Your AI agent is broken in production right now. You just don't know it yet.
Production hardening for n8n AI Agents. Force tool order. Validate every step. Stop silent failures before they cost you a client.

{kind=link}
{kind=link}
{kind=link}
Last month I built a WhatsApp sales agent for a UK agency client. n8n AI Agent node, Groq Llama 70B as the brain, three tools: MySQL customer lookup, Stripe payment link, WhatsApp send.
Customer texts "I want to pay". Agent is supposed to do steps 1, 2, 3 in order.
Instead, around 15 to 20 percent of the time, Llama just skipped step 1. Decided it didn't need the database. Made up a customer_id. Sent a broken Stripe link to a real customer.
Client lost two sales in one day before I caught it.
I tried the official advice. Better system prompt. Few shot examples. Stricter tool descriptions. None of it actually worked at production volume. The model is probabilistic. My business logic is not. When they fight, the model wins and money goes out the window.
So I built n8n-rails.
It puts your AI agent on rails. The LLM cannot skip steps, cannot reorder them, cannot send hallucinated parameters to your real APIs.
Three things, simple:
- Forces tool order. The LLM only sees the tool it is supposed to call right now. It literally cannot pick a different one because the others are not in the prompt.
- Validates between steps. Coming in v0.2: every output checked with a Zod schema before the next step runs.
- Falls back on failure. Coming in v0.3: if Groq Llama refuses to cooperate, retry with Claude or GPT automatically.
n8n-rails uses the OpenAI-compatible chat completions API. That is the industry standard now. Any provider that speaks it works with this node.
Tested and verified with:
- OpenAI (GPT-4o, GPT-4 Turbo, GPT-4o-mini)
- Groq (Llama 3.3 70B, Llama 4, Mixtral)
- DeepSeek (V3, V4, R1)
