ML Repository: weaveforward_fiber_model
Django API Integration: Export-ready — model artifacts are copied to the WeaveForward Django API via the DJANGO_ML_DIR environment variable (see Section 8-E in the notebook).
The WeaveForward Fiber-Artisan Match Pipeline & Recommendation Model is a machine learning pipeline that predicts whether a garment donation request should be routed to a specific artisan business for upcycling. The model scores every (donor request, artisan) pair and outputs is_match = 1 if the garment's fiber composition, biodegradability score, and geographic proximity all meet the artisan's material requirements.
The pipeline is designed to power the WeaveForward Django API, where artisan businesses in Metro Manila receive routed donation requests from the platform's donor-facing interface.
Textile waste in the Philippines remains largely unrecovered due to a lack of infrastructure connecting individual garment donors to artisan upcyclers who can actually use the material. Key friction points include:
- No automated way to assess whether a donated garment meets an artisan's fiber requirements
- Biodegradability standards are not applied to routing decisions
- Geographic proximity is not factored into donation logistics
- Manual matching is slow and does not scale
Target Users: WeaveForward platform operators, artisan upcycling businesses (NCR), and individual garment donors.
The pipeline solves garment-to-artisan matching by:
- Extracting per-fiber composition percentages from scraped brand catalog data
- Scoring each donated garment against each registered artisan's accepted fiber list, biodegradability minimum, and collection radius
- Training a binary CatBoost classifier (
is_match) on the resulting pair matrix - Exporting the trained model and metadata to the WeaveForward Django API
Match Gates (all three must pass for is_match = 1):
| Gate | Condition |
|---|---|
| Fiber share | pct_target_fiber >= 85% (biodegradability standard) |
| Biodegradability | biodeg_score >= artisan.min_biodeg_score |
| Proximity | distance_km <= artisan.max_distance_km |
%%{init: {'theme': 'neutral'}}%%
flowchart TD
A["Web Scraper<br/>webscraper_extraction.py"] -->|scraper.py| B["webscraped_catalog.csv<br/>raw brand fiber records"]
A -->|archive merge · 1-D| B2["webscraped_catalog_archive.csv<br/>first_scraped_at · last_seen_at · is_active"]
B --> C1["1-C-3 · BRAND_FIBER_LOOKUP<br/>median fiber profile per brand"]
B2 -->|enrich lookup · 1-D| C1
C1 -->|live catalog lookup| FB["fiber_approximation() · 1-E<br/>Tier1: brand+type · Tier2: brand<br/>Tier3: type-median · Tier4: global"]
B2 -->|discontinued / missing item| FB
FB -->|resolved fiber profile| C["Spark SQL<br/>feature transforms + UDFs"]
C --> D["expand_fibers()<br/>per-fiber pct columns"]
D --> E["df_base<br/>donor request rows"]
F["Artisan Registry<br/>NCR profiles"] --> G
E --> G["Cross-Join<br/>df_pairs"]
G --> H["Label Computation<br/>pct_target_fiber ≥ 85%<br/>biodeg_score ≥ min<br/>distance_km ≤ max_dist"]
H --> I["Train / Test Split<br/>stratified on is_match"]
I --> J["Optuna HPO<br/>30 trials · 3-fold CV<br/>maximize F1-binary"]
J --> K["CatBoost Training<br/>iterations=611 · depth=9<br/>lr=0.2256"]
K --> L["Model Artifacts<br/>catboost_fiber_match.cbm<br/>fiber_match_metadata.json<br/>fiber_match_eval_report.json"]
L --> M["Django API Export<br/>DJANGO_ML_DIR<br/>/api/match-predict/"]
Important: Synthetic vs. Scraped Data
| Data | Source | Status |
|---|---|---|
| Brand fiber lookup JSON | Derived from catalog — maps brand to known fiber composition | Real scraped data |
| Donor request records | Generated synthetically from the catalog with NCR geocoding via Nominatim OSM | Synthetic — for pipeline testing |
| Artisan business registry | 6 Metro Manila artisan profiles (names, coordinates, fiber preferences) | Synthetic — for pipeline testing |
The artisan registry in cell 35 (Section 5-A-2) carries a prominent SYNTHETIC DATA DISCLAIMER. In production, this registry will be populated from the WeaveForward Django API's artisan_profiles database table (/api/artisans/).
- Built using CatBoost Gradient Boosted Decision Trees (GBDT)
- Task: Binary classification —
is_match(1 = route donation to artisan, 0 = no match) - Optimized via Optuna (30 trials, 3-fold stratified CV, maximize binary F1)
| Parameter | Value |
|---|---|
iterations |
611 |
depth |
9 |
learning_rate |
0.2256 |
l2_leaf_reg |
8.816 |
bagging_temperature |
0.446 |
border_count |
159 |
loss_function |
Logloss |
eval_metric |
AUC |
| Metric | Score |
|---|---|
| Accuracy | 97.67% |
| F1 (binary) | 95.24% |
| F1 (macro) | 96.85% |
| Precision | 100.00% |
| Recall | 90.91% |
| ROC-AUC | 1.0000 |
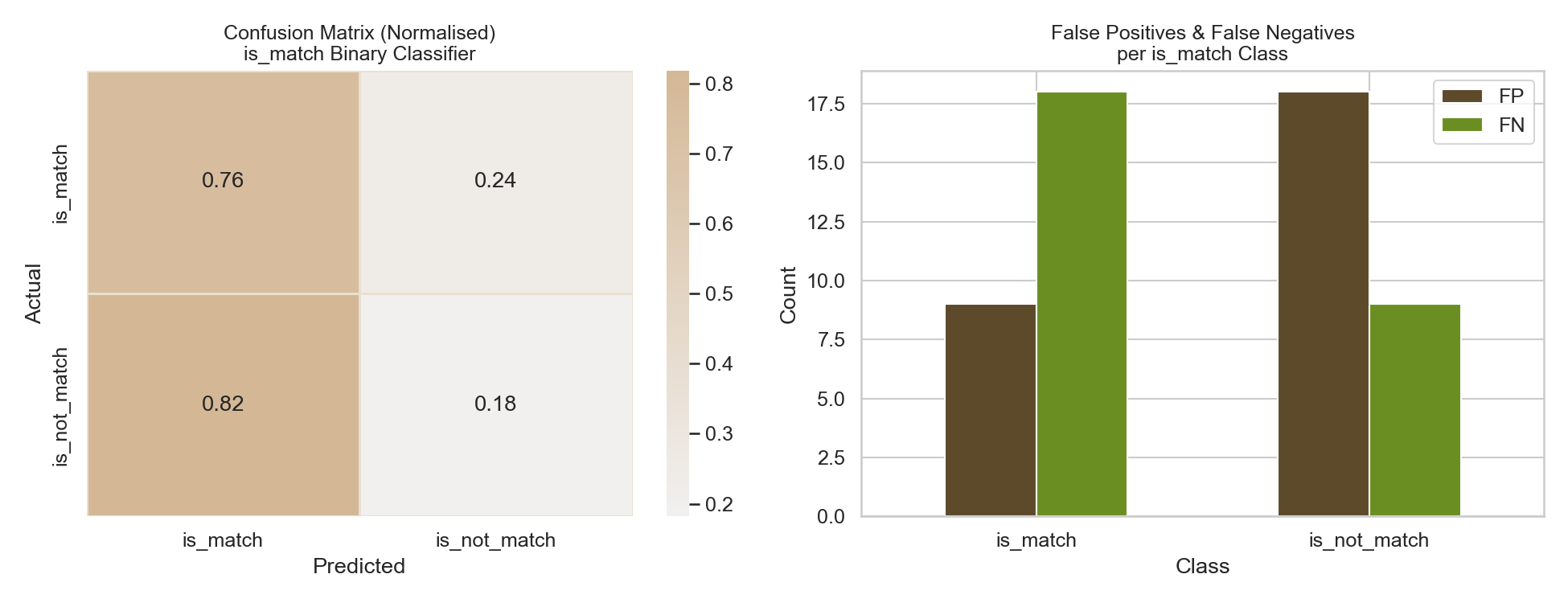
Precision = 1.00 means the model made zero false routing decisions — every request it routed to an artisan was a confirmed match. Recall = 0.91 means it correctly captured 10 of 11 true matches in the test set, missing 1.
