CPU fastpath: lower per-step overhead (Boris, Yee update, filters)#72
CPU fastpath: lower per-step overhead (Boris, Yee update, filters)#72rogeriojorge wants to merge 2 commits intouwplasma:mainfrom
Conversation
|
For now, this is too much of a change for too little gains. Doing a final pass, otherwise I'll close this PR |
|
Update (commit 5184a38): added opt-in fast modes and more CPU reductions.\n\n- New : .\n - : x64 off + shape_factor=1 + J filter none + forces all outputs off + compiles full-run when possible.\n - : same as aggressive + forces (explicitly a physics approximation).\n- now uses the numerically-stable relativistic KE formula so fp32 fast modes don’t produce negative kinetic energies.\n- Fixed 2D stacked-field interpolation broadcasting (multi-component interpolation now expands weights).\n\nTwo-stream long bench (CPU, , , plotting disabled):\n- origin/main: (from CLI output)\n- fast_mode=aggressive: (~3.2×)\n- fast_mode=extreme: (~3.6×)\n\nI’m still not seeing a physics-preserving path to a true 5×+ on this workload without a much larger refactor (e.g., monolithic particle state like JAX-in-Cell) or additional physics approximations (electrostatic / frozen species / non-relativistic). |
|
Update (commit 5184a38): added opt-in fast modes and more CPU reductions.
Two-stream long bench (CPU,
I’m still not seeing a physics-preserving path to a true 5×+ on this workload without a much larger refactor (e.g., monolithic particle state like JAX-in-Cell) or additional physics approximations (electrostatic / frozen species / non-relativistic). |
Summary
