Hello there! First of all I'd like to congratulate you all for this work and the paper. Really impressive stuff and I hope it to be useful for me as a graduate computer science student.
As I was checking out the demo I couldn't help but notice it was way too slow. I've checked my browsers dev tools and found out the main reason is the frontends call to getPapers endpoint.
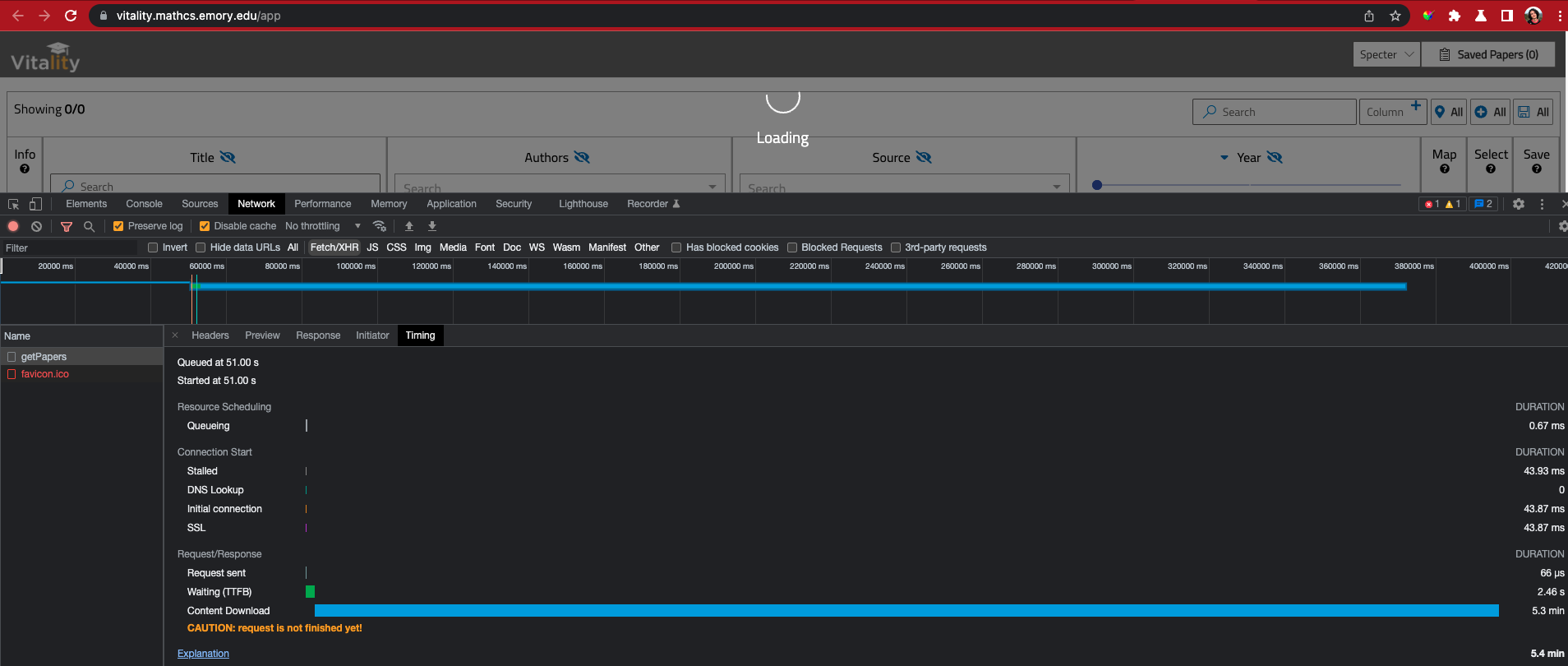
The demo kept loading for a long while until I realize the reason: it's really a full data fetch.
I'd like to propose a improvement to tackle this performance issue and introduce pagination parameters to the getPapers endpoint, so you can fetch papers as they are required/a small set at a time.
Of course eventually it would require a change in frontend to consume this feature, but I think the tool is completely inviable without it. I mean, the demo still haven't load for me (20 minutes downloading the response and counting) in a macbook pro, imagine what would look like in low specs computers and mobiles.
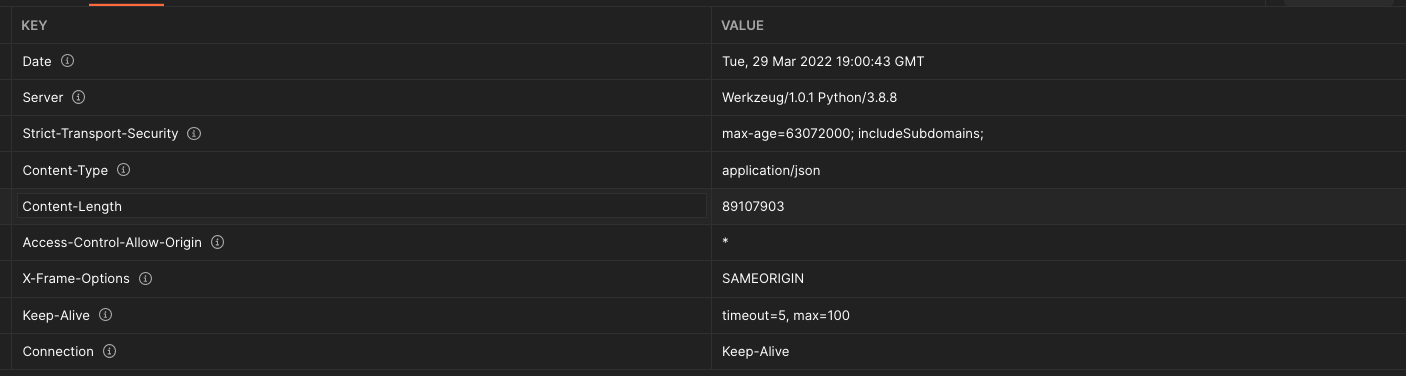
I mean, you are requiring the browser to download around 90MB of compressed data and then parse it.
What are your thoughts? I could help implement it myself as I'm a bit experienced in this kind of problem.
Hello there! First of all I'd like to congratulate you all for this work and the paper. Really impressive stuff and I hope it to be useful for me as a graduate computer science student.
As I was checking out the demo I couldn't help but notice it was way too slow. I've checked my browsers dev tools and found out the main reason is the frontends call to
getPapersendpoint.The demo kept loading for a long while until I realize the reason: it's really a full data fetch.
I'd like to propose a improvement to tackle this performance issue and introduce pagination parameters to the getPapers endpoint, so you can fetch papers as they are required/a small set at a time.
Of course eventually it would require a change in frontend to consume this feature, but I think the tool is completely inviable without it. I mean, the demo still haven't load for me (20 minutes downloading the response and counting) in a macbook pro, imagine what would look like in low specs computers and mobiles.
I mean, you are requiring the browser to download around 90MB of compressed data and then parse it.
What are your thoughts? I could help implement it myself as I'm a bit experienced in this kind of problem.