


Genai-bench is a powerful benchmark tool designed for comprehensive token-level performance evaluation of large language model (LLM) serving systems.
It provides detailed insights into model serving performance, offering both a user-friendly CLI and a live UI for real-time progress monitoring.
- 🛠️ CLI Tool: Validates user inputs and initiates benchmarks seamlessly.
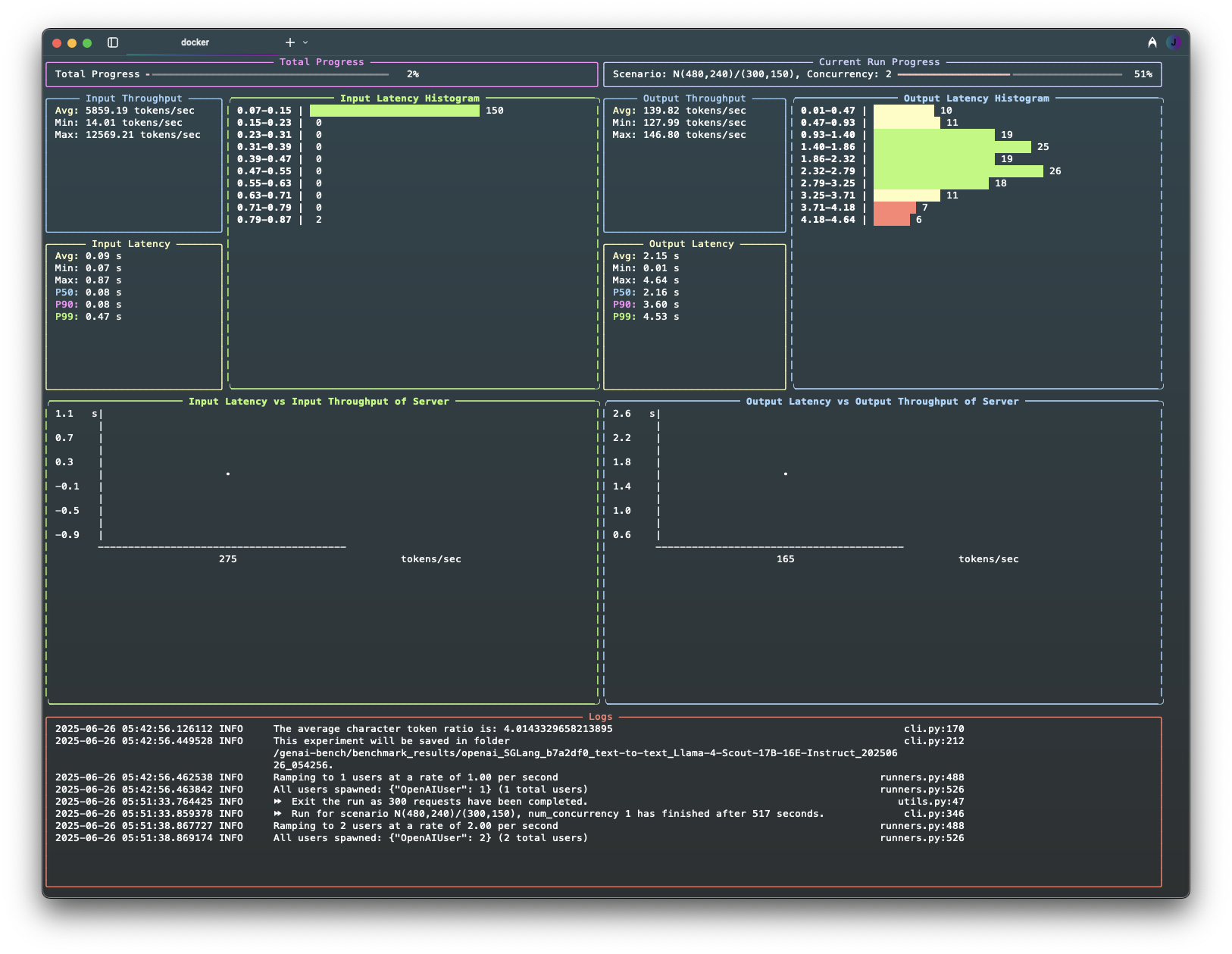
- 📊 Live UI Dashboard: Displays current progress, logs, and real-time metrics.
- 📝 Rich Logs: Automatically flushed to both terminal and file upon experiment completion.
- 📈 Experiment Analyzer: Generates comprehensive Excel reports with pricing and raw metrics data, plus flexible plot configurations (default 2x4 grid) that visualize key performance metrics including throughput, latency (TTFT, E2E, TPOT), error rates, and RPS across different traffic scenarios and concurrency levels. Supports custom plot layouts and multi-line comparisons.
Quick Start: Install with pip install genai-bench.
Alternatively, check Installation Guide for other options.
-
Run a benchmark against your model:
genai-bench benchmark --api-backend openai \ --api-base "http://localhost:8080" \ --api-key "your-api-key" \ --api-model-name "your-model" \ --task text-to-text \ --max-time-per-run 5 \ --max-requests-per-run 100
-
Generate Excel reports from your results:
genai-bench excel --experiment-folder ./experiments/your_experiment \ --excel-name results --metric-percentile mean
-
Create visualizations:
genai-bench plot --experiments-folder ./experiments \ --group-key traffic_scenario --preset 2x4_default
If you're new to GenAI Bench, check out the Getting Started page.
For detailed instructions, advanced configuration options, and comprehensive examples, check out the User Guide.
If you are interested in contributing to GenAI-Bench, you can use the Development Guide.