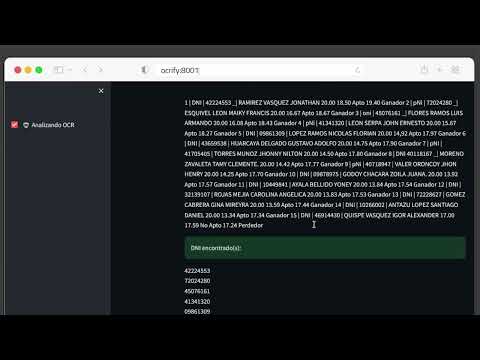
Objetivo: El programa tiene como objetivo recibir una imagen como entrada, reconocer los caracteres que contiene y extraerlos. Una vez que se ha extraído el texto, el programa señala el porcentaje de palabras, buenas o malas, existen en el texto de la imagen basándose en un pequeño conjunto de palabras preregistradas. Finalmente, el programa busca encontrar documentos de indentidad.
Herramientas:
✔️ Pytesseract: biblioteca Python para aplicaciones OCR, documentación (https://pypi.org/project/pytesseract/).
✔️ Streamlit: marco Python para crear la página web, documentación (https://docs.streamlit.io/en/stable/).
Para utilizar este proyecto, sigue estos pasos:
- Clona este repositorio en tu máquina local.
- Instala las dependencias necesarias ejecutando el siguiente comando en tu terminal:
pip install streamlit numpy pillow pytesseract regex
- Ejecuta el siguiente comando para iniciar el proyecto:
python -m streamlit run main.py