Tải github repository
git clone https://github.com/ToTuanAn/FPT-Case-Challenge
Câu 1: chạy file Cau1_Linear_Regression.py
Câu 2: chạy file Cau2_KNN.py
Định nghĩa
"Hồi quy tuyến tính" là một phương pháp thống kê để hồi quy dữ liệu với biến phụ thuộc có giá trị liên tục trong khi các biến độc lập có thể có một trong hai giá trị liên tục hoặc là giá trị phân loại. Nói cách khác "Hồi quy tuyến tính" là một phương pháp để dự đoán biến phụ thuộc (Y) dựa trên giá trị của biến độc lập (X).
Tóm tắt những gì đã làm
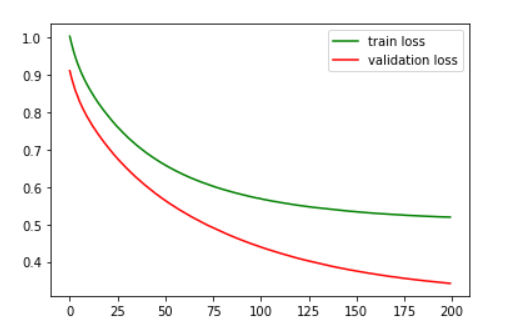
Nhóm đã cài đặt phương thức build_linear_regression_model với tham số truyền vào là input_dim (chiều của input). Sử dụng duy nhất một fully-connected layer trong thư viện keras bằng cách dùng hàm keras.layer.Dense với bias được khởi tạo bằng hàm tf.keras.initializers.GlorotNormal(), phương thức sẽ cho ra một mô hình có kiểu dữ liệu là keras.model.Model. Mô hình đã được thử nghiệm trên tập dữ liệu diabetes với 200 epoch và thu được chỉ số R2 là 0,49 và biểu đồ loss như hình.
Link diabetes dataset: https://archive.ics.uci.edu/ml/datasets/diabetes
Điểm yếu và cách khắc phục
Thuật toán Linear Regression được xây dựng khá đơn giản với một hàm tuyến tính duy nhất nên chạy khá nhanh. Tuy nhiên, thuật toán không đủ chiều sâu để chạy những datasets phức tạp nên ta phải xây dựng những model có nhiều layer hơn để khắc phục được điểm yếu đó (Neural Network)
Định nghĩa
K-nearest neighbor là một trong những thuật toán supervised-learning đơn giản nhất (mà hiệu quả trong một vài trường hợp) trong Machine Learning. Khi training, thuật toán này không học một điều gì từ dữ liệu training (đây cũng là lý do thuật toán này được xếp vào loại lazy learning), mọi tính toán được thực hiện khi nó cần dự đoán kết quả của dữ liệu mới. K-nearest neighbor có thể áp dụng được vào cả hai loại của bài toán Supervised learning là Classification và Regression. KNN còn được gọi là một thuật toán Instance-based hay Memory-based learning.
Tóm tắt những gì đã làm
Nhóm đã cài mô hình K-nearest neighbor với số điểm gần nhất (KNN) tự chọn, với một điểm mới cần gán nhãn thuật toán của nhóm sẽ xác định k điểm gần nhất với điểm đó theo độ đo L2, gán nhãn điểm đó theo nhãn của phần lớn k điểm gần nhất. Mô hình đã được thử trên tập dữ liệu iris dataset với KNN là 4 và thu được độ chính xác tới 95%.
Link iris dataset: https://archive.ics.uci.edu/ml/datasets/iris
Điểm yếu và cách khắc phục
Điểm yếu của code nhóm cài là chưa chọn được số điểm gần nhất (KNN) tối ưu nhất cho các dataset khác nhau, để khắc phục điểm yếu này nhóm đề xuất xài phương pháp grid search, với grid search ta sẽ thử các tham số KNN phổ biến như 10, 50, 100, 500,..., đánh giá độ hiệu quả của các tham số bằng k-fold Cross-Validation sau đó chọn tham số có độ chính xác cao nhất và chạy cho tập test, k-fold Cross-Validation là chia tập validation thành nhiều tập con khác nhau và lấy độ chính xác trung bình trong các tập con đấy, với cách làm này ta sẽ được độ chính xác chuẩn hơn, tránh may rủi.
Link đọc grid search: https://scikit-learn.org/stable/modules/grid_search.html
Link đọc k-fold Cross-Validation: https://machinelearningmastery.com/k-fold-cross-validation/