O checklist proposto combina conceitos de transparência e interpretabilidade propostos por diversos trabalhos na literatura [1][2][3][4][5]. O objetivo é aplicar esses conceitos de forma categórica destinado a avaliar quanto a transparência e interpretabilidade de frameworks de AutoML. A pontuação das perguntas é baseada no número de formas em que o framework atende a cada critério, variando de 0 a 2 pontos, dependendo do grau de cumprimento. Essa pontuação é então normalizada em uma escala de 0 a 100% para cada nível de avaliação, garantindo uma comparação justa e consistente entre diferentes frameworks. A abordagem considera tanto questões específicas, como a funcionalidade das etapas do pipeline, quanto aspectos mais amplos, como a análise estatística e a transparência algorítmica, proporcionando uma avaliação abrangente e detalhada dos frameworks examinados.
Seja:
-
$S$ a pontuação atribuída ao framework para uma determinada categoria. -
$N$ o número de formas (ex,. métodos, algoritmos) nas quais o framework satisfaz a pergunta da categoria.
Então, a pontuação
Essa formulação matemática expressa claramente as condições de pontuação para cada pergunta:
| "N"= Não se aplica | "P"= Parcial | "T"= Total |
|---|---|---|
|
|
|
|
No caso em que o número de possibilidades de resposta é conhecido, como no exemplo das etapas do pipeline de um framework, as pontuações são atribuídas da seguinte forma:
- "N" (Não se aplica) = 0 pontos
- "P" (Parcial) = 1 ponto
- "T" (Total) = 2 pontos
Porém, em situações em que a pergunta pode levar a um número indefinido de possibilidades de resposta, como no caso do framework oferecer modelos com interpretabilidade intrínseca, a pontuação é atribuída da seguinte maneira:
- "N" (Não se aplica) = 0 pontos, se nenhum modelo intrínseco de interpretabilidade for utilizado.
- "P" (Parcial) = 1 ponto, se pelo menos um modelo de interpretabilidade intrínseca for utilizado.
- "T" (Total) = 2 pontos, se dois ou mais modelos de interpretabilidade intrínseca forem utilizados pelo framework.
Essa abordagem permite uma avaliação flexível, levando em consideração o contexto específico de cada pergunta e a possibilidade de múltiplas respostas, garantindo uma atribuição adequada de pontos com base nas características do framework em questão.
A forma de pontuação proposta garante que a pontuação final de um framework para um determinado nível esteja normalizada em uma escala que varia de 0 a 100%. Isso é alcançado calculando-se a pontuação real obtida pelo framework para todas as perguntas do nível e dividindo essa soma pelo produto do número total de perguntas e da pontuação máxima atribuída por pergunta. Essa relação garante que a pontuação final possa variar de 0% a 100%, independentemente do número de perguntas em cada nível ou da escala de pontuação máxima. Assim, essa abordagem proporciona uma maneira justa e consistente de avaliar o desempenho dos frameworks, permitindo uma comparação direta entre eles, onde uma pontuação mais alta indica um maior cumprimento dos critérios de transparência e interpretabilidade.
Seja:
-
$S$ a pontuação final normalizada do framework para a categoria. -
$P_i$ a pontuação obtida pelo framework para a i-ésima pergunta da categoria. -
$N$ o número total de perguntas nesta categoria. -
$W$ a pontuação máxima atribuída por pergunta.
