[feat] [broker] PIP-188 support blue-green cluster migration [part-2]#9
Open
vineeth1995 wants to merge 174 commits intomaster-apachefrom
Open
[feat] [broker] PIP-188 support blue-green cluster migration [part-2]#9vineeth1995 wants to merge 174 commits intomaster-apachefrom
vineeth1995 wants to merge 174 commits intomaster-apachefrom
Conversation
### Motivation Super users must be always allowed to abort a transaction even if they're not the original owner. ### Modifications * Check that only owner or superusers are allowed to perform txn operations (end, add partition and add subscription)
Signed-off-by: tison <wander4096@gmail.com>
Fixes: apache#19478 ### Motivation See issue for additional context. Essentially, we are doing a shallow clone when we needed a deep clone. The consequence is leaked labels, annotations, and tolerations. ### Modifications * Add a `deepClone` method to the `BasicKubernetesManifestCustomizer.RuntimeOpts` method. Note that this method is not technically a deep clone for the k8s objects. However, based on the way we "merge" these objects, it is sufficient to copy references to the objects. ### Verifying this change Added a test that fails before the change and passes afterwards. ### Documentation - [x] `doc-not-needed` This is an internal bug fix. No docs needed. ### Matching PR in forked repository PR in forked repository: michaeljmarshall#27
…18273) Master Issue: apache#16913 ### Motivation Implement an abortedTxnProcessor to handle the storage of the aborted transaction ID. ### Modifications The structure overview: 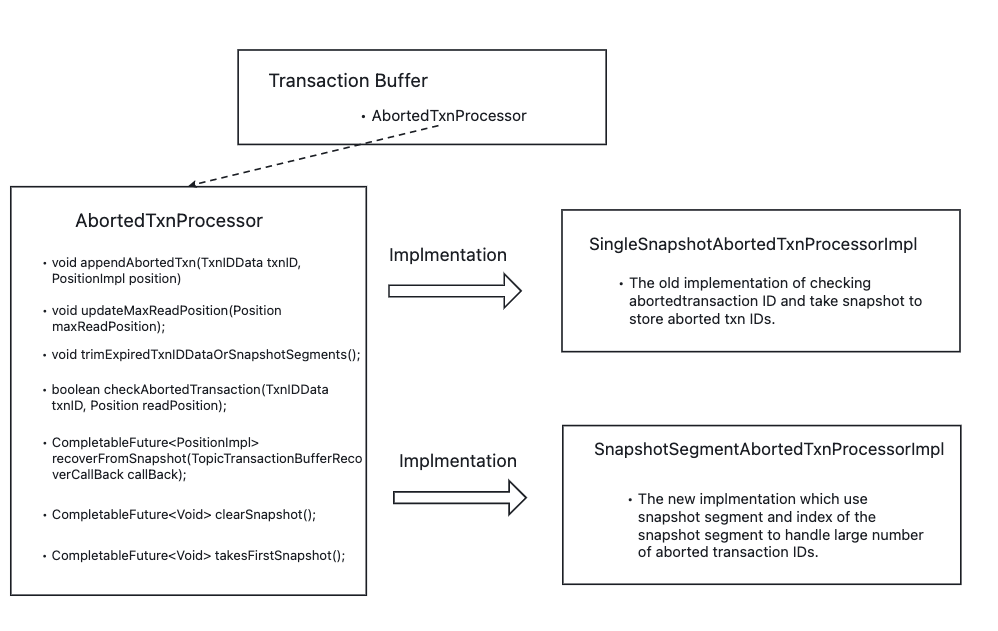 The main idea is to move the logic of the operation of checking and persistent aborted transaction IDs(take snapshots) and the operation of updating maxReadPosition into the AbortedTxnProcessor. And the AbortedTxnProcessor can be implemented in different designs. **Add `persistentWorker` to handle snapshot persistenting** : <img width="1003" alt="image" src="https://user-images.githubusercontent.com/55571188/198528131-3cde19bc-2034-4693-a8b1-4d6345e6db36.png"> The first four items below are the corresponding four tasks in the figure. The fifth item is not strictly a task, but a part of the first two tasks. * takeSnapshotSegmentAsync -> writeSnapshotSegmentAsync * These two method is used to persist the snapshot segment. * deleteSnapshotSegment * This method is used to delete the snapshot segment. * clearSnapshotSegmentAndIndexes * Delete all segments and then delete the index of this topic. * updateSnapshotIndex * Called by the deleteSnapshotSegment and writeSnapshotSegmentAsync. Do update the index after writing the snapshot segment. * Called to update index snapshot by `takeSnapshotByChangeTimes` and `takeSnapshotByTimeout`. * Called by recovery as a compensation mechanism for updating the index.
