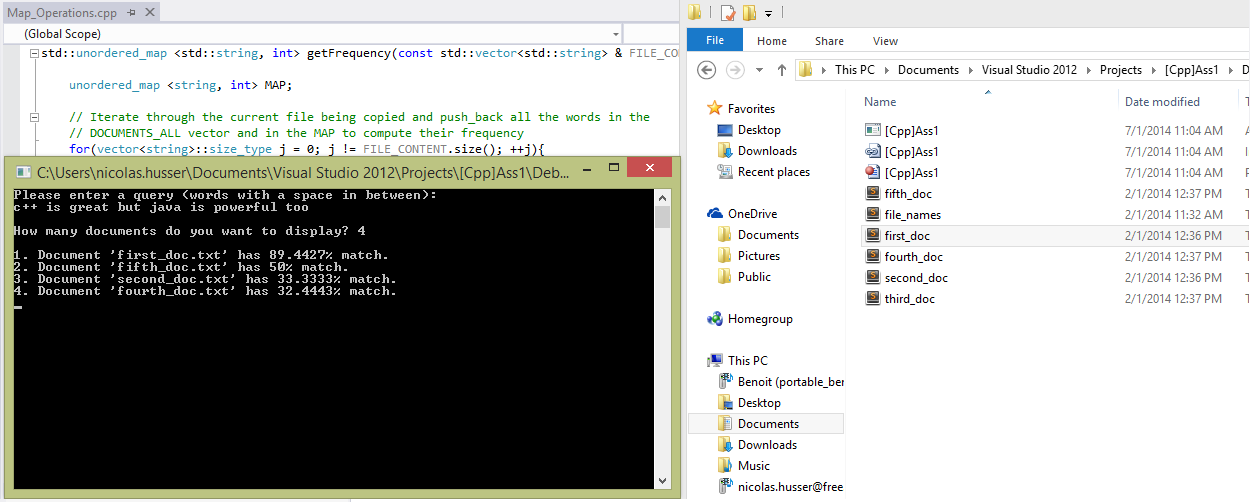
Take queries from the user (i.e., a list of keywords), and for each query generate the top-n files that best match the query entered.
- Read a list of document file names from a file (each filename on one line, and each of these documents contains plain text only);
- Read each of these documents in order to construct an indexing data structure based on their content;
- Then take queries from the user (i.e., a list of keywords), and for each query generate the top-n files that best match the query.
For example, to process two documents d1 and d2, where d1 contains the words "Java is great" and d2 contains "Awesome C++ is awesome" I built two vectors (one for d1, one for d2), each with a length of 5 (since we have five different words overall: ["awesome", "c++", "great", "is", "java"]. Each document vector di records how often each word appeared in the document di (if a particular word doesn't appear, the frequency is 0). In the example, d1 = (0; 0; 1; 1; 1) and d2 = (2; 1; 0; 1; 0). After reading in M documents, there are M of these vectors: d1;...;dM, each with a length N, where N is the total number of different words across all documents: di = (w1;w2;...;wN).
To get the final purcentage, I used this formula that computes angles between vector to know which one is the closest to the query (the closer is the difference between the query vector and the document vector, the better is the match):
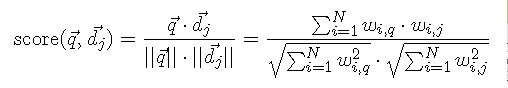
Note: If a the number of documents entered by the user is less or more than the original number of documents it will display them all.