Então, a fórmula pode ser formalizada como:
Essa formulação expressa a pontuação final
| Categoria | Pergunta | Avaliação | Pontuação | Score |
|---|---|---|---|---|
| Descrição Funcional | É possível identificar quais são as etapas do pipeline? | T | 2 | 100 |
| É possível identificar os componentes utilizados em cada etapa? | T | 2 | ||
| Está claro quais são as entradas e saídas? | T | 2 | ||
| Está claro como o processo é executado na prática? | T | 2 | ||
| Análise Estatística | As previsões do modelo são apresentadas para as classes (malwares e benignos)? | T | 2 | 100 |
| Mantém o histórico dos dados utilizados para treinar e testar o modelo? | T | 2 | ||
| Na seleção de características é informado ao usuário quais são as mais relevantes? | T | 2 | ||
| As métricas de desempenho do modelo são apresentadas? | T | 2 | ||
| Existem formas de visualizar os resultados (gráficos, tabelas)? | T | 2 | ||
| Transparência Algorítmica | É possível identificar quais modelos são utilizados? | T | 2 | 100 |
| É possível identificar avisos, informações e erros registrados nos logs do sistema? | T | 2 | ||
| É possível identificar os hiperparâmetros dos modelos gerados? | T | 2 | ||
| É possível identificar se os dados são balanceados? | T | 2 | ||
| Interpretabilidade | O motivo da redução da dimensionalidade é explicado? (Pré-Modelo) | T | 2 | 100 |
| Existem técnicas específicas de redução de dimensionalidade para o domínio? (Pré-Modelo) | T | 2 | ||
| Há métodos de interpretabilidade global disponíveis? | T | 2 | ||
| O framework oferece modelos com interpretabilidade intrínseca? (In-Modelo) | T | 2 | ||
| É possível avaliar a diferença entre previsões e valores reais? | T | 2 | ||
| Há métodos de interpretabilidade independentes do modelo? (Pós-Modelo) | T | 2 | ||
| Análise Interna | Existem métodos para visualizar a estrutura do modelo? (Pós-Modelo) | T | 2 | 100 |
-
Descrição Funcional: Tem como objetivo avaliar se os frameworks de AutoML cumprem suas funções de maneira clara e transparente para o usuário. Isso envolve a identificação das diferentes etapas do pipeline, a compreensão dos componentes utilizados em cada etapa, a clareza das entradas e saídas do sistema e a explicação detalhada de como o processo é executado na prática. Ao assegurar que todas essas informações estejam disponíveis e compreensíveis, a categoria "Descrição Funcional" garante que os usuários possam entender e confiar no funcionamento do framework, promovendo uma utilização mais eficiente e eficaz da ferramenta.
-
Análise Estatística: Tem como objetivo avaliar a capacidade dos frameworks de AutoML em apresentar e explicar os resultados estatísticos e métricas de desempenho de maneira clara e detalhada. Esta categoria verifica se as previsões do modelo são devidamente apresentadas para diferentes classes, como malwares e benignos, e se o histórico dos dados utilizados para treinamento e teste é mantido. Além disso, avalia se os usuários são informados sobre as características mais relevantes durante a seleção de características, se as métricas de desempenho do modelo são claramente exibidas e se existem métodos visuais, como gráficos e tabelas, para a visualização dos resultados. Cumprindo esses critérios, a categoria "Análise Estatística" contribui para que os usuários possam entender e confiar na eficácia dos modelos gerados pelo framework, promovendo uma maior transparência e interpretabilidade na etapa de pré-Modelo.
-
Transparência Algorítmica: A categoria tem como objetivo avaliar a clareza e a objetividade com que os frameworks de AutoML apresentam informações sobre os algoritmos utilizados. Esta categoria verifica se é possível identificar quais modelos são empregados em cada etapa do processo, se os avisos, informações e erros são registrados e acessíveis nos logs do sistema, se os hiperparâmetros dos modelos gerados são claramente apresentados, e se os dados são balanceados em termos de proporcionalidade das classes. Ao cumprir esses critérios, a categoria "Transparência Algorítmica" assegura que os usuários possam compreender detalhadamente os eventos do sistema, facilitando a análise e a interpretação dos modelos, além de garantir uma otimização eficiente e justa dos dados utilizados.
-
Interpretabilidade: A categoria "Interpretabilidade" é crucial para garantir que os usuários compreendam não apenas os resultados, mas também os processos internos dos modelos gerados pelos frameworks de AutoML. Esta categoria está dividida em três subcategorias: pré-modelo, in-modelo e pós-modelo, cada uma abordando aspectos específicos da interpretabilidade. No estágio pré-modelo, é importante que o motivo da redução da dimensionalidade seja explicado e que existam técnicas específicas de redução de dimensionalidade para o domínio em questão. No estágio in-modelo, a ênfase está em oferecer modelos com interpretabilidade intrínseca, permitindo aos usuários entender como as previsões são geradas. Finalmente, no estágio pós-modelo, é fundamental avaliar a diferença entre previsões e valores reais e disponibilizar métodos de interpretabilidade independentes do modelo. Essas práticas asseguram que os usuários possam confiar nas decisões tomadas pelos modelos, promover uma melhor compreensão dos resultados e facilitar a identificação de possíveis melhorias no processo de modelagem.