| Detail | Value |
|---|---|
| Donor requests (base) | 71 garments |
| Artisan businesses | 6 (synthetic, NCR) |
| Pair matrix | 426 rows (71 × 6) |
Matches (is_match=1) |
54 (12.7%) — applying 85% threshold |
No-match (is_match=0) |
372 (87.3%) |
| Train / Test split | 340 / 86 (stratified) |
| Total features | 30 |
| Categorical features | 11 |
Fiber percentages (7): pct_alpaca, pct_cotton, pct_elastane, pct_nylon, pct_polyester, pct_tencel, pct_viscose
Match-signal numerics (5): pct_target_fiber, distance_km, biodeg_target_fiber, artisan_min_biodeg, artisan_max_dist_km
Standard numerics (7): pct_bio_lookup, fs_bio_share, biodeg_score, demand_index, weight_kg, latitude, longitude
Categoricals (11): brand, clothing_type, source, most_dominant_fiber, dominant_fiber_lookup, matched_fiber, biodeg_tier, ncr_city, barangay, artisan_id, artisan_target_fibers_str
| Fiber | Score | Bio-Degradable |
|---|---|---|
| hemp | 96 | Yes |
| linen | 95 | Yes |
| cotton | 92 | Yes |
| tencel / lyocell | 91 | Yes |
| silk | 83 | Yes |
| denim | 78 | Yes |
| wool / cashmere | 74 | Yes |
| bamboo / alpaca | 73 | Yes |
| modal / viscose / rayon | 72–76 | Yes |
| nylon | 12 | No |
| polyester | 8 | No |
| acrylic | 5 | No |
| elastane / spandex / lycra | 4 | No |
