Autoencoding is a data compression algorithm where the compression and decompression functions are:
-
data-specific: which means that they will only be able to compress data similar to what they have been trained on.
-
lossy : which means that the decompressed outputs will be degraded compared to the original inputs
-
learned automatically from examples rather than engineered by a human. It doesn’t require any new engineering, just appropriate training data.
-
Application : Restore distorted images, image denoising , convert B&W to color images, watermark removal.
-
unsupervised or self-supervised learning

Why we need the bottleneck model and is important?
If number of neurons in the middle layer < the number of neurons in the input layer, the network extracts the more effective information. The middle layer will not have any other option but to learn the most important image patterns, ignoring the noises.
If number of neurons in the middle layer > the number of neurons in the input layer, the neural network will have a higher capacity to learn the pattern, making the network lazy. It will copy and paste the input values to the output values, learn noises, and not extract any feature.
- Encoding network will compress the input layer values (bottleneck)/ lower-dimensional representation.
- Its results will work as input (compressed data) that is going to be fed to decoder.
- Decoder reconstruct the encoded data as close to the input data as possible. The output is a lossy reconstruction of the orignal data.
Why use Autoencoders? To remove noise from images, it is import to reduce dimensionality. Autoencoders introduce non-linearity in the network with the help of their non-linear activation functions and the stack of multiple layers. Outliers, a by-product of dimensionality reduction, can easily be detected.
Autoencoders are only able to compress data similiar to what they have been trained on. They are lossy in nature which means the outpur will be degraded compared to the original output.
- Code size : number of nodes in the middle layer. The smaller the code size more the compression is and the bigger the code size will result less compression.
- Number of layers : there are only 2 layers in encoder and decoder but we can make it as deep we want it to be.
- Number of nodes per layer : the number of nodes per layer decreases with each subsequent layer of an encoder and then starts increasing again with each subsequent layer of the decoder.
- Loss function : Mean squared error(MSE) or binary cross-entropy. If the input values are in the range [0,1] then binary cross-entropy is favored as compared to MSE. Otherwise, we just use MSE.
- process of finding abnormalities in data. Abnormal data means the ones that deviate significantly from general behavior of data.
- Application : fraud detection, fault detection
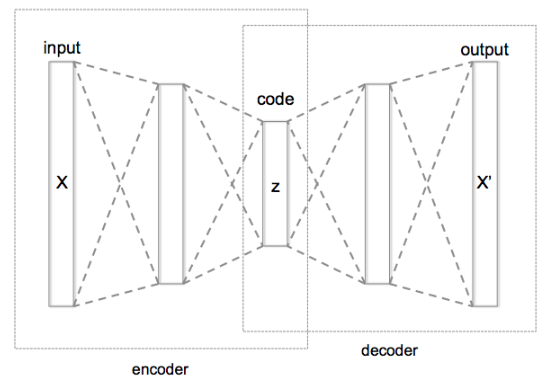
code as known as latent space/vector/variables or bottleneck.