-
Análise Interna: Essa categoria foca na capacidade dos frameworks de AutoML em fornecer métodos para visualizar a estrutura interna dos modelos gerados. A visualização da estrutura do modelo é essencial para que os usuários compreendam como os dados são processados e como as decisões são tomadas dentro do modelo. Por exemplo, a visualização de uma árvore de decisão permite que os usuários vejam claramente as ramificações e critérios usados em cada nó para realizar uma previsão, facilitando a interpretação do processo de decisão. Este entendimento profundo permite não apenas uma melhor interpretação dos resultados, mas também facilita a identificação de possíveis problemas ou áreas de melhoria. Ao oferecer ferramentas de visualização da estrutura, os frameworks capacitam os usuários a realizar uma análise crítica e detalhada, promovendo a transparência e a confiança nos modelos desenvolvidos.
A avaliação completa para cada ferramenta pode ser acessada aqui ⬇️
| Categoria | Ferramenta | Pontuação Total |
|---|---|---|
| Descrição Funcional | AutoGluon | 100 |
| MH-AutoML | 100 | |
| Auto-Sklearn | 100 | |
| TPOT | 100 | |
| AutoPyTorch | 100 | |
| LightAutoML | 100 | |
| HyperGBM | 100 | |
| MLJar | 100 | |
| Análise Estatística | AutoGluon | 80 |
| MH-AutoML | 70 | |
| Auto-Sklearn | 60 | |
| TPOT | 60 | |
| AutoPyTorch | 60 | |
| LightAutoML | 60 | |
| HyperGBM | 80 | |
| MLJar | 100 | |
| Transparência Algorítmica | AutoGluon | 75 |
| MH-AutoML | 87.5 | |
| Auto-Sklearn | 50 | |
| TPOT | 50 | |
| AutoPyTorch | 75 | |
| LightAutoML | 75 | |
| HyperGBM | 75 | |
| MLJar | 75 | |
| Interpretabilidade | AutoGluon | 41.6 |
| MH-AutoML | 41.6 | |
| Auto-Sklearn | 25 | |
| TPOT | 8.33 | |
| AutoPyTorch | 33.33 | |
| LightAutoML | 41.6 | |
| HyperGBM | 50 | |
| MLJar | 58.33 | |
| Análise Interna | AutoGluon | 50 |
| MH-AutoML | 0 | |
| Auto-Sklearn | 50 | |
| TPOT | 100 | |
| AutoPyTorch | 0 | |
| LightAutoML | 0 | |
| HyperGBM | 100 | |
| MLJar | 100 |
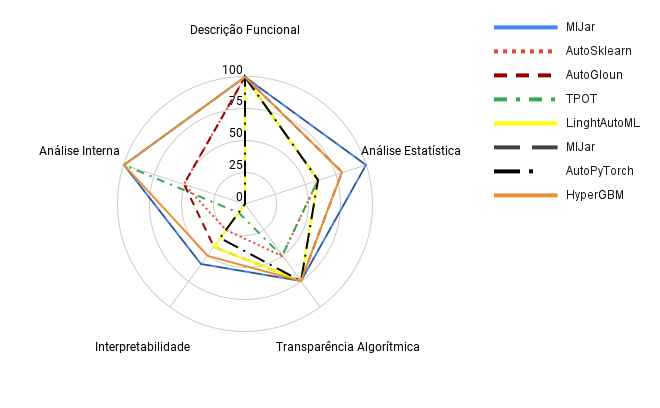
Na avaliação dos frameworks de AutoML a categoria de Descrição Funcional, todas as ferramentas, incluindo AutoGluon, MH-AutoML, Auto-Sklearn, TPOT, AutoPyTorch, LightAutoML, HyperGBM e MLJar, alcançaram a pontuação máxima de 100 pontos, indicando clareza e transparência de suas funções. Na Análise Estatística, MLJar liderou com 100 pontos, seguido por AutoGluon e HyperGBM, ambos com 80 pontos. LightAutoML, Auto-Sklearn, TPOT, MH-AutoML e AutoPyTorch tiveram um desempenho mediano entre 70 e 60 pontos. Esses resultados indicam que essas ferramentas não mantêm um histórico dos dados utilizados para treinar e testar o modelo e não apresentam, ou apresentam parcialmente, as características mais relevantes para o usuário. Em termos de Transparência Algorítmica, MH-AutoML destacou-se com 87,5 pontos. AutoGluon, AutoPyTorch, LightAutoML, HyperGBM e MLJar seguiram com 75 pontos cada. Auto-Sklearn e TPOT mostraram necessidade de melhorias, alcançando apenas 50 pontos cada. As principais deficiências dessas ferramentas estão relacionadas à falta de transparência quanto ao balanceamento de classes e nos logs do sistema.