The table below shows confirmed model routes (TP) from the test set — donor requests the model predicted is_match=1 and ground truth confirms. Columns ordered by CatBoost feature importance.
All artisan business data is synthetic. Donor request data is generated from real scraped catalog records with simulated NCR coordinates.
== DONOR REQUESTS ROUTED TO ARTISAN BUSINESSES (MODEL PREDICTIONS) =======
Threshold: 85.0% | Test rows: 86 | Model-routed requests: 11
-- Correctly routed (TP) — requests the model routes AND ground truth confirms
Habi Weaves Ermita (accepts: cotton,tencel) <-- 3 incoming request(s)
Marikina Heritage Weavers (accepts: alpaca,cotton) <-- 4 incoming request(s)
Pasig Natural Threads (accepts: viscose,cotton) <-- 3 incoming request(s)
Columns shown: donation_id | brand | clothing_type | ncr_city | matched_fiber
pct_target_fiber | biodeg_score | distance_km | match_prob
-- Incorrectly routed (FP): 0 — model made no incorrect routing decisions
See cell 55 (Section 8-D) in the notebook to regenerate this report interactively after retraining.
All plots are saved to data/visualizations/. Run Section 6 and Section 8 cells to regenerate.
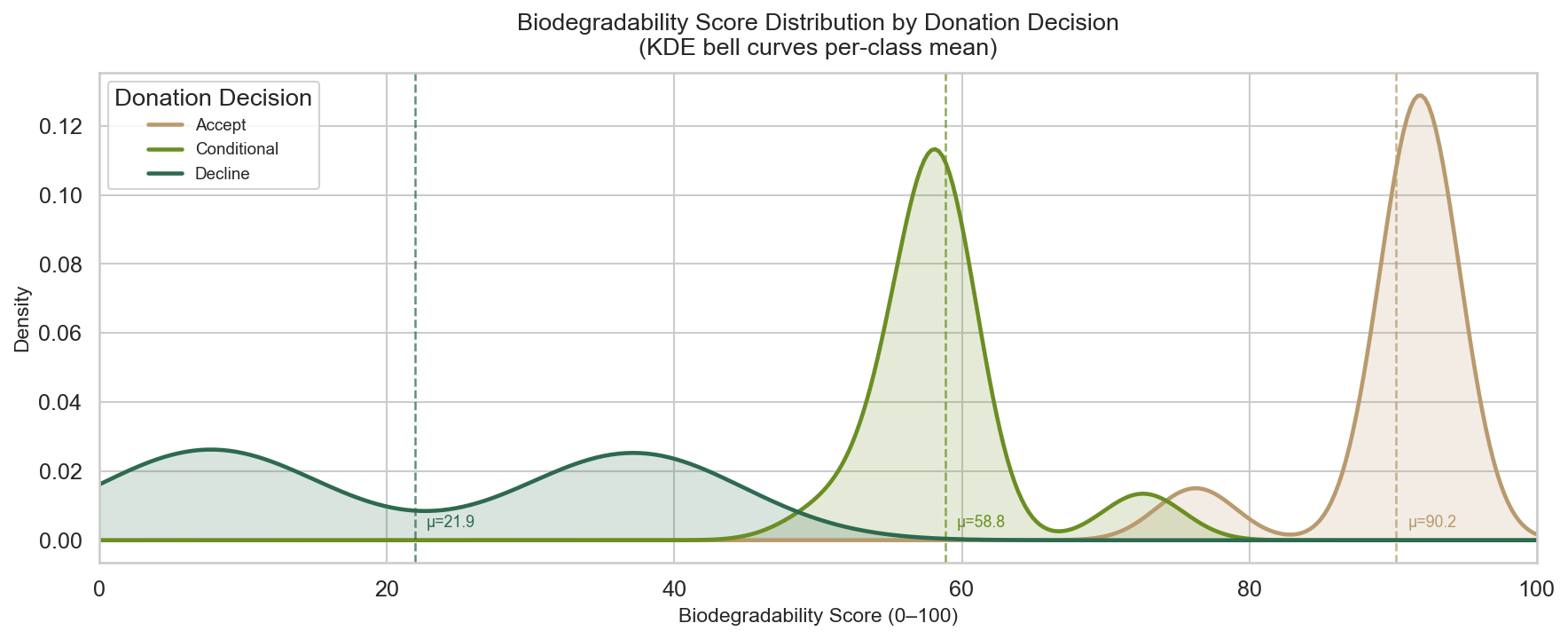
4E1 — Biodegradability Score KDE
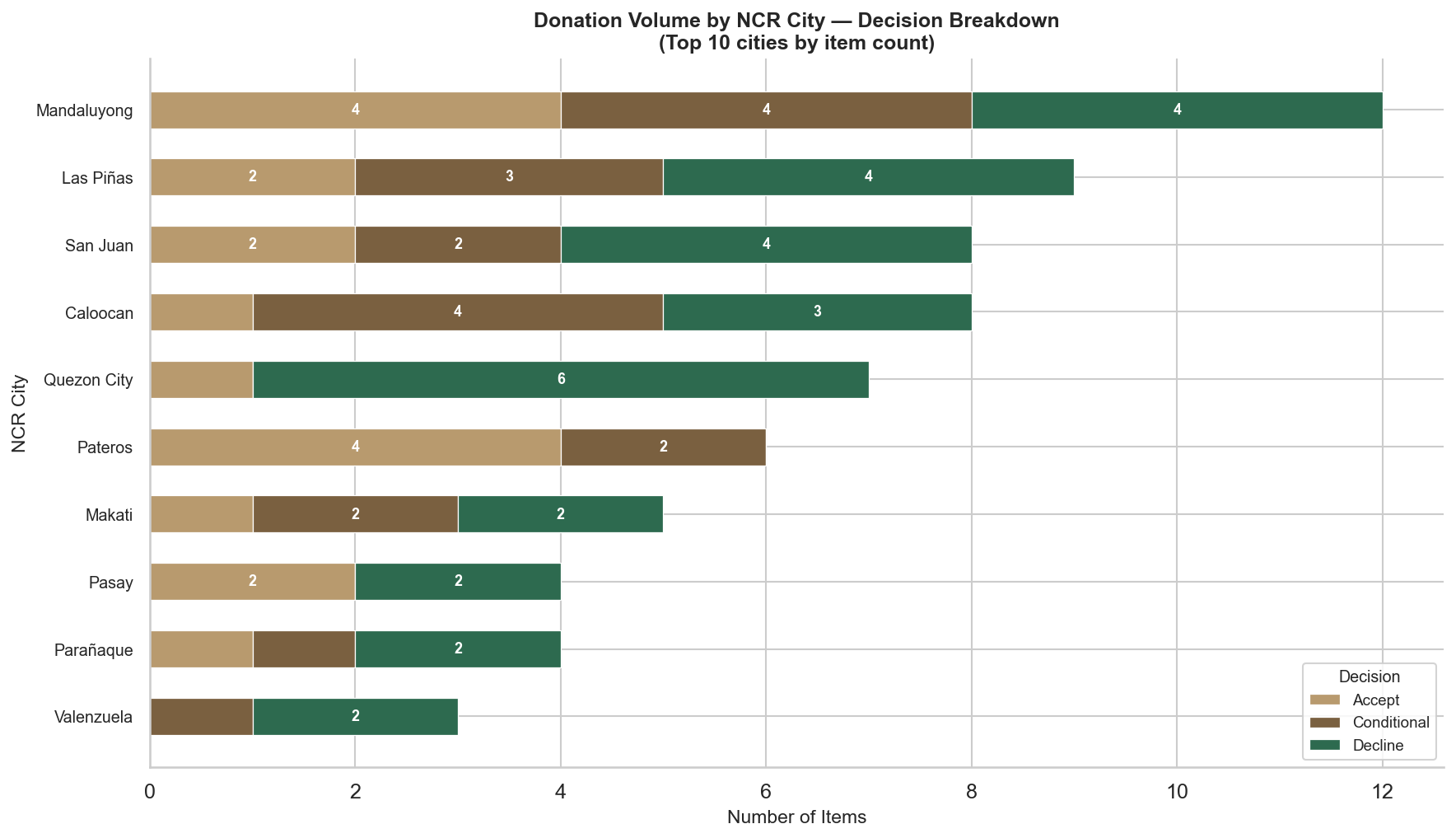
4E2 — Donation Volume by NCR City
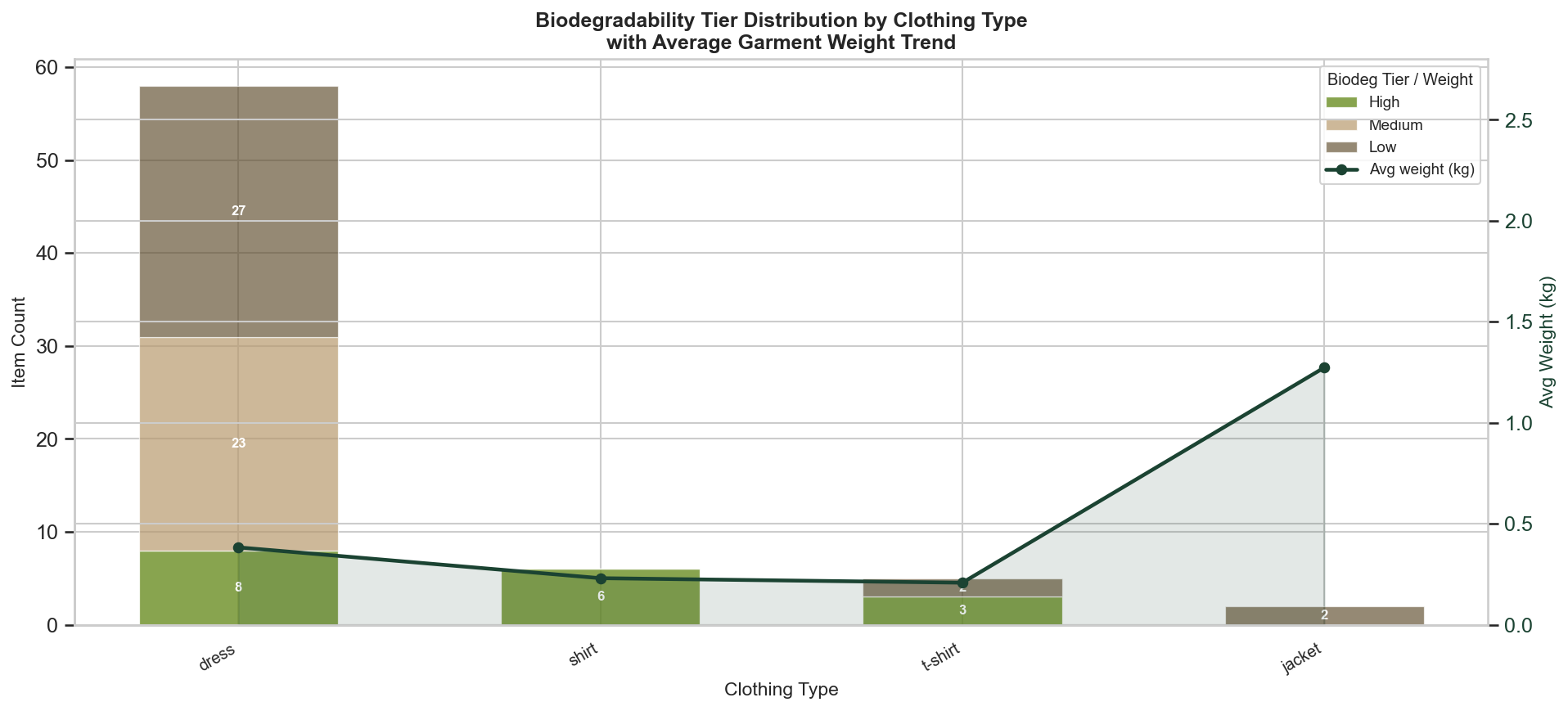
