Attentive Eraser: Unleashing Diffusion Model’s Object Removal Potential via Self-Attention Redirection Guidance (AAAI2025 Oral)




2025-02-17: The Huggingface demo is now available in Demo 🤗🤗
2025-02-09: Happy Chinese New Year! Demo Released! 🎉🎉
2025-01-25: The Stable Diffusion XL Attentive Eraser Pipeline is now available in Diffusers🧨 🤗🤗
2025-01-18: AttentiveEraser has been selected for oral presentation at the AAAI2025 conference 🥳🥳
Attentive Eraser is a novel tuning-free method that enhances object removal capabilities in pre-trained diffusion models. This official implementation demonstrates the method's efficacy, leveraging altered self-attention mechanisms to prioritize background over foreground in the image generation process.
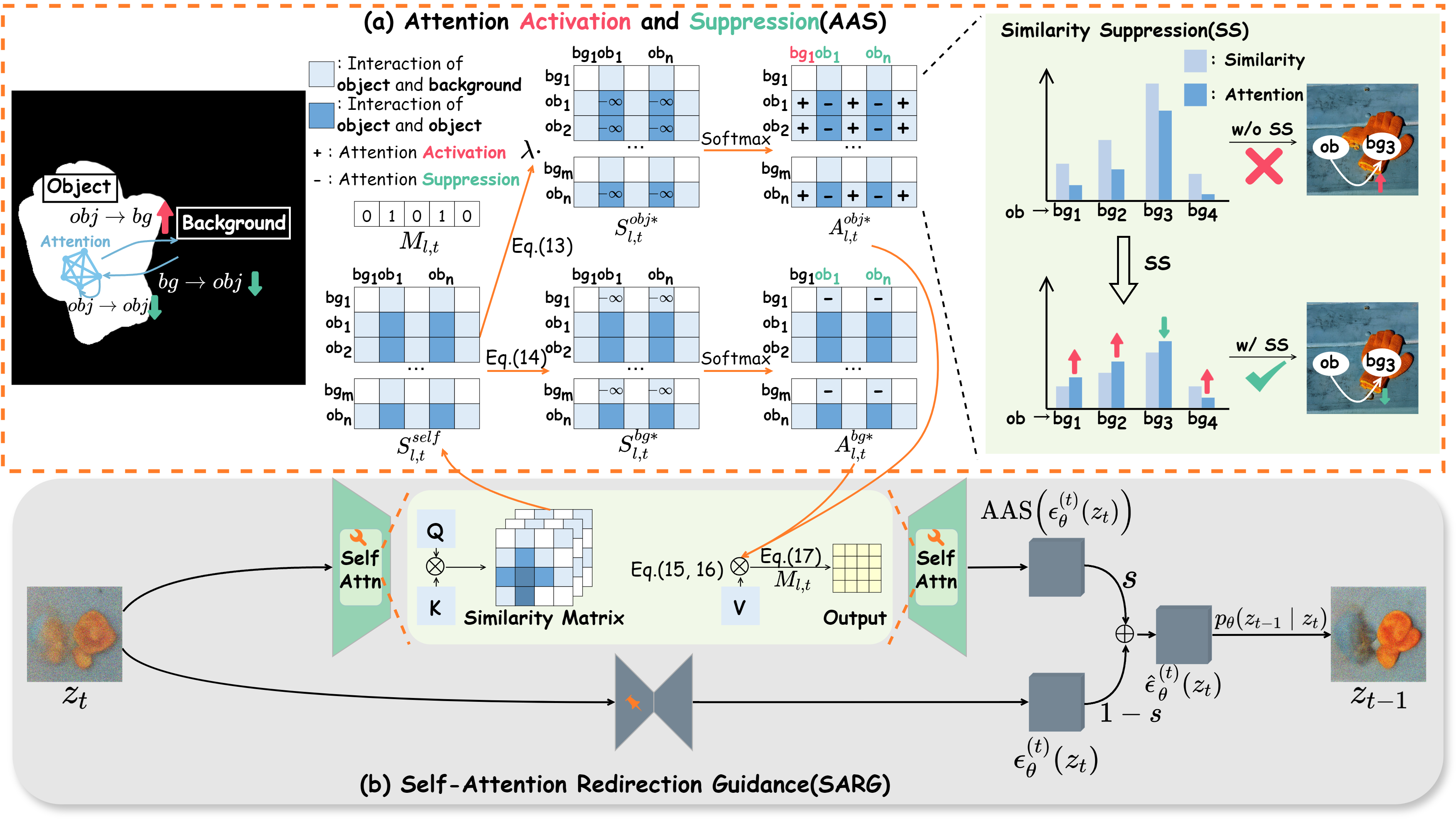
The overview of our proposed Attentive Eraser
The pretrained diffusion models can be downloaded from the link below for offline loading.
