{kind=link}
{kind=link}
![]()

TranscriberApp es una aplicación web moderna para transcribir audios, generar resúmenes inteligentes y conversar con un asistente IA contextual.
Toda la inteligencia se ejecuta mediante APIs externas:
- Groq Whisper para transcripción
- Gemini para resumen, análisis y chat
La aplicación está diseñada para ejecutarse de forma estable en Kubernetes, con almacenamiento persistente y acceso seguro mediante Tailscale + HTTPS.
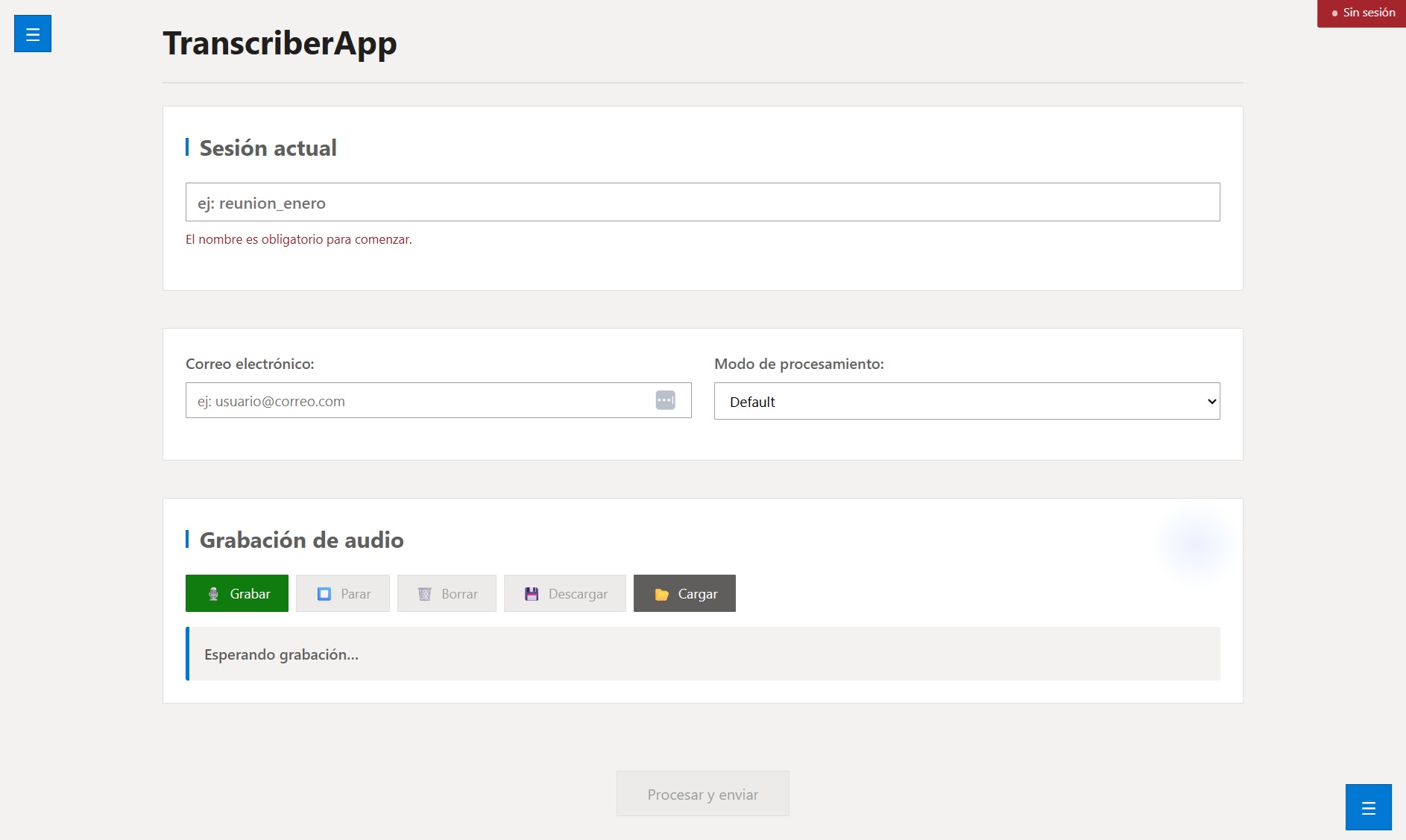
- Transcripción de audio vía Groq Whisper API
- Resumen y análisis con Gemini
- Chat IA con streaming de tokens
- Interfaz web ligera (HTML/JS)
- Resultados persistentes en PVCs
- HTTPS automático con certificados de Tailscale
- API REST con FastAPI
- Arquitectura modular y extensible
- Linux
- macOS
- Windows
- Kubernetes (k3s, k8s estándar, MicroK8s, etc.)