4E3 — Biodegradability Tier by Clothing Type
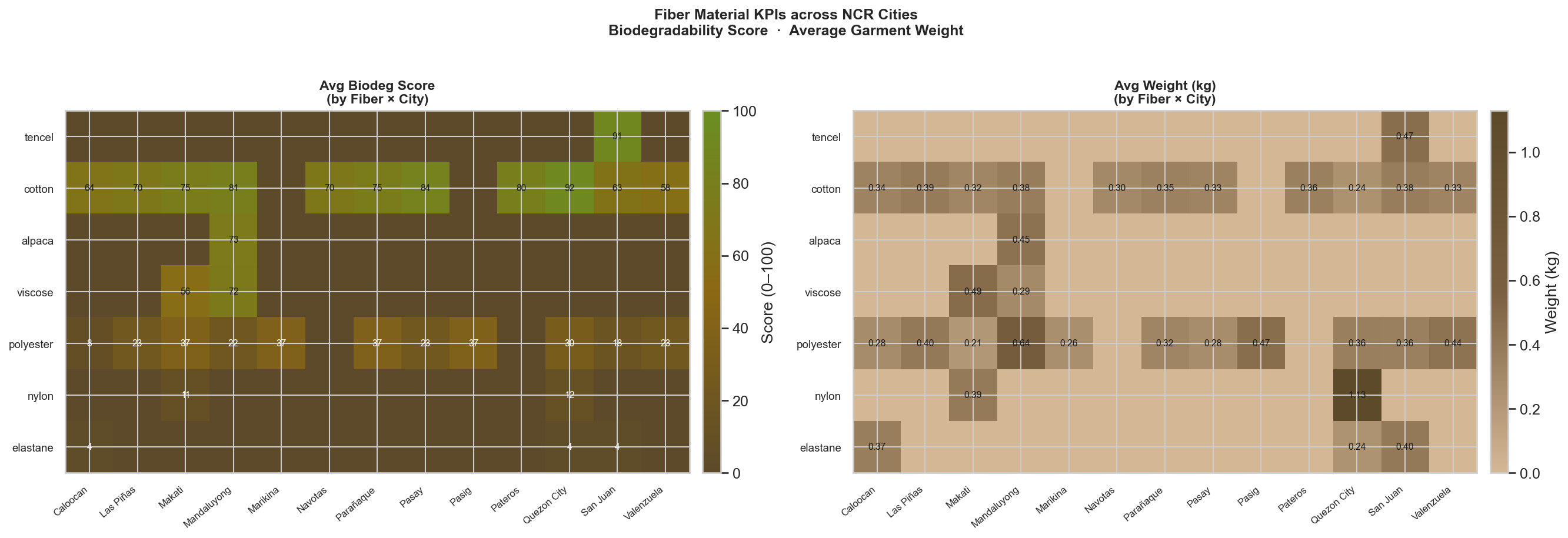
4E4 — Fiber KPI City Heatmap
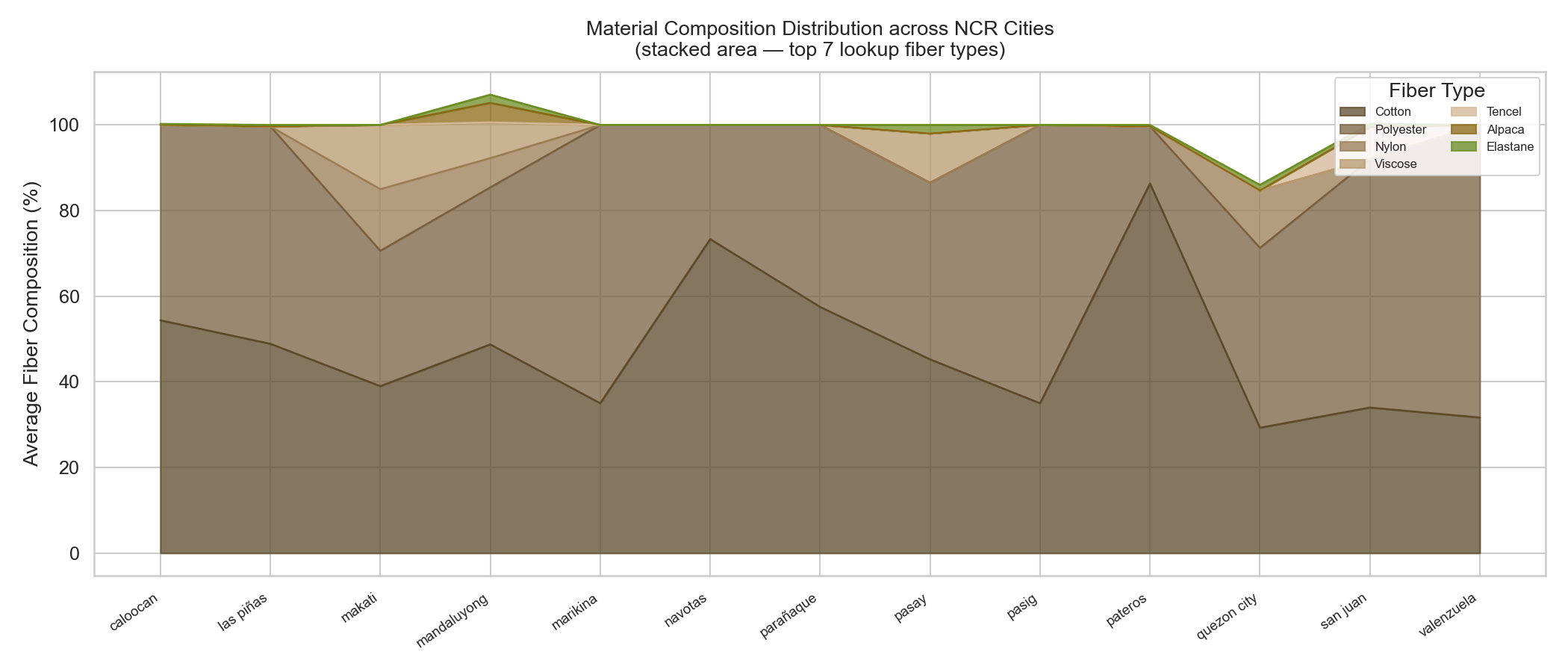
6A — Average Fiber Composition per NCR City (Stacked Area)
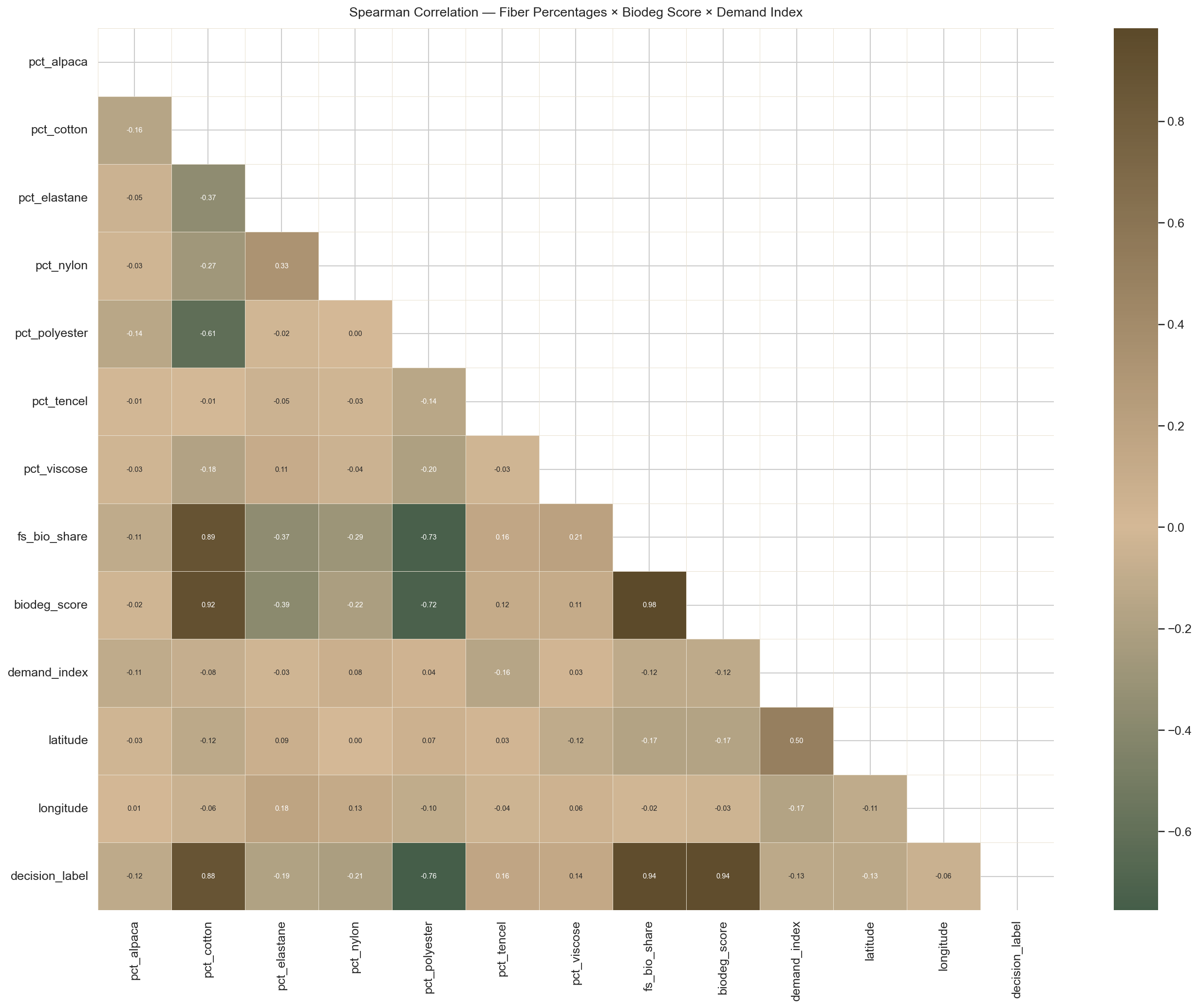
6B — Spearman Correlation Heatmap
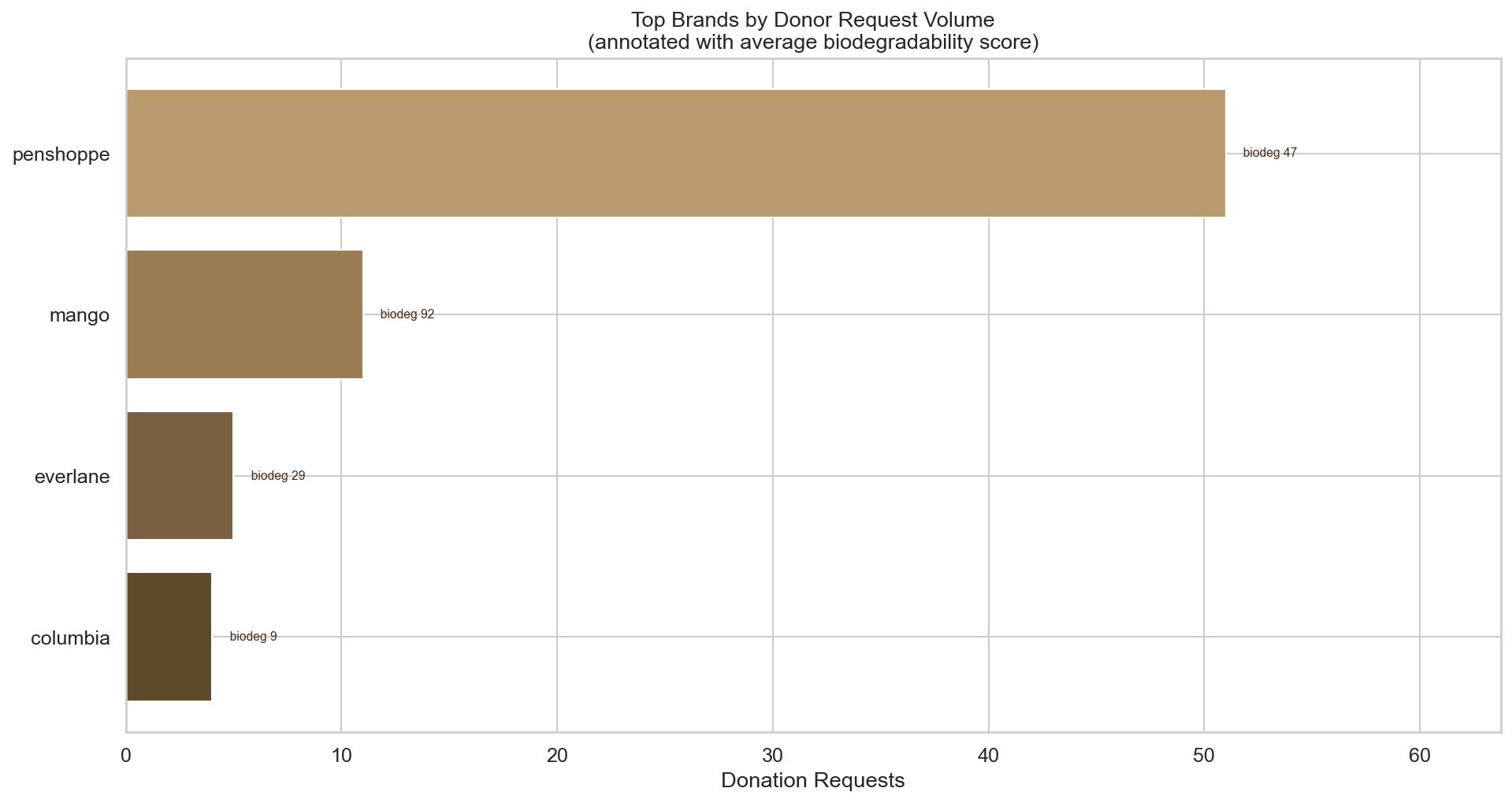
6C — Top 20 Brands by Donation Volume
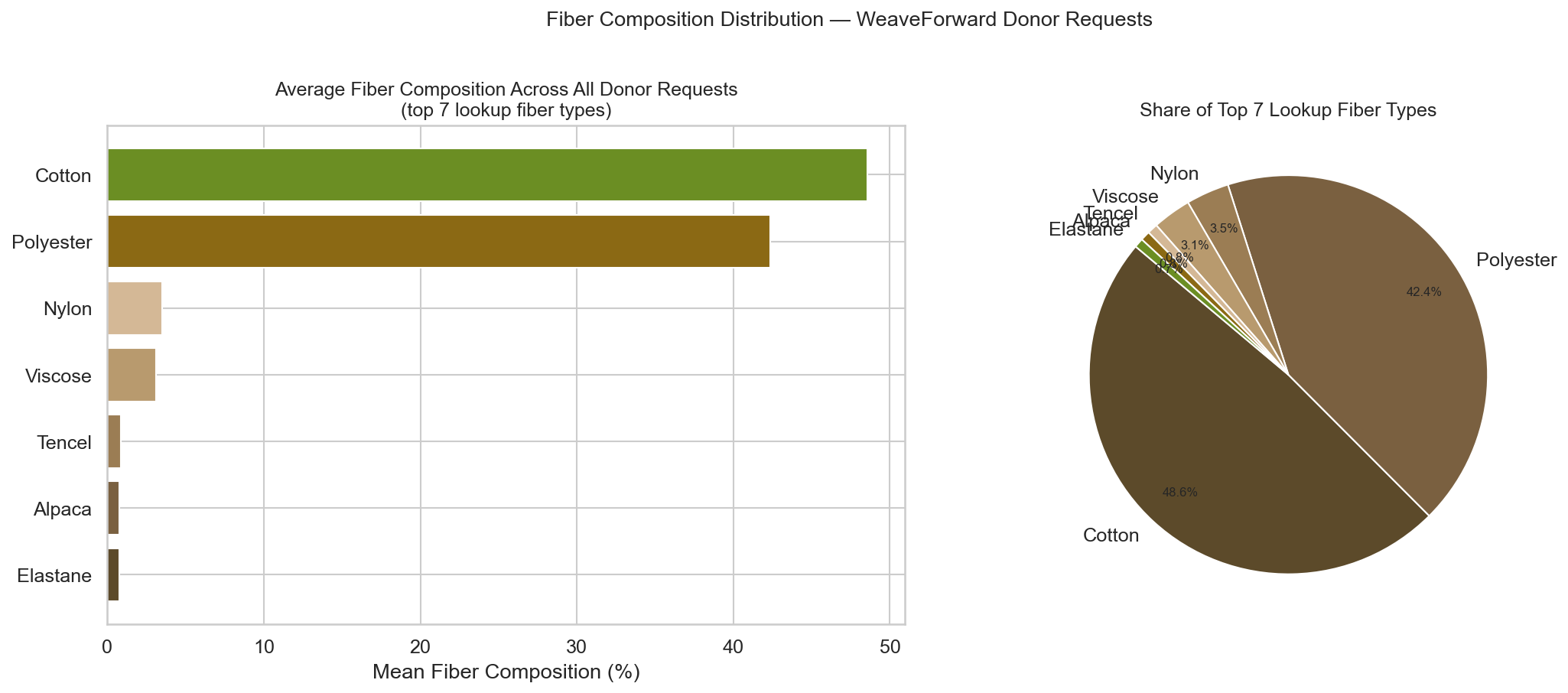
6D — Average Fiber Composition Across Donor Requests
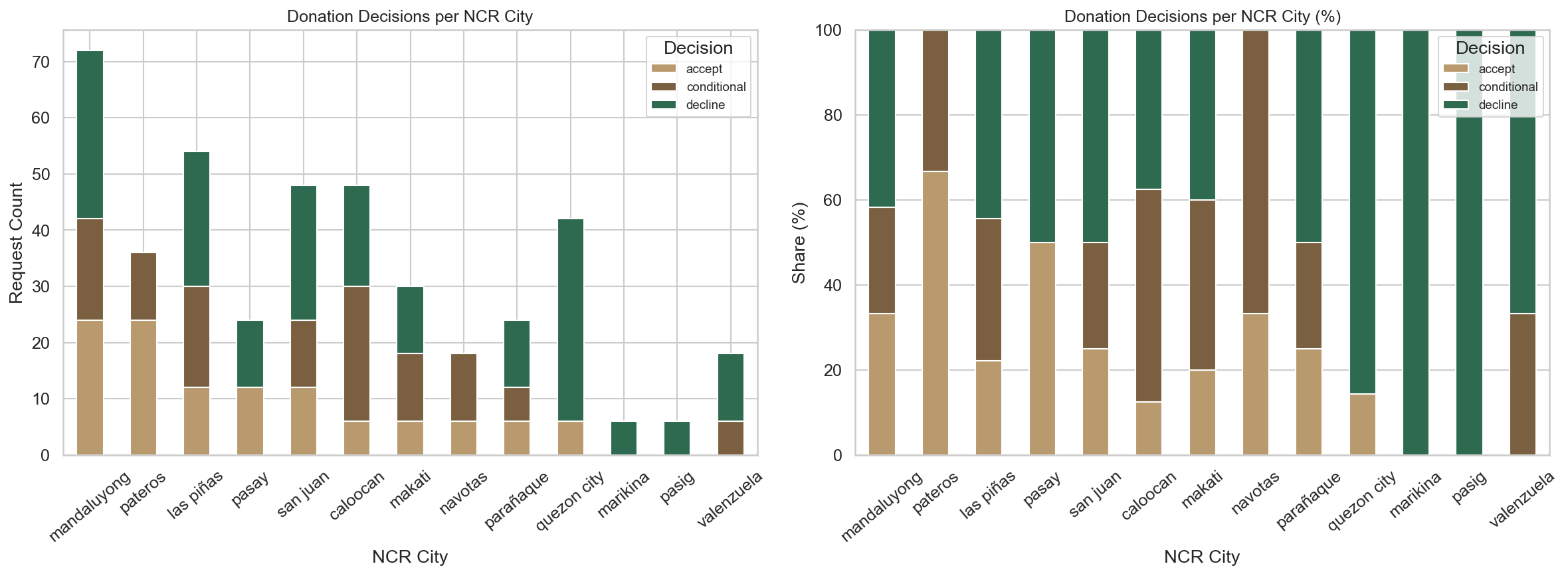
6E — Donation Decisions per NCR City
8B — Confusion Matrix + FP/FN Bar Chart
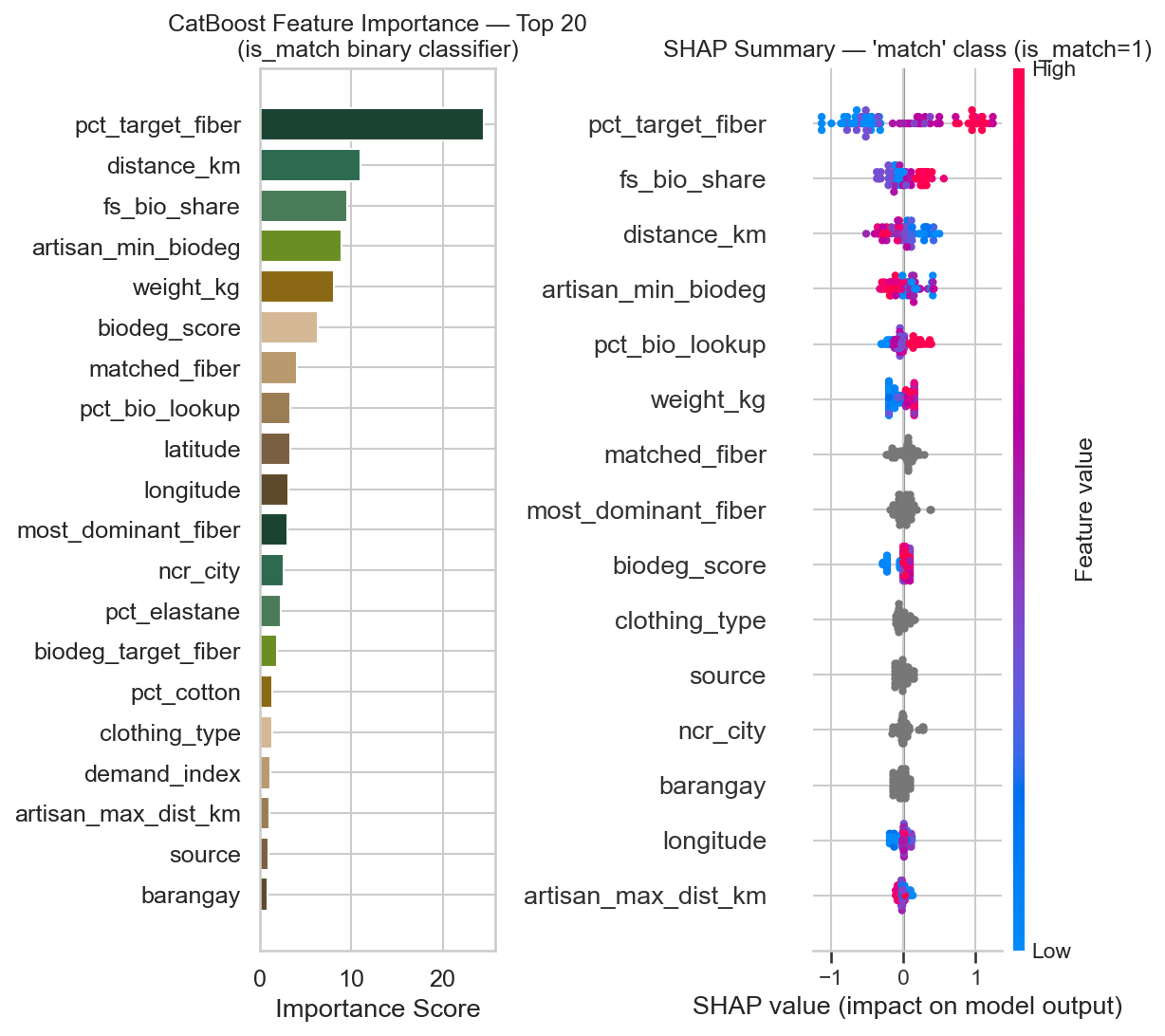
8C — Feature Importance + SHAP Summary (Match Class)
The notebook is fully sequential. Run cells top-to-bottom. Key dependencies:
Section 1–2 Imports + Spark session
Section 3 Brand fiber lookup JSON loading (_FIBERS_OF_INTEREST derivation)
Section 4 Donor request generation + NCR geocoding (Nominatim OSM)
-- geocoding makes live HTTP requests; results are cached in 4-F
Section 5-A-2 Artisan registry (SYNTHETIC) + haversine distance function
Section 5-B-1 Base feature expansion (FIBER_MATCH_THRESHOLD = 85.0)
Section 5-B-2 Donation x artisan cross-join -> df_pairs
Section 5-B-3 is_match label computation
Section 5-C Feature column definitions
