📘 Overview | ✨ Features | 🚀 Getting Started | 🧭 Usage | 🤝 Contributing | 📄 License
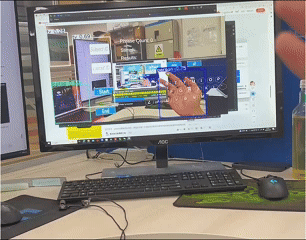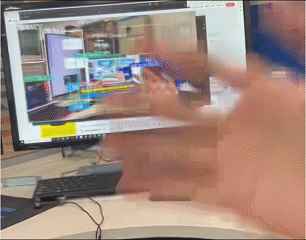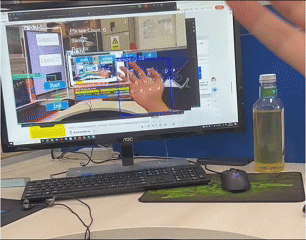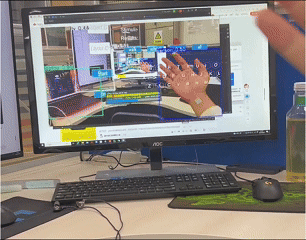
The Context Awareness Text Augmented System is an open-source project developed under the guidance of Professor Junxiao Shen at the University of Bristol's BIG Lab. The system uses HoloLens 2 as a data collection platform and enables real-time communication of multimodal data (video, audio, eye-tracking) via a Peer-to-Peer (P2P) connection between XR and PC systems based on HL2SS. This project aims to capture and process user behavior in an immersive environment and generate textual descriptions of these actions using AI models.
If your research aligns with AR/VR, XR sensing, or context-aware AI, we welcome discussions and collaboration.
-
Real-Time Multimodal Data Communication
Supports the transmission of video, audio, and eye-tracking data in real time between HoloLens 2 and a PC system via a stable P2P connection. 🌐 -
Data-to-Text AI Models
Utilizes AI-based models to convert raw multimodal data into text representations of user behavior. 🧠➡️📝 -
Multithreading for Parallel Data Handling
Implements multithreading to ensure efficient data processing and timestamp synchronization for accurate communication. 💻⚙️
-
Clone this repository:
git clone https://github.com/username/context-awareness-text-augmented-system.git
-
Install required dependencies:
pip install -r requirements.txt
-
Set up the HoloLens 2 device for data collection and ensure the P2P connection is active between the device and the PC. 🔌
Note: HL2SS must be properly configured on HoloLens 2 and the PC endpoint. Ensure both devices are discoverable within the same network segment.
- Ensure both HoloLens 2 and the PC are connected via the P2P connection.
- Use HoloLens 2 to collect video, audio, and eye-tracking data.
- The data will be processed by AI models to generate text versions of user actions.
- Use the generated text to interact with the Question-Answering System for daily behavior tracking.
python MainSys.py├── MainSys.py # Main entry point of the system
│
├── Components/ # Multimodal data modules
│ ├── Audio_Component.py # Audio data handling
│ ├── Eyetracking_Component.py # Eye-tracking data capture & processing
│ ├── IMU_Component.py # IMU sensor integration
│ ├── Video_Component.py # Video frame streaming
│ └── __init__.py
│
├── clip/ # CLIP-based text augmentation module
│ ├── __init__.py
│ ├── clip.py
│ ├── model.py
│ ├── simple_tokenizer.py
│ └── bpe_simple_vocab_16e6.txt.gz
│
├── requirements.txt
└── README.md
Contributions are welcome! To contribute, fork this repository, make your changes, and submit a pull request. 🔄💡
Please follow conventional commits and open an issue for major feature proposals.
This project is licensed under the MIT License. 📄 See LICENSE for details.