{kind=link}
{kind=link}
…tateChannel` instead of ZK when handling bundle split (apache#18858)
…ad of multiple topics subscription (apache#19502)
Fixes apache#19431 ### Motivation `authenticationData` is already `volatile`. We use `originalAuthData` when set, so we should match the style. In apache#19431, I proposed that we find a way to not use `volatile`. I still think this might be a "better" approach, but it will be a larger change, and since we already use `volatile` for `authenticationData`, I think this is the right change for now. It's possible that this is not a bug, given that the `originalAuthData` does not change frequently. However, we always want to use up to date values for authorization. ### Modifications * Add `volatile` keyword to `ServerCnx#originalAuthData`. ### Verifying this change This change is a trivial rework / code cleanup without any test coverage. ### Documentation - [x] `doc-not-needed` ### Matching PR in forked repository PR in forked repository: skipping test in fork.
…pal (apache#19455) Co-authored-by: Lari Hotari <lhotari@apache.org>
Co-authored-by: Lari Hotari <lhotari@users.noreply.github.com>
…cy on java consumer (apache#19486)
When calling the method `PulsarWebResource.getRedirectionUrl`, reuse the same `PulsarServiceNameResolver` instance.
…Readonly (apache#19513) Co-authored-by: lushiji <lushiji@didiglobal.com>
…rce expire after access (apache#19532)
…NotFoundException (apache#19458)
Signed-off-by: xiaolongran <xiaolongran@tencent.com>
…19519) Signed-off-by: Zixuan Liu <nodeces@gmail.com>
… met for resetCursor (apache#19541)
…-client-all (apache#19937) Signed-off-by: tison <wander4096@gmail.com>
…ioned-topic stat (apache#19942) ### Motivation Pulsar will merge the variable `PartitionedTopicStatsImpl.replication[x].connected` by the way below when we call `pulsar-admin topics partitioned-stats` ``` java this.connected = this.connected & other.connected ``` But the variable `connected` of `PartitionedTopicStatsImpl.replication` is initialized `false`, so the expression `this.connected & other.connected` will always be `false`. Then we will always get the value `false` if we call `pulsar-admin topics partitioned-stats`. ### Modifications make the variable `` of `PartitionedTopicStatsImpl` is initialized `true`
…pache#19851) PIP: apache#16691 ### Motivation Raising a PR to implement apache#16691. We need to support delete namespace bundle admin API. ### Modifications * Support delete namespace bundle admin API. * Add units test.
…9926) Co-authored-by: lushiji <lushiji@didiglobal.com>
Co-authored-by: tison <wander4096@gmail.com>
Master Issue: Master Issue: apache#16691, apache#18099 ### Motivation Raising a PR to implement Master Issue: apache#16691, apache#18099 We want to reduce unload frequencies from flaky traffic. ### Modifications This PR - Introduced a config `loadBalancerSheddingConditionHitCountThreshold` to further restrict shedding conditions based on the hit count. - Normalized offload traffic - Lowered the default `loadBalanceSheddingDelayInSeconds` value from 600 to 180, as 10 mins are too long. 3 mins can be long enough to catch the new load after unloads. - Changed the config `loadBalancerBundleLoadReportPercentage` to `loadBalancerMaxNumberOfBundlesInBundleLoadReport` to make the topk bundle count absolute instead of relative. - Renamed `loadBalancerNamespaceBundleSplitConditionThreshold` to `loadBalancerNamespaceBundleSplitConditionHitCountThreshold` to be consistent with `*ConditionHitCountThreshold`. - Renamed `loadBalancerMaxNumberOfBrokerTransfersPerCycle ` to `loadBalancerMaxNumberOfBrokerSheddingPerCycle`. - Added LoadDataStore cleanup logic in BSC monitor. - Added `msgThroughputEMA` in BrokerLoadData to smooth the broker throughput info. - Updated Topk bundles sorted in a ascending order (instead of descending) - Update some info logs to only show in the debug mode. - Added load data tombstone upon Own, Releasing, Splitting - Added the bundle ownership(isOwned) check upon split and unload. - Added swap unload logic
…pache#19956) Signed-off-by: tison <wander4096@gmail.com>
…9951) Motivation Kafka's schema has "Optional" flag that used there to validate data/allow nulls. Pulsar's schema does not have such info which makes conversion to kafka schema lossy. Modifications Added a config parameter that lets one force primitive schemas into optional ones. KV schema is always optional. Default is false, to match existing behavior.