This PR adds a CPU-focused fast path (still pure Python/JAX; no C++/numba) aimed at reducing per-step overhead while keeping the physics the same.
Core changes are confined to a small set of runtime-critical files:
PyPIC3D/boris.py: vectorized Boris push; cheaper field interpolation; shape-factor treated as static where possible.PyPIC3D/solvers/first_order_yee.py: removes per-steppad(..., mode="wrap")+ slice; uses direct periodicrollstencils.PyPIC3D/utils.py: replaces conv-basedbilinear_filter/digital_filterwith roll-based equivalents (same kernels).PyPIC3D/J.py: reduces current-deposition overhead and fuses component handling.PyPIC3D/evolve.py: enables buffer donation for(particles, fields).PyPIC3D/initialization.py: ensuresE/B/Jare tuples (stable PyTree); addsenable_x64+scan_chunkconfig keys.PyPIC3D/__main__.py: optional chunked stepping; lazy-imports VTK diagnostics; readsenable_x64from config.Benchmarks (CPU)
Benchmark artifacts (plots + raw numbers + perfetto traces) are stored on a separate branch/commit so they do not need to be merged into
main:rogeriojorge:codex/cpu-5x-fastpath-artifacts8dca5d0Runtime (steady-state s/step)
Raw numbers:
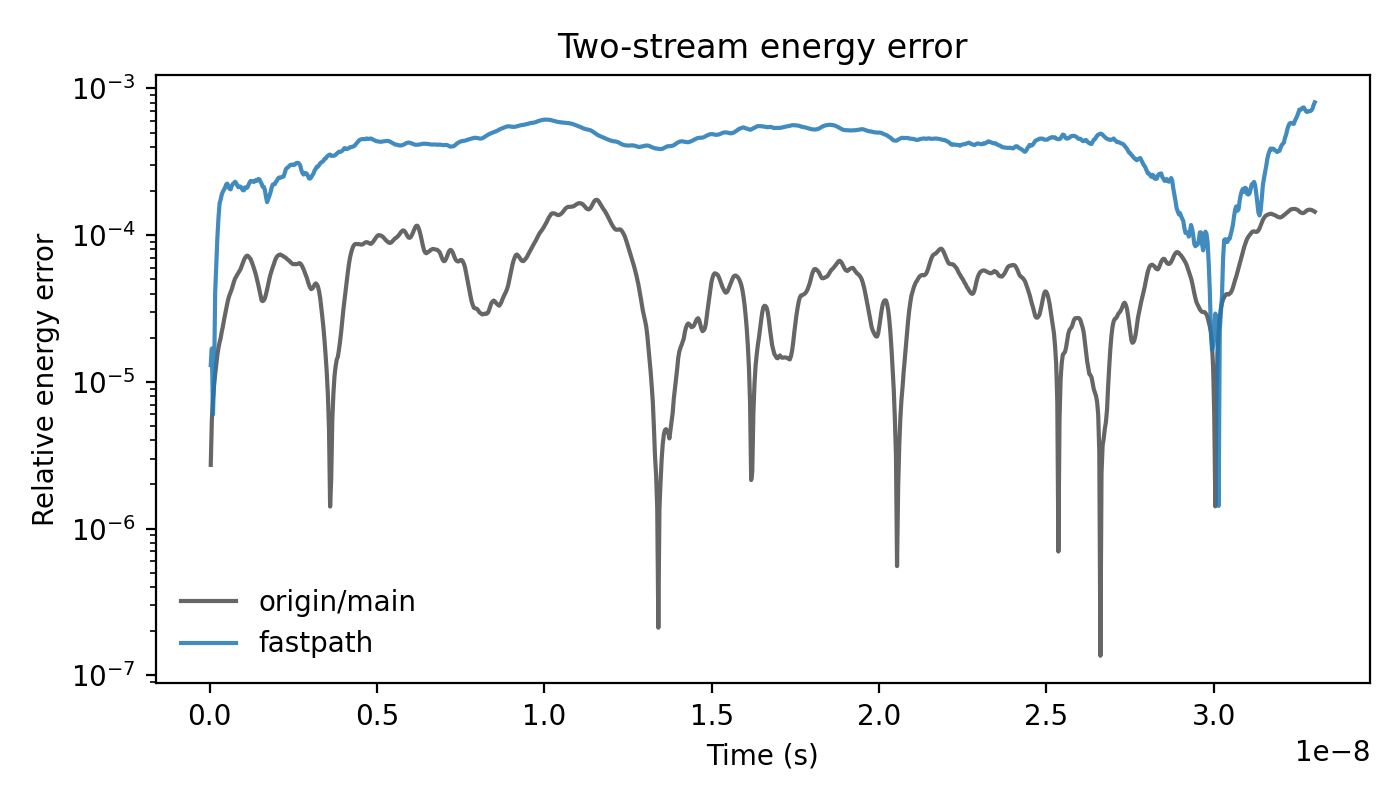
Accuracy (two-stream)
Electric field energy:
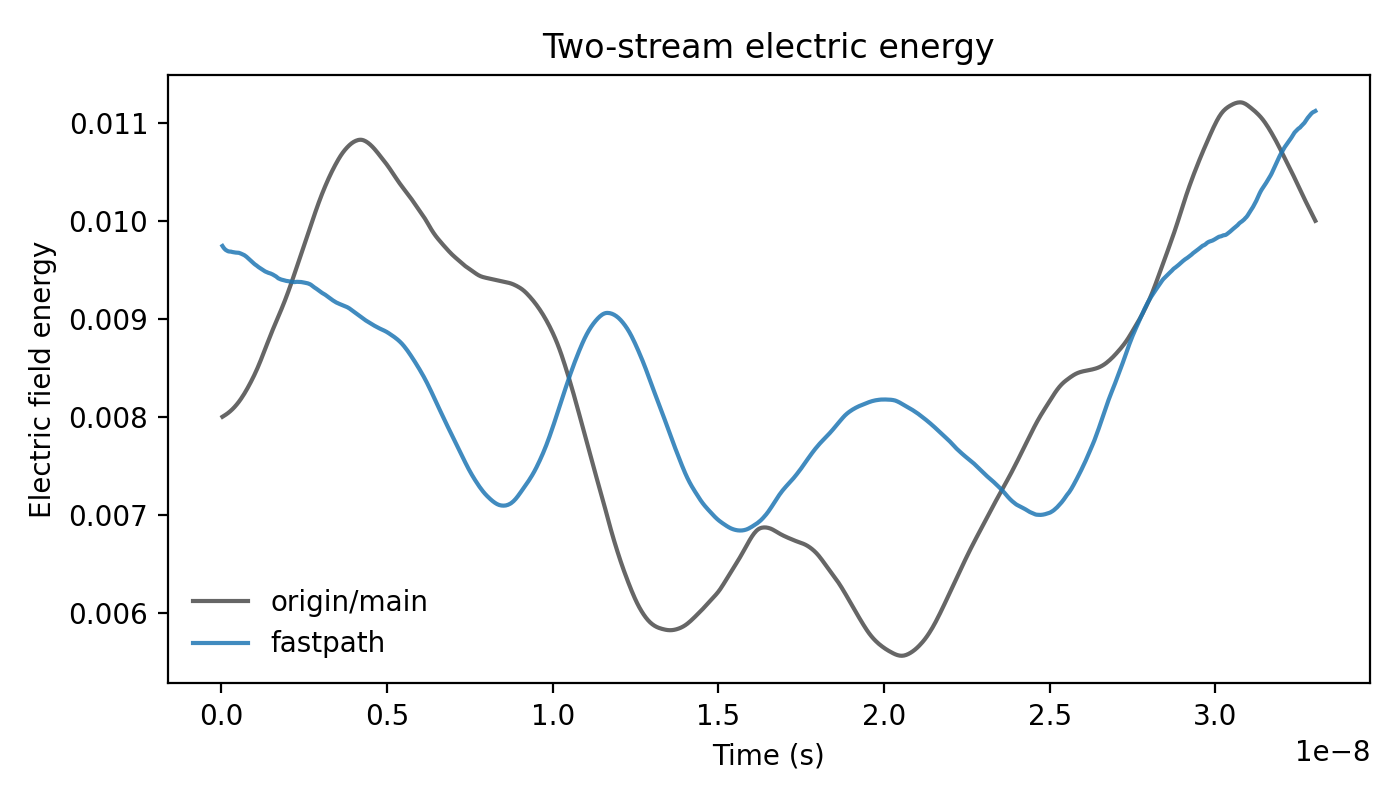
Relative energy error:
Raw traces (
.npz):docs/benchmarks/results/two_stream_origin_main_energy.npzdocs/benchmarks/results/two_stream_fastpath_energy.npzProfiling (Perfetto)
Perfetto traces (
.trace.json.gz):docs/benchmarks/profiles/two_stream_origin_main.trace.json.gzdocs/benchmarks/profiles/two_stream_fastpath.trace.json.gzRepro
demos/two_stream/two_stream.toml(plotting disabled for timing)np.random.seed(0)enable_x64=true