroadcastPkts
+ "broadcastPktlimit": 0, #broadcastPkt的上限,如果采集计算出的包速率超过这个数值,则抛弃不上报。如果填0,则不进行最大值比较。
+ "ignoreMulticastPkt": true, #不采集IfHCInMulticastPkts和IfHCOutMulticastPkts
+ "multicastPktlimit": 0, #multicastPkt的上限,如果采集计算出的包速率超过这个数值,则抛弃不上报。如果填0,则不进行最大值比较。
+ "ignoreDiscards": true, #不采集IfInDiscards和IfOutDiscards
+ "discardsPktlimit": 0, #discardsPkt的上限,如果采集计算出的包速率超过这个数值,则抛弃不上报。如果填0,则不进行最大值比较。
+ "ignoreErrors": true, #不采集IfInErrors和IfOutErros
+ "errorsPktlimit": 0, #errorsPkt的上限,如果采集计算出的包速率超过这个数值,则抛弃不上报。如果填0,则不进行最大值比较。
+ "ignoreUnknownProtos":true, #不采集IfInUnknownProtos
+ "unknownProtosPktlimit": 0, #unknownProtosPkt的上限,如果采集计算出的包速率超过这个数值,则抛弃不上报。如果填0,则不进行最大值比较。
+ "ignoreOutQLen":true, #不采集IfOutQLen
+ "outQLenPktlimit": 0, #outQLenPkt的上限,如果采集计算出的包速率超过这个数值,则抛弃不上报。如果填0,则不进行最大值比较。
+ "fastPingMode": true,
+ "limitConcur": 1000, #交换机采集的并发限制
+ "limitCon": 4 #对于单台交换机上,多个指标采集的并发限制
+ },
+ "switchhosts":{
+ "enabled":true,
+ "hosts":"./hosts.json" #自定义的host与Ip地址对应表,如果配置,则上报时会用这里的host替换ip地址
+ },
+ "customMetrics":{
+ "enabled":true,
+ "template":"./custom.json" #自定义的metric列表,如果配置,会根据这个配置文件,采集额外的自定义metric
+ },
+ "transfer": {
+ "enabled": true,
+ "addr": "127.0.0.1:8433",
+ "interval": 60,
+ "timeout": 1000
+ },
+ "http": {
+ "enabled": true,
+ "listen": ":1989"
+ }
+}
+
+```
+自定义 host 配置说明
+```
+{
+ "hosts":
+ {
+ "192.168.160":"test1",
+ "192.168.88.161":"test2",
+ "192.168.33.2":"test3",
+ "192.168.31.51":"test4"
+ }
+}
+```
+自定义 oid 配置说明
+
+```
+{
+ "metrics":
+ [
+ {
+ "ipRange":[
+ "192.168.0.1-192.168.0.2", #使用该自定义 oid 采集的地址
+ "192.168.1.1"
+ ],
+ "metric":"switch.AnyconnectSession", #自定义的 metric
+ "tag":"", #自定义的 tag
+ "type":"GAUGE",
+ "oid":"1.3.6.1.4.1.9.9.392.1.3.35.0" #自定义的 oid
+ },
+ #自定义的 oid 只支持 snmp get 方式采集,因此务必填写完整,建议先通过 snmpwalk 验证一下。
+ #这是 cisco asa 上 anyconnect 的在线数量
+ {
+ "ipRange":[
+ "192.168.1.160-192.168.1.161"
+ ],
+ "metric":"switch.ConnectionStat",
+ "tag":"",
+ "type":"GAUGE",
+ "oid":"1.3.6.1.4.1.9.9.147.1.2.2.2.1.5.40.6"
+ },
+ #这是 cisco asa 上的防火墙连接数
+ {
+ "ipRange":[
+ "192.168.33.2"
+ ],
+ "metric":"switch.TempStatus",
+ "tag":"",
+ "type":"GAUGE",
+ "oid":"1.3.6.1.4.1.9.9.13.1.3.1.3.1004"
+ }
+ #这是 cisco 交换机的温度,注意通用的 oid 是 "1.3.6.1.4.1.9.9.13.1.3.1.3",这里 1004 是硬件 index。框式交换机可能会有多个温度(多块线卡),请根据实际需要填具体的 oid 值和相应的 tag
+ ]
+}
+```
+
+#### 部署说明
+由于是并发采集,因此每个周期的采集耗时,主要取决于被采集的交换机中,最慢的那个。
+因此我们可以在 debug 模式下观察每个交换机的采集耗时。
+```
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.10.1 PingResult: true len_list: 440 UsedTime: 5
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.10.252 PingResult: true len_list: 97 UsedTime: 2
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.13.1 PingResult: true len_list: 24 UsedTime: 1
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.14.1 PingResult: true len_list: 23 UsedTime: 1
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.23.1 PingResult: true len_list: 61 UsedTime: 2
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.12.1 PingResult: true len_list: 55 UsedTime: 1
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.12.5 PingResult: true len_list: 26 UsedTime: 2
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.12.6 PingResult: true len_list: 26 UsedTime: 2
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.12.11 PingResult: true len_list: 26 UsedTime: 2
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.12.12 PingResult: true len_list: 26 UsedTime: 2
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.12.13 PingResult: true len_list: 26 UsedTime: 2
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.12.14 PingResult: true len_list: 26 UsedTime: 2
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.12.15 PingResult: true len_list: 26 UsedTime: 2
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.12.16 PingResult: true len_list: 26 UsedTime: 2
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.12.17 PingResult: true len_list: 26 UsedTime: 2
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.12.18 PingResult: true len_list: 26 UsedTime: 2
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.12.19 PingResult: true len_list: 26 UsedTime: 2
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.12.20 PingResult: true len_list: 26 UsedTime: 2
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.12.21 PingResult: true len_list: 26 UsedTime: 2
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.12.22 PingResult: true len_list: 26 UsedTime: 2
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.12.23 PingResult: true len_list: 26 UsedTime: 2
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.12.24 PingResult: true len_list: 26 UsedTime: 2
+2016/08/16 21:31:24 swifstat.go:121: IP: 192.168.12.25 PingResult: true len_list: 26 UsedTime: 2
+2016/08/16 21:31:29 swifstat.go:121: IP: 192.168.11.2 PingResult: true len_list: 348 UsedTime: 10
+2016/08/16 21:31:29 swifstat.go:177: UpdateIfStats complete. Process time 10.700895998s.
+```
+如下所示,我们可以发现 192.168.11.2 这个交换机的采集耗时最长,用掉了 10 秒钟,这个占用了采集周期大部分的耗时。
+
+我们可以根据这些信息将交换机做一下分类,snmp 响应快的放在一起用一个 swcollector 采集,snmp 的超时时间可以设置的短一些,采集周期也可以设的小一点,比如30秒
+响应慢的放在一起,用另外一个 swcollector 采集,snmp 的超时时间可以设置的长一点,采集周期也可以适当的放久一点,比如5分钟。
+
+snmp 报文的响应需要消耗 cpu,因此交换机多少都对 snmp 报文的响应有速率限制,在 CPU 过高时,还可能会丢弃 snmp,icmp等优先级不高的请求。
+不同品牌的对此的限定都有不同,有些型号可以通过配置修改。如果允许的话,也可以通过放开其对 snmp 的限速控制,来加快交换机对 snmp 报文的响应速度。
+
+如此,在我们调节了 *“木桶” *中 *“木板”* 的长度后,选择了合适的采集周期后,swcollector 的单个实例可以很轻松的带起上百台乃至更多的交换机。
+
+#### v3-v4 升级说明(重要!!!!)
