Using Driver class to call main implementation is in LowerCasing#193
Using Driver class to call main implementation is in LowerCasing#193Sandeep-1-Kumar wants to merge 4 commits intokscanne:masterfrom
Conversation
S23/sandeep-1-kumar/LowerCasing.java
Outdated
| public static void main(String[] args) | ||
| { | ||
|
|
||
| } |
There was a problem hiding this comment.
would it be better if we can avoid this extra main method?
There was a problem hiding this comment.
Yes ! I have removed it.
S23/sandeep-1-kumar/LowerCasing.java
Outdated
| String returningValue = word; | ||
| if(language.equals("tr") || language.equals("az")) | ||
| { | ||
| returningValue = word.replace('I' ,'\u0131'); |
There was a problem hiding this comment.
would it be better if we can explain what '\u0131' explains?
There was a problem hiding this comment.
Absolutely ! Thanks for the suggestion.
| { | ||
| if (word.endsWith("Σ")) | ||
| { | ||
| returningValue = word.substring(0, word.length() - 1) + "\u03c2"; |
There was a problem hiding this comment.
would it be better if we can explain what '\u03c2' explains?
There was a problem hiding this comment.
Absolutely ! Thanks for the suggestion.
S23/sandeep-1-kumar/LowerCasing.java
Outdated
| { | ||
| if((word.charAt(0) == 'n' || word.charAt(0) == 't')) | ||
| { | ||
| char[] vowelArray = {'A','E','I','O'}; |
There was a problem hiding this comment.
can you confirm this as all test cases are not being handled uppercase Irish vowel (A,E,I,O,U,Á,É,Í,Ó,Ú),
There was a problem hiding this comment.
Yes , Thanks I have added the Irish vowel cases.
| } | ||
| else if(language.equals("el")) | ||
| { | ||
| if (word.endsWith("Σ")) |
There was a problem hiding this comment.
ΠΌΛΗΣΠΌΛΗΣ el-GR ---> πόλησπόλης
this test case fails
There was a problem hiding this comment.
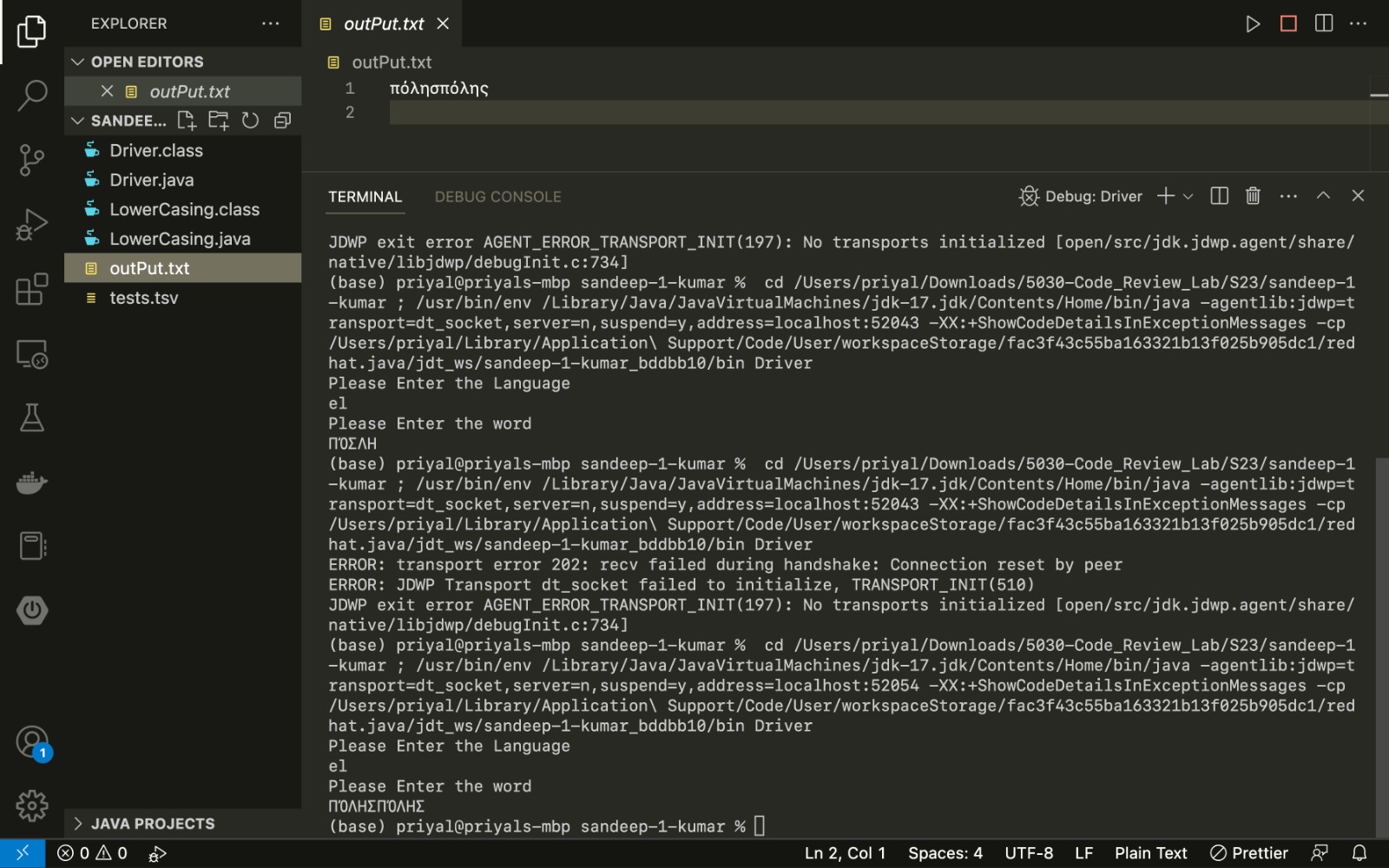
I can clearly see that the response is fine please check the screen shot and confirm.
