{kind=link}
This is the repository for the text2brain hackathon from the IMAGINE Lab The aim of the hackathon was to train a model to take input text descriptions of brain areas and output a mask in MNI space of the brain area
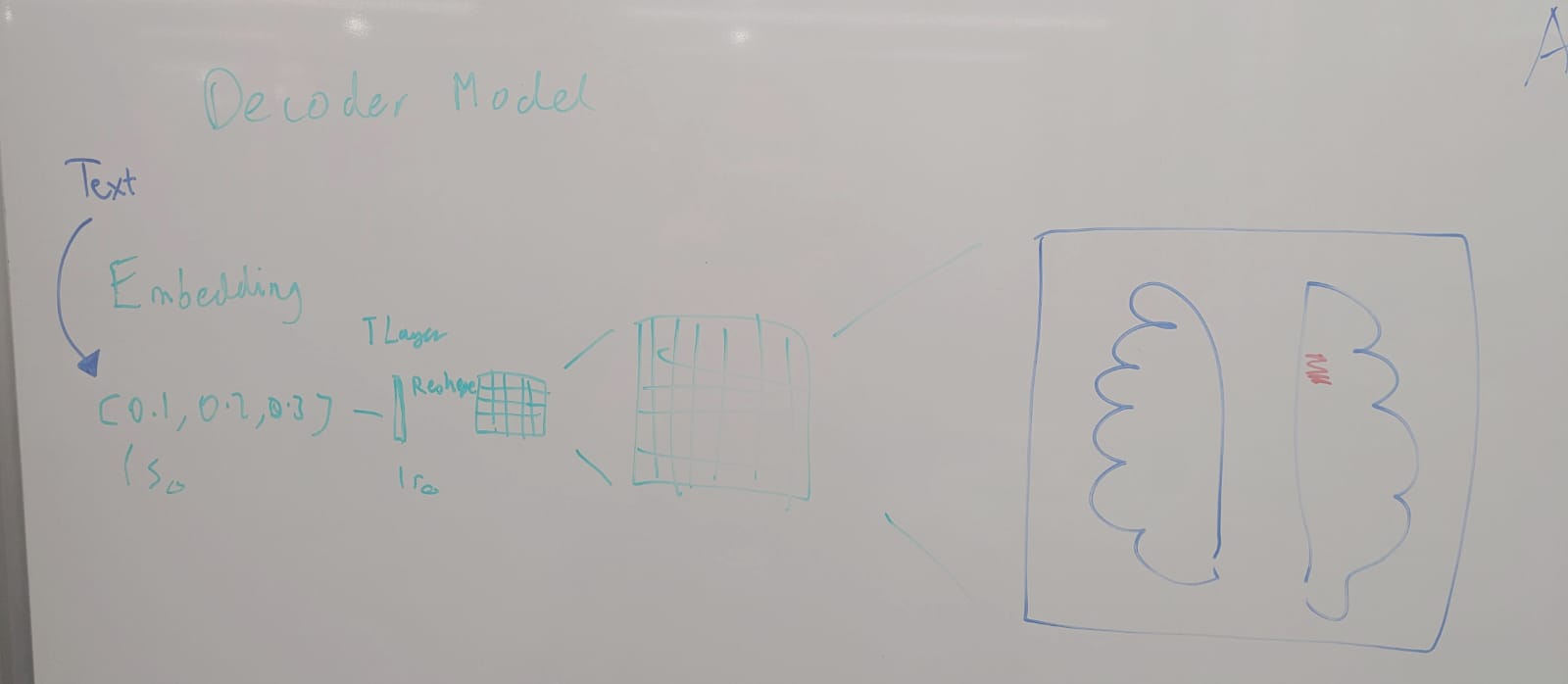 (Replace with nice overview picture)
(Replace with nice overview picture)
Get the text2brain package:
git clone https://github.com/imaginelab/text2brain.gitIn the text2brain package, open a terminal and create the main environment:
conda env create -f environment.yml
conda activate text2brain
pip install -e .All data is readily available in the dataset directory (see below). The following was used to create the dataset:
- Neurparch: https://github.com/neurodata/neuroparc
- MIST: https://figshare.com/articles/dataset/MIST_A_multi-resolution_parcellation_of_functional_networks/5633638/1?file=9811081
- Lobar atlas: Lobar labels created by merging Desikan–Killiany regions
data_generation/get_neurparc.shGenerate language-friendly versions of atlas labels:
python data_generation/create_language_versions.py
text2brain/
└── data/
├── atlases/
│ ├── labels/
│ │ ├── Anatomical-labels-csv/
│ │ └── Anatomical-labels-csv-language/
│ └── volumes/
└── data_generation/
└── datasets.csv
Example on the atlas aparc+aseg_mni152.
To generate the training data, place your atlas in the folder atlases using the following format:
You will need the atlas in MNI space (decoder/data/atlas_<my_atlas>.nii) as well as a look up table (decoder/data/lut_<my_atlas>.txt).
-
First, we create a csv spreadsheet of brain regions and labels Run the notebook
decoder/convert_lut_csv.ipynbThis create the csv indecoder/data/labels_<my_atlas>.csv -
Create the embedding vector for each label of the atlas
python text_preprocessing/get_embeddings.py --input_file decoder/data/labels_<my_atlas>.csv --output_file decoder/data/embedding_<my_atlas>.pkl- Create the final file containing the embeddings and masks for each label of the atlas
python decoder/create_data_model.py --atlas_nii decoder/data/atlas_<my_atlas>.nii --embedding_file decoder/data/embedding_<my_atlas>.pkl --output_file decoder/data/trainingdata_<my_atlas>.pkltraining baseline:
- batch: 1
- lr: 1e-3
- model: v1
- epochs: 45
- atlas : DK
- training loss function at the end: 0.001212 Able to predict location on train set and val set
To preprocess ROIs into a ready-to-train format, look at the README.md file /text_preprocessing. The scripts in this folder include functions to:
- Extract ROIs from text, like radiological reports.
- Renamed atlas labels into natural language.
- Translate non-English text into English, since the text embedding are optimized for English text.
- Generate ROIs labels synonyms to augment the training set.