An on-premises document information extraction and benchmarking toolkit.

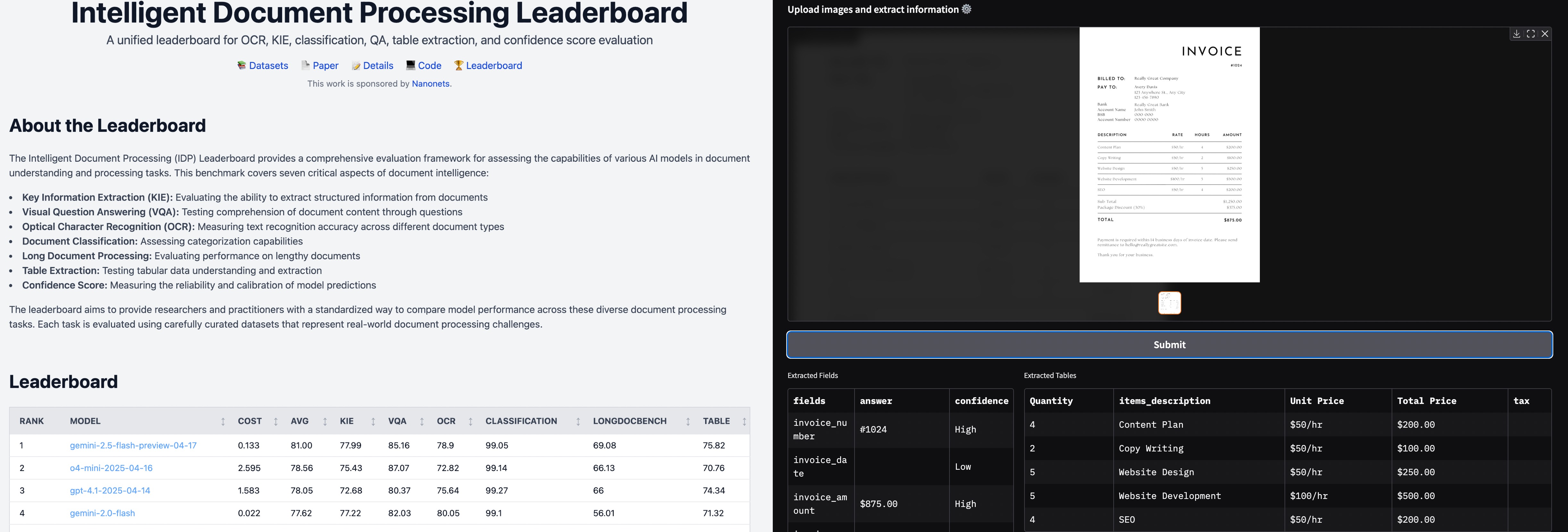
docext is an OCR-free tool for extracting structured information from documents such as invoices, passports, and other documents. It leverages vision-language models (VLMs) to accurately identify and extract both field data and tabular information from document images.
The Intelligent Document Processing Leaderboard tracks and evaluates performance vision-language models across OCR, Key Information Extraction (KIE), document classification, table extraction, and other intelligent document processing tasks.
This benchmark evaluates performance across seven key document intelligence challenges:
- Key Information Extraction (KIE): Extract structured fields from unstructured document text.
- Visual Question Answering (VQA): Assess understanding of document content via question-answering.
- Optical Character Recognition (OCR): Measure accuracy in recognizing printed and handwritten text.
- Document Classification: Evaluate how accurately models categorize various document types.
- Long Document Processing: Test models' reasoning over lengthy, context-rich documents.
- Table Extraction: Benchmark structured data extraction from complex tabular formats.
- Confidence Score Calibration: Evaluate the reliability and confidence of model predictions.
🔍 For in-depth information, see the release blog.
📊 Live leaderboard: https://idp-leaderboard.org
For setup instructions and additional details, check out the full feature guide for the Intelligent Document Processing Leaderboard.
- Flexible extraction: Define custom fields or use pre-built templates
- Table extraction: Extract structured tabular data from documents
- Confidence scoring: Get confidence levels for extracted information
- On-premises deployment: Run entirely on your own infrastructure (Linux, MacOS)
- Multi-page support: Process documents with multiple pages
- REST API: Programmatic access for integration with your applications
- Pre-built templates: Ready-to-use templates for common document types:
- Invoices
- Passports
- Add/delete new fields/columns for other templates.
For more details (Installation, Usage, and so on), please check out the feature guide.
- 17-05-2025 – Added
InternVL3-38B-Instruct,qwen2.5-vl-32b-instructevaluation metrics to the leaderboard. - 16-05-2025 – Added
gemma-3-27b-itevaluation metrics to the leaderboard. - 12-05-2025 – Added
Claude 3.7 sonnet,mistral-medium-3evaluation metrics to the leaderboard.
Older Changes
docext is developed by Nanonets, a leader in document AI and intelligent document processing solutions. Nanonets is committed to advancing the field of document understanding through open-source contributions and innovative AI technologies. If you are looking for information extraction solutions for your business, please visit our website to learn more.
We welcome contributions! Please see contribution.md for guidelines. If you have a feature request or need support for a new model, feel free to open an issue—we'd love to discuss it further!
If you encounter any issues while using docext, please refer to our Troubleshooting guide for common problems and solutions.
This project is licensed under the Apache License 2.0 - see the LICENSE file for details.