这只是一个最最最基础版本的Python爬虫入门,代码是我两年前写的,最近两天没事翻出来再写(shui)一篇博客。就是爬取王者荣耀英雄的皮肤。然后备注也是写的十分的详细,所以就不做过多的解释,如果想提高自己Python水平的同学可以照着敲一遍。
打开王者荣耀官网。
然后随便点一个英雄的界面,然后按f12打开开发者调试工具。
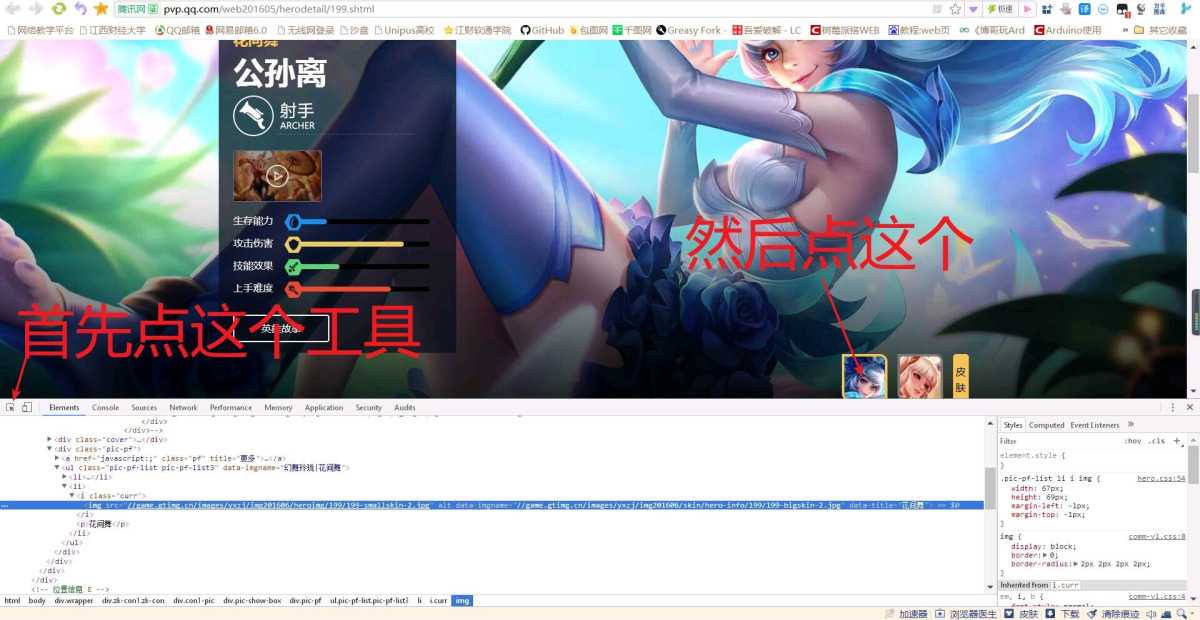
我们一般会多打开几张图片,然后观察他们的共性。


我们可以发现,就只有上面的141和bigskin后面的代码不一样,那我们就可以猜测414和199应该就是英雄的代号,2和3就是指第几张图片,这就好办了,那我们又怎么知道英雄的代码和皮肤的代号呢。 