- Together AI (Llama, Mistral, Qwen)
- Fireworks AI
- Mistral La Plateforme
- xAI Grok
- Cerebras and SambaNova
- OpenRouter as a gateway to 200+ models including Claude, Gemini, Mistral
- Ollama (local models)
- LM Studio (local models)
- vLLM (self-hosted)
- Any LiteLLM proxy
Just set Provider to "Custom" and point Base URL to your provider's endpoint.
Native Anthropic Claude and Google Gemini support is coming in v0.3. For now, route them through OpenRouter and they work today.
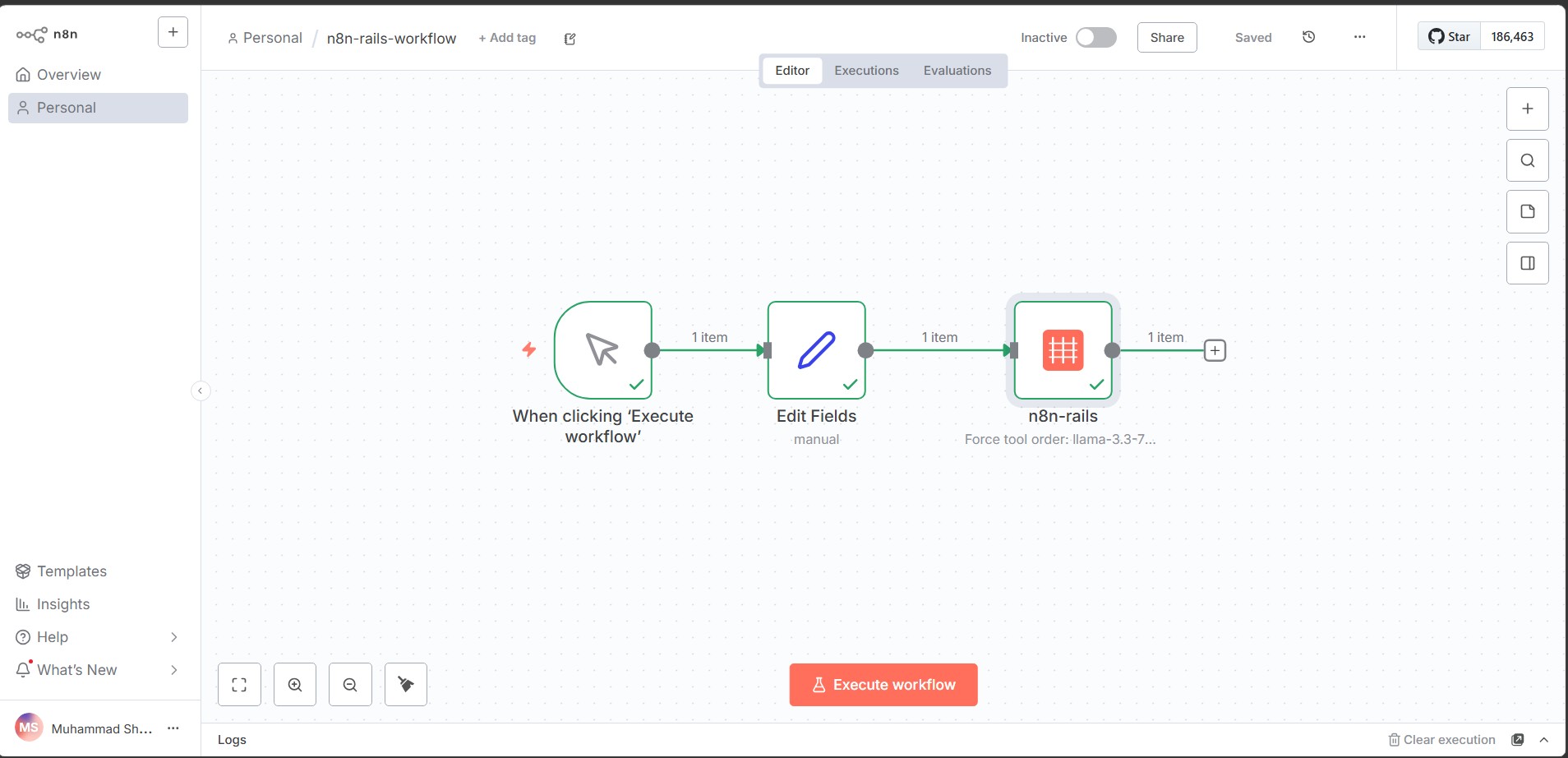
The workflow on n8n canvas:
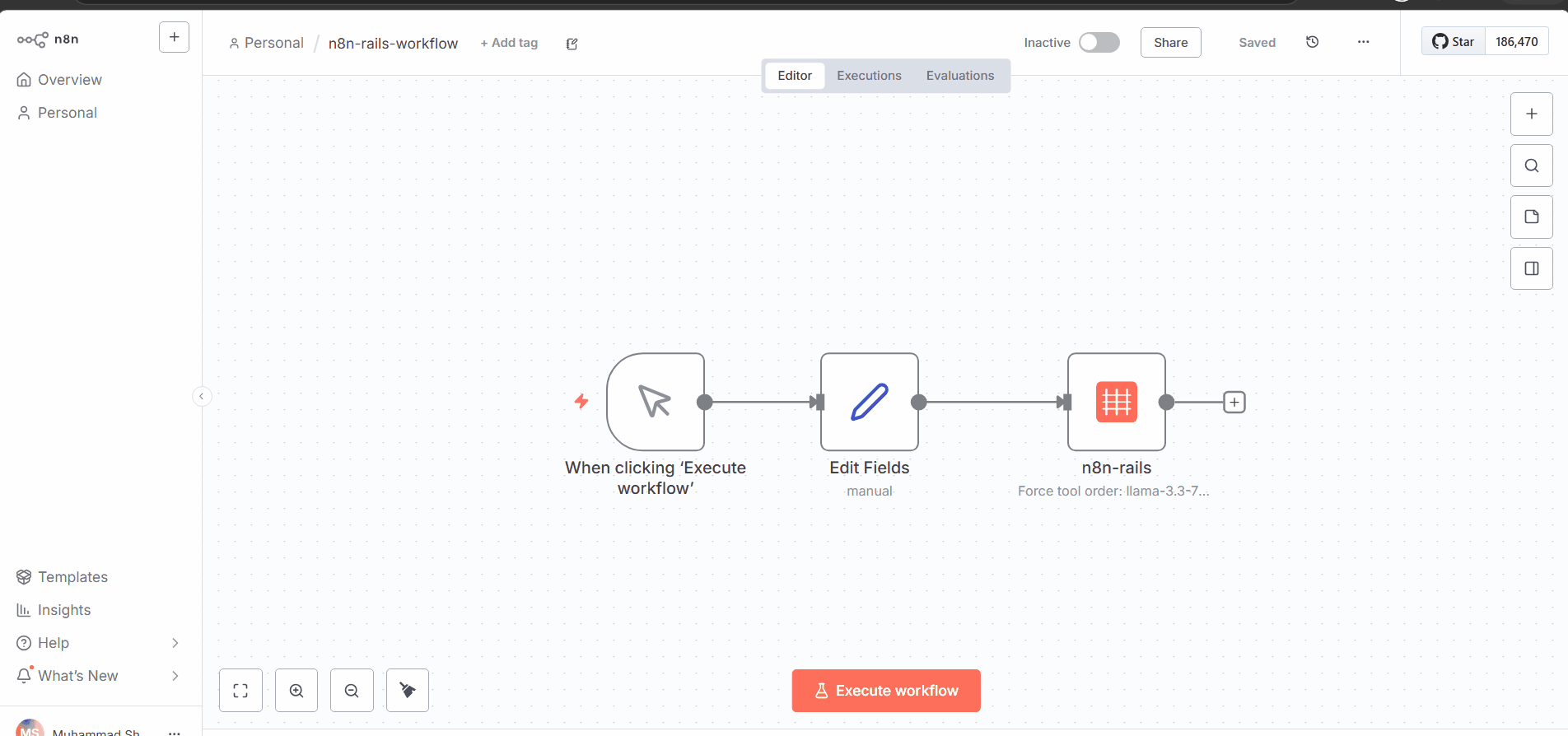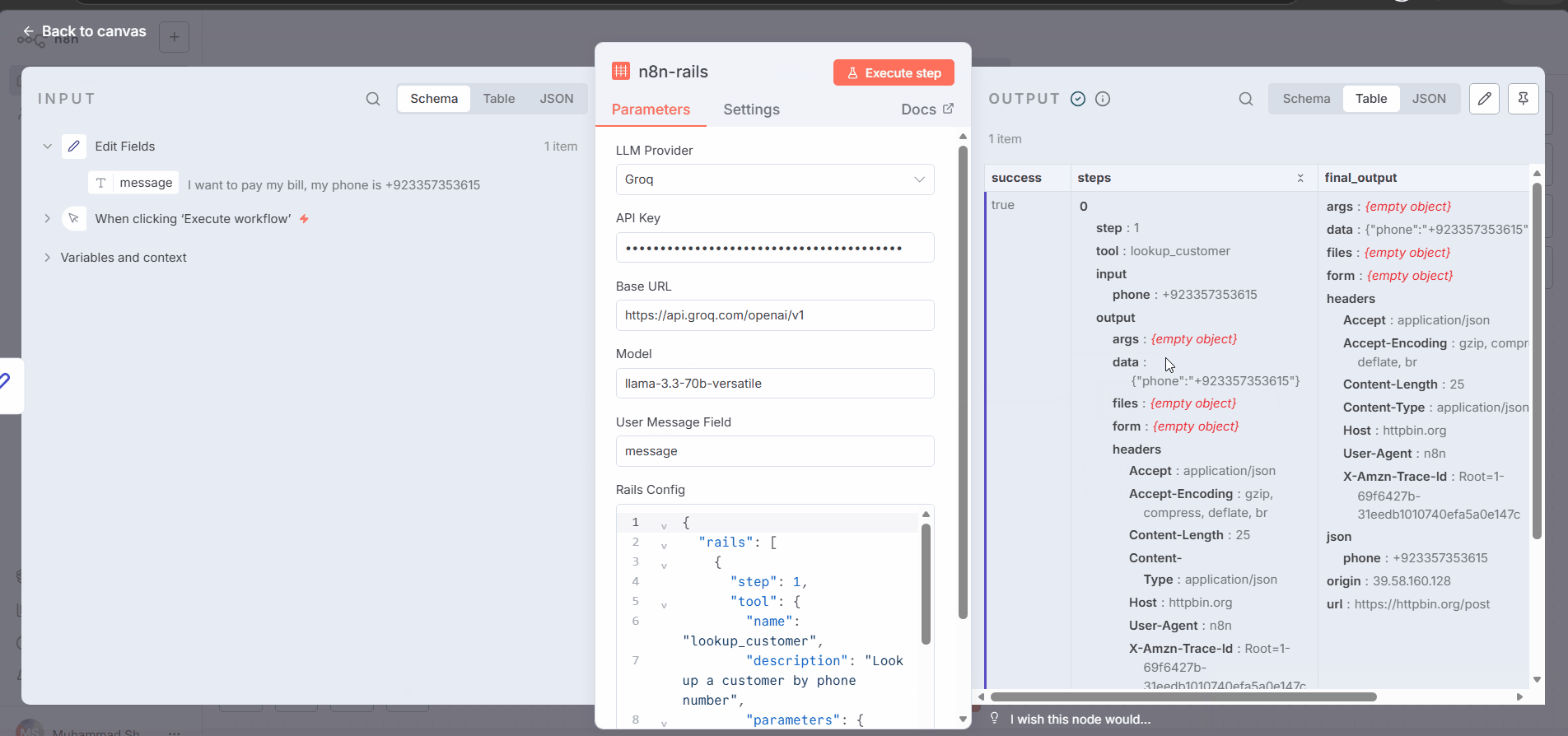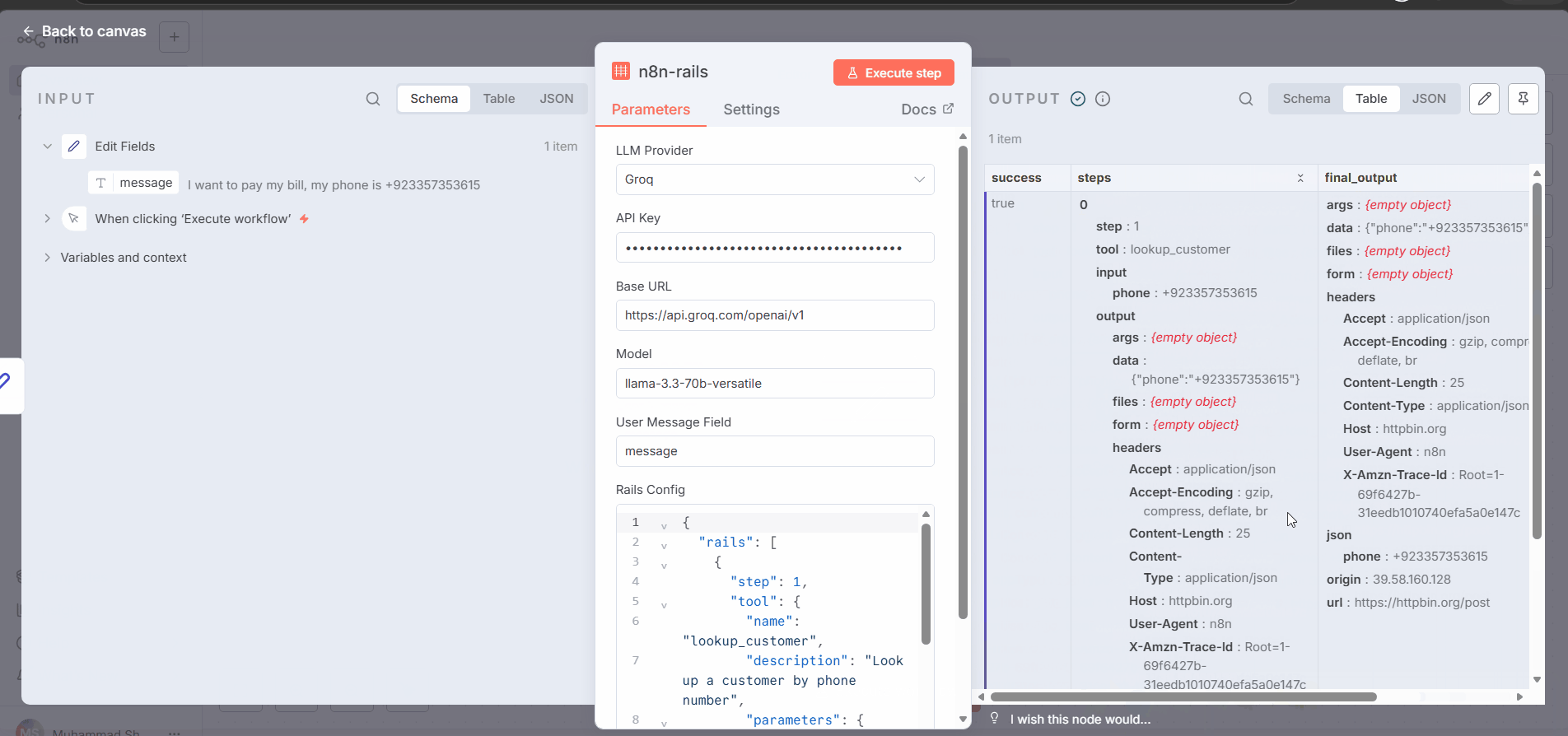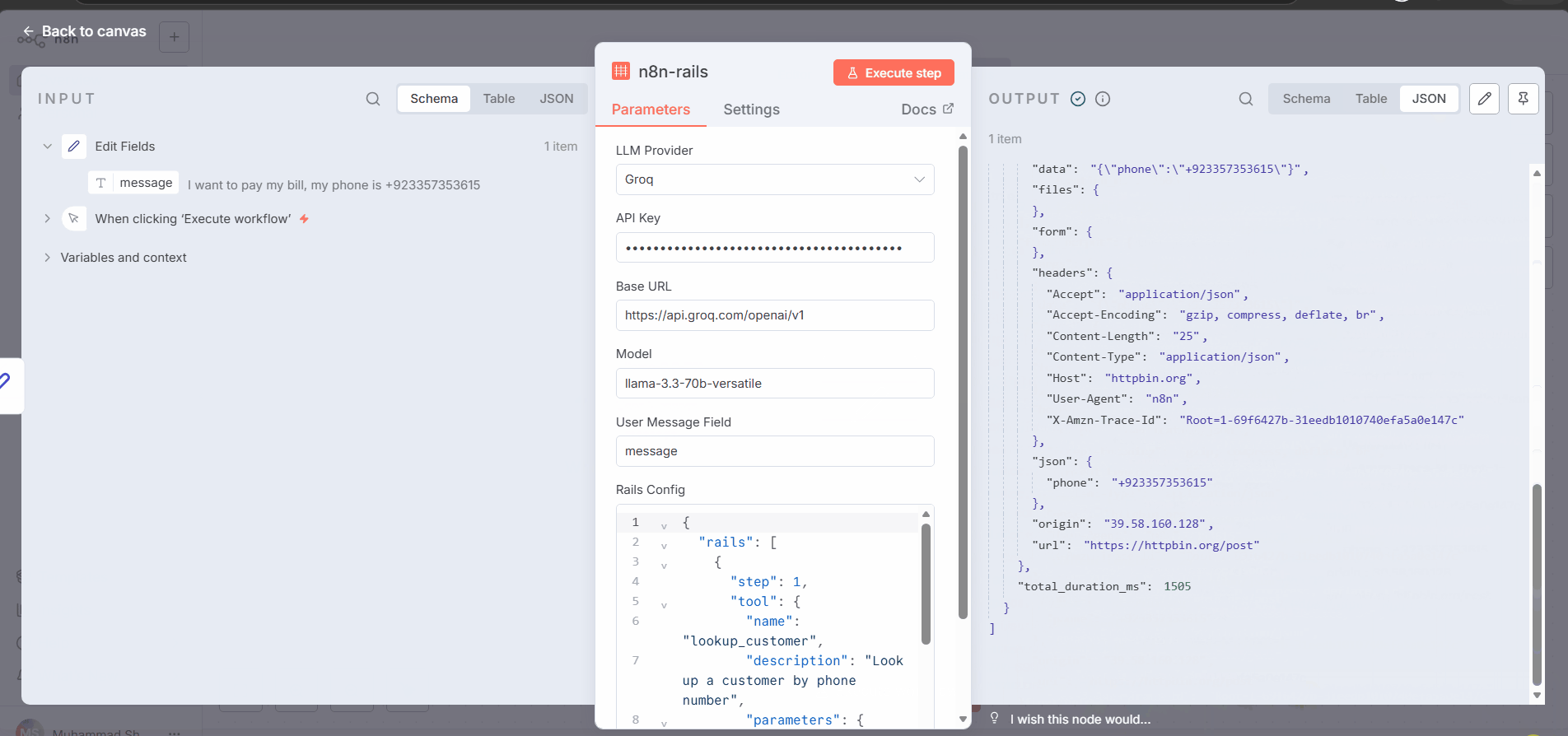
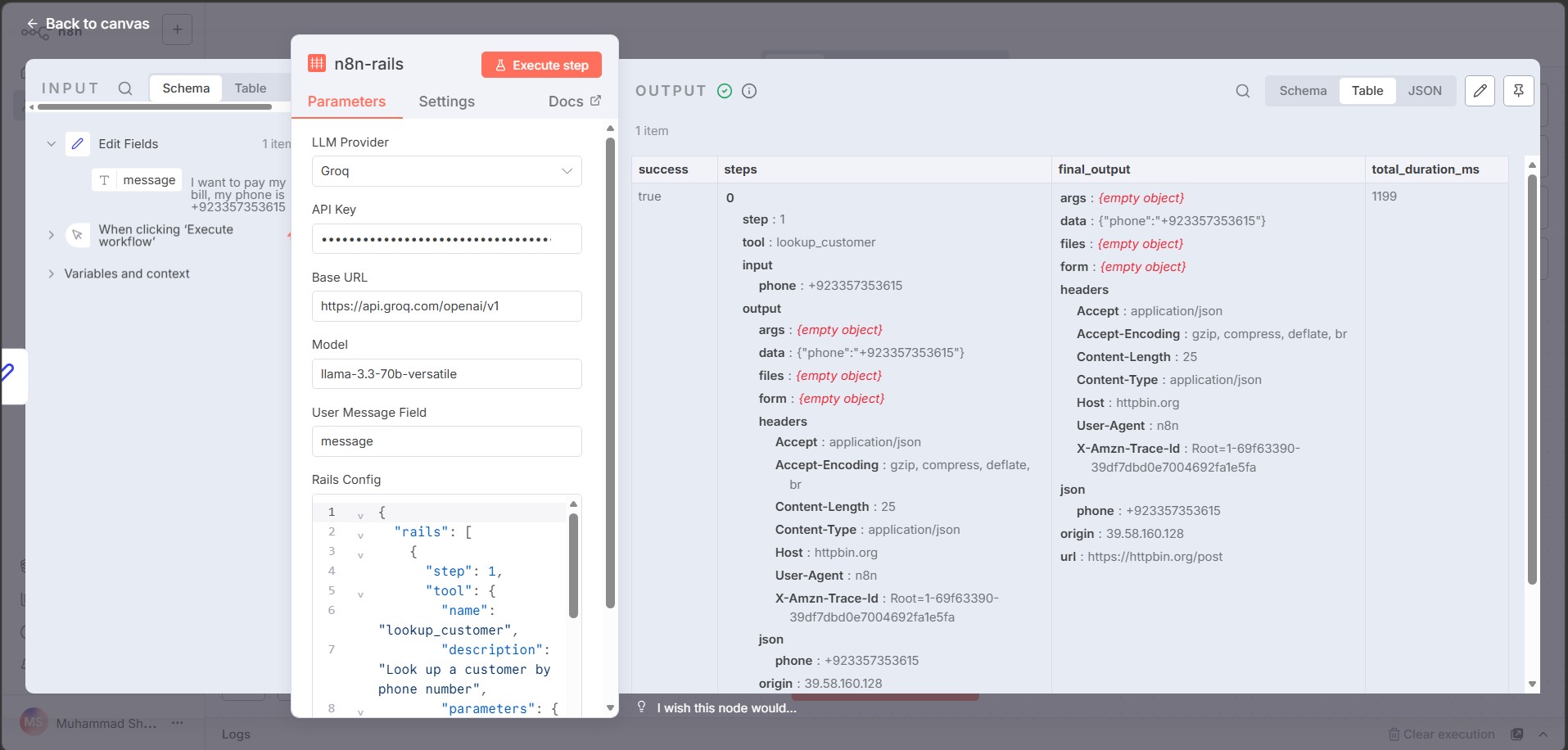
Step-by-step output (proof it works):
npm install n8n-nodes-rails
Or in your n8n instance: Settings then Community Nodes then search n8n-nodes-rails then install.