+由于 v4 版本的 swcollector 修改了接口数据的上报格式,从Counter修改为GAUGE。因此如果同一个 endpoint,使用升级后的 swcollector 采集时,graph 内原有数据会**全部丢失!**
+因此建议在升级时,开启自定义 host 功能,将交换机的 ip 地址通过 host 自定义为新的 endpoint,例如原先采集的 ip 为
+```
+ "ipRange":[
+ "192.168.0.1-192.168.0.2",
+ "192.168.1.1"
+ ],
+```
+开启 switchhosts.enabled = true,然后配置 hosts.json
+```
+{
+ "hosts":
+ {
+ "192.168.0.1":"sw-192.168.0.1",
+ "192.168.0.2":"sw-192.168.0.1",
+ "192.168.1.1":"sw-192.168.1.1"
+ }
+}
+```
+这样他会以新的 "sw-192.168.x.x" 作为 endpoint 上报,原有的 192.168.x.x 依然继续保留,历史纪录不会丢失。
\ No newline at end of file
diff --git a/zh_0_3/usage/urlooker.md b/zh_0_3/usage/urlooker.md
new file mode 100644
index 0000000..a5265b7
--- /dev/null
+++ b/zh_0_3/usage/urlooker.md
@@ -0,0 +1,64 @@
+
+
+## [urlooker][1]
+监控web服务可用性及访问质量,采用go语言编写,易于安装和二次开发
+
+## Feature
+- 返回状态码检测
+- 页面响应时间检测
+- 页面关键词匹配检测
+- 带cookie访问
+- agent多机房部署,指定机房访问
+- 检测结果支持向open-falcon推送
+- 支持短信和邮件告警
+
+## Architecture
+![此处输入图片的描述][2]
+
+## ScreenShot
+
+![看图][3]
+
+![此处输入图片的描述][4]
+
+![添加监控项][5]
+
+## 上报项(详情见[wiki][6])
+- metric: url_status
+- endpoint: url_id (id为上图2中的id)
+- tag: creator=username(上图右上角的username)
+- counterType: GAUGE
+- step: 60(可在web组件配置文件设置)
+- value: 0 (0~4 0表示正常,其他表示异常)
+
+## Install
+
+**环境依赖**
+安装mysql & redis
+wget http://x2know.qiniudn.com/schema.sql
+将schema.sql 导入数据库
+
+二进制安装(Ubuntu 14.4 Go1.6下编译):
+
+ wget http://x2know.qiniudn.com/urlooker.tar.gz
+ tar xzvf urlooker.tar.gz
+ cd urlooker
+ # 修改下cfg.json中的mysql和redis配置
+ web/control start
+ alarm/control start
+ agent/control start
+
+打开浏览器访问 http://127.0.0.1:1984 即可
+
+
+## 使用帮助
+源码安装及详细介绍见:[urlooker][7]
+
+
+ [1]: https://github.com/urlooker
+ [2]: https://github.com/urlooker/wiki/raw/master/img/urlooker4.png
+ [3]: https://github.com/urlooker/wiki/raw/master/img/urlooker1.png
+ [4]: https://github.com/urlooker/wiki/raw/master/img/urlooker3.png
+ [5]: https://github.com/urlooker/wiki/raw/master/img/urlooker2.png
+ [6]: https://github.com/URLooker/wiki/wiki/open-falcon-%E4%B8%8A%E6%8A%A5%E9%A1%B9%E4%BB%8B%E7%BB%8D
+ [7]: https://github.com/710leo/urlooker/blob/master/README.md
\ No newline at end of file
diff --git a/zh_0_3/usage/vsphere-esxi.md b/zh_0_3/usage/vsphere-esxi.md
new file mode 100644
index 0000000..fae42b2
--- /dev/null
+++ b/zh_0_3/usage/vsphere-esxi.md
@@ -0,0 +1,402 @@
+### falcon-vsphere
+这是一个适用于Open-Falcon的,用于监控Vsphere及由Vsphere监管的所有esxi性能指标的agent。地址:[https://github.com/tpinellia/vsphere](https://github.com/tpinellia/vsphere)
+#### 一.特性
+1. 支持多vsphere同时采集
+2. 支持vsphere与esxi监控项归并/拆分,支持自定义endpoint或监控项头部
+3. esxi监控项包含基础跟扩展监控两类,扩展监控可选择启用,同时可配置
+4. 配置支持热加载(例如添加vsphere,增删扩展监控等等),不需要重新启动agent
+#### 二.使用说明
+1. export WorkDir="$HOME/falcon-vsphere"
+2. mkdir -p $WorkDir
+3. tar -xzvf falcon-vsphere-x.x.x.tar.gz -C $WorkDir
+4. cd $WorkDir
+5. ./control start
+#### 三.配置说明
+```
+{
+ "debug": false,
+ "extend": "./extend.json", #扩展监控项列表
+ "heartbeat": {
+ "enabled": true, #是否开启HBS
+ "addr": "127.0.0.1:6030", #HBS地址
+ "timeout": 1000 #超时时间
+ },
+ "transfer": {
+ "enabled": true, #是否开启Transfer
+ "addrs": [
+ "127.0.0.1:8433" #Transfer地址,可配置多个
+ ],
+ "interval": 60, #上传时间间隔
+ "timeout": 1000 #超时时间
+ },
+ "vsphere": [
+ {
+ "hostname": "VC-1.1.1.1", #上传的Vsphere Endpoint名
+ "ip": "1.1.1.1", #Vsphere IP
+ "addr": "https://1.1.1.1/sdk", #Vsphere SDK地址
+ "user":"vsphere1-user", #Vsphere 用户名
+ "pwd":"vsphere1-pwd", #Vsphere 密码
+ "port": 443, #Vsphere 端口
+ "split": true, #是否切分。如果选择true,那么VC将与esxi的监控项单独出来,esxi将作为单独的endpoint上传,esxi endpoint名称可以添加endpointhead作为头部;如果选择false,那么esxi的监控项将与VC的监控项合并上传,esxi的监控项会收集在VC下面作为一个大的endpoint,此时可以选择配置metrichead作为esxi的监控项头部,以区分vc跟esxi的监控项
+ "endpointhead": "ESXI-", #在split为true时生效,作为esxi endpoint的扩展头部,可为空
+ "metrichead":"esxi.", #在split为false时生效,作为esxi监控项的扩展头部,以区分vc的监控项跟esxi的监控项
+ "extend": true #是否启用扩展监控
+ },
+ {
+ "hostname": "VC-2.2.2.2",
+ "ip": "2.2.2.2",
+ "addr": "https://2.2.2.2/sdk",
+ "user":"vsphere2-user",
+ "pwd":"vsphere2-pwd",
+ "port": 443,
+ "split": true,
+ "endpointhead": "ESXI-",
+ "metrichead":"esxi.",
+ "extend": true
+ }
+ ]
+}
+```
+#### 四.监控项说明
+1. 基础监控项
+
+|监控项名称|说明|
+|---|---|
+|agent.alive|默认上传1|
+|agent.power|1:关机;2:开机;3:待机;4:未知,表示主机断开连接或者无响应|
+|agent.status|1:状态未知;2:实体没问题;3:实体肯定有问题;4:实体可能有问题|
+|agent.uptime|开机时间|
+|cpu.busy|cpu使用百分比|
+|cpu.free.average|cpu空闲(单位:HZ)|
+|cpu.total|cpu总量(单位:HZ)|
+|cpu.usage.average|cpu使用(单位:HZ)|
+|datastore.totalReadLatency.average|Average amount of time for a read operation from the datastore. Total latency = kernel latency + device latency.|
+|datastore.totalWriteLatency.average|Average amount of time for a write operation to the datastore. Total latency = kernel latency + device latency.|
+|df.bytes.free.percent|存储器空闲比例(单块存储器)|
+|df.bytes.free|存储器空余量(单块存储器)|
+|df.bytes.total|存储器总量(单块存储器)|
+|df.bytes.used.Percent|存储器使用率(单块存储器)|
+|df.bytes.used|存储器使用量(单块存储器)|
+|df.statistics.free|存储器空余量(所有存储器)|
+|df.statistics.free.percent|存储器空闲比例(所有存储器)|
+|df.statistics.total|存储器总量(所有存储器)|
+|df.statistics.used|存储器使用量(所有存储器)|
+|df.statistics.used.percent|存储器使用率(所有存储器)|
+|mem.memfree|内存空闲量|
+|mem.memfree.percent|内存空闲百分比|
+|mem.memtotal|总内存|
+|mem.memused|内存使用量|
+|mem.memused.percent|内存使用百分比|
+|net.bytesRx.average|Average amount of data received per second.|
+|net.bytesTx.average|Average amount of data transmitted per second.|
+
+2. 扩展监控项
+
+**类型声明**
+
+|NAME|DESCRIPTION|
+|-|-|
+|absolute|Represents an actual value, level, or state of the counter. For example, the “uptime” counter (system group) represents the actual number of seconds since startup. The “capacity” counter represents the actual configured size of the specified datastore. In other words, number of samples, samplingPeriod, and intervals have no bearing on an “absolute” counter“s value.|
+|delta|Represents an amount of change for the counter during the samplingPeriod as compared to the previous interval. The first sampling interval|
+|rate|Represents a value that has been normalized over the samplingPeriod, enabling values for the same counter type to be compared, regardless of interval. For example, the number of reads per second.|
+
+- hbr类监控项
+
+|监控项名称|描述|类型|
+|---|---|---|
+|hbr.hbrNetTx.average|Average amount of data transmitted per second|rate|
+|hbr.hbrNetRx.average|Kilobytes per second of outgoing host-based replication network traffic (for this virtual machine or host)|rate|
+|hbr.hbrNumVms.average|Number of powered-on virtual machines running on this host that currently have host-based replication protection enabled.|absolute|
+
+- rescpu类监控项
+
+|监控项名称|描述|类型|
+|---|---|---|
+|rescpu.runav15.latest|CPU running average over 15 minutes|absolute|
+|rescpu.actav1.latest|CPU running average over 1 minute|absolute|
+|rescpu.actpk15.latest|CPU active peak over 15 minutes|absolute|
+|rescpu.actav5.latest|CPU running average over 5 minutes|absolute|
+|rescpu.runpk1.latest|CPU running peak over 1 minute|absolute|
+|rescpu.maxLimited5.latest|Amount of CPU resources over the limit that were refused, average over 5 minutes|absolute|
+|rescpu.actpk1.latest|CPU active peak over 1 minute|absolute|
+|rescpu.sampleCount.latest|Group CPU sample count.|absolute|
+|rescpu.samplePeriod.latest|Group CPU sample period.|absolute|
+|rescpu.maxLimited1.latest|Amount of CPU resources over the limit that were refused, average over 1 minute|absolute|
