Ideally we would have infinite resources (eg. Google)
Low-resource alternative: Optimize the dataset for model refinement
Ansatz: Let the model “see“ examples at least once.
Our task: Mine rare words. Find example sentences and and their translations.
The Wikimatrix* dataset aims to mine parallel sentences from Wikipedia articles in different language pairs. WikiMatrix.LANG_1-LANG_2.tsv contains sentences in LANG_1 and their counterparts in LANG_2
Sentence pairs are classified by score** measuring quality of correspondance.
** Maximum margin criterion from Haifeng Li, Tao Jiang and Keshu Zhang, "Efficient and robust feature extraction by maximum margin criterion," IEEE Transactions on Neural Networks (2006)
-
Identify LANG_1 as preferent based on resources availible.
-
Create dictionary frequency of lemmas* for LANG_1.
-
Reduce dictionary to instances occurring (n,m) times not too frequent, not extremely rare (possible mispellings, wrong lemmatizations, etc.)
-
Revisit Wikimatrix and extract 1 sentence for each lemma
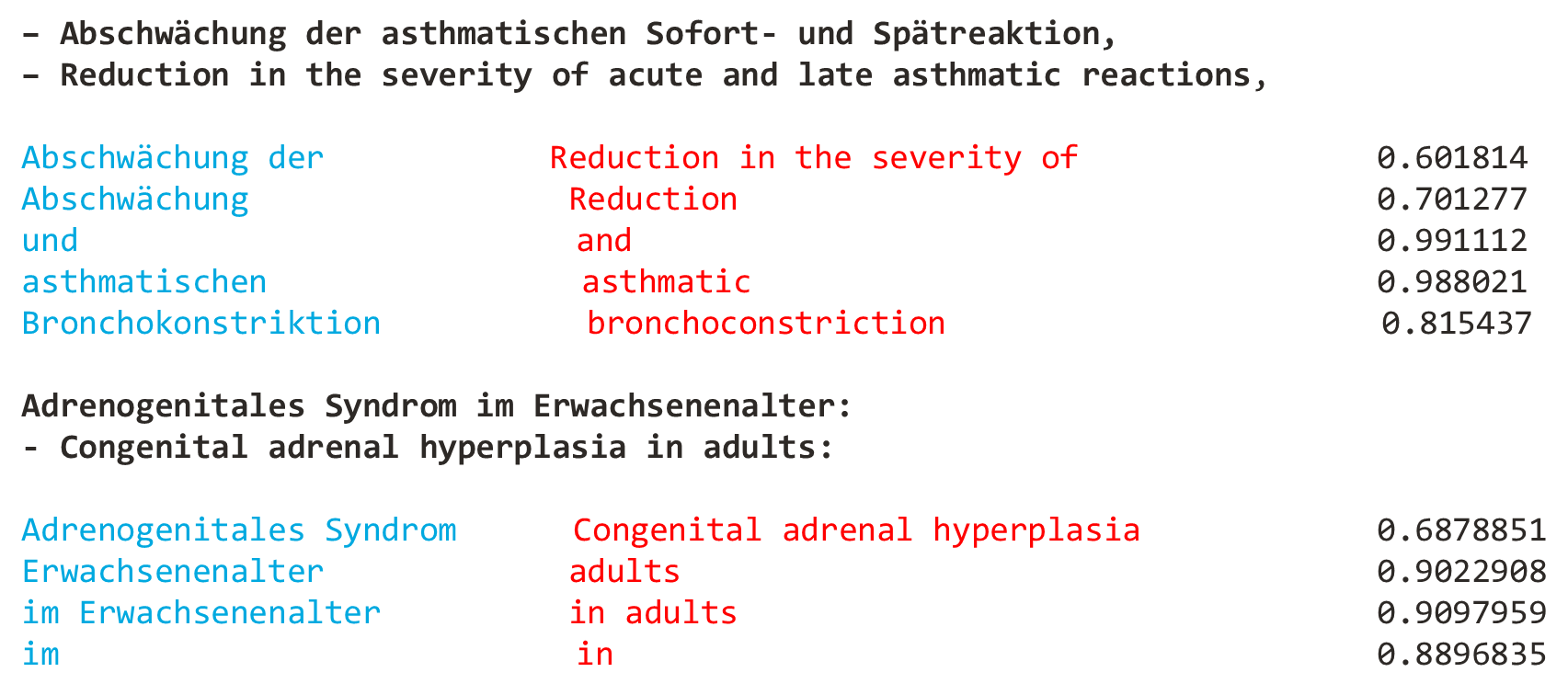
- Eg: Furthermore, individual V1 neurons in humans and animals with binocular vision have ocular dominance
Just one sencence deals as example for three rare words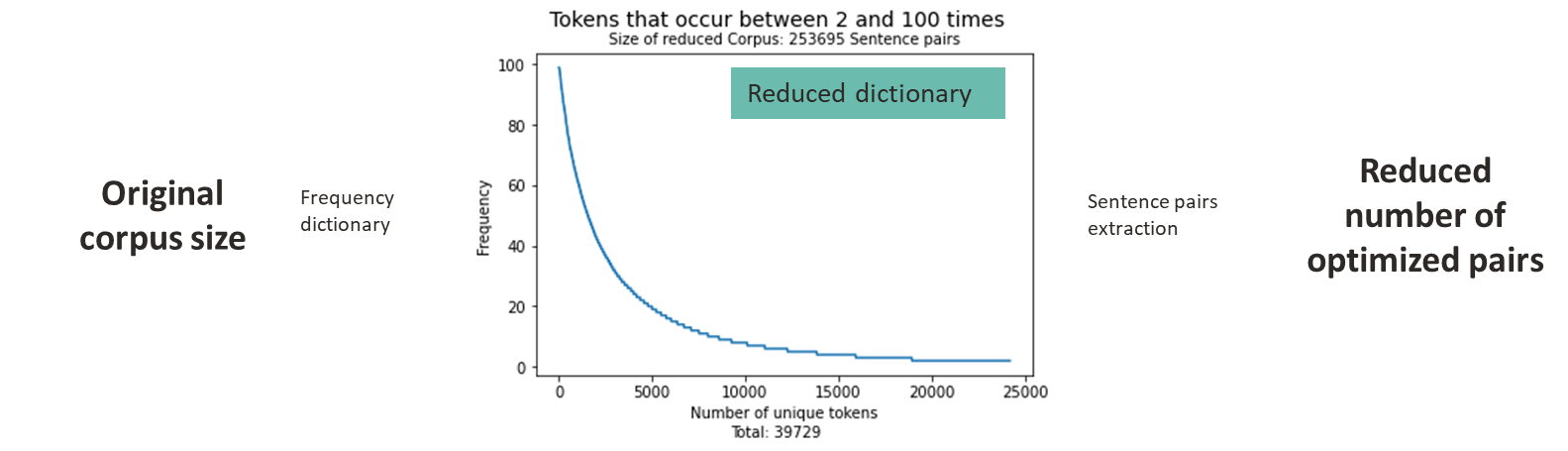
An all-to-all extension was built, altering the pipeline accounting for language-specific characteristics.
- Language-specific RegEX
- Different lemmatizers (Spacy, simplemma)
- Lemmatization may not apply (Chinese)
- Special tokenizers (konlpy, qalsadi, jieba, sudachipy)
- Preprocess sentences
- Get possible alignments (1- or 2-gram to arbitrary)
- Encode source n-gram and translations (Multilingual encoder)
- Perform cosine similarity and keep best if score over 0.7