n8n version 1.20 or higher.
- Drop the n8n-rails node into your workflow before any AI Agent node
- Set your LLM provider, API key, base URL, and model name
- Define your tool order in the Rails Config JSON (see example below)
- Connect a trigger node and a Set node that creates a message field
- Execute. The LLM cannot skip your steps anymore.
Example Rails config:
{
"rails": [
{
"step": 1,
"tool": {
"name": "lookup_customer",
"description": "Look up customer by phone",
"parameters": {
"type": "object",
"properties": {
"phone": { "type": "string" }
},
"required": ["phone"]
},
"endpoint": {
"url": "https://your-api.com/customers",
"method": "POST",
"headers": { "Authorization": "Bearer YOUR_TOKEN" }
}
},
"on_fail": "halt"
}
]
}
Vanilla n8n AI Agent versus n8n-rails:
- Tool order: Vanilla hopes the prompt works. n8n-rails locks it, cannot skip.
- Hallucination handling: Vanilla sends bad data. n8n-rails halts or retries.
- Multi-model failover: Vanilla manual. n8n-rails automatic in v0.3.
- Step debugging: Vanilla raw execution logs. n8n-rails step-by-step replay in v0.4.
- Production safe: Vanilla for demos. n8n-rails for client work.
The native Guardrails node validates the CONTENT of text (NSFW, prompt injection, PII). It does not enforce tool execution order.
n8n-rails forces deterministic execution flow at the orchestration layer. Different problem, different solution. They are complementary, not competing. You can run both in the same workflow.
Structured Output Parser validates the FINAL agent output against a schema. It does not validate intermediate tool calls. By the time it catches a hallucination, the bad data has already hit Stripe or your DB.
n8n-rails validates BEFORE each tool fires. Catch hallucinations before they cost money.
- v0.1: Forced tool execution order (DONE)
- v0.2: Zod validation between steps
- v0.3: Multi-model retry and failover, native Claude and Gemini
- v0.4: Step-by-step replay UI for debugging
- v0.5: Portable TypeScript engine for LangChain and CrewAI users
I am Muhammad Shaheer, n8n Verified Creator with 100+ workflows shipped. I build agentic AI systems for clients in US, UK, and Pakistan. I have been burned by exactly this problem in three different production projects. Prompt engineering does not solve probabilistic models meeting deterministic business logic. Code does.
If you find this useful, the best thank you is starring the repo and sharing with one other n8n builder.
PRs welcome. If you have lost money or sleep to an LLM hallucinating an API call in production, I want your help.
- Fork the repo
- Branch off main: git checkout -b feature/your-thing
- Commit your work
- Open a PR with a description of the production scar that motivated it
MIT, Muhammad Shaheer
- LinkedIn: linkedin.com/in/muhammad-shaheer-898513192
- GitHub: github.com/masteranime
- Email: shaheerawan001@gmail.com
If you are an n8n agency or running production agents and want help hardening them, reach out.