Section 6 EDA visualizations (requires df_feat from 5-B-3)
Section 7-A Train/test split
Section 7-B Optuna hyperparameter search (30 trials -- takes ~5 min)
Section 7-C Final model training with plot=True (live Logloss + AUC chart)
Section 8 Evaluation, confusion matrix, SHAP, routed request report
If you change
FIBER_MATCH_THRESHOLDin Section 5-B-1, re-run 5-B-1 through 7-A before retraining.
WeaveForward_FiberClassificationML/
├── data/
│ ├── processed/ # Parquet output from Spark transforms
│ ├── raw/ # Raw donor request CSVs (Spark source)
│ ├── spark_warehouse/ # Spark SQL warehouse
│ ├── visualizations/ # All saved PNG charts
│ └── webscraped_data/
│ ├── webscraped_catalog.csv # Scraped brand fiber catalog (latest run)
│ └── webscraped_catalog_archive.csv # Cumulative archive — all runs, with is_active flag
├── models/
│ ├── catboost_fiber_match.cbm # Trained CatBoost model binary
│ ├── fiber_match_metadata.json # Feature columns, artisan registry, best params
│ └── fiber_match_eval_report_latest.json # Latest evaluation metrics
├── notebooks/
│ ├── fiber_recommendation_model.ipynb # Main ML pipeline notebook
│ └── webscraper_extraction.ipynb # Brand catalog scraping notebook
├── .env # DJANGO_ML_DIR path for artifact export
├── .gitignore
└── README.md