SDXL: https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0
SD2.1: https://huggingface.co/stabilityai/stable-diffusion-2-1-base
git clone https://github.com/Anonym0u3/AttentiveEraser.git
cd AttentiveEraser
conda create -n AE python=3.9
conda activate AE
pip install -r requirements.txt
# run SDXL+SIP
python main.pyMore experimental versions can be found in the notebook folder.
To use the Stable Diffusion XL Attentive Eraser Pipeline(SDXL+SIP), you can initialize it as follows:
import torch
from diffusers import DDIMScheduler, DiffusionPipeline
from diffusers.utils import load_image
import torch.nn.functional as F
from torchvision.transforms.functional import to_tensor, gaussian_blur
dtype = torch.float16
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
scheduler = DDIMScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", clip_sample=False, set_alpha_to_one=False)
pipeline = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
custom_pipeline="pipeline_stable_diffusion_xl_attentive_eraser",
scheduler=scheduler,
variant="fp16",
use_safetensors=True,
torch_dtype=dtype,
).to(device)
def preprocess_image(image_path, device):
image = to_tensor((load_image(image_path)))
image = image.unsqueeze_(0).float() * 2 - 1 # [0,1] --> [-1,1]
if image.shape[1] != 3:
image = image.expand(-1, 3, -1, -1)
image = F.interpolate(image, (1024, 1024))
image = image.to(dtype).to(device)
return image
def preprocess_mask(mask_path, device):
mask = to_tensor((load_image(mask_path, convert_method=lambda img: img.convert('L'))))
mask = mask.unsqueeze_(0).float() # 0 or 1
mask = F.interpolate(mask, (1024, 1024))
mask = gaussian_blur(mask, kernel_size=(77, 77))
mask[mask < 0.1] = 0
mask[mask >= 0.1] = 1
mask = mask.to(dtype).to(device)
return mask
prompt = "" # Set prompt to null
seed=123
generator = torch.Generator(device=device).manual_seed(seed)
source_image_path = "https://raw.githubusercontent.com/Anonym0u3/Images/refs/heads/main/an1024.png"
mask_path = "https://raw.githubusercontent.com/Anonym0u3/Images/refs/heads/main/an1024_mask.png"
source_image = preprocess_image(source_image_path, device)
mask = preprocess_mask(mask_path, device)
image = pipeline(
prompt=prompt,
image=source_image,
mask_image=mask,
height=1024,
width=1024,
AAS=True, # enable AAS
strength=0.8, # inpainting strength
rm_guidance_scale=9, # removal guidance scale
ss_steps = 9, # similarity suppression steps
ss_scale = 0.3, # similarity suppression scale
AAS_start_step=0, # AAS start step
AAS_start_layer=34, # AAS start layer
AAS_end_layer=70, # AAS end layer
num_inference_steps=50, # number of inference steps # AAS_end_step = int(strength*num_inference_steps)
generator=generator,
guidance_scale=1,
).images[0]
image.save('./removed_img.png')
print("Object removal completed")| Source Image | Mask | Output |
|---|---|---|
 |
 |
 |
If you find this project useful in your research, please consider citing it:
@inproceedings{sun2025attentive,
title={Attentive Eraser: Unleashing Diffusion Model’s Object Removal Potential via Self-Attention Redirection Guidance},
author={Sun, Wenhao and Cui, Benlei and Dong, Xue-Mei and Tang, Jingqun},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={39},
number={19},
pages={20734--20742},
year={2025}
}This repository is built upon and utilizes the following repositories:
We would like to express our sincere thanks to the authors and contributors of these repositories for their incredible work, which greatly enhanced the development of this repository.
This project is licensed under the Apache License 2.0. See the LICENSE file for details.
Welcome to contribute by submitting issues and PRs! Special thanks to the following friends for their contributions:
- @nuwandda - Add Hugging Face Demo