+|rescpu.runpk15.latest|CPU running peak over 15 minutes|absolute|
+|rescpu.maxLimited15.latest|Amount of CPU resources over the limit that were refused, average over 15 minutes|absolute|
+|rescpu.runav5.latest|CPU running average over 5 minutes|absolute|
+|rescpu.runav1.latest|CPU running average over 1 minute|absolute|
+|rescpu.actav15.latest|CPU active average over 15 minutes|absolute|
+|rescpu.actpk5.latest|CPU active peak over 5 minutes|absolute|
+|rescpu.runpk5.latest|CPU running peak over 5 minutes|absolute|
+
+- storagePath类监控项
+
+|监控项名称|描述|类型|
+|---|---|---|
+|storagePath.totalReadLatency.average|Average amount of time for a read issued on the storage path. Total latency = kernel latency + device latency.|absolute|
+|storagePath.commandsAveraged.average|Average number of commands issued per second on the storage path during the collection interval|rate|
+|storagePath.numberReadAveraged.average|Average number of read commands issued per second on the storage path during the collection interval|rate|
+|storagePath.write.average|Rate of writing data on the storage path|rate|
+|storagePath.maxTotalLatency.latest|Highest latency value across all storage paths used by the host|absolute|
+|storagePath.read.average|Rate of reading data on the storage path|rate|
+|storagePath.numberWriteAveraged.average|Average number of write commands issued per second on the storage path during the collection interval|rate|
+|storagePath.totalWriteLatency.average|Average amount of time for a write issued on the storage path. Total latency = kernel latency + device latency.|absolute|
+- storageAdapter类监控项
+
+|监控项名称|描述|类型|
+|---|---|---|
+|storageAdapter.read.average|Rate of reading data by the storage adapter|rate|
+|storageAdapter.numberReadAveraged.average|Average number of read commands issued per second by the storage adapter during the collection interval|rate| |storageAdapter.maxTotalLatency.latest|Highest latency value across all storage adapters used by the host|rate|
+|storageAdapter.numberWriteAveraged.average|Average number of write commands issued per second by the storage adapter during the collection interval|rate|
+|storageAdapter.totalWriteLatency.average|Average amount of time for a write operation by the storage adapter. Total latency = kernel latency + device latency.|absolute|
+|storageAdapter.totalReadLatency.average|Average amount of time for a read operation by the storage adapter. Total latency = kernel latency + device latency.|absolute|
+|storageAdapter.commandsAveraged.average|Average number of commands issued per second by the storage adapter during the collection interval|rate|
+|storageAdapter.write.average|Rate of writing data by the storage adapter|rate|
+- power类监控项
+
+|监控项名称|描述|类型|
+|---|---|---|
+|power.power.average|Current power usage.|rate|
+|power.powerCap.average|Maximum allowed power usage.|rate|
+|power.energy.summation|Total energy used since last stats reset.|rate|
+- sys类监控项
+
+|监控项名称|描述|类型|
+|---|---|---|
+|sys.resourceCpuUsage.average|Amount of CPU used by the Service Console and other applications during the interval by the Service Console and other applications.|rate|
+|sys.resourceCpuUsage.maximum|Amount of CPU used by the Service Console and other applications during the interval by the Service Console and other applications.|rate|
+|sys.resourceMemMapped.latest|Memory mapped by the system resource group|absolute|
+|sys.resourceMemAllocShares.latest|Memory allocation shares of the system resource group|absolute|
+|sys.resourceMemCow.latest|Memory shared by the system resource group|absolute|
+|sys.resourceMemShared.latest|Memory saved due to sharing by the system resource group|absolute|
+|sys.resourceCpuAct1.latest|CPU active average over 1 minute of the system resource group|absolute|
+|sys.resourceCpuUsage.minimum|Amount of CPU used by the Service Console and other applications during the interval by the Service Console and other applications.|rate|
+|sys.resourceMemZero.latest|Zero filled memory used by the system resource group|absolute|
+|sys.resourceCpuAct5.latest|CPU active average over 5 minutes of the system resource group|absolute|
+|sys.resourceCpuMaxLimited1.latest|CPU maximum limited over 1 minute of the system resource group|absolute|
+|sys.resourceFdUsage.latest|Number of file descriptors used by the system resource group|absolute|
+|sys.resourceMemConsumed.latest|Memory consumed by the system resource group |absolute|
+|sys.resourceCpuRun5.latest|CPU running average over 5 minutes of the system resource group|absolute|
+|sys.uptime.latest|Total time elapsed, in seconds, since last system startup |absolute|
+|sys.resourceCpuAllocMin.latest|CPU allocation reservation (in MHz) of the system resource group|absolute|
+|sys.resourceCpuAllocShares.latest|CPU allocation shares of the system resource group|absolute|
+|sys.resourceCpuMaxLimited5.latest|CPU maximum limited over 5 minutes of the system resource group|absolute|
+|sys.resourceMemOverhead.latest|Overhead memory consumed by the system resource group|absolute|
+|sys.resourceCpuUsage.none|Amount of CPU used by the Service Console and other applications during the interval by the Service Console and other applications.|rate|
+|sys.resourceCpuRun1.latest|CPU running average over 1 minute of the system resource group|absolute|
+|sys.resourceMemSwapped.latest|Memory swapped out by the system resource group|absolute|
+|sys.resourceMemTouched.latest|Memory touched by the system resource group|absolute|
+|sys.resourceMemAllocMax.latest|Memory allocation limit (in KB) of the system resource group|absolute|
+|sys.resourceMemAllocMin.latest|Memory allocation reservation (in KB) of the system resource group|absolute|
+- net类监控项
+
+|监控项名称|描述|类型|
+|---|---|---|
+|net.unknownProtos.summation|Number of frames with unknown protocol received during the sampling interval|delta|
+|net.packetsRx.summation|Total number of packets received on all virtual machines running on the host.|delta|
+|net.received.average|The rate at which data is received across each physical NIC instance on the host.|rate|
+|net.errorsRx.summation|Number of packets with errors received during the sampling interval.|delta|
+|net.transmitted.average|The rate at which data is transmitted across each physical NIC instance on the host.|rate|
+|net.usage.none|Sum of data transmitted and received across all physical NIC instances connected to the host.|rate|
+|net.bytesRx.average|Average amount of data received per second.|rate|
+|net.multicastTx.summation|Number of multicast packets transmitted during the sampling interval.|delta|
+|net.droppedTx.summation|Number of transmitted packets dropped during the collection interval.|delta|
+|net.usage.minimum|Sum of data transmitted and received across all physical NIC instances connected to the host.|rate|
+|net.multicastRx.summation|Number of multicast packets received during the sampling interval.|delta|
+|net.bytesTx.average|Average amount of data transmitted per second.|rate|
+|net.broadcastRx.summation|Number of broadcast packets received during the sampling interval.|delta|
+|net.packetsTx.summation|Number of packets transmitted across each physical NIC instance on the host.|delta|
+|net.errorsTx.summation|Number of packets with errors transmitted during the sampling interval.|delta|