- Python 3.10
No requiere GPU, CUDA ni dependencias de hardware específicas.
- FastAPI
- Groq Whisper API
- Gemini (Google Generative AI)
- Requests / HTTPX
- FastAPI-Mail
- HTML / CSS / JavaScript
- Streaming SSE
- Renderizado Markdown
- Overlay de carga
- Impresión PDF
- Kubernetes
- PVCs para audios, transcripts y outputs
- Tailscale para HTTPS
- NodePort para exposición del servicio
TranscriberApp/
├── audios/
├── transcripts/
├── outputs/
├── k3s/
├── transcriber_app/
│ ├── modules/
│ ├── web/
│ ├── runner/
│ └── main.py
├── requirements.txt
├── README.md
└── .env
git clone <repositorio>
cd TranscriberApp
python3 -m venv venv_transcriber
source venv_transcriber/bin/activate
pip install -r requirements.txtConfigurar API Keys:
echo "GROQ_API_KEY=tu_clave" >> .env
echo "GOOGLE_API_KEY=tu_clave" >> .env| Modo | Descripción |
|---|---|
default |
Resumen general |
tecnico |
Resumen técnico |
refinamiento |
Tareas, backlog, decisiones |
ejecutivo |
Resumen corto |
bullet |
Puntos clave |
python -m transcriber_app.main audio ejemplo tecnicouvicorn transcriber_app.web.web_app:app --host 0.0.0.0 --port 9000Acceso:
http://localhost:9000
TranscriberApp está diseñada para ejecutarse de forma estable en Kubernetes.
- Deployment
- Service NodePort
- PVCs
- Secrets
- Certificados Tailscale montados desde el host
apiVersion: v1
kind: Secret
metadata:
name: transcriberapp-secrets
type: Opaque
stringData:
groq_api_key: "GSK_XXXX"
google_api_key: "AIzaXXXX"Montados desde:
/var/lib/tailscale/certs
https://ubuntu.tailXXXX.ts.net:30090/
sudo tailscale cert ubuntu.tailXXXX.ts.net
Esto crea:
/var/lib/tailscale/certs/ubuntu.tailXXXX.ts.net.crt
/var/lib/tailscale/certs/ubuntu.tailXXXX.ts.net.key
El Deployment monta estos archivos en /certs.
transcripts/
outputs/
TranscriberApp incluye una batería completa de tests:
- Tests unitarios de módulos internos
- Tests de integración del pipeline
- Tests del frontend (JS)
- Tests del backend (FastAPI)
pytest -qpytest --cov=transcriber_appVariables en .env:
GROQ_API_KEY=...
GOOGLE_API_KEY=...
SMTP_HOST=...
SMTP_PORT=465
SMTP_USER=...
SMTP_PASS=...
USE_MODEL=gemini-2.5-flash-lite
LANGUAGE=esDescargar audio desde YouTube:
python transcriber_app/modules/audio_downloader.py "URL"Ejecutar pipeline completo:
python -m transcriber_app.main audio ejemplo tecnicoVer logs en Kubernetes:
kubectl logs -l app=transcriberapp -fReiniciar la app:
kubectl delete pod -l app=transcriberappEste documento describe todo el proceso real seguido para desplegar TranscriberApp en un usando:
- Docker optimizado para Jetson (L4T)
- Kubernetes k3s
- Tailscale para acceso remoto seguro
- HTTPS automático con certificados de Tailscale
- NodePort para exposición del servicio
- Persistencia con PVCs
Incluye además una sección completa de troubleshooting, basada en los problemas reales encontrados durante la instalación.