我们先返回到这个英雄界面,我们知道,网页要加载这些图片,肯定不是一开始就这样排好的,肯定有一个文件里面存了这些图片的信息,所以一般只需要更新那个文件就可以更新这个网页的内容了,我们先把那个文件找出来,一般这种文件都是json或者js为后缀的。
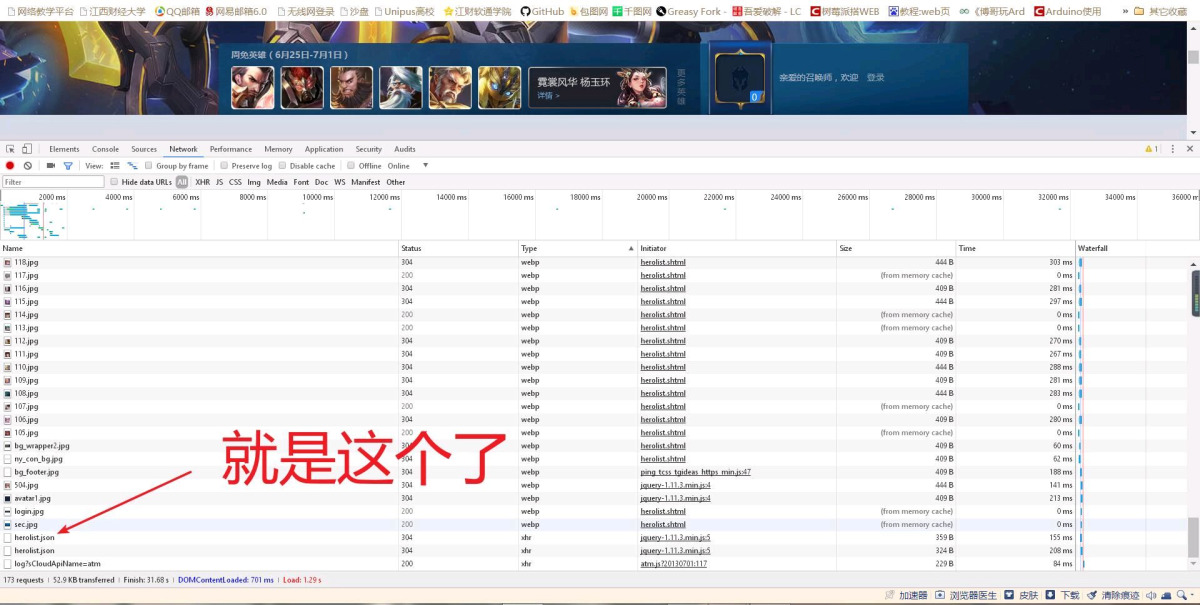
先按F12,然后刷新网页,就可以看到network下面加载出一堆的文件,然后把json一个个都找一遍。
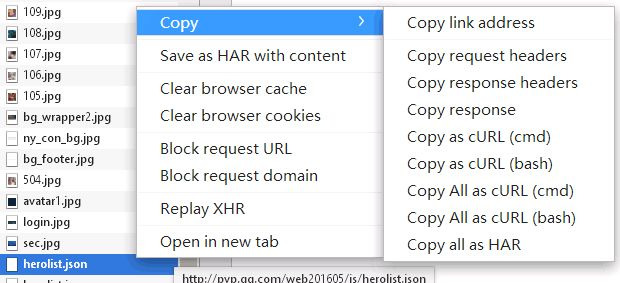