+|net.broadcastTx.summation|Number of broadcast packets transmitted during the sampling interval.|delta|
+|net.usage.maximum|Sum of data transmitted and received across all physical NIC instances connected to the host.|rate|
+|net.usage.average|Sum of data transmitted and received across all physical NIC instances connected to the host.|rate|
+|net.droppedRx.summation|Number of received packets dropped during the collection interval.|delta|
+- disk类监控项
+
+|监控项名称|描述|类型|
+|---|---|---|
+|disk.usage.maximum|Aggregated disk I/O rate. For hosts, this metric includes the rates for all virtual machines running on the host during the collection interval.|rate|
+|disk.deviceWriteLatency.average|Average amount of time, in milliseconds, to write to the physical device|absolute|
+|disk.queueWriteLatency.average|Average amount of time spent in the VMkernel queue, per SCSI write command, during the collection interval|absolute|
+|disk.commands.summation|Number of SCSI commands issued during the collection interval|delta|
+|disk.busResets.summation|Number of SCSI-bus reset commands issued during the collection interval|delta|
+|disk.numberRead.summation|Number of times data was read from each LUN on the host.|delta|
+|disk.deviceLatency.average|Average amount of time, in milliseconds, to complete a SCSI command from the physical device|absolute|
+|disk.deviceReadLatency.average|Average amount of time, in milliseconds, to read from the physical device|absolute|
+|disk.usage.average|Aggregated disk I/O rate. For hosts, this metric includes the rates for all virtual machines running on the host during the collection interval.|rate|
+|disk.numberWriteAveraged.average|Average number of write commands issued per second to the datastore during the collection interval.|rate|
+|disk.usage.none|Aggregated disk I/O rate. For hosts, this metric includes the rates for all virtual machines running on the host during the collection interval.|rate|
+|disk.totalWriteLatency.average|Average amount of time taken during the collection interval to process a SCSI write command issued by the guest OS to the virtual machine|absolute|
+|disk.queueLatency.average|Average amount of time spent in the VMkernel queue, per SCSI command, during the collection interval.|absolute|
+|disk.kernelLatency.average|Average amount of time, in milliseconds, spent by VMkernel to process each SCSI command|absolute|
+|disk.write.average|Rate at which data is written to each LUN on the host.write rate = # blocksRead per second x blockSize|rate|
+|disk.numberWrite.summation|Number of times data was written to each LUN on the host.|delta|
+|disk.commandsAveraged.average|Average number of SCSI commands issued per second during the collection interval|rate|
+|disk.totalLatency.average|Average amount of time taken during the collection interval to process a SCSI command issued by the guest OS to the virtual machine.|absolute|
+|disk.totalReadLatency.average|Average amount of time taken during the collection interval to process a SCSI read command issued from the guest OS to the virtual machine|absolute|
+|disk.kernelWriteLatency.average|Average amount of time, in milliseconds, spent by VMkernel to process each SCSI write command|absolute|
+|disk.maxTotalLatency.latest|Highest latency value across all disks used by the host. Latency measures the time taken to process a SCSI command issued by the guest OS to the virtual machine. The kernel latency is the time VMkernel takes to process an IO request. The device latency is the time it takes the hardware to handle the request.|absolute|
+|disk.numberReadAveraged.average|Number of times data was read from each LUN on the host.|delta|
+|disk.read.average|Rate at which data is read from each LUN on the host.read rate = # blocksRead per second x blockSize|rate|
+|disk.queueReadLatency.average|Average amount of time spent in the VMkernel queue, per SCSI read command, during the collection interval|absolute|
+|disk.usage.minimum|Aggregated disk I/O rate. For hosts, this metric includes the rates for all virtual machines running on the host during the collection interval.|rate|
+|disk.commandsAborted.summation|Number of SCSI commands aborted during the collection interval|delta|
+|disk.maxQueueDepth.average|Maximum queue depth.|absolute|
+|disk.kernelReadLatency.average|Average amount of time, in milliseconds, spent by VMkernel to process each SCSI read command|absolute|
+- cpu类监控项
+
+|监控项名称|描述|类型|
+|---|---|---|
+|cpu.reservedCapacity.average|Total CPU capacity reserved by virtual machines |absolute|
+|cpu.usagemhz.average|Sum of the actively used CPU of all powered on virtual machines on a host. The maximum possible value is the frequency of the processors multiplied by the number of processors. For example, if you have a host with four 2GHz CPUs running a virtual machine that is using 4000MHz, the host is using two CPUs completely.4000 / (4 x 2000) = 0.50|rate|
+|cpu.usage.none|Actively used CPU of the host, as a percentage of the total available CPU. Active CPU is approximately equal to the ratio of the used CPU to the available CPU. available CPU = # of physical CPUs x clock rate.100% represents all CPUs on the host. For example, if a four-CPU host is running a virtual machine with two CPUs, and the usage is 50%, the host is using two CPUs completely.|rate|
+|cpu.coreUtilization.maximum|CPU utilization of the corresponding core (if hyper-threading is enabled) as a percentage during the interval (A core is utilized if either or both of its logical CPUs are utilized).|rate|
+|cpu.costop.summation|Time the virtual machine is ready to run, but is unable to run due to co-scheduling constraints|delta|
+|cpu.totalCapacity.average|Total CPU capacity reserved by and available for virtual machines|absolute|
+|cpu.latency.average|Percent of time the virtual machine is unable to run because it is contending for access to the physical CPU(s)|rate|
+|cpu.usage.average|Actively used CPU of the host, as a percentage of the total available CPU. Active CPU is approximately equal to the ratio of the used CPU to the available CPU. available CPU = # of physical CPUs x clock rate.100% represents all CPUs on the host. For example, if a four-CPU host is running a virtual machine with two CPUs, and the usage is 50%, the host is using two CPUs completely.|rate|
+|cpu.utilization.maximum|CPU utilization as a percentage during the interval (CPU usage and CPU utilization might be different due to power management technologies or hyper-threading)|rate|
+|cpu.coreUtilization.minimum|CPU utilization of the corresponding core (if hyper-threading is enabled) as a percentage during the interval (A core is utilized if either or both of its logical CPUs are utilized).|rate|
+|cpu.wait.summation|Total CPU time spent in wait state.The wait total includes time spent the CPU Idle, CPU Swap Wait, and CPU I/O Wait states.|rate|
+|cpu.swapwait.summation|CPU time spent waiting for swap-in.|delta|
+|cpu.ready.summation|Time that the virtual machine was ready, but could not get scheduled to run on the physical CPU during last measurement interval. CPU ready time is dependent on the number of virtual machines on the host and their CPU loads.|delta|
