| arxiv | Openreview | Poster |
{kind=link}
This repository contains an official implementation for the paper AMiD: Knowledge Distillation for LLMs with α-mixture Assistant Distribution in ICLR 2026.
Donghyeok Shin, Yeongmin Kim, Suhyeon Jo, Byeonghu Na, and Il-Chul Moon


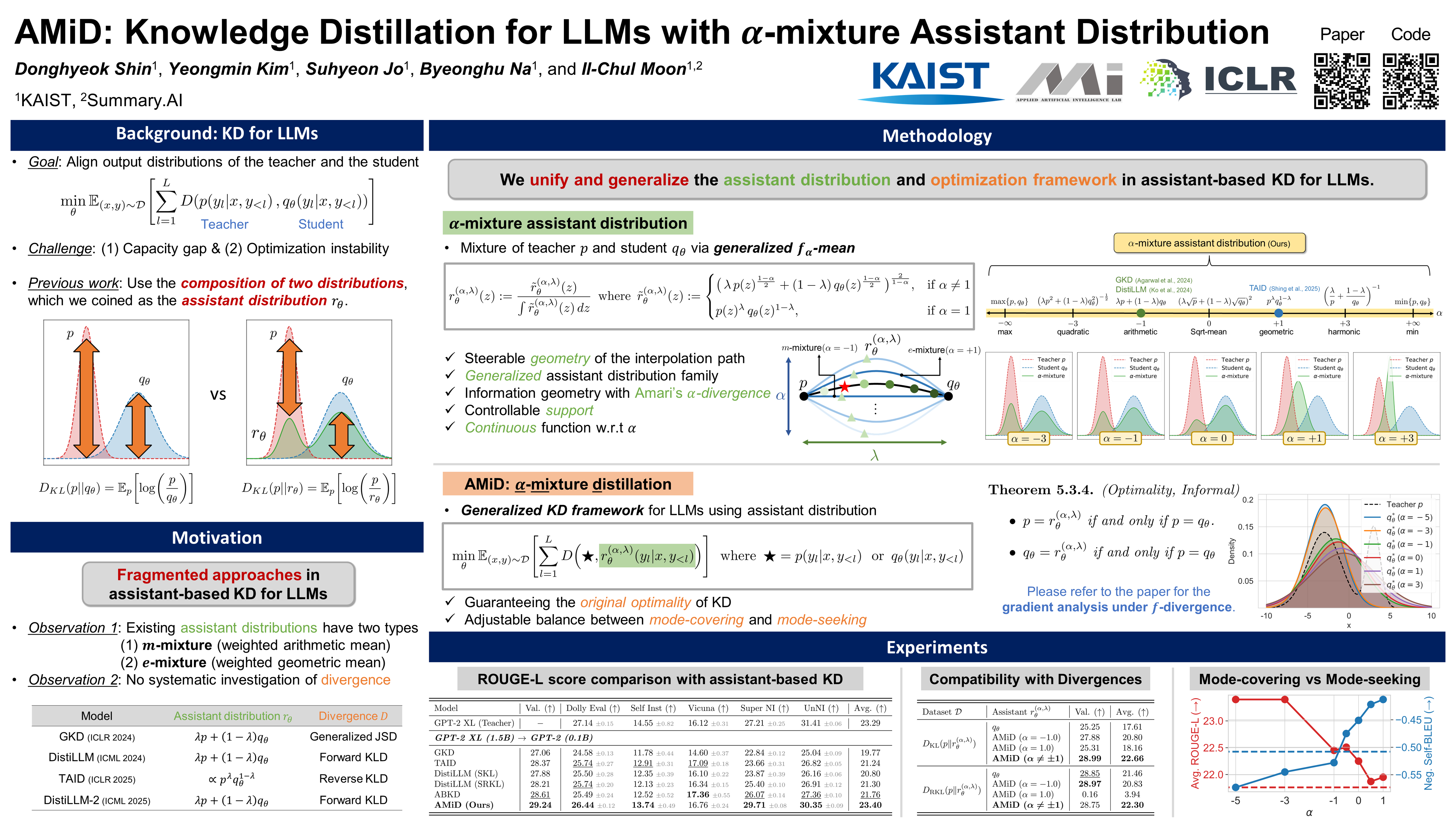
Abstract Autoregressive large language models (LLMs) have achieved remarkable improvement across many tasks but incur high computational and memory costs. Knowledge distillation (KD) mitigates this issue by transferring knowledge from a large teacher to a smaller student through distributional alignment. Previous studies have proposed various discrepancy metrics, but the capacity gap and training instability caused by near-zero probabilities, stemming from the high-dimensional output of LLMs, remain fundamental limitations. To overcome these challenges, several approaches implicitly or explicitly incorporating assistant distribution have recently been proposed. However, the past proposals of assistant distributions have been a fragmented approach without a systematic investigation of the interpolation path and the divergence. This paper proposes α-mixture assistant distribution, a novel generalized family of assistant distributions, and α-mixture distillation, coined AMiD, a unified framework for KD using the assistant distribution. The α-mixture assistant distribution provides a continuous extension of the assistant distribution by introducing a new distribution design variable α, which has been fixed in all previous approaches. Furthermore, AMiD generalizes the family of divergences used with the assistant distributions based on optimality, which has also been restricted in previous works. Through extensive experiments, we demonstrate that AMiD offers superior performance and training stability by leveraging a broader and theoretically grounded assistant distribution space.