TranscriberApp/
├── transcriber_app/
├── utils/
├── requirements.txt
├── Dockerfile
├── docker-compose.yml
├── k8s/
│ ├── deployment.yaml
│ ├── service.yaml
│ ├── ingress/ (no usado)
│ └── storage/
├── audios/ (PVC)
├── transcripts/ (PVC)
├── outputs/ (PVC)
└── .dockerignore
Las primeras imágenes pesaban 16.2 GB, lo que hacía imposible:
- subirlas a Docker Hub
- que containerd las extrajera
- que k3s las ejecutara
Se creó un Dockerfile optimizado basado en:
FROM nvcr.io/nvidia/l4t-base:r36.3.0
Este contenedor es:
- compatible con JetPack 6.x
- mucho más ligero que
l4t-jetpack - suficiente para Python + FFmpeg
Para evitar copiar basura dentro de la imagen:
venv/
audios/
outputs/
transcripts/
wheels/
__pycache__/
*.pyc
k8s/secret.yaml
Esto redujo la imagen final a ~2 GB.
El contenedor se arranca con Uvicorn en modo SSL:
command:
- uvicorn
- transcriber_app.web.web_app:app
- --host
- "0.0.0.0"
- --port
- "9000"
- --ssl-keyfile
- /certs/ubuntu.tailXXXXXX.ts.net.key
- --ssl-certfile
- /certs/ubuntu.tailXXXXXX.ts.net.crtLos certificados se montan desde el host:
volumeMounts:
- name: tailscale-certs
mountPath: /certs
readOnly: true
volumes:
- name: tailscale-certs
hostPath:
path: /var/lib/tailscale/certs
type: DirectoryPara acceso desde Tailscale:
type: NodePort
ports:
- port: 9000
targetPort: 9000
nodePort: 30090Acceso final:
https://ubuntu.tailXXXXXX.ts.net:30090/
Tailscale solo permite certificados para dominios válidos del tailnet.
Comando correcto:
sudo tailscale cert ubuntu.tailXXXXXX.ts.net
Esto genera:
/var/lib/tailscale/certs/ubuntu.tailXXXXXX.ts.net.crt
/var/lib/tailscale/certs/ubuntu.tailXXXXXX.ts.net.key
Tailscale renueva los certificados sin intervención manual.
- TranscriberApp funcionando en Kubernetes
- HTTPS real con certificados de Tailscale
- Acceso remoto seguro desde cualquier dispositivo
- Imagen Docker ligera y optimizada
- PVCs funcionando
- Traefik no necesario para este caso
- Clúster estable
https://ubuntu.tailXXXXXX.ts.net:30090/
Ver pods:
kubectl get pods -A
Ver logs:
kubectl logs -l app=transcriberapp -f
Reiniciar la app:
kubectl delete pod -l app=transcriberapp
docker system df
docker rmi <imagen>
docker system prune -a
Este README documenta todo el proceso real, incluyendo errores, decisiones técnicas y soluciones aplicadas.
Es una guía completa para reproducir el despliegue en cualquier Jetson con k3s + Tailscale.
---
# 🔐 Configuración de Autenticación OAuth2
TranscriberApp soporta autenticación mediante OAuth2. Esta sección documenta la configuración necesaria.