There was a problem hiding this comment.
here, I hope check is implemented for lang "el" but not for all lang belonging to type "el", i.e "el-GR"
| } | ||
| else | ||
| { | ||
| returningValue = word.replace("Σ", "σ"); |
There was a problem hiding this comment.
ΠΌΛΗΣΠΌΛΗΣ el-GR ---> πόλησπόλης
hope this test case fails
There was a problem hiding this comment.
This test haven't failed and working fine the issue is with utf-8 visualization.
There was a problem hiding this comment.
here, I hope check is implemented for lang "el" but not for all lang belonging to type "el", i.e "el-GR"
S23/sandeep-1-kumar/LowerCasing.java
Outdated
| returningValue = word.replace("Σ", "σ"); | ||
| } | ||
| } | ||
| else if(language.equals("ga")) |
There was a problem hiding this comment.
hope this test case is not handled : word : "nÓg" language "ga-IE"
There was a problem hiding this comment.
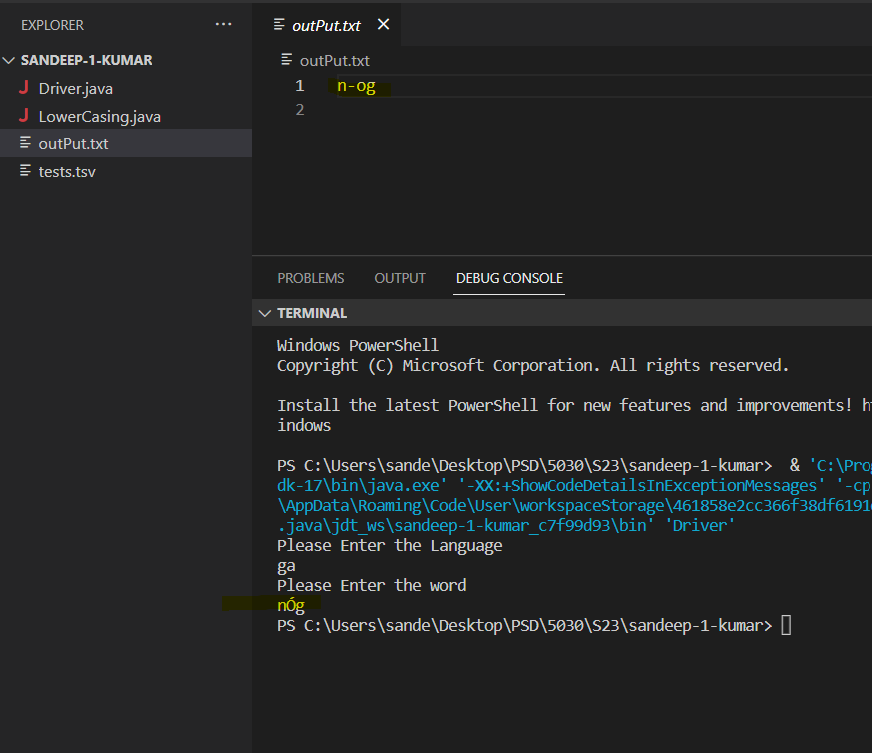
The taste case is working fine , Please verify
There was a problem hiding this comment.
here, I hope the check is implemented for lang "ga" but not for all lang belonging to type "ga", i.e "ga-IE"
|
|
||
| public String lowerCaseConversion(String languageType,String word) | ||
| { | ||
| String[] exceptedLanguages = {"zh" , "ja" , "th"}; |
There was a problem hiding this comment.
Maybe a hashmap in case this list gets long?
| } | ||
| } | ||
| String returningValue = word; | ||
| if(language.startsWith("tr") || language.startsWith("az")) |
There was a problem hiding this comment.
Some language codes have three letters, so "startswith" won't work here.
| String returningValue = word; | ||
| if(language.startsWith("tr") || language.startsWith("az")) | ||
| { //->'/u0131' is a Unicode representation of the lowercase dotless I. | ||
| returningValue =word.replaceAll("[iI]", "\u0131"); |
There was a problem hiding this comment.
This doesn't look like the right behavior. Did you add tests for all combinations of these characters?
| @@ -0,0 +1,70 @@ | |||
| import static org.junit.Assert.*; | |||
There was a problem hiding this comment.
Good job with these. Could add more edge cases, but this is a very good start.
Please validate and accept the pull request to submit assignment