我们把它下载下来。
右键,copy,第一个,然后复制链接地址,再粘贴到地址栏,就可以下载了。
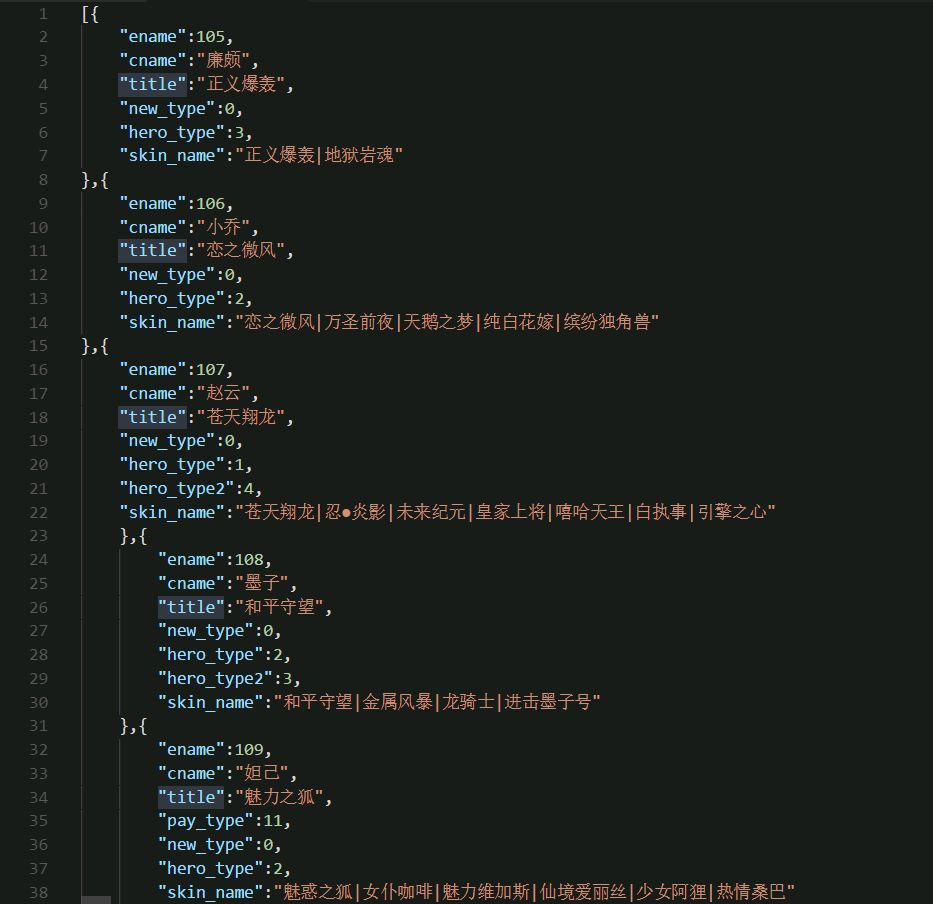
可以看到里面的东西都非常详细,第一个ename就是英雄的代码了,第二个是英雄的中文名字,第三个就是默认皮肤的意思,第四个不知道啥玩意,别理他,第五个,好像是英雄的属性,法师坦克射手之类的,最后一个就是皮肤的名字啦。
现在我们既然可以得到文件的准确地址,那么只要能够组合出图片地址就可以直接下载下来了。下面直接写代码。因为是古老的代码了,而且有些不全,我就不贴代码了,直接给图片吧。