+|cpu.utilization.average|CPU utilization as a percentage during the interval (CPU usage and CPU utilization might be different due to power management technologies or hyper-threading)|rate|
+|cpu.used.summation|Time accounted to the virtual machine. If a system service runs on behalf of this virtual machine, the time spent by that service (represented by cpu.system) should be charged to this virtual machine. If not, the time spent (represented by cpu.overlap) should not be charged against this virtual machine.|delta|
+|cpu.utilization.none|CPU utilization as a percentage during the interval (CPU usage and CPU utilization might be different due to power management technologies or hyper-threading)|rate|
+|cpu.idle.summation|Total time that the CPU spent in an idle state|delta|
+|cpu.coreUtilization.none|CPU utilization of the corresponding core (if hyper-threading is enabled) as a percentage during the interval (A core is utilized if either or both of its logical CPUs are utilized).|rate|
+|cpu.coreUtilization.average|CPU utilization of the corresponding core (if hyper-threading is enabled) as a percentage during the interval (A core is utilized if either or both of its logical CPUs are utilized).|rate|
+|cpu.readiness.average|Percentage of time that the virtual machine was ready, but could not get scheduled to run on the physical CPU.|rate|
+|cpu.usage.maximum|Actively used CPU of the host, as a percentage of the total available CPU. Active CPU is approximately equal to the ratio of the used CPU to the available CPU. available CPU = # of physical CPUs x clock rate.100% represents all CPUs on the host. For example, if a four-CPU host is running a virtual machine with two CPUs, and the usage is 50%, the host is using two CPUs completely.|rate|
+|cpu.usagemhz.none|Host - Sum of the actively used CPU of all powered on virtual machines on a host. The maximum possible value is the frequency of the processors multiplied by the number of processors. For example, if you have a host with four 2GHz CPUs running a virtual machine that is using 4000MHz, the host is using two CPUs completely.4000 / (4 x 2000) = 0.50|rate|
+|cpu.usage.minimum|Actively used CPU of the host, as a percentage of the total available CPU. Active CPU is approximately equal to the ratio of the used CPU to the available CPU. available CPU = # of physical CPUs x clock rate.100% represents all CPUs on the host. For example, if a four-CPU host is running a virtual machine with two CPUs, and the usage is 50%, the host is using two CPUs completely.|rate|
+|cpu.demand.average|The amount of CPU resources a virtual machine would use if there were no CPU contention or CPU limit|absolute|
+|cpu.usagemhz.maximum|Host - Sum of the actively used CPU of all powered on virtual machines on a host. The maximum possible value is the frequency of the processors multiplied by the number of processors. For example, if you have a host with four 2GHz CPUs running a virtual machine that is using 4000MHz, the host is using two CPUs completely.4000 / (4 x 2000) = 0.50|rate|
+|cpu.utilization.minimum|CPU utilization as a percentage during the interval (CPU usage and CPU utilization might be different due to power management technologies or hyper-threading)|rate|
+|cpu.usagemhz.minimum|Host - Sum of the actively used CPU of all powered on virtual machines on a host. The maximum possible value is the frequency of the processors multiplied by the number of processors. For example, if you have a host with four 2GHz CPUs running a virtual machine that is using 4000MHz, the host is using two CPUs completely.4000 / (4 x 2000) = 0.50|rate|
+- mem类监控项
+
+|监控项名称|描述|类型|
+|---|---|---|
+|mem.llSwapOut.maximum|Amount of memory swapped-out to host cache|absolute|
+|mem.swapin.maximum|Sum of swapin values for all powered-on virtual machines on the host.|bsolute|
+|mem.compressed.average|Amount of memory reserved by userworlds.|absolute|
+|mem.overhead.none|Total of all overhead metrics for powered-on virtual machines, plus the overhead of running vSphere services on the host.|absolute|
+|mem.heap.maximum|VMkernel virtual address space dedicated to VMkernel main heap and related data|absolute|
+|mem.unreserved.none|Amount of memory that is unreserved. Memory reservation not used by the Service Console, VMkernel, vSphere services and other powered on VMs’ user-specified memory reservations and overhead memory. This statistic is no longer relevant to virtual machine admission control, as reservations are now handled through resource pools.|absolute|
+|mem.reservedCapacity.average|Total amount of memory reservation used by powered-on virtual machines and vSphere services on the host.|absolute|
+|mem.swapoutRate.average|Rate at which memory is being swapped from active memory to disk during the current interval. This counter applies to virtual machines and is generally more useful than the swapout counter to determine if the virtual machine is running slow due to swapping, especially when looking at real-time statistics.|rate|
+|mem.vmmemctl.none|The sum of all vmmemctl values for all powered-on virtual machines, plus vSphere services on the host. If the balloon target value is greater than the balloon value, the VMkernel inflates the balloon, causing more virtual machine memory to be reclaimed. If the balloon target value is less than the balloon value, the VMkernel deflates the balloon, which allows the virtual machine to consume additional memory if needed.|absolute|
+|mem.vmfs.pbc.sizeMax.latest|Maximum size the VMFS Pointer Block Cache can grow to|absolute|
+|mem.consumed.maximum|Amount of machine memory used on the host. Consumed memory includes Includes memory used by the Service Console, the VMkernel, vSphere services, plus the total consumed metrics for all running virtual machines. host consumed memory = total host memory - free host memory|absolute|
+|mem.swapin.minimum|Sum of swapin values for all powered-on virtual machines on the host.|absolute|
+|mem.vmmemctl.maximum|The sum of all vmmemctl values for all powered-on virtual machines, plus vSphere services on the host. If the balloon target value is greater than the balloon value, the VMkernel inflates the balloon, causing more virtual machine memory to be reclaimed. If the balloon target value is less than the balloon value, the VMkernel deflates the balloon, which allows the virtual machine to consume additional memory if needed.|absolute|
+|mem.llSwapUsed.maximum|Space used for caching swapped pages in the host cache|absolute|
+|mem.sharedcommon.average|Amount of machine memory that is shared by all powered-on virtual machines and vSphere services on the host.Subtract this metric from the shared metric to gauge how much machine memory is saved due to sharing: shared - sharedcommon = machine memory (host memory) savings (KB)|absolute|
+|mem.active.minimum|Sum of all active metrics for all powered-on virtual machines plus vSphere services (such as COS, vpxa) on the host.|absolute|
+|mem.sysUsage.none|Amount of host physical memory used by VMkernel for core functionality, such as device drivers and other internal uses. Does not include memory used by virtual machines or vSphere services.|absolute|
+|mem.swapin.average|Sum of swapin values for all powered-on virtual machines on the host.|absolute|
