This is the code release for paper Efficient Online Reinforcement Learning Fine-Tuning Need Not Retain Offline Data. We provide the implementation of WSRL (Warm-Start Reinforcement Learning), as well as popular actor-critic RL algorithms in JAX and Flax: IQL, CQL, CalQL, SAC, RLPD. Variants of SAC also supported, such as TD3, REDQ, and IQL policy extraction supports both AWR and DDPG+BC. We support the following environments: D4RL antmaze, adroit, kitchen, and Mujoco locomotion, but the code can be easily adpated to work with other environments and datasets.
The code for the Franka robot experiments is located at wsrl-robot. See running instructions in that repo.
{kind=link}
@article{zhou2024efficient,
author = {Zhiyuan Zhou and Andy Peng and Qiyang Li and Sergey Levine and Aviral Kumar},
title = {Efficient Online Reinforcement Learning Fine-Tuning Need Not Retain Offline Data},
conference = {arXiv Pre-print},
year = {2024},
url = {http://arxiv.org/abs/2412.07762},
}
conda create -n wsrl python=3.10 -y
conda activate wsrl
pip install -r requirements.txtFor jax, install
pip install --upgrade "jax[cuda11_pip]==0.4.20" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
To use the D4RL envs, you would also need my fork of the d4rl envs below. This fork incorporates the antmaze-ultra environments and fixes the kitchen environment rewards to be consistent between the offline dataset and the environment.
git clone git@github.com:zhouzypaul/D4RL.git
cd D4RL
pip install -e .
To use Mujoco, you would also need to install mujoco manually to ~/.mujoco/ (for more instructions on download see here), and use the following environment variables
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HOME/.mujoco/mujoco210/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/lib/nvidiaTo use the adroit envs, you would need
git clone --recursive https://github.com/nakamotoo/mj_envs.git
cd mj_envs
git submodule update --remote
pip install -e .
Download the adroit dataset from here and unzip the files into ~/adroit_data/.
If you would like to put the adroit datasets into another directory, use the environment variable DATA_DIR_PREFIX (checkout the code here for more details).
export DATA_DIR_PREFIX=/path/to/your/dataThe main run script is finetune.py. We provide bash scripts in experiments/scripts/<ENV> to train WSRL/IQL/CQL/CalQ/RLPD on the different environments.
The shared agent configs are in experiments/configs/*, and the environment-specific configs are in experiments/configs/train_config.py and in the bash scripts.
For example, to run CalQL (with Q-ensemble) pre-training
# on antmaze
bash experiments/scripts/antmaze/launch_calql_finetune.sh --use_redq --env antmaze-large-diverse-v2
# on adroit
bash experiments/scripts/adroit/launch_calql_finetune.sh --use_redq --env door-binary-v0
# on kitchen
bash experiments/scripts/kitchen/launch_calql_finetune.sh --use_redq --env kitchen-mixed-v0
# on mujoco locomotion (CQL pre-train because MC returns are hard to estimate)
bash experiments/scripts/locomotion/launch_cql_finetune.sh --use_redq --env halfcheetah-medium-replay-v0To run WSRL fine-tuning from a pre-trained checkpoint
# on antmaze
bash experiments/scripts/antmaze/launch_wsrl_finetune.sh --env antmaze-large-diverse-v2 --resume_path /path/to/checkpoint
# on adroit
bash experiments/scripts/adroit/launch_wsrl_finetune.sh --env door-binary-v0 --resume_path /path/to/checkpoint
# on kitchen
bash experiments/scripts/kitchen/launch_wsrl_finetune.sh --env kitchen-mixed-v0 --resume_path /path/to/checkpoint
# on mujoco locomotion
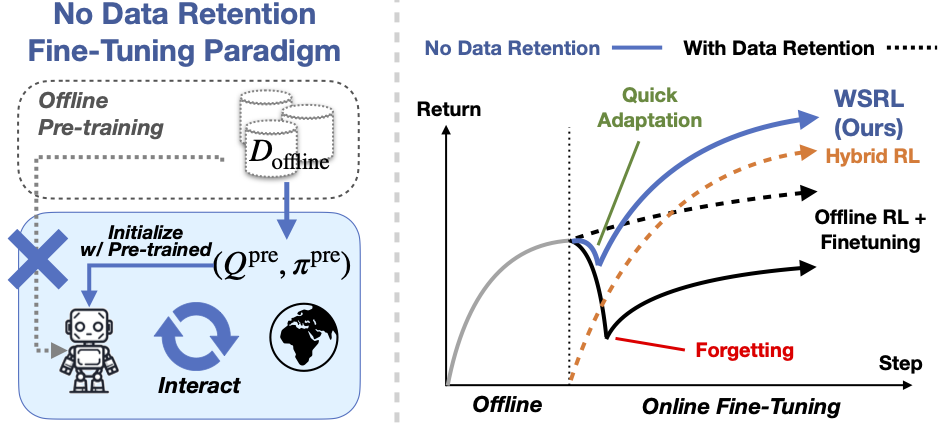
bash experiments/scripts/locomotion/launch_wsrl_finetune.sh --env halfcheetah-medium-replay-v0 --resume_path /path/to/checkpointThe default setting is to not retain offline data during fine-tuning, as described in the paper. However, if you wish to retain the data, you can use the --offline_data_ratio <> or --online_sampling_method append option. Checkout finetune.py for more details.
For a detailed explanation of how the codebase works, please checkout the contributing.md file.
To enable code checks and auto-formatting, please install pre-commit hooks (run this in the root directory):
pre-commit install
The hooks should now run before every commit. If files are modified during the checks, you'll need to re-stage them and commit again.
This repo is built upon a version of Dibya Ghosh's jaxrl_minimal repository, which also included contributions from Kevin Black, Homer Walke, Kyle Stachowicz, and others.