The ERD below reflects the logical data model used by the WeaveForward Django API. The pipeline's feature matrix is derived from these entities.
erDiagram
donation_requests {
string donation_id PK
string brand
string clothing_type
json fiber_json
string ncr_city
string barangay
float latitude
float longitude
float weight_kg
float biodeg_score
string biodeg_tier
string source
datetime requested_at
}
artisan_profiles {
string artisan_id PK
string artisan_name
string target_fibers
float min_biodeg_score
float max_distance_km
float latitude
float longitude
}
match_predictions {
string pair_id PK
string donation_id FK
string artisan_id FK
int is_match
float match_prob
string matched_fiber
float pct_target_fiber
float distance_km
datetime predicted_at
}
brand_fiber_lookup {
string brand PK
string fiber_type
float pct_composition
float biodeg_score
}
garment_items {
string item_id PK
string brand FK
string clothing_type
json fiber_json
string dominant_fiber
}
donation_requests ||--o{ match_predictions : "scored against"
artisan_profiles ||--o{ match_predictions : "receives"
brand_fiber_lookup ||--o{ donation_requests : "fiber source for"
garment_items ||--o{ donation_requests : "instantiates"
| Category | Technology / Library |
|---|---|
| Backend / API | Python, Django, Django REST Framework |
| Machine Learning | CatBoost, scikit-learn, Optuna, SHAP |