+|mem.zero.none|Sum of zero metrics for all powered-on virtual machines, plus vSphere services on the host.|absolute|
+|mem.llSwapOut.average|Amount of memory swapped-out to host cache|absolute|
+|mem.granted.minimum|Sum of all granted metrics for all powered-on virtual machines, plus machine memory for vSphere services on the host.|absolute|
+|mem.granted.none|Sum of all granted metrics for all powered-on virtual machines, plus machine memory for vSphere services on the host.|absolute|
+|mem.consumed.minimum|Amount of machine memory used on the host. Consumed memory includes Includes memory used by the Service Console, the VMkernel, vSphere services, plus the total consumed metrics for all running virtual machines.host consumed memory = total host memory - free host memory|absolute|
+|mem.vmmemctl.minimum|The sum of all vmmemctl values for all powered-on virtual machines, plus vSphere services on the host. If the balloon target value is greater than the balloon value, the VMkernel inflates the balloon, causing more virtual machine memory to be reclaimed. If the balloon target value is less than the balloon value, the VMkernel deflates the balloon, which allows the virtual machine to consume additional memory if needed.|absolute|
+|mem.consumed.average|Amount of machine memory used on the host. Consumed memory includes Includes memory used by the Service Console, the VMkernel, vSphere services, plus the total consumed metrics for all running virtual machines.host consumed memory = total host memory - free host memory|absolute|
+|mem.active.none|Sum of all active metrics for all powered-on virtual machines plus vSphere services (such as COS, vpxa) on the host.|absolute|
+|mem.vmfs.pbc.overhead.latest|Amount of VMFS heap used by the VMFS PB Cache| absolute|
+|mem.swapout.average|Sum of swapout metrics from all powered-on virtual machines on the host.|absolute|
+|mem.usage.minimum|Percentage of available machine memory:consumed ÷ machine-memory-size|absolute|
+|mem.consumed.none|Amount of machine memory used on the host. Consumed memory includes Includes memory used by the Service Console, the VMkernel, vSphere services, plus the total consumed metrics for all running virtual machines.host consumed memory = total host memory - free host memory|absolute|
+|mem.heapfree.none|Free address space in the VMkernel main heap.Varies based on number of physical devices and configuration options. There is no direct way for the user to increase or decrease this statistic. For informational purposes only: not useful for performance monitoring.|absolute|
+|mem.vmfs.pbc.size.latest|Space used for holding VMFS Pointer Blocks in memory|absolute|
+|mem.llSwapOut.none|Amount of memory swapped-out to host cache|absolute|
+|mem.totalCapacity.average|Total amount of memory reservation used by and available for powered-on virtual machines and vSphere services on the host|absolute|
+|mem.sysUsage.minimum|Amount of host physical memory used by VMkernel for core functionality, such as device drivers and other internal uses. Does not include memory used by virtual machines or vSphere services.|absolute|
+|mem.granted.average|Sum of all granted metrics for all powered-on virtual machines, plus machine memory for vSphere services on the host.|absolute|
+|mem.activewrite.average|Estimate for the amount of memory actively being written to by the virtual machine.|absolute|
+|mem.unreserved.average|Amount of memory that is unreserved. Memory reservation not used by the Service Console, VMkernel, vSphere services and other powered on VMs’ user-specified memory reservations and overhead memory. This statistic is no longer relevant to virtual machine admission control, as reservations are now handled through resource pools.|absolute|
+|mem.llSwapIn.average|Amount of memory swapped-in from host cache|absolute|
+|mem.overhead.maximum|Total of all overhead metrics for powered-on virtual machines, plus the overhead of running vSphere services on the host.|absolute|
+|mem.llSwapOut.minimum|Amount of memory swapped-out to host cache|absolute|
+|mem.shared.none|Sum of all shared metrics for all powered-on virtual machines, plus amount for vSphere services on the host. The host's shared memory may be larger than the amount of machine memory if memory is overcommitted (the aggregate virtual machine configured memory is much greater than machine memory). The value of this statistic reflects how effective transparent page sharing and memory overcommitment are for saving machine memory.|absolute|
+|mem.usage.average|Percentage of available machine memory:consumed ÷ machine-memory-size|absolute|
+|mem.llSwapInRate.average|Rate at which memory is being swapped from host cache into active memory|rate|
+|mem.sysUsage.average|Amount of host physical memory used by VMkernel for core functionality, such as device drivers and other internal uses. Does not include memory used by virtual machines or vSphere services.|absolute|
+|mem.lowfreethreshold.average|Threshold of free host physical memory below which ESX/ESXi will begin reclaiming memory from virtual machines through ballooning and swapping|absolute|
+|mem.zero.average|Sum of zero metrics for all powered-on virtual machines, plus vSphere services on the host.|absolute|
+|mem.vmfs.pbc.capMissRatio.latest|Trailing average of the ratio of capacity misses to compulsory misses for the VMFS PB Cache|absolute|
+|mem.state.latest|One of four threshold levels representing the percentage of free memory on the host. The counter value determines swapping and ballooning behavior for memory reclamation.0 (high) Free memory >= 6% of machine memory minus Service Console memory;1 (soft) 4%;2 (hard) 2%; 3 (low) 1%; 0 (high) and 1 (soft): Ballooning is favored over swapping.2 (hard) and 3 (low): Swapping is favored over ballooning.|absolute|
+|mem.heap.average|VMkernel virtual address space dedicated to VMkernel main heap and related data|absolute|
+|mem.heapfree.average|Free address space in the VMkernel main heap.Varies based on number of physical devices and configuration options. There is no direct way for the user to increase or decrease this statistic. For informational purposes only: not useful for performance monitoring.|absolute|
+|mem.granted.maximum|Sum of all granted metrics for all powered-on virtual machines, plus machine memory for vSphere services on the host.|absolute|
+|mem.llSwapIn.maximum|Amount of memory swapped-in from host cache|absolute|
+|mem.llSwapUsed.none|Space used for caching swapped pages in the host cache|absolute|
+|mem.swapout.minimum|Sum of swapout metrics from all powered-on virtual machines on the host.|absolute|
+|mem.active.average|Sum of all active metrics for all powered-on virtual machines plus vSphere services (such as COS, vpxa) on the host.|absolute|
+|mem.llSwapIn.minimum|Amount of memory swapped-in from host cache|absolute|
+|mem.overhead.minimum|Total of all overhead metrics for powered-on virtual machines, plus the overhead of running vSphere services on the host.|absolute|
+|mem.llSwapUsed.minimum|Space used for caching swapped pages in the host cache|absolute|
