The goal of our classifier model based on Machine learning which also include Deep Learning algorithms will be able to classify sample audio files regardless any language used in audio file, our classifier which is also known as Voice recognition, it used librosa in which, analog audio be converted into digital signals, known as analog-to-digital conversion.
We have used multiple machine learning algorithm for training purpose. Beside Machine learning we also implemented neural network by using Tensor flow. After training we choose the best algorithm for prediction and used for test data.
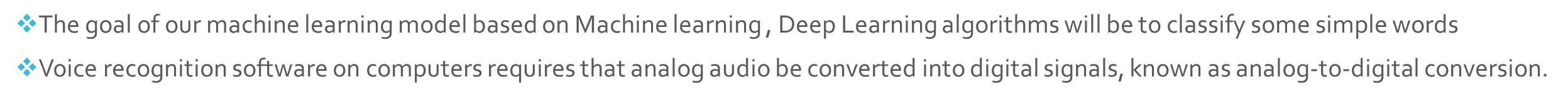
Tool and technology used for data analysis and model development is open source Python.
Audio based data downloaded from Kaggle and combined with locally human audio for testing and training.
After the Data Analysis we prepared the data for model training. Data preparation includes cleaning data, imputing missing values, normalizing data and so on.
We trained our first model on KNN with default parameters.

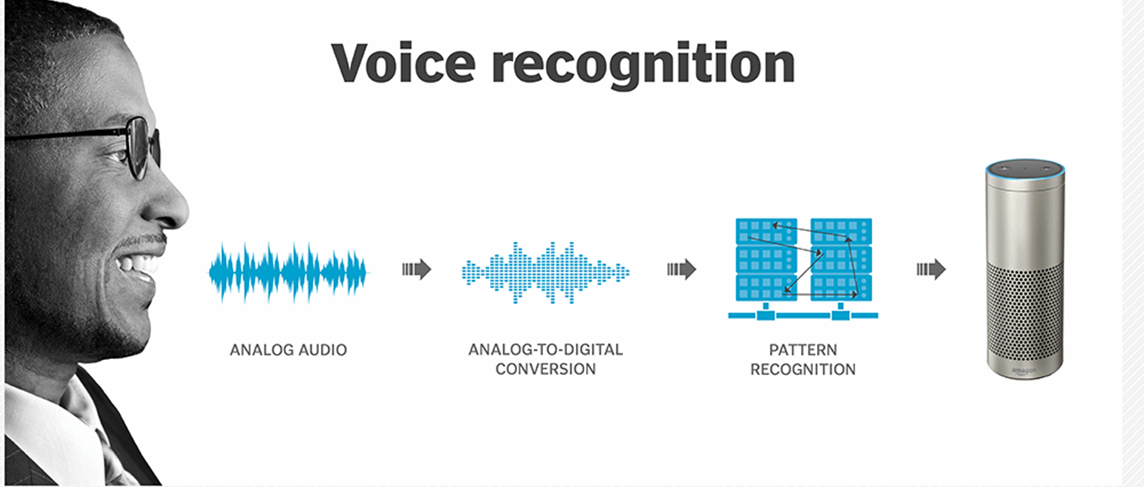
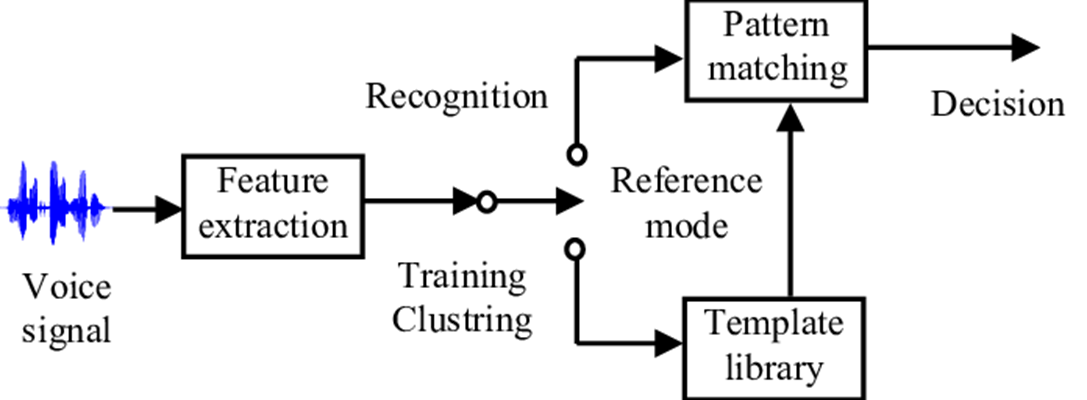

Our model predict audio file but also have ability to varifiy fake and real audio file.
Our model also perform efficiently and have ability to embed into application for verification.
Our model is efficient and scalable.
