一个模型就能够分割出很多很多东西,优质的数据往往比网络容量要重要的多。
我们先看看有那些损失
任务目标:
- 分类任务(Classification):分类任务旨在将输入数据映射到预定义的离散类别中。模型需要判断输入属于哪个类别,例如图像分类任务,将图像分类为"猫"、"狗"、"车"等类别;或者文本分类任务,将文本归类为"体育"、"科技"、"政治"等类别。
- 回归任务(Regression):回归任务旨在预测连续数值输出。模型需要根据输入数据的特征,预测一个或多个实数值,例如房价预测,根据房屋的面积、地理位置等特征预测房价;或者股票价格预测,根据历史股票价格等数据预测未来的股价。
首先损失函数有哪些?
- 分类任务: 0-1 Loss、交叉熵Loss、SoftMax、KL散度、Focal Loss
- 回归任务:L1、L2、MAE、MSE
主要是为了解决one-stage目标检测中,正负样本不平衡的问题。
一张图像中,能够匹配到的检测框只有十几个(正样本),但是没有匹配到的样本数量可能会有上万个(负样本)该情况下就会出现正负样本极其不平衡。
- 过多的负样本不仅对训练没用,而且还会淹有助于训练的正样本。
Why Not Two Stage?
不方便,训练效率也不行,部署也费劲。
FocalLoss基于二分类交叉熵。
先看看Cross Entropy
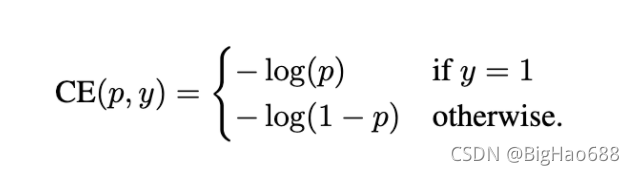
- y=1 or -1 代表 前景 or 背景
- p (0,1)
- y==1 ? pt = p : pt=1-p
因此可以化简:
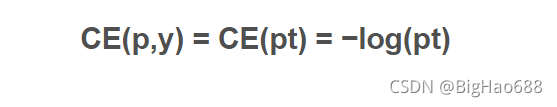
Balance Cross Entropy 平衡交叉熵
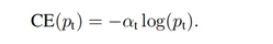
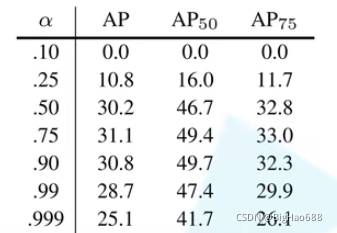
Focal Loss 不光解决了正负样本不平衡的问题,还区分了简单与困难样本
- Cuz:当容易区分的负样本很多的时候,整个训练过程会围绕着易区分的负样本进行;从而淹没了正样本。
我们聚焦难区分的样本,因此引入了调制因子:
- gamma取值为【0,5】
- alpha取值为【0,1】
总结:
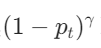
- 当pt趋近于1时,说明该样本是易于区分的 -- 分对了,此时
**趋近于0, **
- 表明:对损失的贡献很小,降低了易区分样本的损失比例
- 当pt很小,说明该样本为前景的概率特别小,即被分错了。
- 调制因子趋近于1,对loss没有影响

{kind=link}
{kind=link}
为什么dice loss可以解决正负样本不平衡的问题?
dice loss是一个区域相关的loss,即当前像素的loss不光与当前像素的预测值有关,也和其他点的值有关系,diceloss的求交形式可以理解为mask掩码操作。 -- 不光图片有多大,固定大小的正样本区域的计算loss是不变的。
为什么diceloss会让训练变得不稳定?
正样本一般为小目标时候会发生严重的震荡,在前景和背景的情况下,小目标一旦有部分像素错误,会导致loss大幅度的变化
总的来说,dice可以优化一些小目标的物体检测问题,而focal loss可以处理正负样本失衡的问题。
- SAM
- RITM : 开源的自动标注软件
- SimpleClick
- FocalClick
图像编码器是一普通的ViT-H/16 。
- 输入图像是3x1024 x 1024
- 图像嵌入张量为64 x 64 【1024 / 16】尺寸
- 为了减少图像序列的维度,使用1x1卷积缩减到256。
最终输出是B,256,64,64
文中提出,无论是稀疏提示、稠密提示,所有的提示都是256的维度的,我们需要映射到一个256维度的张量中。
def forward(
self,
points: Optional[Tuple[torch.Tensor, torch.Tensor]],
boxes: Optional[torch.Tensor],
masks: Optional[torch.Tensor],
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Embeds different types of prompts, returning both sparse and dense
embeddings.
Arguments:
points (tuple(torch.Tensor, torch.Tensor) or none): point coordinates
and labels to embed.
boxes (torch.Tensor or none): boxes to embed
masks (torch.Tensor or none): masks to embed
Returns:
torch.Tensor: sparse embeddings for the points and boxes, with shape
BxNx(embed_dim), where N is determined by the number of input points
and boxes.
torch.Tensor: dense embeddings for the masks, in the shape
Bx(embed_dim)x(embed_H)x(embed_W)
"""在原始代码中输入输出给的不明确
- 输入点提示 & 输入点的Pos/Neg 是意义对应的 格式为 (torch.tensor([[[100, 120], [100, 120], [100, 120], [100, 120]]], device="cuda"),torch.tensor([[1, 1, 1, 1]], device="cuda"))
- 输入的点坐标为X,Y;维度是 B,N,2
- 输入的Pos/Neg提示为:B,N ,0代表Neg、1代表Positive
- 输入Boxes,如果只给定一个box,可以使用points进行修正
- 如果多个box则不能与points混合输入input_boxes = torch.tensor([[75, 275, 1725, 850],[425, 600, 700, 875]], device="cuda")
- 我们分析完成一次之后都会进行token的更新,格式是一个** torch.zeros((1,1,1024,1024),device="cuda") -- B,1,256,256**
最后编码器给我们返回2个张量,分别是对应的是稀疏提示B,N,256 与 稠密提示B,256,64,46[与ImageEncoder对应]