Faster DAN: Multi-target Queries with Document Positional Encoding for End-to-end Handwritten Document Recognition
This project is under CeCILL-C license (full details in LICENSE_CECILL-C.md).
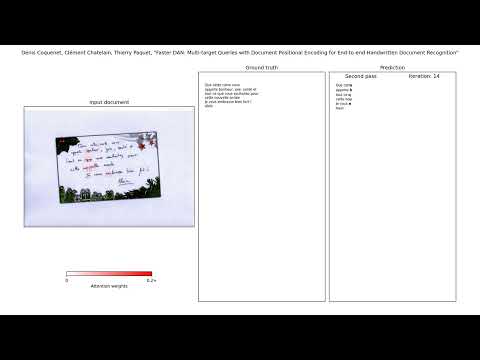
This repository is a public implementation of the paper: "Faster DAN: Multi-target Queries with Document Positional Encoding for End-to-end Handwritten Document Recognition", International Conference on Document Analysis and Recognition, 2023.
The paper is available on Arxiv.
Click to see the demo:
Pretrained model weights are available here and here
Table of contents:
We used Python 3.10.4, Pytorch 1.12.0 and CUDA 10.2.
Clone the repository:
git clone https://github.com/FactoDeepLearning/FasterDAN.git
Install the dependencies in conda env:
conda create --name fdan
conda activate fdan
cd FasterDAN
pip install -e .
cd faster_dan
We used three datasets in the paper: RIMES 2009, READ 2016 and MAURDOR.
RIMES dataset at page level was distributed during the evaluation compaign of 2009.
The MAURDOR dataset was distributed during the evaluation compaign of 2013. It is now available here.
READ 2016 dataset corresponds to the one used in the ICFHR 2016 competition on handwritten text recognition. It can be found here
Raw dataset files must be placed in Datasets/raw/{dataset_name}
where dataset name is "READ 2016", "RIMES" or "Maurdor".
Step 1: Download the datasets and place the raw files in the following folder: Datasets/raw/{dataset_name}
python3 Datasets/dataset_formatters/read2016_formatter.py
python3 Datasets/dataset_formatters/rimes_formatter.py
python3 Datasets/dataset_formatters/maurdor_formatter.py
cd OCR/line_OCR/ctc/
python3 main_syn_line.py # generation
python3 main_line_ctc_syn.py # training
There are two lines in this script to adapt to the used dataset:
model.generate_syn_line_dataset("READ_2016_syn_line")
dataset_name = "READ_2016"
Weights and evaluation results are stored in OCR/line_OCR/ctc/outputs
cd OCR/document_OCR/faster_dan/
python3 main_faster_dan.py # faster dan
python3 main_std_dan.py # original dan
Weights and evaluation results are stored in OCR/document_OCR/dan/outputs
Scripts are given for the READ 2016 dataset and must be adapted for RIMES 2009 and MAURDOR (mostly dataset_name parameter, and pretraining paths)
All hyperparameters are specified and editable in the training scripts (meaning are in comments).
Evaluation is performed just after training ending (training is stopped when the maximum elapsed time is reached or after a maximum number of epoch as specified in the training script).
The outputs files are split into two subfolders: "checkpoints" and "results".
"checkpoints" contains model weights for the last trained epoch and for the epoch giving the best CER on the validation set.
"results" contains tensorboard log for loss and metrics as well as text file for used hyperparameters and results of evaluation.
@inproceedings{Coquenet2023fasterdan,
author = {Coquenet, Denis and Chatelain, Clément and Paquet, Thierry},
title = {Faster DAN: Multi-target Queries with Document Positional Encoding for End-to-end Handwritten Document Recognition},
booktitle={International Conference on Document Analysis and Recognition (ICDAR)},
year={2023},
pages={182--199},
series={Lecture Notes in Computer Science},
volume={14190},
doi={10.1007/978-3-031-41685-9_12},
url={https://arxiv.org/abs/2301.10593},
}This project is under CeCILL-C license.