Program ilk çalıştırıldığı anda kullanicidan bir okuyucu ismi seçmesi istenir ve bu “NU”lardan biri olacağı kabul edilmiştir. Soruda istenen NU ve K değerleri kullanıcıdan alındıktan sonra excel işlemleri yapmak üzere değişkenler atanır. (booknames, booktemp, booktemp2) bu değişkenler excel’in ilk satırındaki kitap isimlerini almak için oluşturuldu. While içerisinde ilk linedaki kelimeler “;” ile ayrıştırıldı ve satırın ilk kelimesi olan “USERS” atlatıldı, devamındakiler ise diziye alındı. Daha sonrasında gelen her userı oluşturmak adına createnode isimli fonksiyona gönderilir.
Burada klasik bir linkli listeye ekleme, oluşturma işlemleri yapılmaktadır. Her user için gelen puanları bir for döngüsü ile ekledik.
user *r: linkli listenin en başı(root) readert[20]: Okuyucu ismi (NUx) bookn[][200]: kitap isimleri p[8]: Kullanıcının kitaplara verdiği puanlar.
İkinci struct için linkli listeye ekleme işlemleri burada gerçekleştiriliyor. NUx ve hedef olan Ux için similarity değerleri hesaplanır linkli liste yapısıyla bir structta tutuluyor.
Stsim *r: linkli listenin en başı(root) reader[20]: Okuyucu ismi (NUx) readert[20]: Okuyucu ismi (Ux) float s: *sim fonksiyonundan gelecek olan similarity değeri.
Bu fonksiyonda similarity hesabı yapılır. Bu hesabı yapmak için gelen root değişkenini 2 farklı temp değişkeninde tutuyorum bunun sebebi biri kullanıcının gönderdiği “NU”lar için diğeri ise gezeceğim Ux değerleri. Her bir kullanıcı için (for 0 to 20) ve her bir verilen puan için (for 0 to 8) döngüleri ve temp değişkenleri kullanılarak ra, rb, rap, rbp değişkenleri hesaplanır. Bunu hesaplamak için küçük bi kontrol yeterlidir (NUx ve o andaki Ux için o kitabın puanı 0’dan farklıysa, yani iki kullanıcı da bunu okuduysa) ra, rb, rap, rbp hesaplanabilir.
Bu değişkenleri elde ettikten sonra formülde bahsedilen pay ve paydayı bir değişkene atıp similarity bulmak için sim = pay/ payda yapıyor ve bu similarity değerini, o kullanıcı adına tutmak için 2. Struct yapıma yani stsim struct’una gönderiyorum.
Char ad[20]: NUx
Öncelikle kullanıcıdan gelecek olan ad değerini tutmak için iter2 değişkenini kullandık ve bu değişkende (NUx) bulunacak. Hemen sonrasında sabit olan ra değeri hesaplanmak üzere yani her bir kullanıcı için değişmeyeceğinden dolayı (for 0 to 8) kullanılarak NUx için ra değeri hesaplanmıştır.
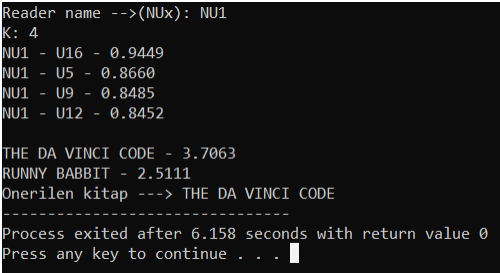
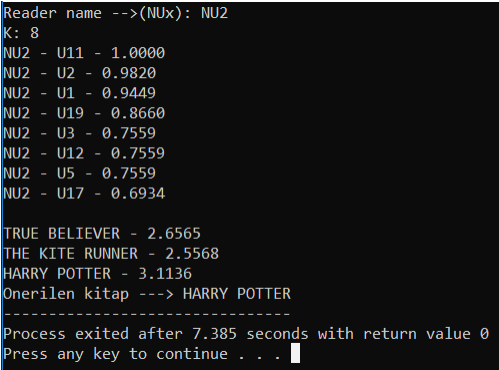
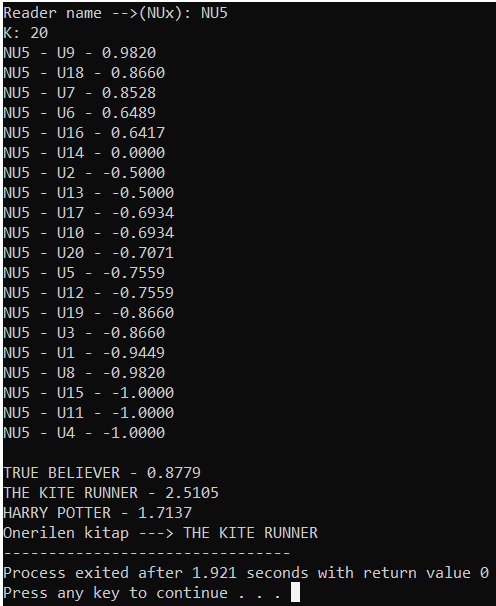
Daha sonrasında kullanıcıya kitap önermek için en benzer K kişiyi kullanacaktık ve hali hazırda similarityleri tutan dizimiz sıralıydı. En dışta kullandığım (for 0 to 3) döngüsü K kişiye ulaşmak adına yapıldı. Daha sonrasında her kullanıcı ulaşmak ve okumadığı kitapları bulmak adına U1-U20 aralığı için bir (for 0 to 20) ve her kullanıcı için puanları kontrol etmek için (for 0 to 8)kullandım. Her iki kullanıcının da okumadığı kitapları bulup bunlar için RBP değerini ve aynı zamanda RB değerini hesapladım ve bu RB değerini bir dizide tuttum çünkü aşağıda girilen K değeri için bu predictionu yapacak while döngüsünde kullanacağım.
Yukarıda hesaplanan, Ra, Rb, Rbp gibi değerleri ile prediction hesaplamak sadece girilen K değerine kadar ilerleyecek bir while döngüsüyle kolayca halledilebilir. K değerine ulaşana kadar pay ve paydaları hesaplayıp predictionu hesaplıyorum. Daha sonrasında bu prediction değerlerinden en büyüğünü bulup, bulunan bu değer için var olan kitap ismi ekrana yazdırılır.