| Data Processing | pandas, NumPy, PySpark / Spark SQL |
| Geospatial | geopy (Nominatim OSM), haversine distance |
| Data Scraping | requests, BeautifulSoup, Selenium |
| Visualization | Matplotlib, Seaborn |
| Storage | Parquet (Spark), CSV, CatBoost .cbm binary |
| Notebook | Jupyter (VS Code), ipywidgets (live training chart) |
| Hyperparameter Tuning | Optuna (30 trials, 3-fold stratified CV) |
All 6 artisan profiles below are fabricated for pipeline development. They do not represent real businesses. In production, replace with a live call to
/api/artisans/.
| ID | Artisan Name | Accepted Fibers | Min Biodeg | Max Radius |
|---|---|---|---|---|
| art-001 | Habi Weaves Ermita | cotton, tencel | 60 | 12.0 km |
| art-002 | Diliman Fiber Collective | tencel, viscose | 70 | 18.0 km |
| art-003 | Makati Upcycle Studio | cotton, viscose, tencel | 55 | 10.0 km |
| art-004 | Pasig Natural Threads | viscose, cotton | 50 | 15.0 km |
| art-005 | Marikina Heritage Weavers | alpaca, cotton | 65 | 20.0 km |
| art-006 | Taguig EcoFabric Lab | nylon, polyester | 30 | 14.0 km |
- A fiber match threshold of 85% enforces biodegradability standards and meaningfully reduces the match pool (from 26% to 12.7% of pairs), ensuring artisans only receive suitable materials.