## Variables de Entorno Requeridas
Para que el login funcione correctamente, debes configurar las siguientes variables de entorno:
```bash
# URLs del servidor OAuth2
PUBLIC_OAUTH2_URL=https://oauth2.tudominio.com # URL pública para el frontend
OAUTH2_URL=http://oauth2-server:8080 # URL interna para el backend
# Credenciales del cliente (deben coincidir con las registradas en el servidor OAuth2)
OAUTH2_CLIENT_ID=transcriberapp
OAUTH2_CLIENT_SECRET=tu_client_secret
# URI de callback
PUBLIC_REDIRECT_URI=https://transcriber.tudominio.com/oauth/callback
Las variables se encuentran en:
.env(desarrollo local).env.prod(producción)
Ejemplo en .env.prod:
PUBLIC_OAUTH2_URL=https://oauth2.nbes.blog
OAUTH2_URL=http://oauth2-server-prod:8080
OAUTH2_CLIENT_ID=transcriberapp
OAUTH2_CLIENT_SECRET=transcriberapp
PUBLIC_REDIRECT_URI=https://transcriber.nbes.blog/oauth/callback
OAUTH2_TOKEN_ENDPOINT=/oauth2/token
OAUTH2_USERINFO_ENDPOINT=/user/meEl flujo OAuth2 con PKCE funciona así:
- Usuario hace clic en "Iniciar sesión"
- Frontend llama a
/api/auth/oauth2/start - Backend genera:
code_verifier(secreto)code_challenge(hash del verifier)statecodificado en Base64URL
- Backend guarda la sesión en memoria (
OAUTH_SESSIONS) y devuelve la URL de autorización - Usuario es redirigido al servidor OAuth2
- Usuario se autentica en el servidor OAuth2
- Servidor OAuth2 redirige a
/oauth/callback?code=...&state=... - Backend intercambia el código por tokens y establece cookies de sesión
- Usuario es redirigido a la página principal
El code_verifier se guarda en un diccionario en memoria (OAUTH_SESSIONS) vinculado al state codificado. Esto es más seguro que las cookies porque:
- El
code_verifiernunca se expone al navegador - Evita problemas con cookies bloqueadas o no transmitidas
- Limpieza automática de sesiones expiradas (5 minutos)
Nota: En producción con múltiples instancias, considera usar Redis en lugar de memoria local.
Tras un login exitoso, se establecen las siguientes cookies:
| Cookie | Descripción | Duración |
|---|---|---|
logged_in |
Indica sesión activa | 24 horas |
user_id |
ID del usuario | 24 horas |
email |
Email del usuario | 24 horas |
username |
Nombre de usuario | 24 horas |
Todas las cookies usan:
httponly=True(no accesibles desde JS)samesite="lax"(compatibilidad)secure=False(HTTP) oTrue(HTTPS según configuración)
El servidor OAuth2 debe:
-
Registrar el cliente con:
client_id:transcriberappclient_secret: debe coincidir conOAUTH2_CLIENT_SECRETredirect_uri: debe coincidir conPUBLIC_REDIRECT_URI
-
Soportar PKCE (
code_challenge_method=S256) -
Endpoints requeridos:
/oauth2/authorize- Autorización/oauth2/token- Intercambio de tokens/user/me- Información del usuario
Puedes verificar que el servidor OAuth2 funciona correctamente:
# Intercambiar code por token (desde el servidor)
curl -X POST http://oauth2-server-prod:8080/oauth2/token \
-H "Content-Type: application/x-www-form-urlencoded" \
-u "transcriberapp:transcriberapp" \
-d "grant_type=client_credentials"Debe devolver 200 OK con un token.
Causa: El state en el callback no coincide con lo guardado.
Solución:
- Verifica que
OAUTH2_URLsea accesible desde el contenedor - Revisa los logs buscando
[OAUTH_START] Session storedy[OAUTH_CALLBACK] State - Asegúrate de que el
redirect_uricoincida exactamente
Causa: CORS o configuración de cookies.
Solución:
- Verifica que
credentials: 'include'está en el fetch del frontend - Asegúrate de que
expose_headersincluyeSet-Cookieen CORS - Revisa la configuración de cookies ( secure, samesite, path)
Causa: Credenciales incorrectas o mal formateadas.
Solución:
- Verifica que
OAUTH2_CLIENT_SECRETcoincida con el servidor - Usa Basic Auth en el header:
Authorization: Basic base64(client_id:client_secret) - No envíes
client_idyclient_secreten el body
Causa: Cookie logged_in no se detecta.
Solución:
- Verifica que el fetch usa
credentials: 'include' - Revisa que las cookies tengan
path="/" - En Chrome DevTools → Application → Cookies, verifica que las cookies existen después del login
MIT
OpenAI, Google, NVIDIA, FastAPI, comunidad Jetson.