The goal of this side project is to create and train a model to estimate the location of 98 face landmarks. These landmarks can be used for head pose estimation, sentiment analysis, action recognition, face filtering and more.
As dataset, I chose the Wider Facial Landmarks in-the-wild (WFLW)1 from Wayne Wu et al., containing a total of 10000 annotated faces (7500 for training and 2500 for testing).
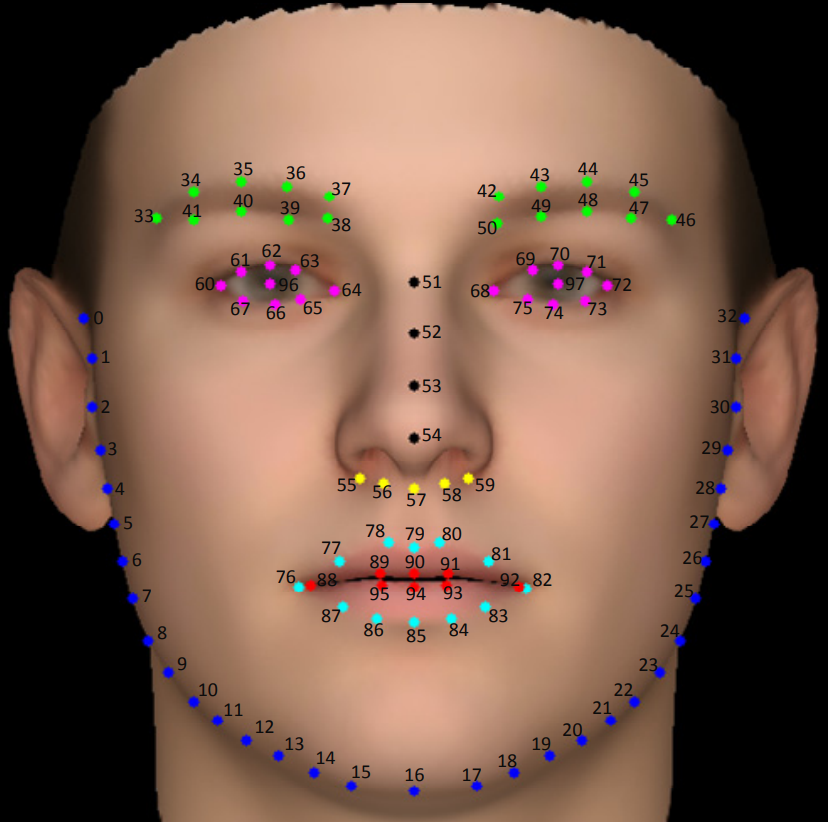
The following figure shows where the landmarks are located:
For the first implementation of this model, we assume that the input model will already be cropped around each face by another algorithm. Next models, might take as input directly the entire image without face pre-detection.
The dataset provides along each landmarks annotation list, the corresponding face bounding box. Hence, each training image is first cropped (while still keeping a padding mask around the box), converted into float32, resized to 224x224 and lastly, normalized with a mean equal to 0.5.
Although the heatmap based methods seems to be more accurate in this type of tasks, I decide to start with a traditional convolutional architecture. Then, based on results and future developments, other approaches may be taken into consideration.
| model | test loss |
|---|---|
| ResNet50 | 10.1 |
The first version is a standard CNN architecture using ResNet502 as backbone. The last layer of the ResNet has been changed to produce a 196 dimensional output tensor, i.e. x,y for each one of the 98 markers. The model has been trained for 200 epochs using Wing loss3.
Model 1 outputs on test set elements:

The following plot contains training loss (blue) and validation loss (red):