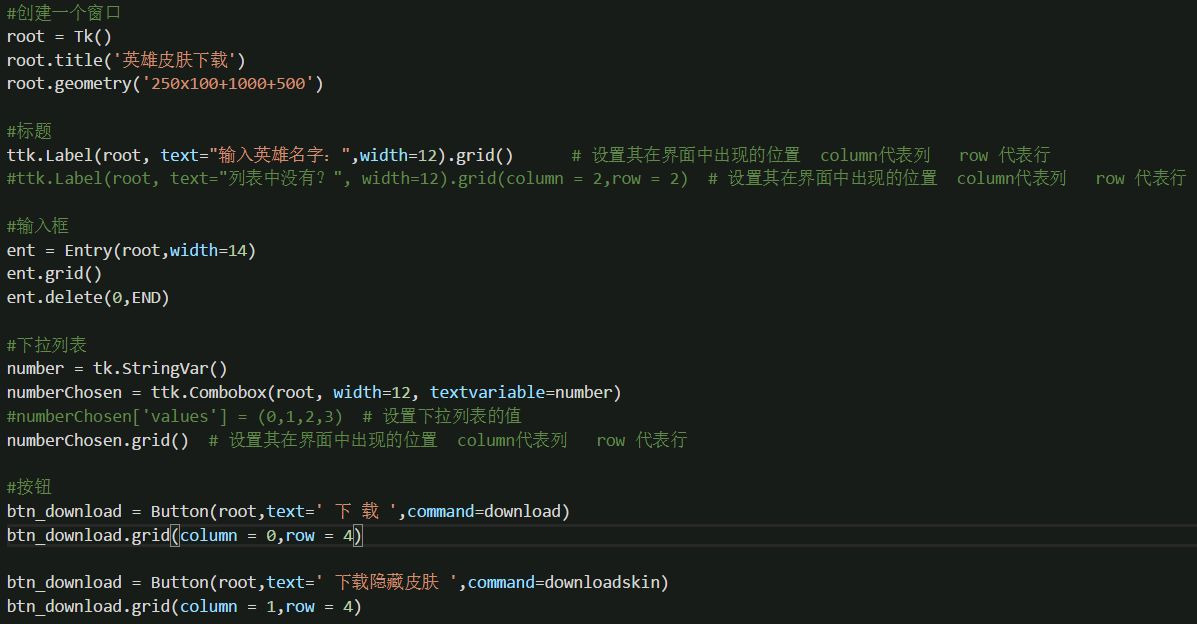
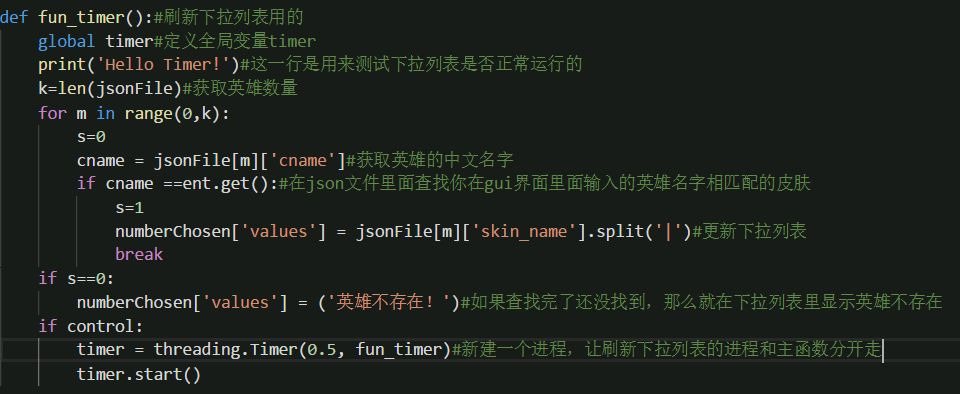
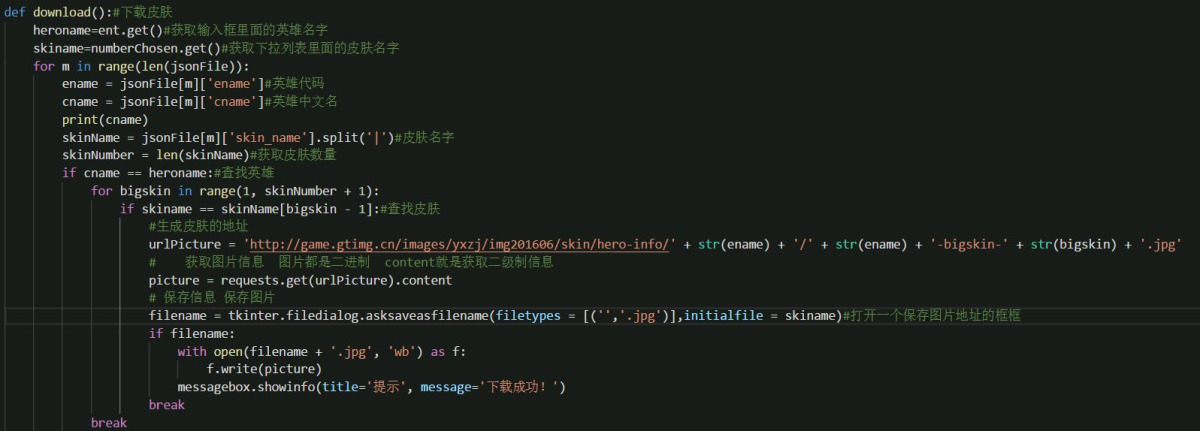
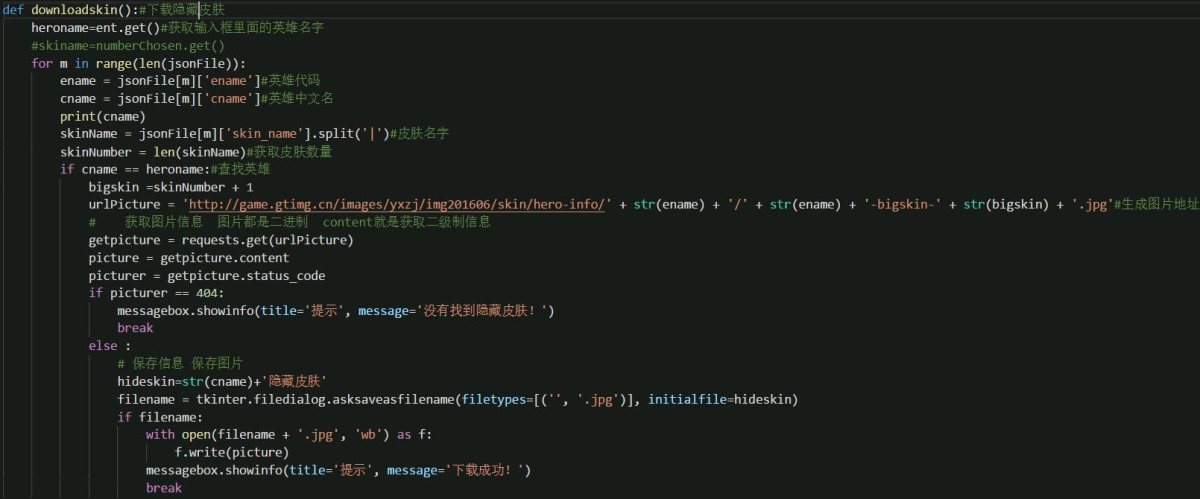
然后最后我这里是用pyinstaller打包成exe文件了,如果你用的win10 x64的系统的话,可以直接运行,我也把源码贴上去。 下载地址:百度云 提取码:nos3
非常非常简单的爬虫,可以用作Python入门级的教程了。