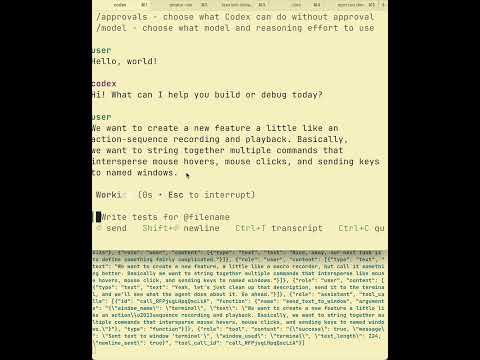
Voice dictation assistant that uses an LLM to turn speech into text and send that text to target windows.
This is a slightly cleaned up version of code I use every day and am always hacking on. I stripped out a lot of stuff (screenshot and image pasting, command sequences, todo list memos) to make this more approachable, but if there's interest in maintaining and extending this, we can add features back in!
Current features:
- keep track of target windows by name
- dictate in "immediate mode" or "accumulate mode"
- clean up text before sending to target window
- run JSON-defined action sequences (focus, move, click, type, wait)
- record clicks/keys into JSON sequences for easy playback
Window name/position mappings are persisted in ~/.pipecat-dictation/window_memory.json
(See platform specific notes, below, too ...)
export OPENAI_API_KEY=...
uv run bot-realtime-api.py
Then open http://localhost:7860 in your browser to connect to the bot.
Try saying:
- "Use the current window as the target window and name it terminal"
- "Let's test, send hello world to the terminal"
A TUI for macOS
uv run tui_dicatation.py --file bot-realtime-api.py
This has:
- A local transport for macOS with echo cancellation (macos/local_mac_transport.py)
- Some semi-reusable components for voice agent TUIs. (In the tui directory.)
At some point I'll pull both of these out into their own repos and maybe make Python packages for them. I like TUIs. :-)
The bot is a Pipecat voice agent that uses OpenAI's Realtime API and a few window management tools. You can use other models and different pipeline designs if you want to! Smaller/older models require different prompting and, in general, can't handle as much ambiguity in conversation flow and instructions.
We run the bot process locally and connect to it via a serverless WebRTC connection. We use WebRTC for flexibility and because Pipecat comes with a bunch of helpful client-side SDK tooling. (For example, we get echo cancellation and a simple developer playground UI by using the pipecat-ai-small-webrtc-prebuilt Python package and connecting via the browser.)
The bot loads instructions from prompt-realtime-api.txt. The current version of the prompt was largely written by GPT-5.
If you don’t want to use WebRTC for local testing on macOS, this repo includes a local transport that uses Apple’s VoiceProcessingIO (VPIO) audio unit for capture/playback with built‑in echo cancellation and noise reduction.
- File:
macos/local_mac_transport.py - Helper:
macos/vpio_helper.c(compiled intomacos/libvpio.dylib)
Build the helper once:
# Requires Xcode Command Line Tools
clang -dynamiclib -o macos/libvpio.dylib macos/vpio_helper.c \
-framework AudioToolbox -framework AudioUnitRun the bot with the local transport:
uv run bot-realtime-api.py -t localNotes:
- The transport loads
macos/libvpio.dylibby default. You can override withVPIO_LIB=/path/to/libvpio.dylib. - Set
VPIO_DEBUG=1to log pacing/underflow metrics once per second. - Audio format is 16‑bit PCM mono at the configured sample rate (defaults to 16 kHz). The helper runs a small C pacing thread for low‑latency playback.
Python must have Accessibility/Input Monitoring permissions to send keystrokes (System Settings → Privacy & Security → Accessibility and Input Monitoring).
We use ydotool to send keystrokes. The venerable xdotool no longer works on modern systems that use Wayland.
On Ubuntu:
sudo apt install ydotool
sudo usermod -a -G input $USER
# log out/in for group change to apply or run `newgrp input`Note that we are using an old version of ydotool because that's what you can install via apt. If you're on a distro with a newer ydotool or you've built ydotool from source, the arguments to ydotool will be incompatible. PRs are welcome!
You can define and run multi-step UI sequences without touching the keyboard.
action_runner.pyexecutes a JSON list of actions: focus windows, move/hover/click the mouse, type text, press keys, and wait between steps.- The
prompt_pointaction lets the runner ask you to hover the mouse somewhere; it captures coordinates after a short countdown.
Examples:
-
Play a sequence:
uv run python action_runner.py play sequences/restart_and_connect.json
-
Append a capture step to a sequence:
uv run python action_runner.py capture-point sequences/restart_and_connect.json connect_btn --message "Hover over Connect" --countdown 3
Integrating with the bot (Pipecat):
- A tool
run_actionsis exposed to the LLM, so it can propose a batch of actions (includingprompt_point) and execute them in order. This enables guided, hands-free flows: the model can ask you to hover, then click/type across different windows.
You can capture your own clicks and keystrokes and save them as a JSON sequence for later playback.
-
Start recording and save to a file (press
Escto stop):uv run python action_runner.py record sequences/my_macro.json
-
Append to an existing file:
uv run python action_runner.py record sequences/my_macro.json --append
-
Tag keystrokes to a specific remembered window (so keys go to that window on playback):
uv run python action_runner.py record sequences/my_macro.json --window terminal
-
Insert
focus_windowactions on the fly using function keys mapped to names:uv run python action_runner.py record sequences/my_macro.json --window-map "1:bot,2:browser"- While recording, press
F1to insert{ "type": "focus_window", "name": "bot" },F2forbrowser, etc.
Notes:
- The recorder inserts a
waitaction when you pause longer than--min-wait(default 0.25s). - Mouse clicks are recorded as
move_mouseto the click location followed byclick. Close-together clicks are merged into multi-clicks (configurable with--double-click-window). - Regular typing is batched into
send_textactions. Special keys like Enter/Tab/Arrow keys are recorded askeyactions. If--windowis provided, these are sent to that window on playback.
The bot exposes tools to both execute and create sequences by voice:
run_actions: Provide a JSON array of actions (focus/move/hover/click/send_text/key/wait/prompt_point) to execute.start_action_recording: Begin background recording of clicks/keys. You can optionally set a default window and F-key focus hotkeys (e.g., F1→bot).stop_action_recording: Stop recording and return the captured actions; optionally save to a file and/or append.save_sequence: Save actions (or the most recent recording) under a friendly name and update the index.list_sequences: List saved sequences with names and file paths.delete_sequence: Remove a sequence by name (and optionally delete its file).run_sequence: Run a named sequence from the index.
Example flows you can say to the bot:
- “Start recording a sequence for the terminal window.”
- (click, type, navigate)
- “Stop recording and save it as sequences/my_macro.json.”
- “Run that sequence now.”
- “Save this sequence as ‘restart and connect’.”
- “List my sequences.”
- “Run ‘restart and connect’.”
- “Delete the sequence ‘restart and connect’.”