…ache#19939) Signed-off-by: tison <wander4096@gmail.com>
…pic with ProtoBuf schema (apache#19767) ### Motivation 1. There is a topic1 with a protobuf schema. 2. Create a producer1 with AutoProduceBytes schema. 3. The producer1 will be created failed because the way to get the schema of protobuf schema is not supported. ### ### ### Modification Because the Protobuf schema is implemented from the AvroBaseStructSchema. So we add a way to get Protobuf schema just like the AvroSchema.
…, when the updateStats method is executed (apache#19887) Co-authored-by: lordcheng10 <lordcheng1020@gmail.com>
apache#19990) ### Motivation While debugging an issue, I noticed that we call `super.exceptionCaught(ctx, cause);` in the `ProxyConnection` class. This leads to the following log line: > An exceptionCaught() event was fired, and it reached at the tail of the pipeline. It usually means the last handler in the pipeline did not handle the exception. io.netty.channel.unix.Errors$NativeIoException: recvAddress(..) failed: Connection reset by peer Because we always handle exceptions, there is no need to forward them to the next handler. ### Modifications * Remove a single method call ### Verifying this change This is a trivial change. Note that we do not call the super method in any other handler implementations in the project. ### Documentation - [x] `doc-not-needed` <!-- Your PR changes do not impact docs --> ### Matching PR in forked repository PR in forked repository: skipping PR for this trivial change
… cluster is absent (apache#19972)
a7d95f3 to
6ce3799
Compare
|
The pr had no activity for 30 days, mark with Stale label. |
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
20 participants
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
Motivation
This completes apache#16551 and extension to this part-1 pr apache#17962
This handles Replicator and message ordering guarantee part for blue-green deployment.
Replicator and message ordering handling
A. Incoming replication messages from other region's replicator producers to Blue cluster
This will not impact ordering messages coming from the other regions to blue/green cluster. After marking blue cluster, blue cluster will reject replication writes from remote regions and redirects remote producers to the Green cluster where new messages will be written. Consumers of Blue clusters will only be redirected to green once they received all messages from blue. So, migration gives an ordering guarantee for messages replicating from remote regions.
B. Outgoing replication messages from Blue cluster's replicator producers to other regions
The broker can give an ordering guarantee in this case with the trade-off of topic unavailability until the blue cluster replicates all existing published messages in the blue cluster before the topic gets terminated.
Blue cluster marks topic terminated and migrated
Topic will not redirect producers/consumers until all the replicators reaches end of topic and replicates all messages to remote regions. Topic will send TOPIC_UNAVAILABLE message to producers/consumers so, they can keep retrying until replicators reach to end of topics.
Broker disconnects all the replicators and delete them once they reach end of topic.
Broker start sending migrated-command to producer/consumers to redirect clients to green cluster.
Modifications
Example use case:
producer1 sends messages msg1, msg2 -> region1
region1 replicator -> msg1 ->region2
but region2 has a connectivity issue with region1
as a result region1 has a replication backlog msg2 with region2
Marked blue-green
region1 -> region1A
If you redirect producer1 to region1A
producer1 sends msg3 to region1A
region1A is connected to region2
region1A sends msg3 to region2
Meanwhile if region1 gets it's connection back to region2
region1 sends msg2(replication backlog) to region2
region2 consumer consumes in the order msg1, msg3, msg2
which is a wrong order of messages as it should be msg1, msg2, msg3
So we don't want to redirect producer1 until Replicator has no backlog. This pr handles this use case by making sure replication backlog is drained before redirecting the producers to green cluster.
Verifying this change
Added end t end test to verify this change.
Does this pull request potentially affect one of the following parts:
If the box was checked, please highlight the changes
Documentation
docdoc-requireddoc-not-neededdoc-complete