+|mem.swapinRate.average|Rate at which memory is swapped from disk into active memory during the interval. This counter applies to virtual machines and is generally more useful than the swapin counter to determine if the virtual machine is running slow due to swapping, especially when looking at real-time statistics.|rate|
+|mem.heapfree.maximum|Free address space in the VMkernel main heap.Varies based on number of physical devices and configuration options. There is no direct way for the user to increase or decrease this statistic. For informational purposes only: not useful for performance monitoring.|absolute|
+|mem.shared.average|Sum of all shared metrics for all powered-on virtual machines, plus amount for vSphere services on the host. The host's shared memory may be larger than the amount of machine memory if memory is overcommitted (the aggregate virtual machine configured memory is much greater than machine memory). The value of this statistic reflects how effective transparent page sharing and memory overcommitment are for saving machine memory.|absolute|
+|mem.zero.maximum|Sum of zero metrics for all powered-on virtual machines, plus vSphere services on the host.|absolute|
+|mem.swapout.maximum|Sum of swapout metrics from all powered-on virtual machines on the host.|absolute|
+|mem.swapin.none|Sum of swapin values for all powered-on virtual machines on the host.|absolute|
+|mem.heap.minimum|VMkernel virtual address space dedicated to VMkernel main heap and related data|absolute|
+|mem.decompressionRate.average|Rate of memory decompression for the virtual machine.|rate|
+|mem.compressionRate.average|Rate of memory compression for the virtual machine.|rate|
+|mem.shared.minimum|Sum of all shared metrics for all powered-on virtual machines, plus amount for vSphere services on the host. The host's shared memory may be larger than the amount of machine memory if memory is overcommitted (the aggregate virtual machine configured memory is much greater than machine memory). The value of this statistic reflects how effective transparent page sharing and memory overcommitment are for saving machine memory.|absolute|
+|mem.unreserved.maximum|Amount of memory that is unreserved. Memory reservation not used by the Service Console, VMkernel, vSphere services and other powered on VMs’ user-specified memory reservations and overhead memory. This statistic is no longer relevant to virtual machine admission control, as reservations are now handled through resource pools.|absolute|
+|mem.zero.minimum|Sum of zero metrics for all powered-on virtual machines, plus vSphere services on the host.|absolute|
+|mem.llSwapIn.none|Amount of memory swapped-in from host cache|absolute|
+|mem.swapused.minimum|Amount of memory that is used by swap. Sum of memory swapped of all powered on VMs and vSphere services on the host.|absolute|
+|mem.sharedcommon.minimum|Amount of machine memory that is shared by all powered-on virtual machines and vSphere services on the host.Subtract this metric from the shared metric to gauge how much machine memory is saved due to sharing: shared - sharedcommon = machine memory (host memory) savings (KB)|absolute|
+|mem.active.maximum|Sum of all active metrics for all powered-on virtual machines plus vSphere services (such as COS, vpxa) on the host.|absolute|
+|mem.vmfs.pbc.workingSet.latest|Amount of file blocks whose addresses are cached in the VMFS PB Cache|absolute|
+|mem.latency.average|Percentage of time the virtual machine is waiting to access swapped or compressed memory|absolute|
+|mem.unreserved.minimum|Amount of memory that is unreserved. Memory reservation not used by the Service Console, VMkernel, vSphere services and other powered on VMs’ user-specified memory reservations and overhead memory. This statistic is no longer relevant to virtual machine admission control, as reservations are now handled through resource pools.|absolute|
+|mem.vmfs.pbc.workingSetMax.latest|Maximum amount of file blocks whose addresses are cached in the VMFS PB Cache|absolute|
+|mem.llSwapUsed.average|Space used for caching swapped pages in the host cache|absolute|
+|mem.sharedcommon.maximum|Amount of machine memory that is shared by all powered-on virtual machines and vSphere services on the host.Subtract this metric from the shared metric to gauge how much machine memory is saved due to sharing:shared - sharedcommon = machine memory (host memory) savings (KB)|absolute|
+|mem.swapout.none|Sum of swapout metrics from all powered-on virtual machines on the host.|absolute|
+|mem.swapused.maximum|Amount of memory that is used by swap. Sum of memory swapped of all powered on VMs and vSphere services on the host.|absolute|
+|mem.usage.none|Percentage of available machine memory:consumed ÷ machine-memory-size|absolute|
+|mem.heapfree.minimum|Free address space in the VMkernel main heap.Varies based on number of physical devices and configuration options. There is no direct way for the user to increase or decrease this statistic. For informational purposes only: not useful for performance monitoring.|absolute|
+|mem.heap.none|VMkernel virtual address space dedicated to VMkernel main heap and related data|absolute|
+|mem.vmmemctl.average|The sum of all vmmemctl values for all powered-on virtual machines, plus vSphere services on the host. If the balloon target value is greater than the balloon value, the VMkernel inflates the balloon, causing more virtual machine memory to be reclaimed. If the balloon target value is less than the balloon value, the VMkernel deflates the balloon, which allows the virtual machine to consume additional memory if needed.|absolute|
+|mem.sysUsage.maximum|Amount of host physical memory used by VMkernel for core functionality, such as device drivers and other internal uses. Does not include memory used by virtual machines or vSphere services.|absolute|
+|mem.llSwapOutRate.average|Rate at which memory is being swapped from active memory to host cache|rate|
+|mem.swapused.none|Amount of memory that is used by swap. Sum of memory swapped of all powered on VMs and vSphere services on the host.|absolute|
+|mem.overhead.average|Total of all overhead metrics for powered-on virtual machines, plus the overhead of running vSphere services on the host.|absolute|
+|mem.swapused.average|Amount of memory that is used by swap. Sum of memory swapped of all powered on VMs and vSphere services on the host.|absolute|
+|mem.shared.maximum|Sum of all shared metrics for all powered-on virtual machines, plus amount for vSphere services on the host. The host's shared memory may be larger than the amount of machine memory if memory is overcommitted (the aggregate virtual machine configured memory is much greater than machine memory). The value of this statistic reflects how effective transparent page sharing and memory overcommitment are for saving machine memory.|absolute|
+|mem.sharedcommon.none|Amount of machine memory that is shared by all powered-on virtual machines and vSphere services on the host.Subtract this metric from the shared metric to gauge how much machine memory is saved due to sharing: shared - sharedcommon = machine memory (host memory) savings (KB)|absolute|
+|mem.usage.maximum|Percentage of available machine memory:consumed ÷ machine-memory-size|absolute|
+- datastore类监控项
+
+|监控项名称|描述|类型|
+|---|---|---|
