1. Process
I meeting si sono svolti online con frequenza settimanale utilizzando la piattaforma Microsoft Teams. Ispirandoci al modello Scrum abbiamo scelto di proseguire in questo modo:
-
Meeting iniziale: l'obiettivo di questo primo meeting è stato quello di comprendere il dominio applicativo e gli obiettivi del progetto. Sono stati scelti:
- Product Owner (Alex Baiardi)
- Domain Expert (Nicholas Ricci)
- Scrum Master (Giulio Zaccaroni)
- Planning Poker: in questo meeting si è valutata la difficoltà dei task individuati in fase di analisi. In particolare per ogni task ogni membro del team esprime la propria stima della difficoltà e si assegna al task la media delle valutazioni.
- Sprint settimanali: abbiamo scelto una cadenza settimanale per gli sprint, per ottenere brevi ma intense sessioni di lavoro. Il carico è stato poi diviso in maniera equilibrata grazie alla stima della difficoltà di ogni task.
- Meeting inizio sprint e Meeting fine sprint: per comodità e per questioni legate a limiti di tempo abbiamo deciso di eseguire un'unica riunione per chiudere lo sprint attuale e preparare quello successivo. In questo meeting viene effettuata la sprint review, in cui si valuta lo sprint passato e si controlla il raggiungimento dei goals. Infine vengono definiti i nuovi goal e la suddivisione in task degli obiettivi settimanali, con tanto di assegnazione di essi agli sviluppatori.
Per ogni task viene valutata la complessità e si stima la difficoltà di sviluppo a priori, nel nostro caso la scala scelta è stata quella di Fibonacci (0, 1, 2, 3, 5, 8, 13, 21) mentre nel product backlog viene riportata la media di tutti i voti dei membri. Tali task successivamente vengono assegnati agli sviluppatori, tentando per quanto possibile di mantenere un carico di lavoro bilanciato.

Per il mantenimento dello stato di svolgimento dei task si è deciso di utilizzare GitHub Projects, per la comodità di averlo integrato direttamente nel repository di GitHub.
Tale strumento permette di assegnare i task agli sviluppatori, in particolare la sezione Assignees indica le persone mentre lo Status a che punto è il task in questione:
- New: per i task aggiunti e pronti ad essere presi in carico.
- In progress: per i task che vengono presi in carico e sono in fase di svolgimento/completamento.
- Done: per tutti i task che sono definiti come conclusi.
Abbiamo cercato di mantenere immutabile l'elenco dei task durante il corso degli sprint, le uniche eccezioni sono state nel sesto sprint dove è stato necessario aggiungere dei task per concludere dei raffinamenti (ma comunque eseguite nel meeting di fine/inizio sprint, mai durante). Per ogni task assegnato è stata considerata la seguente definizione di completato, un task è da considerarsi terminato nel momento in cui:
- è stato adeguatamente testato
- tutti i test hanno successo
- l'analisi di SonarQube non riporta codice duplicato, bug o debito tecnico
- soddisfa le aspettative del committente.
Per i test automatici abbiamo usato la libreria ScalaTest in particolare sfruttando AnyFunSuite e i Matchers per una maggiore dichiaratività.
Come modello di branching abbiamo usato il Trunk Based Development, qui gli sviluppatori collaborano al codice in un singolo ramo chiamato "trunk" ed è assolutamente vietata la creazione di un qualsiasi altro branch di sviluppo di lunga durata (long-lived). Quando viene fatta una release viene impostato un tag sul commit corrispondente nel branch principale.
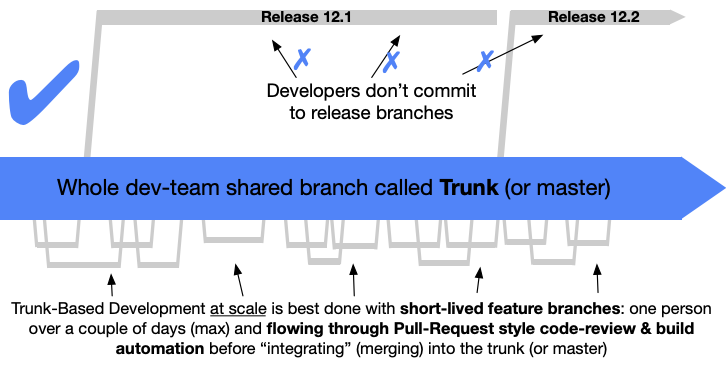
Ogni volta che uno sviluppatore deve lavorare sulla repository quindi:
- crea un nuovo branch chiamato
feature/nome-funzioneobugfix/nome-fix; - quando ha completato lo sviluppo crea una Pull Request su
main; - la pull request viene verificata automaticamente in più modi per assicurarsi non vi siano regressioni e la qualità del codice sia rispettata;
- quando è stata approvata dagli altri sviluppatori viene unita (merged) in
main
Nonostante tipicamente si utilizzi lo Squash and Merge (tutti i commit vengono sostituiti con un unico commit che ha il nome della pull request) per rendere più trasparente il processo abbiamo utilizzato il normale Merge dove tutti i commit finiscono nel main singolarmente. Il risultato è un branch principale sicuramente più caotico che però permette ad un esterno una visione completa del flusso di lavoro.
Per aumentare il significato dei commit si è scelto di utilizzare la specifica Conventional Commits, che ha permesso di automatizzare la creazione del changelog e ha reso più leggibile il flusso dei commit.
Inoltre, abbiamo deciso di utilizzare Scalafmt per verificare la formattazione del codice.
Per confermare una pull request è necessario che essa superi due tipologie di controllo:
- Manuale: altri membri del team devono revisionare il codice scritto e approvare i cambiamenti fatti (Code Review).
-
Automatico: ogni pull request fa partire la verifica delle seguenti condizioni nel branch:
- tutti i test devono completare con successo;
- l'analisi di SonarQube non deve riportare debito tecnico, bug o codice duplicato;
- tutti i commit e il nome della pull request devono rispettare la specifica Conventional Commits;
- il codice deve essere stato formattato correttamente secondo le specifiche.
La build automation è stata gestita tramite Scala-Build Tool (Sbt), un build tool automator che ha permesso una gestione efficiente del progetto attraverso la gestione delle dipendenze e di vari plugins utili come ad esempio sbt-jacoco per la coverage.
Nel repository GitHub è stato configurato anche l'aggiornamento automatico delle dipendenze attraverso l'utilizzo del tool Renovate; il quale quando rileva nuove versioni delle librerie utilizzate, genera una pull request con gli aggiornamenti che viene sottoposta ai controlli necessari affinché tutto continui a funzionare correttamente.
Per semplificare la generazione automatica del changelog e il versioning abbiamo deciso di utilizzare Release Please. Questo strumento ogni volta che del codice viene unito (merged) nel trunk principale crea (o aggiorna se è già presente) una pull request con il numero della nuova versione (determinato automaticamente sfruttando i Conventional Commits) e le modifiche. Se qualcuno fa il merge di questa pull request nel main automaticamente viene:
- aggiornato il changelog;
- aggiornato il numero di versione in
version.txt; - assemblato il progetto in un Uber-JAR (un jar contenente anche tutte le sue dipendenze);
- creata una nuova release in Releases con allegato il jar generato.