Na categoria de Interpretabilidade, MLJar foi a melhor avaliada com 58,33 pontos, destacando-se por fornecer modelos e resultados facilmente compreensíveis. HyperGBM também obteve uma boa pontuação de 50 pontos. LightAutoML, AutoGluon e MH-AutoML alcançaram 41,6 pontos cada. AutoPyTorch teve uma pontuação mediana de 33,33 pontos, enquanto Auto-Sklearn obteve 25 pontos. TPOT teve a menor pontuação, com 8,33 pontos, indicando dificuldades significativas de interpretabilidade. As principais deficiências dessas ferramentas incluem a falta de opções para utilizar exclusivamente métodos de interpretabilidade intrínseca, métodos específicos para domínios particulares, explicações sobre a escolha de métodos de redução de dimensionalidade e a ausência de métodos de interpretabilidade independentes de modelo, como SHAP e LIME.
Finalmente, na Análise Interna, TPOT, HyperGBM e MLJar se destacaram com 100 pontos cada, evidenciando sua capacidade de apresentar detalhadamente a estrutura dos modelos utilizados, como árvores de decisão, por exemplo. AutoGluon e Auto-Sklearn receberam 50 pontos nesta categoria, indicando uma apresentação moderada da estrutura dos modelos. Por outro lado, MH-AutoML, AutoPyTorch e LightAutoML mostraram uma necessidade significativa de melhorias, alcançando 0 pontos, o que reflete a falta de detalhamento na apresentação da estrutura dos modelos utilizados.
Esta análise destaca que, apesar de algumas ferramentas apresentarem excelente desempenho em métricas como acurácia, recall, F1 score e precisão, é igualmente crucial considerar questões de interpretabilidade e transparência. Estes aspectos não só aumentam a confiança nos resultados, mas também tornam o entendimento das decisões mais sólido. É fundamental que as ferramentas de AutoML sejam transparentes e interpretáveis, além de apresentarem bom desempenho, especialmente no contexto da detecção de malwares em dispositivos Android.
Em resumo, as ferramentas de AutoML, de maneira geral, demonstram boa transparência em relação ao seu pipeline. No entanto, há uma lacuna significativa em termos de transparência e interpretabilidade dos resultados e dos artefatos gerados. Embora algumas ferramentas se destaquem pela clareza funcional, a habilidade de fornecer modelos compreensíveis e de visualizar a estrutura interna ainda requer melhorias substanciais. Estas melhorias são essenciais para aumentar a confiança nos resultados e facilitar a compreensão das decisões tomadas pelos modelos, especialmente em aplicações críticas como a detecção de malwares em dispositivos Android. Para abordar estas questões, as ferramentas poderiam adotar uma opção de interpretabilidade de modelos onde apenas modelos de aprendizado de máquina com interpretabilidade intrínseca, como KNN (K-Nearest Neighbors) e Árvores de Decisão fossem utilizados, tambem utilizar técnicas de interpretabilidade independentes de modelo, como SHAP (Shapley Additive Explanations) e LIME (Local Interpretable Model-agnostic Explanations), juntamente com logs de sistemas claros e objetivos. Essas abordagens ajudariam a tornar os modelos mais transparentes e as decisões mais compreensíveis para os usuários finais.
Referências:
-
Arrieta, A. B., Díaz-Rodríguez, N., Del Ser, J., Bennetot, A., Tabik, S., Barbado, A., ... & Benjamins, R. (2020). Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Information fusion, 58, 82-115. Link
-
Love, P. E., Fang, W., Matthews, J., Porter, S., Luo, H., & Ding, L. (2023). Explainable artificial intelligence (XAI): Precepts, models, and opportunities for research in construction. Advanced Engineering Informatics, 57, 102024. Link
-
Mi, J. X., Li, A. D., & Zhou, L. F. (2020). Review study of interpretation methods for future interpretable machine learning. IEEE Access, 8, 191969-191985. Link
-
Carvalho, D. V., Pereira, E. M., & Cardoso, J. S. (2019). Machine learning interpretability: A survey on methods and metrics. Electronics, 8(8), 832. Link
-
Brännström, M. (2023). Transparency of Complex Systems: The Semantic Transparency Framework. Link