Autoencoder
Autoencoder(오토인코더)는 인풋과 아웃풋 노드의 수가 같은 인공신경망을 이용해 Unsupervised Learning으로 feature를 추출하는 방법이다.
input layer 노드 수와 output layer 노드 수가 같으므로 hidden layer의 수가 그보다 많고(sparsity) 적음(reconstructed)의 여부가 중요하다. 따라서 Autoencoder를 통해 hidden layer에 input 데이터를 압축적으로 저장함으로써 원본 데이터의 feature을 효과적으로 추출할 수 있다.
- hidden layer에서 추출한 feature를 SVM, 인공신경망, Softmax Classifier에 집어넣어 분류 성능을 향상시킬 수 있다.
고차원의 vector 값들을 저차원의 vector로 나타낼 수 있게 목적이다. 예를 들어 Word2Vec과 같이 One-hot encoding(어느 벡터에서 각각의 단어가 하나의 차원을 가지도록 인코딩) 수만~수십만 개의 단어를 200차원의 vector로 만들 때 Autoencoder를 사용할 수 있다.
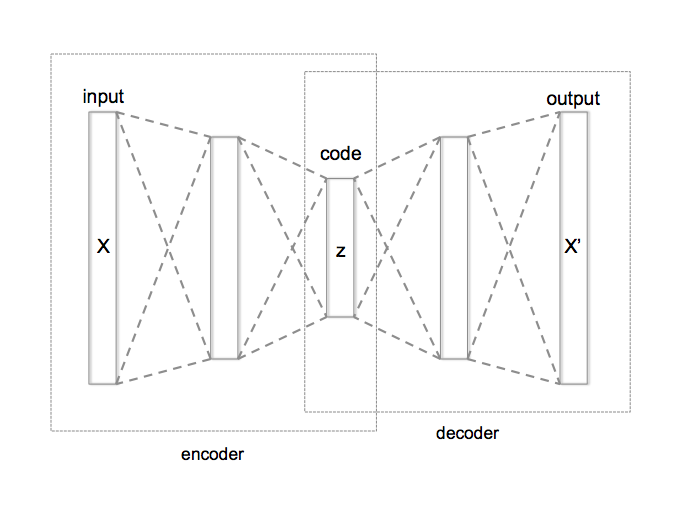
Autoencoder의 구조는 아래 그림과 같다. 이 Model의 목적은 어느 값을 입력하면 똑같은 값을 그대로 출력하는 것이다. encoder 부분에선 추상적인 feature를 찾고, decoder 부분에선 추상적인 feature를 바탕으로 다시 원래 값을 추정하는 것이다. Code Layer의 값이 feature가 추출된 값이다. 여기서 Code Layer의 크기는 Input/Output Layer의 크기보다 작아야 한다. 그렇지 않으면 Input Layer의 값을 그대로 복제해서 Output Layer로 내 놓게 되며, 고차원의 vector를 저차원 vector로 줄이고자 하는 Autoencoder의 목적과도 맞지 않는다.
- 비지도 학습 - 오토인코더(Autoencoder): Autoencoder 소개 및 MNIST 예제
- 인공 신경망에 관한 설명. 스탠포드 대학 앤드류 응 교수의 sparse autoencoder 정리 노트로 인공신경망 이해하기
- 오토 인코더를 이용한 비정상 거래 검출 모델의 구현: Autoencoder의 decoder가 학습되지 않은 데이터에 대해서 잘 동작하지 않는다는 점을 이용해 비정상 거래 검출 모델을 만들었음
- hidden layer의 수가 더 많을 때, 사용하는 sparsity를 수학적으로 이해하기