- Precision = 1.00 on the test set confirms the model makes no incorrect routing decisions — artisans are never sent garments that fail their criteria.
- The closest misses (FP = 0, test set) were all distance failures on garments with 100% target fiber — indicating the proximity gate is the binding constraint in this synthetic dataset.
- PySpark feature engineering scales the pair-matrix construction to production-size donor and artisan tables without refactoring.
- The pipeline is fully export-ready:
catboost_fiber_match.cbm+fiber_match_metadata.jsonare copied to the Django API at the end of Section 8.
- Historical catalog archiving was added to
webscraper_extraction.ipynb(Section 1-D): each scrape run merges into a cumulativewebscraped_catalog_archive.csv, stamping every product withfirst_scraped_at,last_seen_at, andis_active. Products absent from the latest run automatically flip tois_active = False. After the archive merge,BRAND_FIBER_LOOKUPis enriched with any brands present in the archive but missing from the current scrape — sobrand_fiber_lookup.jsonwritten by Save Outputs and consumed by the recommendation model reflects the full historical brand set, not just the current-run snapshot. - Discontinued-item fiber approximation (
fiber_approximation(), Section 1-E) infers a plausible fiber profile for donor requests referencing garments no longer in the live catalogue. Namedfiber_approximation(notfiber_match) to distinguish it from theis_matchbinary classification performed by CatBoost in the recommendation model. The function applies a Greedy Priority-Ordered Nearest-Neighbour Lookup across the historical archive — resolving fiber composition through four priority tiers: (1) exact brand + clothing_type from archive, (2) brand match any clothing type, (3) clothing_type median profile across all archived brands, (4) global median profile. Greedy early-exit returns the most specific approximation available at query time. Output keys (fiber_json,most_dominant_fiber,fs_bio_share,fs_biodeg_tier,approx_tier,approx_reason) are schema-compatible withbrand_fiber_lookup.json, requiring no changes to the downstream ML pipeline.
- Built an automated ETL pipeline web-scraping brand fiber composition data from fashion retailers using custom scrapers (
scraper.py), producingwebscraped_catalog.csv— the real-data source for all downstream fiber feature engineering. - Engineered 30 features via PySpark / Spark SQL — implemented
expand_fibers()UDF to extract per-fiber percentage columns (pct_alpaca,pct_cotton,pct_elastane,pct_nylon,pct_polyester,pct_tencel,pct_viscose) from raw JSON fiber composition; computedpct_target_fiber,biodeg_target_fiber, andbiodeg_scoreper pair; addedclip(upper=100.0)guard to handle malformed fiber JSON values exceeding 100%. - Constructed a donation × artisan cross-join pair matrix (71 donors × 6 artisans = 426 rows) and computed binary
is_matchlabels using three-gate logic: fiber share ≥ 85%, biodegradability score ≥ artisan minimum, and haversine distance ≤ artisan collection radius. - Geocoded 71 synthetic donor request records across NCR barangays using Nominatim OSM (live HTTP, cached via 4-F Spark persist) and implemented haversine distance computation for each donor–artisan pair.
- Optimized a CatBoost GBDT binary classifier (
is_match) via Optuna (30 trials, 3-fold stratified CV, maximize binary F1) — best params: iterations=611, depth=9, lr=0.2256, l2_leaf_reg=8.816; achieved 97.67% accuracy, 95.24% F1-binary, 100.00% precision, 90.91% recall, and 1.0000 ROC-AUC on the 86-row stratified test set. - Produced a normalized confusion matrix and FP/FN bar chart confirming zero false routing decisions (Precision = 1.00) — 10/11 true matches correctly captured, with the single FN being a distance failure on a 100% target-fiber garment.
- Generated 11 diagnostic visualizations including KDE of biodegradability scores, donation volume by NCR city, fiber KPI heatmaps, a Spearman correlation heatmap across fiber percentages and biodeg/demand features, brand distribution, and a SHAP summary plot identifying
pct_target_fiber,distance_km, andbiodeg_target_fiberas the primaryis_matchdrivers. - Exported the trained model artifacts (
catboost_fiber_match.cbm,fiber_match_metadata.json,fiber_match_eval_report_latest.json) to the WeaveForward Django API viaDJANGO_ML_DIRenvironment variable for live inference at/api/match-predict/. - Designed and implemented a cumulative historical product archive (
webscraped_catalog_archive.csv) inwebscraper_extraction.ipynb(Section 1-D) — merges every scrape run into a single growing record keyed on(brand, product_name), trackingfirst_scraped_at,last_seen_at, andis_activeprovenance per product; items absent from the latest run are automatically markedis_active = False; after each archive merge,BRAND_FIBER_LOOKUPis enriched in-place with median fiber profiles for any brands present in the archive but missing from the current scrape, ensuringbrand_fiber_lookup.jsonwritten by Save Outputs and read by the recommendation model covers the full historical brand set rather than only the current-run snapshot. - Built
fiber_approximation()(Section 1-E) implementing a Greedy Priority-Ordered Nearest-Neighbour Lookup across the historical archive for donor requests referencing garments no longer in the live catalogue — function is intentionally namedfiber_approximation(notfiber_match) to distinguish archive-based profile inference from theis_matchbinary classification performed by CatBoost in the recommendation model; resolves fiber composition through four deterministic tiers (exact brand+type → brand-only match → clothing-type median profile → global median), returning a schema-compatible dict (fiber_json,most_dominant_fiber,fs_bio_share,fs_biodeg_tier,approx_tier,approx_reason) that integrates directly with the existing Section 5-B-1 feature engineering step in the main ML notebook.
- Ellen MacArthur Foundation (2017). A New Textiles Economy: Redesigning Fashion's Future. https://ellenmacarthurfoundation.org/a-new-textiles-economy
- UNEP (2019). UN Alliance for Sustainable Fashion. https://unfashionalliance.org
- Nominatim / OpenStreetMap — NCR Geocoding (used in Section 4 donor geocoding) https://nominatim.openstreetmap.org
- CatBoost — Gradient Boosted Decision Trees https://catboost.ai
- Optuna — Hyperparameter Optimization Framework https://optuna.org
- SHAP — SHapley Additive exPlanations https://shap.readthedocs.io