+|datastore.datastoreWriteBytes.latest|Storage DRS datastore bytes written|absolute|
+|datastore.datastoreIops.average|Average amount of time for an I/O operation to the datastore or LUN across all ESX hosts accessing it.|absolute|
+|datastore.siocActiveTimePercentage.average|Percentage of time Storage I/O Control actively controlled datastore latency|absolute|
+|datastore.numberWriteAveraged.average|Average number of write commands issued per second to the datastore during the collection interval|rate|
+|datastore.totalWriteLatency.average|Average amount of time for a write operation to the datastore. Total latency = kernel latency + device latency. |absolute|
+|datastore.datastoreNormalWriteLatency.latest|Storage DRS datastore normalized write latency|absolute|
+|datastore.sizeNormalizedDatastoreLatency.average|Storage I/O Control size-normalized I/O latency|absolute|
+|datastore.datastoreVMObservedLatency.latest|The average datastore latency as seen by virtual machines|absolute|
+|datastore.datastoreReadLoadMetric.latest|Storage DRS datastore metric for read workload model|absolute|
+|datastore.datastoreMaxQueueDepth.latest|Storage I/O Control datastore maximum queue depth|absolute|
+|datastore.maxTotalLatency.latest|Highest latency value across all datastores used by the host|absolute|
+|datastore.datastoreReadIops.latest|Storage DRS datastore read I/O rate|absolute|
+|datastore.datastoreReadBytes.latest|Storage DRS datastore bytes read|absolute|
+|datastore.datastoreWriteIops.latest|Storage DRS datastore write I/O rate|absolute|
+|datastore.datastoreWriteLoadMetric.latest|Storage DRS datastore metric for write workload model|absolute|
+|datastore.datastoreWriteOIO.latest|Storage DRS datastore outstanding write requests|absolute|
+|datastore.datastoreReadOIO.latest|Storage DRS datastore outstanding read requests|absolute|
+|datastore.numberReadAveraged.average|Average number of read commands issued per second to the datastore during the collection interval|rate|
+|datastore.totalReadLatency.average|Average amount of time for a read operation from the datastore. Total latency = kernel latency + device latency.|absolute|
+|datastore.read.average|Rate of reading data from the datastore|rate|
+|datastore.datastoreNormalReadLatency.latest|Storage DRS datastore normalized read latency|absolute|
+|datastore.write.average|Rate of writing data to the datastore|absolute|
diff --git a/zh_0_3/usage/vsphere.md b/zh_0_3/usage/vsphere.md
new file mode 100644
index 0000000..724388e
--- /dev/null
+++ b/zh_0_3/usage/vsphere.md
@@ -0,0 +1,110 @@
+
+
+## vsphere 监控
+
+在[数据采集](../philosophy/data-collect.md)一节中我们介绍了常见的监控数据源。open-falcon作为一个监控框架,可以去采集任何系统的监控指标数据,只要将监控数据组织为open-falcon规范的格式就OK了。
+
+vsphere 的运行指标监控,可以通过脚本采集 vsphere 的各项状态,包括 Esxi,datastore,vm 等然后推送给 Open-Falcon 即可。
+
+可以直接使用 [vsphere-monitor](https://github.com/freedomkk-qfeng/vsphere-monitor) 来实现对 vsphere 集群的监控指标采集。
+
+#### 工作原理
+
+vsphere-monitor 通过 [pyvmomi](https://github.com/vmware/pyvmomi) 采集 vsphere 集群的数据。只需要连接 vcenter 就可以采集集群内的包括 ESXi,datastore,vm 等各种监控数据。数据通过 open-falcon 的数据接口上报给 open-falcon。
+
+#### 版本需求
+python 2.7
+
+#### 上报数据字段
+
+ metric | tag | type | note
+-----|------|------|------
+datastore.capacity|datacetner=datacenter,datastore=datastore,type=type|GAUGE| 存储容量
+datastore.free|datacetner=datacenter,datastore=datastore,type=type|GAUGE| 存储剩余容量
+datastore.freePercent|datacetner=datacenter,datastore=datastore,type=type|GAUGE| 存储剩余容量
+esxi.alive|datacetner=datacenter,cluster_name=cluster_name,host=host|GAUGE|esxi 存活,值为 1,可以用来做 Nodata
+esxi.net.if.in|datacetner=datacenter,cluster_name=cluster_name,host=host|GAUGE|esxi 网络进流量(所有网卡总和)
+esxi.net.if.out|datacetner=datacenter,cluster_name=cluster_name,host=host|GAUGE|esxi 网络出流量(所有网卡总和)
+esxi.memory.freePercent|datacetner=datacenter,cluster_name=cluster_name,host=host|GAUGE|esxi 剩余内存百分比
+esxi.memory.usage|datacetner=datacenter,cluster_name=cluster_name,host=host|GAUGE|esxi 内存使用量
+esxi.memory.capacity|datacetner=datacenter,cluster_name=cluster_name,host=host|GAUGE|esxi 内存总量
+esxi.cpu.usage|datacetner=datacenter,cluster_name=cluster_name,host=host|GAUGE|esxi CPU 使用率
+esxi.uptime|datacetner=datacenter,cluster_name=cluster_name,host=host|GAUGE|esxi uptime
+vm.power|vm=vm_name|GAUGE|虚机是否开机,开机 = 1,关机 = 0,可以用来做 nodata
+vm.net.if.in|vm=vm_name|GAUGE|虚机网络进流量(所有网卡总和)
+vm.net.if.out|vm=vm_name|GAUGE|虚机网络出流量(所有网卡总和)
+vm.datastore.io.write_latency|vm=vm_name|GAUGE|虚机存储 io 写延迟
+vm.datastore.io.read_latency|vm=vm_name|GAUGE|虚机存储 io 读延迟
+vm.datastore.io.write_numbers|vm=vm_name|GAUGE|虚机存储写 IOPS
+vm.datastore.io.read_numbers|vm=vm_name|GAUGE|虚机存储读 IOPS
+vm.datastore.io.write_bytes|vm=vm_name|GAUGE|虚机存储写流量
+vm.datastore.io.read_bytes|vm=vm_name|GAUGE|虚机存储读流量
+vm.memory.freePercent|vm=vm_name|GAUGE|虚机内存剩余百分比
+vm.memory.usage|vm=vm_name|GAUGE|虚机内存量使用量
+vm.memory.capacity|vm=vm_name|GAUGE|虚机内存量总量
+vm.cpu.usage|vm=vm_name|GAUGE|虚机 cpu 使用量
+vm.uptime|vm=vm_name|GAUGE|虚机 uptime
+
+
+#### 安装
+获取代码
+```
+git clone https://github.com/freedomkk-qfeng/vsphere-monitor.git
+```
+安装依赖
+```
+yum install -y python-virtualenv
+cd vsphere-monitor
+virtualenv ./env
+./env/bin/pip install -r requirement.txt
+```
+#### 配置
+修改配置文件 `config.py`
+```
+# falcon
+endpoint = "vcenter" # 上报给 open-falcon 的 endpoint
+push_api = "http://127.0.0.1:6060/api/push" # 上报的 http api 接口
+interval = 60 # 上报的 step 间隔
+
+# vcenter
+host = "vcenter.host" # vcenter 的地址
+user = "administrator@vsphere.local" # vcenter 的用户名
+pwd = "password" # vcenter 的密码
+port = 443 # vcenter 的端口
+
+# esxi
+esxi_names = [] # 需要采集的 esxi ,留空则全部采集
+
+# datastore
+datastore_names = [] # 需要采集的 datastore ,留空则全部采集
+
+# vm
+vm_enable = True # 是否要采集虚拟机信息
+vm_names = [ # 需要采集的虚拟机,留空则全部采集
+ "vm1",
+ "vm2",
+ "vm3"
+ ]
+```
+
+#### 运行
+先尝试跑一下,假定 `vsphere-monitor` 放在 `/opt` 下
+```
+/opt/vsphere-monitor/env/bin/python /opt/vsphere-monitor/vsphere-monitor.py
+```
+没有问题的话,将他放入定时任务
+```
+crontab -e
+0-59/1 * * * * /opt/vsphere-monitor/env/bin/python /opt/vsphere-monitor/vsphere-monitor.py
+```
+
+#### 问题
+部分 vm 可能会采集不到 `vm.net.if.in` 和 `vm.net.if.out` 指标,这是因为网络指标是通过 `vsphere` 的 `PerformanceManager` 采集的。可以在 `vcenter` 中查看虚拟机的 `性能` 图表时,也会发现显示错误 `未指定衡量指标` 或者 `No Metric Specified` 。这是 `vmware` 的 bug,在 `vSphere 6.0 Update 1` 以上版本被修复
+
+详见官方 Knowledge —— [在 VMware vSphere Client 6.0 中查看虚拟机网络的实时性能图表时显示错误:未指定衡量指标 (2125021)](https://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=2125021)
+
+#### 截图
+esxi
+
+vm
+
diff --git a/zh_0_3/usage/win.md b/zh_0_3/usage/win.md
new file mode 100644
index 0000000..b74b97c
--- /dev/null
+++ b/zh_0_3/usage/win.md
@@ -0,0 +1,15 @@
+
+
+# 监控Windows平台
+
+在[数据采集](../philosophy/data-collect.md)一节中我们介绍了常见的监控数据源。open-falcon作为一个监控框架,可以去采集任何系统的监控指标数据,只要将监控数据组织为open-falcon规范的格式就OK了。
+
+Windows主机的运行指标的采集,可以写Python脚本,通过windows的计划任务来每分钟执行采集各项运行指标,包括内存占用、CPU使用、磁盘使用量、网卡流量等。
+
+可以直接使用以下 window 监控程序进行 windows 主机的监控指标采集。
+
+- [windows_collect](https://github.com/freedomkk-qfeng/falcon-scripts/tree/master/windows_collect):python脚本
+- [windows-agent](https://github.com/LeonZYang/agent): go 语言实现的 agent
+- [Windows-Agent](https://github.com/AutohomeRadar/Windows-Agent):汽车之家开源的作为Windows Service运行的Agent,python实现。
+- [windows-agent](https://github.com/freedomkk-qfeng/windows-agent):另一个 go 语言实现的 windows-agent。支持端口,进程监控,支持后台服务运行。
+