Create a new virtual environment and install the required dependencies using the install.sh file:
bash install.sh
- The training/evaluation intruction-response data before processing can be downloaded from MiniLLM.
huggingface-cli download MiniLLM/dolly --repo-type dataset --local-dir ./data/dolly/
huggingface-cli download MiniLLM/self-inst --repo-type dataset --local-dir ./data/self-inst/
huggingface-cli download MiniLLM/Vicuna --repo-type dataset --local-dir ./data/vicuna/
huggingface-cli download MiniLLM/sinst --repo-type dataset --local-dir ./data/sinst/
huggingface-cli download MiniLLM/uinst --repo-type dataset --local-dir ./data/uinst/
- The processed data can be downloaded from MiniLLM.
huggingface-cli download MiniLLM/dolly-processed --repo-type dataset --local-dir ./processed_data/dolly/
huggingface-cli download MiniLLM/openwebtext-processed --repo-type=dataset --local-dir ./processed_data/openwebtext/gpt2/512/10M/
To run fine-tuning or standard KD baselines, you need to download the model checkpoints from Huggingface Model Hub and put them in checkpoints/. For example, for gpt2-large, you can download the model from this link and put them in checkpoints/gpt2-large.
huggingface-cli download gpt2 --repo-type model --local-dir ./checkpoints/gpt2-base
huggingface-cli download gpt2-medium --repo-type model --local-dir ./checkpoints/gpt2-medium
huggingface-cli download gpt2-large --repo-type model --local-dir ./checkpoints/gpt2-large
huggingface-cli download gpt2-xl --repo-type model --local-dir ./checkpoints/gpt2-xlarge
The main hyperparameters of AMiD are as follows:
amid-div-name: Name of divergenceamid-div-order: Order of distributions in divergenceamid-alpha: Value of alphaamid-lam: Value of lambda
Detailed values for these hyperparameters can be found in our paper. Please refer to the provided bash scripts for detailed arguments when running experiments.
We provide example commands for gpt2-base. Please refer to scripts for other model architectures. The final checkpoints are selected by the ROUGE-L scores. Please refer to MiniLLM, DistiLLM, and ABKD for instructions on how to run baselines.
bash ./scripts/gpt2/sft/sft_xlarge.sh ${/PATH/TO/AMiD} ${MASTER_PORT} ${GPU_NUM}
or download from MiniLLM.
huggingface-cli download MiniLLM/teacher-gpt2-1.5B --repo-type model --local-dir ./results/gpt2/train/sft/gpt2-xlarge
The final checkpoints are selected by the validation loss.
bash ./scripts/gpt2/init/init_base.sh ${/PATH/TO/AMiD} ${MASTER_PORT} ${GPU_NUM}
or download from MiniLLM.
huggingface-cli download MiniLLM/init-gpt2-120M --repo-type model --local-dir ./results/gpt2/train/init/gpt2-base
bash ./scripts/gpt2/amid/train_0.1B_1.5B.sh ${/PATH/TO/AMiD} ${MASTER_PORT} ${GPU_NUM} ${amid-div-name} ${amid-div-order} ${amid-alpha} ${amid-lam} ${batch-size} ${lr}
bash ./scripts/gpt2/eval/run_eval.sh ${/PATH/TO/AMiD_CKPT} ${MASTER_PORT}
If you find the code useful for your research, please consider citing our paper.
@inproceedings{
shin2026amid,
title={{AM}iD: Knowledge Distillation for {LLM}s with \${\textbackslash}alpha\$-mixture Assistant Distribution},
author={Donghyeok Shin and Yeongmin Kim and Suhyeon Jo and Byeonghu Na and Il-chul Moon},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://openreview.net/forum?id=7WPJ0EgPdW}
}This work is heavily built upon the code from